3 [Gao et al., Retrieval-Augmented Generation for Large Language Models: A Survey, arxiv ] [Wei et al., Chain-of-Thought Prompting Elicits Reasoning in Large Language Models, NIPS 2022] 実際には明確には分けられず, 両⽅の特徴を持つ⼿法も (DeepResearchなど)
4 [Gao et al., Retrieval-Augmented Generation for Large Language Models: A Survey, arxiv ] [Wei et al., Chain-of-Thought Prompting Elicits Reasoning in Large Language Models, NIPS 2022] この論⽂の対象はこっち 外部知識ベースは使⽤しない
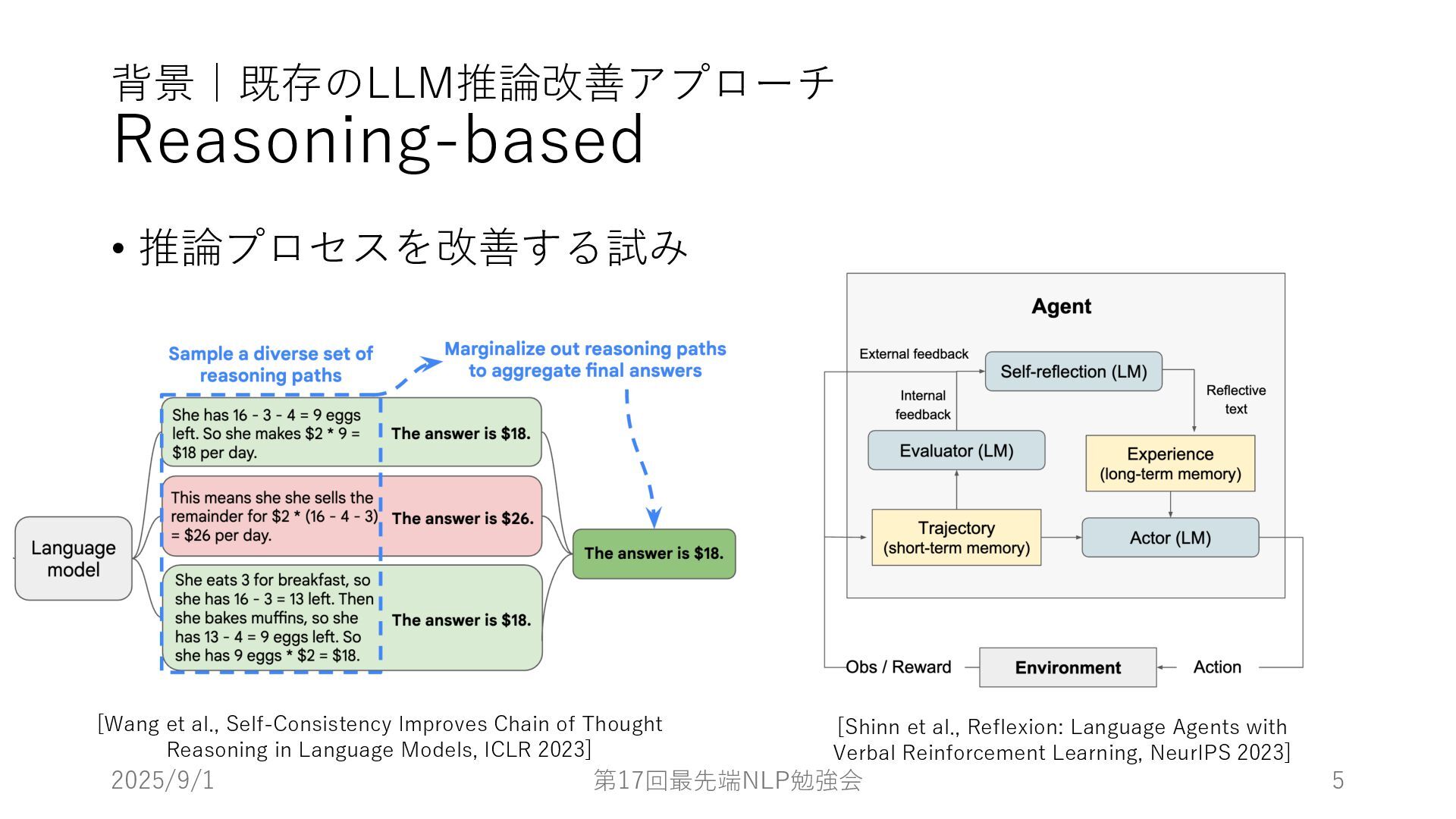
Self-Consistency Improves Chain of Thought Reasoning in Language Models, ICLR 2023] [Shinn et al., Reflexion: Language Agents with Verbal Reinforcement Learning, NeurIPS 2023]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![背景|既存のLLM推論改善アプローチ Planning-token [Wang et al., COLM2024] • ⽬的:構造的な推論ステップの⽣成によるCoTの改善 • ⼿法:各ステップの先頭に計画トークンを配置して学習・推論](https://files.speakerdeck.com/presentations/f20de0235ab0474683978d4d83da340f/slide_5.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
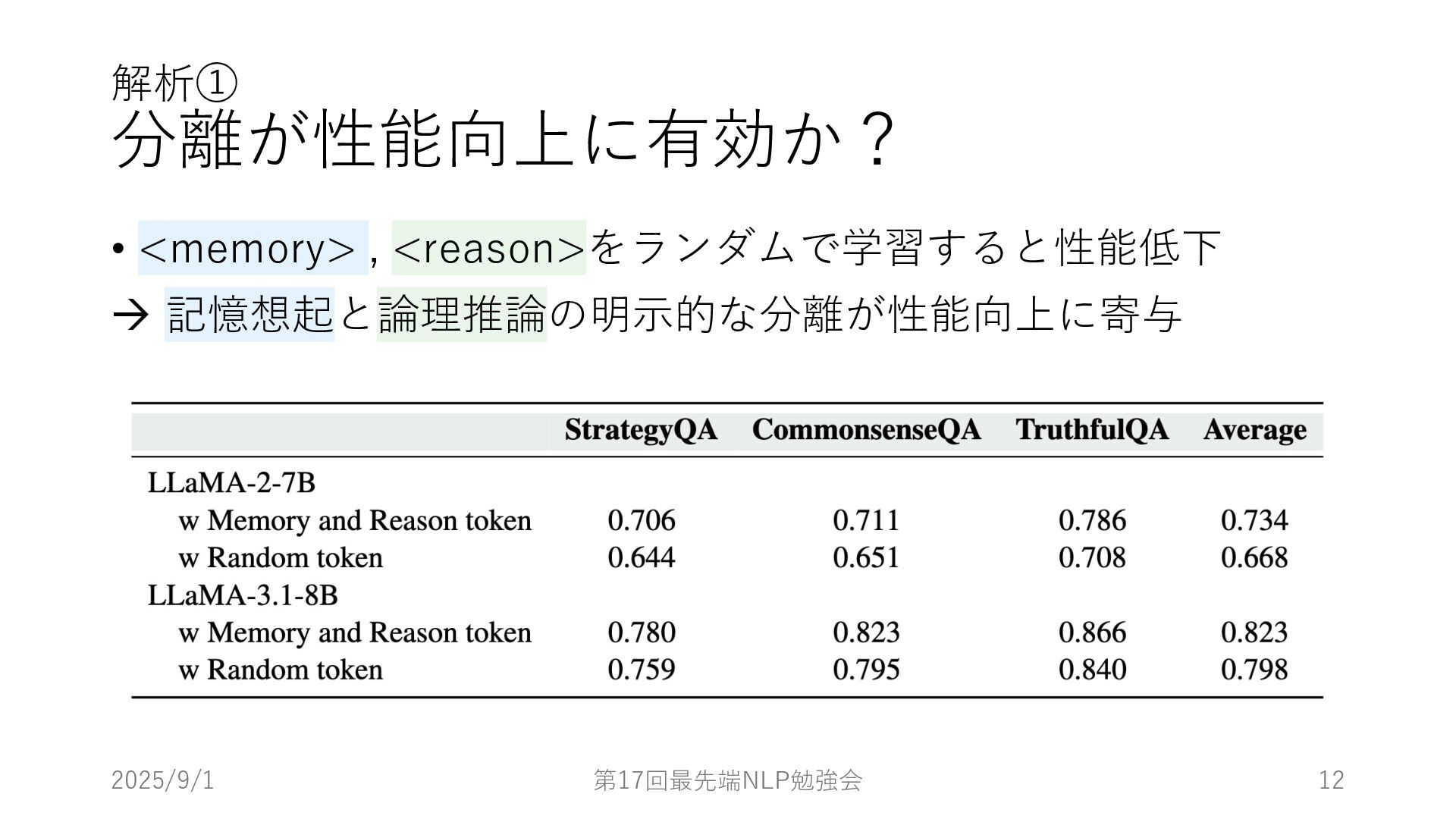{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}