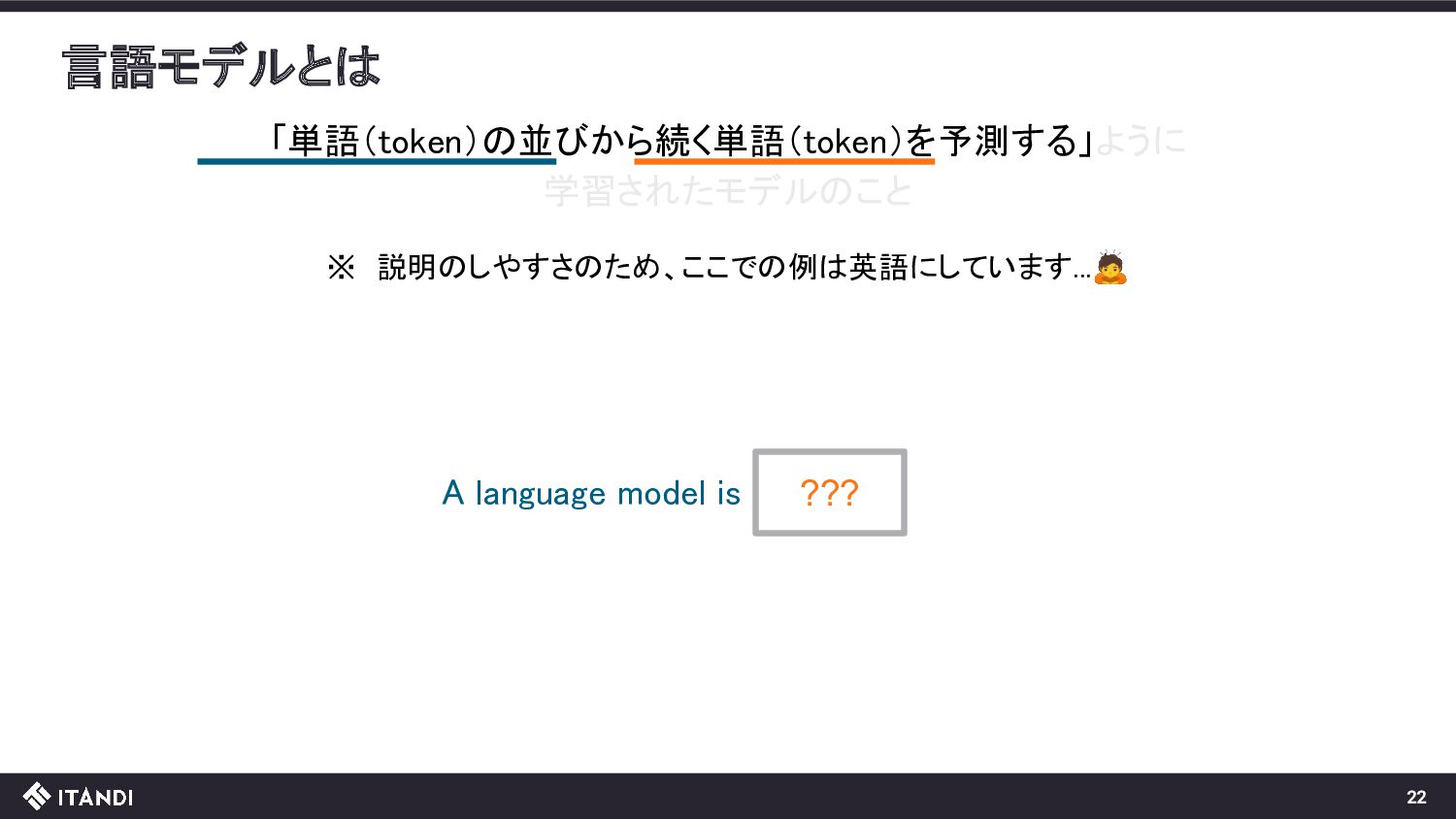
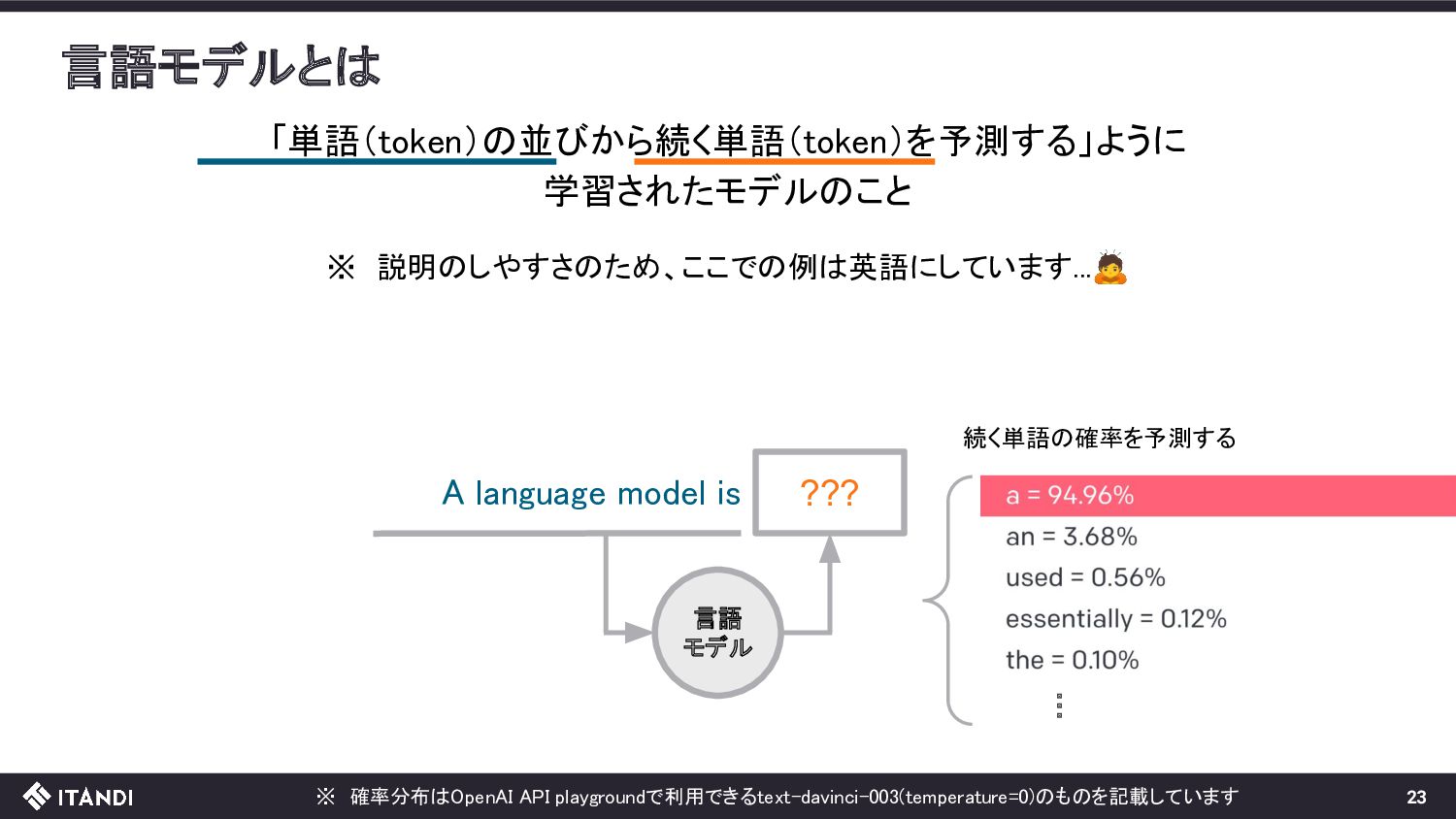
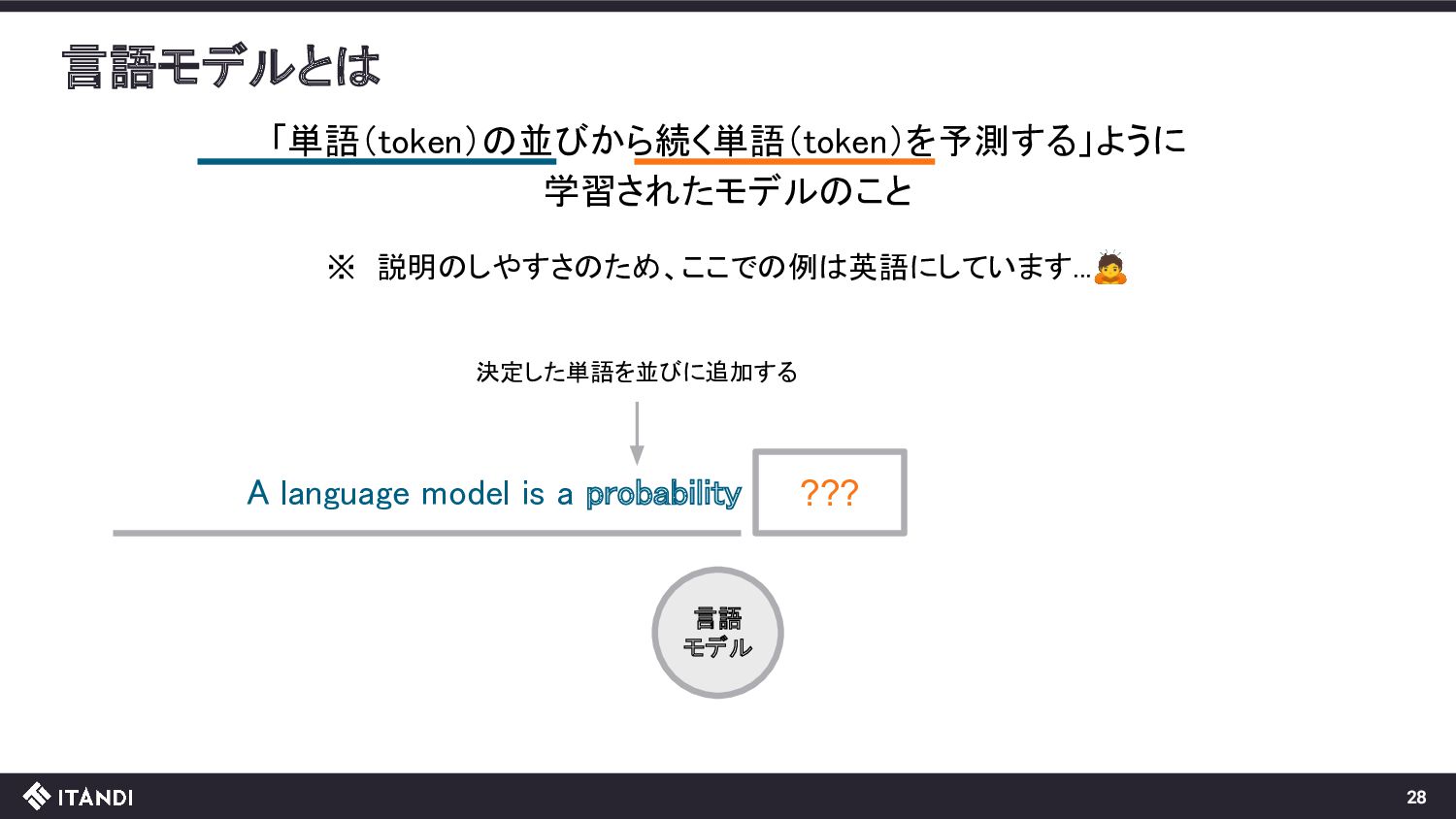
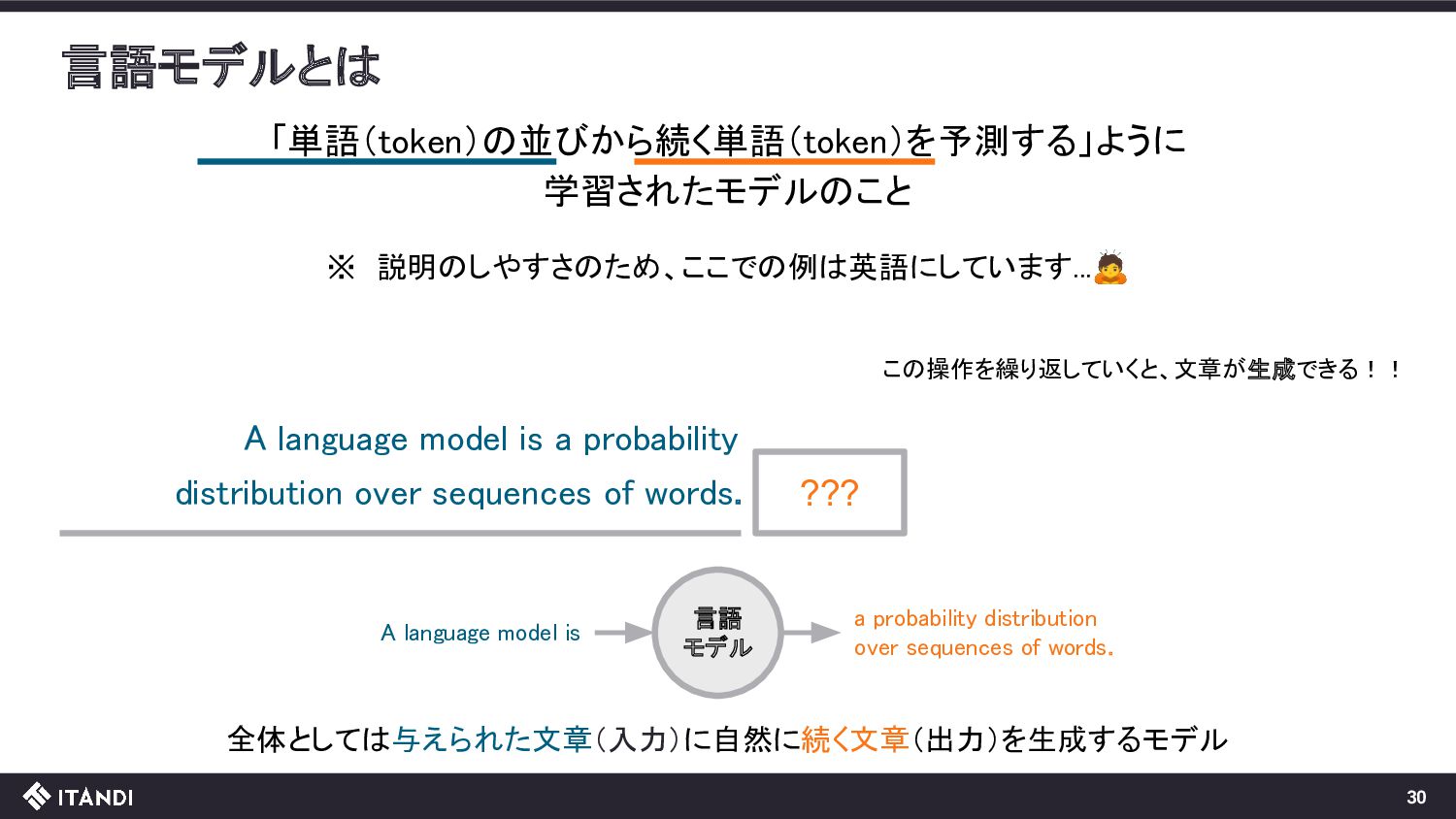
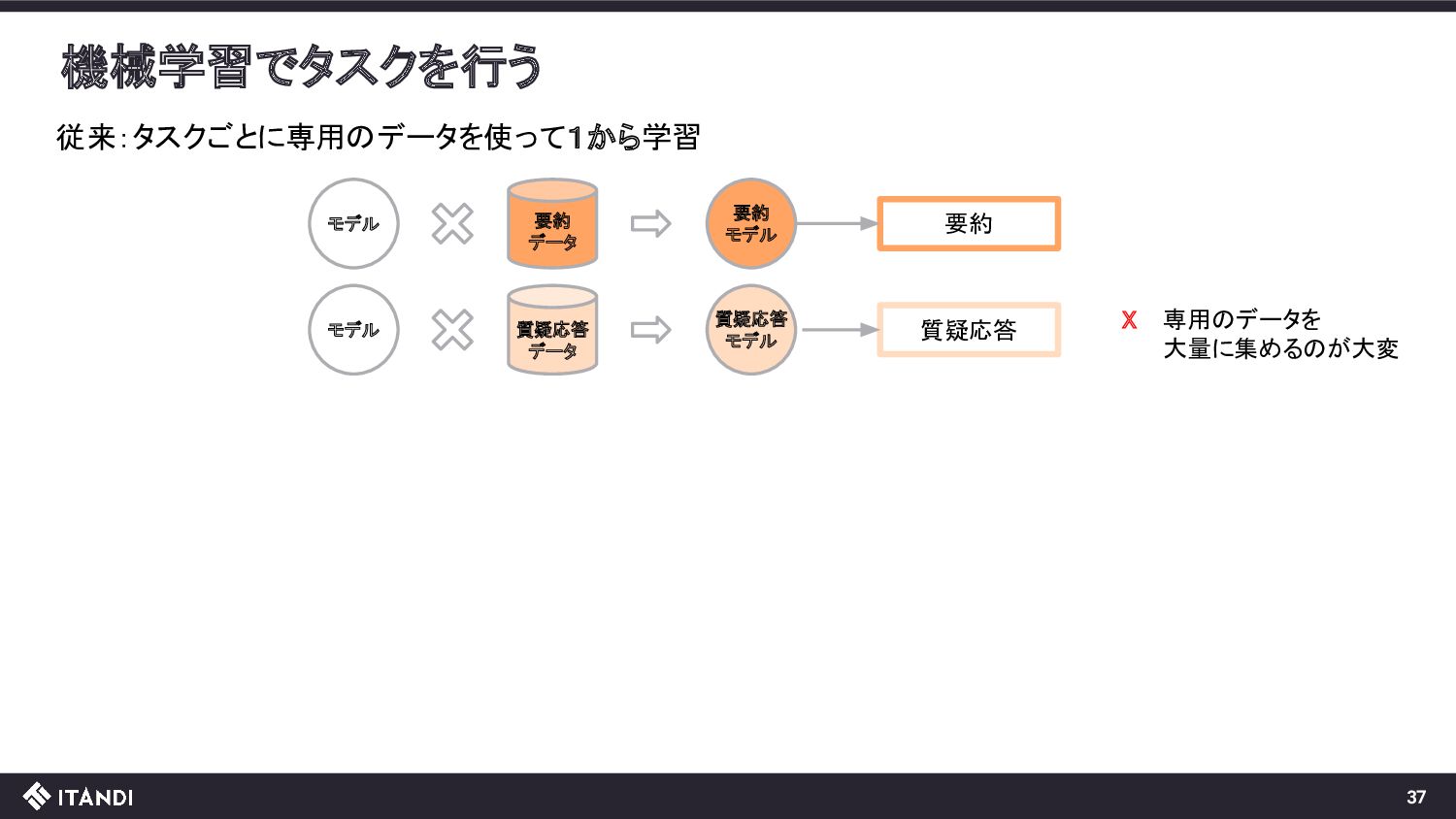
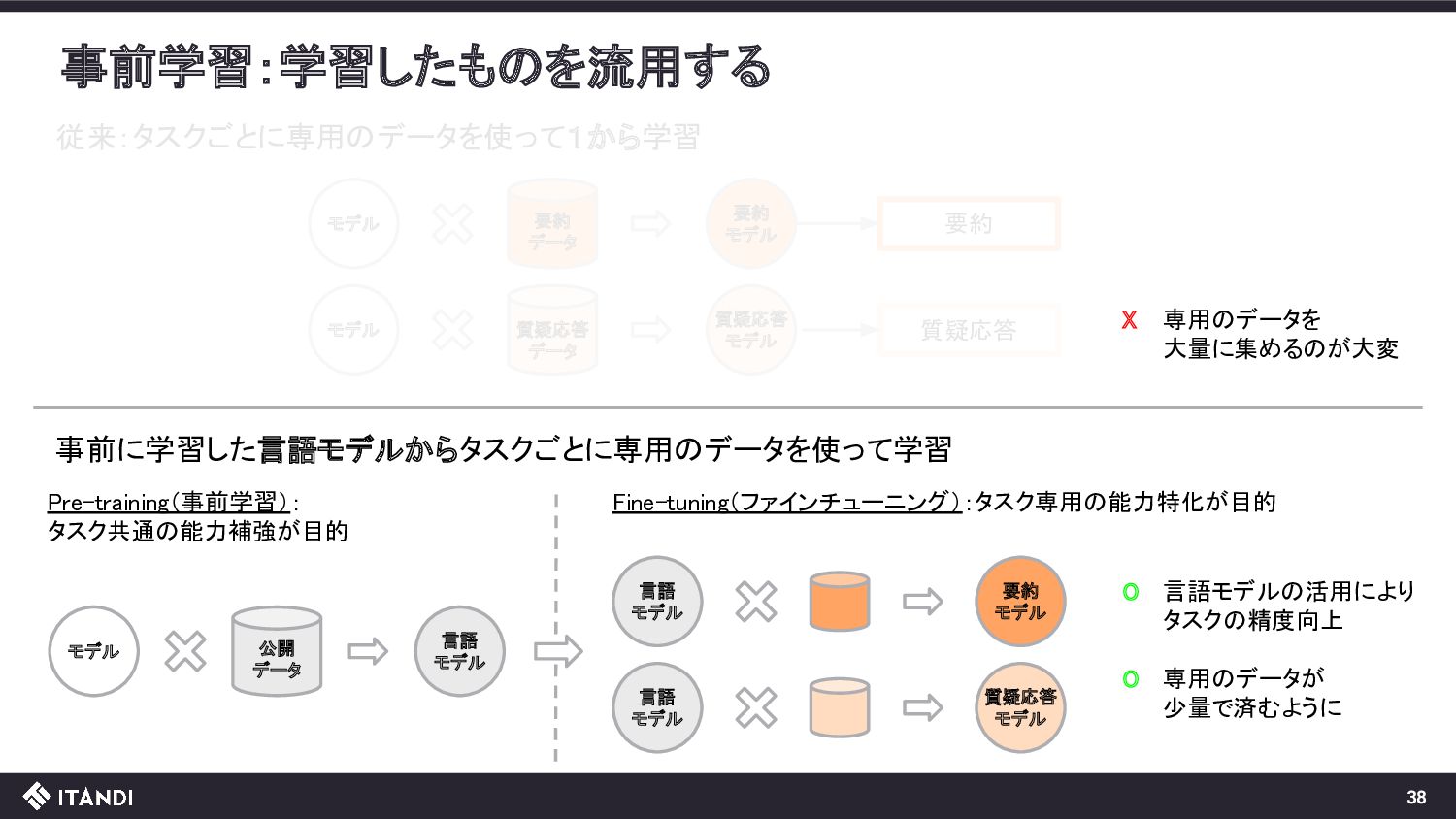
??? 言語 モデル この操作を繰り返していくと、文章が生成できる!! A language model is a probability A language model is a probability distribution over sequences of words. 全体としては与えられた文章(入力)に自然に続く文章(出力)を生成するモデル
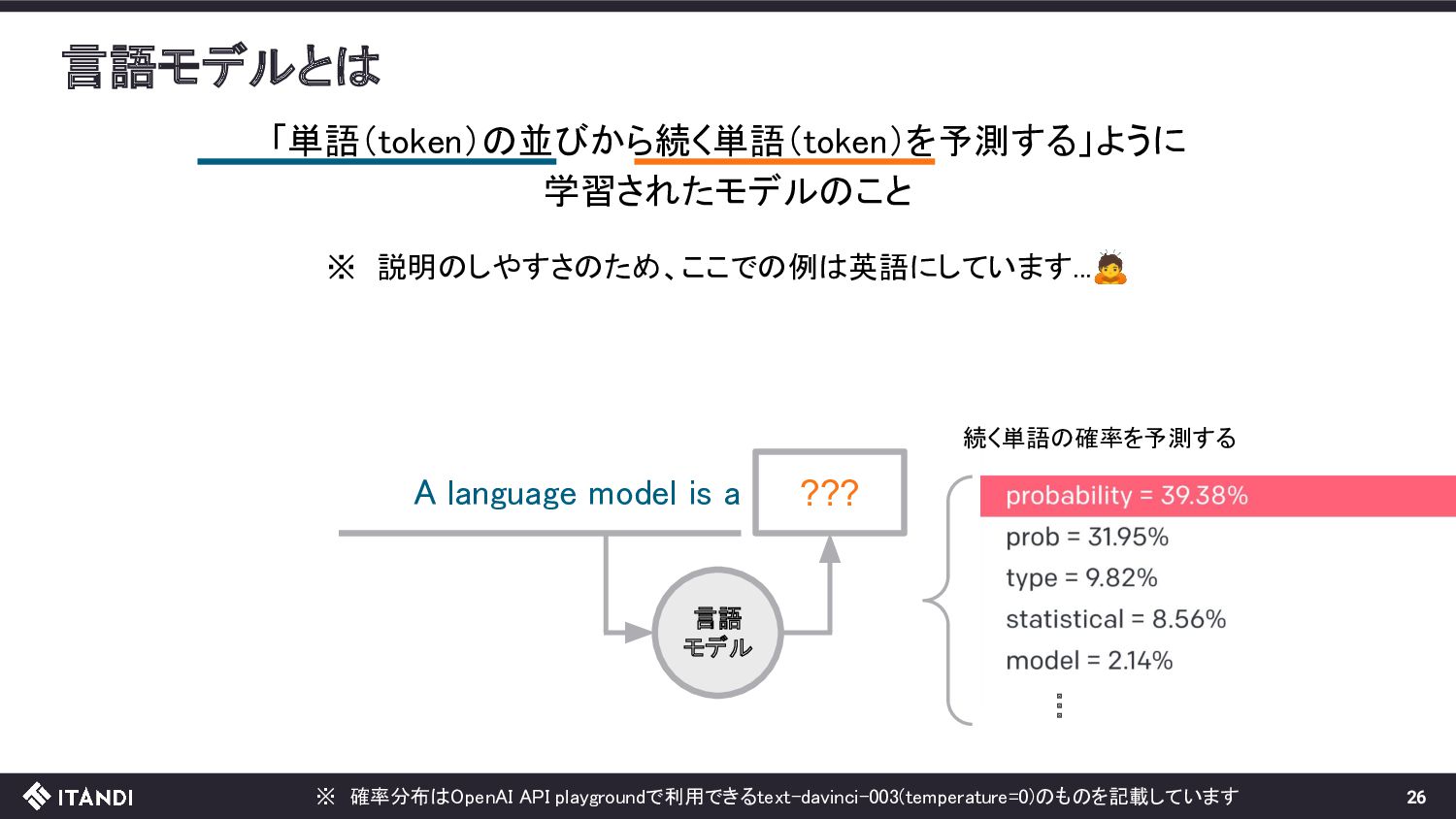
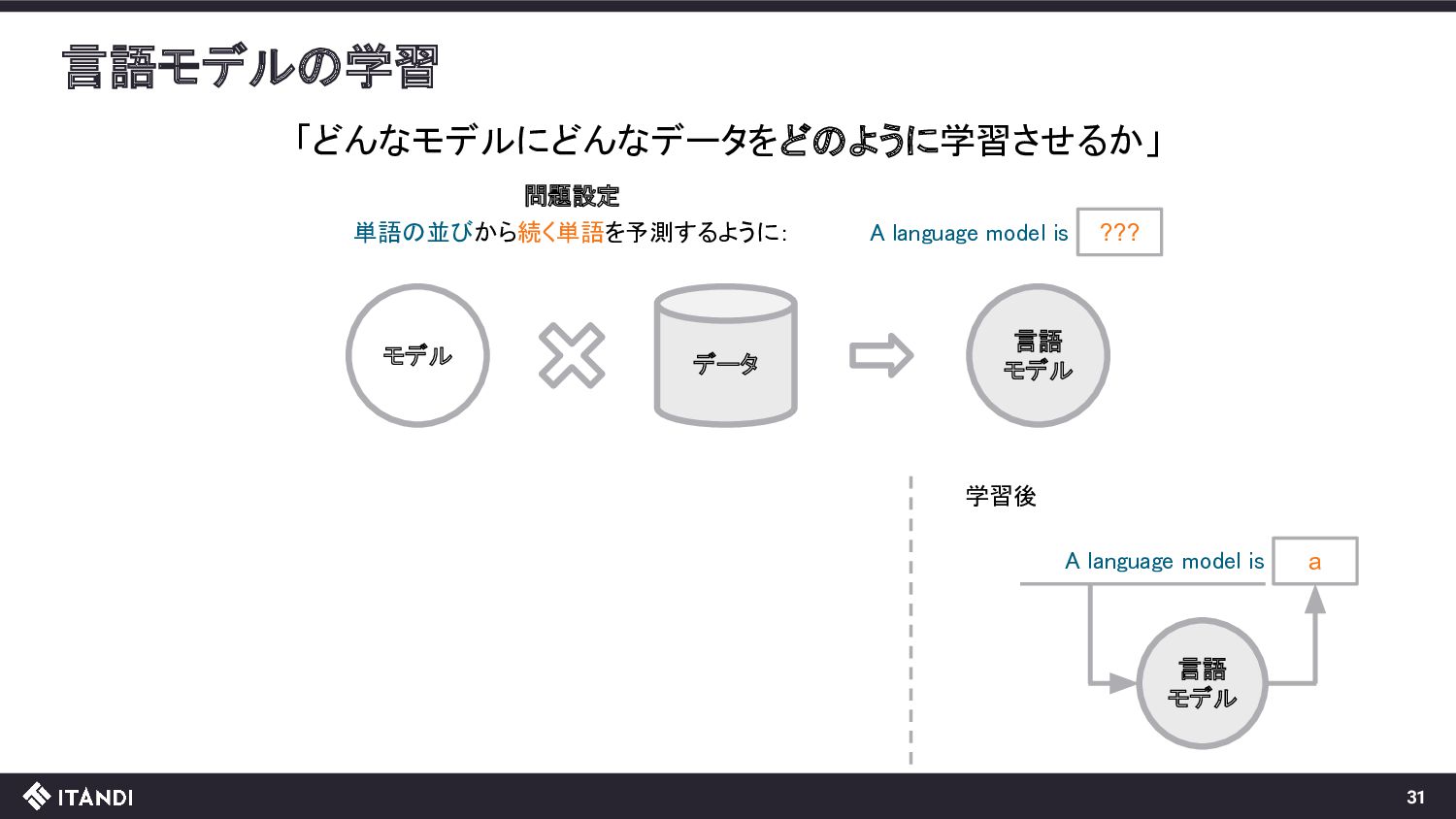
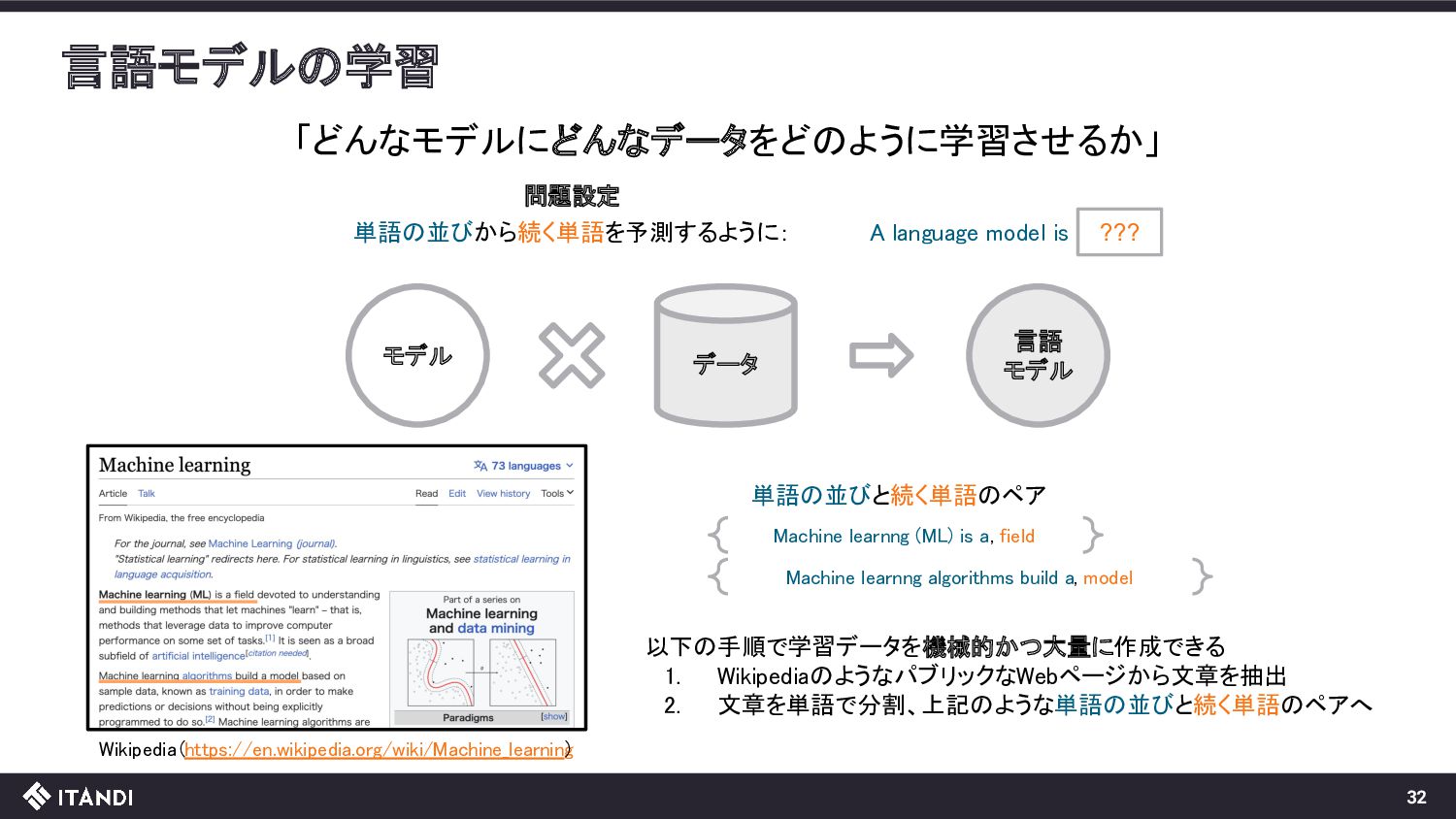
model is ??? 単語の並びから続く単語を予測するように: Wikipedia(https://en.wikipedia.org/wiki/Machine_learning ) 単語の並びと続く単語のペア Machine learnng (ML) is a , field Machine learnng algorithms build a , model 以下の手順で学習データを機械的かつ大量に作成できる 1. WikipediaのようなパブリックなWebページから文章を抽出 2. 文章を単語で分割、上記のような単語の並びと続く単語のペアへ
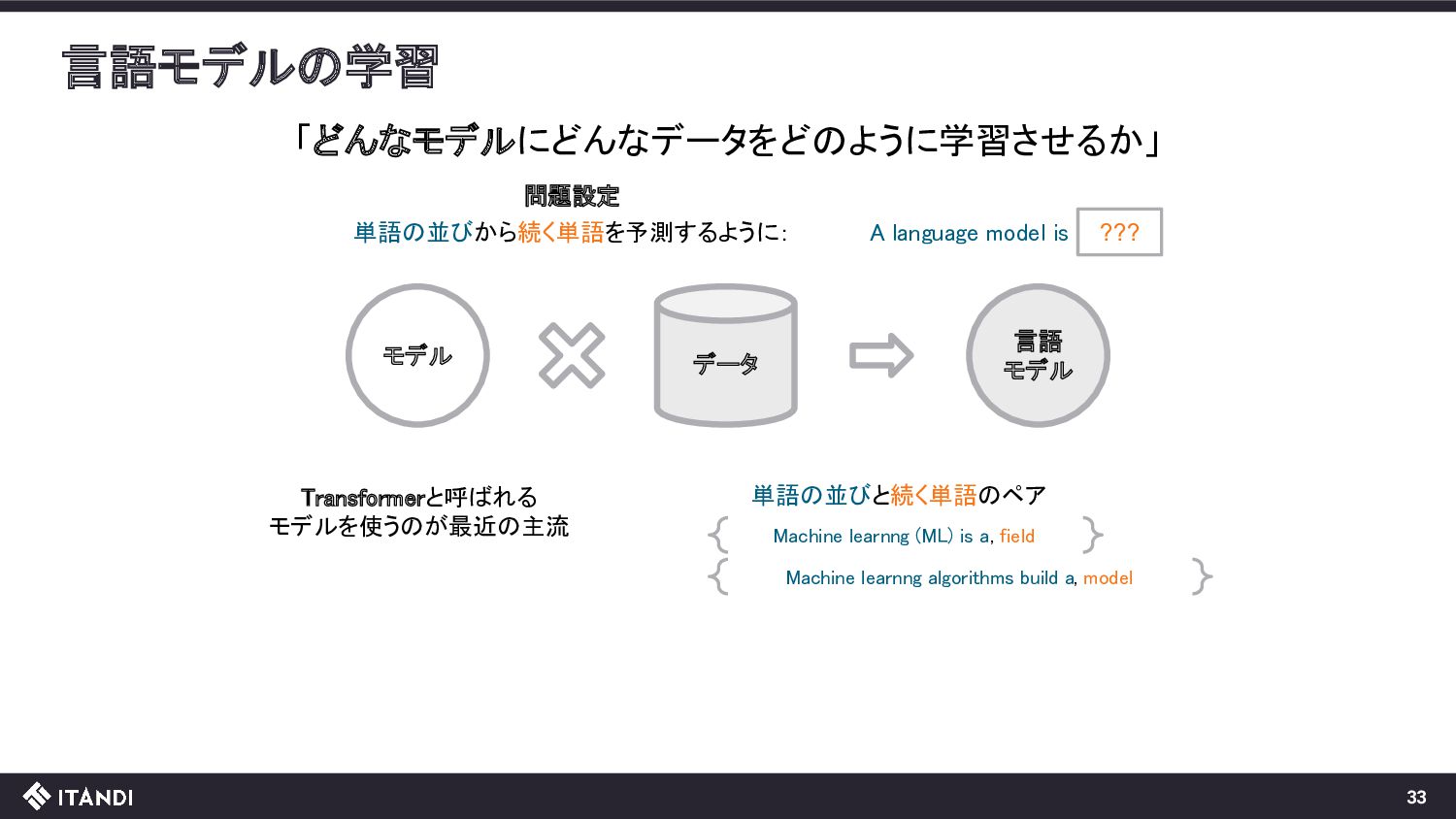
model is ??? 単語の並びから続く単語を予測するように: 単語の並びと続く単語のペア Machine learnng (ML) is a , field Transformerと呼ばれる モデルを使うのが最近の主流 Machine learnng algorithms build a , model
to {run, banana} 文法的な知識 First grade arithmetic exam: 3 + 8 + 4 = {15, 11} 算数力 [...] Iroh went into the kitchen to make some tea. Standing next to Iroh, Zuko pondered his destiny. Zuko left the {kitchen, store} 空間的な論理思考力 The word for “pretty” in Spanish is {bonita, hola} 翻訳する能力 Movie review: I was engaged and on the edge of my seat the whole time. The movie was {good, bad} 感情を推定する能力 The capital of Denmark is {Copenhagen, London} 世界に関する知識 I went to the zoo to see giraffes, lions, and {zebras, spoon} 単語の意味に関する知識 ※ 英語の例は次の資料から引用しています: Scaling, emergence, and reasoning (Jason Wei, NYU)
{15, 11} 算数力 言語モデルは何を学習している? 35 言語モデルも続く単語を予測するという問題を通して 暗黙的に「文章理解に役立つ一般的な知識や能力を学習している」と考えられる! ※ 英語の例は次の資料から引用しています: Scaling, emergence, and reasoning (Jason Wei, NYU) 左の英語の文章に続く単語を埋める問題を考えてみてください! In my free time, I like to {run, banana} 文法的な知識 [...] Iroh went into the kitchen to make some tea. Standing next to Iroh, Zuko pondered his destiny. Zuko left the {kitchen, store} 空間的な論理思考力 The word for “pretty” in Spanish is {bonita, hola} 翻訳する能力 Movie review: I was engaged and on the edge of my seat the whole time. The movie was {good, bad} 感情を推定する能力 The capital of Denmark is {Copenhagen, London} 世界に関する知識 I went to the zoo to see giraffes, lions, and {zebras, spoon} 単語の意味に関する知識
{15, 11} 算数力 言語モデルは何を学習している? 36 言語モデルも続く単語を予測するという問題を通して 暗黙的に「文章理解に役立つ一般的な知識や能力を学習している」と考えられる! ここで学習したものを他のタスクにも流用しよう!というのがGPTの始まり ※ 英語の例は次の資料から引用しています: Scaling, emergence, and reasoning (Jason Wei, NYU) 左の英語の文章に続く単語を埋める問題を考えてみてください! In my free time, I like to {run, banana} 文法的な知識 [...] Iroh went into the kitchen to make some tea. Standing next to Iroh, Zuko pondered his destiny. Zuko left the {kitchen, store} 空間的な論理思考力 The word for “pretty” in Spanish is {bonita, hola} 翻訳する能力 Movie review: I was engaged and on the edge of my seat the whole time. The movie was {good, bad} 感情を推定する能力 The capital of Denmark is {Copenhagen, London} 世界に関する知識 I went to the zoo to see giraffes, lions, and {zebras, spoon} 単語の意味に関する知識
- Wikipedia [url] • Cat and Dog dataset - Kaggle [url] • Machine Learning - Wikipedia [url] • Jason Wei, Scaling, emergence, and reasoning [url] • Jared Kaplan et al., “Scaling Laws for Neural Language Models” [arXiv] • Wayne Xin Zhao et al., “A Survey of Large Language Models” [arXiv] • GPT-4 - OpenAI [url] • OpenAI’s CEO Says the Age of Giant AI Models Is Already Over - Wired [url]
CSCI-GA.2590 Natural Language Processing, Spring 2023 [url] • Jason Wei et al., “Finetuned Language Models Are Zero-Shot Learners” [arXiv] • Long Ouyang et al., “Training language models to follow instructions with human feedback” [arXiv]
Wei et al. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models( arxiv) Kojima et al. Large Language Models are Zero-Shot Reasoners( arxiv) Wang et al. Self-Consistency Improves Chain of Thought Reasoning in Language Models( arxiv) Yao et al. ReAct: Synergizing Reasoning and Acting in Language Models( arxiv) Elvis. Prompt Engineering Guide( url) Armstrong & Gorman. Using GPT-Eliezer against ChatGPT Jailbreaking( url) Chase. LangChain(url) 宮脇. Prompt Engineeringについて( url) 107
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
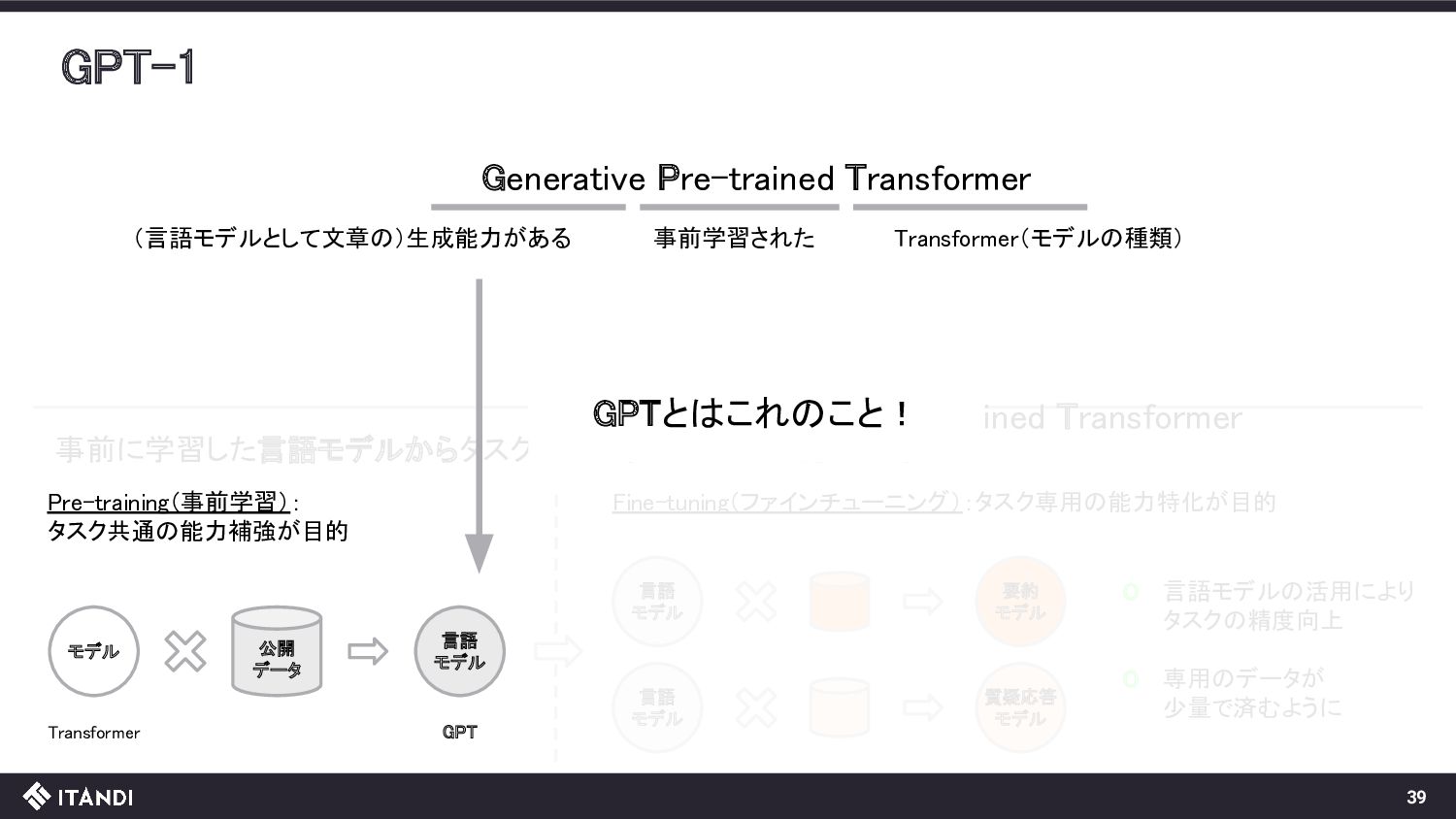{kind=link}
{kind=link}
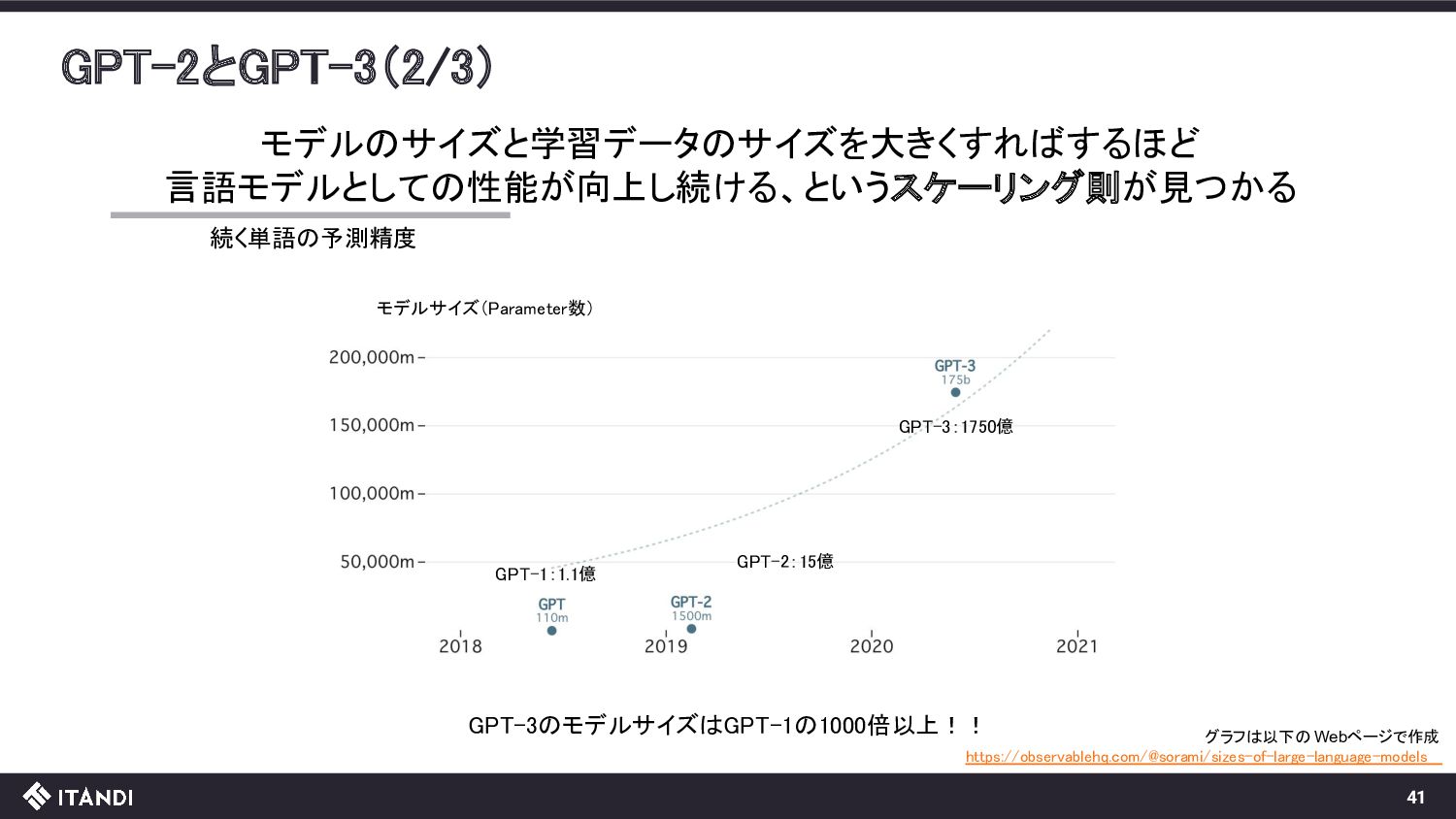{kind=link}
![GPT-2とGPT-3(3/3) 42 モデルのサイズと学習データのサイズを大きくすればするほど 言語モデルとしての性能が向上し続ける、というスケーリング則が見つかる 続く単語の予測精度 GPT-3時点でスケーリング則の終わりが見えない … 図は次の論文から引用 [2001.08361]](https://files.speakerdeck.com/presentations/a5878de0edda444a940a71f282b8dbe4/slide_41.jpg){kind=link}
![大規模言語モデル時代へ 43 大規模言語モデル … モデルパラメータ数が100億を超える言語モデル 図は次の論文から引用: [2303.18223] A Survey of](https://files.speakerdeck.com/presentations/a5878de0edda444a940a71f282b8dbe4/slide_42.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
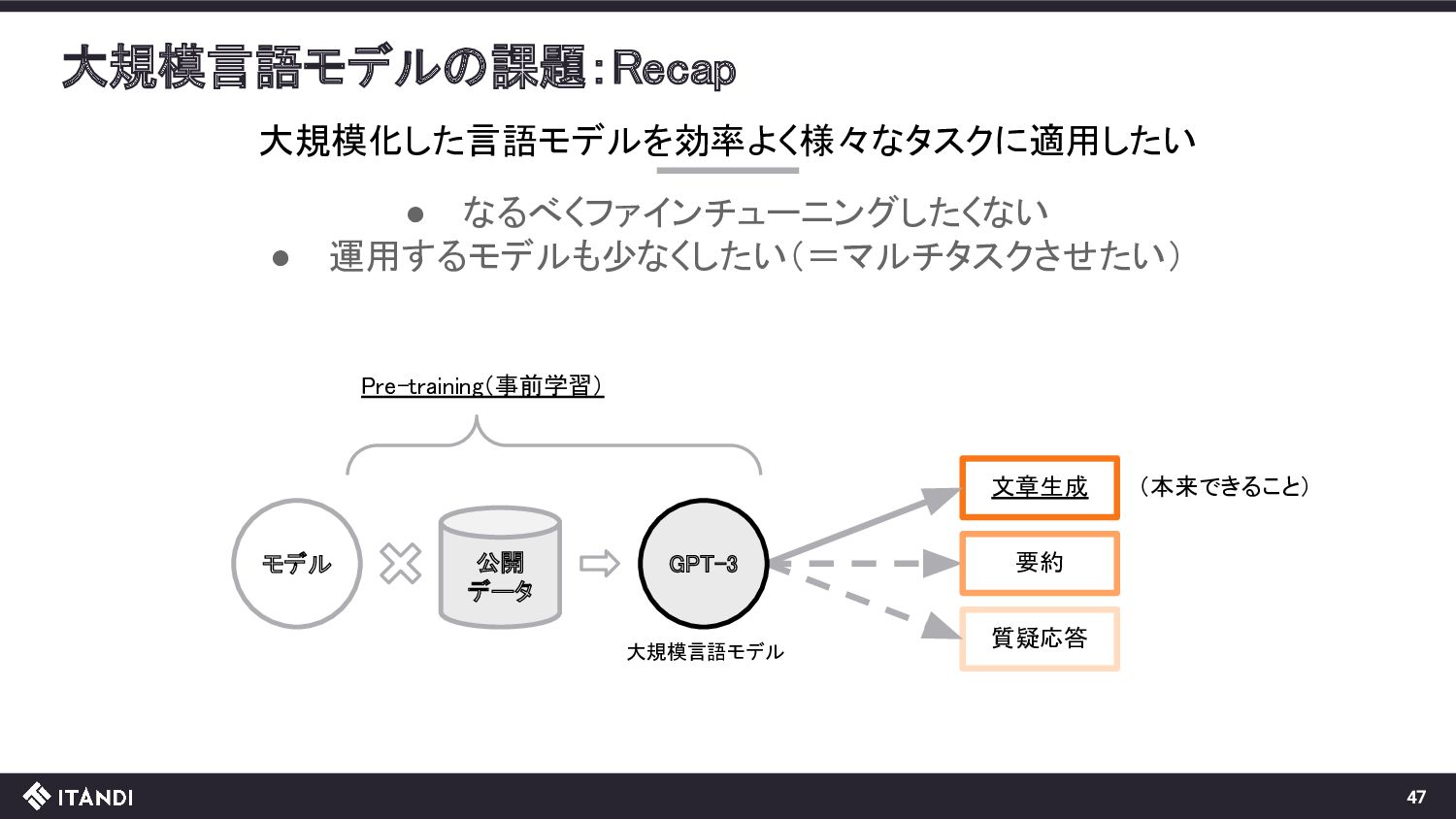{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
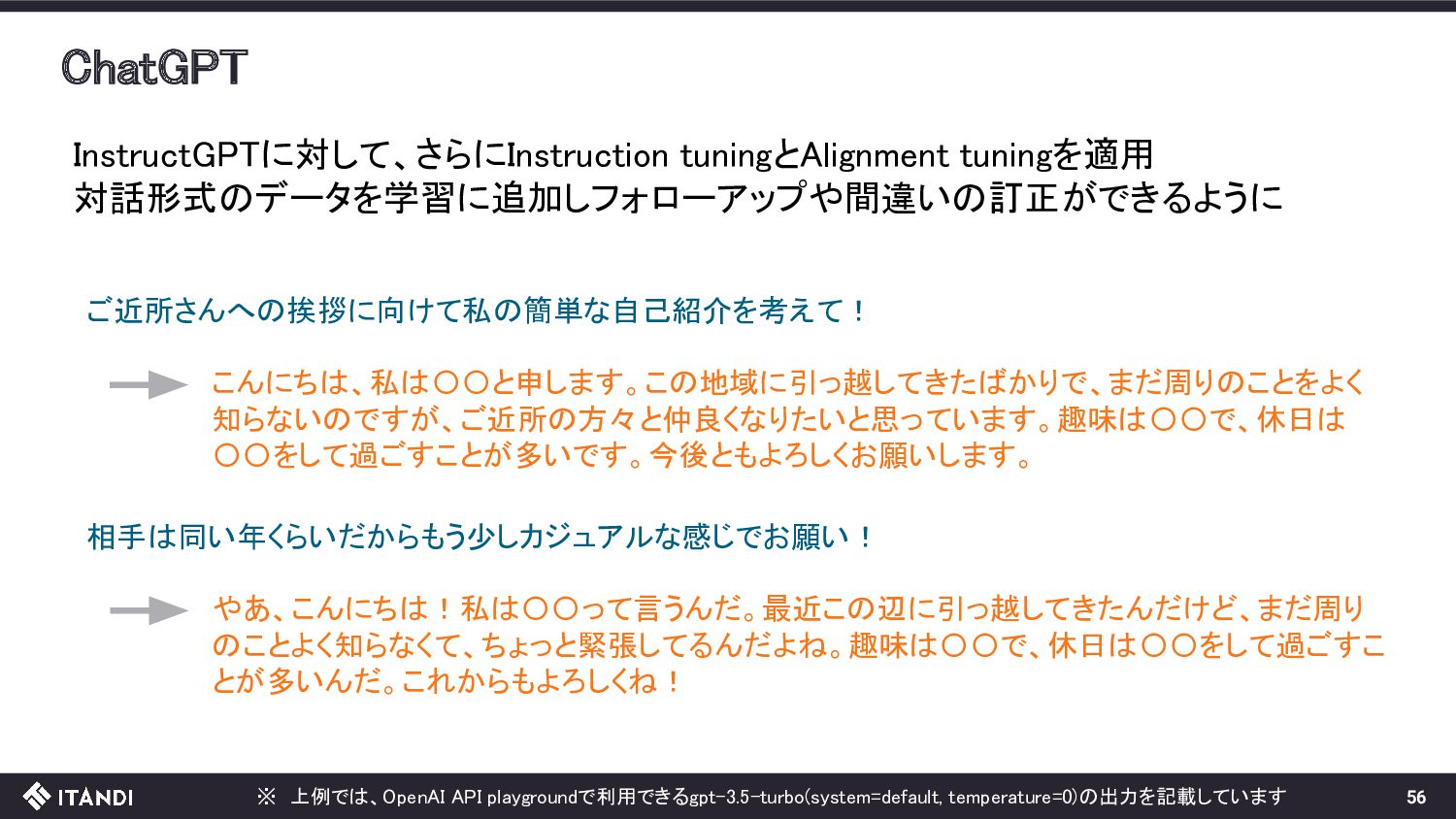{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![利用したサービス 64 • OpenAI, OpenAI API Playground [url] ◦ GPT-3,](https://files.speakerdeck.com/presentations/a5878de0edda444a940a71f282b8dbe4/slide_63.jpg){kind=link}
![引用した資料 65 • Introducing ChatGPT - OpenAI [url] • ChatGPT](https://files.speakerdeck.com/presentations/a5878de0edda444a940a71f282b8dbe4/slide_64.jpg){kind=link}
![参考にした資料 66 • 岡崎 直観, “大規模言語モデルの驚異と脅威” [url] • Slides -](https://files.speakerdeck.com/presentations/a5878de0edda444a940a71f282b8dbe4/slide_65.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
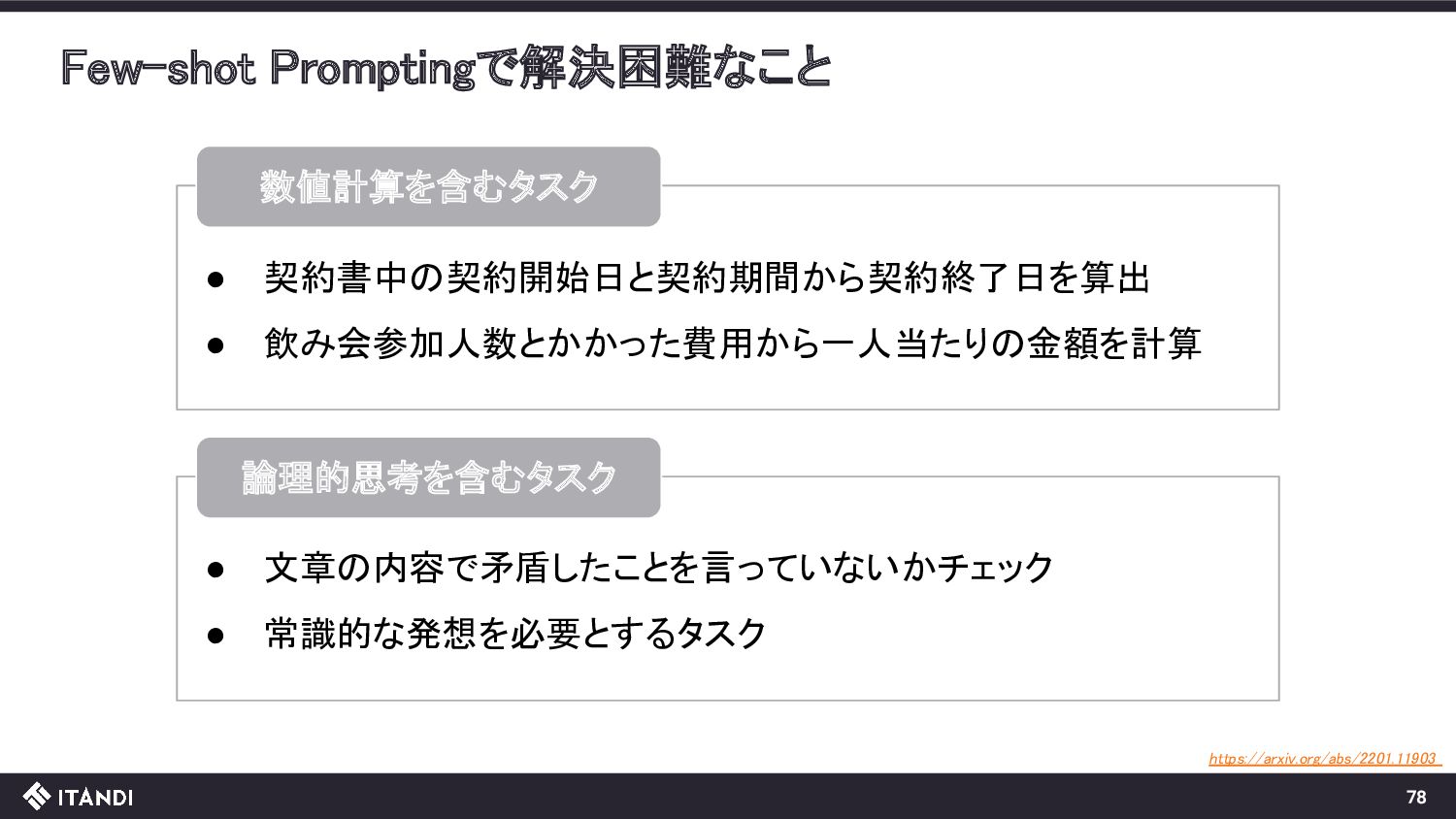{kind=link}
{kind=link}
{kind=link}
{kind=link}
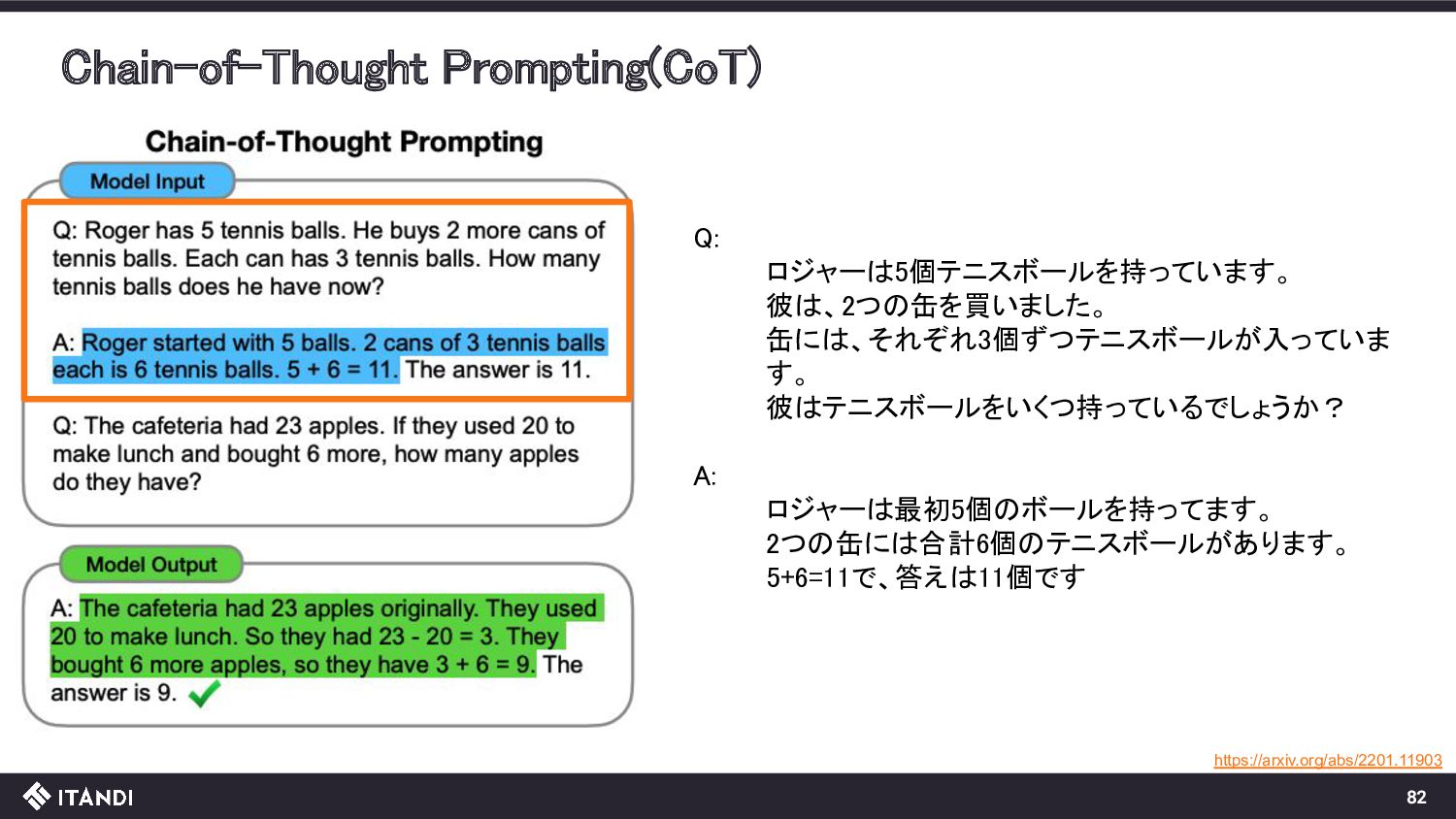{kind=link}
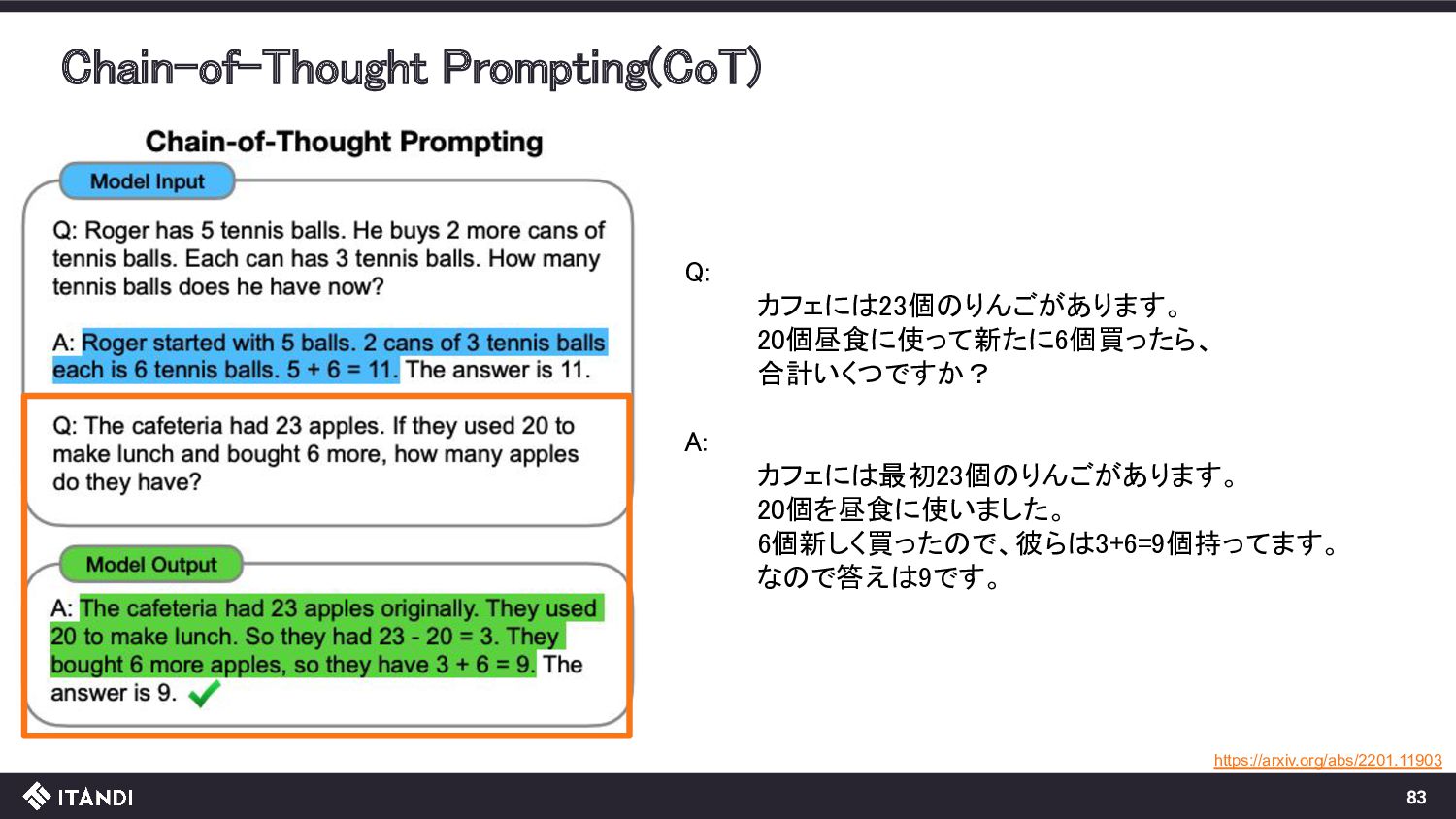{kind=link}
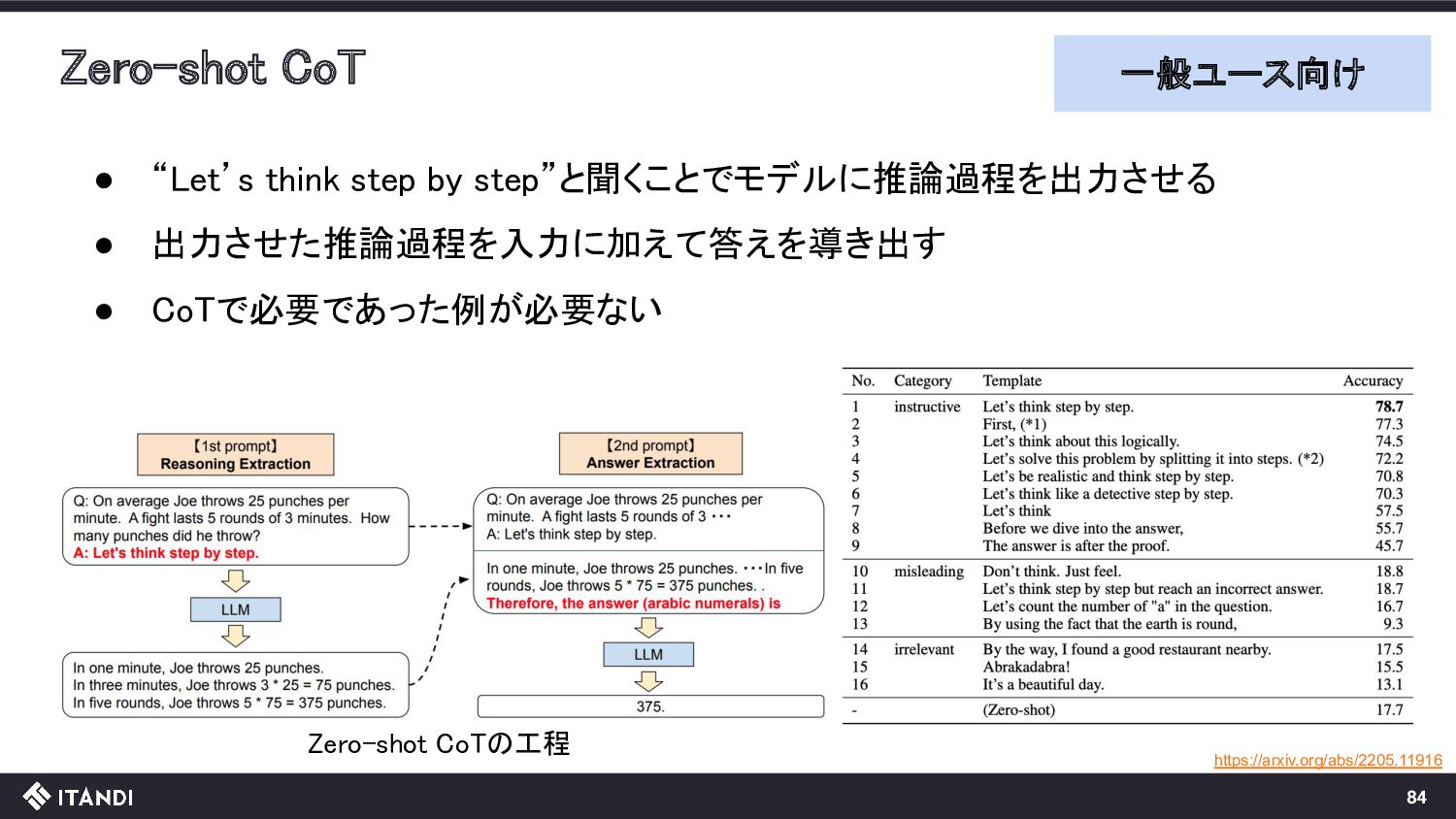{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}