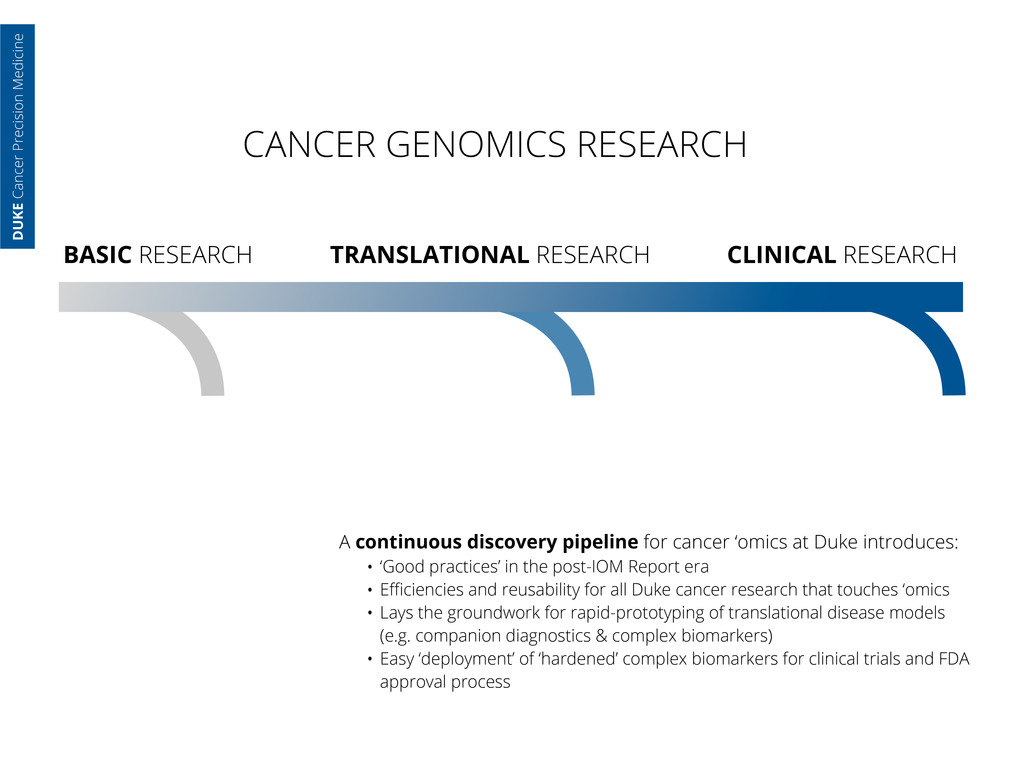
continuous discovery pipeline for cancer ‘omics at Duke introduces: • ‘Good practices’ in the post-IOM Report era • Efficiencies and reusability for all Duke cancer research that touches ‘omics • Lays the groundwork for rapid-prototyping of translational disease models (e.g. companion diagnostics & complex biomarkers) • Easy ‘deployment’ of ‘hardened’ complex biomarkers for clinical trials and FDA approval process DUKE Cancer Precision Medicine
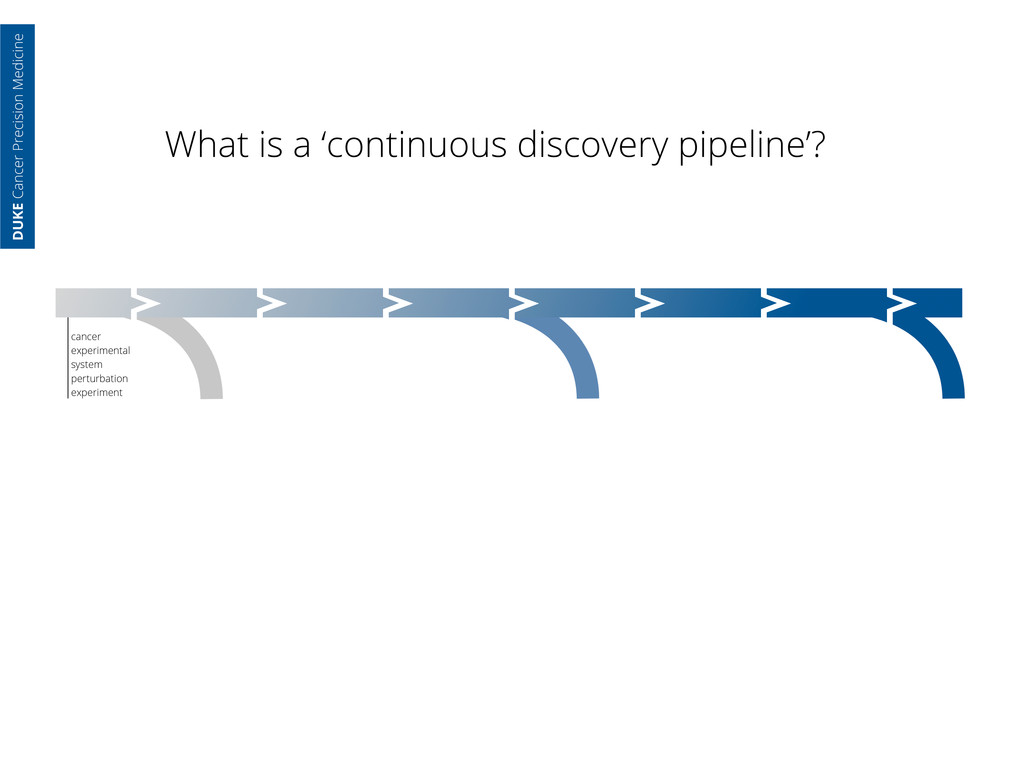
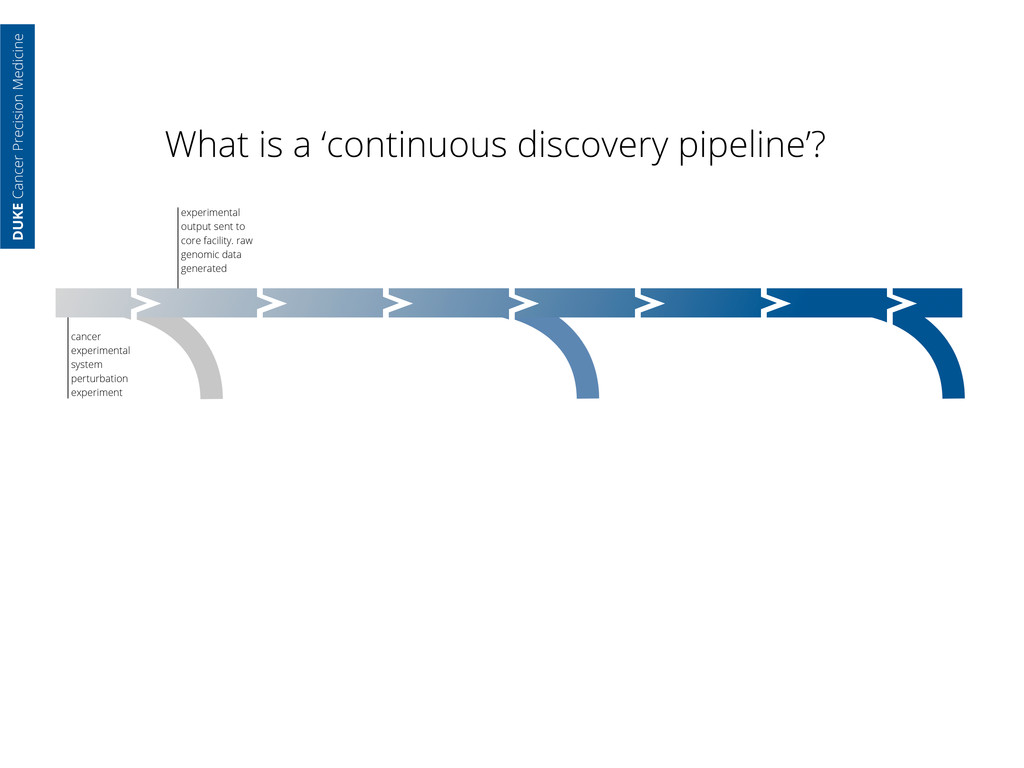
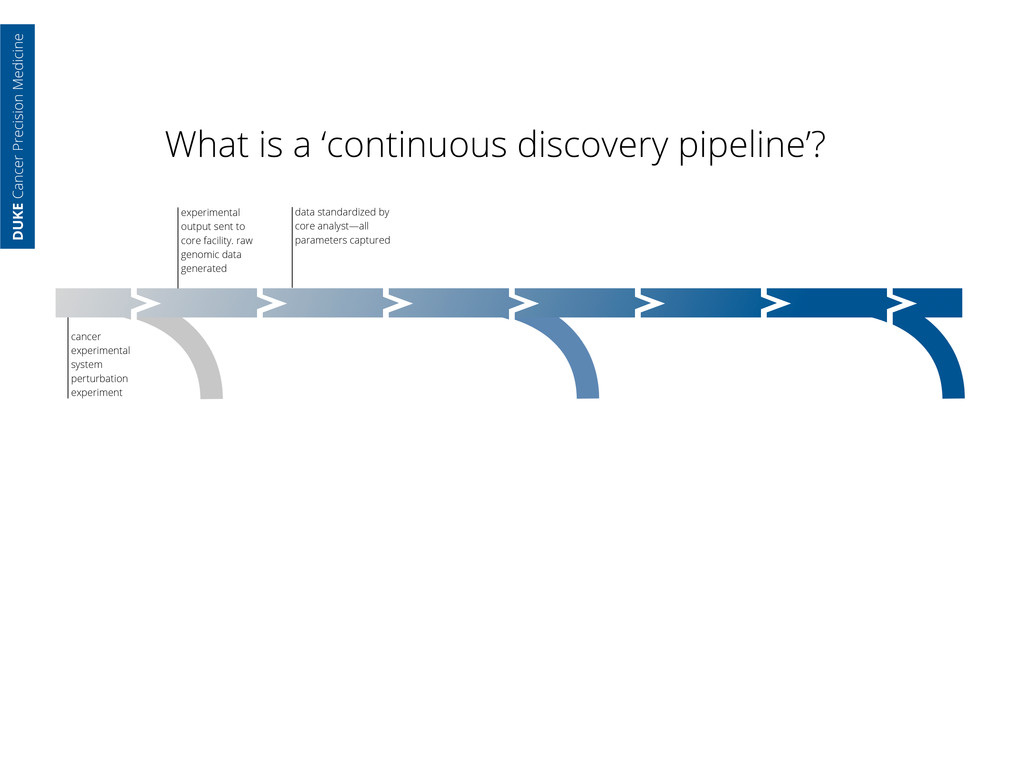
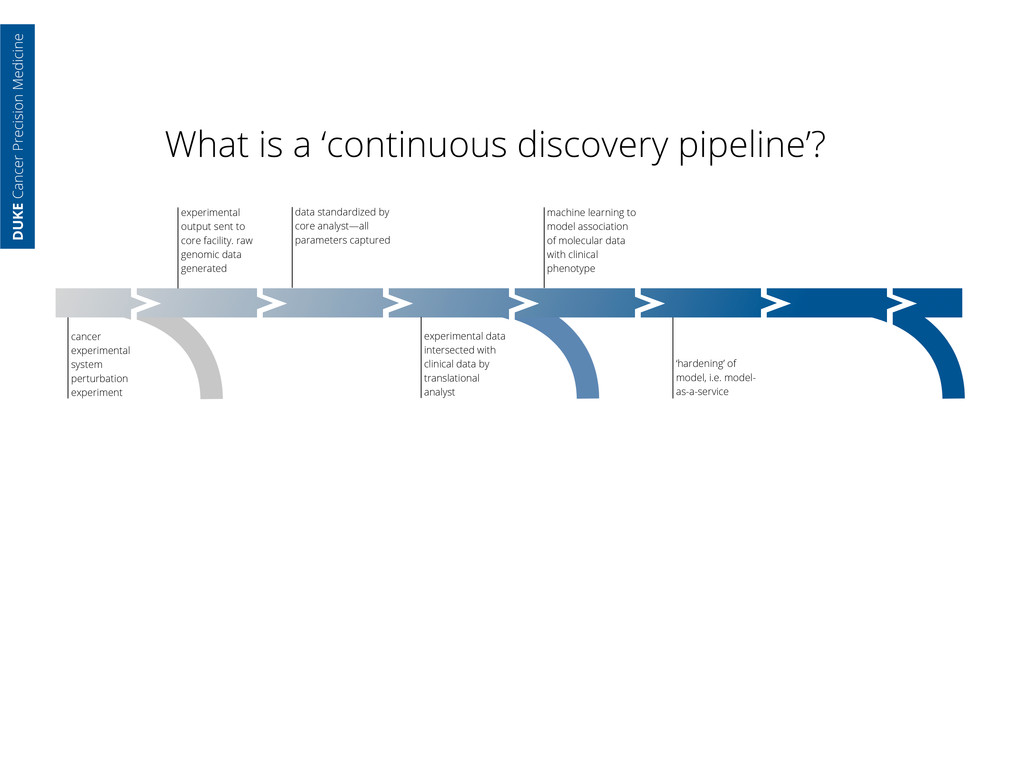
core facility. raw genomic data generated data standardized by core analyst—all parameters captured cancer experimental system perturbation experiment DUKE Cancer Precision Medicine
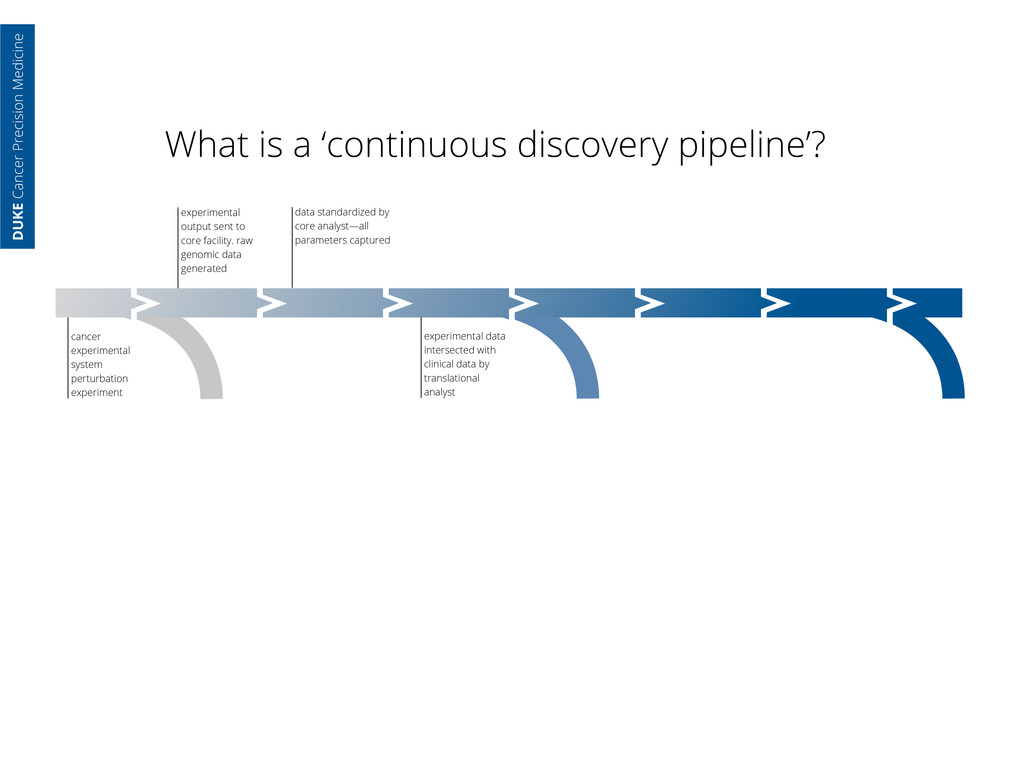
core facility. raw genomic data generated data standardized by core analyst—all parameters captured cancer experimental system perturbation experiment experimental data intersected with clinical data by translational analyst DUKE Cancer Precision Medicine
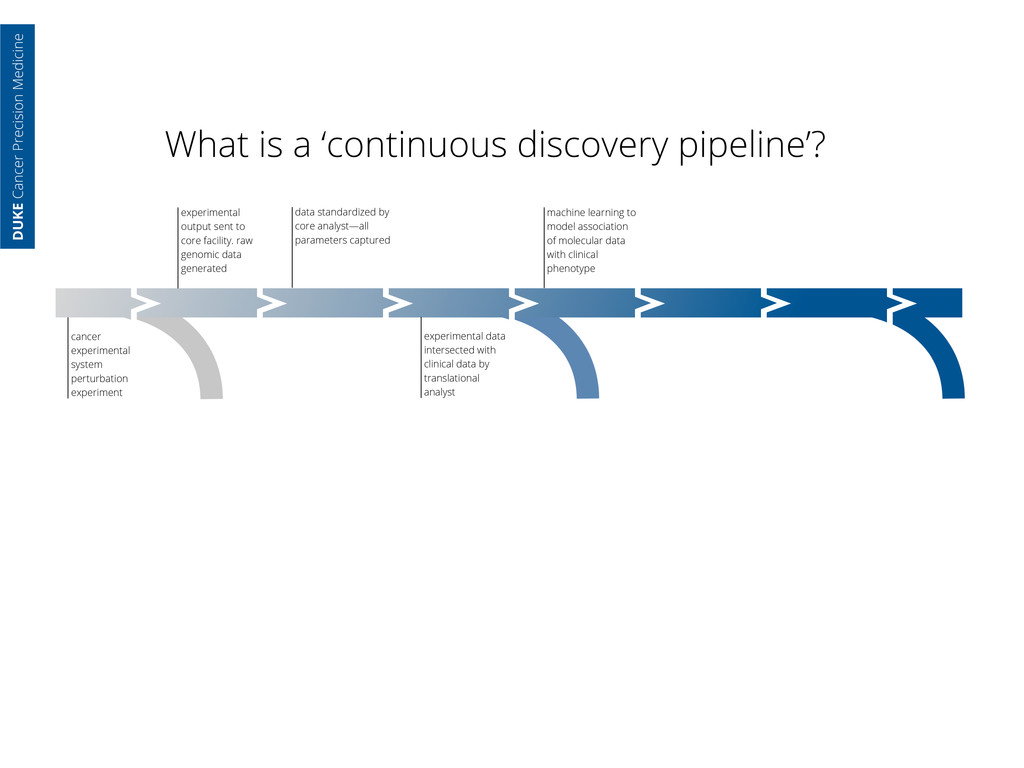
core facility. raw genomic data generated data standardized by core analyst—all parameters captured cancer experimental system perturbation experiment experimental data intersected with clinical data by translational analyst machine learning to model association of molecular data with clinical phenotype DUKE Cancer Precision Medicine
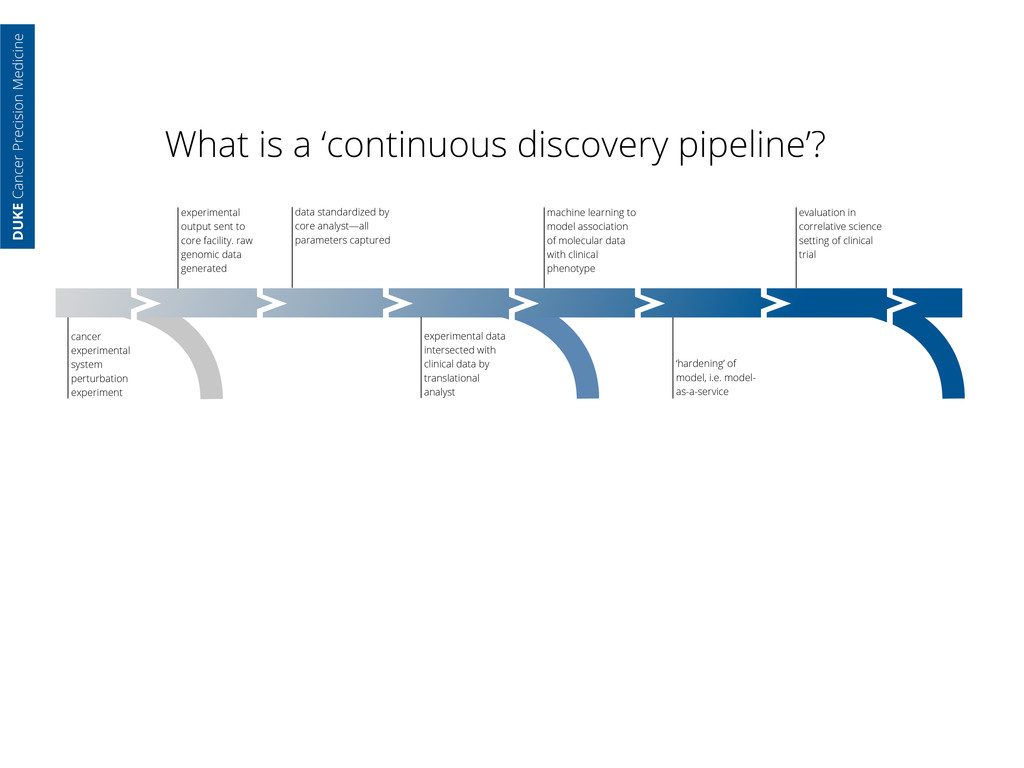
core facility. raw genomic data generated data standardized by core analyst—all parameters captured cancer experimental system perturbation experiment experimental data intersected with clinical data by translational analyst machine learning to model association of molecular data with clinical phenotype ‘hardening’ of model, i.e. model- as-a-service DUKE Cancer Precision Medicine
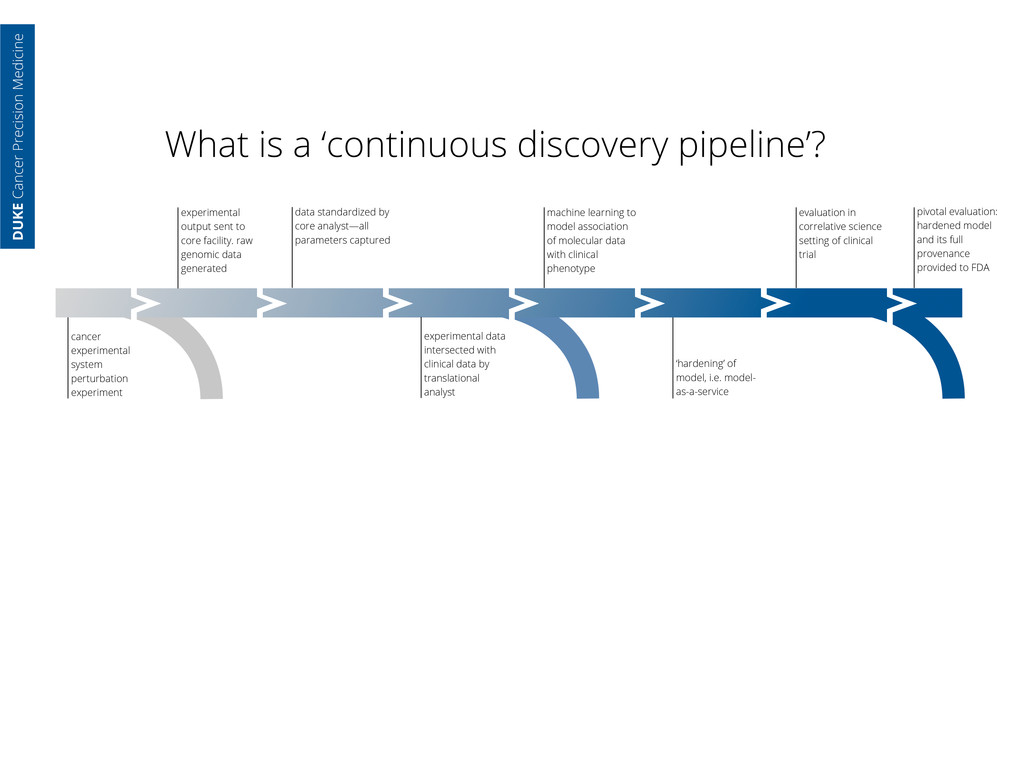
core facility. raw genomic data generated data standardized by core analyst—all parameters captured cancer experimental system perturbation experiment experimental data intersected with clinical data by translational analyst machine learning to model association of molecular data with clinical phenotype ‘hardening’ of model, i.e. model- as-a-service evaluation in correlative science setting of clinical trial DUKE Cancer Precision Medicine
core facility. raw genomic data generated data standardized by core analyst—all parameters captured cancer experimental system perturbation experiment experimental data intersected with clinical data by translational analyst machine learning to model association of molecular data with clinical phenotype ‘hardening’ of model, i.e. model- as-a-service evaluation in correlative science setting of clinical trial pivotal evaluation: hardened model and its full provenance provided to FDA DUKE Cancer Precision Medicine
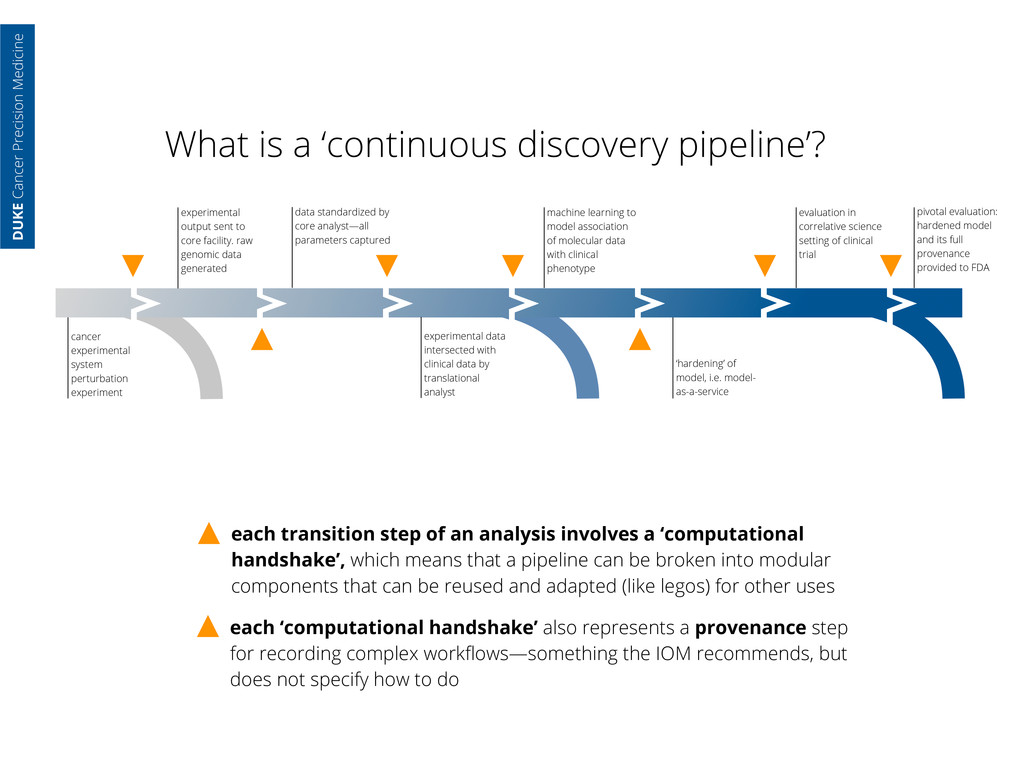
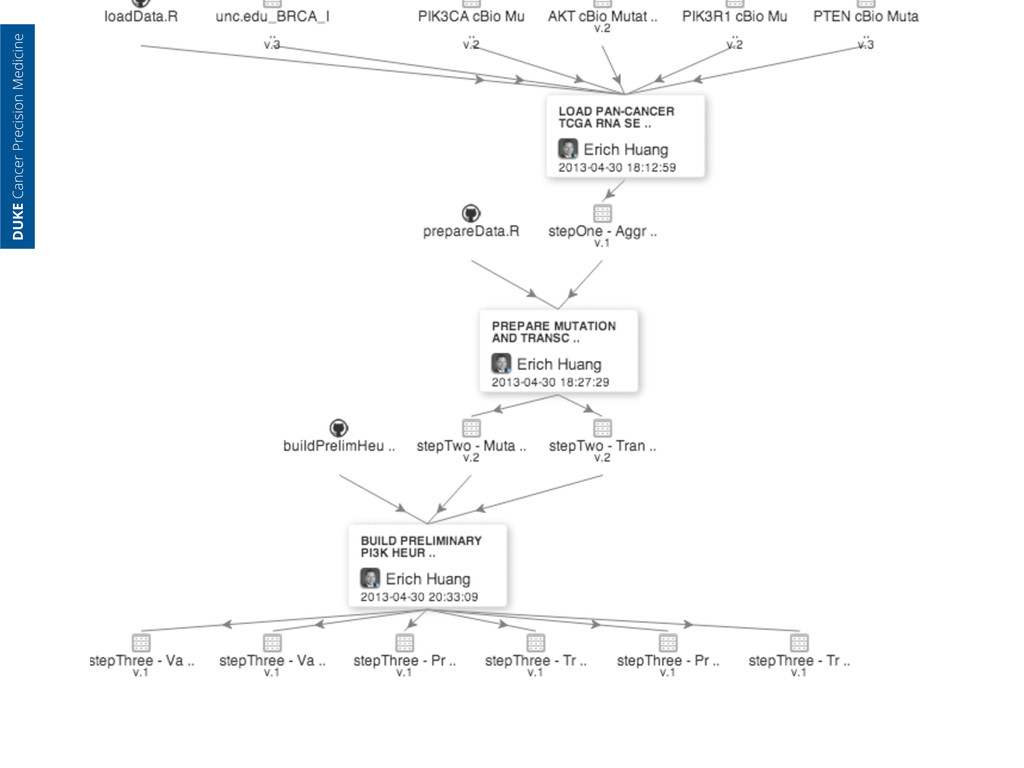
an analysis involves a ‘computational handshake’, which means that a pipeline can be broken into modular components that can be reused and adapted (like legos) for other uses experimental output sent to core facility. raw genomic data generated data standardized by core analyst—all parameters captured cancer experimental system perturbation experiment experimental data intersected with clinical data by translational analyst machine learning to model association of molecular data with clinical phenotype ‘hardening’ of model, i.e. model- as-a-service evaluation in correlative science setting of clinical trial pivotal evaluation: hardened model and its full provenance provided to FDA each ‘computational handshake’ also represents a provenance step for recording complex workflows—something the IOM recommends, but does not specify how to do DUKE Cancer Precision Medicine
of Sciences. All rights reserved. This summary plus thousands more available at http://www.nap.edu mittee envisions these data repositories as essential infrastructure, necessary both for creating the New Taxonomy and, more broadly, for integrating basic biological knowledge with medical histories and health outcomes of individual patients. The Committee believes that building this infrastructure—the Infor- mation Commons and Knowledge Network—is a grand challenge that, if met, would both modernize the ways in which biomedical research is conducted and, over time, lead to dramatically improved patient care (see Figure S-1). The Committee envisions this ambitious program, which would play out on a time scale of decades rather than years, as proceeding through a blend of top-down and bottom-up activity. A major top-down component, initiated by public and private agencies that fund and regulate biomedical research, would be required to ensure that results of individual projects could be combined to Figure S-1, 1-3 Bitmapped FIGURE S-1 Creation of a New Taxonomy first requires an “Information Commons” in which data on large populations of patients become broadly available for research use and a “Knowledge Network” that adds value to these data by highlighting their inter-connectedness and integrating them with evolving knowledge of fundamental biological processes. SOURCE: Committee on A Framework for Developing a New Taxonomy of Disease. DUKE Cancer Precision Medicine
of Sciences. All rights reserved. This summary plus thousands more available at http://www.nap.edu mittee envisions these data repositories as essential infrastructure, necessary both for creating the New Taxonomy and, more broadly, for integrating basic biological knowledge with medical histories and health outcomes of individual patients. The Committee believes that building this infrastructure—the Infor- mation Commons and Knowledge Network—is a grand challenge that, if met, would both modernize the ways in which biomedical research is conducted and, over time, lead to dramatically improved patient care (see Figure S-1). The Committee envisions this ambitious program, which would play out on a time scale of decades rather than years, as proceeding through a blend of top-down and bottom-up activity. A major top-down component, initiated by public and private agencies that fund and regulate biomedical research, would be required to ensure that results of individual projects could be combined to Figure S-1, 1-3 Bitmapped FIGURE S-1 Creation of a New Taxonomy first requires an “Information Commons” in which data on large populations of patients become broadly available for research use and a “Knowledge Network” that adds value to these data by highlighting their inter-connectedness and integrating them with evolving knowledge of fundamental biological processes. SOURCE: Committee on A Framework for Developing a New Taxonomy of Disease. multiple layers of ‘omic and clinical data provide inference DUKE Cancer Precision Medicine
of Sciences. All rights reserved. This summary plus thousands more available at http://www.nap.edu mittee envisions these data repositories as essential infrastructure, necessary both for creating the New Taxonomy and, more broadly, for integrating basic biological knowledge with medical histories and health outcomes of individual patients. The Committee believes that building this infrastructure—the Infor- mation Commons and Knowledge Network—is a grand challenge that, if met, would both modernize the ways in which biomedical research is conducted and, over time, lead to dramatically improved patient care (see Figure S-1). The Committee envisions this ambitious program, which would play out on a time scale of decades rather than years, as proceeding through a blend of top-down and bottom-up activity. A major top-down component, initiated by public and private agencies that fund and regulate biomedical research, would be required to ensure that results of individual projects could be combined to Figure S-1, 1-3 Bitmapped FIGURE S-1 Creation of a New Taxonomy first requires an “Information Commons” in which data on large populations of patients become broadly available for research use and a “Knowledge Network” that adds value to these data by highlighting their inter-connectedness and integrating them with evolving knowledge of fundamental biological processes. SOURCE: Committee on A Framework for Developing a New Taxonomy of Disease. multiple layers of ‘omic and clinical data provide inference that provide data-driven taxonomic disease classes DUKE Cancer Precision Medicine
of Sciences. All rights reserved. This summary plus thousands more available at http://www.nap.edu mittee envisions these data repositories as essential infrastructure, necessary both for creating the New Taxonomy and, more broadly, for integrating basic biological knowledge with medical histories and health outcomes of individual patients. The Committee believes that building this infrastructure—the Infor- mation Commons and Knowledge Network—is a grand challenge that, if met, would both modernize the ways in which biomedical research is conducted and, over time, lead to dramatically improved patient care (see Figure S-1). The Committee envisions this ambitious program, which would play out on a time scale of decades rather than years, as proceeding through a blend of top-down and bottom-up activity. A major top-down component, initiated by public and private agencies that fund and regulate biomedical research, would be required to ensure that results of individual projects could be combined to Figure S-1, 1-3 Bitmapped FIGURE S-1 Creation of a New Taxonomy first requires an “Information Commons” in which data on large populations of patients become broadly available for research use and a “Knowledge Network” that adds value to these data by highlighting their inter-connectedness and integrating them with evolving knowledge of fundamental biological processes. SOURCE: Committee on A Framework for Developing a New Taxonomy of Disease. multiple layers of ‘omic and clinical data provide inference that provide data-driven taxonomic disease classes facilitating more precise care delivery DUKE Cancer Precision Medicine
of Sciences. All rights reserved. This summary plus thousands more available at http://www.nap.edu mittee envisions these data repositories as essential infrastructure, necessary both for creating the New Taxonomy and, more broadly, for integrating basic biological knowledge with medical histories and health outcomes of individual patients. The Committee believes that building this infrastructure—the Infor- mation Commons and Knowledge Network—is a grand challenge that, if met, would both modernize the ways in which biomedical research is conducted and, over time, lead to dramatically improved patient care (see Figure S-1). The Committee envisions this ambitious program, which would play out on a time scale of decades rather than years, as proceeding through a blend of top-down and bottom-up activity. A major top-down component, initiated by public and private agencies that fund and regulate biomedical research, would be required to ensure that results of individual projects could be combined to Figure S-1, 1-3 Bitmapped FIGURE S-1 Creation of a New Taxonomy first requires an “Information Commons” in which data on large populations of patients become broadly available for research use and a “Knowledge Network” that adds value to these data by highlighting their inter-connectedness and integrating them with evolving knowledge of fundamental biological processes. SOURCE: Committee on A Framework for Developing a New Taxonomy of Disease. multiple layers of ‘omic and clinical data provide inference that provide data-driven taxonomic disease classes facilitating more precise care delivery more data for refining disease models DUKE Cancer Precision Medicine
of Sciences. All rights reserved. This summary plus thousands more available at http://www.nap.edu mittee envisions these data repositories as essential infrastructure, necessary both for creating the New Taxonomy and, more broadly, for integrating basic biological knowledge with medical histories and health outcomes of individual patients. The Committee believes that building this infrastructure—the Infor- mation Commons and Knowledge Network—is a grand challenge that, if met, would both modernize the ways in which biomedical research is conducted and, over time, lead to dramatically improved patient care (see Figure S-1). The Committee envisions this ambitious program, which would play out on a time scale of decades rather than years, as proceeding through a blend of top-down and bottom-up activity. A major top-down component, initiated by public and private agencies that fund and regulate biomedical research, would be required to ensure that results of individual projects could be combined to Figure S-1, 1-3 Bitmapped FIGURE S-1 Creation of a New Taxonomy first requires an “Information Commons” in which data on large populations of patients become broadly available for research use and a “Knowledge Network” that adds value to these data by highlighting their inter-connectedness and integrating them with evolving knowledge of fundamental biological processes. SOURCE: Committee on A Framework for Developing a New Taxonomy of Disease. multiple layers of ‘omic and clinical data provide inference that provide data-driven taxonomic disease classes facilitating more precise care delivery more data for refining disease models and kickstart a virtuous cycle for integrating basic research more rapidly into actionable insights DUKE Cancer Precision Medicine
& technical metadata straight off a shared resource’s machines ANALYTIC SOURCE CODE best practices in scientific programming using version code repositories DUKE Cancer Precision Medicine
& technical metadata straight off a shared resource’s machines ANALYTIC SOURCE CODE best practices in scientific programming using version code repositories ANALYTIC PROVENANCE DUKE Cancer Precision Medicine
& technical metadata straight off a shared resource’s machines ANALYTIC SOURCE CODE best practices in scientific programming using version code repositories ANALYTIC PROVENANCE explicitly linking data and code into human- and machine-readable provenance DUKE Cancer Precision Medicine
& technical metadata straight off a shared resource’s machines ANALYTIC SOURCE CODE best practices in scientific programming using version code repositories ANALYTIC PROVENANCE explicitly linking data and code into human- and machine-readable provenance COMPUTE RESOURCES DUKE Cancer Precision Medicine
& technical metadata straight off a shared resource’s machines ANALYTIC SOURCE CODE best practices in scientific programming using version code repositories ANALYTIC PROVENANCE explicitly linking data and code into human- and machine-readable provenance COMPUTE RESOURCES secure, private cloud computing resources to provide all of the above as campus-wide services DUKE Cancer Precision Medicine
& technical metadata straight off a shared resource’s machines ANALYTIC SOURCE CODE best practices in scientific programming using version code repositories ANALYTIC PROVENANCE explicitly linking data and code into human- and machine-readable provenance COMPUTE RESOURCES secure, private cloud computing resources to provide all of the above as campus-wide services PRED. MODELS AS-A-SERVICE DUKE Cancer Precision Medicine
& technical metadata straight off a shared resource’s machines ANALYTIC SOURCE CODE best practices in scientific programming using version code repositories ANALYTIC PROVENANCE explicitly linking data and code into human- and machine-readable provenance COMPUTE RESOURCES secure, private cloud computing resources to provide all of the above as campus-wide services PRED. MODELS AS-A-SERVICE wrap a complex analytic insight into a predictive model deployed as a webservice that can be accessed by clinicians DUKE Cancer Precision Medicine
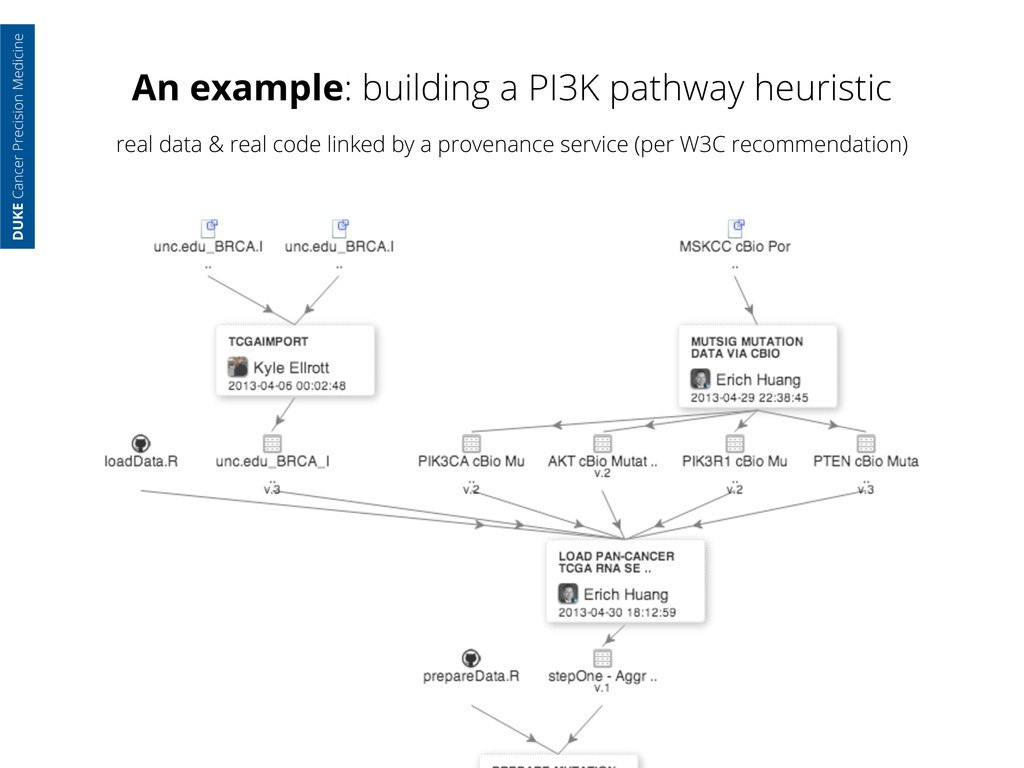
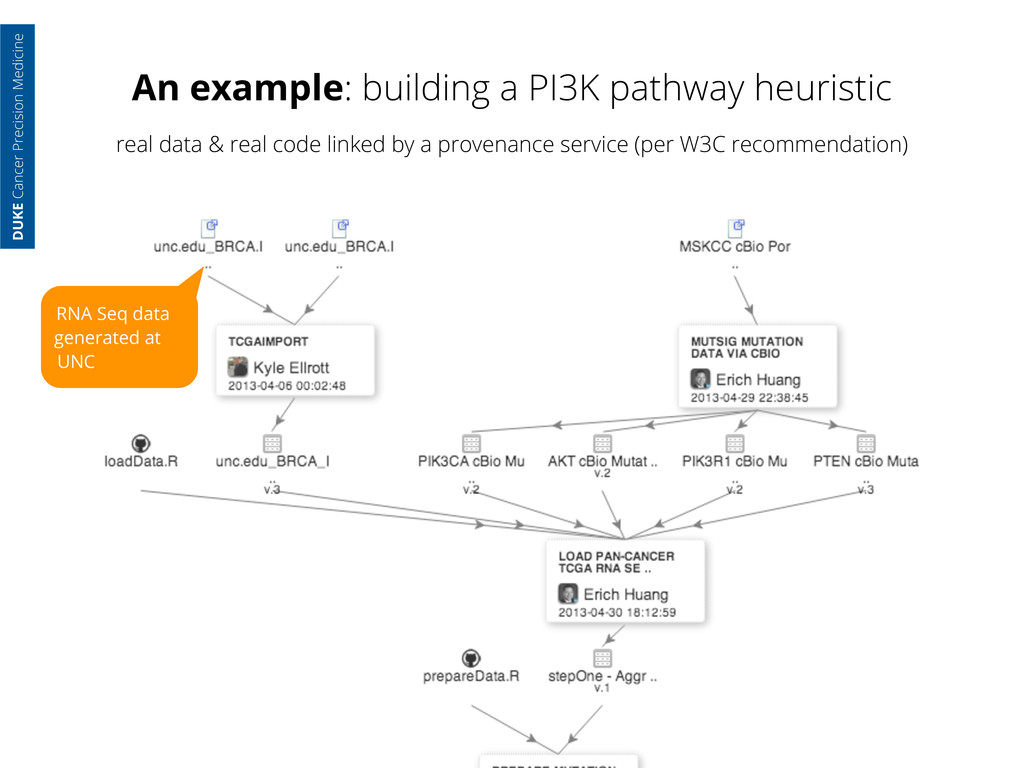
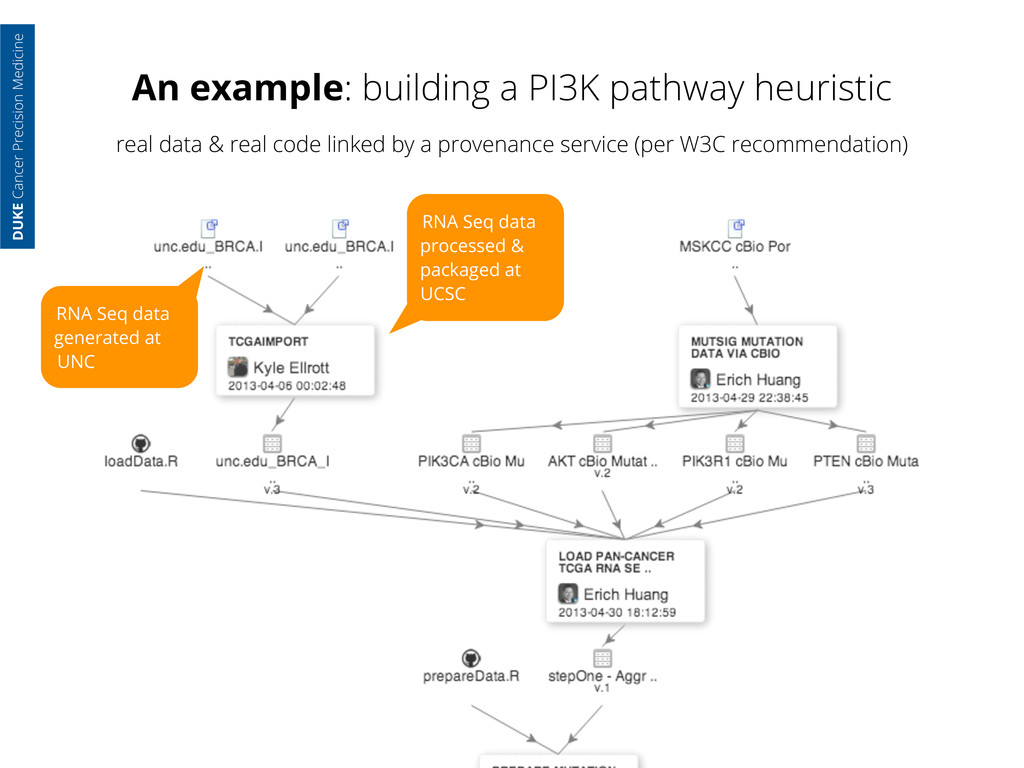
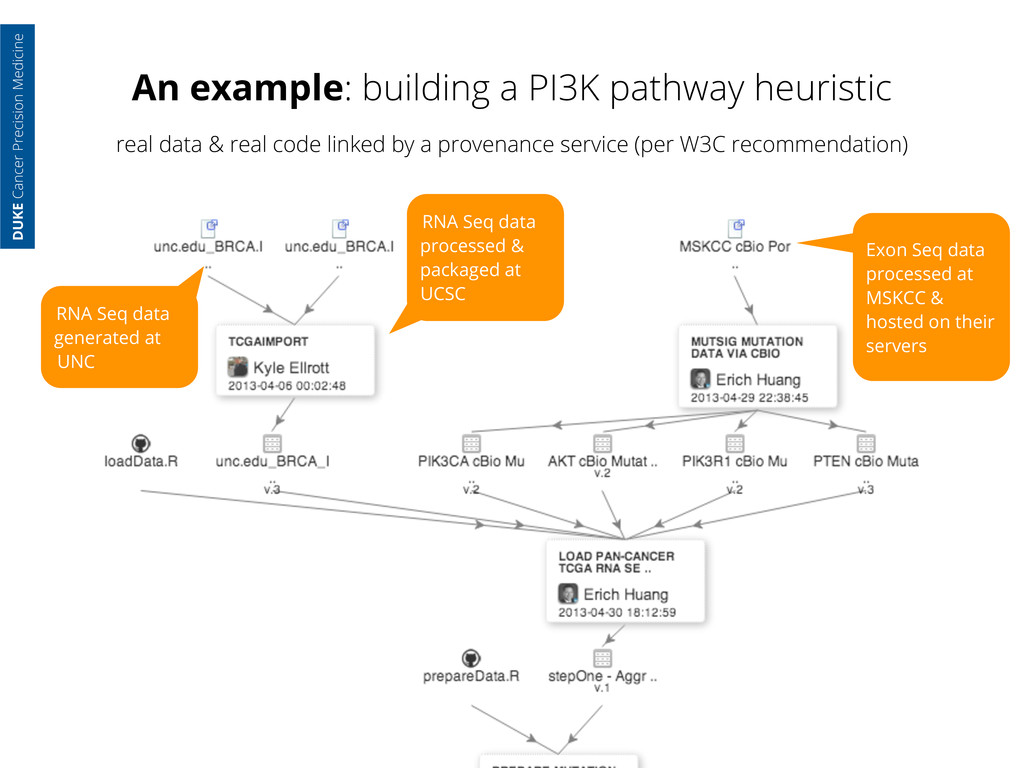
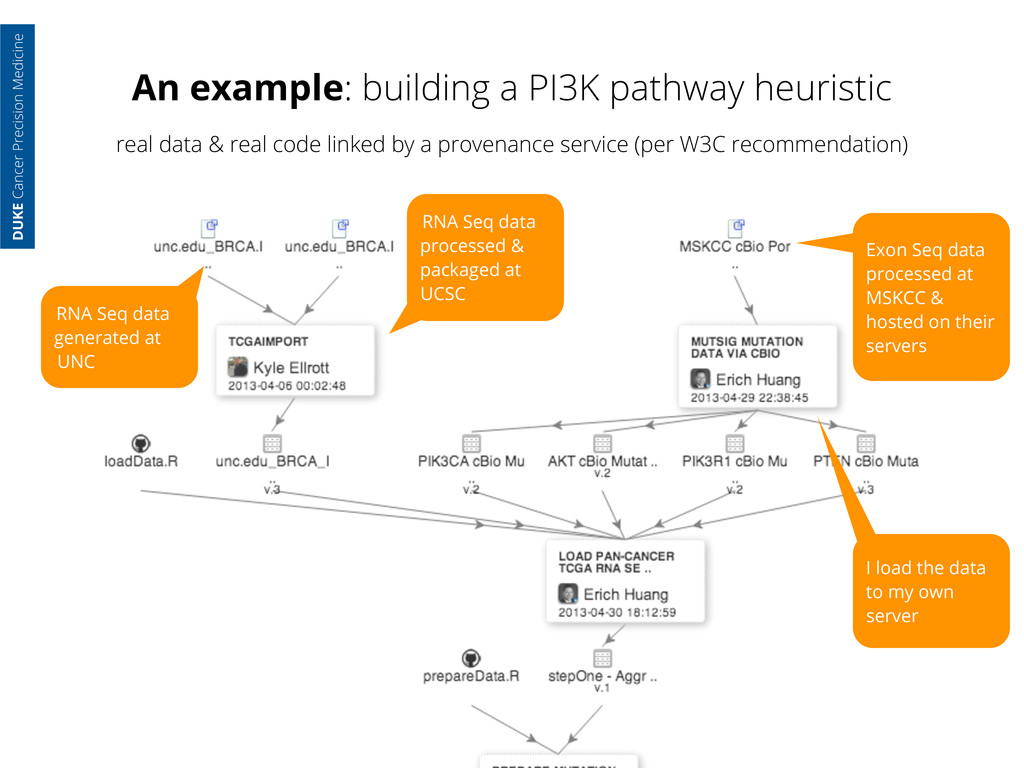
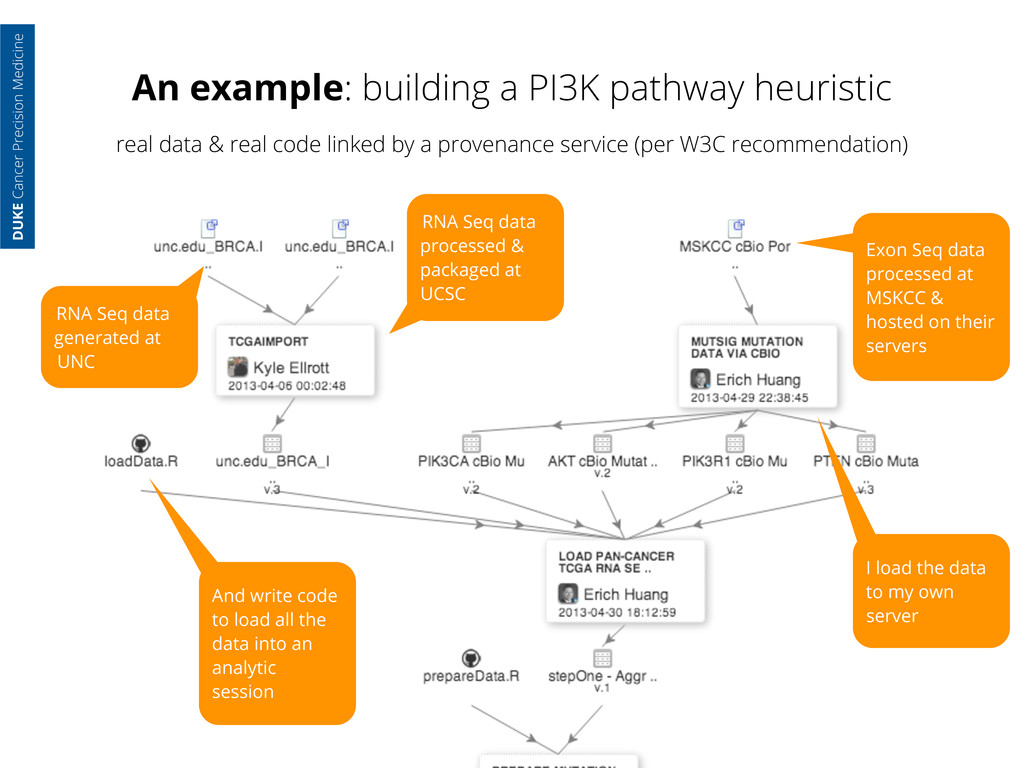
generated at UNC RNA Seq data processed & packaged at UCSC DUKE Cancer Precision Medicine real data & real code linked by a provenance service (per W3C recommendation)
generated at UNC RNA Seq data processed & packaged at UCSC Exon Seq data processed at MSKCC & hosted on their servers DUKE Cancer Precision Medicine real data & real code linked by a provenance service (per W3C recommendation)
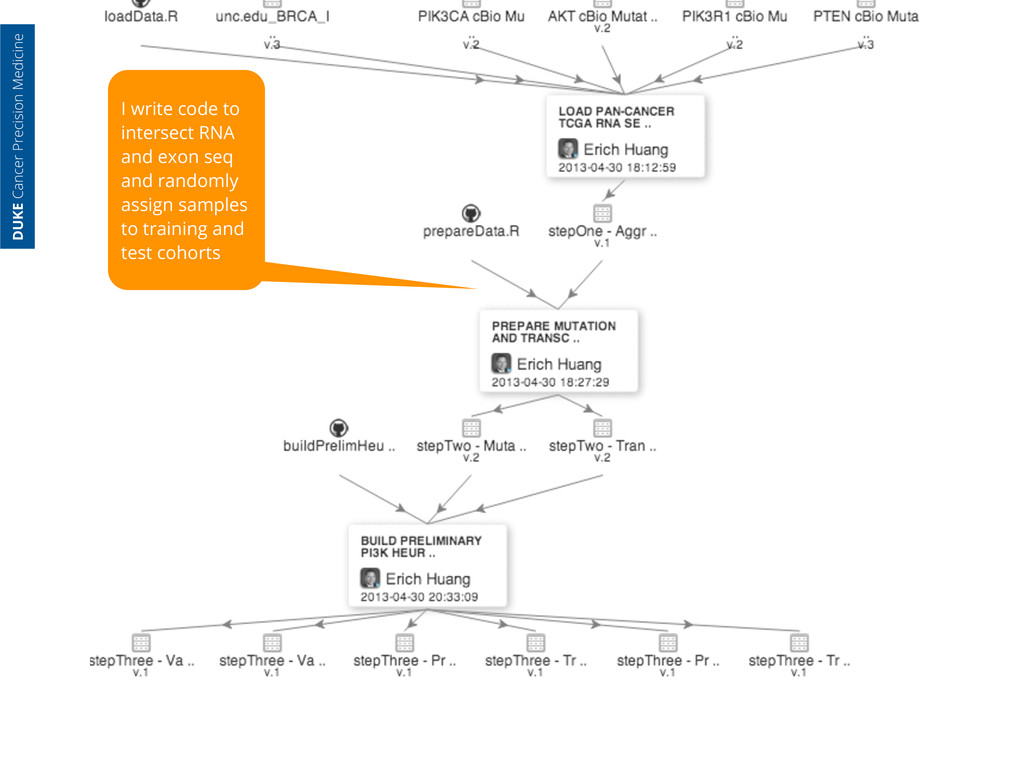
generated at UNC RNA Seq data processed & packaged at UCSC Exon Seq data processed at MSKCC & hosted on their servers I load the data to my own server DUKE Cancer Precision Medicine real data & real code linked by a provenance service (per W3C recommendation)
generated at UNC RNA Seq data processed & packaged at UCSC Exon Seq data processed at MSKCC & hosted on their servers I load the data to my own server And write code to load all the data into an analytic session DUKE Cancer Precision Medicine real data & real code linked by a provenance service (per W3C recommendation)
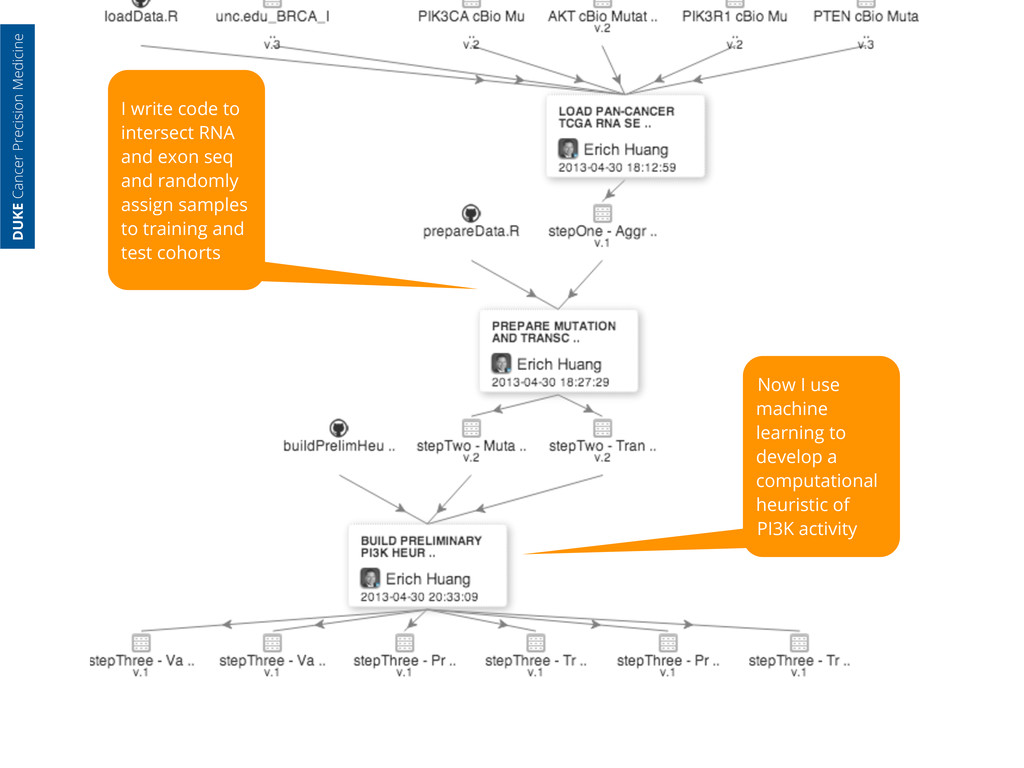
randomly assign samples to training and test cohorts Now I use machine learning to develop a computational heuristic of PI3K activity DUKE Cancer Precision Medicine
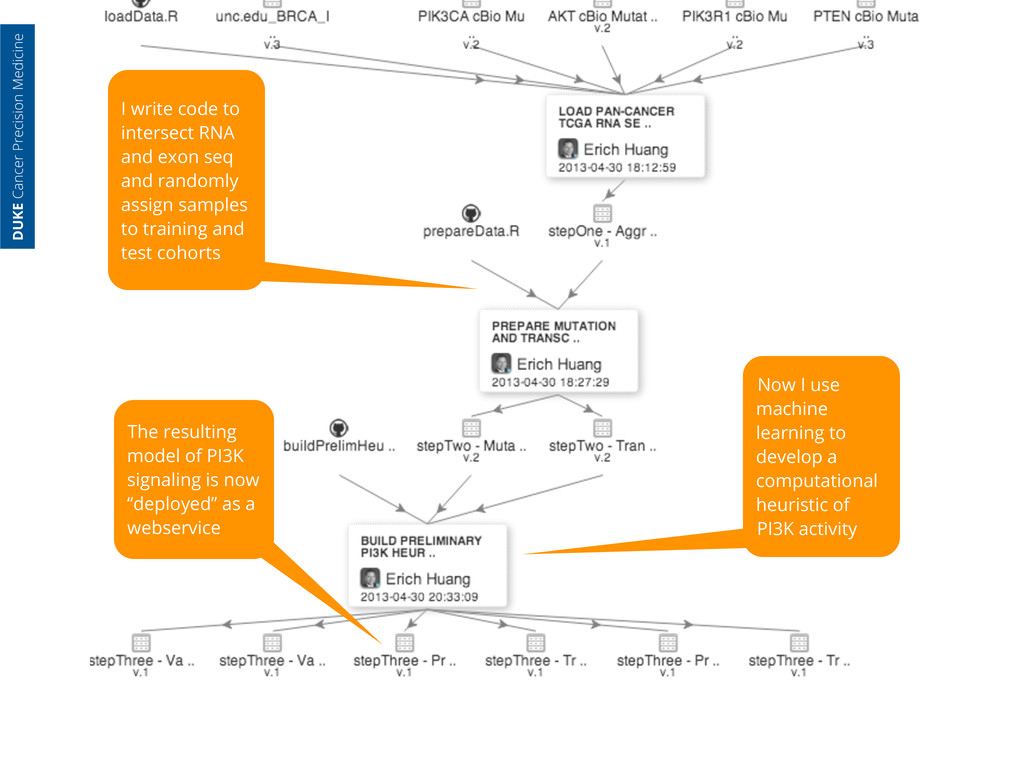
randomly assign samples to training and test cohorts Now I use machine learning to develop a computational heuristic of PI3K activity The resulting model of PI3K signaling is now “deployed” as a webservice DUKE Cancer Precision Medicine
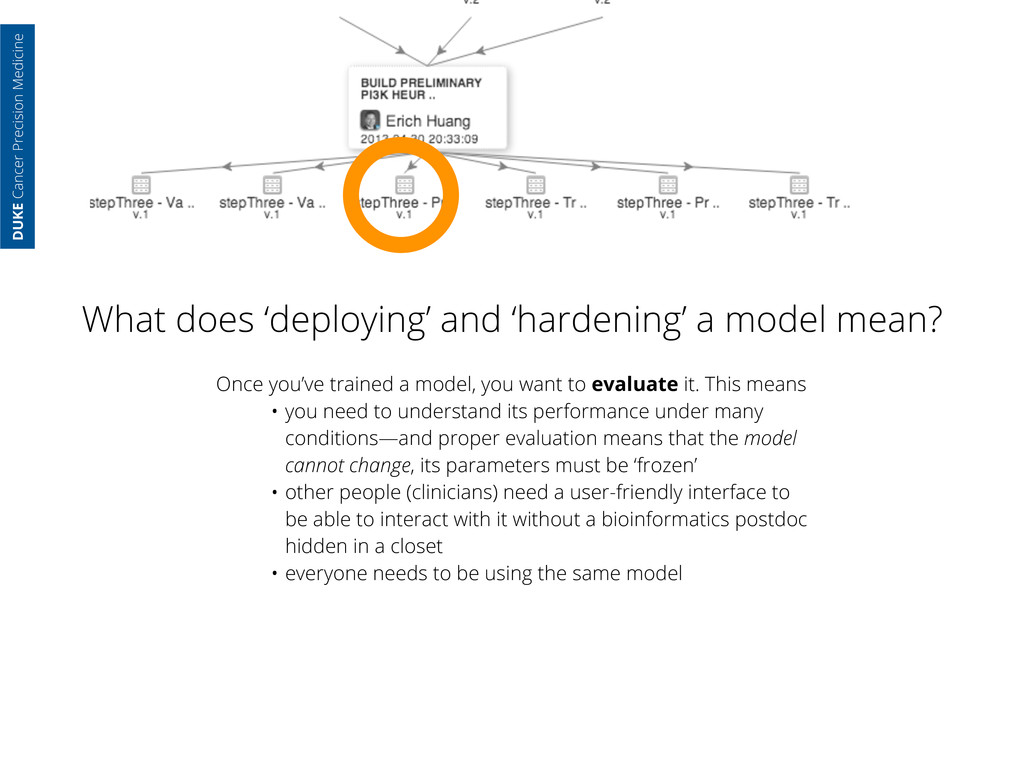
model mean? Once you’ve trained a model, you want to evaluate it. This means • you need to understand its performance under many conditions—and proper evaluation means that the model cannot change, its parameters must be ‘frozen’ • other people (clinicians) need a user-friendly interface to be able to interact with it without a bioinformatics postdoc hidden in a closet • everyone needs to be using the same model
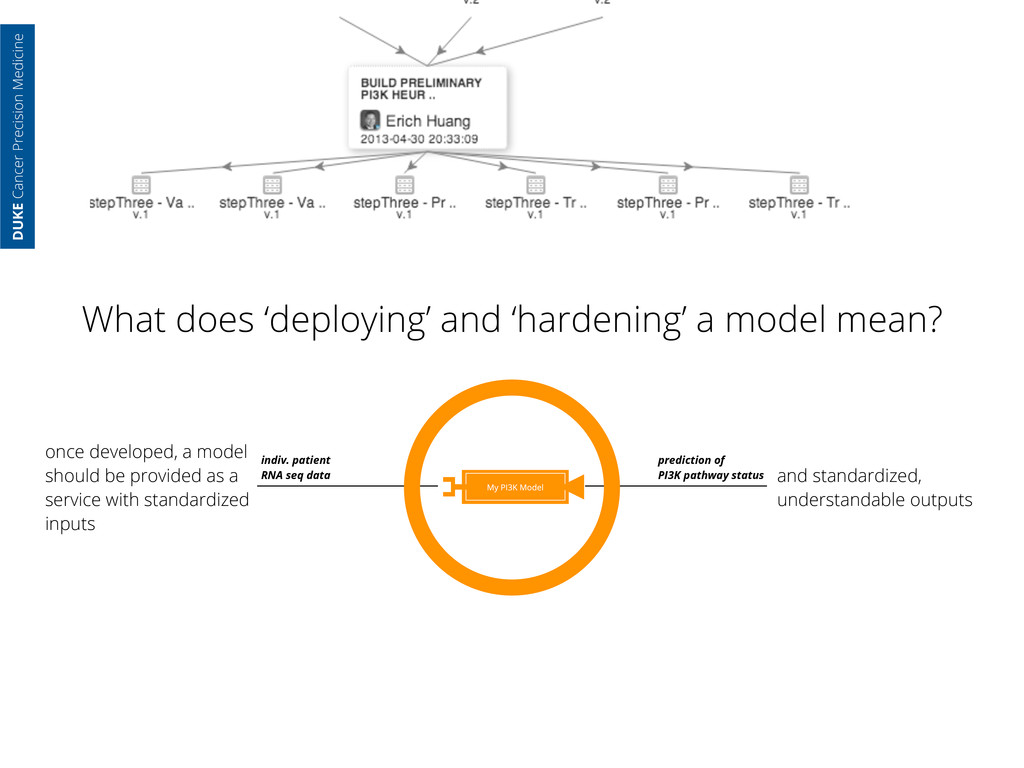
with standardized inputs indiv. patient RNA seq data prediction of PI3K pathway status and standardized, understandable outputs DUKE Cancer Precision Medicine What does ‘deploying’ and ‘hardening’ a model mean?
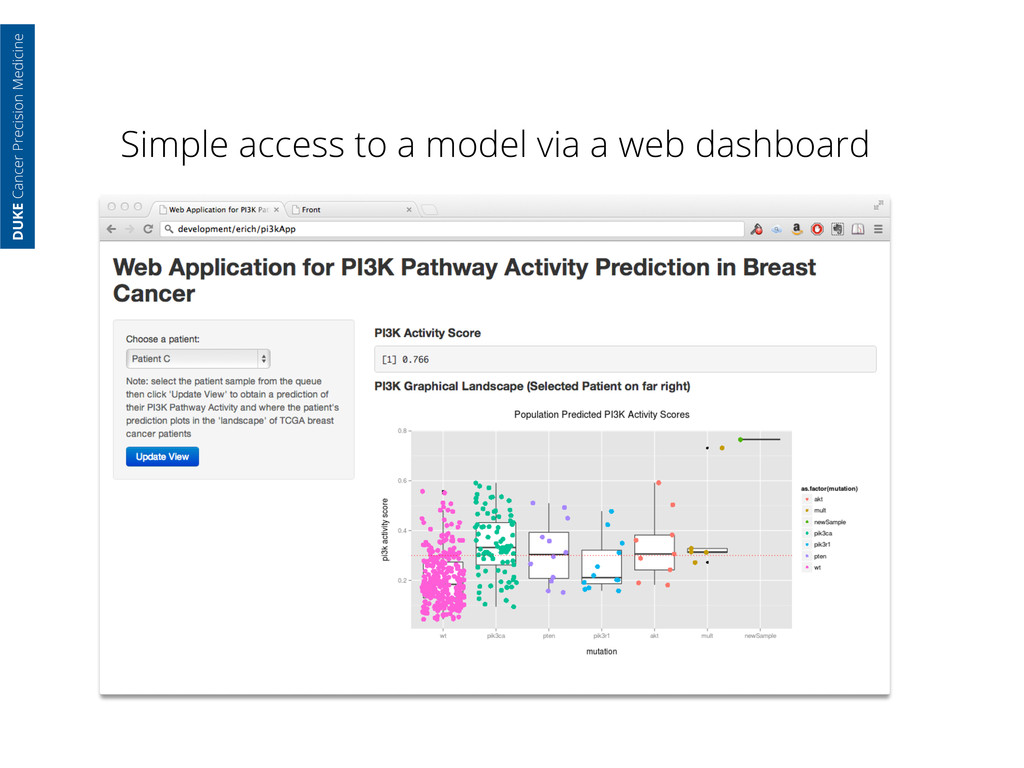
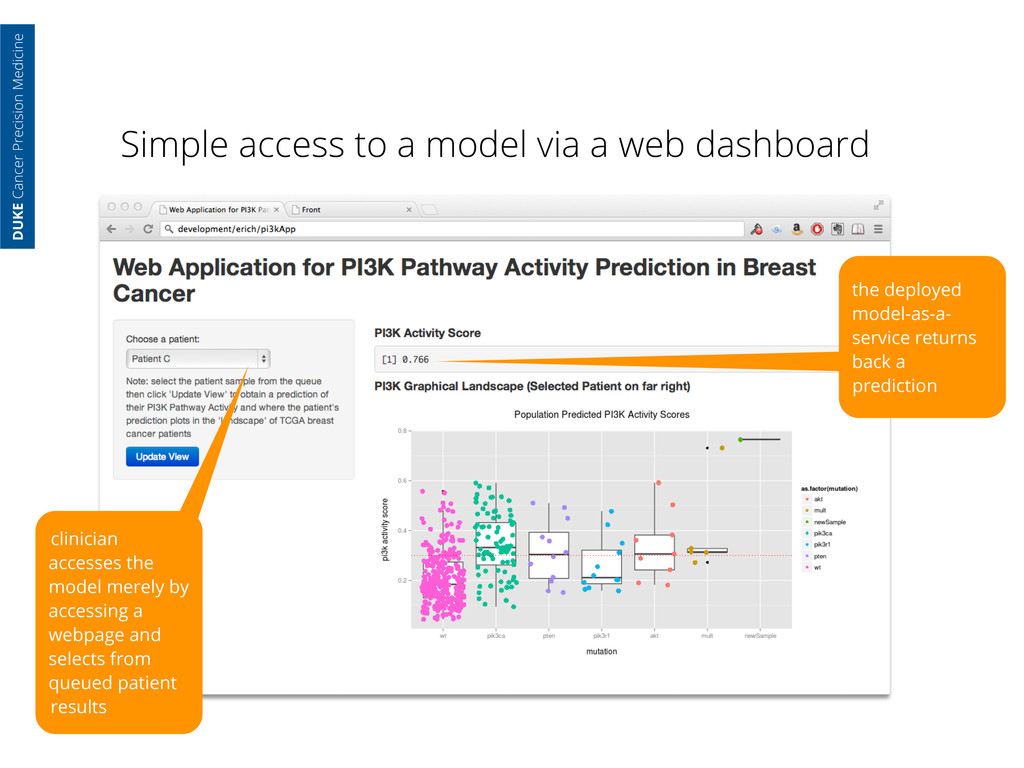
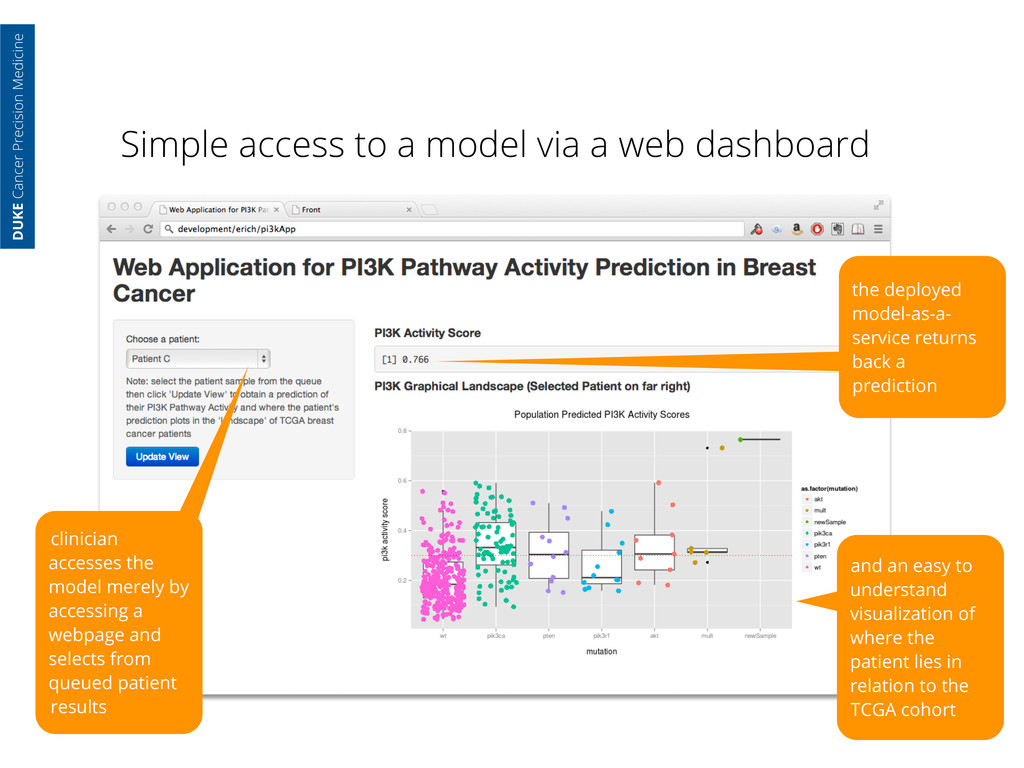
Cancer Precision Medicine clinician accesses the model merely by accessing a webpage and selects from queued patient results the deployed model-as-a- service returns back a prediction
Cancer Precision Medicine clinician accesses the model merely by accessing a webpage and selects from queued patient results the deployed model-as-a- service returns back a prediction and an easy to understand visualization of where the patient lies in relation to the TCGA cohort
raw genomic data and metadata from cores • services for pulling data from clinical data warehouses • version-controlled programmatic scripting of data access and analysis DUKE Cancer Precision Medicine
raw genomic data and metadata from cores • services for pulling data from clinical data warehouses • version-controlled programmatic scripting of data access and analysis • a service for declaring the provenance of an interwoven analysis (data, code & compute resources) DUKE Cancer Precision Medicine
raw genomic data and metadata from cores • services for pulling data from clinical data warehouses • version-controlled programmatic scripting of data access and analysis • a service for declaring the provenance of an interwoven analysis (data, code & compute resources) • a service for deploying analyses, or models within health system compute resources DUKE Cancer Precision Medicine
raw genomic data and metadata from cores • services for pulling data from clinical data warehouses • version-controlled programmatic scripting of data access and analysis • a service for declaring the provenance of an interwoven analysis (data, code & compute resources) • a service for deploying analyses, or models within health system compute resources • simple interfaces for practitioners to interact with models DUKE Cancer Precision Medicine
raw genomic data and metadata from cores • services for pulling data from clinical data warehouses • version-controlled programmatic scripting of data access and analysis • a service for declaring the provenance of an interwoven analysis (data, code & compute resources) • a service for deploying analyses, or models within health system compute resources • simple interfaces for practitioners to interact with models • internal, secure virtualized computing resources for efficiently handling all of the above DUKE Cancer Precision Medicine
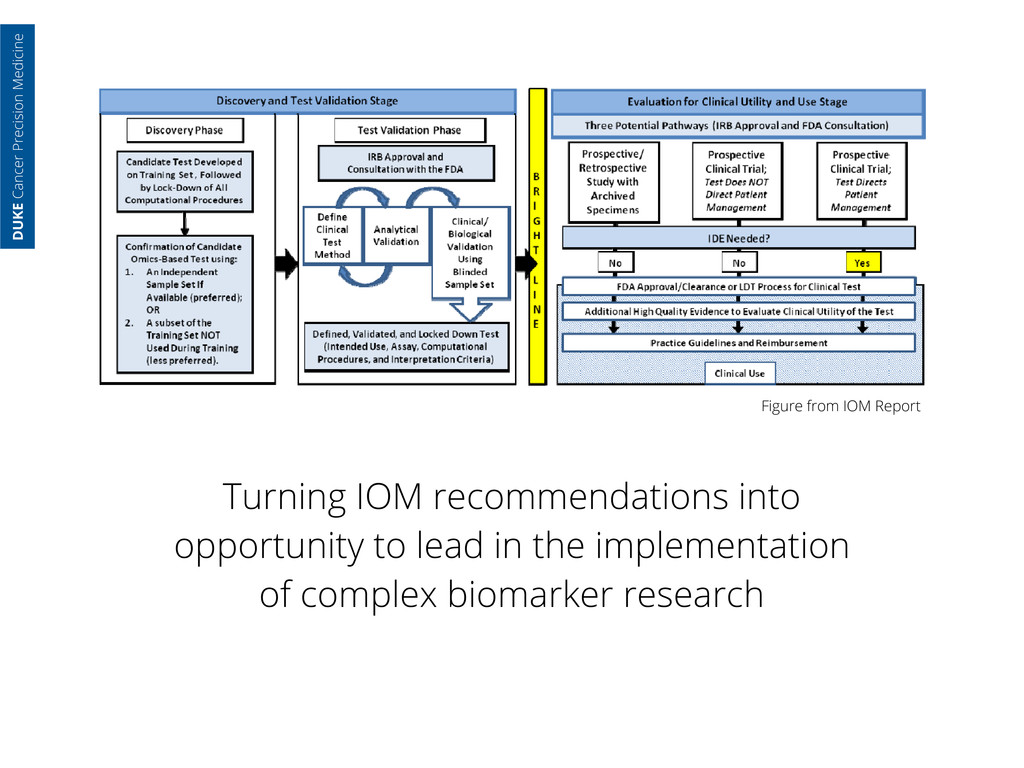
for researchers with workflows that regulatory bodies, e.g. the FDA, can easily audit • Modularizes research so that components can be repurposed DUKE Cancer Precision Medicine
for researchers with workflows that regulatory bodies, e.g. the FDA, can easily audit • Modularizes research so that components can be repurposed • Provides multiple views on complex data: DUKE Cancer Precision Medicine
for researchers with workflows that regulatory bodies, e.g. the FDA, can easily audit • Modularizes research so that components can be repurposed • Provides multiple views on complex data: • A clinician needs easy to use interfaces that help them take care of their patients DUKE Cancer Precision Medicine
for researchers with workflows that regulatory bodies, e.g. the FDA, can easily audit • Modularizes research so that components can be repurposed • Provides multiple views on complex data: • A clinician needs easy to use interfaces that help them take care of their patients • A bioinformaticist needs well-documented ‘blinking cursor’ level access DUKE Cancer Precision Medicine
for researchers with workflows that regulatory bodies, e.g. the FDA, can easily audit • Modularizes research so that components can be repurposed • Provides multiple views on complex data: • A clinician needs easy to use interfaces that help them take care of their patients • A bioinformaticist needs well-documented ‘blinking cursor’ level access • A biostatistician needs a model they can evaluate for effect size, performance and integration into clinical trial design DUKE Cancer Precision Medicine
for researchers with workflows that regulatory bodies, e.g. the FDA, can easily audit • Modularizes research so that components can be repurposed • Provides multiple views on complex data: • A clinician needs easy to use interfaces that help them take care of their patients • A bioinformaticist needs well-documented ‘blinking cursor’ level access • A biostatistician needs a model they can evaluate for effect size, performance and integration into clinical trial design • Basic & translational researchers need ways to push interesting observations forward DUKE Cancer Precision Medicine
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}