Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
特徴量エンジニアリング_vol.1.pdf
Search
Haruhisa Kimoto
November 26, 2023
58
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
特徴量エンジニアリング_vol.1.pdf
Haruhisa Kimoto
November 26, 2023
More Decks by Haruhisa Kimoto
See All by Haruhisa Kimoto
第1回統計勉強会.pdf
haru0805
0
24
第9回統計勉強会.pdf
haru0805
0
31
第1回統計モデル勉強会.pdf
haru0805
0
51
LLM勉強会_vol.7_大規模言語モデルの進展.pdf
haru0805
0
29
Featured
See All Featured
Tell your own story through comics
letsgokoyo
1
990
<Decoding/> the Language of Devs - We Love SEO 2024
nikkihalliwell
1
270
How Fast Is Fast Enough? [PerfNow 2025]
tammyeverts
3
650
XXLCSS - How to scale CSS and keep your sanity
sugarenia
249
1.3M
The SEO identity crisis: Don't let AI make you average
varn
0
510
10 Git Anti Patterns You Should be Aware of
lemiorhan
PRO
659
62k
The Power of CSS Pseudo Elements
geoffreycrofte
82
6.4k
Digital Ethics as a Driver of Design Innovation
axbom
PRO
1
340
30 Presentation Tips
portentint
PRO
1
350
Impact Scores and Hybrid Strategies: The future of link building
tamaranovitovic
0
340
Designing Dashboards & Data Visualisations in Web Apps
destraynor
231
55k
GraphQLの誤解/rethinking-graphql
sonatard
75
12k
Transcript
https://www.academix.jp/ AcademiX 特徴量エンジニアリング 勉強会 特徴量エンジニアリング勉強会 vol.1 木本晴久(Kimoto Haruhisa) 2023/11/26
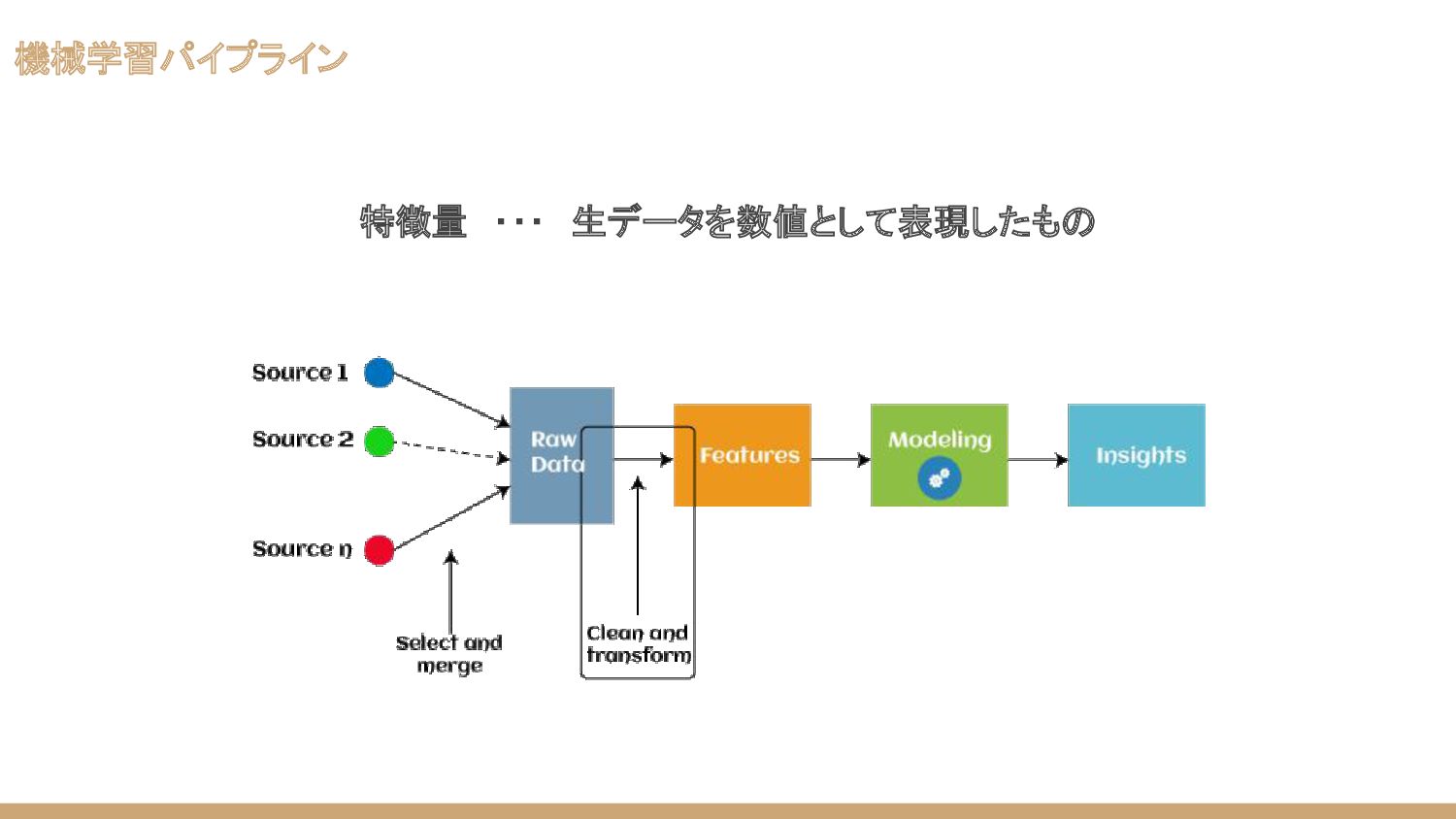
機械学習パイプライン 特徴量 ・・・ 生データを数値として表現したもの
機械学習パイプライン 特徴量作成の際には、 • データに合わせた特徴量の作成 • モデルに合わせた特徴量の作成 の2つを考える必要がある。 同じ特徴量の作成方法でも、データが異なると効果は変化する 同じデータでも、モデルが違うと特徴量の良し悪しは変化する ドメイン知識が必要
特徴量エンジニアリングを体系的に学ぶことは難しい。。。
2. 数値データの扱い 数値データで確認すべきこと 良い特徴量とは? データの重要な側面を表現する 機械学習モデルが数理的に仮定する条件を満たす 解くべきタスク密接している モデルに取り込むことができる
2. 数値データの扱い 数値データで確認すべきこと • その値に意味があるか 必要な粒度はどのくらい? • 取りうる範囲 最小値は?最大値は? ◦ 入力のスケールに、出力のスケールが影響を受けるもの ▪
モデルが滑らかな関数として表現される場合 ▪ ユークリッド距離を使用するモデル ▪ k-means, kNN, RBFカーネル ◦ 入力のスケールに、出力のスケールが影響を受けないもの ▪ 論理関数 ▪ 決定木系モデル • データの分布 正規分布に従っている? ◦ 線形回帰モデルは誤差が正規分布に従うことを仮定
2. 数値データの扱い スカラ・ベクトル・ベクトル空間 多くの機械学習モデルは、入力として数値ベクトルを受け取る 特徴量エンジニアリングとは、生データを数値ベクトルに変換し、 ベクトル空間に配置すること
2. 数値データの扱い カウントデータの取り扱い • カウントデータの特徴 ◦ 発生頻度 ◦ 非負の整数 ◦
ゼロ周辺に集中し、右に裾を引いた形 ◦ ポアソン分布で表すことが多い • 扱い方 ◦ 数値をそのまま使う ◦ 有無を示す二値データに変換する → 二値化 ◦ 粒度を荒くする → 離散化
2. 数値データの扱い カウントデータの取り扱い 線形モデルの場合には、1にも1000にも同じ係数をかけることになる。。。 ユークリッド距離を測る場合にも、大きな値が問題を起こす。。。 二値化 • 0と1以上のもので分ける ◦ カウントデータは0付近に偏るが、極端に大きい値を取ることもある
◦ 機械学習モデルは大きな値に引っ張られて、正確な予測ができなくなる 離散化 • カウントを固定幅によって階級にグループ化する(年齢など) ◦ 一定の階級幅、10の累乗によるグループ化 ◦ カウントデータに大きなギャップがあると空の階級ができてしまう。。。 • カウントを分位数によって階級にグループ化する ◦ データ数を均等に分ける(中央値、四分位数) → データの分布から階級を決める
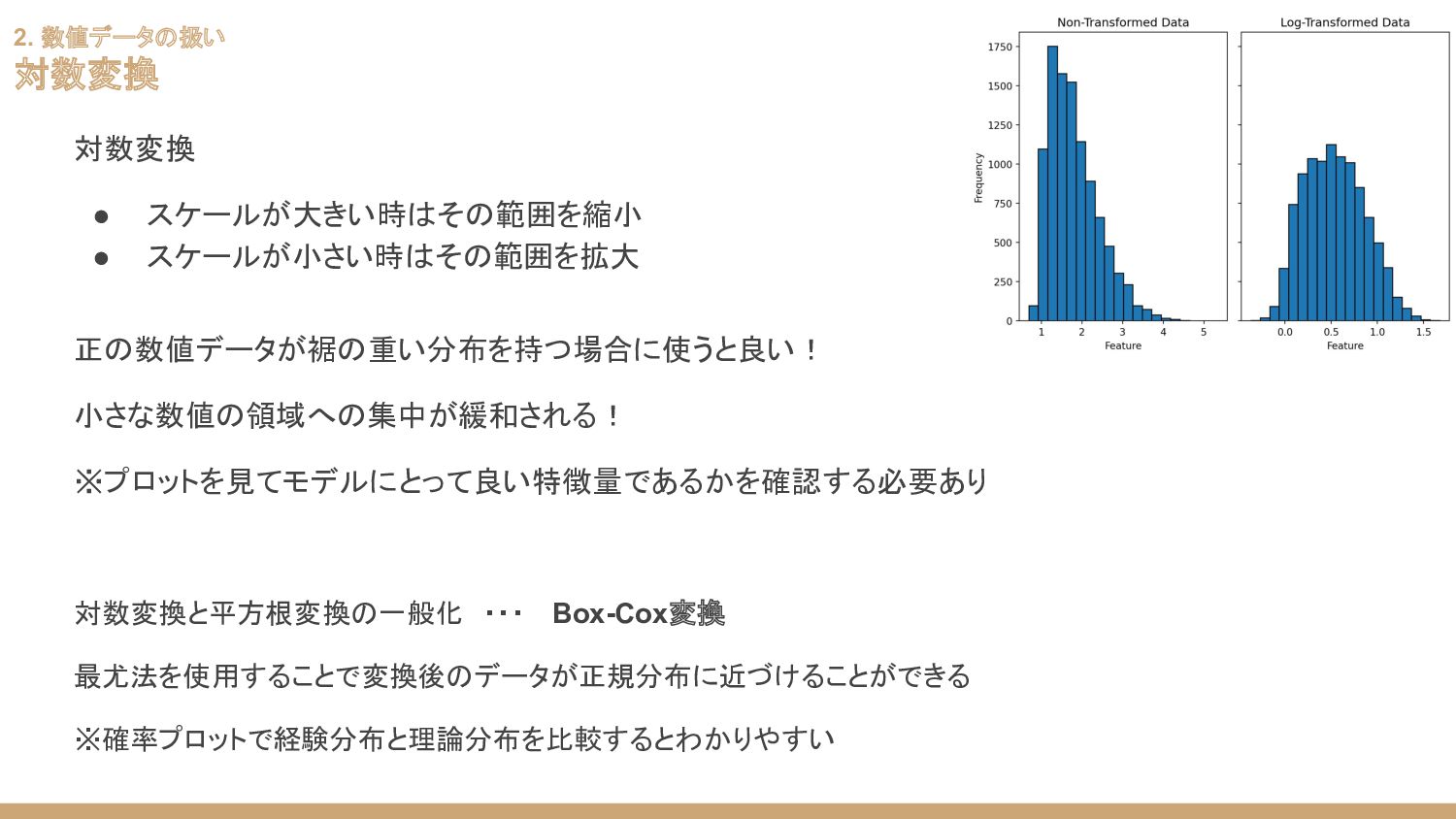
2. 数値データの扱い 対数変換 対数変換 • スケールが大きい時はその範囲を縮小 • スケールが小さい時はその範囲を拡大 正の数値データが裾の重い分布を持つ場合に使うと良い! 小さな数値の領域への集中が緩和される!
※プロットを見てモデルにとって良い特徴量であるかを確認する必要あり 対数変換と平方根変換の一般化 ・・・ Box-Cox変換 最尤法を使用することで変換後のデータが正規分布に近づけることができる ※確率プロットで経験分布と理論分布を比較するとわかりやすい
2. 数値データの扱い スケーリングと正規化 モデルが入力のスケールに敏感な場合、特徴量スケーリングが役に立つ! 入力される特徴量のスケール・単位が異なる際にも役に立つ! (ECサイトの訪問者数と購入者数を入力とする際など) 「特徴量のスケーリング」 = 「特徴量の正規化」 ※スケーリングでは、特徴量の分布は変化しない
2. 数値データの扱い スケーリングと正規化 • Min-Maxスケーリング ◦ 特徴量の値を[0, 1]の範囲に縮小する。 • 標準化
◦ 特徴量の平均が0、分散が1になる • l2正規化 ◦ 特徴量のノルムが1になる。 ◦ ※l2正則化ではない
2. 数値データの扱い 交互作用特徴量 交互作用特徴量 ・・・ 複数の特徴量の積 二つの特徴量の積の時はペアワイズ交互作用特徴量という 複数の特徴量を組み合わせることで、ターゲット変数をうまく表現できることがある! ※線形モデルの場合は明示的にモデルに組み込む必要あり PolynomialFeaturesを使うと便利! https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.PolynomialFeatures.html 商品購買有無を予測する際に、居住地域と年齢を別で考えるよりも、
「シアトルに住む35歳」という情報の方が役に立つ場合がある。
2. 数値データの扱い 交互作用特徴量 • メリット ◦ 精度が上がる場合がある • デメリット ◦
学習コストが増大する ◦ 線形モデルの学習時間とテストスコア算出時間はO(n)からO(n^2)に増大する デメリットを解消するには、次に説明する「特徴選択」が有効な場合がある!
2. 数値データの扱い 特徴選択 特徴選択 ・・・ 有用でない特徴量を取り除く → モデルの複雑さを軽減 モデルの予測精度を悪化させることなく、計算速度を上げることができる! ただ。。。 複数のモデルを学習させることになるため、学習時間を短縮できるとは限らない。。。
2. 数値データの扱い 特徴選択 • フィルタ法 ◦ 閾値を使用して、有用ではない特徴量を削除する手法 ◦ 特徴量とターゲット変数の相関や相互情報量を確認 する
◦ 計算コストが小さい ◦ モデルにとって良い特徴量であるかは不明 → 有用な特徴量を削除してしまう 可能性 • ラッパー法 ◦ 特徴量の一部を使用してモデルを学習して評価 する ◦ モデルをブラックボックスとして使う ◦ 計算コストが大きい ◦ 有用な特徴量を削除することを防ぐ • 組み込み法 ◦ モデルの学習プロセスに特徴量選択が組み込まれている こと → 決定木、L1正則化 ◦ ラッパー法よりも結果の品質は劣る ◦ 計算コストが少ない ◦ 計算コストと精度のバランスの良い手法
参考文献 ・機械学習のための特徴量エンジニアリング ―その原理とPythonによる実践 Alice Zheng、Amanda Casari 著、株式会社ホクソエム 訳 https://www.oreilly.co.jp/books/9784873118680/ 16
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![2. 数値データの扱い スケーリングと正規化 • Min-Maxスケーリング ◦ 特徴量の値を[0, 1]の範囲に縮小する。 • 標準化](https://files.speakerdeck.com/presentations/b9893e8c9a4641c6a46d96e3503edb18/slide_10.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}