Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
2024新卒技術研修_機械学習
Search
DMM.com_新卒採用
September 10, 2024
160
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
2024新卒技術研修_機械学習
DMM.comの24新卒エンジニア技術研修_機械学習研修の資料です。
DMM.com_新卒採用
September 10, 2024
More Decks by DMM.com_新卒採用
See All by DMM.com_新卒採用
【技育祭2026春】技育祭最年少登壇者が語る「必要とされる人になるための3つの方法」
dmm_recuruit
1
200
DDD‗20250716_traP×DMM
dmm_recuruit
0
63
組織運営‗20250716_traP×DMM
dmm_recuruit
0
68
DMMにおけるレコメンドの紹介‗20250716_traP×DMM
dmm_recuruit
0
230
KC3Hack2025向け_ハッカソンのコツ.pdf
dmm_recuruit
0
120
DMM.com_技育祭2024秋講演資料
dmm_recuruit
0
340
2024新卒技術研修_BE
dmm_recuruit
0
140
2024新卒技術研修_FE①
dmm_recuruit
1
110
2024新卒技術研修_FE②
dmm_recuruit
0
96
Featured
See All Featured
We Have a Design System, Now What?
morganepeng
55
8.2k
Sam Torres - BigQuery for SEOs
techseoconnect
PRO
0
440
WENDY [Excerpt]
tessaabrams
11
39k
Navigating the Design Leadership Dip - Product Design Week Design Leaders+ Conference 2024
apolaine
1
380
Money Talks: Using Revenue to Get Sh*t Done
nikkihalliwell
0
420
The AI Search Optimization Roadmap by Aleyda Solis
aleyda
1
6k
A Modern Web Designer's Workflow
chriscoyier
698
190k
For a Future-Friendly Web
brad_frost
183
10k
The Hidden Cost of Media on the Web [PixelPalooza 2025]
tammyeverts
2
390
I Don’t Have Time: Getting Over the Fear to Launch Your Podcast
jcasabona
34
2.8k
Keith and Marios Guide to Fast Websites
keithpitt
413
23k
The Cost Of JavaScript in 2023
addyosmani
55
10k
Transcript
© DMM.com 新卒研修2024 機械学習 担当: 田代真生 special thanks to arata
furukawa, daiki maruo, hiroyuki moriya, futami yuki and their great works. https://git.dmm.com/ai/training 1
© DMM.com 自己紹介 田代真生(Tahiro-Masaki) • 職種 : 機械学習エンジニア • 来歴
: ◦ DMM 22新卒 ◦ 大学院時代はPLM(BERT, GPT-2)を研究 ◦ 趣味はサッカー、アイドル、キャンプ • 仕事 ◦ 動画、電子書籍の検索のパーソナライズ ◦ 検索UIの改善 ◦ 2
© DMM.com …座学の前に 実践編で利用する環境構築をお願いします! (DockerのImageが大きいので先にやっちゃいます💦) 以下のテンプレートからリポジトリを作成してください https://git.dmm.com/dmm-bootcamp/ml-training-2023 3
© DMM.com データサイエンスグループとは データ・機械学習のプロフェッショナルとして、 データに基づく計測・分析・施策判断を通した事業成長と ユーザー体験の向上を目指しています。 DMM の検索・レコメンドシステムが最先端の自然言語処理・機械学習・ 情報検索のテクノロジーによって支えられていること
4
© DMM.com 目的 - 機械学習の技術に触れて、機械学習に対する敷居を下げる - 機械学習とは - 機械学習技術の使いかたが何となくわかる -
機械学習の応用先 - どこで機械学習を使えそうか - 機械学習の技術を扱うときにindexとなるような知識を得る - 機械学習を適用する手順 - どうやって適用するか - 注意すべきところはどこか 5
© DMM.com 機械学習とは と、聞かれて言葉で説明できますか? 6
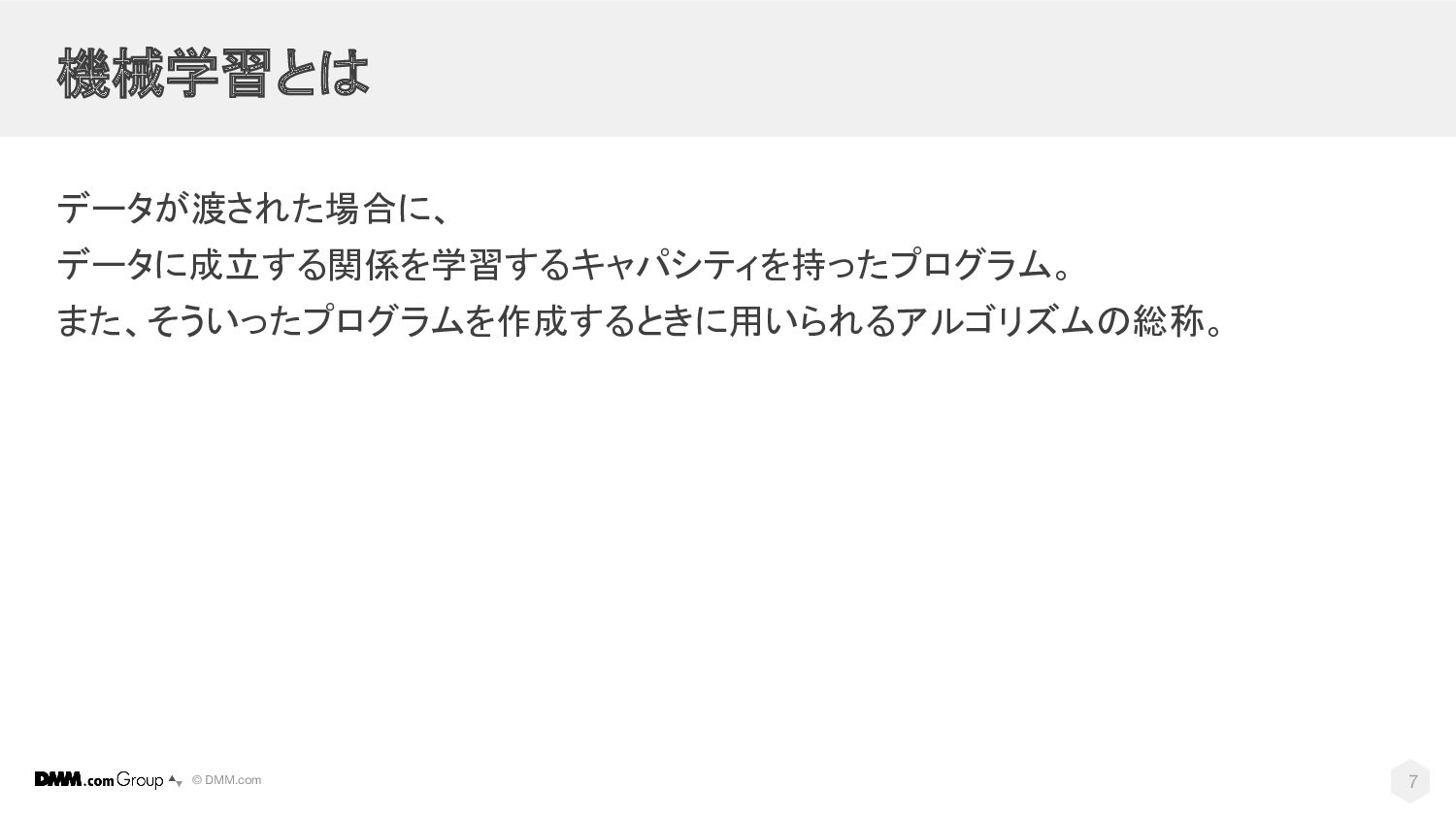
© DMM.com 機械学習とは データが渡された場合に、 データに成立する関係を学習するキャパシティを持ったプログラム。 また、そういったプログラムを作成するときに用いられるアルゴリズムの総称。 7
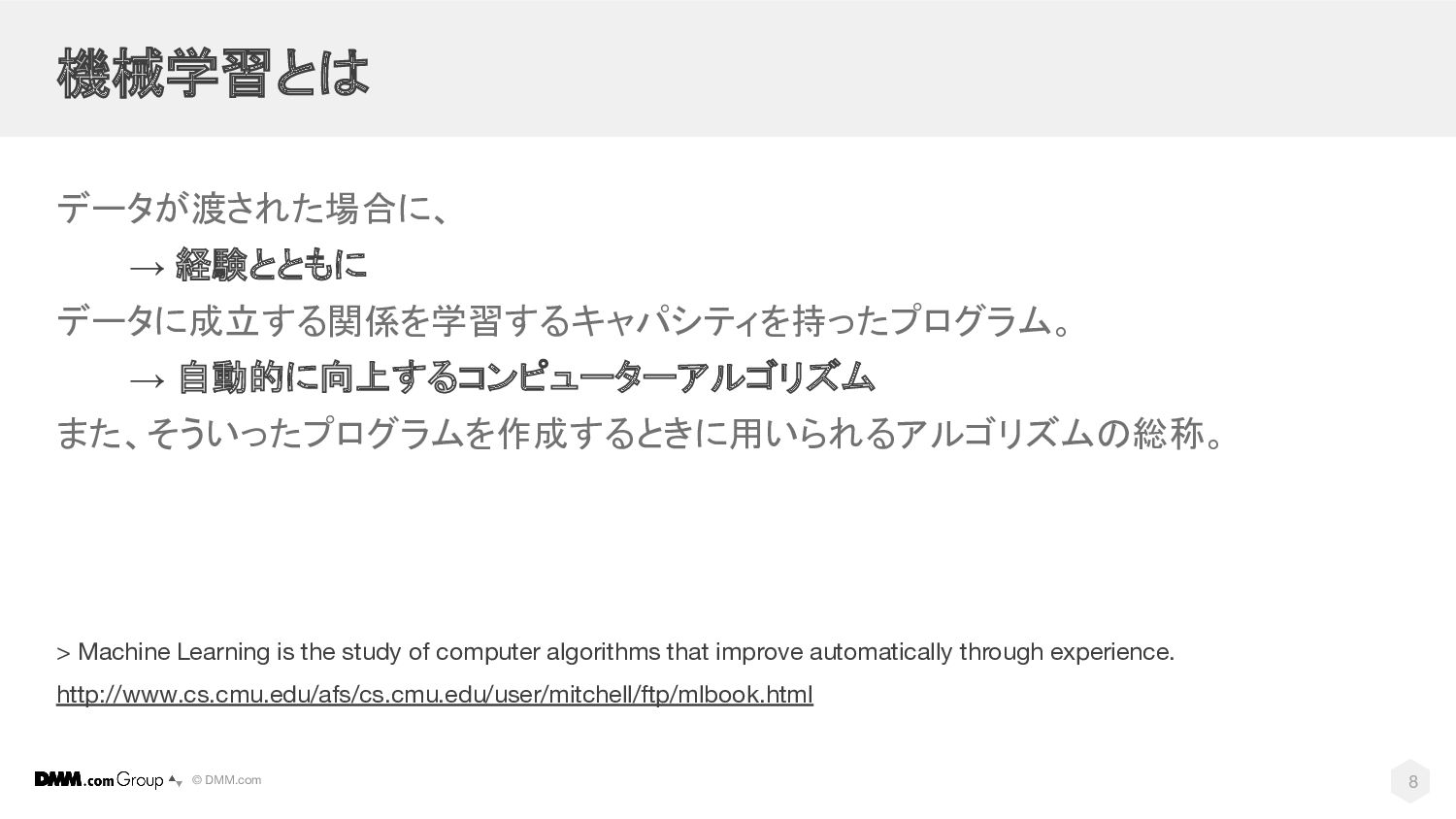
© DMM.com 機械学習とは データが渡された場合に、 → 経験とともに データに成立する関係を学習するキャパシティを持ったプログラム。 → 自動的に向上するコンピューターアルゴリズム また、そういったプログラムを作成するときに用いられるアルゴリズムの総称。
> Machine Learning is the study of computer algorithms that improve automatically through experience. http://www.cs.cmu.edu/afs/cs.cmu.edu/user/mitchell/ftp/mlbook.html 8
© DMM.com AIの歴史 総務省HPより引用 https://www.soumu.go.jp/johotsusintokei/whitepaper/ja/h28/html/nc142120.html 9
© DMM.com 機械学習を構成する要素 1. モデル : データの構造に対する仮説のようなもの。簡単なのだとy=ax + b -
パラメータ: モデルの構造を表現する値。a, b - 特徴量 : 予測に使うデータ。x - ラベル : 予測したいデータ。y 2. 評価関数 : 現状のモデルの当てはまりの良さを測るもの。 - 損失関数、目的関数 : モデルの学習で最適化したい関数。学習中に使う。 3. 最適化ルーチン : 損失関数に基づいてモデルのパラメータを変更するロ ジック 10
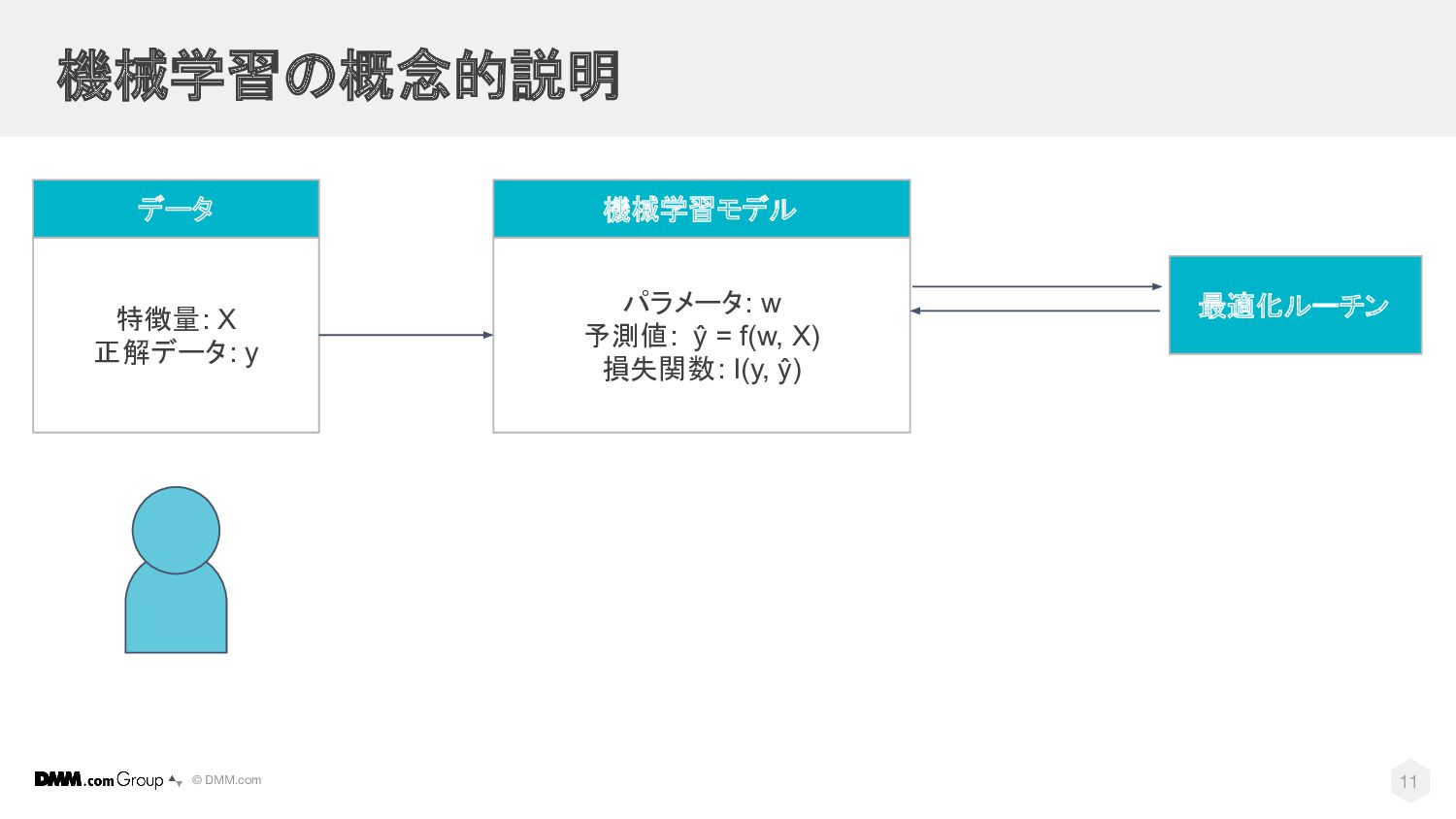
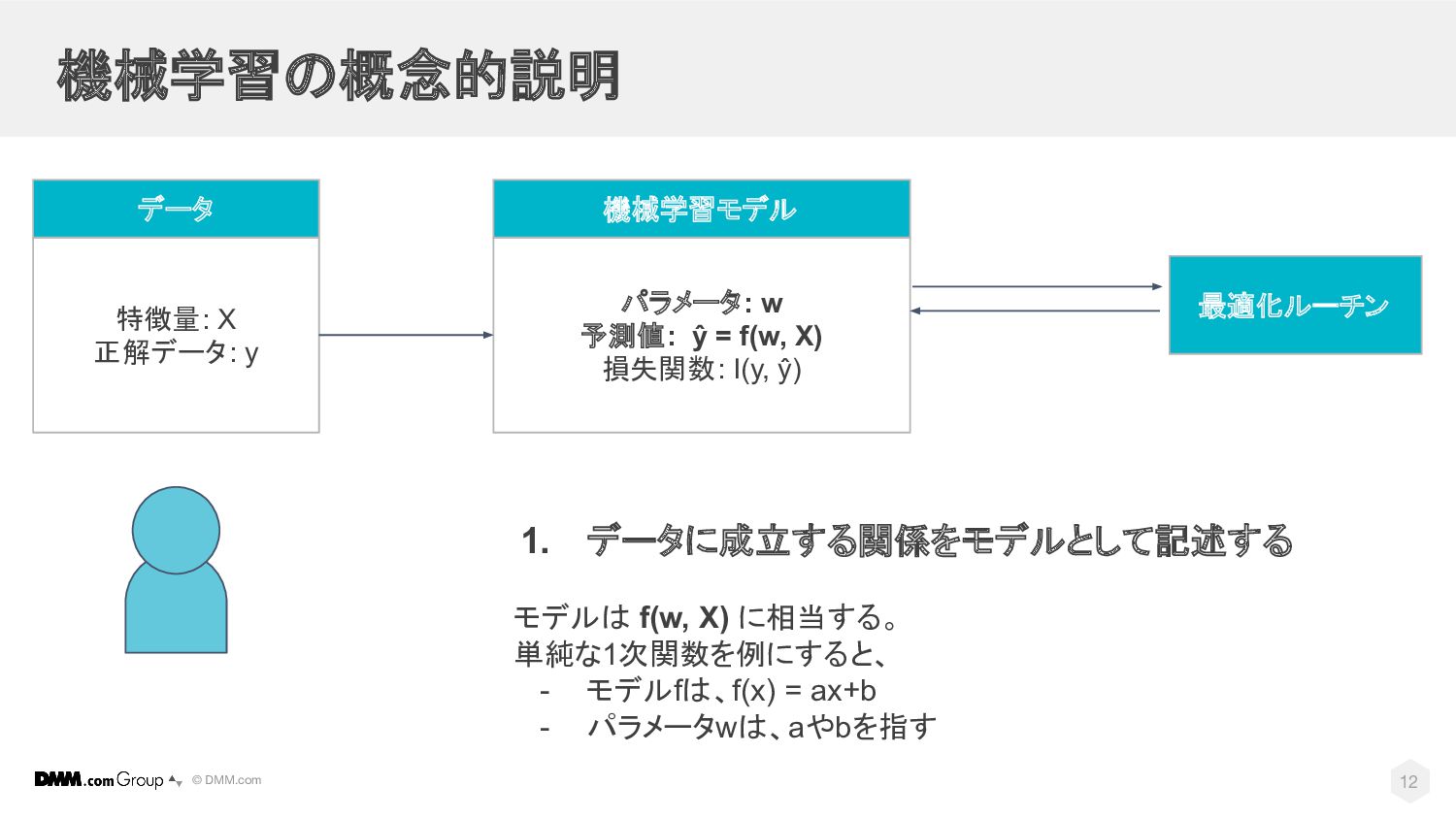
© DMM.com 機械学習の概念的説明 パラメータ: w 予測値: ŷ = f(w, X)
損失関数: I(y, ŷ) 機械学習モデル 最適化ルーチン 特徴量: X 正解データ: y データ 11
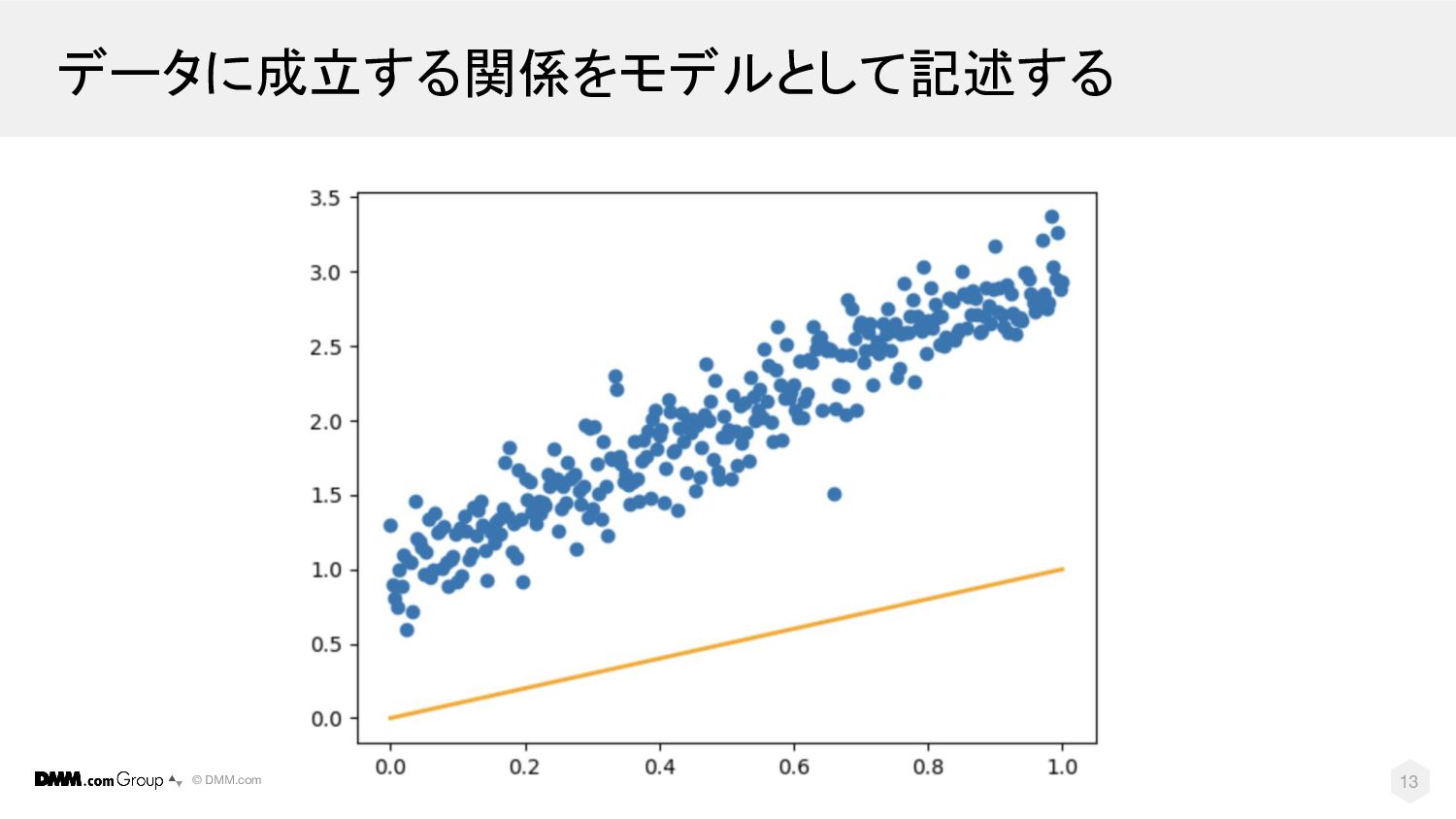
© DMM.com 1. データに成立する関係をモデルとして記述する モデルは f(w, X) に相当する。 単純な1次関数を例にすると、 -
モデルfは、f(x) = ax+b - パラメータwは、aやbを指す 機械学習の概念的説明 パラメータ: w 予測値: ŷ = f(w, X) 損失関数: I(y, ŷ) 機械学習モデル 最適化ルーチン 特徴量: X 正解データ: y データ 12
© DMM.com データに成立する関係をモデルとして記述する 13
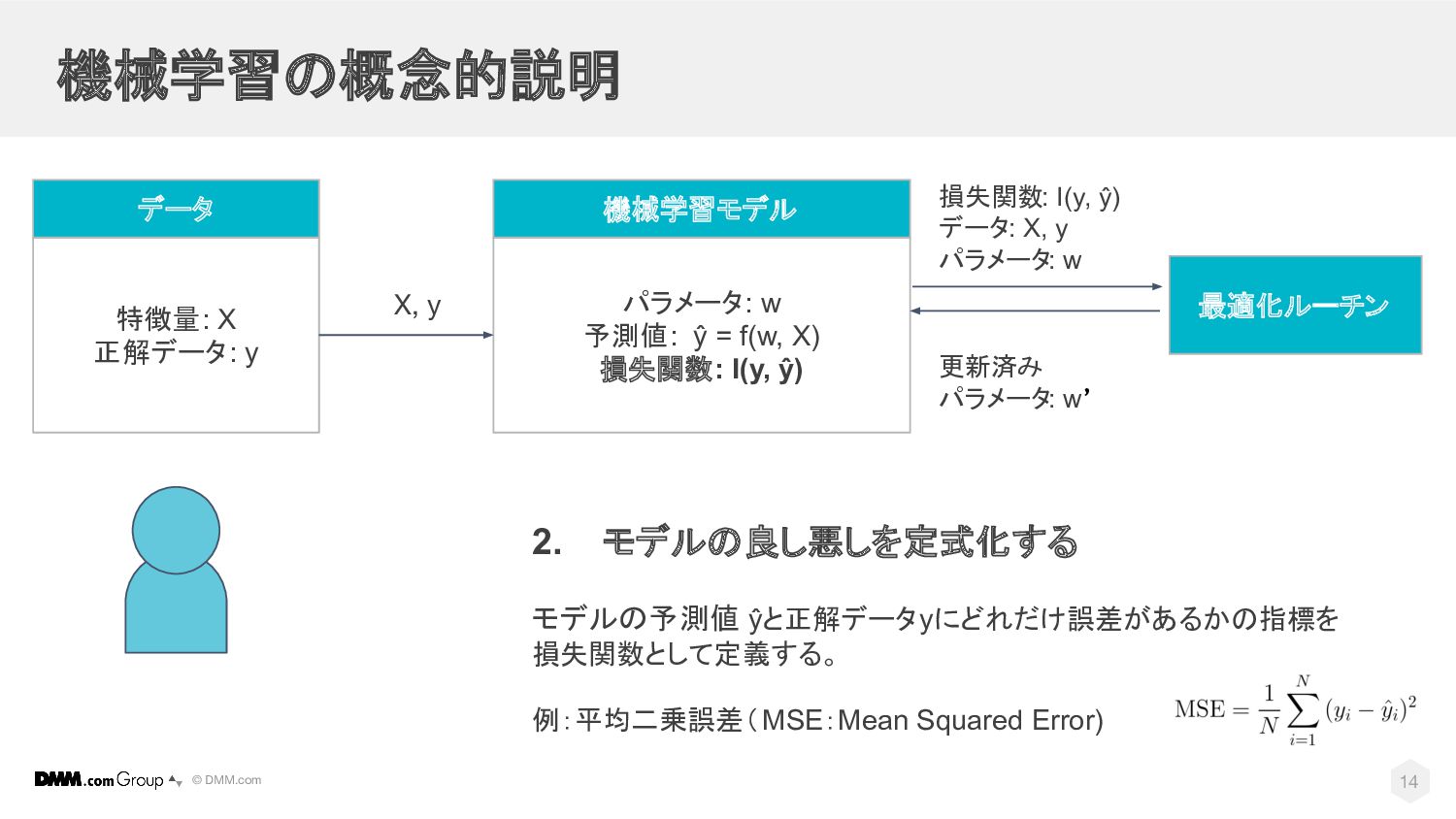
© DMM.com 機械学習の概念的説明 パラメータ: w 予測値: ŷ = f(w, X)
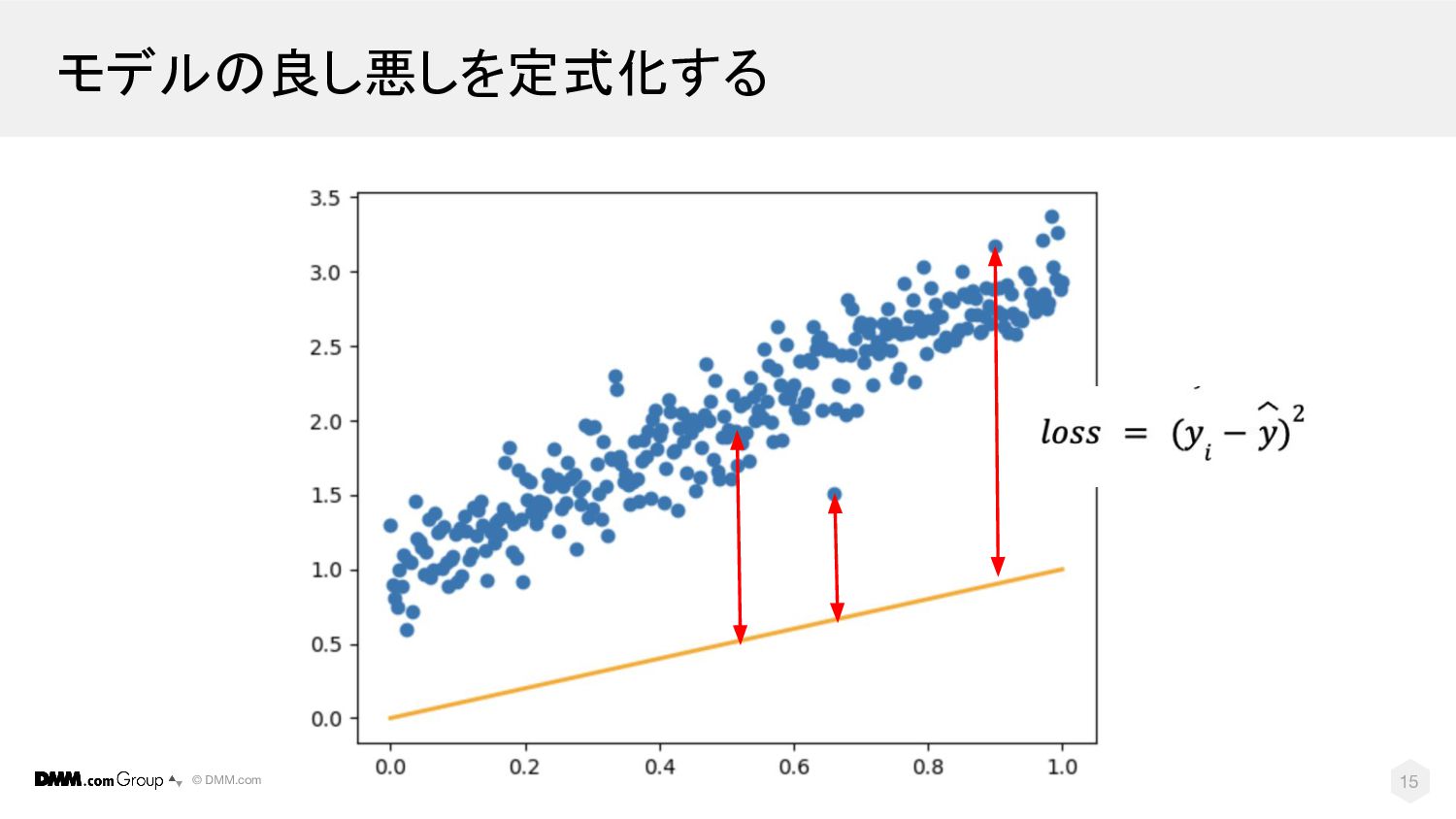
損失関数: I(y, ŷ) 機械学習モデル 最適化ルーチン 特徴量: X 正解データ: y データ X, y 2. モデルの良し悪しを定式化する モデルの予測値 ŷと正解データyにどれだけ誤差があるかの指標を 損失関数として定義する。 例:平均二乗誤差(MSE:Mean Squared Error) 損失関数: I(y, ŷ) データ: X, y パラメータ: w 更新済み パラメータ: w’ 14
© DMM.com モデルの良し悪しを定式化する 15
© DMM.com 機械学習の概念的説明 パラメータ: w 予測値: ŷ = f(w, X)
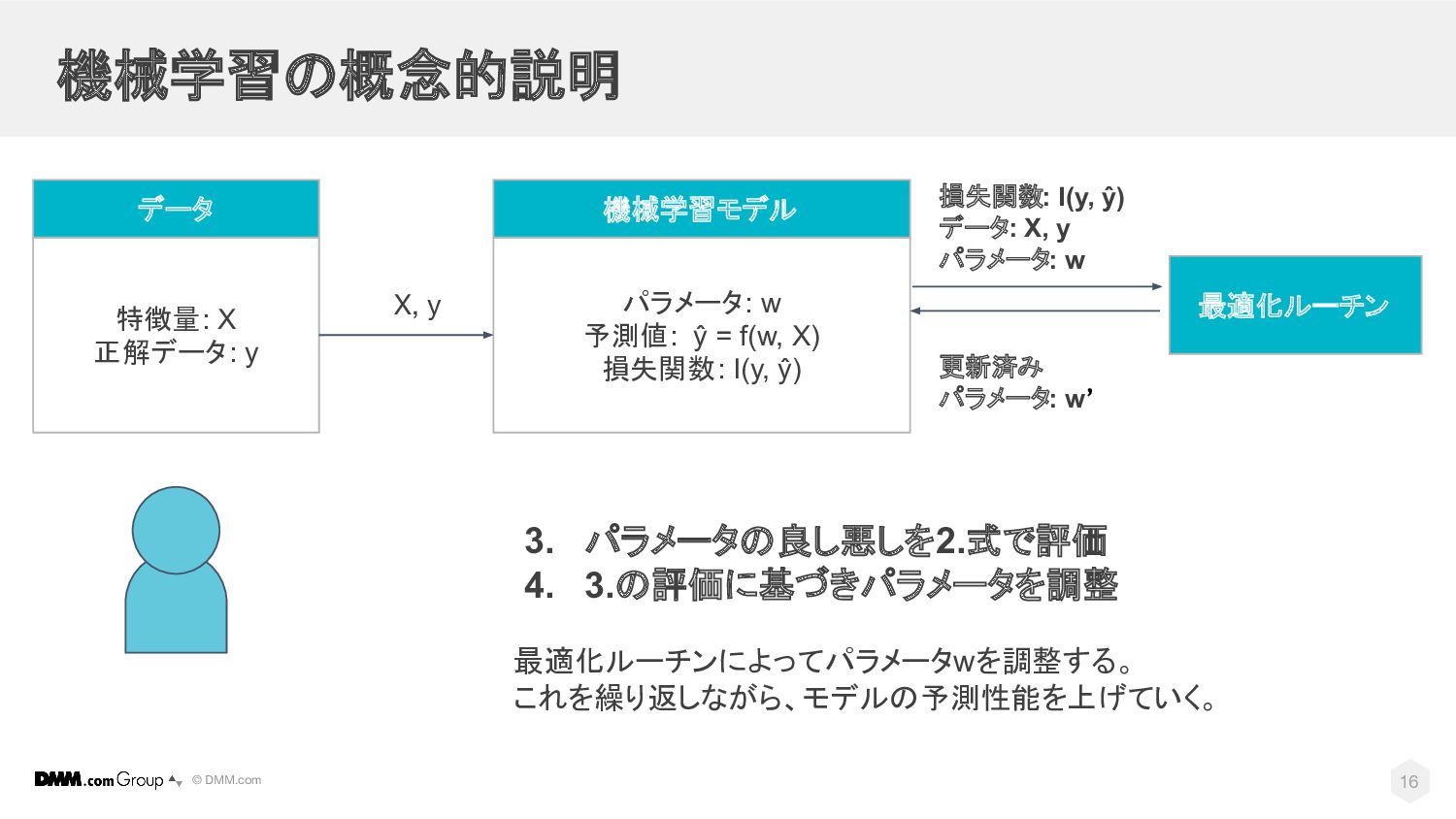
損失関数: I(y, ŷ) 機械学習モデル 最適化ルーチン 特徴量: X 正解データ: y データ X, y 3. パラメータの良し悪しを2.式で評価 4. 3.の評価に基づきパラメータを調整 最適化ルーチンによってパラメータwを調整する。 これを繰り返しながら、モデルの予測性能を上げていく。 損失関数: I(y, ŷ) データ: X, y パラメータ: w 更新済み パラメータ: w’ 16
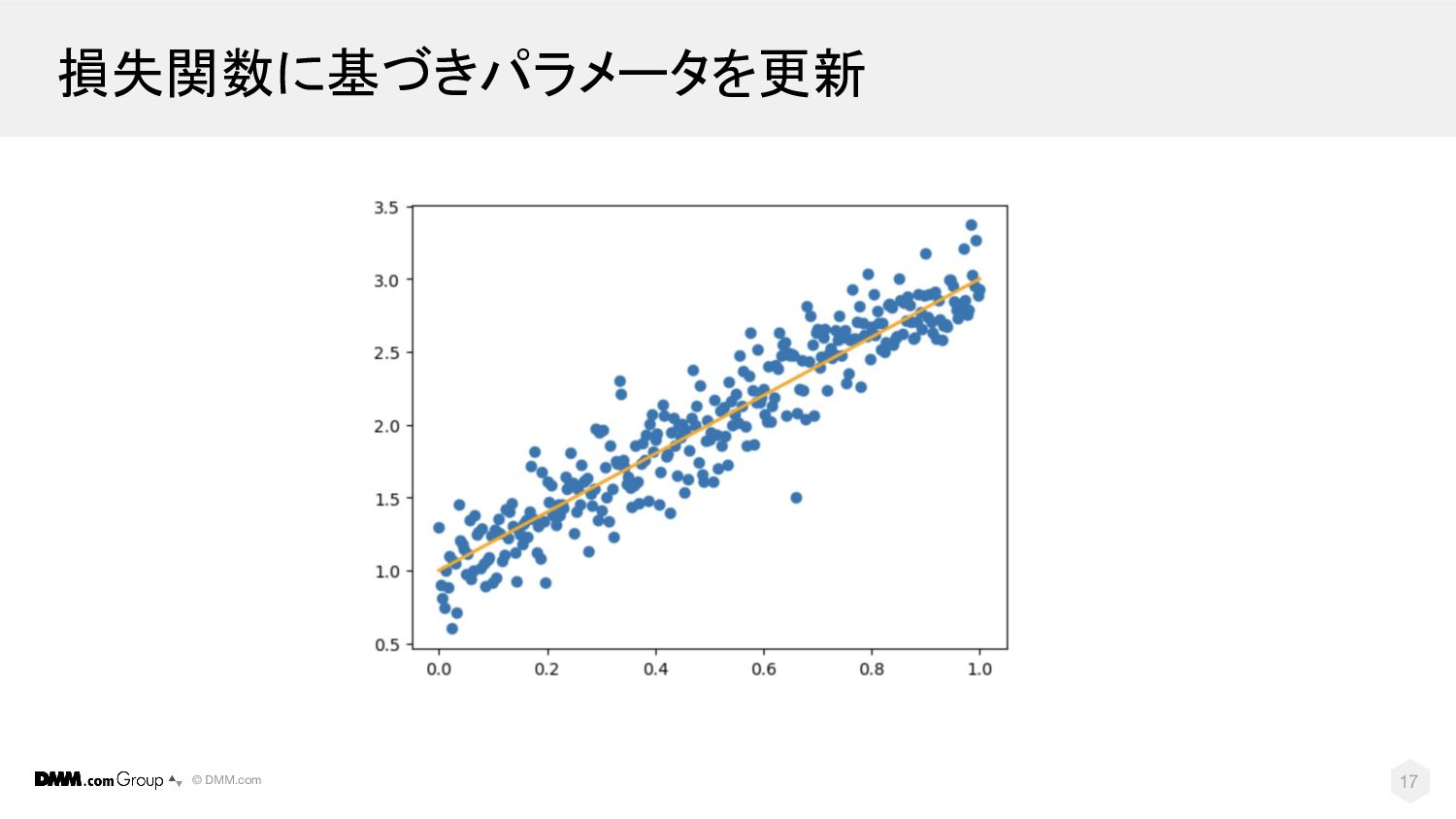
© DMM.com 損失関数に基づきパラメータを更新 17
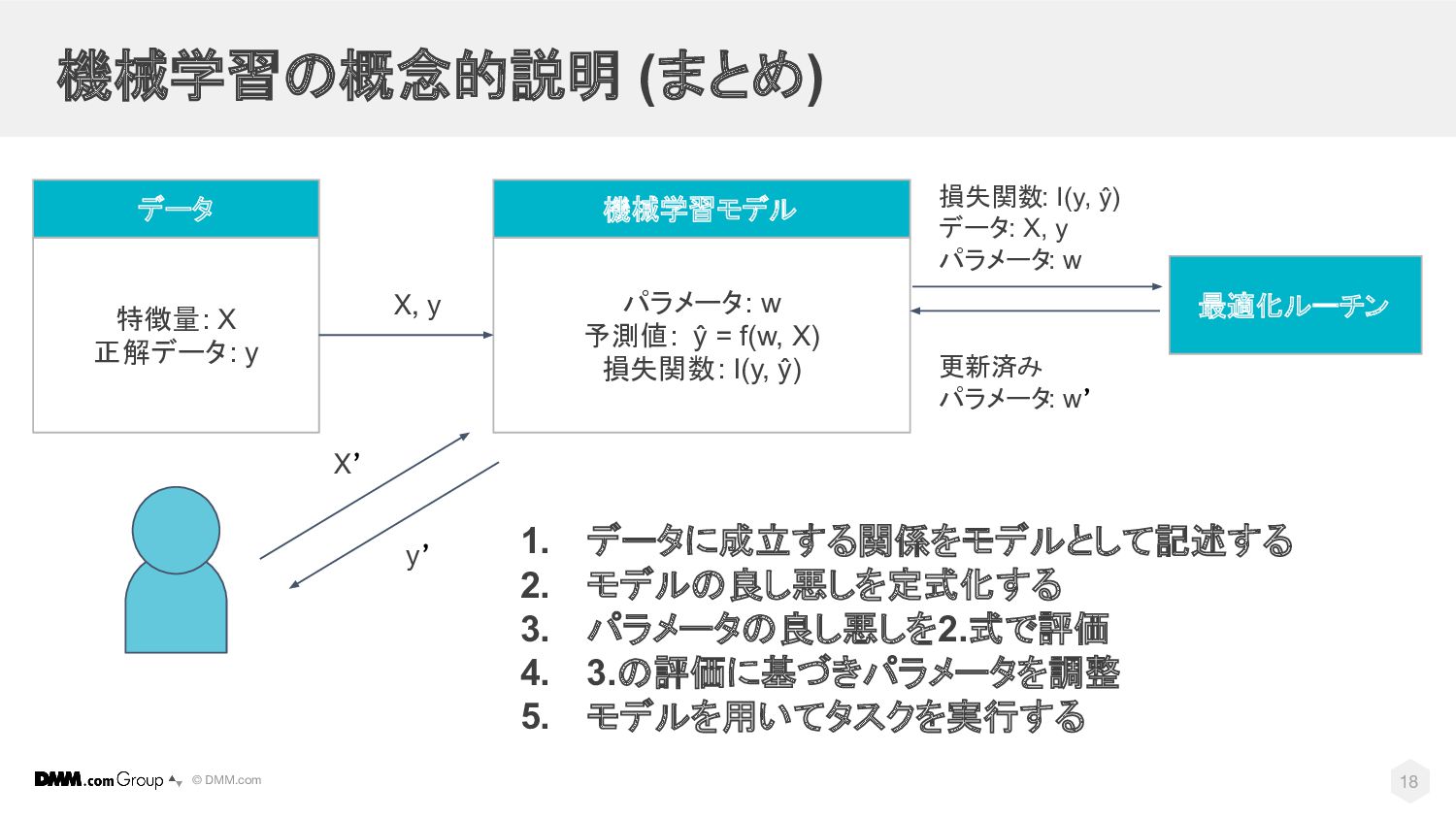
© DMM.com 機械学習の概念的説明 (まとめ) パラメータ: w 予測値: ŷ = f(w,
X) 損失関数: I(y, ŷ) 機械学習モデル 最適化ルーチン 特徴量: X 正解データ: y データ X, y 1. データに成立する関係をモデルとして記述する 2. モデルの良し悪しを定式化する 3. パラメータの良し悪しを2.式で評価 4. 3.の評価に基づきパラメータを調整 5. モデルを用いてタスクを実行する X’ y’ 損失関数: I(y, ŷ) データ: X, y パラメータ: w 更新済み パラメータ: w’ 18
© DMM.com 機械学習の問題定式 3パターン 特徴量Xとそのデータが属する ク ラスYが与えられたとき、 特徴量Xを元にどのクラスYに 属 するかをあてる問題
例: - 服装から性別をあてる - 購買行動から継続購買して く れるかをあてる 代表的な手法 - ロジスティック回帰 - SVM - 決定木 - ニューラルネットワーク 分類問題 特徴量Xと予測したい 連 続量Yが与えられたとき、 特徴量Xを元にYはどれくらいの値 になるかをあてる問題 例: - 天気と期間から気温をあてる - 商品のラインナップから予想売上 をあてる 代表的な手法 - 線形回帰 - リッジ回帰 - 決定木 - ニューラルネットワーク 回帰問題 特徴量Xのみが与えられた場合 に、どのような法則性が見られるか をXから見出す問題 例: - よく使うページからユーザーをいく つかのクラスタに分解する - あるアイテムと一緒に買われてい るアイテムを抽出する 代表的な手法 - k-means - PCA/t-SNE - NMF (クラスタリング・次元削減など) 教師あり学習 教師なし学習 19
© DMM.com 機械学習の応用先 20
© DMM.com 機械学習でできること - 画像処理 - 自然言語処理 - 音声処理 -
その他 21
© DMM.com 画像処理 - image classification(画像分類) - object detection(物体検出) -
semantic segmentation(セマンティックセグメンテーション) - pose estimation(姿勢推定) - image generation(画像生成) - … - https://arxiv.org/abs/1506.02640 22
© DMM.com 自然言語処理 - text classification(テキスト分類) - named entity recognition(固有表現認識)
- question answering(質問応答) - language model(言語モデル) - machine translation(機械翻訳) - text summarization(文章要約) - … https://arxiv.org/abs/2005.14165 23
© DMM.com 音声処理 - speech recognition(音声認識) - speech synthesis(音声生成) 24
© DMM.com その他 - 表データ - 推薦 - 時系列データ -
異常検知 - グラフデータ - クラスタ検出 - 強化学習 - ゲームAI, 自動運転 25
© DMM.com マルチモーダル処理 - 言語 <-> 画像 - 言語 <->
映像 - 言語 <-> 音声 詳細はLLMのところで。 26
© DMM.com ワーク1 DMMのサービスの中で適用できそうな機械学習を用いた施策を考えてみる。 それがどのようにサービスの質を上げたり、利益をあげたりすることに繋がりそ うか。 27
© DMM.com 機械学習をどう実装するか 28
© DMM.com 機械学習プロジェクトのライフサイクル 1. Scoping 2. Data 3. Modeling 4.
Deployment 29
© DMM.com scoping(要件定義) - 取り組むタスクの定義 - 評価指標の定義 - train/val/test -
precision/recall/f1 - リソース、タイムラインの見積り 30
© DMM.com Data - データパイプラインの作成 - データの前処理 31
© DMM.com Data(データパイプラインの作成) - データパイプラインの作成 - データソース - どうやってデータを集めるか、ユーザーログ、商品の DB、サードパーティデータ
- データの保存形式 - どうやってデータを保存するか - 構造化データ vs 非構造化データ (gcs, s3, bigquery, DynamoDB) - どのようにシリアライズするか (json, csv, parquet, pickle) - データの処理 - ストリーミング処理 vs バッチ処理 32
© DMM.com Data(データの前処理) - データの前処理 - データのサンプリング - データのラベリング -
少量データへの対応 - 弱教師学習、半教師学習 (psedo labeling)、自己教師あり学習、転移学習、能動学習 - data augmentation - 不均衡データへの対応 - 評価指標の設定 - 不均衡さを考慮した lossの設定 - データのサンプリングの工夫 33
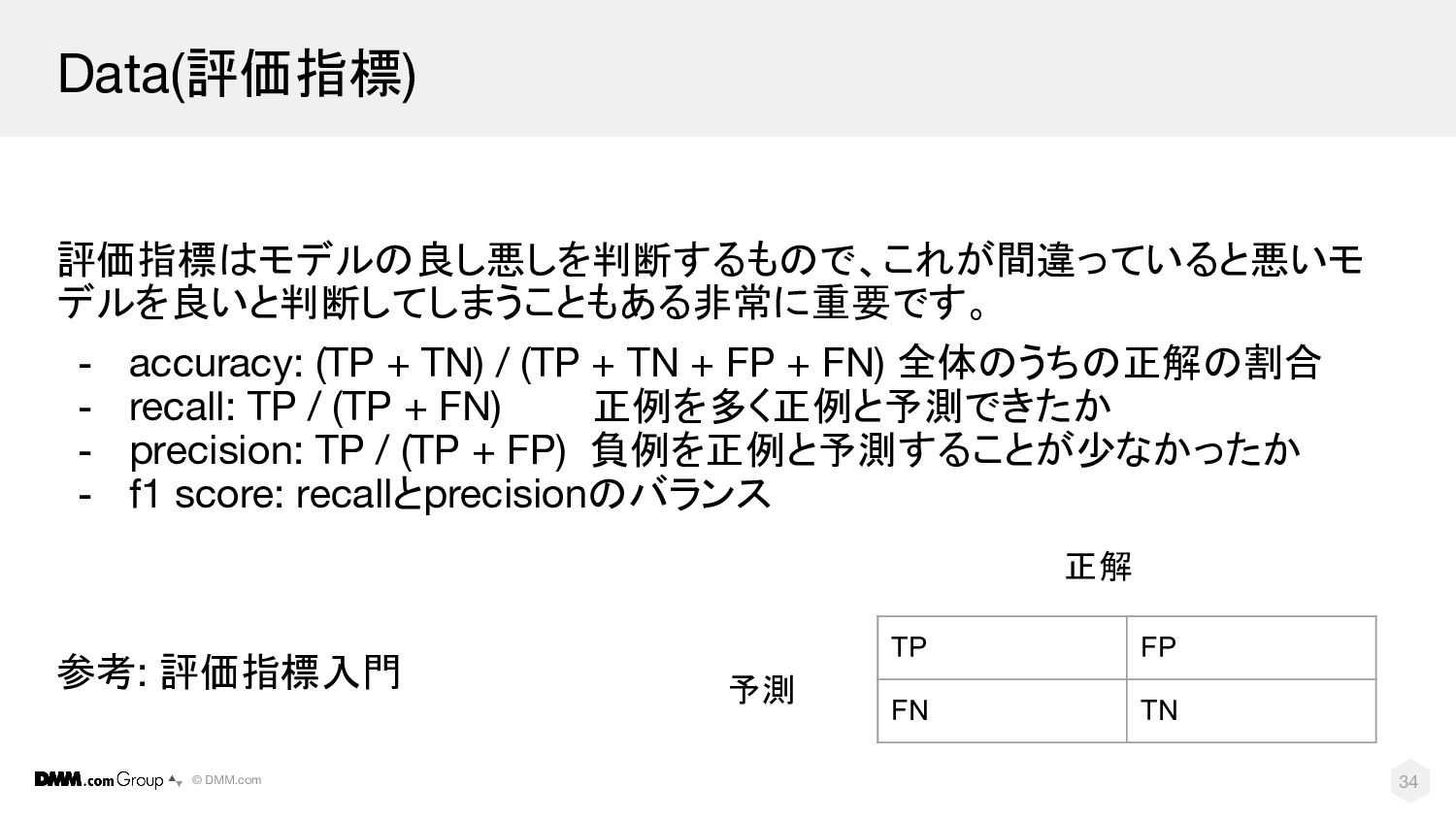
© DMM.com Data(評価指標) 評価指標はモデルの良し悪しを判断するもので、これが間違っていると悪いモ デルを良いと判断してしまうこともある非常に重要です。 - accuracy: (TP + TN)
/ (TP + TN + FP + FN) 全体のうちの正解の割合 - recall: TP / (TP + FN) 正例を多く正例と予測できたか - precision: TP / (TP + FP) 負例を正例と予測することが少なかったか - f1 score: recallとprecisionのバランス 参考: 評価指標入門 TP FP FN TN 予測 正解 34
© DMM.com Data(評価指標) 以下のような疾患の識別モデルを作成している時にaccuracyを採用してしまう と問題が起きます。 - accuracy: (TP + TN)
/ (TP + TN + FP + FN) 全体のうちの正解の割合 - recall: TP / (TP + FN) 正例を多く正例と予測できたか - precision: TP / (TP + FP) 負例を正例と予測することが少なかったか - f1 score: recallとprecisionのバランス TP(10件) FP(10件) FN(90件) TN(890件) モデルAの予測 正解 TP(80件) FP(200件) FN(20件) TN(800件) モデルBの予測 正解 35 1 0 1(疾患あり) 0(疾患なし)
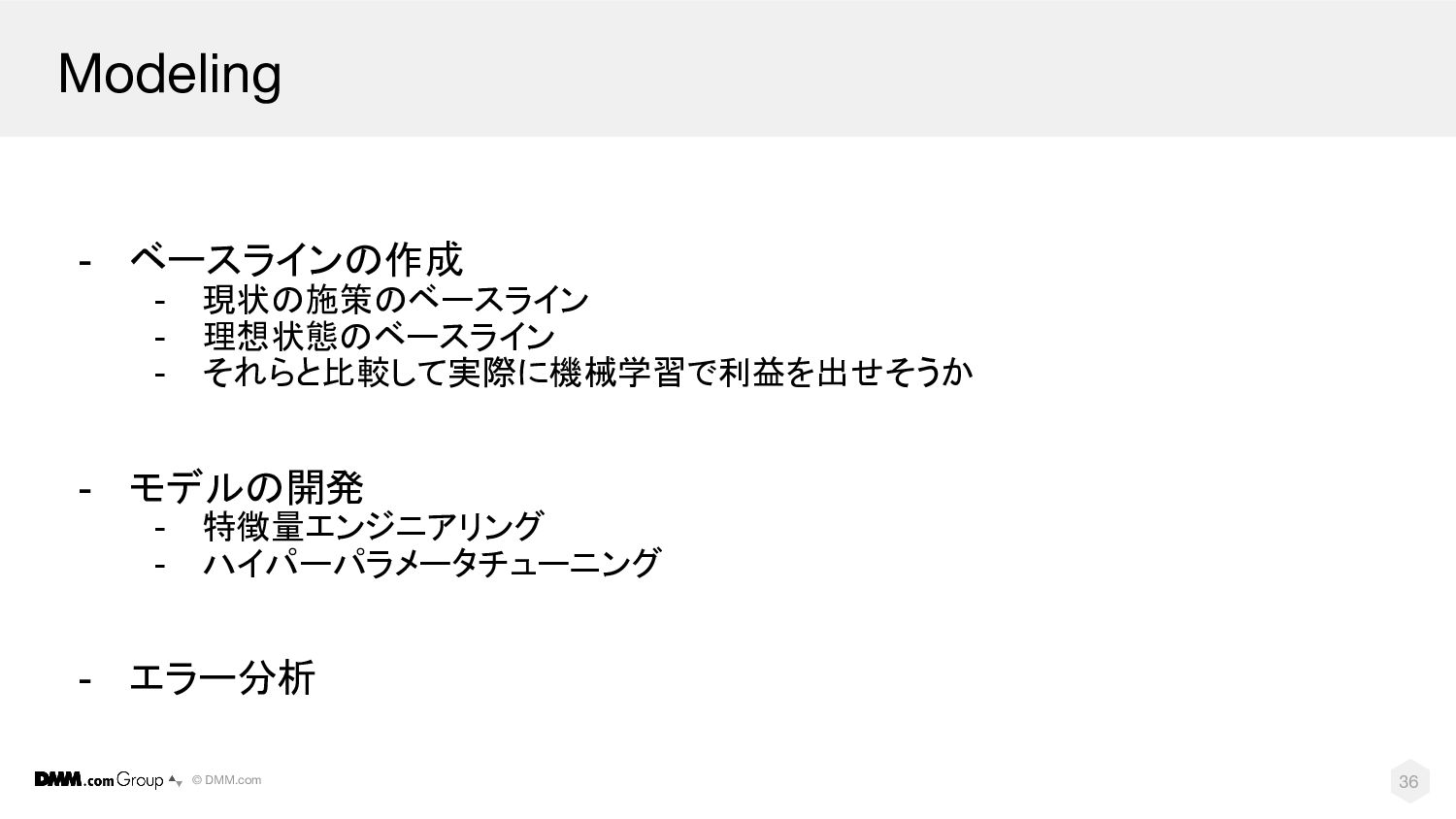
© DMM.com Modeling - ベースラインの作成 - 現状の施策のベースライン - 理想状態のベースライン -
それらと比較して実際に機械学習で利益を出せそうか - モデルの開発 - 特徴量エンジニアリング - ハイパーパラメータチューニング - エラー分析 36
© DMM.com Modeling(ベースラインの作成) - 現状の施策のベースライン - モデルの性能を上げるのには時間がかかる。見積もるのが難しい - ベースラインでモデルがどの程度の性能が出るのかの目安を掴む -
ベースラインと比較することでモデルの性能の向上幅も見積もれる - 理想状態のベースライン - 少量データで人間やデプロイ不可能なLLMなどの性能と比較する - 使える時と使えない時があるが、モデルの向上幅を見積もれる - それらと比較して実際に機械学習で利益を出せそうか 37
© DMM.com Modeling(モデルの開発) - 特徴量エンジニアリング - 機械学習モデルが解釈しやすいようにデータを変形する - 住所の特徴量 ->
緯度・経度の数値特徴量に変形 - 年収の特徴量 -> 外れ値の振る舞いを抑えるために logをとる - … - - ハイパーパラメータチューニング - あらかじめ定めておくパラメーター - 学習率、モデルのサイズ - アンサンブル - 複数のモデルを組み合わせるとモデルの性能が上がりやすい 38
© DMM.com Deployment - デプロイ - デプロイのパターン(バッチ処理、学習頻度、モデル圧縮) - 監視 -
モデル性能の監視 - データの監視 - 効果測定 - ABテスト - ビジネスKPIを改善することが重要 39
© DMM.com Deployment(デプロイ) 機械学習のモデルは計算が比較的重いことが多く、何も気にせずにデプロイするとレイテンシーが問題と なることがある。 コストの問題や、レイテンシーが遅いことによるUXの悪化などを避けるためにもデプロイのアーキテクチャ を考えることが必要 - バッチ処理かオンライン処理か -
バッチ処理だとレイテンシーの問題を軽減することができる。ただし性能として最新のデータを 使いづらいという問題もある。 - 学習頻度 - データは時間が経つにつれ変化するためモデルも学習をしてアップデートをする必要がある。 ビジネス毎にデータの変化の具合も変わるため必要な学習頻度も変わる - モデル圧縮 - オンライン予測をする場合、モデルを軽量にするアプローチがある。低ランク分解、蒸留 (distillation)、枝狩り(pruning)、量子化(quantization)など 40
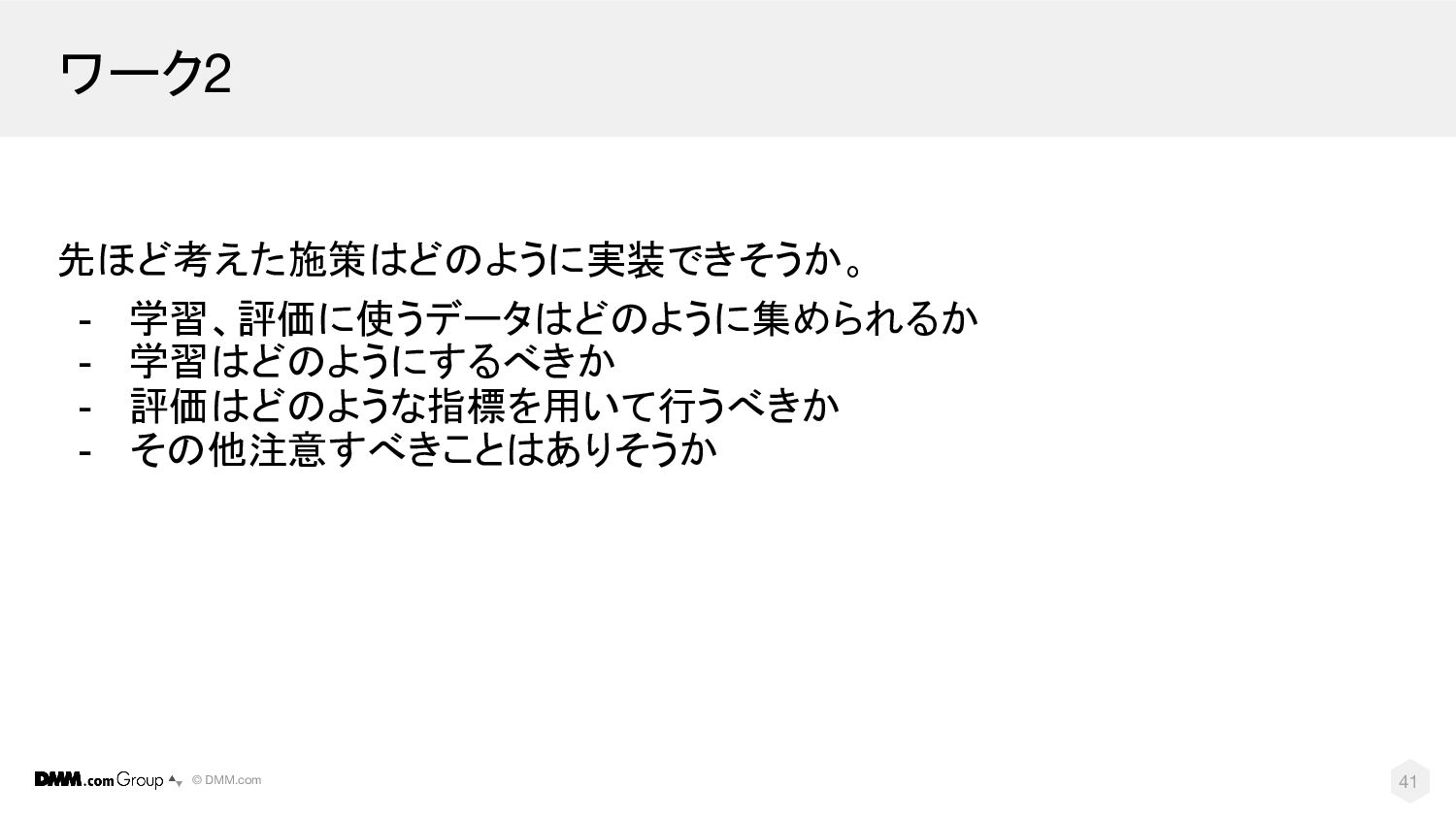
© DMM.com ワーク2 先ほど考えた施策はどのように実装できそうか。 - 学習、評価に使うデータはどのように集められるか - 学習はどのようにするべきか - 評価はどのような指標を用いて行うべきか
- その他注意すべきことはありそうか 41
© DMM.com まとめ - 機械学習の技術に触れて、機械学習に対する敷居を下げる - 機械学習とはモデル、評価関数、最適化ルーチンによって構成される。 - 機械学習技術の使いかたが何となくわかる -
機械学習の応用先(画像、言語、表データ、有名なタスク) - どこで機械学習を使えそうか - 機械学習の技術を扱うときにindexとなるような知識を得る - 機械学習を適用する手順 - どうやって適用するか - 注意すべきところはどこか(モデルの評価) 42
© DMM.com 参考資料 - 機械学習システムデザイン - 仕事ではじめる機械学習 - 評価指標入門 43
© DMM.com 実践 手を動かしながら理解する 44
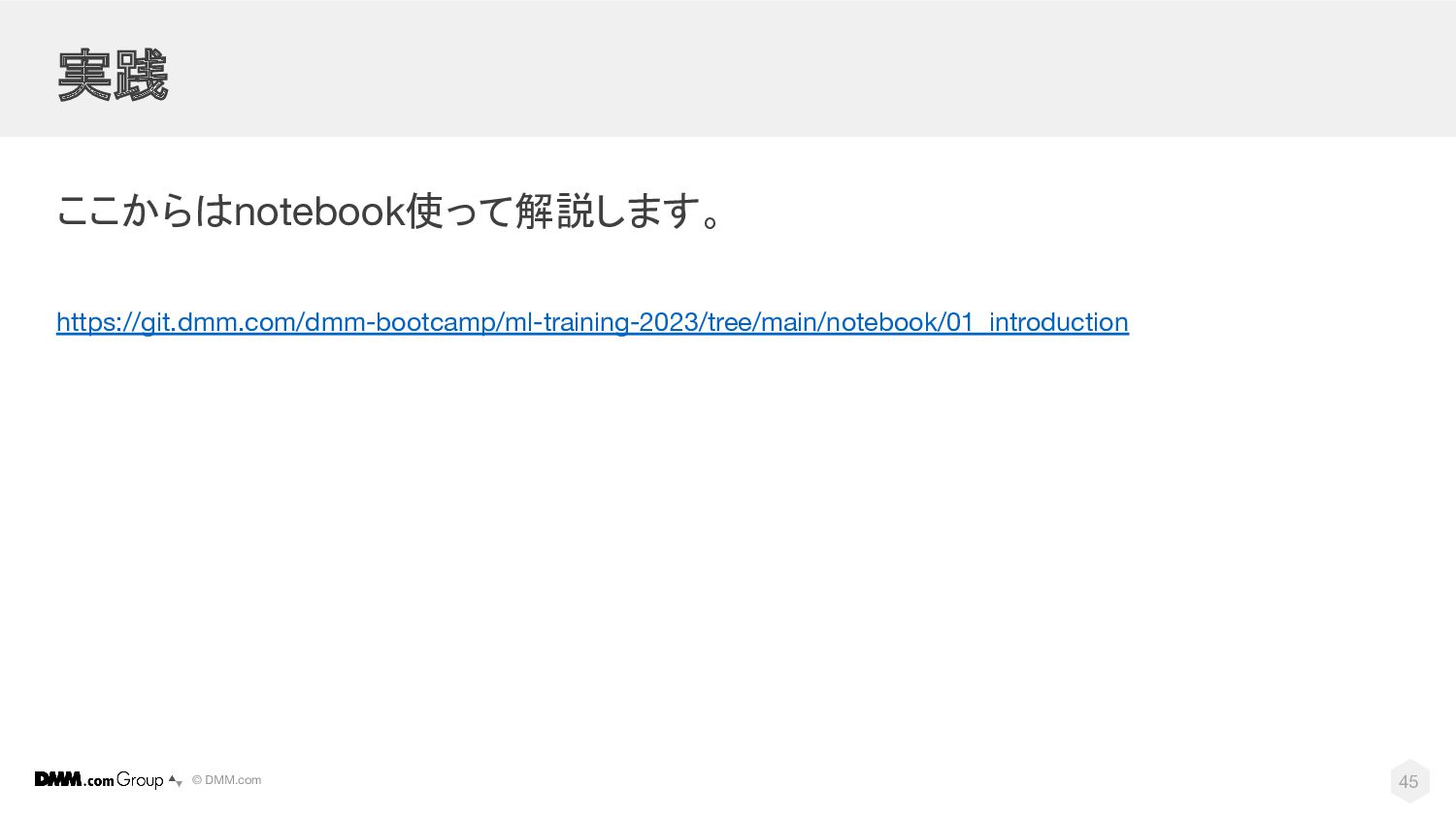
© DMM.com 実践 ここからはnotebook使って解説します。 https://git.dmm.com/dmm-bootcamp/ml-training-2023/tree/main/notebook/01_introduction 45
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}