Jacob Schreiber, Paul G. Allen School of Computer Science, University of Washington
Audience level: Intermediate
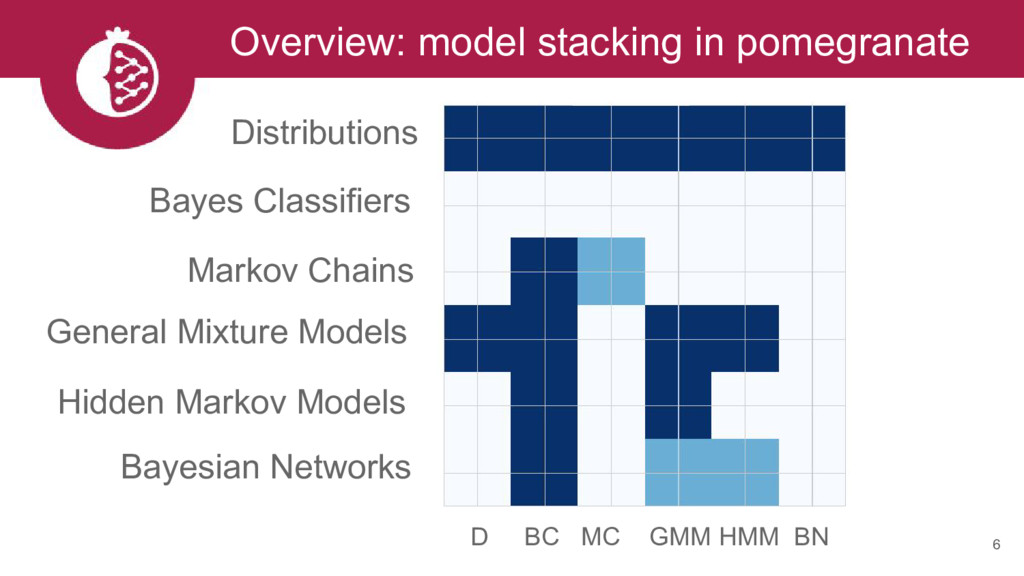
Topic area: Modeling
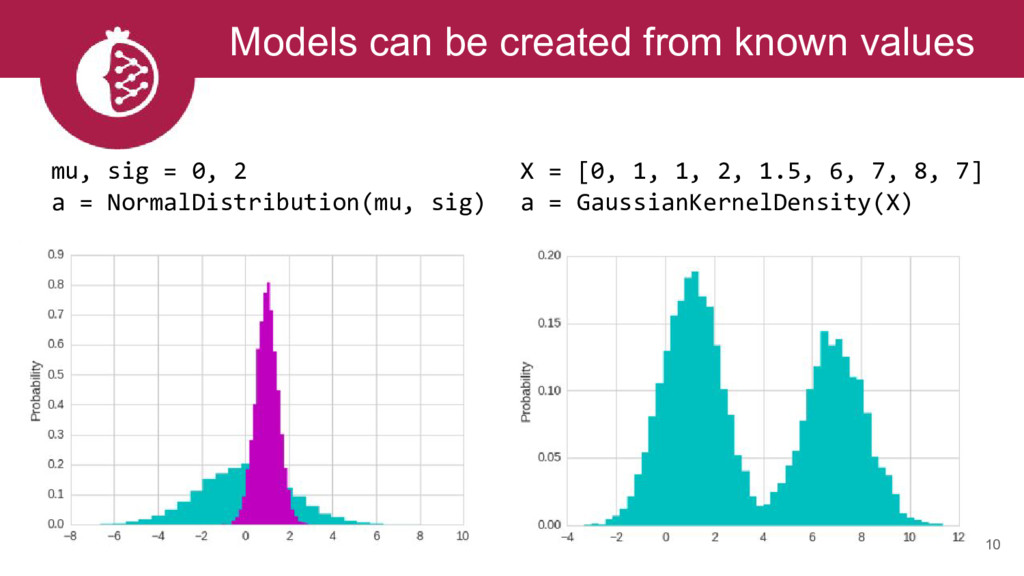
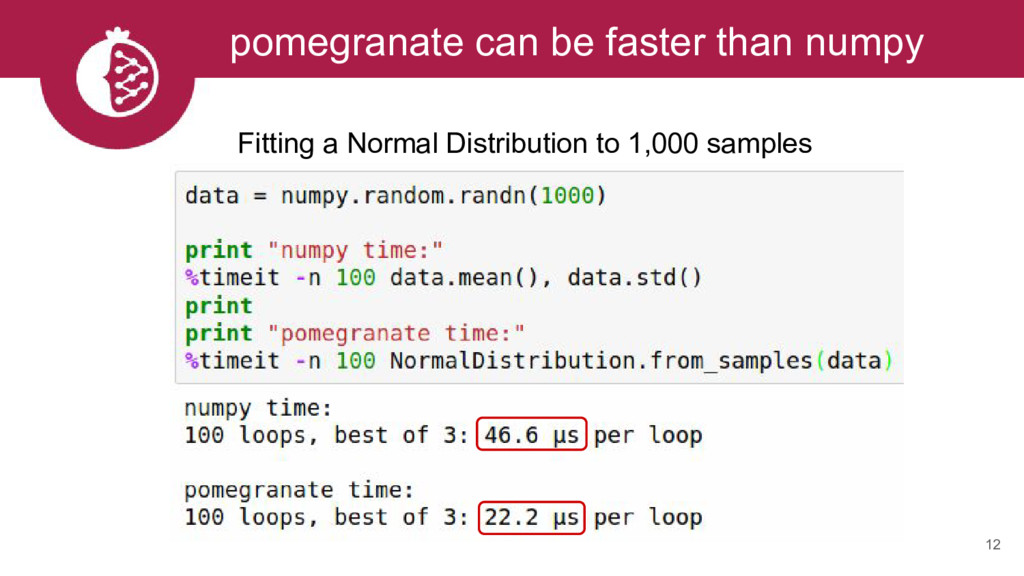
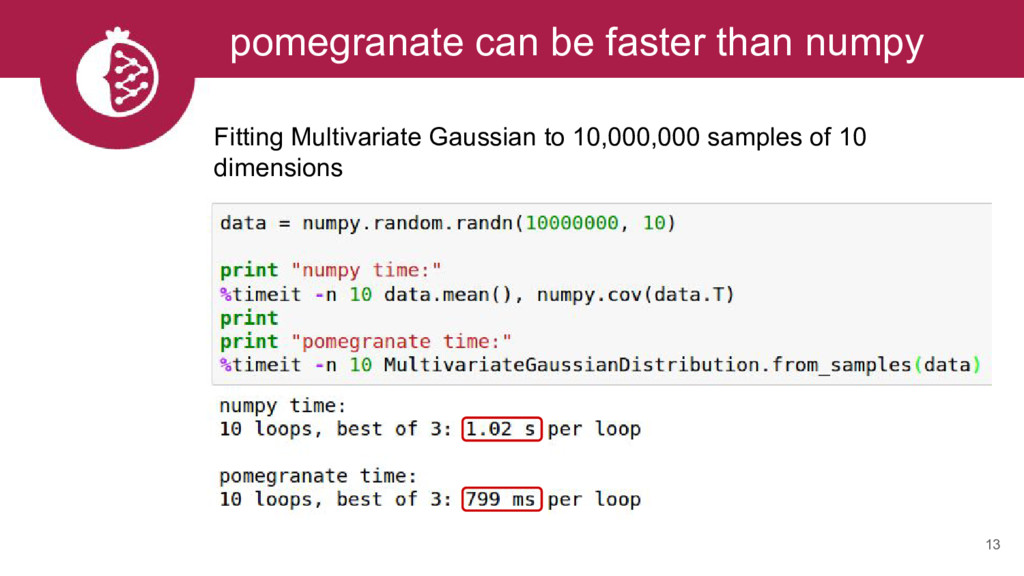
We will describe the python package pomegranate, which implements flexible probabilistic modeling. We will highlight several supported models including mixtures, hidden Markov models, and Bayesian networks. At each step we will show how the supported flexibility allows for complex models to be easily constructed. We will also demonstrate the parallel and out-of-core APIs.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
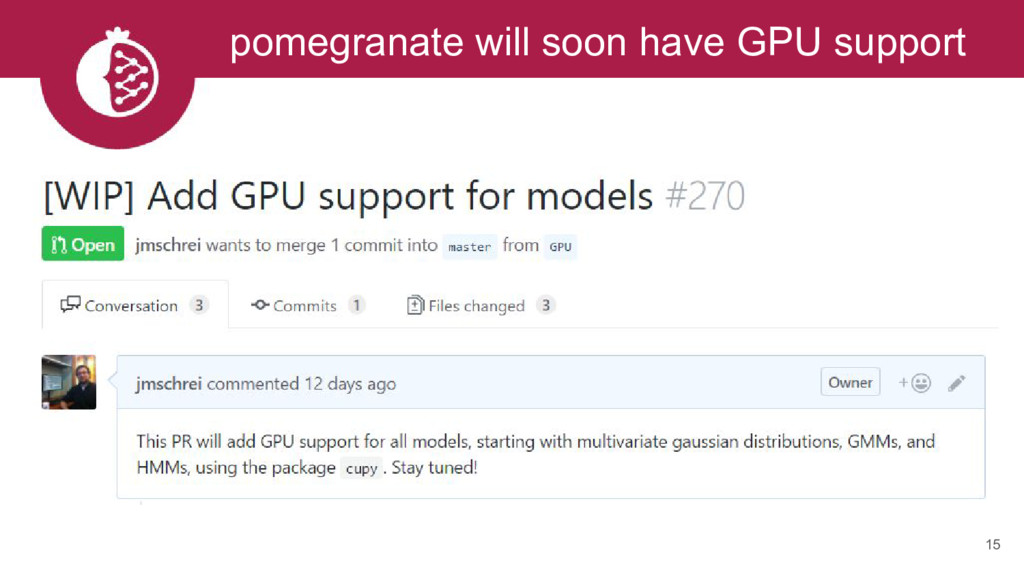{kind=link}
{kind=link}
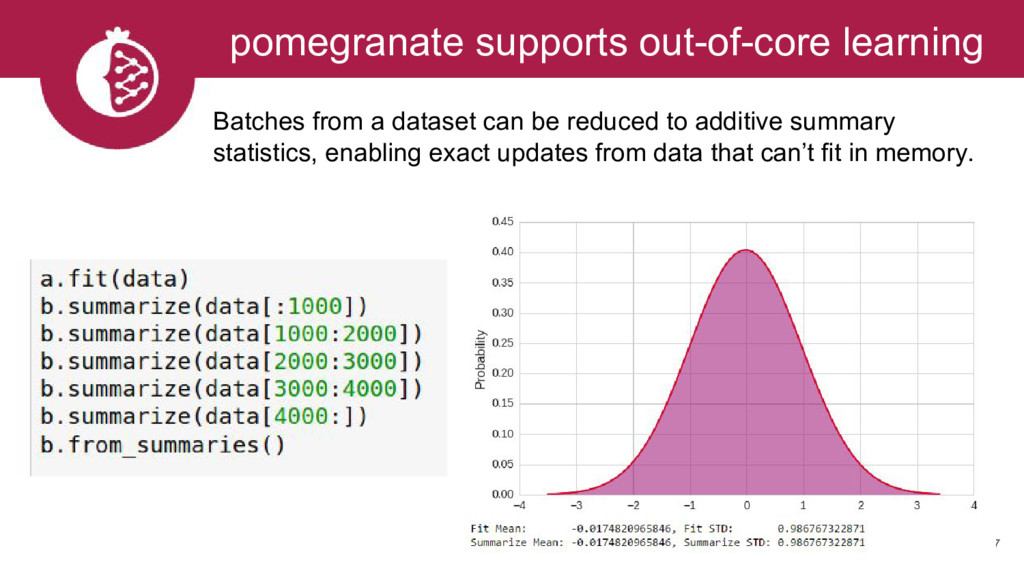{kind=link}
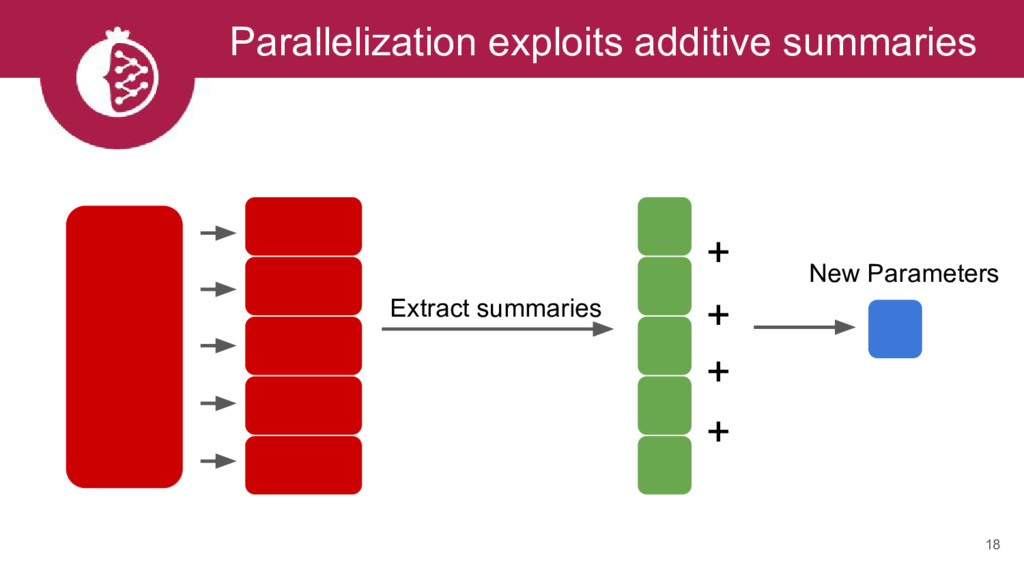{kind=link}
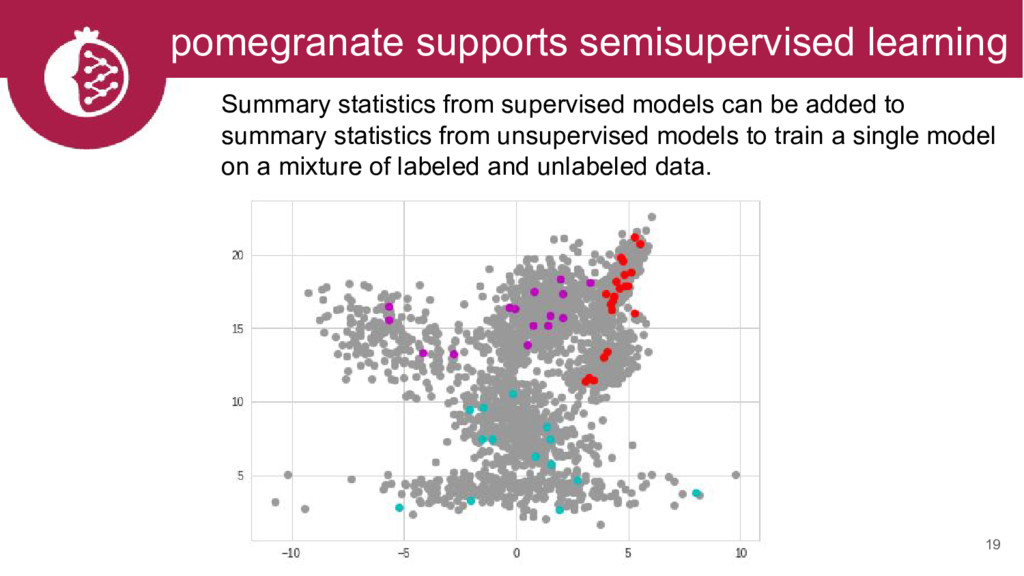{kind=link}
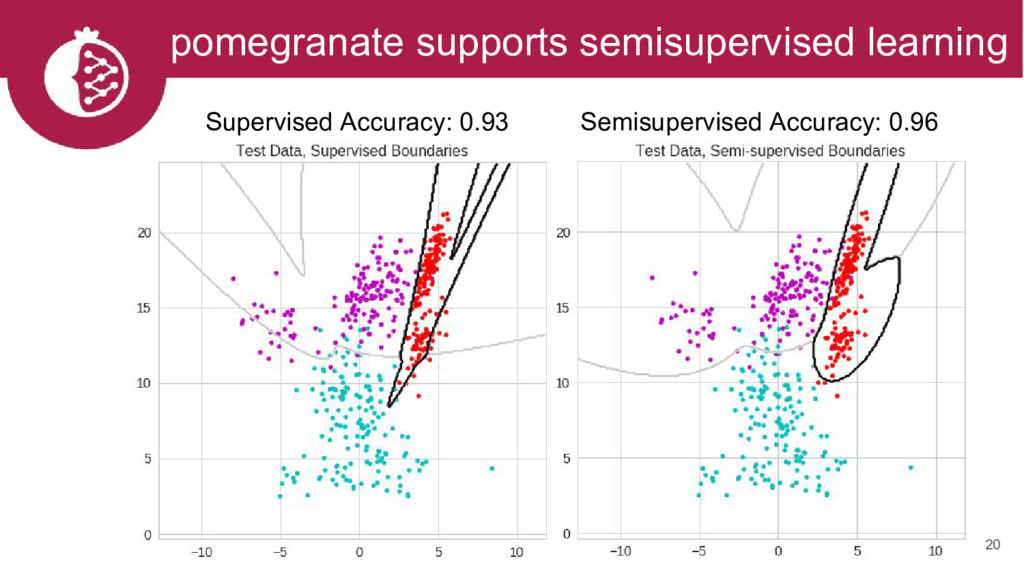{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
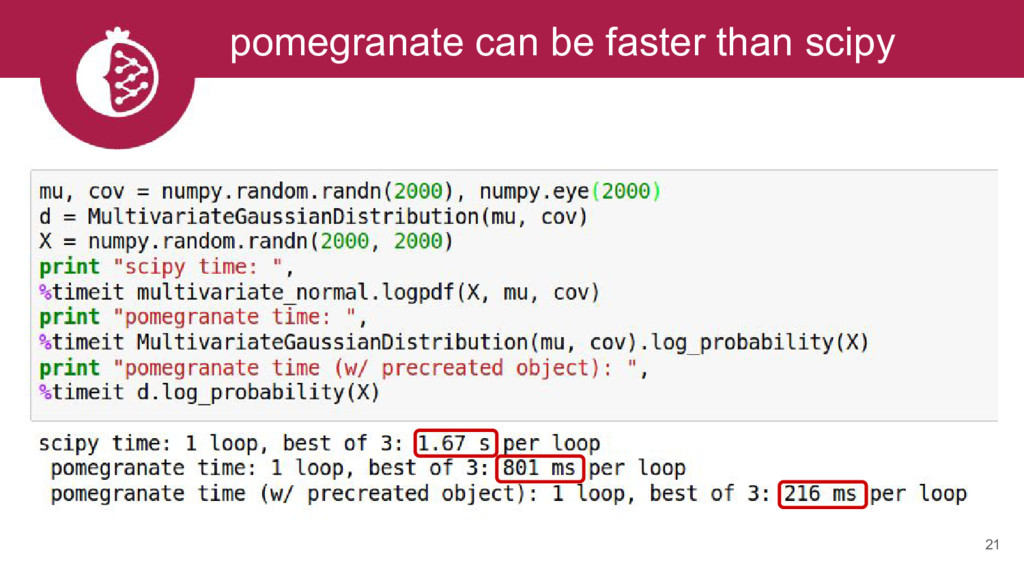
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
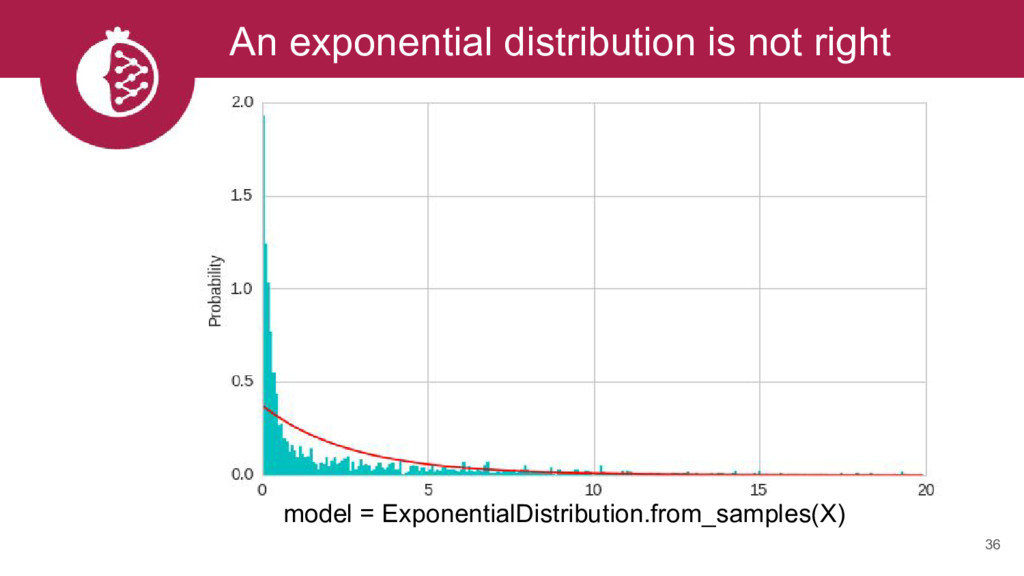{kind=link}
{kind=link}
![Heterogeneous mixtures natively supported 38 model = GeneralMixtureModel.from_samples([ExponentialDistribution, UniformDistribution], 2,](https://files.speakerdeck.com/presentations/6256268778d9430f875cd8cf87515ddb/slide_37.jpg){kind=link}
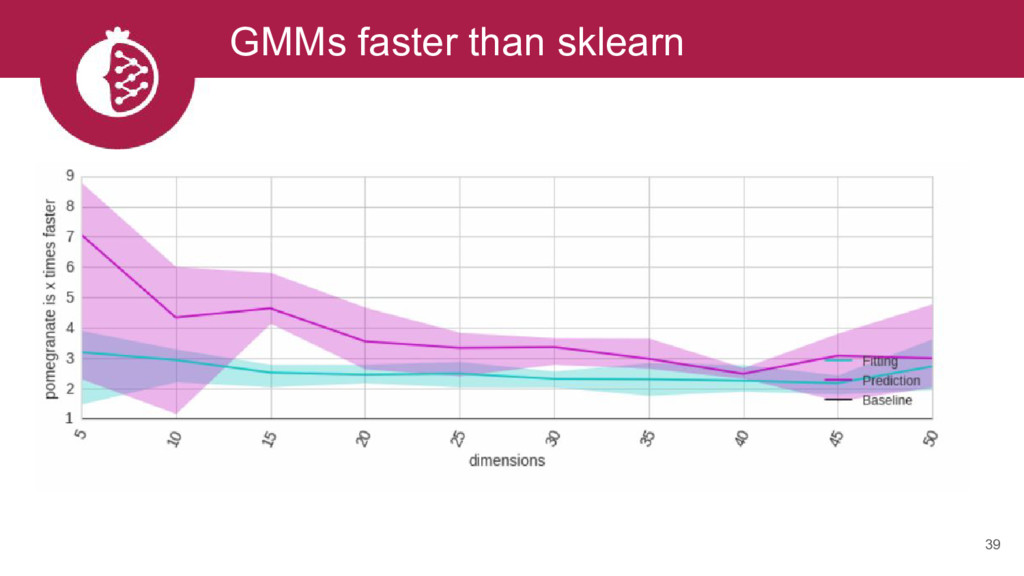{kind=link}
{kind=link}
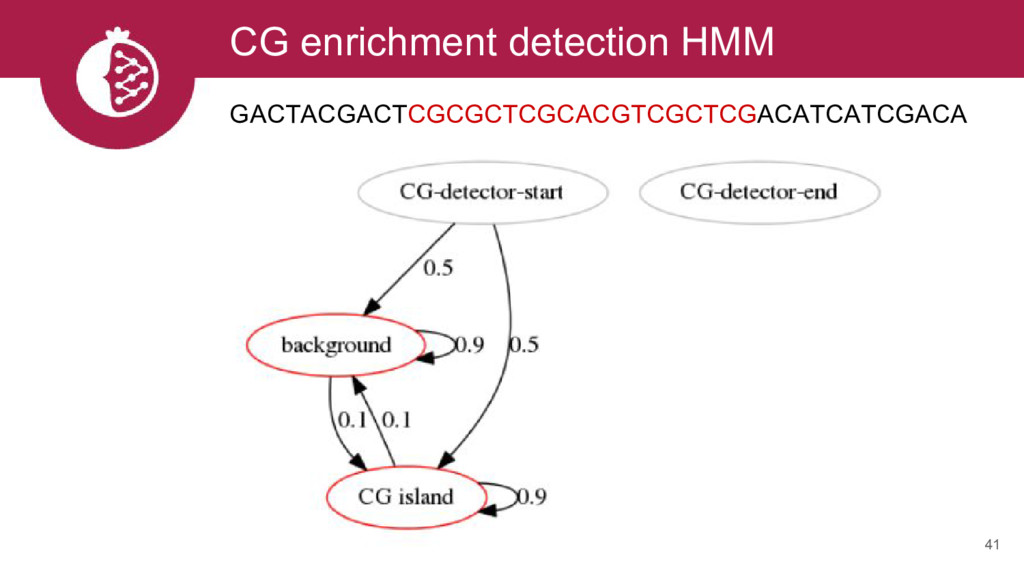{kind=link}
{kind=link}
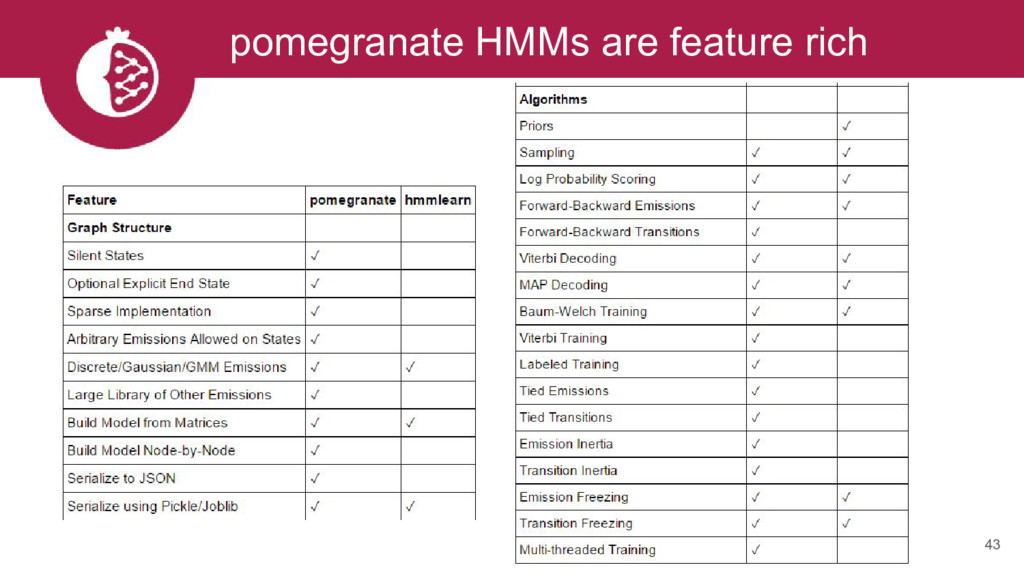{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
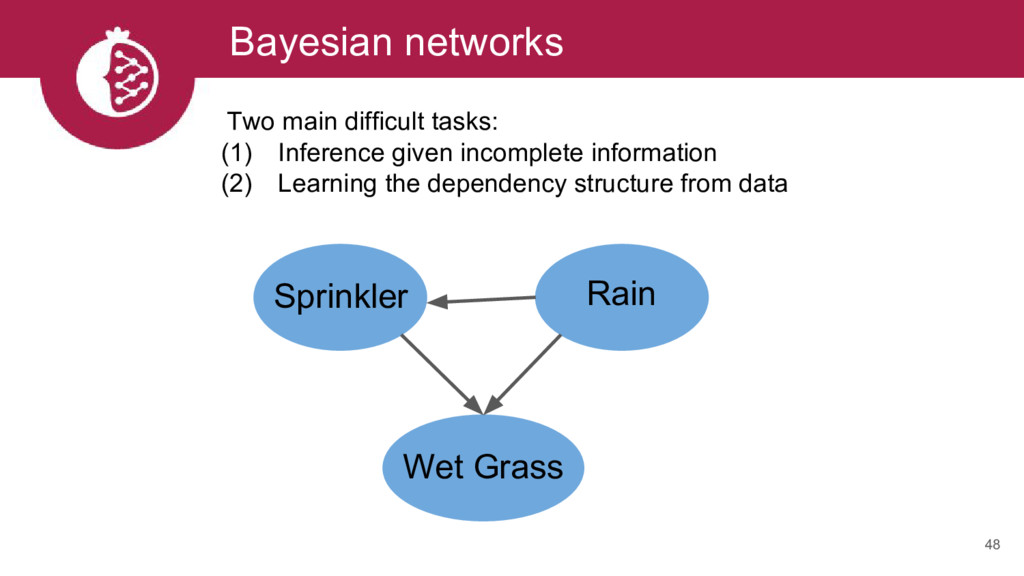{kind=link}
{kind=link}
{kind=link}
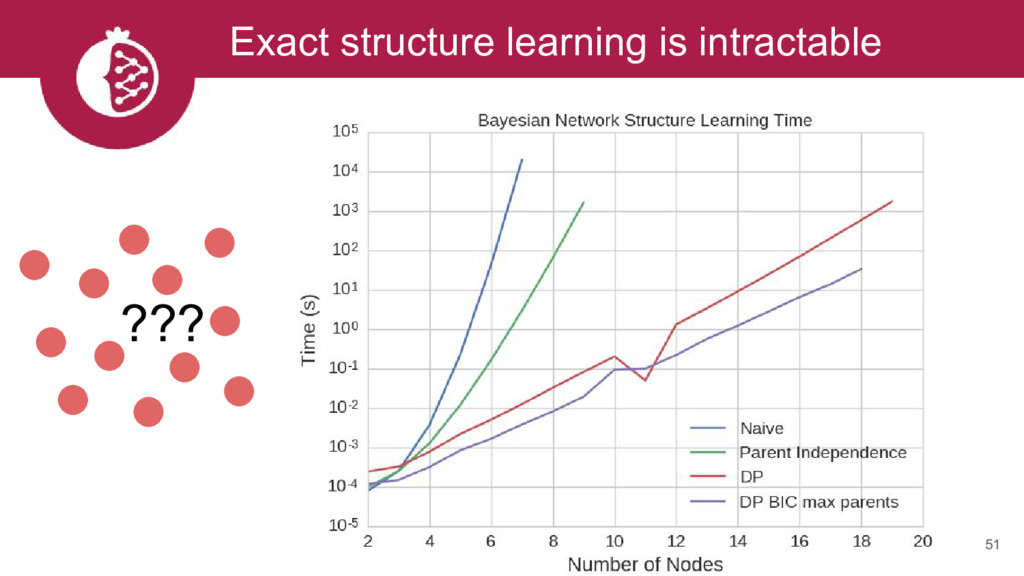{kind=link}
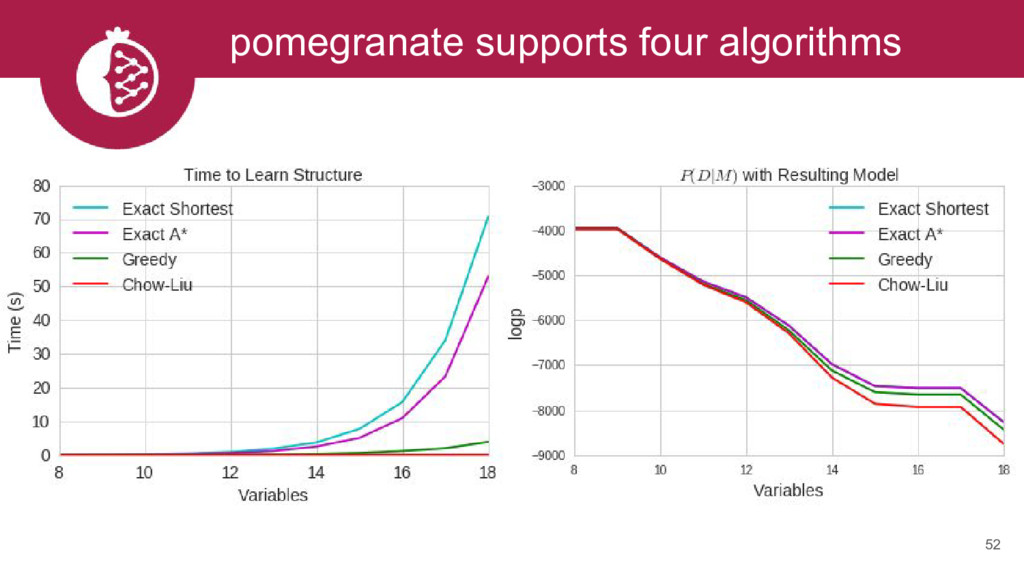{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
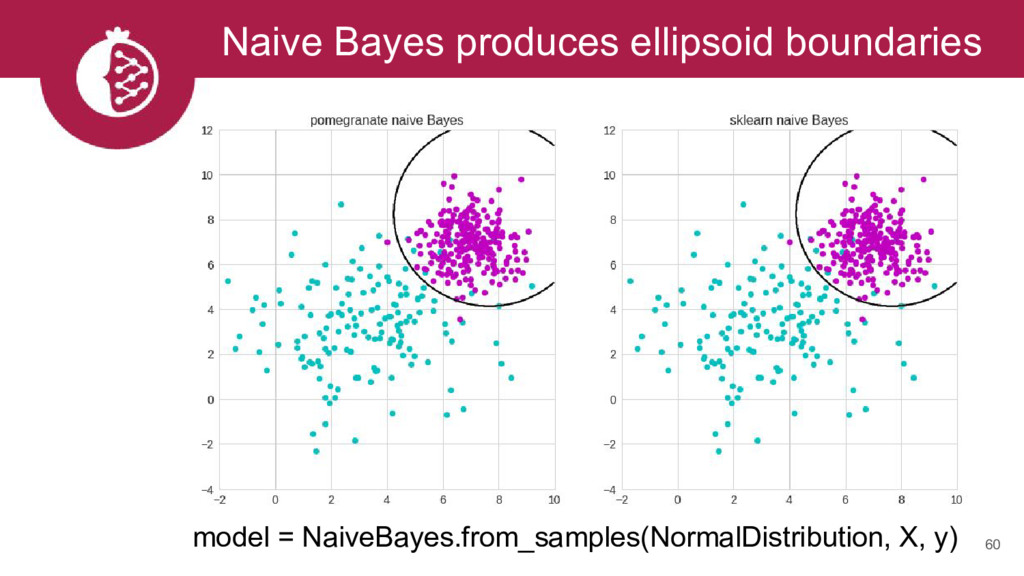{kind=link}
{kind=link}
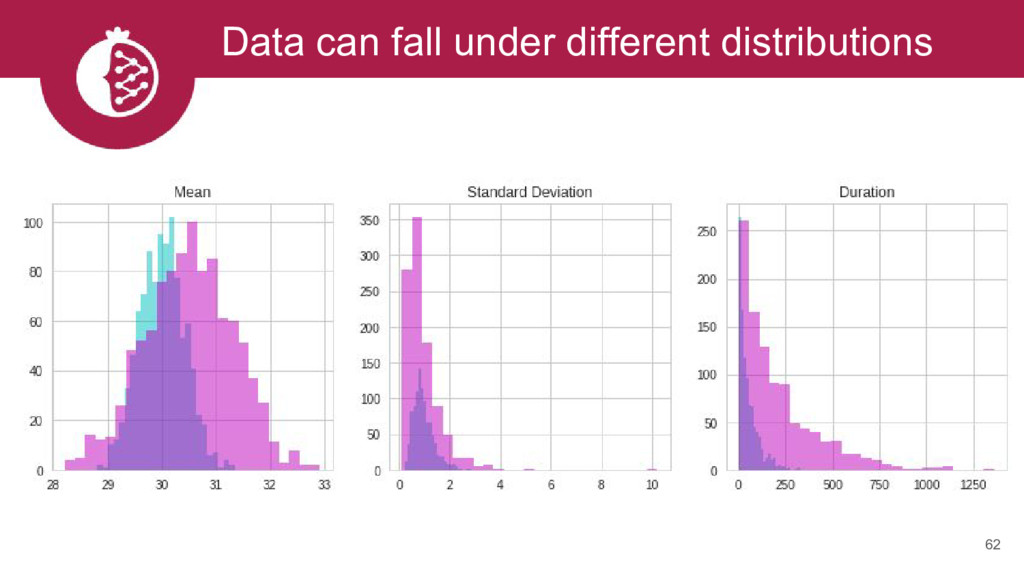{kind=link}
{kind=link}
{kind=link}
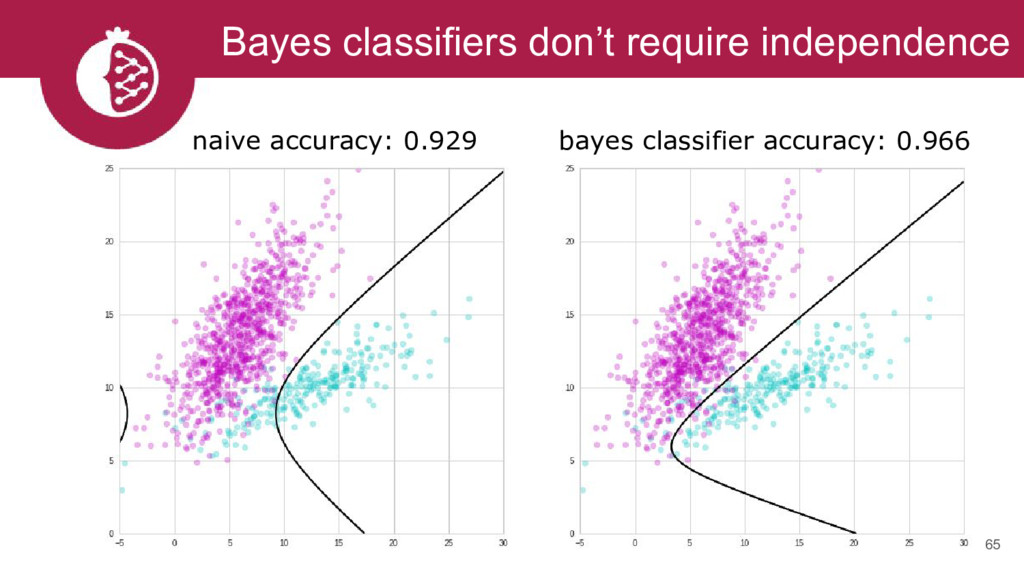{kind=link}
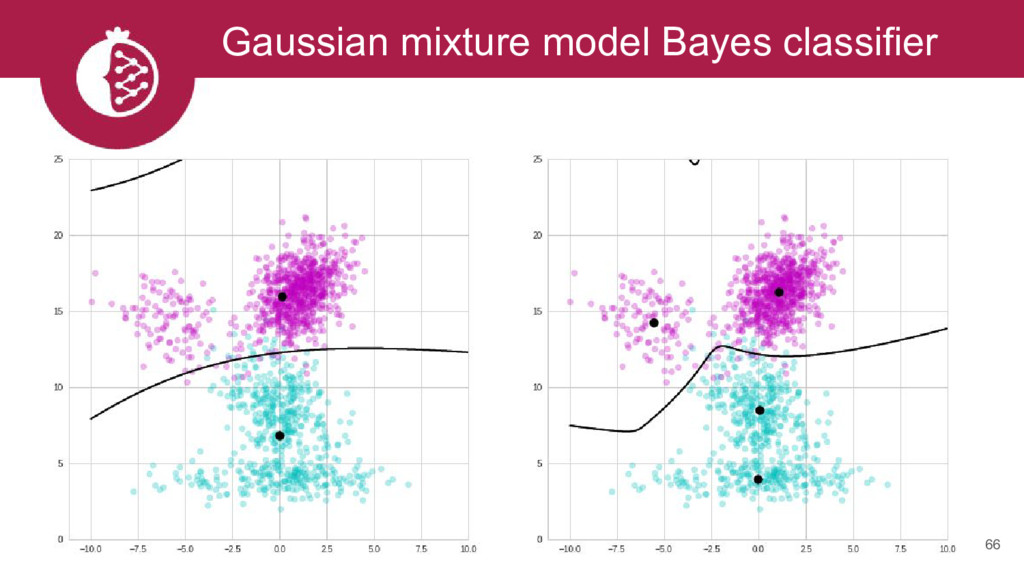{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
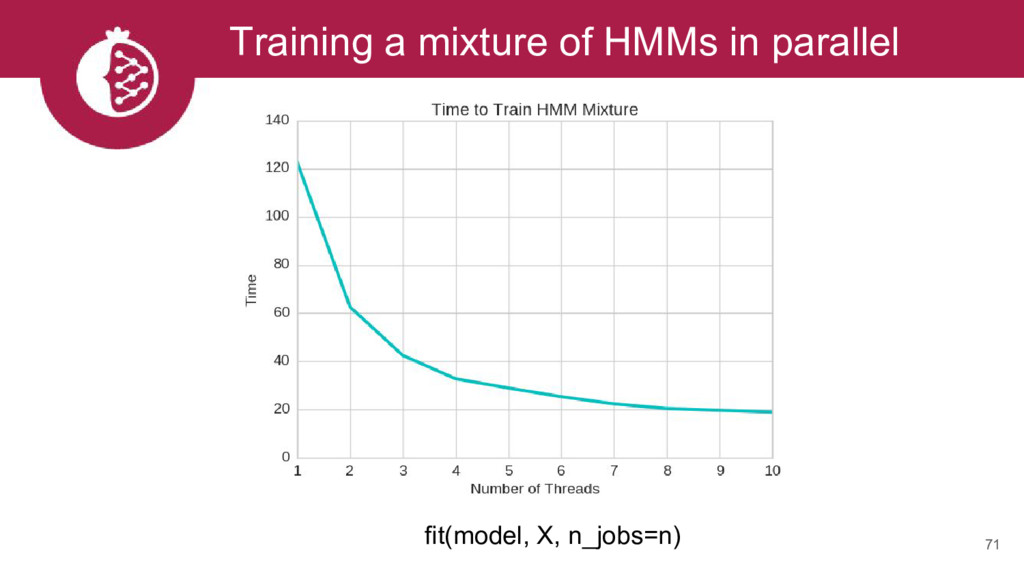{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}