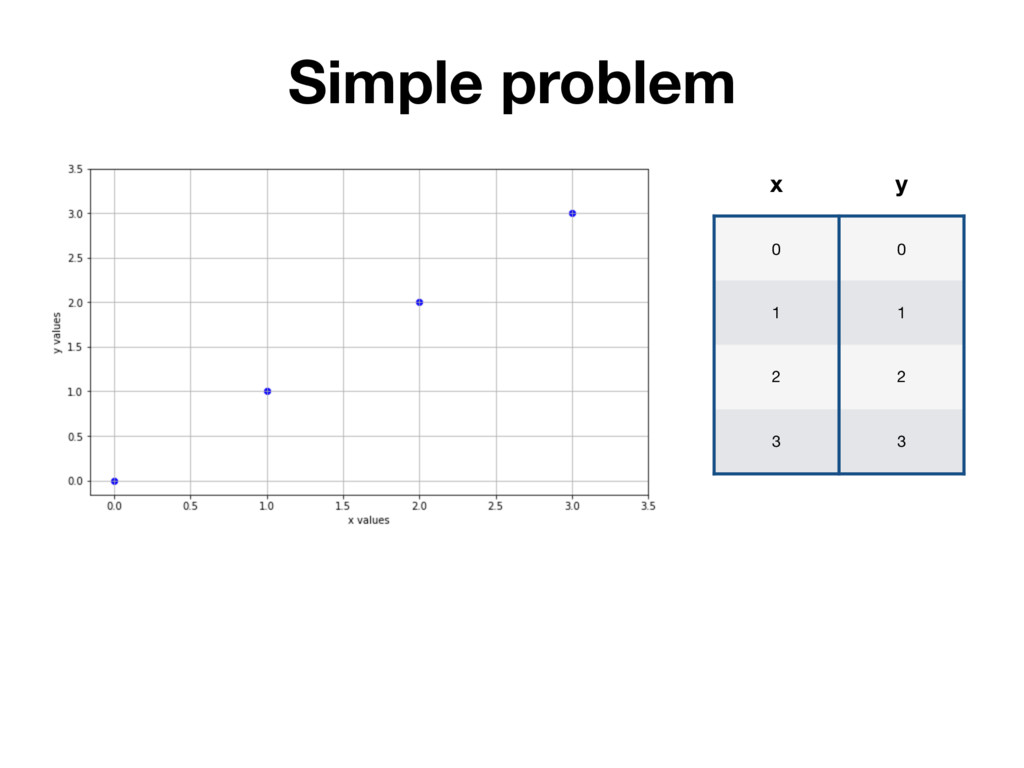
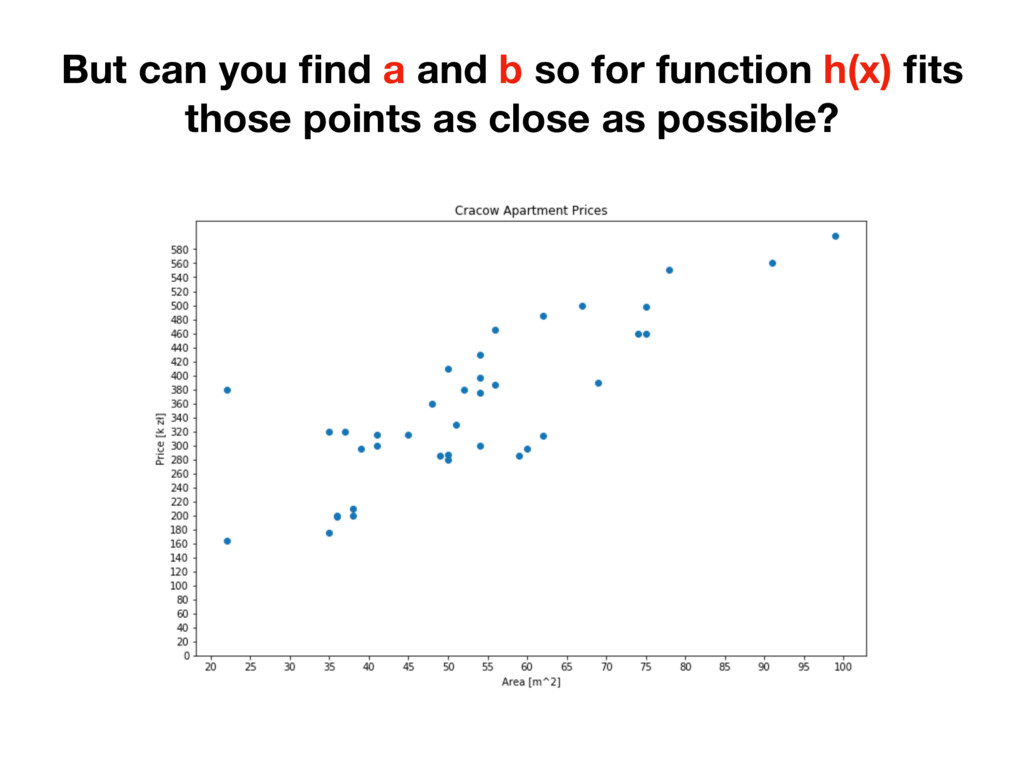
it. But first engineer has to create that “intelligence” by implementing learning algorithm in code. But engineer has to know what code to write. He/she needs some instruction. Luckily math can be turned into code easily!
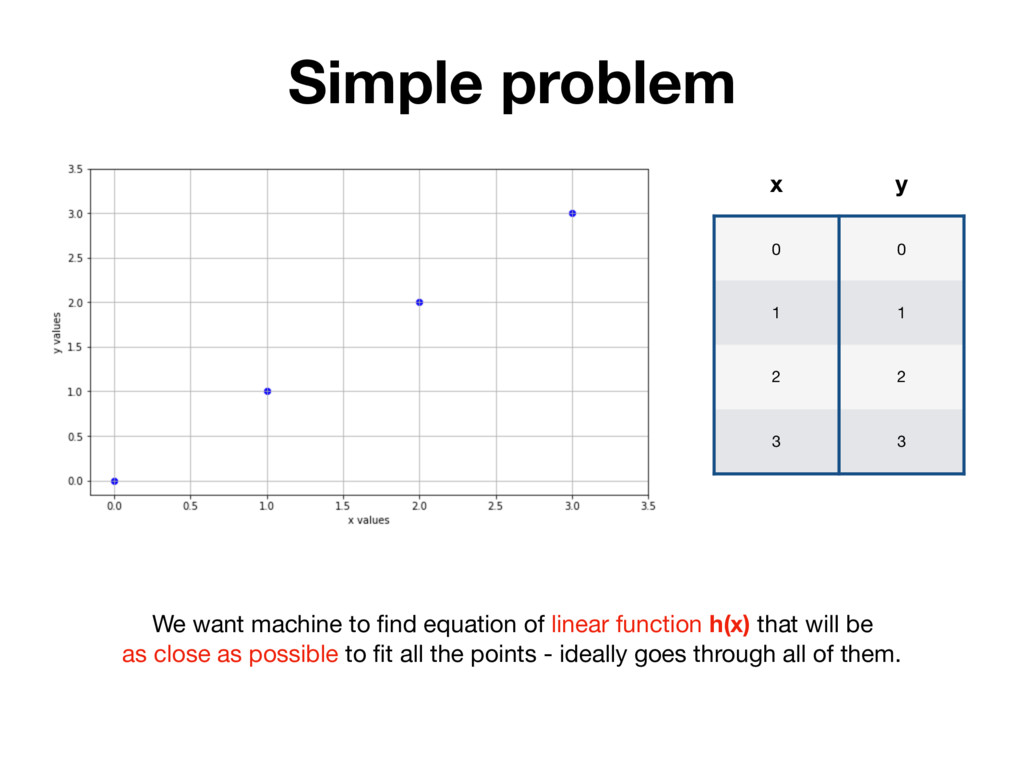
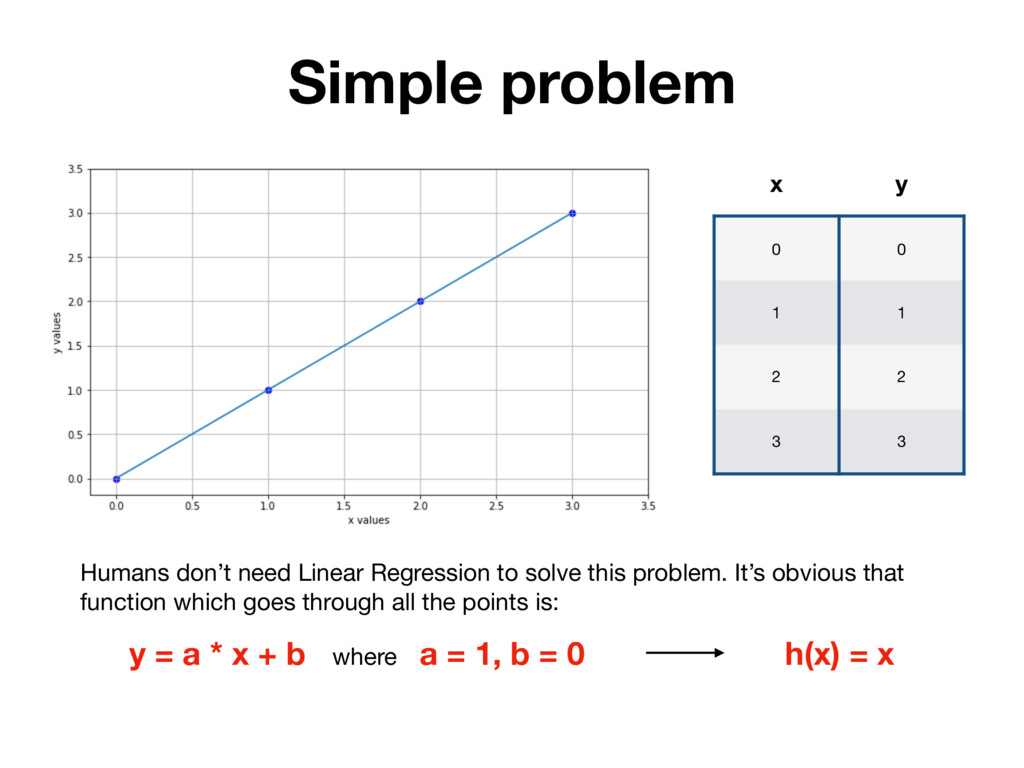
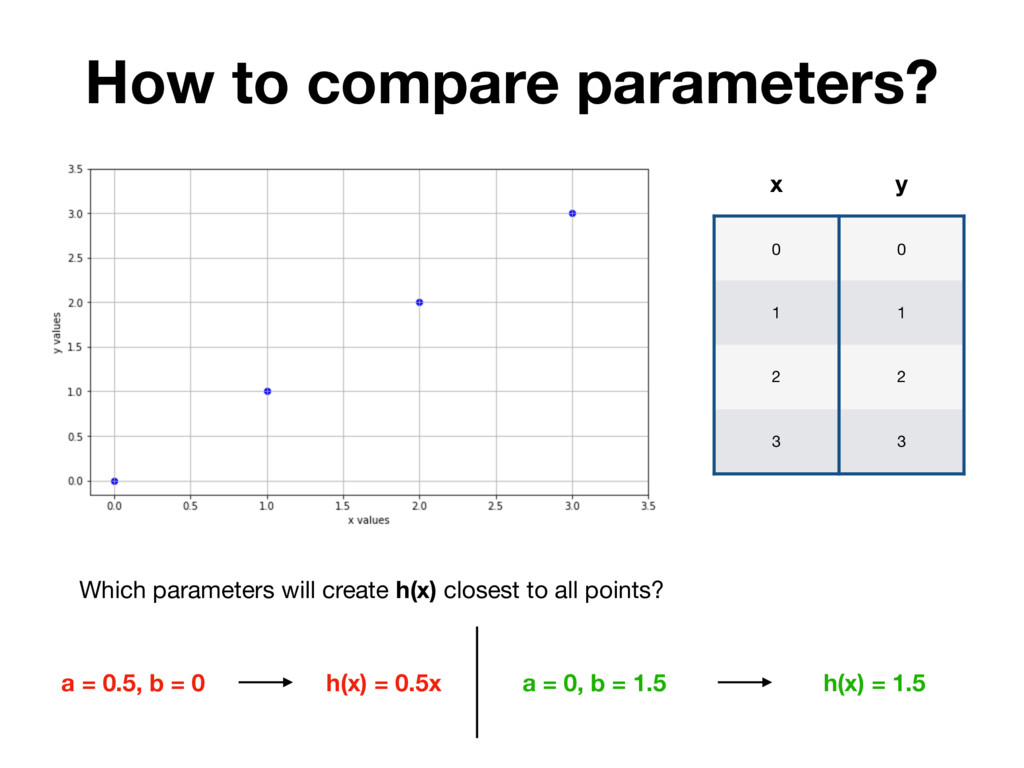
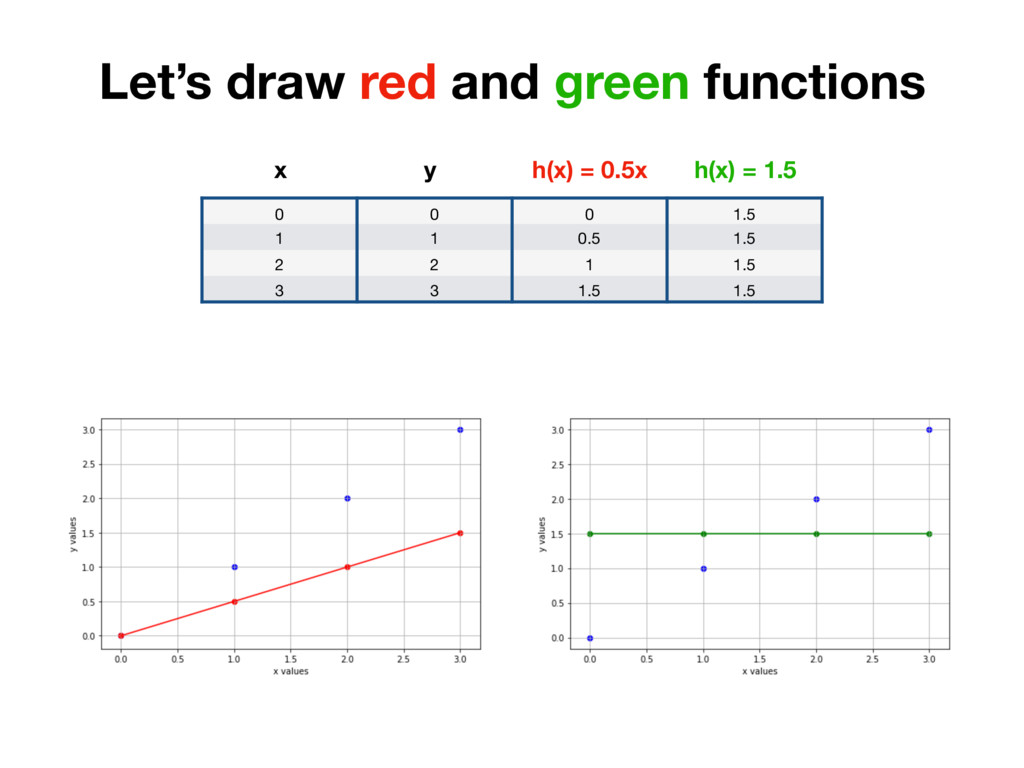
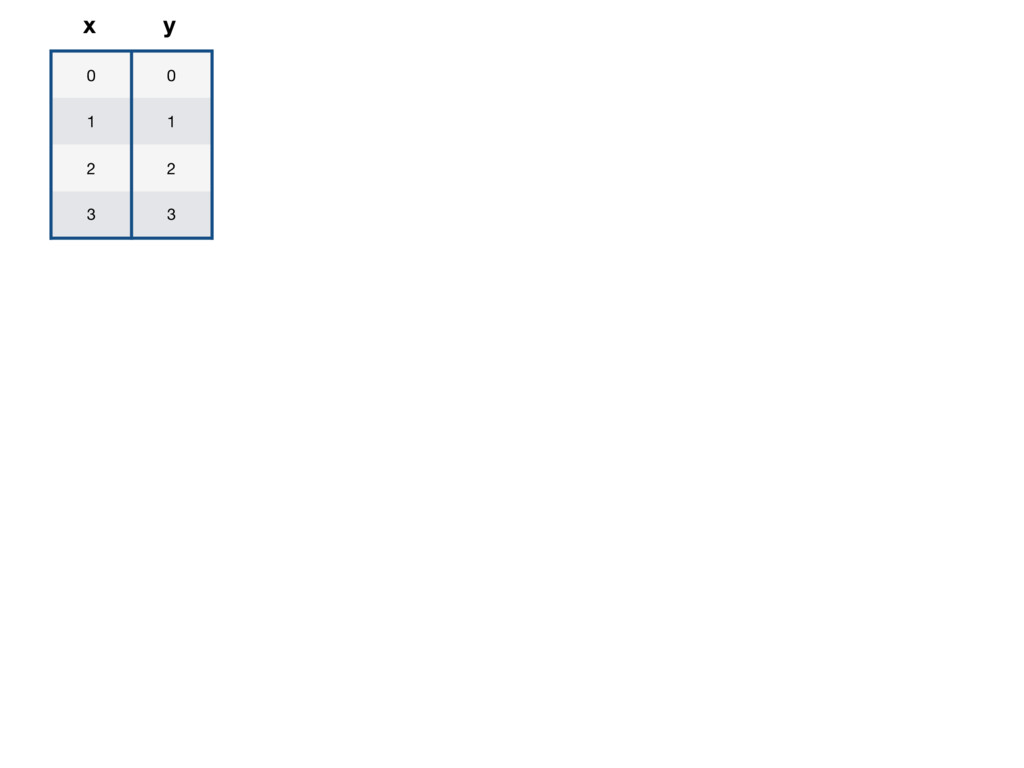
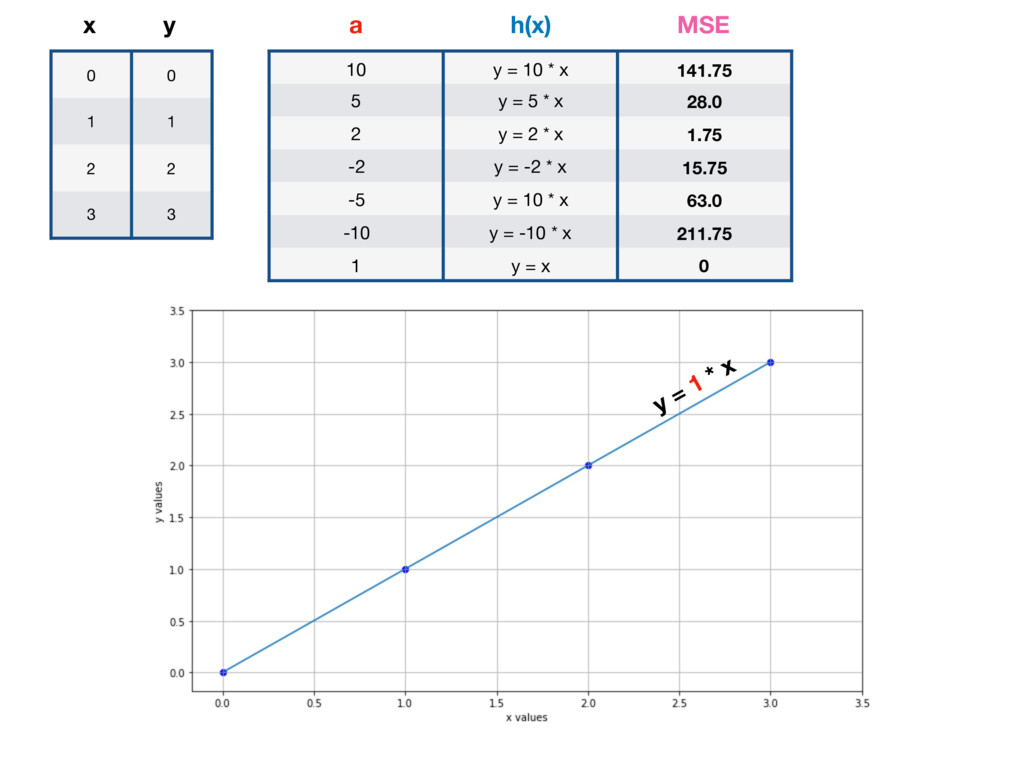
x y Humans don’t need Linear Regression to solve this problem. It’s obvious that function which goes through all the points is: h(x) = x y = a * x + b where a = 1, b = 0
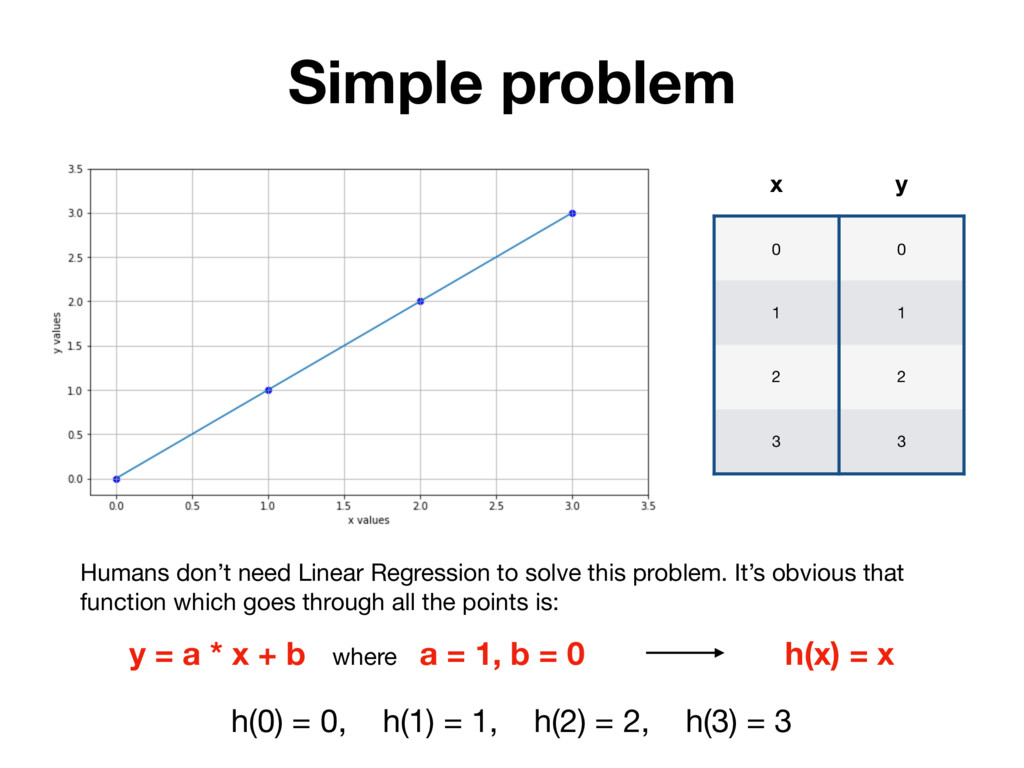
x y Humans don’t need Linear Regression to solve this problem. It’s obvious that function which goes through all the points is: h(x) = x y = a * x + b where a = 1, b = 0 h(0) = 0, h(1) = 1, h(2) = 2, h(3) = 3
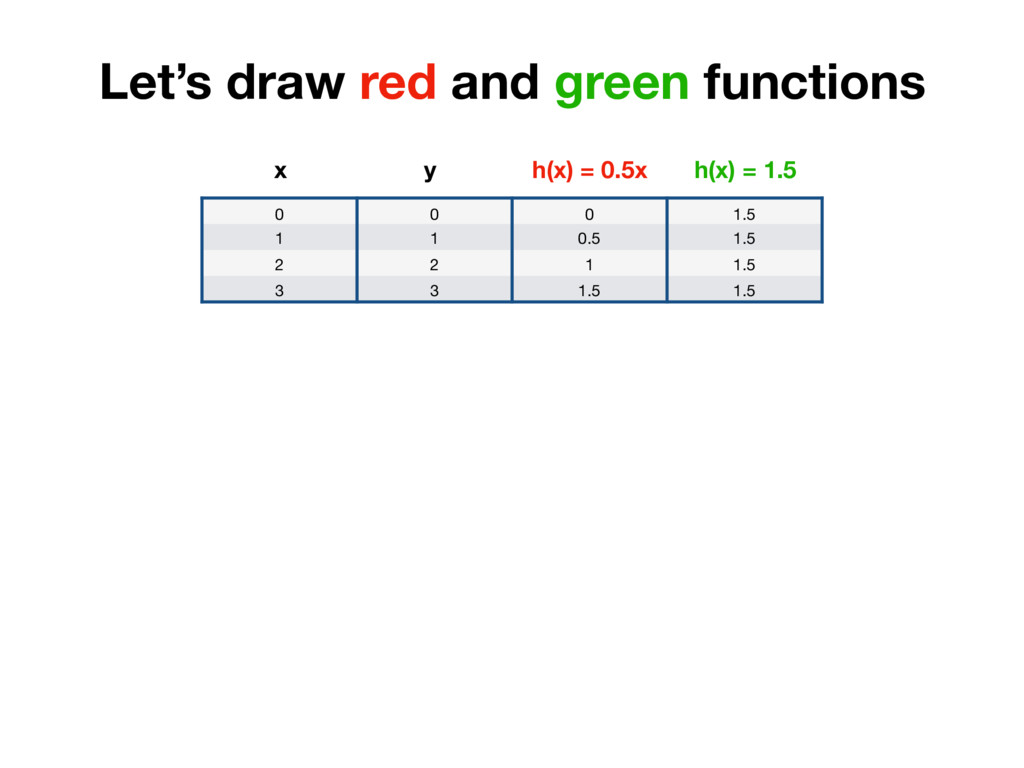
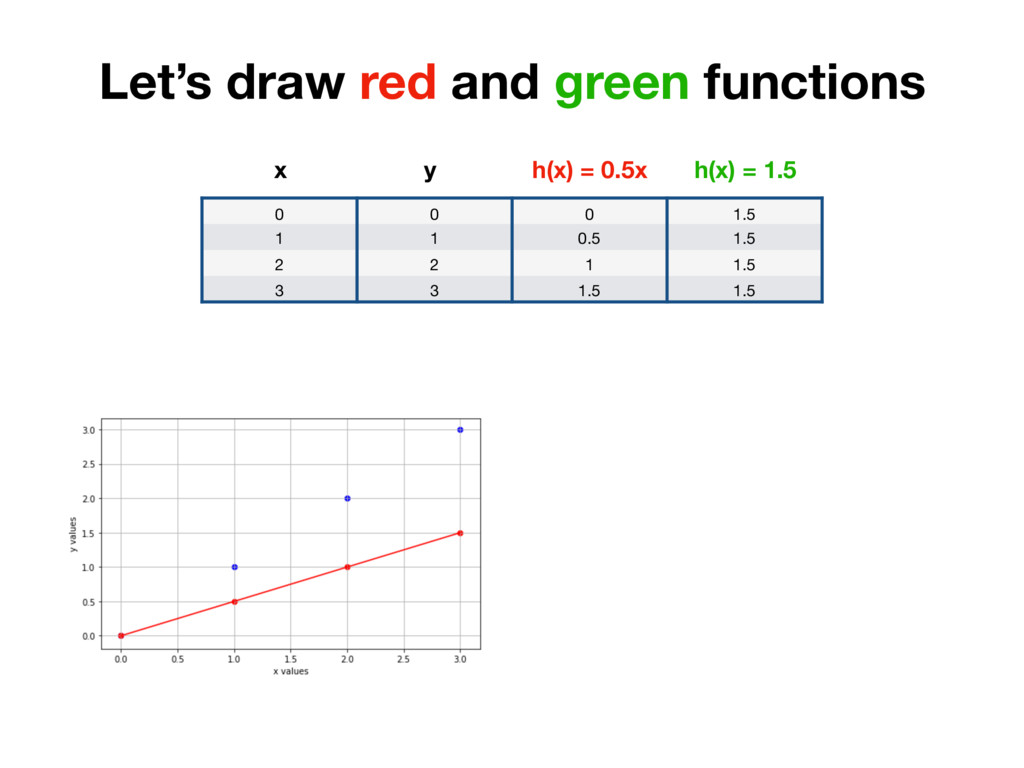
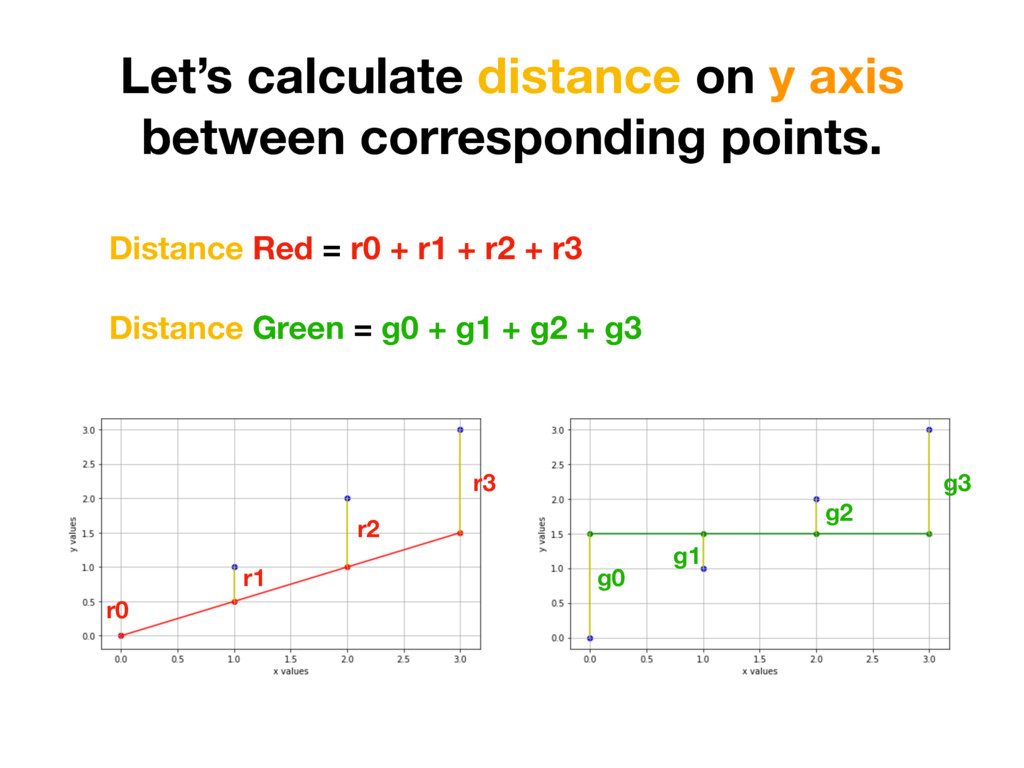
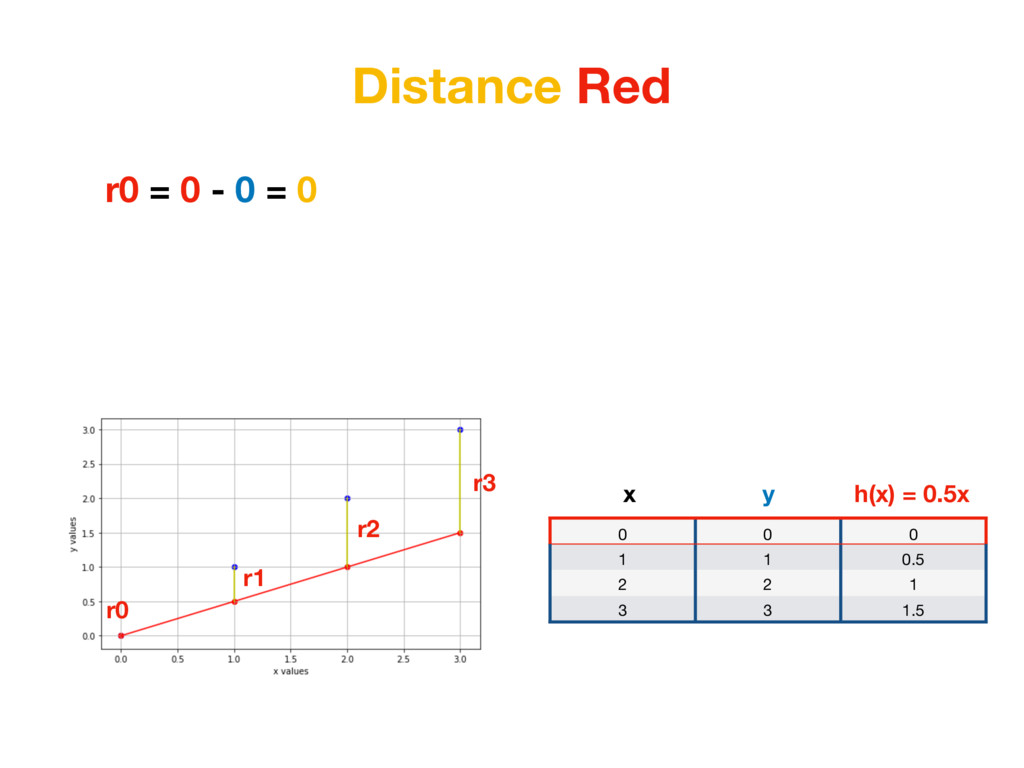
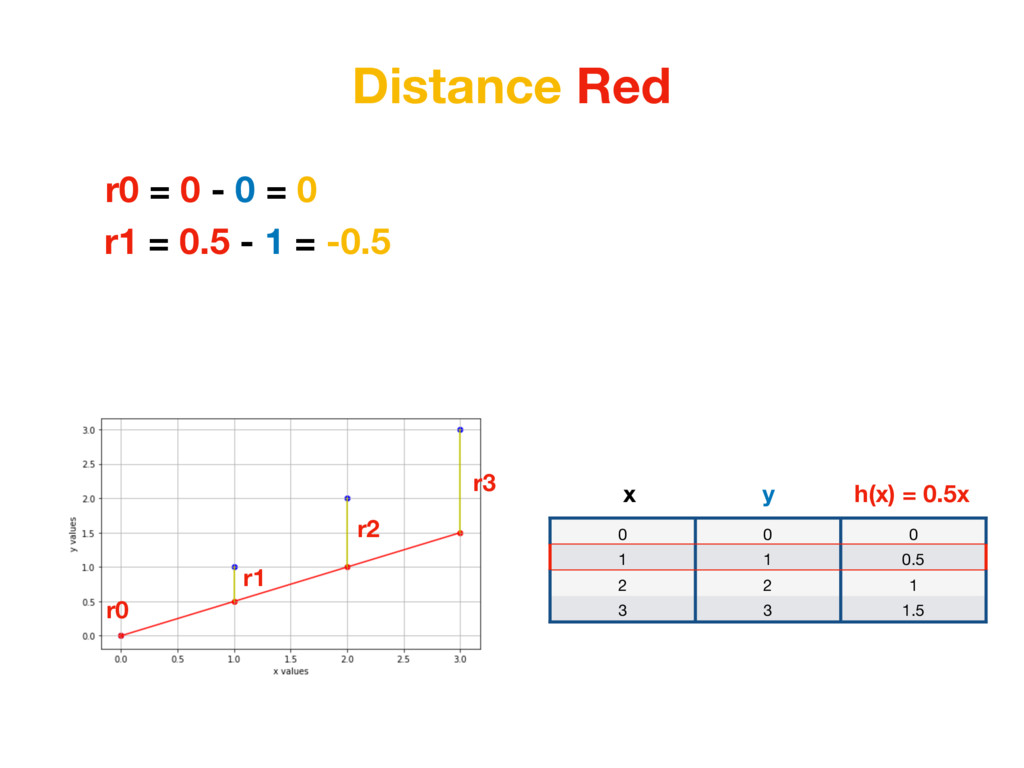
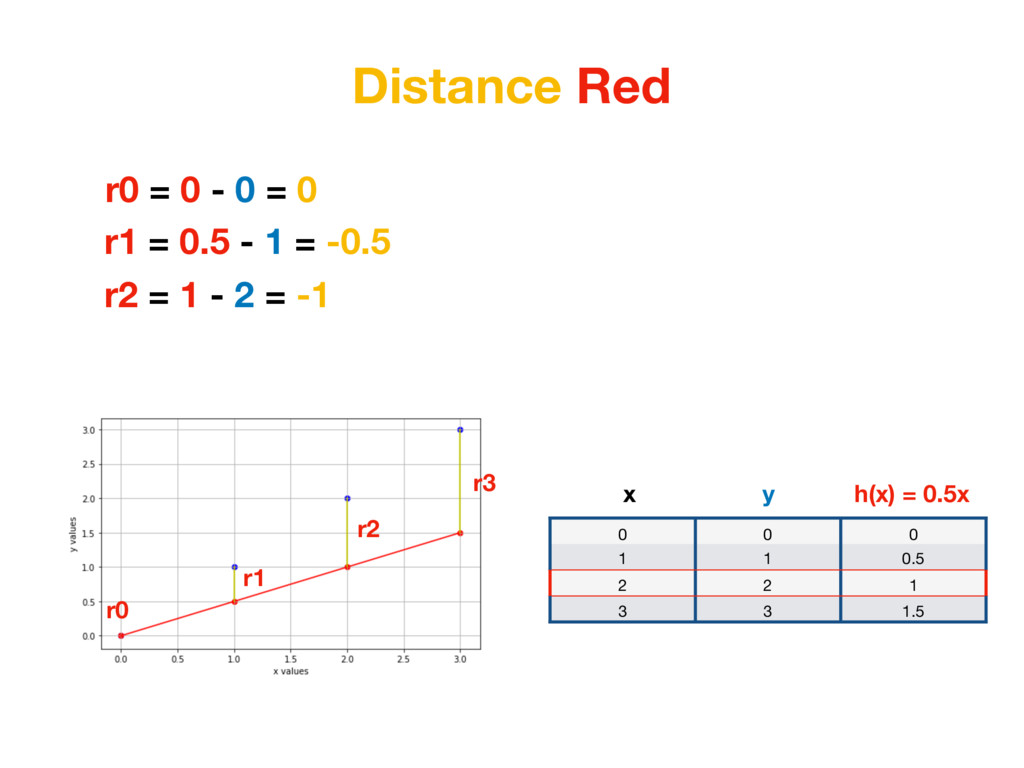
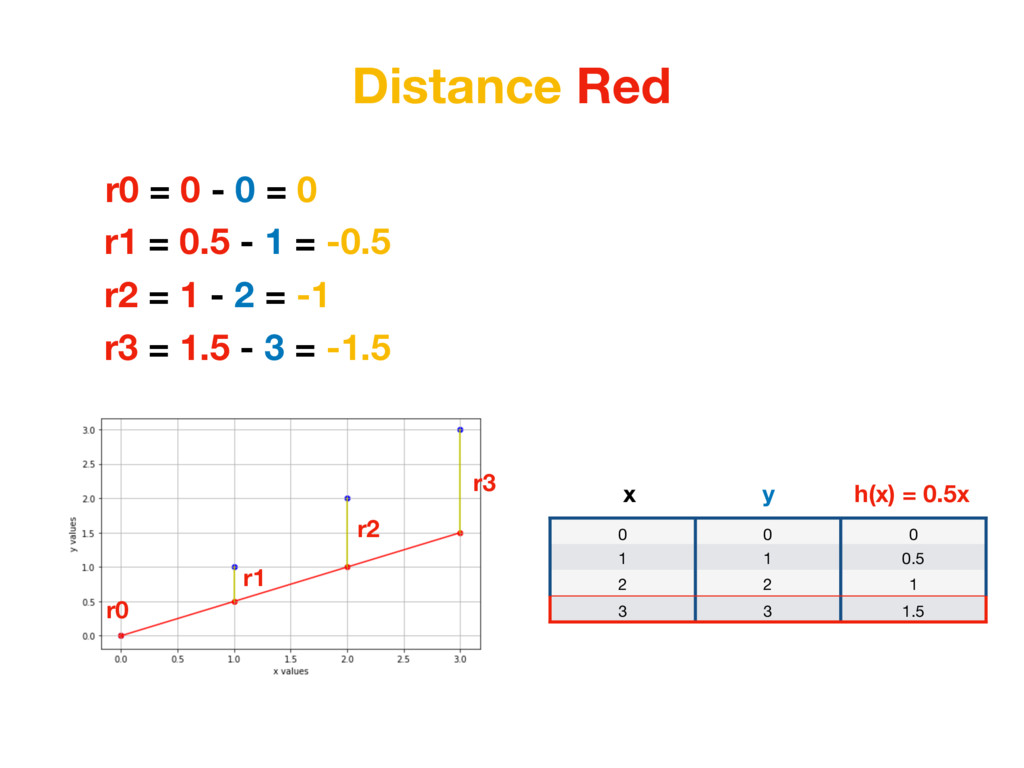
1 0.5 2 2 1 3 3 1.5 x h(x) = 0.5x y r0 = |0 - 0| = 0 r1 = |0.5 - 1| = 0.5 r2 = |1 - 2| = 1 r3 = |1.5 - 3| = 1.5 We care about distance - distance value shouldn’t be negative. We could take absolute value of each number. (In Machine Learning world this is called L1 Distance)
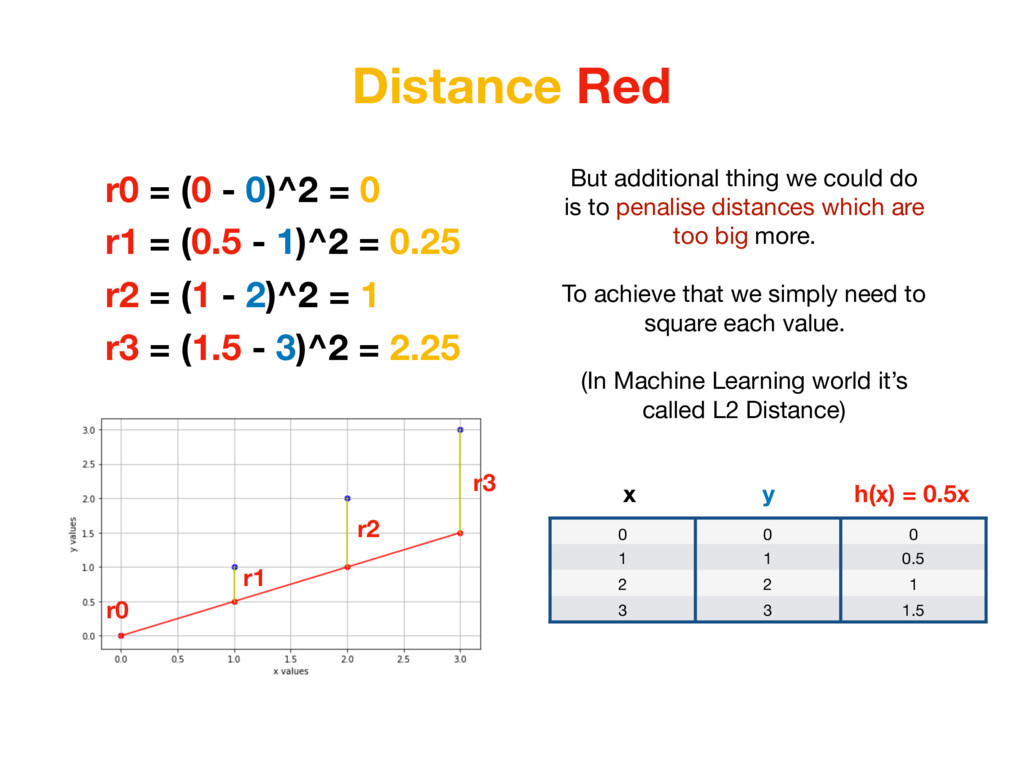
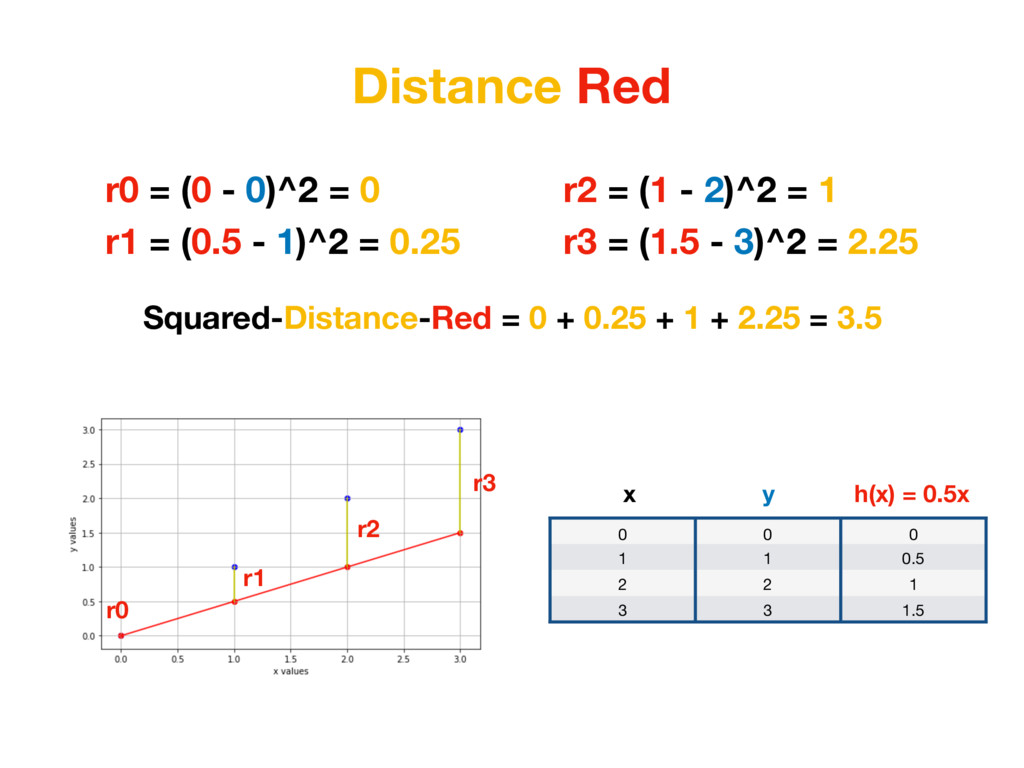
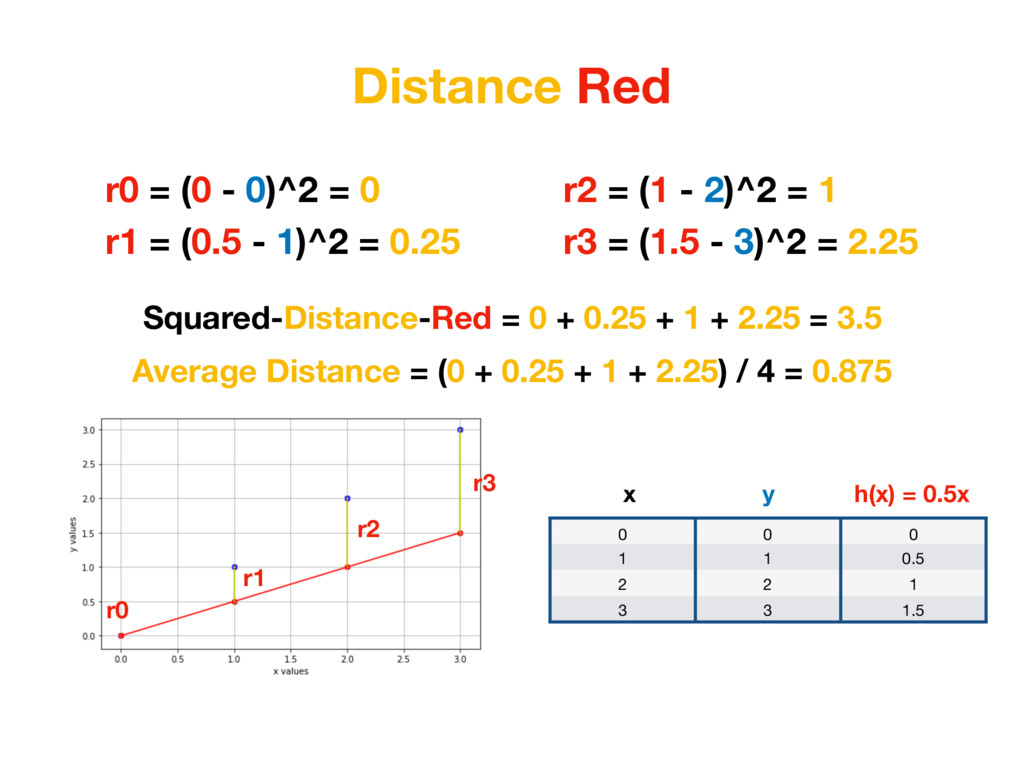
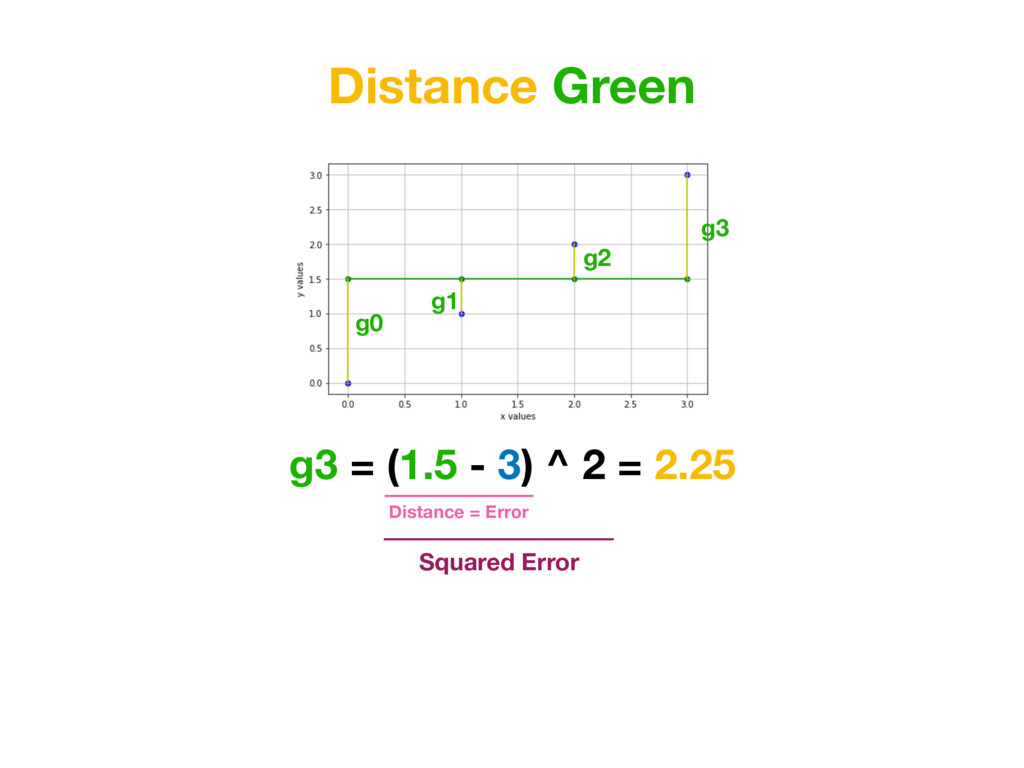
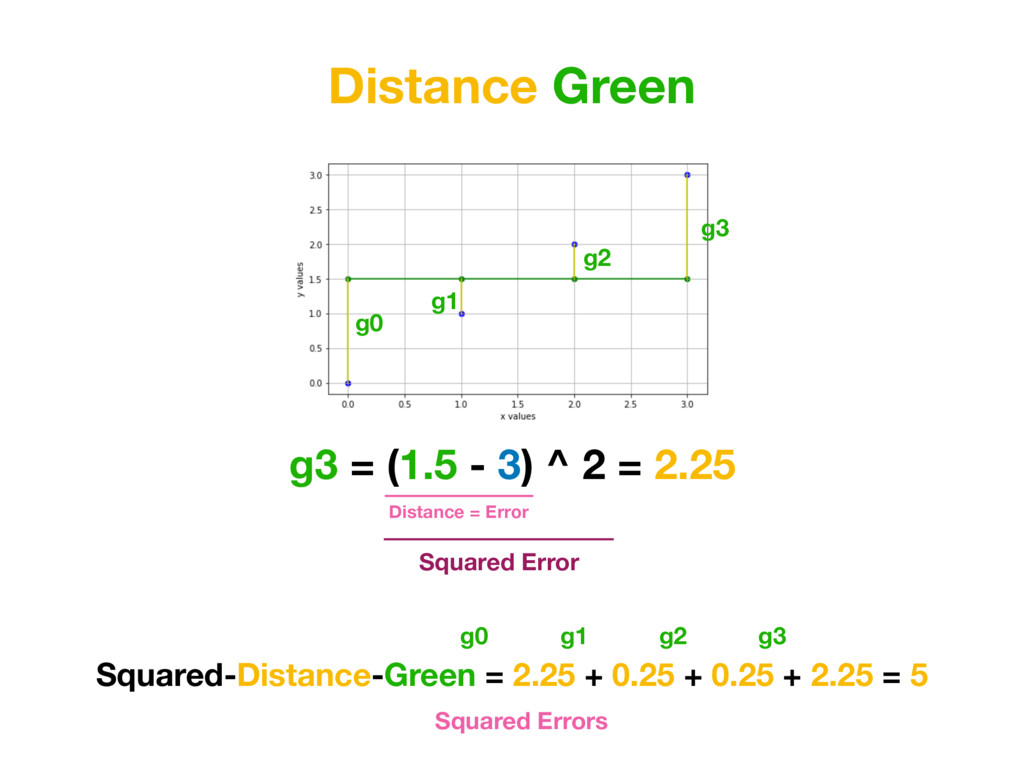
1 0.5 2 2 1 3 3 1.5 x h(x) = 0.5x y r0 = (0 - 0)^2 = 0 r1 = (0.5 - 1)^2 = 0.25 r2 = (1 - 2)^2 = 1 r3 = (1.5 - 3)^2 = 2.25 But additional thing we could do is to penalise distances which are too big more. To achieve that we simply need to square each value. (In Machine Learning world it’s called L2 Distance)
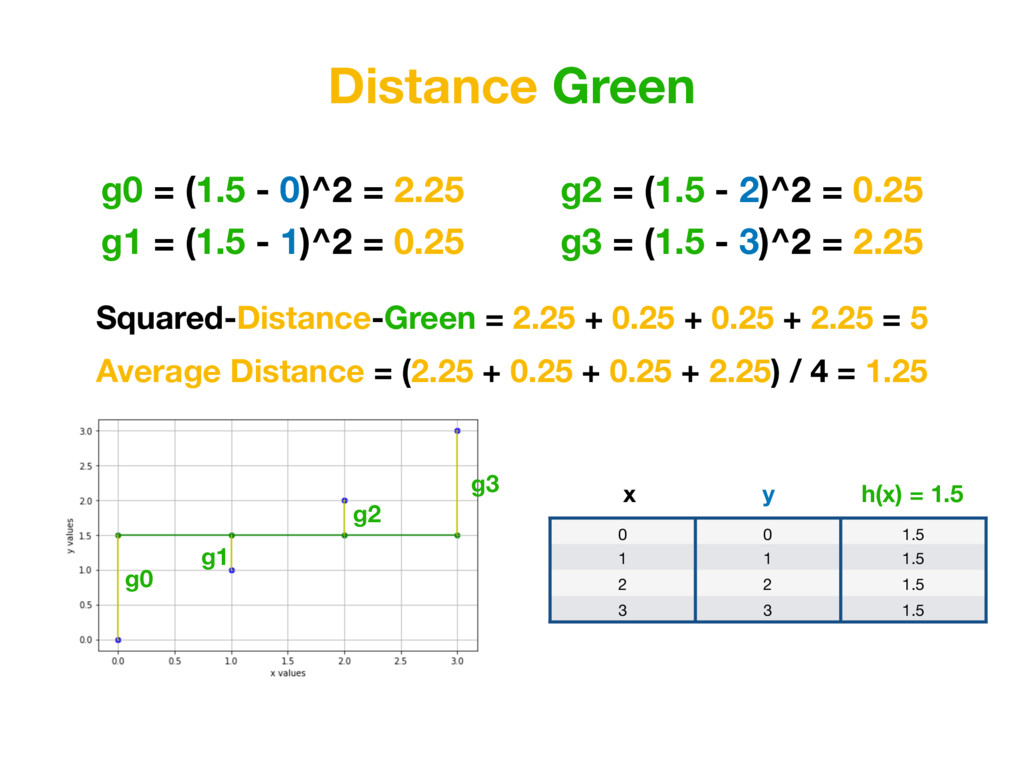
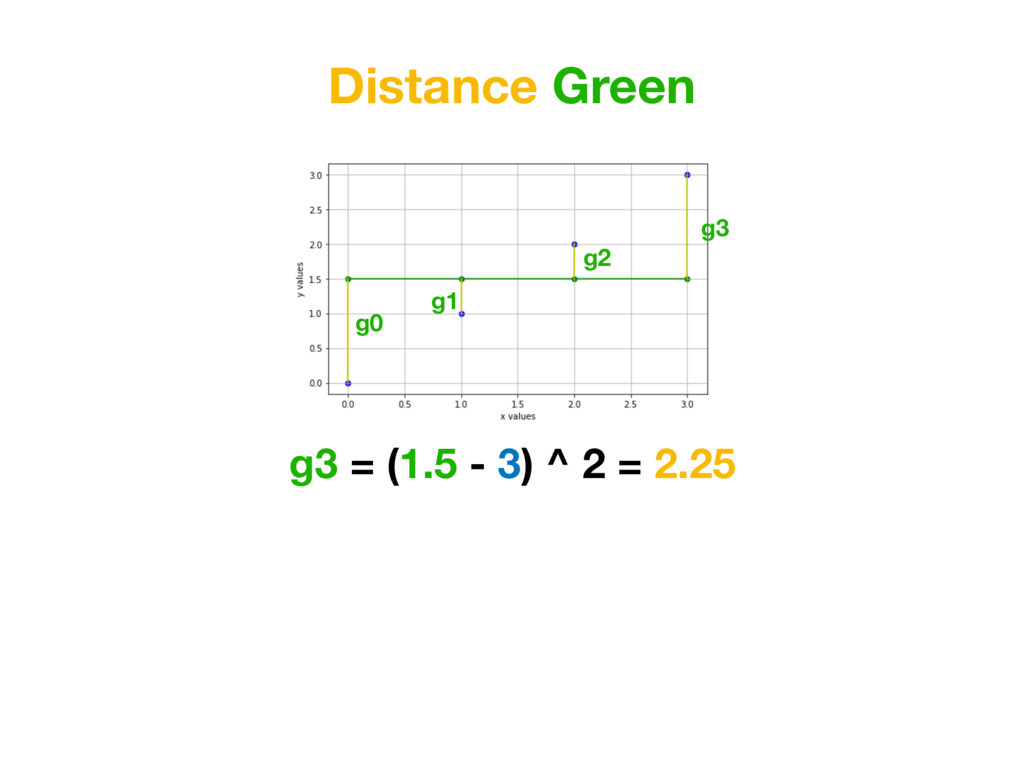
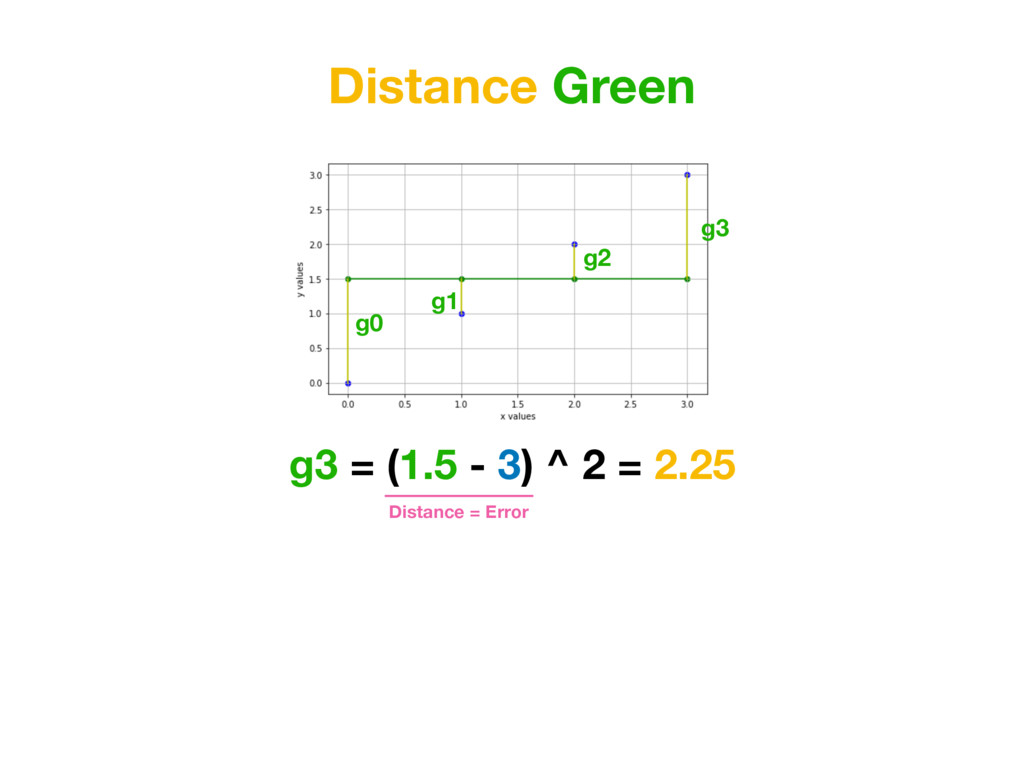
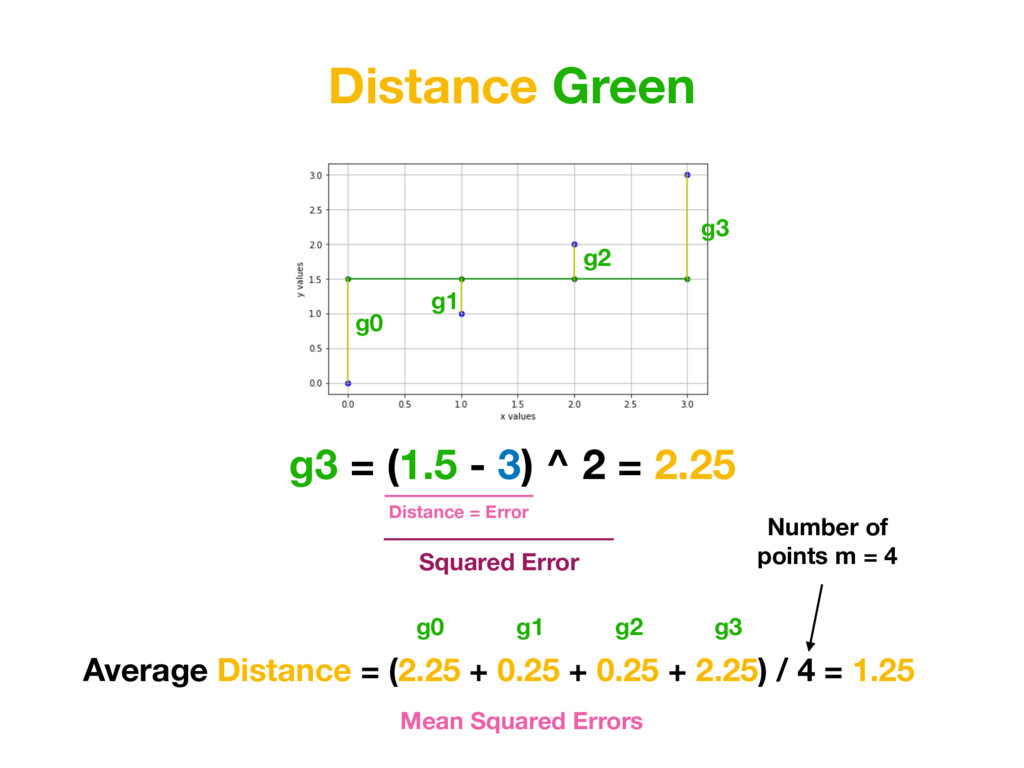
than a=0, b=1.5… Because value of MEAN SQUARED-ERRORS for function created with red parameters is smaller than for function created with green parameters. Average Distance Green = 1.25 Average Distance Red = 0.875 (Average Distance Red) < (Average Distance Green )
than a=0, b=1.5… Because value of for function created with red parameters is smaller than for function created with green parameters. MSE Green = 1.25 MSE Red = 0.875 (MSE Red) < (MSE Green )
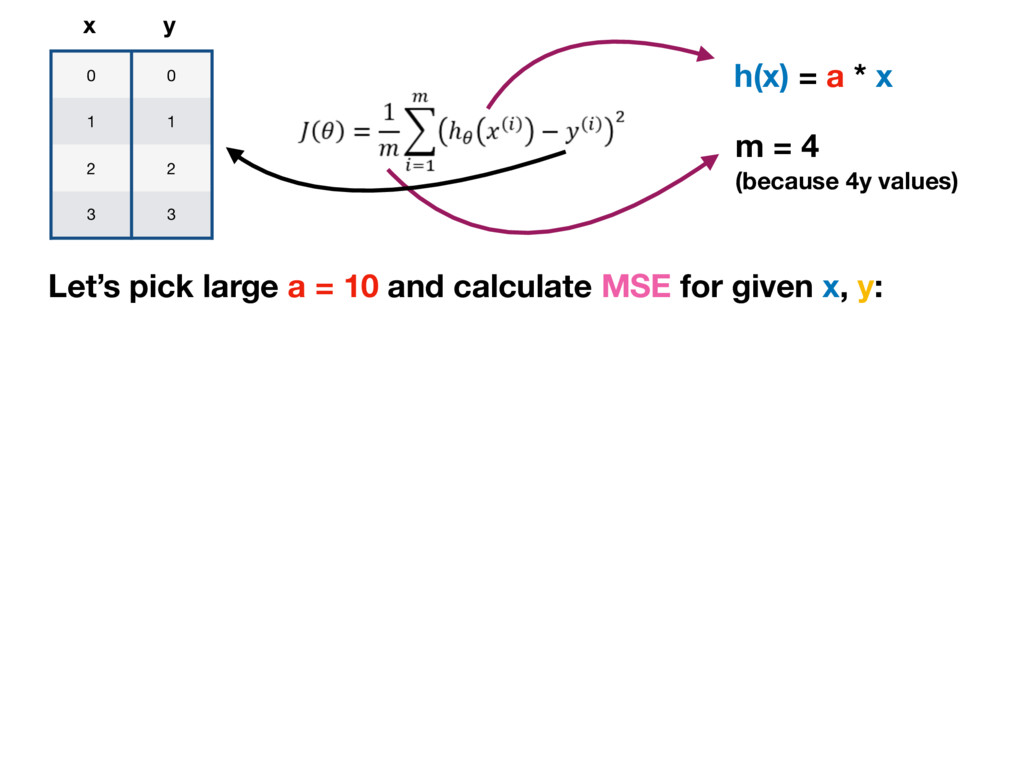
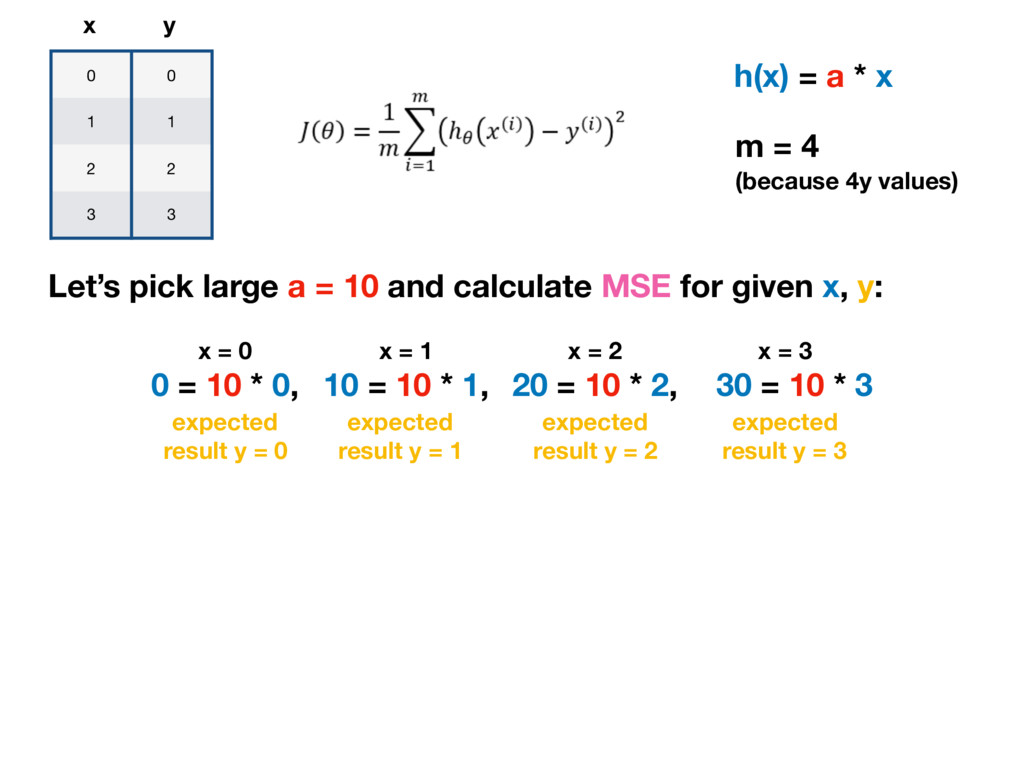
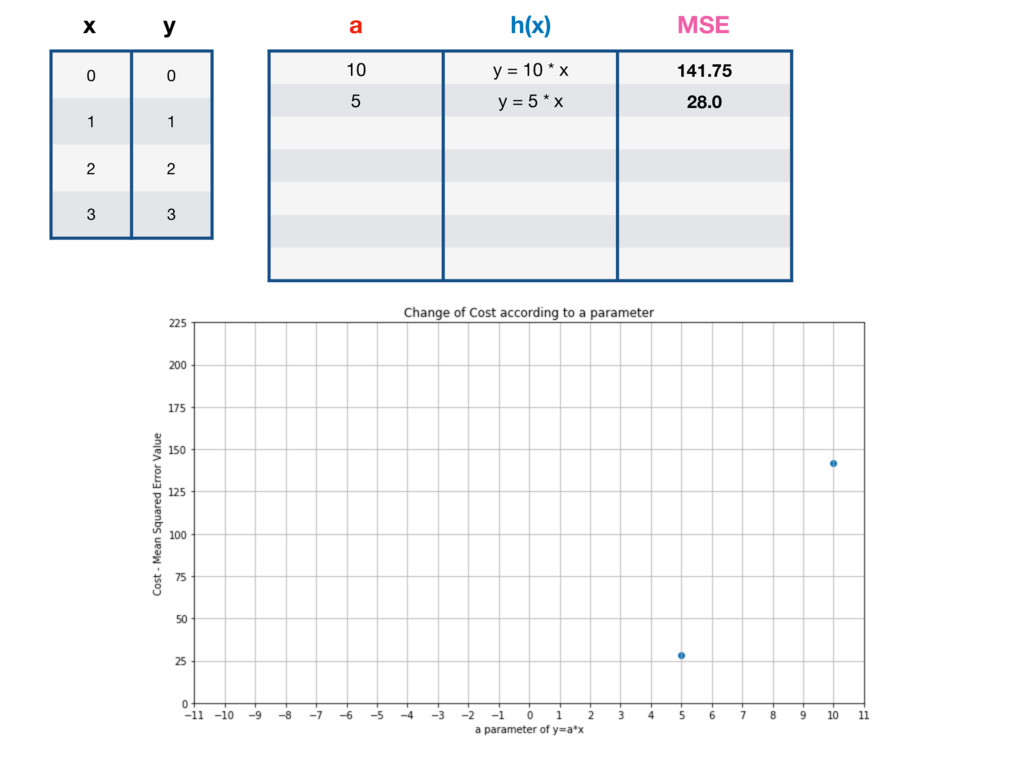
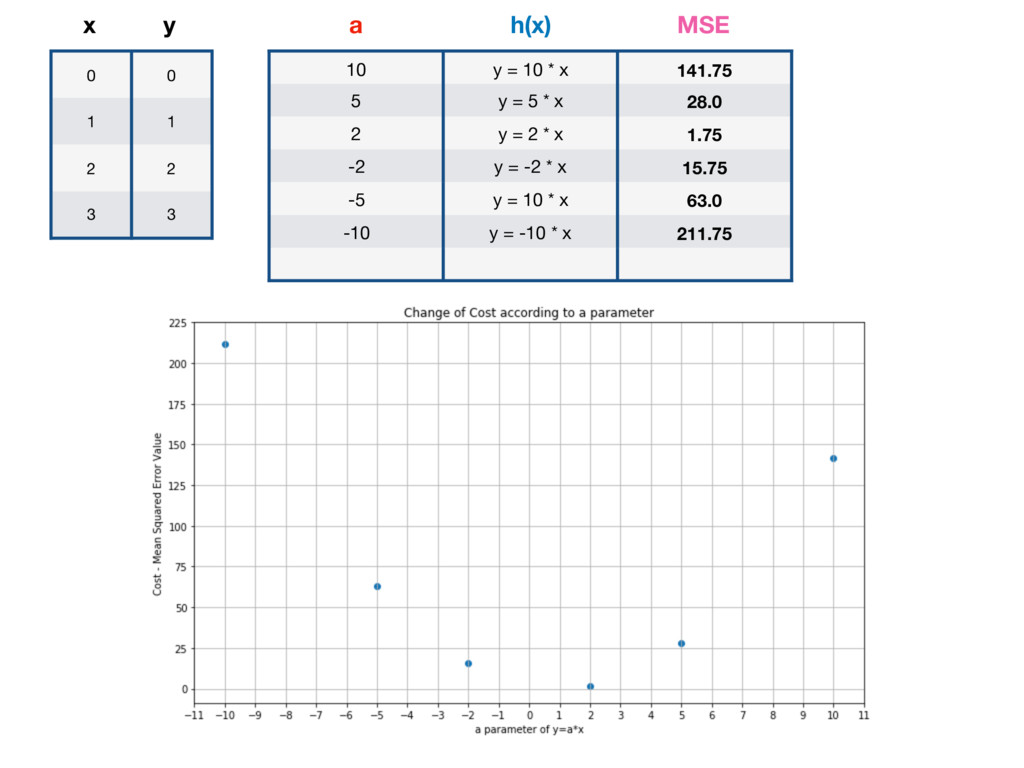
h(x) = a * x m = 4 (because 4y values) Let’s pick large a = 10 and calculate MSE for given x, y: 0 = 10 * 0, x = 0 10 = 10 * 1, x = 1 20 = 10 * 2, x = 2 30 = 10 * 3 x = 3 expected result y = 0 expected result y = 1 expected result y = 2 expected result y = 3
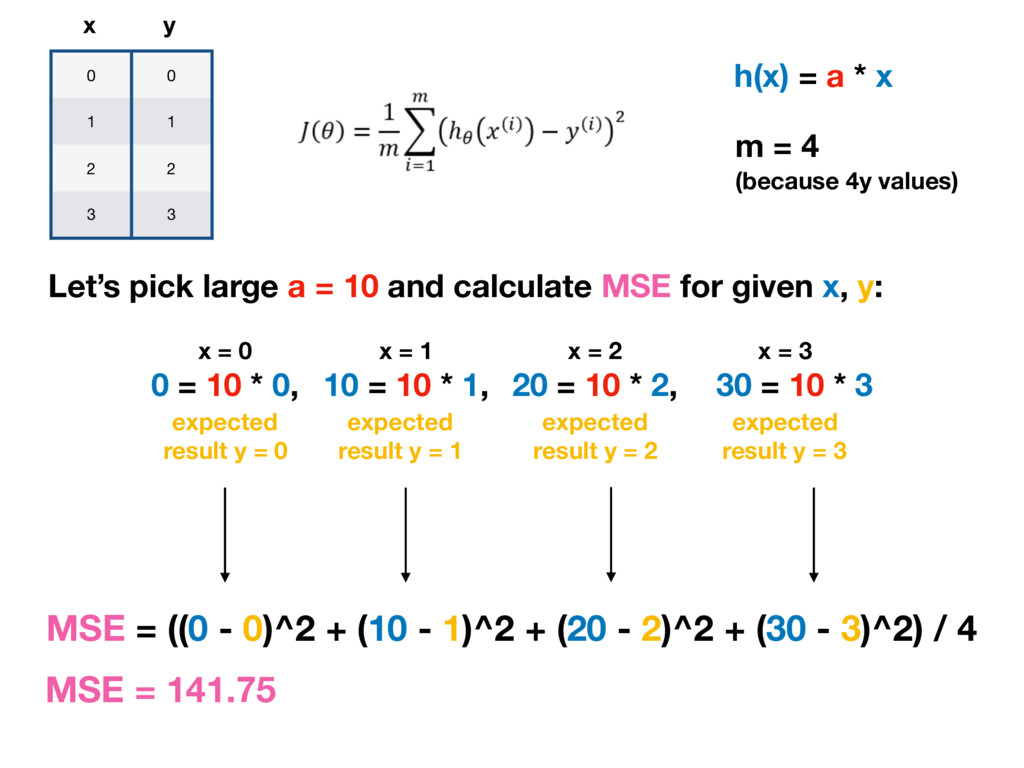
Let’s pick large a = 10 and calculate MSE for given x, y: h(x) = a * x 0 = 10 * 0, m = 4 (because 4y values) x = 0 10 = 10 * 1, x = 1 20 = 10 * 2, x = 2 30 = 10 * 3 x = 3 expected result y = 0 expected result y = 1 expected result y = 2 expected result y = 3 MSE = ((0 - 0)^2 + (10 - 1)^2 + (20 - 2)^2 + (30 - 3)^2) / 4 MSE = 141.75
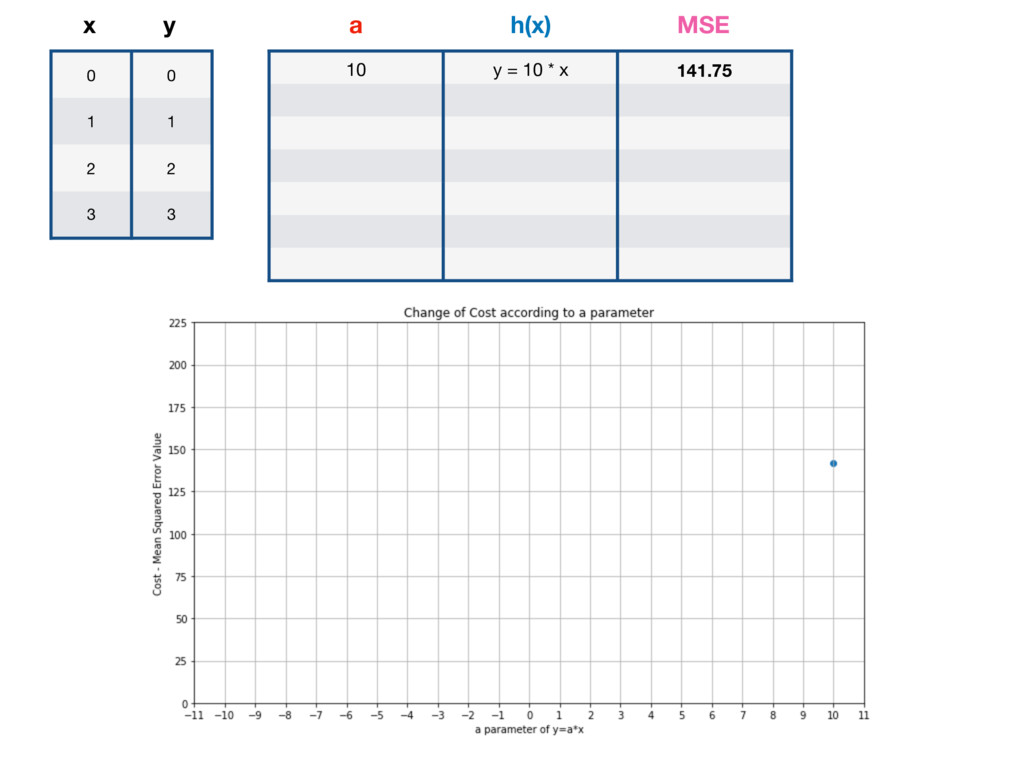
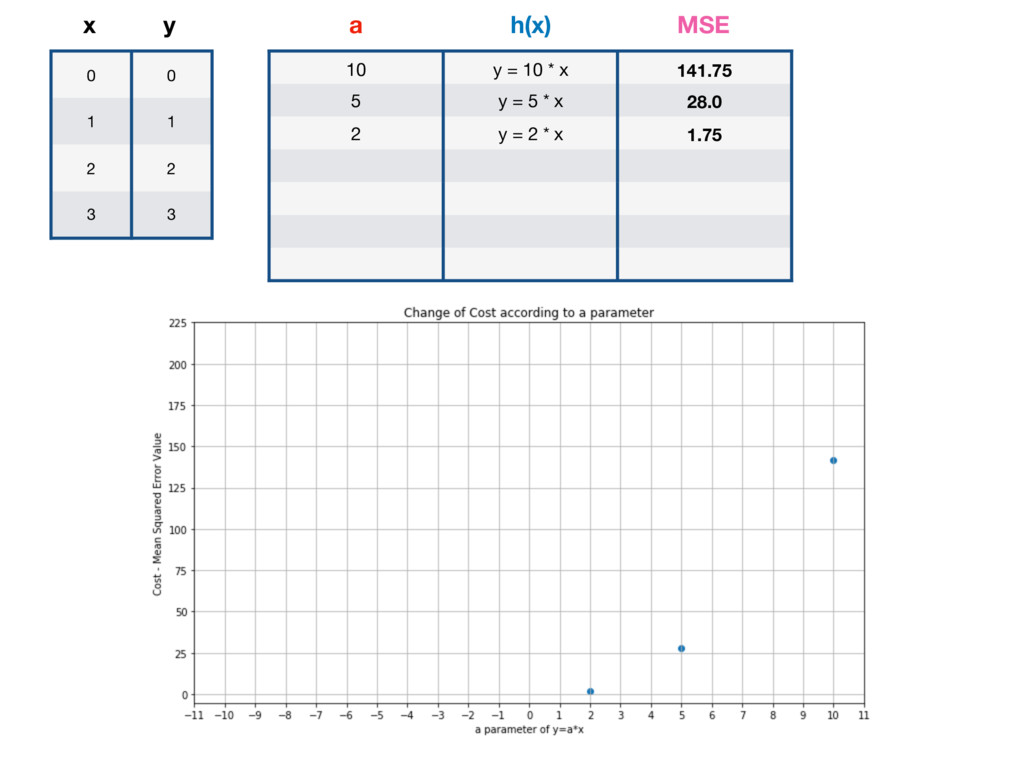
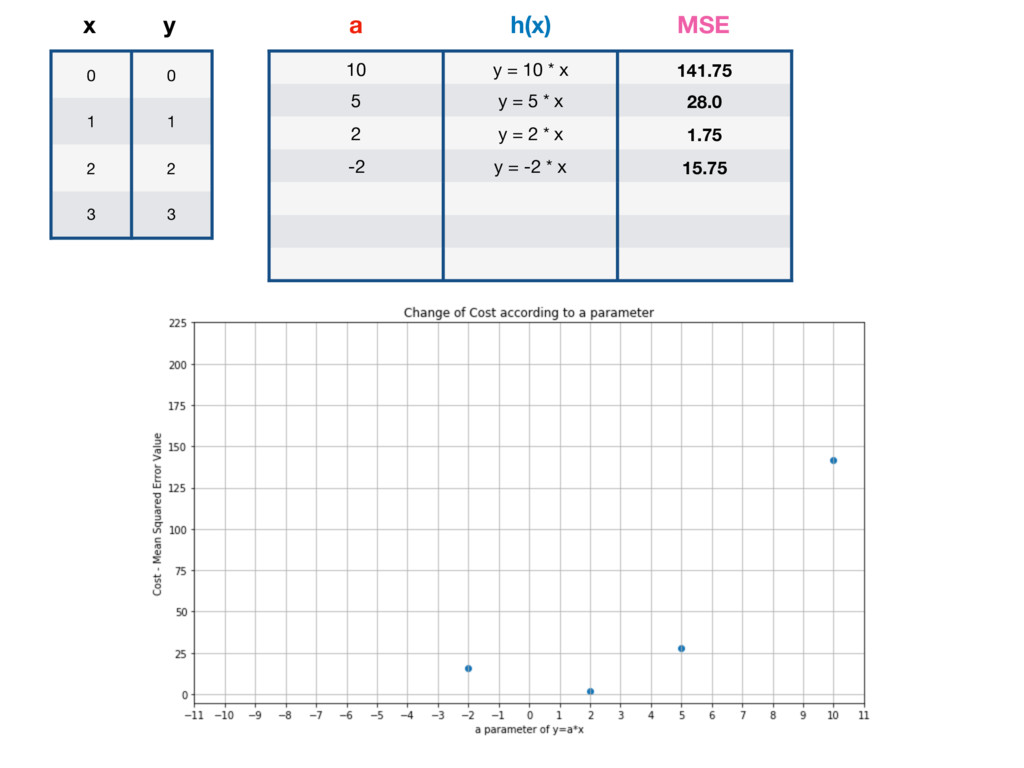
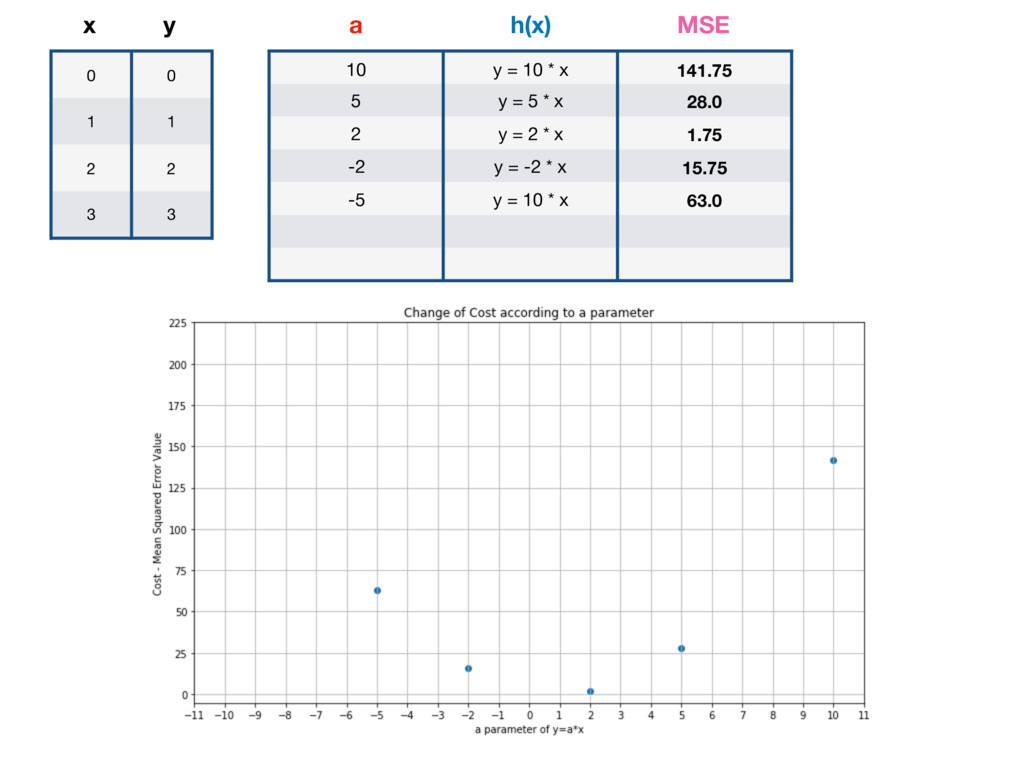
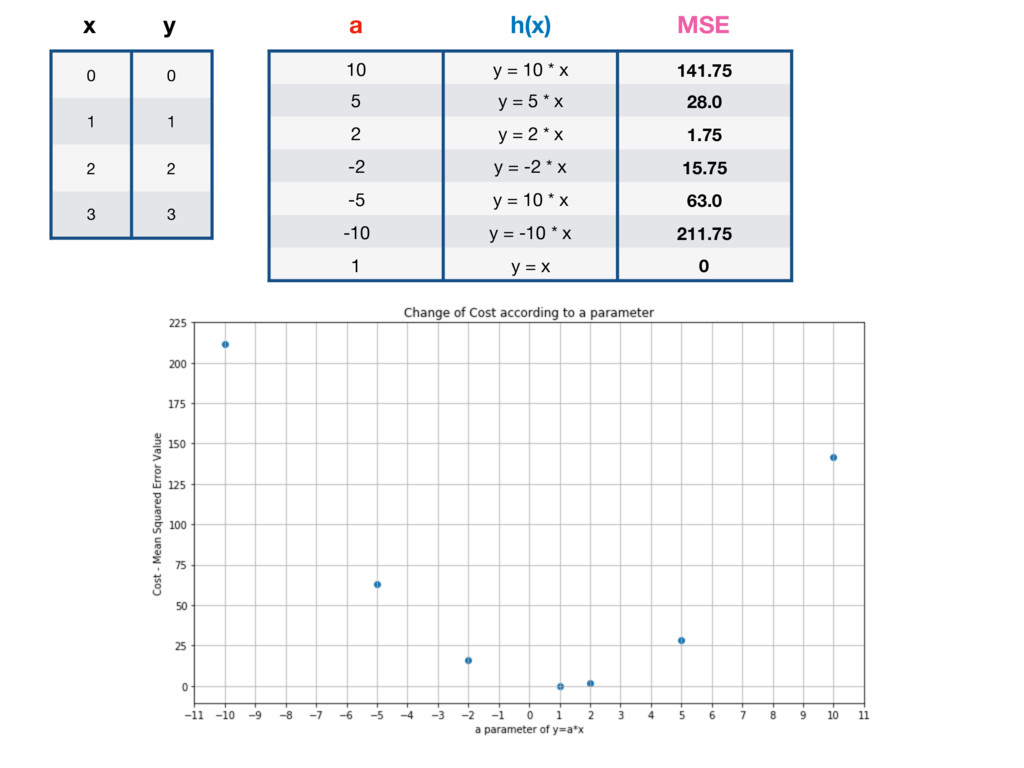
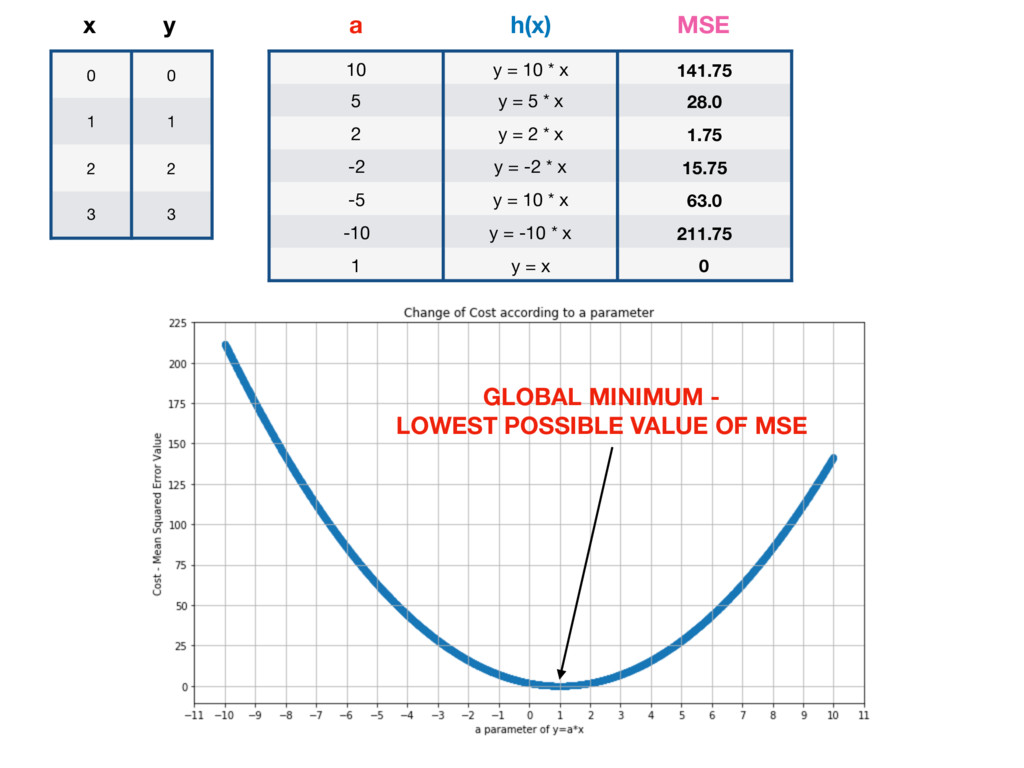
10 y = 10 * x 141.75 5 y = 5 * x 28.0 2 y = 2 * x 1.75 -2 y = -2 * x 15.75 -5 y = 10 * x 63.0 -10 y = -10 * x 211.75 1 y = x 0 a h(x) MSE GLOBAL MINIMUM - LOWEST POSSIBLE VALUE OF MSE
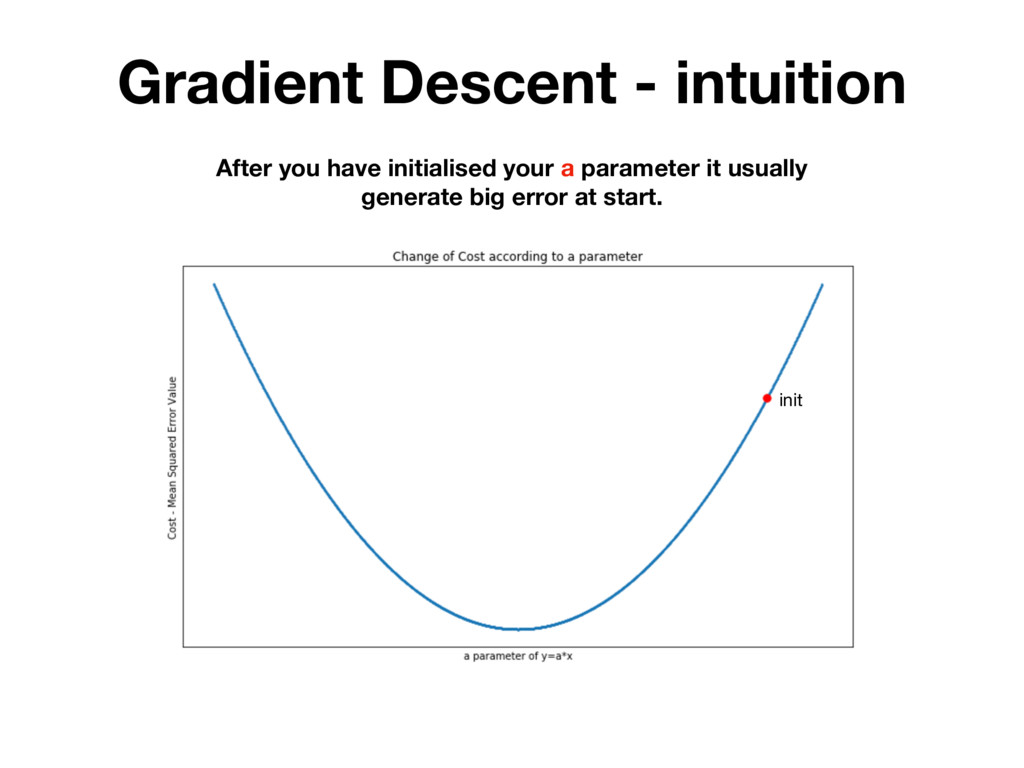
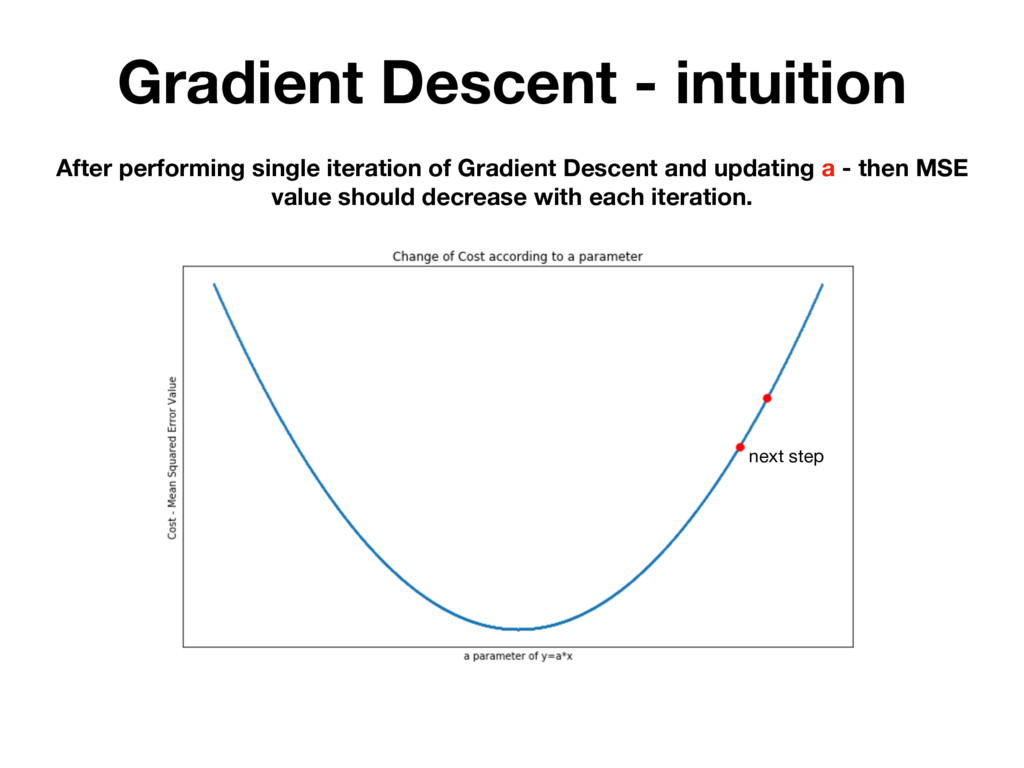
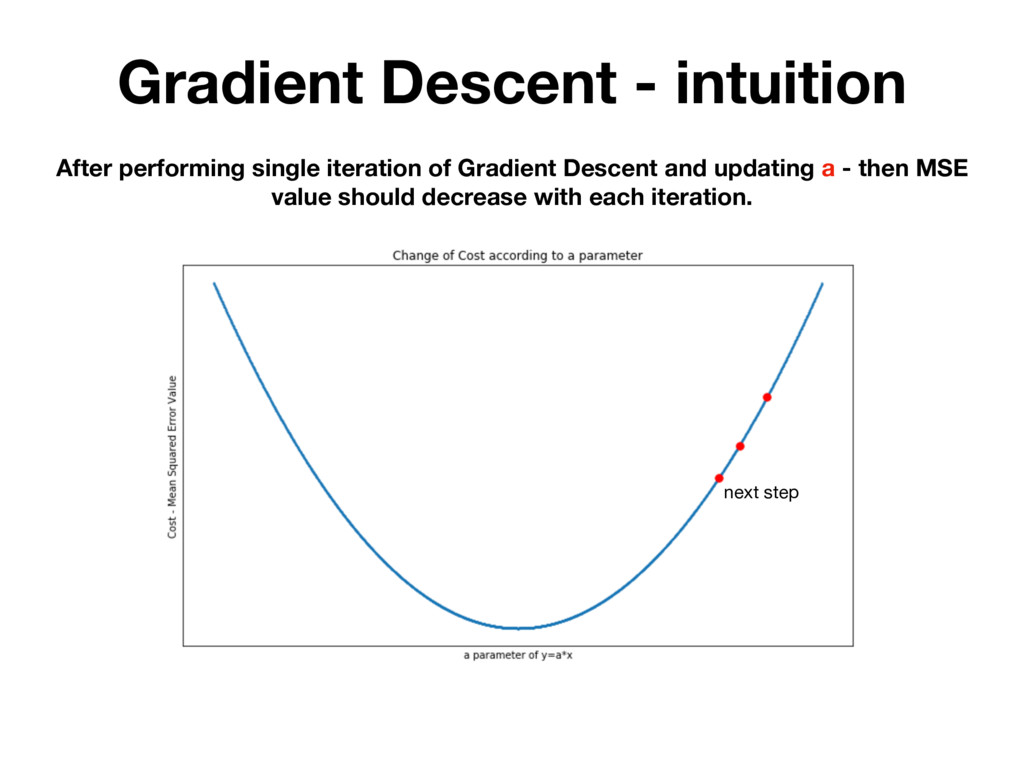
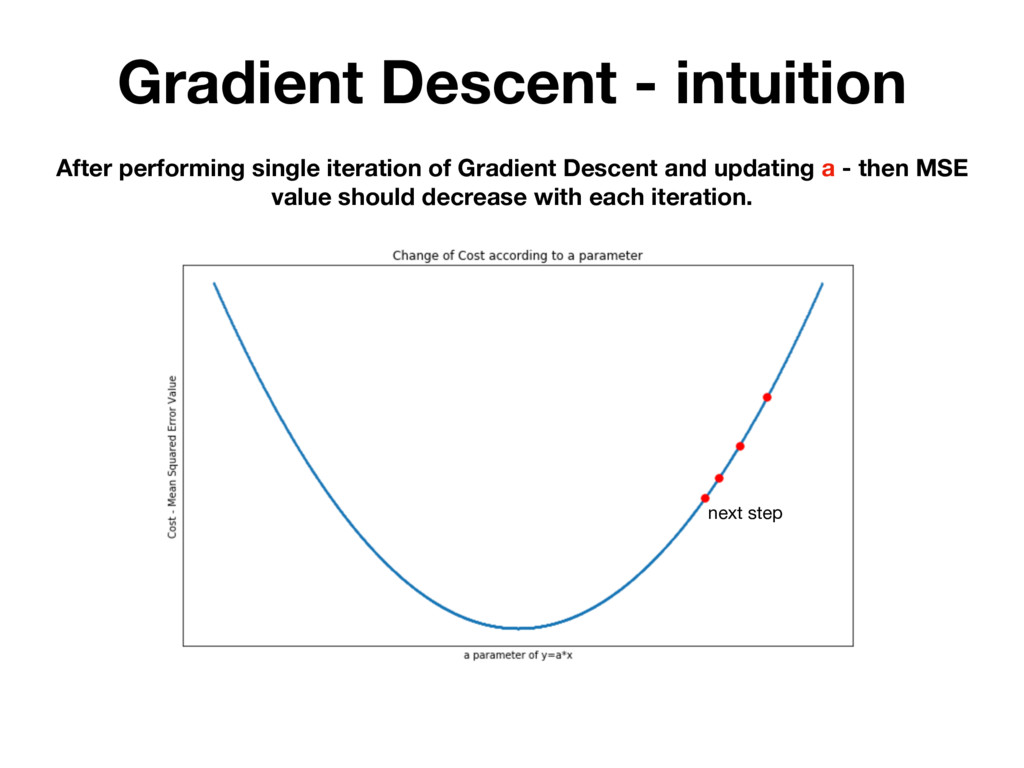
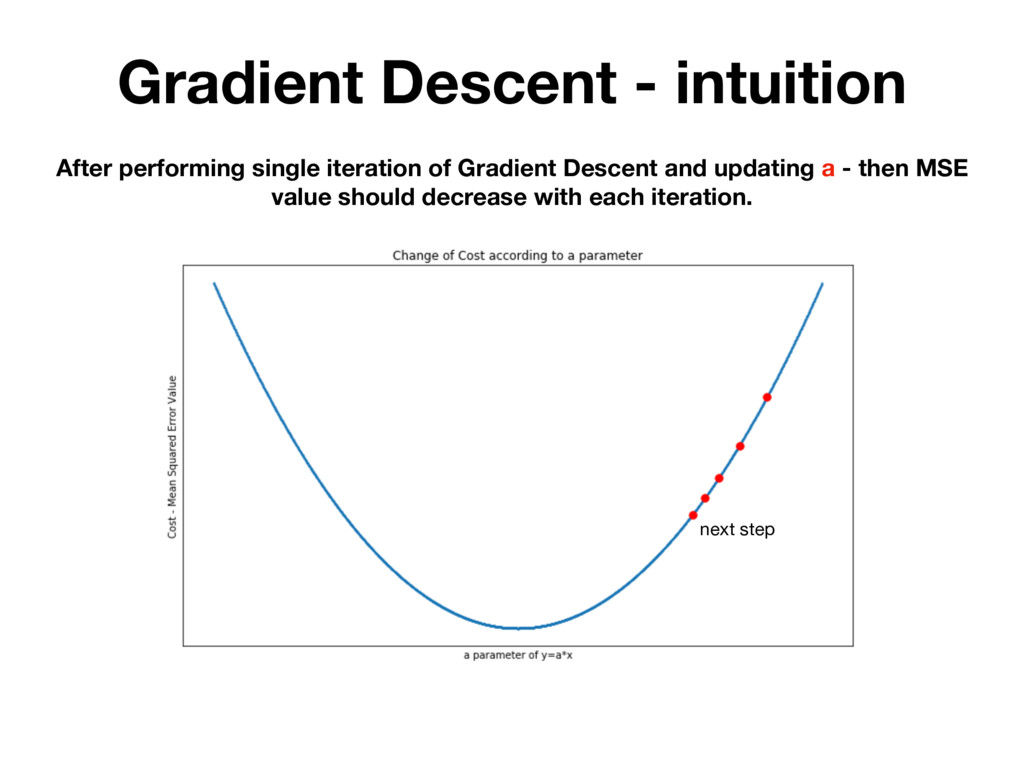
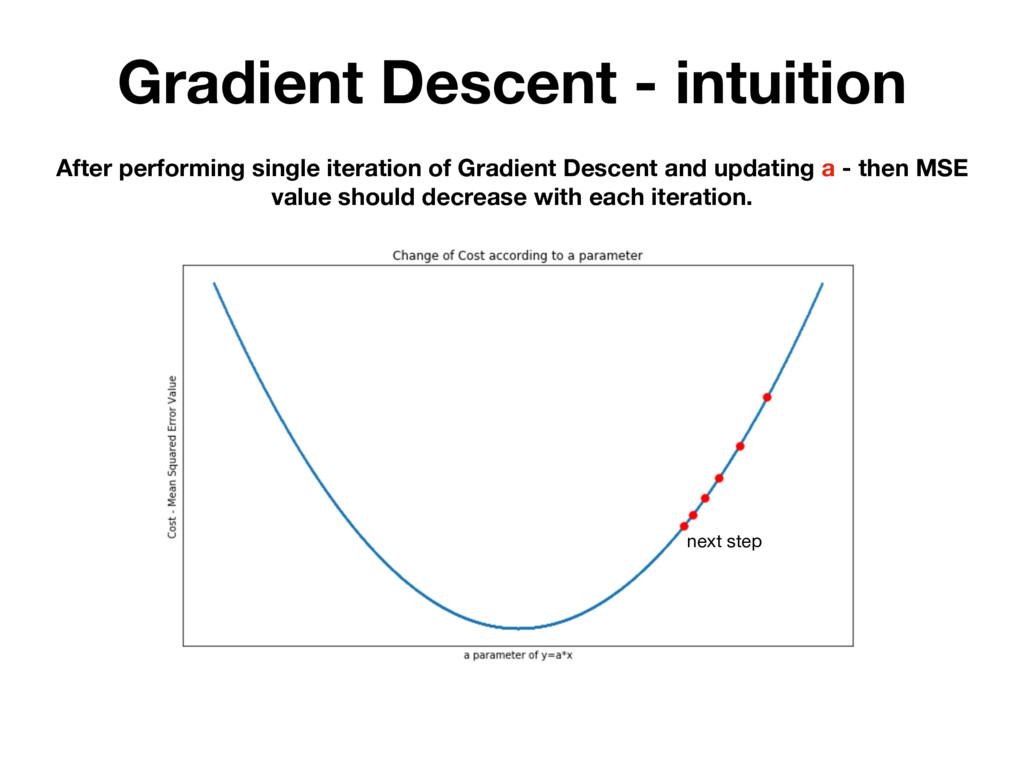
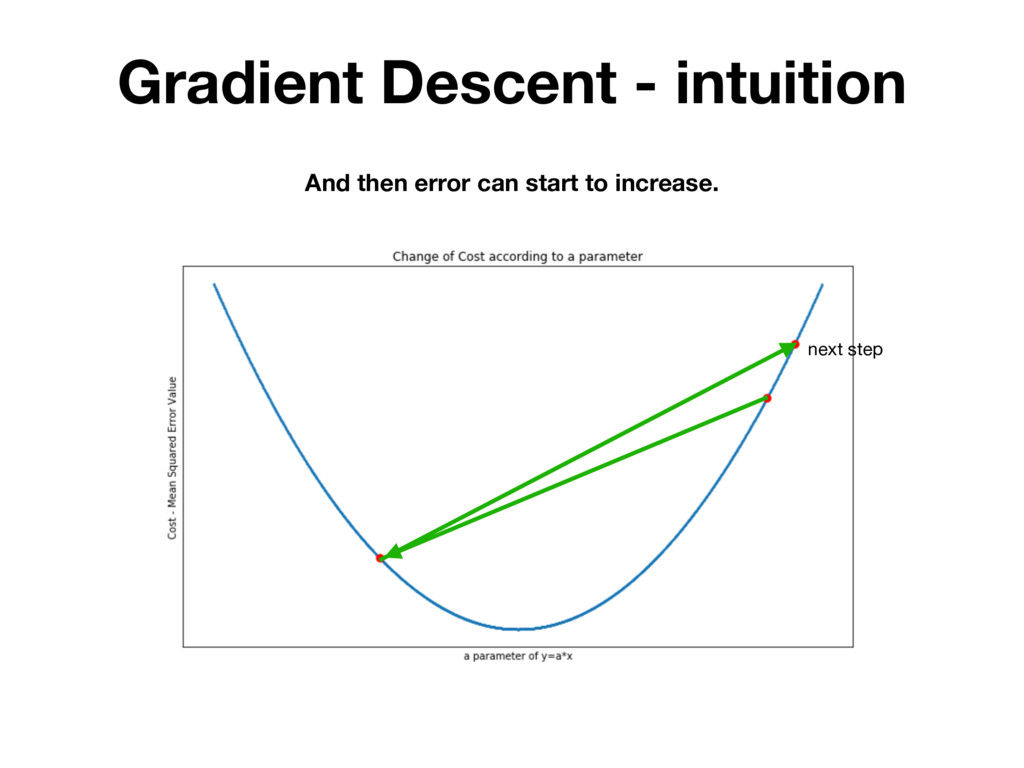
randomly testing many different parameters and picking the one for which MSE is the lowest. BUT IT'S INEFFICIENT! There is a mathematical method that allows you to change h(x) parameters in many iterations. Which each iteration MSE value is getting closer to it’s local minimum.
h(x) you want to find h(x) = a * x + b parameters to find: a, b Step 2: Decide on function that measures efficiency of h(x) Mean Squared Errors the lower value the better a, b parameters
h(x) you want to find h(x) = a * x + b parameters to find: a, b Step 2: Decide on function that measures efficiency of h(x) Mean Squared Errors the lower value the better a, b parameters Step 3: Take derivatives of MSE in respect to a, b dMSE(h(x), y) da = dMSE(h(x), y) db =
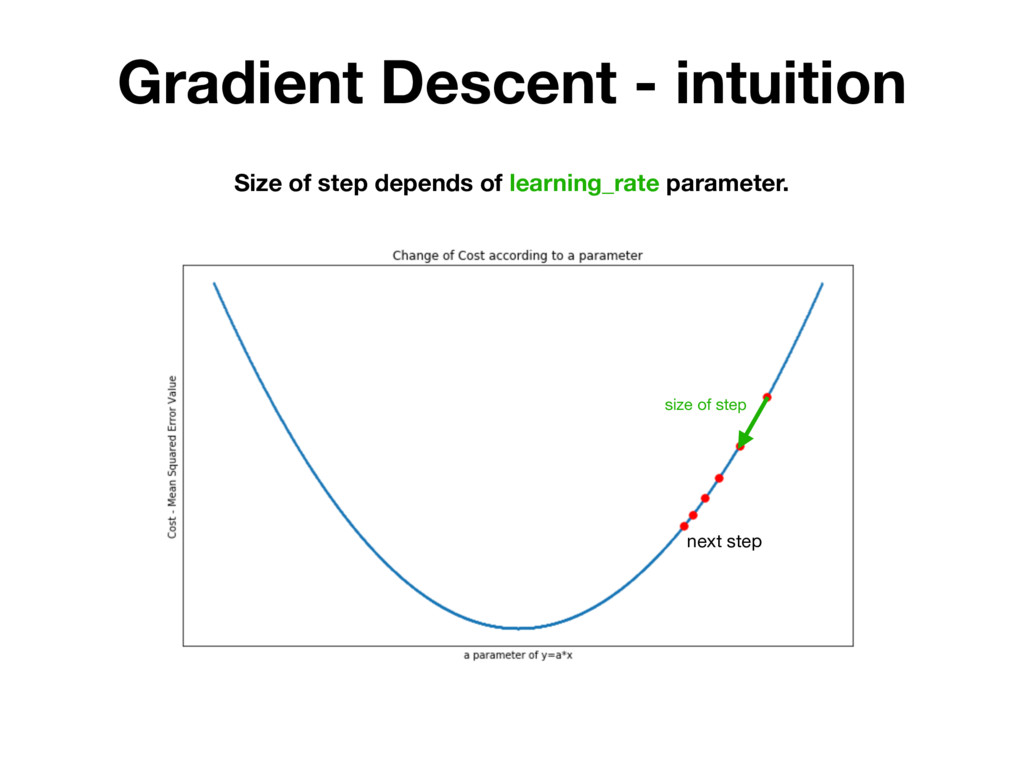
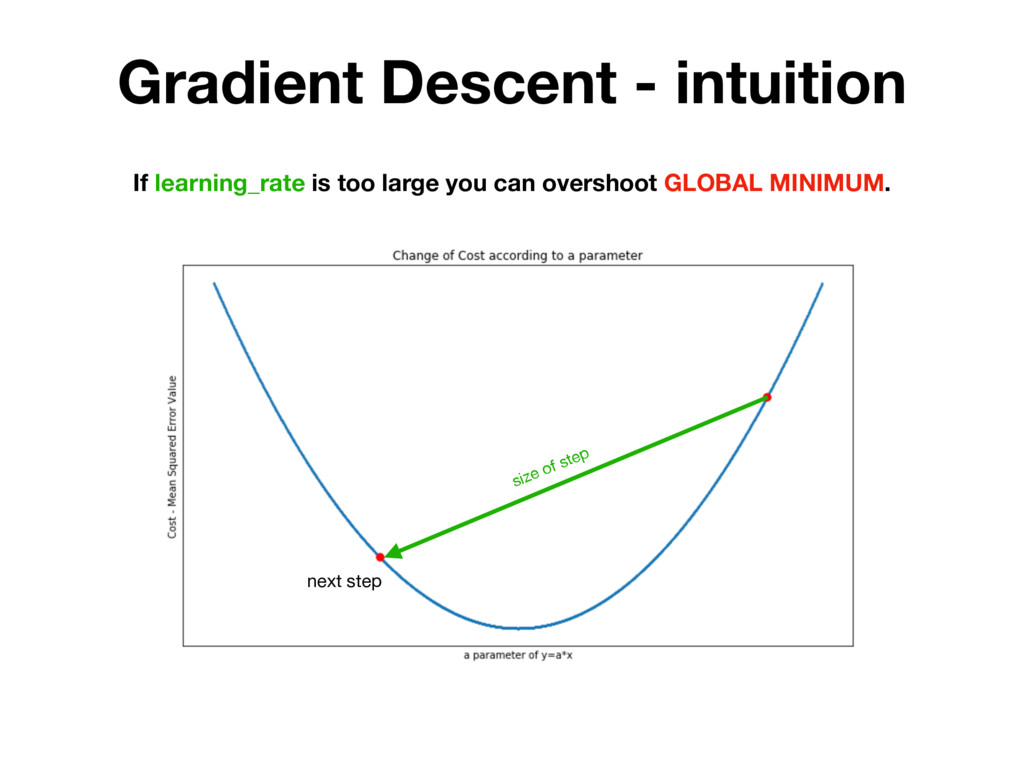
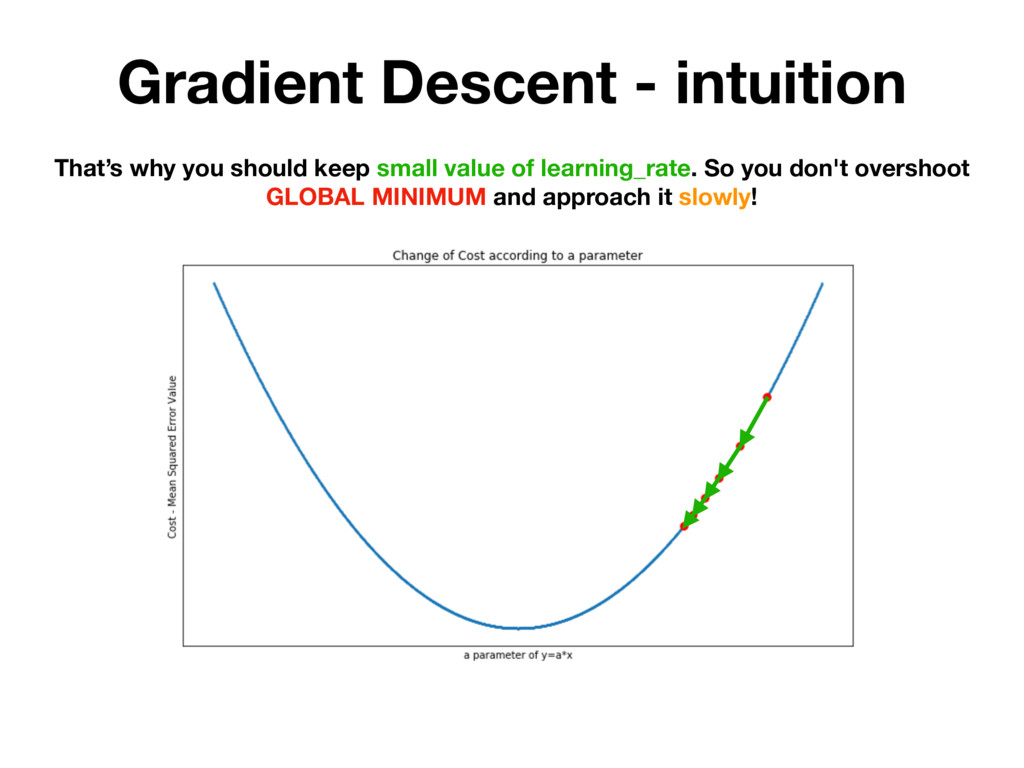
h(x) you want to find h(x) = a * x + b parameters to find: a, b Step 2: Decide on function that measures efficiency of h(x) Mean Squared Errors the lower value the better a, b parameters Step 3: Take derivatives of MSE in respect to a, b dMSE(h(x), y) da = dMSE(h(x), y) db = Step 4: Update a, b a = a - lr * b = b - lr * dMSE(h(x), y) da dMSE(h(x), y) db lr - small value between 0.001 - 0.1
h(x) you want to find h(x) = a * x + b parameters to find: a, b Step 2: Decide on function that measures efficiency of h(x) Mean Squared Errors the lower value the better a, b parameters Step 3: Take derivatives of MSE in respect to a, b dMSE(h(x), y) da = dMSE(h(x), y) db = Step 4: Update a, b a = a - lr * b = b - lr * dMSE(h(x), y) da dMSE(h(x), y) db lr - small value between 0.001 - 0.1 REPEAT UNTIL MSE IS SMALL
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}