Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
ACL読み会2025@名大:A Theory of Response Sampling in ...
Search
Ryuki Ida
September 22, 2025
100
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
ACL読み会2025@名大:A Theory of Response Sampling in LLMs: Part Descriptive and Part Prescriptive
Ryuki Ida
September 22, 2025
More Decks by Ryuki Ida
See All by Ryuki Ida
最先端NLP勉強会2025: Disentangling Memory and Reasoning Ability in Large Language Models
iryuki1110
0
190
輪講資料:KGDM: A Diffusion Model to Capture Multiple Relation Semantics for Knowledge Graph Embedding
iryuki1110
0
19
ACL読み会2024@名大:SCIMON : Scientific Inspiration Machines Optimized for Novelty
iryuki1110
0
81
最先端NLP勉強会2024: TTM-RE Memory-Augmented Document-Level Relation Extraction
iryuki1110
0
180
Featured
See All Featured
RailsConf 2023
tenderlove
30
1.5k
Public Speaking Without Barfing On Your Shoes - THAT 2023
reverentgeek
1
460
Agile Leadership in an Agile Organization
kimpetersen
PRO
0
190
The browser strikes back
jonoalderson
0
1.4k
Rails Girls Zürich Keynote
gr2m
96
14k
10 Git Anti Patterns You Should be Aware of
lemiorhan
PRO
659
62k
What does AI have to do with Human Rights?
axbom
PRO
1
2.3k
Avoiding the “Bad Training, Faster” Trap in the Age of AI
tmiket
0
200
VelocityConf: Rendering Performance Case Studies
addyosmani
333
25k
エンジニアに許された特別な時間の終わり
watany
108
250k
Facilitating Awesome Meetings
lara
57
7k
Digital Projects Gone Horribly Wrong (And the UX Pros Who Still Save the Day) - Dean Schuster
uxyall
1
2.1k
Transcript
※ 図表は論⽂・発表スライドより引⽤ @ACL 2025 読み⼿:井⽥ ⿓希(豊⽥⼯業⼤学 知識データ⼯学研究室 D2)
論⽂概要 • LLMのサンプリングにおける選択基準を分析 • 統計的な平均だけでなく,規範的な理想へ偏る傾向を発⾒ • 例:病気からの回復期間を過度に短く⾒積もるなど • 選定理由: •
LLMの出⼒のバイアスに関する新たな視点を提供しており ⾯⽩そうだったため • 統計的な平均より規範的に良い答えを出⼒しがちという視点から 複数の検証実験をしており興味深いため 2025/9/26 ACL2025読み会@名⼤ 2
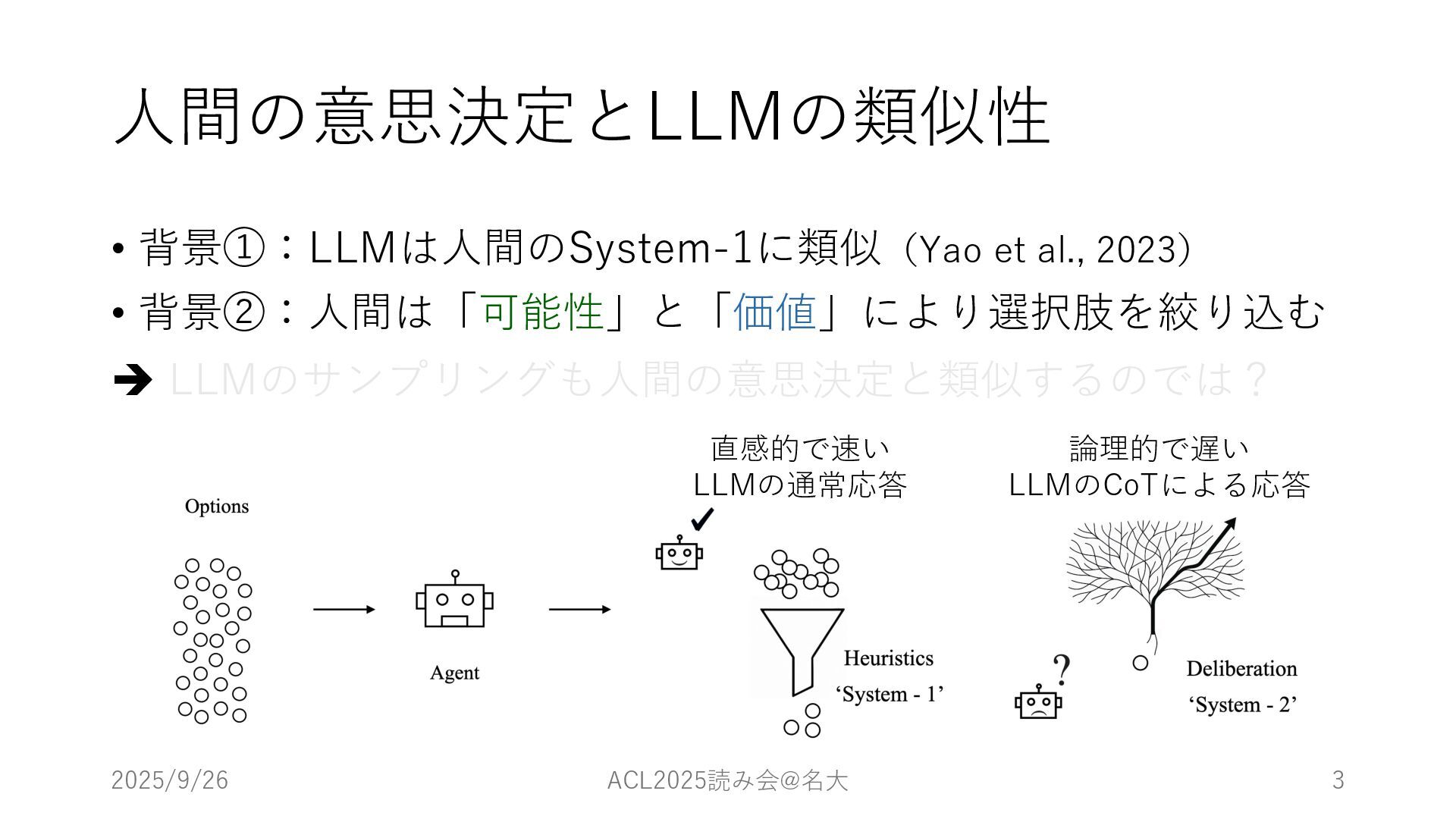
⼈間の意思決定とLLMの類似性 • 背景①:LLMは⼈間のSystem-1に類似(Yao et al., 2023) • 背景②:⼈間は「可能性」と「価値」により選択肢を絞り込む è LLMのサンプリングも⼈間の意思決定と類似するのでは?
2025/9/26 ACL2025読み会@名⼤ 3 直感的で速い LLMの通常応答 論理的で遅い LLMのCoTによる応答
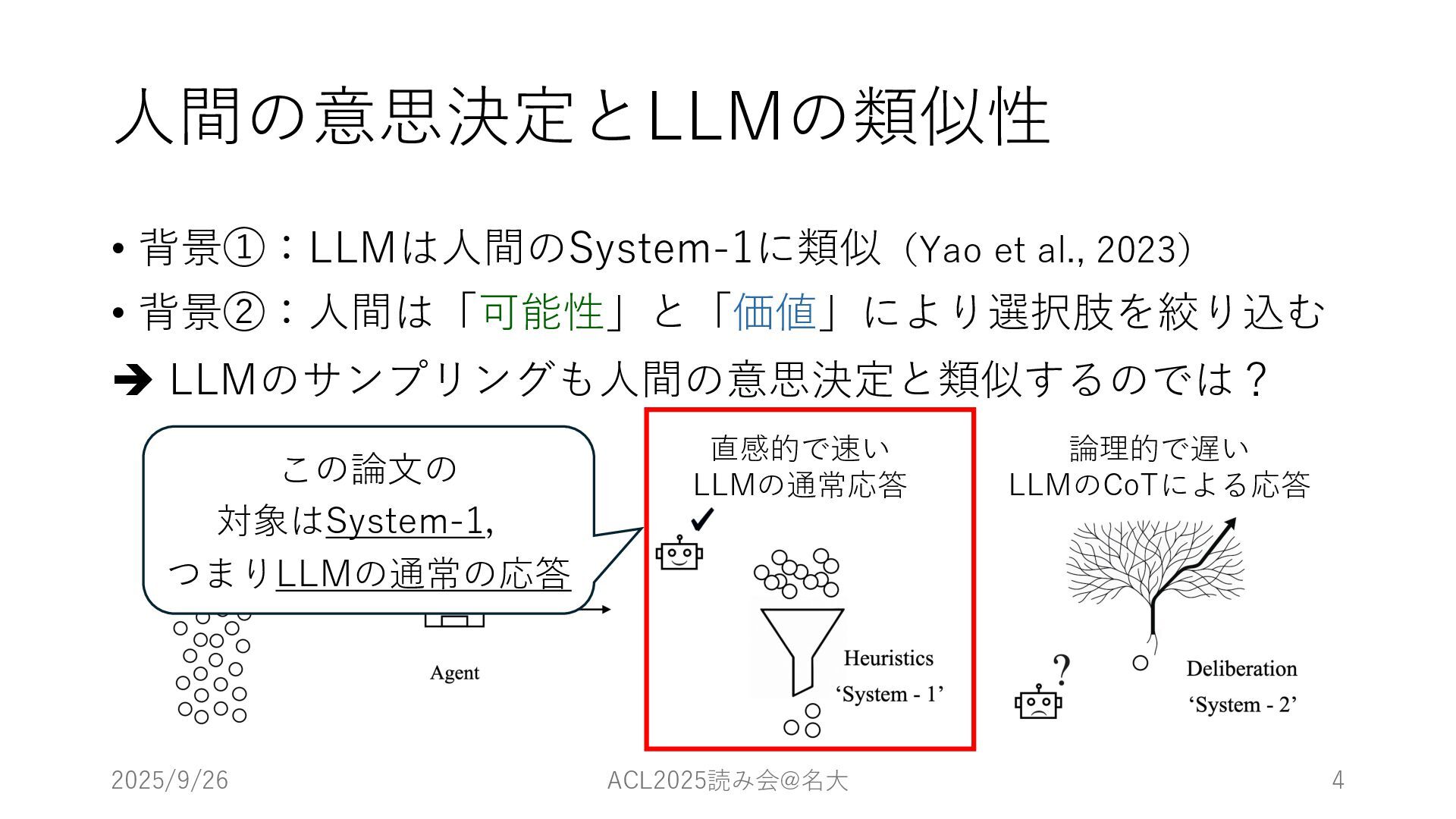
⼈間の意思決定とLLMの類似性 • 背景①:LLMは⼈間のSystem-1に類似(Yao et al., 2023) • 背景②:⼈間は「可能性」と「価値」により選択肢を絞り込む è LLMのサンプリングも⼈間の意思決定と類似するのでは?
2025/9/26 ACL2025読み会@名⼤ 4 直感的で速い LLMの通常応答 論理的で遅い LLMのCoTによる応答 この論⽂の 対象はSystem-1, つまりLLMの通常の応答
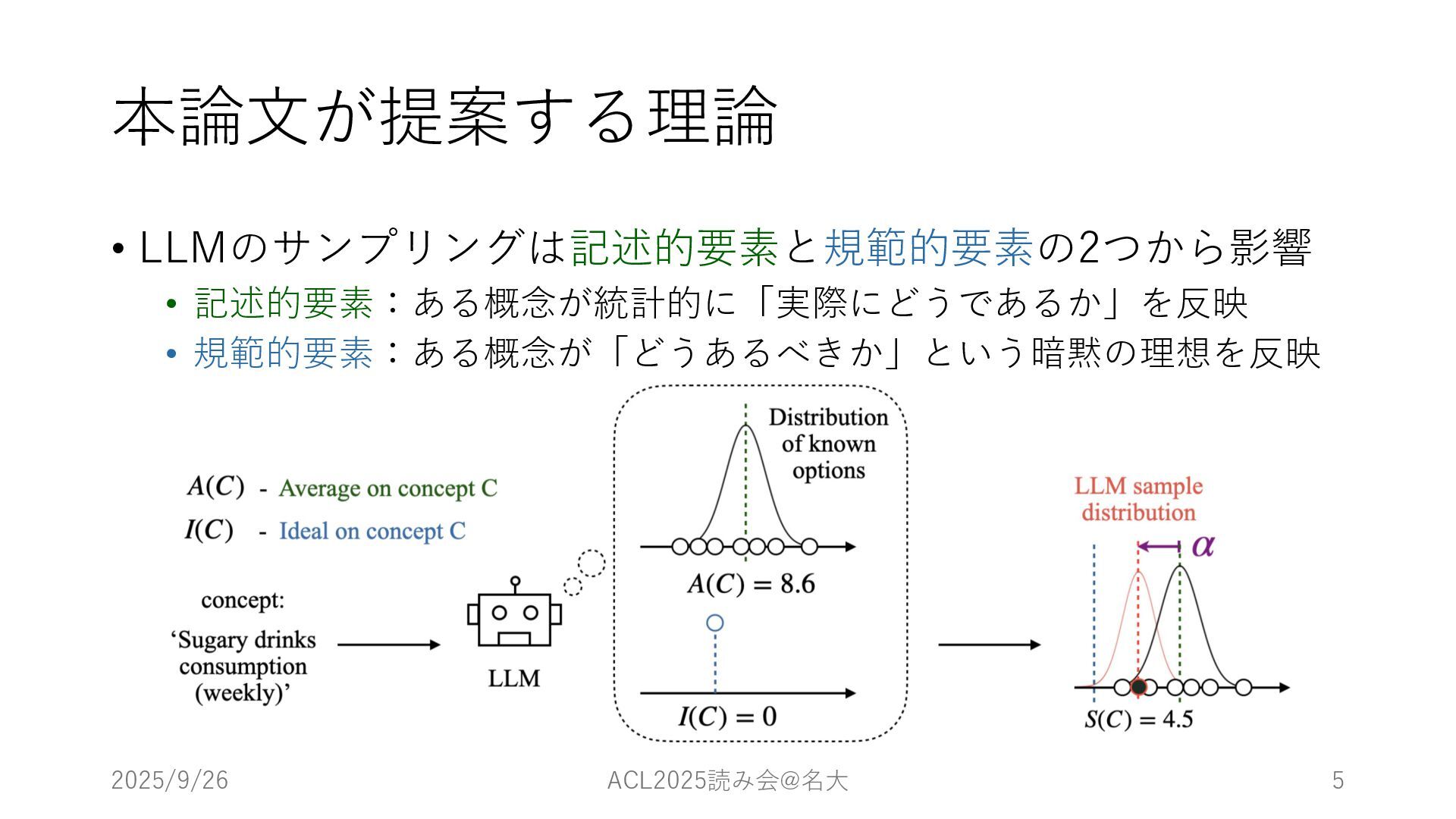
本論⽂が提案する理論 • LLMのサンプリングは記述的要素と規範的要素の2つから影響 • 記述的要素:ある概念が統計的に「実際にどうであるか」を反映 • 規範的要素:ある概念が「どうあるべきか」という暗黙の理想を反映 2025/9/26 ACL2025読み会@名⼤ 5
⼈間の意思決定に関する実験 (Bear et al., 2020) • 被験者に架空の概念を提⽰,100個のデータと評価値を提供 • 平均の推定と直感的なサンプルの想起をそれぞれ実施 •
3つの価値尺度で検証した結果,平均ではなく理想の⽅向へ • 例:〇〇の時間は多い/少ない⽅が良い 2025/9/26 ACL2025読み会@名⼤ 6 “flubbing”は健康に良い趣味です. 医師はできるだけ多く“flubbing”を⾏うよう推奨しています. 以下は100⼈の“flubbing”時間(分)と健康評価 (D- ~ A+)です. 43:C,35:C-,63:B+,...,35:C- 質問:頭に最初に浮かぶ“flubbing”時間は何分ですか? ⼈間への指⽰⽂(Positive Idealの例)
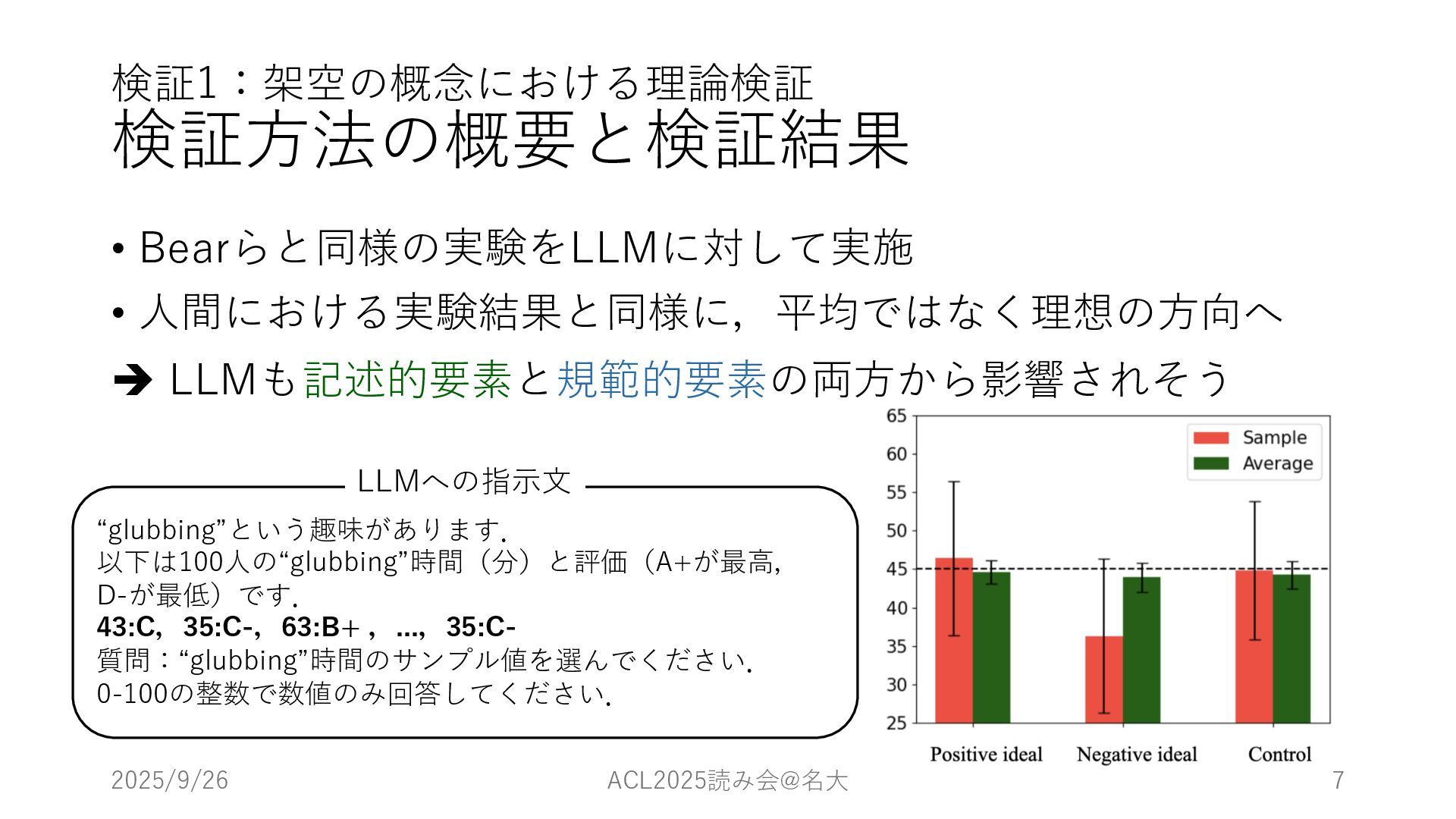
検証1:架空の概念における理論検証 検証⽅法の概要と検証結果 • Bearらと同様の実験をLLMに対して実施 • ⼈間における実験結果と同様に,平均ではなく理想の⽅向へ è LLMも記述的要素と規範的要素の両⽅から影響されそう 2025/9/26 ACL2025読み会@名⼤
7 “glubbing”という趣味があります. 以下は100⼈の“glubbing”時間(分)と評価(A+が最⾼, D-が最低)です. 43:C,35:C-,63:B+ ,...,35:C- 質問:“glubbing”時間のサンプル値を選んでください. 0-100の整数で数値のみ回答してください. LLMへの指⽰⽂
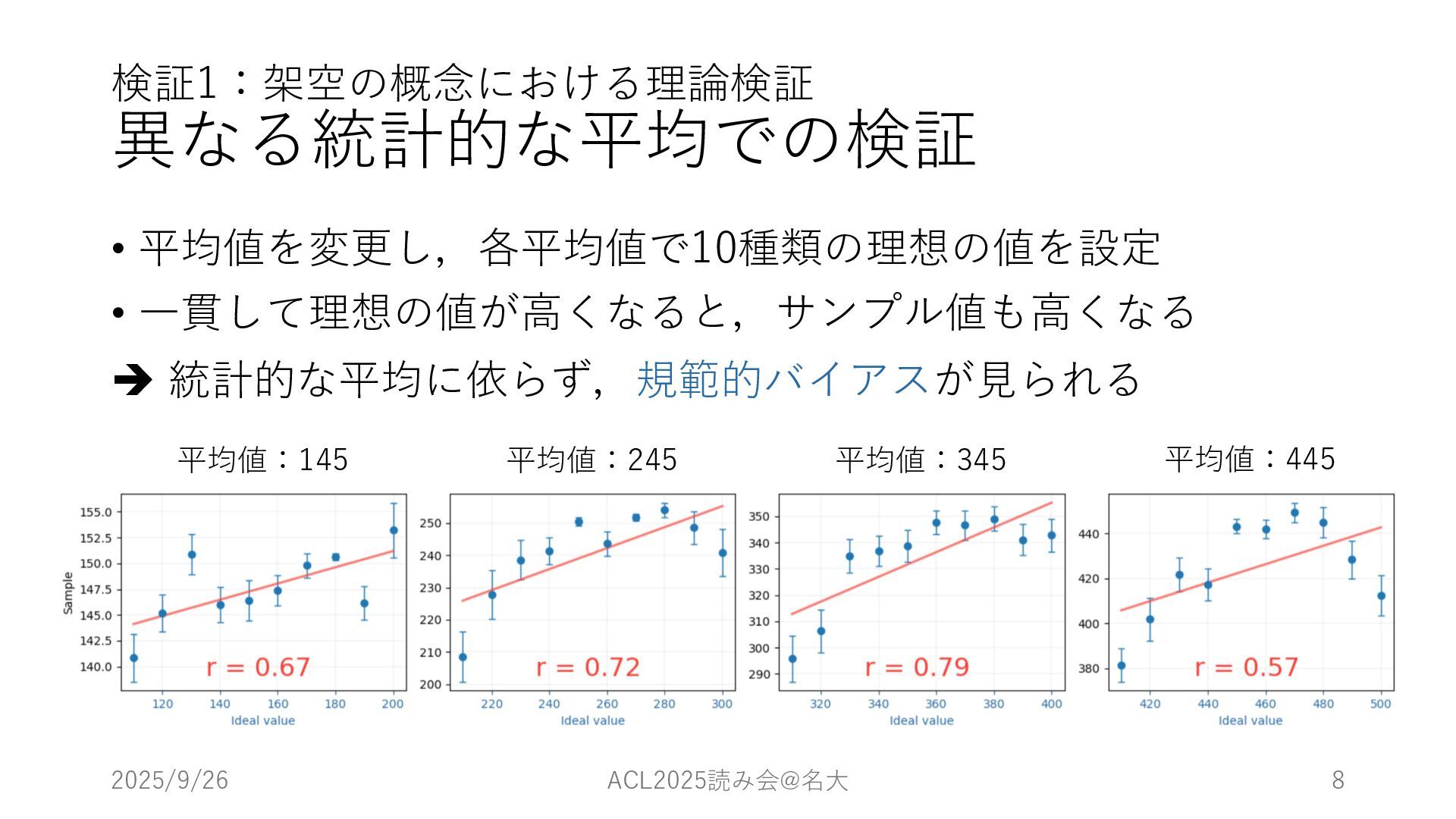
検証1:架空の概念における理論検証 異なる統計的な平均での検証 • 平均値を変更し,各平均値で10種類の理想の値を設定 • ⼀貫して理想の値が⾼くなると,サンプル値も⾼くなる è 統計的な平均に依らず,規範的バイアスが⾒られる 2025/9/26 ACL2025読み会@名⼤
8 平均値:145 平均値:245 平均値:345 平均値:445
検証2:既存概念における理論検証 検証⽅法の概要 • LLMが学習済みの知識での規範的バイアスを調査 • TV視聴時間,運動時間など10分野500概念を対象 • 平均値,理想値,サンプル値を独⽴に質問 2025/9/26 ACL2025読み会@名⼤
9
検証2:既存概念における理論検証 検証結果 • LLMが学習済みの概念においても規範的要素の影響 • モデルサイズが⼤きいほど,強い傾向 • 規範的バイアスは事前学習段階で⽣じ, RLHFによって増強される傾向 2025/9/26
ACL2025読み会@名⼤ 10 モデル名 理想値寄りに サンプルした 概念の割合 Llama-3-8b 0.608 Llama-3-8b-Instruct 0.716 Llama-3-70b 0.726 Llama-3-70b-Instruct 0.777 Claude 0.688 Mixtral-8x7B 0.716 Mistral-7B 0.608 GPT-4 0.680
検証2:既存概念における理論検証 検証結果 • LLMが学習済みの概念においても規範的要素の影響 • モデルサイズが⼤きいほど,強い傾向 • 規範的バイアスは事前学習段階で⽣じ, RLHFによって増強される傾向 2025/9/26
ACL2025読み会@名⼤ 11 モデル名 理想値寄りに サンプルした 概念の割合 Llama-3-8b 0.608 Llama-3-8b-Instruct 0.716 Llama-3-70b 0.726 Llama-3-70b-Instruct 0.777 Claude 0.688 Mixtral-8x7B 0.716 Mistral-7B 0.608 GPT-4 0.680
検証2:既存概念における理論検証 検証結果 • LLMが学習済みの概念においても規範的要素の影響 • モデルサイズが⼤きいほど,強い傾向 • 規範的バイアスは事前学習段階で⽣じ, RLHFによって増強される傾向 2025/9/26
ACL2025読み会@名⼤ 12 モデル名 理想値寄りに サンプルした 概念の割合 Llama-3-8b 0.608 Llama-3-8b-Instruct 0.716 Llama-3-70b 0.726 Llama-3-70b-Instruct 0.777 Claude 0.688 Mixtral-8x7B 0.716 Mistral-7B 0.608 GPT-4 0.680
検証2:既存概念における理論検証 医療診断におけるケーススタディ • 設定:LLMを医師として,35症状の患者の回復時間を予測 • 結果:26/35ケースで予測時間が理想側(短め)にシフト è 医療分野でのLLM使⽤は予期しない危険を⽣む可能性 2025/9/26 ACL2025読み会@名⼤
13
検証3:LLMはプロトタイプをどのように捉えているか? 検証⽅法の概要 • ⼈間において,プロトタイプは理想に影響される • プロトタイプ:概念に期待される典型的な特徴を持つ代表例 • 例:「空を⾶ぶ」という理想的特徴を持つコマドリは, ⾶べないペンギンよりも「⿃」のプロトタイプとして認識されやすい •
LLMも同様の傾向を持つかを検証 2025/9/26 ACL2025読み会@名⼤ 14
検証3:LLMはプロトタイプをどのように捉えているか? 検証結果 • 8つの概念について,具体的な内容を複数提⽰,3つの軸で評価 • 3つの軸:平均らしさ,理想度,典型度 (プロトタイプ) • LLMのプロトタイプは平均ではなく理想に近い 2025/9/26
ACL2025読み会@名⼤ 15 ⾼校教師・事例1: 「30歳の⼥性.基本的に教える内容は理解しているが, ⽐較的つまらなく,退屈で,仕事をあまり好んでいない.」 ⾼校教師・事例2: 「25歳の⼥性.⽣徒を魅⼒的な実演で惹きつけ, 驚くほど速く課題を採点し,すべての⽣徒を成功に導く.」 ⼊⼒例
まとめ • LLMの応答は,統計的な平均だけでなく,規範的な理想に偏る • 特に⼤規模・RLHF済みモデルで顕著 • LLMは医療予測での偏りなど実応⽤で問題を⽣む可能性 • バイアスの起源を解明し,制御・軽減する⼿法の開発 2025/9/26
ACL2025読み会@名⼤ 16
所感 • 感想 • LLMが統計的な分布より規範的に良い出⼒を好むという発⾒は直感的 • 架空の概念・既存の概念など,複数の観点からの検証は興味深い • 疑問点 •
架空の概念と既存の概念での結果は,バイアスの性質を考える上で 意味合いが異なるのでは? • LLMが⼈間とは異なる振る舞いをする時もあるが,その違いは? • プロンプト設計への依存性が⾼そう,他のプロンプトではどうなる? 2025/9/26 ACL2025読み会@名⼤ 17
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}