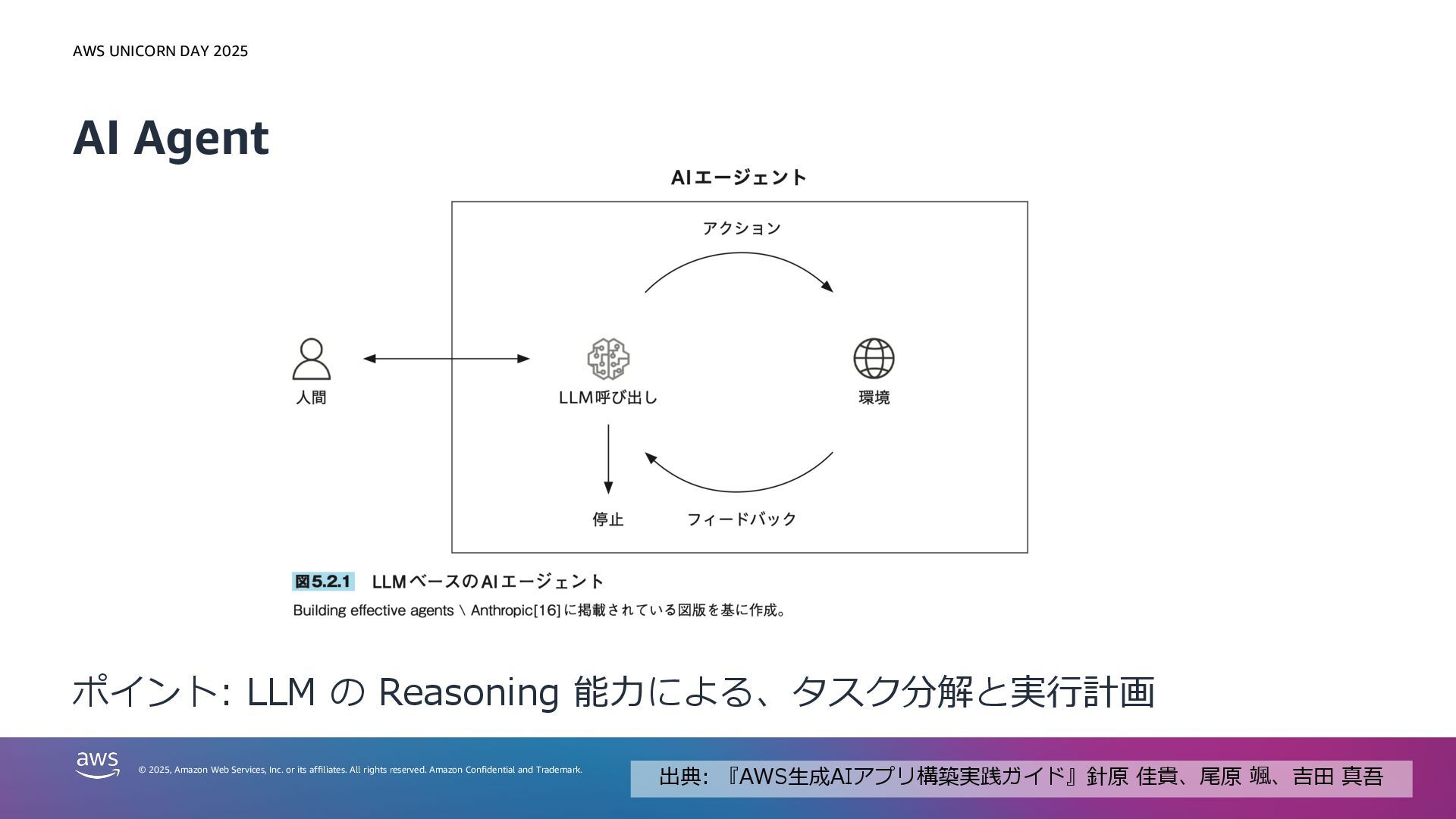
or its affiliates. All rights reserved. Amazon Confidential and Trademark. AI Agent ポイント: LLM の Reasoning 能⼒による、タスク分解と実⾏計画 出典: 『AWS⽣成AIアプリ構築実践ガイド』針原 佳貴、尾原 颯、吉⽥ 真吾
or its affiliates. All rights reserved. Amazon Confidential and Trademark. AWS Generative AI Accelerator (GAIA) 2025年はグローバルコホートにおいて⽇本から2社採択 • SDio株式会社は、⻑時間・マルチメディアに対応可能な新しい 動画基盤モデルを開発し、コスト効率化を実現しながら分析と 検索を可能にするプラットフォームを提供します。 • SyntheticGestalt株式会社は、世界最⼤の分⼦の⽴体構造情報の 基盤モデルを提供することで、ライフサイエンス・化学企業の 新分⼦の発⾒・分析の加速を⽀援します。 https://press.aboutamazon.com/jp/news/aws/2025/10/announcing-the-2- japanese-startups-selected-for-the-2025-aws-generative-ai-accelerator 43
rights reserved. Amazon Confidential and Trademark. 46 Amazon Bedrock Marketplace での国産基盤モデル公開 EVOLUTIONARY SCALE WIDN CAMB.AI GRETEL ARCEE AI PREFERRED NETWORKS WRITER UPSTAGE NCSOFT STOCKMARK KARAKURI JOHN SNOW LABS LIQUID DATABRICKS CYBERAGENT HUGGING FACE STABILITY AI LG AI RESEARCH MISTRAL AI SNOWFLAKE NVIDIA
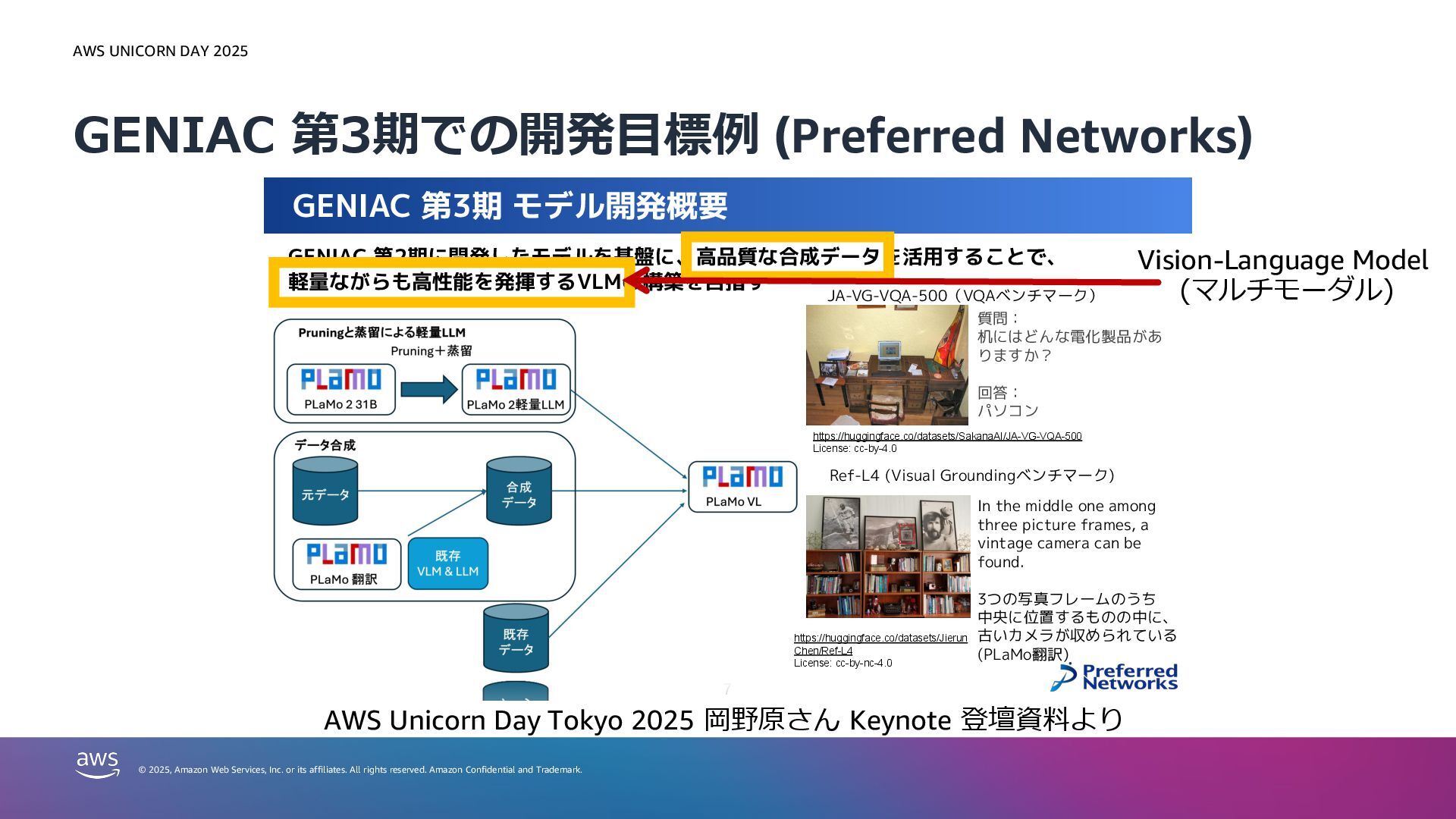
or its affiliates. All rights reserved. Amazon Confidential and Trademark. GENIAC 第3期での開発⽬標例 (Preferred Networks) GENIAC 第3期 モデル開発概要 7 GENIAC 第2期に開発したモデルを基盤に、高品質な合成データを活用することで、 軽量ながらも高性能を発揮するVLMの構築を目指す JA-VG-VQA-500(VQAベンチマーク) 質問: 机にはどんな電化製品があ りますか? 回答: パソコン https://huggingface.co/datasets/SakanaAI/JA-VG-VQA-500 License: cc-by-4.0 Ref-L4 (Visual Groundingベンチマーク) https://huggingface.co/datasets/Jierun Chen/Ref-L4 License: cc-by-nc-4.0 In the middle one among three picture frames, a vintage camera can be found. 3つの写真フレームのうち 中央に位置するものの中に、 古いカメラが収められている (PLaMo翻訳) AWS Unicorn Day Tokyo 2025 岡野原さん Keynote 登壇資料より Vision-Language Model (マルチモーダル)
or its affiliates. All rights reserved. Amazon Confidential and Trademark. π0 : VLA by Physical Intelligence (PI) https://arxiv.org/abs/2410.24164 VLM + Action Expert
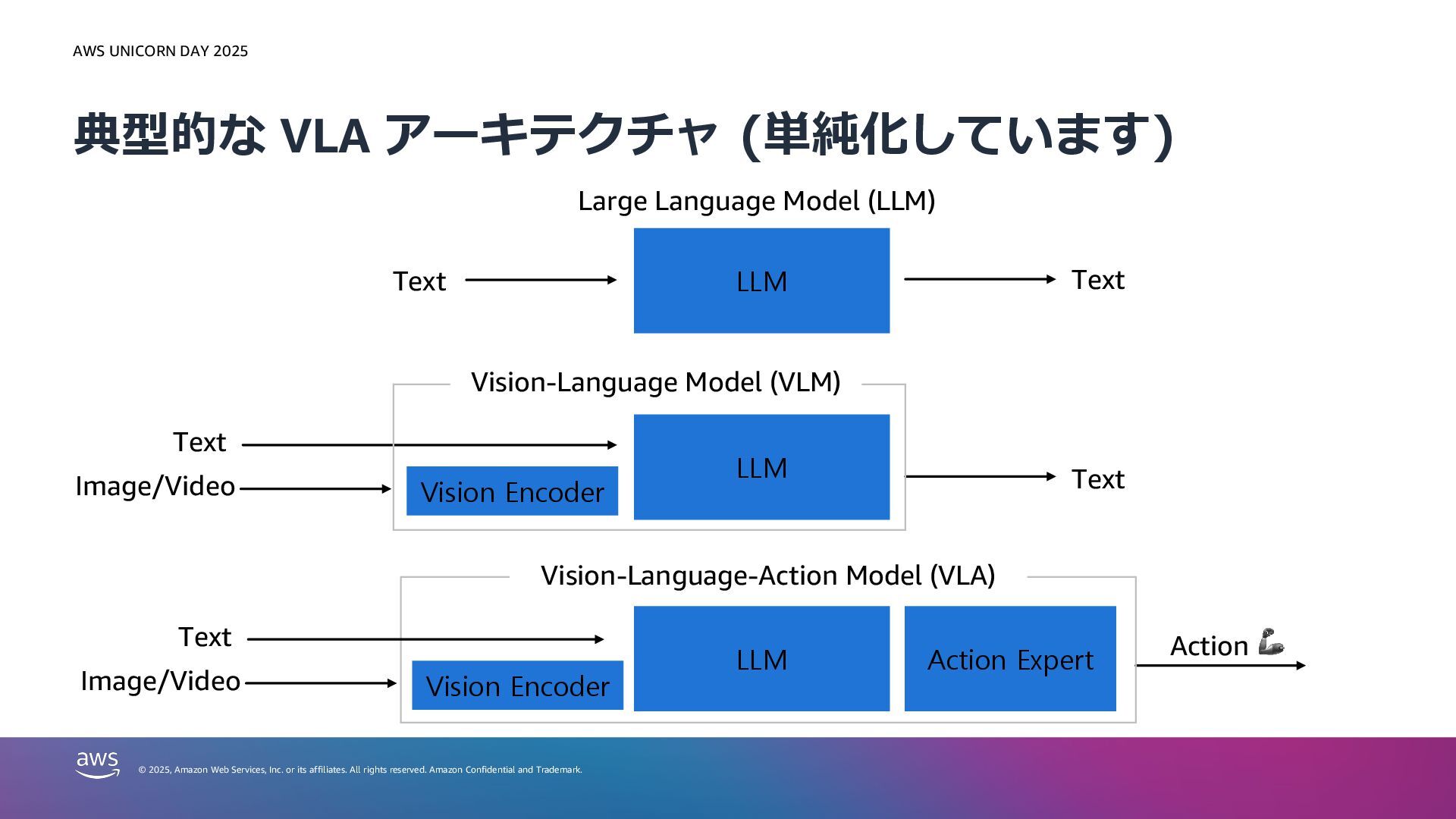
or its affiliates. All rights reserved. Amazon Confidential and Trademark. 典型的な VLA アーキテクチャ (単純化しています) Vision Encoder LLM Action Expert LLM LLM Large Language Model (LLM) Text Text Text Image/Video Text Action 🦾 Vision-Language Model (VLM) Vision-Language-Action Model (VLA) Vision Encoder Text Image/Video
or its affiliates. All rights reserved. Amazon Confidential and Trademark. References: Robotics FM 1. 基盤モデルとロボットの融合 マルチモーダル AI でロボットはどう変わるのか (KS 理⼯学専⾨書)、河原塚健⼈、松嶋達也 (著) https://www.amazon.co.jp/dp/4065395852 2. Robotics Foundation Models (RFMs) 1. R3M https://arxiv.org/abs/2203.12601 - ResNet-based model trained with egocentric data 2. MVP https://arxiv.org/abs/2210.03109 - Vision Transformer (ViT)-based 3. Visual Cortex-1 https://arxiv.org/abs/2303.18240 - ViT-based 4. PaLM-E https://arxiv.org/abs/2303.03378 embodiment by embedding (e.g. image with ViT) concatenated with PaLM 5. RoboVQA https://arxiv.org/abs/2311.00899 - post-training of vision language model (VLM) VideoCoCa 383M with annotated action data 6. MT-Opt https://arxiv.org/abs/2104.08212 - reinforcement learning (RL) with robot arm data 7. Robotics Transformer (RT)-1 https://arxiv.org/abs/2212.06817, RT-2, and RT-X https://arxiv.org/abs/2310.08864 with Open X-Embodiment (OXE) dataset https://robotics-transformer-x.github.io 8. RT-Trajectory, RT-Sketch, Auto-RT 9. Octo https://arxiv.org/abs/2405.12213 - modular architecture based on RT-X 10. OpenVLA https://arxiv.org/abs/2406.09246 - open Vision-Langage-Action (VLA) model based on ViT (DinoV2 + SigLIP) + Llama2 7B trained on OXE dataset 11. RDT-1B https://arxiv.org/abs/2410.07864 - diffusion-based 12. π0 https://arxiv.org/abs/2410.24164v1, π0.5 https://arxiv.org/abs/2504.16054 - by Physical Intelligence (PI) 13. NoMaD 14. In-context Robot Transformer (ICRT) https://arxiv.org/abs/2408.15980 15. GraspVLA https://arxiv.org/abs/2505.03233 - pre-trained on billion-scale synthetic data 3. Dataset 1. Bridge v2 https://rail-berkeley.github.io/bridgedata/ 2. OXE https://robotics-transformer-x.github.io/ 3. DROID https://droid-dataset.github.io 4. Data Capture System 1. ALOHA 2. GELLO 3. UMI 4. Dobb-E
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}