ExcelR offers Data Science course, the most comprehensive Data Science course in the market, covering the complete Data Science lifecycle concepts from Data Collection, Data Extraction, Data Cleansing, Data Exploration, Data Transformation, Feature Engineering, Data Integration, Data Mining, building Prediction models, Data Visualization and deploying the solution to the customer. Skills and tools ranging from Statistical Analysis, Text Mining, Regression Modelling, Hypothesis Testing, Predictive Analytics, Machine Learning, Deep Learning, Neural Networks, Natural Language Processing, Predictive Modelling, R Studio, Tableau, Spark, Hadoop, programming languages like R programming, Python are covered extensively as part of this Data Science training. ExcelR is considered as the best Data Science training institute which offers services from training to placement as part of the Data Science training program with over 400+ participants placed in various multinational companies including E&Y, Panasonic, Accenture, VMWare, Infosys, IBM, etc. ExcelR imparts the best Data Science training and considered to be the best in the industry.
{kind=link}
{kind=link}
{kind=link}
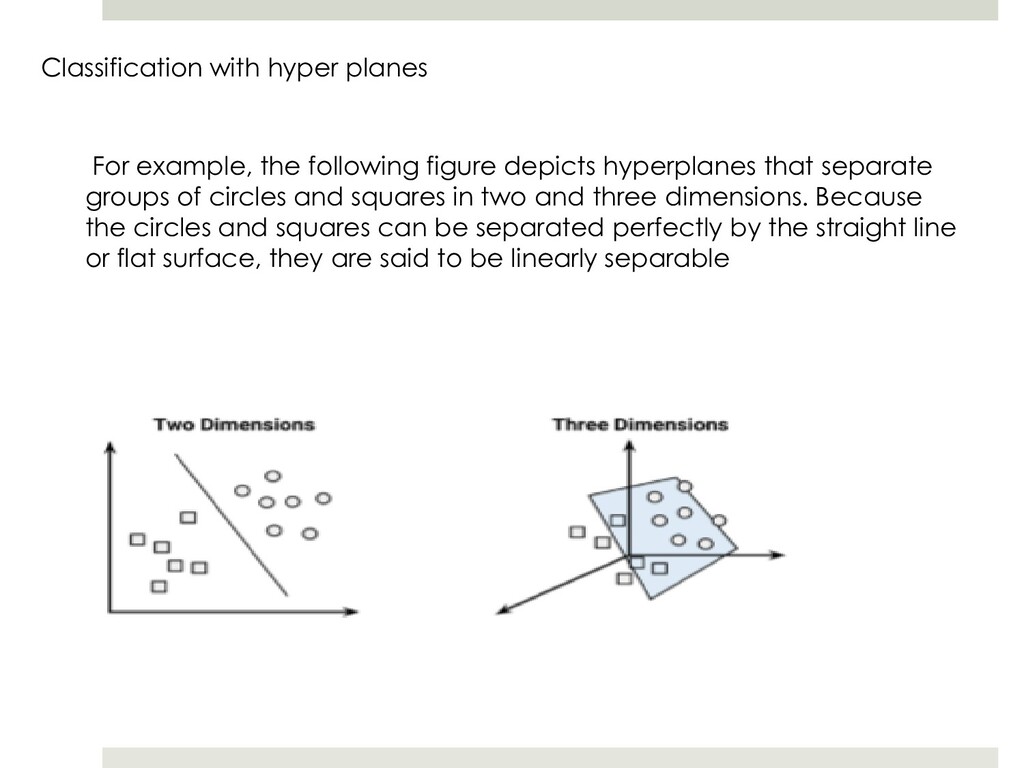{kind=link}
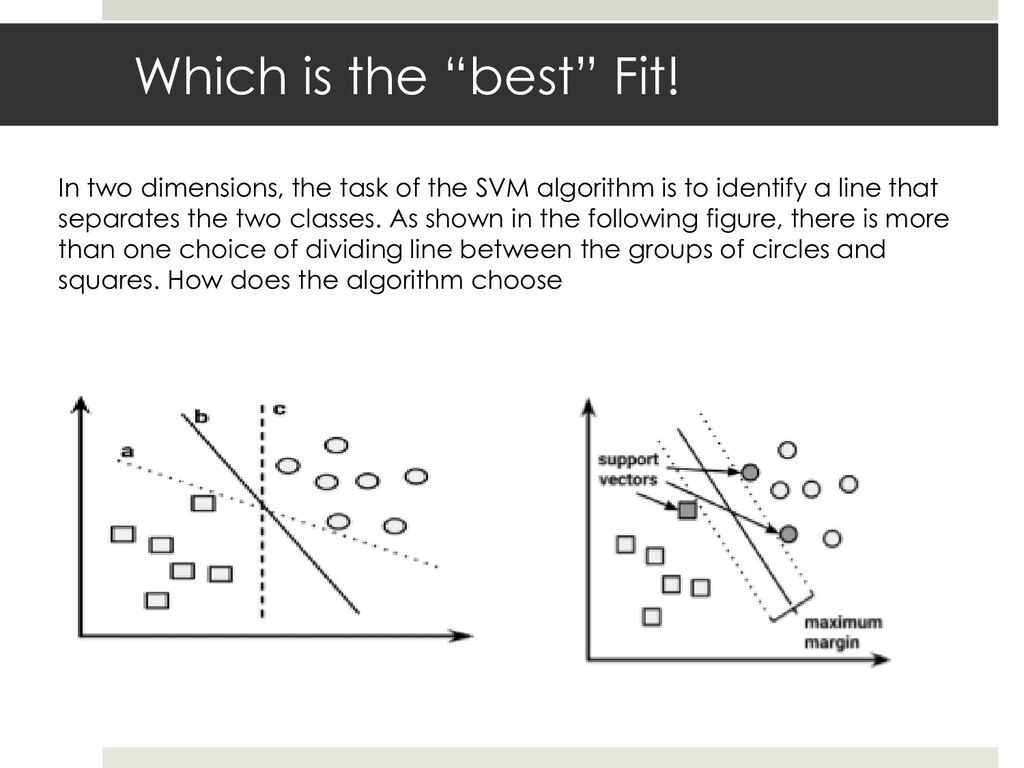{kind=link}
{kind=link}
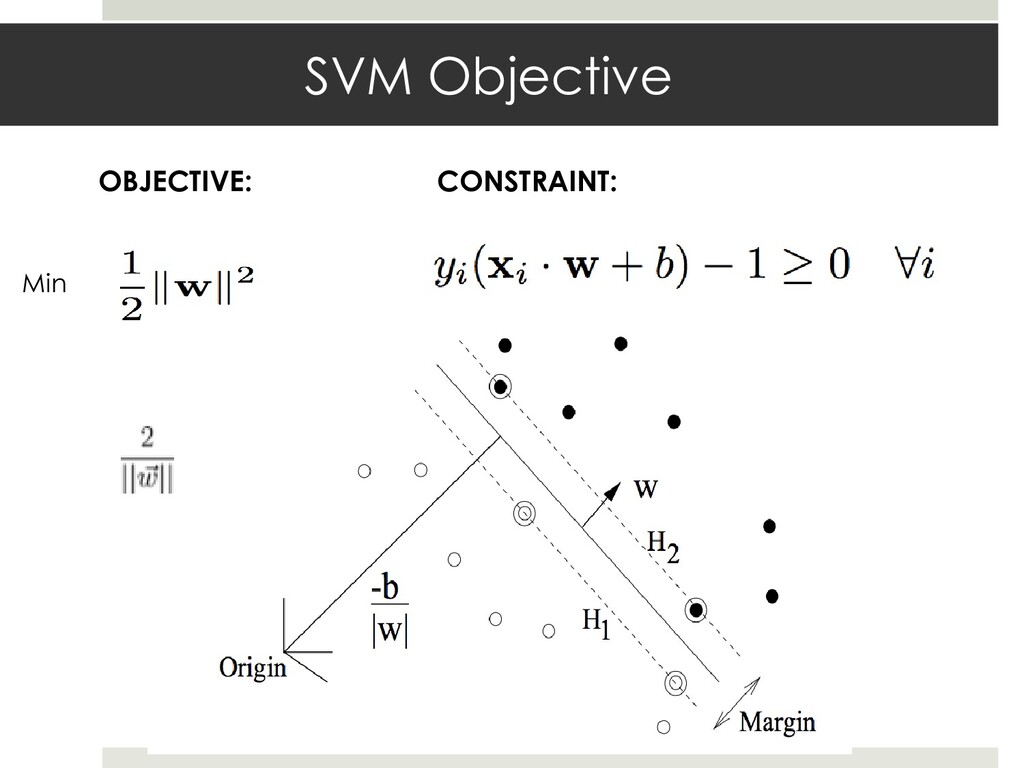{kind=link}
{kind=link}
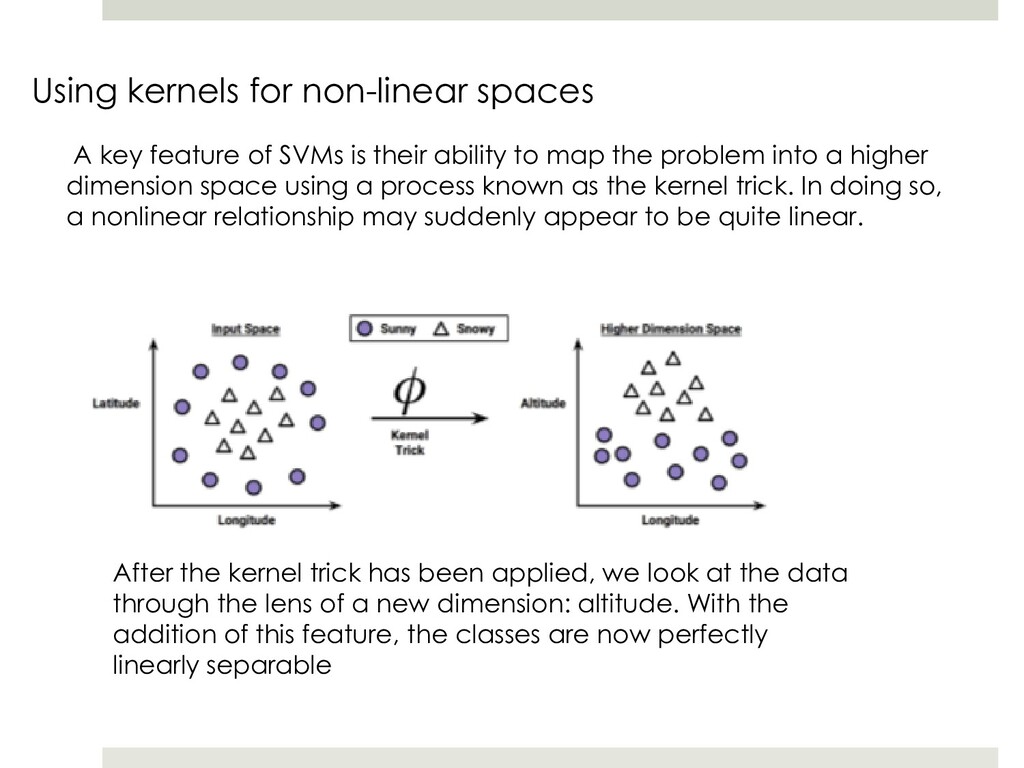{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}