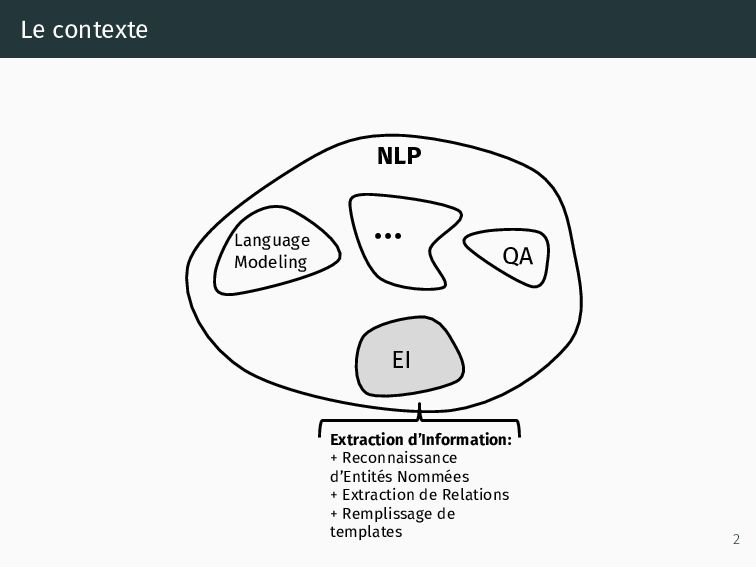
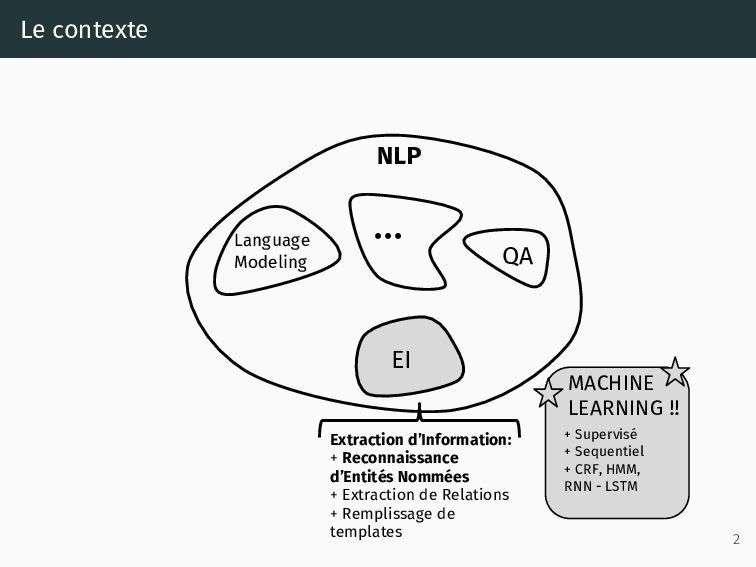
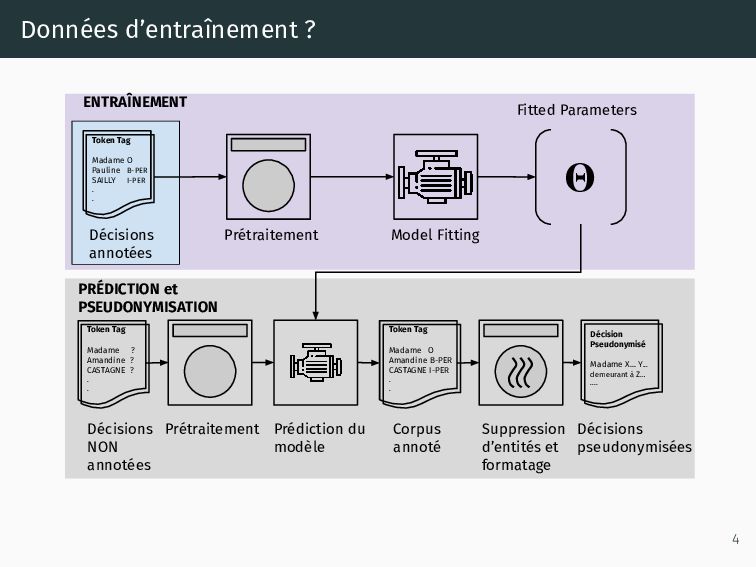
justice au grand public, • Pour y arriver, on doit supprimer les informations sensibles, • La solution existante fonctionne à base de règles (regex) et dictionnaires (noms/prénoms), • Une solution fondée sur le Traitement Automatique du Langage Naturel (TALN, ou NLP en anglais) pourrait fournir une solution plus flexible et performante. • Etalab accompagne le Conseil d’État avec une première approche de la pseudonymisation avec du NLP. 1
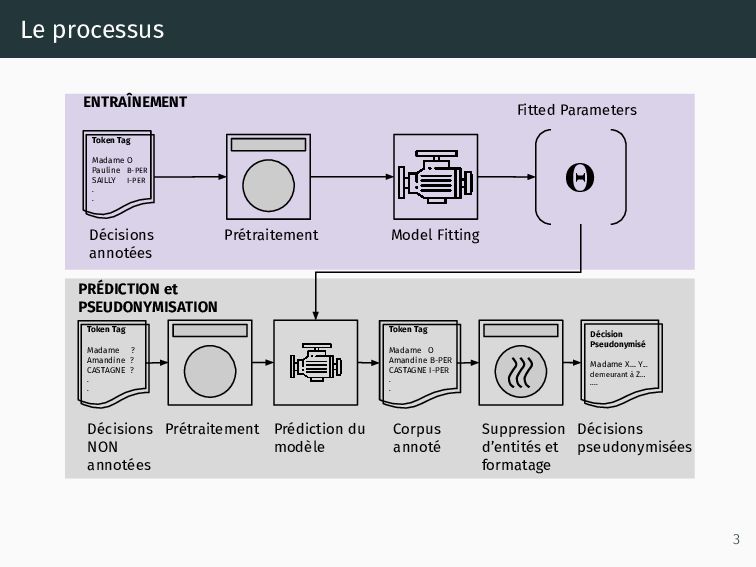
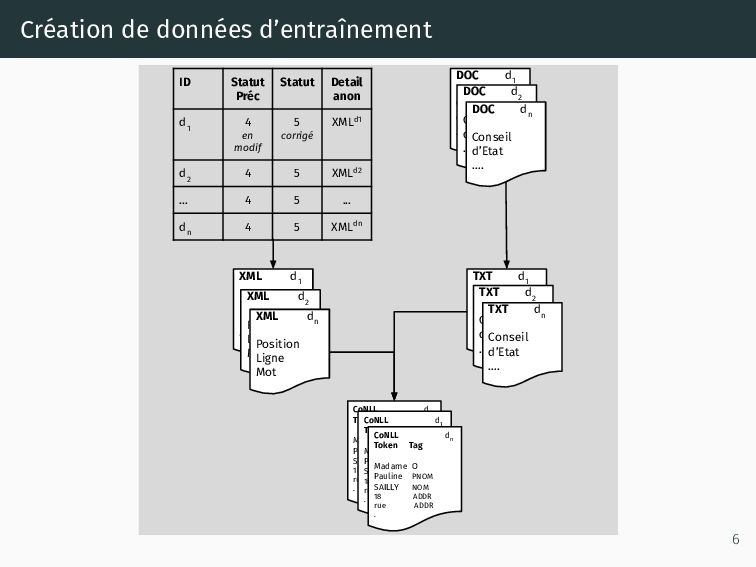
manuelles fournissent des ”annotations” indirectes, • Le système sauvegarde la localisation, le mot, et l’entité (nom/prénom/adresse) détectée (sous forme de XML), • Nous profitons de ces XMLs pour générer un corpus annoté à distance. 5
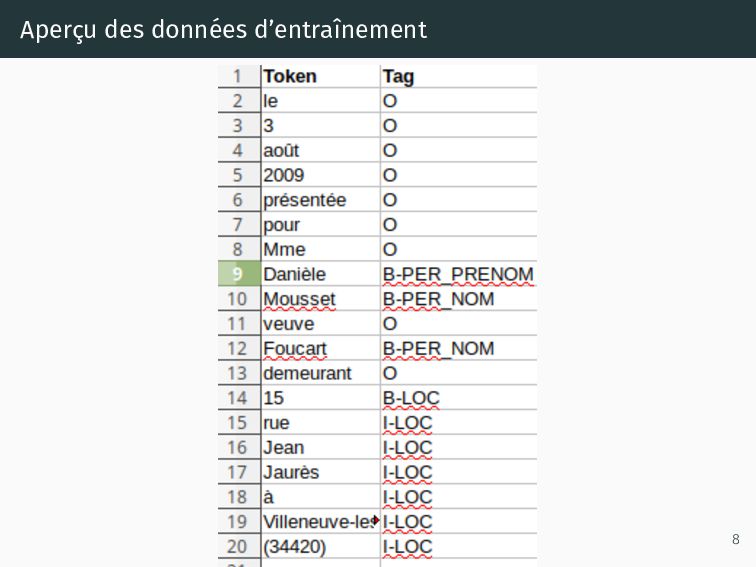
d 1 4 en modif 5 corrigé XMLd1 d 2 4 5 XMLd2 ... 4 5 ... d n 4 5 XMLdn XML d 1 Position Ligne Mot XML d 2 Position Ligne Mot XML d n Position Ligne Mot DOC d 1 Conseil d’Etat …. DOC d 2 Conseil d’Etat …. DOC d n Conseil d’Etat …. TXT d 1 Conseil d’Etat …. TXT d 2 Conseil d’Etat …. TXT d n Conseil d’Etat …. CoNLL d 1 Token Tag Madame O Pauline PNOM SAILLY NOM 18 ADDR rue ADDR . CoNLL d 1 Token Tag Madame O Pauline PNOM SAILLY NOM 18 ADDR rue ADDR . CoNLL d n Token Tag Madame O Pauline PNOM SAILLY NOM 18 ADDR rue ADDR . 6
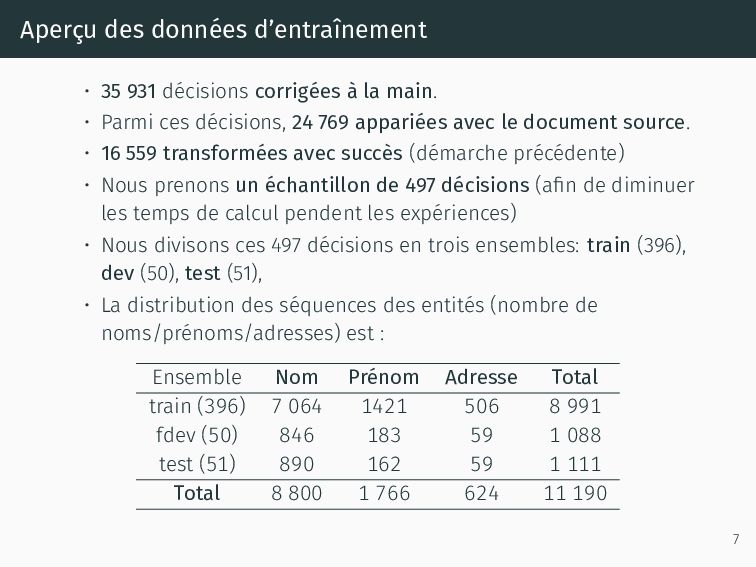
la main. • Parmi ces décisions, 24 769 appariées avec le document source. • 16 559 transformées avec succès (démarche précédente) • Nous prenons un échantillon de 497 décisions (afin de diminuer les temps de calcul pendent les expériences) • Nous divisons ces 497 décisions en trois ensembles: train (396), dev (50), test (51), • La distribution des séquences des entités (nombre de noms/prénoms/adresses) est : Ensemble Nom Prénom Adresse Total train (396) 7 064 1421 506 8 991 fdev (50) 846 183 59 1 088 test (51) 890 162 59 1 111 Total 8 800 1 766 624 11 190 7
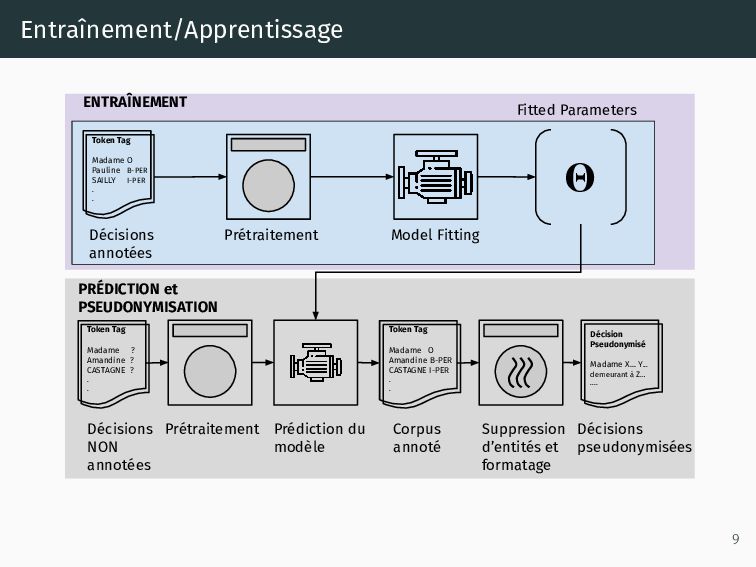
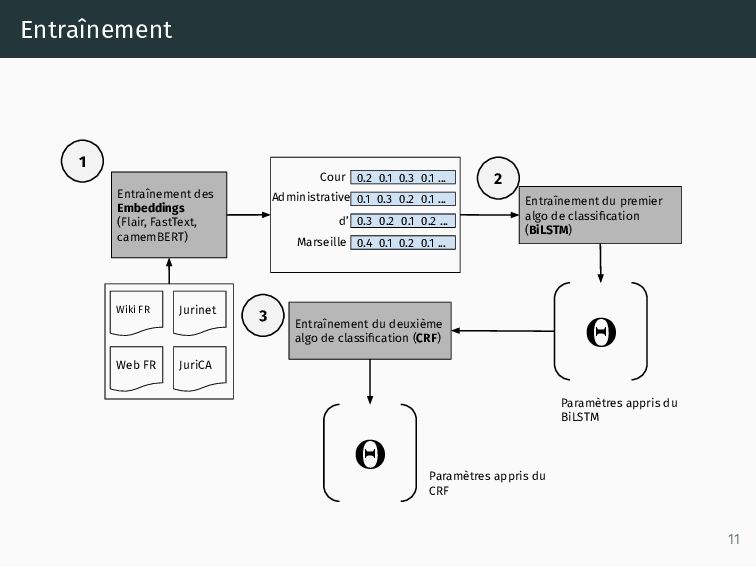
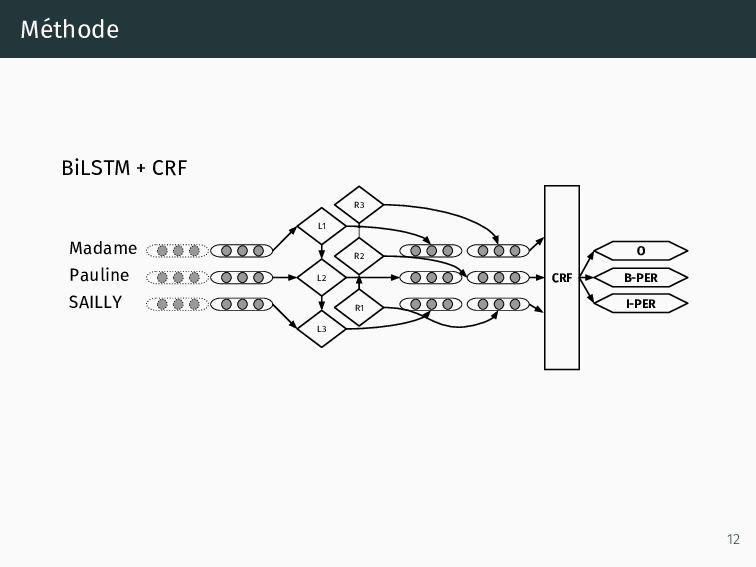
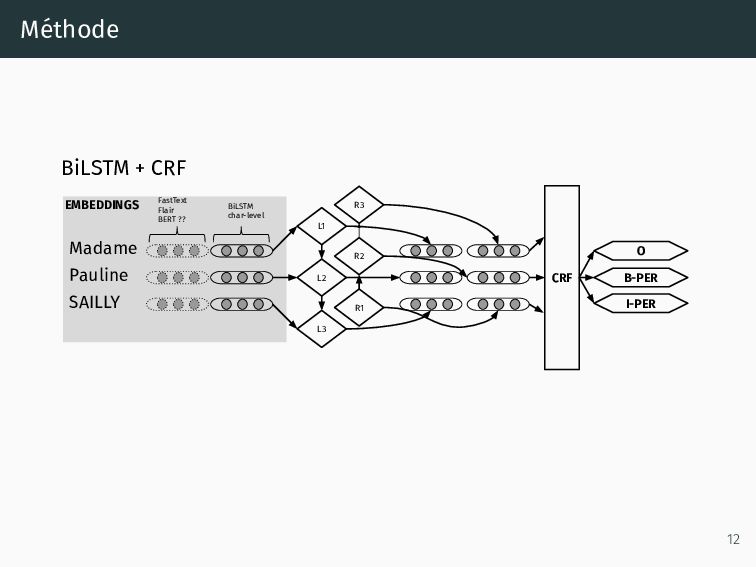
: obtenir des représentations performantes (une seule fois*), 2. Classifieur : obtenir les paramètres nécessaires pour prédire les labels (chaque expérience), 3. Classifieur séquentiel : deuxième algo pour prendre en compte les mots et prédictions précédentes et suivantes (chaque expérience). 10
1. Un ensemble de test que nous avons déjà créé précédemment, 2. Un ensemble de métriques (si on prends les noms comme exemple) : • Précision : taux des noms correctement identifiés comme un nom parmi tous les noms identifiés par le modèle, • Rappel : taux de noms correctement identifiés comme un nom parmi tous les vrais noms dans l’ensemble de test, • F-score : moyenne harmonique de la précision et du rappel. • Taux d’erreur : nombre de décisions avec une erreur sur n décisions (à creuser). 14
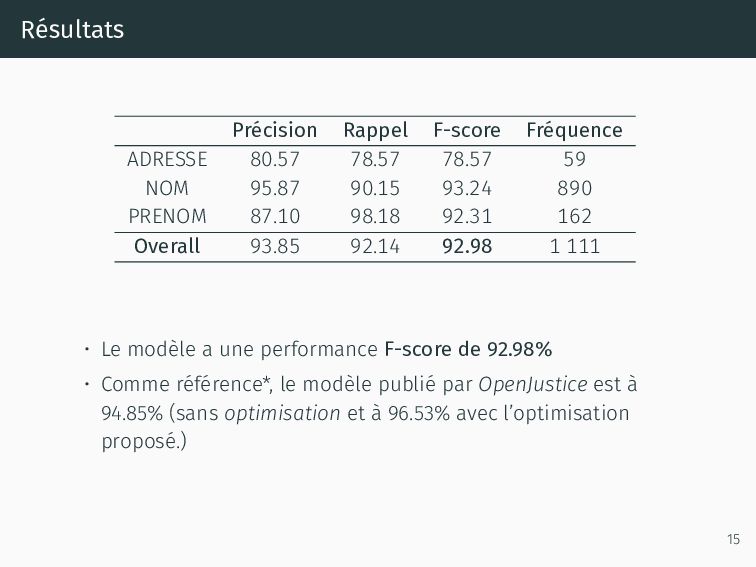
NOM 95.87 90.15 93.24 890 PRENOM 87.10 98.18 92.31 162 Overall 93.85 92.14 92.98 1 111 • Le modèle a une performance F-score de 92.98% • Comme référence*, le modèle publié par OpenJustice est à 94.85% (sans optimisation et à 96.53% avec l’optimisation proposé.) 15
ajoutons du bruit au modèle car il y a des informations incomplètes dans la base de données fournie), 2. Nous testons avec un échantillon assez réduit. Élargir l’échantillon devra permettre d’améliorer les résultats, 3. Réaliser plus d’expériences avec les embeddings disponibles (soit entraînés par nous mêmes, soit ceux crées par OpenJustice ou autres). 4. Définir la performance de la solution actuelle (à base de règles) et puis sélectionner une échantillon pour calculer le taux d’erreur. 17
v1.0 et tout l’outillage pour le générer à partir de vos données, 2. La v1.0 du code pour générer un modèle type à partir ces données, 3. Un modèle Flair qui tourne sur CentOS 7. • À venir : 1. Version 2.0 avec des données mieux intégrées (et comprises) avec une alignement parfait entre XMLs et TXTs, 2. Code v2.0 avec les expériences en utilisant des autres embeddings, 3. Le modèle et le code installables de manière facile sous un autre système CentOS sous forme d’API. 18
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}