Software Quality Journal paper presented at ICST'21 as journal-first paper.
DOI: https://dx.doi.org/10.1007/s11219-019-09446-5
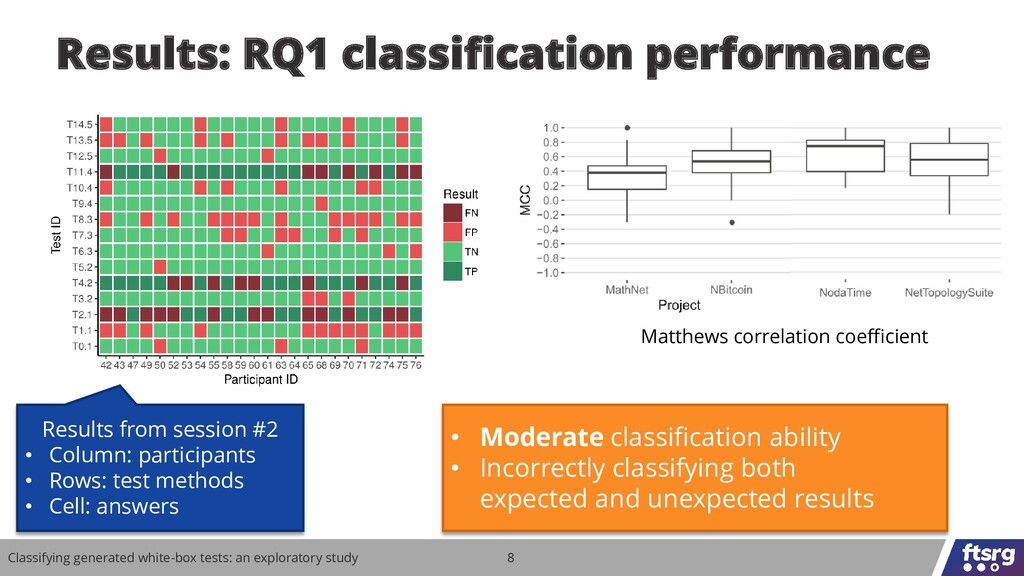
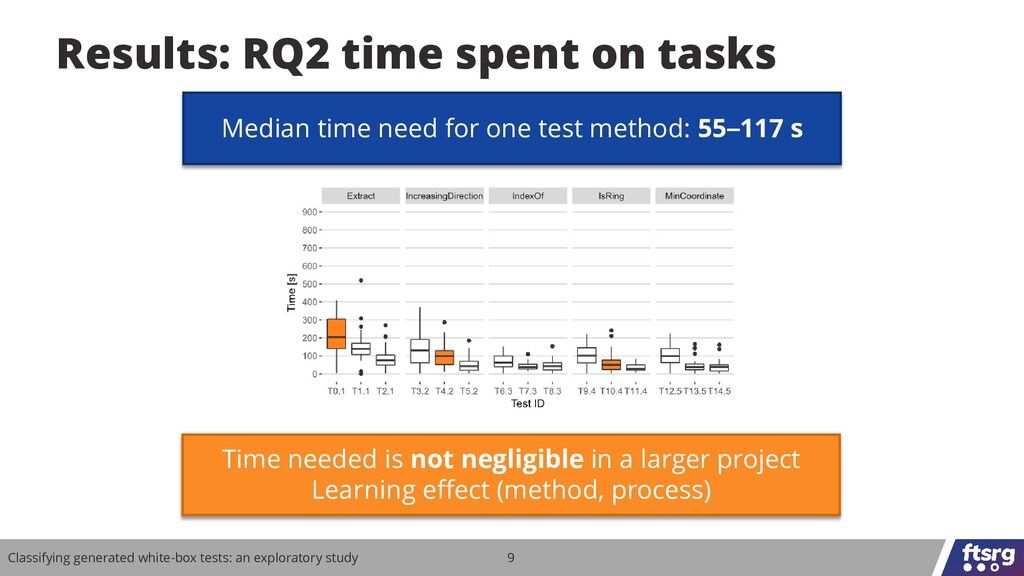
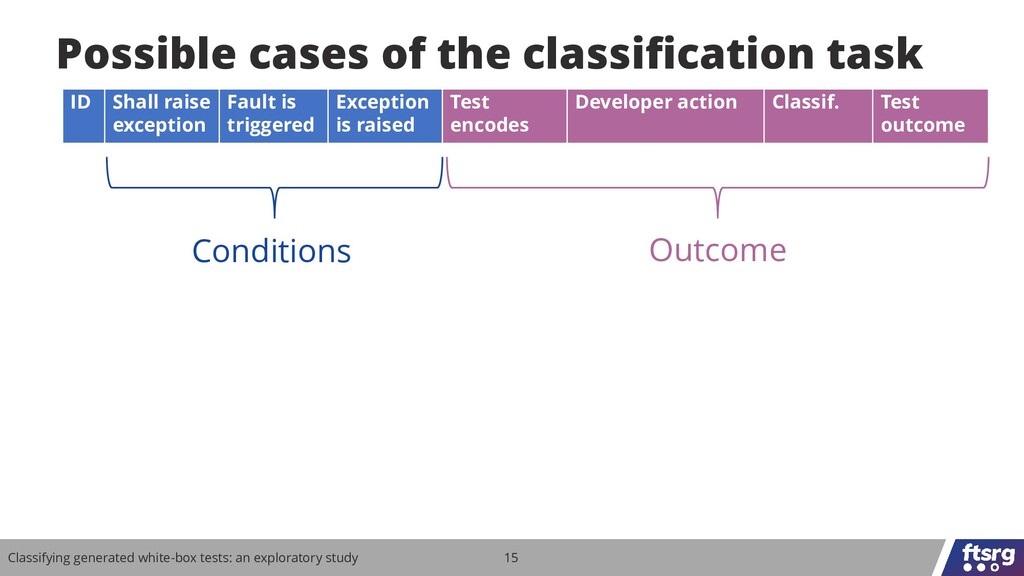
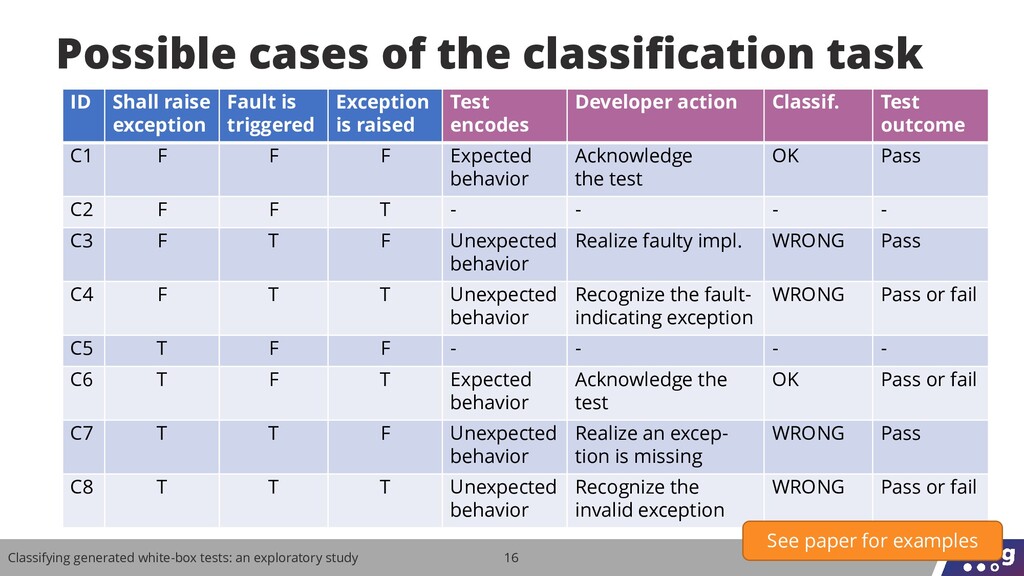
Can developers understand tests generated from the source code? We performed a study with 106 participants and the results show that this is a non-trivial task that can affect the practical fault-finding capability of test generators.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}