Rebecca Bilbro Bytecubed & District Data Labs
Audience level: Intermediate
Topic area: Modeling
Description
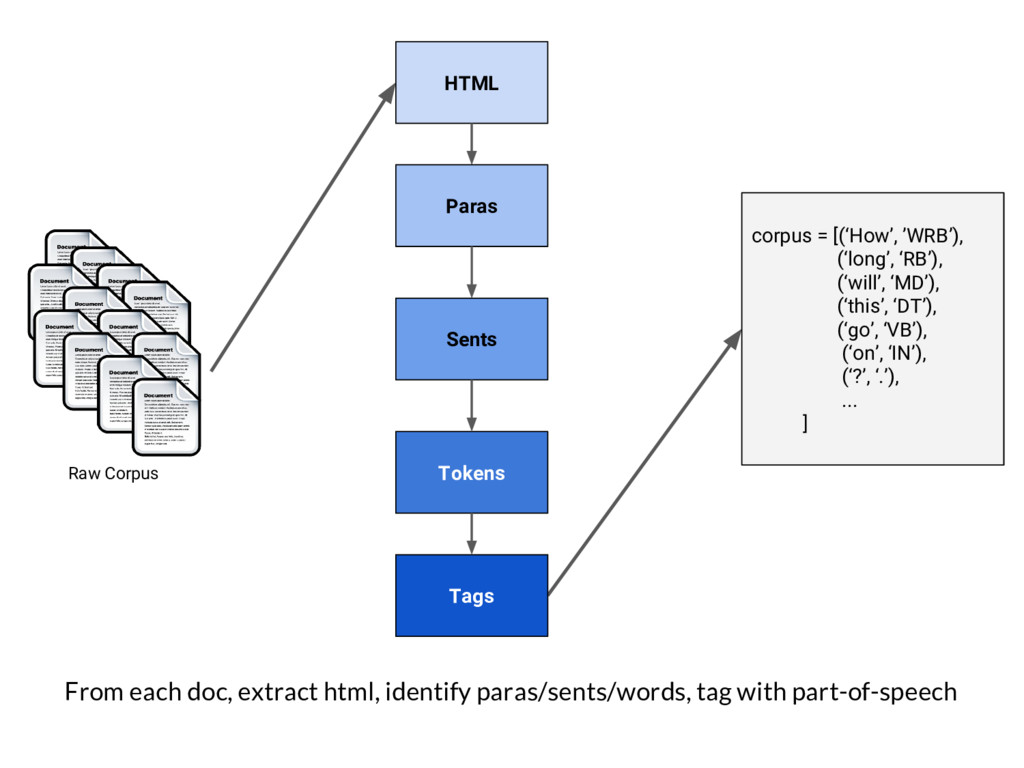
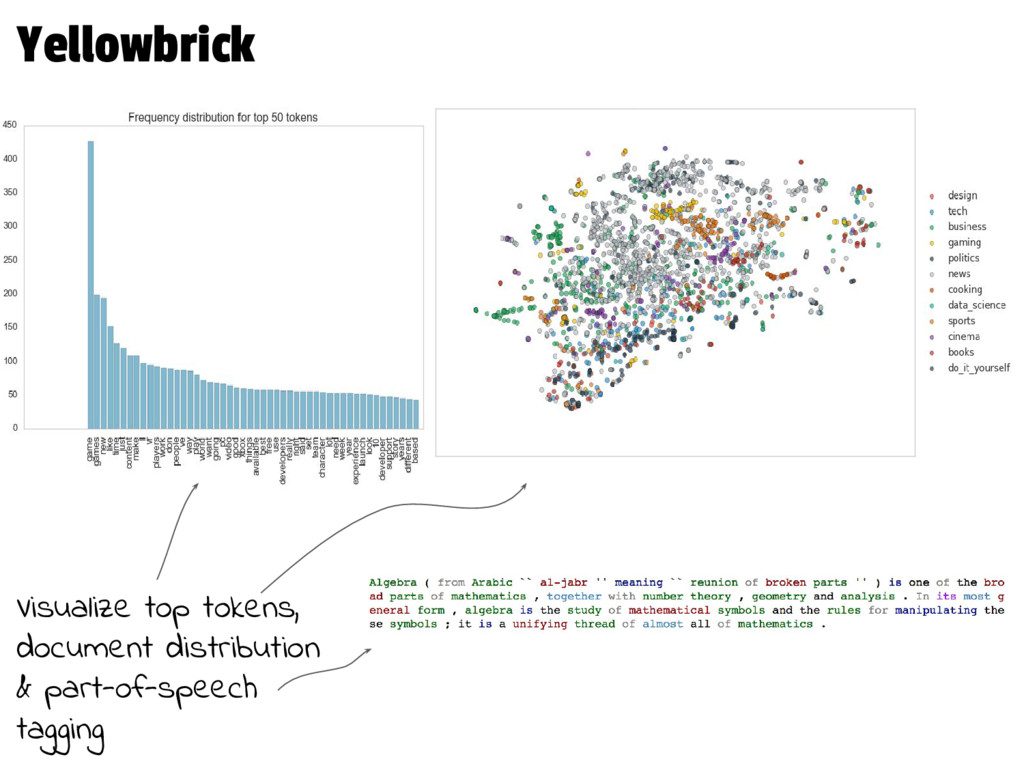
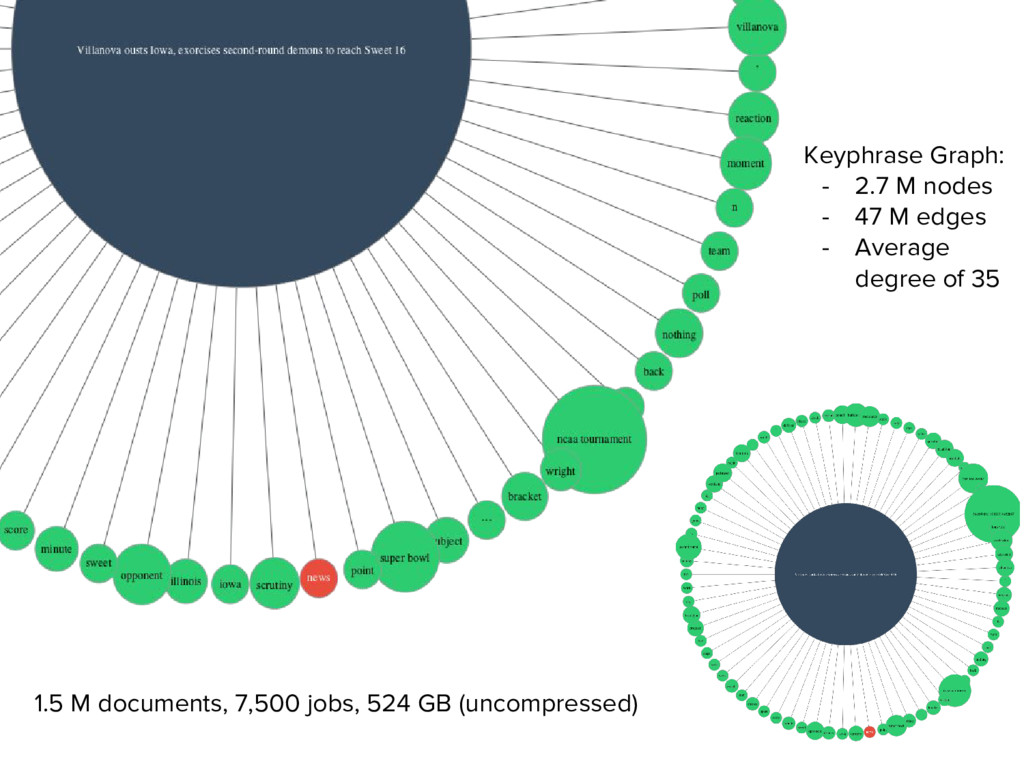
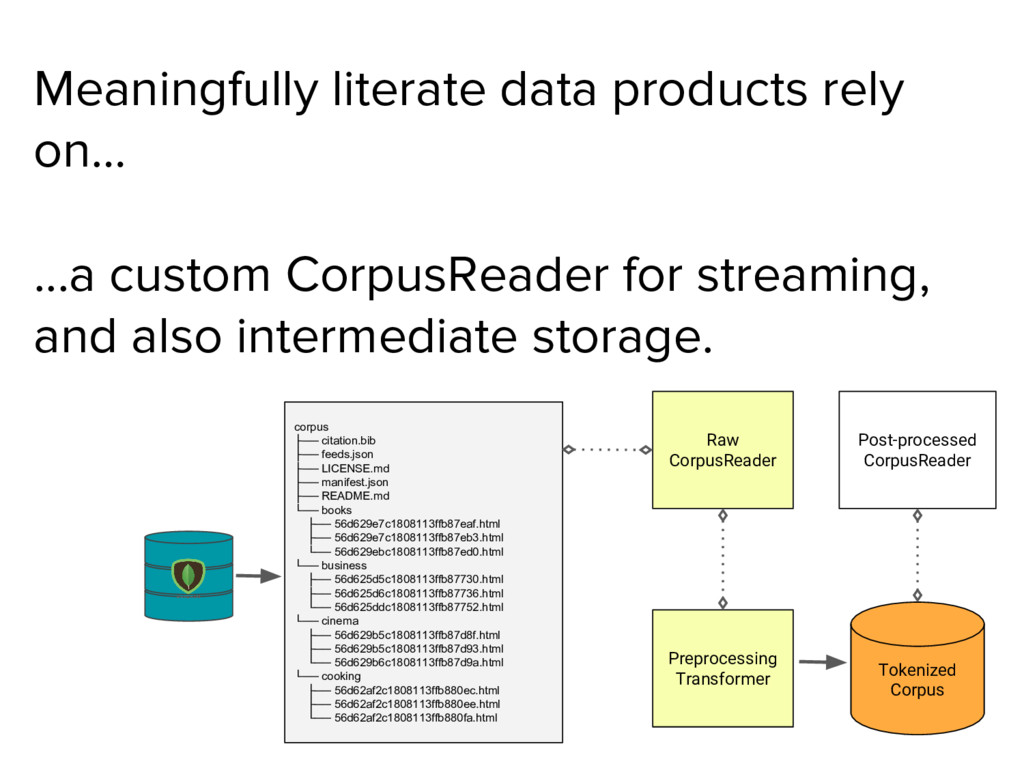
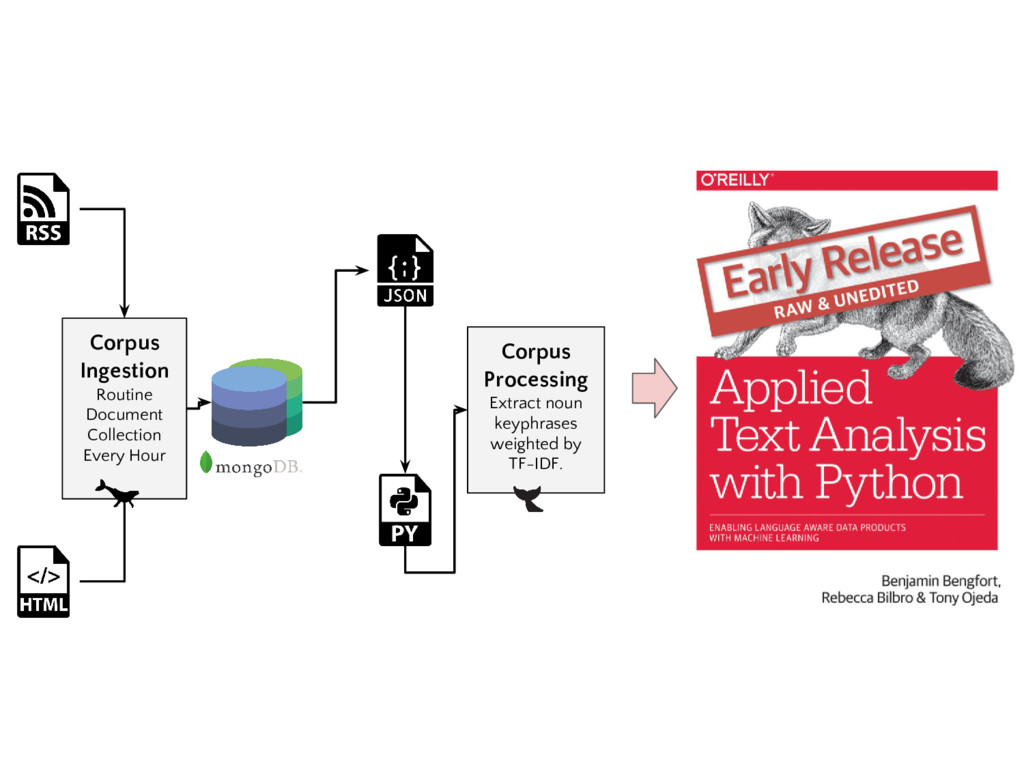
As the applications we build are increasingly driven by text, doing data ingestion, management, loading, and preprocessing in a robust, organized, parallel, and memory-safe way can get tricky. In this talk we walk through the highs (a custom billion-word corpus!), the lows (segfaults, 400 errors, pesky mp3s), and the new Python libraries we built to ingest and preprocess text for machine learning.
{kind=link}
{kind=link}
{kind=link}
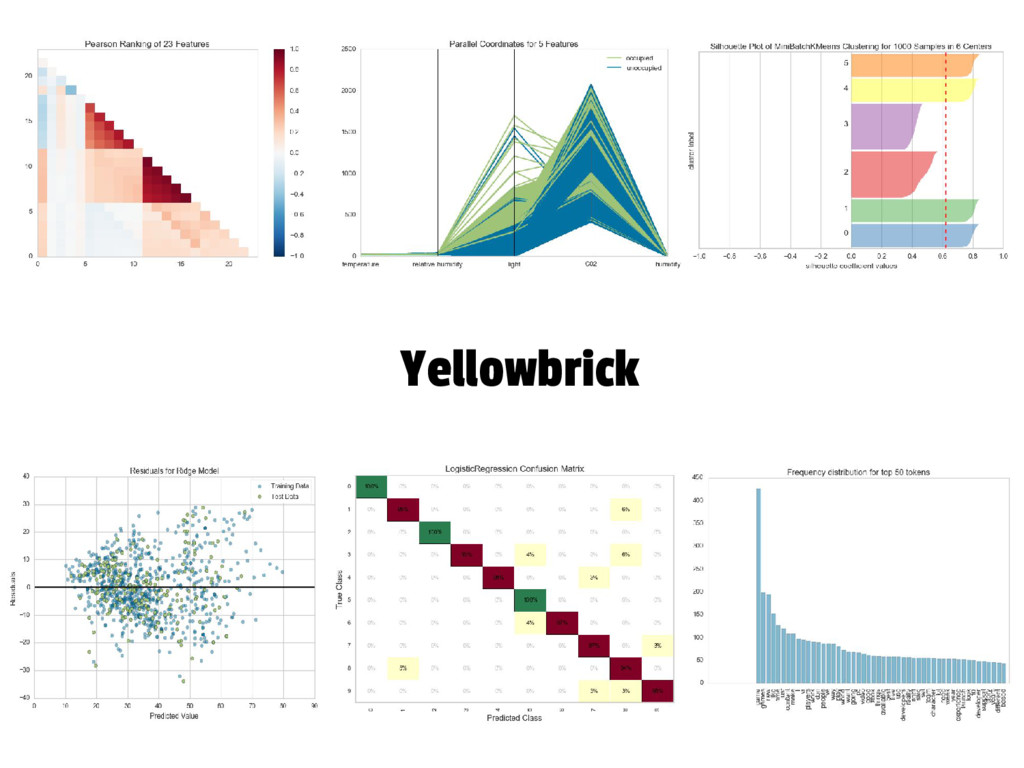{kind=link}
{kind=link}
{kind=link}
{kind=link}
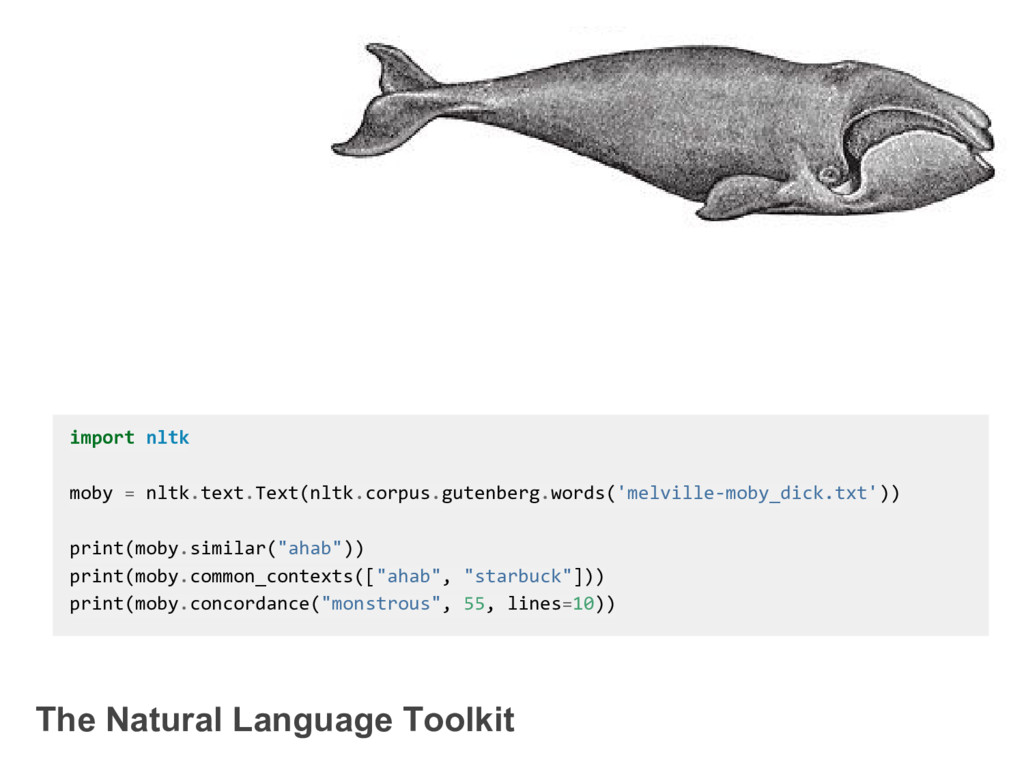{kind=link}
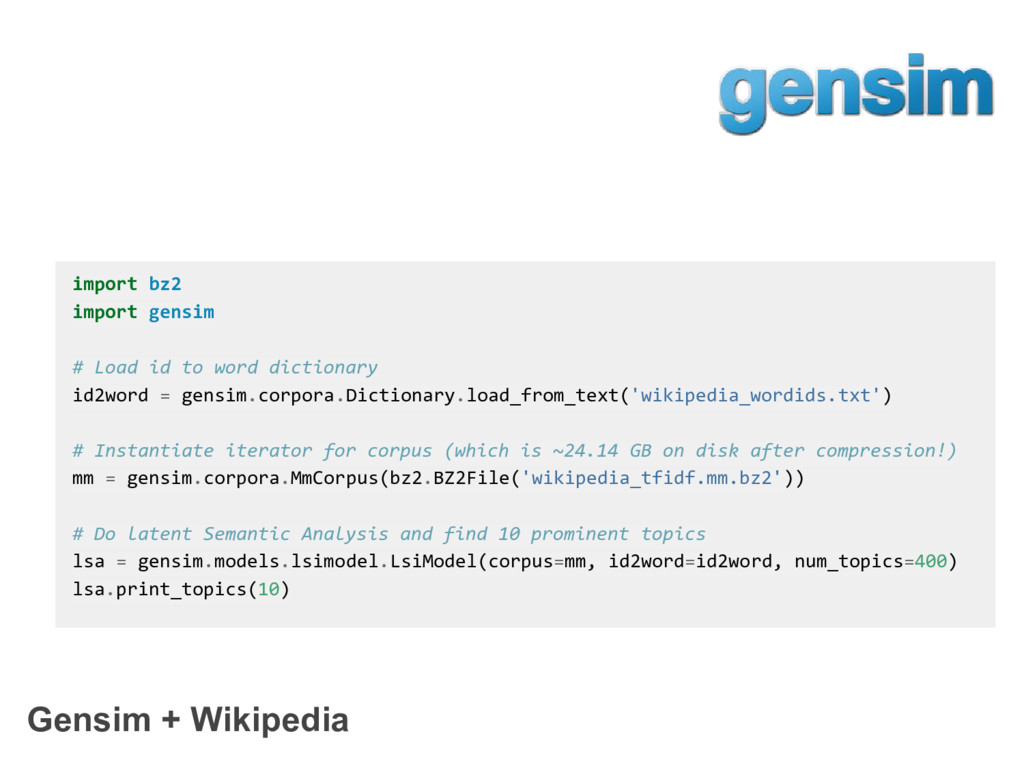{kind=link}
{kind=link}
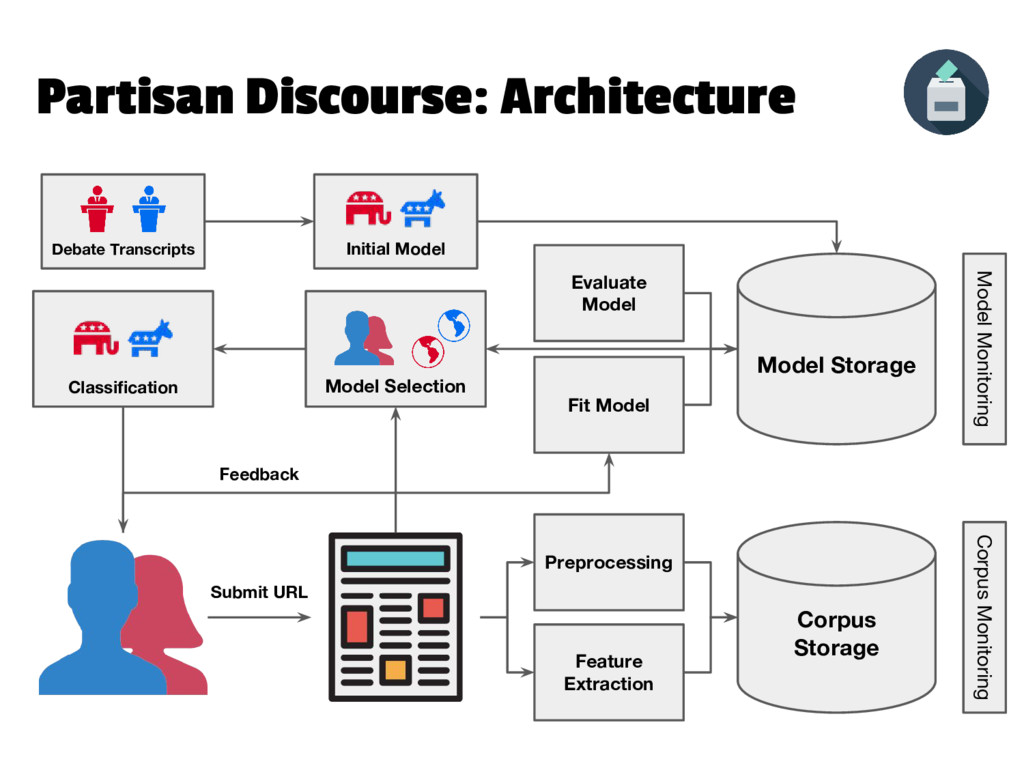{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank you! Rebecca Bilbro Twitter: twitter.com/rebeccabilbro Github: github.com/rebeccabilbro Email: [email protected]](https://files.speakerdeck.com/presentations/041b564bb0bd49128b0319a7bdeb93e2/slide_34.jpg){kind=link}