Conception d’un outil d’anonymisation (locale) des données d’utilisateurs de plateformes numériques afin de leur permettre de contribuer des informations sectorielles aux administrations
de certaines plateformes numériques. => Idée : inviter les utilisateurs à utiliser les possibilités de l’article 20 du RGPD pour demander leurs données personnelles et les contribuer à des administrations. • Ces données sont éminemment personnelles (risques pour les contributeurs, RGPD, etc), tandis que les administrations ne cherchent qu’un panorama sectoriel. => Idée : anonymiser localement (au sein de l’appareil de l’utilisateur, avant tout envoi) les données personnelles pour que les serveurs les recevant ne voient que des données largement censurées. • Secteur d’expérimentation ? VTC / livreurs à vélo : indicateurs publiés (LOM) / sécurité juridique de la portabilité (LOM) / secteurs organisés (associations représentatives et syndicats) / besoin de données pour aborder le sujet.
ne cherche pas à anonymiser une base de données complète pour en extraire des statistiques / la publier (= visibilité sur l’intégralité des données dans le processus d’anonymisation) • Ici, anonymisation localement (au sein de l’enclave de l’appareil de l’utilisateur) => visibilité sur l’intégralité des données de l’utilisateur mais uniquement sur des statistiques anonymisées sur le reste de la base • Construire ce processus d’anonymisation est un challenge => revue des solutions techniques publiées par le PEReN.
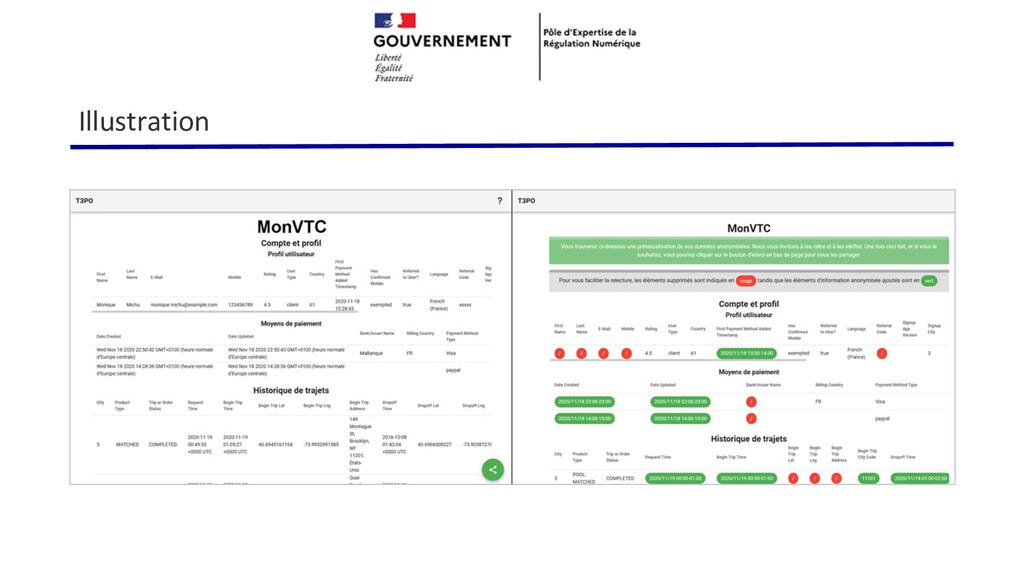
• L’utilisateur arrive sur l’outil et suit la démarche pour demander la portabilité de ses données. • Une fois ses données récupérées, il revient sur l’outil pour les visualiser. Il peut en partager un extrait anonymisé s’il le souhaite. • Interaction unique avec l’utilisateur : au moment de l’envoi de ses données. Contacts réguliers ou actions régulières de sa part non requises. • Modèle d’attaque : • Attaquant récupère le jeu de données (fuite) ou les KPIs • Protection contre ces attaques (anonymat suffisant pour éviter les risques RGPD ou représailles contre les travailleurs)
Inadapté (mémoire utilisateur persistante ou tiers de confiance) • Secure Multi-Party Computation • Complexe en asynchrone distribué • TOR et VPN • Ne protège pas grand chose dans notre modèle d’attaque • Obfuscations diverses • Garanties souvent complexes à mesurer • Private Information Retrieval • « Symétrique » de notre problème • Zero Knowledge Proof • Intéressant si on pense que ça peut nous aider (notamment si tiers parti capable de les vérifier) • Trusted Execution Environment • Besoin de matériel récent, modèle de confiance difficile à vulgariser, mais intéressant sur le fond • Chiffrement homomorphe • Beaucoup plus simple avec des interactions
en trois champs : • identifiantes (nom/prénom), elles sont supprimées • quasi-identifiantes (date de naissance/lieu de naissance), elles sont « élargies » pour avoir toujours au moins k individus identiques • sensibles (diagnostic médical), elles sont maintenues en clair, mais supposées non-rattachables aux individus Dans notre cas : aucune donnée « sensible » (selon cette définition), on ne veut rien garder en clair.
d’un individu (Bob) ou une valeur indistinguable : • Proba(Algo(Données) = X) < exp(Ɛ) × Proba(Algo(Données sans Bob) = X) • Algo probabiliste : ajout d’un bruit aléatoire • Paramètre Ɛ : proche de 0 = plus de sécurité, mais plus de bruit • Garanties formelles fortes Jaune : avec Bob Bleu : sans Bob Abscisse : valeur réelle (e.g. nombre de trajets, etc. ) Ordonnée : distribution de Algo(Données) (e.g. pourcentage de…)
: besoin d’un certain nombre de clés avant de pouvoir déchiffrer • Travailleur : chiffre ses données, envoie les chiffrés • Travailleur (facultatif, avec des conditions à définir) : envoie une clé • PEReN : attend de recevoir k clés pour pouvoir déchiffrer les envois • Le déchiffrement n’est possible que pour les messages concernés par la clé Note : si besoin, possible avec du chiffrement homomorphe.
Base de réflexion : STAR: Distributed Secret Sharing for Private Threshold Aggregation Reporting • Travailleur : envoie ses valeurs chiffrées, et des clés (chiffrement par seuil) pour celles-ci • Besoin d’un tiers indépendant pour fournir de l’aléatoire (ne manipulera aucune donnée) • Lorsqu’on a au moins k valeurs identiques, on peut déchiffrer • k-anonyme par construction Choix des valeurs chiffrées : • Trajets ? (attention, k = nb individus ayant fait le trajet ≠ nb trajets effectués) • Nombre de trajets ? • Période temporelle ? • Est-ce sa source principale de revenus ? • Comparaison avec les indicateurs publiés par la LOM : Décret n°2021-501 du 22 avril 2021 relatif aux indicateurs d’activité des travailleurs ayant recours à des plateformes de mise en relation par voie électronique
mises à jour (résolu) • Éviter que ré-envoyer ses données par inadvertance ne déchiffre illégitimement • Division par échelle (en cours de résolution) • Envoi de plusieurs versions à différentes échelles, pour raffiner l’information à mesure des réponses. Exemple : Déverrouillages successifs du code postal, du quartier, de la rue. • Ajout de complexité au protocole pour conserver les garanties de k-anonymat • Ajout de méta-données differentially private (revue par les pairs souhaitée) • Techniquement possible (prévu dans STAR) • Déchiffrés en même temps que le reste, mais pas forcément identiques • Exemples : tarif de la course, nombre de trajets effectués, etc. • Garanties complexes à quantifier, problèmes possibles
parti indépendant ? (Administration ? Organisation syndicale ? Autre ?) • Contraintes faibles mais non-nulles : héberger une partie du socle logiciel pour émettre des clés par exemple. • En cas de tiers parti plus puissant (vérifiant des ZKP) : meilleurs protocoles possibles. • Quantification de la robustesse aux adversarial attacks (de la part de la plateforme par exemple) • Pour biaiser nos calculs • Pour nous forcer à déchiffrer des infos sensibles (même si on ne diffuse pas) • Quantification du risque pour les données des clients • On protège les travailleurs, mais quid de la réidentification des clients ? • Intuitivement, problème marginal (éviter les échelles trop fines), mais à quantifier plus finement • Quantification précise des garanties formelles dans le schéma le plus abouti • Notamment si on mélange k-anonymat et differential privacy
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}