• On the season filter form, iterate through all • Click on link to see all subjects • Iterate through every subject • Iterate through every page and scrape it
= session f['UCBasicSearch$showAllSub.x'] = 150 f['UCBasicSearch$showAllSub.y'] = 24 scrape_exam_subjects f.submit(), index end end e.g. session = 'ac6a501b-2f3b-4638-af29-48c8075a5fb9'
$<stuff>$SubjectList$<stuff>$subjectName contains(@attr, 'value') rather than @attr='value' //input[ contains(@name, "UCBasicSearch2$UCPostBackSubjectList$subjectsRepeater") and contains(@name, "SubjectList") and contains(@name, "subjectName") ]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
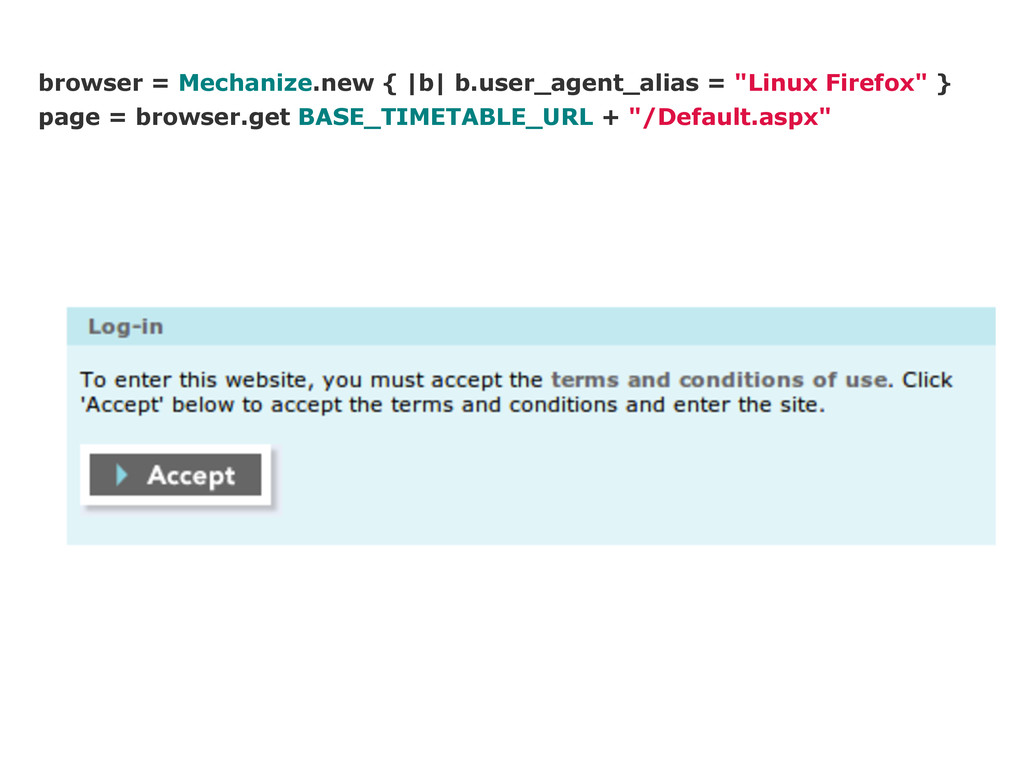
![page.form_with(:name => 'aspnetForm') do |f| f['ctl00$mainContent$accept.x'] = 50 f['ctl00$mainContent$accept.y'] =](https://files.speakerdeck.com/presentations/50683a4ec4bd74000205e555/slide_10.jpg){kind=link}
{kind=link}
![sessions.each_with_index do |session, index| page.form_with(:name => 'search') do |f| f['UCBasicSearch$ddSession']](https://files.speakerdeck.com/presentations/50683a4ec4bd74000205e555/slide_12.jpg){kind=link}
![Click on Link to See All Subjects f['UCBasicSearch2$UCSearchByLetter$btnAll'] = 'All'](https://files.speakerdeck.com/presentations/50683a4ec4bd74000205e555/slide_13.jpg){kind=link}
{kind=link}
{kind=link}
![//input - all input elements //input [@name='UCBasicSearch2$UCPostBackSubjectList$subj ectsRepeater$ctl00$SubjectList$ctl01$subjectName'] - all](https://files.speakerdeck.com/presentations/50683a4ec4bd74000205e555/slide_16.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![next_button = page.parser.xpath( "//input[ @name='UCResultsTable$topNavigation$btnNext' ]" ).first if next_button page.form_with(:name](https://files.speakerdeck.com/presentations/50683a4ec4bd74000205e555/slide_20.jpg){kind=link}
![results = page.parser.xpath("//table[@class='results']").first results = results.xpath( '//table[@id="UCResultsTable_resultsTbl"] //tr[td/@class = "results](https://files.speakerdeck.com/presentations/50683a4ec4bd74000205e555/slide_21.jpg){kind=link}
![results.map! { |row| row.xpath("td[not(input)]") results.map! { |row| row.map { |cell|](https://files.speakerdeck.com/presentations/50683a4ec4bd74000205e555/slide_22.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}