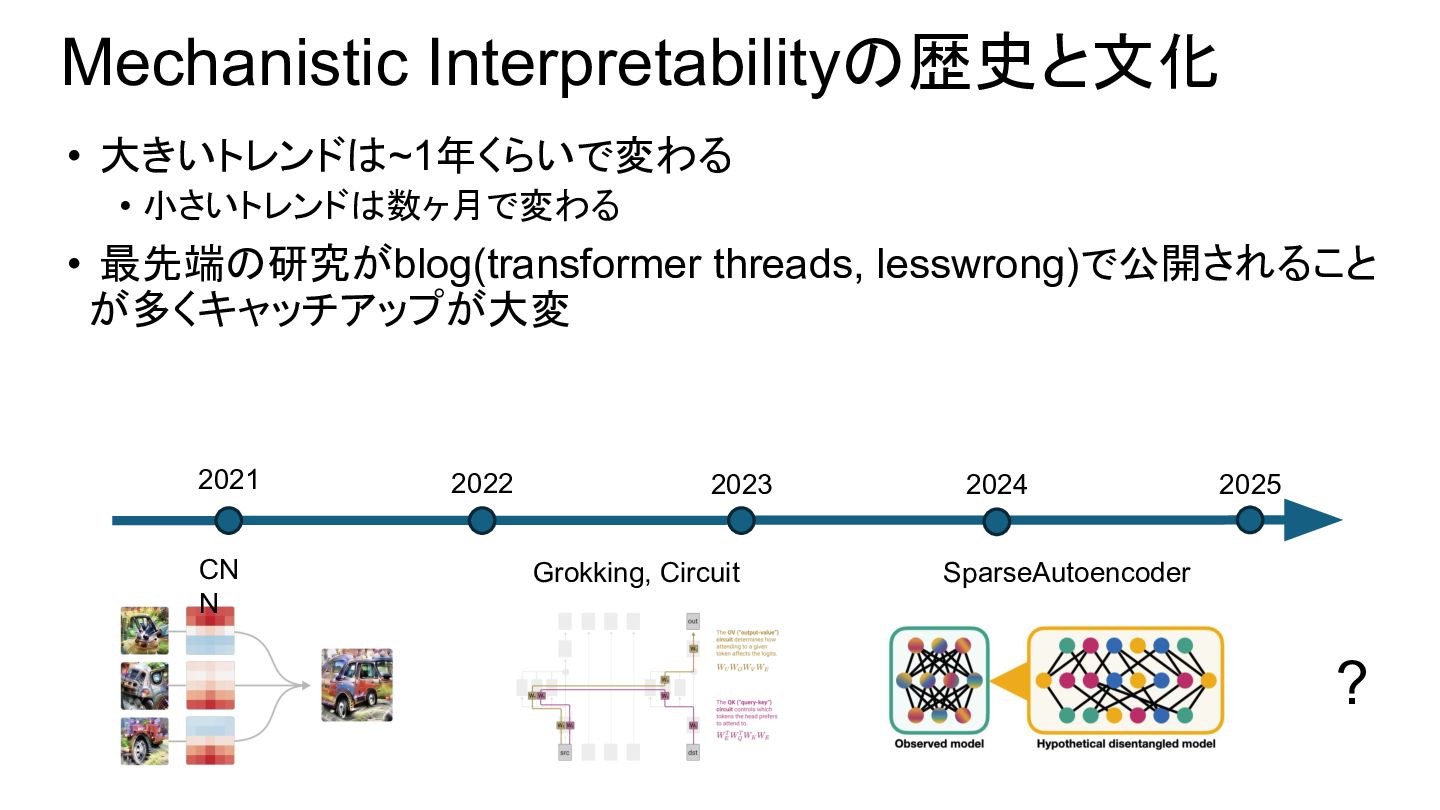
mechanistic interpretability • ICLR’23(oral), Omnigrok: Grokking Beyond Algorithmic Data • Neurips’23(oral), The Clock and the Pizza: Two Stories in Mechanistic Explanation of Neural Networks • ICML’25(oral), Emergence in non-neural models: grokking modular arithmetic via average gradient outer product • ただ実世界のLLMに対する貢献がわかりづらく最近はあまり研究されて いない • Neel自身もGrokking研究を2025年現在行うことを推奨していない
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}