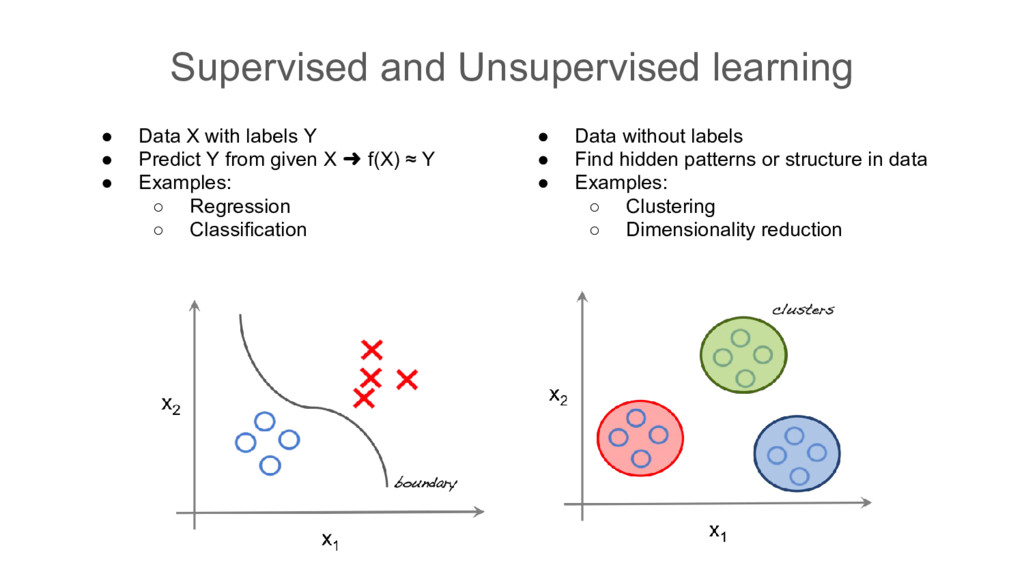
• Predict Y from given X ➜ f(X) ≈ Y • Examples: ◦ Regression ◦ Classification • Data without labels • Find hidden patterns or structure in data • Examples: ◦ Clustering ◦ Dimensionality reduction
above. • Both labeled and unlabeled examples are present in dataset. But data is mostly unlabeled. • In many real world applications getting labels is expensive, on the contrary there can be a lot of unlabeled data. • Semi supervised methods help put surplus of unlabeled data to use.
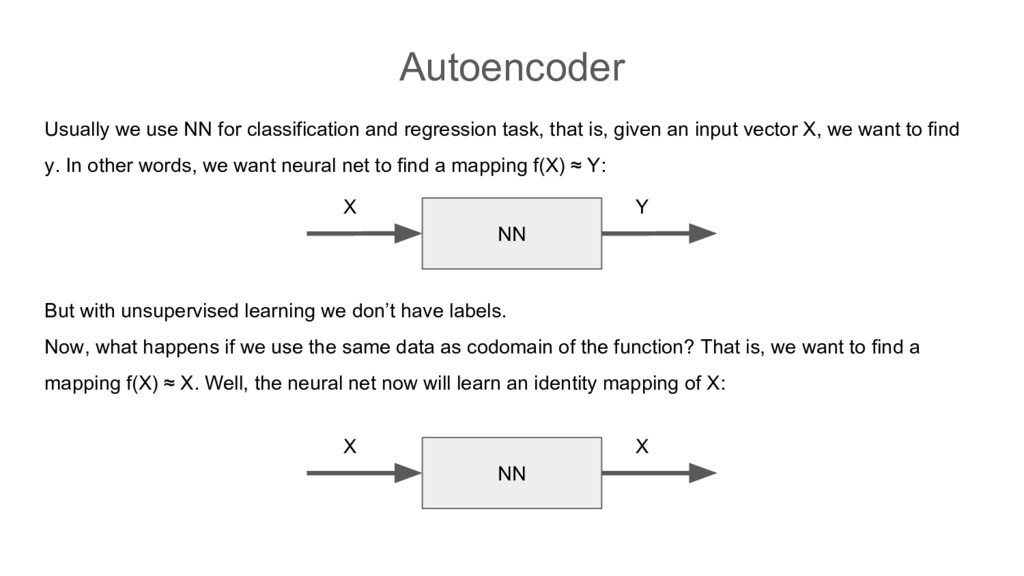
that is, given an input vector X, we want to find y. In other words, we want neural net to find a mapping f(X) ≈ Y: But with unsupervised learning we don’t have labels. Now, what happens if we use the same data as codomain of the function? That is, we want to find a mapping f(X) ≈ X. Well, the neural net now will learn an identity mapping of X: NN X Y NN X X
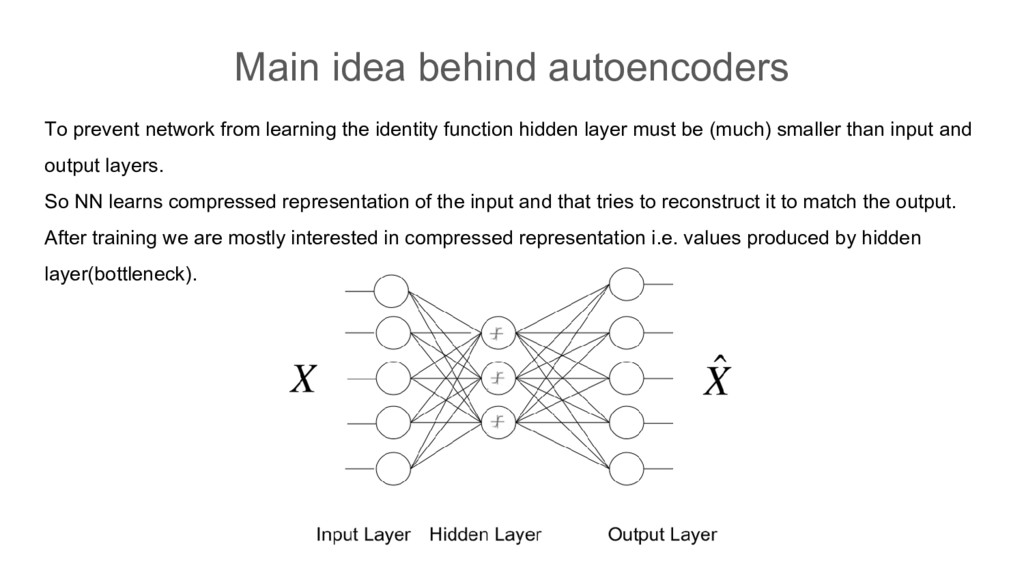
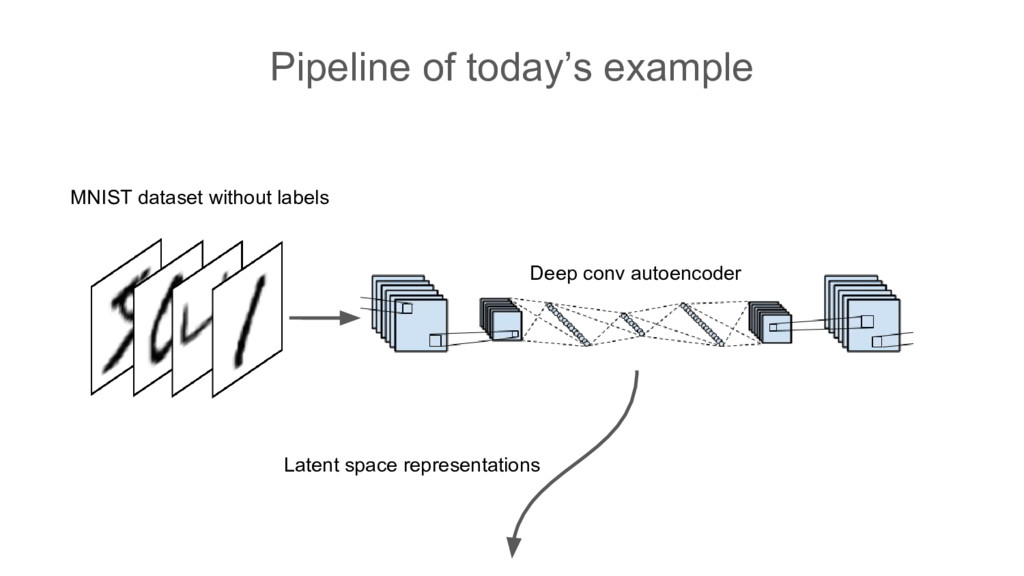
identity function hidden layer must be (much) smaller than input and output layers. So NN learns compressed representation of the input and that tries to reconstruct it to match the output. After training we are mostly interested in compressed representation i.e. values produced by hidden layer(bottleneck).
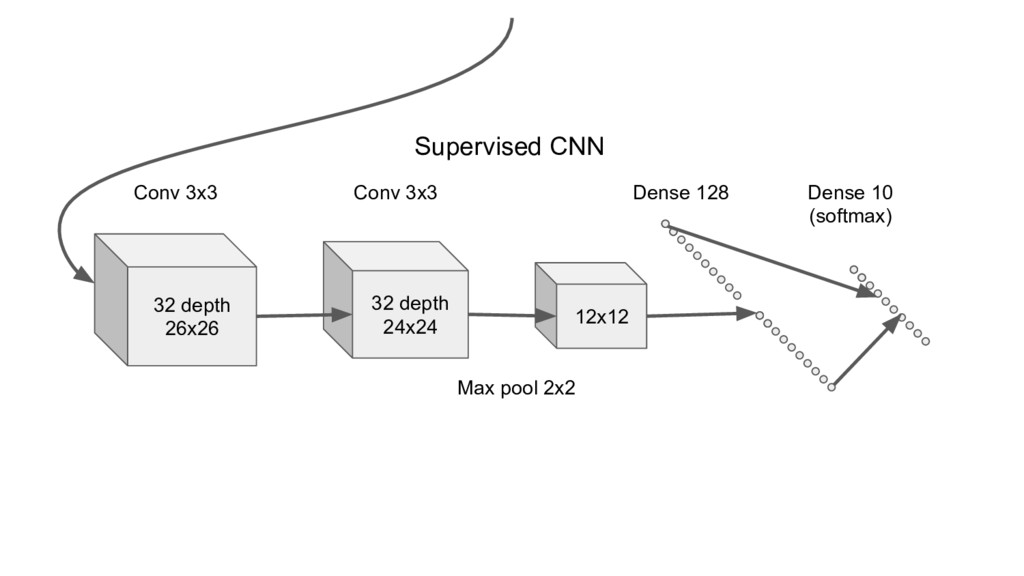
Here we have huge(25628*28) input space of all possible images. But the ones that we are meaningful for us are only tiny subset of it. Therefore there is hope that if we input only pictures that we are interested in, NN will be able to extract some more abstract features than raw pixel intensities ... ...
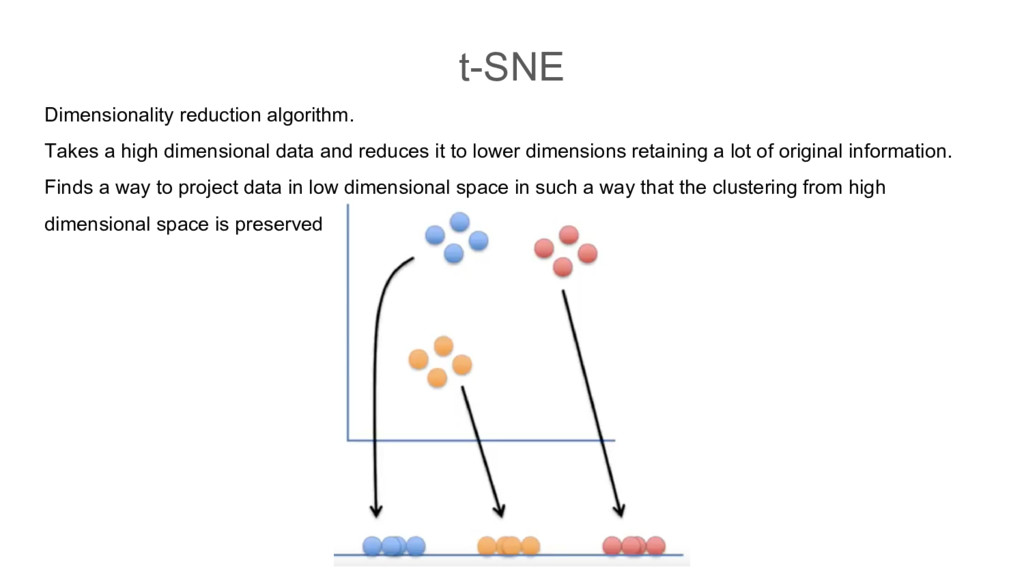
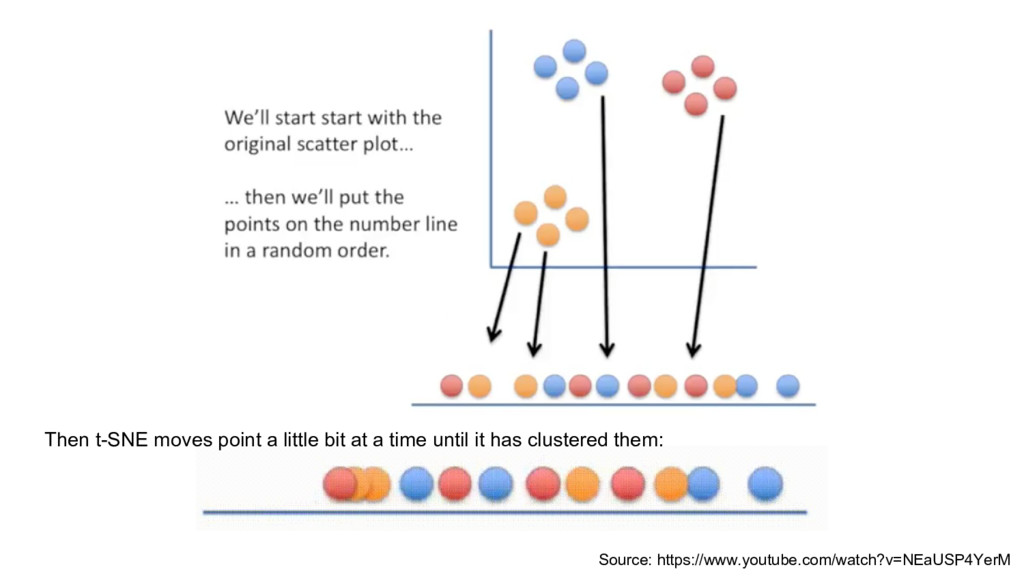
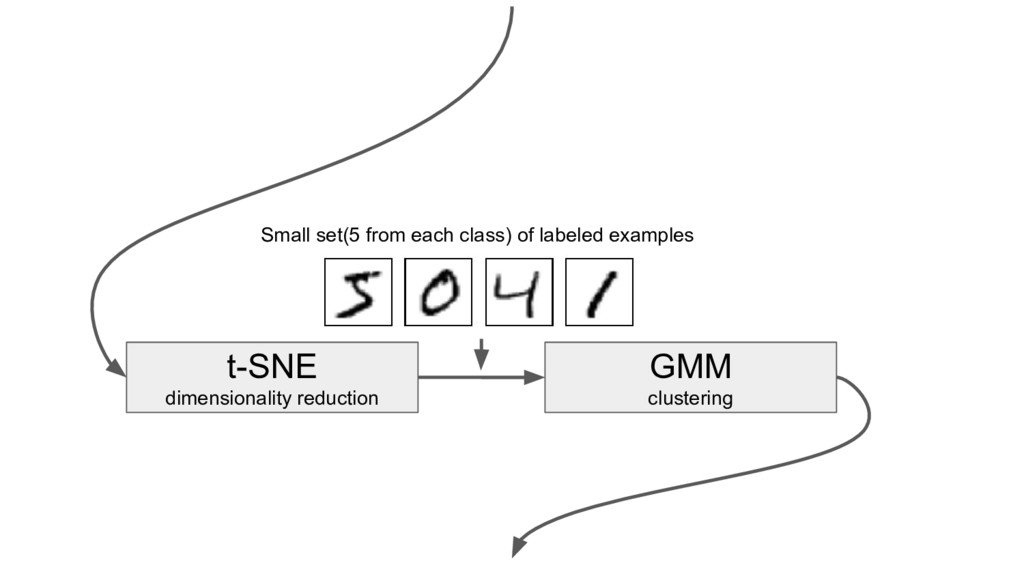
reduces it to lower dimensions retaining a lot of original information. Finds a way to project data in low dimensional space in such a way that the clustering from high dimensional space is preserved
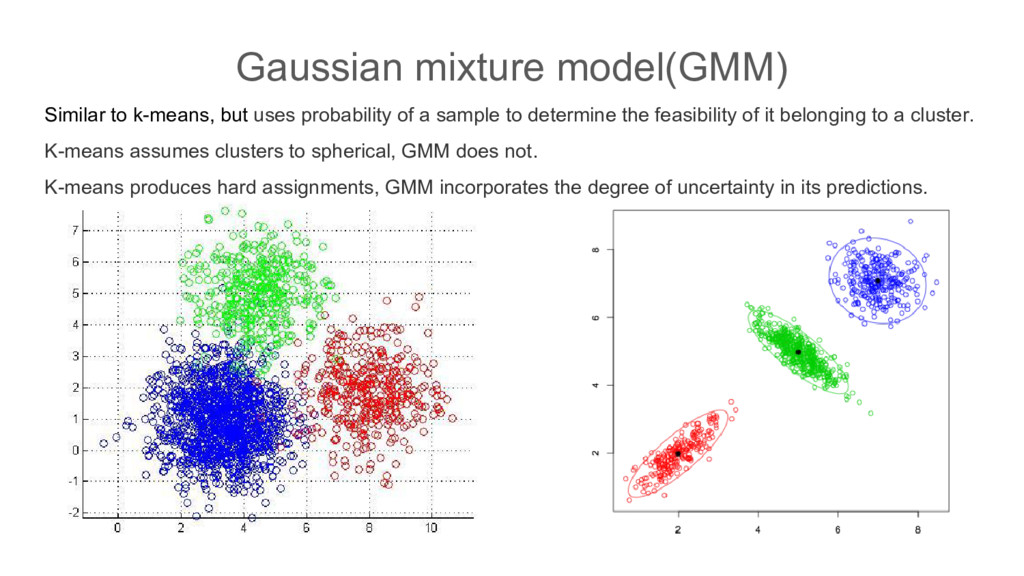
a sample to determine the feasibility of it belonging to a cluster. K-means assumes clusters to spherical, GMM does not. K-means produces hard assignments, GMM incorporates the degree of uncertainty in its predictions.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}