Scaling Log Aggregation At Fitbit with Elasticsearch by Breandan Dezendorf
A walkthrough of scaling a Elasticsearch based log aggregation pipeline from 30,000 logs per second to over 225,000 logs per second in a demanding multi-user environment. This process involved upgrades to every part of the pipeline and changing out major architectural features along the way. Also discussed will be some of the design considerations and challenges for disaster recovery, long term archiving and practical limitations of running very large cost effective Elasticsearch clusters.
Breandan has been working in UNIX and Linux operations for over 15 years. His specialties include monitoring, alerting, trending, and log aggregation at scale. Recently he has been focused on scaling log aggregation for Fitbit, Inc to over 225,000 logs per second.
https://www.meetup.com/Elastic-Triangle-User-Group/events/240095445/
![SCALABLE LOG AGGREGATION AT FITBIT BREANDAN DEZENDORF [email protected] @BWDEZEND](https://files.speakerdeck.com/presentations/bcbc98eb74f240488c2f336bcad97ac8/slide_0.jpg){kind=link}
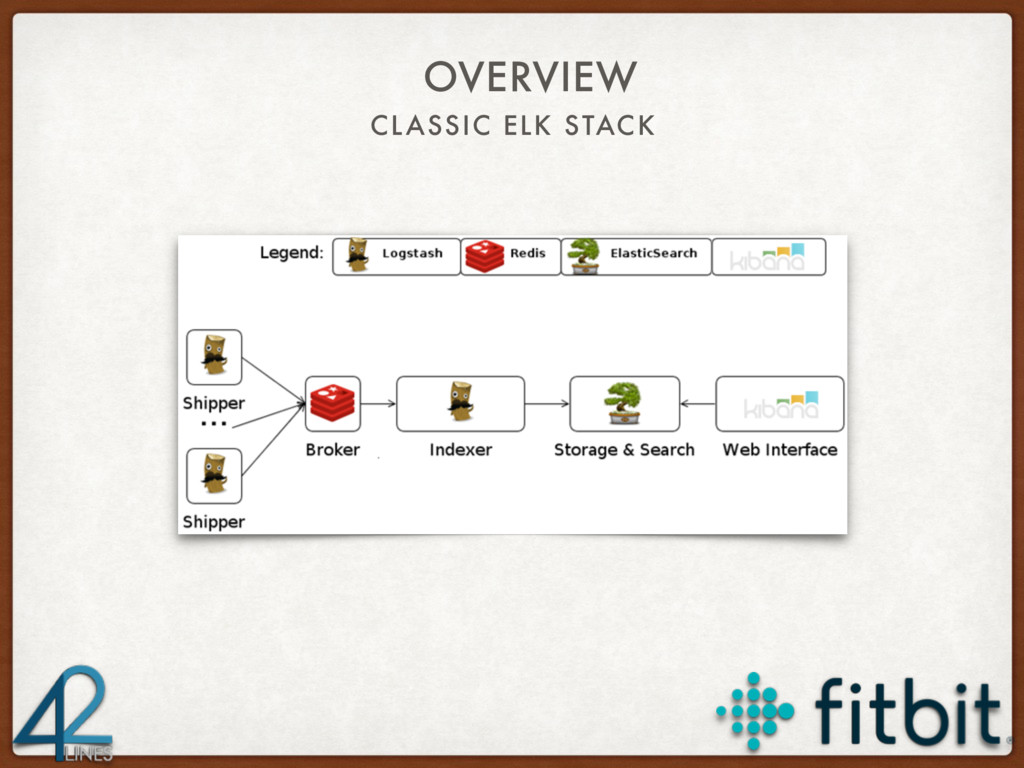{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
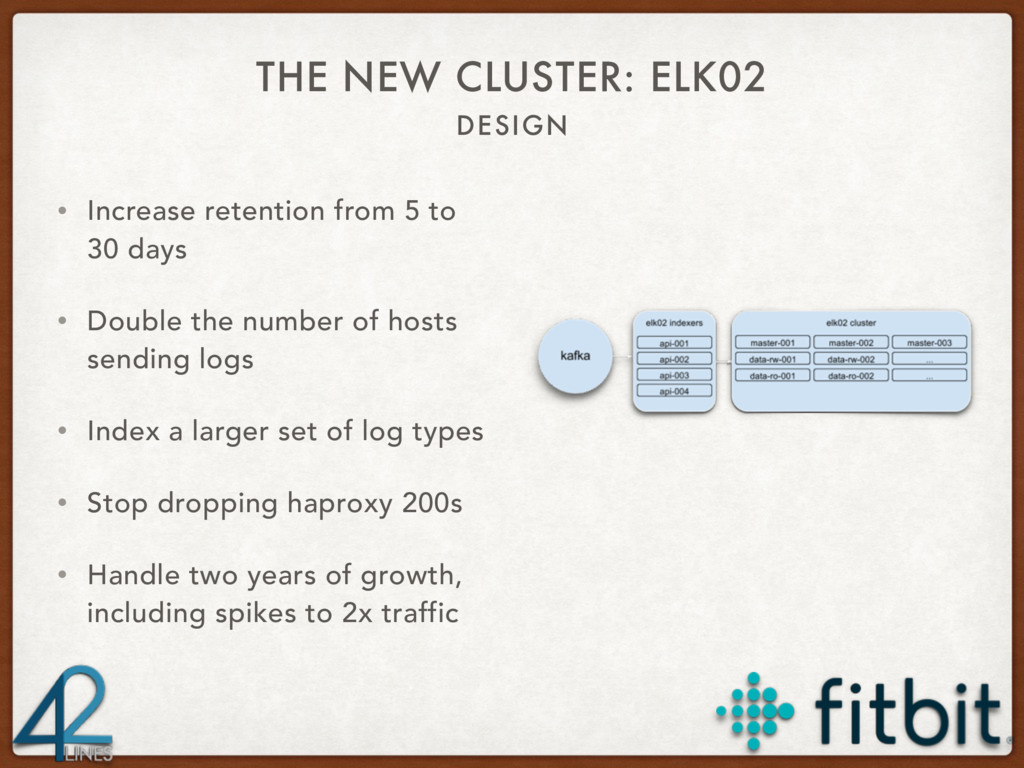{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
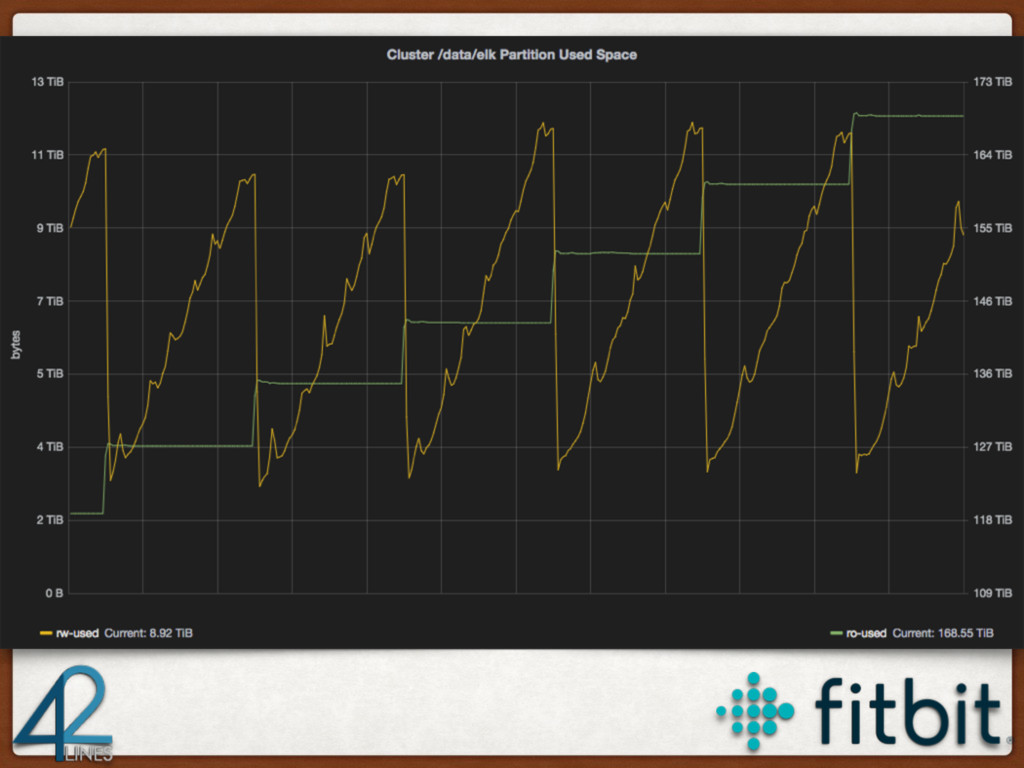{kind=link}
{kind=link}
![OTHER GOOD IDEAS if [type] == "elasticsearch" { grok {](https://files.speakerdeck.com/presentations/bcbc98eb74f240488c2f336bcad97ac8/slide_19.jpg){kind=link}
![if [type] == "es_slow_query" { grok { match => {](https://files.speakerdeck.com/presentations/bcbc98eb74f240488c2f336bcad97ac8/slide_20.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
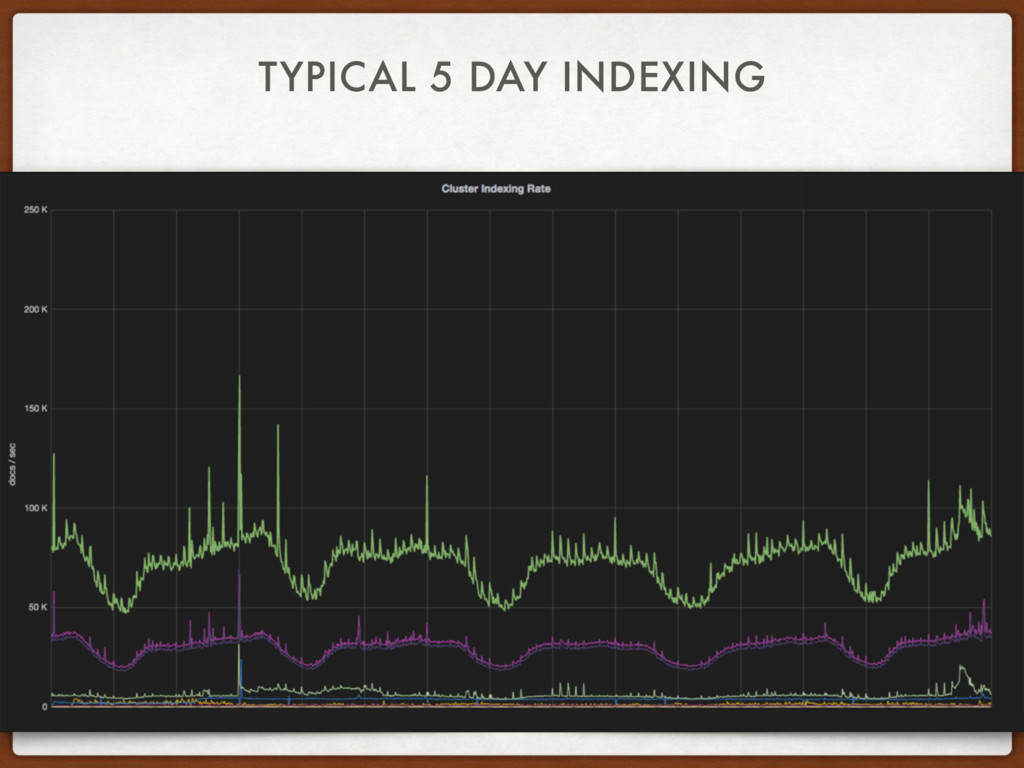{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![QUESTIONS? • @bwdezend • [email protected] • http://operations.fm](https://files.speakerdeck.com/presentations/bcbc98eb74f240488c2f336bcad97ac8/slide_61.jpg){kind=link}