Peeking Behind the Curtain: The Anatomy of a Major Incident
A largely unredacted true-story recap of a real major incident that occurred at PagerDuty. The incident is shared in full to demonstrate how we approach system failures with response and postmortem processes you can use with your own teams.
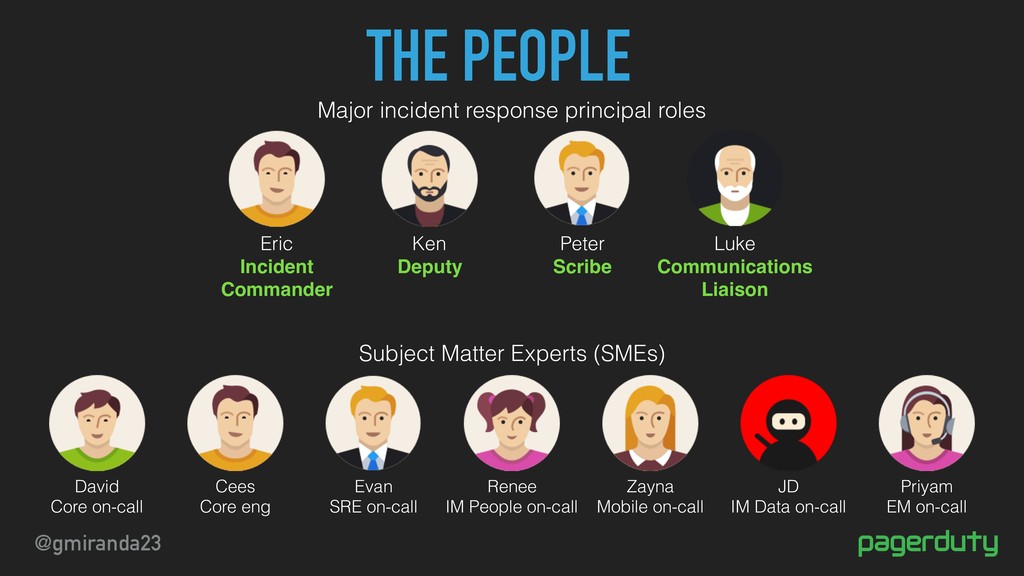
Luke Communications Liaison Major incident response principal roles David Core on-call Cees Core eng Evan SRE on-call Renee IM People on-call Zayna Mobile on-call JD IM Data on-call Priyam EM on-call Subject Matter Experts (SMEs)
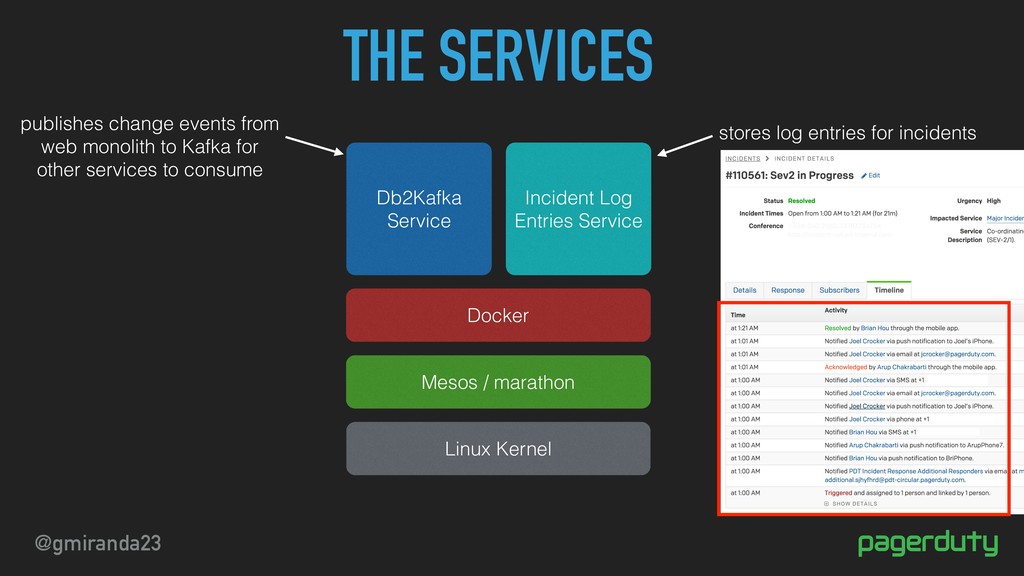
BOT Paging Incident Commander(s) ✔ Eric has been paged. ✔ Ken has been paged. ✔ Peter has been paged. Incident triggered in the following service: https://pd.pagerduty.com/services/PERDDFI David: SME db2kafka is down, and I'm not sure what's going on kicked off the major incident process [3:21 PM] Eric: IC Taking IC [incident command] Eric took the Incident Commander role (he was the IC primary on-call)
during a major incident • GOAL: drive the incident to resolution quickly and effectively • Gather data: ask subject matter experts to diagnose and debug various aspects of the system • Listen: collect proposed repair actions from SMEs • Decide: decide on a course of action • Act (via delegation): once a decision is made, ask the team to act on it. IC should always delegate all diagnosis and repair actions to the rest of the team.
• Monitor the status of the incident • Follow up on time-boxed tasks • Be prepared to page other people • Keep the IC focused on the incident THE DEPUTY (BACKUP IC)
to find Mesos experts Evan: Looking for logs & dashboards Zayna: SME seeing a steady rise in crashes in Android app around trigger incident log entires [3:24 PM] JD: SME No incident log entries will be generated due to Log Entry Service not being able to query db2kafka [3:25 PM] Eric: David, what have you looked at? David: trolling logs, see errors David: tried restarting, doesn’t help [3:23 PM] Ken: DEPUTY Notifications are still going out, subject lines are filled in but not email bodies (they use incident log entries) Renee: SME Peter becomes the scribe Discussing customer-visible impact of the incident Ken is both deputy and scribe
the chatroom when findings are determined or significant actions are taken • Add TODOs to the room that indicate follow- ups for later (generally after the incident) • Generate notes that will be helpful when reconstructing the timeline of events
issue affecting the incident log entries component of our web application causing the application to display errors. We are actively investigating." [3:29 PM] David: No incident log entries can be created Renee: no incident details, error msg in the UI [3:27 PM] Peter: SCRIBE Eric: Comms rep on the phone? Luke Eric to Luke: Please compose a message to our customers Peter: SCRIBE Eric: What’s the customer impact? [3:26 PM] Peter: SCRIBE Luke to post the message [to our status page and Twitter] Peter: SCRIBE Incident Commander asked the customer liaison to write a message to customers The message was sent out to customers
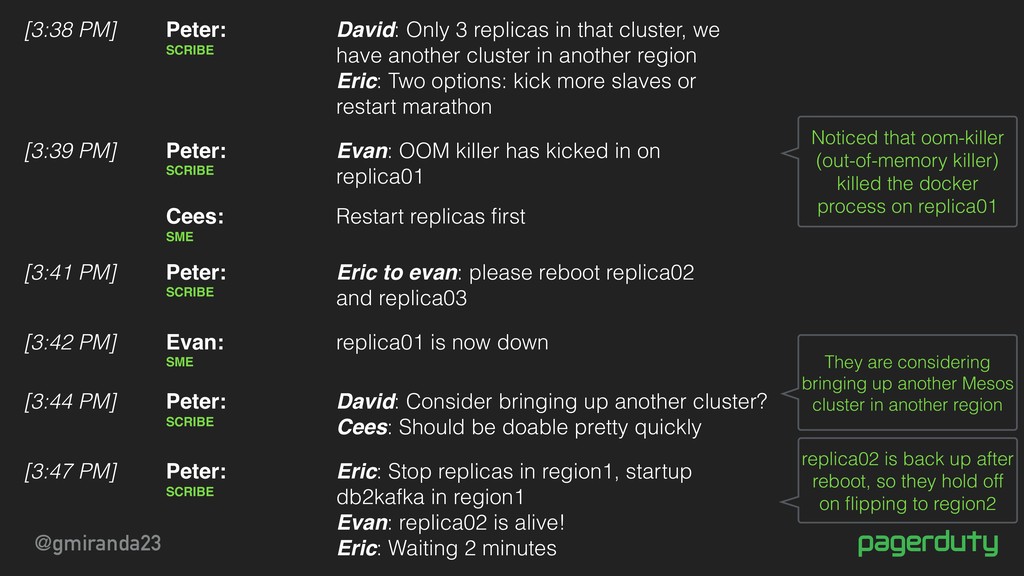
at a pub for dinner. [3:36 PM] @cees Would you join us on the bridge? We have a few Mesos questions Eric: IC Evan: might need to kick new hardware if system is actually unreachable. Evan: replica01 is reachable David: replica02 is not reachable. David: replica03 is not reachable. David: only 3 replicas for mesos Eric: We are down to only one host Evan: Seeing some stuff. Memory exhaustion. [3:37 PM] Peter: SCRIBE TODO: Create a runbook for mesos to stop the world and start again Peter: SCRIBE David added Cees to the incident Eric: Is there a runbook for mesos? David: Yes, but not for this issue. [3:34 PM] Peter: SCRIBE Scribe captured a TODO to record & remember a follow-up that should happen after the incident is resolved We paged a Mesos expert who is not on-call The Mesos expert joined the chat
another cluster in another region Eric: Two options: kick more slaves or restart marathon [3:38 PM] Peter: SCRIBE Evan: OOM killer has kicked in on replica01 [3:39 PM] Peter: SCRIBE Eric: Stop replicas in region1, startup db2kafka in region1 Evan: replica02 is alive! Eric: Waiting 2 minutes [3:47 PM] Peter: SCRIBE David: Consider bringing up another cluster? Cees: Should be doable pretty quickly [3:44 PM] Peter: SCRIBE Eric to evan: please reboot replica02 and replica03 [3:41 PM] Peter: SCRIBE Restart replicas first Cees: SME replica01 is now down [3:42 PM] Evan: SME They are considering bringing up another Mesos cluster in another region replica02 is back up after reboot, so they hold off on flipping to region2 Noticed that oom-killer (out-of-memory killer) killed the docker process on replica01
start, exiting with code 137 [3:49 PM] Peter: SCRIBE Evan: Replica03 is quiet. Evan: 137 means it’s being killed by OOM, OOM is killing docker containers continuously Peter: SCRIBE [3:53 PM] Proposed Action: David is going to configure marathon to allow more memory Peter: SCRIBE [3:54 PM] Proposed Action: Evan to force reboot replica01 Peter: SCRIBE [3:56 PM] David: Db2kafka appears to be running Eric: Looks like all things are running Renee: Things are fine with notifications JD: Log Entry Service is seeing progress Peter: SCRIBE [3:55 PM] Customer impact: there are 4 tickets so far and 2 customers chatting with us, which is another 2 tickets Luke: CUST LIAISON They realized the problem: oom-killer is killing the docker containers over and over The resolution action was to redeploy db2kafka with a higher cgroup/Docker memory limit: 2GB (vs 512 MB before) The customer liaison provided an update on the customer impact The system is recovering
db2kafka to increase its memory usage • This caused the Linux oom-killer to kill the process • Then, mesos / marathon immediately restarted it, it ramped up memory again, oom-killer killed it, and so on. • After doing this restart-kill cycle multiple times, we hit a race-condition bug in the Linux kernel causing a kernel panic and killing the host • Other services running on the host were impacted, notably the Log Entries Service
to fast decision making and action • Takes practice and experience Deputy • Do anything necessary to keep Incident Commander focused • Tracks follow-ups & action items (e.g. IC says "Evan, do X, report back in 5 mins") Scribe • Provides context in chatroom (not a stenographer) • Produces realtime documentation helpful for the the post-mortem Communications Liaison • Communicates status to customers & stakeholders
first responder on the Core team, became the owner 2. Schedule the post-mortem meeting scheduled for Jan 11 (incident happened on Jan 6) 3. Create a draft of the post-mortem report 4. Conduct the post-mortem meeting 5. Finalize the post-mortem report based on the discussion in the meeting Recommend: have a fast turnaround for the post- mortem, SLA of 3-5 days One owner only, owner can pull in additional resources as needed POST-MORTEM PROCESS
timeline • Customer and business impact • Root cause / contributing factors • How we resolved the incident • What went well, what didn’t go so well • Action items }These components are written by the owner ahead of the PM meeting } These components are discussed and created in the PM meeting
traffic 22:50:26 First instance of OOM-killer killing db2kafka 22:57 First page to Core on-call (David) 22:57 David acknowledges the page 23:09 replica03 freezes 23:12 Incident manually escalated to Core Secondary (Joseph) 23:18 Incident manually assigned to Cees 23:20 SEV-2 incident manually triggered 23:25 Ken starts trying to reach Cees (not on-call) 23:26 Discussion about customer impact 23:29 "Investigating issue" tweet from support account 23:29 Ken Rose starts trying to reach Div (not on-call) 23:30:39 replica02 freezes 23:34 Evan says that replica03 is unreachable 23:35 Cees joins call 23:37:00 Evan says replica01 is reachable, 02 and 03 are not. David confirms. 23:39 Evan says OOM killer has kicked in on slave01 23:39 Rich says replica02 is failing status check in cloud provider Time-To-Detect of 7min Time-To-Acknowledge <1min Incident escalated to SEV-2 in 23min David tried to get help from secondary and from Cees
to reboot replica02 and replica03 23:41 replica01 is frozen. All replicas now frozen. 23:42 Evan says replica01 is now unreachable as well 23:43 Discussion about Chef changes affecting Mesos, and discussion about bringing web2kafka up in another Mesos cluster. 23:46:28 replica02 is back up 23:46:37 replica03 is back up 23:49 Evan reports replica02 failing to start containers, they are exiting with code 137 23:51 Evan reports code 137 is "killed by OOM" 23:53 start db2kafka with 2 GB allowed memory, David takes action 23:53 force reboot replica01, Evan takes action 23:53:43 Last insance of OOM-killer killing db2kafka 23:56 David confirms db2kafka running. Discussion about backlog, other services catching up. 23:59:08 replica01 is back up 0:05 David reports db2kafka has cleared backlog 0:10 Recovery tweet posted 0:11 Other services have caught up / are catching up fine. Call closed. Issue is diagnosed Remediation actions are taken Issue is recovering Issue is fully recovered
increase in traffic, or possibly larger records, causing db2kafka to increase its memory usage. It was exacerbated by the Linux kernel bug causing Mesos slaves to freeze up. What happened Resolution The temporary resolution was to increase db2kafka's cgroup/Docker memory limit to 2 GB from 512 MB. Longer-term, we should investigate why this memory usage increased.
SEV-1 0 Notifications delivered out of SLA 0 Customers experiencing 500s on incident details page 1% Customers experiencing error message on /incidents page when clicking “Show Details” link 2% Customers experiencing errors in Android app 1% Support requests raised 8
Ensure everyone agrees the timeline is accurate and comprehensive 3. Talk about what the group has learned from going through the timeline. This can include but is not limited to action items. Do this in a brainstorming format 4. Talk about what went well, what didn’t go so well Capture this in the Post-Mortem report 5. Create the list of action items
team members were able to help resolve issue • SRE on-calls were very helpful in identifying issues and restarting boxes • Notifications still went out, with less detailed bodies WHAT DIDN'T GO SO WELL • Core primary on-call was unsure about when to initiate SEV-2 incident response due to lack of db2kafka SLA • Failing db2kafka caused cascading failures in other Mesos-hosted applications • Various UI components and the Android app did not handle missing log entries well (lack of graceful degradation)
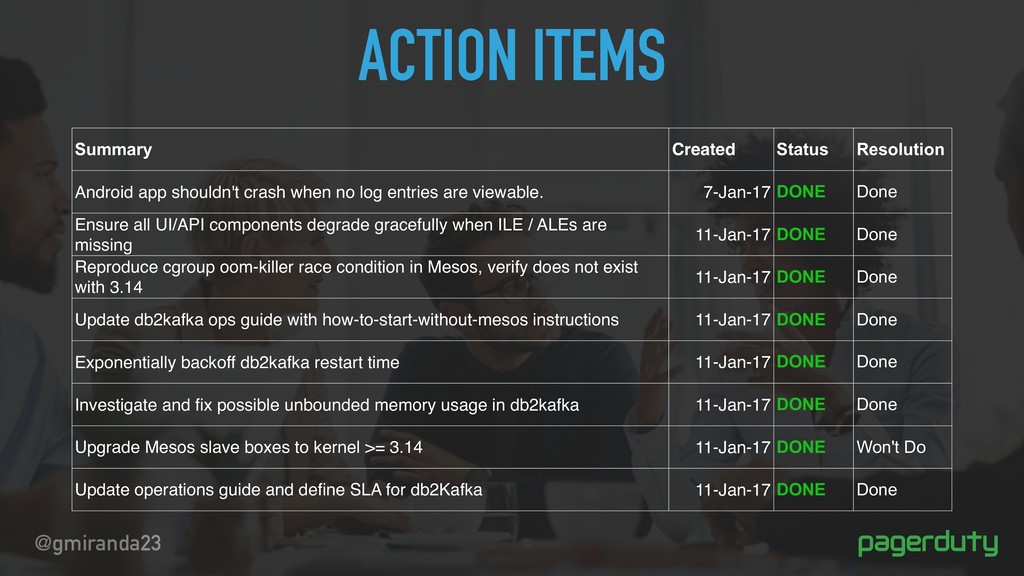
crash when no log entries are viewable. 7-Jan-17 DONE Done Ensure all UI/API components degrade gracefully when ILE / ALEs are missing 11-Jan-17 DONE Done Reproduce cgroup oom-killer race condition in Mesos, verify does not exist with 3.14 11-Jan-17 DONE Done Update db2kafka ops guide with how-to-start-without-mesos instructions 11-Jan-17 DONE Done Exponentially backoff db2kafka restart time 11-Jan-17 DONE Done Investigate and fix possible unbounded memory usage in db2kafka 11-Jan-17 DONE Done Upgrade Mesos slave boxes to kernel >= 3.14 11-Jan-17 DONE Won't Do Update operations guide and define SLA for db2Kafka 11-Jan-17 DONE Done
the PM for public consumption • 3 sections • Summary • What happened? • What are we doing about this? Posted on our status page: https://status.pagerduty.com/incidents/510k1bnvwv6g
• Use the Incident Command System • Publishing a post-mortem is what closes an incident • Use open-source resources to develop your own plan (or contribute to the community!)
{kind=link}
{kind=link}
{kind=link}
![George Miranda Engineer, Traveler, First Responder Talky Person @PagerDuty [email protected]](https://files.speakerdeck.com/presentations/4d95c298081f4fdea87ea427362f98c5/slide_3.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![@gmiranda23 [3:21 PM] David: SME !ic page Officer URL: Chat](https://files.speakerdeck.com/presentations/4d95c298081f4fdea87ea427362f98c5/slide_9.jpg){kind=link}
{kind=link}
![@gmiranda23 Priyam: SME I’m here from EM [event management] Evan:](https://files.speakerdeck.com/presentations/4d95c298081f4fdea87ea427362f98c5/slide_11.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}