Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
AlphaZero輪読会(4章 強化学習)
Search
Sponsored
·
SiteGround - Reliable hosting with speed, security, and support you can count on.
→
hookbook
July 30, 2019
Technology
0
38
AlphaZero輪読会(4章 強化学習)
hookbook
July 30, 2019
Tweet
Share
Other Decks in Technology
See All in Technology
Oracle Base Database Service 技術詳細
oracle4engineer
PRO
15
93k
茨城の思い出を振り返る ~CDKのセキュリティを添えて~ / 20260201 Mitsutoshi Matsuo
shift_evolve
PRO
1
430
ファインディの横断SREがTakumi byGMOと取り組む、セキュリティと開発スピードの両立
rvirus0817
1
1.7k
Oracle AI Database 移行・アップグレード勉強会 - RAT活用編
oracle4engineer
PRO
0
110
学生・新卒・ジュニアから目指すSRE
hiroyaonoe
2
770
AzureでのIaC - Bicep? Terraform? それ早く言ってよ会議
torumakabe
1
620
Ruby版 JSXのRuxが気になる
sansantech
PRO
0
170
Agent Skils
dip_tech
PRO
0
140
Amazon Bedrock Knowledge Basesチャンキング解説!
aoinoguchi
0
170
pool.ntp.orgに ⾃宅サーバーで 参加してみたら...
tanyorg
0
1.4k
私たち準委任PdEは2つのプロダクトに挑戦する ~ソフトウェア、開発支援という”二重”のプロダクトエンジニアリングの実践~ / 20260212 Naoki Takahashi
shift_evolve
PRO
2
210
SREが向き合う大規模リアーキテクチャ 〜信頼性とアジリティの両立〜
zepprix
0
480
Featured
See All Featured
Put a Button on it: Removing Barriers to Going Fast.
kastner
60
4.2k
Exploring the relationship between traditional SERPs and Gen AI search
raygrieselhuber
PRO
2
3.6k
Agile that works and the tools we love
rasmusluckow
331
21k
How to Ace a Technical Interview
jacobian
281
24k
How to Grow Your eCommerce with AI & Automation
katarinadahlin
PRO
1
110
Evolving SEO for Evolving Search Engines
ryanjones
0
130
How Software Deployment tools have changed in the past 20 years
geshan
0
32k
New Earth Scene 8
popppiees
1
1.5k
Being A Developer After 40
akosma
91
590k
Lessons Learnt from Crawling 1000+ Websites
charlesmeaden
PRO
1
1.1k
<Decoding/> the Language of Devs - We Love SEO 2024
nikkihalliwell
1
130
[Rails World 2023 - Day 1 Closing Keynote] - The Magic of Rails
eileencodes
38
2.7k
Transcript
4章 強化学習 2019/07/30 AlphaZero輪読会
自己紹介 • 仕事はSE • 強化学習初学者 • 囲碁の次は将棋も覚えたい • チェスもポーカーもやりたい •
いろいろやりたい @hookbook_
目次 1. 強化学習とは 2. 4-1 多腕バンディット問題 3. 4-2 方策勾配法で迷路ゲーム 4.
4-3 SarsaとQ学習で迷路ゲーム 5. 4-4 DQNでCartPole 6. 書籍紹介 7. 強化学習環境紹介
1.強化学習とは
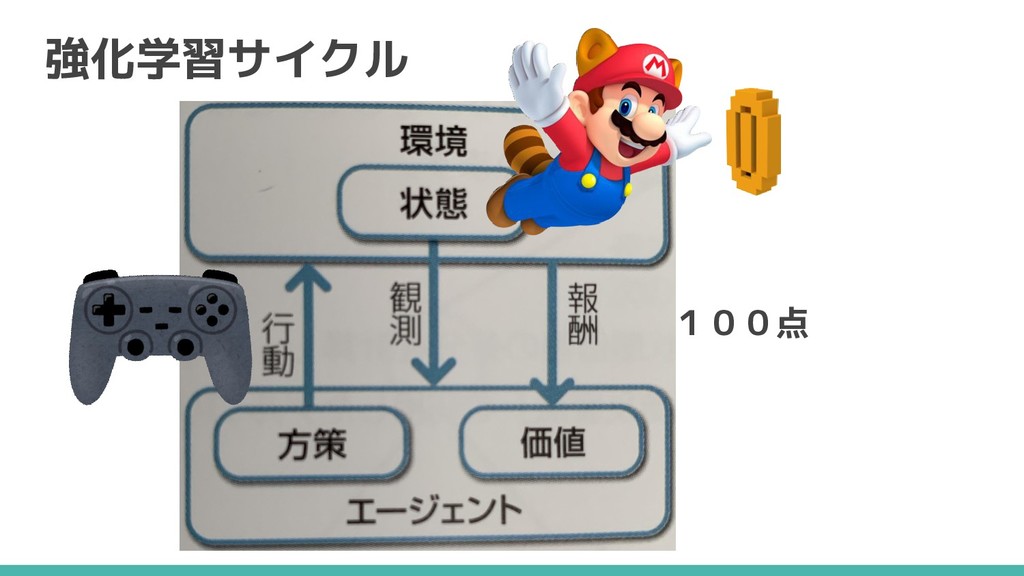
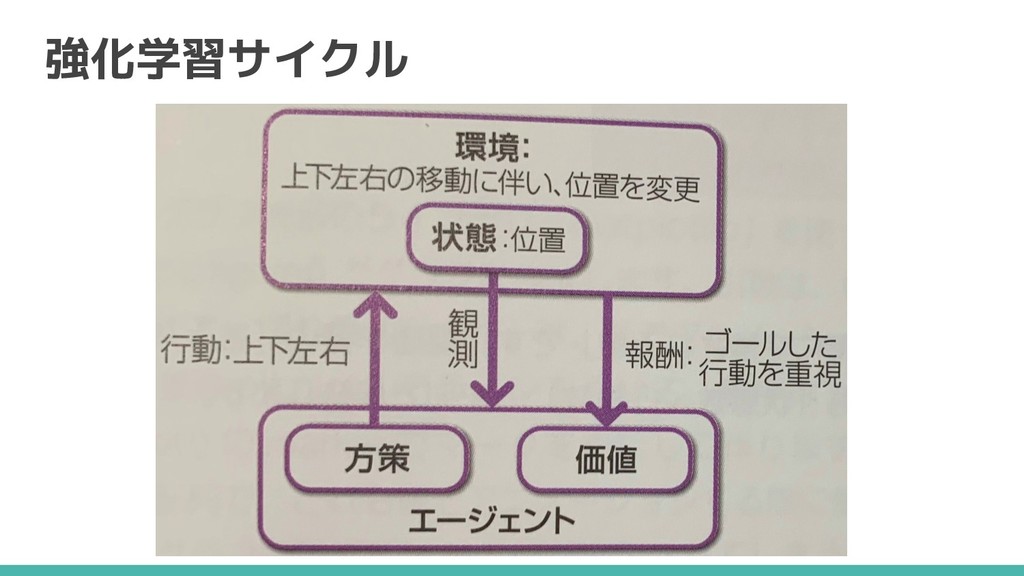
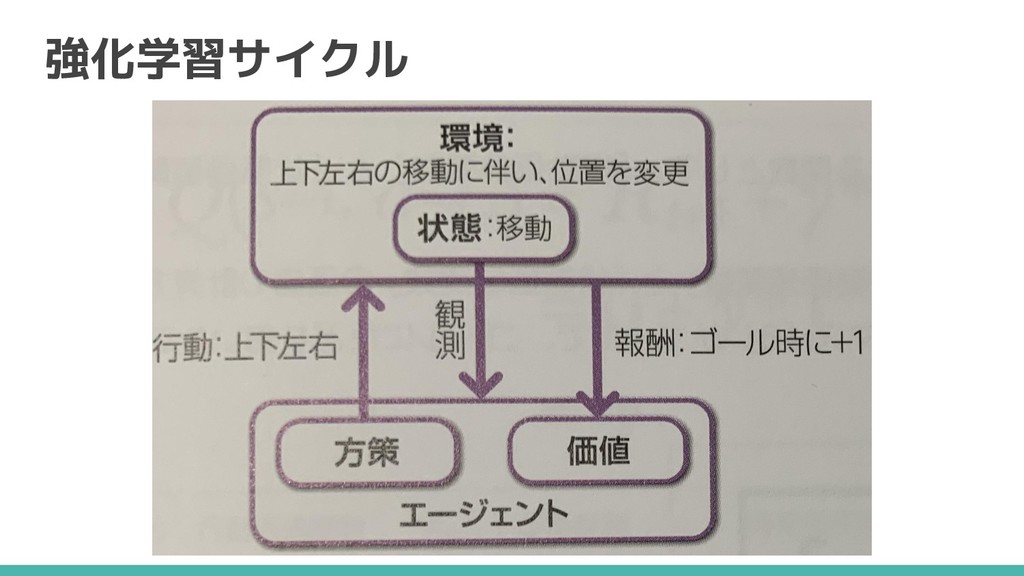
強化学習とは 連続した行動を通じて獲得できる 「報酬の総和」を最大化する行動の学習 マリオでいえば 連続した行動 → 1−1ゴールまで 報酬の総和 → 獲得点数
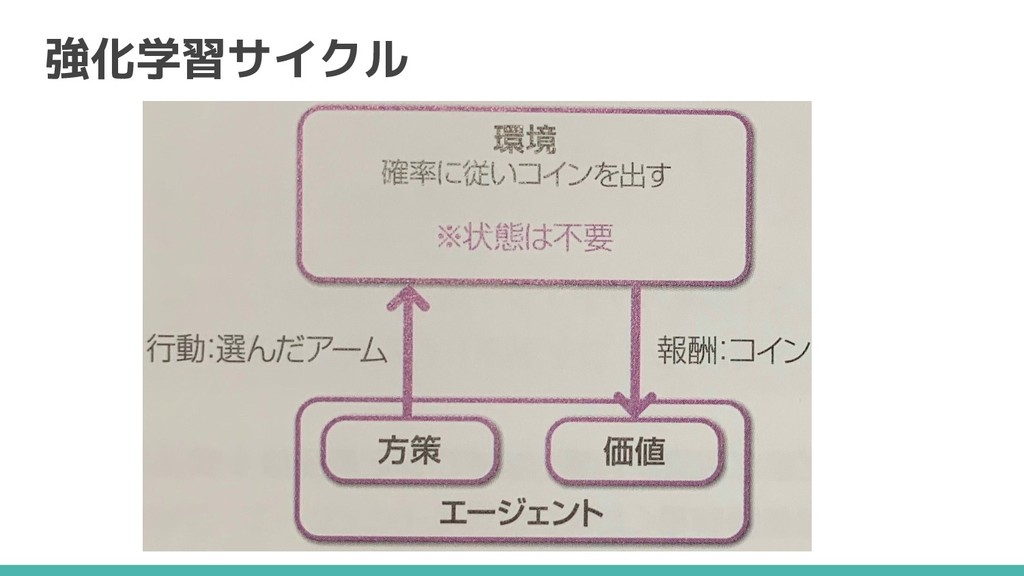
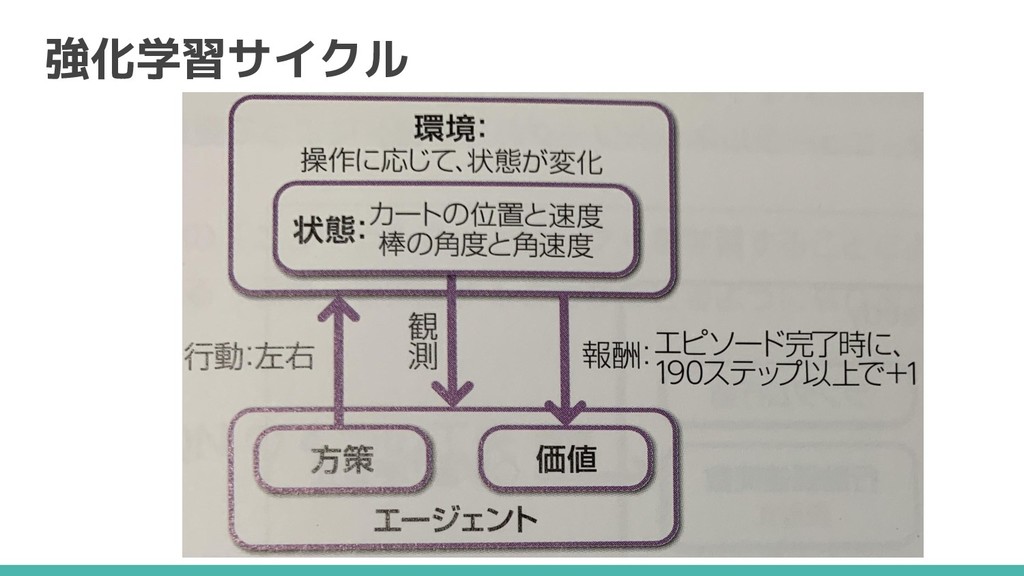
強化学習サイクル 100点
教師あり学習との違い - 教師データがなくても学習可能(サンプリングしながら学習) - 時間の概念がある - サンプルの相関が高い - 学習結果がサンプルに影響
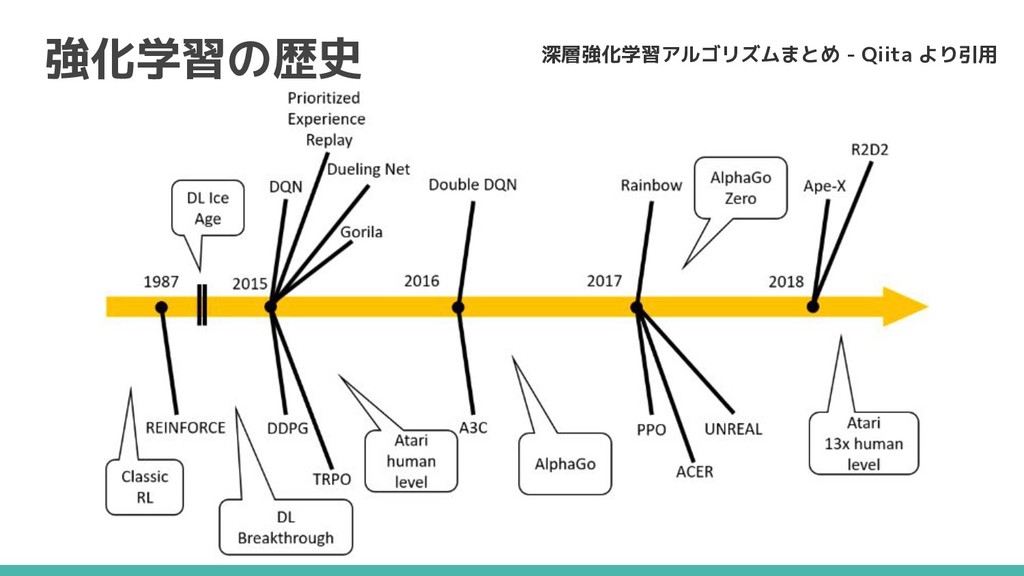
強化学習の歴史 深層強化学習アルゴリズムまとめ - Qiita より引用
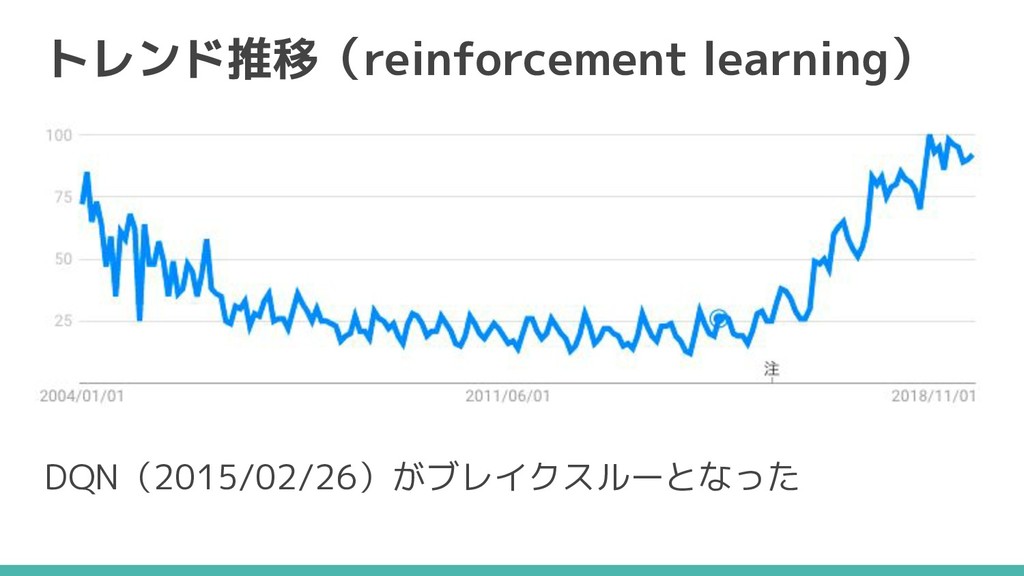
トレンド推移(reinforcement learning) DQN(2015/02/26)がブレイクスルーとなった
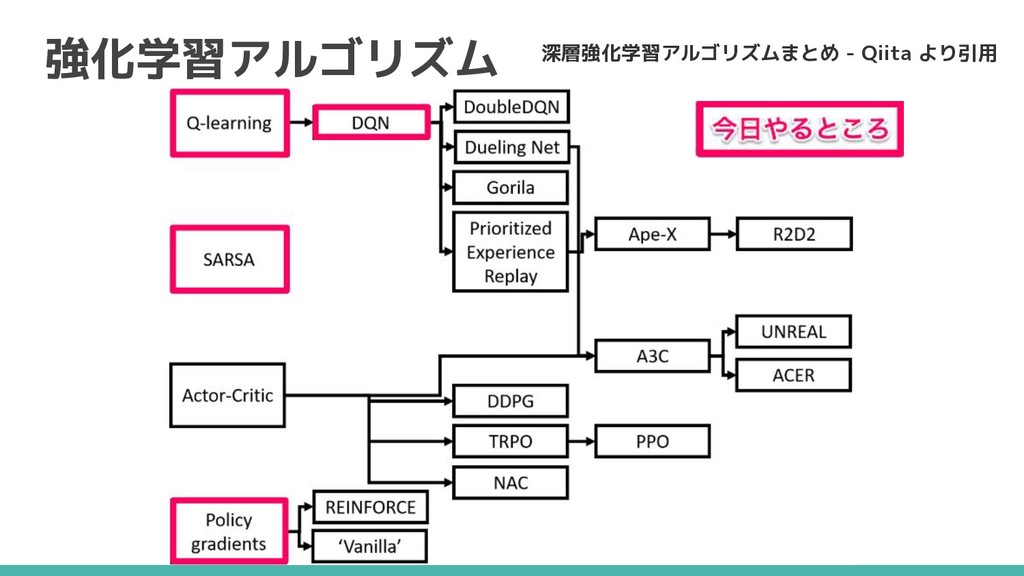
強化学習アルゴリズム 深層強化学習アルゴリズムまとめ - Qiita より引用
4-1 多腕バンディット問題
多腕バンディット問題 - 各スロットマシンで当たる確率は見えない - 決められた回数で多く当たりを引くには?
強化学習サイクル
探索と利用 - 探索 情報収集のために未知の行動選択 - 利用 いままでに学習した内容をもとに行動選択 探索と利用はトレードオフ、バランスが重要
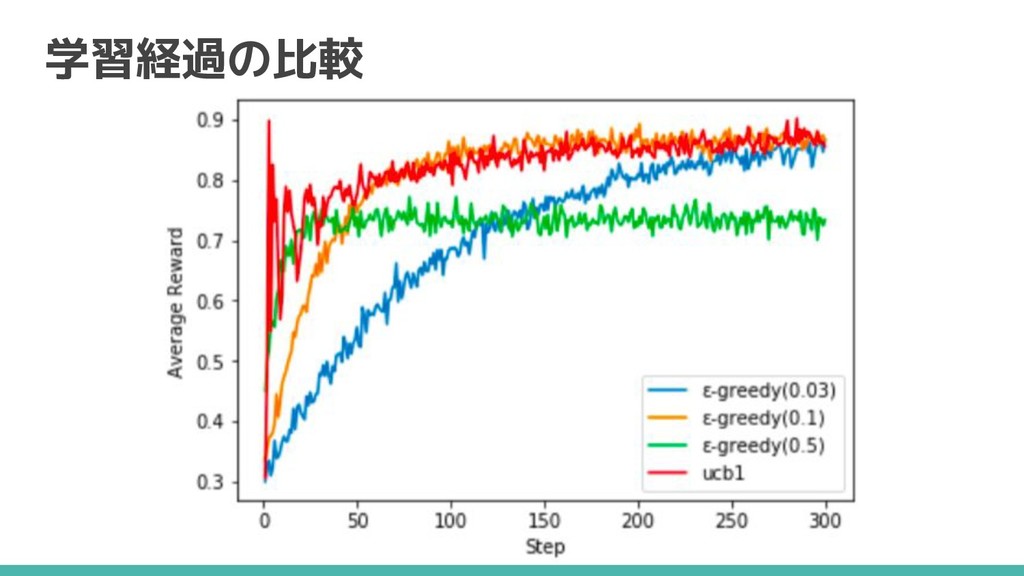
探索と利用のバランスを取る手法 - ε-greedy 確率ε : ランダムに行動を選択 = 探索 確率1-ε :
期待報酬が最大の行動を選択 = 利用 - UCB1 ハイパーパラメータ(ε)ではなく アルゴリズムでバランスを取る手法
UCB1 「成功率+バイアス」を最大化する行動を選択する 「バイアス」は「偶然による成功率のばらつき大きさ」
学習経過の比較
Google Colabで確認
4-2 方策勾配法で迷路ゲーム
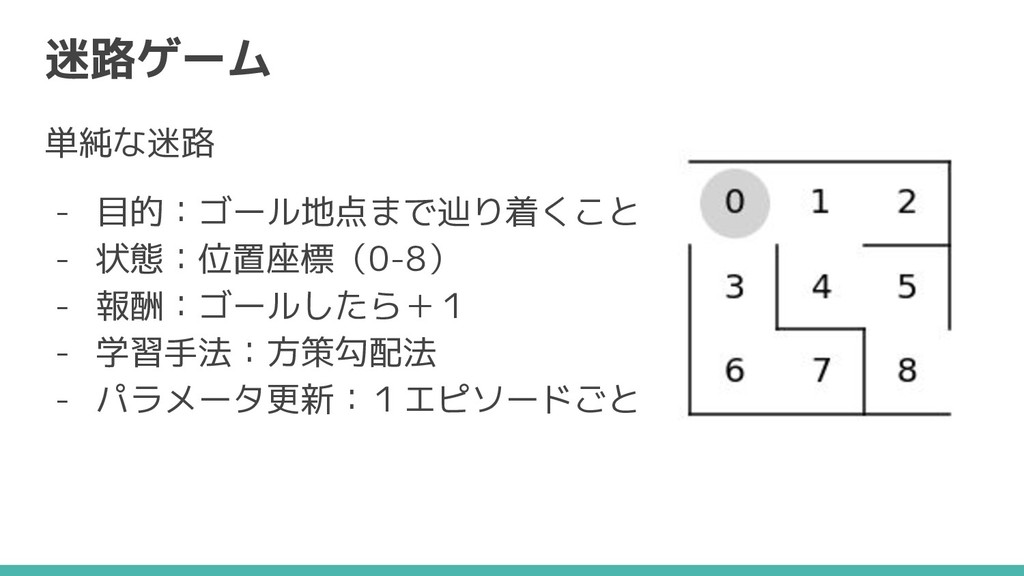
迷路ゲーム 単純な迷路 - 目的:ゴール地点まで辿り着くこと - 状態:位置座標(0-8) - 報酬:ゴールしたら+1 - 学習手法:方策勾配法
- パラメータ更新:1エピソードごと
強化学習サイクル
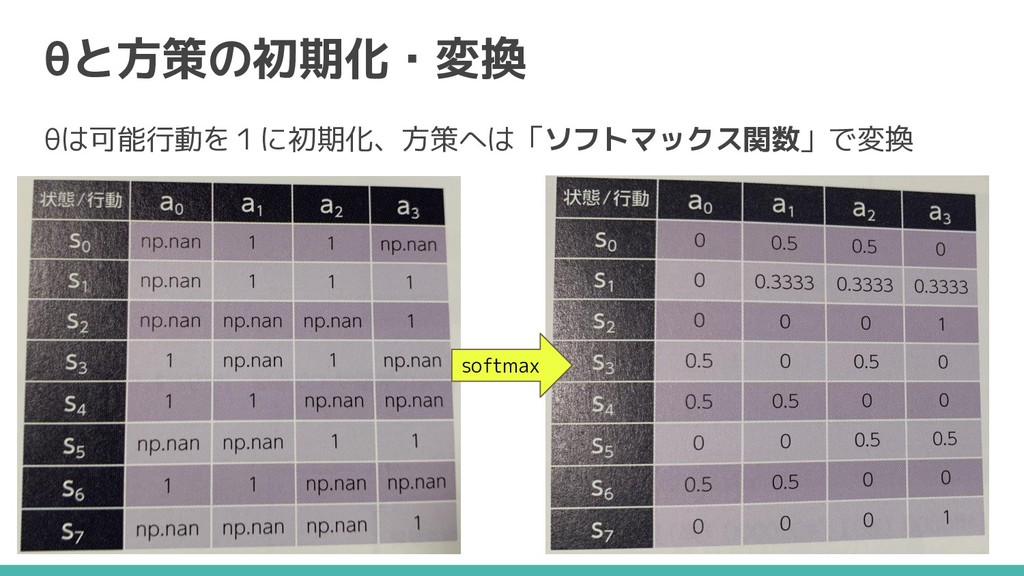
方策勾配法の学習手順 1.パラメータθの準備 2.パラメータθを方策に変換 3.方策に従って、行動をゴールまで繰り返す 4.成功した行動を多く取り入れるように、パラメータθを更新 5.方策の変化量が閾値以下に、2.〜4.を繰り返す
θと方策の初期化・変換 θは可能行動を1に初期化、方策へは「ソフトマックス関数」で変換 softmax
ソフトマックス関数
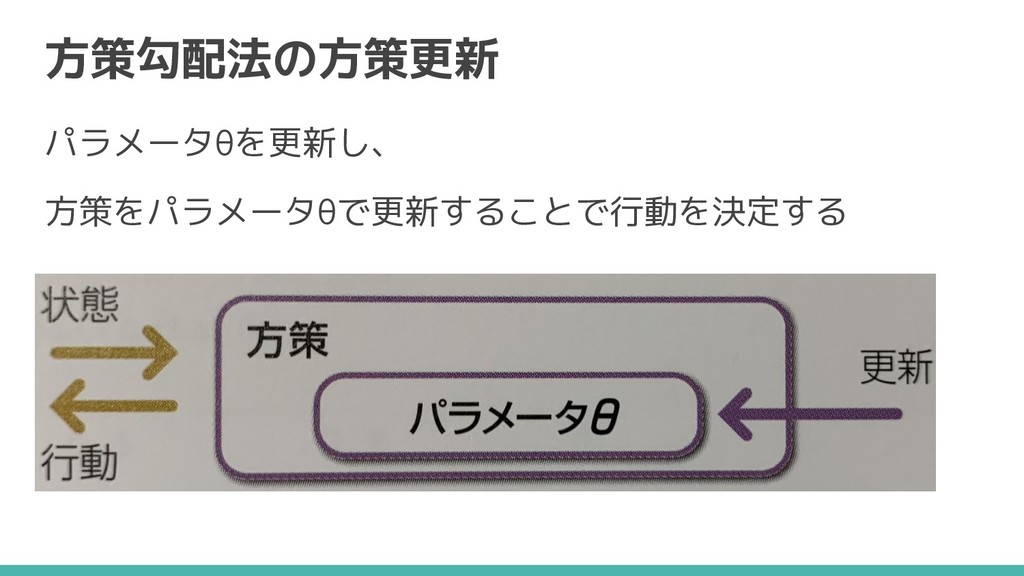
方策勾配法の方策更新 パラメータθを更新し、 方策をパラメータθで更新することで行動を決定する
パラメータθの更新式
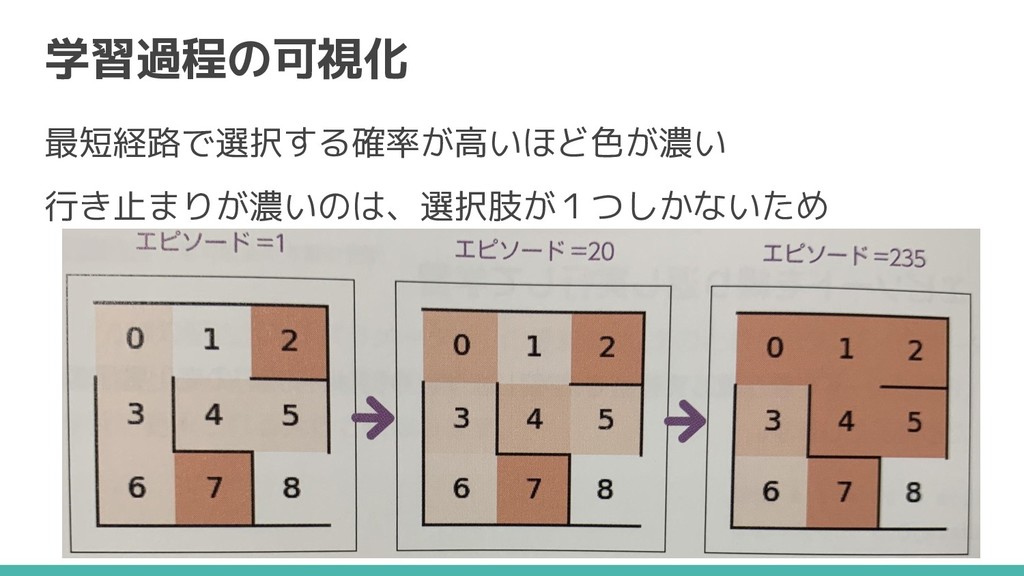
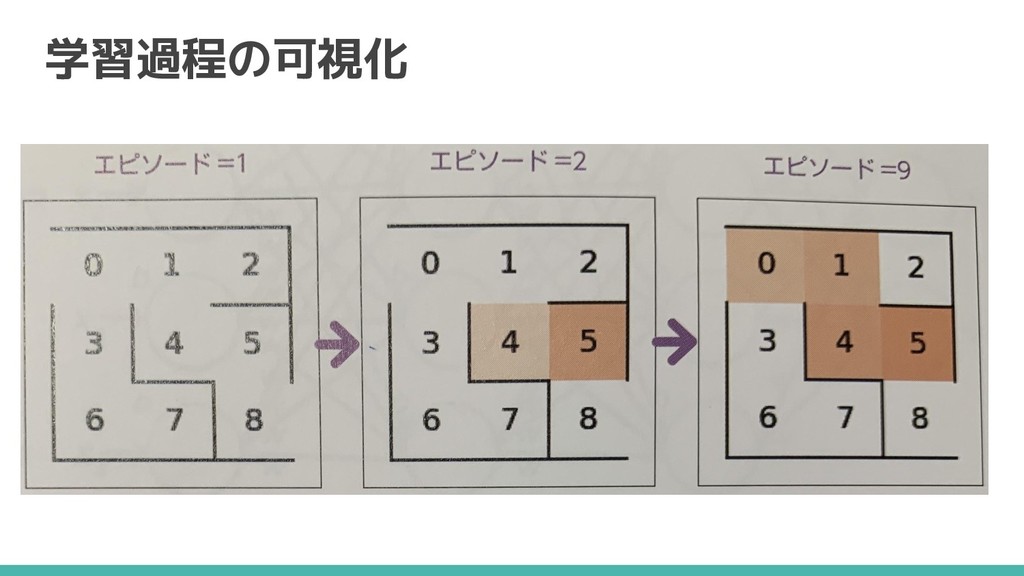
学習過程の可視化 最短経路で選択する確率が高いほど色が濃い 行き止まりが濃いのは、選択肢が1つしかないため
Google Colabで確認
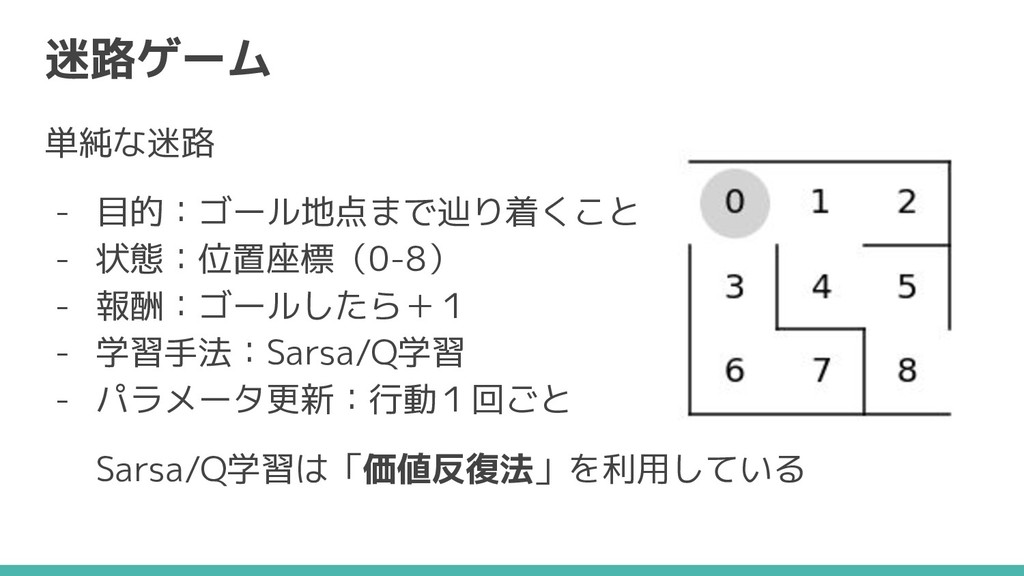
4-3 SarsaとQ学習で迷路ゲーム
迷路ゲーム 単純な迷路 - 目的:ゴール地点まで辿り着くこと - 状態:位置座標(0-8) - 報酬:ゴールしたら+1 - 学習手法:Sarsa/Q学習
- パラメータ更新:行動1回ごと Sarsa/Q学習は「価値反復法」を利用している
強化学習サイクル
収益 1エピソードで得られる すべての報酬和を「収益」と呼ぶ → これを最大化するように学習したい
割引報酬和 将来得られる報酬の「現在の価値」として考える 確実性が下がるため時間割引率(γ)が用いられることが多い
時間割引率γ γ:0.99 の場合 5ステップ後: 0.99^5 = 0.95 20ステップ後: 0.99^5 = 0.82
50ステップ後: 0.99^5 = 0.61 例)今日もらえる10,000円、 20日後にもらえる8,200円、どちらが価値がある?
行動価値関数(Q関数) ある状態(s) で ある行動(a) をとる価値を表す Q(s, a) で表すため、「Q関数」とも呼ばれる
行動価値関数の例
行動価値関数の例
ベルマン方程式(行動価値関数) 一般的な形に書き直した式を「ベルマン方程式」と呼ぶ - Sarsa, Q学習では行動価値関数を学習する
状態価値関数(V) ある状態(s) の価値を表し、V(s) と表記する
状態価値関数の例
ベルマン方程式(状態価値関数) 一般的な形に書き直した式を「ベルマン方程式」と呼ぶ - A2Cなどで用いる(本書では取り扱わない)
マルコフ決定過程(MDP) ベルマン方程式はマルコフ決定過程を満たすことが前提 マルコフ性(Markov property) - 遷移先の状態が直前の状態とそこでの行動にのみ依存 - 報酬は、直前の状態と遷移先に依存 → 未来が過去に依存しない マルコフ性に従う環境のことをマルコフ決定過程と呼ぶ
(Markov Decision Process:MDP)
価値反復法の学習手順 1.ランダム行動の準備 2.行動価値関数の準備 3.行動に従って、次の状態の取得 4.ランダムまたは行動価値関数に従って、行動の取得 5.行動価値関数の更新 6.ゴールするまで、ステップ3.〜5.を繰り返す 7.エピソード3.〜6.を繰り返し実行して学習
Sarsaによる行動価値関数の更新 TD誤差 行動前評価と行動後評価の誤差 これを0に近づけるように学習
Q学習による行動価値関数の更新 TD誤差の行動後の評価値をmaxに変えたもの - Sarsaと違い行動後評価値にランダム性が含まれない
学習過程の可視化
Google Colabで確認
4-4 DQNでCartPole
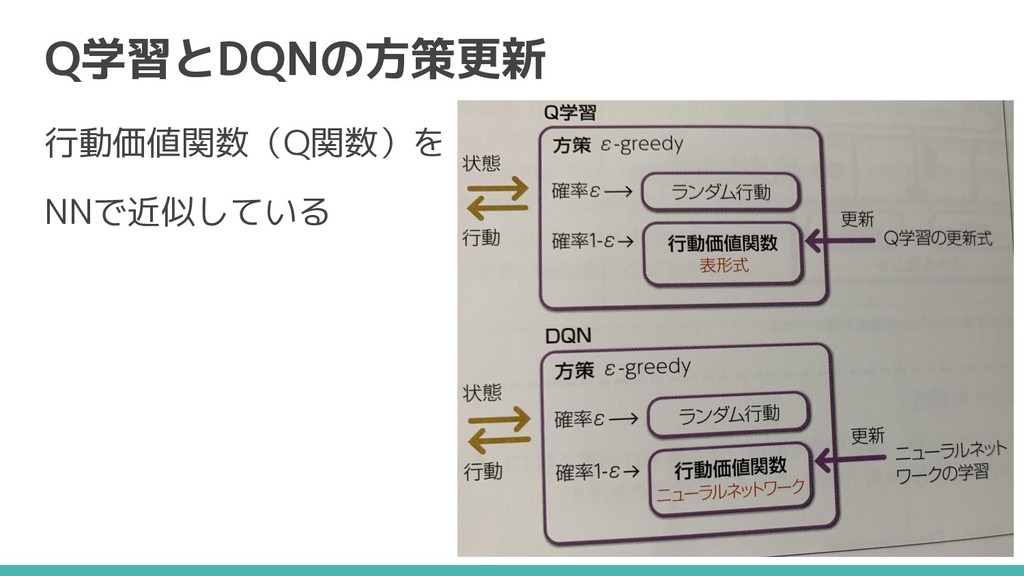
DQN(deep Q-network)とは Q学習の行動価値関数(Q関数)をNNで近似した (+4つの工夫) - 状態が増えると適切に学習できない問題を解決 - 状態を画像として視たまま学習できるように - ゲームと相性がよく、Atariのゲームで高得点
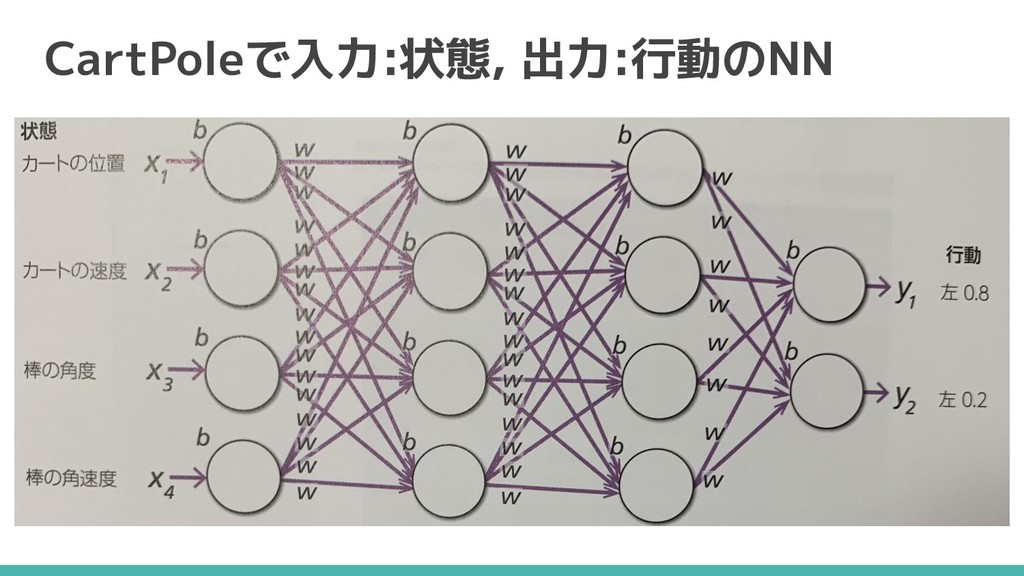
CartPole ほうきを手のひらの上でバランスとるやつ - 目的:棒がたおれないようにする - 状態:カート,棒の位置と速度(連続値) - 報酬:190ステップ以上なら+1(※) - 学習手法:DQN
- パラメータ更新:行動1回ごと (※)報酬が与えられるのはエピソード終了時
CartPoleで入力:状態, 出力:行動のNN
強化学習サイクル
Q学習とDQNの方策更新 行動価値関数(Q関数)を NNで近似している
DQNの学習手順 1.ニューラルネットワークの入力と出力の準備 2.バッチサイズ分の経験をランダムに取得 3.ニューラルネットワークの入力と出力の生成 3−1.入力に状態を指定 3−2.採った行動の価値を計算(※次ページ) 3−3.出力に行動ごとの価値を指定 4.行動価値関数の更新
3−2.採った行動の価値を計算
DQNの4つの工夫 - Experience Replay - Fixed Target Q-Network - Reward
Clipping - Huber Loss
Experience Replay 行動結果をそのまま学習せず いちど行動履歴をためておく 行動履歴からランダムにサンプリングして学習することで 経験の偏りを防ぎ、学習を安定化させることができる
Fixed Target Q-Network Q学習は「行動価値関数」の更新に「行動価値関数」を利用 それにより学習が安定しない傾向があった 行動決定用ニューラルネットワーク(main-netwok) 更新計算用ニューラルネットワーク(target-network) を用意することで解決
Reward Clipping 報酬を「−1」「0」「1」に固定(正規化)する 環境によらず、同じハイパーパラメータで学習できる 報酬に重みをつけられないというデメリットもある
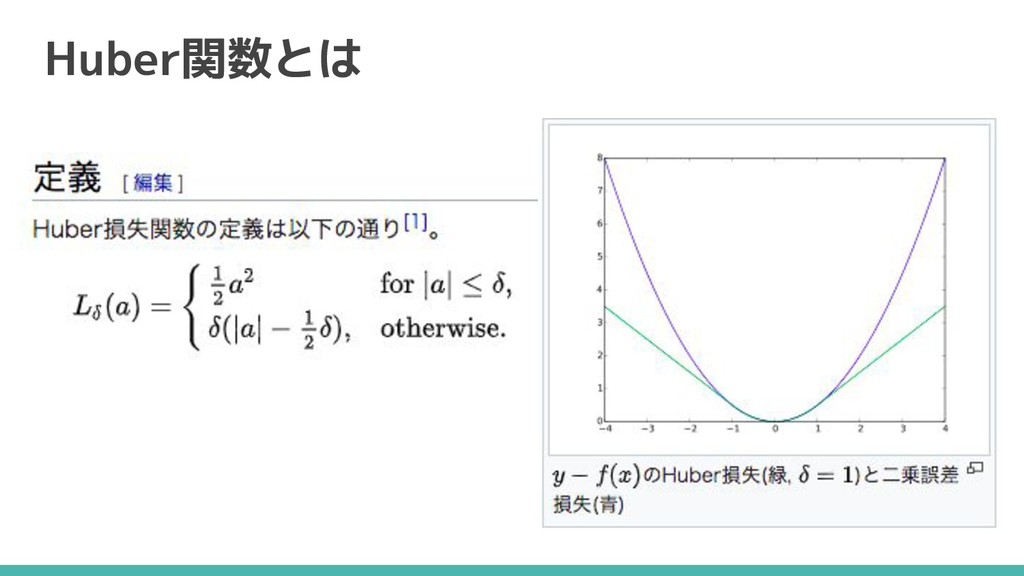
Huber Loss 誤差が大きい場合に、 誤差関数に「平均二乗誤差」(mse)を使用すると 出力が大きすぎて学習が安定しない傾向がある 誤差が大きい場合でも安定する「Huber関数」を使う 誤差が1まではMSEと同じ、それ以上は誤差の絶対値となる
Huber関数とは
Google Colabで確認
6.書籍紹介
Pythonで学ぶ強化学習 (機械学習スタートアッ プシリーズ) つくりながら学ぶ! 深層強化学習 強化学習 (機械学習プロフェッ ショナルシリーズ) 8月8日まで Kindleストアで
30%OFF!!
7.強化学習環境紹介
OpenAI Gym いつもの。 Atariのゲーム環境等 - パックマン - インベーダーゲーム - PONG
https://github.com/openai/gym
AWS DeepRacer $400で買えるおもちゃ シミュレータ・実環境での リーグが開催されている https://aws.amazon.com/jp/deepracer/
MineRL マインクラフトの強化学習環境 NeurIPS 2019で MineRLコンペが開催される - ダイヤモンド入手までを競う - 原木収集、鉄ピッケル作成等の中間タスクあり -
Round1締め切りが9/22
Unity Obstacle Tower Challenge Unity ML-Agentを使って作った環境で 障害物タワーにチャレンジする https://ledge.ai/unity-obstacle-tower-challenge/
fightingICE 格闘ゲームの強化学習環境 Gym API準拠版が 最近(2019/06)公開された http://www.ice.ci.ritsumei.ac.jp/~ftgaic/index.htm
まとめ
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}