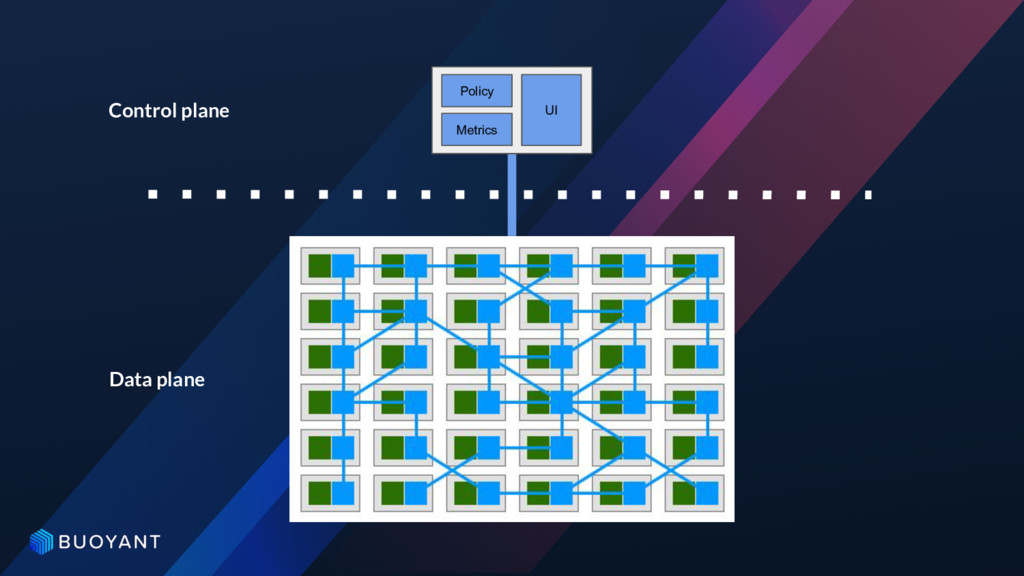
the application • Application requests/messages flow through proxies • Applications may or may not be explicitly aware of these proxies • The proxies make up the “data plane” of a service mesh • Ability to understand what’s happening between our apps... HUGE!! • The “control plane” used to observe/configure/manage the behavior of data plane
released Feb 2016 (2 years) • ~50 companies running in production • Multi-platform (Docker, K8s, DC/OS, Amazon ECS, and more) • Built-in service discovery, latency-aware load balancing, retries, circuit breaking, protocol upgrades (TLS by default), top-line metrics, distributed tracing, per request routing (useful for CI/CD, testing, and more) • Support for H2, gRPC, HTTP/1.x, and all tcp traffic • Handles tens of thousands of requests per second, per instance • http://linkerd.io
architectures • Open sourced by (@mattklein123) and Lyft.com October 2016 • C++, highly performant, non-blocking architecture • Low tail latencies at scale/load (P99) • L3/4 filter at its core with many L7 filters out of the box • HTTP 2, gRPC support (upstream/downstream) • API-driven, dynamic configuration • Amenable to shared-proxy/sidecar-proxy deployment models • Foundation for more advanced application proxies
IBM, Google • Provides a control plane for service proxies (default Envoy) • Brings clustering control and observability • Fine grained routing • mTLS/RBAC/security • Resiliency • Policy control • Observability
written in Rust, Control plane written in Go • Sub 1ms p99 latency, ~1MB footprint, designed for sidecar deployments • “Minimum viable service mesh” or a Zero Config philosophy • Supports gRPC, H2, HTTP1.x, and all tcp traffic out of the box • Performance based load-balancing • Export Prometheus metrics & Automatic TLS (0.4.0) • Controllable timeouts/deadlines, OpenTracing, & key rotation (0.5.0) • Rich ingress routing, auth policy, auto alerts & composable resiliency (0.6.0) • Late April 2018 ETA for 0.6 • https://conduit.io/roadmap/
service mesh? • What problems am I having today? • What platforms do you need to support? • What level of observability do your services have today? • What functionalities of a service mesh do you already have? How will that play out in your when you introduce a service mesh? • What does the division of responsibility look like in your teams? • Centralized or decentralized functionality? • Support expectations and team needs?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}