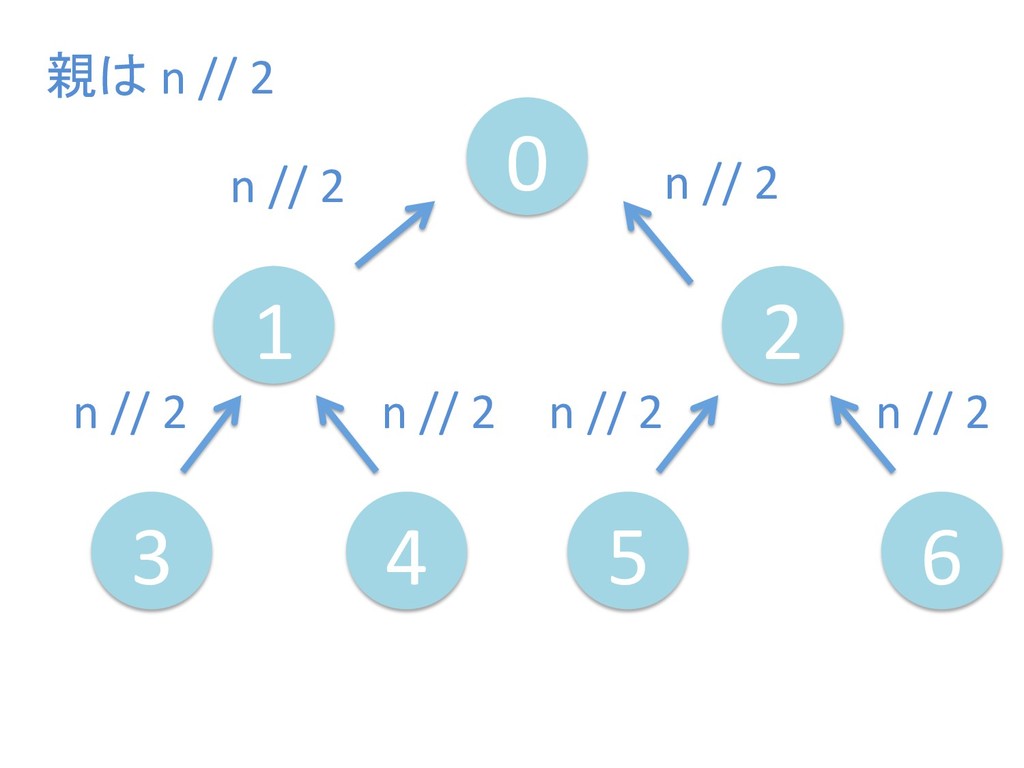
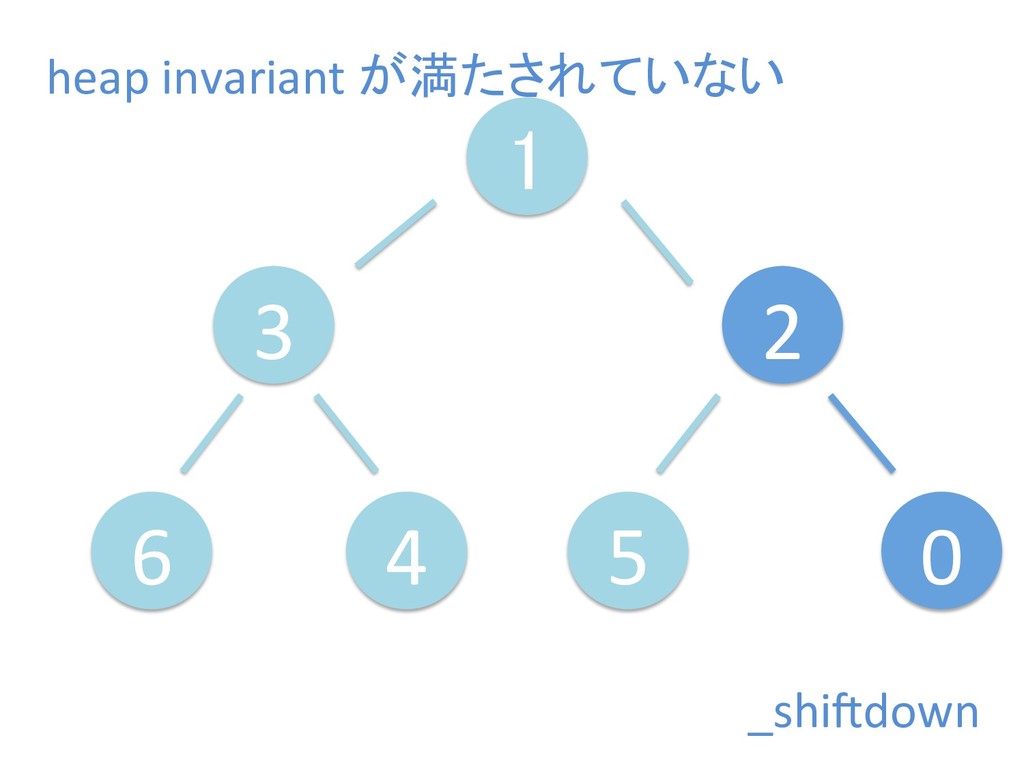
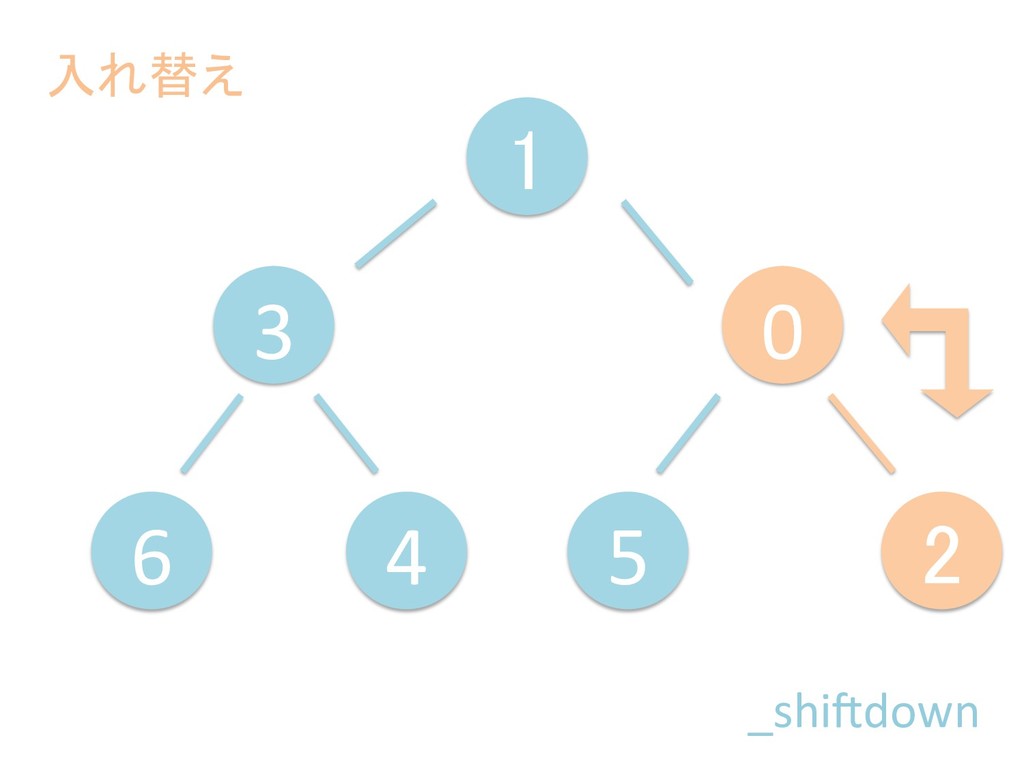
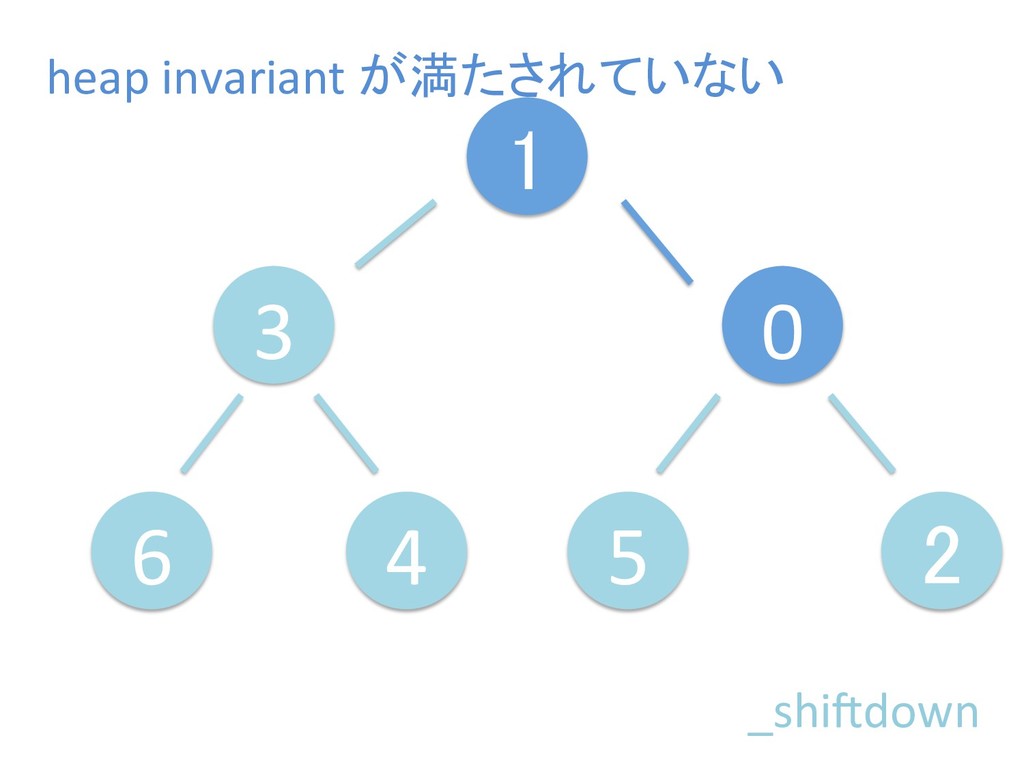
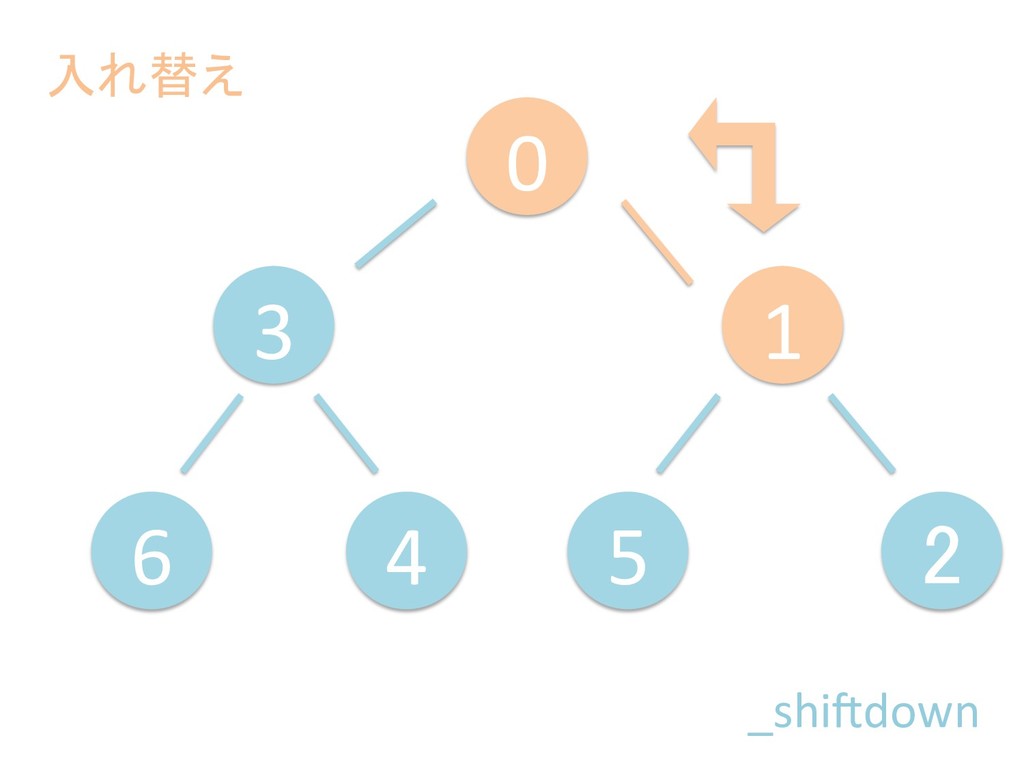
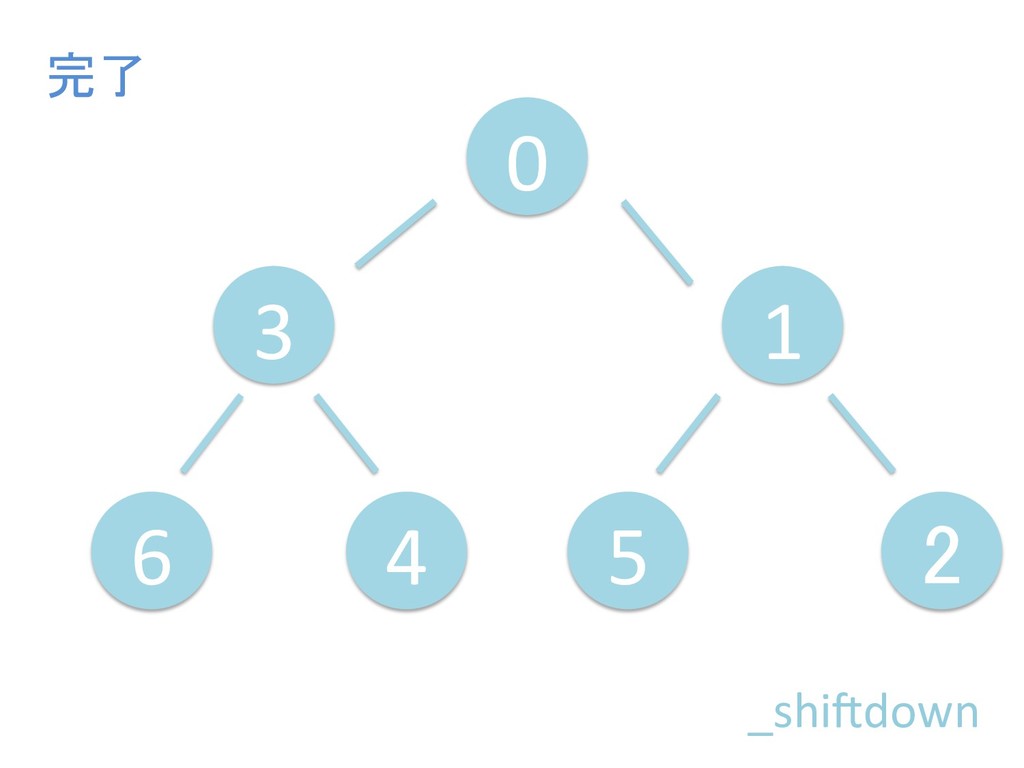
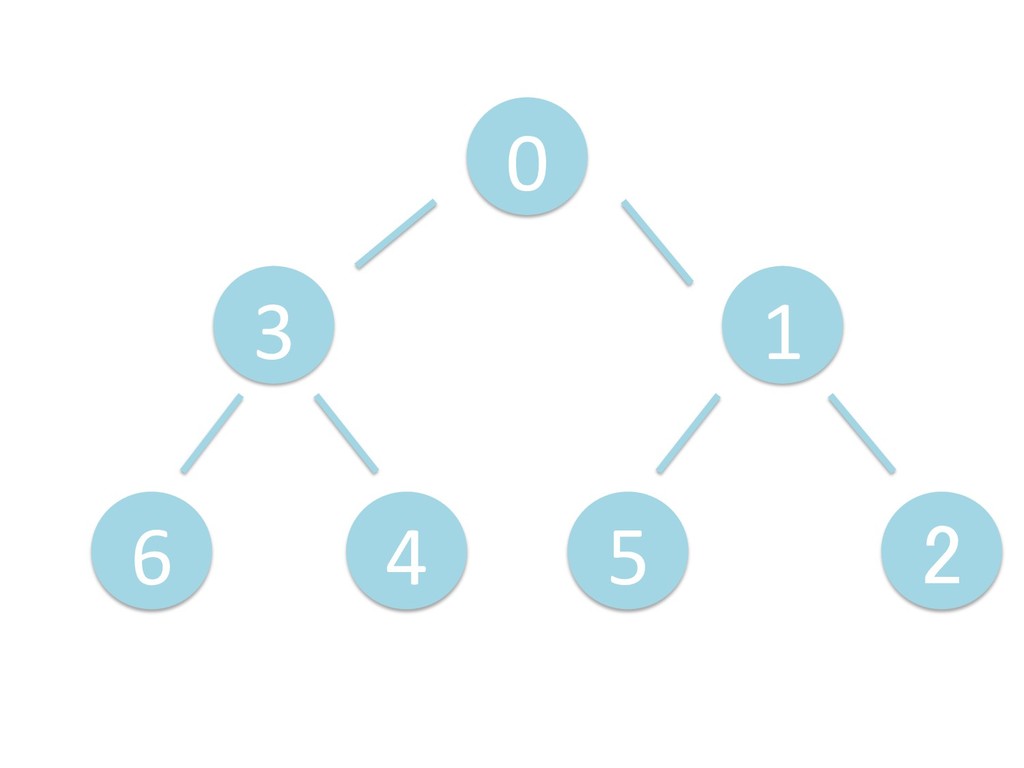
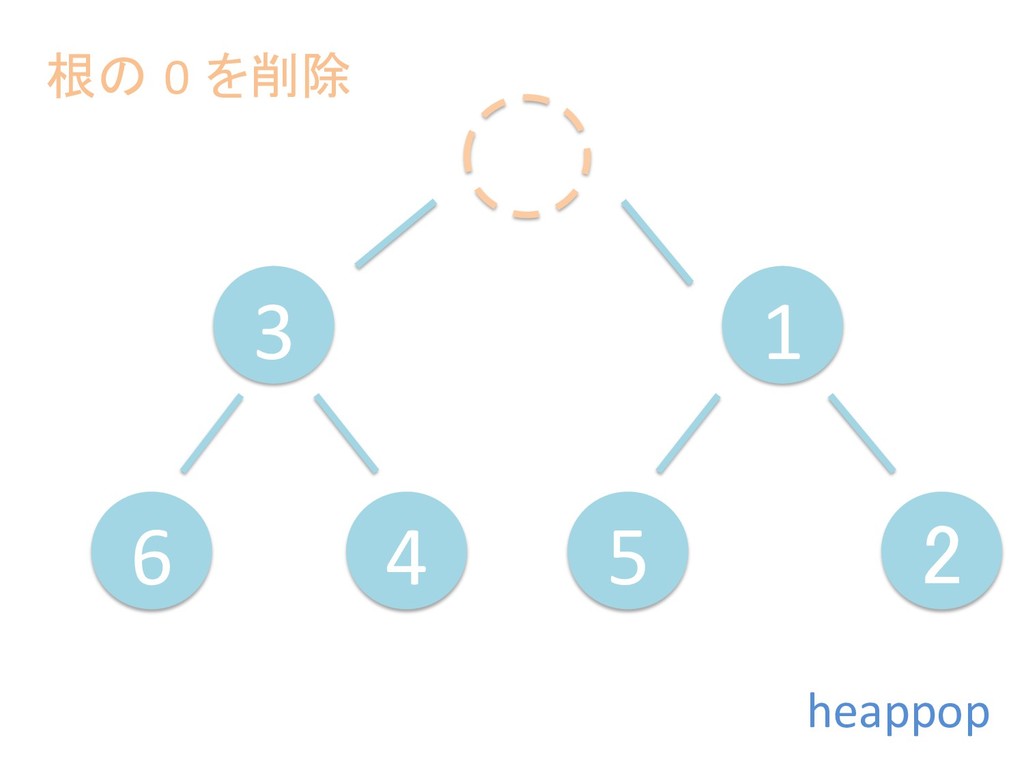
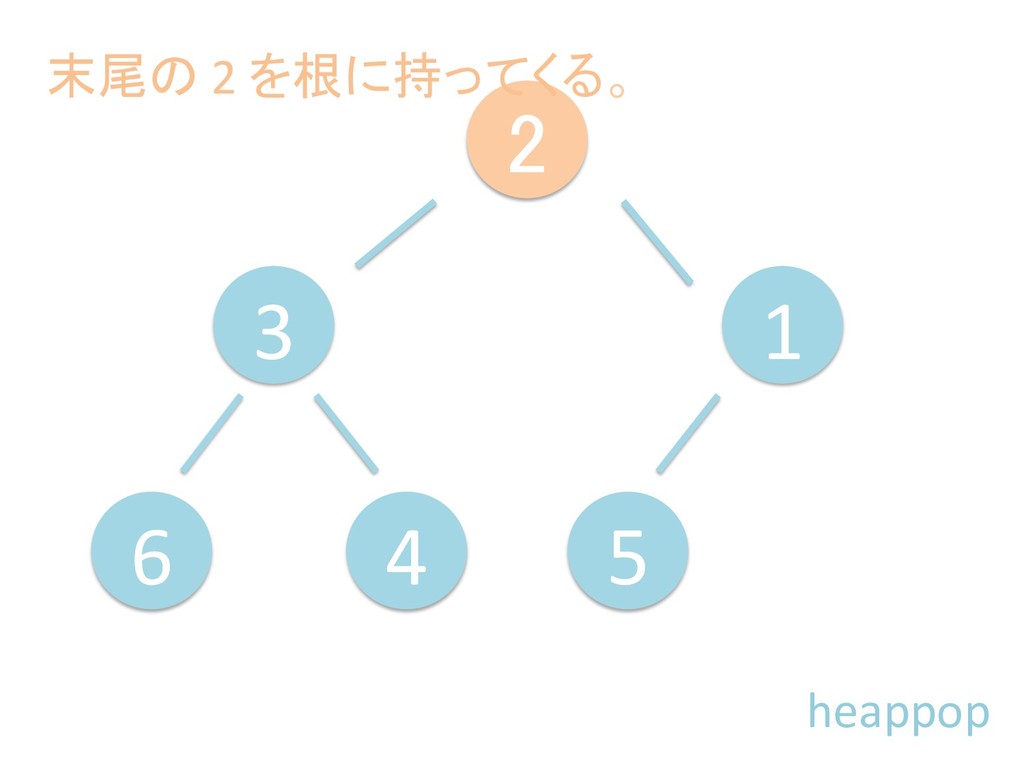
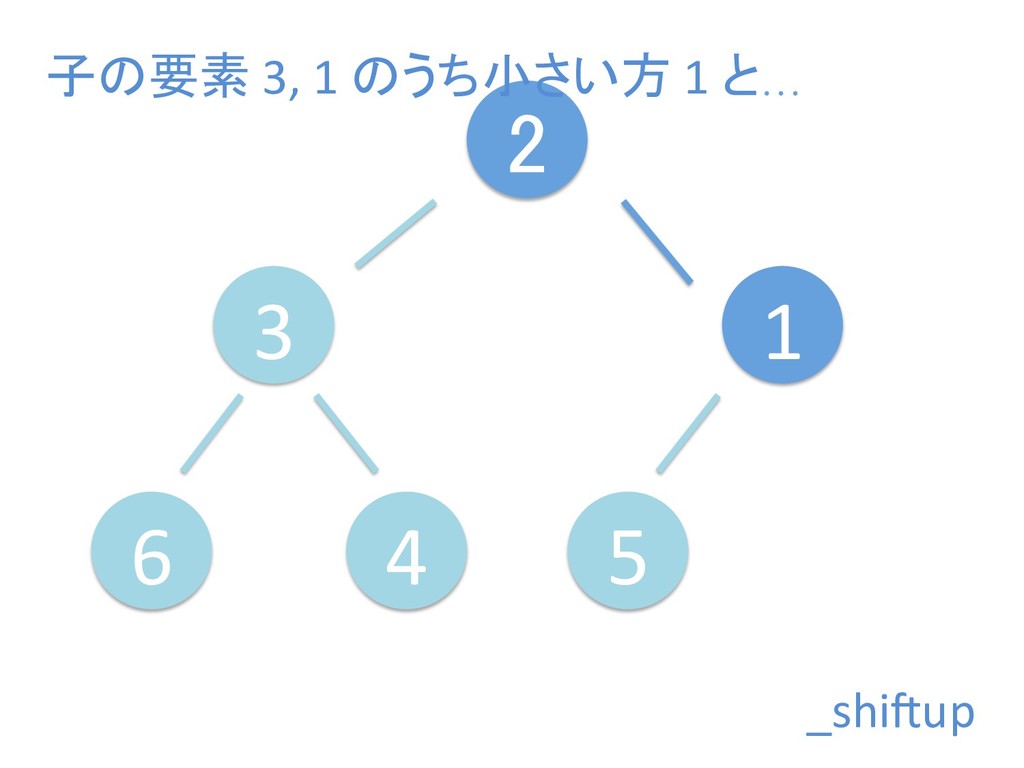
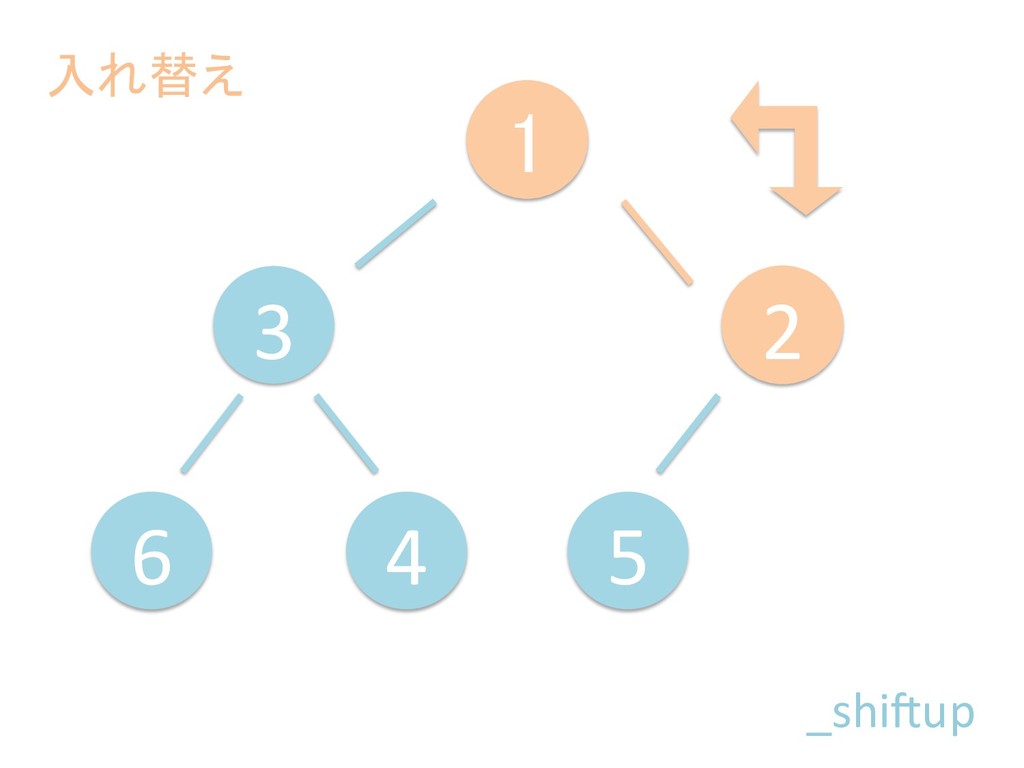
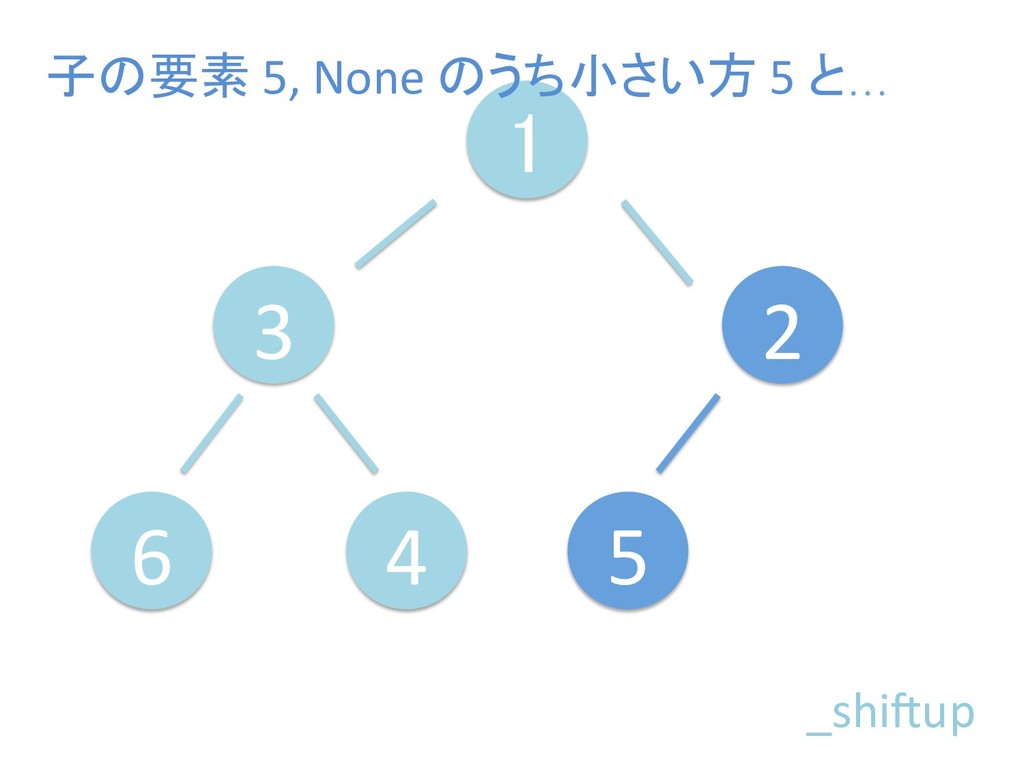
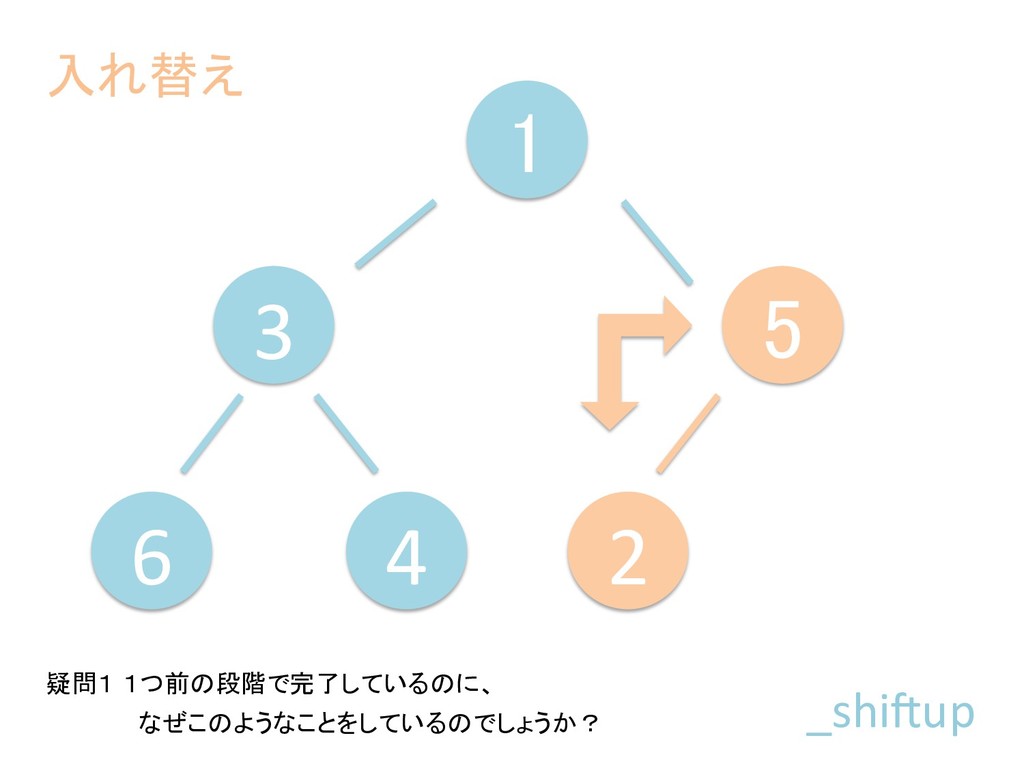
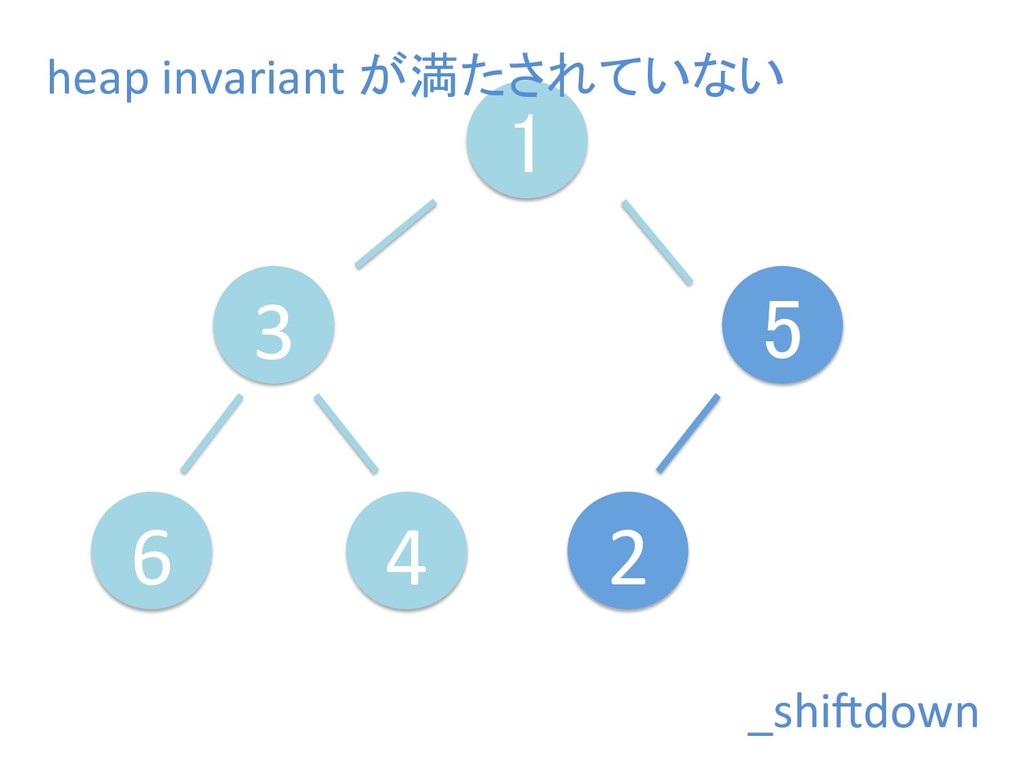
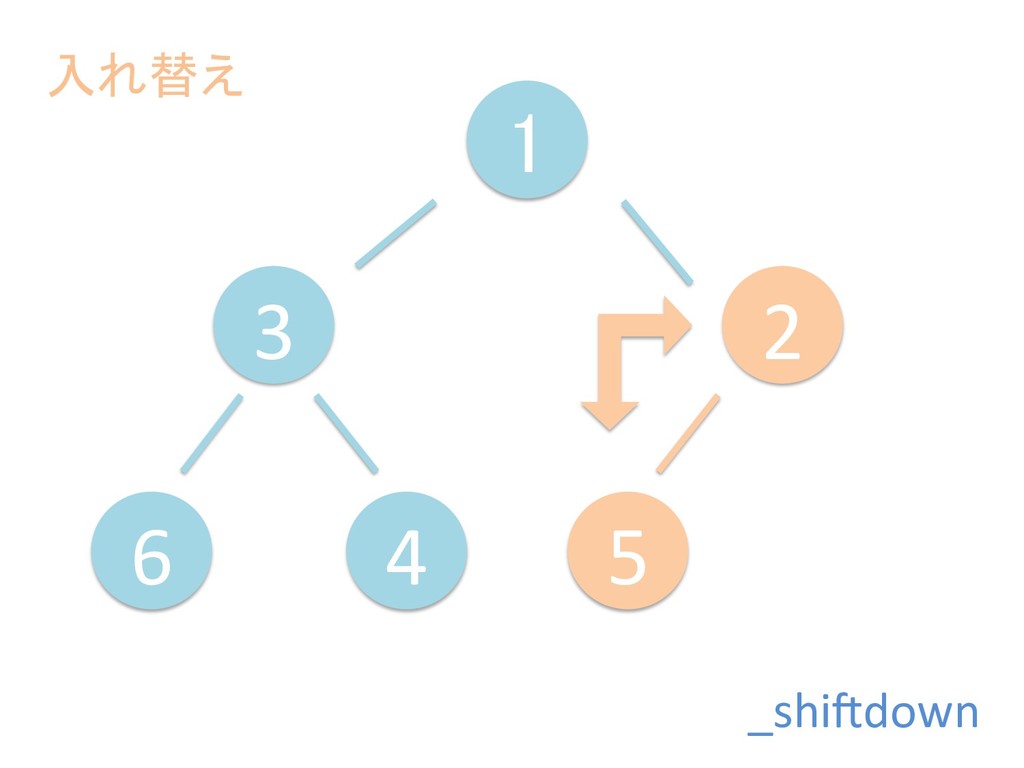
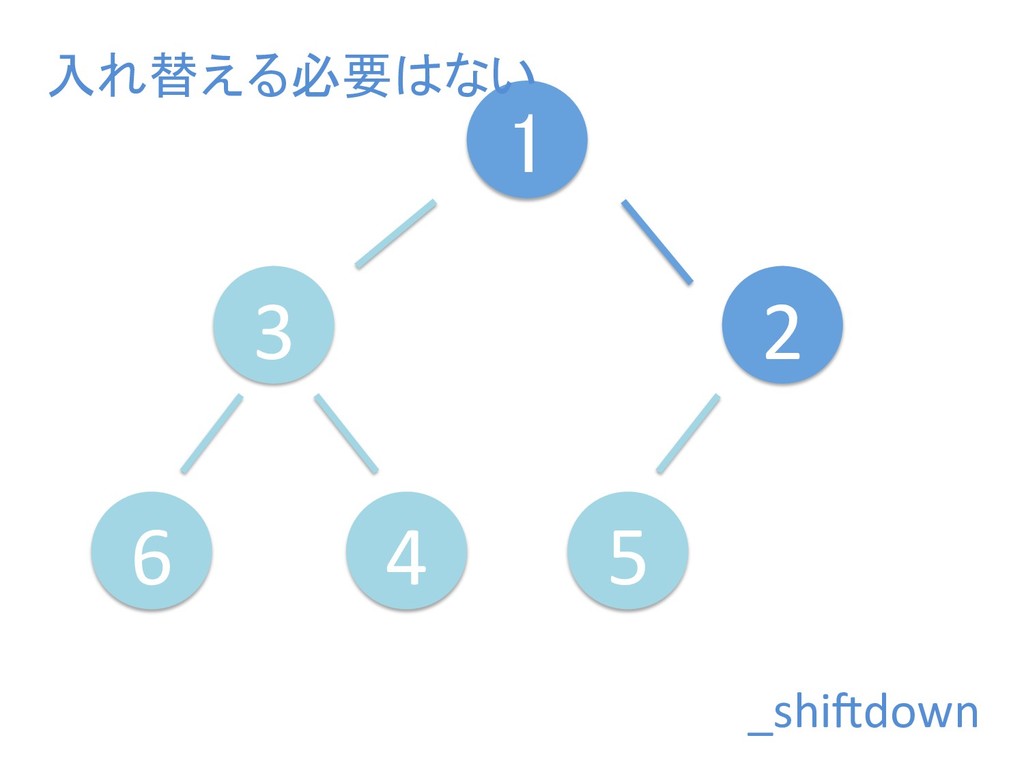
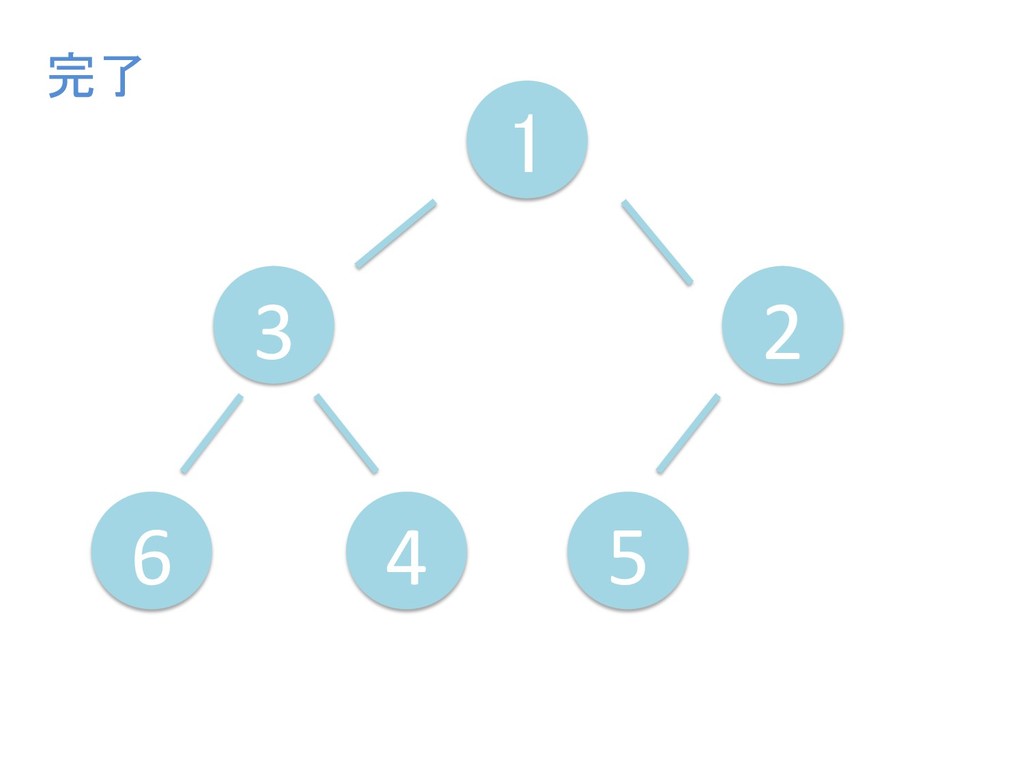
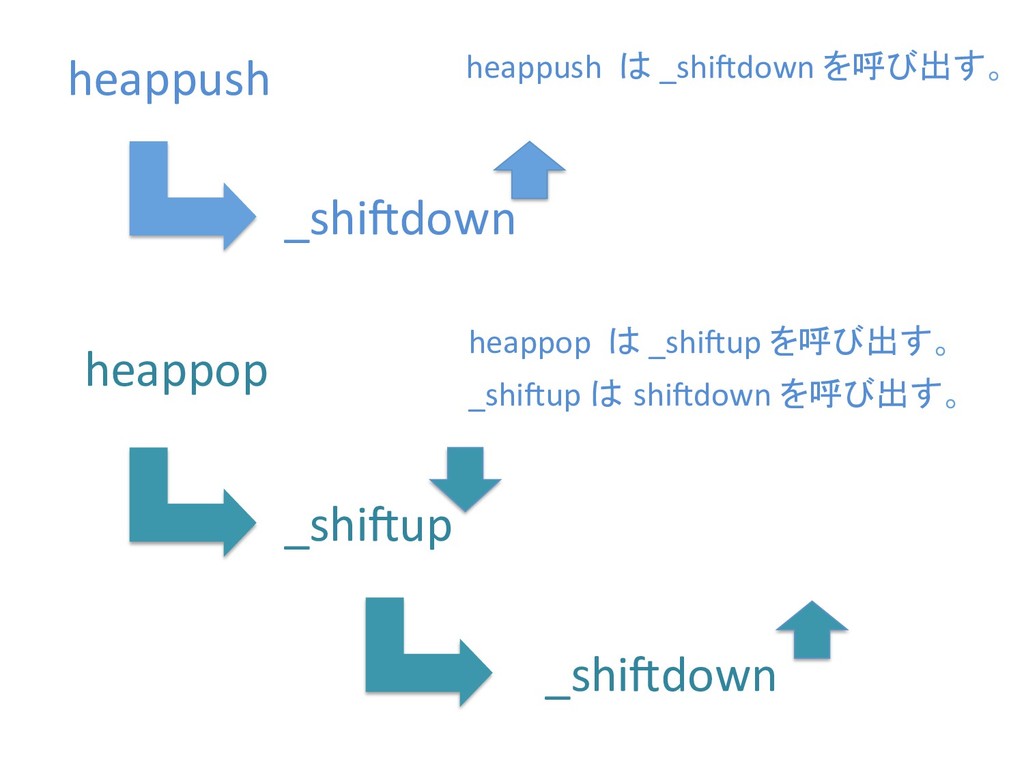
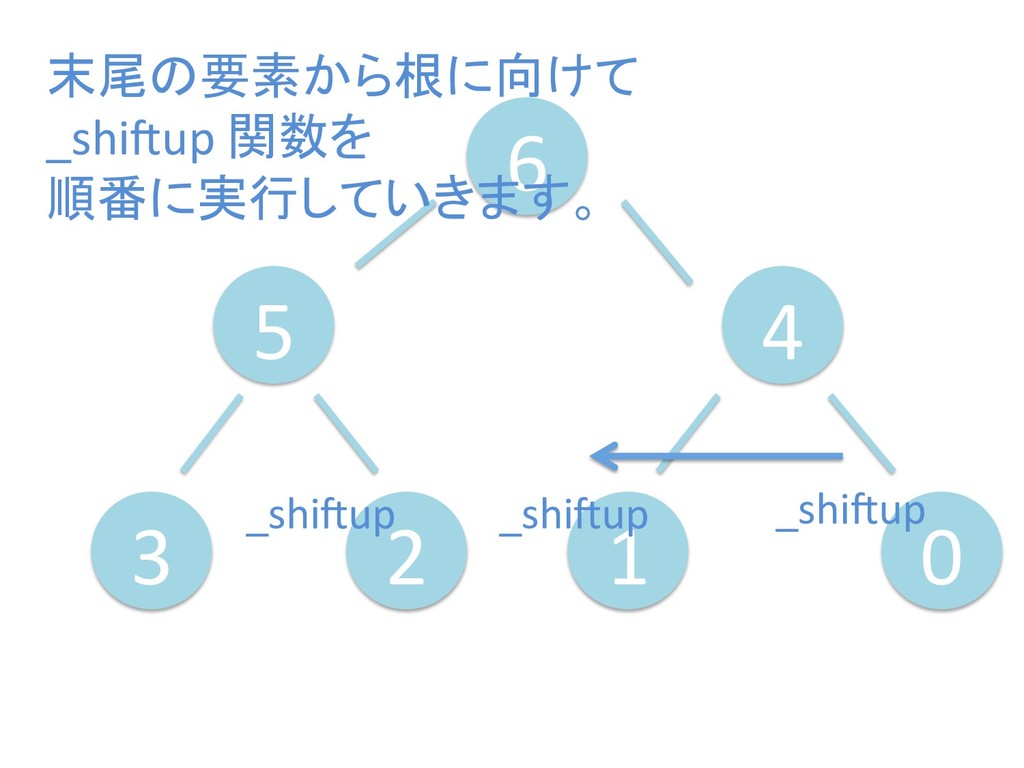
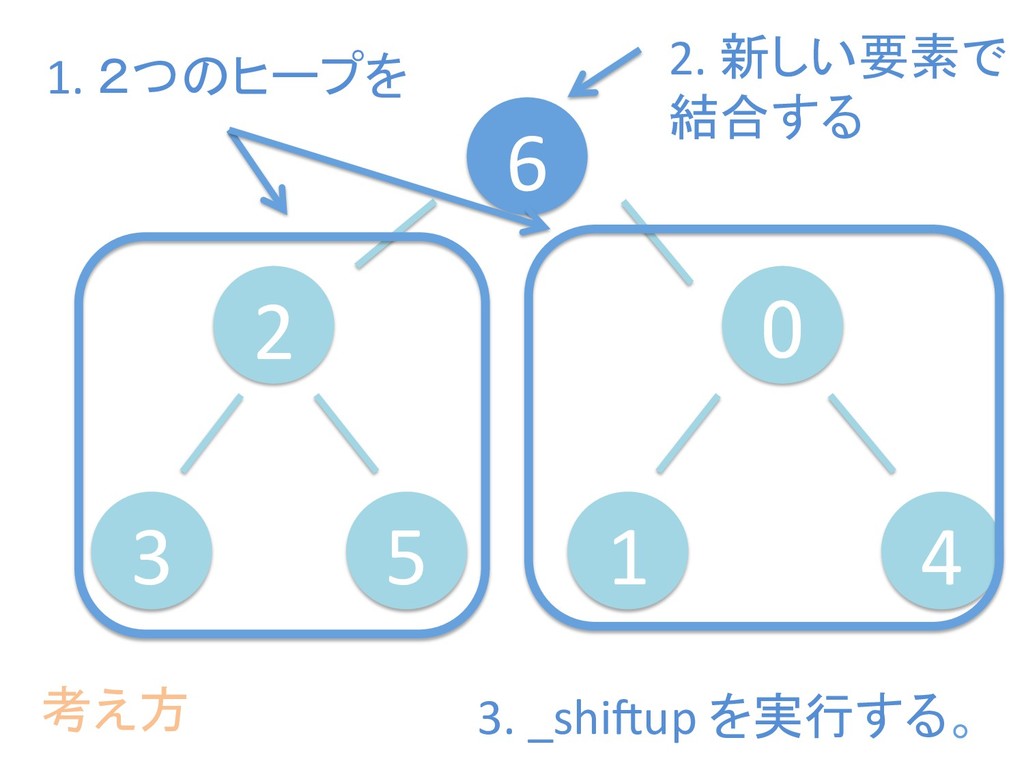
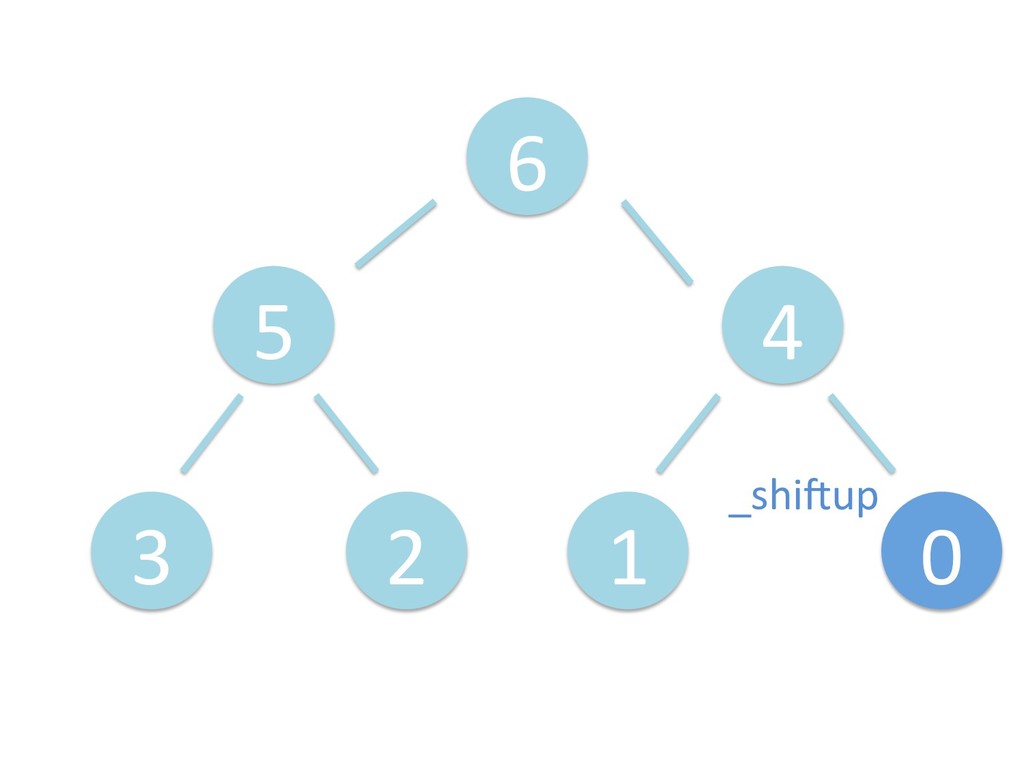
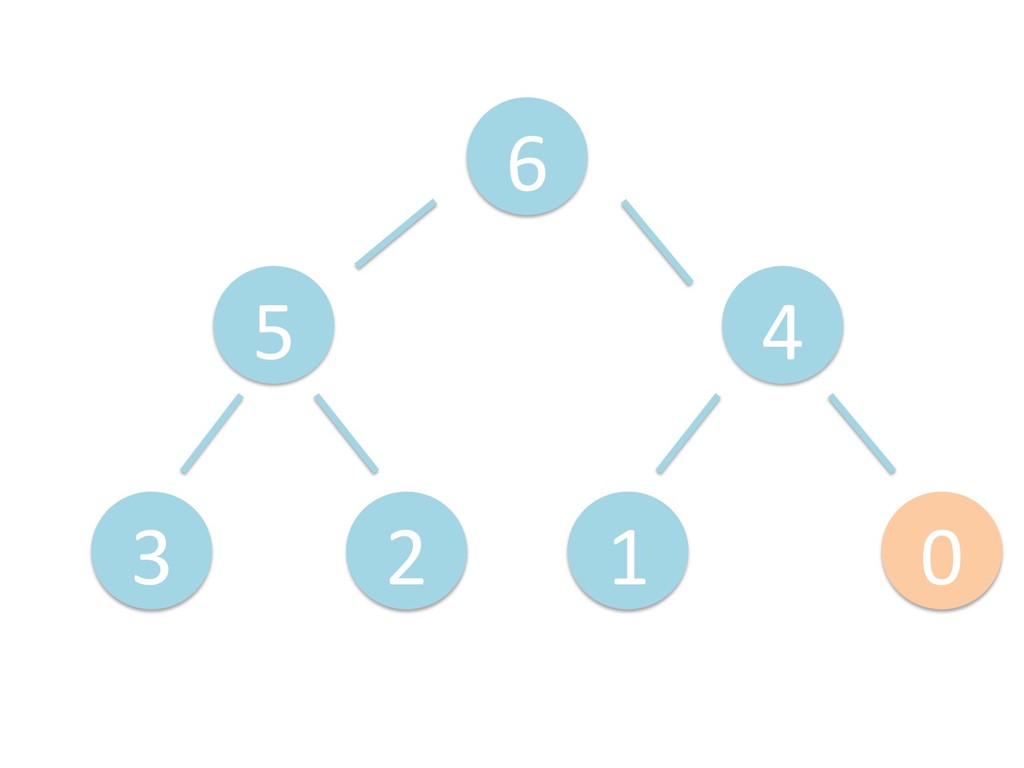
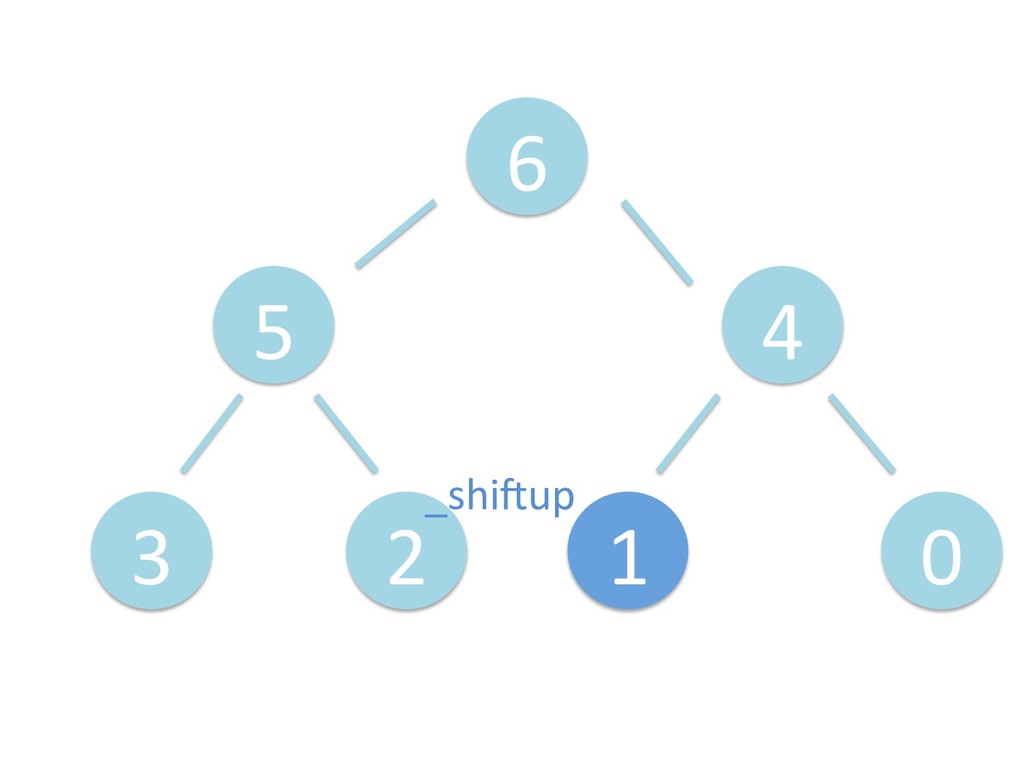
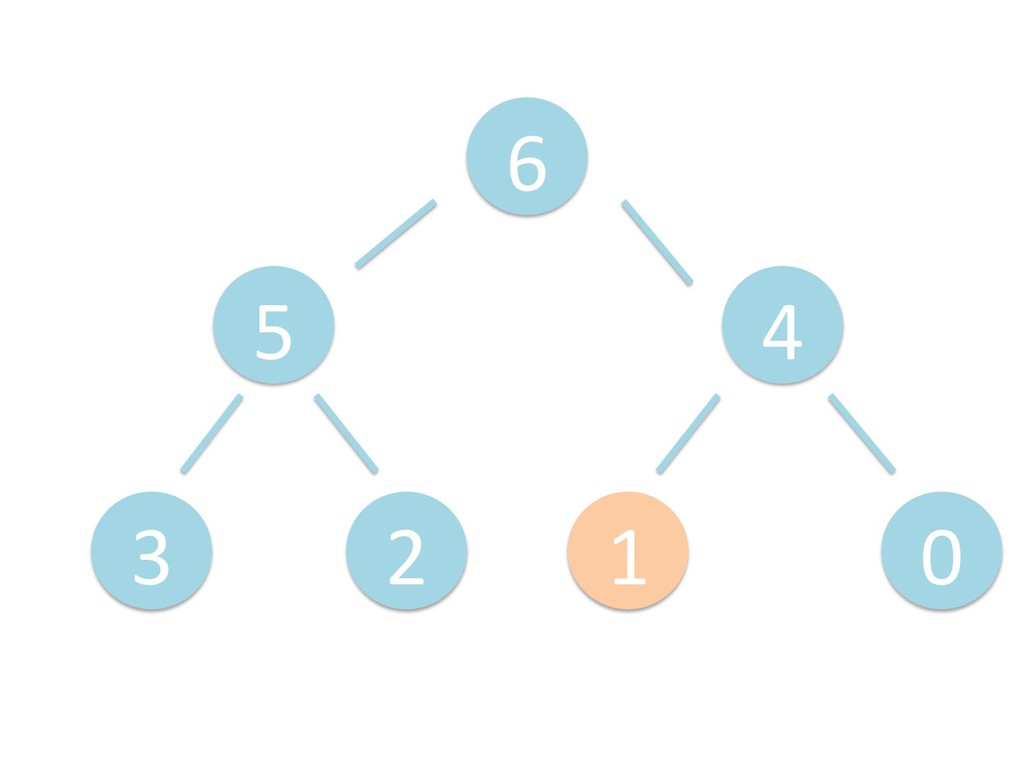
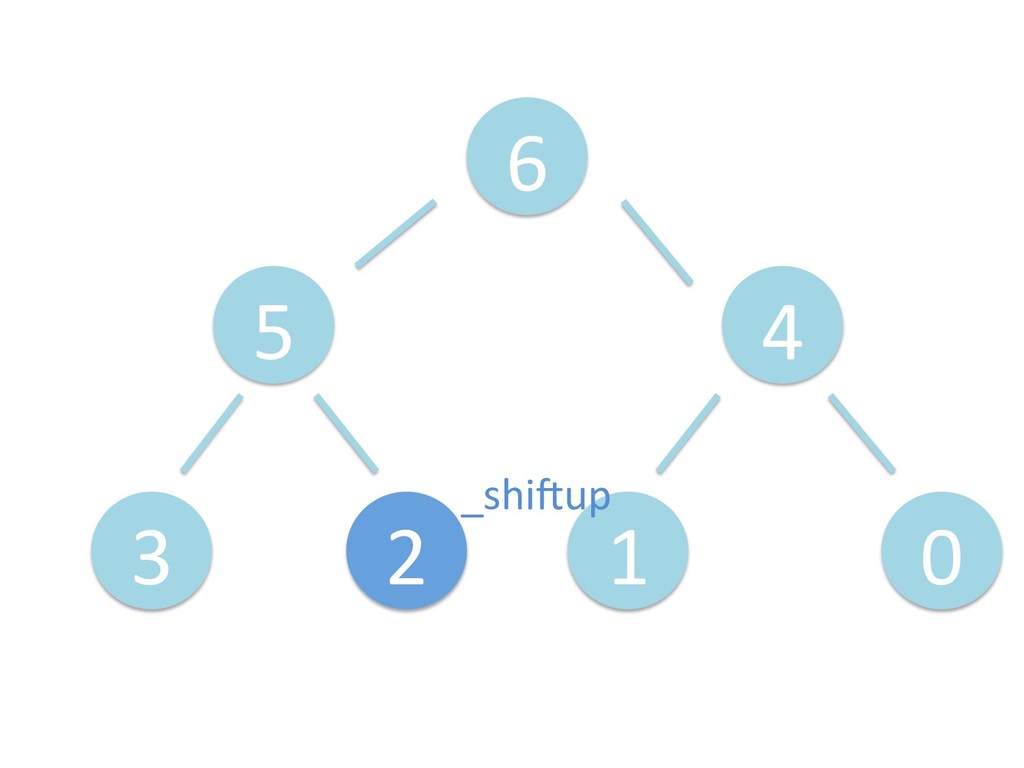
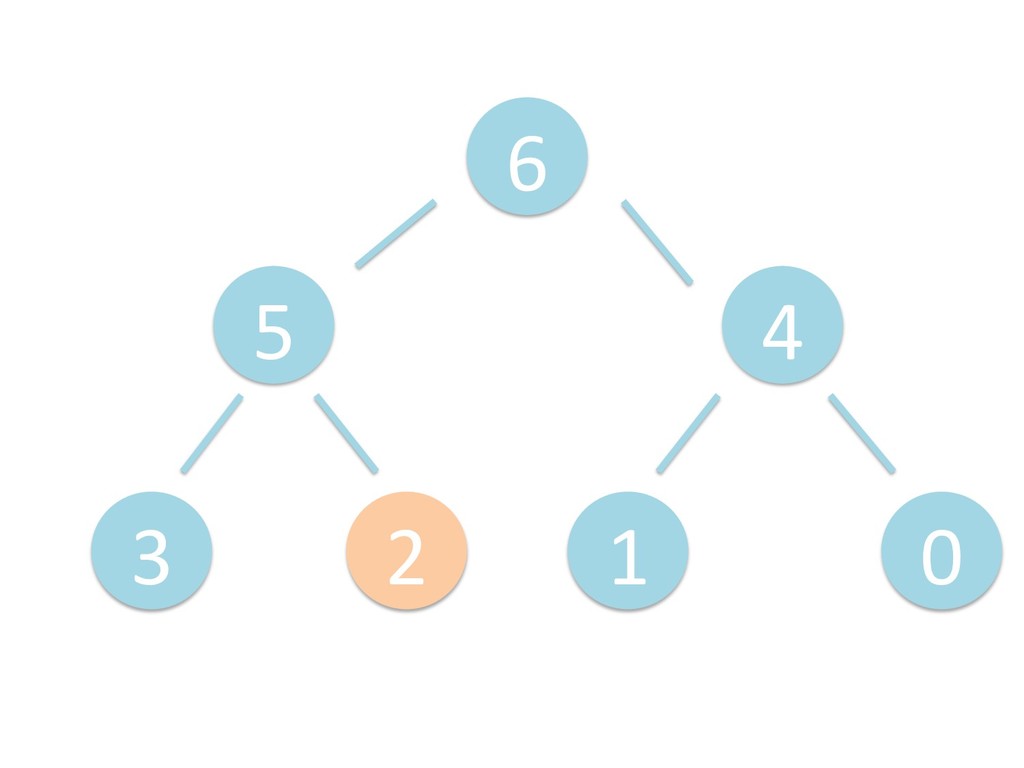
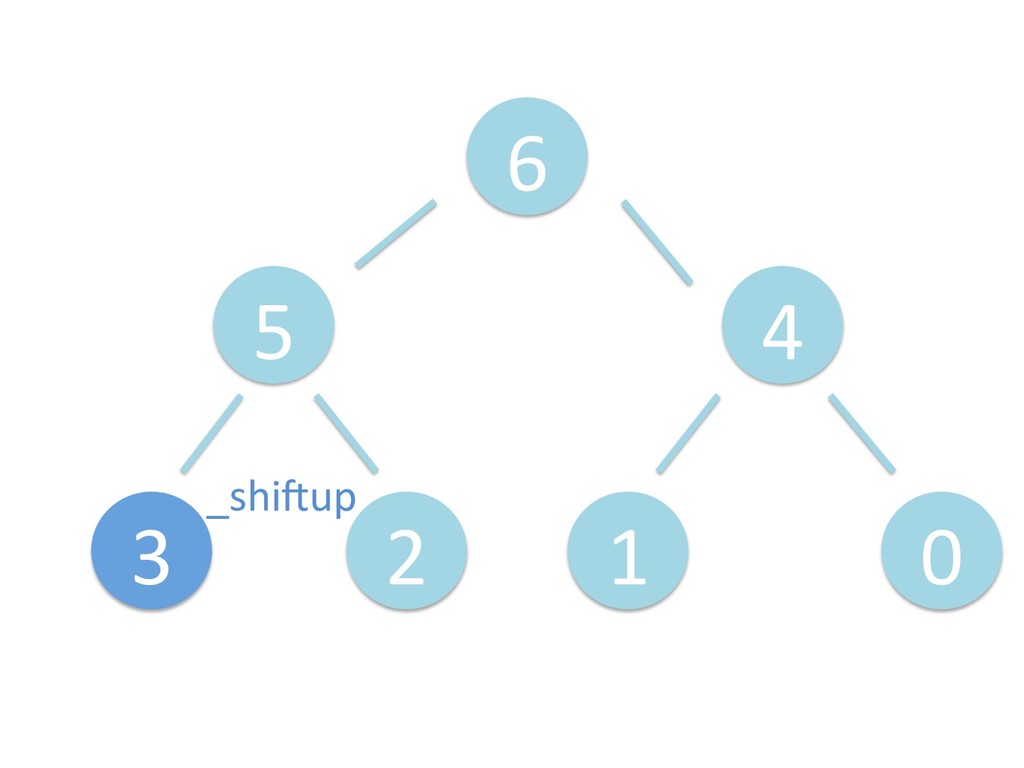
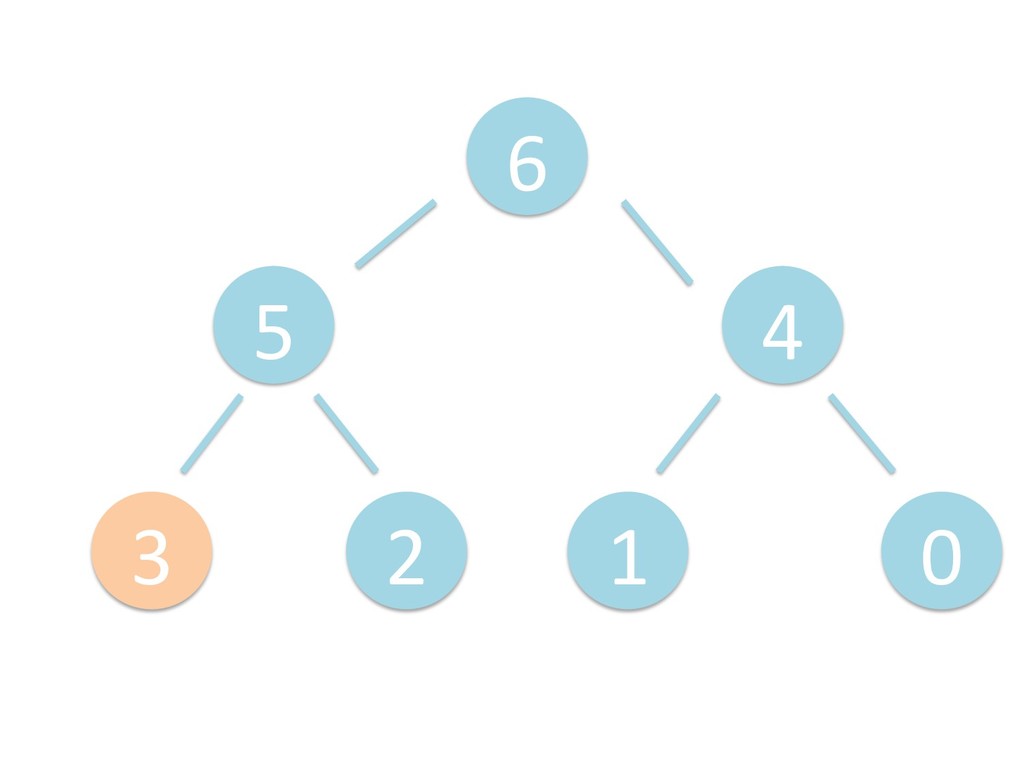
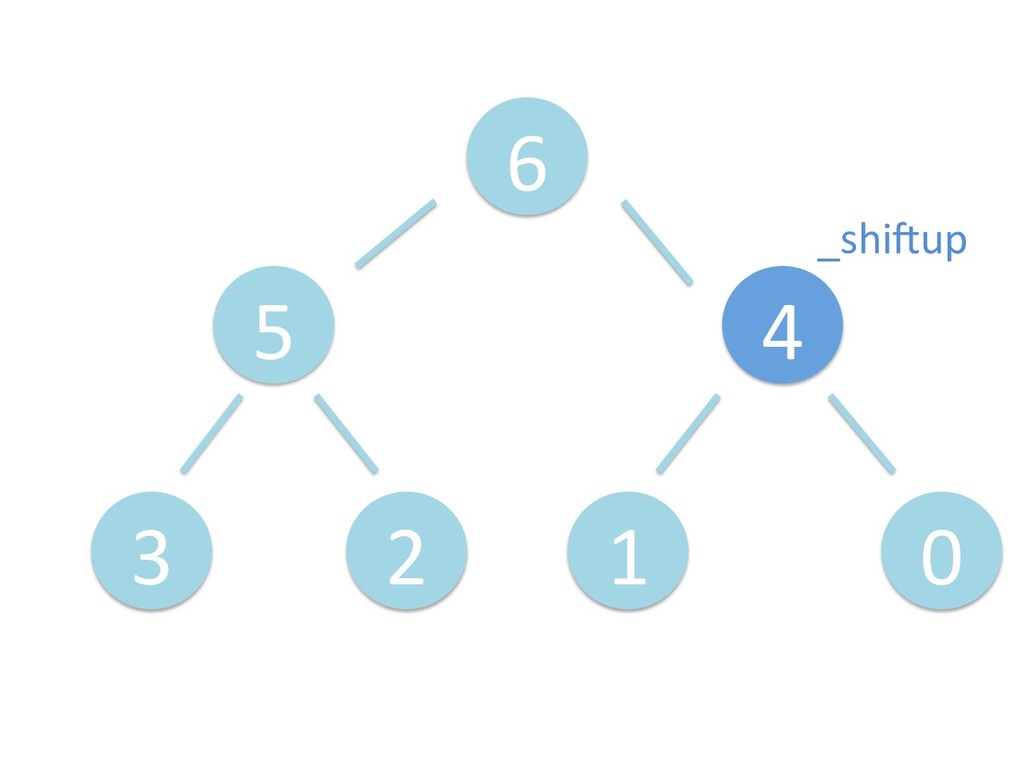
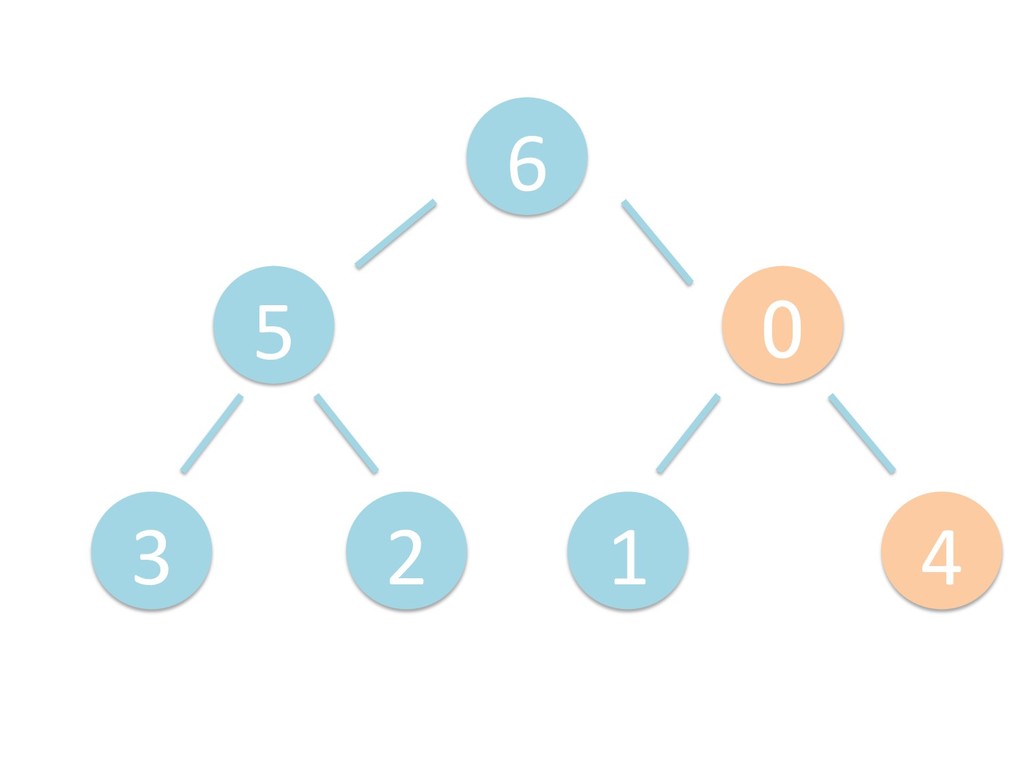
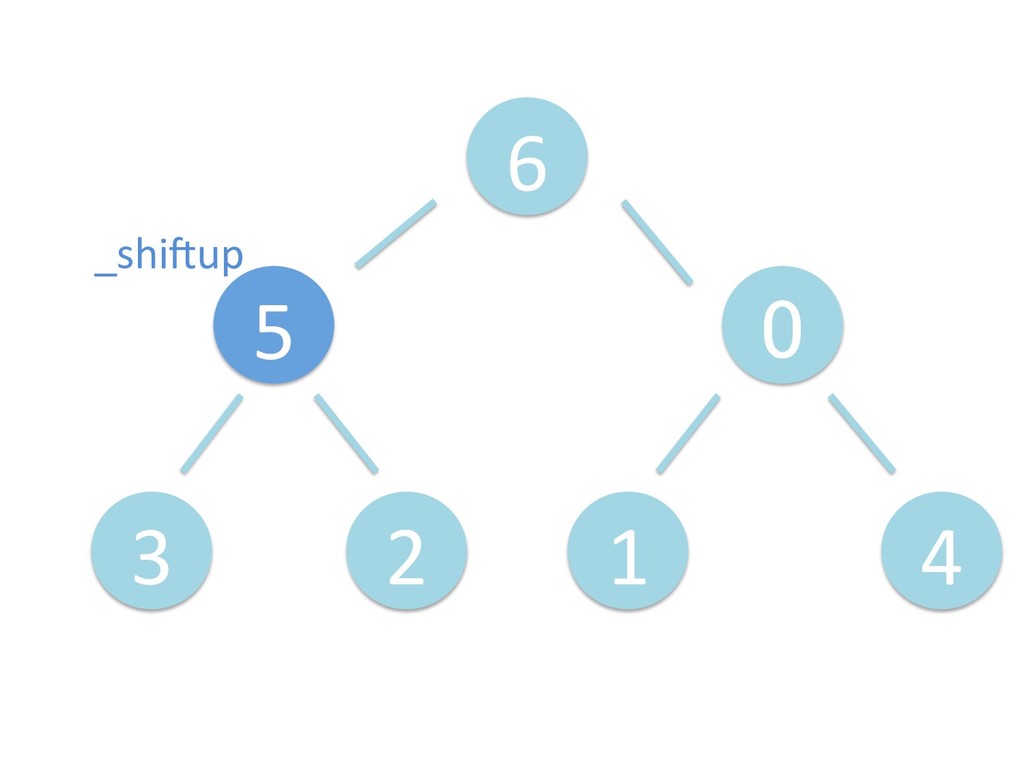
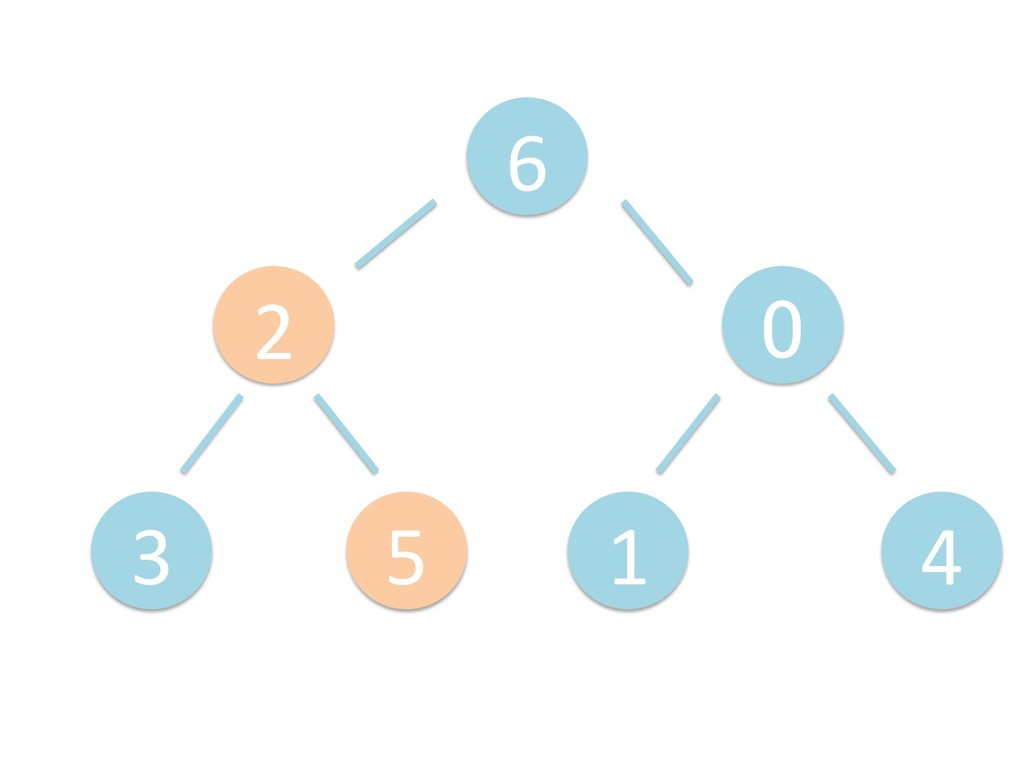
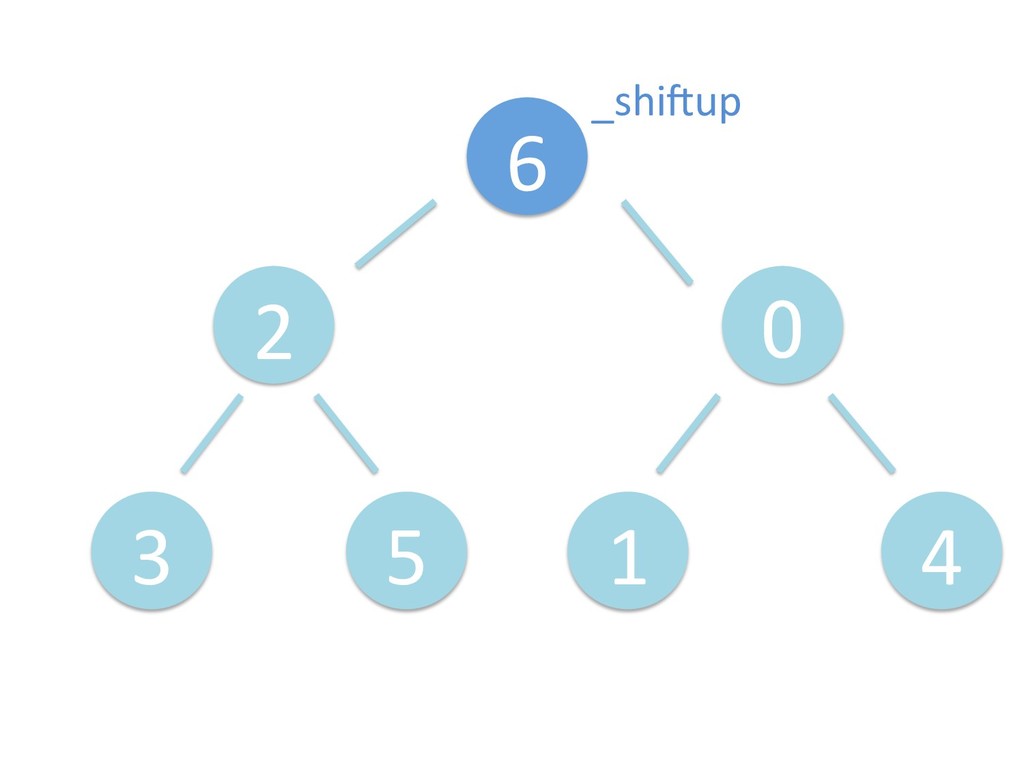
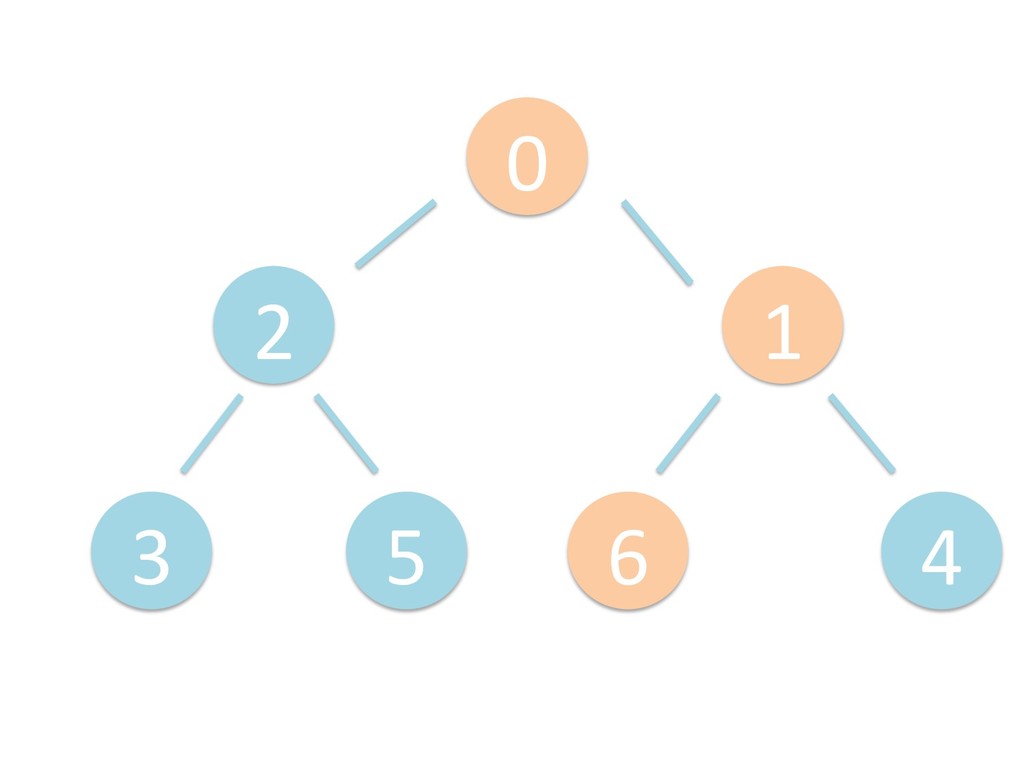
に ある要素の小さい方の子を葉に当 たるまで (そしてその子の子などと 同様に) バブリングしてから、 _si>down を使用して、もともと pos のところにあった要素を正しい位置 に移動します。 The child indices of heap index pos are already heaps, and we want to make a heap at index pos too. We do this by bubbling the smaller child of pos up (and so on with that child's children, etc) unNl hiOng a leaf, then using _si>down to move the oddball originally at index pos into place.
out of the loop as soon as we find a pos where newitem <= both its children, but turns out that's not a good idea, and despite that many books write the algorithm that way.
Knuth の第 3 巻を参照してください、 演習の中で、このことが説明され定 量化されています。 During a heap pop, the last array element is si>ed in, and that tends to be large, so that comparing it against values starNng from the root usually doesn't pay (= usually doesn't get us out of the loop early). See Knuth, Volume 3, where this is explained and quanNfied in an exercise. 葉の値を根に持ってきても値は大きいので、 途中で break させようとしても、かなり下まで行かなと break できないので意味がないということかな…
したがって、比較は潜在的に高価で あると言えます。 CuOng the # of comparisons is important, since these rouNnes have no way to extract "the priority" from an array element, so that intelligence is likely to be hiding in custom comparison methods, or in array elements storing (priority, record) tuples. Comparisons are thus potenNally expensive. int 型の比較ならそうでもないですが 比較演算子を定義したユーザ定義クラスだと 比較の処理が重くなる “可能性” があるということかな。
幅に削減されました、理論に沿って。 これは 3 回の実行からの典型的な 結果です(分散がどれほど小さいか を示すためだけに3 回)。 On random arrays of length 1000, making this change cut the number of comparisons made by heapify() a li^le, and those made by exhausNve heappop() a lot, in accord with theory. Here are typical results from 3 runs (3 just to demonstrate how small the variance is): よくわからない… コードを修正した時の 修正前と修正後の話をしてるのかな 「この変更」 “this change” ってなに?
-------------------------------- 1837 cut to 1663 14996 cut to 8680 1855 cut to 1659 14966 cut to 8678 1847 cut to 1660 15024 cut to 8703 よくわからない… コードを修正した時の 修正前と修正後の話をしてるのかな
2198, 2148, and 2219 compares: heapify() を使用すると、 より効率的です。 Building the heap by using heappush() 1000 Nmes instead required 2198, 2148, and 2219 compares: heapify() is more efficient, when you can use it. よくわからない… ただ heappop より heapify で整列させた方が 効率的だという文章は収穫かな…
list.sort() は (驚くことではありませんが!) より 効率的です。 The total compares needed by list.sort() on the same lists were 8627, 8627, and 8632 (this should be compared to the sum of heapify() and heappop() compares): list.sort() is (unsurprisingly!) more efficient for sorNng. Python の sort には TimSort という アルゴリズムが使われているらしいです。 それと比較したらという話をしているのでしょうか。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}