SDS* Truth Input Relative to prior state-of-the- art SDS: - 30% relative improvement in accuracy (67.2% on VOC 2012) results FCN SDS* Truth Input Relative to prior sta art SDS: - 30% relative improvement in accuracy (67.2% on VO Input Relative to prior state-of-the- art SDS: - 30% relative improvement in accuracy (67.2% on VOC 2012) ڭࢣϚεΫ͋Γ ڭࢣϚεΫͳ͠Ͱϥϕϧ͚ͩʢҎԼʮഅʯʣ ↑ͬͯΈͨ݁Ռྫ
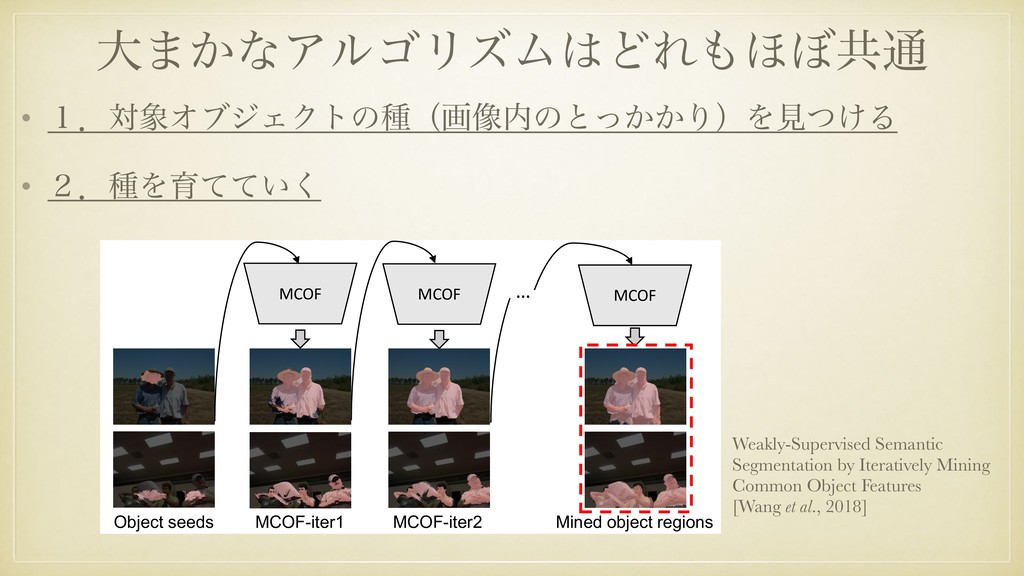
Common Object Features [Wang et al., 2018] • ଟ͘ਂֶशʴը૾ॲཧ • ਂֶश୯ମͰ݁͢Δख๏·ͩແ͍༷ t=0 t=1 t=T ··· ··· ··· t=0 t=1 t=T ··· FCs For each Region Softmax Predict Segmentation Loss Region Classification Loss RegionNet PixelNet (a) Image (b) Superpixel (c) RegionNet (d) Object Masks (f) Object Regions (g) PixelNet Final Mined Object Regions Initial Object Seeds iteration Predict (e) Saliency-guided Refinement Figure 2. Pipeline of the proposed MCOF framework. At first (t=0), we mine common object features from initial object seeds. We segment (a) image into (b) superpixel regions and train the (c) region classification network RegionNet with the (d) initial object seeds. We then re-predict the training images regions with the trained RegionNet to get object regions. While the object regions may still only focus on discriminative regions of object, we address this by (e) saliency-guided refinement to get (f) refined object regions. The refined object regions are then used to train the (g) PixelNet. With the trained PixelNet, we re-predict the (d) segmentation masks of training images, are then used them as supervision to train the RegionNet, and the processes above are conducted iteratively. With the iterations, we can mine finer object regions and the PixelNet trained in the last iteration is used for inference. coarsely classified into two categories: MIL-based meth- ods, which directly predict segmentation masks with clas- sification networks; and localization-based methods, which utilize classification networks to produce initial localization and use them to supervise segmentation networks. Multi-instance learning (MIL) based methods [21, 22, 13, 25, 5] formulate weakly-supervised learning as a MIL framework in which each image is known to have at least one pixel belonging to a certain class, and the task is to find these pixels. Pinheiro et al. [22] proposed Log-Sum- Exp (LSE) to pool the output feature maps into image- localization. They rely on the classification network to se- quentially produce the most discriminative regions in erased images. It will cause error accumulation and the mined ob- ject regions will have coarse object boundary. The proposed MCOF method mines common object features from coarse object seeds to predict finer segmentation masks, and then iteratively mines features from the predicted masks. Our method progressively expands object regions and corrects inaccurate regions, which is robust to noise and thus can tol- erate inaccurate initial localization. By taking advantages of superpixel, the mined object regions will have clear bound-
Engineering, Tsinghua University Australian National University b@}tsinghua.edu.cn, [email protected] Person MCOF MCOF MCOF … (a) Mined object regions Object seeds MCOF-iter1 MCOF-iter2 Weakly-Supervised Semantic Segmentation by Iteratively Mining Common Object Features [Wang et al., 2018]
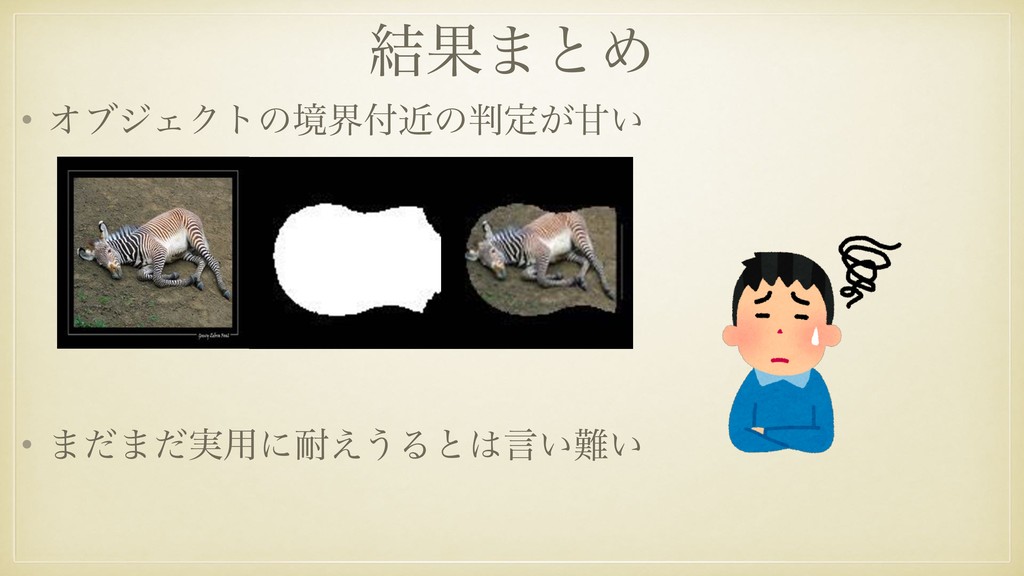
image with gt boxes dog person … candidate masks update network update masks BoxSup training feedback iteration estimated masks epoch #5 epoch #1 epoch #20 network for segmentation Figure 1: Overview of our training approach supervised by bounding boxes. ed class score is mapped back to the previous convolutional layer to generate the class e class-specific discriminative regions. impact on the he class score, (1) r class c, where (2) c(x, y) directly at spatial grid Figure 3. The CAMs of four classes from ILSVRC [20]. The maps highlight the discriminative image regions used for image classifi- cation e.g., the head of the animal for briard and hen, the plates in barbell, and the bell in bell cote. ྨͷఆࠜڌͷՄࢹԽख๏ ʮͲ͜Λݟͯఆ͠ͷ͔ʯ BoxSup[Dai et al., 2015] Ͱ͞Ε͍ͯΔख๏
An overview of the Discriminative Feature Network. (a) Network Architecture. (b) Components of the Refinement Residual Block (RRB). (c) Components of the Channel Attention Block (CAB). The red and blue lines represent the upsample and downsample operators, respectively. The green line can not change the size of feature maps, just a path of information passing. Channel Attention ͕ັྗɻ ମͷۭؒใΛ ͏·͘र͑Δ Α͏ʹɻ
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![ͬͯΈͨख๏ • ̍ɽCAM[Zhou et al., 2015]Λ࠷ॳͷͱ͔͔ͬΓͱ͢Δ • ̎ɽ1ΤϙοΫલͷηάϝϯςʔγϣϯ݁ՌΛڭࢣͱͯ͠ηάϝϯςʔ γϣϯΛҭ͍ͯͯ͘ train](https://files.speakerdeck.com/presentations/86e8391fc6a7420d8125a634cc2eb171/slide_5.jpg){kind=link}
{kind=link}
![ωοτϫʔΫߏ • Discriminative Feature Network[Yu et al., 2018]ϕʔεͷωοτϫʔΫΛ࣮ Figure 2.](https://files.speakerdeck.com/presentations/86e8391fc6a7420d8125a634cc2eb171/slide_7.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}