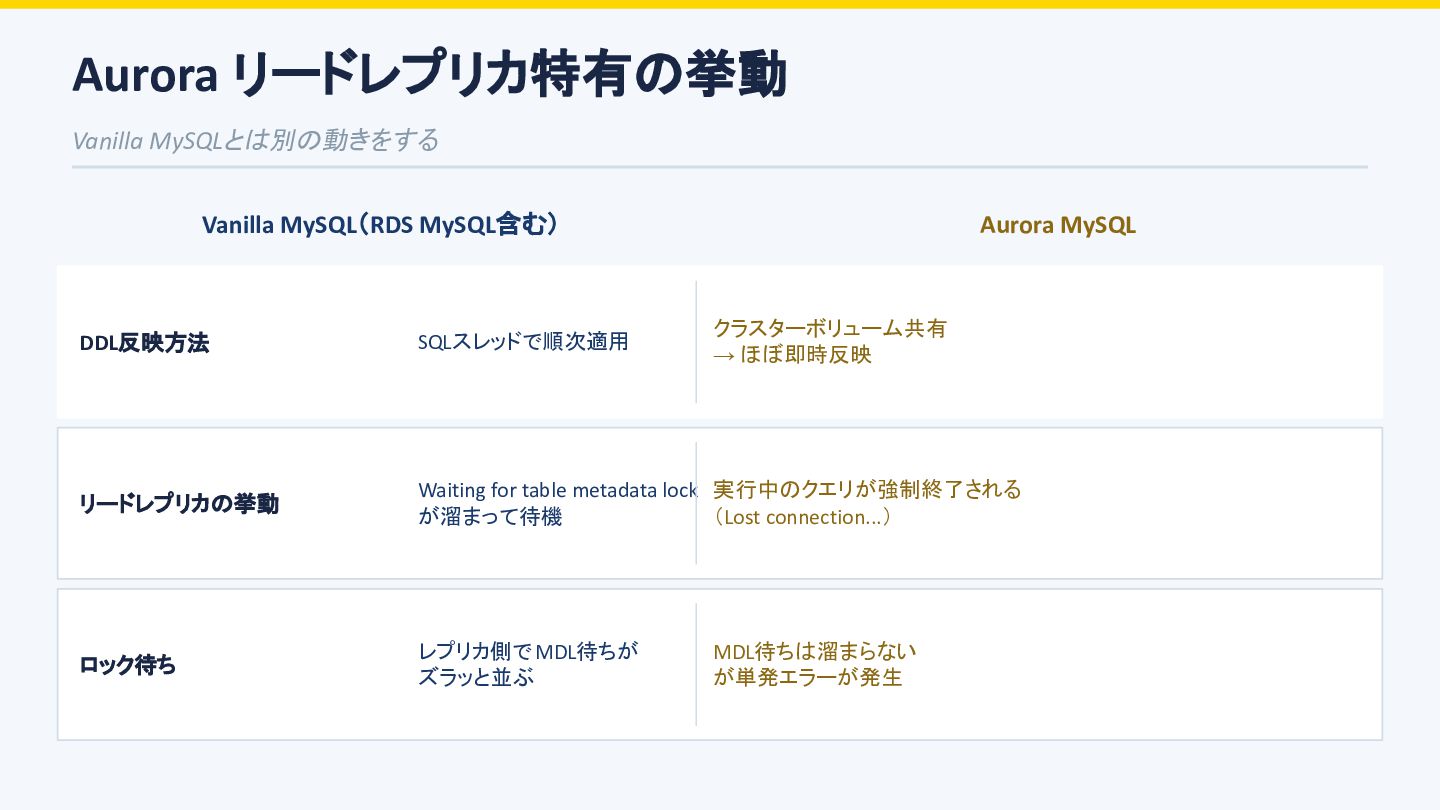
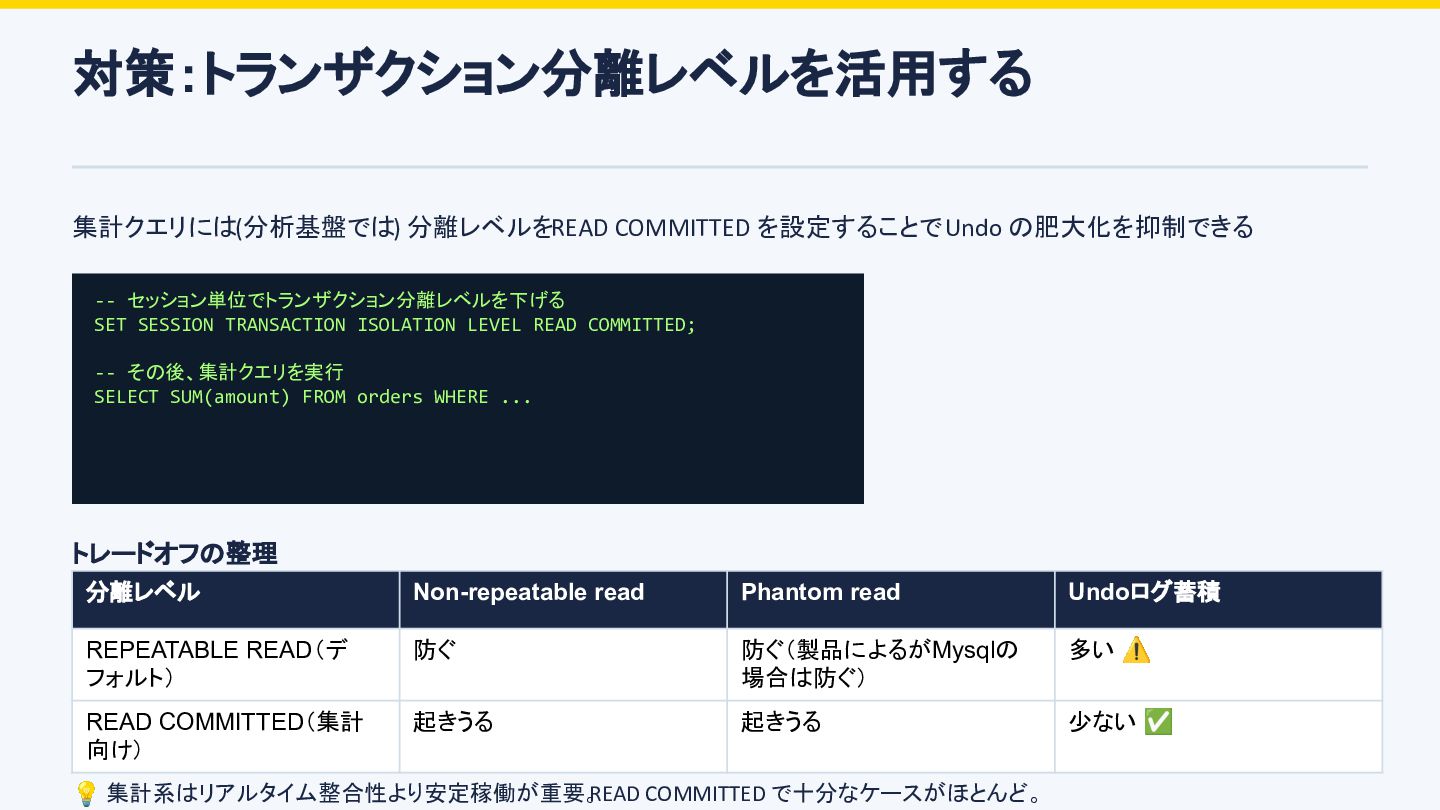
実行タイミングで Readレプリカで実行中のSELECTが 「Lost connection to MySQL server during query」エラーで落ちる 弊社の対応方針 Rails の7.1から導入された自動リトライ機能を活用し、 lost connection エラー発生時に 一定回数クエリを自動リトライするよう設定。 (リトライするかは一定の 条件あり) ALTER 完了後にリトライが成功するため アプリ側にはリカバリされる。
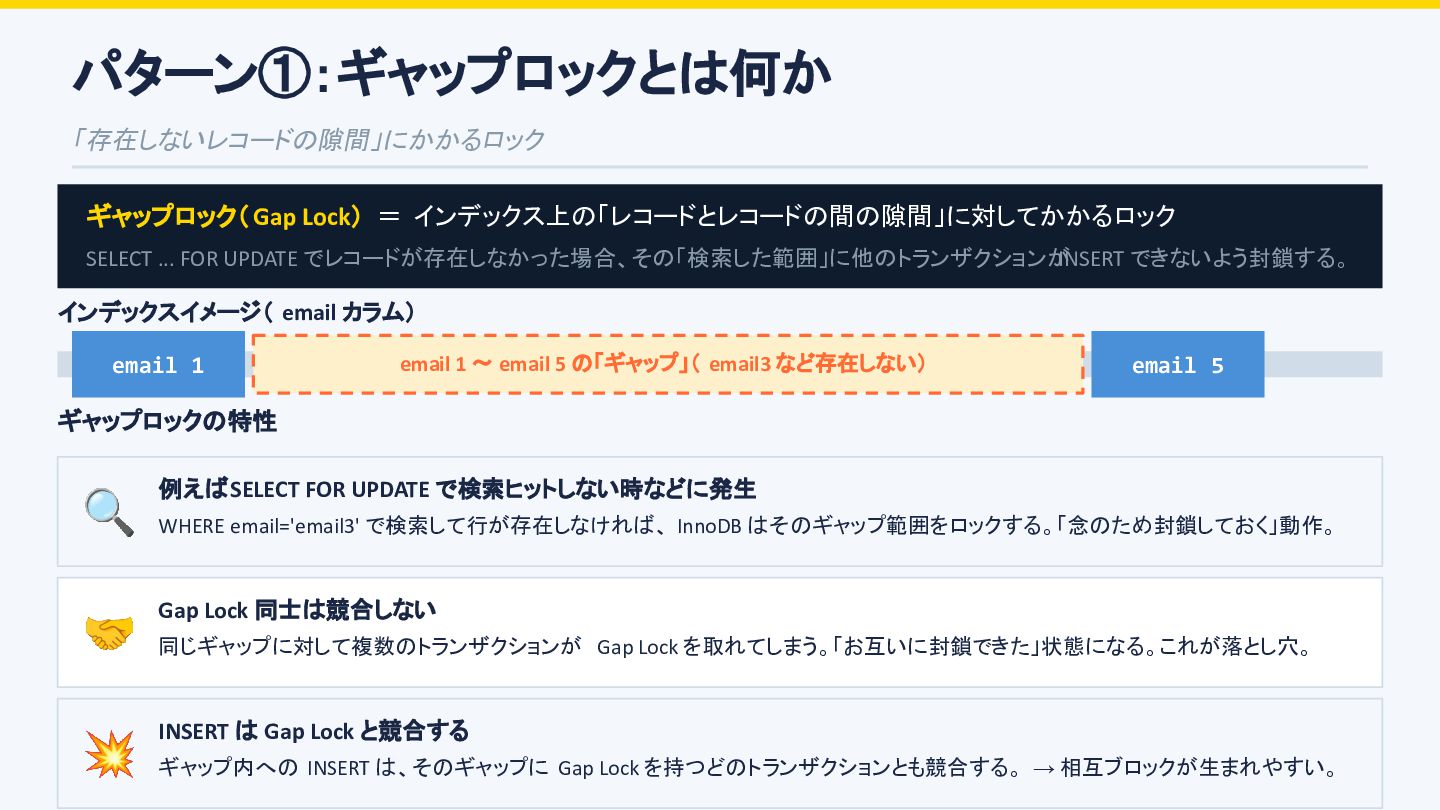
A と Tx B が同時に「email3 を検索して、なければ INSERT する」という処理を実行する Tx A Tx B ① SELECT FOR UPDATE → email3 が存在しない → Gap Lock 取得 SELECT * FROM users WHERE email='email3' FOR UPDATE; -- 存在しない → Gap Lock ✅ Gap Lock SELECT * FROM users WHERE email='email3' FOR UPDATE; -- 存在しない → Gap Lock ✅ Gap Lock 💡 Gap Lock 同士は競合しない → 両方が「取れた」と思っている ② INSERT email3 を試みる → 相手の Gap Lock に阻まれる INSERT INTO users (email) VALUES('email3'); -- Tx B の Gap Lock に阻まれる -- → 待機 ⏸ WAIT INSERT INTO users (email) VALUES('email3'); -- Tx A の Gap Lock に阻まれる -- → 待機 ⏸ WAIT ③ Tx A は Tx B の待ち、Tx B は Tx A の待ち → 相互待機 → デッドロック 💥
SELECT * FROM users WHERE email='email3' FOR UPDATE; -- 存在しない → Gap Lock INSERT INTO users (email) VALUES ('email3'); -- 相手の Gap Lock に阻まれる → WAIT 対策 ✅ ① INSERT IGNORE または INSERT ... ON DUPLICATE KEY UPDATE 「存在チェックしてから INSERT」という2ステップをやめて、1クエリで 完結させる。 Gap Lock が取れない→そもそも競合しない。 INSERT IGNORE INTO users (email) VALUES ('email3'); -- または INSERT INTO users (email) VALUES ('email3') ON DUPLICATE KEY UPDATE updated_at = NOW(); ✅ ② FOR UPDATE をやめる(存在確認だけなら共有ロック or ロックなし) 「INSERT するかどうか未定」の段階で FOR UPDATE(X ロック)を取 るから Gap Lock が問題になる。 本当に X ロックが必要か設計を見直す。 -- 存在確認だけなら FOR UPDATE は不要 SELECT * FROM users WHERE email='email3'; -- INSERT するときに UNIQUE 制約に任せる
SHARE MODE 「読み取り中。他が更新するのは待ってほしい」 S ロックを持っている間、他の S ロックは許可される。 ただし X ロックはブロックされる。 X ロック(排他ロック) 取得方法:SELECT ... FOR UPDATE / UPDATE / DELETE 「更新中。誰も触らないでほしい」 X ロックは他のいかなるロック( S も X も)とも競合する。 X ロックを取るには全ての S ロックが解放される必要がある。 ロック互換性 S + S 競合しない ✅ 両方が同時に読める S + X 競合する ❌ 読んでいる間は更新できない X + X 競合する ❌ 更新中は誰も触れない 💥 落とし穴:「S ロックを持ったまま X ロックに昇格しようとする」と、相手の S ロックが邪魔になる → 相互ブロック
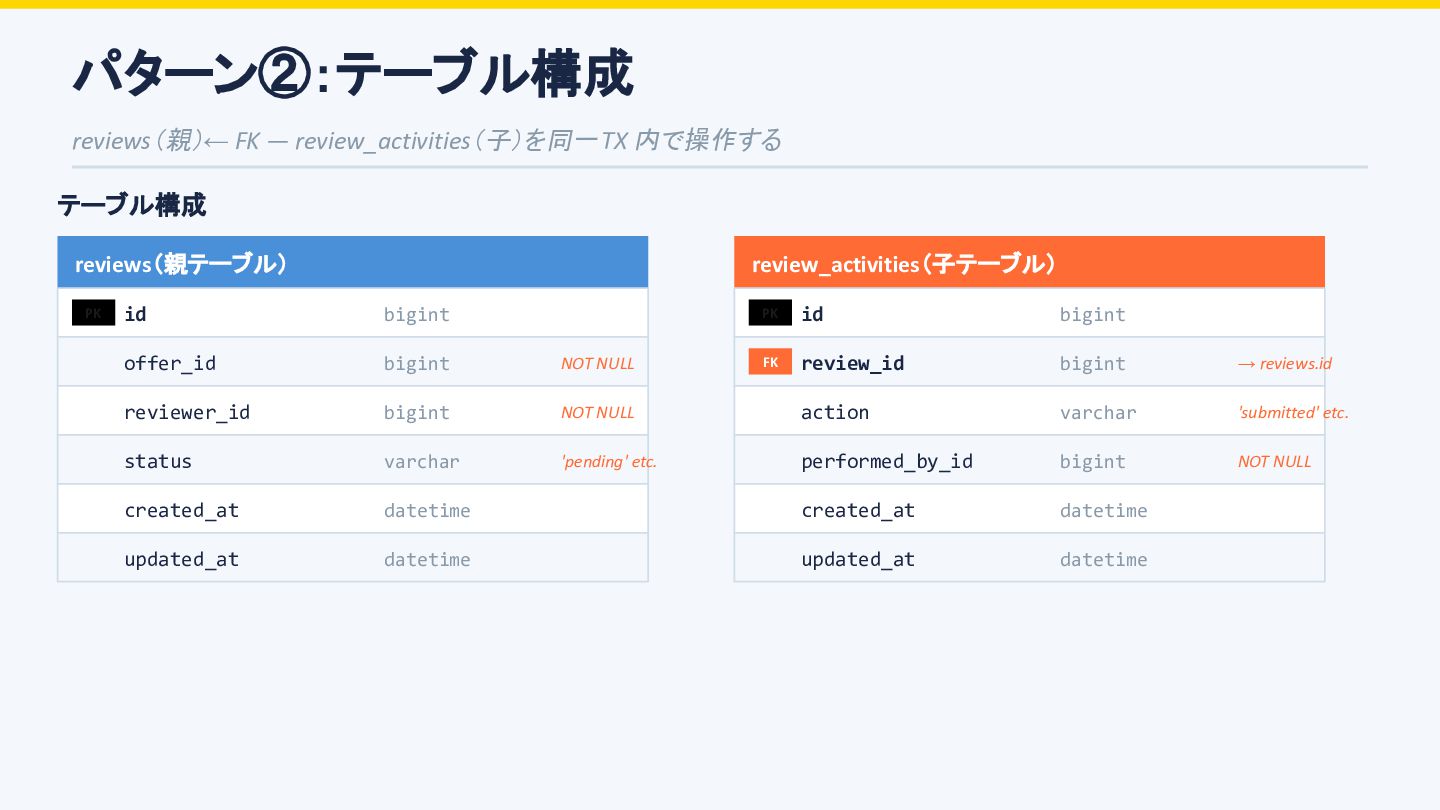
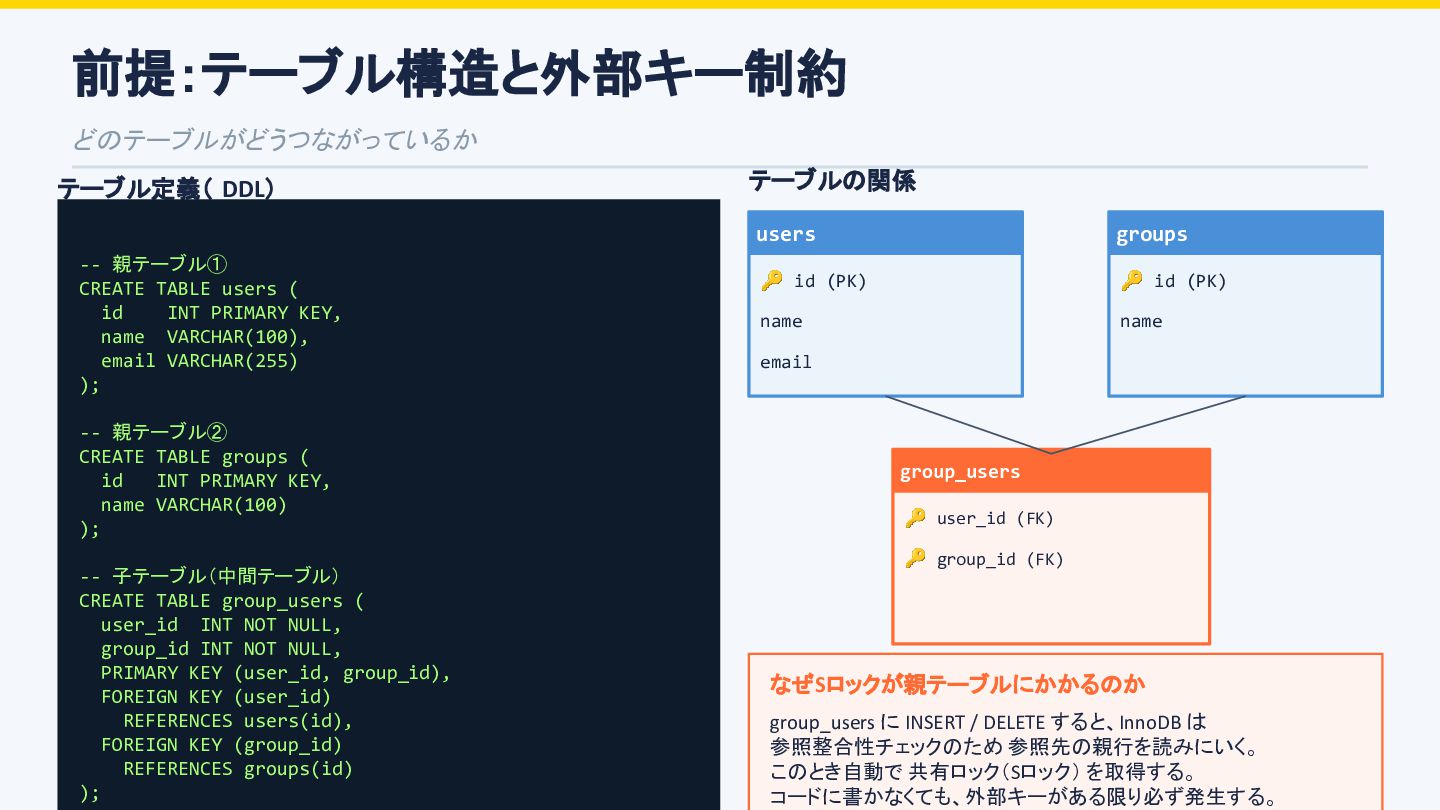
id bigint offer_id bigint NOT NULL reviewer_id bigint NOT NULL status varchar 'pending' etc. created_at datetime updated_at datetime review_activities(子テーブル) PK id bigint FK review_id bigint → reviews.id action varchar 'submitted' etc. performed_by_id bigint NOT NULL created_at datetime updated_at datetime
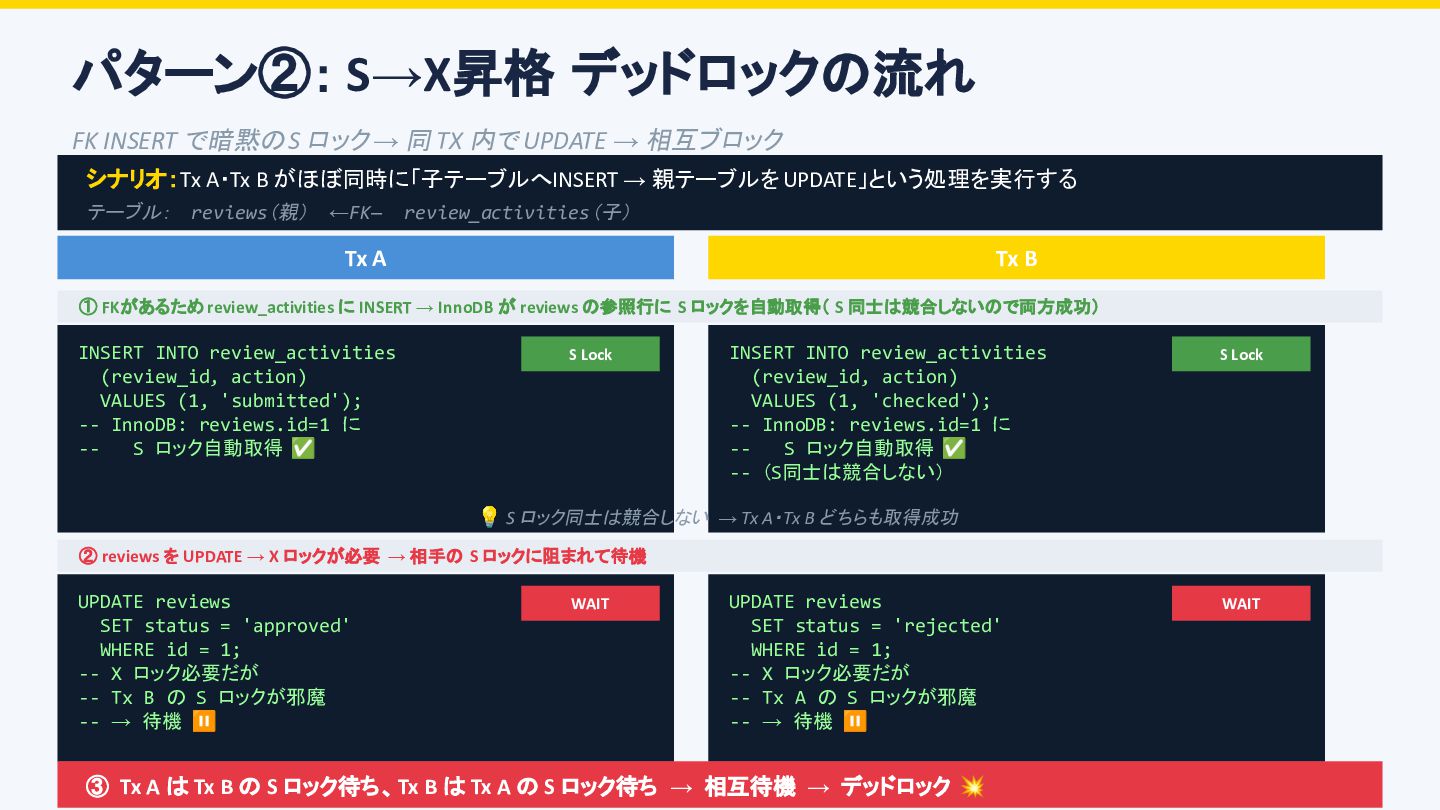
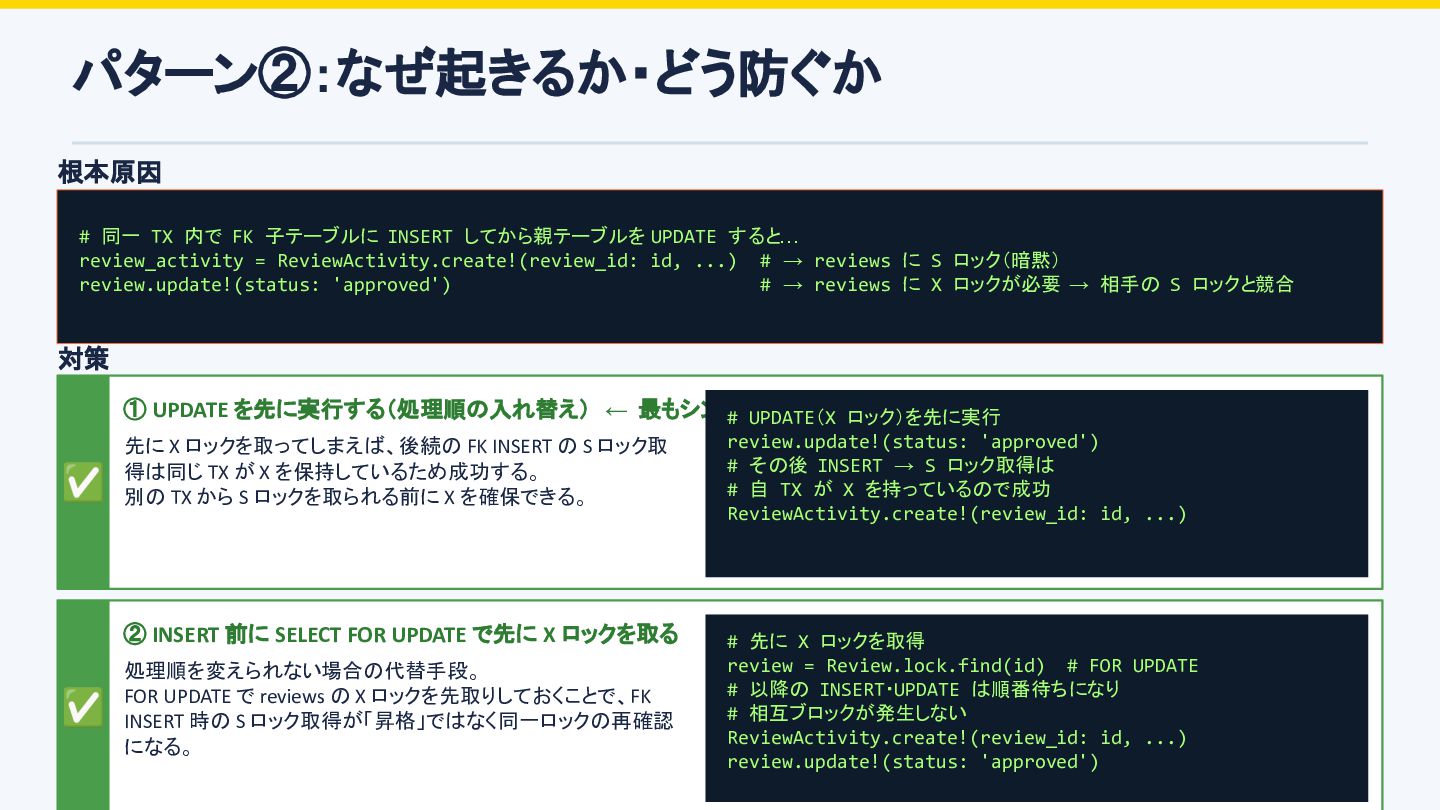
TX 内で UPDATE → 相互ブロック シナリオ:Tx A・Tx B がほぼ同時に「子テーブルへ INSERT → 親テーブルを UPDATE」という処理を実行する テーブル: reviews(親) ←FK— review_activities(子) Tx A Tx B ① FKがあるため review_activities に INSERT → InnoDB が reviews の参照行に S ロックを自動取得( S 同士は競合しないので両方成功) INSERT INTO review_activities (review_id, action) VALUES (1, 'submitted'); -- InnoDB: reviews.id=1 に -- S ロック自動取得 ✅ S Lock INSERT INTO review_activities (review_id, action) VALUES (1, 'checked'); -- InnoDB: reviews.id=1 に -- S ロック自動取得 ✅ -- (S同士は競合しない) S Lock 💡 S ロック同士は競合しない → Tx A・Tx B どちらも取得成功 ② reviews を UPDATE → X ロックが必要 → 相手の S ロックに阻まれて待機 UPDATE reviews SET status = 'approved' WHERE id = 1; -- X ロック必要だが -- Tx B の S ロックが邪魔 -- → 待機 ⏸ WAIT UPDATE reviews SET status = 'rejected' WHERE id = 1; -- X ロック必要だが -- Tx A の S ロックが邪魔 -- → 待機 ⏸ WAIT ③ Tx A は Tx B の S ロック待ち、Tx B は Tx A の S ロック待ち → 相互待機 → デッドロック 💥
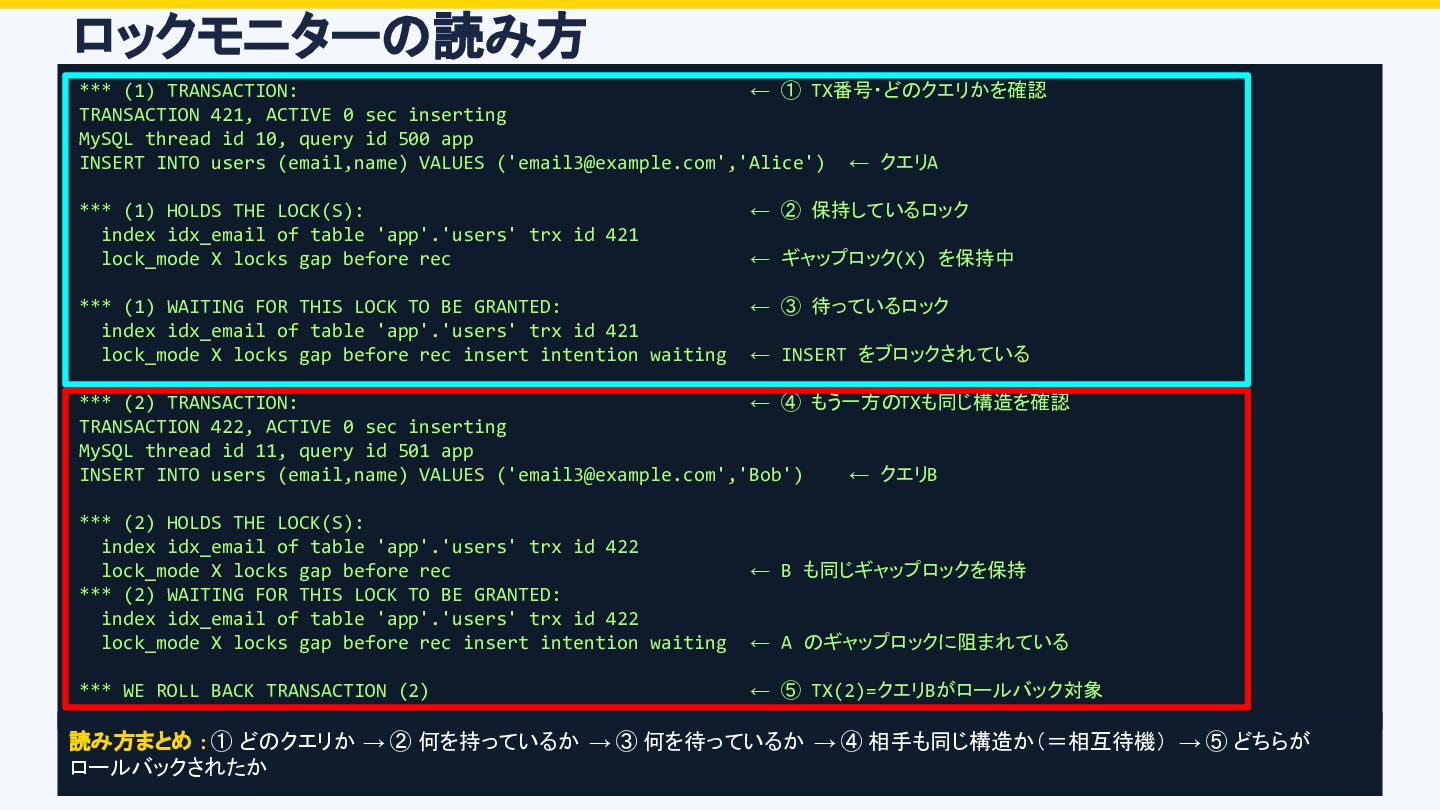
0 sec inserting MySQL thread id 10, query id 500 app INSERT INTO users (email,name) VALUES ('[email protected]','Alice') ← クエリA *** (1) HOLDS THE LOCK(S): ← ② 保持しているロック index idx_email of table 'app'.'users' trx id 421 lock_mode X locks gap before rec ← ギャップロック(X) を保持中 *** (1) WAITING FOR THIS LOCK TO BE GRANTED: ← ③ 待っているロック index idx_email of table 'app'.'users' trx id 421 lock_mode X locks gap before rec insert intention waiting ← INSERT をブロックされている *** (2) TRANSACTION: ← ④ もう一方のTXも同じ構造を確認 TRANSACTION 422, ACTIVE 0 sec inserting MySQL thread id 11, query id 501 app INSERT INTO users (email,name) VALUES ('[email protected]','Bob') ← クエリB *** (2) HOLDS THE LOCK(S): index idx_email of table 'app'.'users' trx id 422 lock_mode X locks gap before rec ← B も同じギャップロックを保持 *** (2) WAITING FOR THIS LOCK TO BE GRANTED: index idx_email of table 'app'.'users' trx id 422 lock_mode X locks gap before rec insert intention waiting ← A のギャップロックに阻まれている *** WE ROLL BACK TRANSACTION (2) ← ⑤ TX(2)=クエリBがロールバック対象 読み方まとめ : ① どのクエリか → ② 何を持っているか → ③ 何を待っているか → ④ 相手も同じ構造か(=相互待機) → ⑤ どちらが ロールバックされたか
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![前ページ補足 [補足説明]なぜ Reader の長時間クエリで Undo ログがパージ不可になるのか MVCC / Read View](https://files.speakerdeck.com/presentations/6d5cc86244b9427894f7ca2fb89cbc77/slide_25.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
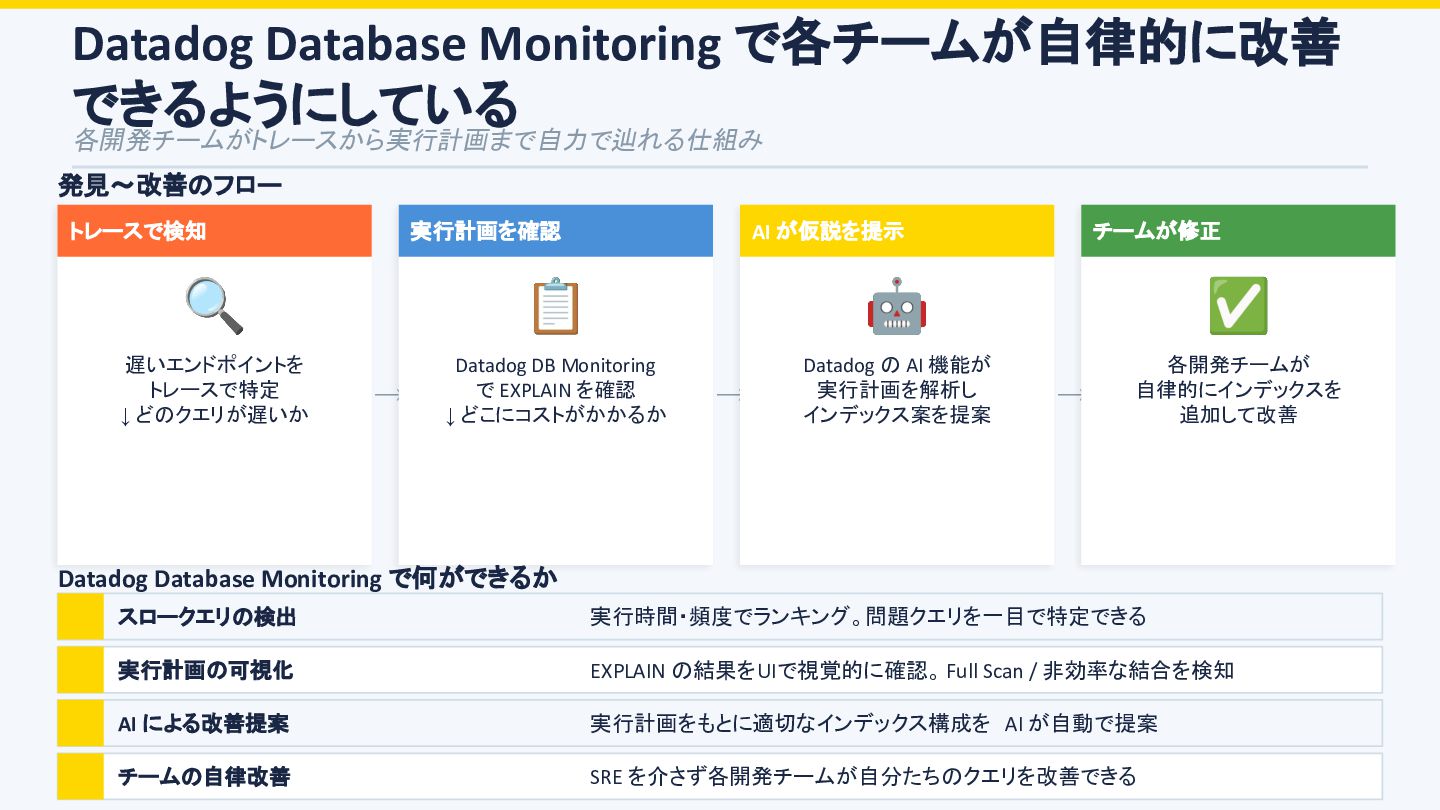{kind=link}
{kind=link}
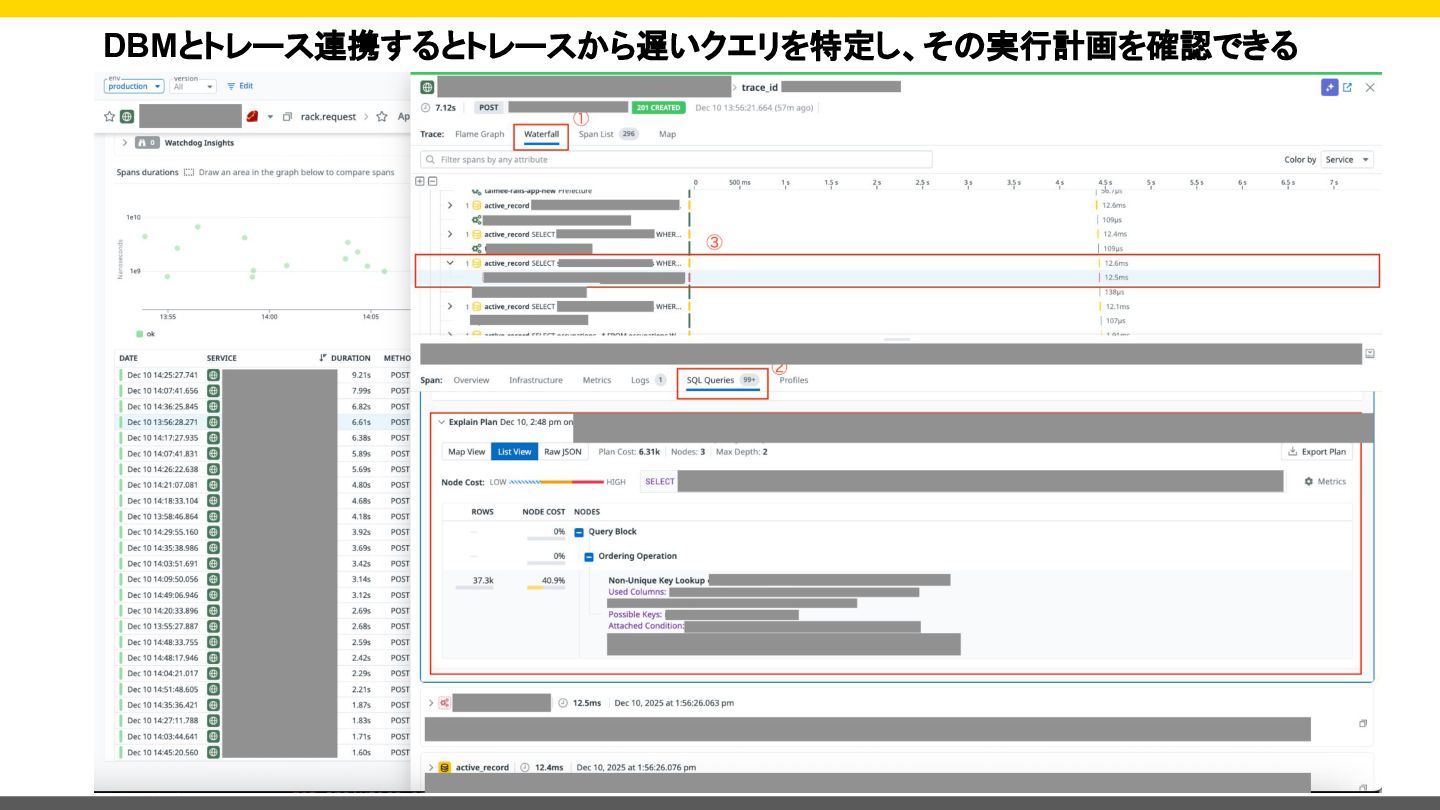{kind=link}
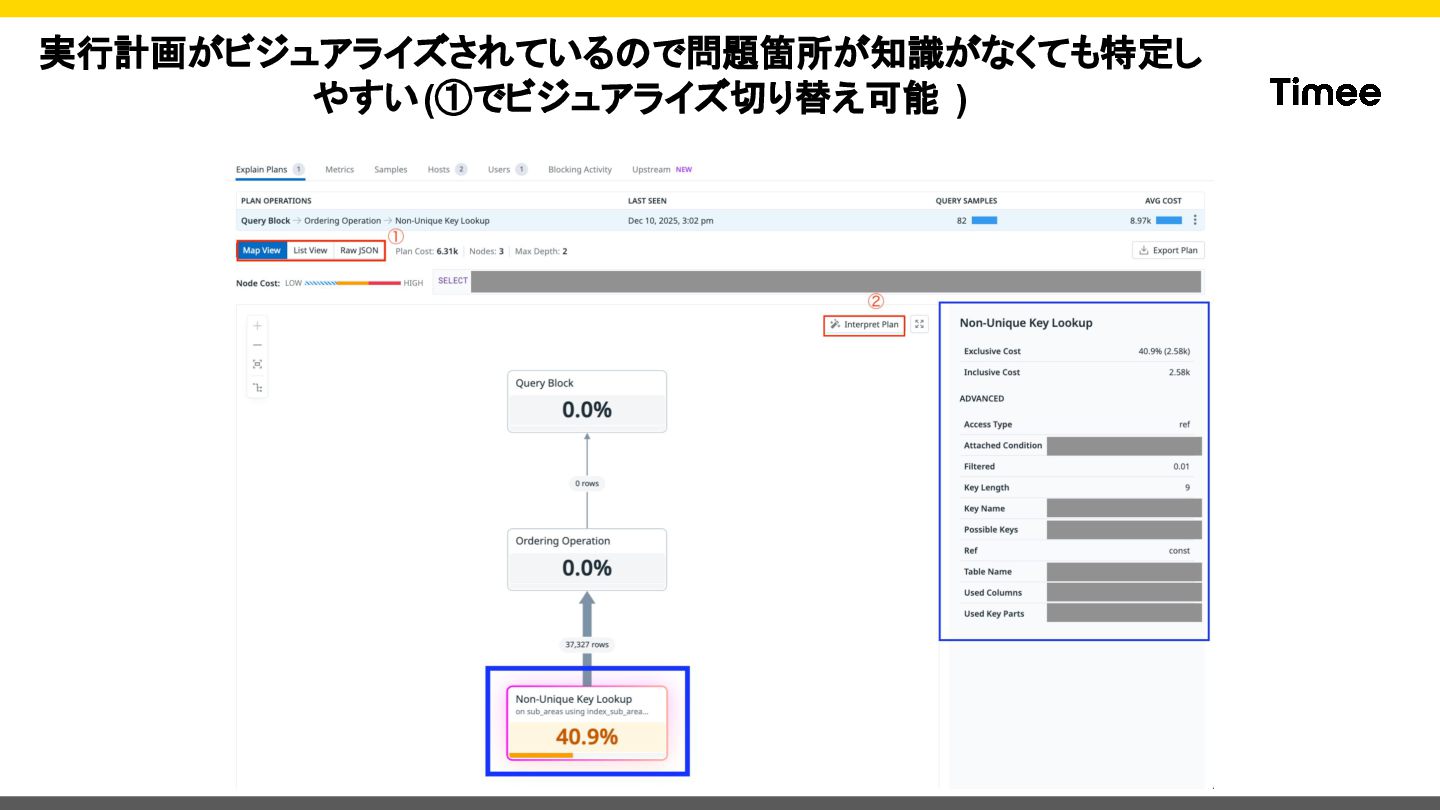{kind=link}
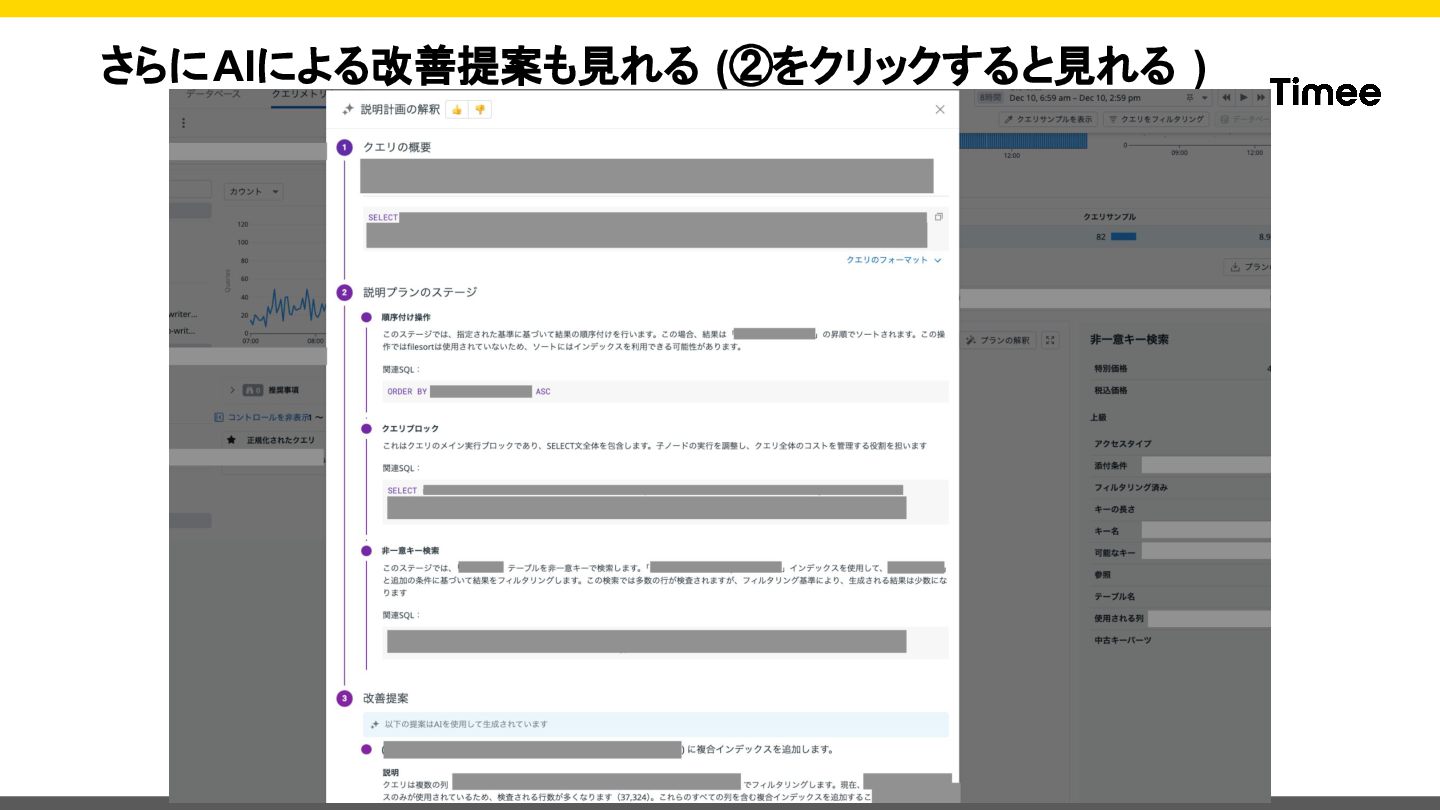{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
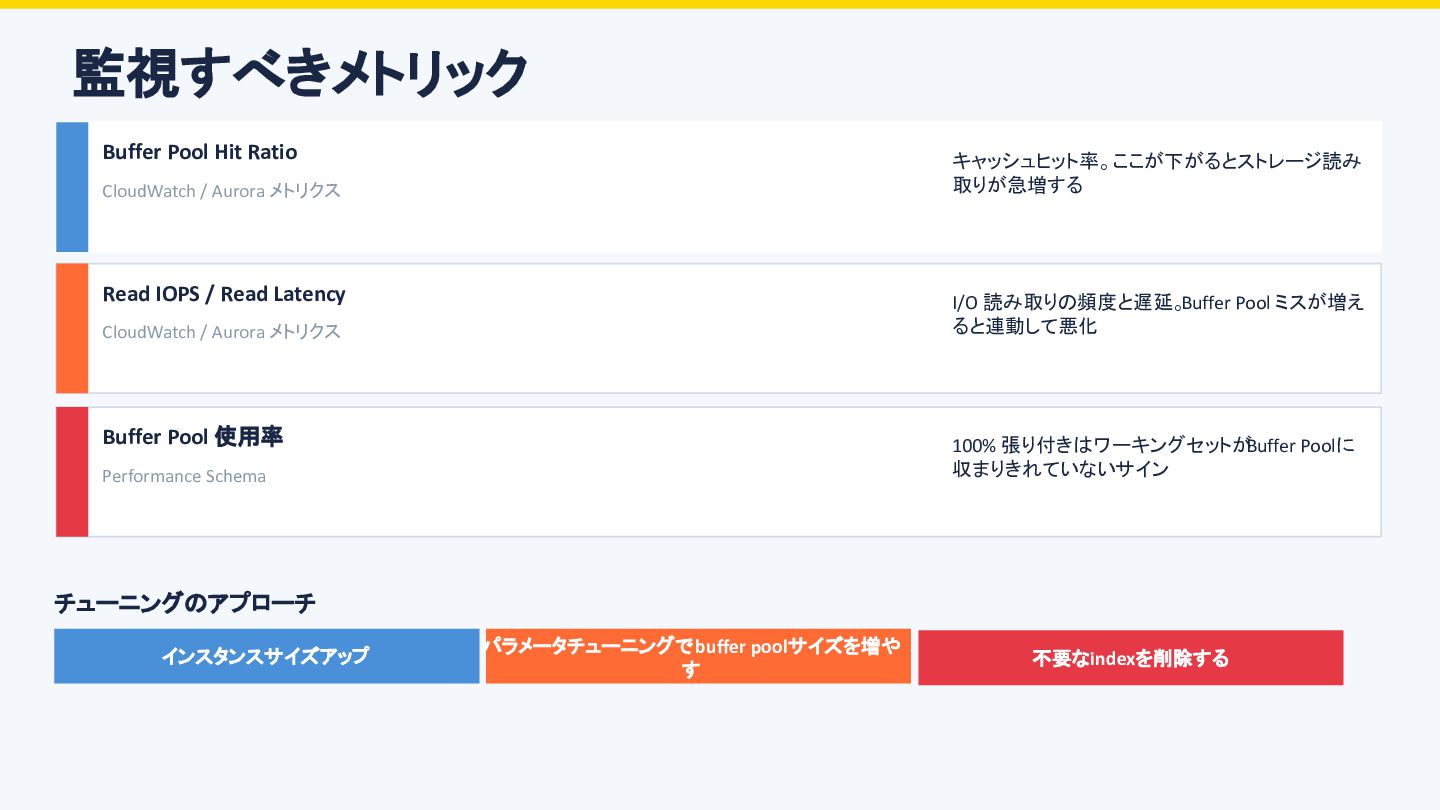{kind=link}
{kind=link}
{kind=link}