= spacy.tokenizer.Tokenizer(textcat_spacy.vocab) classes = list(textcat_spacy.get_pipe("textcat").labels) def predict(texts): texts = [str(text) for text in texts] results = [] for doc in textcat_spacy.pipe(texts): results.append([doc.cats[cat] for cat in classes]) return results
= spacy.tokenizer.Tokenizer(textcat_spacy.vocab) classes = list(textcat_spacy.get_pipe("textcat").labels) def predict(texts): texts = [str(text) for text in texts] results = [] for doc in textcat_spacy.pipe(texts): results.append([doc.cats[cat] for cat in classes]) return results
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![SHAPとは? ③ • 文書分類では、「特徴量の無視 」 == 「単語トークンを[MASK]トークンへの置き換え」 • ある文書中の単語が、その文書の予測ラベルの予測への貢献度を算出。](https://files.speakerdeck.com/presentations/04a08dccb33f420d969bbd6435e58187/slide_5.jpg){kind=link}
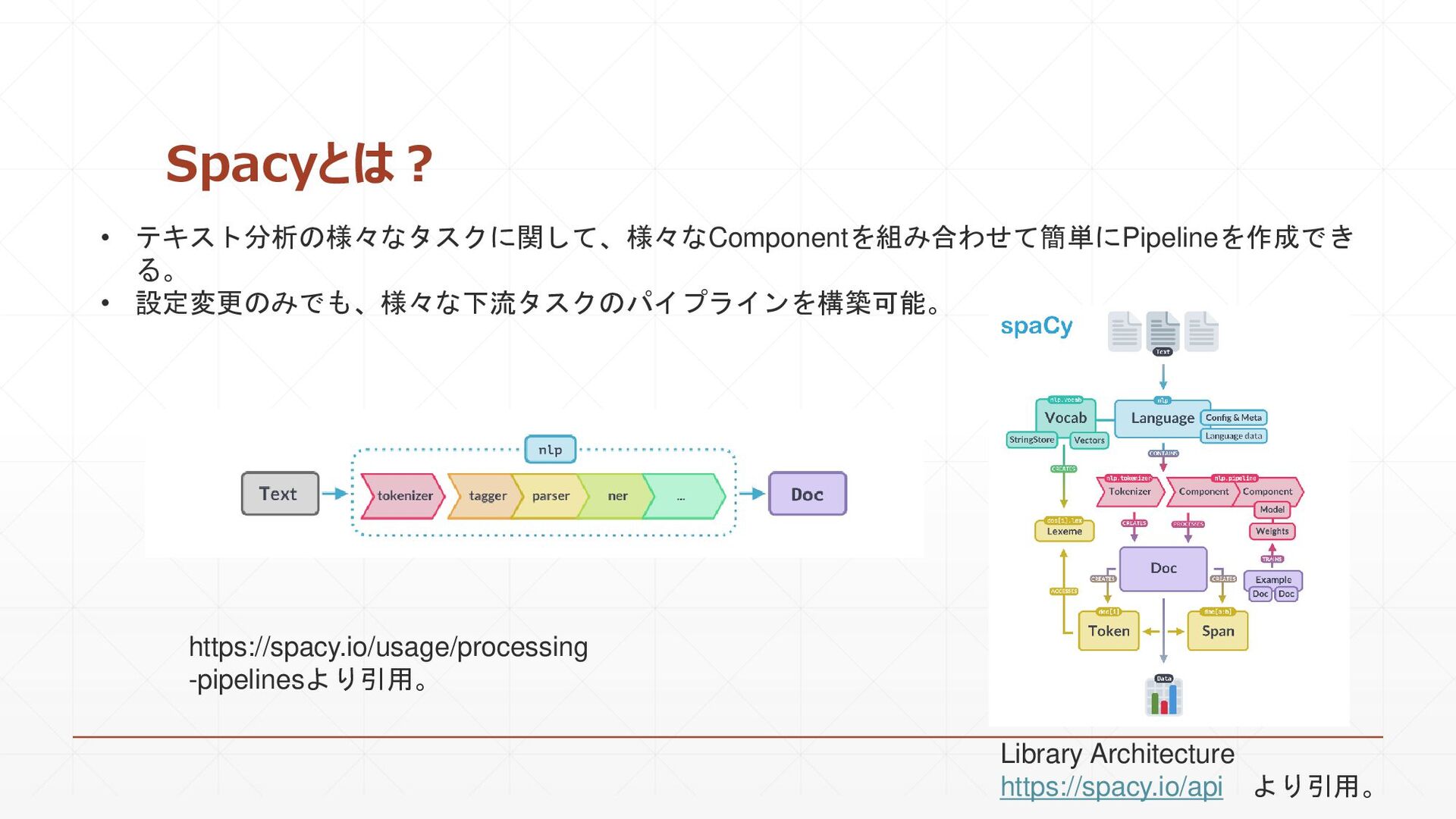{kind=link}
{kind=link}
{kind=link}
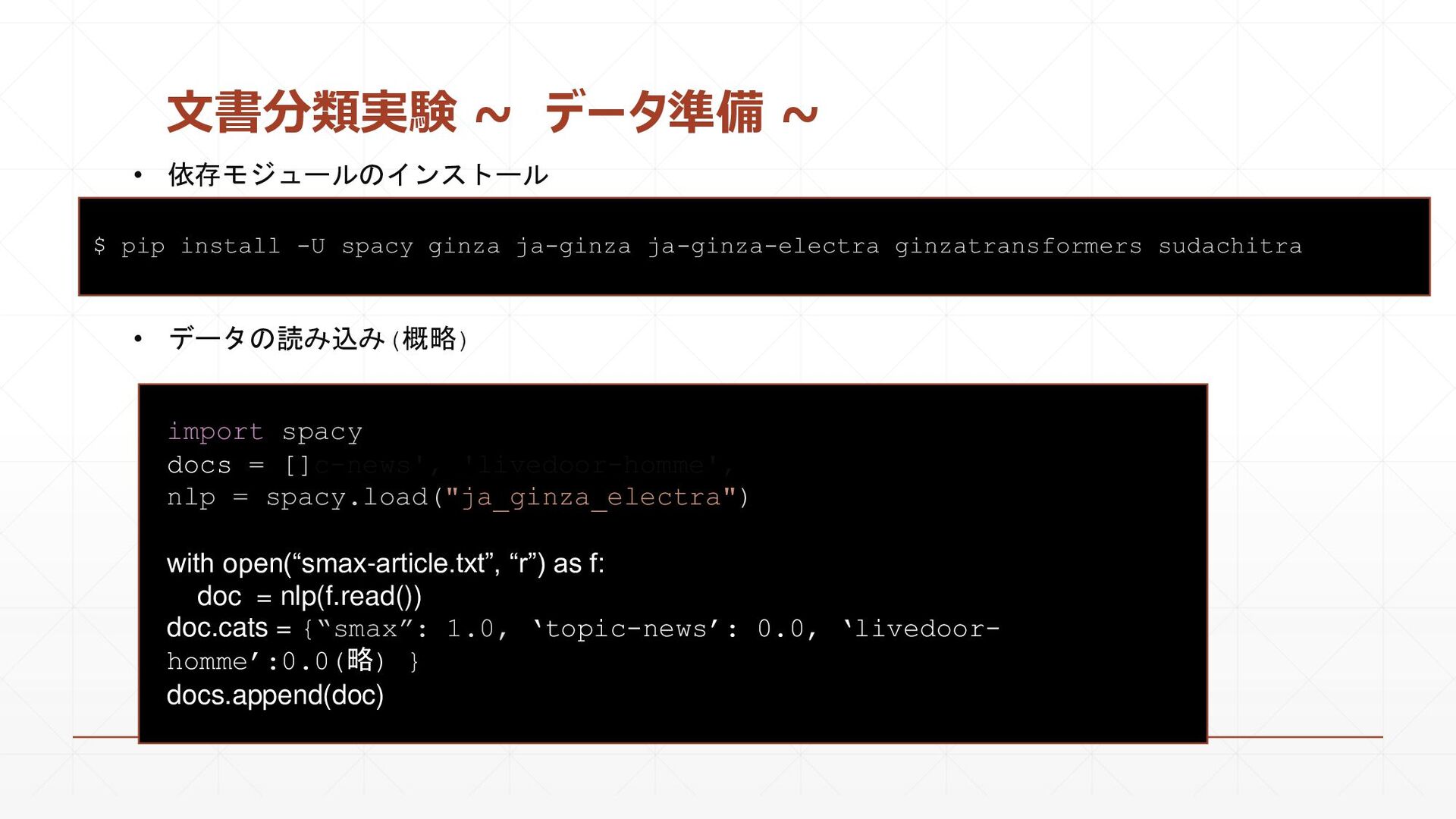{kind=link}
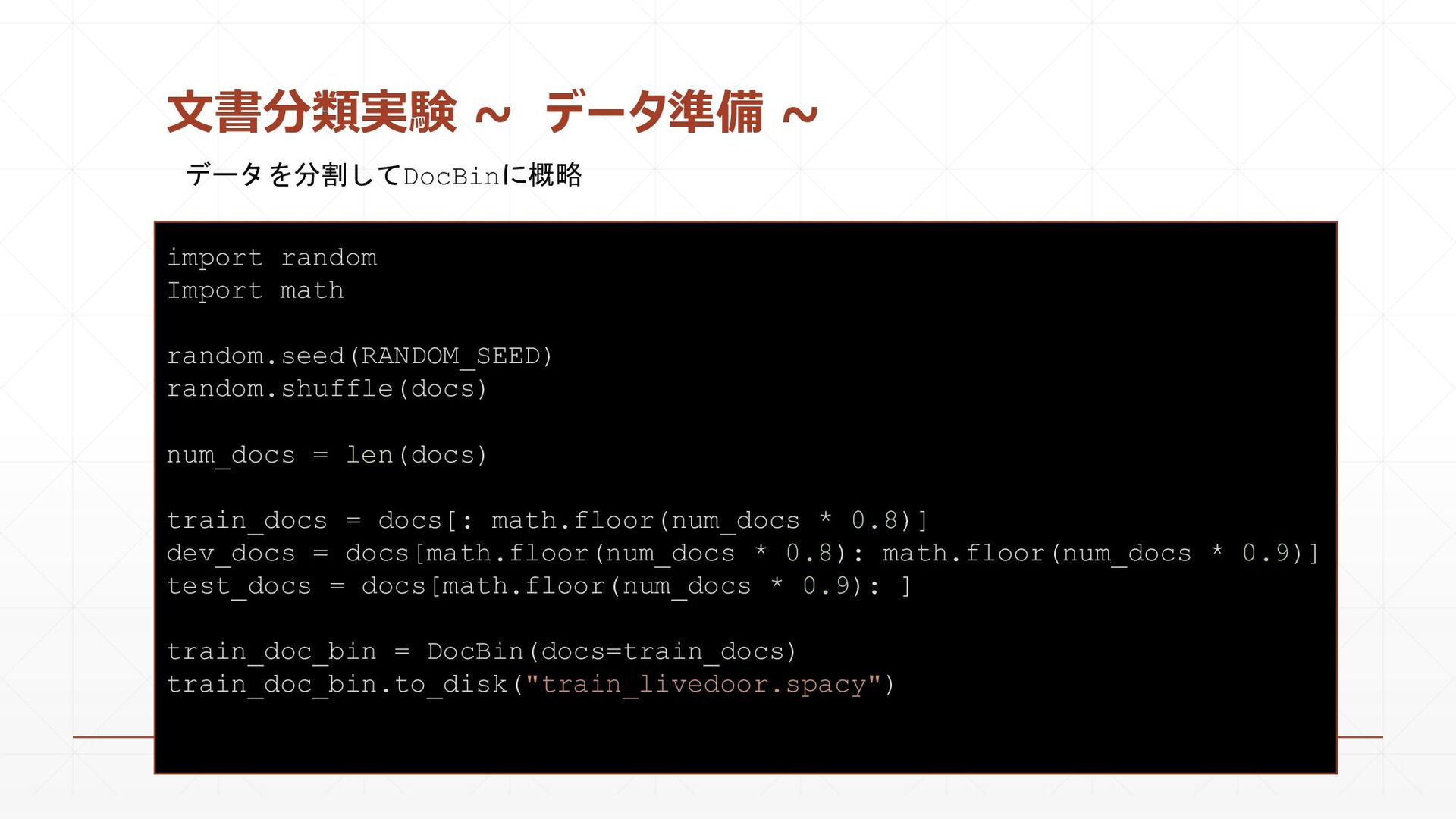{kind=link}
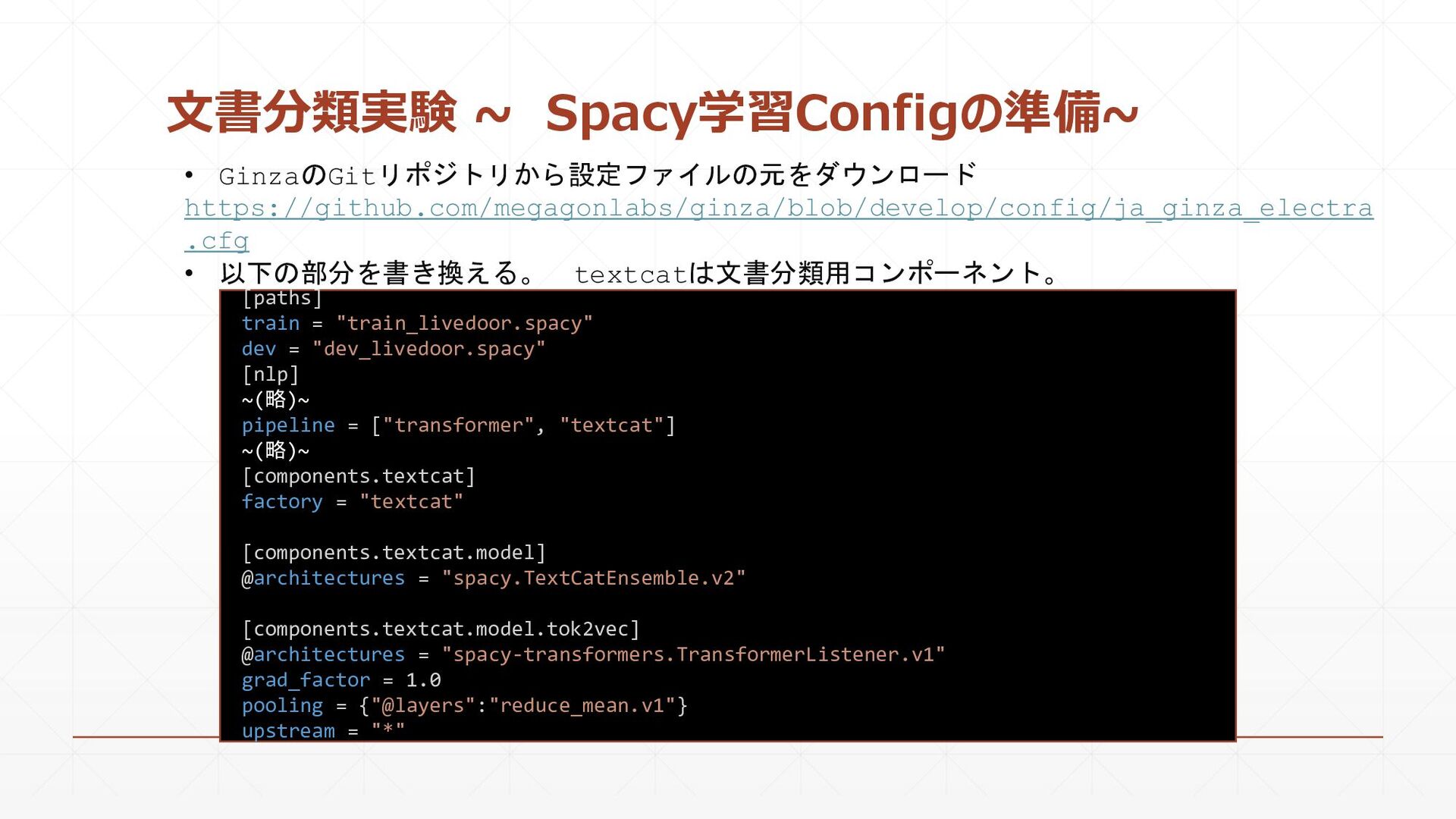{kind=link}
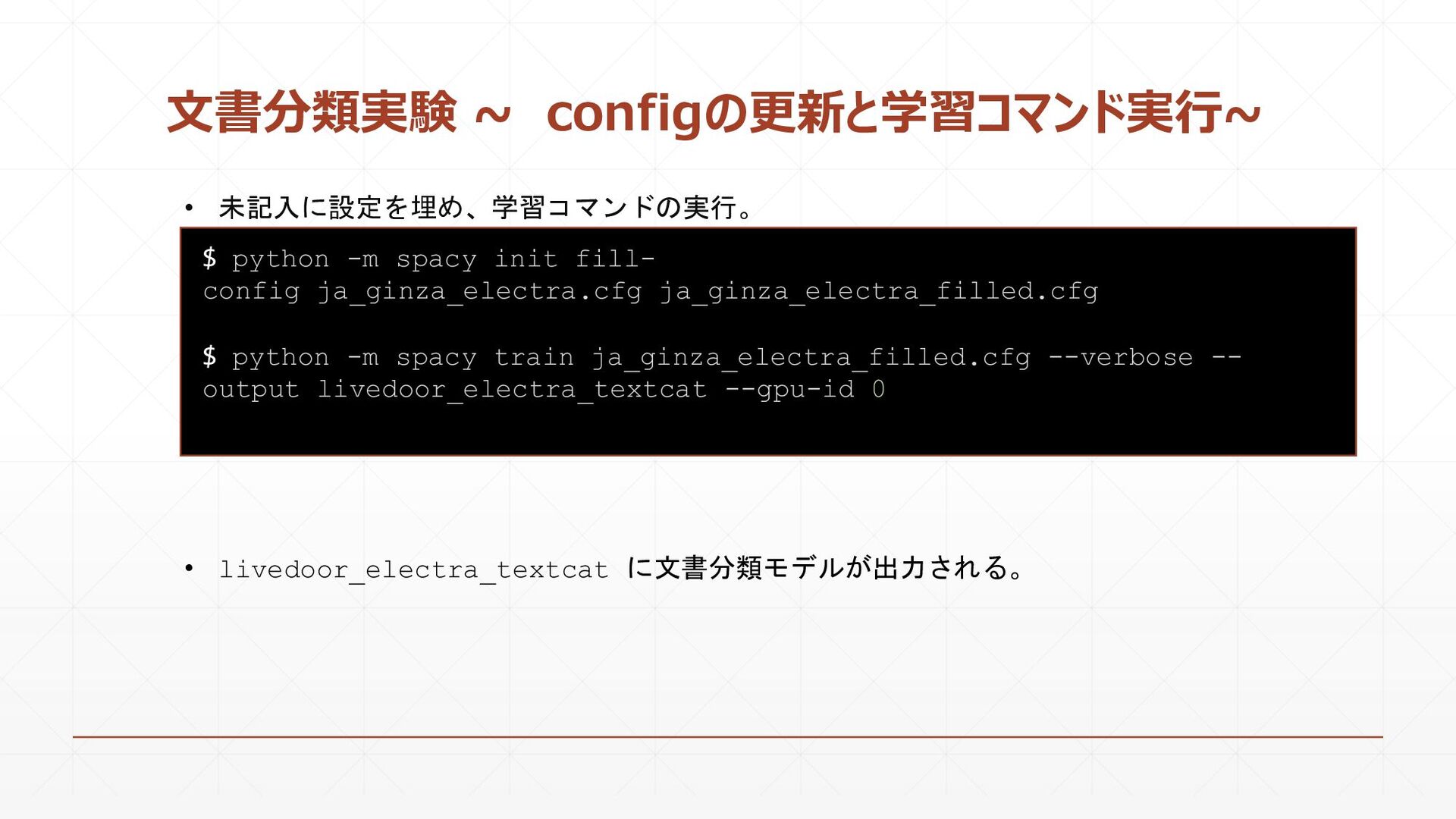{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}