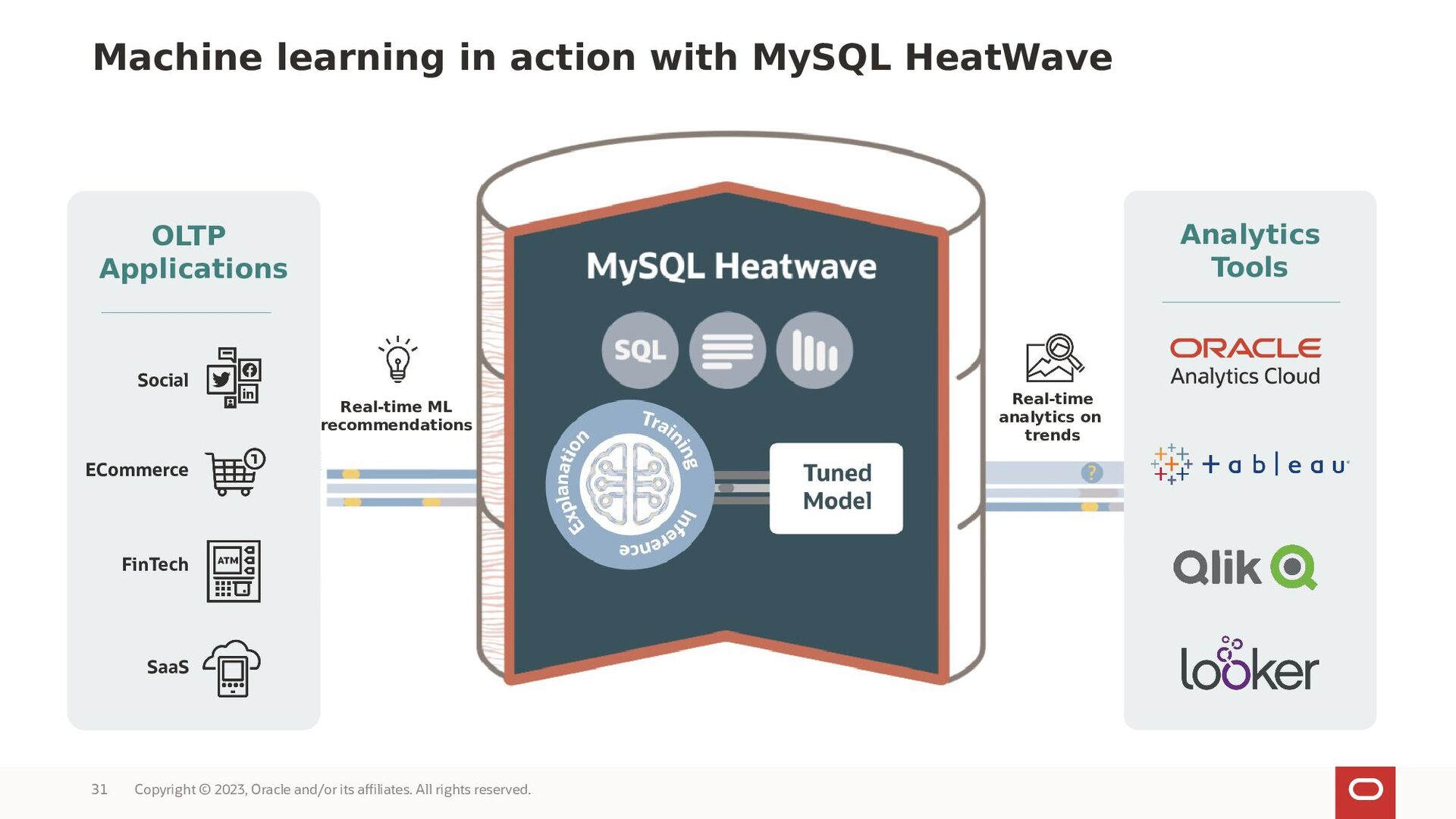
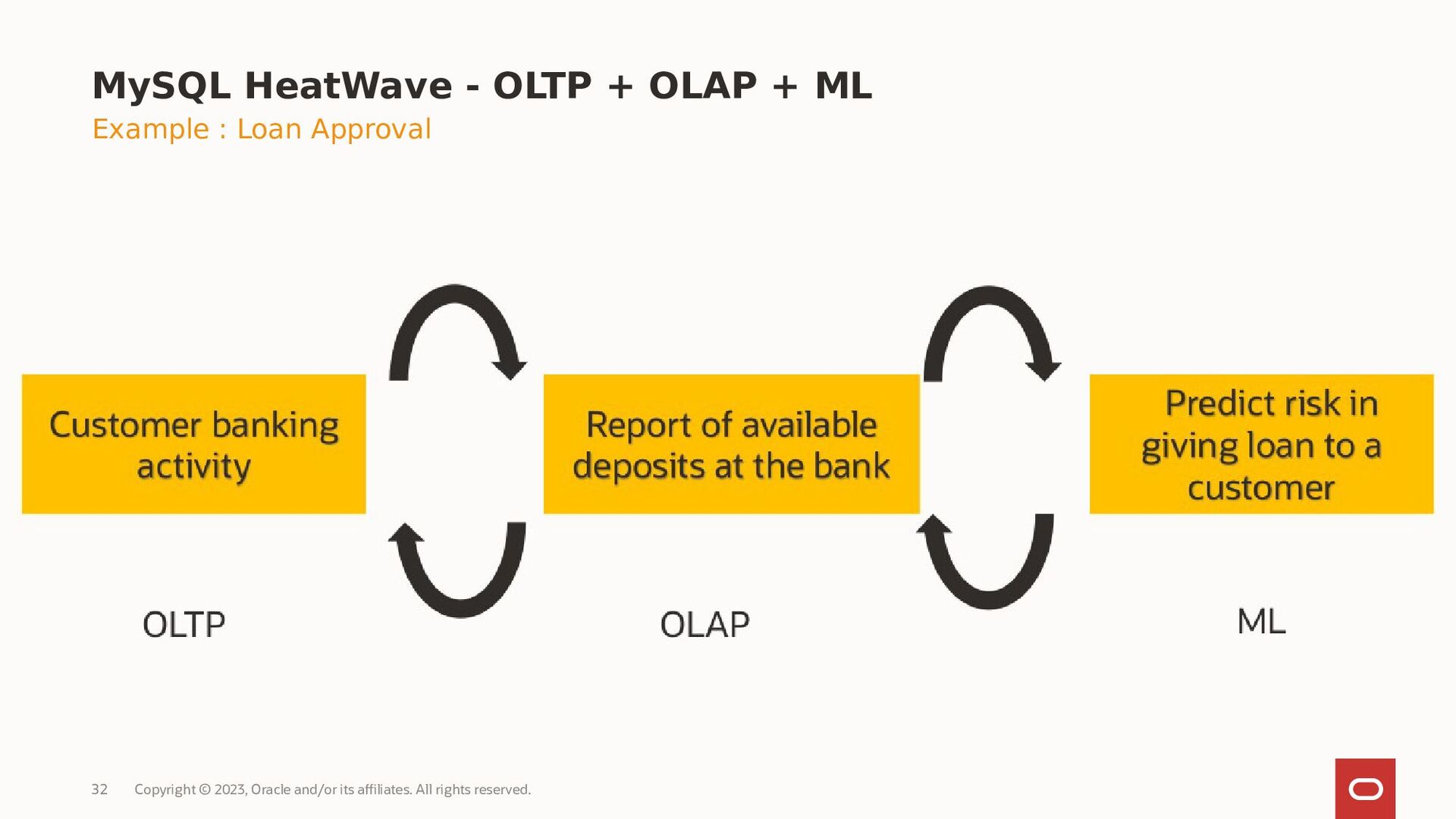
MySQL HeatWave is the only MySQL database service for OLTP, OLAP, ML, and Lakehouse. In this webinar, we will focus on the machine learning capabilities and will explain why it makes it easy to create new ML models for your MySQL applications.
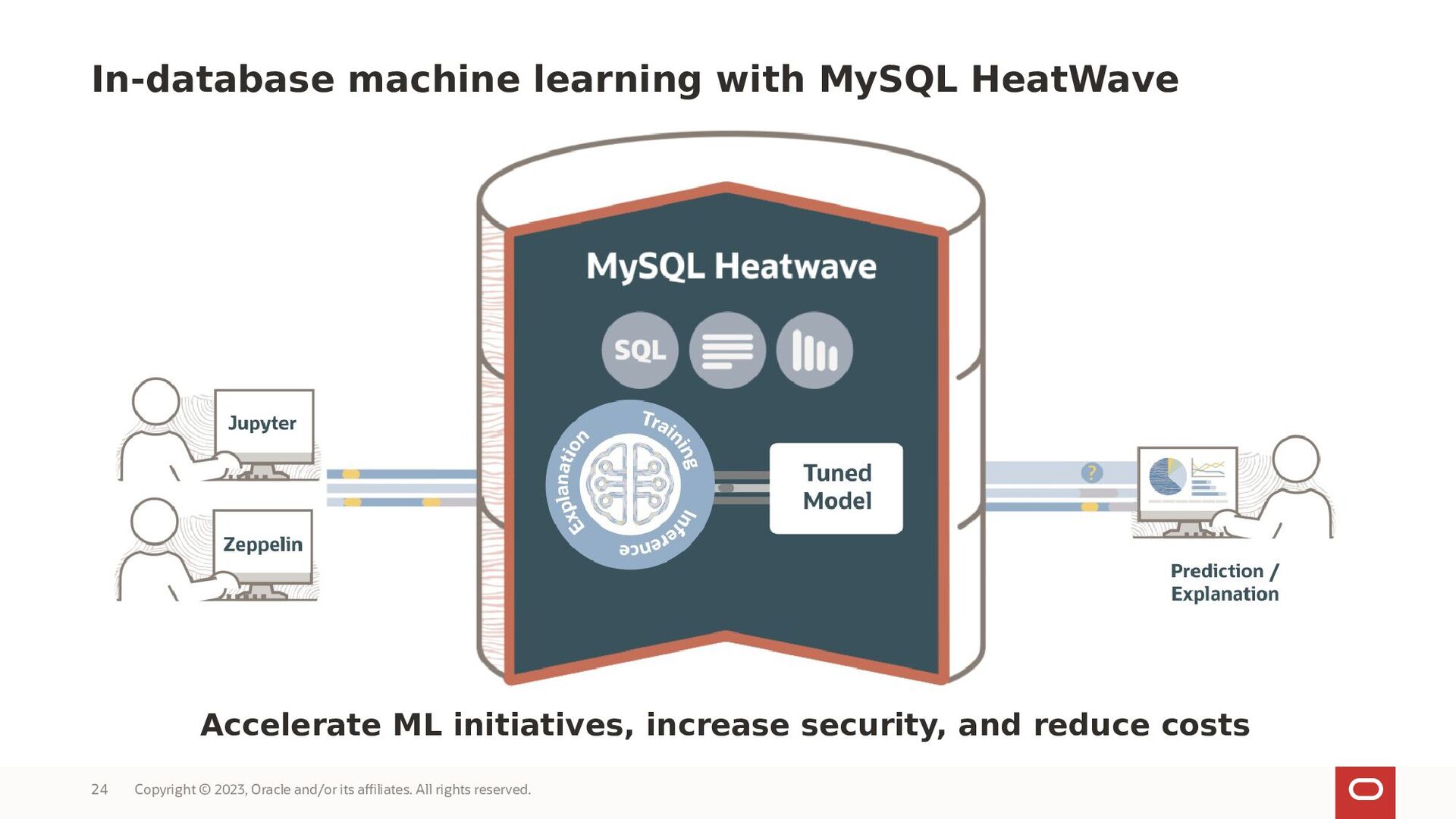
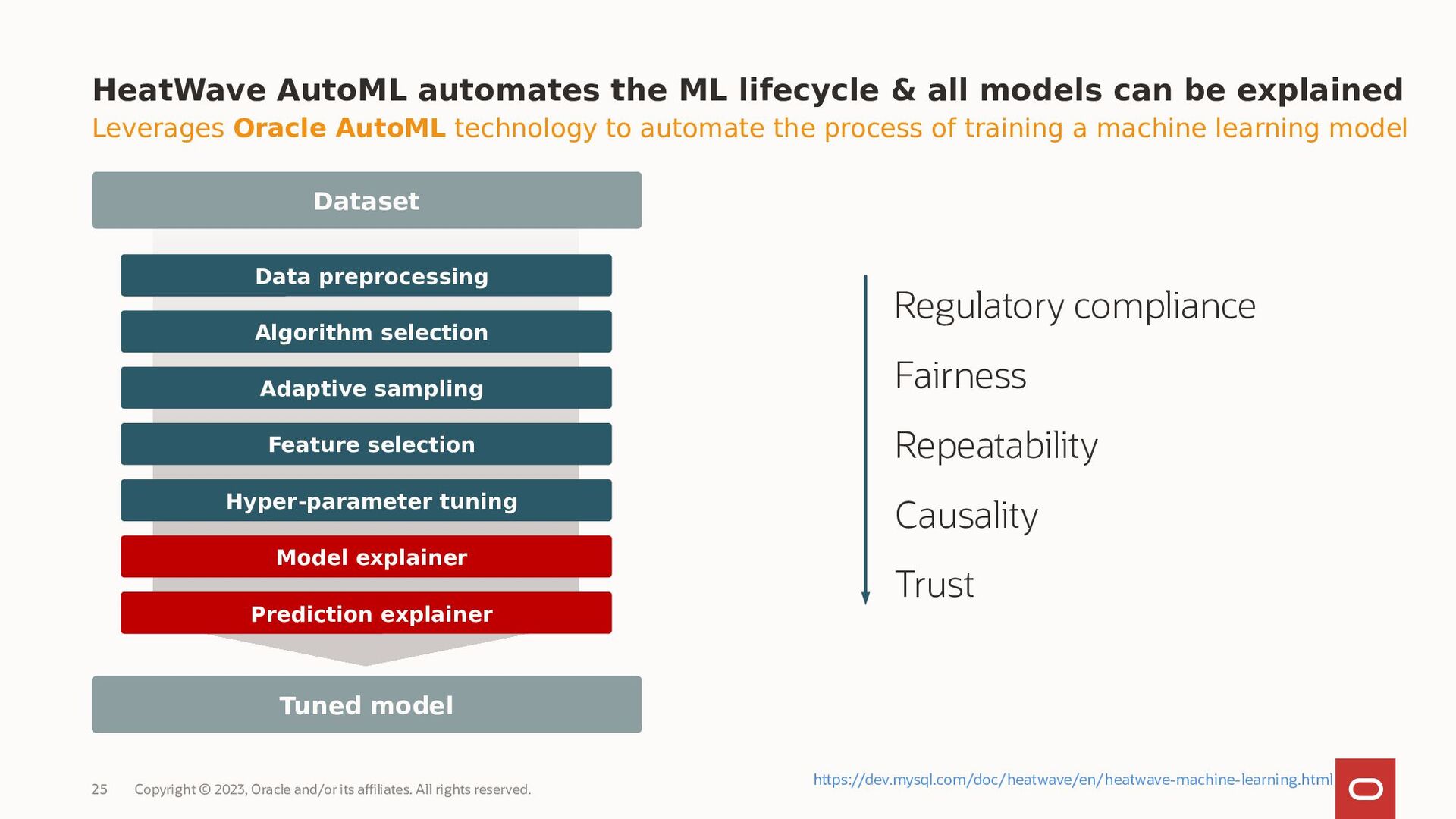
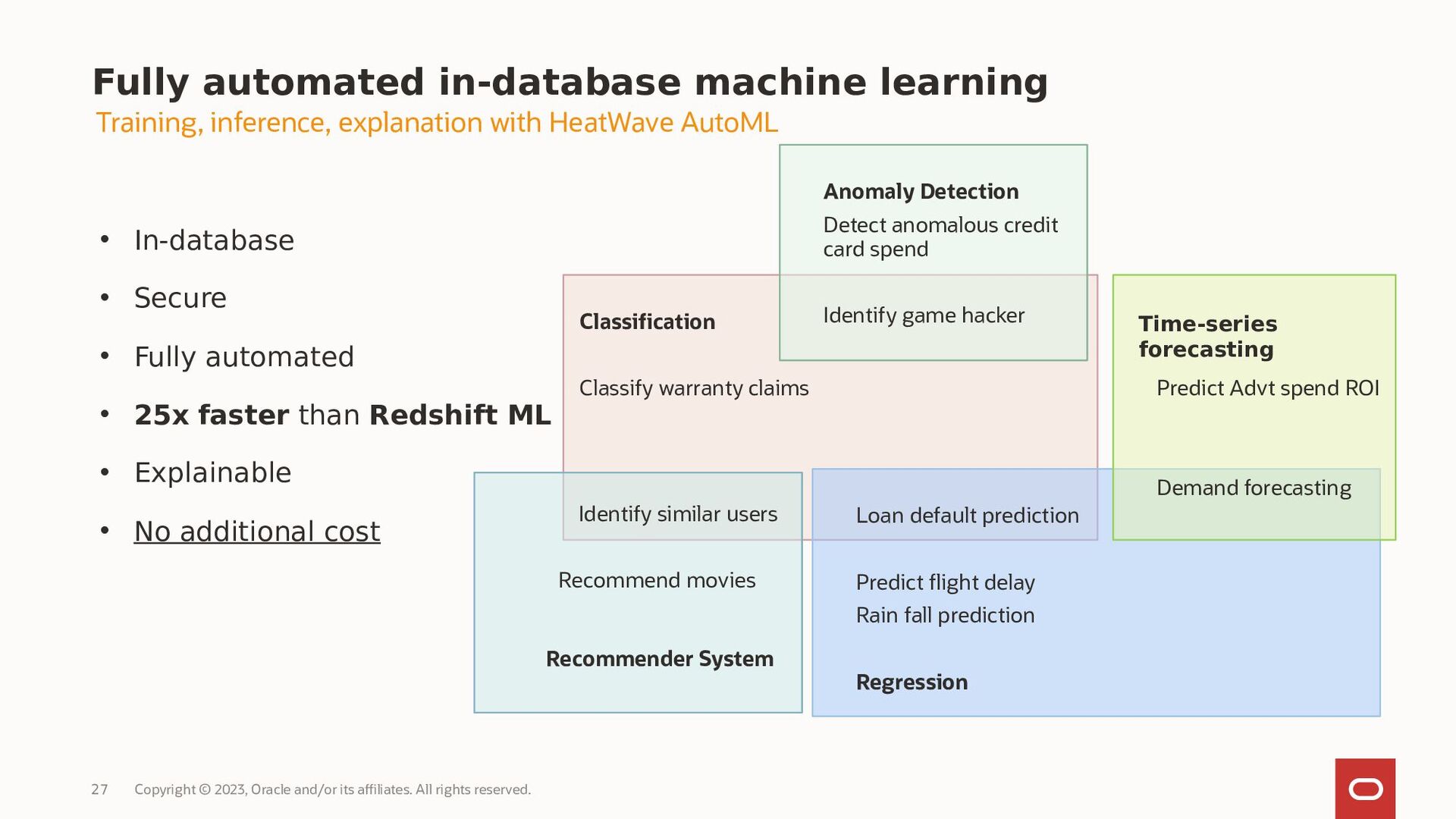
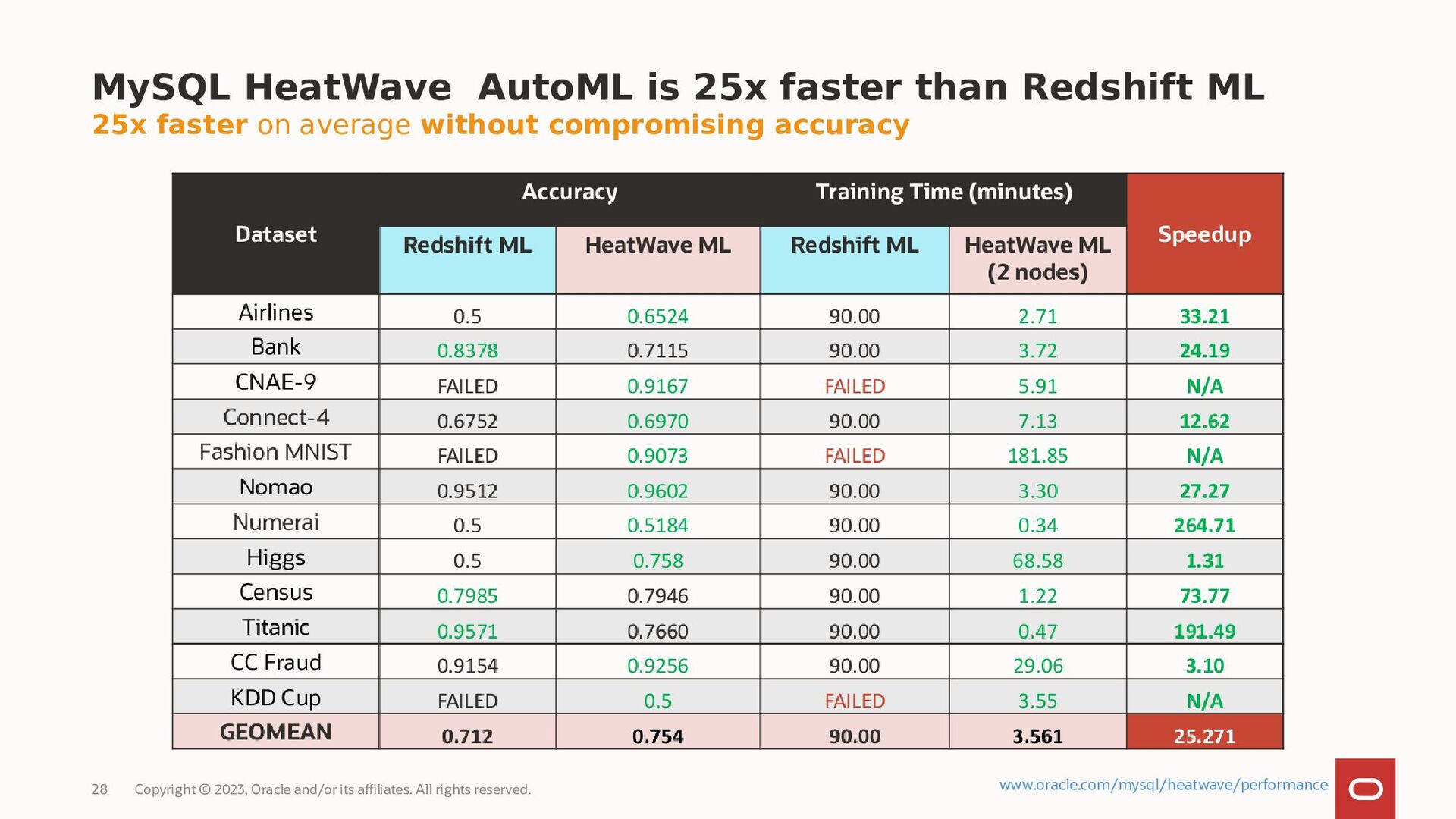
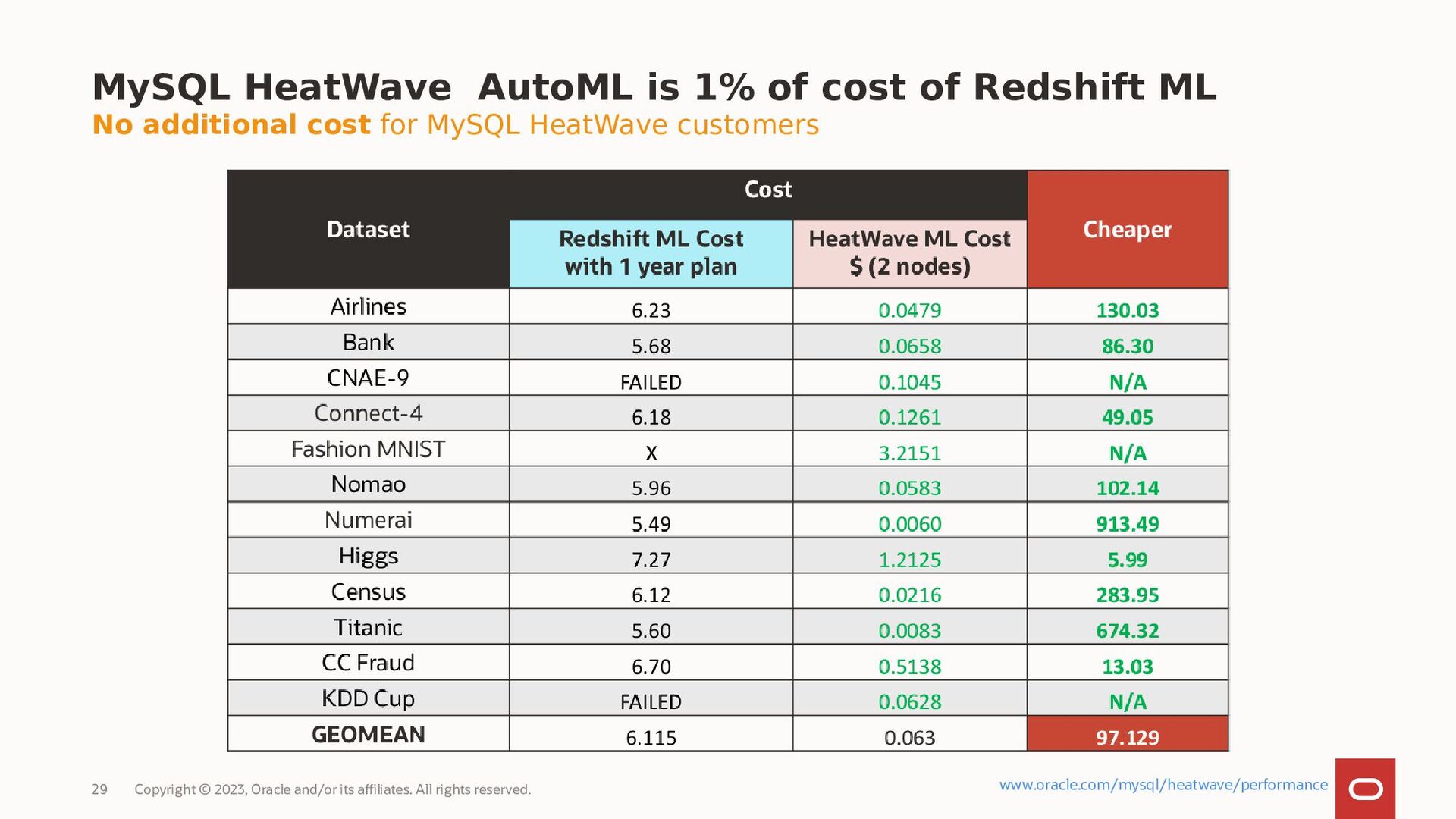
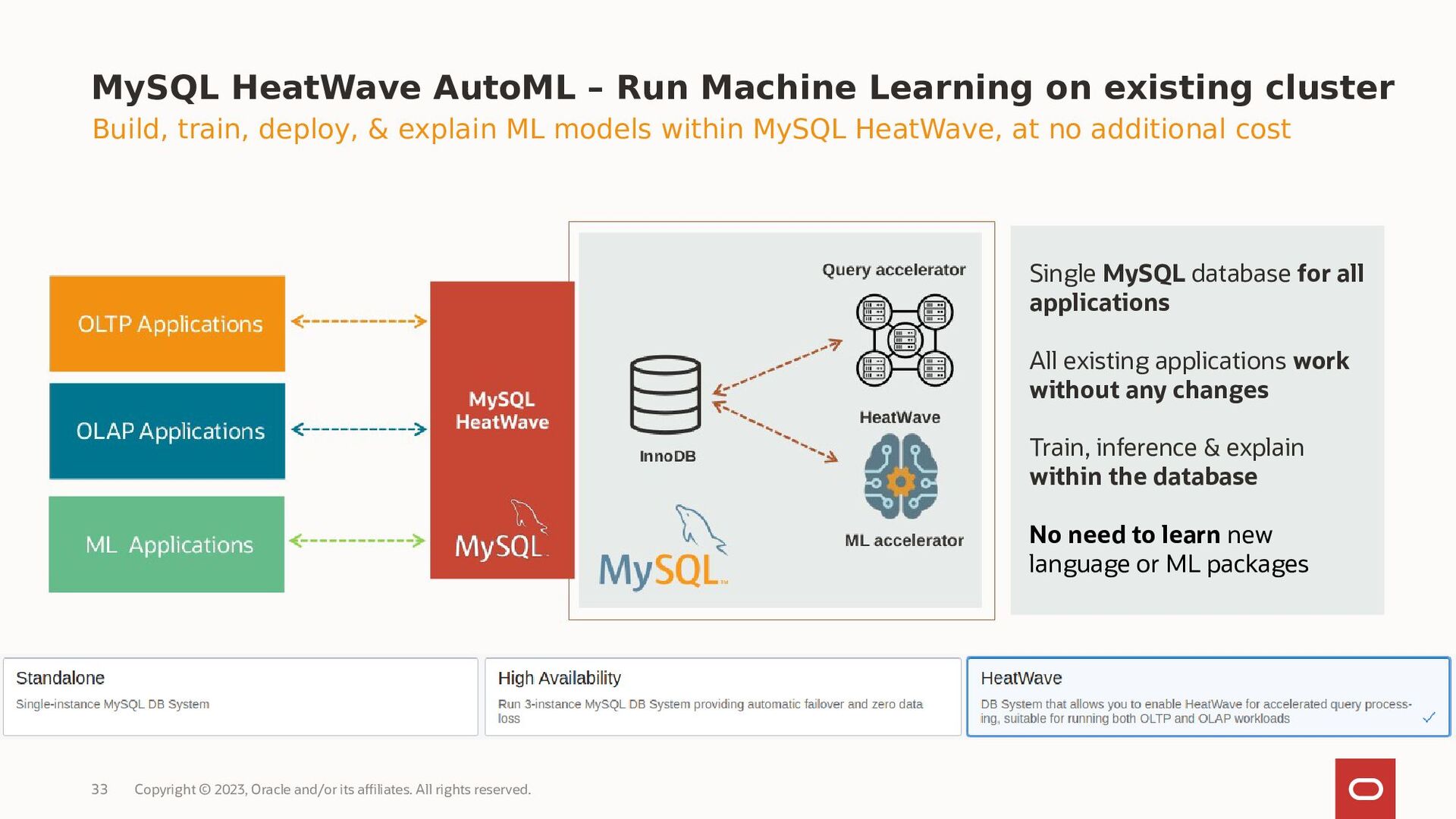
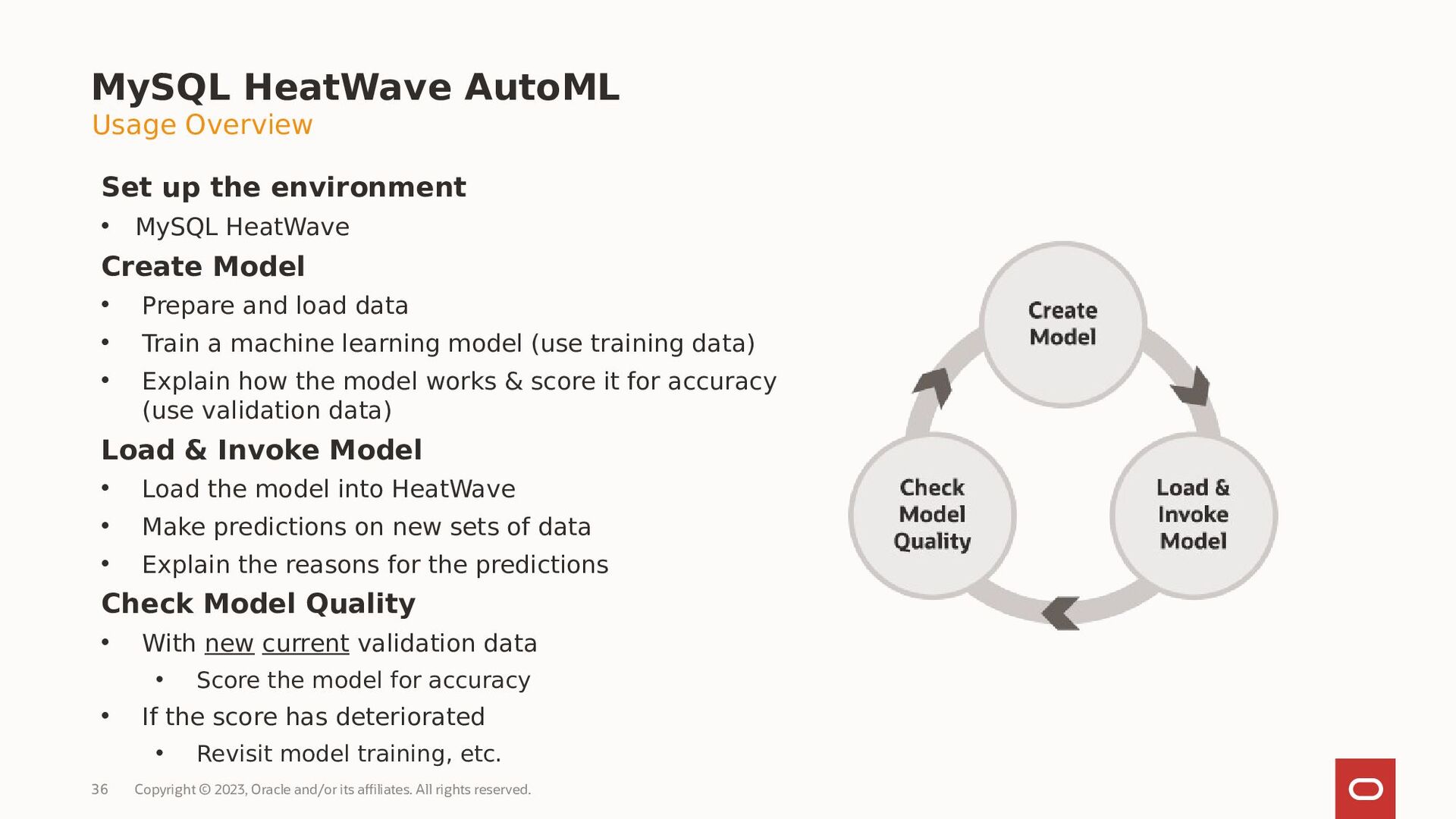
MySQL HeatWave AutoML includes everything users need to build, train, deploy, and explain machine learning models within MySQL HeatWave, at no additional cost.
You will learn:
- What is needed to start using ML with MySQL
- How MySQL HeatWave AutoML works
- What ML algorithms can be used with MySQL HeatWave AutoML
- How to configure ML models with your data
- How to explain the results provided by MySQL HeatWave AutoML
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
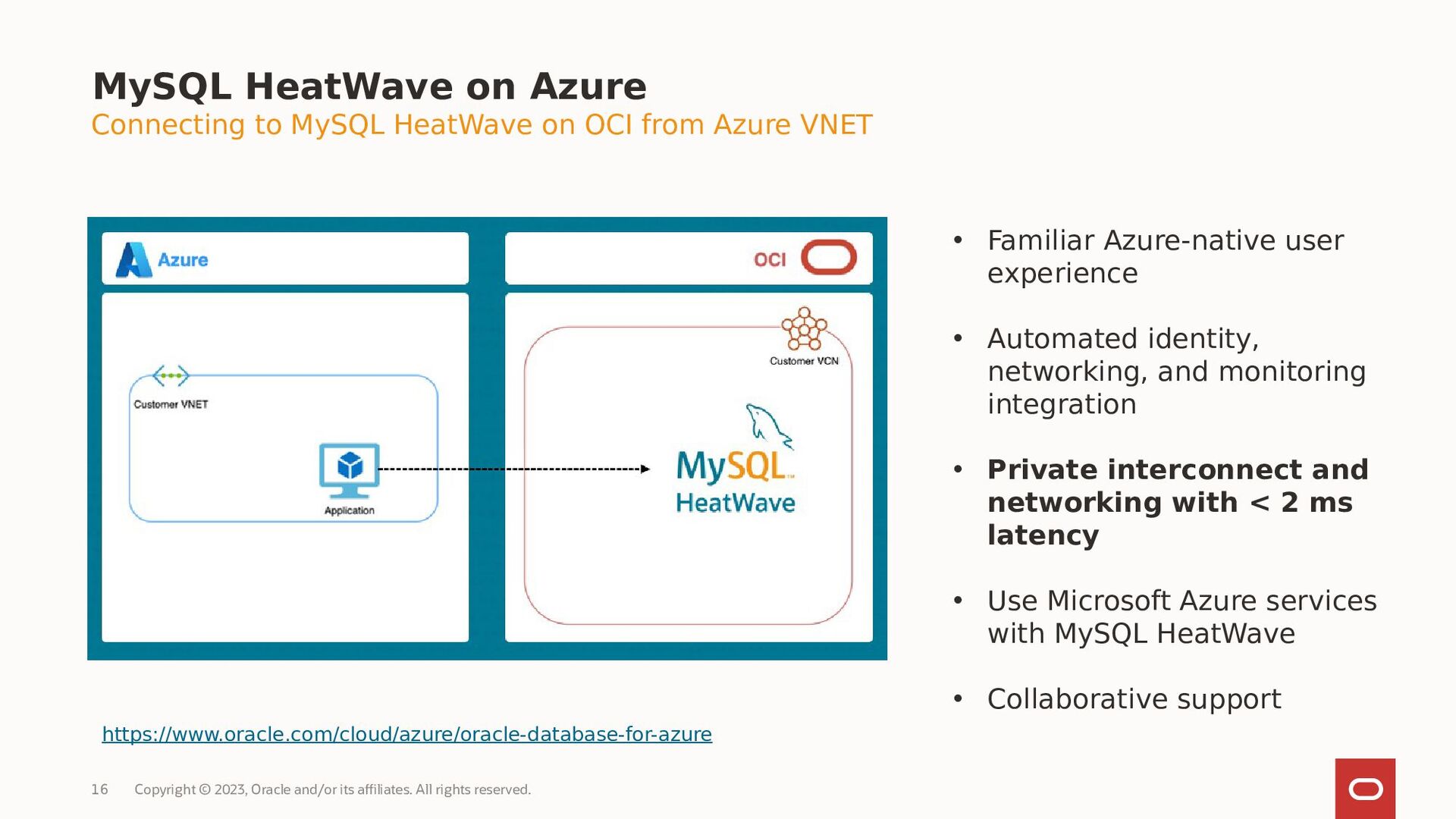{kind=link}
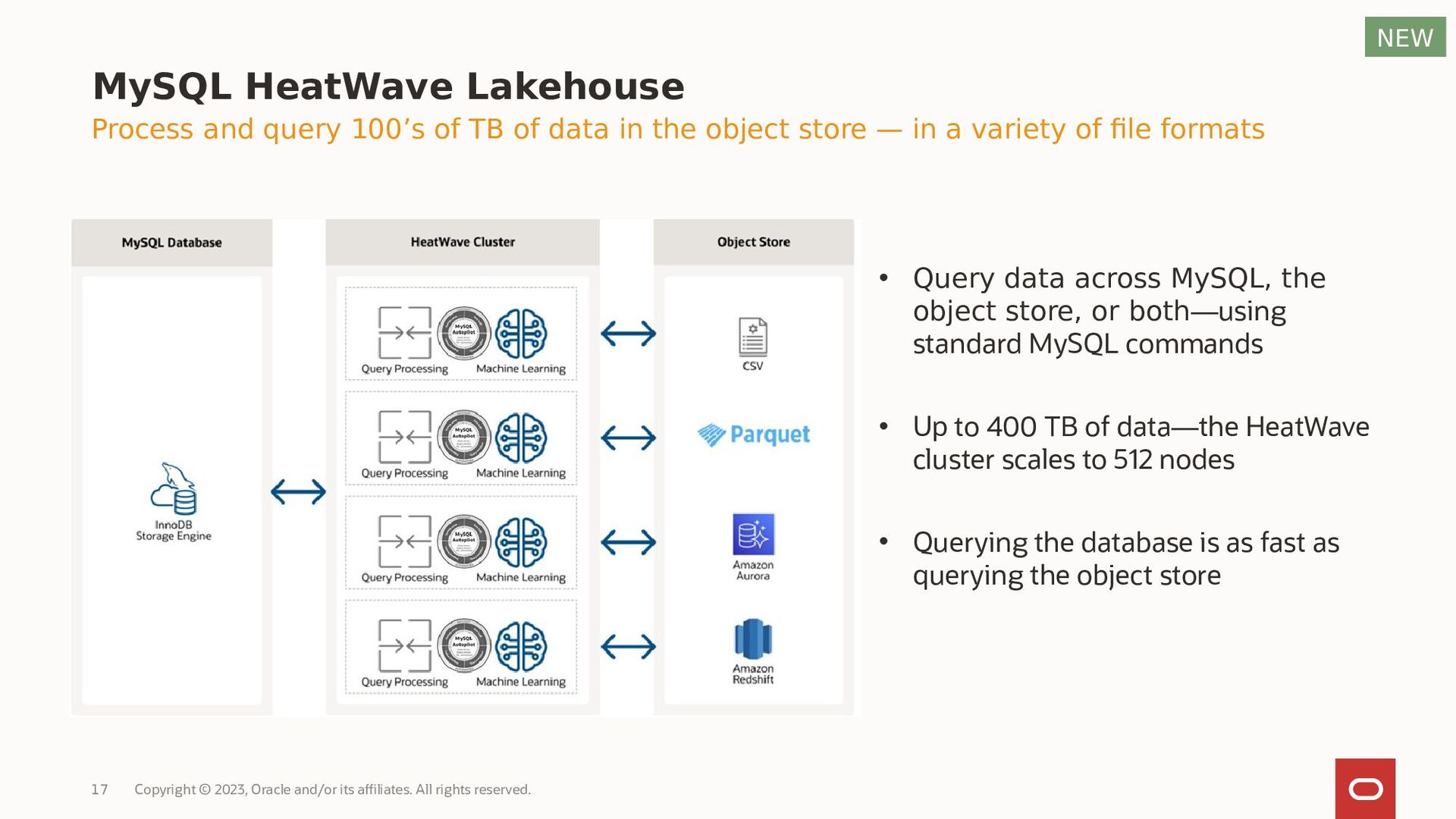{kind=link}
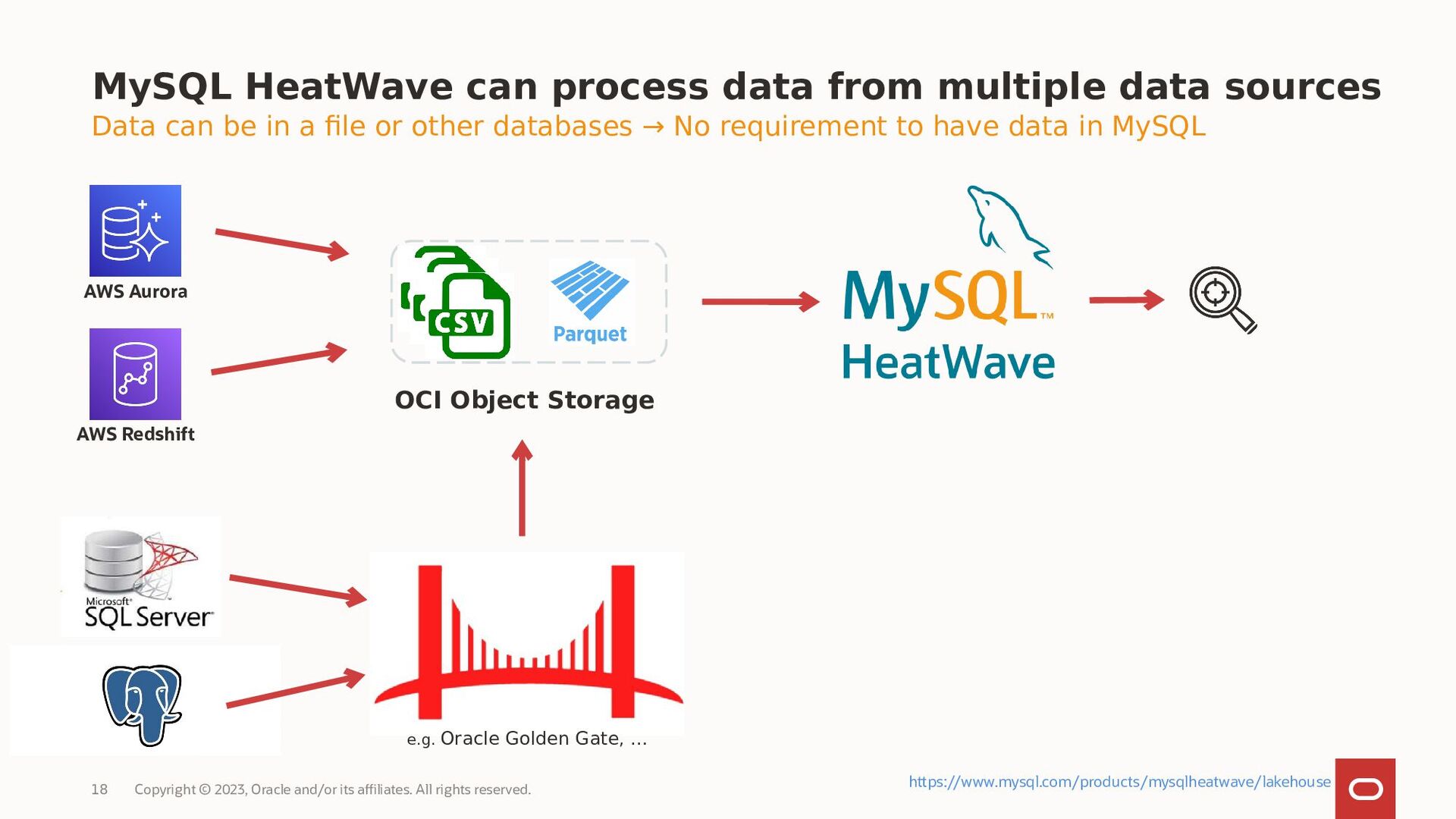{kind=link}
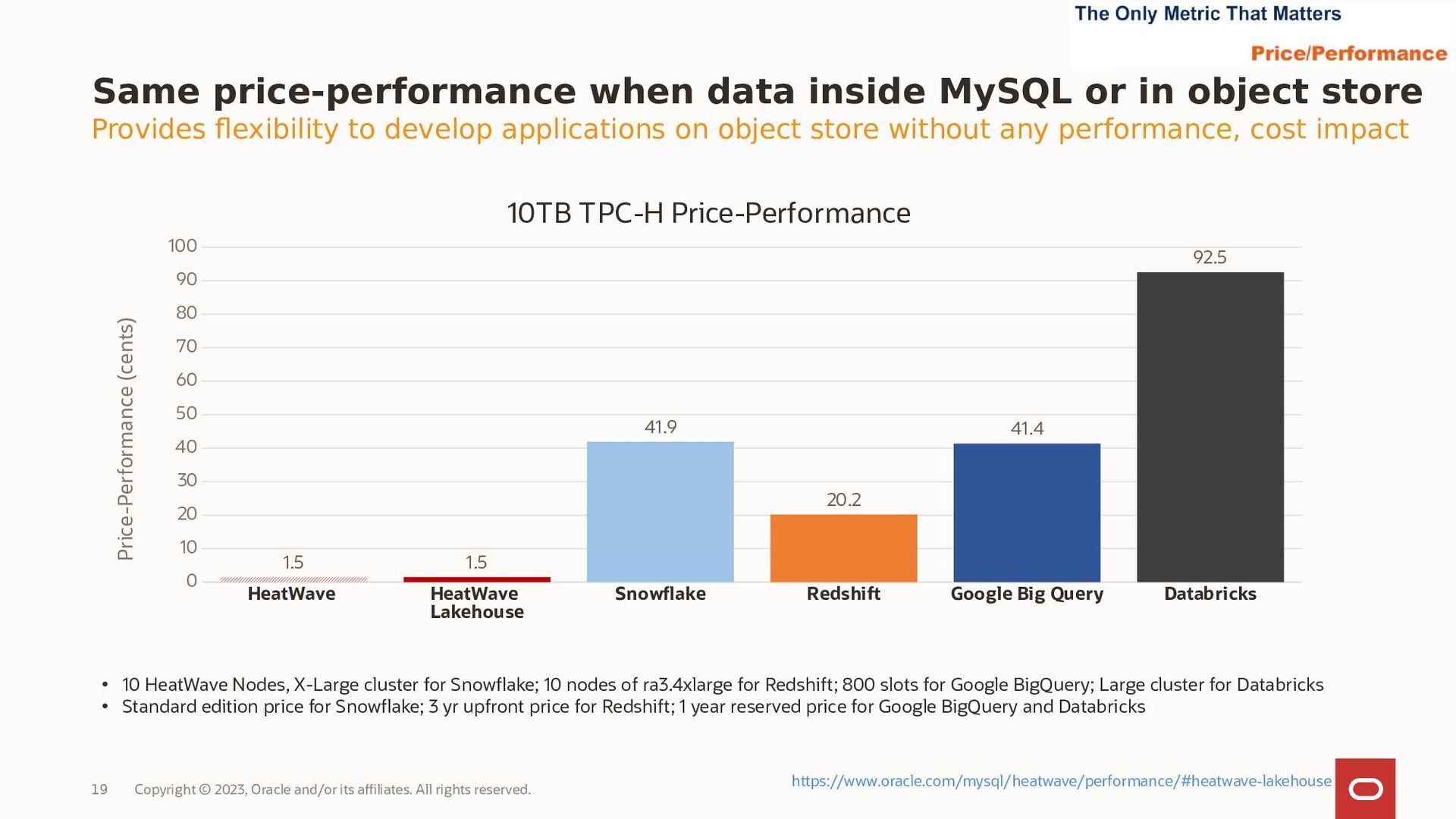{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}