& warum am Code gemacht?” • In einer separaten Branch am Code experimentieren und ohne Aufwand wieder verwerfen oder übernehmen • Code anderen Menschen unter einer Open Source Lizenz bereitstellen
Control System • Es gibt keine Unterteilung in Client und Server (vs. SVN) • Jeder Computer kann ein Repository für andere Nutzende bereitstellen • Alle Nutzenden haben die gesamte Historie und den gesamten Code immer am eigenen Rechner • Server sind einfach Git Repositories, die über SSH oder HTTPS bereitgestellt werden • ALLES kann lokal gemacht werden, es gibt keine Einschränkungen, Server sind nur für Backup und einfachere Zusammenarbeit
mehr gratis für die Entwicklung des Linux Kernels verwendet werden • 6. Apr 2005: Linus Torvalds kündigt die Entwicklung von Git an • 21. Dez 2005: Git 1.0 wird veröffentlicht • 8. Feb 2008: GitHub wird gegründet
von https://git- scm.org • Enthält nur das Command Line Interface • Keine Installation notwendig bei den meisten Linux Distributionen und allen macOS Versionen • Ein guter GUI Client ist SourceTree von Atlassian (BitBucket)
Besteht aus Commits, Branches und Tags • Kann entweder lokal gespeichert sein oder von einem Server über SSH oder HTTPS bereitgestellt werden, aber grundsätzlich schaut alles gleich aus
Rechner Änderungen im Repository zu machen • Enthält Dateien und Ordner, die am Dateisystem existieren und normal mit Programmen bearbeitet werden können • Kann optional mit anderen Nutzenden geteilt werden, die Pull oder Push machen können
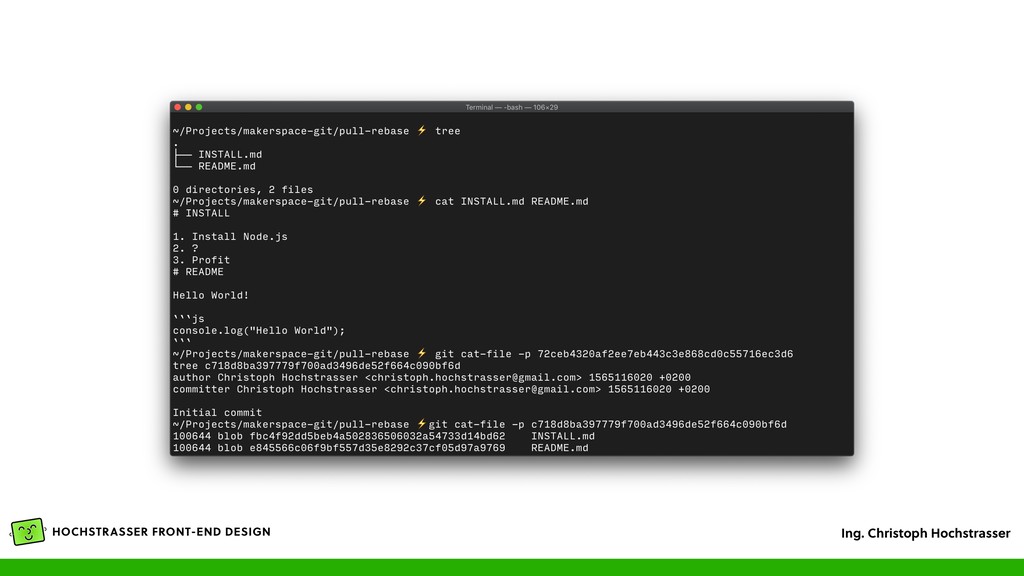
• Größtenteils normale Textdateien, die mit einem Texteditor betrachtet werden können • Enthält alle Änderungen und alle Versionen aller Dateien im Repo • Git ist sehr transparent, es kann sehr viel von außen inspiziert werden, durch Betrachten der Textdateien oder mit einfachen Commands (wie git cat-file)
ein Object • ID ist die Prüfsumme des Inhalts (SHA-1, SHA-256) • z.B. „hello world” = 22596363b3de40b06f981fb85d82312e8c0ed511 • Durch Änderung des Inhalts, ändert sich immer die Prüfsumme • Selber Inhalt = Selbe Prüfsumme = Selbes Objekt • „Content Addressable Filesystem” • Üblicherweise genügen die ersten 6–8 Stellen der ID in der Kommunikation oder CLI
einem Verzeichnisbaum zu, mit Dateinamen und Zugriffsberechtigungen (Unix Modell, z.B. „755”) • Ab dort existiert in Git ein „Dateisystem” • Ist wieder ein Object mit einem SHA Hash, z.B. b701f7c8eaed1d1335e994893cebdf979750d25e
werden zum Index hinzugefügt, bevor aus dem Index ein Commit gemacht wird • Kann dazu verwendet werden um Änderungen an der Arbeitskopie wieder rückgängig zu machen • Ein Index ist ein temporärer Tree, der noch nicht durch einen Commit abgespeichert wurde
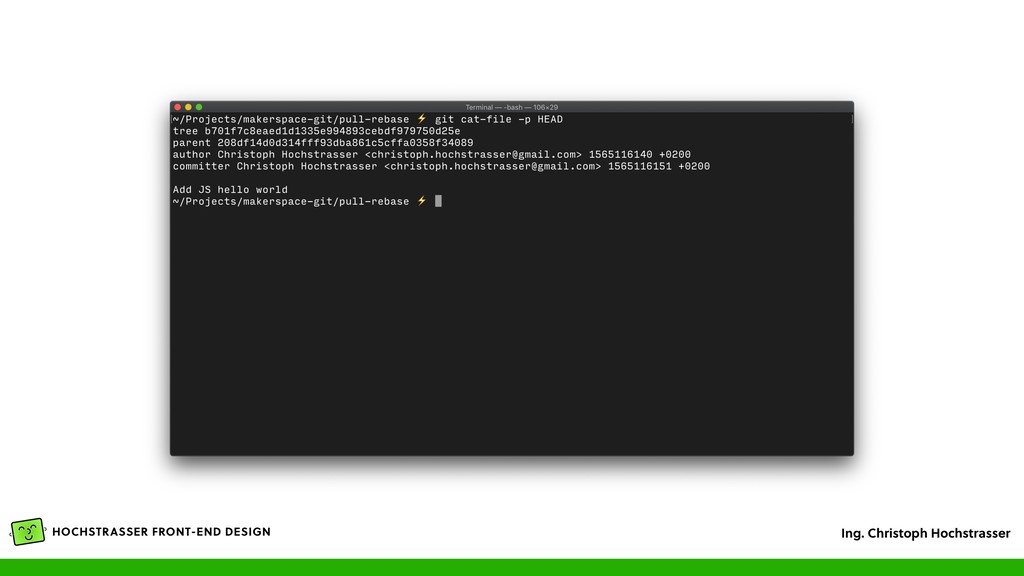
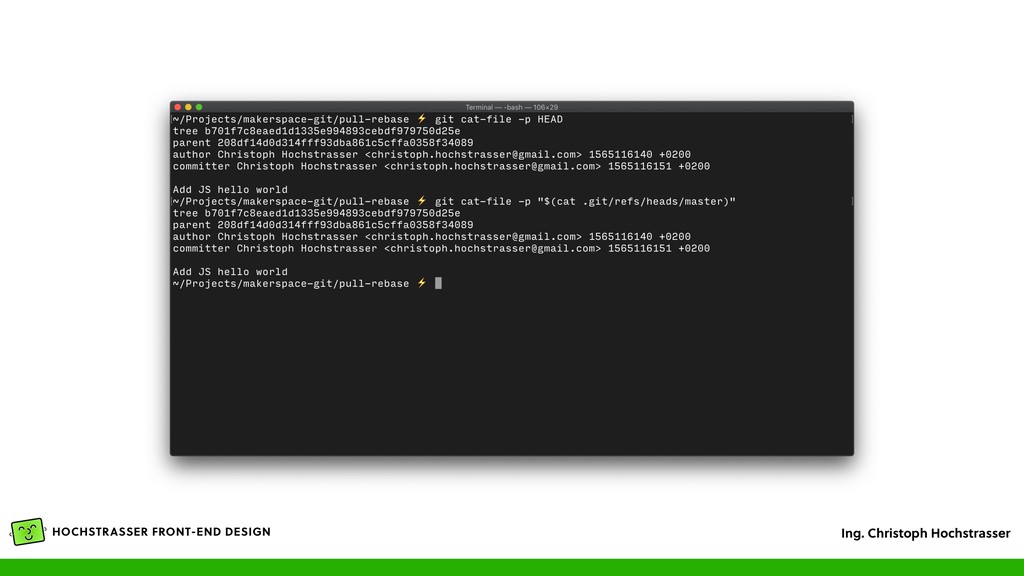
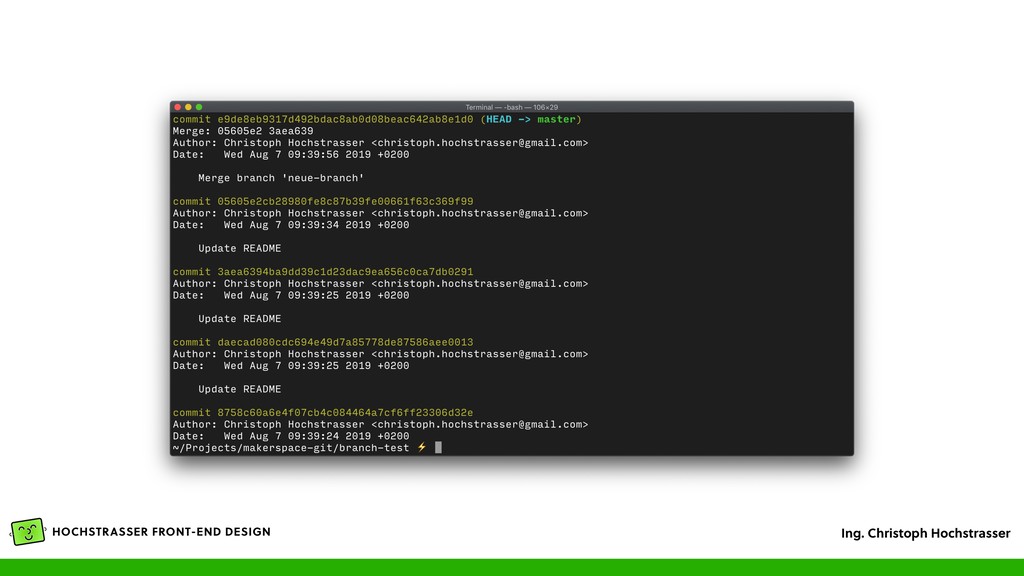
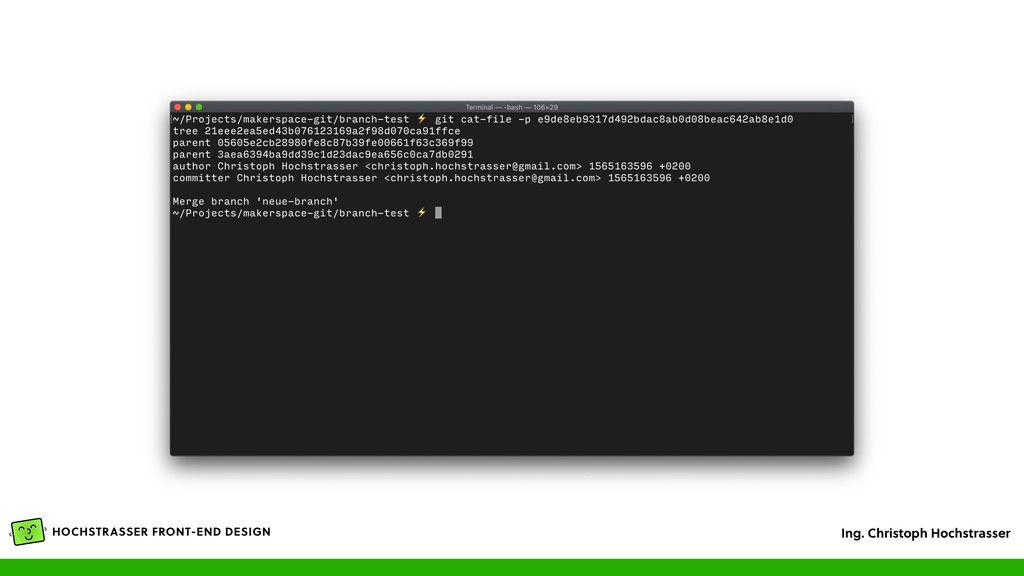
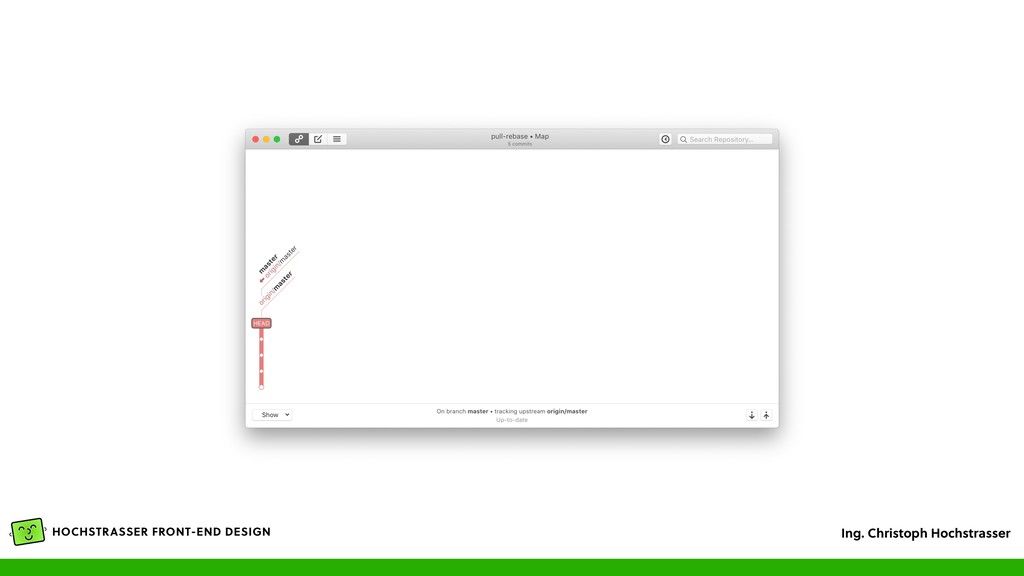
Author, Committer, Timestamp und der Commit Message • Der vorige Commit steht als ID im Feld „parent”, dadurch ergibt sich das Log (auch DAG genannt) — bei einem Merge stehen mehrere Commit IDs im „parent” Feld • Wird wieder als Object gespeichert und bekommt dadurch eine eindeutige ID, die Commit ID • Ein File „HEAD” enthält den aktuellen Commit der aktuellen Arbeitskopie • Eine Textdatei, die so wie die Branch heißt (z.B. „master”) enthält die ID des letzten Commits in der Branch (.git/refs/heads/*)
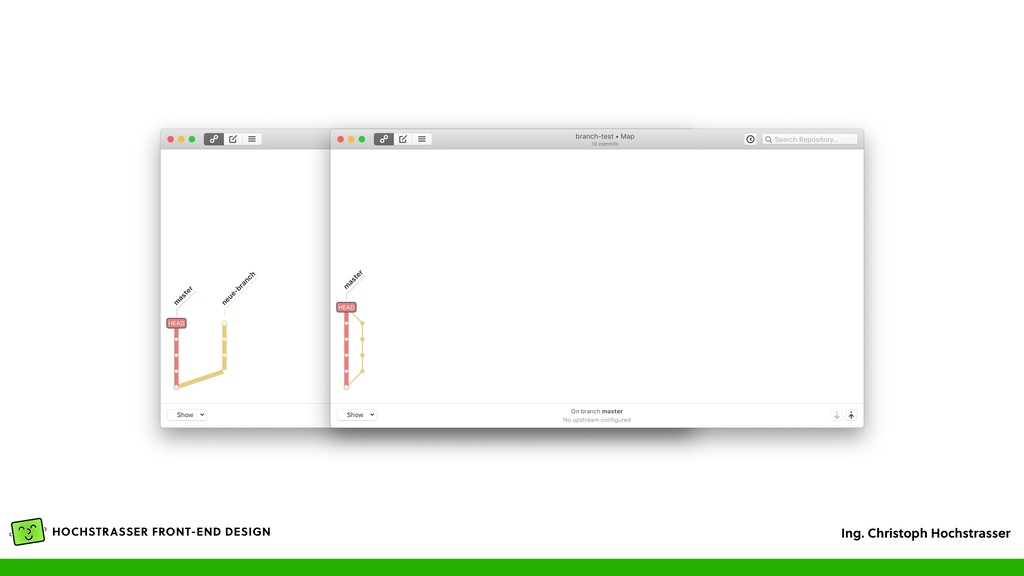
eine „master” Branch (vgl. mit „trunk” in SVN) • Verzweigung in der Historie • Entsteht aus einer anderen Branch (z.B. master) • Enthält dann Änderungen, die nur in dem Zweig bestehen • Kann entweder gelöscht werden, dann werden alle Änderungen verworfen, oder mit „Merge” können die Änderungen in eine Ziel-Branch übernommen werden
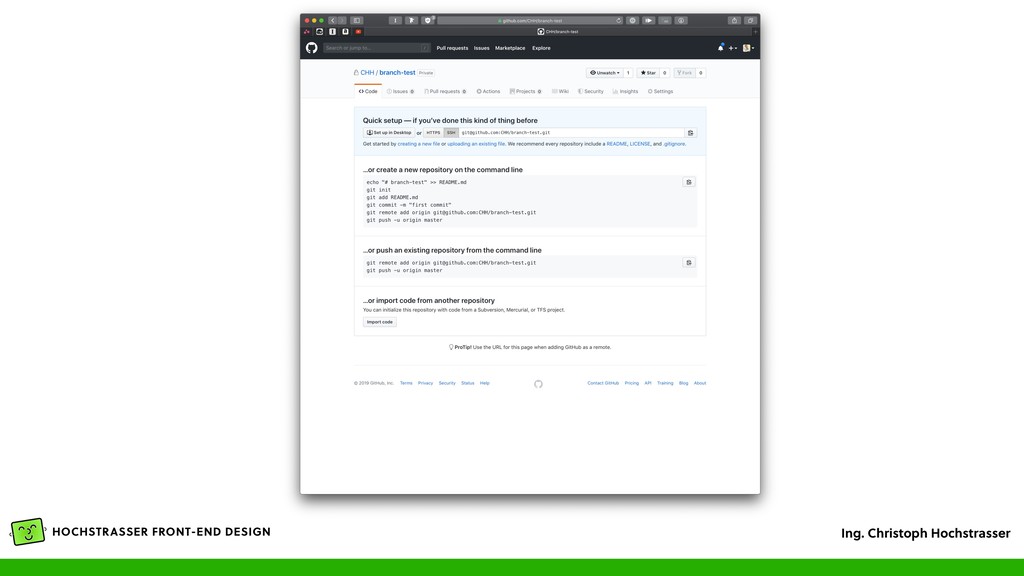
Repository von der URL herunter und erstellt eine Arbeitskopie • BEISPIEL: git clone git://github.com/CHH/php- build • Erstellt eine lokale Arbeitskopie in einem „php- build” Ordner im aktuellen Verzeichnis • Vergleichbar mit „svn checkout”
Git Repository im aktuellen Verzeichnis an • Kann in problemlos in einem Verzeichnis mit bestehenden Dateien & Ordnern gemacht werden • Enthält noch keinen Commit, muss erst mit git add . und git commit gemacht werden • Üblich: git add . && git commit -m „Initial Commit” • Danach kann man den Server hinzufügen, so wie bei GitHub angezeigt (git remote add origin <url>)
Änderungen (üblicherweise ganze Dateien, aber muss nicht sein) zum Index für den nächsten Commit hinzu • add • Änderungen hinzufügen, handhabt mittlerweile eigentlich umbenannte und gelöschte Dateien automatisch, ein git add . genügt • rm • Datei löschen • mv • Datei umbenennen • Änderungen werden erst beim nächsten Commit gespeichert
(alle über git add,… hinzugefügten Änderungen) einen Commit • Ohne Argumente wird der Standard-Editor geöffnet (z.B. vim auf Linux) • -m „Nachricht” • -a Einfach alle Änderungen in den Commit übernehmen (ohne git add)
• Hat verschiedenste Optionen um die Historie zu formatieren und darzustellen • -- format=oneline • Ein Commit pro Zeile • -- graph • Baum-Ansicht, praktisch mit Branches • git log <file> • Zeigt alle Änderungen in einer Datei • git log - - author=<author> • Zeigt alle Änderungen einer Person
Änderungen • Kann mit git stash pop wiederhergestellt werden • Praktisch um Änderungen ohne Commit zwischenzuspeichern, dazwischen einen Pull zu machen und danach wieder weiterzuarbeiten
verwendet werden um in der Arbeitskopie den Stand eines Commits, Tags oder einer Branch herzustellen • GOTCHA: Nicht verwandt mit svn checkout! • GOTCHA: git checkout . • Setzt die Arbeitskopie auf den letzten Commit zurück • PRAKTISCH: git checkout -b <branch> erstellt eine neue Branch und wechselt gleich dorthin • PRAKTISCH: git checkout - wechselt zurück in die letzte Branch (so wie cd -)
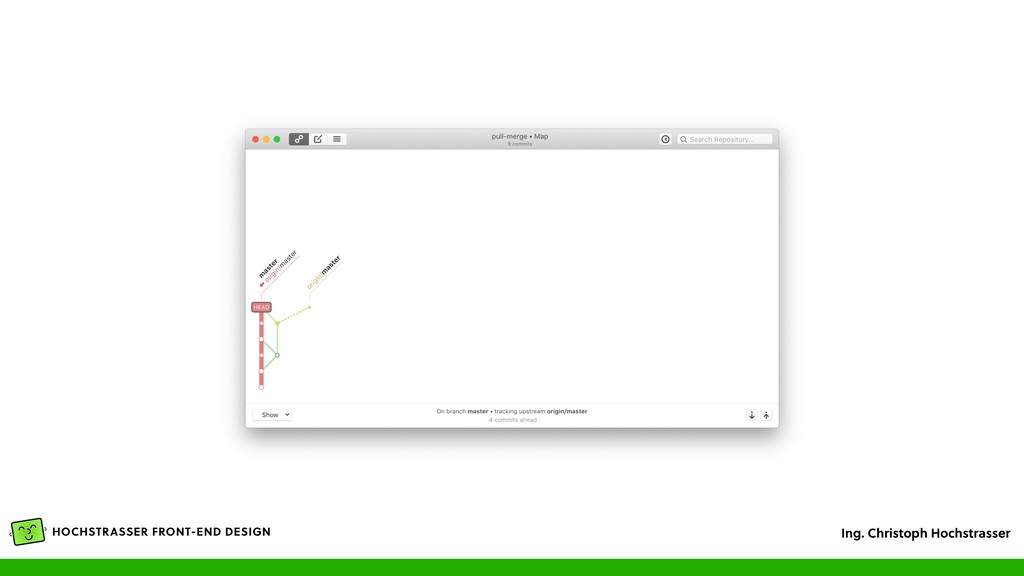
Änderungen der Branch auf den Git Server • Wenn es auf dem Server Änderungen gibt, die noch nicht durch einen Pull abgerufen wurden, dann wird ein Fehler zurückgegeben • Beim ersten Push auf einen Server: • git push --set-upstream <remote> <branch> • Dann kann einfach nur „git pull” oder „git push” gemacht werden, ohne Angabe von Branch
eine Branch vom Server gelöscht werden • Wichtig: Branch kann nicht wiederhergestellt werden, bleibt aber lokal bestehen! • Lokale Branch kann mit git branch -d gelöscht werden
von <branch> in die aktuelle Branch • Wenn Konflikte entstehen, dann Konflikte beheben und die Datei mit git add <file> hinzufügen • Dann git merge --continue, bzw. git commit am Ende des Merges
beginnt üblicherweise mit kann auch mit Prefix erfolgen „feature/*” • Wird angelegt, wenn mit dem Feature begonnen wird • Wenn das Feature fertig entwickelt ist, dann wird ein Pull Request auf „master” gemacht • Code Review • (Deploy auf Production) • Merge des PR
maximal 5 Personen • Continuous Integration ist integriert (auch Windows und macOS verfügbar, z.B. um eine iOS App zu bauen) • Wikis, Pull Requests • Azure Boards ist vergleichbar mit Jira
• Historisch entwickelte sich SSH Public Key • Linux, macOS kein Problem • Neuere Möglichkeit ist HTTPS • Funktioniert auf Windows besser • Die Anbieter leiten durch den Prozess
wird eine Kopie des Repositories im eigenen Account erstellt • Es besteht danach eine Beziehung zwischen den beiden Repos • Dort können dann in einer Branch Änderungen gemacht werden, wie wenn es das eigene Repository wäre • ACHTUNG: Ein Fork auf GitHub/BitBucket ist kein „Fork” im ursprünglichen Open Source Sinn, es geht nur um den Code!
Änderungen, die in einem Fork oder in einer Branch gemacht wurden, jemandem zum Merge vorzuschlagen • Die Empfänger können den Pull Request annehmen und den Merge machen oder den Pull Request ablehnen
![Ing. Christoph Hochstrasser Git Workshop MAKERSPACE[A]](https://files.speakerdeck.com/presentations/e4a1240181cd43e0806dc3f56341fbbf/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[email protected] Wenn dir noch eine Frage einfällt:](https://files.speakerdeck.com/presentations/e4a1240181cd43e0806dc3f56341fbbf/slide_76.jpg){kind=link}