NLPコロキウム,2026/02/18 (Wed) 12:00–13:00 (JST)
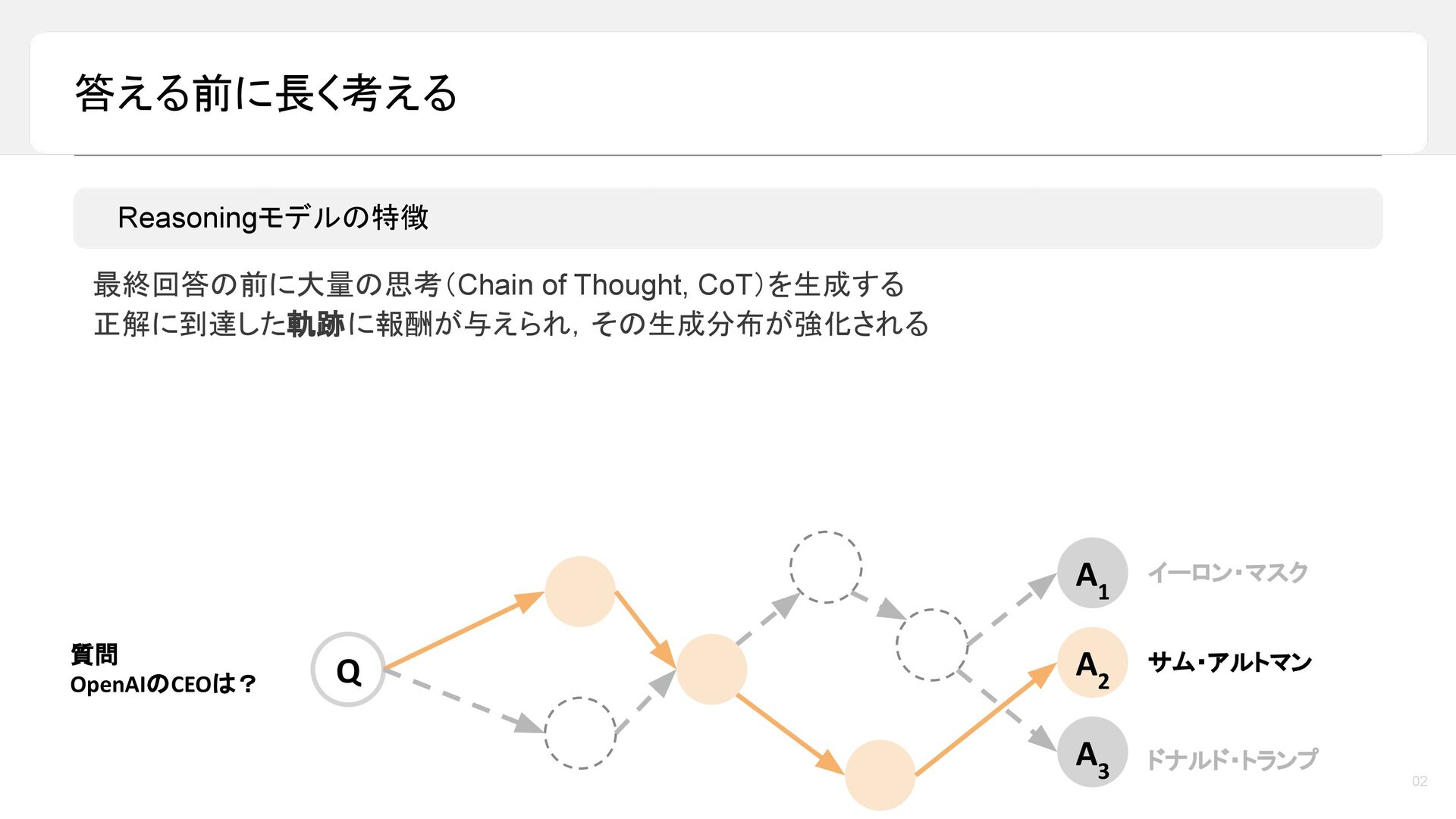
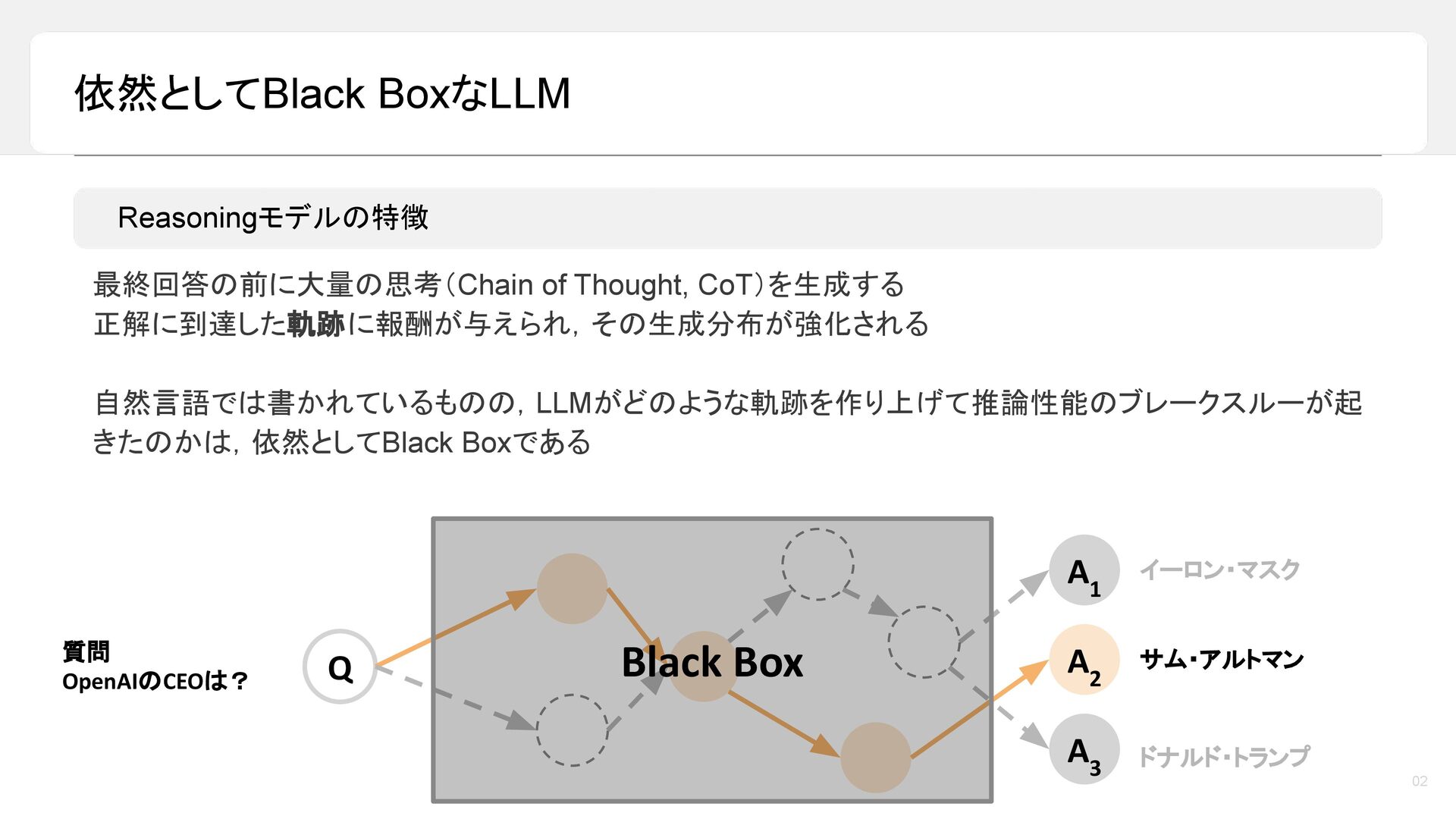
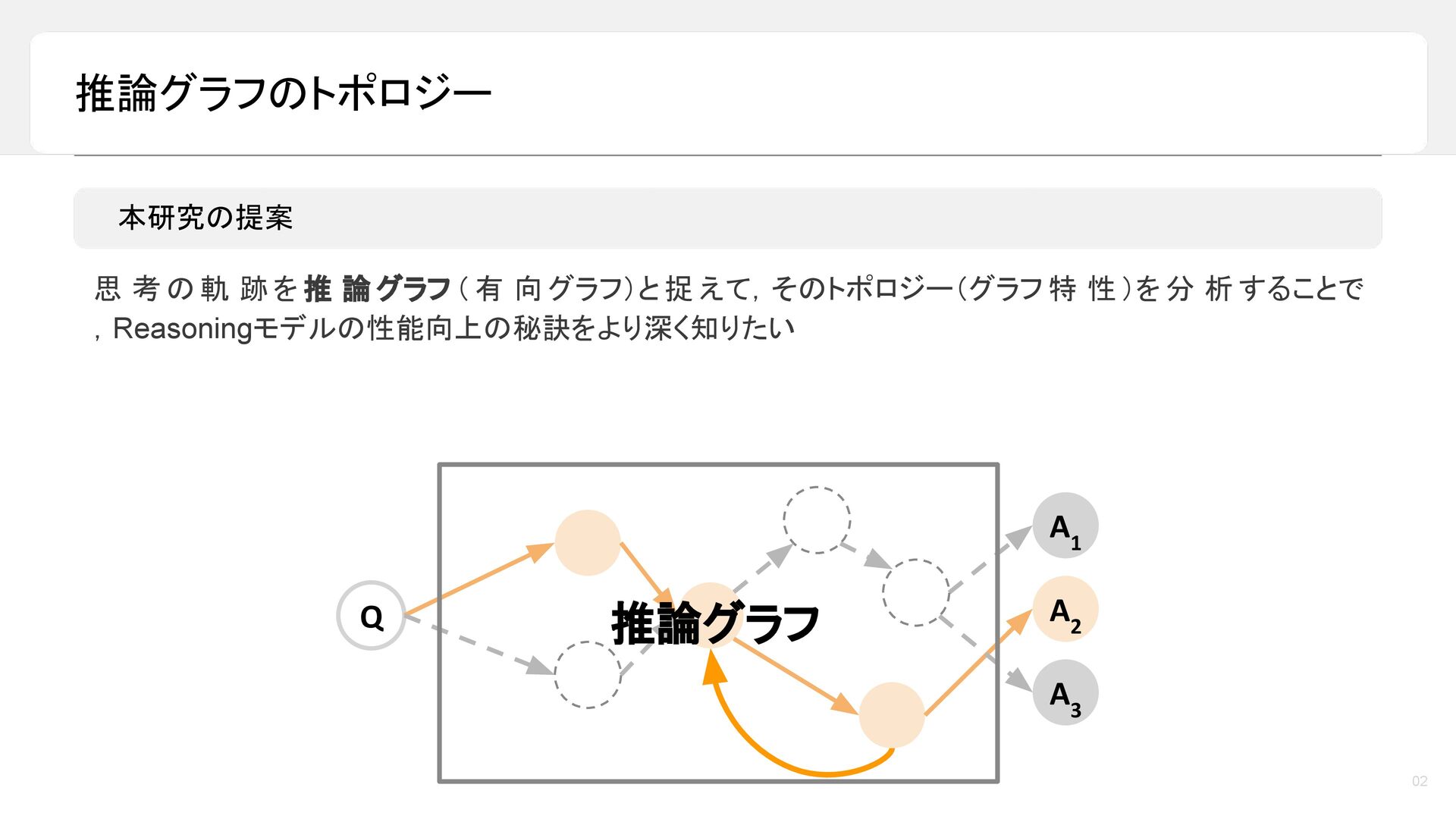
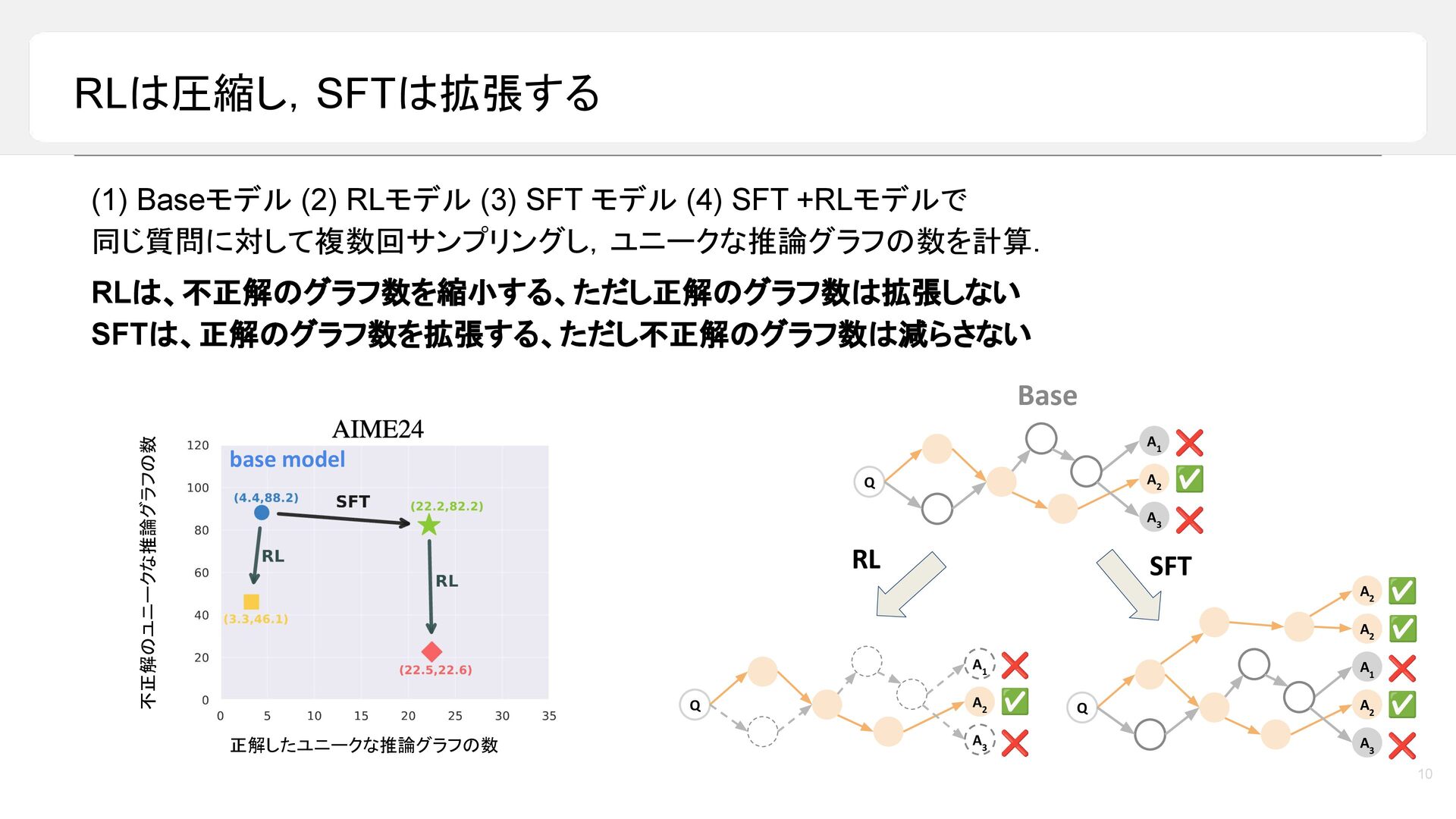
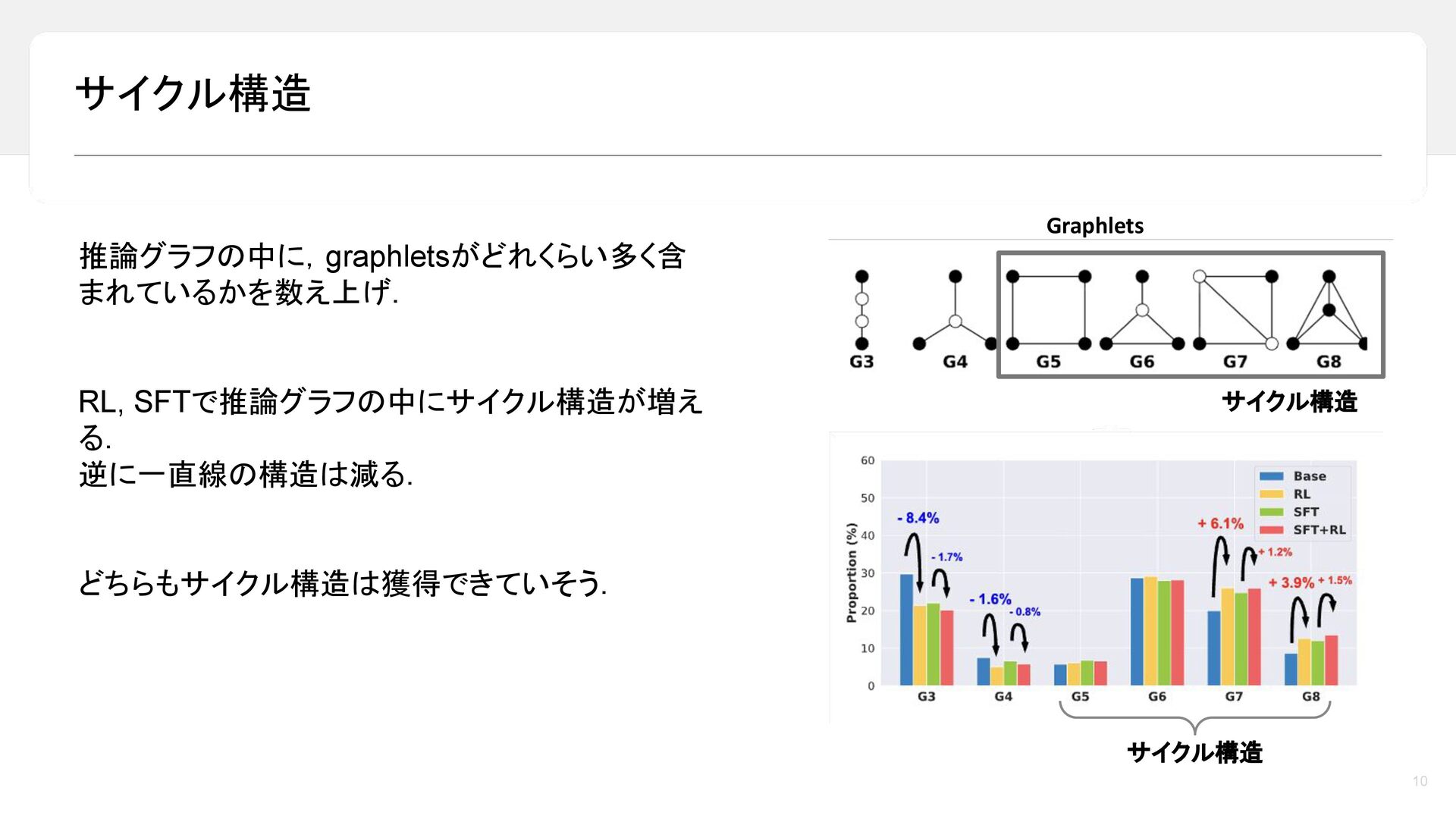
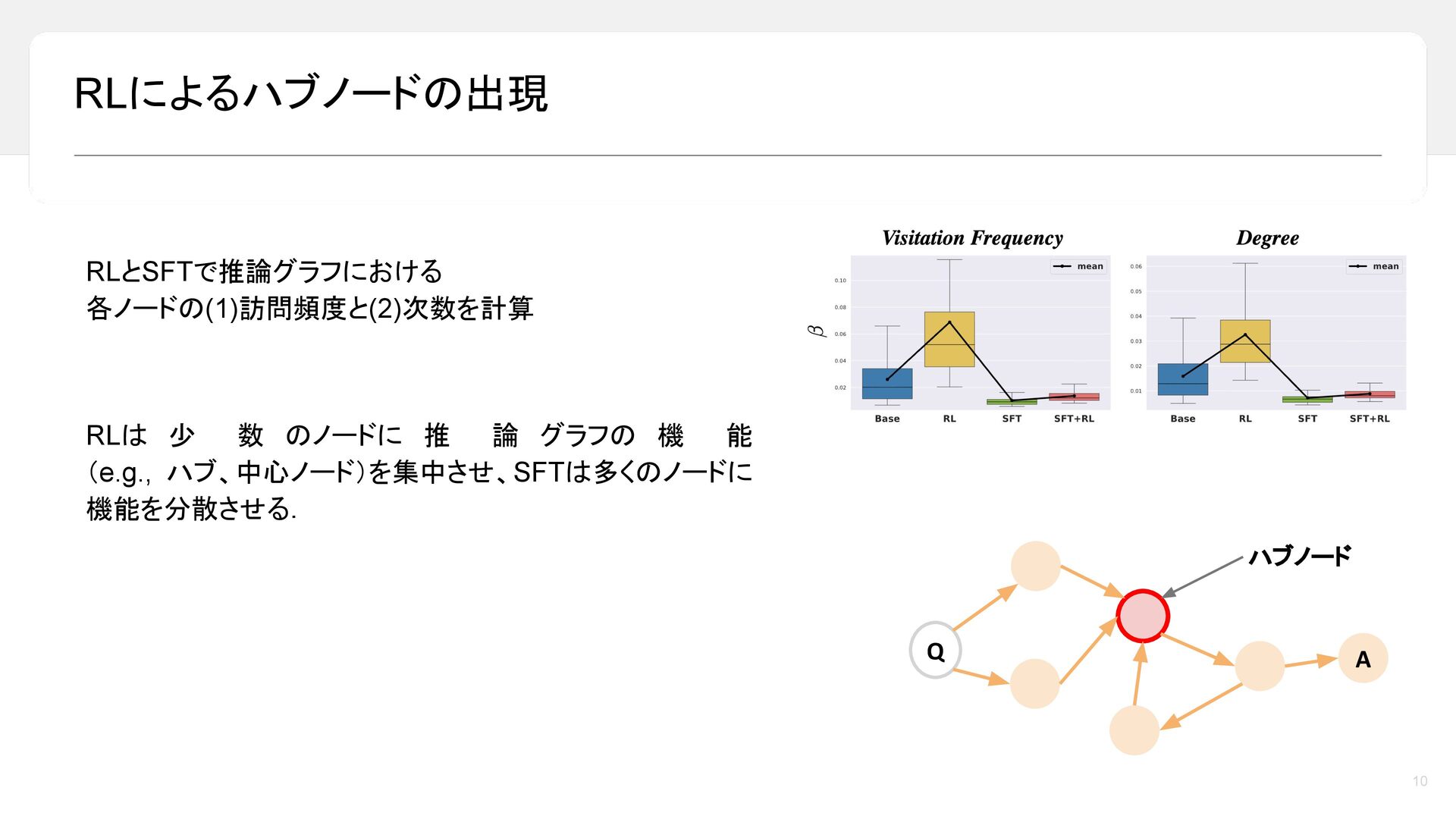
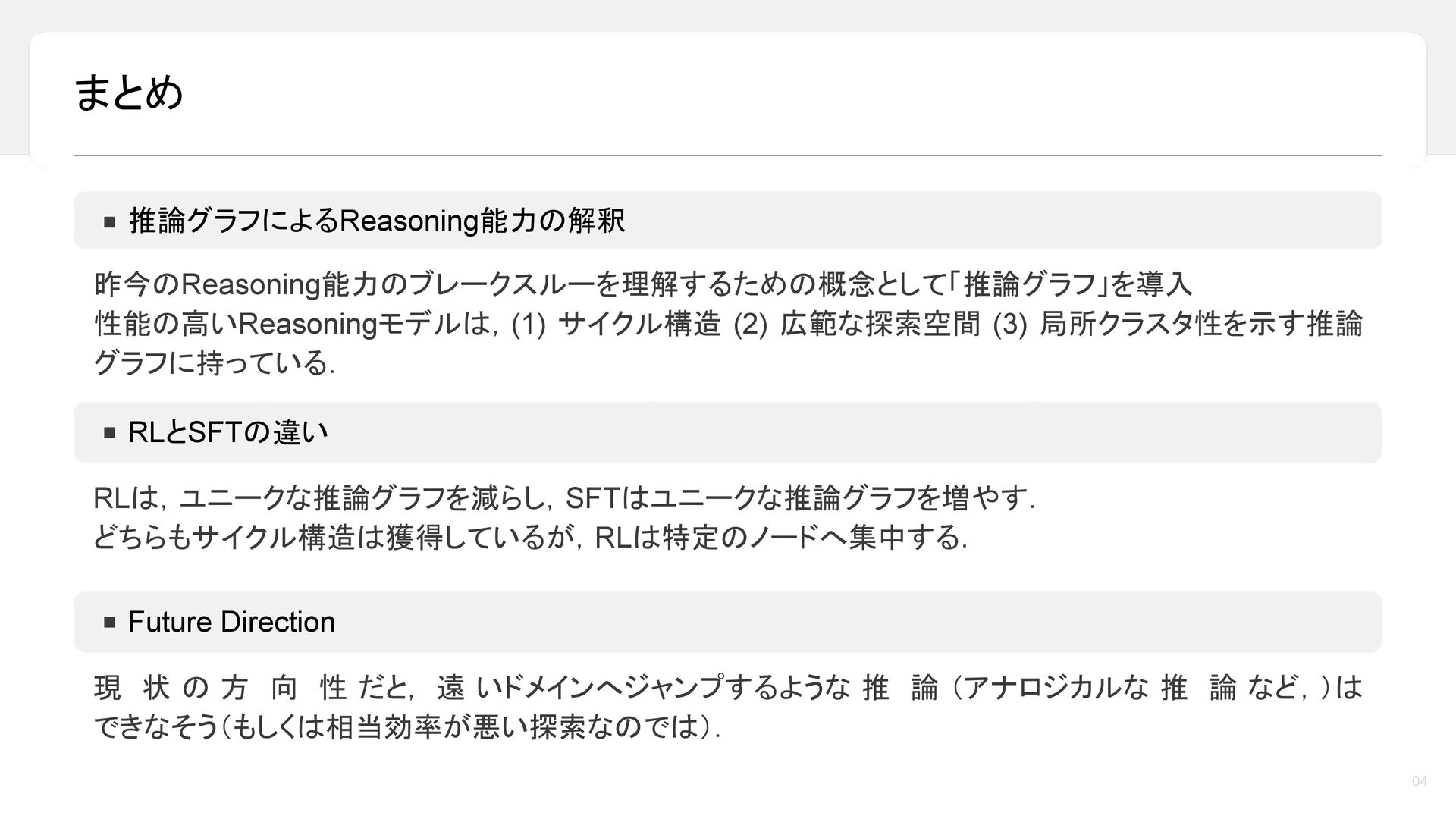
昨今,LLM の reasoning 能力は目覚ましい発展を遂げており,最終的な答えを出す前に長い推論過程を生成することで,数学や論理タスクにおける性能が大きく向上しています。しかし一方で,その「考えている途中」においてモデル内部で何が起きているのかについては,依然として十分に理解されていません。本トークでは,LLM の推論過程を「推論グラフ(reasoning graph)」として捉えることで,Reasoning LLM が内部に持つ「思考のかたち」を可視化・分析します。推論モデルが,循環性や広い探索範囲といった特徴的なグラフ構造を有しており,それらが高い推論性能と関係していることをご紹介します。さらに,reasoning 能力を高める代表的な手法である SFT と RL に着目し,これらがどのように異なる推論グラフを形作るのかを比較・考察します。本トークが,近年の reasoning 能力のブレークスルーを考える上での一つの見方を提供できれば幸いです。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![思考の軌跡でLLMは何をしている? 02 ゴール地点(最終的な答え)があっているかどうかで報酬を与えているため,途中の軌跡では人間が想定し ていなかったような挙動を見せる.(e.g., 自分の生成した軌跡を反省し始める) 他にも,複数の言語が混同する[Li et al.], 同じトークンを繰り返しまくる[Yang et](https://files.speakerdeck.com/presentations/6db3b9538fe94fcf8672537c80685d1f/slide_7.jpg){kind=link}
{kind=link}
{kind=link}
![05 LLMの内部表現をKmeansクラスタリング 推論グラフの抽出方法 LLMの内部表現からグラフを取り出す [Wang et al. ICML’24] 1推論ステップ 数学タスク(e.g.,](https://files.speakerdeck.com/presentations/6db3b9538fe94fcf8672537c80685d1f/slide_10.jpg){kind=link}
![05 各質問ごとに推論グラフを構築 推論グラフの抽出方法 LLMの内部表現からグラフを取り出す [Wang et al. ICML’24] LLMの内部表現をKmeansクラスタリング 1推論ステップ](https://files.speakerdeck.com/presentations/6db3b9538fe94fcf8672537c80685d1f/slide_11.jpg){kind=link}
![推論グラフの抽出方法(詳細) 03 01 LLMの内部表現からグラフを取り出す [Wang et al. ICML’24] ノードの定義(状態の離散化) 全てのデータのsに対してK-meansを適用](https://files.speakerdeck.com/presentations/6db3b9538fe94fcf8672537c80685d1f/slide_12.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}