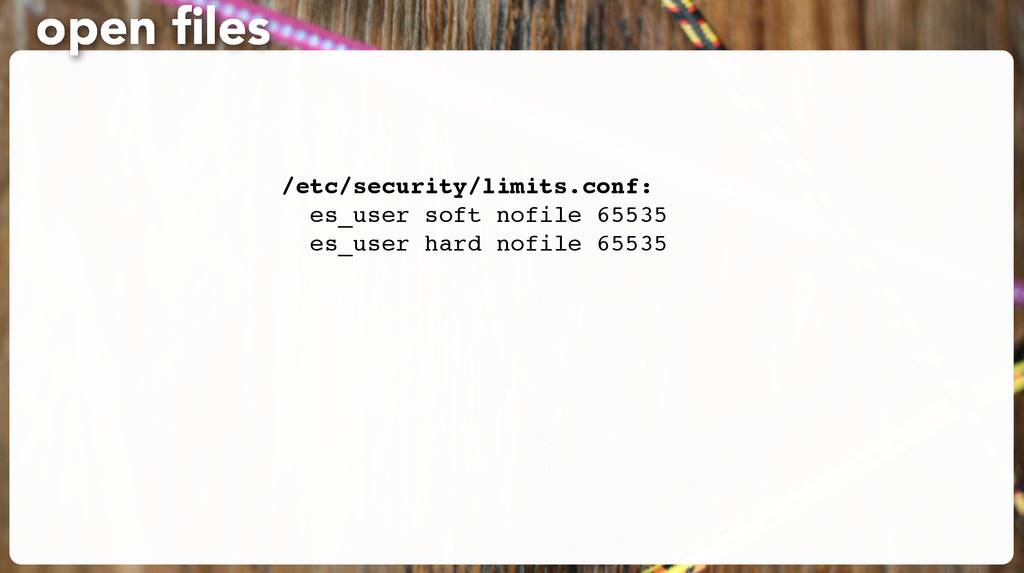
installed it yet and you’re on a Mac, just install 1.1.x. • Exercise code: clone the git repo at (or just visit) https://github.com/erikrose/oscon-elasticsearch/
installed it yet and you’re on a Mac, just install 1.1.x. • Exercise code: clone the git repo at (or just visit) https://github.com/erikrose/oscon-elasticsearch/ • Make faces.
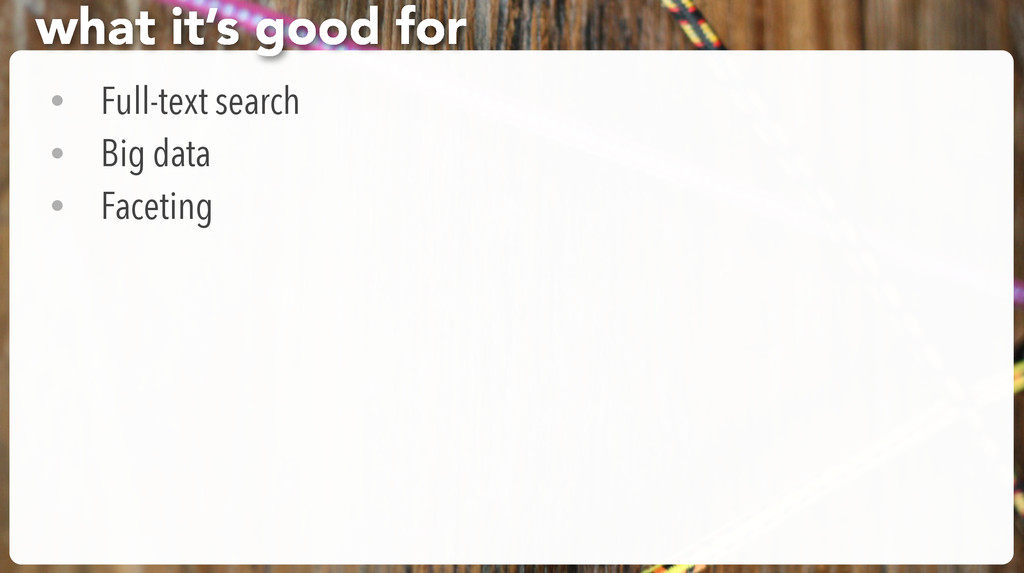
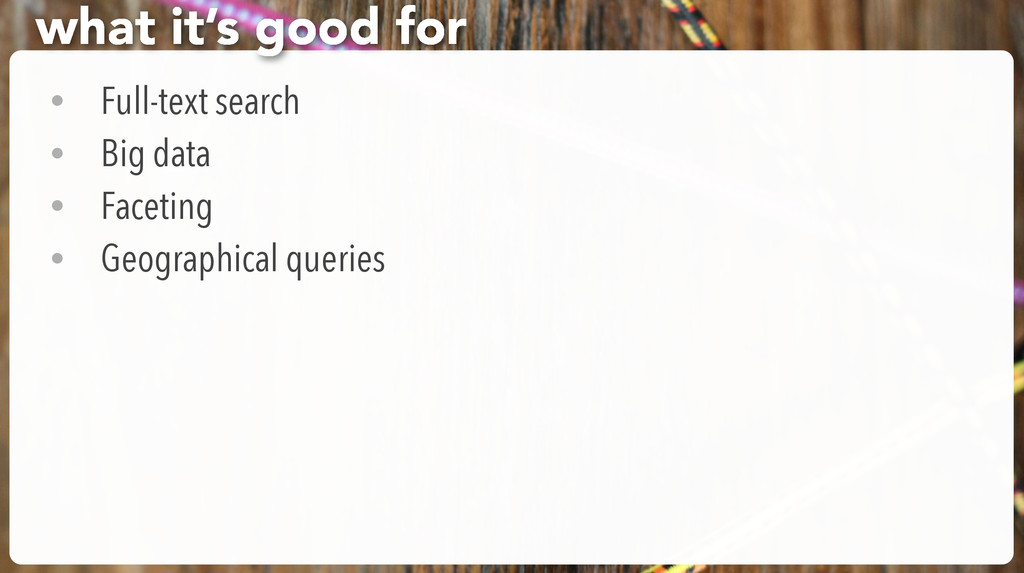
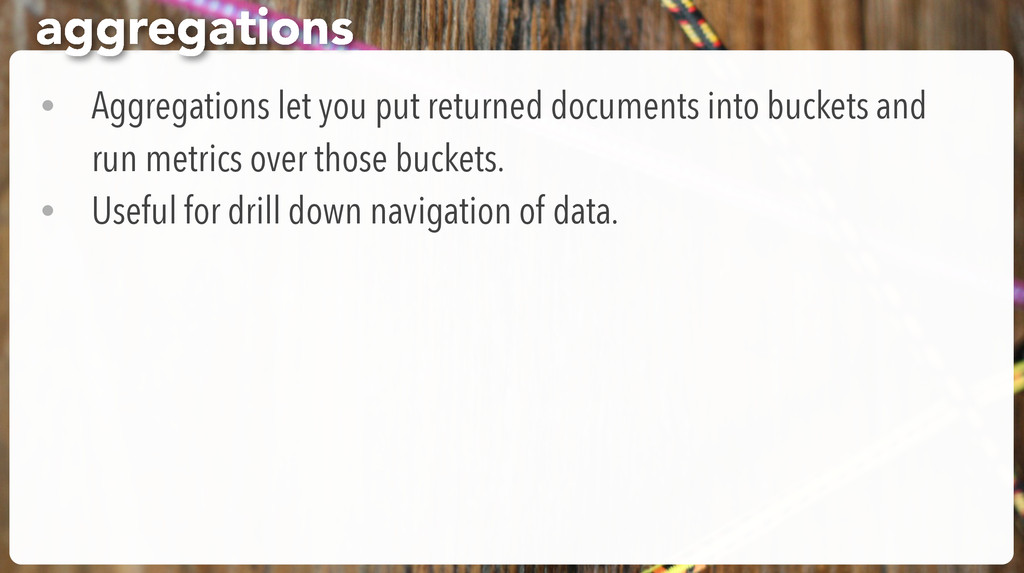
It’s a distributed search engine • Easy to get started • Easy to integrate with your existing web app • Easy to configure it not-too-terribly • Enables fast search with cool features what it’s good for, redux
you store is written to a primary shard. Primary shards are distributed over the cluster. • replica — Each shard has a set of distributed replicas (copies). Data written to a primary shard is copied to replicas on different nodes. shards and replicas
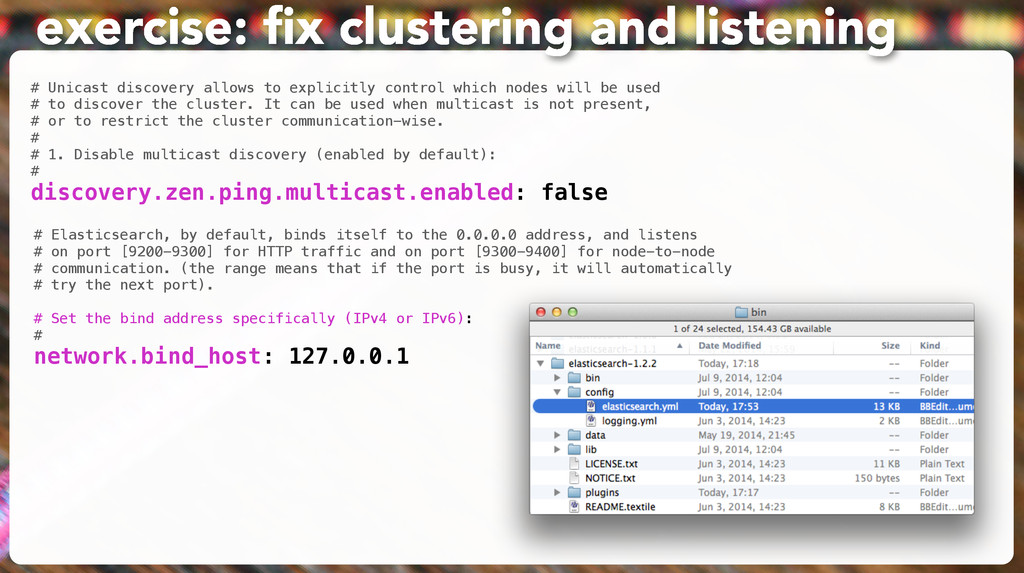
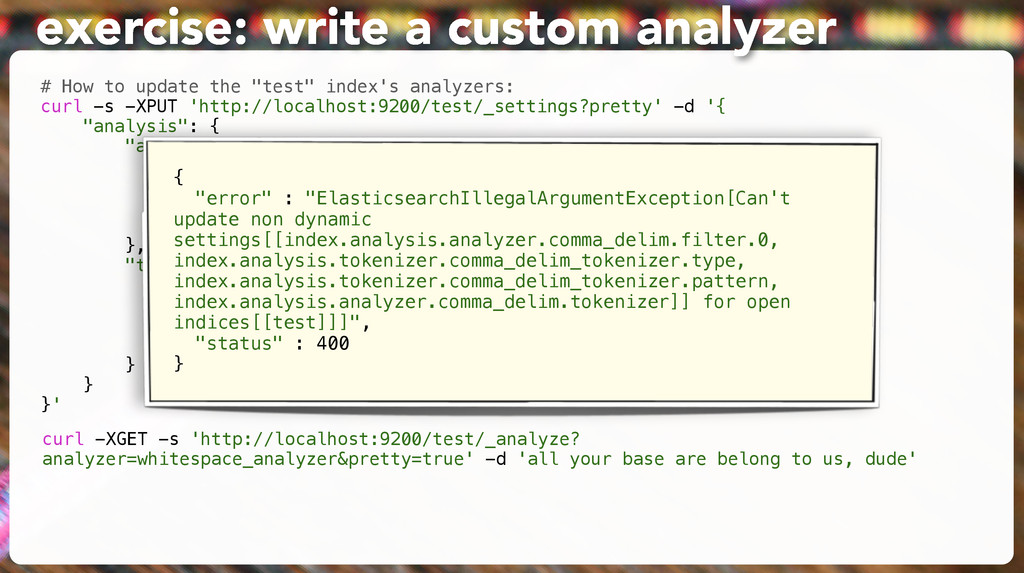
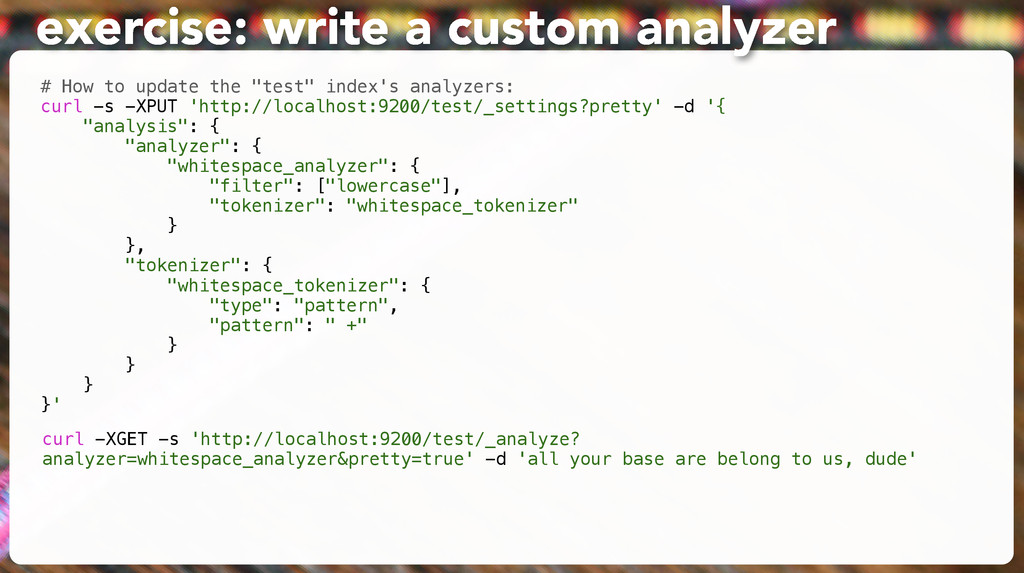
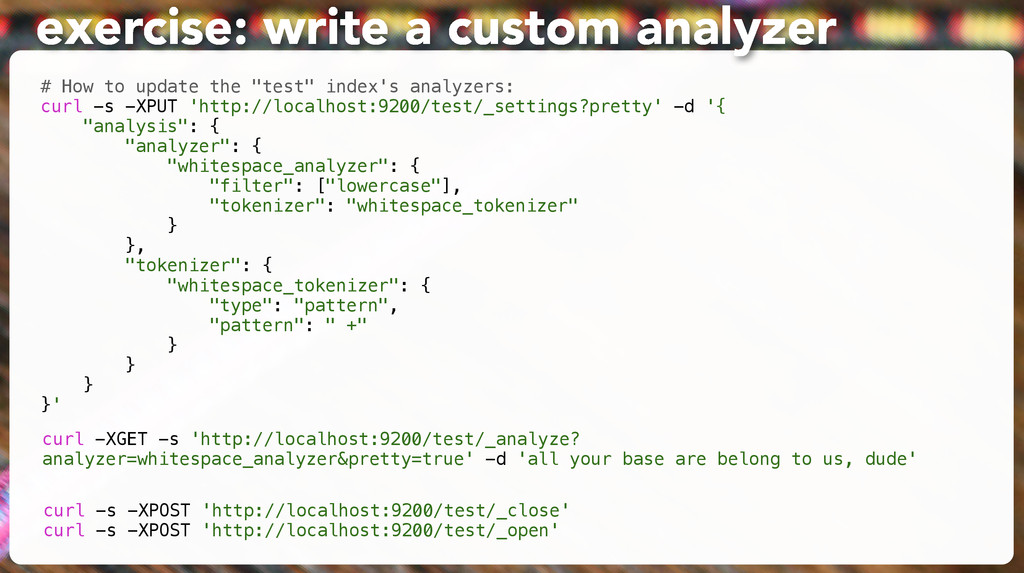
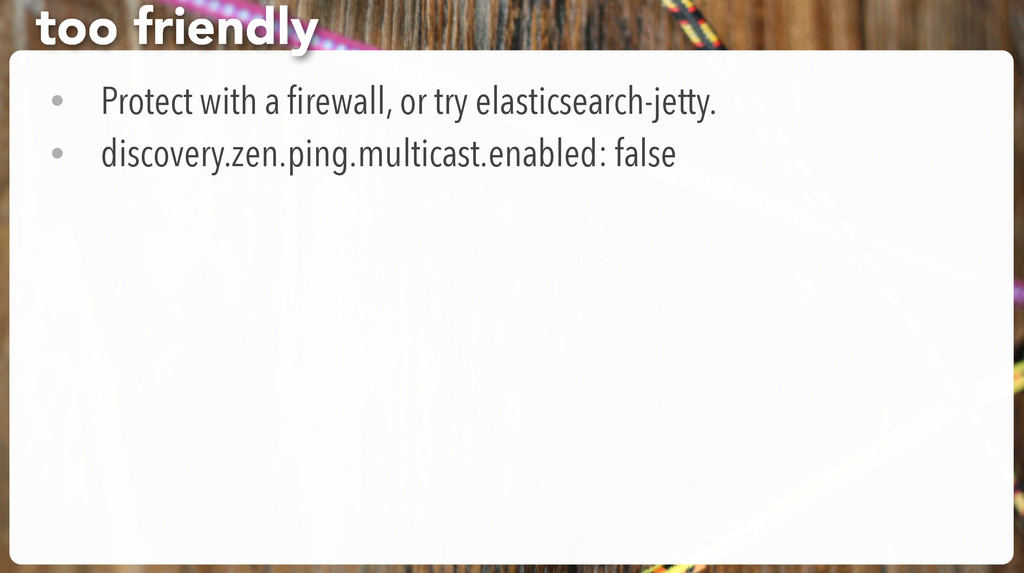
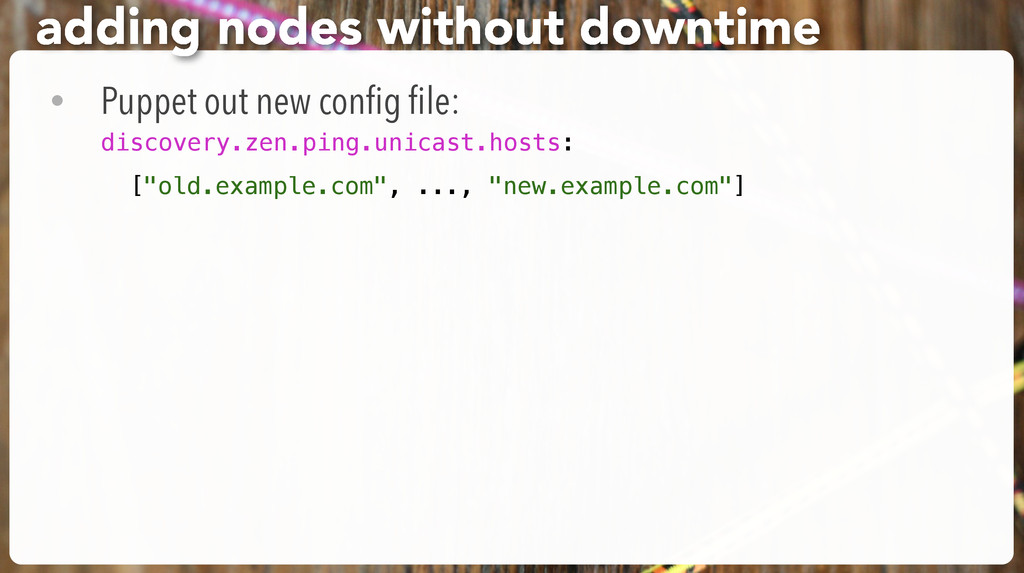
be used # to discover the cluster. It can be used when multicast is not present, # or to restrict the cluster communication-wise. # # 1. Disable multicast discovery (enabled by default): # discovery.zen.ping.multicast.enabled: false exercise: fix clustering and listening # Elasticsearch, by default, binds itself to the 0.0.0.0 address, and listens # on port [9200-9300] for HTTP traffic and on port [9300-9400] for node-to-node # communication. (the range means that if the port is busy, it will automatically # try the next port). # Set the bind address specifically (IPv4 or IPv6): # network.bind_host: 127.0.0.1
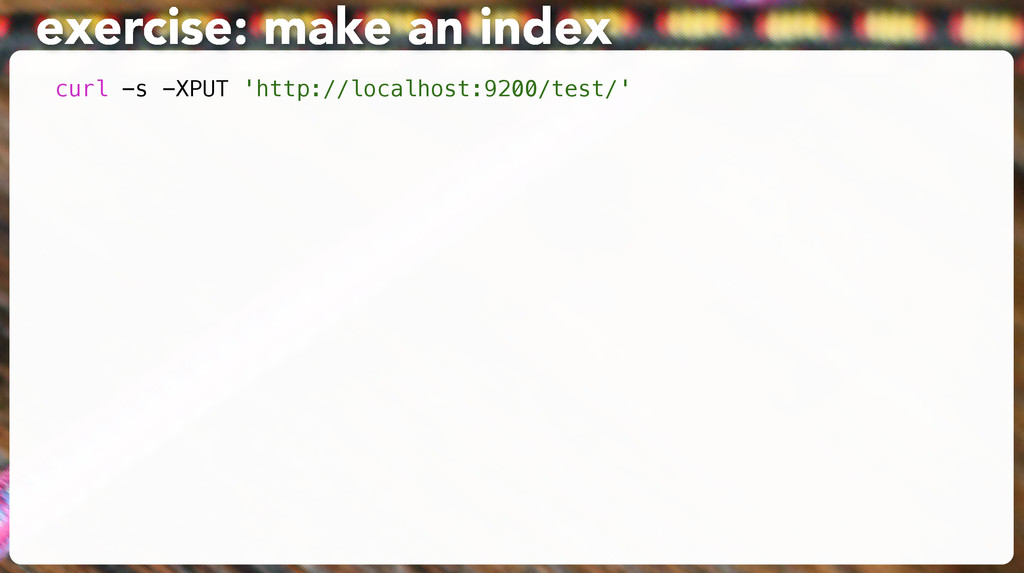
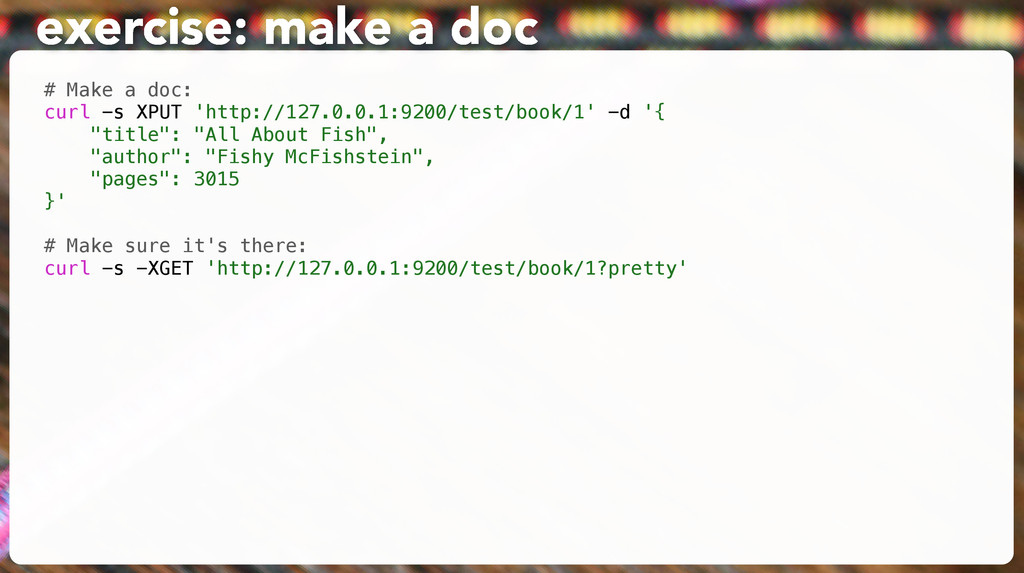
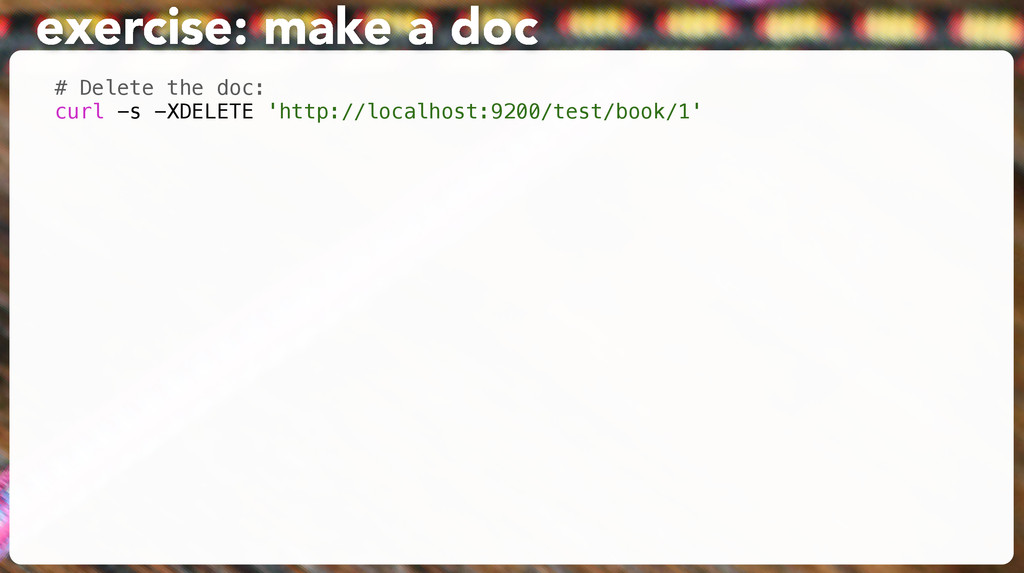
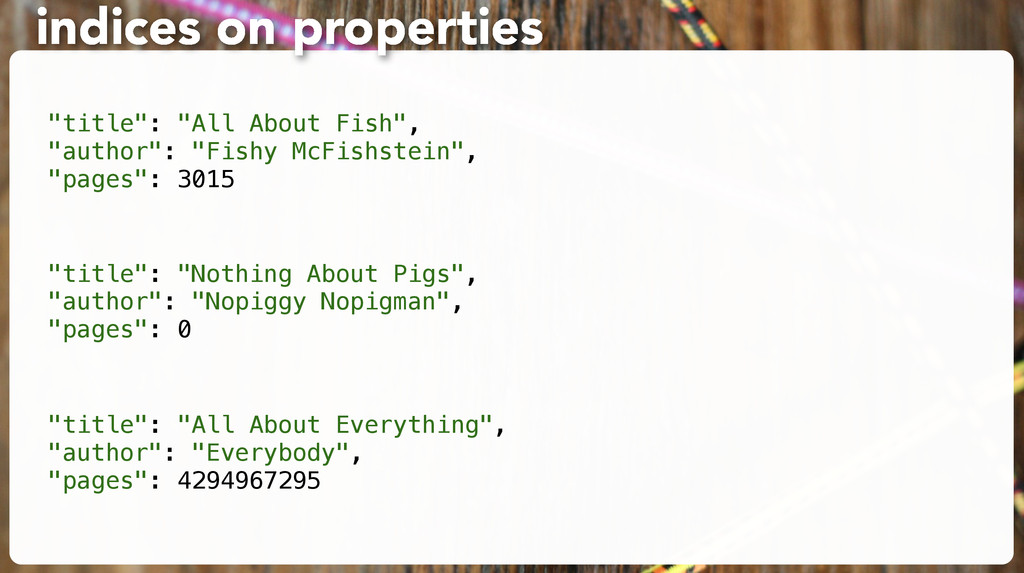
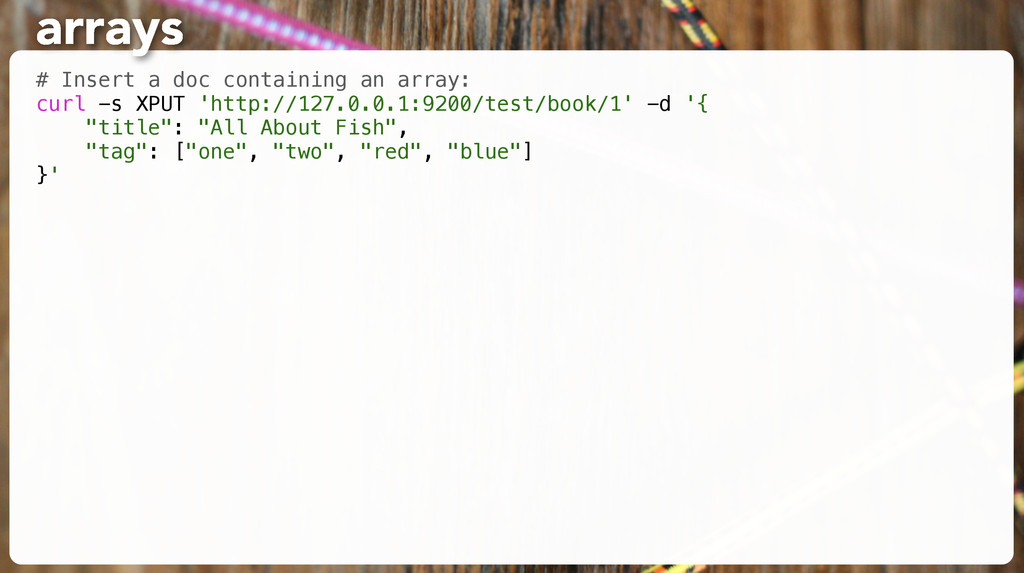
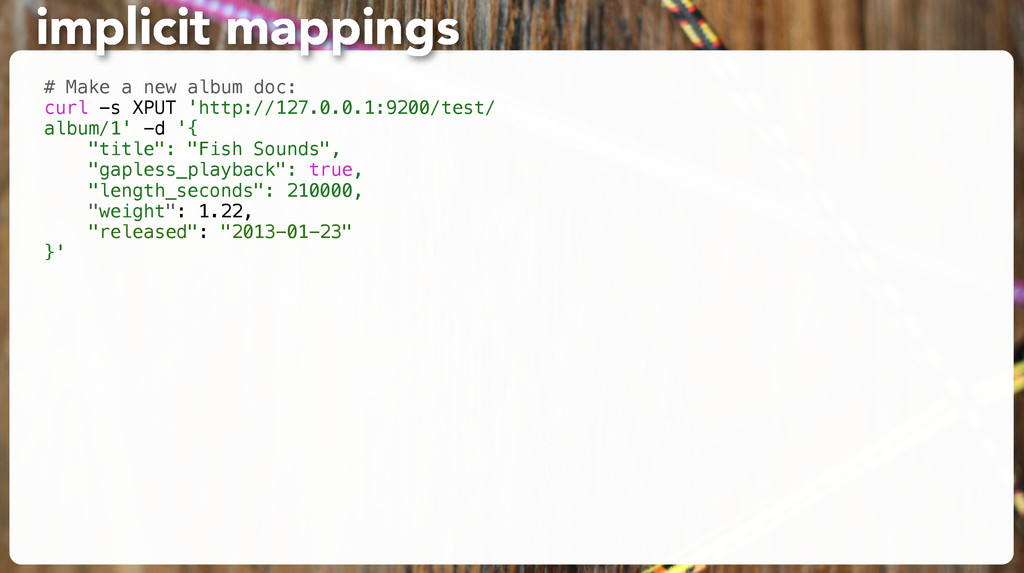
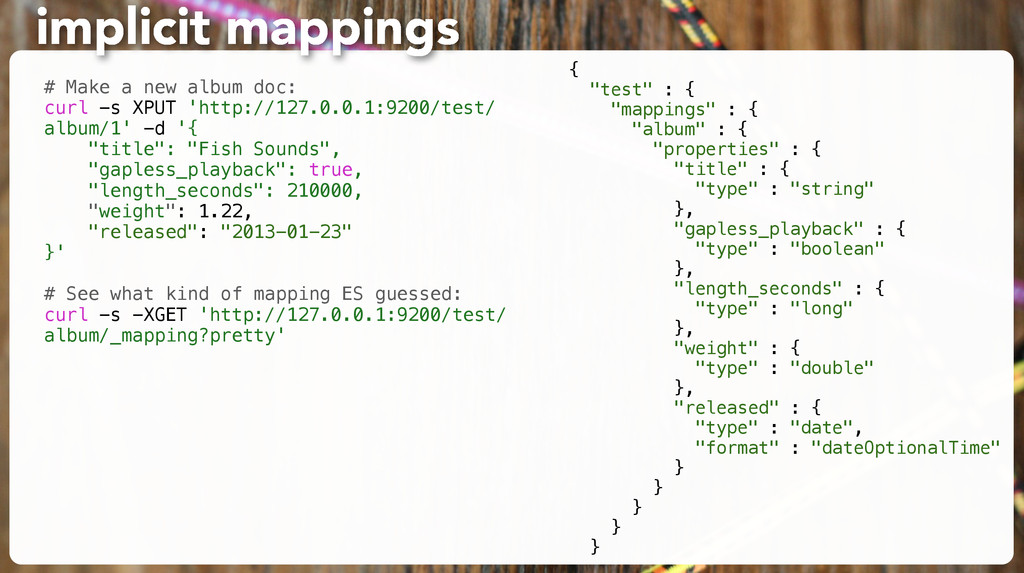
"title": "All About Fish", "author": "Fishy McFishstein", "pages": 3015 }' # Make sure it's there: curl -s -XGET 'http://127.0.0.1:9200/test/book/1?pretty' exercise: make a doc
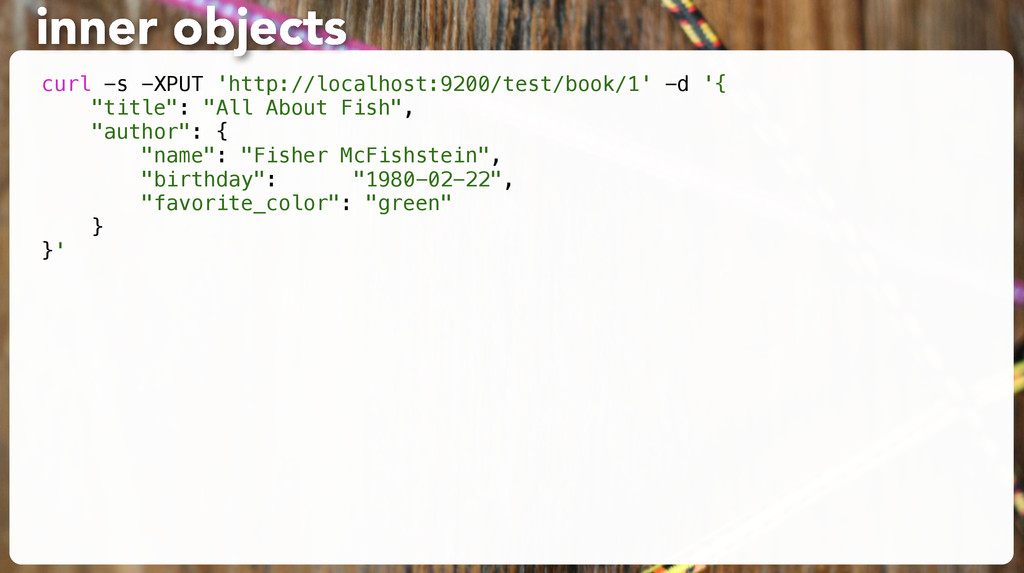
About Fish", "author": { "name": "Fisher McFishstein", "birthday": "1980-02-22", "favorite_color": "green" } }' title: All About Fish author.name: Fisher McFishstein author.birthday: 1980-02-22 author.favorite_color: green
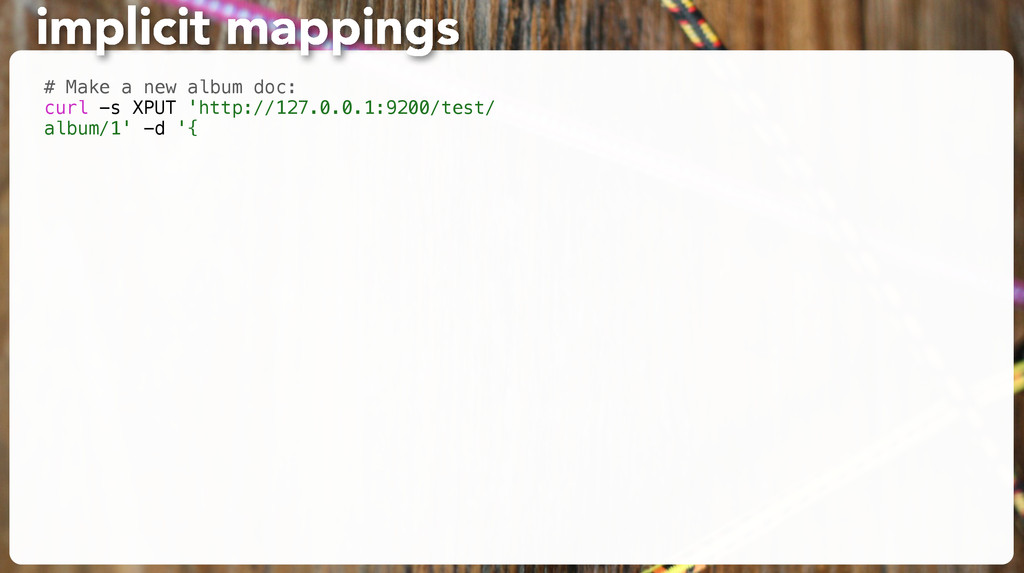
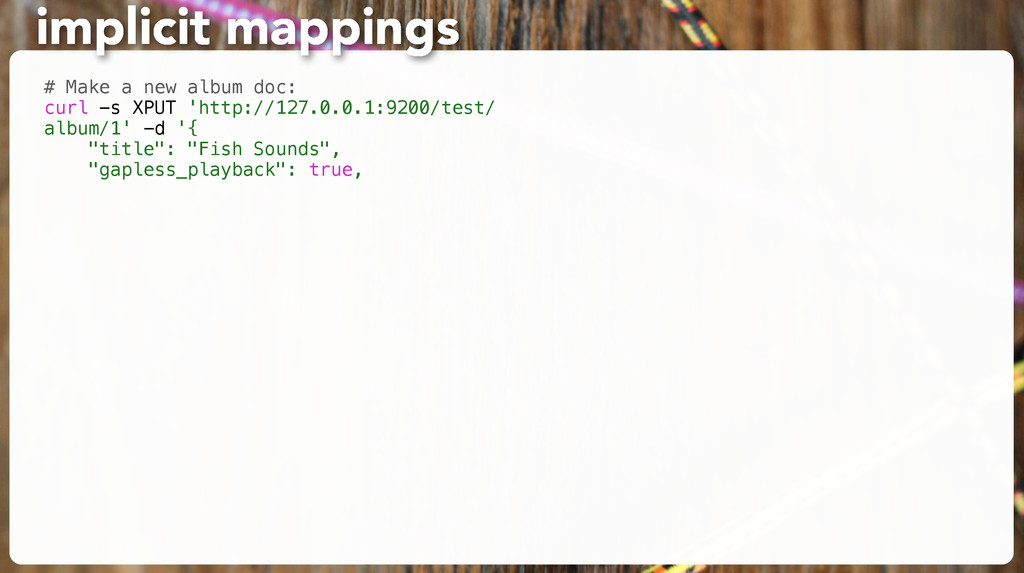
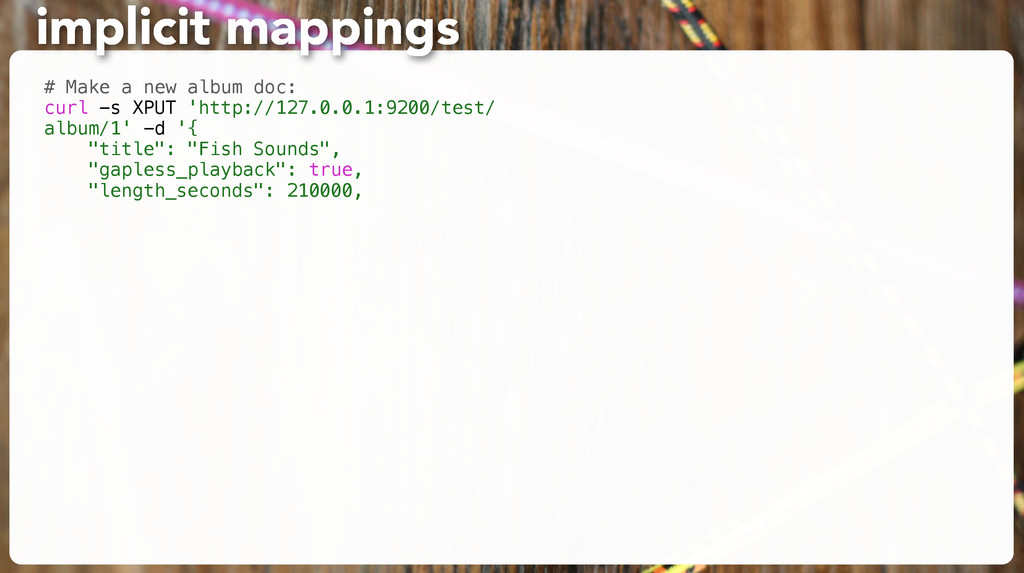
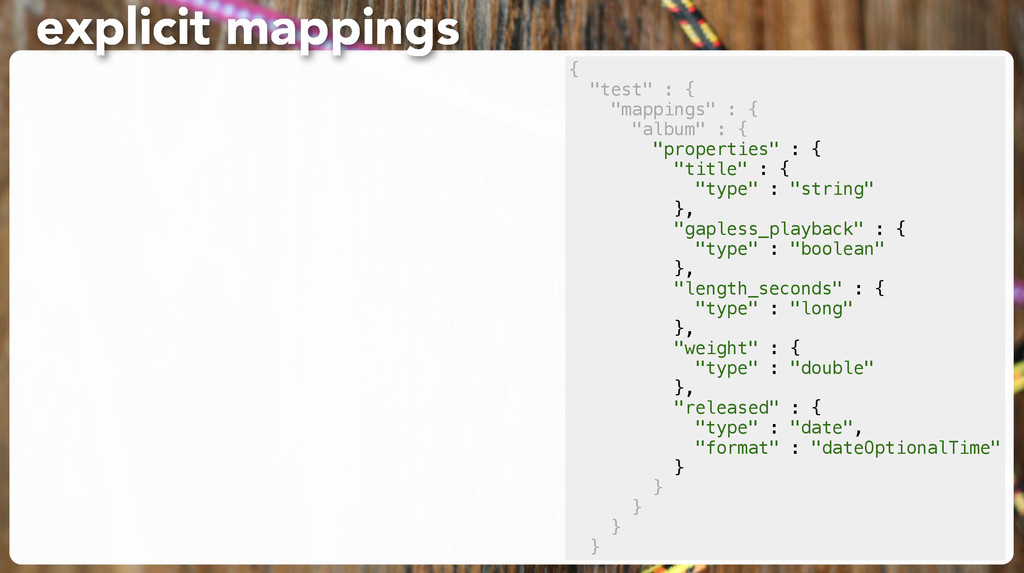
following along. 2. Think of an album which would prompt ES to guess a wrong type. 3. Insert it, and GET the _mapping to show the wrong guess. 4. Delete all “album” docs again so you can change the mapping. 5. Set a mapping explicitly so you can’t fool ES anymore. exercise: use explicit mappings
to use for querying. • This is exercise_1 in the queries/ directory of the git repo, so you can cut and paste, or execute it directly. % curl -XPOST localhost:9200/_bulk --data-binary @data.bulk
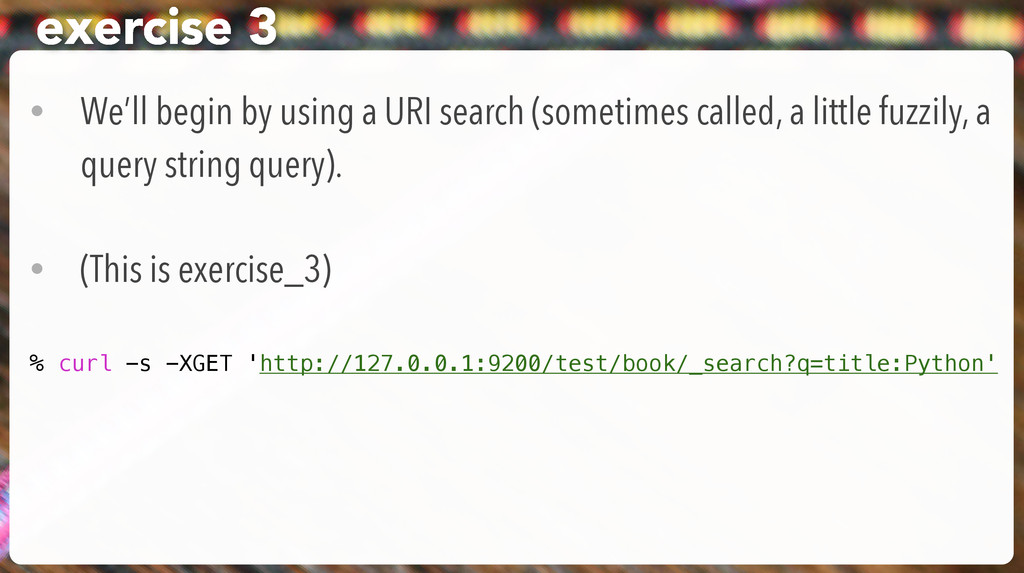
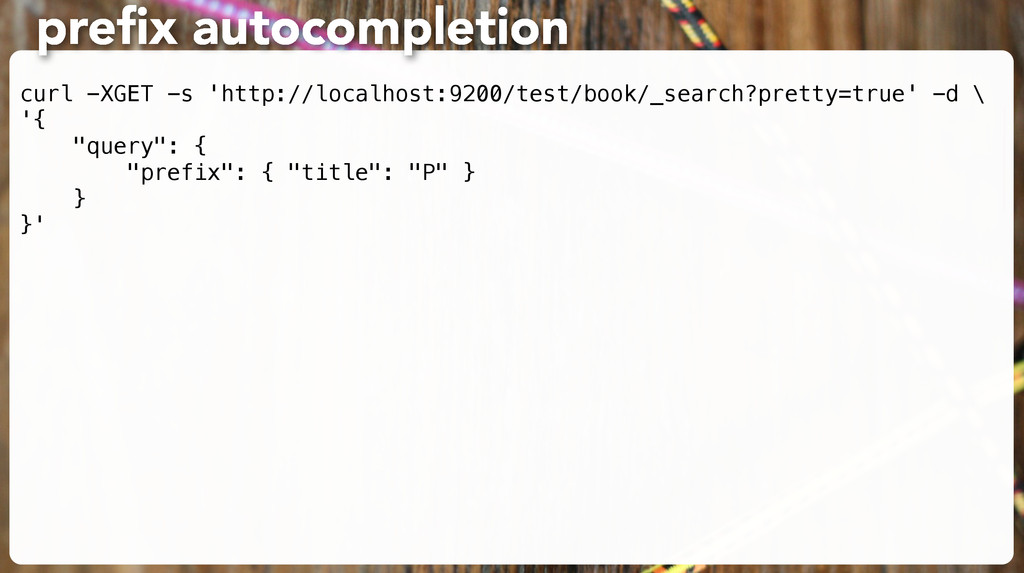
(sometimes called, a little fuzzily, a query string query). • (This is exercise_3) % curl -s -XGET 'http://127.0.0.1:9200/test/book/_search?q=title:Python'
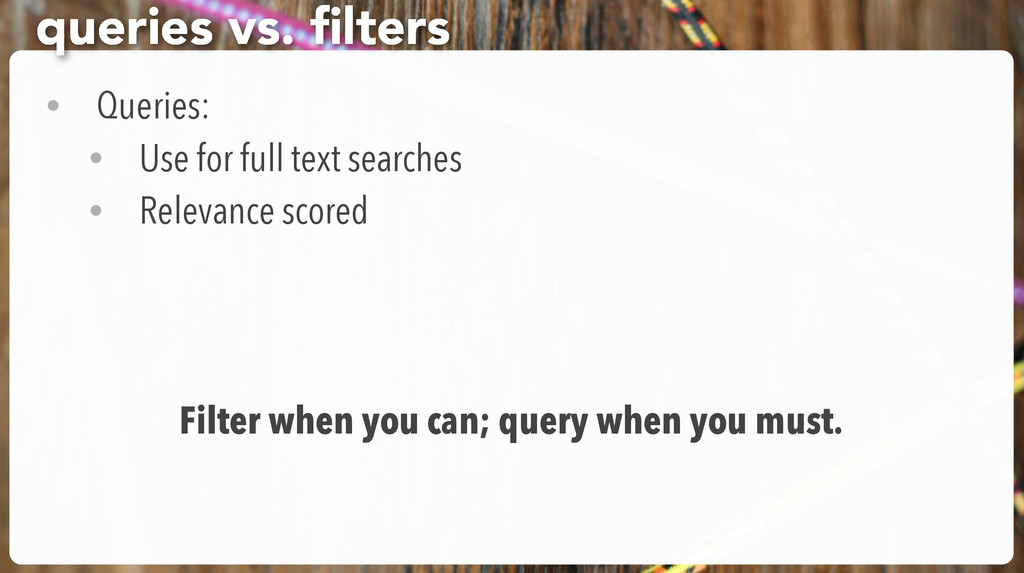
This is fine for running simple queries, basic “is it working” type tests and so on. • Once you have any level of complexity in your query, you’re going to need the query DSL. limited appeal
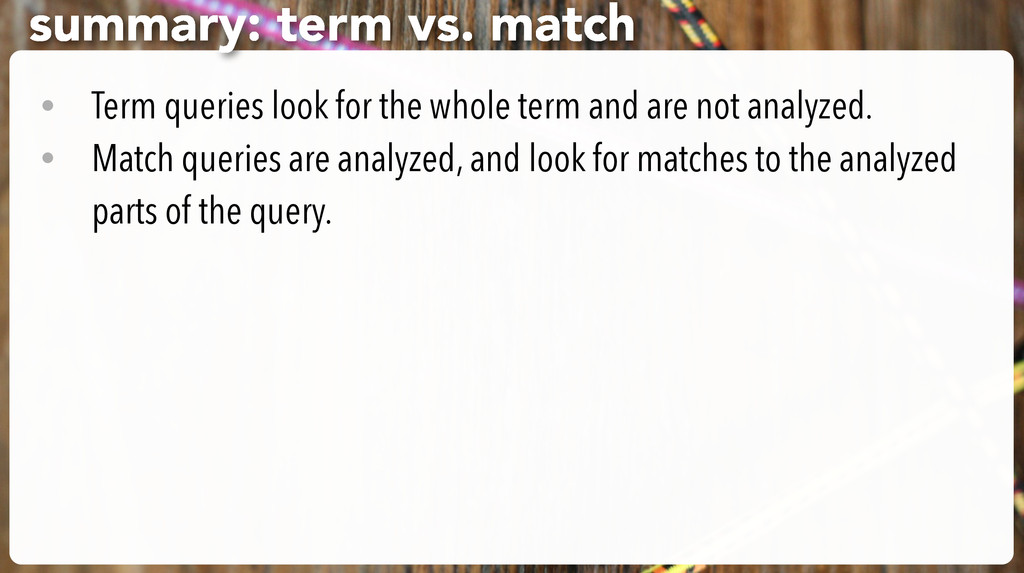
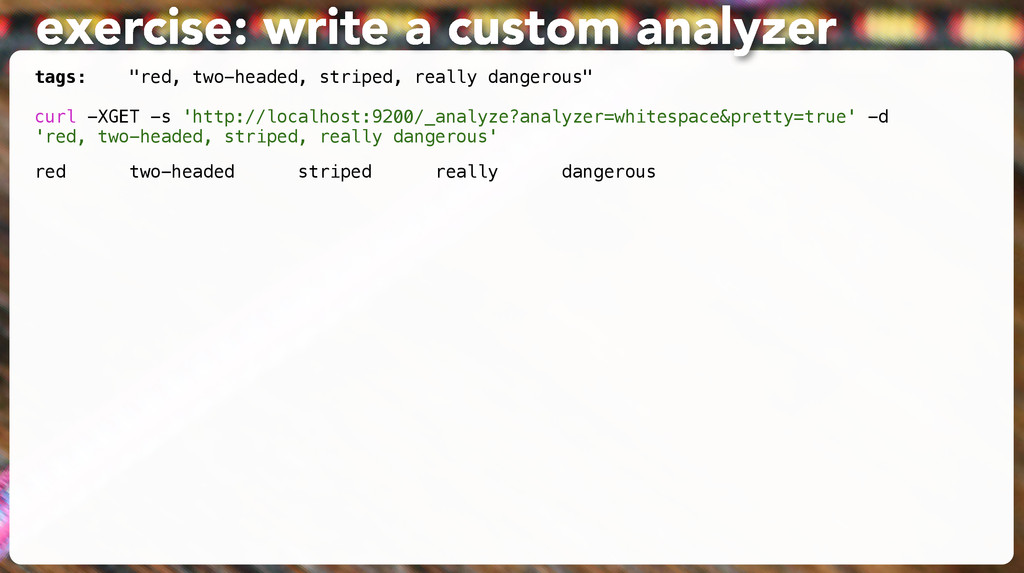
standard analyzer, applied to all fields (by default) “Web Development” will be broken into the terms “web” and “development” and those will be indexed. • The term “Web Development” is not indexed anywhere. analyze that!
so find nothing • But {“match” : “Web Development”} does work. Why? • match queries or filters use analysis: they break this down into searches for “web” or “development” but match works!
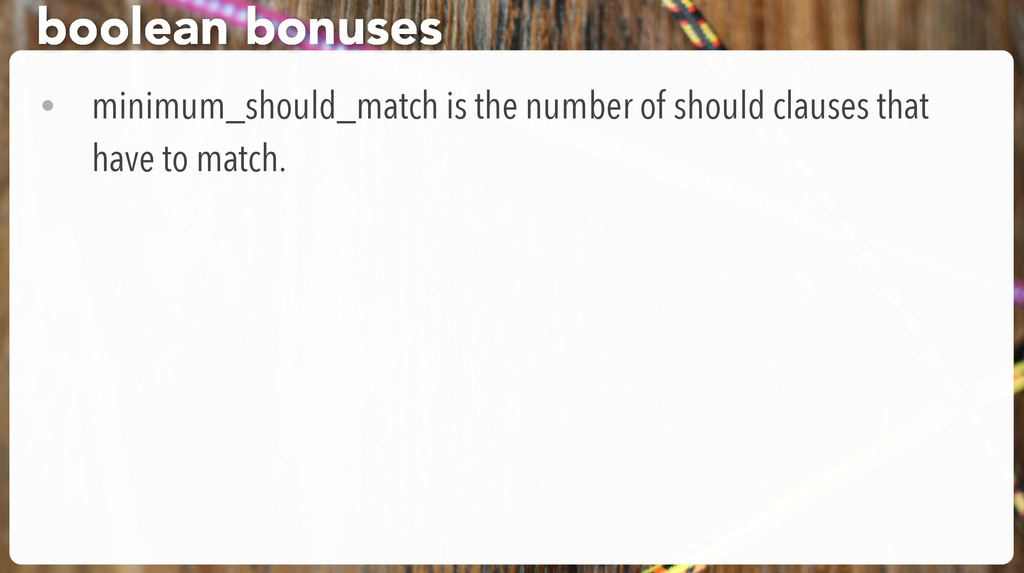
Tortured syntax of the bool query: • must: everything in the must clause is AND • should: everything in the should clause is OR • should not: you guessed it. • Nest them as much as you like boolean queries
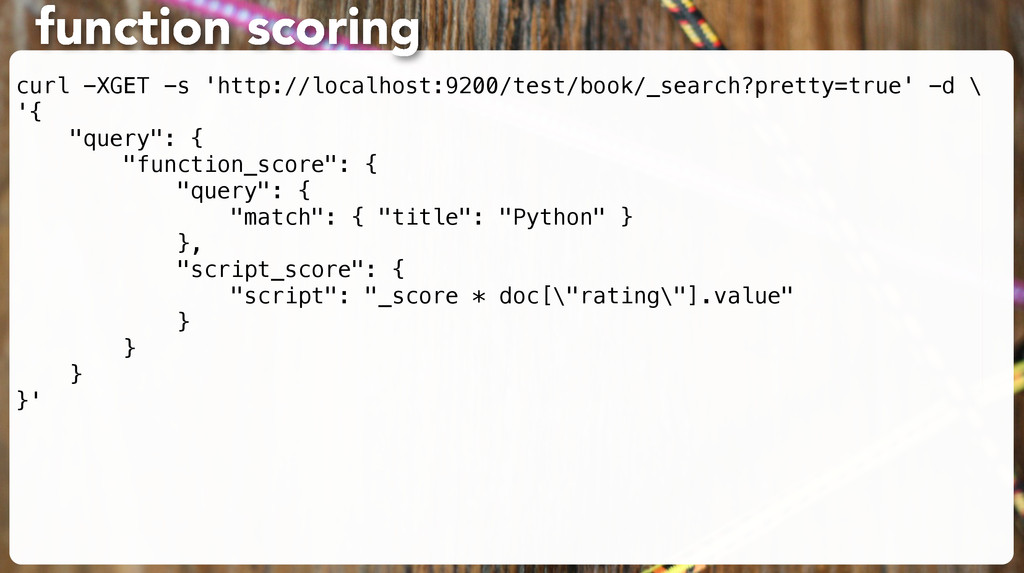
for results. For example: • Boost: weigh one part of a query more heavily than others • Custom function-scoring queries: e.g. weighting more complete user profiles • Constant score queries: pre-set a score for part of a query (useful for filters!) scoring
whitespace: Red-orange gerbils live at #43A Franklin St. standard: red orange gerbils live 43a franklin st simple: red orange gerbils live at a franklin st stop: red orange gerbils live franklin st snowball: red orang gerbil live 43a franklin st
whitespace: Red-orange gerbils live at #43A Franklin St. standard: red orange gerbils live 43a franklin st simple: red orange gerbils live at a franklin st stop: red orange gerbils live franklin st snowball: red orang gerbil live 43a franklin st • stopwords
whitespace: Red-orange gerbils live at #43A Franklin St. standard: red orange gerbils live 43a franklin st simple: red orange gerbils live at a franklin st stop: red orange gerbils live franklin st snowball: red orang gerbil live 43a franklin st • stopwords • stemming
whitespace: Red-orange gerbils live at #43A Franklin St. standard: red orange gerbils live 43a franklin st simple: red orange gerbils live at a franklin st stop: red orange gerbils live franklin st snowball: red orang gerbil live 43a franklin st • stopwords • stemming • punctuation
whitespace: Red-orange gerbils live at #43A Franklin St. standard: red orange gerbils live 43a franklin st simple: red orange gerbils live at a franklin st stop: red orange gerbils live franklin st snowball: red orang gerbil live 43a franklin st • stopwords • stemming • punctuation • case-folding
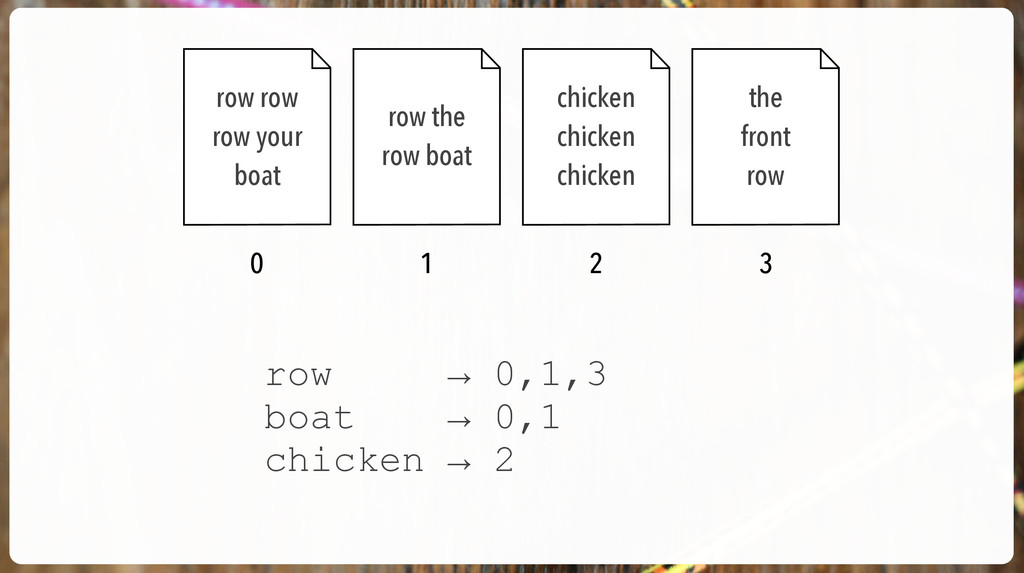
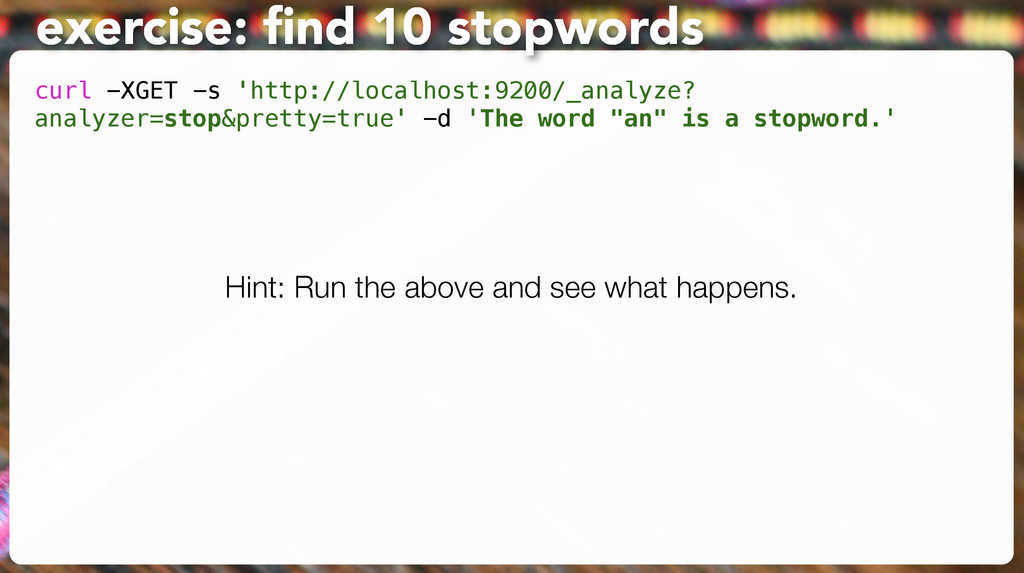
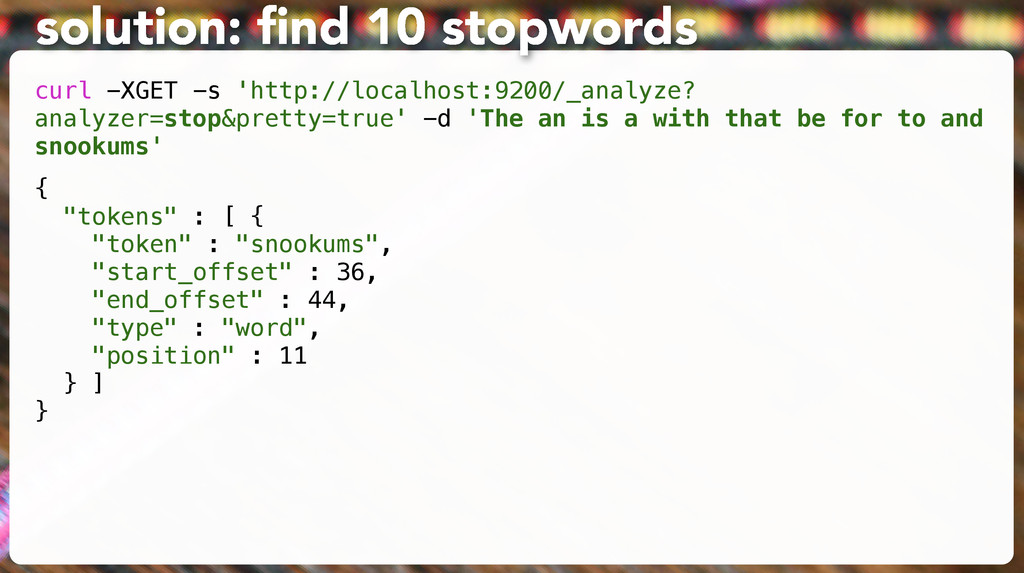
'The an is a with that be for to and snookums' { "tokens" : [ { "token" : "snookums", "start_offset" : 36, "end_offset" : 44, "type" : "word", "position" : 11 } ] }
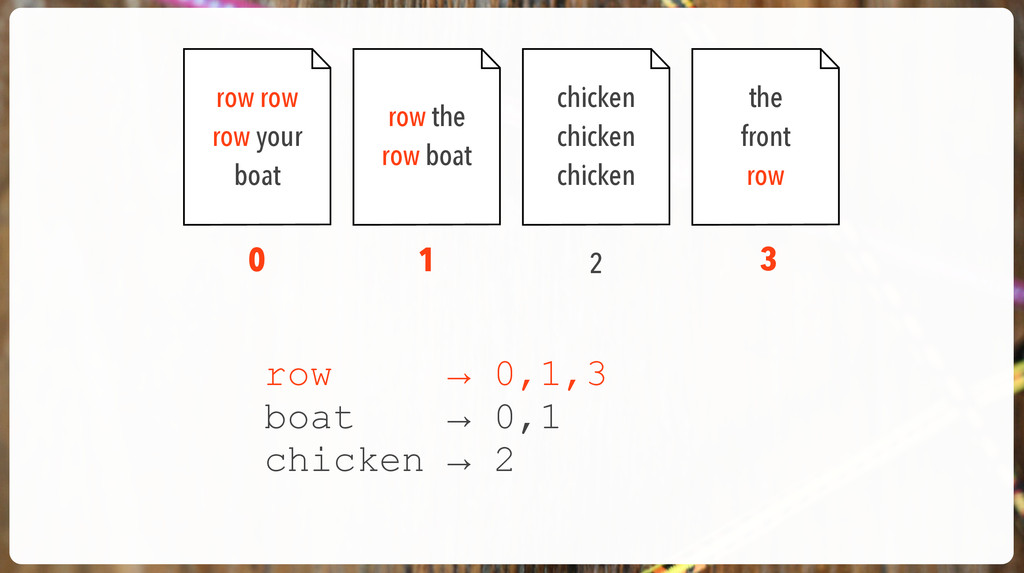
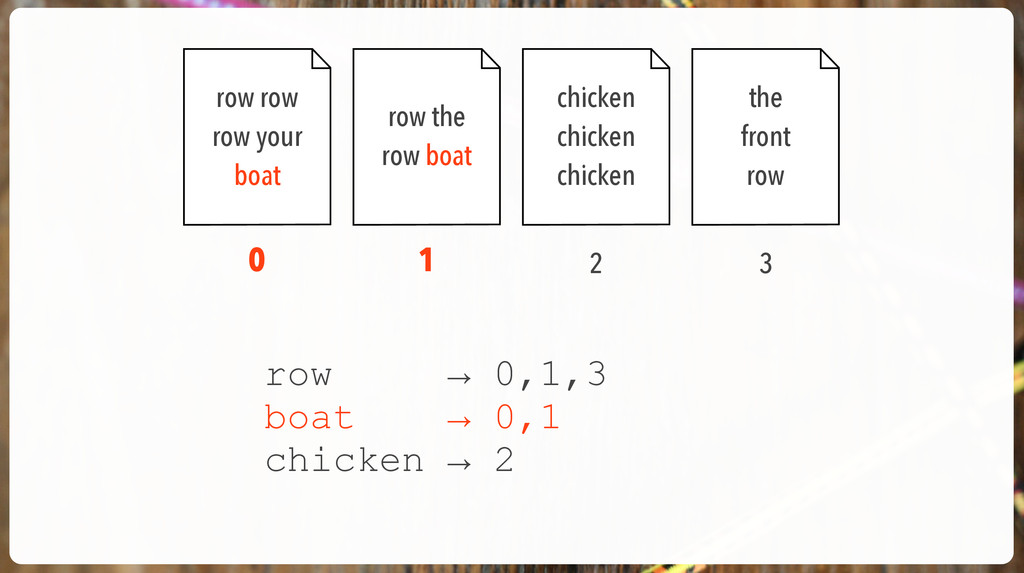
'The an is a with that be for to and snookums' { "tokens" : [ { "token" : "snookums", "start_offset" : 36, "end_offset" : 44, "type" : "word", "position" : 11 } ] } [0,1,2] [0,2] [2] [4] [3] [0,1,2] positions
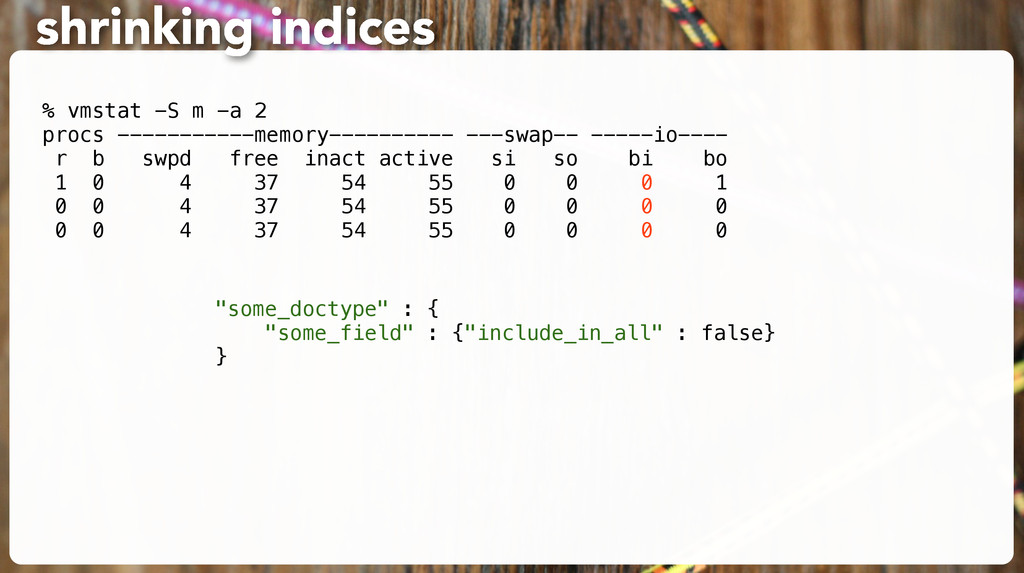
a million • At least 3 nodes. recommendations Avoid split-brain: discovery.zen.minimum_master_nodes: 2 • Get unlucky? Set fire to the data center and walk away.
a million • At least 3 nodes. recommendations Avoid split-brain: discovery.zen.minimum_master_nodes: 2 • Get unlucky? Set fire to the data center and walk away. Or continually repopulate.
an API for that! • Set it up: curl -XPUT 'http://localhost:9200/_snapshot/backups' -d '{ "type": "fs", "settings": { "location": "/somewhere/backups", "compress": true } }' • Run a backup: curl -XPUT "localhost:9200/_snapshot/backups/july20" backups
=> albert, al", "allan => allan, al" ] } } original query: Allan Smith after synonyms: [allan, al] smith original query: Albert Smith after synonyms: [albert, al] smith
query time. • For all that’s beautiful in this world, do it at query time. • At indexing explodes your data size. • You can store synonyms in a file, and reference that file in your mapping. • Many gotchas. • Undocumented limits on the file. • Needs to be uploaded to the config dir on each node. synonym gotchas
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![doc row → 0 [0,1,2] 1 [0,2] 3 [2] boat](https://files.speakerdeck.com/presentations/7962dba0f25301317cca4eebb6e8a062/slide_50.jpg){kind=link}
![doc positions row → 0 [0,1,2] 1 [0,2] 3 [2]](https://files.speakerdeck.com/presentations/7962dba0f25301317cca4eebb6e8a062/slide_51.jpg){kind=link}
![doc positions row → 0 [0,1,2] 1 [0,2] 3 [2]](https://files.speakerdeck.com/presentations/7962dba0f25301317cca4eebb6e8a062/slide_52.jpg){kind=link}
![doc positions row → 0 [0,1,2] 1 [0,2] 3 [2]](https://files.speakerdeck.com/presentations/7962dba0f25301317cca4eebb6e8a062/slide_53.jpg){kind=link}
![doc positions row → 0 [0,1,2] 1 [0,2] 3 [2]](https://files.speakerdeck.com/presentations/7962dba0f25301317cca4eebb6e8a062/slide_54.jpg){kind=link}
![doc positions row → 0 [0,1,2] 1 [0,2] 3 [2]](https://files.speakerdeck.com/presentations/7962dba0f25301317cca4eebb6e8a062/slide_55.jpg){kind=link}
![doc row 232 → 0 [0,1,2] 1 [0,2] 3 [2]](https://files.speakerdeck.com/presentations/7962dba0f25301317cca4eebb6e8a062/slide_56.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![filter caching "filter": { "terms": { "tags": ["red", "green"], "execution":](https://files.speakerdeck.com/presentations/7962dba0f25301317cca4eebb6e8a062/slide_203.jpg){kind=link}
![filter caching "filter": { "terms": { "tags": ["red", "green"], "execution":](https://files.speakerdeck.com/presentations/7962dba0f25301317cca4eebb6e8a062/slide_204.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![thank you @ErikRose [email protected] @lxt [email protected]](https://files.speakerdeck.com/presentations/7962dba0f25301317cca4eebb6e8a062/slide_218.jpg){kind=link}