are run in AW Elastic MapReduce 15-30 different jobs running at any given time 2 c1.mediums running Thrift servers 10-12 nodes running in AWS HBase (0.92) c1.xlarges (8 cores, 7GB RAM, 1.6TB RAID0)
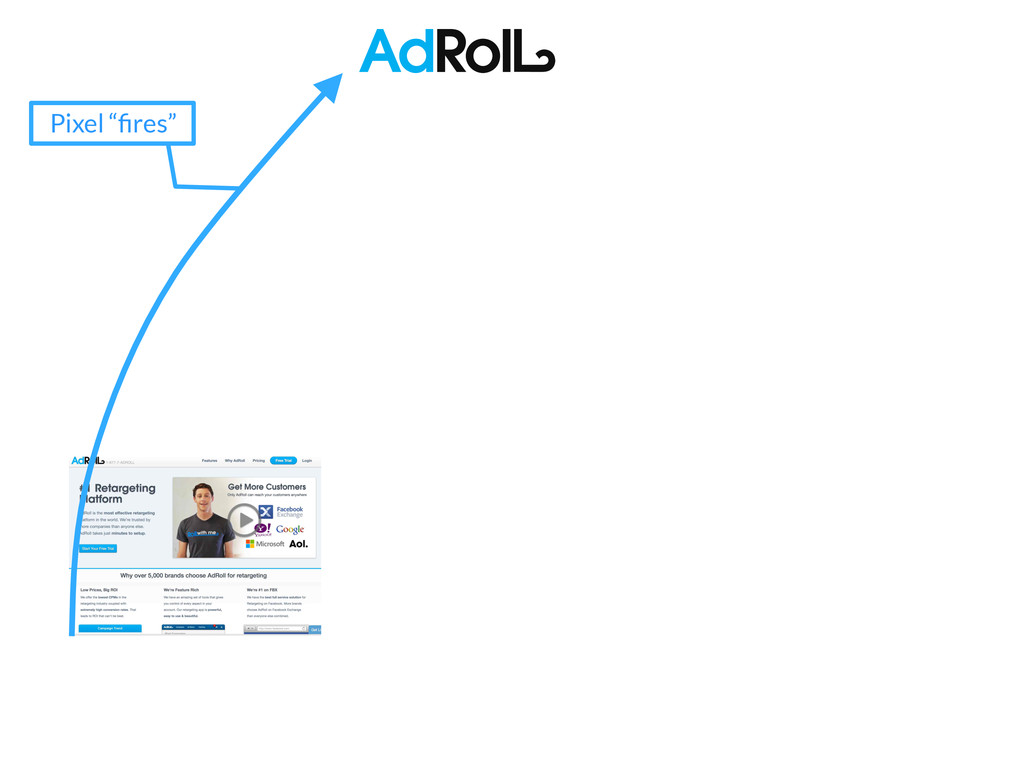
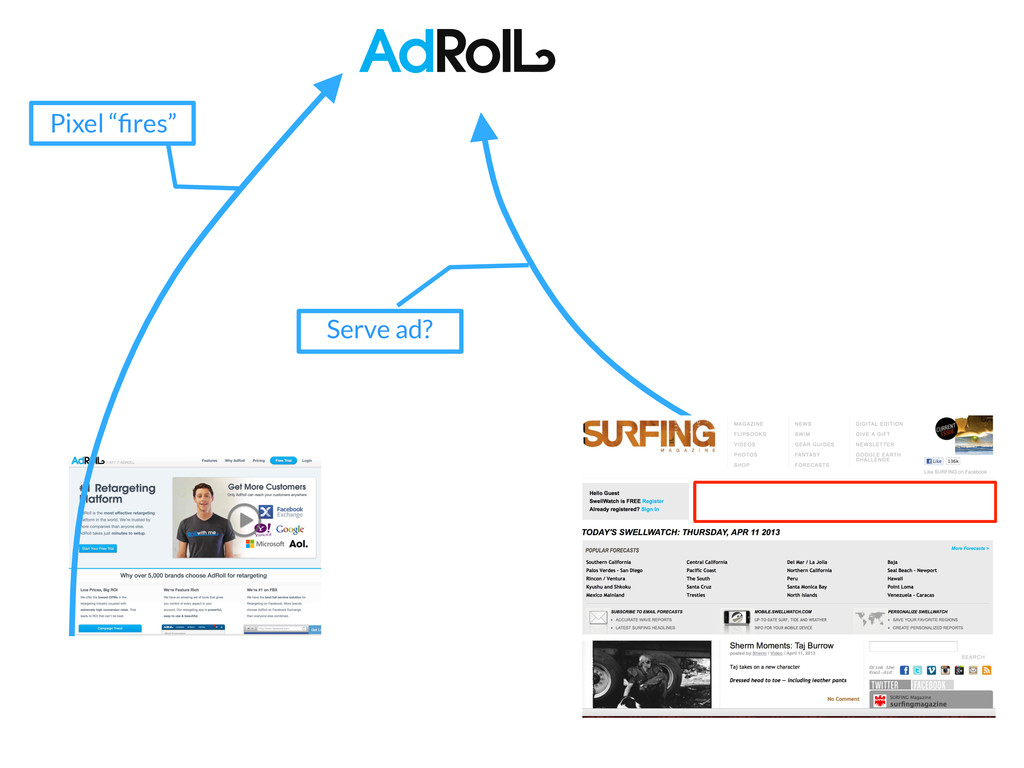
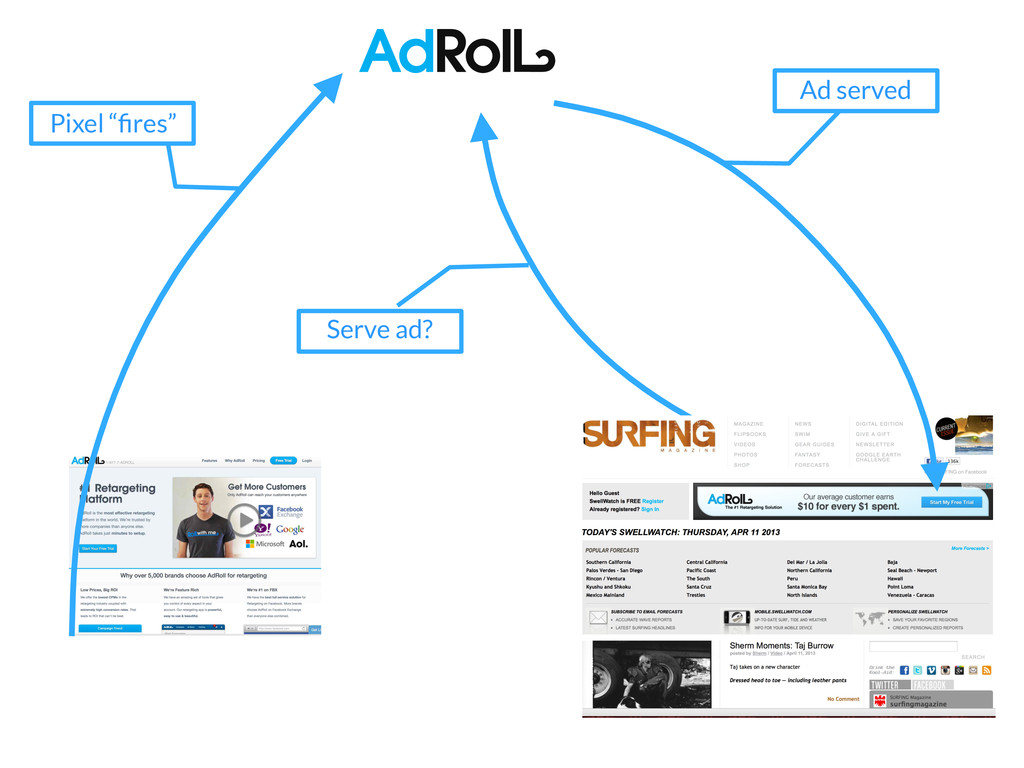
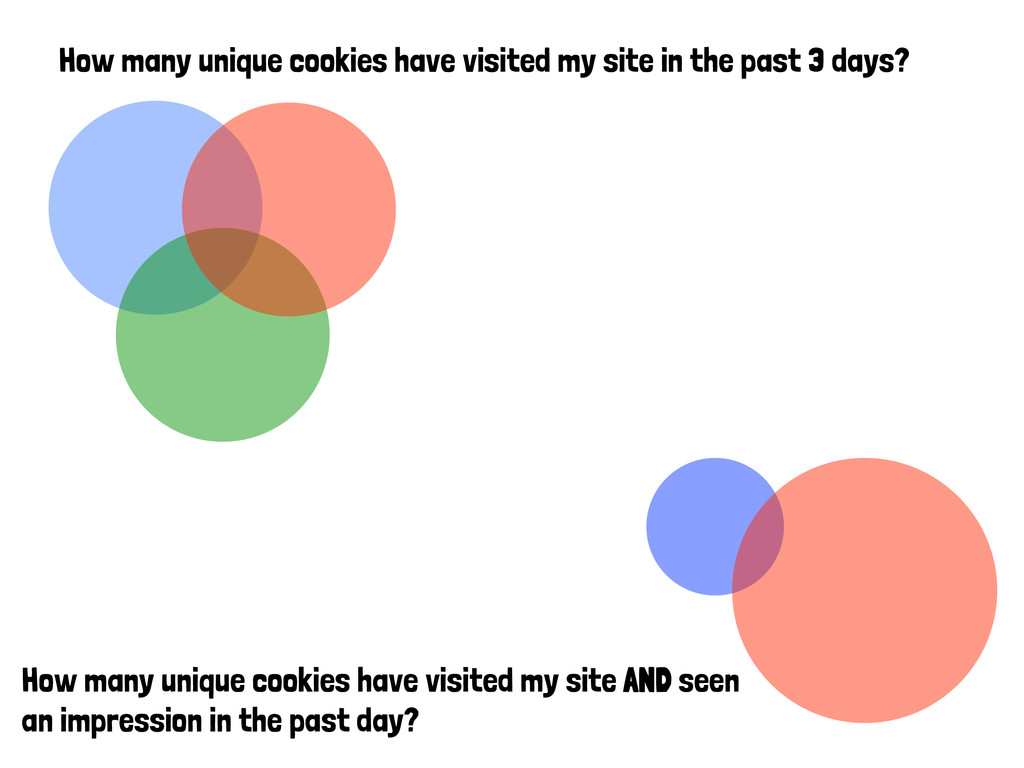
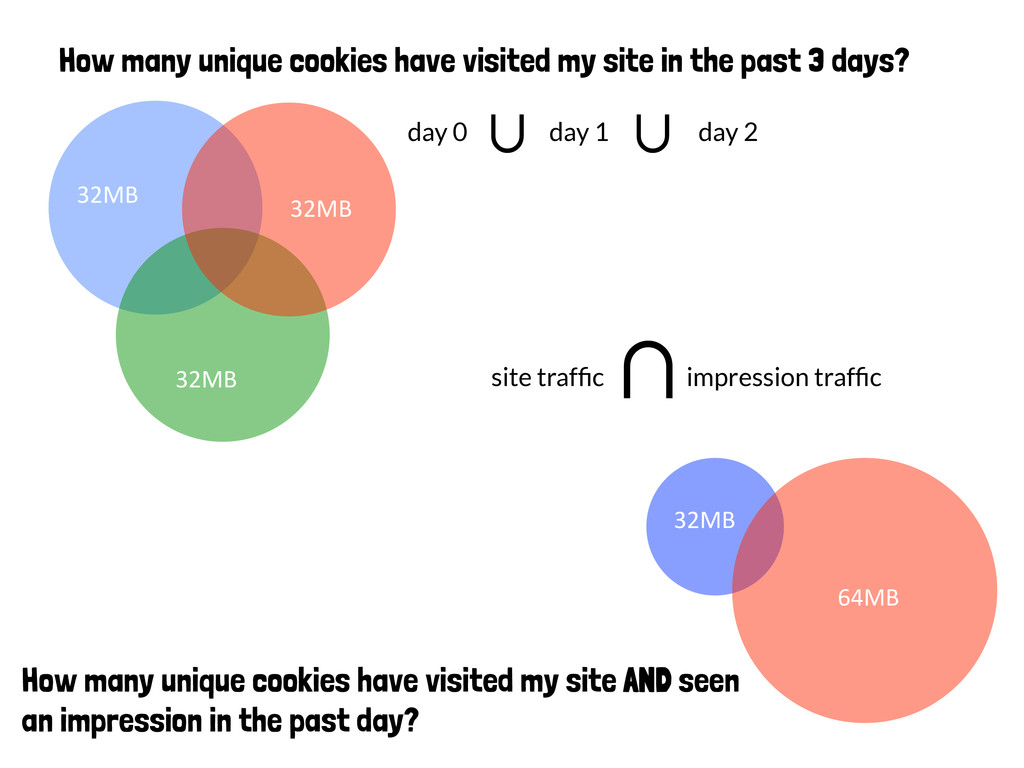
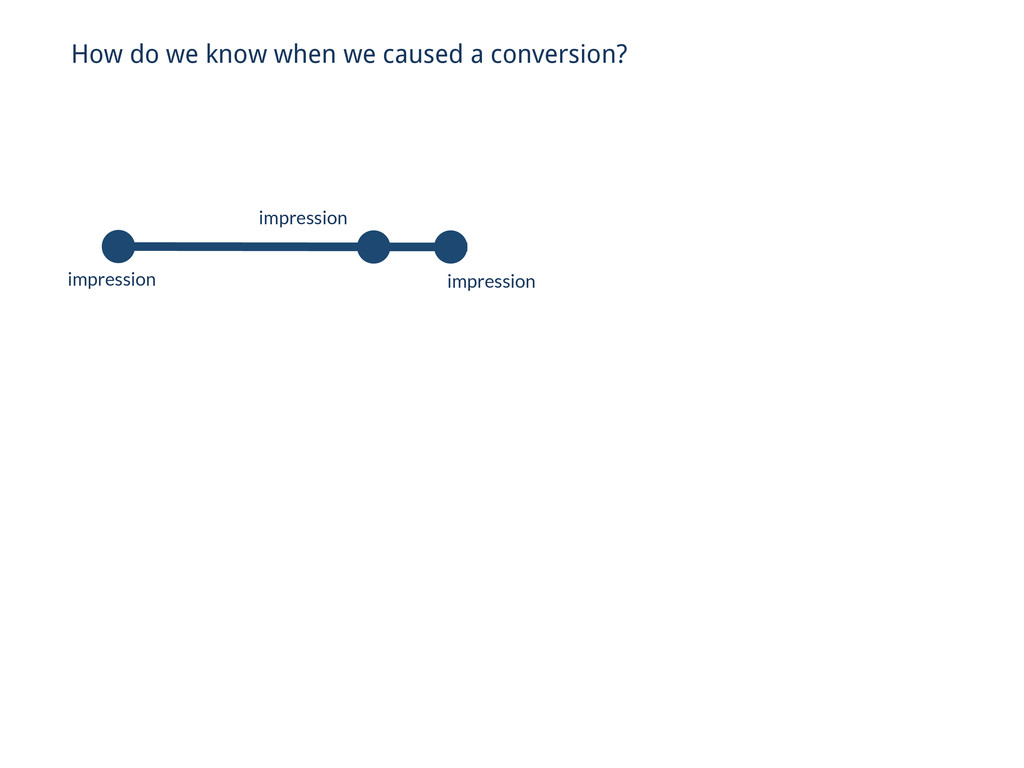
past 3 days? If I combine these two targe<ng lists, how many unique cookies will I be reaching? How many unique cookies have visited my site AND seen an impression in the past day?
past 3 days? How many unique cookies have visited my site AND seen an impression in the past day? ∪ day 2 day 0 day 1 ∪ ∪ site traffic impression traffic
past 3 days? How many unique cookies have visited my site AND seen an impression in the past day? ∪ day 2 day 0 day 1 ∪ 32MB 32MB 32MB 32MB 64MB ∪ site traffic impression traffic
visited my site in the past 3 days? How many unique cookies have visited my site AND seen an impression in the past day? ∪ day 2 day 0 day 1 ∪ 32MB 32MB 32MB 32MB 64MB ✗
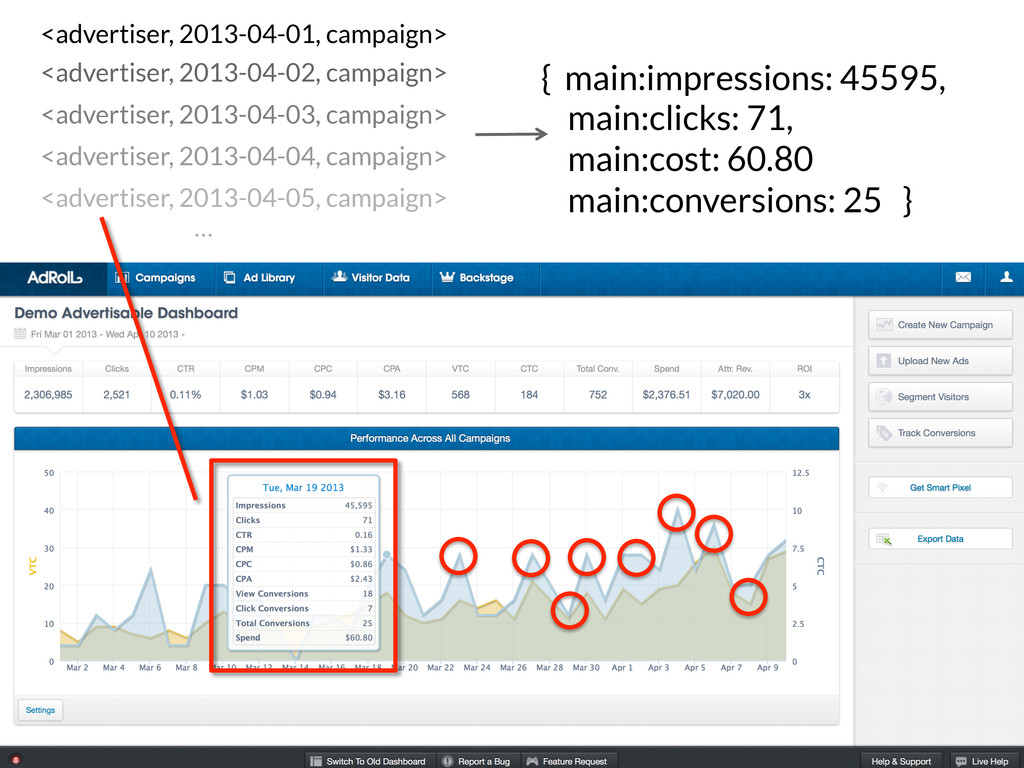
(Text cookie : cookies) { hll.put(cookie.get()); } key.set(advertiser, day); Put put = new Put(); put.add(Bytes.toBytes(“main”), Bytes.toBytes(hll)); // Put it into HBase context.write(row, put); // Mapping over some log data context.write(advertiser, cookie); // Building the HLL counters with Hadoop
<adver<ser0, day2> HLLCounter2 <adver<ser1, day0> HLLCounter0 <adver<ser1, day1> HLLCounter1 key value // Reducer HLLCounter hll = new HLLCounter(); for (Text cookie : cookies) { hll.put(cookie.get()); } key.set(advertiser, day); Put put = new Put(); put.add(Bytes.toBytes(“main”), Bytes.toBytes(hll)); // Put it into HBase context.write(row, put); // Mapping over some log data context.write(advertiser, cookie); // Building the HLL counters with Hadoop
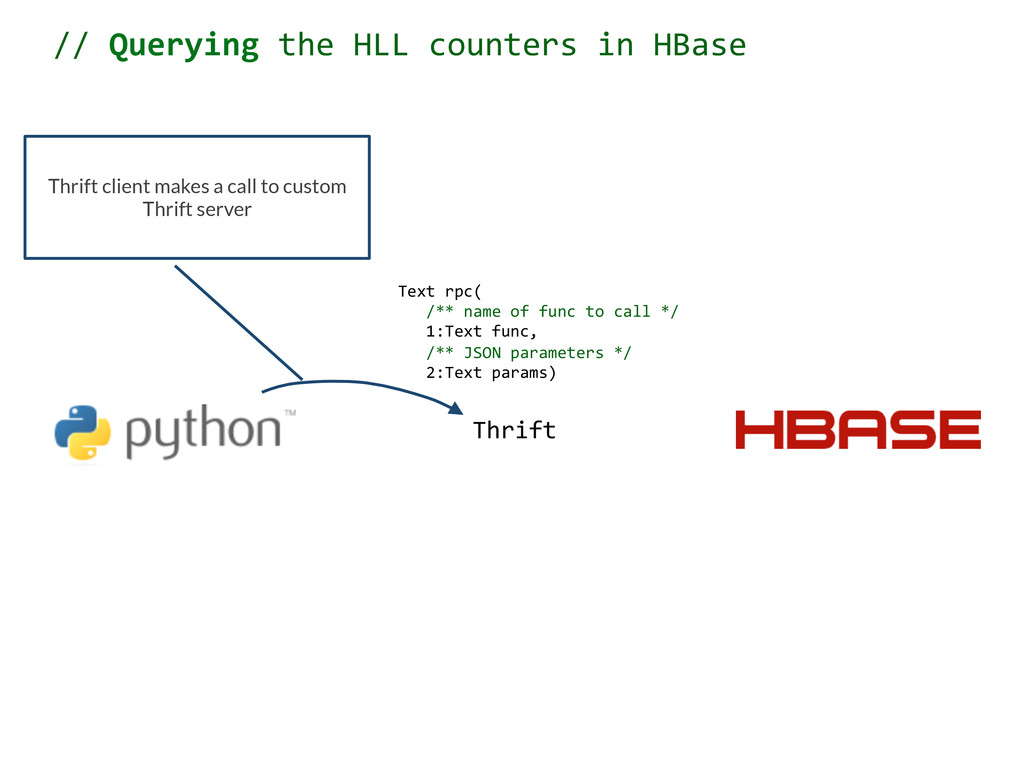
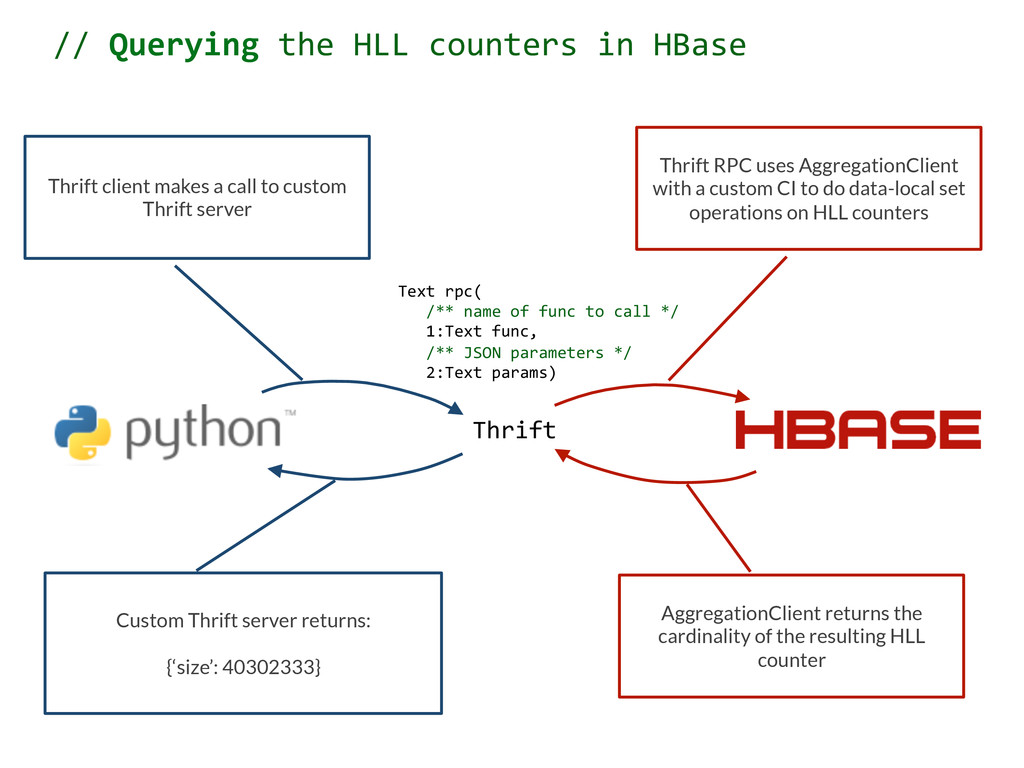
to call */ 1:Text func, /** JSON parameters */ 2:Text params) Thrift Thrift client makes a call to custom Thrift server // Querying the HLL counters in HBase
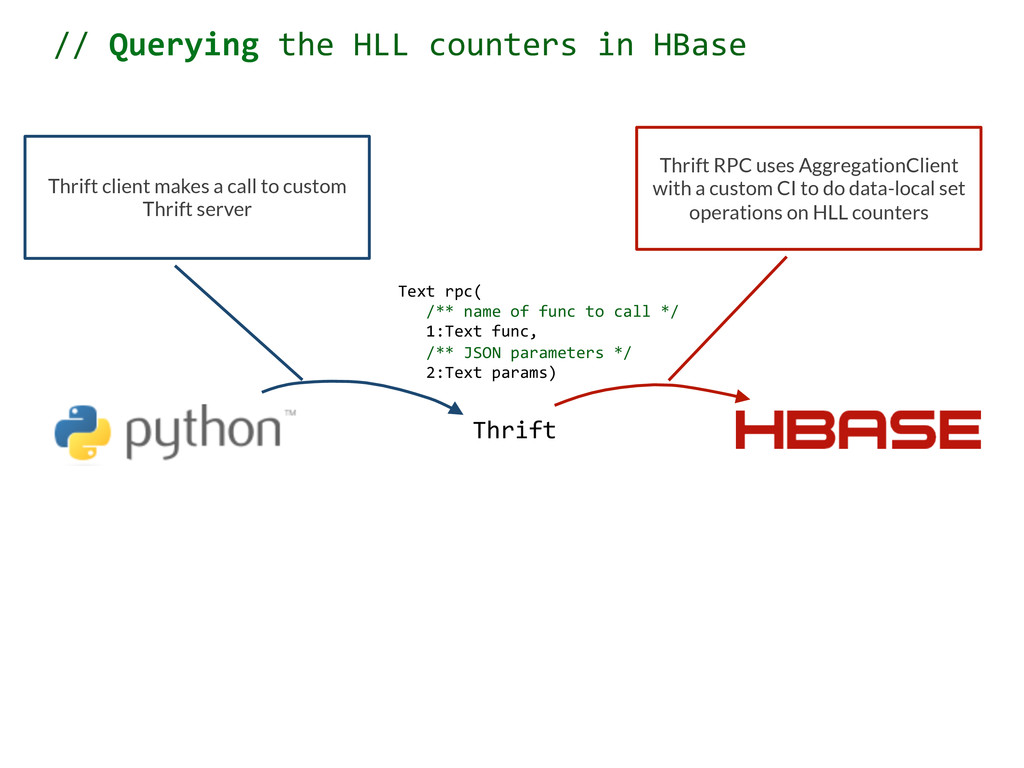
server Thrift RPC uses AggregationClient with a custom CI to do data-local set operations on HLL counters Text rpc( /** name of func to call */ 1:Text func, /** JSON parameters */ 2:Text params) // Querying the HLL counters in HBase
server Thrift RPC uses AggregationClient with a custom CI to do data-local set operations on HLL counters AggregationClient returns the cardinality of the resulting HLL counter Text rpc( /** name of func to call */ 1:Text func, /** JSON parameters */ 2:Text params) // Querying the HLL counters in HBase
server Custom Thrift server returns: {‘size’: 40302333} Thrift RPC uses AggregationClient with a custom CI to do data-local set operations on HLL counters AggregationClient returns the cardinality of the resulting HLL counter Text rpc( /** name of func to call */ 1:Text func, /** JSON parameters */ 2:Text params) // Querying the HLL counters in HBase
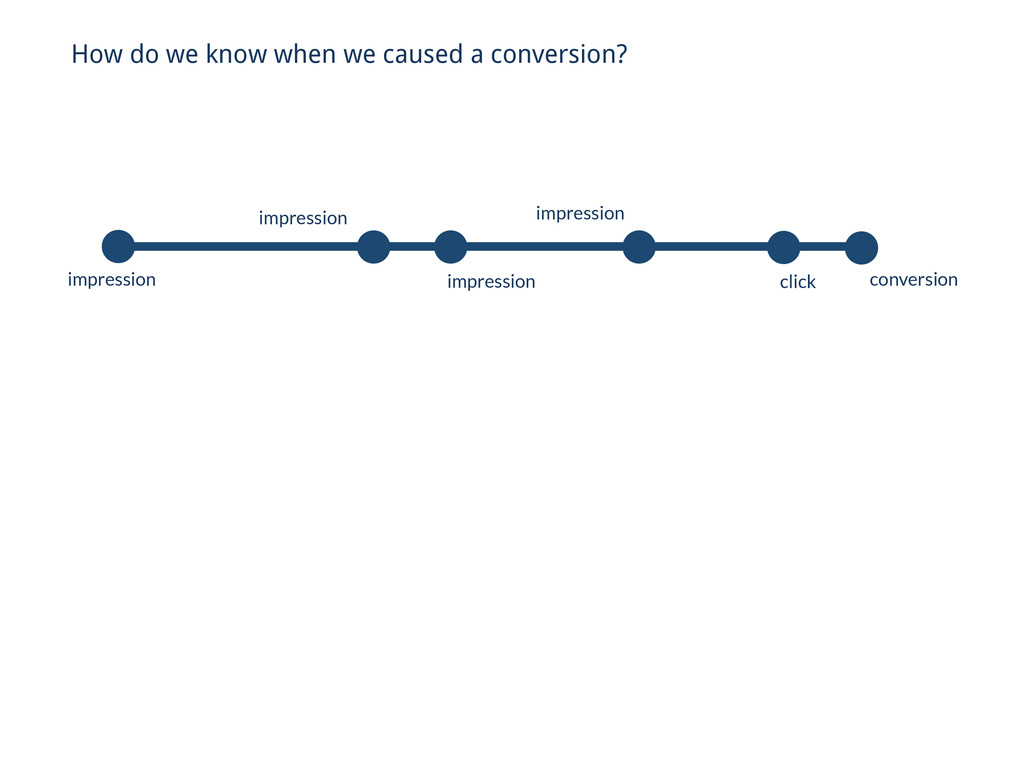
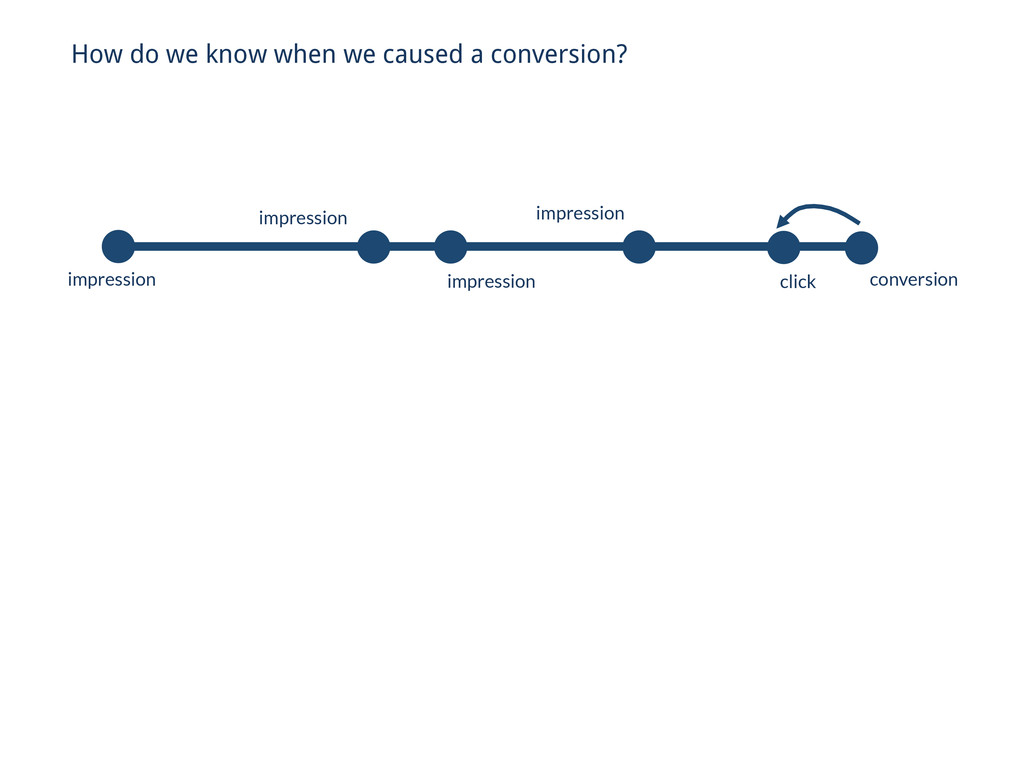
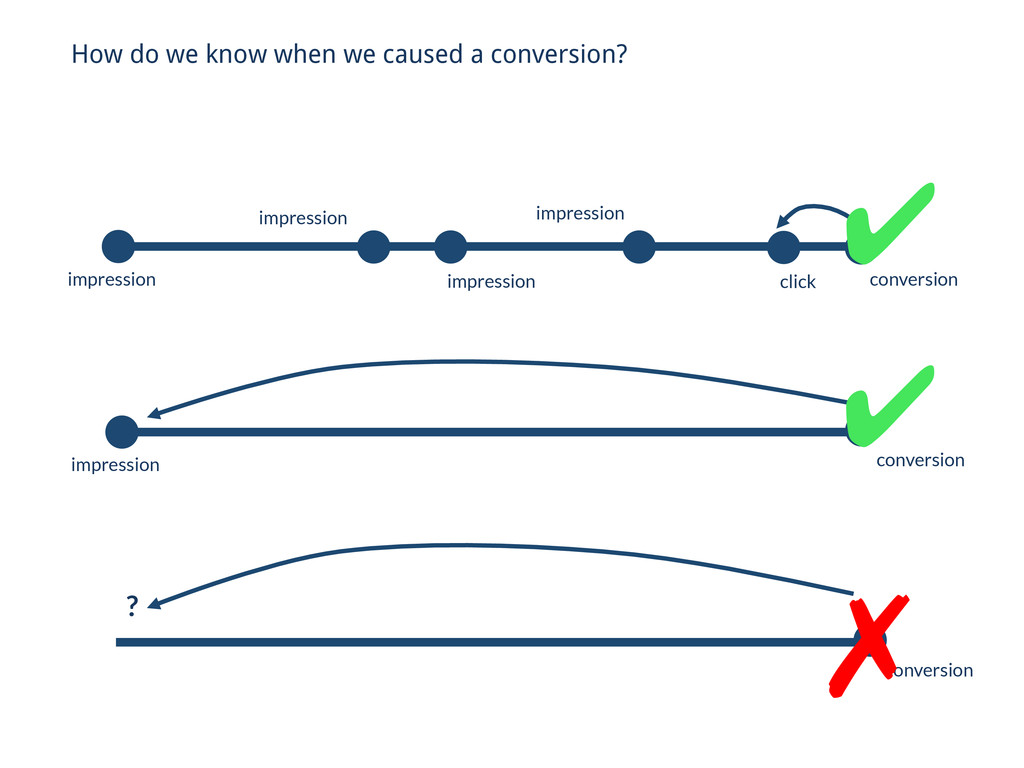
// Reducin’ Collections.sort(events, BY_TIMESTAMP_ASC); Event lastEvent = null; // Iterate over the last 30 days of this cookie’s traffic for (Event ev : ev) { if (isConversionEvent(ev)) { if (lastEvent != null) { context.write(cookie, ev); } } } // . . . // Naïve approach using only Hadoop
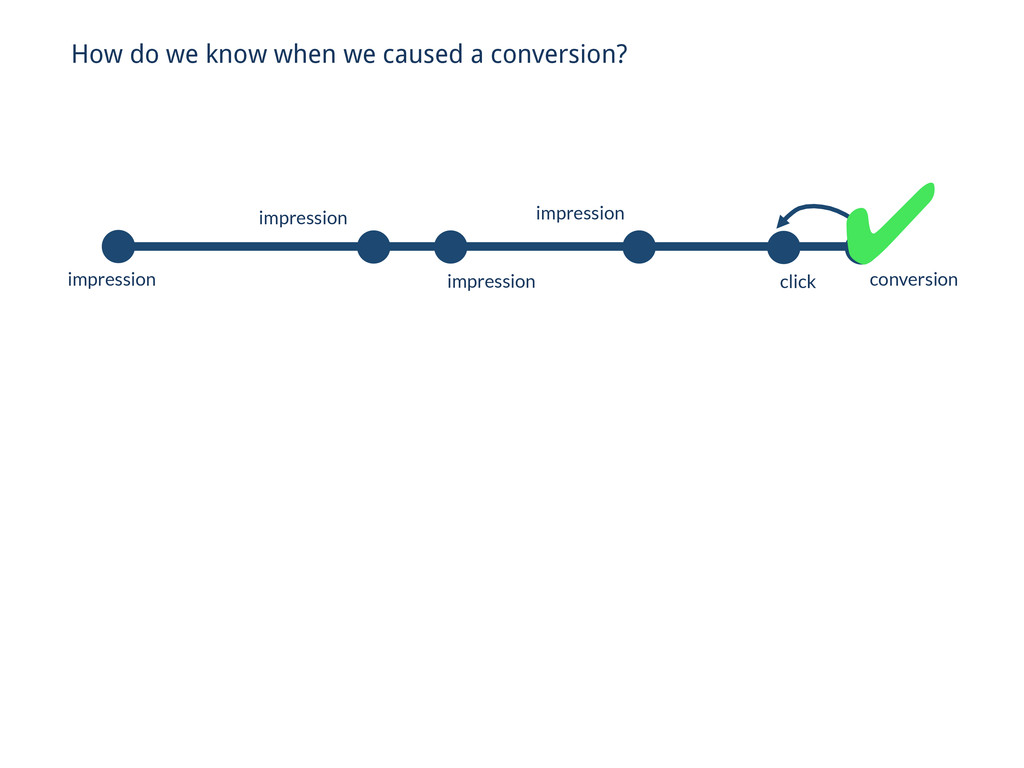
days you looked at the previous day • If only we had random access into all possible conversion triggering events… // Problems… • We’d only need to look at the day we’re generating conversions for…
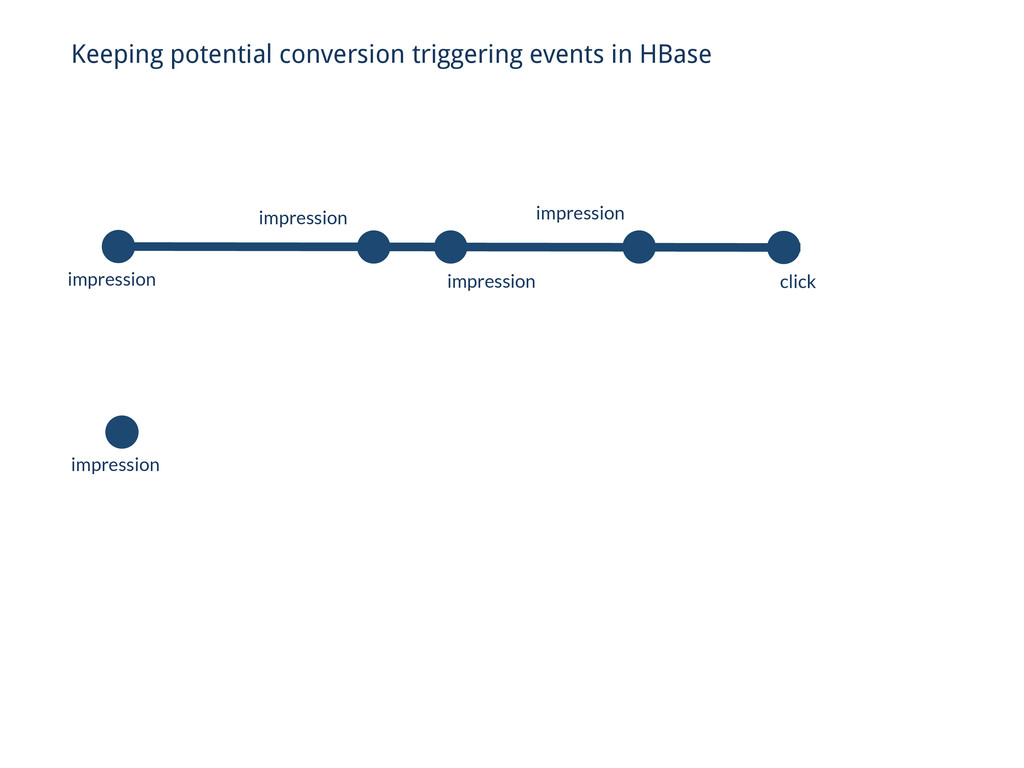
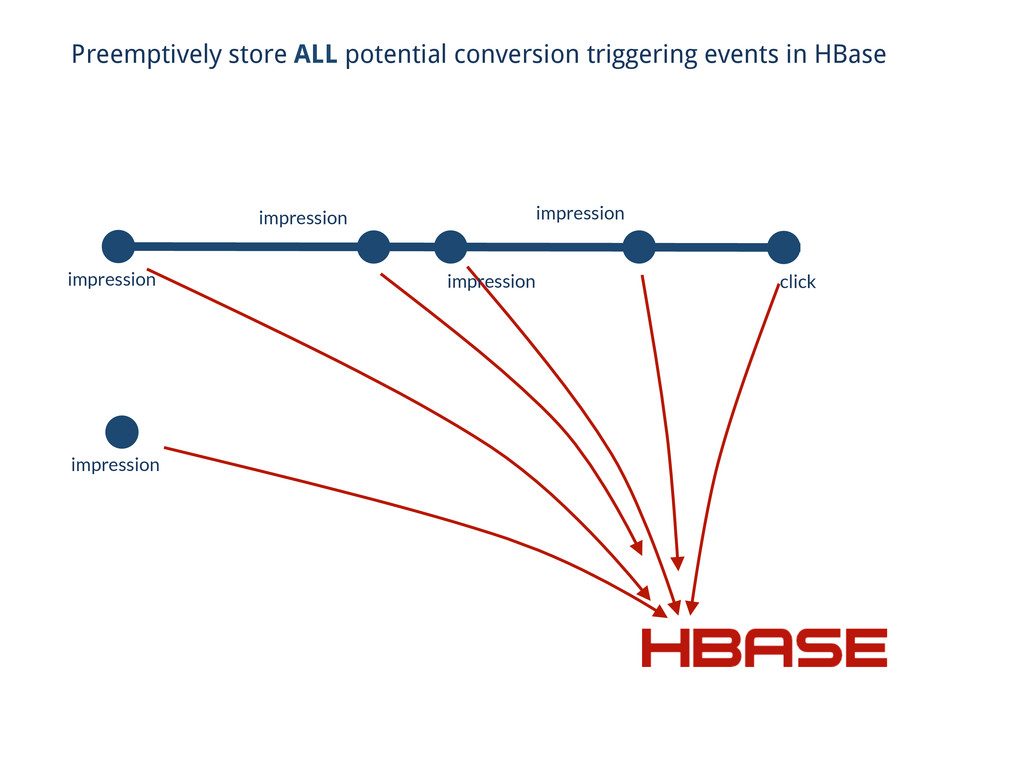
(isConversionEvent) { context.write(cookie, event); } // Reducin’ Get get = new Get(Bytes.toBytes(cookie)); get.setMaxVersions(10000); Result row = triggers.get(get); List<Event> events = rowToEvents(row); // Iterate over the last 30 days of this cookie’s traffic for (Event ev : events) { if (isConversionEvent(ev)) { if (lastEvent != null) { context.write(cookie, ev); } } } // . . . // Better approach using Hadoop + HBase
(isConversionEvent) { context.write(cookie, event); } Get get = new Get(Bytes.toBytes(cookie)); get.setMaxVersions(10000); Result row = triggers.get(get); List<Event> events = rowToEvents(row); // Iterate over the last 30 days of this cookie’s traffic for (Event ev : events) { if (isConversionEvent(ev)) { if (lastEvent != null) { context.write(cookie, ev); } } } // Better approach using Hadoop + HBase impression impression impression impression click conversion
to consume it sequentially all at once • Build interesting data structures with Hadoop, and store them in HBase for querying (remember to customize your Thrift handler here) So…
to consume it sequentially all at once • Build interesting data structures with Hadoop, and store them in HBase for querying • Use HBase to keep state between MapReduce jobs (remember to customize your Thrift handler here) So…
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![? [email protected] Thank you! We’re hiring! [email protected] Derek Nelson](https://files.speakerdeck.com/presentations/70c040e0b76d01302488261a84a70afc/slide_58.jpg){kind=link}