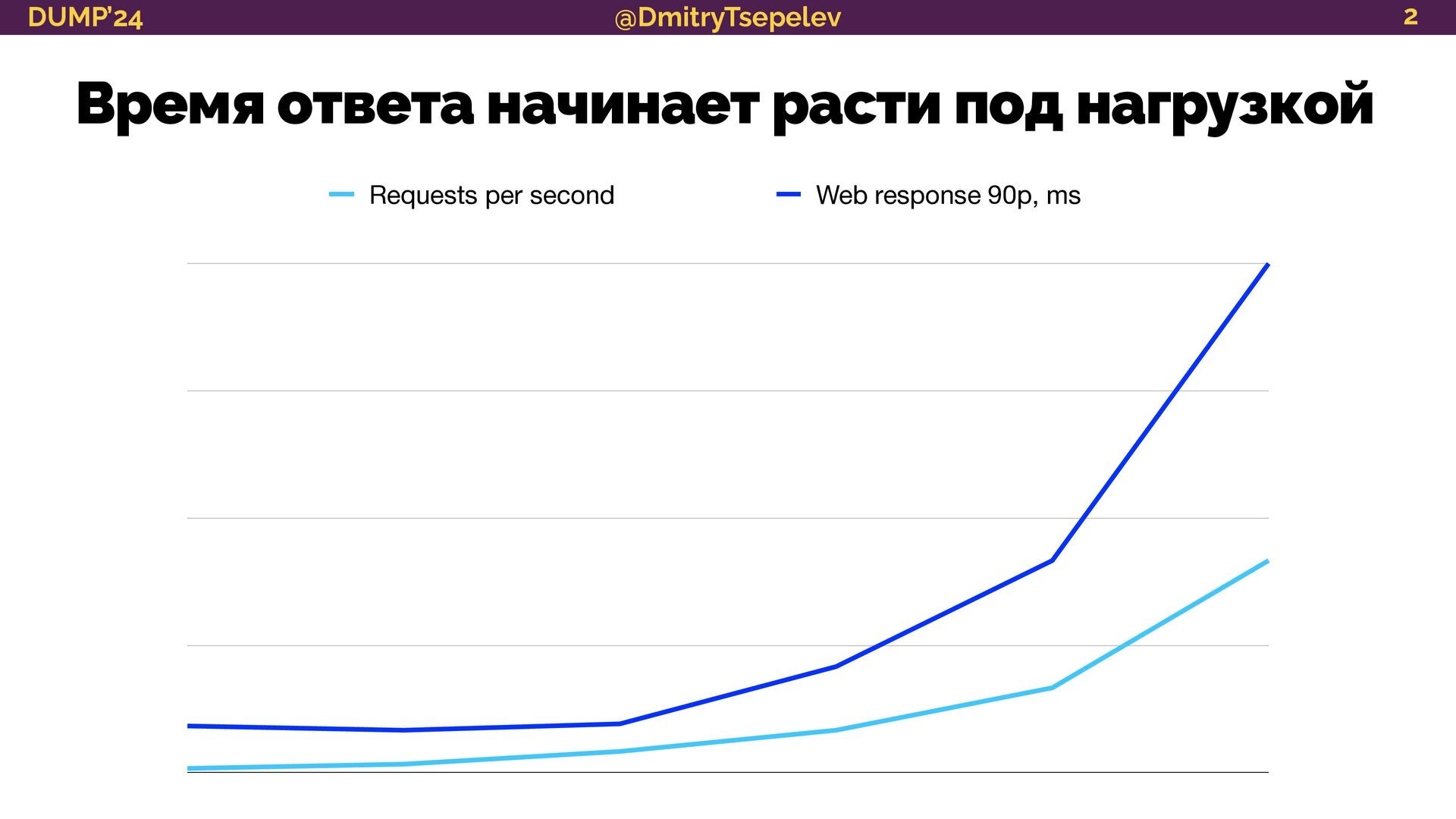
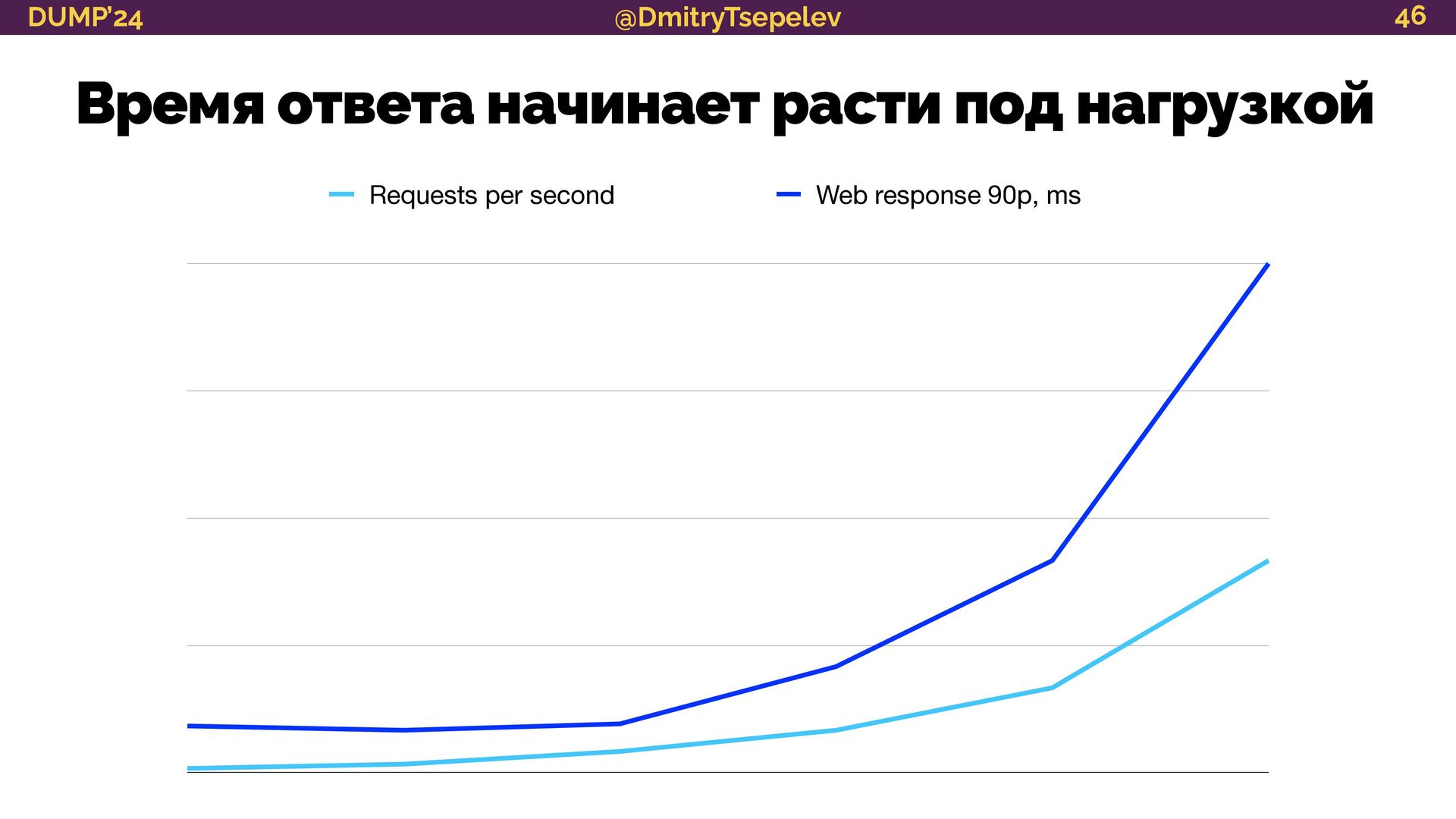
Почти у всех есть мониторинг. Часто он становится надёжным инструментом обнаружения неисправностей и их предотвращения на ранней стадии. Не менее часто в качестве мониторинга выступает APM на бесплатном плане с отчётами «из коробки», где что-то меряется, какие-то алерты падают в чат, никто на них не реагирует, и в один прекрасный солнечный день приложение ложится так, что поднимать его приходится до поздней ночи.
В докладе:
обсудим антипаттерны мониторинга;
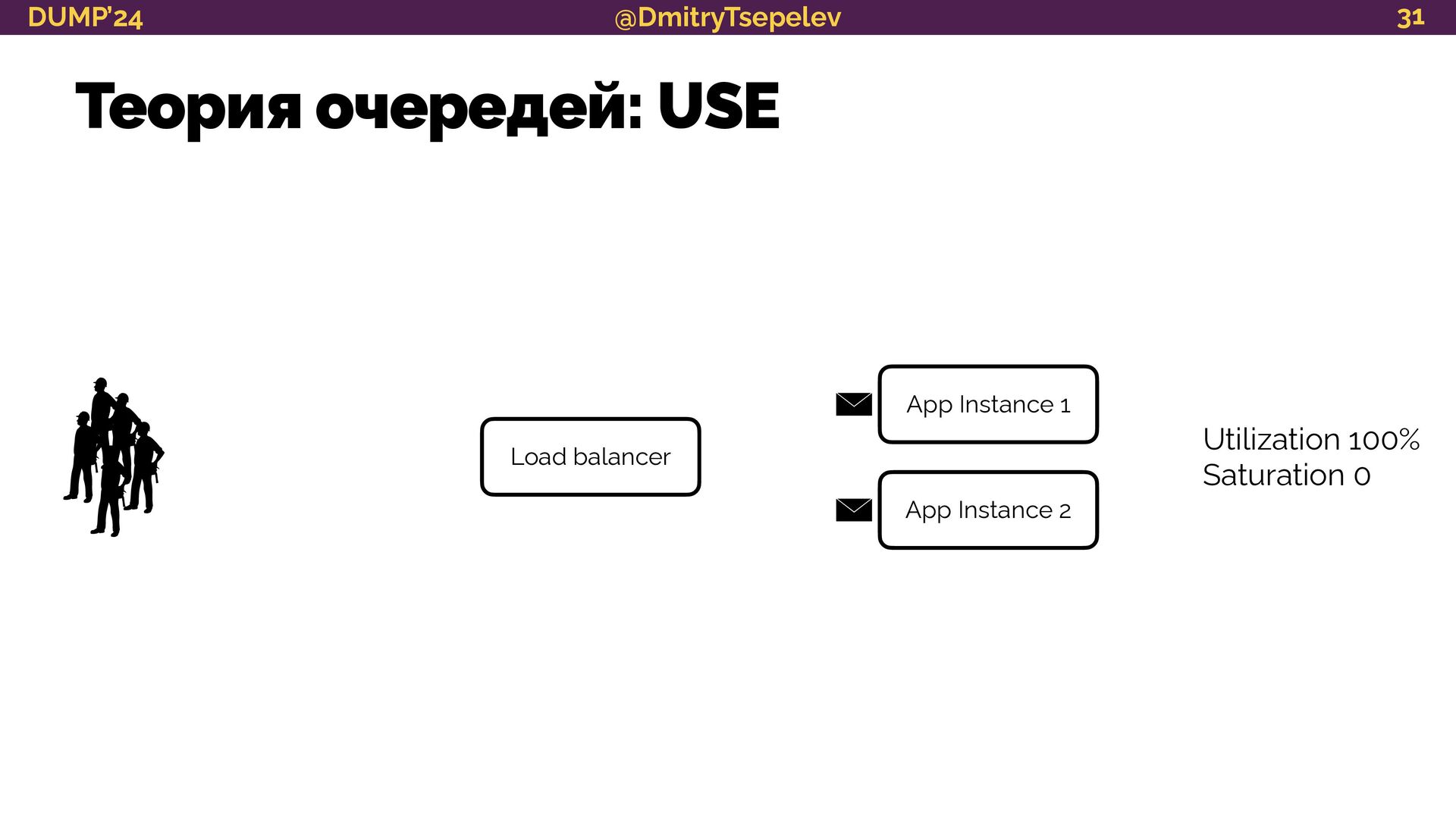
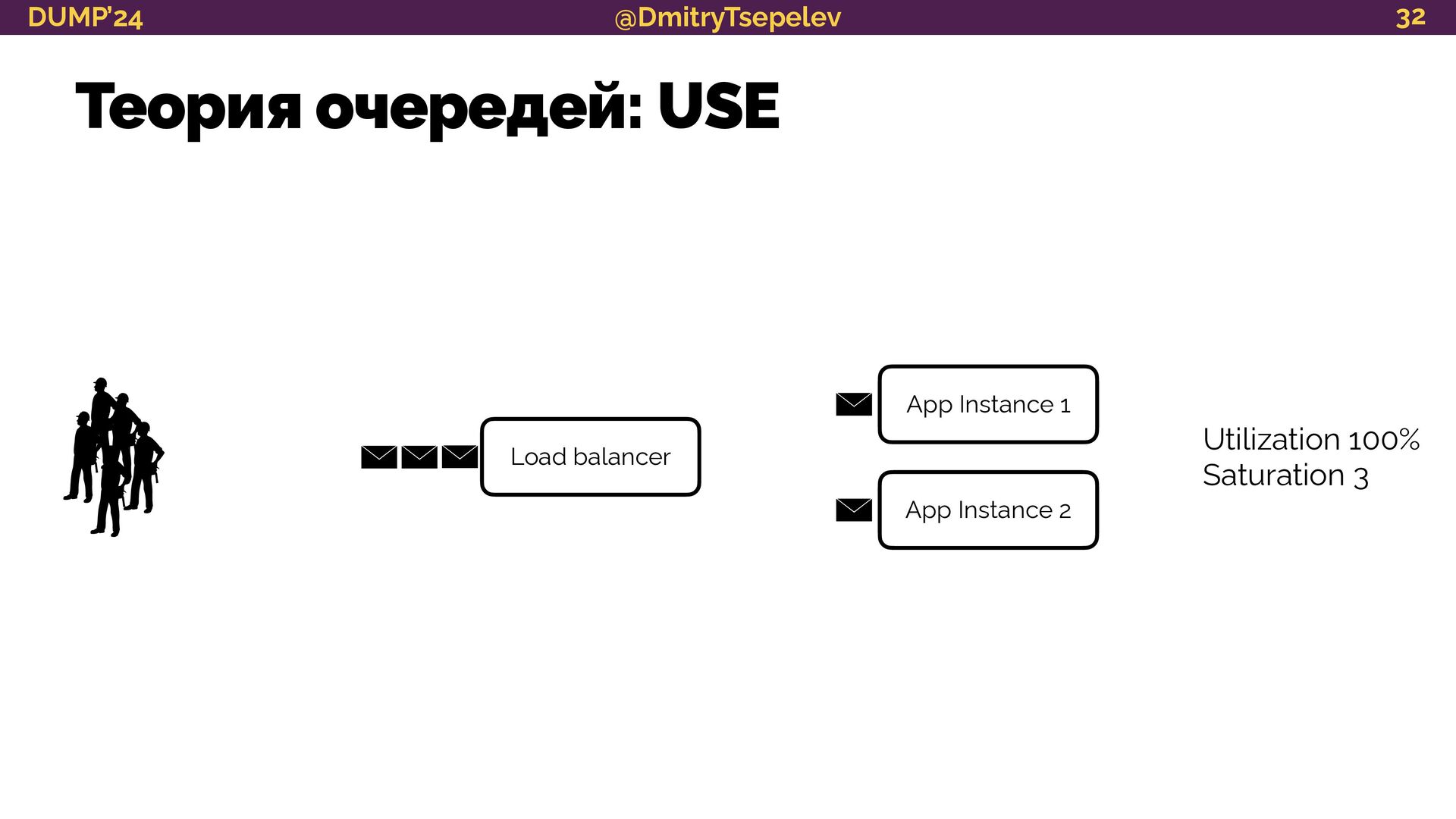
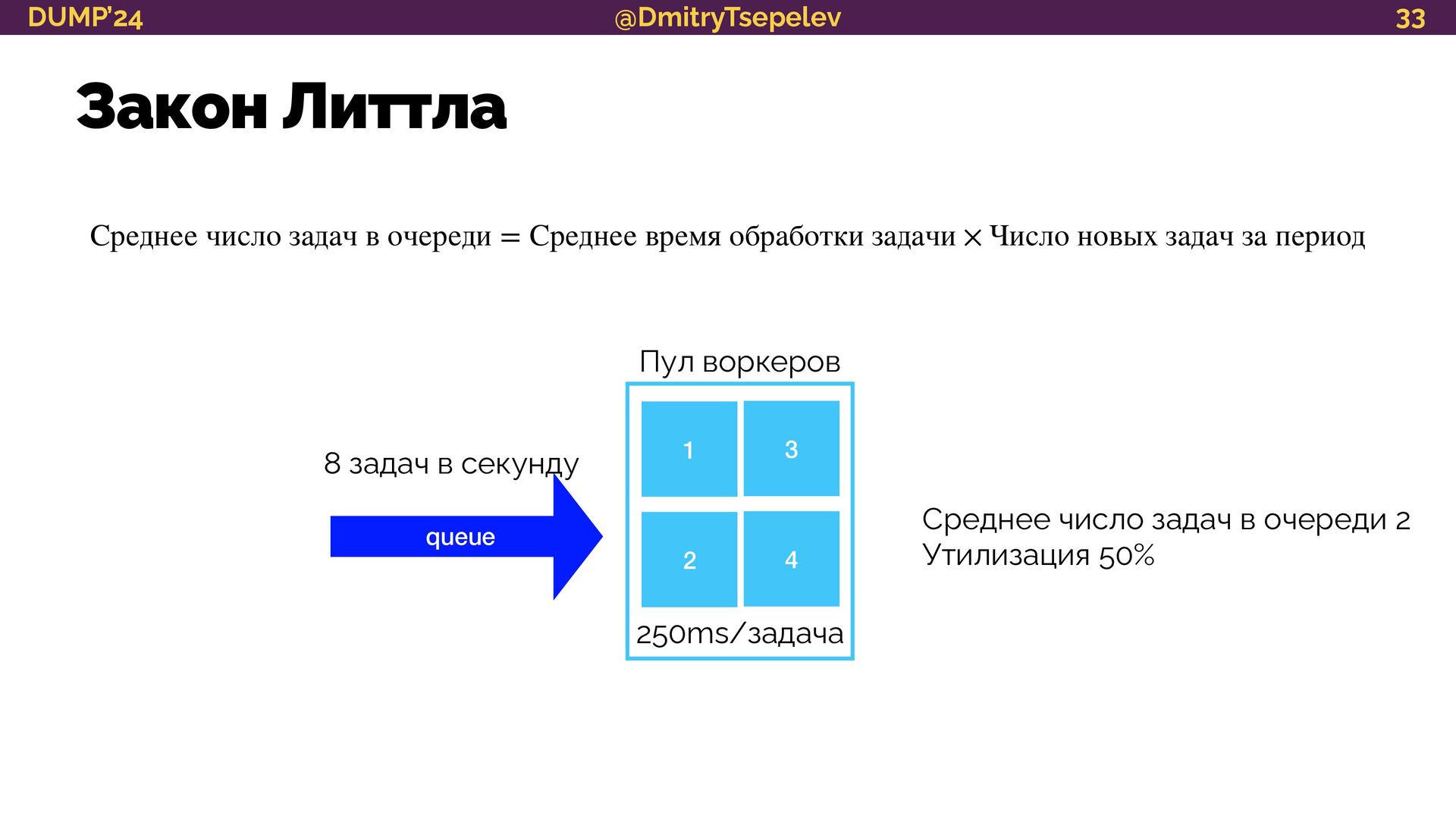
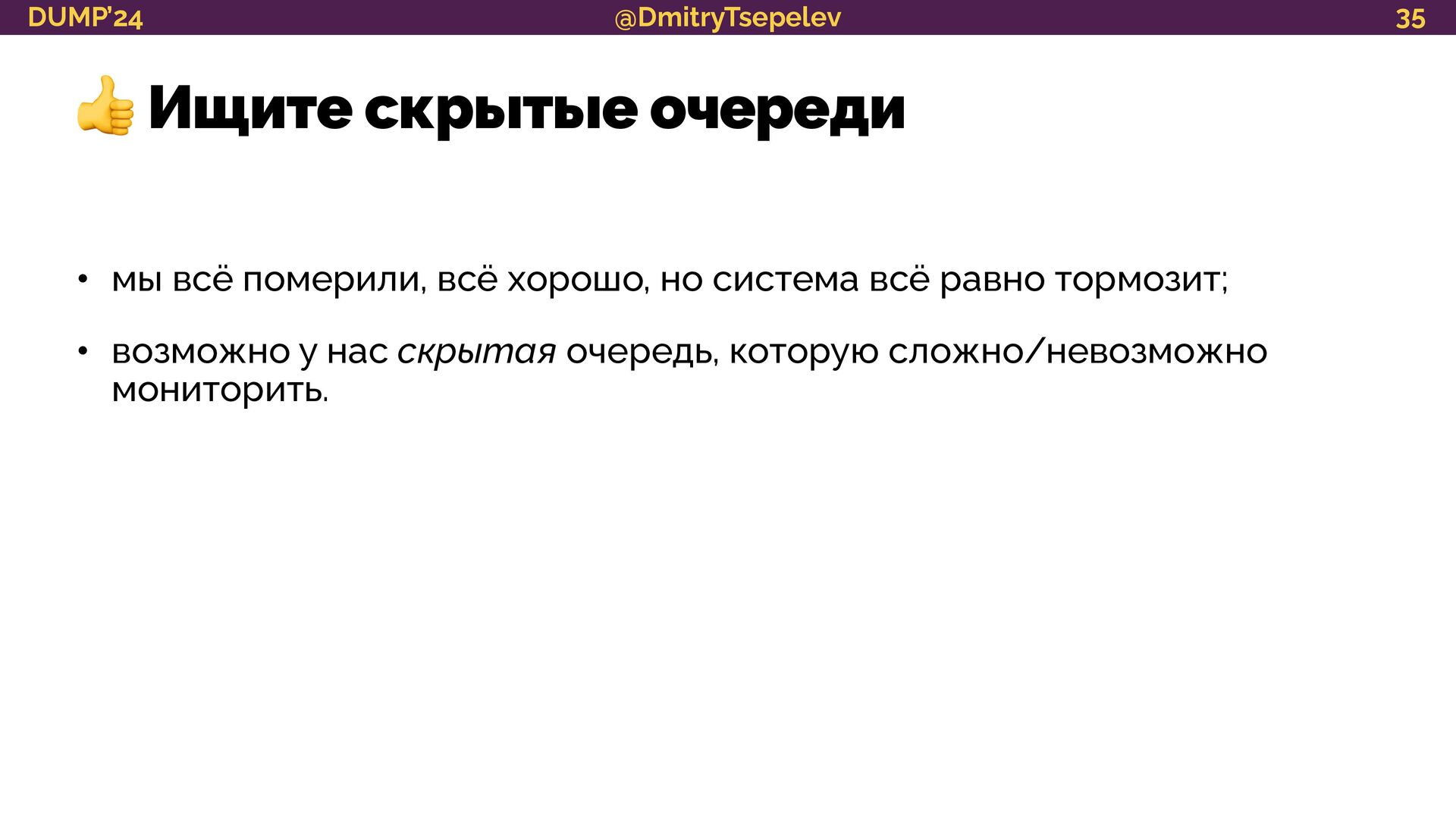
научимся представлять систему в терминологии теории очередей;
выберем самые критичные метрики и настроим их;
разберёмся, какие есть менее критичные метрики, и научимся видеть смысл в их графиках;
разберёмся, зачем нужны алерты и когда они не нужны.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
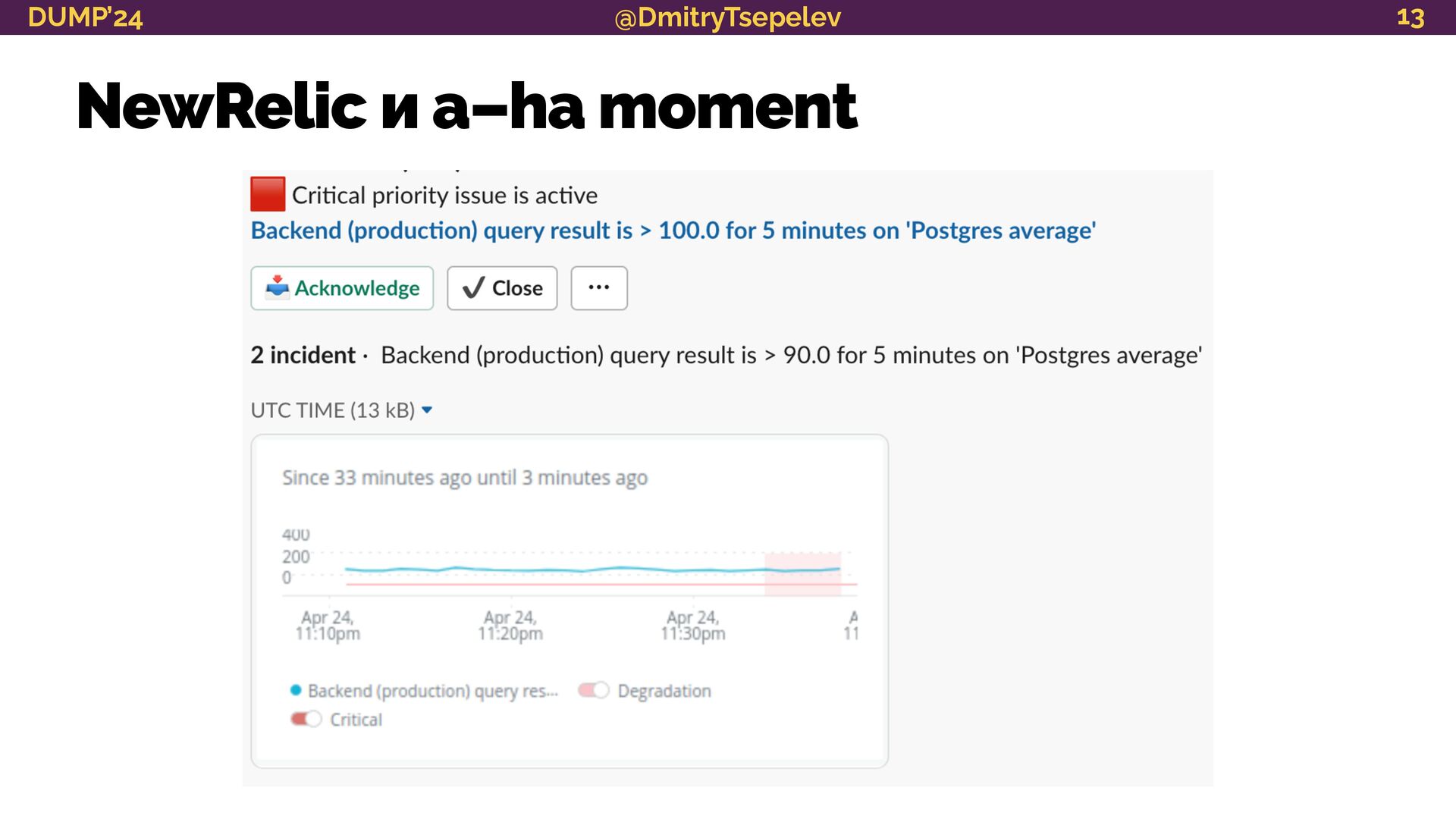{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
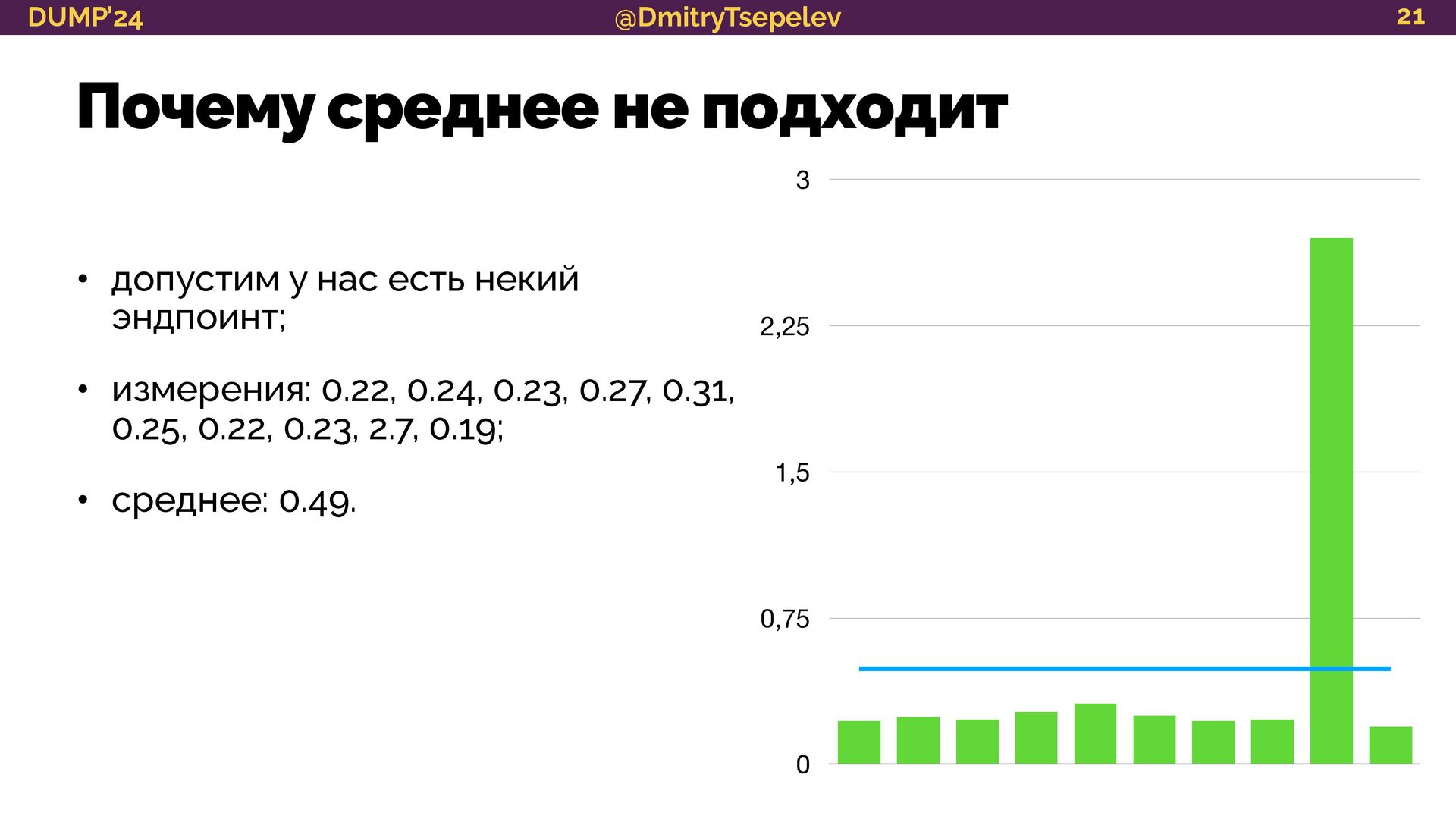{kind=link}
{kind=link}
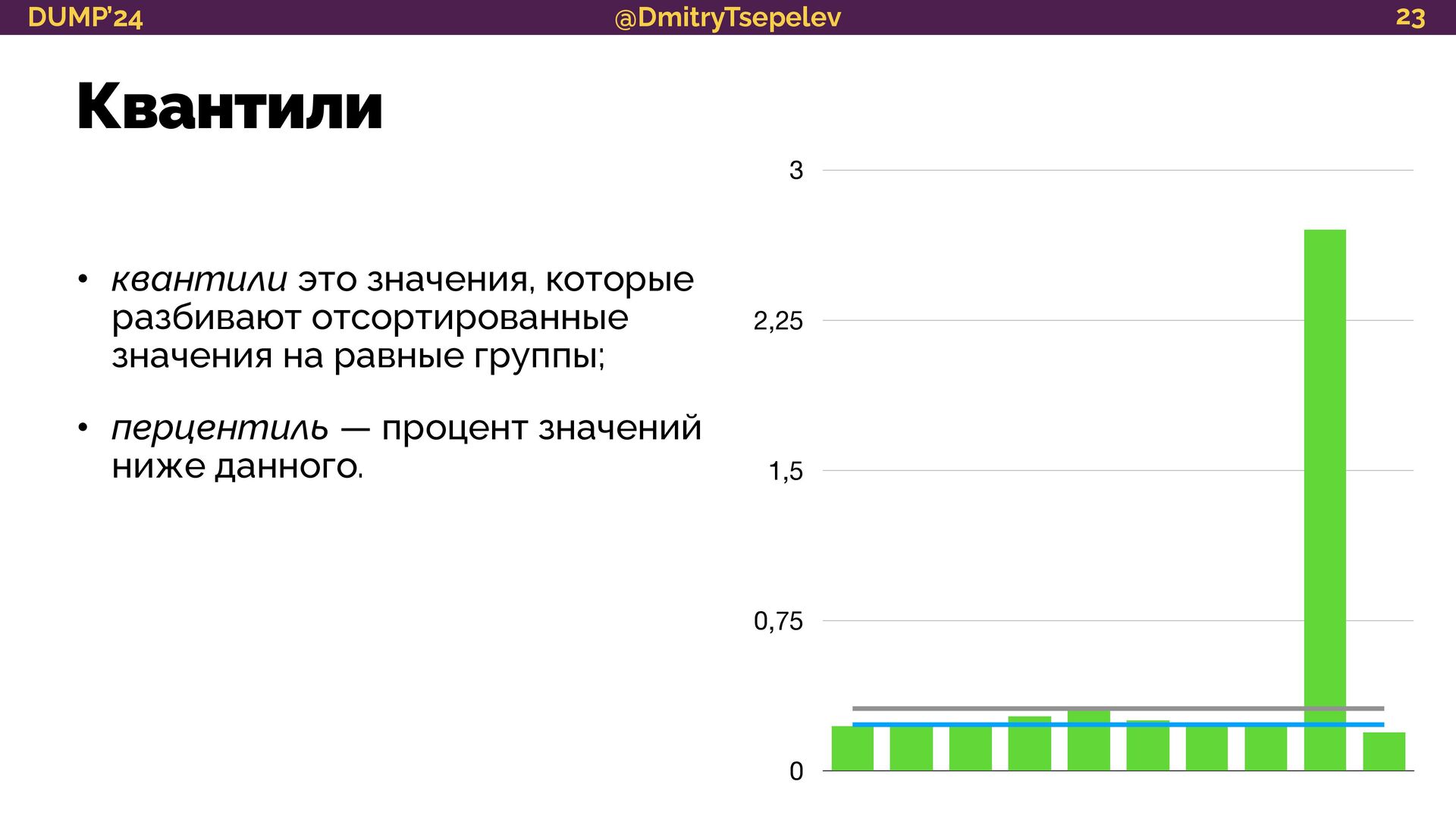{kind=link}
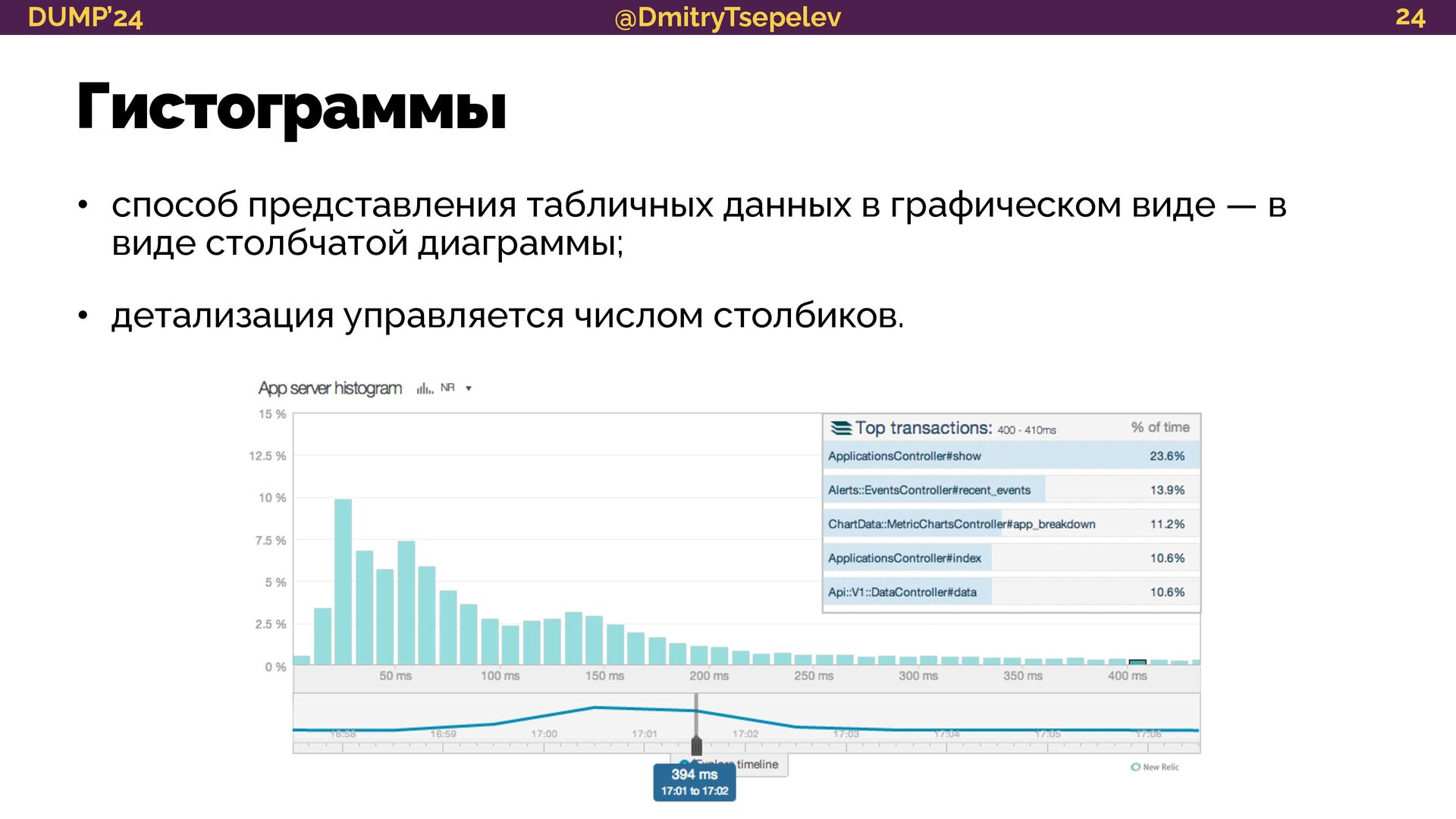{kind=link}
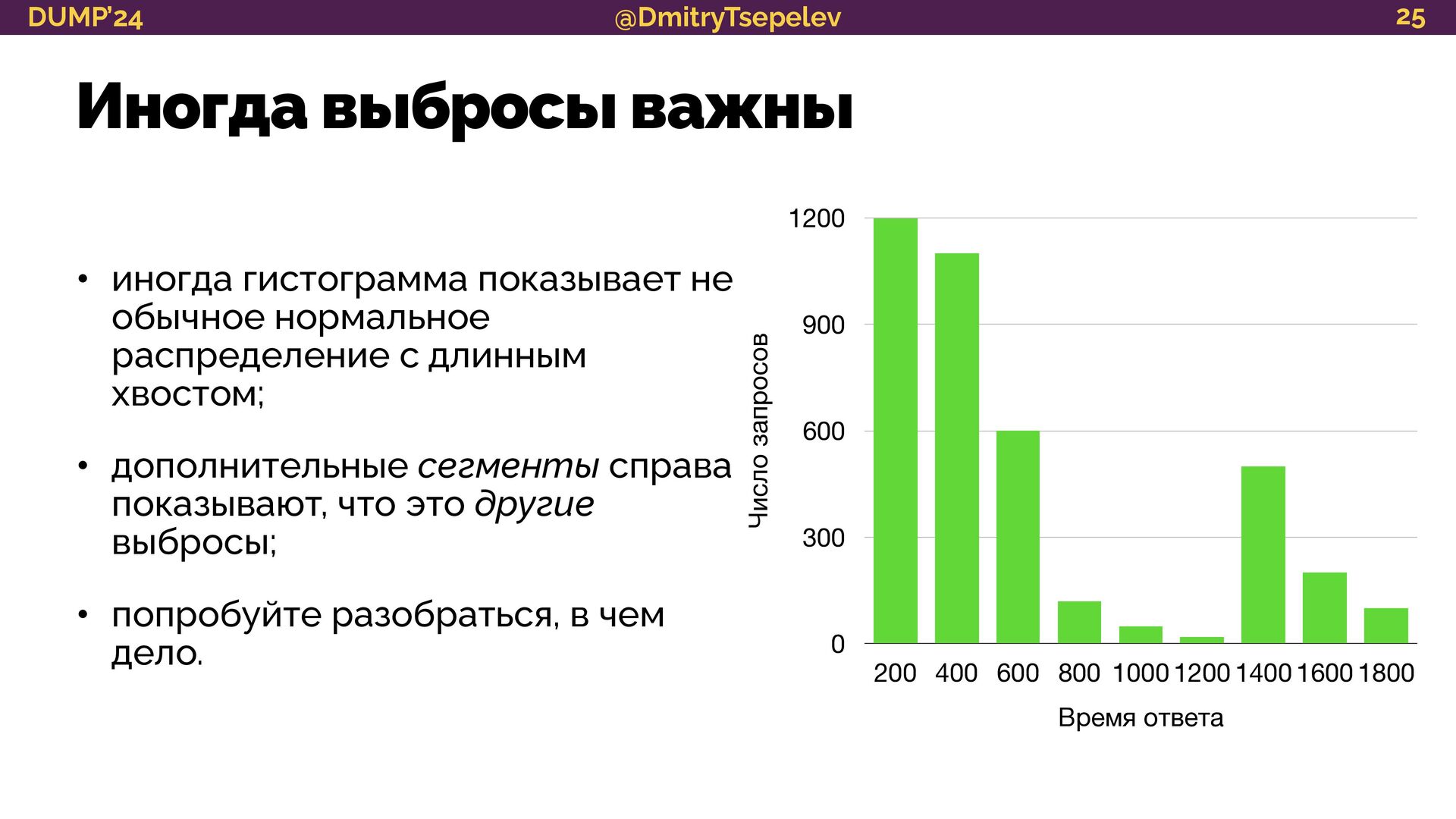{kind=link}
{kind=link}
{kind=link}
{kind=link}
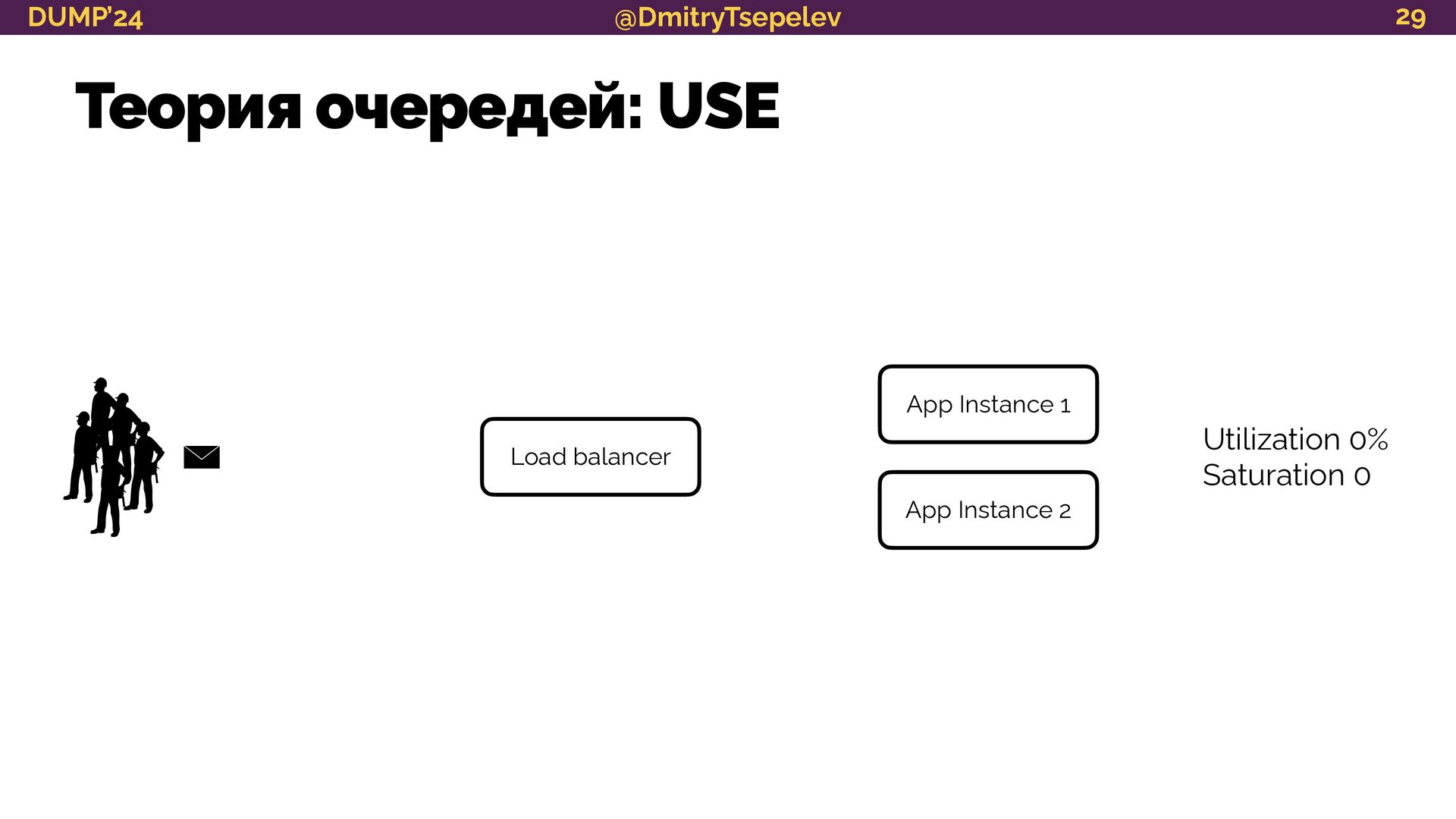{kind=link}
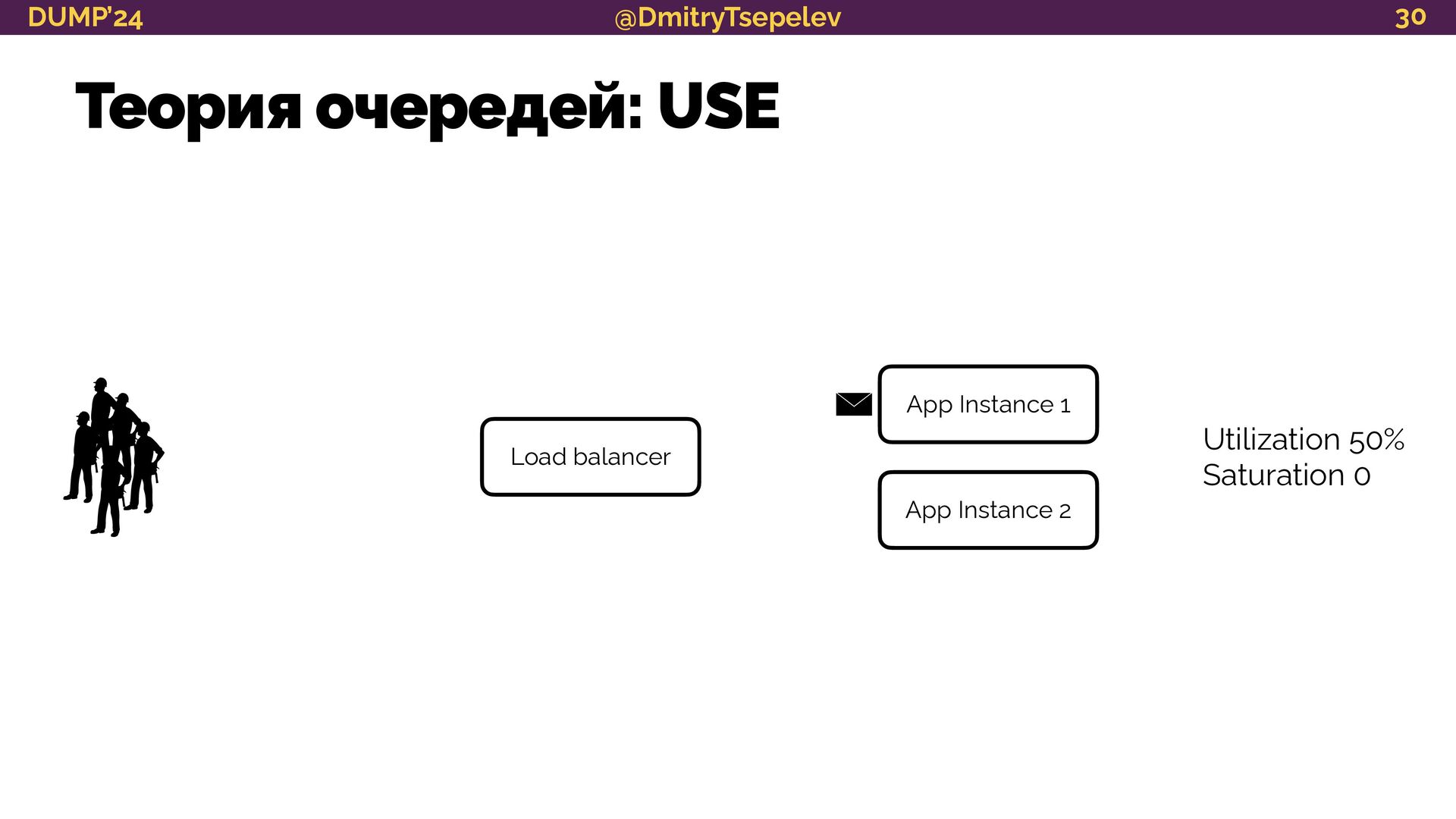{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
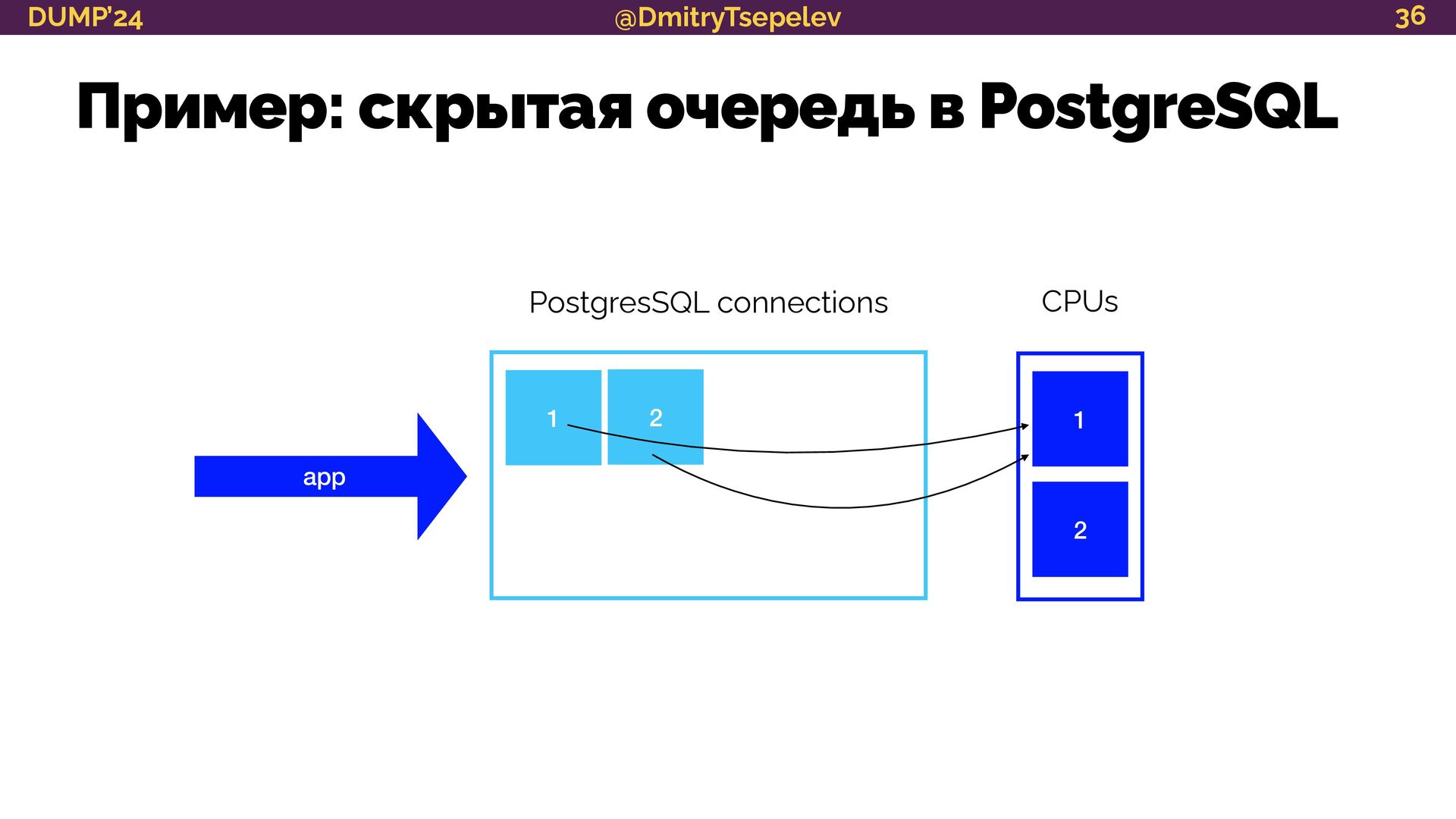{kind=link}
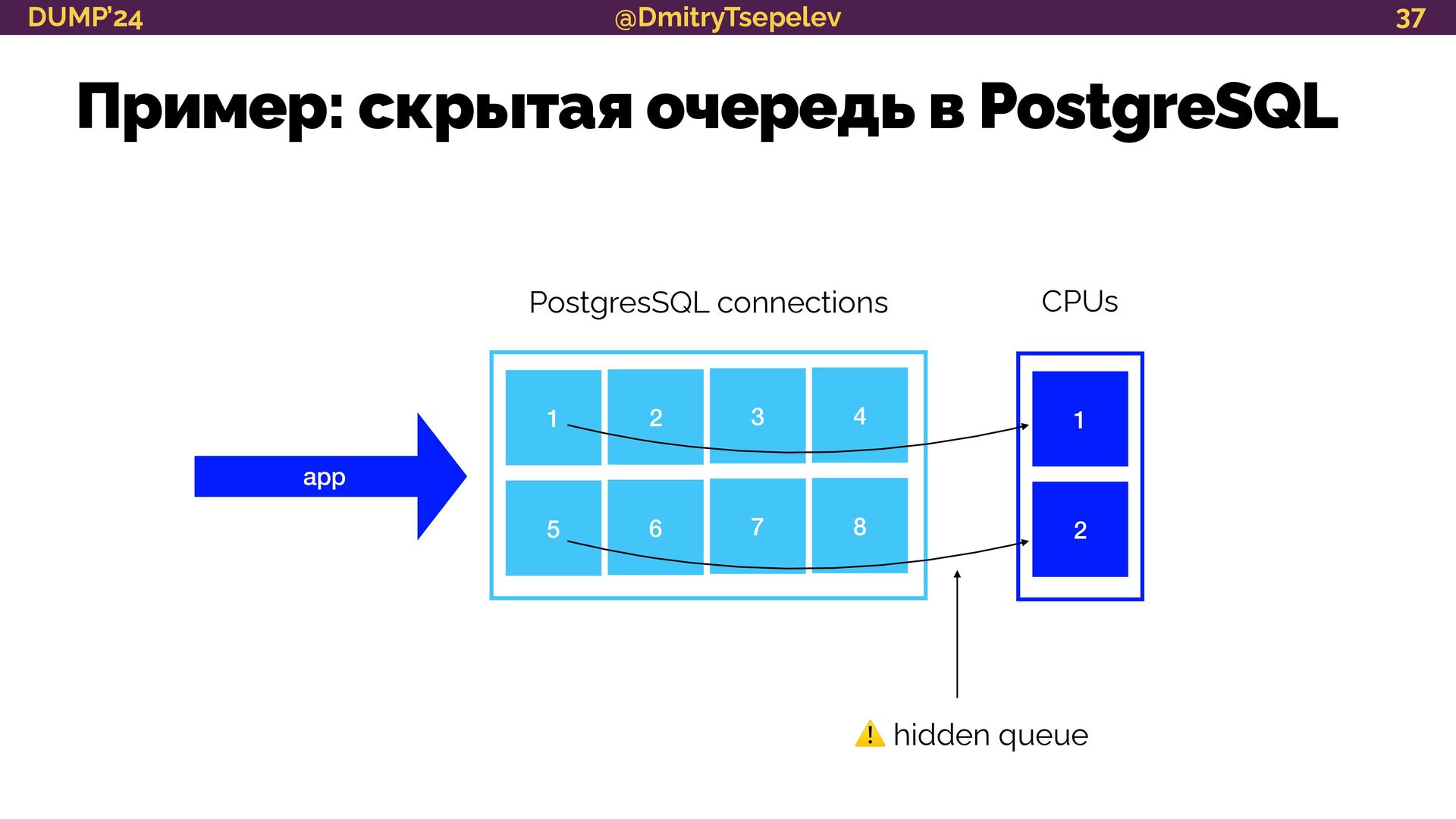{kind=link}
{kind=link}
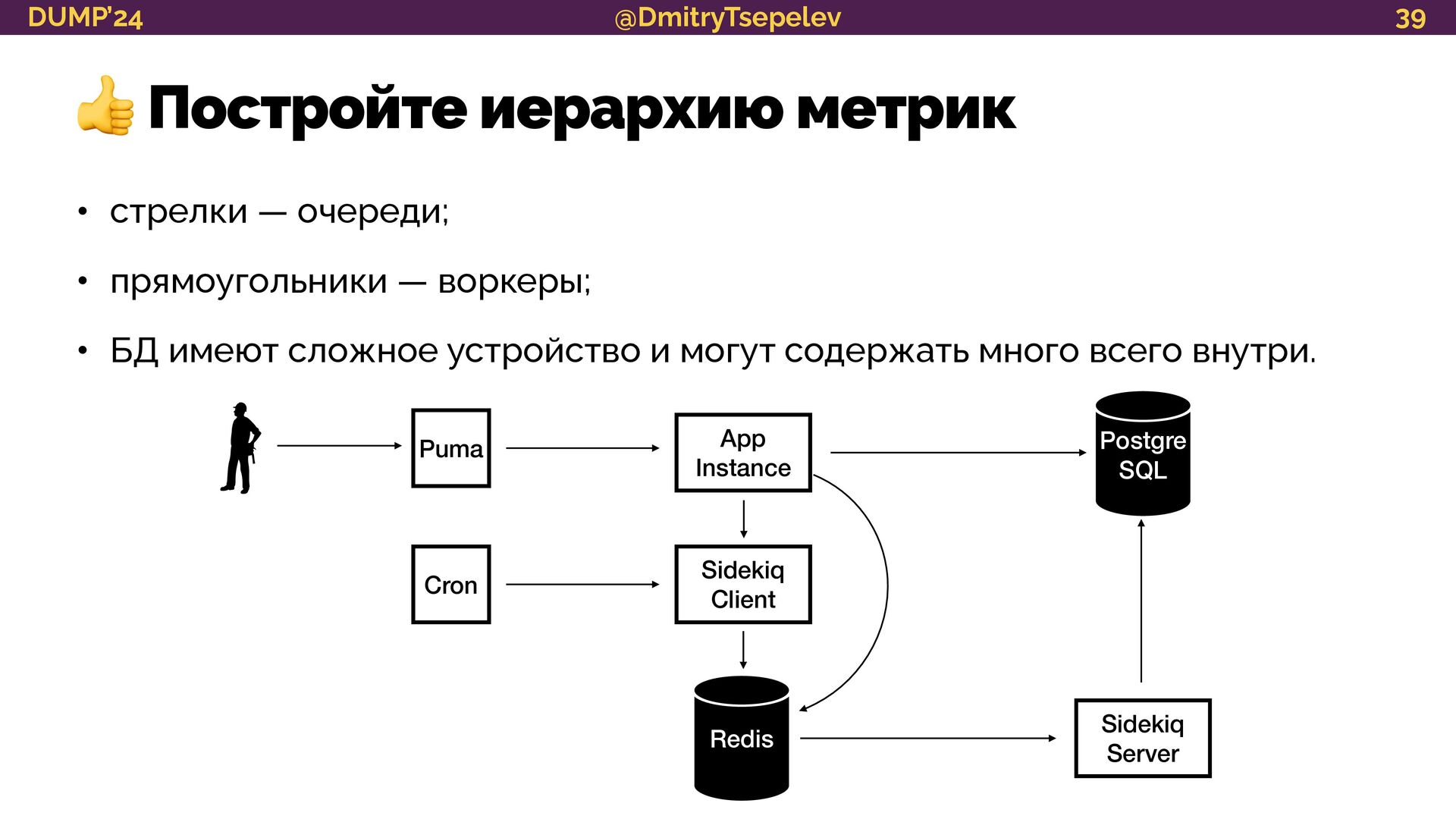{kind=link}
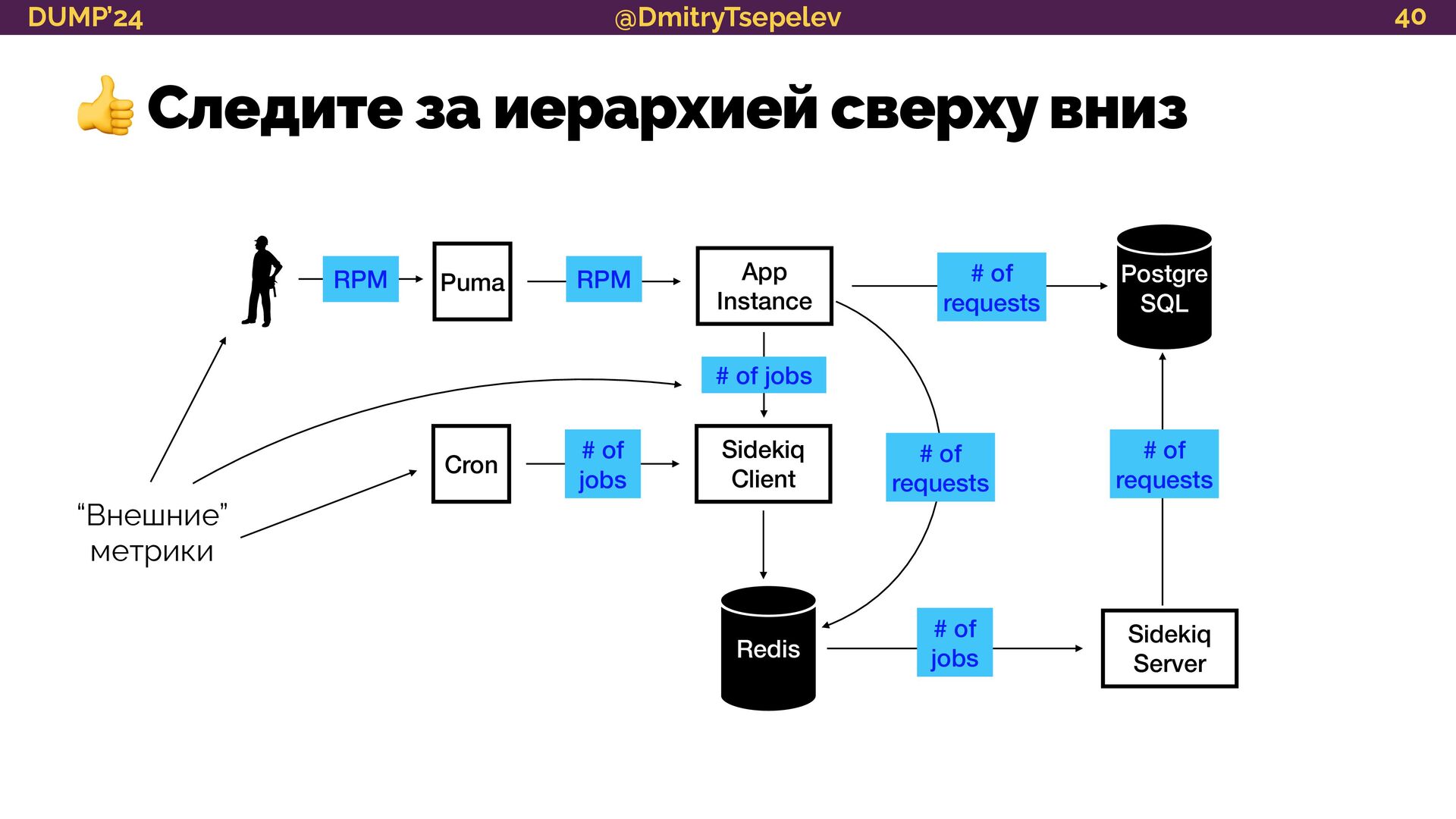{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}