Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
AHC061解説
Search
Shun_PI
February 26, 2026
Programming
610
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
AHC061解説
Shun_PI
February 26, 2026
More Decks by Shun_PI
See All by Shun_PI
AHC045_解説
shun_pi
0
970
短期AHCで勝つためのテクニック
shun_pi
6
4.7k
AHC023参加記(暫定版・手書き図多め)
shun_pi
1
900
Other Decks in Programming
See All in Programming
Strategic Design in the Frontend: Moduliths & Micro Frontends @DDDEurope
manfredsteyer
PRO
0
140
決定論的オーケストレーションの設計と実装 / Design and Implementation of Deterministic Orchestration
nrslib
4
1.6k
ADKを使って簡単にAIエージェントを作ってみよう
k1mu21
0
290
キャリア迷子上等 ─ "ない道"は自分で作ればいい
16bitidol
3
2.8k
Webフレームワークの ベンチマークについて
yusukebe
0
200
Developing with AI Agents — Codex, Claude Code & Cowork Practical Guide
x5gtrn
PRO
0
1.3k
これからAgentCoreを触る方へ トレンドはGatewayです
har1101
6
480
使用 Meilisearch 建立新聞搜尋工具
johnroyer
0
110
TypeScript+Orvalで実現する型安全かつ堅牢でスケーラブルなマルチチャネル通知基盤 / TSKaigi Night talks ~after conference~
d0riven
0
390
エージェンティックRAGにAWSで入門しよう!
har1101
9
1.9k
鹿野さんに聞く!『TypeScriptコードレシピ集』で磨く実践力
tonkotsuboy_com
4
1k
Go1.27で導入されるジェネリクスメソッドでできること
mackee
0
250
Featured
See All Featured
How to Get Subject Matter Experts Bought In and Actively Contributing to SEO & PR Initiatives.
livdayseo
0
150
A Modern Web Designer's Workflow
chriscoyier
698
190k
Dealing with People You Can't Stand - Big Design 2015
cassininazir
367
27k
JavaScript: Past, Present, and Future - NDC Porto 2020
reverentgeek
52
6k
Amusing Abliteration
ianozsvald
1
220
Responsive Adventures: Dirty Tricks From The Dark Corners of Front-End
smashingmag
254
22k
Lessons Learnt from Crawling 1000+ Websites
charlesmeaden
PRO
1
1.3k
What's in a price? How to price your products and services
michaelherold
247
13k
Rebuilding a faster, lazier Slack
samanthasiow
85
9.6k
Become a Pro
speakerdeck
PRO
31
6k
A brief & incomplete history of UX Design for the World Wide Web: 1989–2019
jct
2
410
Navigating the Design Leadership Dip - Product Design Week Design Leaders+ Conference 2024
apolaine
1
370
Transcript
THIRDプログラミングコンテスト 2026(AHC061) 解説 Shun_PI
スライド作成に当たり使用したコードについて 「順位・相対スコア・perf」が記載されているページについて、 計測に使用したコードをAHC061の私の提出で公開しています ページの順番と提出順が対応しています ※全てAI生成コードです ※順位は暫定テスト順位、perfはシステムテスト順位が 暫定テスト順位と同一と仮定した場合の値です 2026/2/26 2
問題概要 • 𝑁 × 𝑁の盤面上で、𝑀人のプレイヤーによる 陣取りゲームを行う • プレイヤー0を高橋くんが、 残りのプレイヤーをAIが操作する •
ゲームは𝑇ターン行い、各ターンでは 高橋くん(プレイヤー0)の移動先を出力する • スコアの最も高いAIに対するプレイヤー0の スコアの比率をできるだけ大きくしたい 2026/2/26
目次 1. 作問について 2. 評価値による貪欲法の改善 3. モンテカルロ法の改善 4. 強化学習について ※サンプル~橙パフォ到達程度までを解説します
2026/2/26 4
作問について 2026/2/26 5
作問の方針について • 「AHCでCodinGameのような 対戦ゲーム系の問題を作りたい!」 • 以前から一番作りたかったタイプの問題だった • AHCで参加者同士の対戦はできないので、 AI(CPU)を相手に戦わせることになる •
ゲームバランスやAIのアルゴリズムを どうするかなど、多くの課題があった 2026/2/26 A Code of Ice & Fire (CodinGame) Hungry Geese (Kaggle)
AIのアルゴリズムをどうするか? • 当然、AIの行動方法は公開する必要がある • 行動方法があまりに複雑だと、問題文に載せるのも大変だし、 読む側も理解が大変 • 行動方法の「必然性」や「納得感」も弱くなる • かといってあまりにAIが弱いと対戦ゲーム感が無くなる
• 簡単なアルゴリズムでそこそこ強く、かつ個性が出せるように するため、まずゲームのルールから工夫する必要がある 2026/2/26
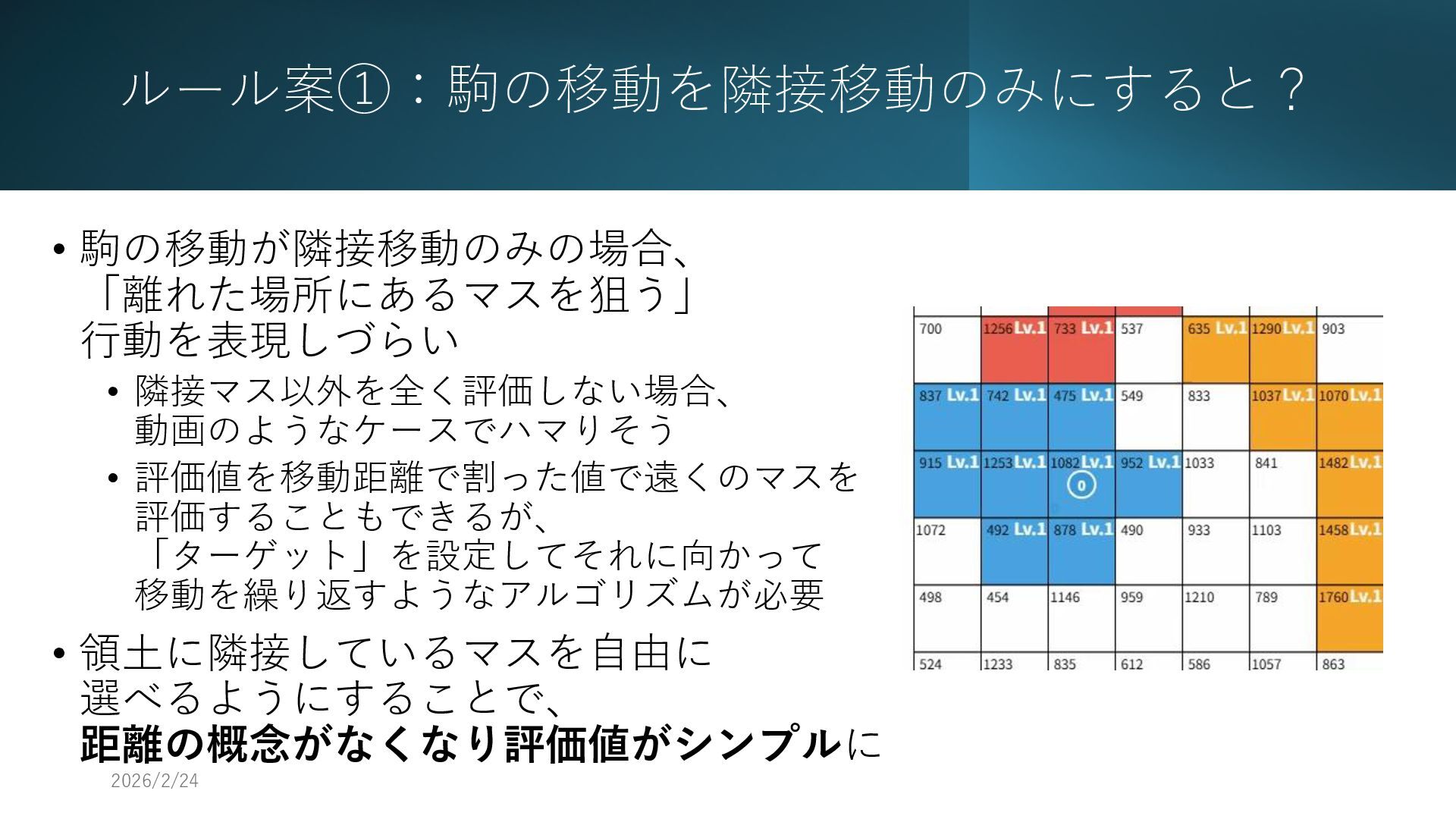
ルール案①:駒の移動を隣接移動のみにすると? • 駒の移動が隣接移動のみの場合、 「離れた場所にあるマスを狙う」 行動を表現しづらい • 隣接マス以外を全く評価しない場合、 動画のようなケースでハマりそう • 評価値を移動距離で割った値で遠くのマスを
評価することもできるが、 「ターゲット」を設定してそれに向かって 移動を繰り返すようなアルゴリズムが必要 • 領土に隣接しているマスを自由に 選べるようにすることで、 距離の概念がなくなり評価値がシンプルに 2026/2/26
ルール案②:AIの行動にランダム要素が無いと… • 敵のAIが貪欲行動をしない 𝜀 = 0 場合、複数のAIがあるマスを獲ろうと 競合し続けてハマってしまう • 当初は温度付きsoftmaxによる
ランダム化を行っていたが、 温度の調整が難しく、 温度が低いと同様のハマり方をした • 最終的にはε-greedyとすると ゲームとして安定した • 原案からの(大きな)変更点はここだけ 2026/2/26
ルール案③:駒の競合・回収処理が無いと? • 複数の駒が同じマスに存在すると、ビジュアライズが難しい • 「駒が必ず領土上にいる」「駒のいるマスは攻撃対象に選べない」 のルールがないと、敵の領土を全滅できてしまったりする • 結果的に今の競合・回収処理になった • ルール的には若干分かりにくかったかも
2026/2/26 0 1 2 ビジュアライズ できない… 0 1 敵領土全滅 できてしまう
その他の工夫 • 「スコア最大AIに対する比率のlog」というスコア関数の工夫 • 当初は自スコア+順位ボーナスなどの案もあったが、この形にすることで「対 戦ゲーム感」を維持しつつもスコアとしてきれいな形になった • マスの種類に応じて評価値の重みを変えることでAIの個性を表現 • Vの生成方法を複雑めにした
• 山が生成されることでAIがそこに集まりやすくなり、 山を狙うか避けるかの戦略性が生まれる 2026/2/26
反省点 • スコアのブレが大きすぎた • 暫定テスト→システムテストの順位変動は今までで一番大きかった • モンテカルロ法が強すぎた • 上位が(1位を除き)ほぼモンテカルロ法で、解法バリエーションは少なかった •
AIの行動決定方法を公開する都合上、モンテカルロ法の精度が非常に高くなる • 生成AIが強すぎた • AIからすると高度な焼きなましやビームサーチが必要とな問題に比べて取り組みやすく、 例えば『パラメータ推定+モンテカルロ法を実装し改善して』といった ゆるふわ指示でもまあまあ高いスコアが出てしまう • 強化学習が優勝した • 強化学習はマシンリソースが必要であり不平等であるという意見 • AHCの歴史上1回くらいそういう回があってもいいよね、というお気持ちで あえて強化学習有利な問題にした(ので反省していません) 2026/2/26
評価値による貪欲法の改善 2026/2/26 13
評価値による貪欲法 • AIと同様、各移動候補について 何らかの行動評価値を計算し、 評価値が最大の行動を選ぶことにする • CodinGameのゲーム系コンペの中には、 これを極めるだけでLegendに行けることも • ゲームの性質を考えながら、評価値の
計算方法を改善していくことにする 2026/2/26 14
Step1:AIと同じアルゴリズム 2026/2/26 15 • サンプルプログラム • Step1: AIと同じアルゴリズム • パラメータは良さそうなものを探索
• 𝑤𝑎 = 1.0, 𝑤𝑏 = 1.0, 𝑤𝑐 = 0.4, 𝑤𝑑 = 0.2 31.2G 833位 904perf 38.4G 722位 1088perf
Step2~4: 評価値の改善 2026/2/26 16 • Step2: スコア最大AIへの攻撃にボーナ ス • スコア最大のAIへの攻撃の場合、
• 𝑤𝑐 = 3.0, 𝑤𝑑 = 0.8 • Step3: 外側のマスほどボーナス • 外側のマスほど攻撃されにくい • 中央からの距離×100を評価値に加算 • Step4: 前ターンと同じマスの競合回避 • 前のターンにあるマスを選んで敵AIと 競合した場合、そのマスを選ばない 42.8G 614位 1218perf 44.8G 556位 1289perf 46.1G 519位 1336perf
Step5: 敵AIにマスが選ばれる確率を求めて評価値補正 2026/2/26 17 • Step5: 敵AIにマスが選ばれる確率を求めて 評価値補正 • 敵AIのパラメータを固定し、各マスで
「最低1人の敵AIに選ばれる確率𝑝」を計算 • 𝑤𝑎 = 1.0, 𝑤𝑏 = 1.0, 𝑤𝑐 = 1.0, 𝑤𝑑 = 1.0, ε = 0.7 • 𝜀が高めなのは、パラメータ推定していないゆえに 敵の貪欲行動先があまり信頼できないため • 自陣の場合は評価値に1 − 𝑝、それ以外の場合は 𝑝を掛けて補正 47.8G 460位 1412perf
Step6: M=2に特化した評価 2026/2/26 18 • M=2の場合は相手の攻撃と自陣の防御 を効率よく行い、相手の領土を 一方的に減らす • ゲーム開始直後は最速で敵に接近
• その後は攻撃と防御を使い分ける 52.2G 346位 1574perf
Step7: U=1に特化した評価 2026/2/26 19 • U=1では領土がすぐに飽和して めまぐるしく変化し、Vに山が ある場合はそこに敵AIが集中する • 敵AIに狙われやすい高Vの山を避け、
あえて低Vを埋める 53.5G 319位 1616perf
評価値貪欲の限界 2026/2/26 20 • 今回の問題は、複数人がランダム行動を含む同時行動をし、それに 応じて盤面が予測不可能に変化していくため、ゲームとして複雑 • 人間が設計する評価値だけだと、どうしてもスコアに限界がある • ここから大きく2つの方針が考えられる
1. モンテカルロ法:シミュレーションの結果を利用して評価 2. 強化学習:人間には困難な複雑な評価値をニューラルネットワー クにより学習 • 以降は主にモンテカルロ法を解説し、強化学習は紹介程度とします
モンテカルロ法の改善 2026/2/26 21
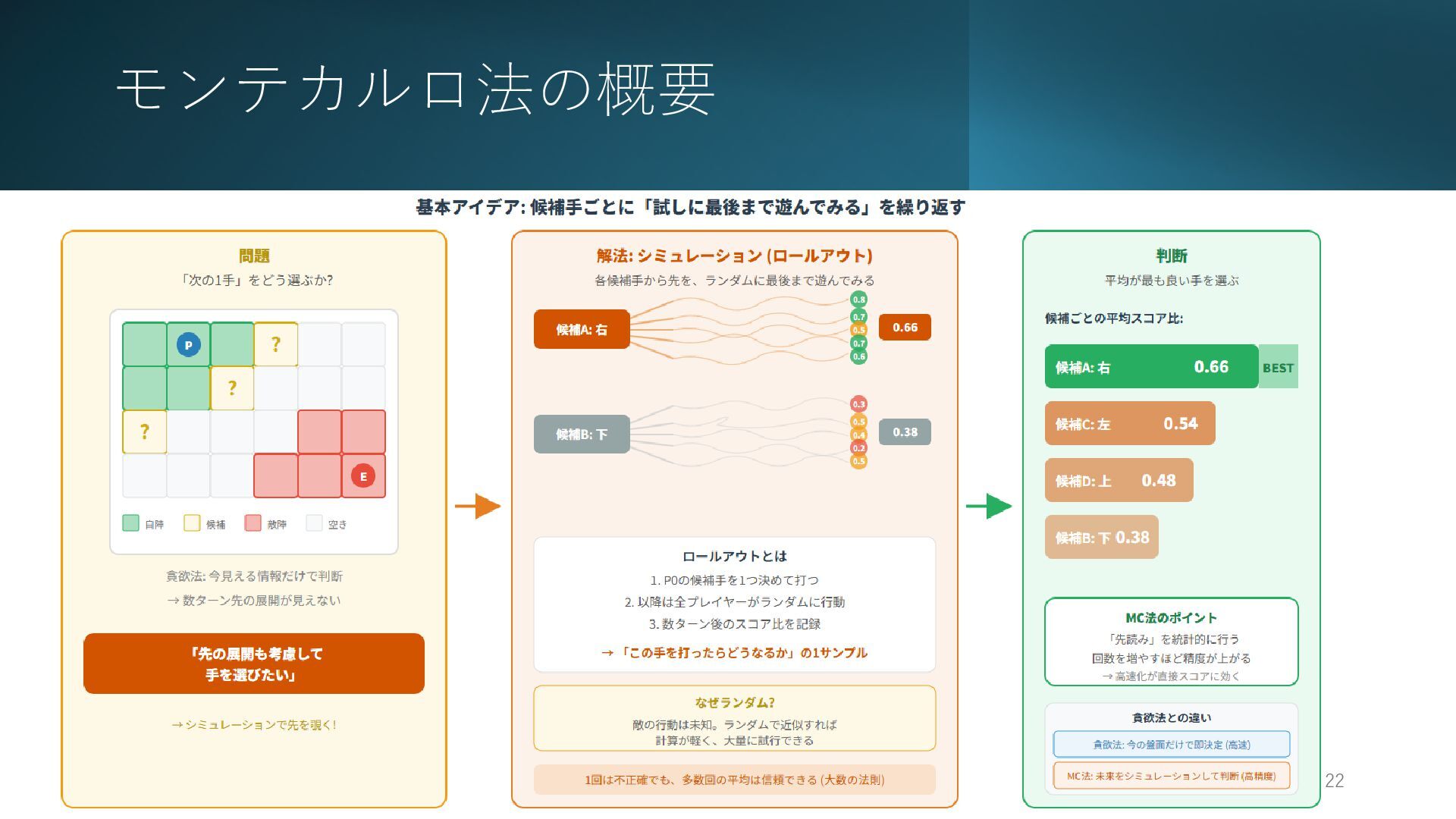
モンテカルロ法の概要 2026/2/26 22
Step8: 敵も自分も完全ランダム行動 2026/2/26 23 • 評価値を一切使わず、敵も自分も候補から ランダムに動くとしてプレイアウトを行う • 各ターン18ms使用して均等に候補を試す •
たったこれだけでも工夫した貪欲と同程度 のスコアが出る 50.7G 376位 1529perf
Step9~11: モンテカルロ法の改善 2026/2/26 24 • Step9: 選択候補から以下を除外する • レベル上限に達した自陣 •
スコア最大でないAIのレベル2以上の敵陣 • Step10:敵の行動方法をε-greedyにする • Step5同様パラメータ推定はせず、以下を使用 𝑤𝑎 = 1.0, 𝑤𝑏 = 1.0, 𝑤𝑐 = 1.0, 𝑤𝑑 = 1.0, ε = 0.8 • Step11:自分の行動方法を評価値貪欲(Step7) に • 自分の行動にもランダム行動確率𝜀 = 0.8を 入れる方が良い • スコアはあまり変わらず (自分の行動はランダムでもあまり問題ない?) 53.0G 327位 1603perf 55.5G 279位 1682perf 55.3G 280位 1680perf
Step12: 粒子フィルタによる敵パラメータ推定 2026/2/26 25 • 粒子フィルタでパラメータ推定を行い、 プレイアウト中の敵の行動や自分の行動 (敵のマスの選択確率の計算)に使用する • 粒子フィルタ以外の推定方法でも
推定精度やスコアに大きな違いは無かった • グリッドベイズ、MCMCなど • そもそもパラメータの推定精度が そこまでスコアに寄与しない? 58.7G 227位 1778perf
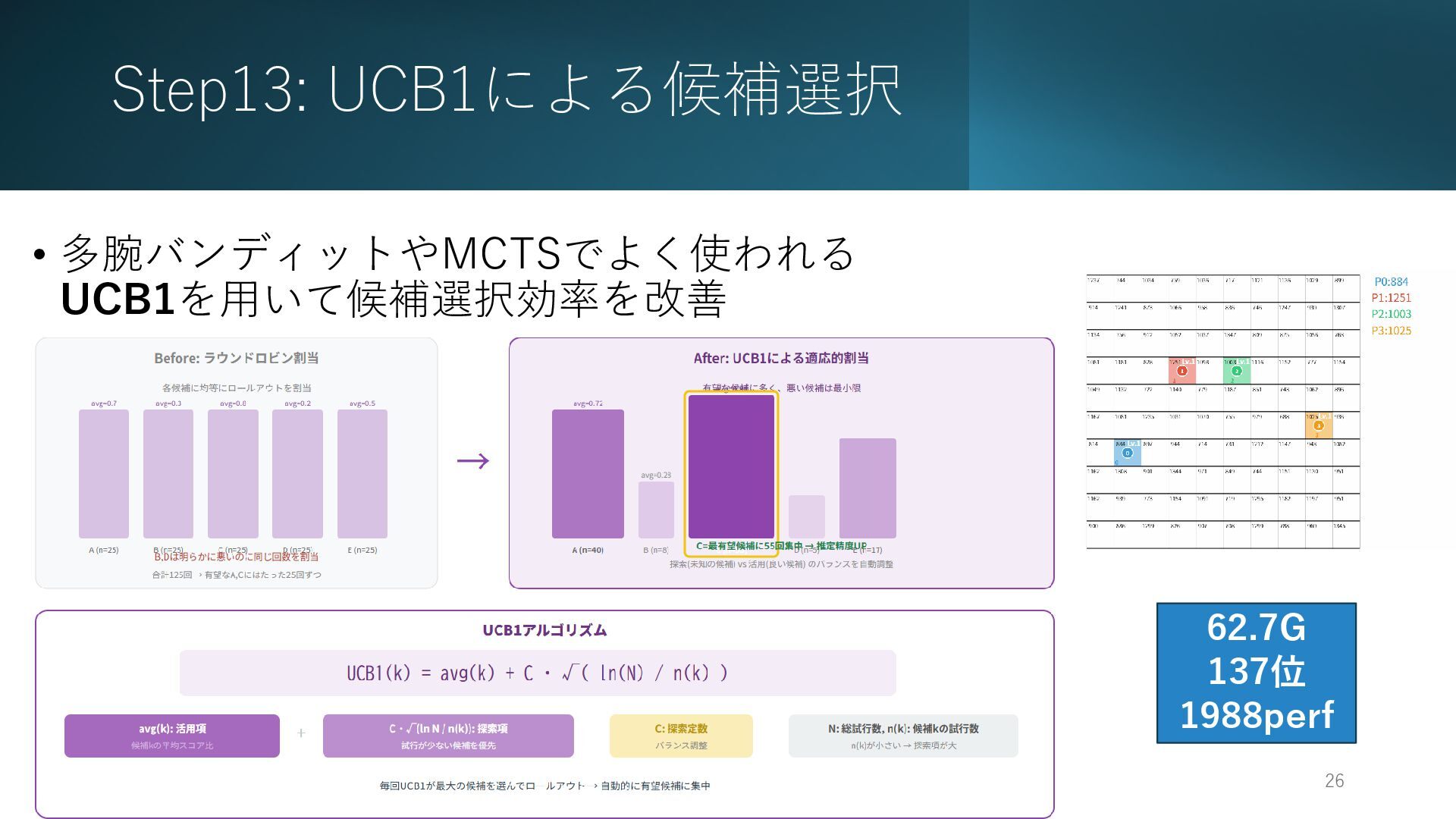
Step13: UCB1による候補選択 2026/2/26 26 • 多腕バンディットやMCTSでよく使われる UCB1を用いて候補選択効率を改善 62.7G 137位 1988perf
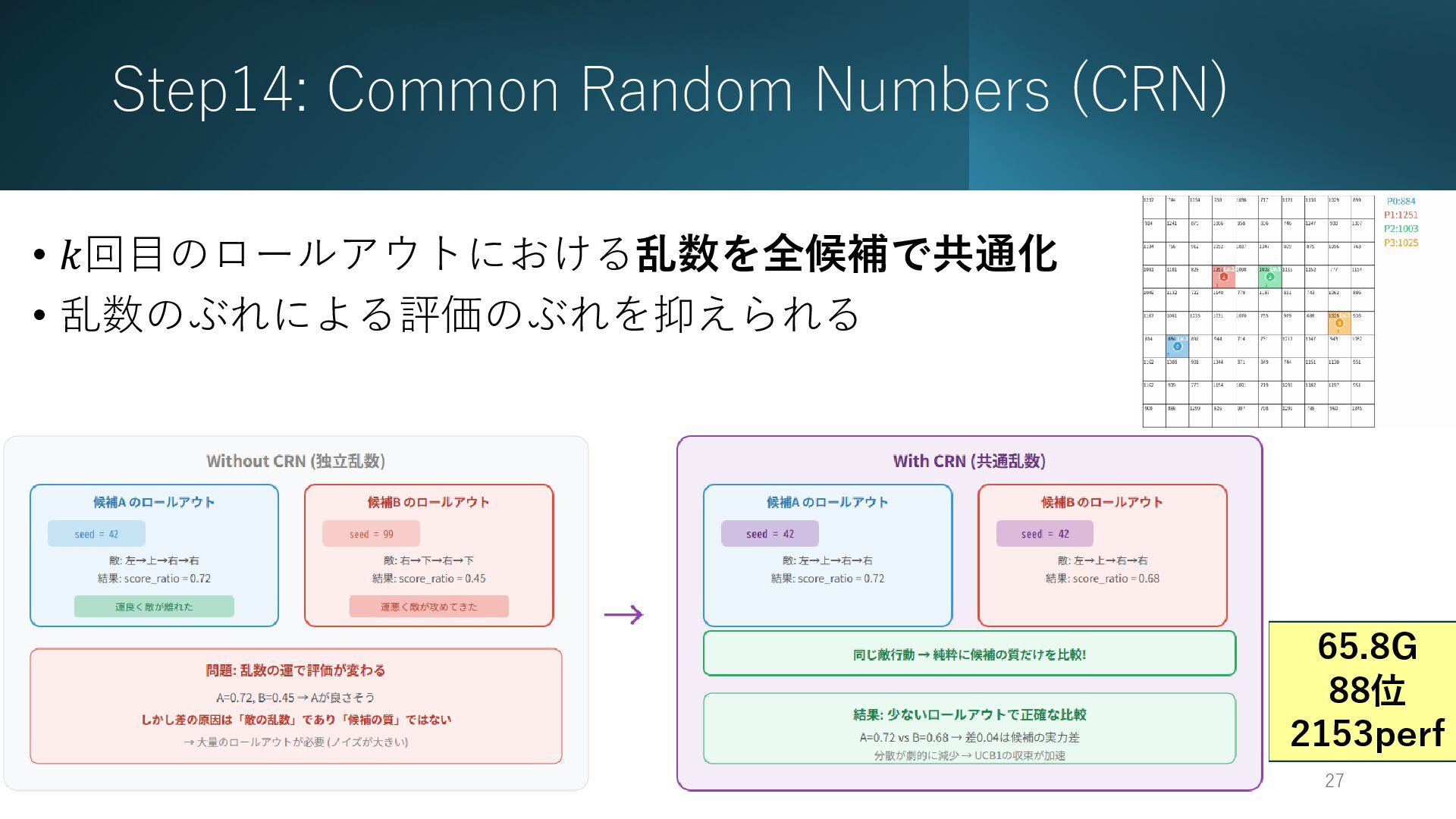
Step14: Common Random Numbers (CRN) 2026/2/26 27 • 𝑘回目のロールアウトにおける乱数を全候補で共通化 •
乱数のぶれによる評価のぶれを抑えられる 65.8G 88位 2153perf
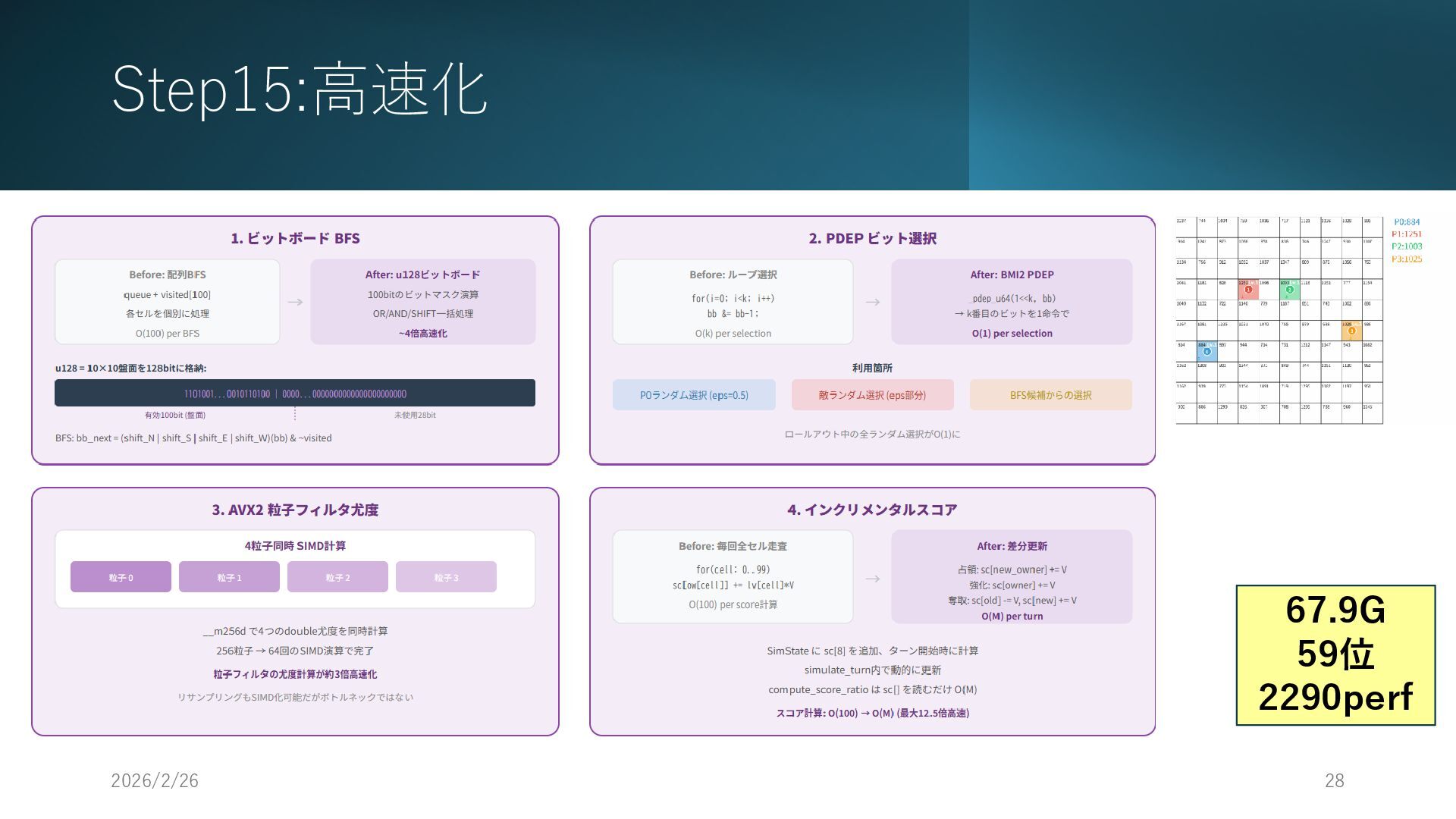
Step15:高速化 2026/2/26 28 • 外側のマスほど攻撃されにくいため 67.9G 59位 2290perf
Step16:M×Uごとにチューニング 2026/2/26 29 • M(2~8)とU(1~5)の35通りで個別に Optunaでパラメータチューニング • 3000seed/150iter 半日くらい •
MやUを区別せずにチューニングするよりも 大幅にスコア向上 70.6G 30位 2500perf
強化学習について 2026/2/26 30
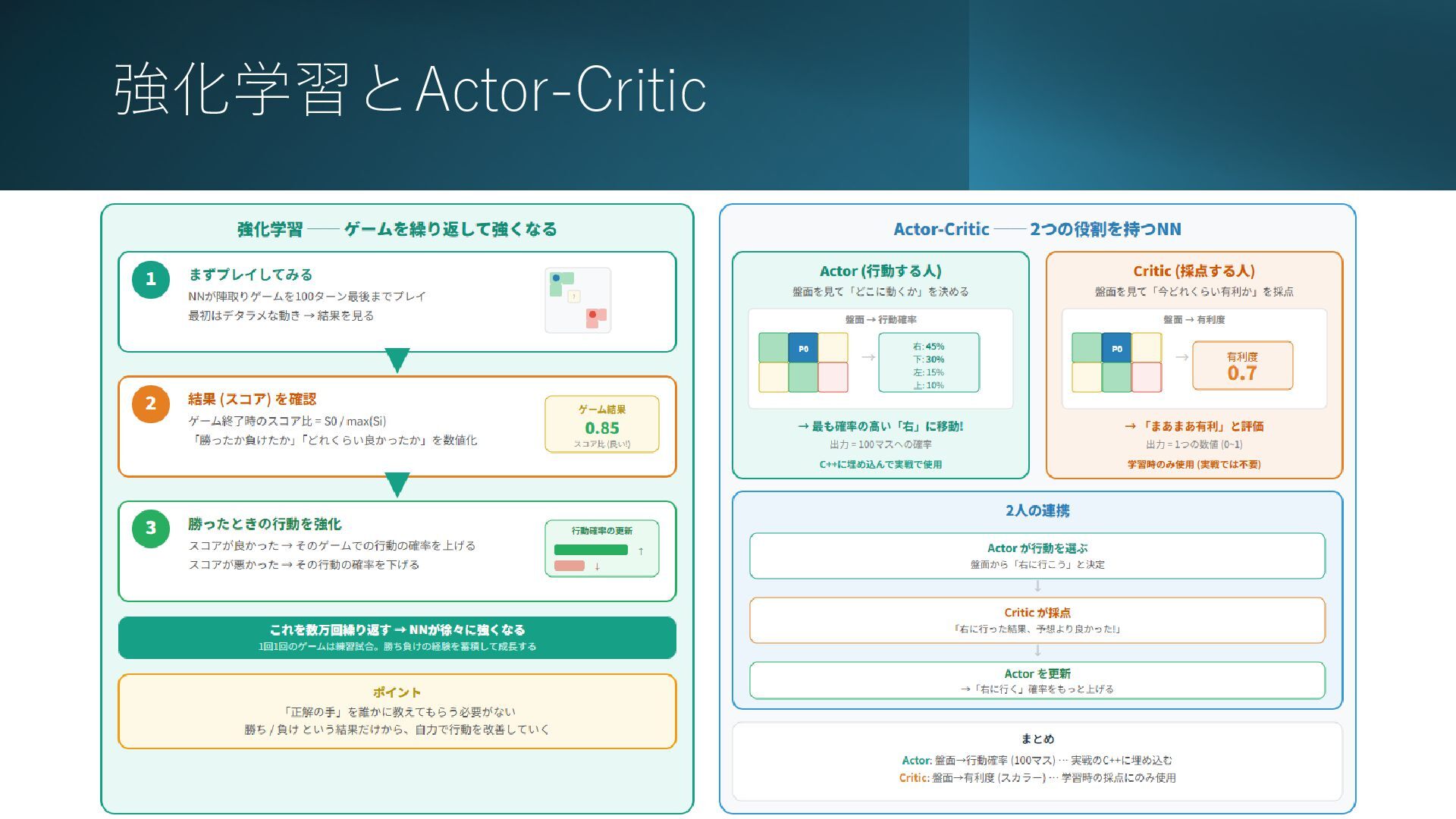
強化学習とActor-Critic 2026/2/26 31
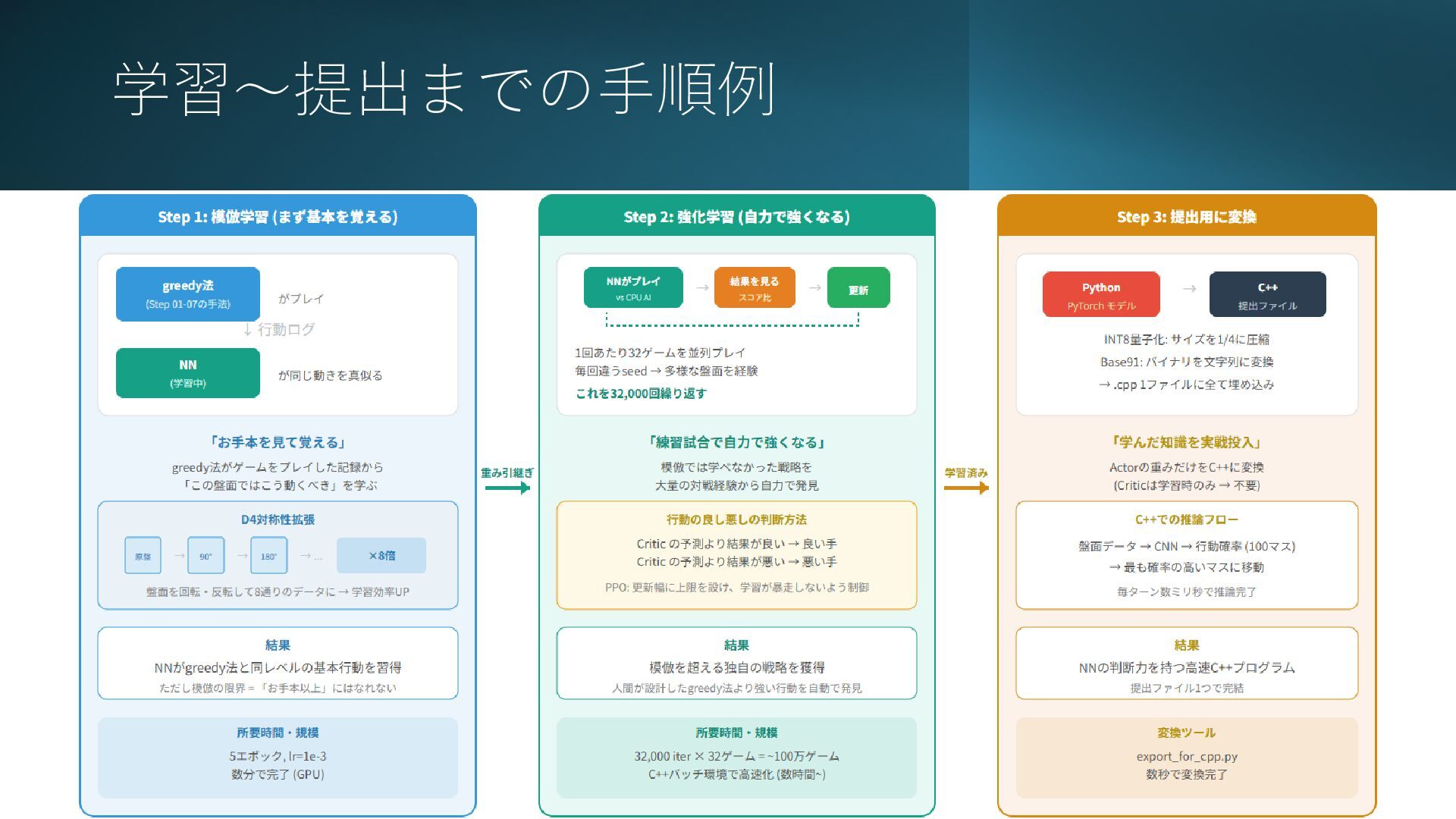
学習~提出までの手順例 2026/2/26 32
強化学習による提出コード 2026/2/26 33 • 50ch/5層CNN(skip connection)の シンプルな提出コード • 学習から提出まで全てのコードをAI生成 •
平均18万点→平均22万点程度まで 強化学習により改善できた • N×Nの方策確率から(移動可能なマスの中 で)最大のものを選択し続ける • 強化学習を始めて2~3日程度でのスコア • 私の学習ではここからなかなか伸ばせなかった 67.9G 59位 2290perf
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}