Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
最先端NLP勉強会2024: TTM-RE Memory-Augmented Document...
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Ryuki Ida
August 25, 2024
180
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
最先端NLP勉強会2024: TTM-RE Memory-Augmented Document-Level Relation Extraction
Ryuki Ida
August 25, 2024
More Decks by Ryuki Ida
See All by Ryuki Ida
ACL読み会2025@名大:A Theory of Response Sampling in LLMs: Part Descriptive and Part Prescriptive
iryuki1110
0
100
最先端NLP勉強会2025: Disentangling Memory and Reasoning Ability in Large Language Models
iryuki1110
0
190
輪講資料:KGDM: A Diffusion Model to Capture Multiple Relation Semantics for Knowledge Graph Embedding
iryuki1110
0
19
ACL読み会2024@名大:SCIMON : Scientific Inspiration Machines Optimized for Novelty
iryuki1110
0
81
Featured
See All Featured
Building a A Zero-Code AI SEO Workflow
portentint
PRO
0
640
Designing Experiences People Love
moore
143
24k
Bridging the Design Gap: How Collaborative Modelling removes blockers to flow between stakeholders and teams @FastFlow conf
baasie
0
620
Easily Structure & Communicate Ideas using Wireframe
afnizarnur
194
17k
The Mindset for Success: Future Career Progression
greggifford
PRO
0
430
Paper Plane (Part 1)
katiecoart
PRO
1
9.8k
The State of eCommerce SEO: How to Win in Today's Products SERPs - #SEOweek
aleyda
2
11k
The SEO identity crisis: Don't let AI make you average
varn
0
520
Avoiding the “Bad Training, Faster” Trap in the Age of AI
tmiket
0
200
[Rails World 2023 - Day 1 Closing Keynote] - The Magic of Rails
eileencodes
38
2.9k
Redefining SEO in the New Era of Traffic Generation
szymonslowik
1
370
JAMstack: Web Apps at Ludicrous Speed - All Things Open 2022
reverentgeek
1
500
Transcript
※図表は論文より引用 TTM-RE: Memory-Augmented Document-Level Relation Extraction 著者:Chufan Gao1 , Xuan
Wang2†, Jimeng Sun13† (1University of Illinois Urbana-Champaign 2Virginia Tech 3Carle Illinois College of Medicine) @ACL2024 読み手:井田龍希(豊田工業大学 知識データ工学研究室 D1) 2024/8/26 第16回最先端NLP勉強会 1
まとめ • 文書レベル関係抽出において,初めてメモリを導入したモデルを提案 • メモリは学習されるパラメタ,エンティティ表現にメモリの情報を追加 • メモリは多様なエンティティに共通する汎用的な表現を表すようになる? • 遠距離教師データを効果的に活用し,大幅な性能向上を実現 •
著者の主張:「遠距離教師データを上手く使うためにメモリ機構を導入」 • 実際は逆?メモリを入れたら,遠距離教師データで上手くいくことが分かった? • 少ないメモリで表現するため,重要な部分だけが残り,ノイズ除去できている? • 本論文の選定理由 • 疑問が残る部分もあるが,メモリ機構の導入のみで遠距離教師データを上手く活用 • 遠距離教師データの作成コストは低いので,他のタスクにも応用しやすい 2024/8/26 第16回最先端NLP勉強会 2
背景|文書レベル関係抽出とは • 文書内のエンティティ間の関係を分類するタスク • 複数の文,複数のメンションを考慮する必要がある 2024/8/26 第16回最先端NLP勉強会 [Yao et al.,
DocRED: A Large-Scale Document-Level Relation Extraction Dataset, ACL2019] 3 入力文書 関係
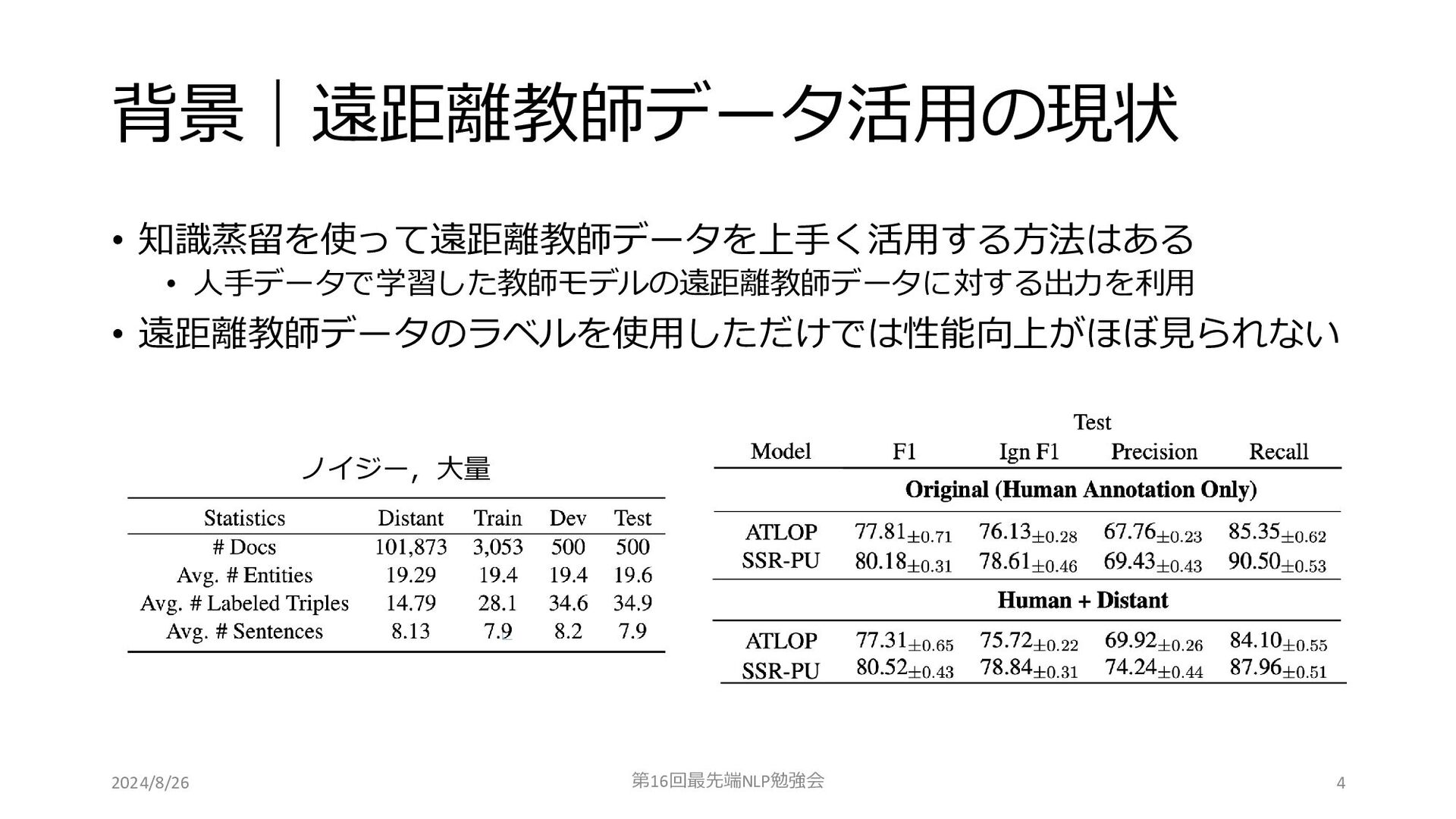
背景|遠距離教師データ活用の現状 • 知識蒸留を使って遠距離教師データを上手く活用する方法はある • 人手データで学習した教師モデルの遠距離教師データに対する出力を利用 • 遠距離教師データのラベルを使用しただけでは性能向上がほぼ見られない 2024/8/26 第16回最先端NLP勉強会 4
ノイジー,大量
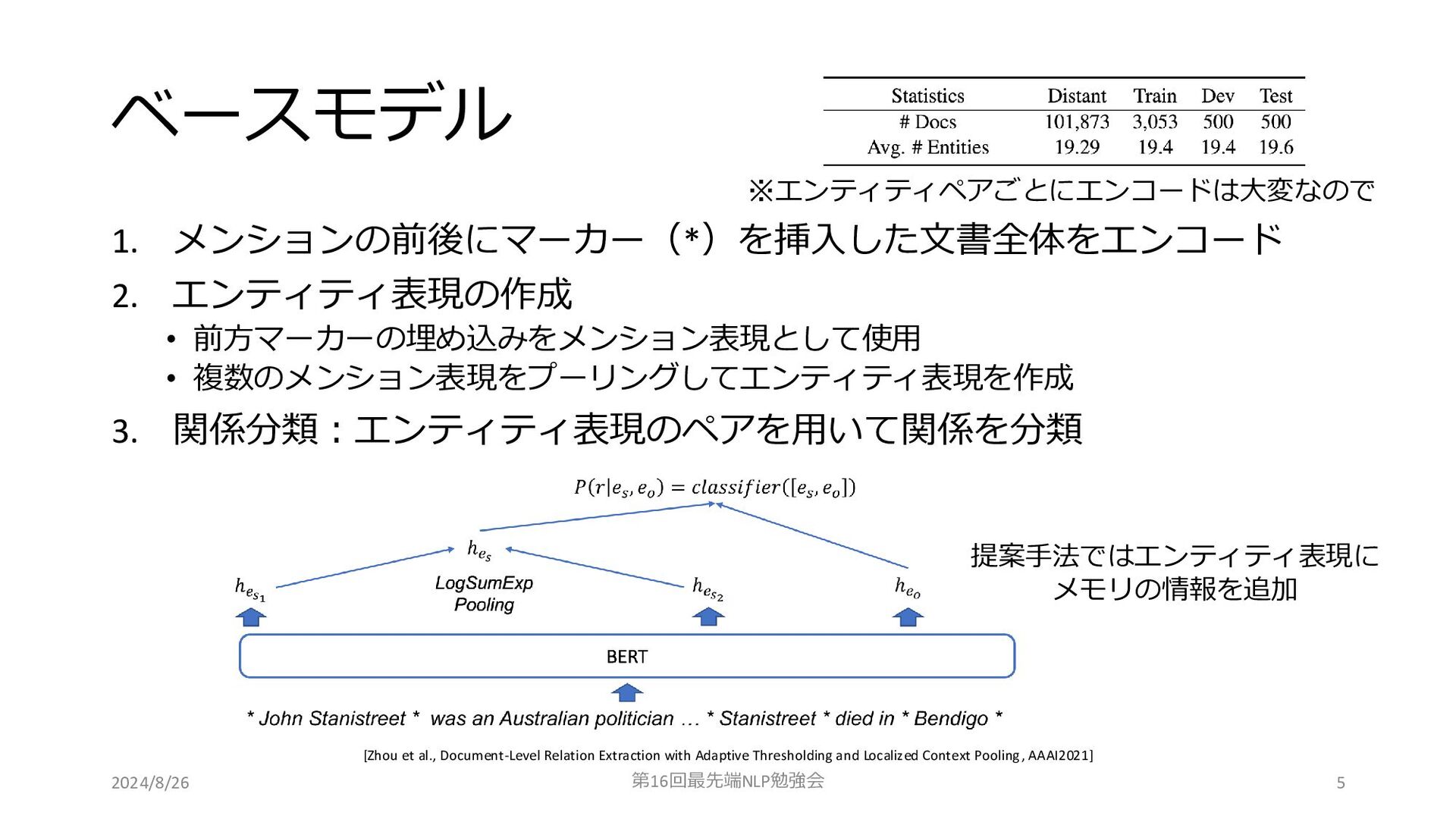
ベースモデル 1. メンションの前後にマーカー(*)を挿入した文書全体をエンコード 2. エンティティ表現の作成 • 前方マーカーの埋め込みをメンション表現として使用 • 複数のメンション表現をプーリングしてエンティティ表現を作成 3.
関係分類:エンティティ表現のペアを用いて関係を分類 2024/8/26 第16回最先端NLP勉強会 [Zhou et al., Document-Level Relation Extraction with Adaptive Thresholding and Localized Context Pooling, AAAI2021] 提案手法ではエンティティ表現に メモリの情報を追加 5 ※エンティティペアごとにエンコードは大変なので
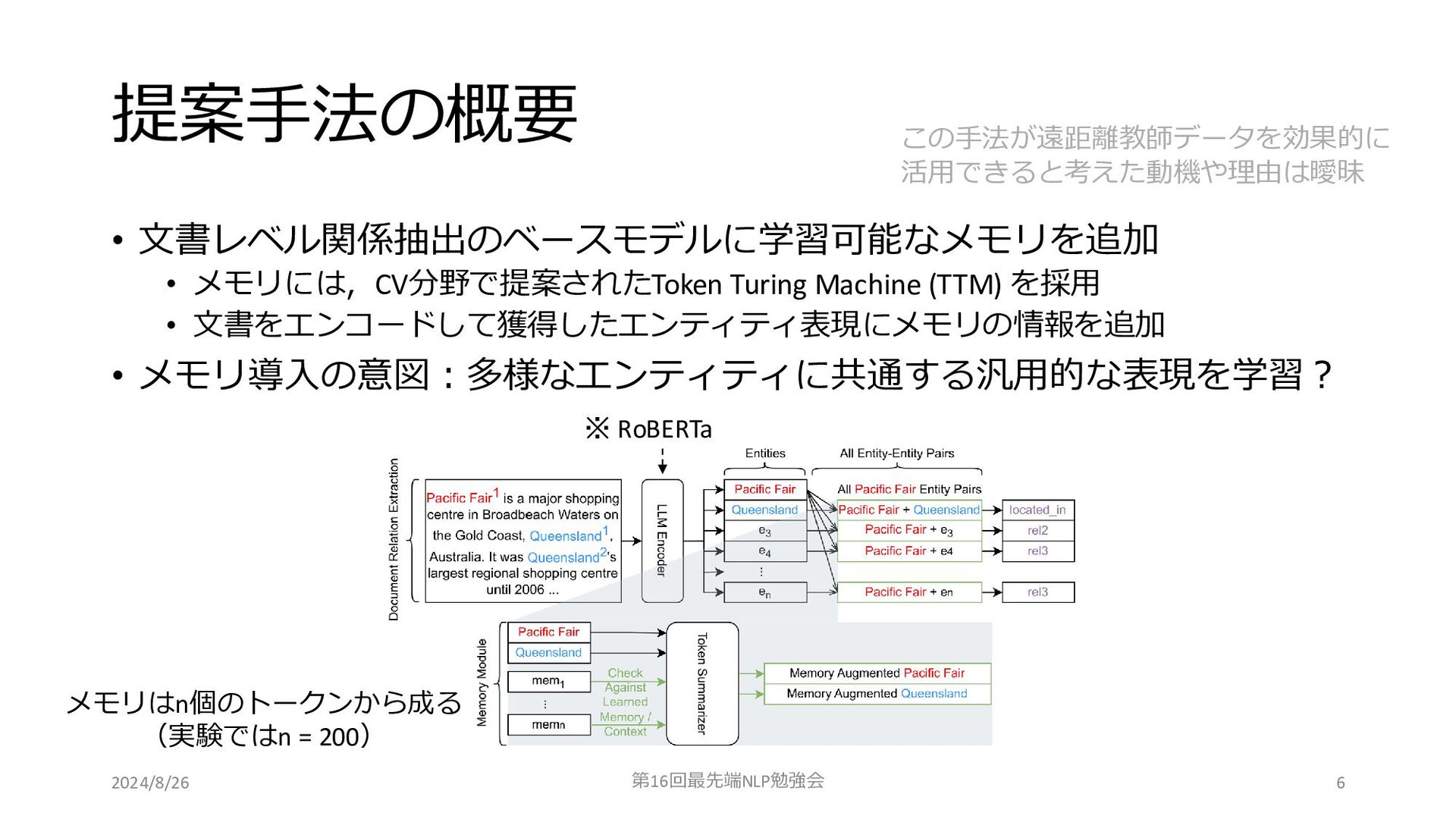
提案手法の概要 • 文書レベル関係抽出のベースモデルに学習可能なメモリを追加 • メモリには,CV分野で提案されたToken Turing Machine (TTM) を採用 •
文書をエンコードして獲得したエンティティ表現にメモリの情報を追加 • メモリ導入の意図:多様なエンティティに共通する汎用的な表現を学習? 2024/8/26 第16回最先端NLP勉強会 この手法が遠距離教師データを効果的に 活用できると考えた動機や理由は曖昧 ※ RoBERTa 6 メモリはn個のトークンから成る (実験ではn = 200)
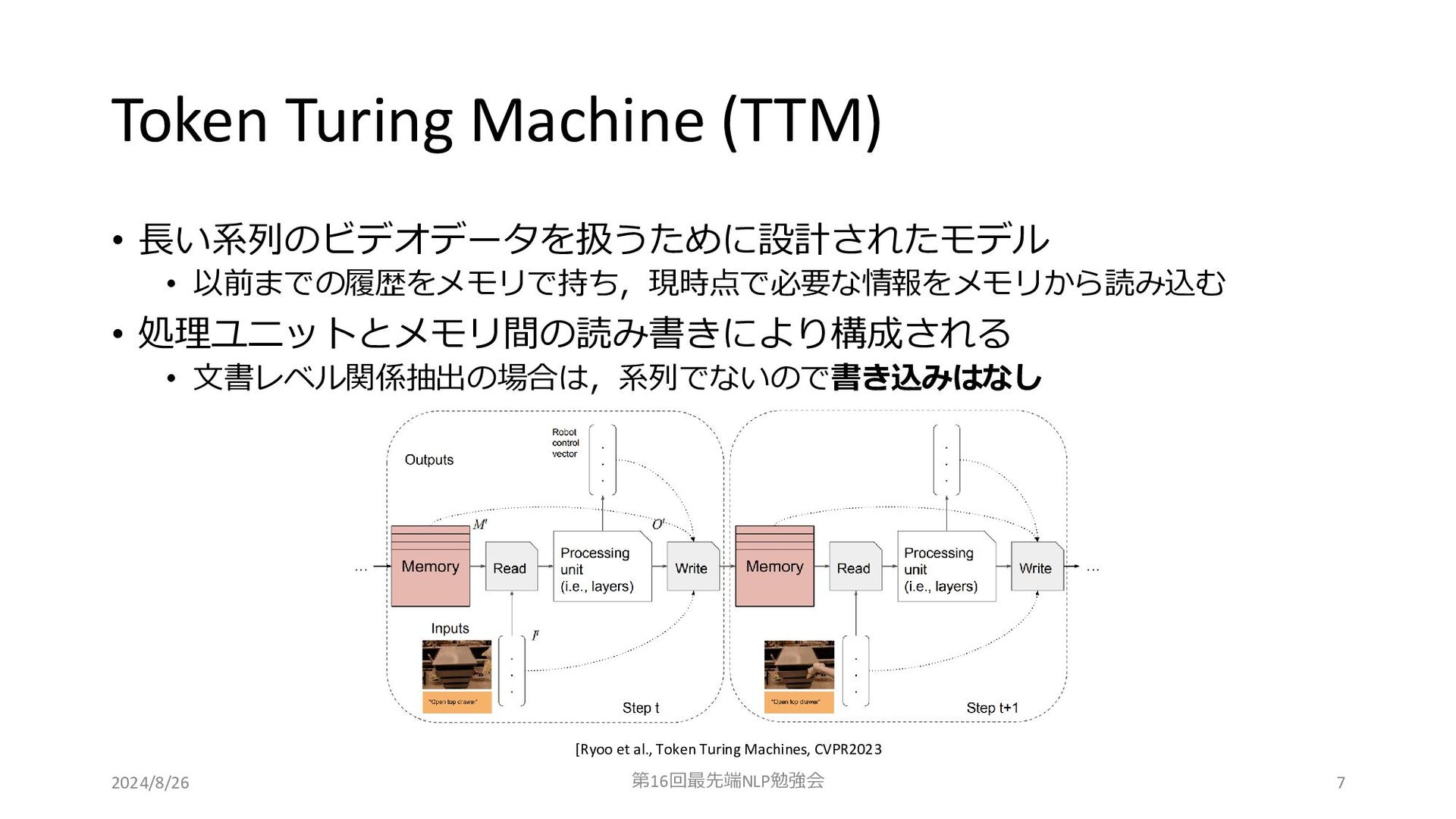
Token Turing Machine (TTM) • 長い系列のビデオデータを扱うために設計されたモデル • 以前までの履歴をメモリで持ち,現時点で必要な情報をメモリから読み込む • 処理ユニットとメモリ間の読み書きにより構成される
• 文書レベル関係抽出の場合は,系列でないので書き込みはなし 2024/8/26 第16回最先端NLP勉強会 [Ryoo et al., Token Turing Machines, CVPR2023 7
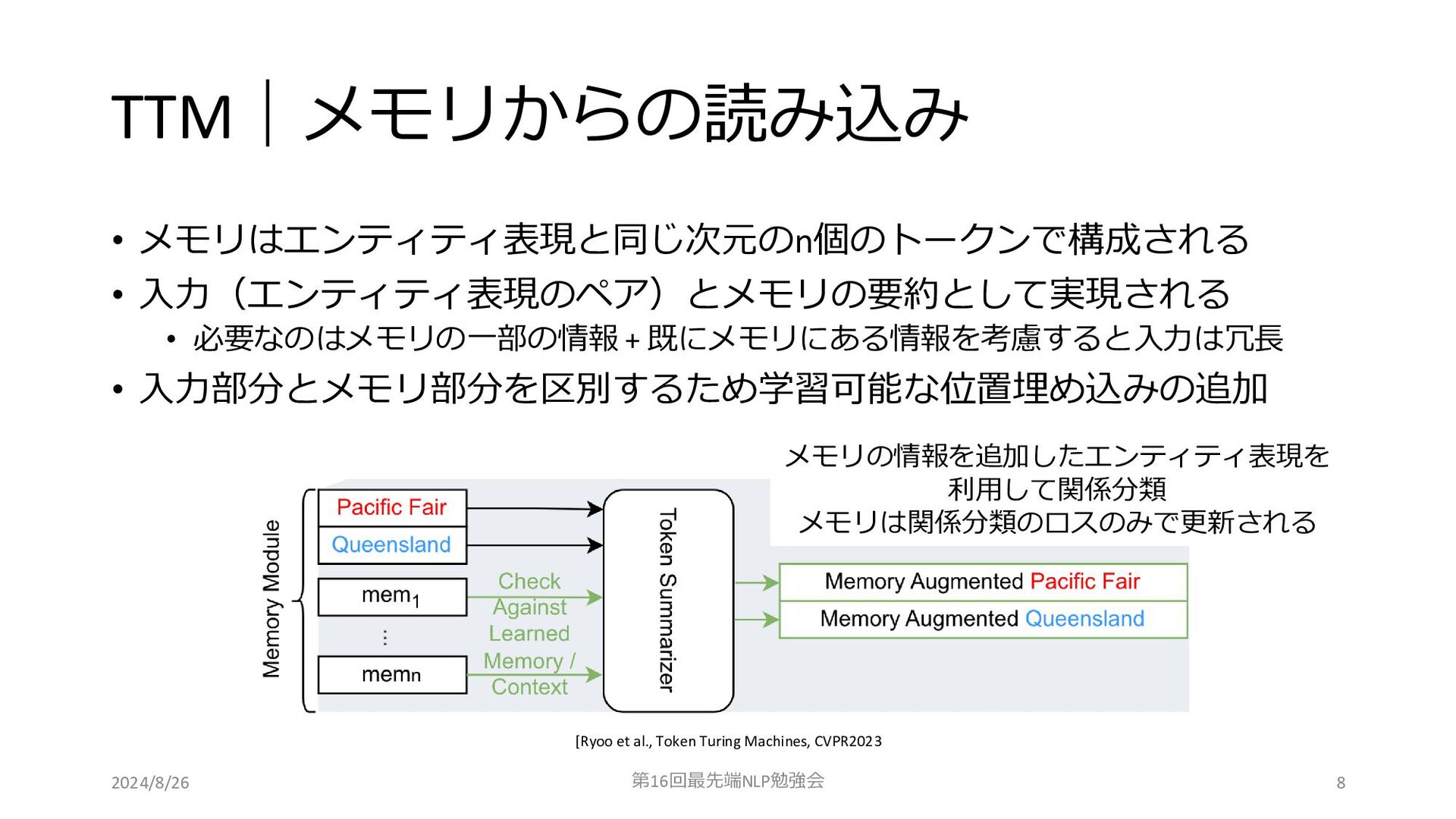
TTM|メモリからの読み込み • メモリはエンティティ表現と同じ次元のn個のトークンで構成される • 入力(エンティティ表現のペア)とメモリの要約として実現される • 必要なのはメモリの一部の情報 + 既にメモリにある情報を考慮すると入力は冗長 •
入力部分とメモリ部分を区別するため学習可能な位置埋め込みの追加 2024/8/26 第16回最先端NLP勉強会 [Ryoo et al., Token Turing Machines, CVPR2023 8 メモリの情報を追加したエンティティ表現を 利用して関係分類 メモリは関係分類のロスのみで更新される
TTM|メモリの要約 • 入力 V:n個のメモリトークンとエンティティ表現のペア • 出力 Z:メモリの情報を追加したエンティティ表現のペア 1. 入力 V
から各トークンの重要度を計算 2. 出力のi番目のトークンは重み付け和で計算される 2024/8/26 第16回最先端NLP勉強会 9 (M : メモリ,I : エンティティ表現のペア)
提案手法の学習方法 • 以下のようなステップで学習 1. 遠距離教師データでfine-tuning(メモリを作成) 2. メモリトークンは固定して,人手データでfine-tuning 2024/8/26 第16回最先端NLP勉強会 10
実験設定|概要 • 提案手法のベースはATLOP + SSR-PU • 評価指標:適合率,再現率,F値 • 5回の異なる乱数シードで実行し標準偏差を算出 •
データセット • ReDocRED:文書レベル関係抽出のベンチマーク • 大量の遠距離教師データが用意されている • ChemDisGene:生物医学ドメインのデータセット • 学習データが遠距離教師データのみ 2024/8/26 第16回最先端NLP勉強会 11 ReDocREDの統計 ChemDisGeneの統計
実験設定|データの使用設定 • ReDocRED • Original (Human Annotation Only):教師データのみで学習 • 比較手法:ATLOP,DREEAM,KD-DocRE,SSR-PU
• Distant Only:遠距離教師データのみで学習 • 比較手法:SSR-PU • Human + Distant:両方のデータで学習 • 比較手法:上記のすべてのモデル • ChemDisGen • 学習データが遠距離教師データなので,Distant Onlyに相当する設定のみ • 比較手法:BRAN,PubmedBert ,PubmedBert + BRAN,ATLOP, SSR-PUの論文の各バリエーション 2024/8/26 第16回最先端NLP勉強会 12
結果|ReDocRED • Human Annotation Only:SOTAと同等 • Distant OnlyとHuman + Distantでは
他の手法を上回る → 大規模な学習データでより効果的 • 他の手法では,+ Distantしても 大幅な改善は見られない → 遠距離教師データを上手く使えている 2024/8/26 第16回最先端NLP勉強会 13
結果|ReDocRED • Human Annotation Only:SOTAと同等 • Distant OnlyとHuman + Distantでは
他の手法を上回る → 大規模な学習データでより効果的 • 他の手法では,+ Distantしても 大幅な改善は見られない → 遠距離教師データを上手く使えている 2024/8/26 第16回最先端NLP勉強会 14
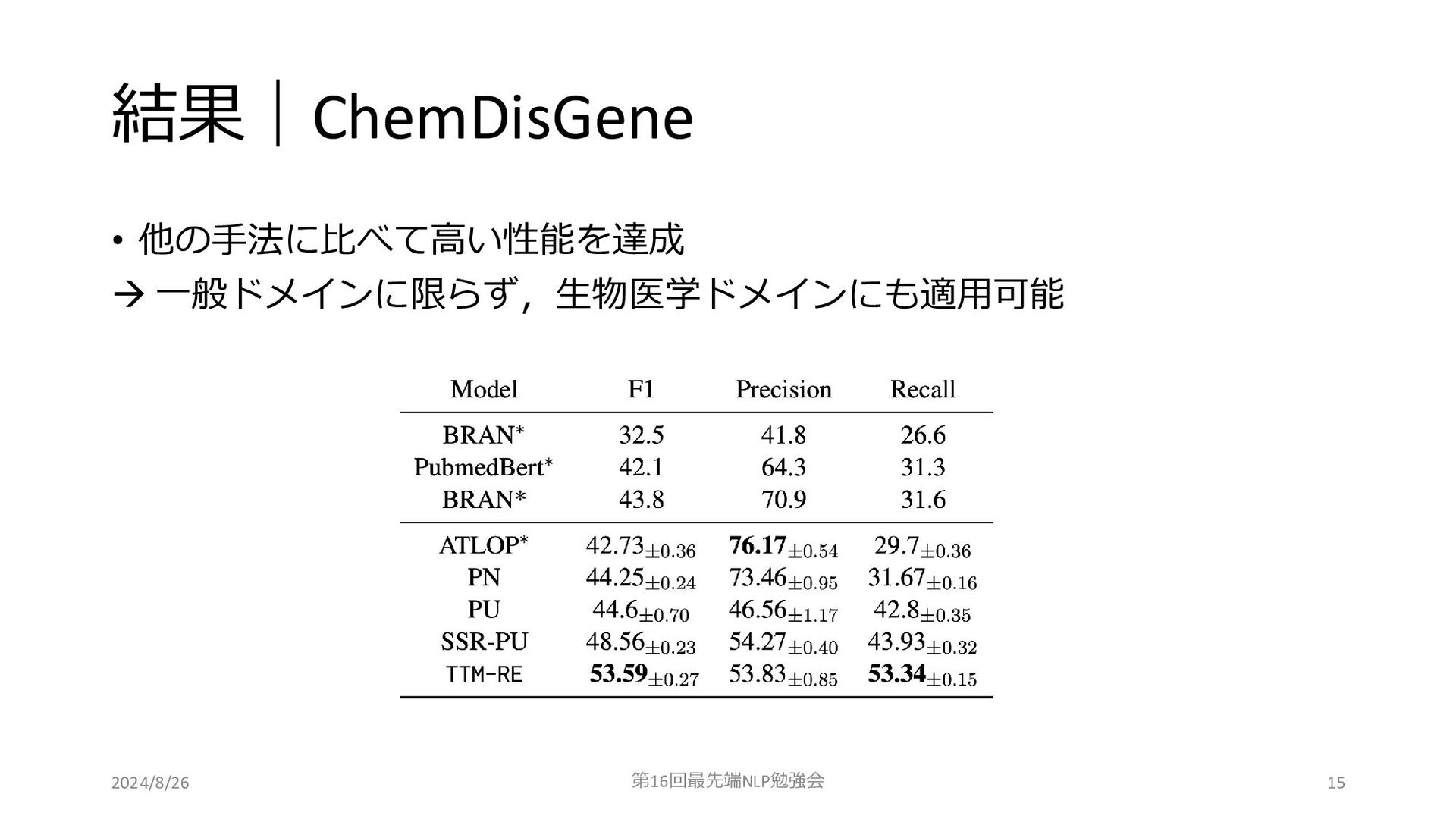
結果|ChemDisGene • 他の手法に比べて高い性能を達成 → 一般ドメインに限らず,生物医学ドメインにも適用可能 2024/8/26 第16回最先端NLP勉強会 15
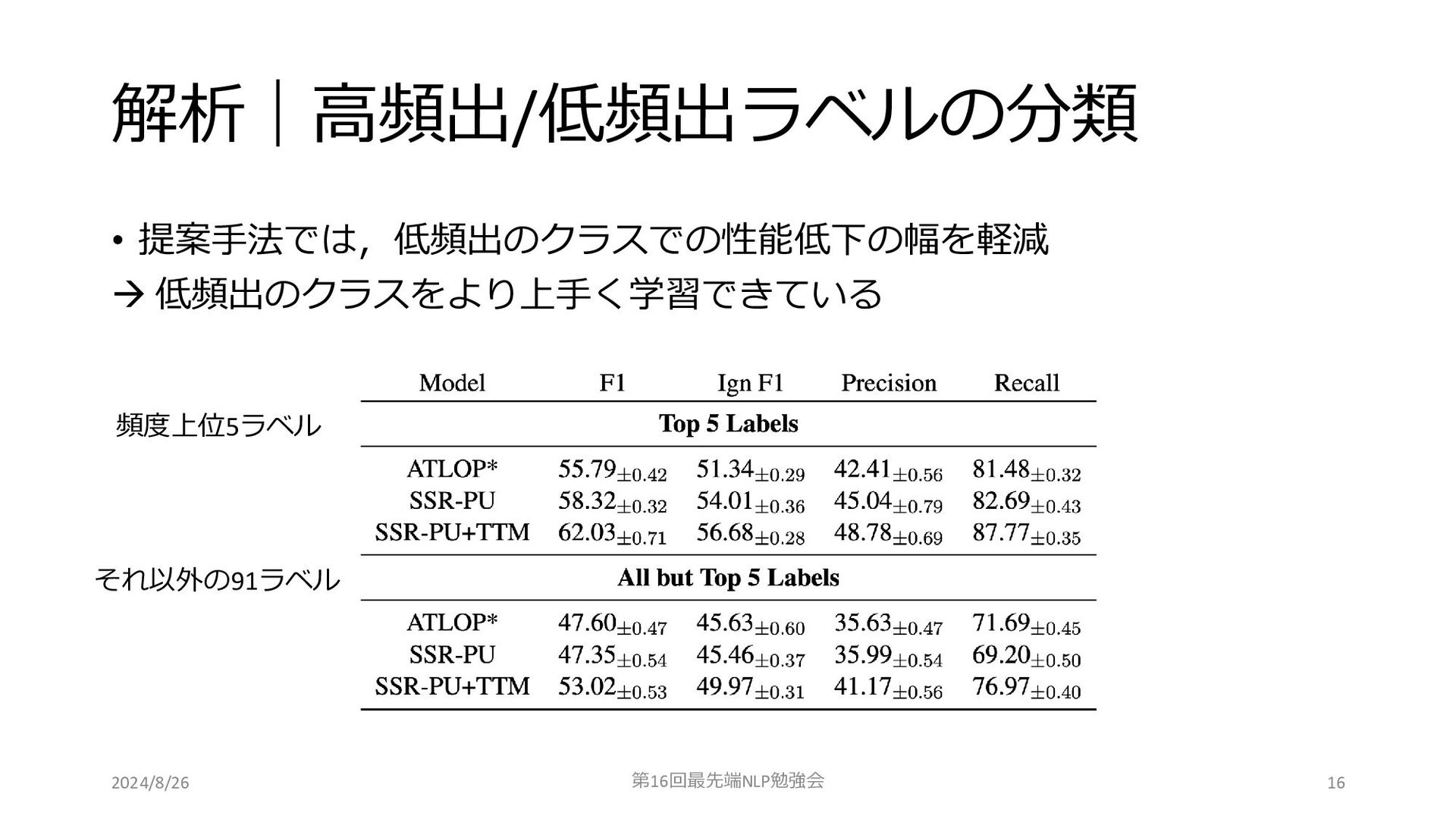
解析|高頻出/低頻出ラベルの分類 • 提案手法では,低頻出のクラスでの性能低下の幅を軽減 → 低頻出のクラスをより上手く学習できている 2024/8/26 第16回最先端NLP勉強会 16 頻度上位5ラベル それ以外の91ラベル
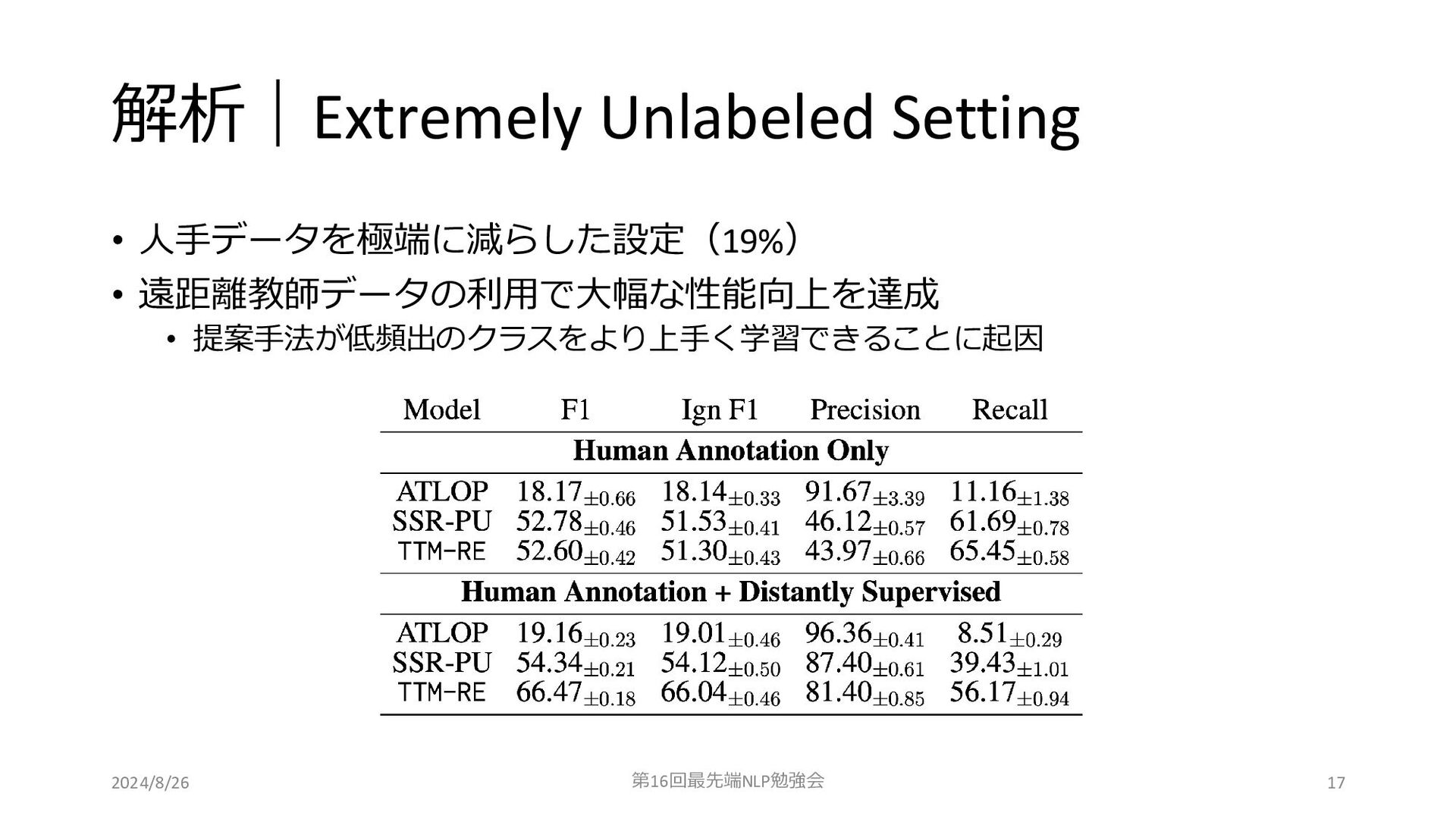
解析|Extremely Unlabeled Setting • 人手データを極端に減らした設定(19%) • 遠距離教師データの利用で大幅な性能向上を達成 • 提案手法が低頻出のクラスをより上手く学習できることに起因 2024/8/26
第16回最先端NLP勉強会 17
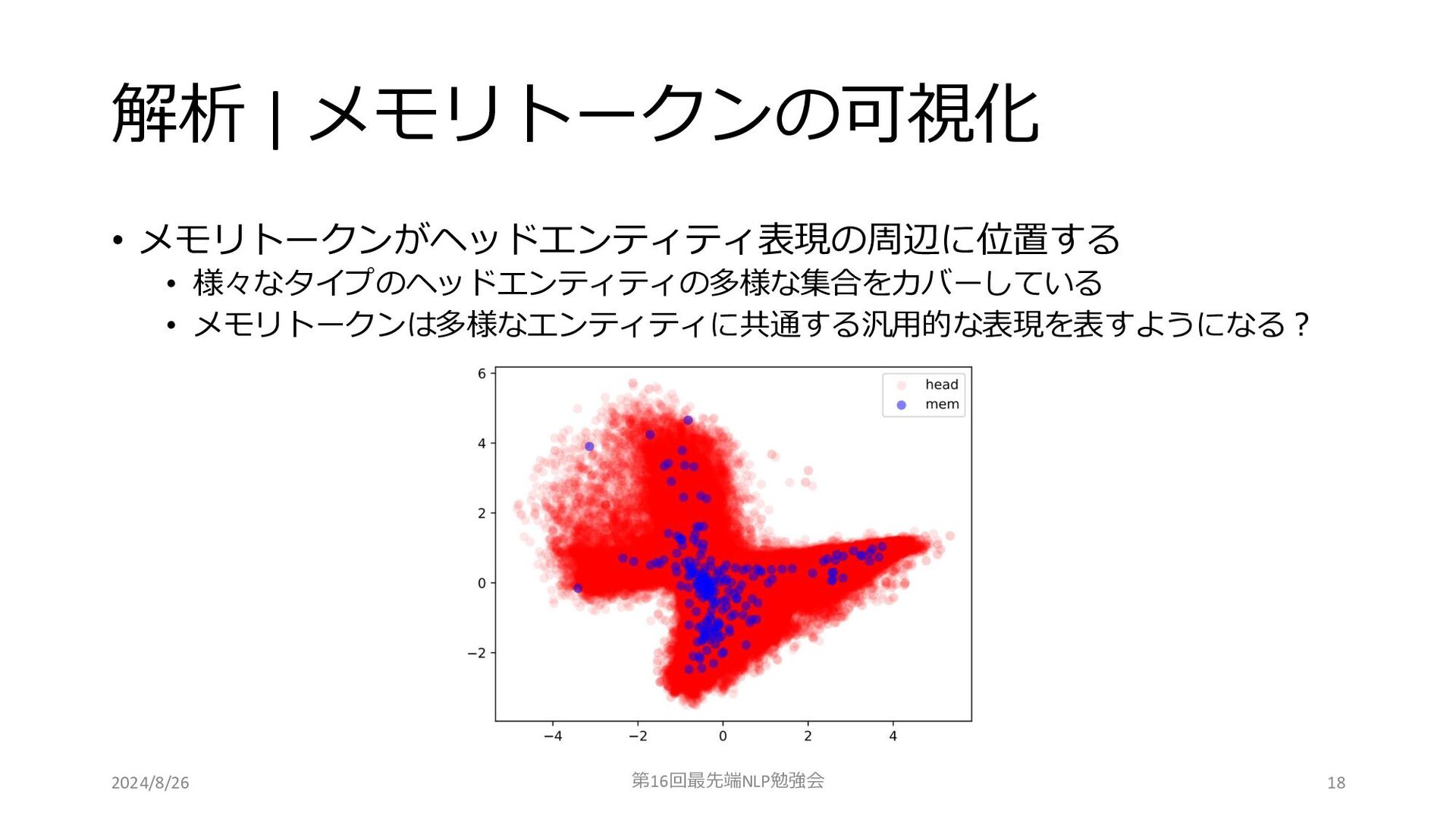
解析 | メモリトークンの可視化 • メモリトークンがヘッドエンティティ表現の周辺に位置する • 様々なタイプのヘッドエンティティの多様な集合をカバーしている • メモリトークンは多様なエンティティに共通する汎用的な表現を表すようになる? 2024/8/26
第16回最先端NLP勉強会 18
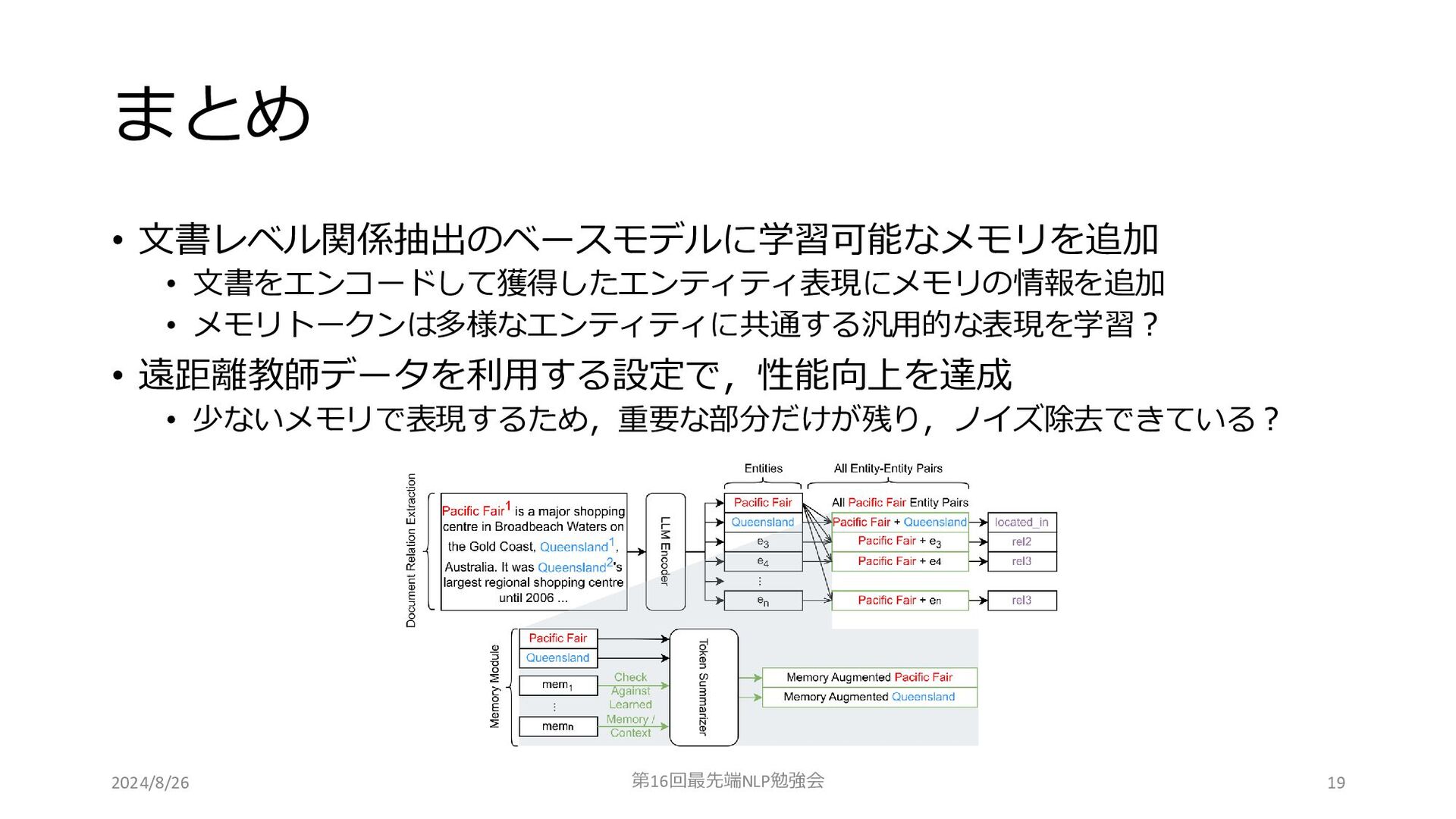
まとめ • 文書レベル関係抽出のベースモデルに学習可能なメモリを追加 • 文書をエンコードして獲得したエンティティ表現にメモリの情報を追加 • メモリトークンは多様なエンティティに共通する汎用的な表現を学習? • 遠距離教師データを利用する設定で,性能向上を達成 •
少ないメモリで表現するため,重要な部分だけが残り,ノイズ除去できている? 2024/8/26 第16回最先端NLP勉強会 19
所感 • 感想 • 簡単なモデルの変更によって,遠距離教師データの効果的な活用を可能にし, 大幅な性能向上を実現している点は良い • 遠距離教師データの活用が成功した理由についての考察が不足している • 気になった点
• メモリトークンをどの程度活用するように学習されているのか? • (全く使わないように学習されれば,ベースラインと等価) • 異なる関係タイプや文脈でのメモリトークンの利用は違いがあるか? 2024/8/26 第16回最先端NLP勉強会 20
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}