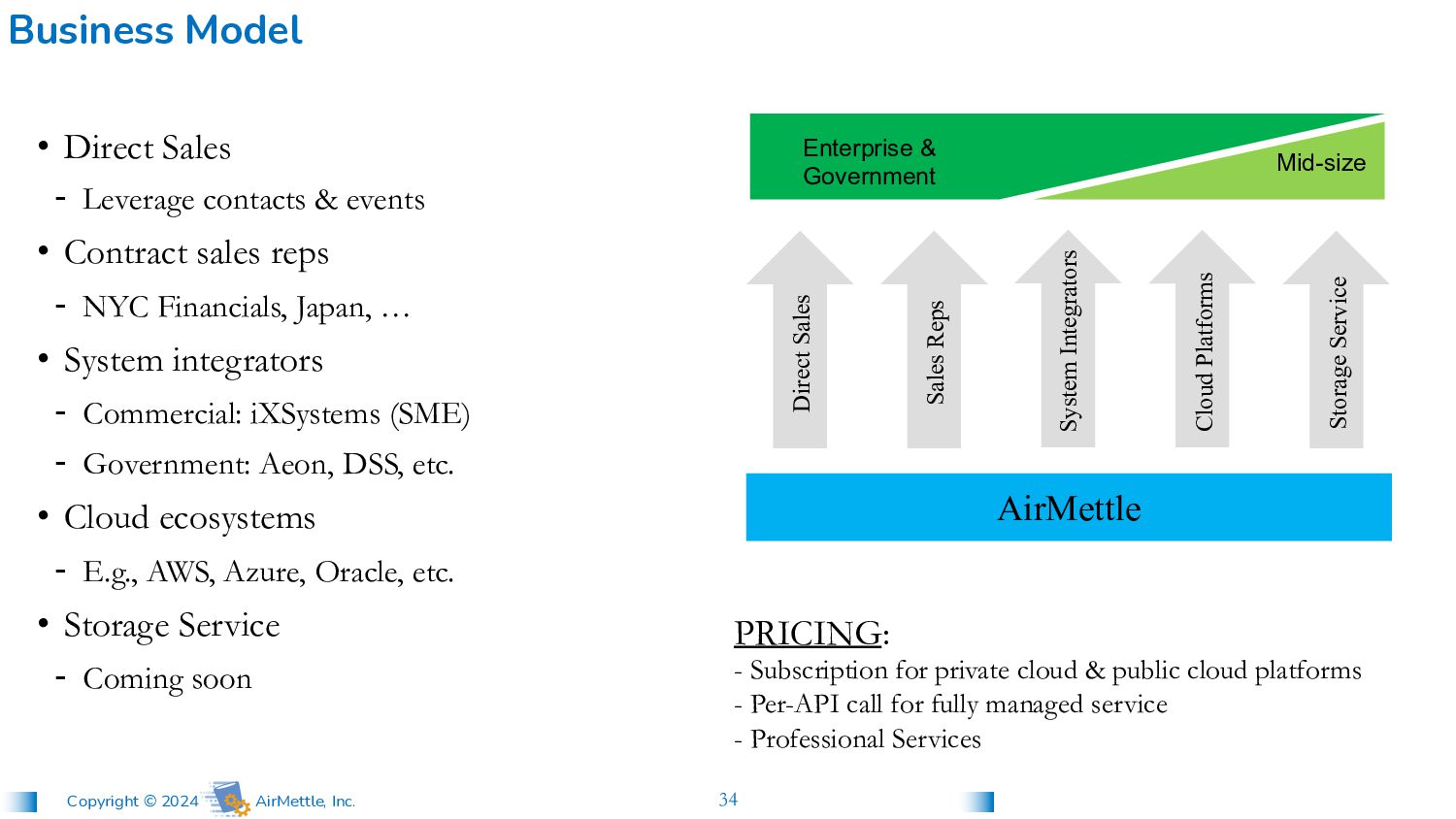
commercial Flash storage, databases, object stores, data pipelines, distributed systems, networking, and cloud services. Vision: Unleash the power of big data to optimize operations and outcomes Mission: Turn the data lake (storage) into an insight-generating platform Strategy: Integrate highly scalable parallel processing of analytics & AI into software-defined object storage on COTS hardware on-premise and in the cloud
in [growing] haystacks” - Relevant data often 2-6 orders of magnitude smaller than the “data of interest” • Data Warehouses are inefficient (redundancy, indices) add complexity, and don’t/can’t accelerate ad hoc queries • Analytics memory is expensive and hitting size limits as data sets grow (e.g., AI) • Analytics compute is expensive way to filter out irrelevant raw data • Faster Networking is expensive, constrained, and adds latency BIG Data Analytics and AI are too slow and expensive … and getting worse as data grows
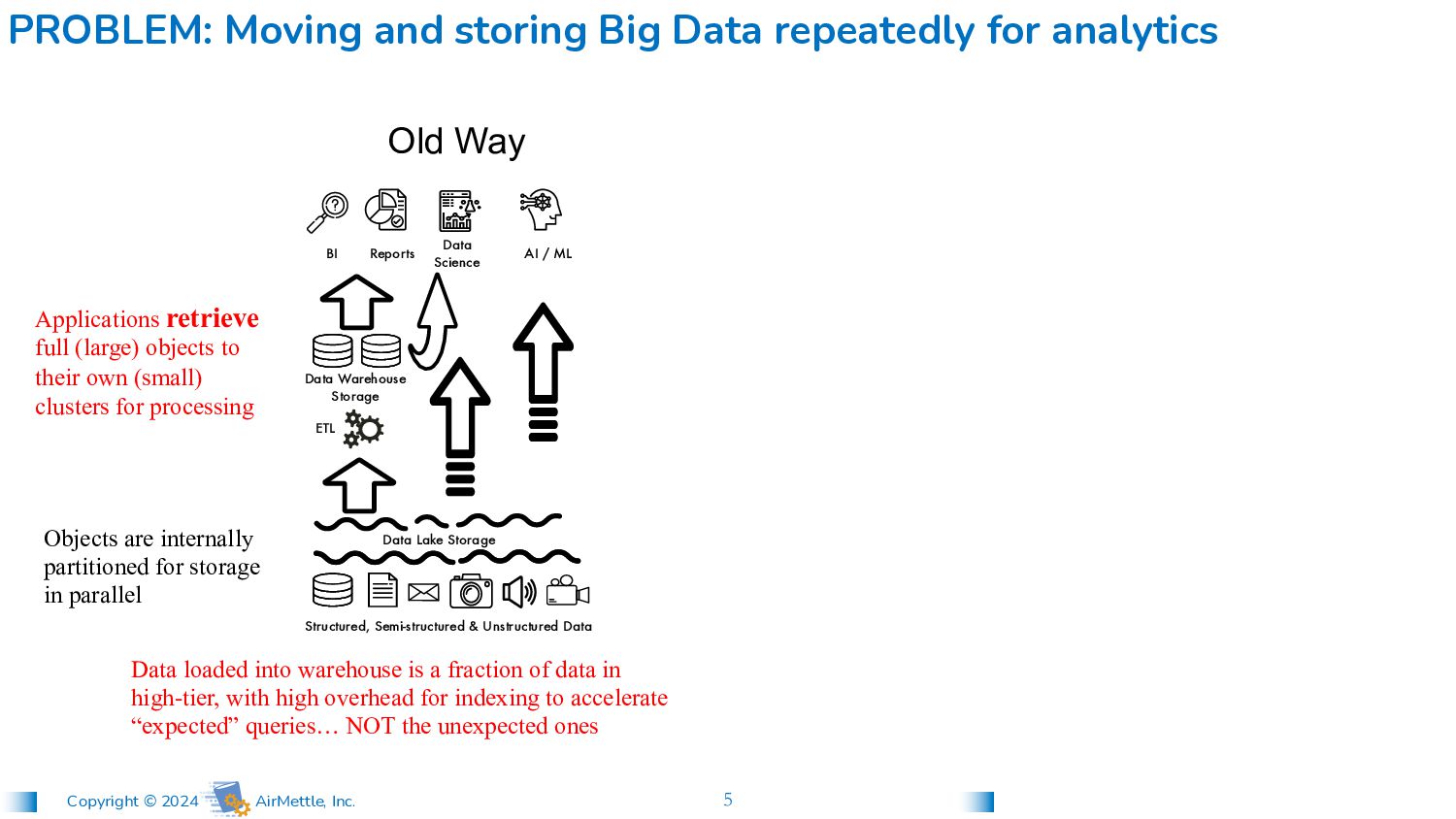
Big Data repeatedly for analytics Data loaded into warehouse is a fraction of data in high-tier, with high overhead for indexing to accelerate “expected” queries… NOT the unexpected ones Applications retrieve full (large) objects to their own (small) clusters for processing ETL Data Warehouse Storage Structured, Semi-structured & Unstructured Data Reports BI Data Science AI / ML Data Lake Storage Objects are internally partitioned for storage in parallel Old Way
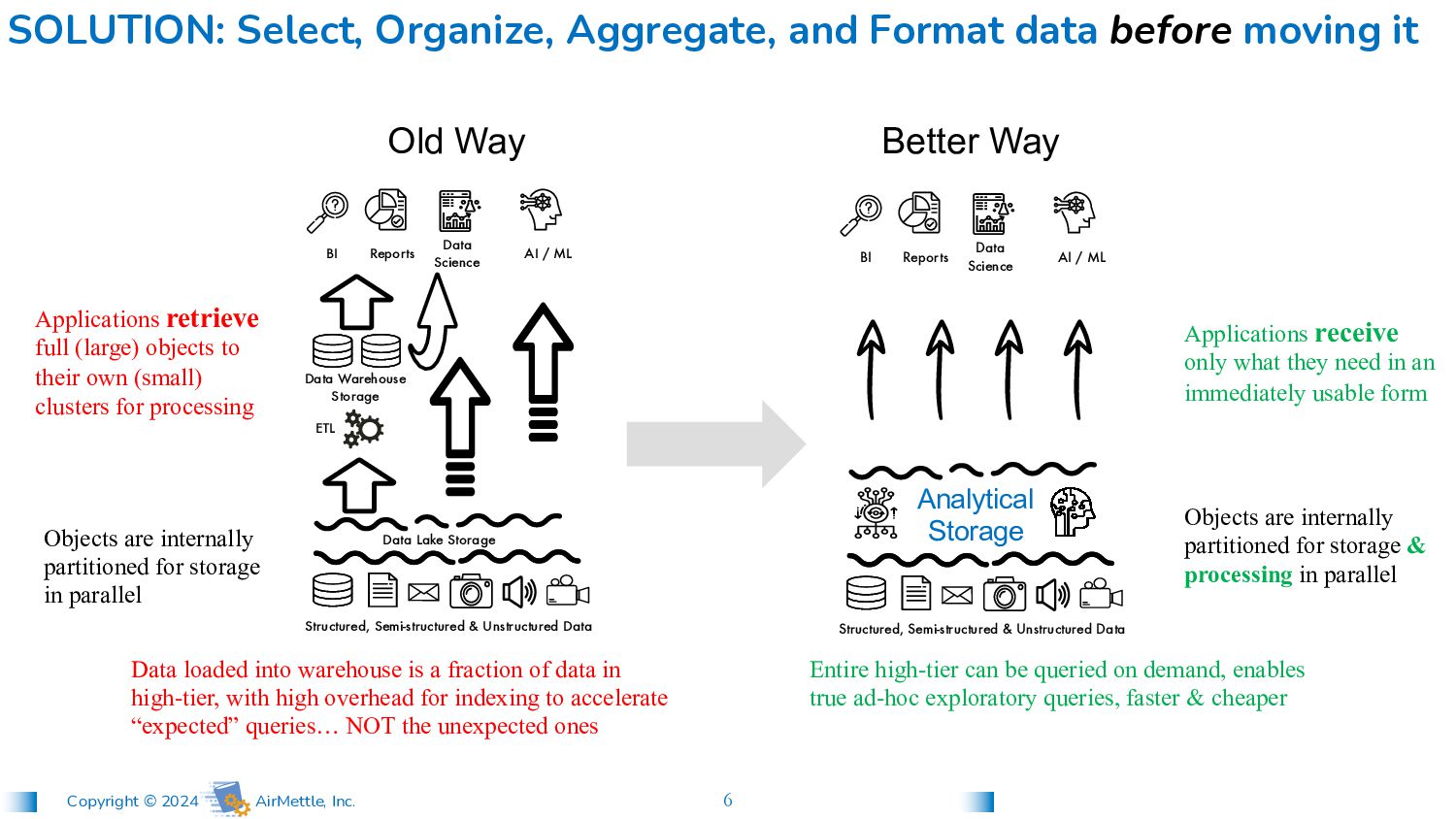
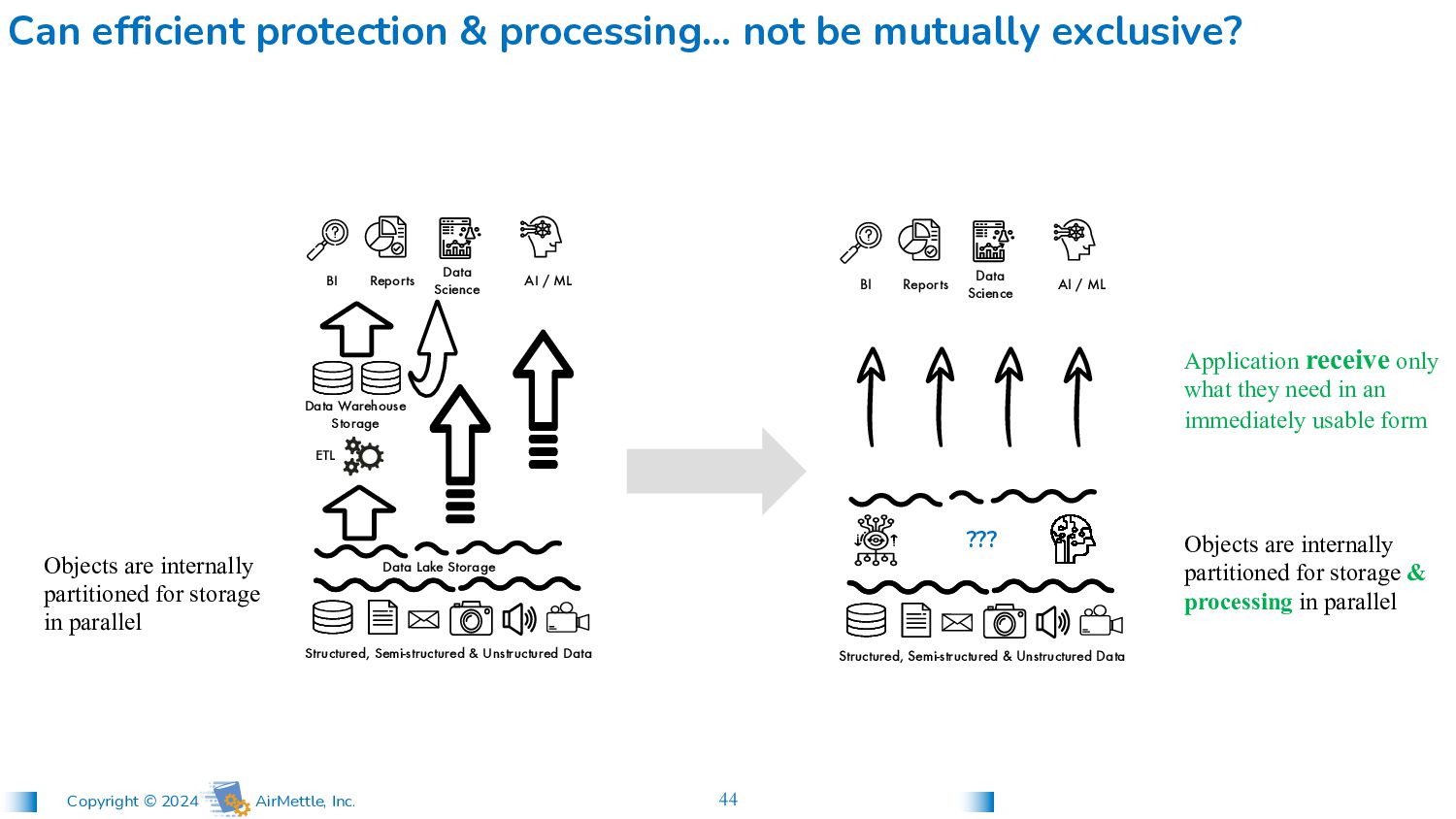
and Format data before moving it Data loaded into warehouse is a fraction of data in high-tier, with high overhead for indexing to accelerate “expected” queries… NOT the unexpected ones Applications retrieve full (large) objects to their own (small) clusters for processing Entire high-tier can be queried on demand, enables true ad-hoc exploratory queries, faster & cheaper Applications receive only what they need in an immediately usable form Objects are internally partitioned for storage & processing in parallel Structured, Semi-structured & Unstructured Data Reports BI Data Science AI / ML Better Way ETL Data Warehouse Storage Structured, Semi-structured & Unstructured Data Reports BI Data Science AI / ML Data Lake Storage Objects are internally partitioned for storage in parallel Old Way Analytical Storage
Storage platform that accelerates big data analytics by orders of magnitude – while reducing analytics memory, storage, compute, and networking costs. Highly-parallel processing integrated in software-defined (object) storage that performs the most widely-used analytics functions for extracting & characterizing big data to: • Accelerate time to insight • Eliminate the data warehouse • Reduce required analytics memory and compute • Reduce network traffic
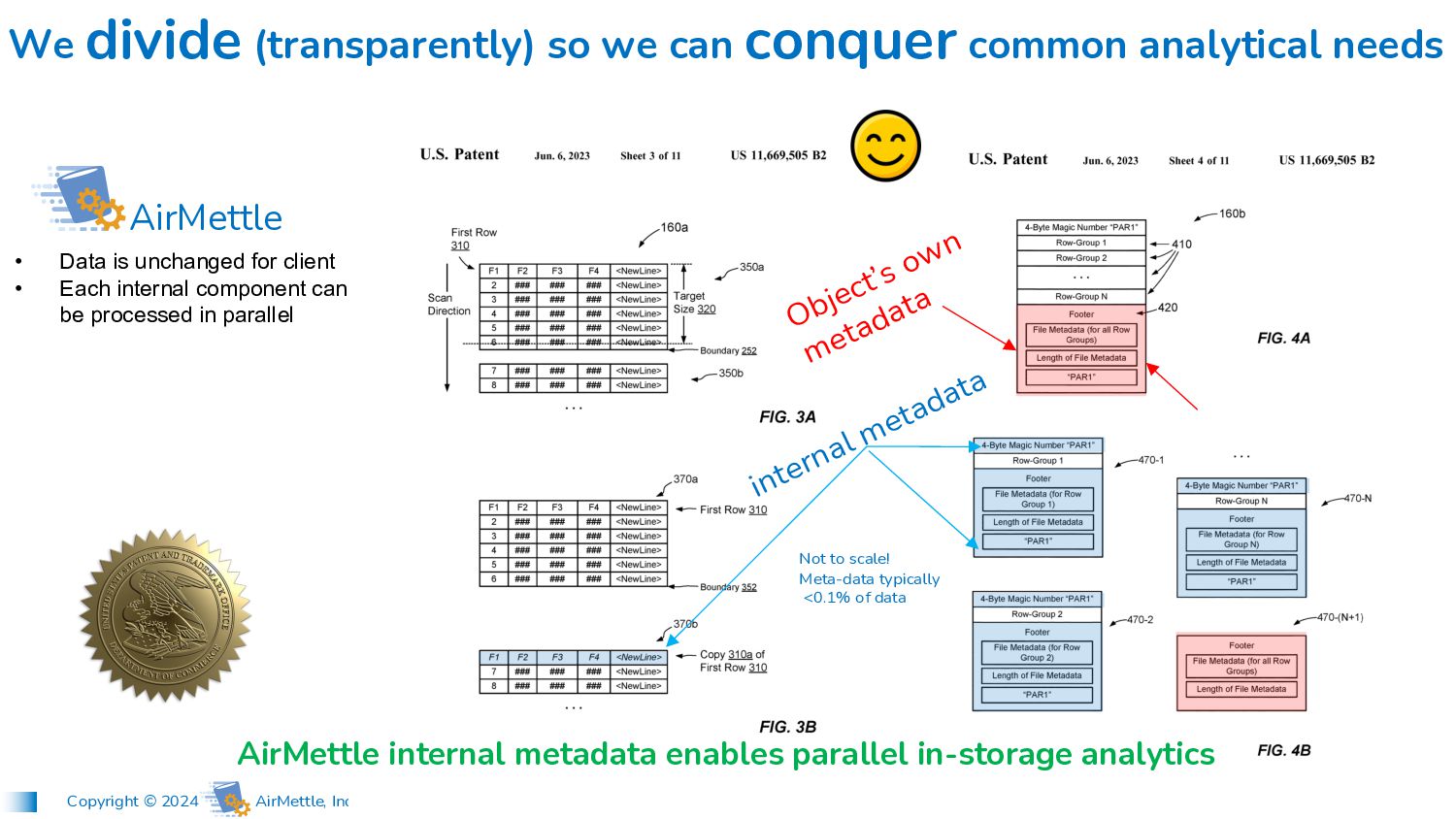
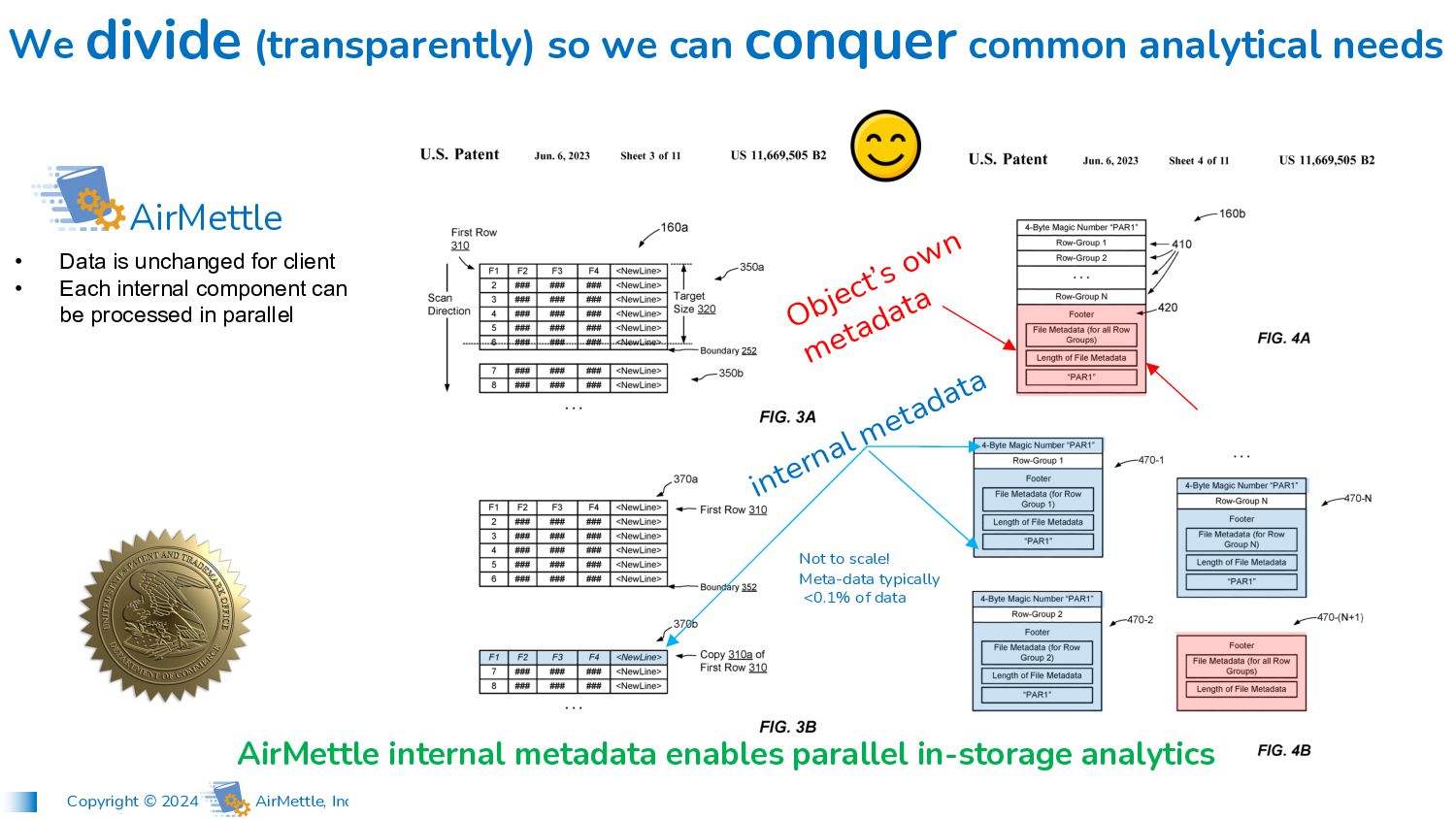
we can conquer common analytical needs AirMettle • Data is unchanged for client • Each internal component can be processed in parallel AirMettle internal metadata enables parallel in-storage analytics Not to scale! Meta-data typically <0.1% of data internal metadata Object’s own metadata
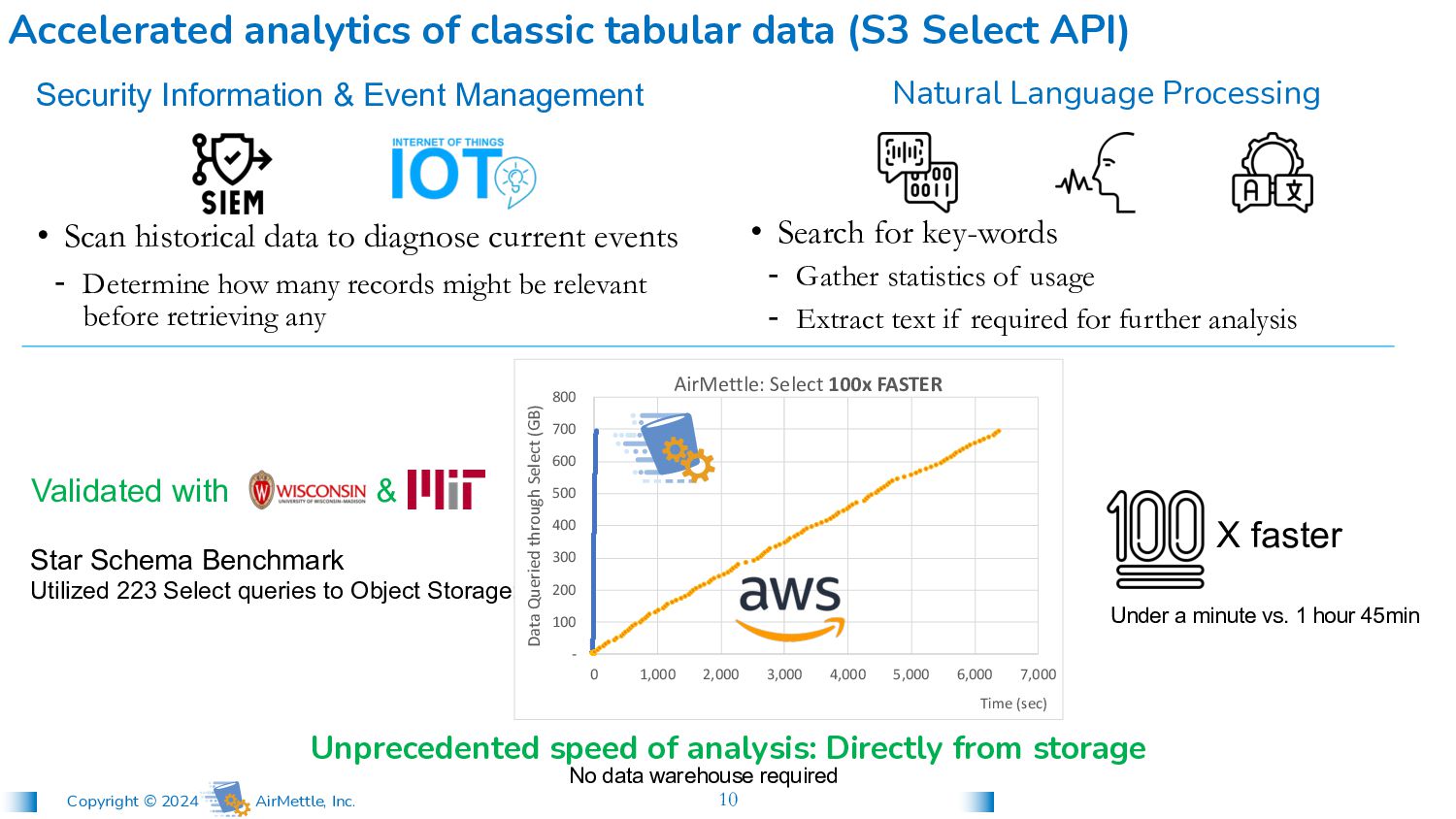
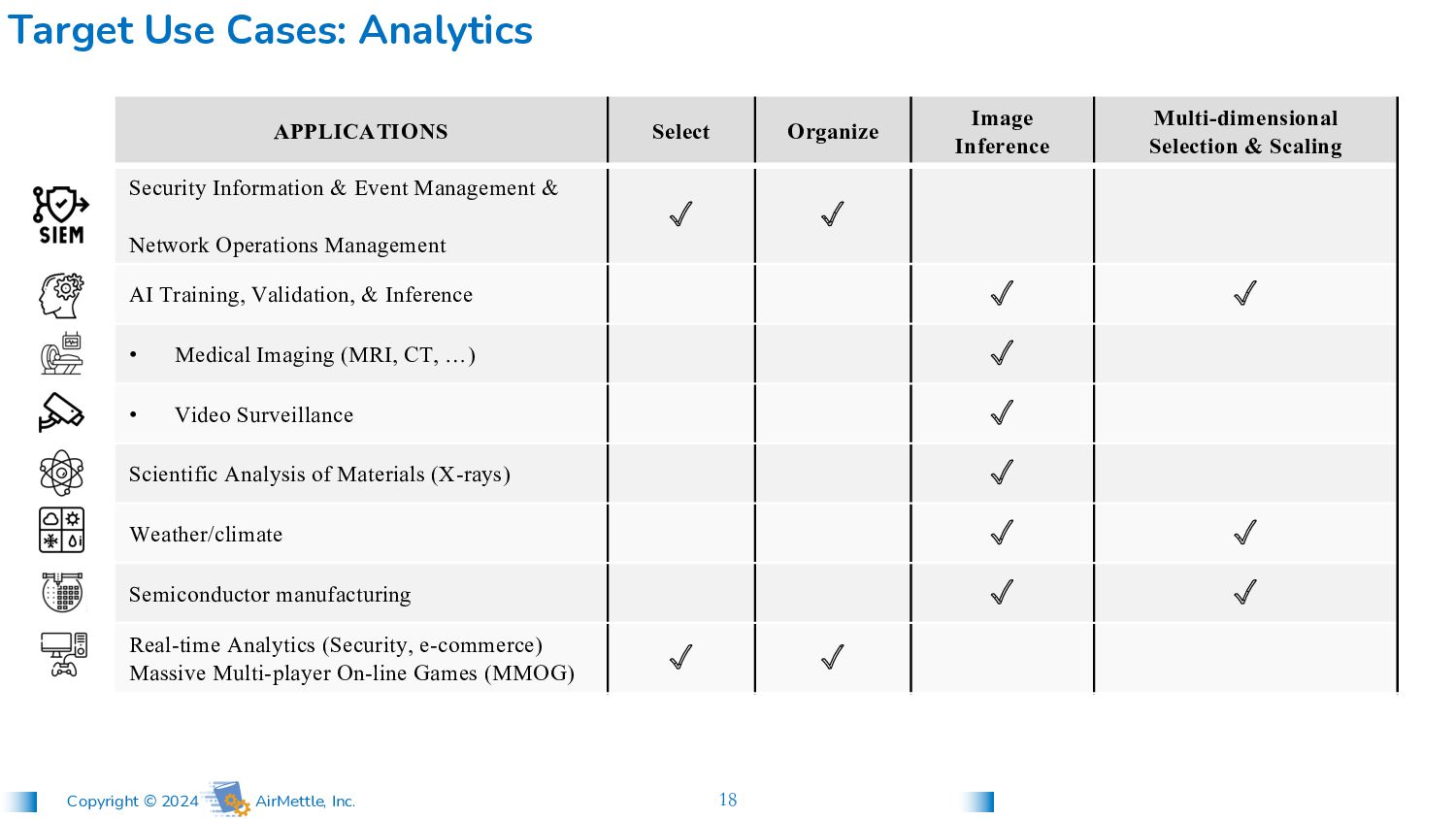
- Gather statistics of usage - Extract text if required for further analysis • Scan historical data to diagnose current events - Determine how many records might be relevant before retrieving any Accelerated analytics of classic tabular data Natural Language Processing Security Information & Event Management
- Gather statistics of usage - Extract text if required for further analysis • Scan historical data to diagnose current events - Determine how many records might be relevant before retrieving any Accelerated analytics of classic tabular data (S3 Select API) Natural Language Processing Security Information & Event Management Under a minute vs. 1 hour 45min Star Schema Benchmark Utilized 223 Select queries to Object Storage: Validated with & Unprecedented speed of analysis: Directly from storage X faster No data warehouse required - 100 200 300 400 500 600 700 800 0 1,000 2,000 3,000 4,000 5,000 6,000 7,000 Data Queried through Select (GB) Time (sec) AirMettle: Select 100x FASTER
4.0 5.0 6.0 1.1 1.2 1.3 Query Acceleration CSV GZIP i3en.6xlarge (x8) c5n.18xlarge c5n.18xlarge Gateway AirMettle Accelerates S3 Select API enables comparison vs. major cloud’s object storage Star Schema Benchmark, Scale Factor 1 with 1 object per table 5x Acceleration on Complete Queries, today… just by using a different storage
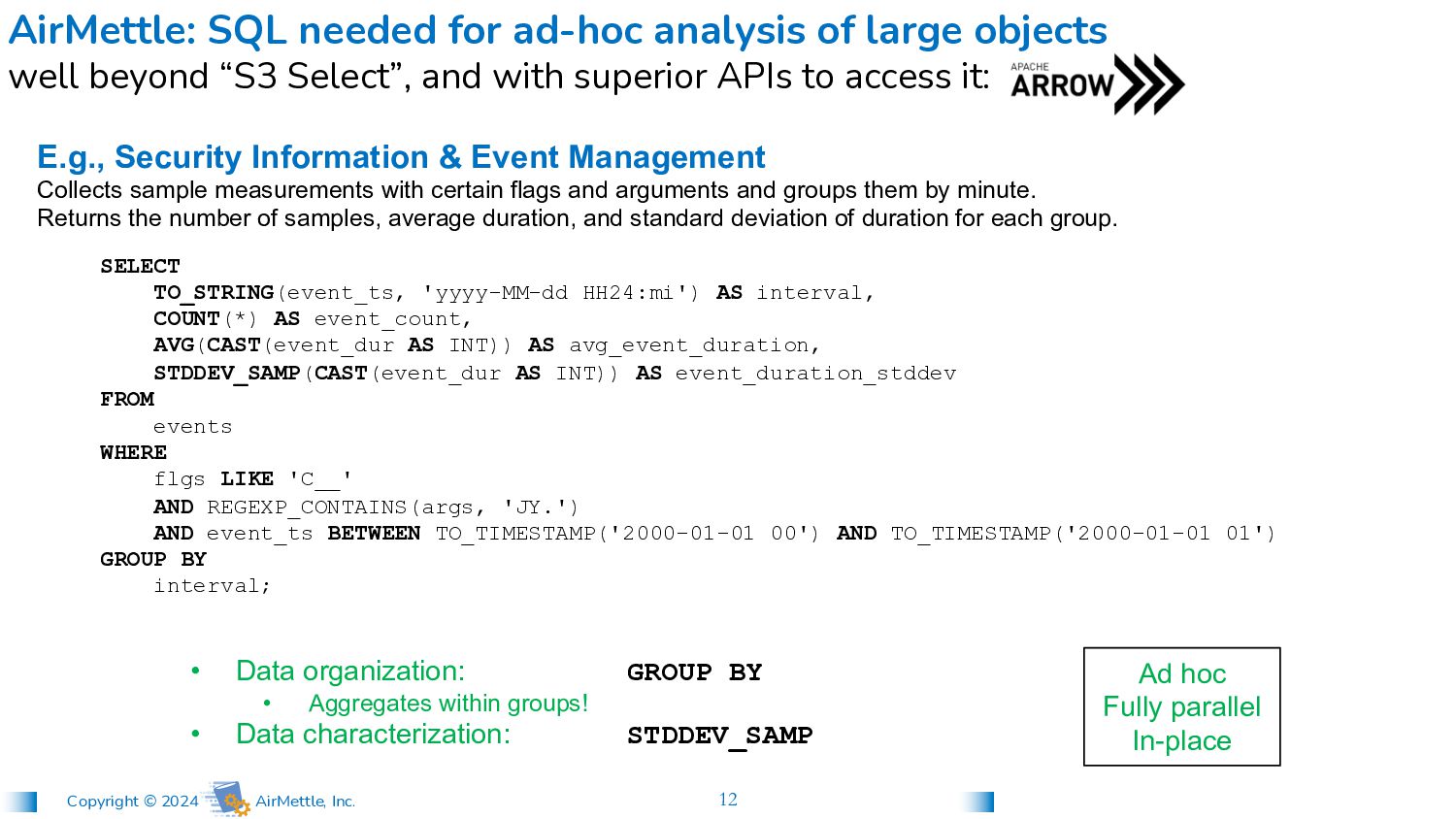
ad-hoc analysis of large objects well beyond “S3 Select”, and with superior APIs to access it: SELECT TO_STRING(event_ts, 'yyyy-MM-dd HH24:mi') AS interval, COUNT(*) AS event_count, AVG(CAST(event_dur AS INT)) AS avg_event_duration, STDDEV_SAMP(CAST(event_dur AS INT)) AS event_duration_stddev FROM events WHERE flgs LIKE 'C__' AND REGEXP_CONTAINS(args, 'JY.') AND event_ts BETWEEN TO_TIMESTAMP('2000-01-01 00') AND TO_TIMESTAMP('2000-01-01 01') GROUP BY interval; E.g., Security Information & Event Management Collects sample measurements with certain flags and arguments and groups them by minute. Returns the number of samples, average duration, and standard deviation of duration for each group. Ad hoc Fully parallel In-place • Data organization: GROUP BY • Aggregates within groups! • Data characterization: STDDEV_SAMP
for Distributed File Systems and Object Storage https://www.emergenresearch.com/industry-report/cloud-object-storage-market Cloud Object Storage Market Published: May 2021 Report ID: ER_00683 Object Storage market: • $4.83B in 2020 à $13.65B in 2028 • 13.6% CAGR On-premise unstructured data storage capacity will triple 2021 à 2026 Software-defined storage (SDS) will be 60% of global unstructured data storage capacity by 2025, up from < 25% in 2021 Published: October 2021 https://www.gartner.com/doc/reprints?id=1-27L6ETTT&ct=211004&st=sb AirMettle®
Customer - Press Release Oct 2023: - https://discover.lanl.gov/news/1010-lab-airmettle-partnership/ • Discussing key capabilities that would drive high volume production - E.g., Characterize /summarize data to inform deeper analysis - Leverageable to mainstream AirMettle products & customers Customer Traction “Our scientific large-scale simulations can generate hundreds of petabytes of highly dimensional floating-point data ... But the data associated with a scientific feature of interest can be orders of magnitude smaller than the written data, so a key challenge is quickly and efficiently finding what’s relevant in this sea of data. To optimize this process, we’ve been drawn towards computational storage — processing data in- place and near storage — to eliminate unnecessary data movement while maintaining parallelism and adequate data protection.” – Gary Grider, High Performance Computing division leader
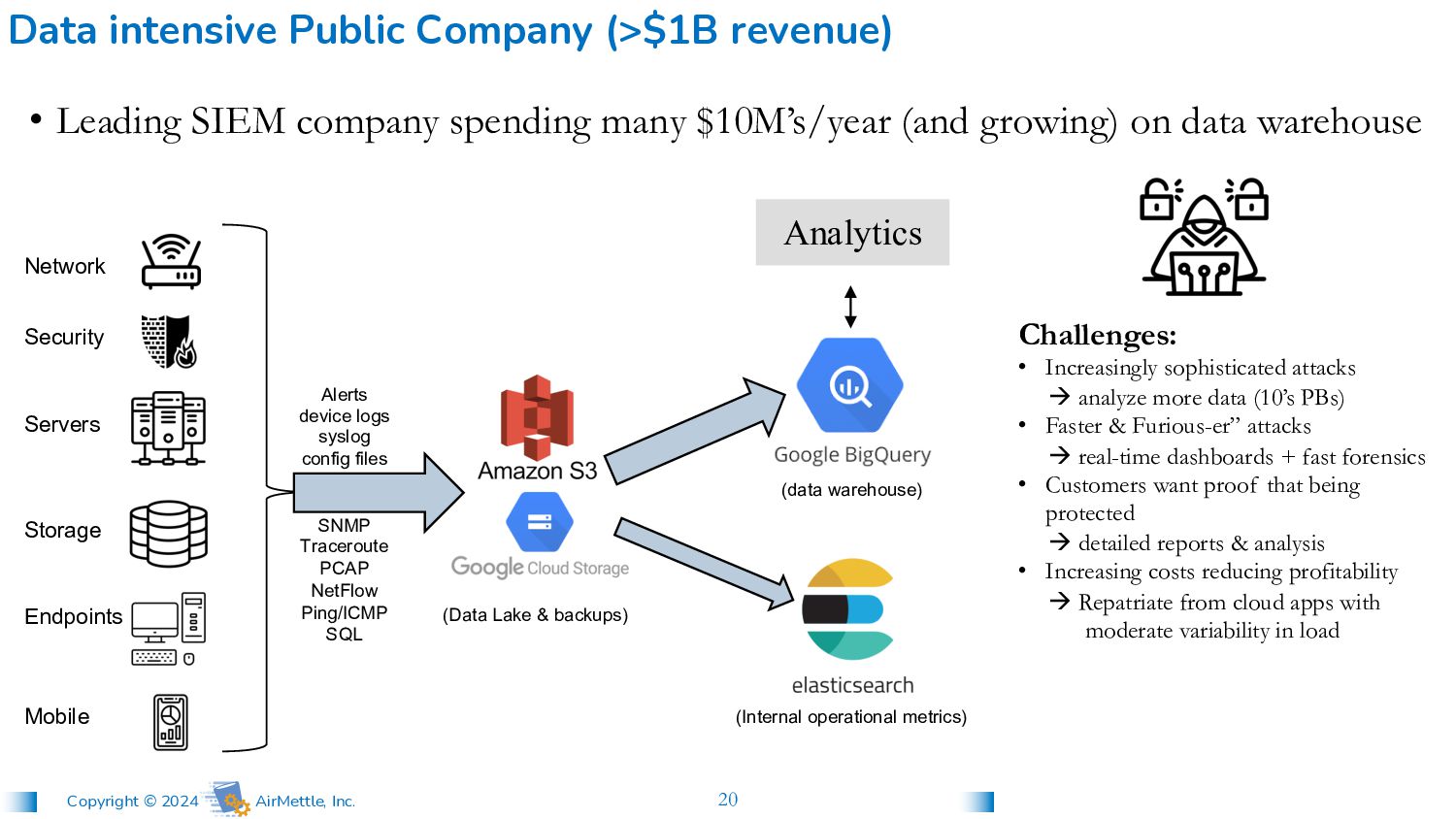
config files SNMP Traceroute PCAP NetFlow Ping/ICMP SQL • Leading SIEM company spending many $10M’s/year (and growing) on data warehouse Data intensive Public Company (>$1B revenue) Analytics Challenges: • Increasingly sophisticated attacks à analyze more data (10’s PBs) • Faster & Furious-er” attacks à real-time dashboards + fast forensics • Customers want proof that being protected à detailed reports & analysis • Increasing costs reducing profitability à Repatriate from cloud apps with moderate variability in load (Data Lake & backups) (data warehouse) (Internal operational metrics) Network Security Servers Storage Endpoints Mobile
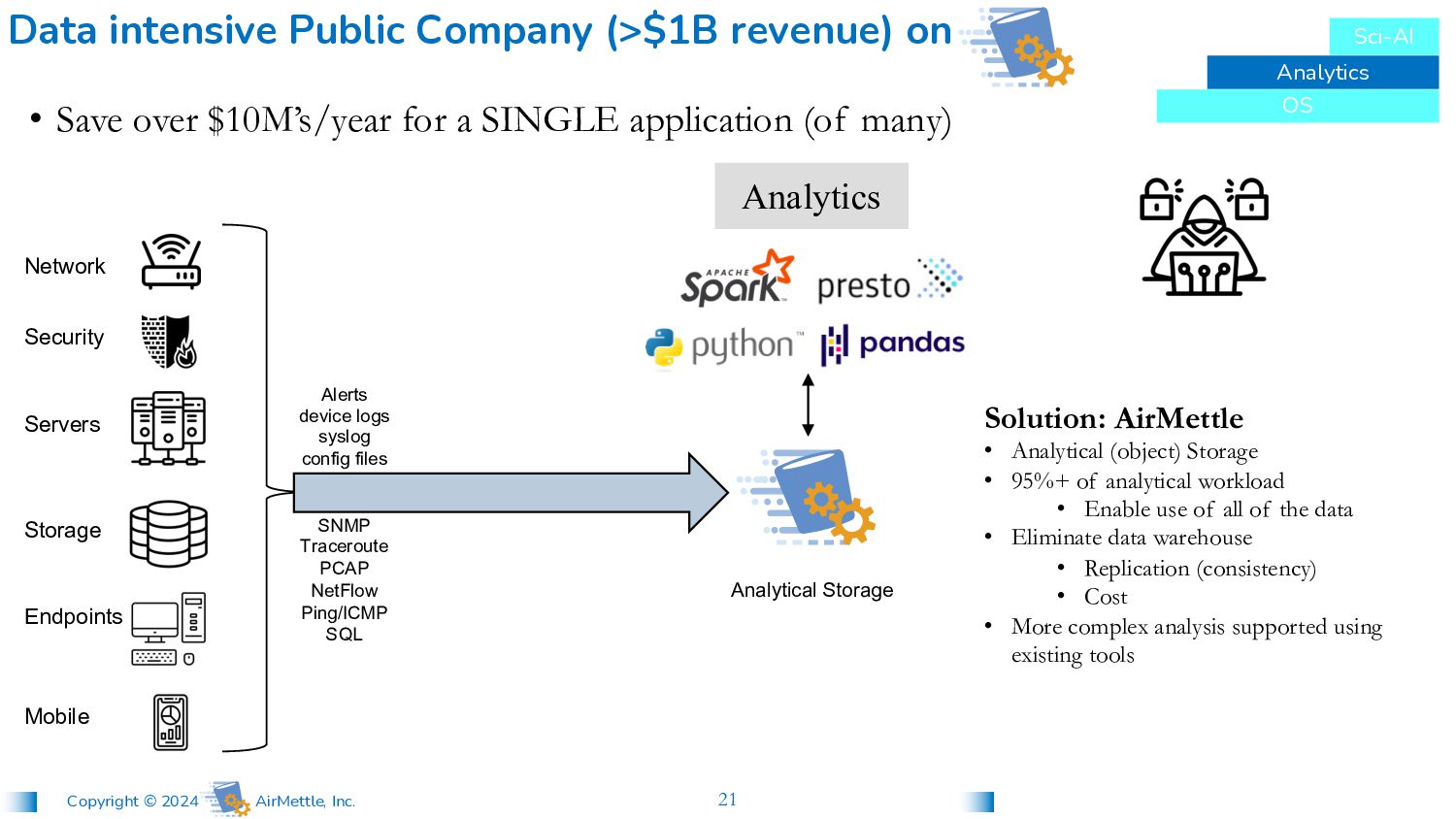
config files SNMP Traceroute PCAP NetFlow Ping/ICMP SQL • Save over $10M’s/year for a SINGLE application (of many) Data intensive Public Company (>$1B revenue) on Analytics Solution: AirMettle • Analytical (object) Storage • 95%+ of analytical workload • Enable use of all of the data • Eliminate data warehouse • Replication (consistency) • Cost • More complex analysis supported using existing tools Analytical Storage Network Security Servers Storage Endpoints Mobile Analytics OS Sci-AI
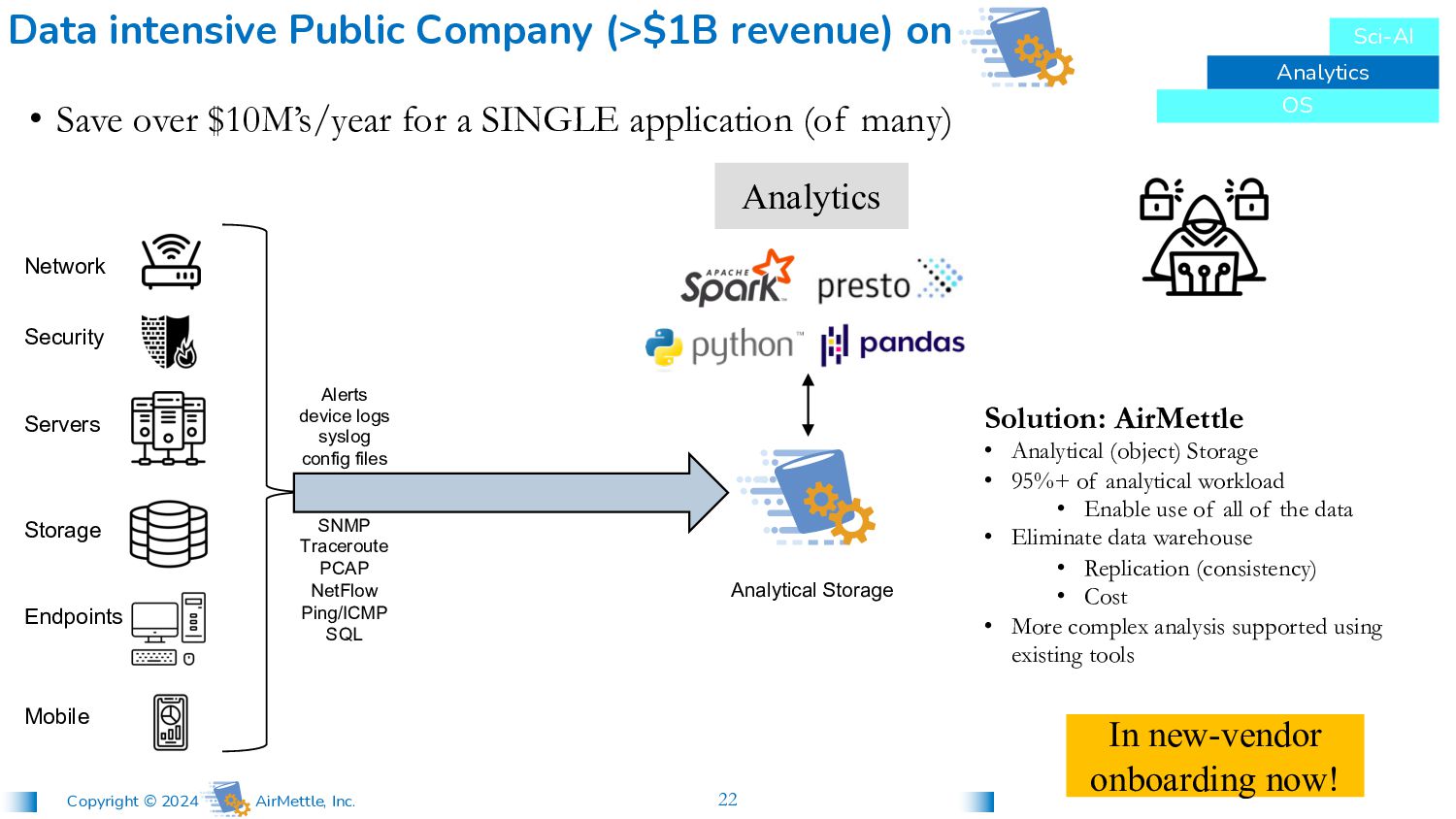
config files SNMP Traceroute PCAP NetFlow Ping/ICMP SQL • Save over $10M’s/year for a SINGLE application (of many) Data intensive Public Company (>$1B revenue) on Analytics Solution: AirMettle • Analytical (object) Storage • 95%+ of analytical workload • Enable use of all of the data • Eliminate data warehouse • Replication (consistency) • Cost • More complex analysis supported using existing tools Analytical Storage Network Security Servers Storage Endpoints Mobile Analytics OS Sci-AI In new-vendor onboarding now!
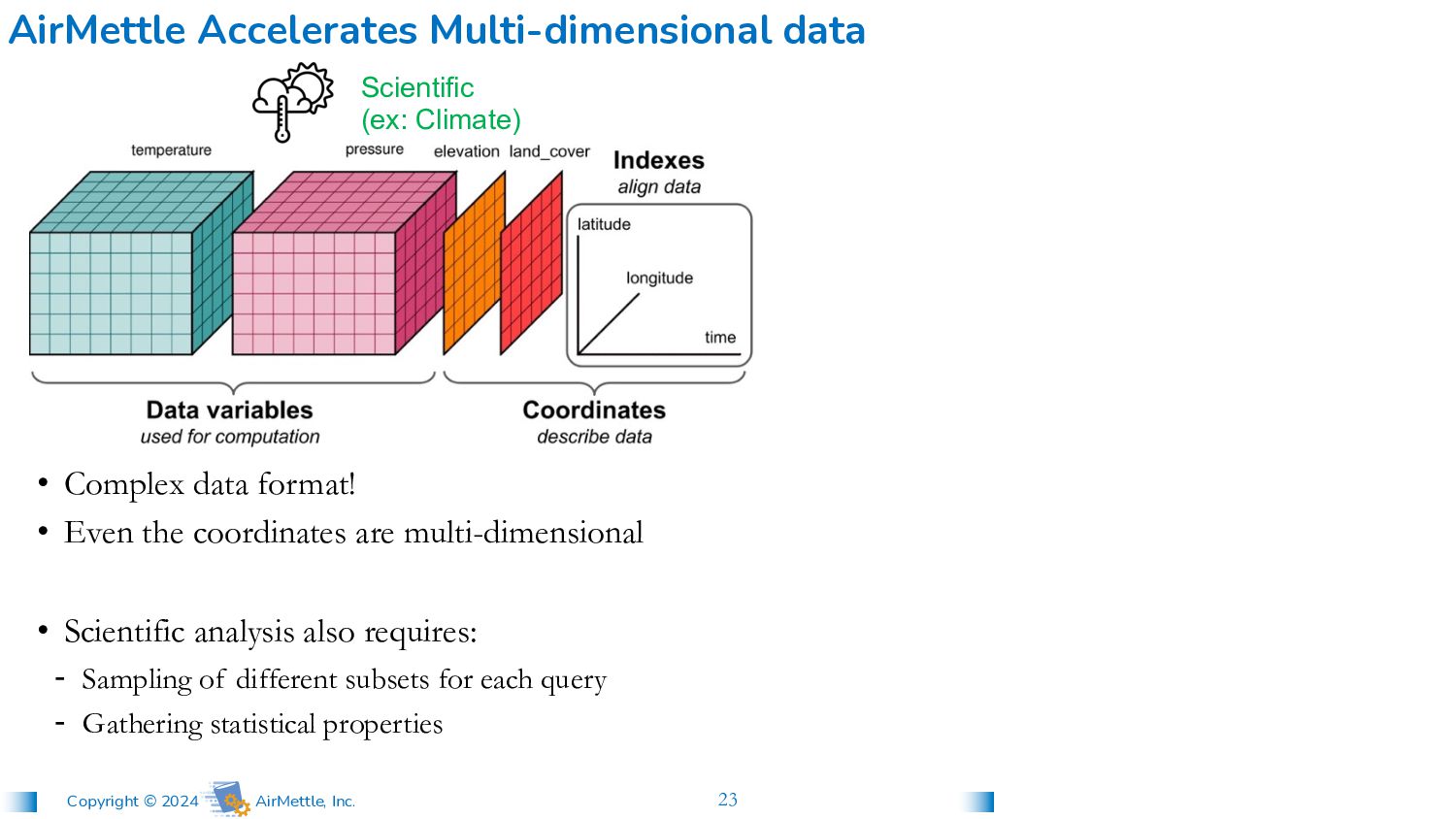
• Even the coordinates are multi-dimensional • Scientific analysis also requires: - Sampling of different subsets for each query - Gathering statistical properties AirMettle Accelerates Multi-dimensional data Scientific (ex: Climate)
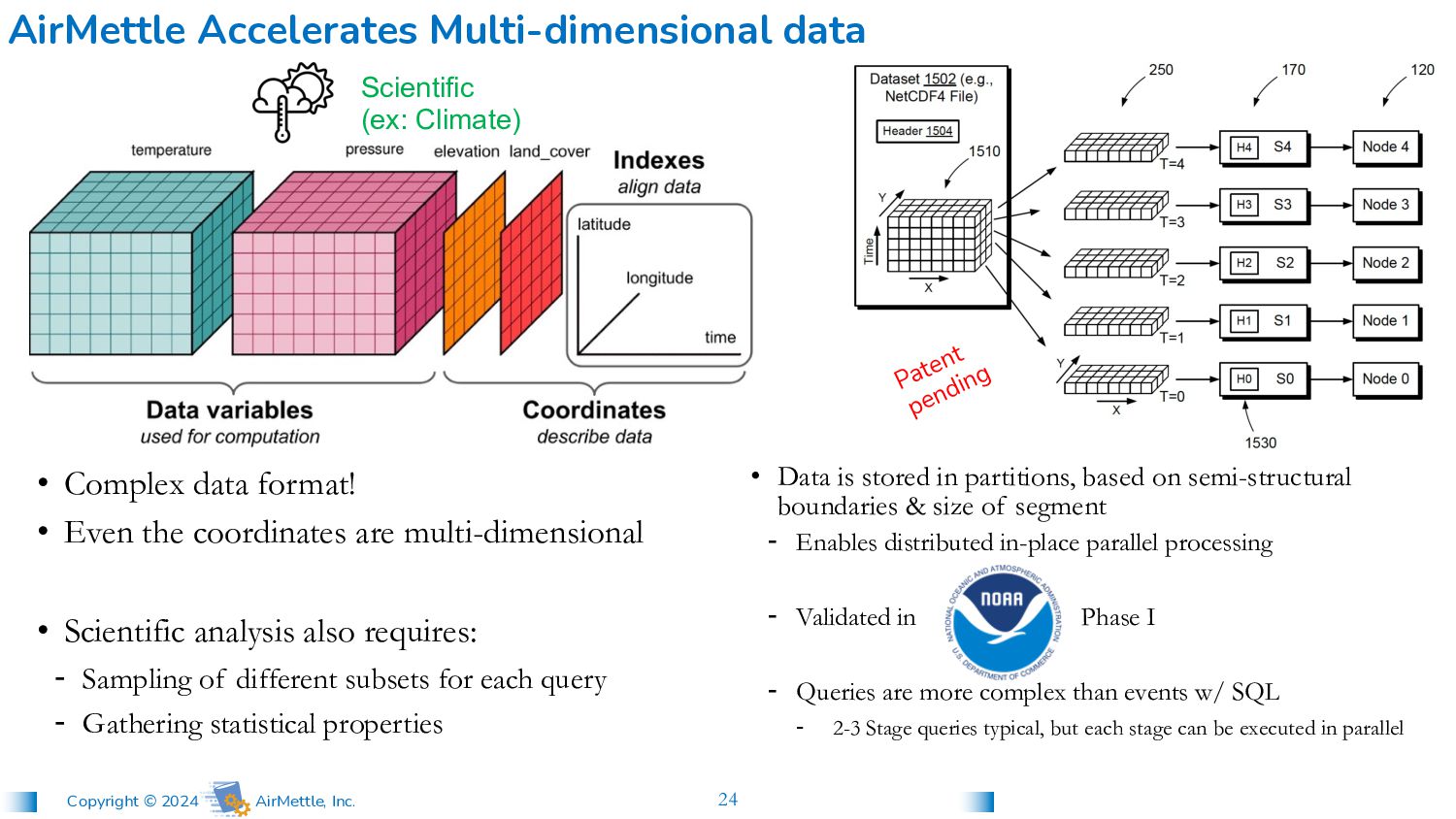
in partitions, based on semi-structural boundaries & size of segment - Enables distributed in-place parallel processing - Validated in Phase I - Queries are more complex than events w/ SQL - 2-3 Stage queries typical, but each stage can be executed in parallel • Complex data format! • Even the coordinates are multi-dimensional • Scientific analysis also requires: - Sampling of different subsets for each query - Gathering statistical properties AirMettle Accelerates Multi-dimensional data Scientific (ex: Climate) Patent pending
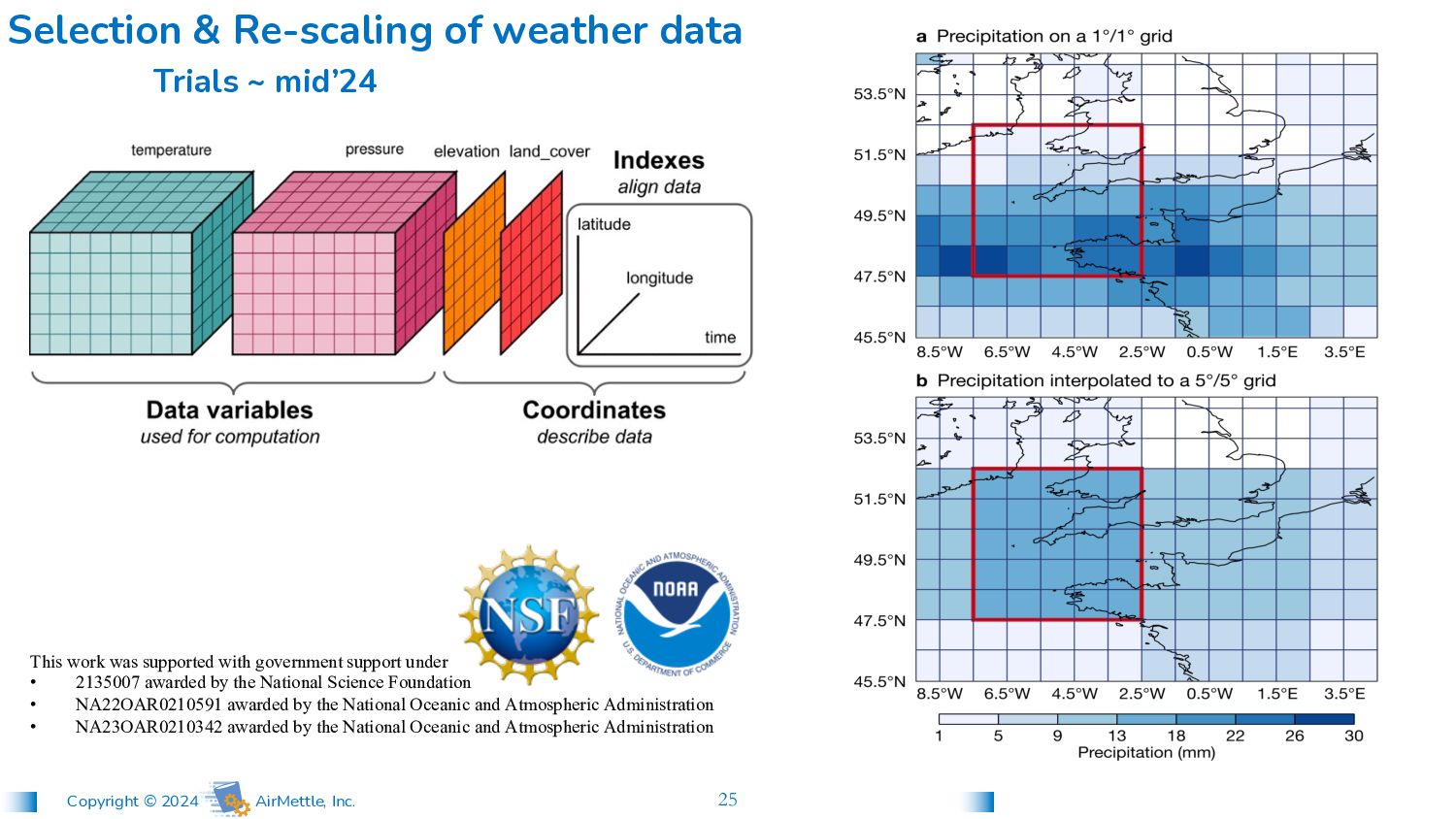
weather data Trials ~ mid’24 This work was supported with government support under • 2135007 awarded by the National Science Foundation • NA22OAR0210591 awarded by the National Oceanic and Atmospheric Administration • NA23OAR0210342 awarded by the National Oceanic and Atmospheric Administration
Movie object 17:40 à 17:41 in Seconds! Director of Fantasy Adventure show Problem: Make sure current-day items (e.g. coffee cup) Do not appear on screen Public Sector applications Find missing people / validate alibi: Problem: • Child not found at amusement park • Parent/guardian has pictures… Private Sector applications With basic model (from photos), can quickly find child NDA
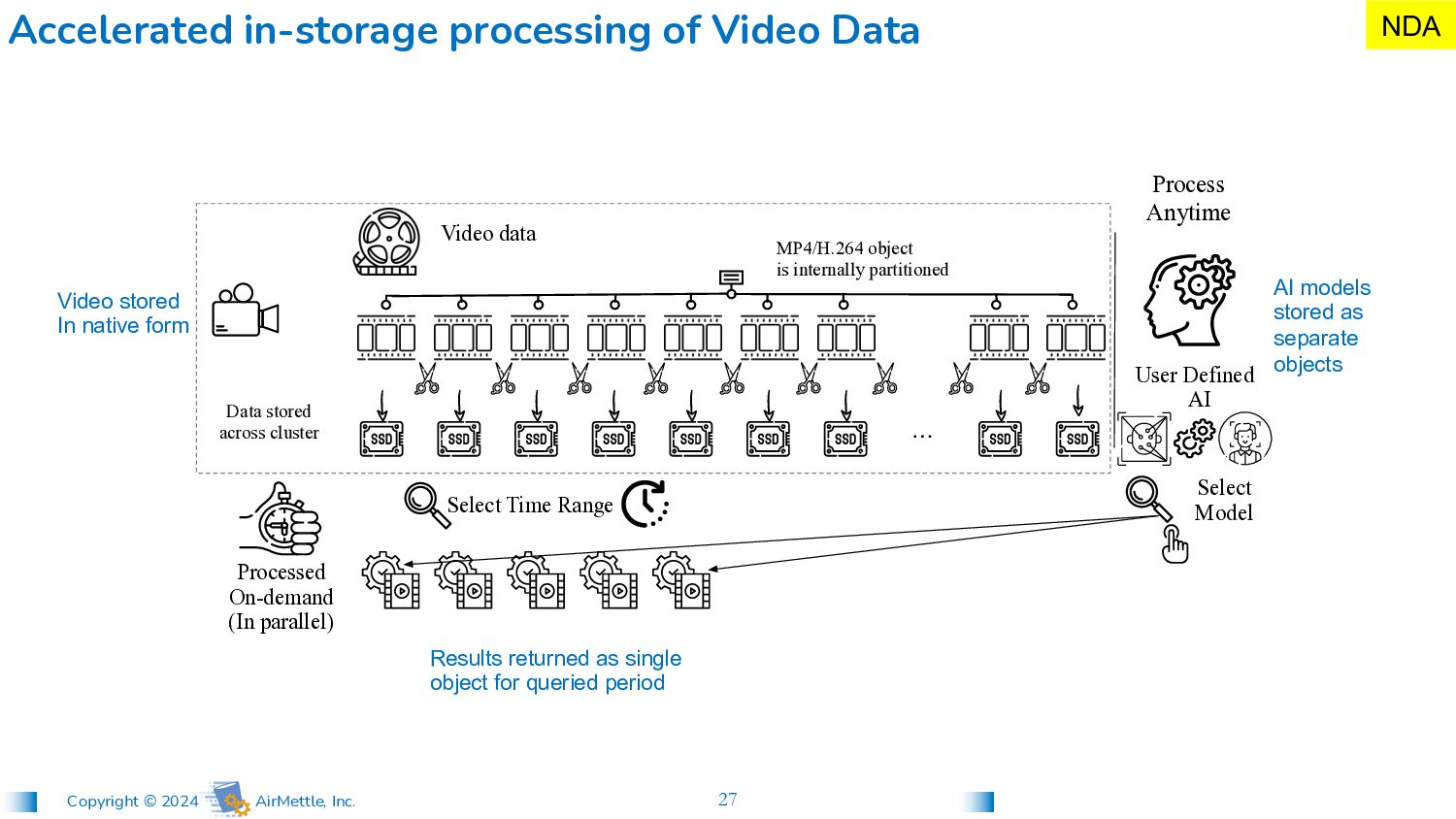
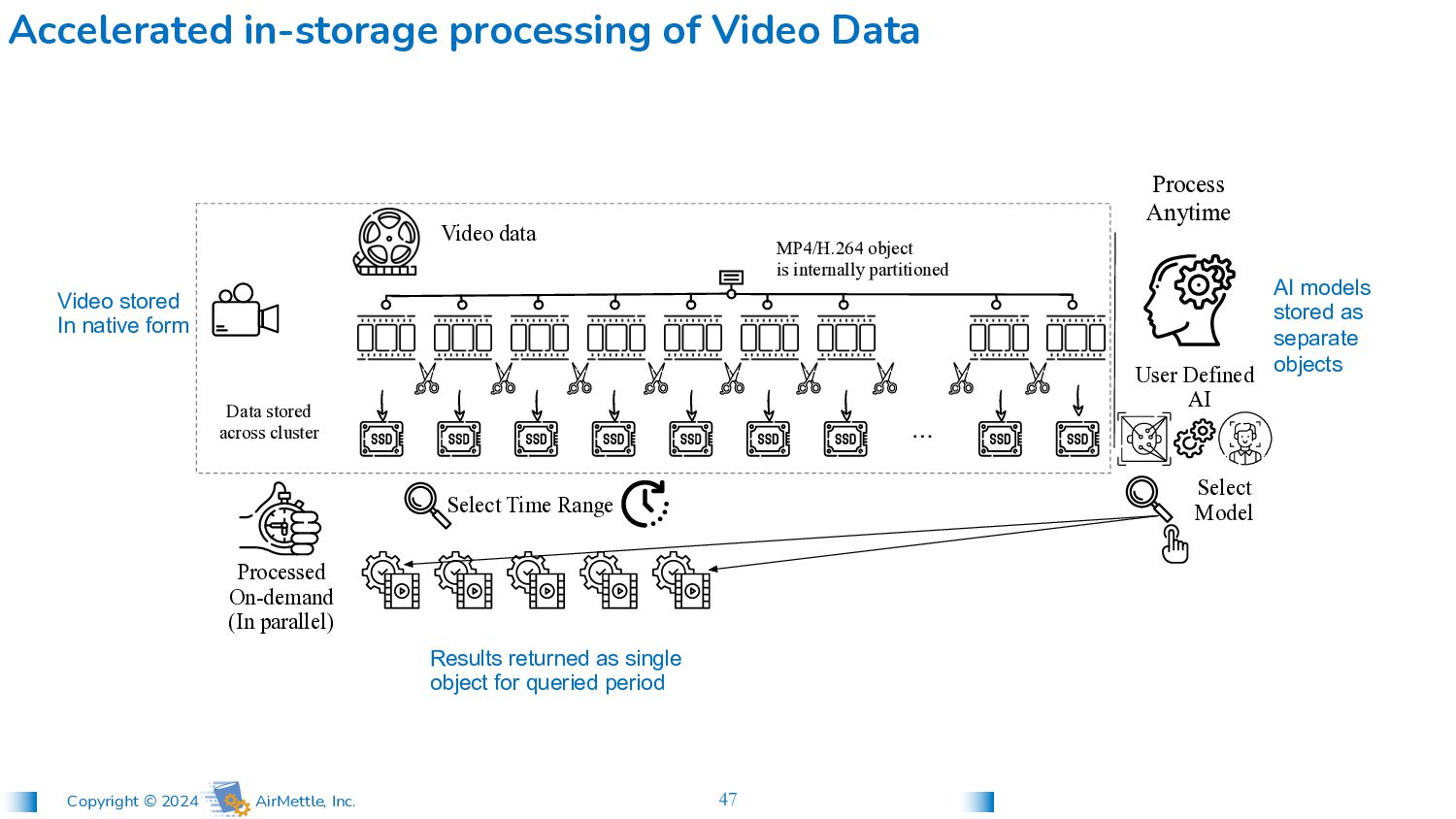
Video Data Video stored In native form AI models stored as separate objects Results returned as single object for queried period MP4/H.264 object is internally partitioned Video data Data stored across cluster … Processed On-demand (In parallel) User Defined AI Select Model Select Time Range Process Anytime NDA
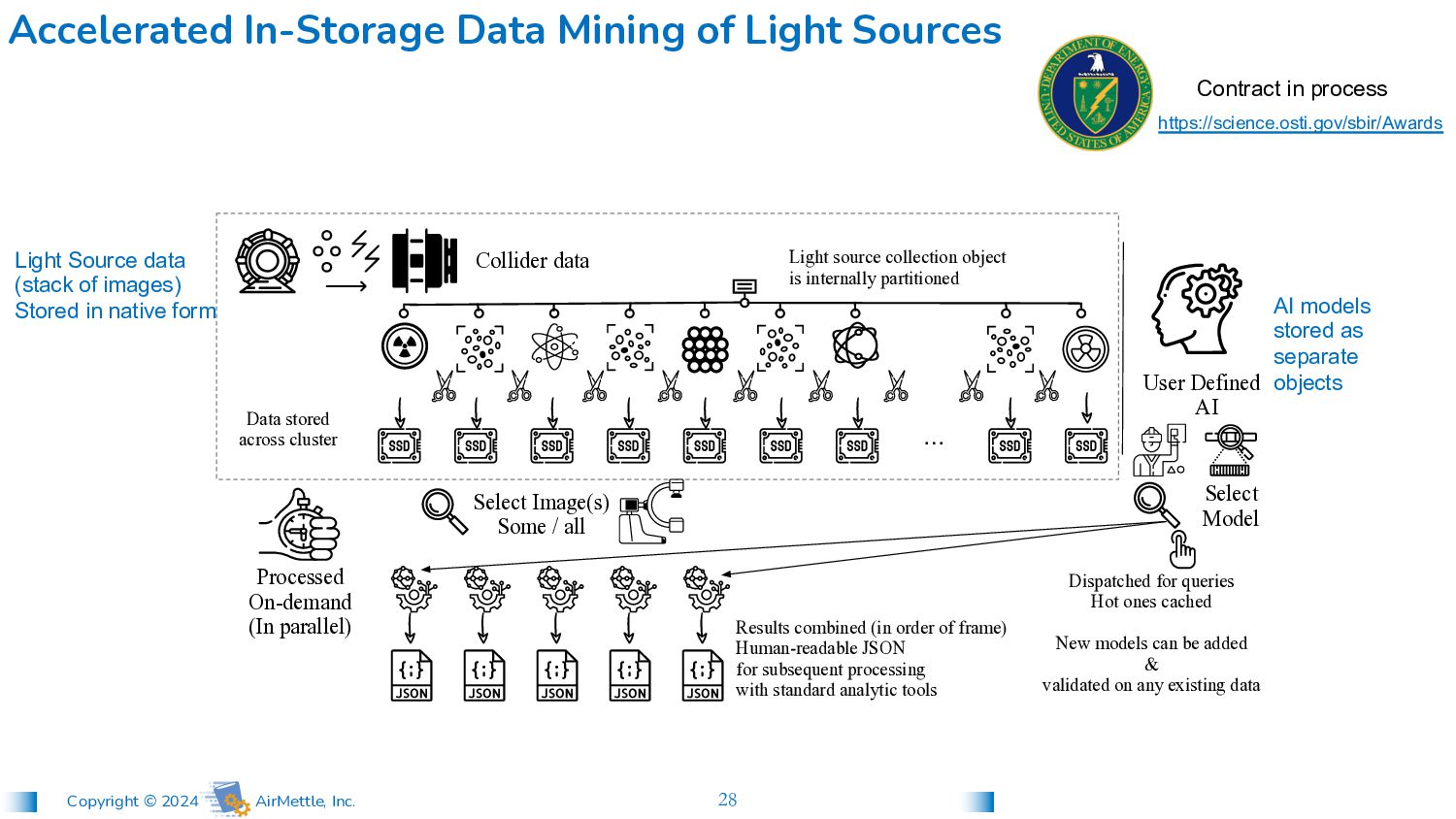
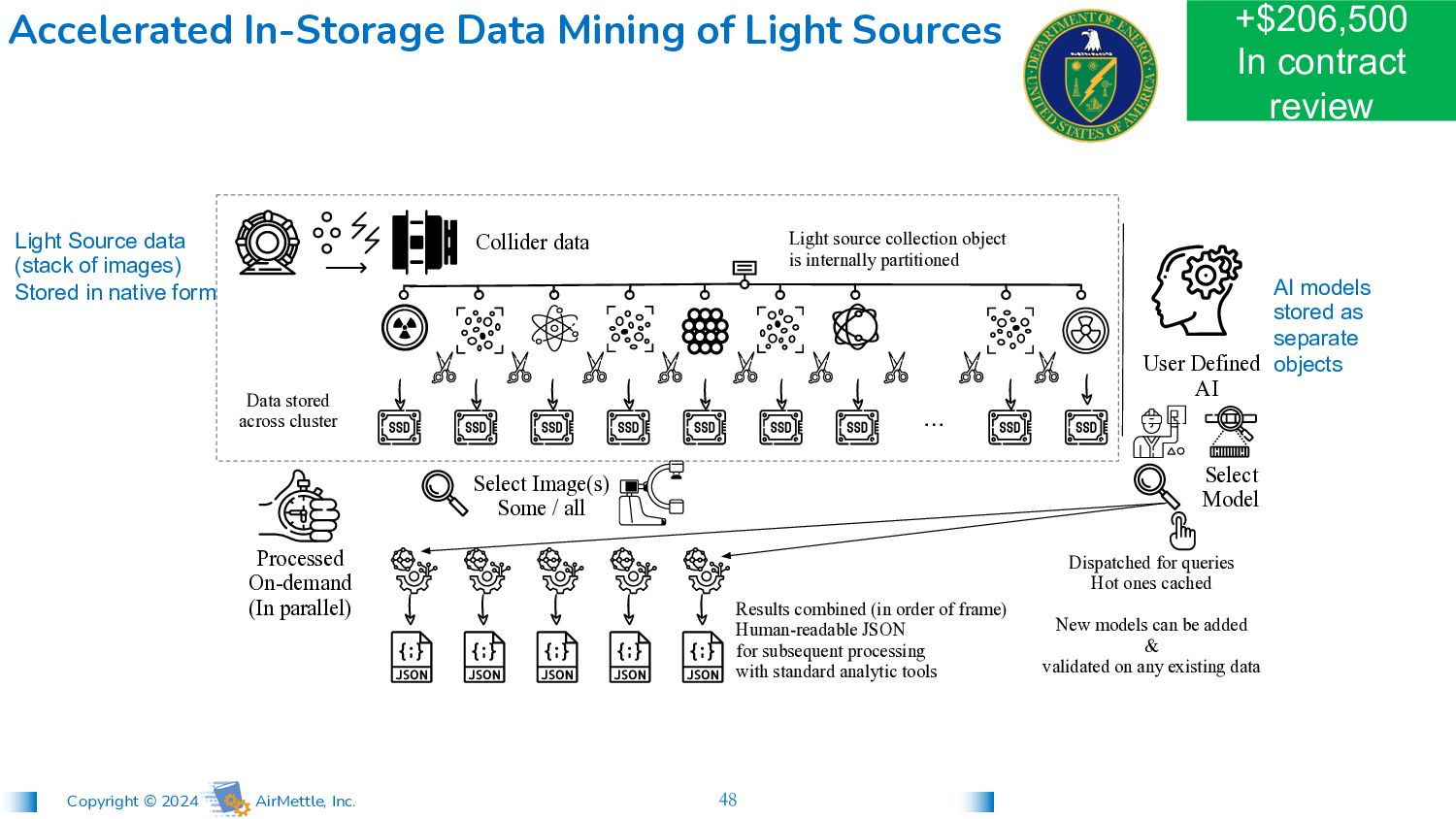
is internally partitioned Data stored across cluster … Processed On-demand (In parallel) User Defined AI Select Model Select Image(s) Some / all Dispatched for queries Hot ones cached New models can be added & validated on any existing data Results combined (in order of frame) Human-readable JSON for subsequent processing with standard analytic tools Collider data Accelerated In-Storage Data Mining of Light Sources Light Source data (stack of images) Stored in native form AI models stored as separate objects Contract in process https://science.osti.gov/sbir/Awards
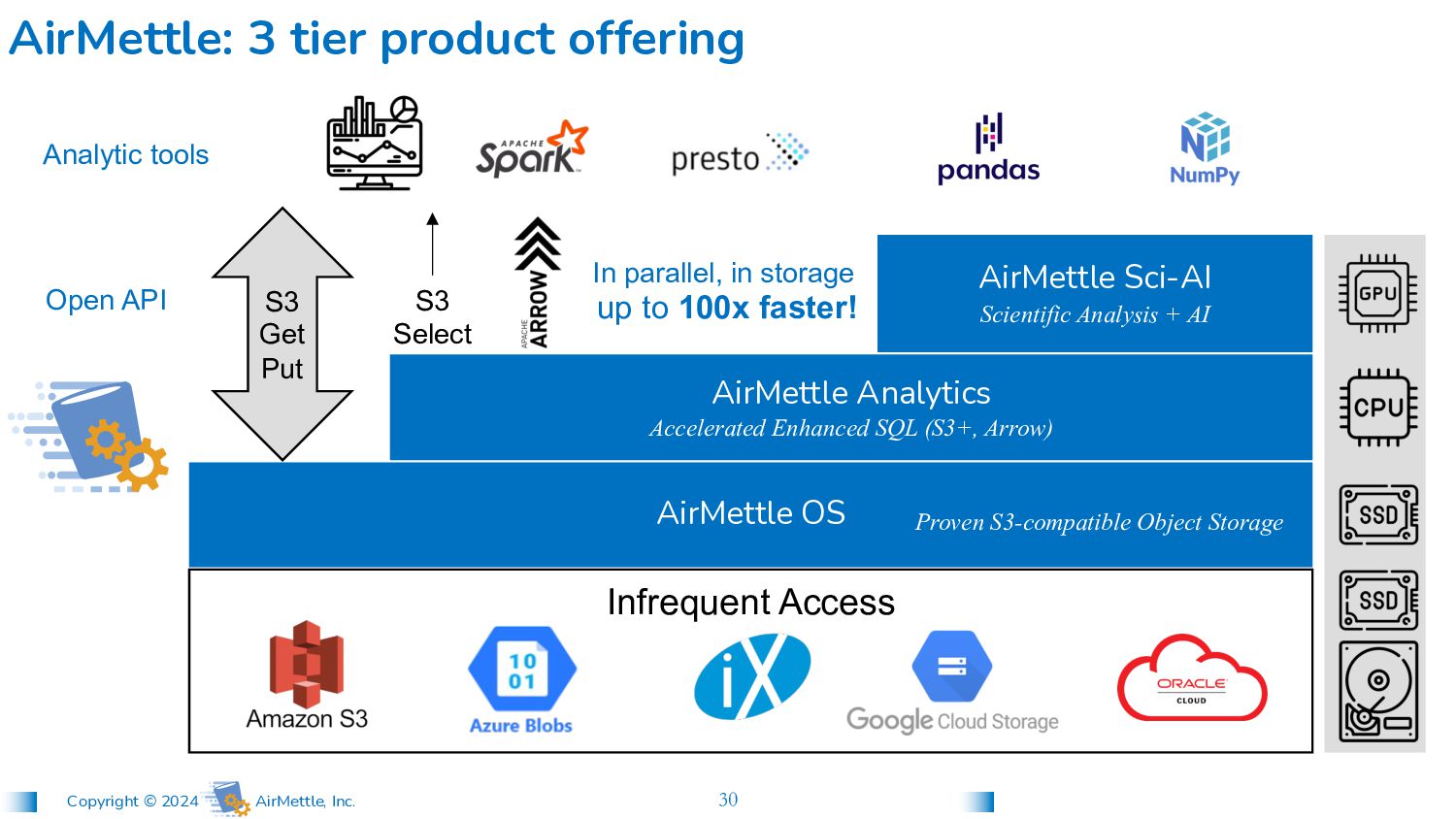
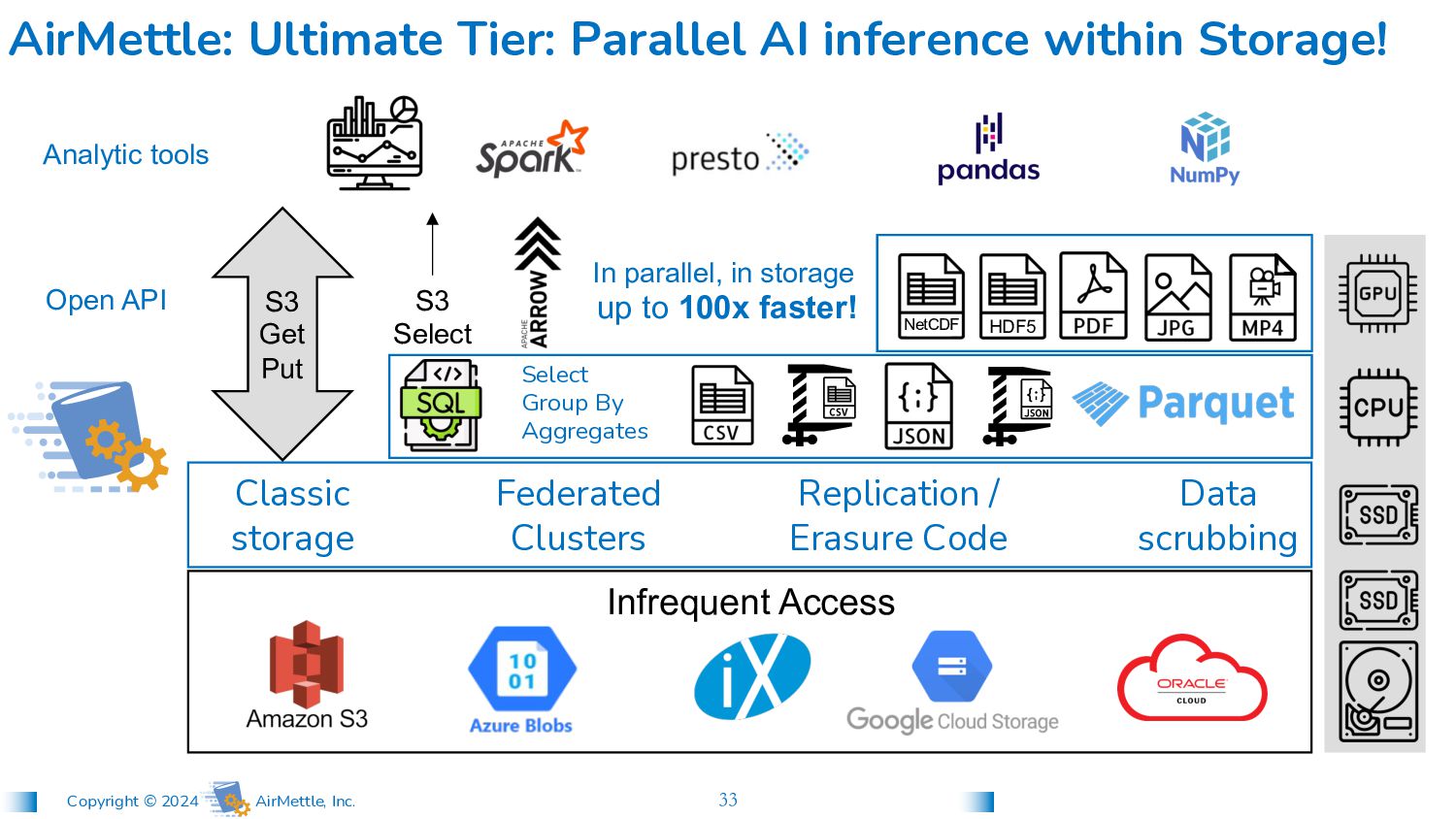
SQL (S3+, Arrow) Infrequent Access AirMettle OS AirMettle: 3 tier product offering S3 Get Put S3 Select Analytic tools Proven S3-compatible Object Storage Open API In parallel, in storage up to 100x faster! AirMettle Sci-AI Scientific Analysis + AI
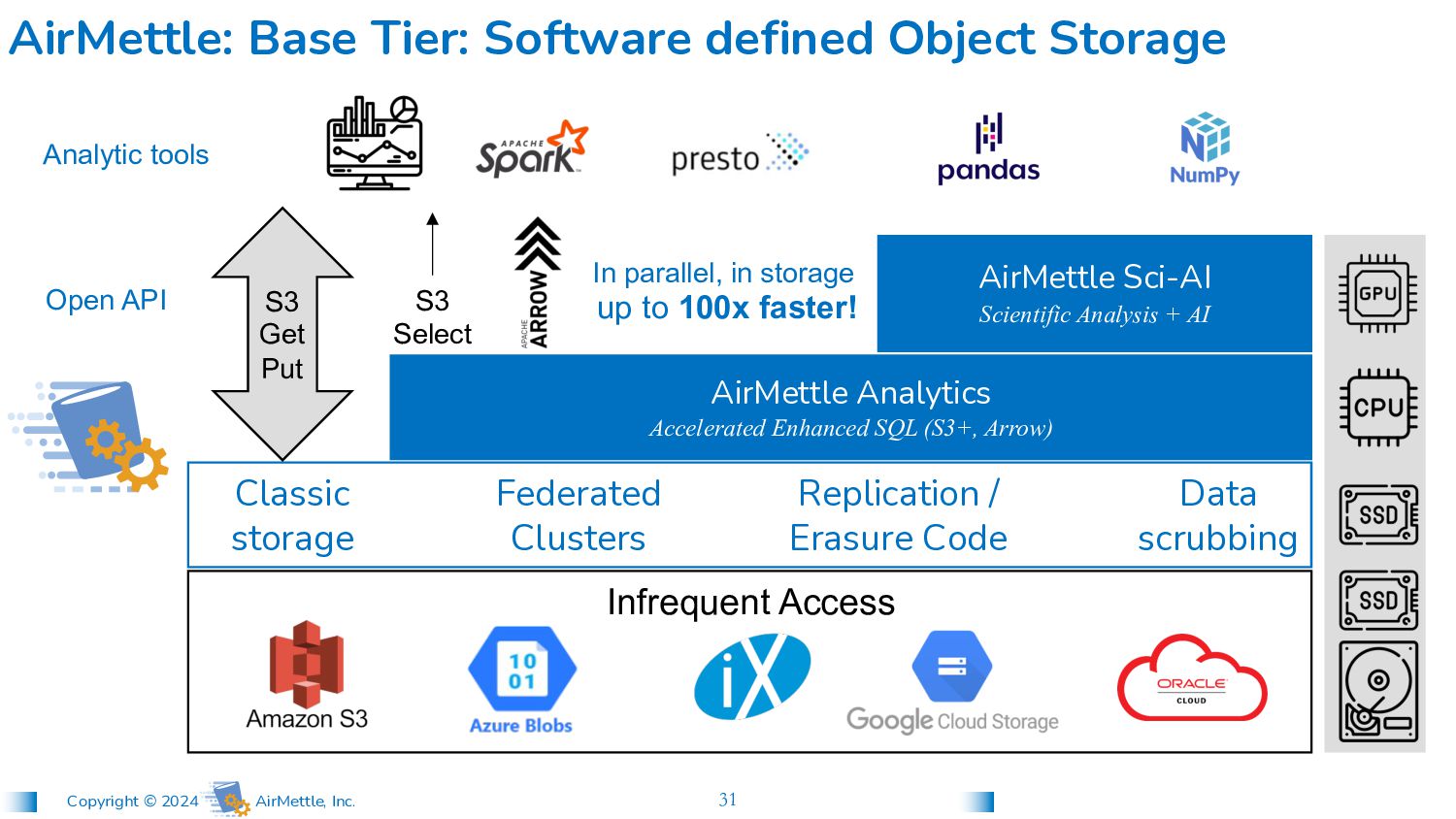
SQL (S3+, Arrow) AirMettle: Base Tier: Software defined Object Storage S3 Get Put S3 Select Analytic tools Open API Federated Clusters Classic storage Data scrubbing Replication / Erasure Code In parallel, in storage up to 100x faster! AirMettle Sci-AI Scientific Analysis + AI Infrequent Access
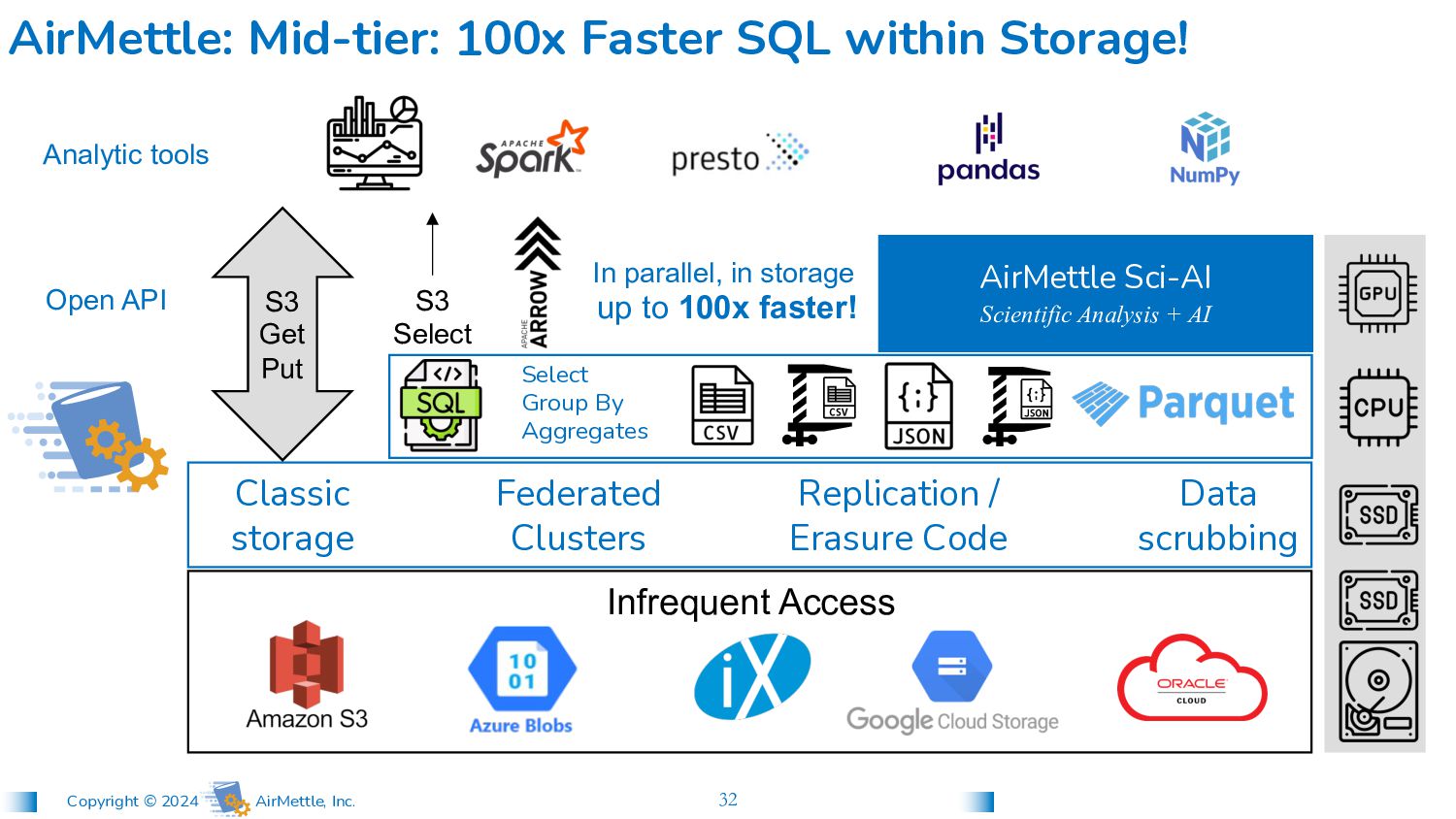
up to 100x faster! S3 Get Put S3 Select Analytic tools AirMettle Sci-AI Scientific Analysis + AI Open API Federated Clusters Classic storage Data scrubbing Replication / Erasure Code Select Group By Aggregates Infrequent Access AirMettle: Mid-tier: 100x Faster SQL within Storage!
AI inference within Storage! In parallel, in storage up to 100x faster! S3 Get Put S3 Select Analytic tools AirMettle Sci-AI Scientific Analysis + AI Open API Federated Clusters Classic storage Data scrubbing Replication / Erasure Code Select Group By Aggregates Infrequent Access HDF5 NetCDF
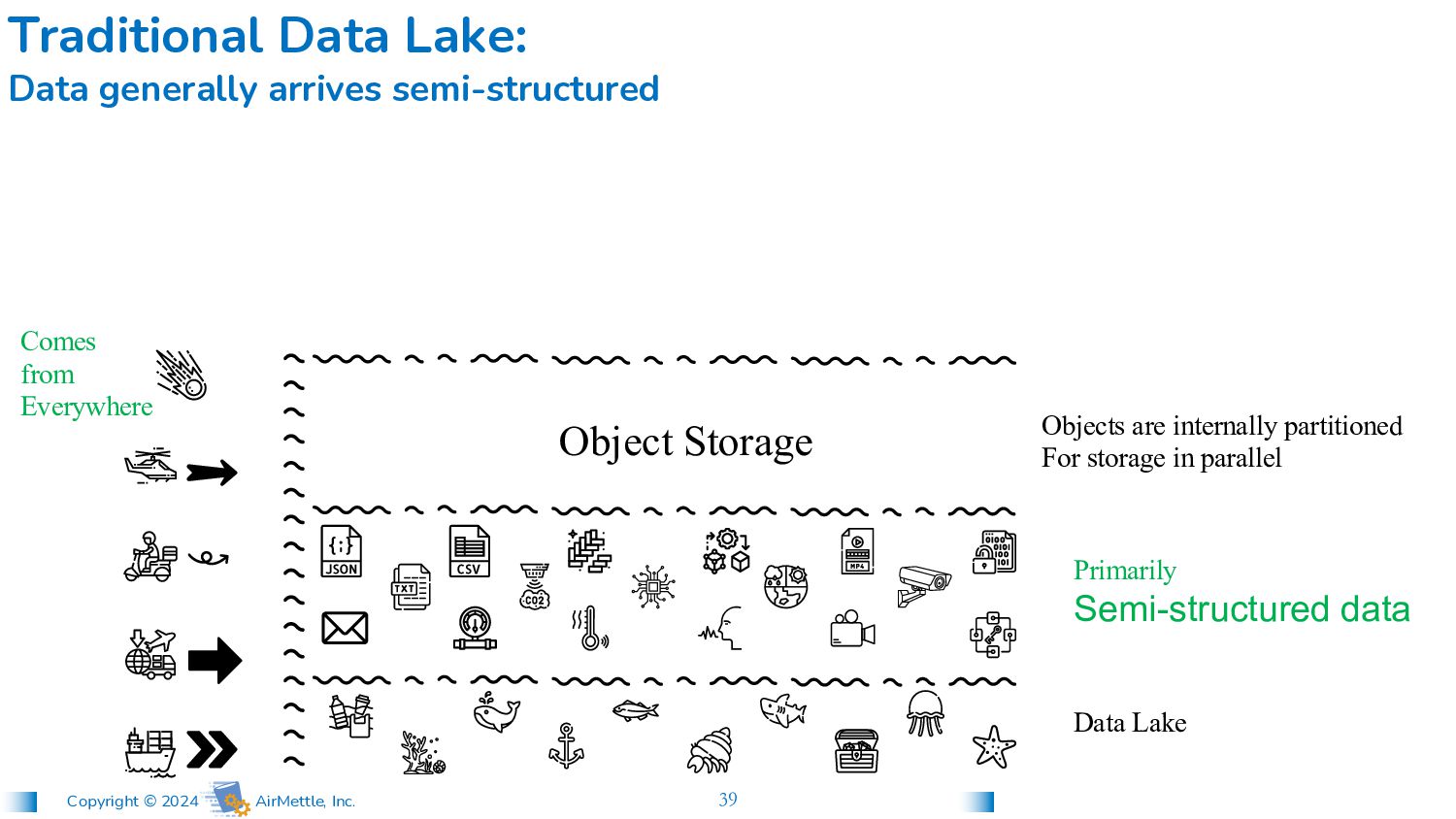
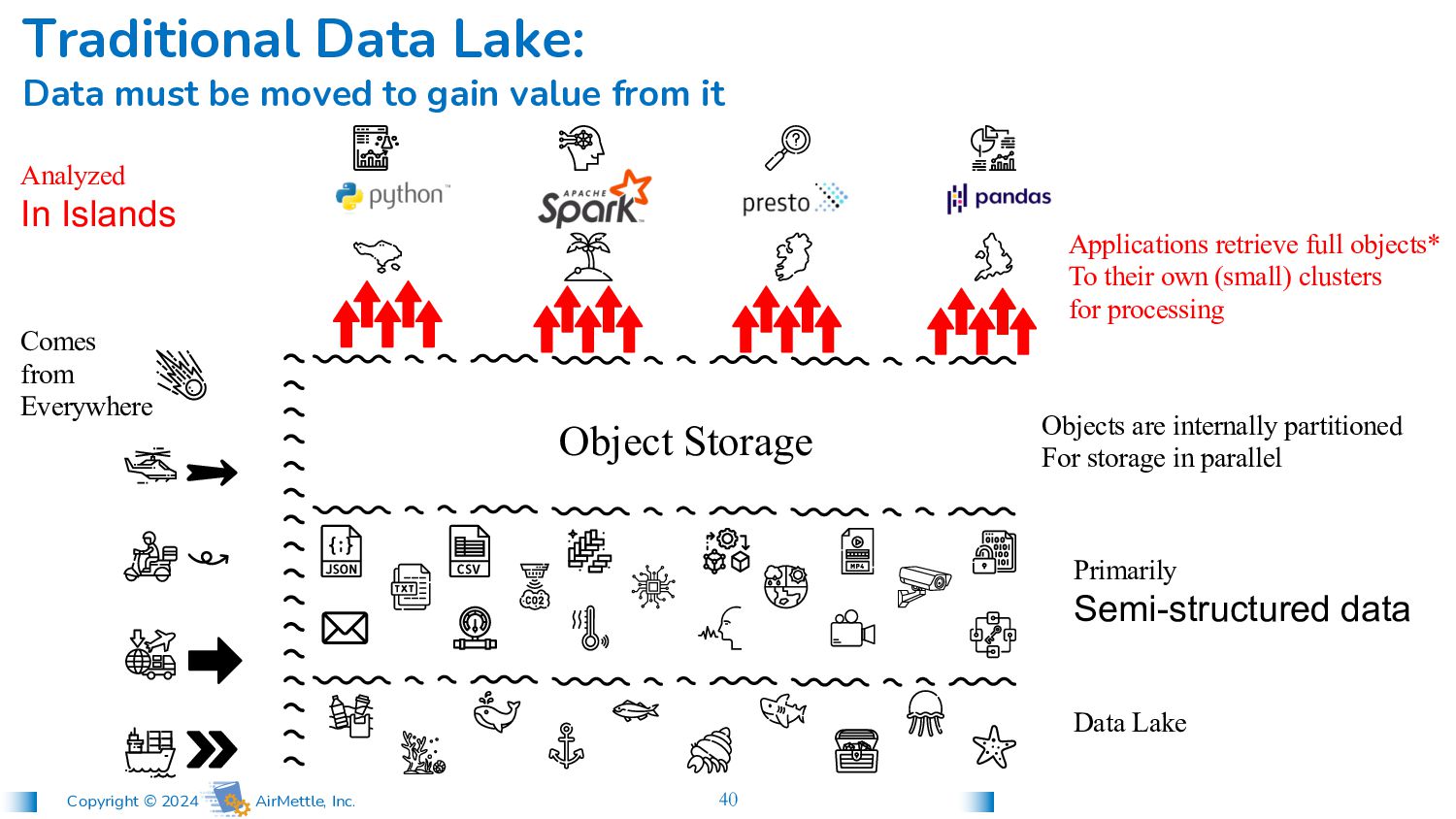
data Comes from Everywhere Traditional Data Lake: Data generally arrives semi-structured Object Storage Objects are internally partitioned For storage in parallel
In Islands Applications retrieve full objects* To their own (small) clusters for processing Traditional Data Lake: Data must be moved to gain value from it Object Storage Data Lake Primarily Semi-structured data Objects are internally partitioned For storage in parallel
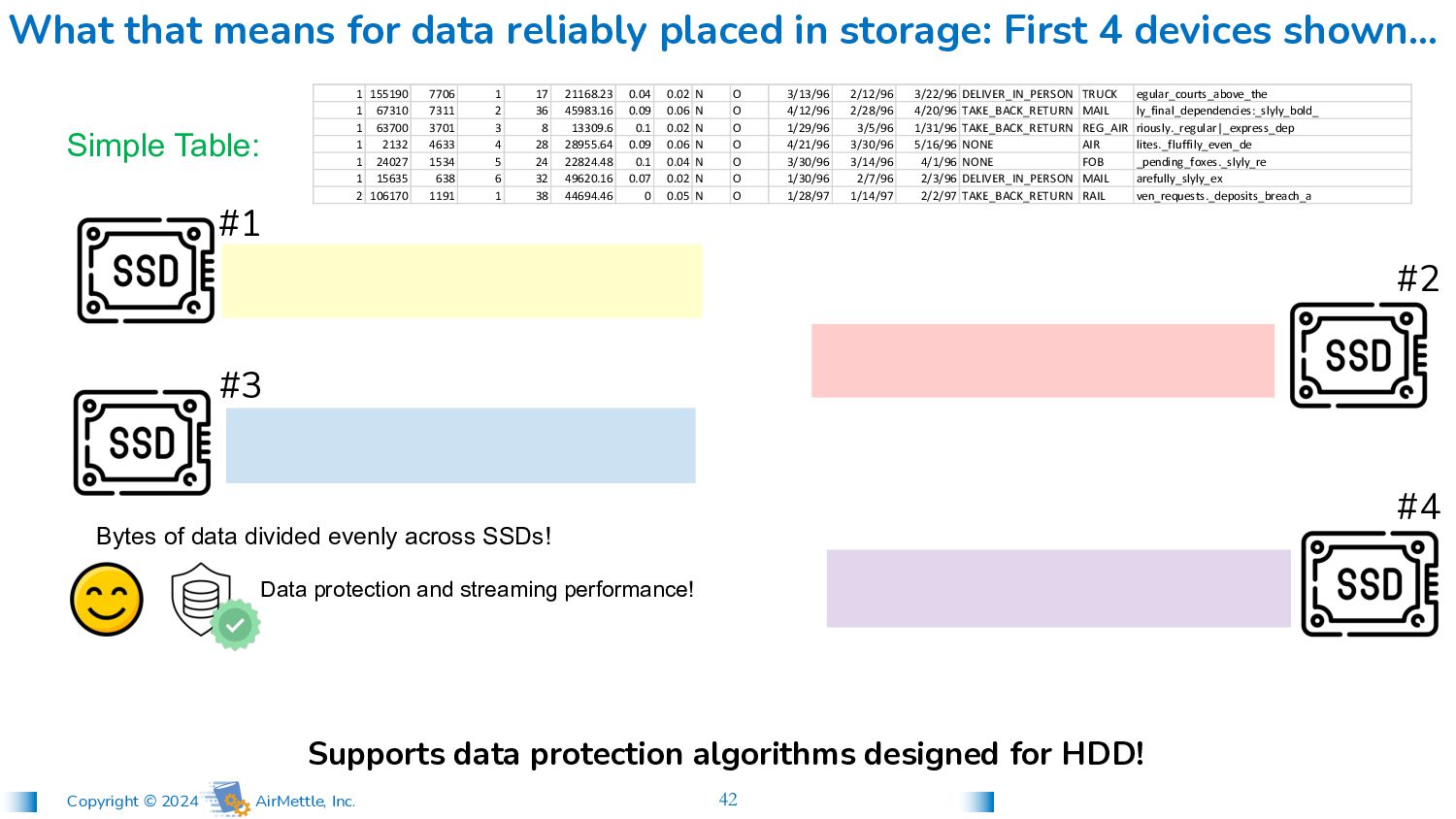
17 21168.23 0.04 0.02 N O 3/13/96 2/12/96 3/22/96 DELIVER_IN_PERSON TRUCK egular_courts_above_the 1 67310 7311 2 36 45983.16 0.09 0.06 N O 4/12/96 2/28/96 4/20/96 TAKE_BACK_RETURN MAIL ly_final_dependencies:_slyly_bold_ 1 63700 3701 3 8 13309.6 0.1 0.02 N O 1/29/96 3/5/96 1/31/96 TAKE_BACK_RETURN REG_AIR riously._regular|_express_dep 1 2132 4633 4 28 28955.64 0.09 0.06 N O 4/21/96 3/30/96 5/16/96 NONE AIR lites._fluffily_even_de 1 24027 1534 5 24 22824.48 0.1 0.04 N O 3/30/96 3/14/96 4/1/96 NONE FOB _pending_foxes._slyly_re 1 15635 638 6 32 49620.16 0.07 0.02 N O 1/30/96 2/7/96 2/3/96 DELIVER_IN_PERSON MAIL arefully_slyly_ex 2 106170 1191 1 38 44694.46 0 0.05 N O 1/28/97 1/14/97 2/2/97 TAKE_BACK_RETURN RAIL ven_requests._deposits_breach_a What that means for data reliably placed in storage: First 4 devices shown… Simple Table: #1 #3 #2 #4 Supports data protection algorithms designed for HDD! Bytes of data divided evenly across SSDs! Data protection and streaming performance!
17 21168.23 0.04 0.02 N O 3/13/96 2/12/96 3/22/96 DELIVER_IN_PERSON TRUCK egular_courts_above_the 1 67310 7311 2 36 45983.16 0.09 0.06 N O 4/12/96 2/28/96 4/20/96 TAKE_BACK_RETURN MAIL ly_final_dependencies:_slyly_bold_ 1 63700 3701 3 8 13309.6 0.1 0.02 N O 1/29/96 3/5/96 1/31/96 TAKE_BACK_RETURN REG_AIR riously._regular|_express_dep 1 2132 4633 4 28 28955.64 0.09 0.06 N O 4/21/96 3/30/96 5/16/96 NONE AIR lites._fluffily_even_de 1 24027 1534 5 24 22824.48 0.1 0.04 N O 3/30/96 3/14/96 4/1/96 NONE FOB _pending_foxes._slyly_re 1 15635 638 6 32 49620.16 0.07 0.02 N O 1/30/96 2/7/96 2/3/96 DELIVER_IN_PERSON MAIL arefully_slyly_ex 2 106170 1191 1 38 44694.46 0 0.05 N O 1/28/97 1/14/97 2/2/97 TAKE_BACK_RETURN RAIL ven_requests._deposits_breach_a What that means for data reliably placed in storage: First 4 devices shown… Simple Table: Bytes of data divided evenly across SSDs! Data protection and streaming performance! #1 #3 #2 #4 HDD-centric RAID/Erasure Coding prevent in-storage analytics
processing… not be mutually exclusive? Application receive only what they need in an immediately usable form Objects are internally partitioned for storage & processing in parallel Structured, Semi-structured & Unstructured Data Reports BI Data Science AI / ML ??? ETL Data Warehouse Storage Structured, Semi-structured & Unstructured Data Reports BI Data Science AI / ML Data Lake Storage Objects are internally partitioned for storage in parallel
we can conquer common analytical needs AirMettle • Data is unchanged for client • Each internal component can be processed in parallel AirMettle internal metadata enables parallel in-storage analytics Not to scale! Meta-data typically <0.1% of data internal metadata Object’s own metadata
object 17:40 à 17:41 in Seconds! Director of Fantasy Adventure show Problem: Make sure current-day items (e.g. coffee cup) Do not appear on screen Public Sector applications Find missing people / validate alibi: Problem: • Child not found at amusement park • Parent/guardian has pictures… Private Sector applications With basic model (from photos), can quickly find child
Video Data Video stored In native form AI models stored as separate objects Results returned as single object for queried period MP4/H.264 object is internally partitioned Video data Data stored across cluster … Processed On-demand (In parallel) User Defined AI Select Model Select Time Range Process Anytime
is internally partitioned Data stored across cluster … Processed On-demand (In parallel) User Defined AI Select Model Select Image(s) Some / all Dispatched for queries Hot ones cached New models can be added & validated on any existing data Results combined (in order of frame) Human-readable JSON for subsequent processing with standard analytic tools Collider data Accelerated In-Storage Data Mining of Light Sources Light Source data (stack of images) Stored in native form AI models stored as separate objects +$206,500 In contract review
supported with government support under • 2135007 awarded by the National Science Foundation • NA22OAR0210591 awarded by the National Oceanic and Atmospheric Administration • NA23OAR0210342 awarded by the National Oceanic and Atmospheric Administration Pending final award contract • US Department of Energy • https://science.osti.gov/sbir/Awards Over $1m R&D Grants awarded to date +$206,500 In contract review
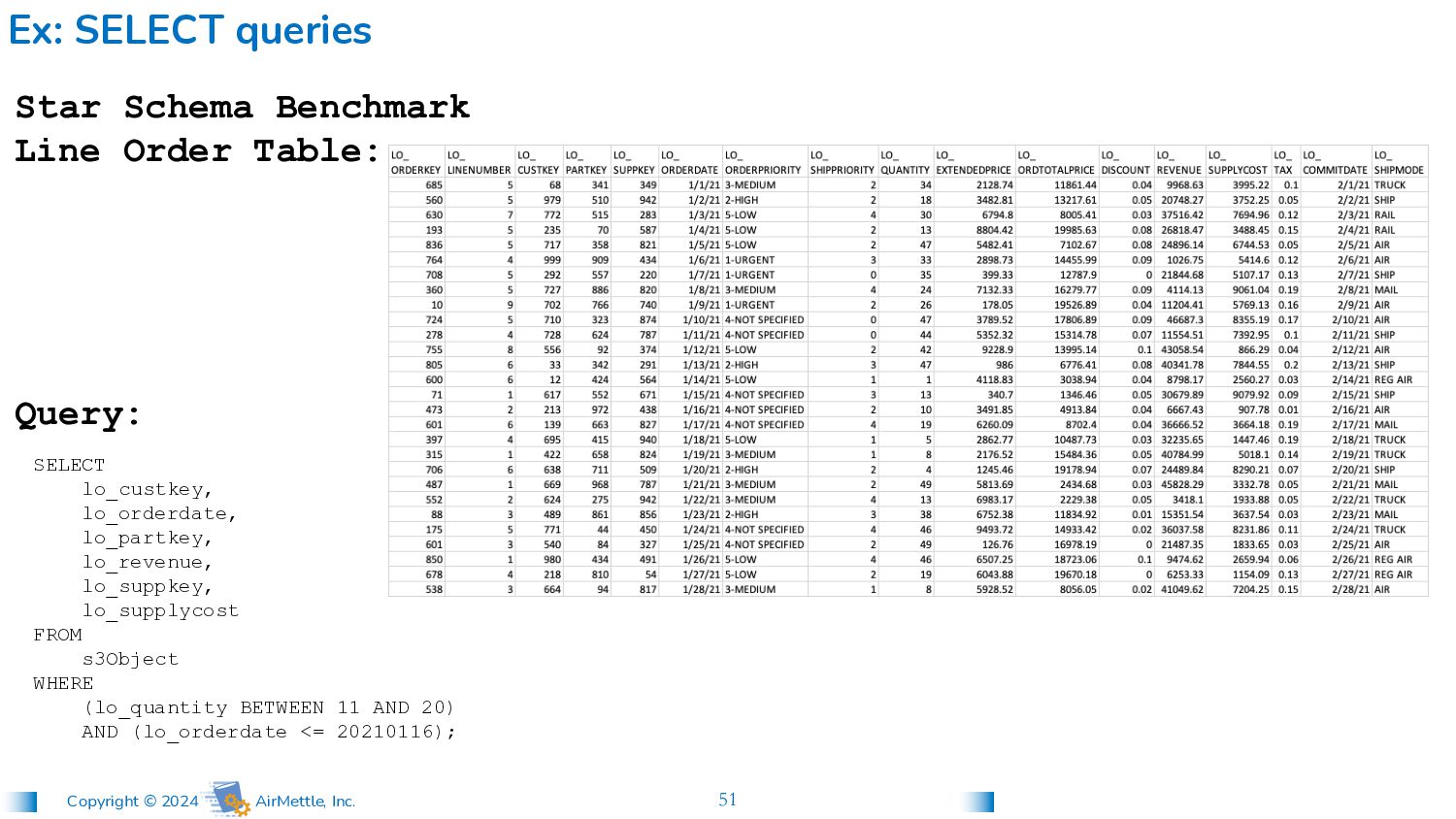
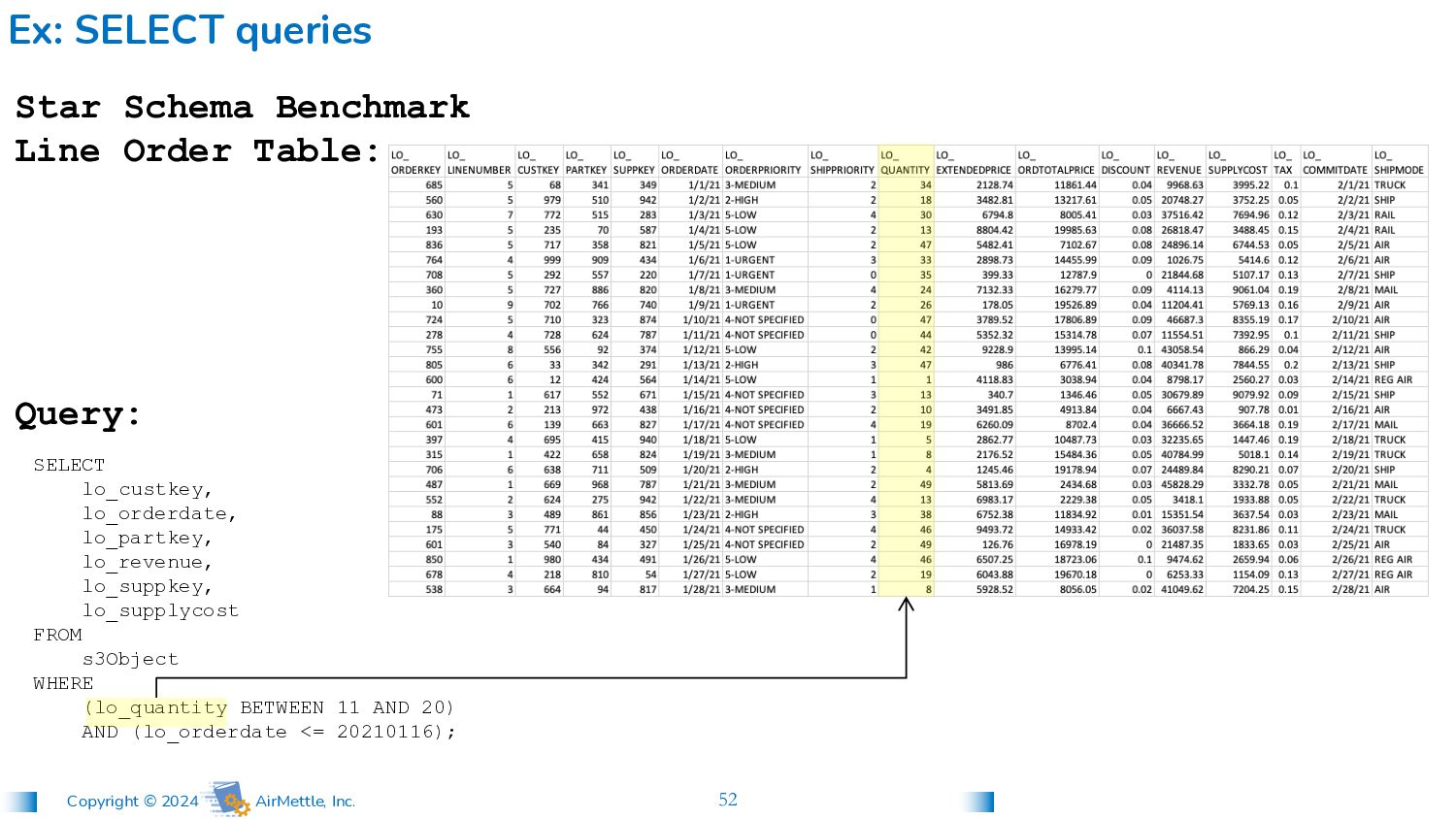
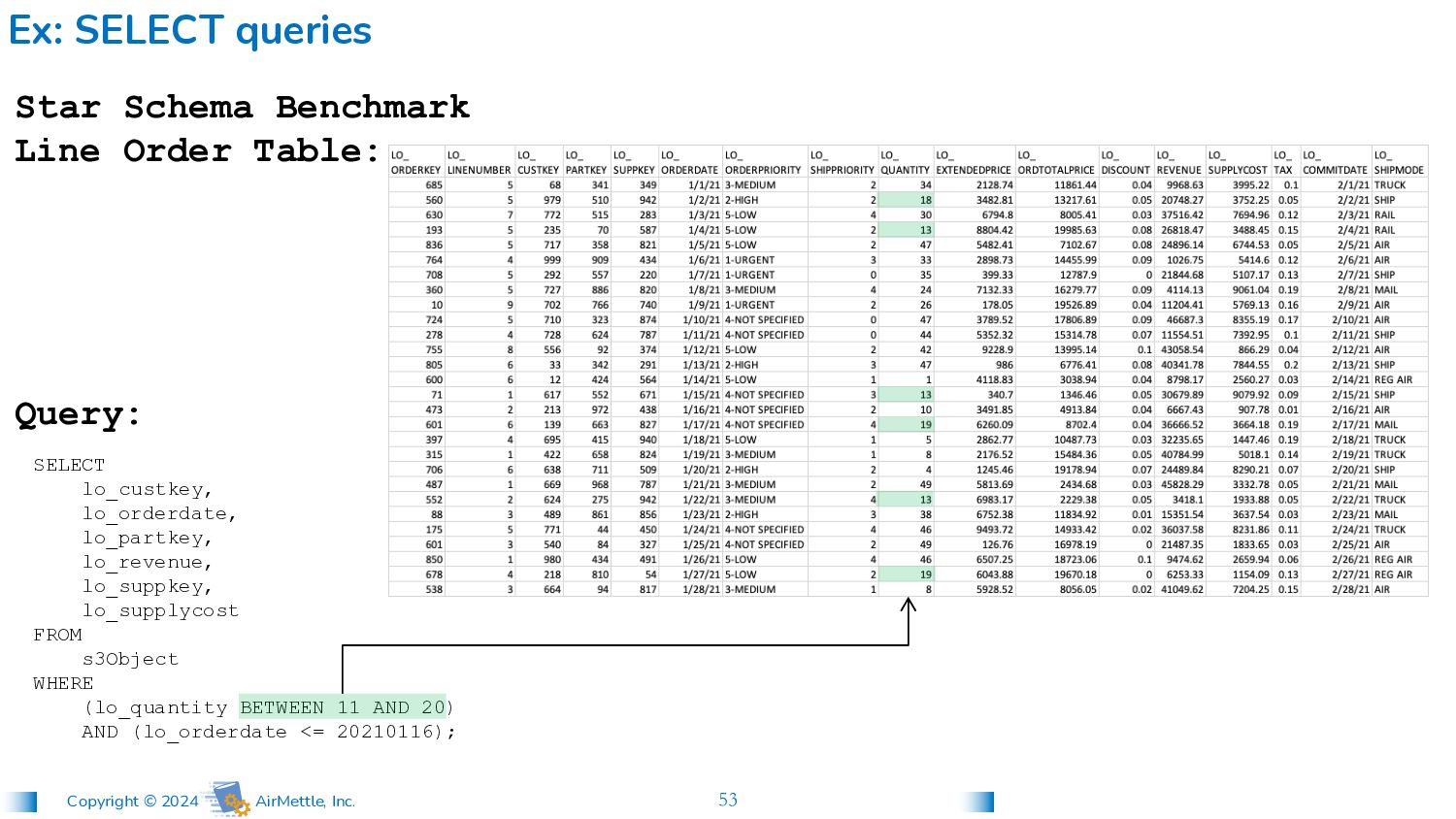
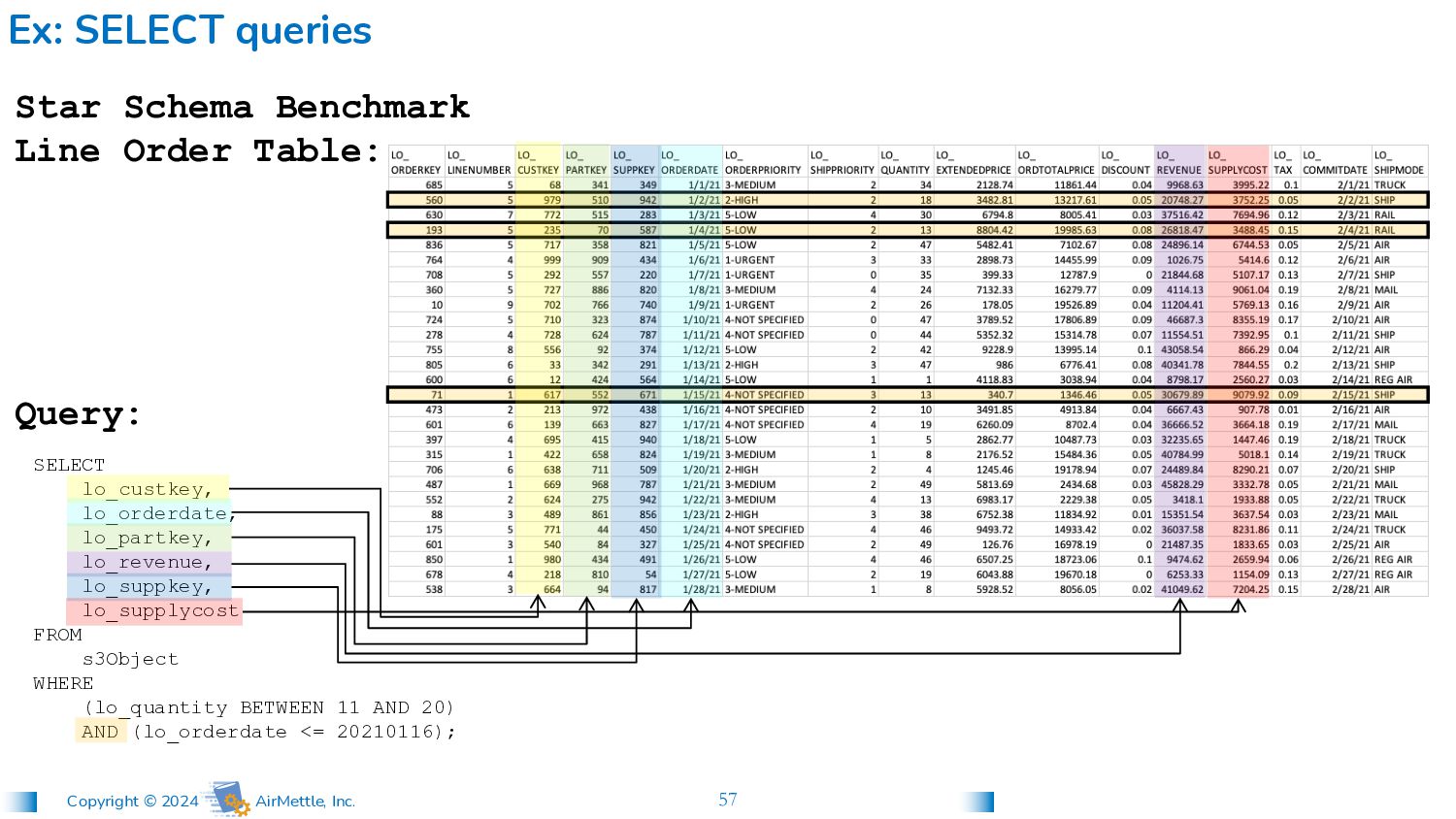
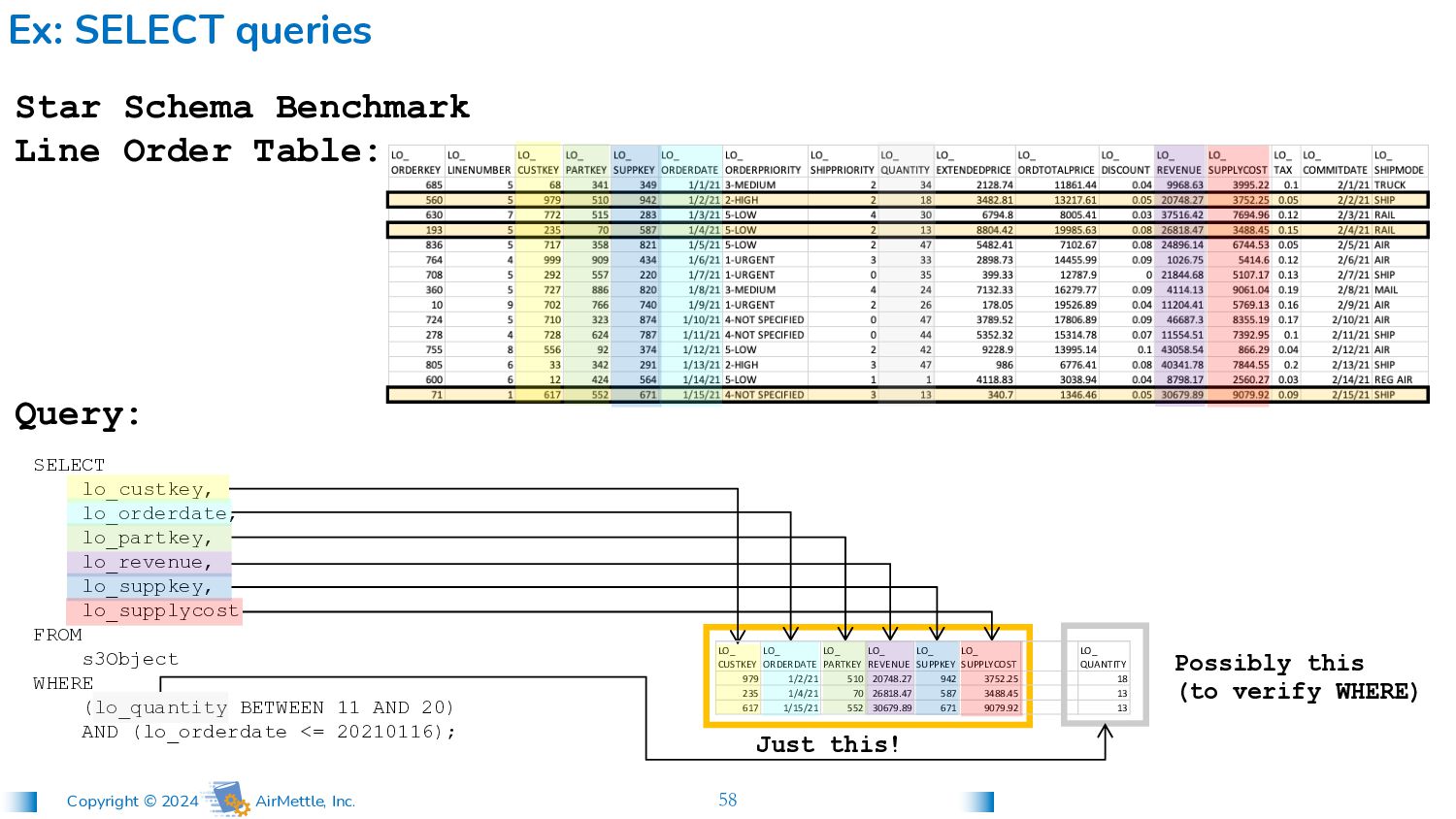
lo_custkey, lo_orderdate, lo_partkey, lo_revenue, lo_suppkey, lo_supplycost FROM s3Object WHERE (lo_quantity BETWEEN 11 AND 20) AND (lo_orderdate <= 20210116); Star Schema Benchmark Line Order Table: Query:
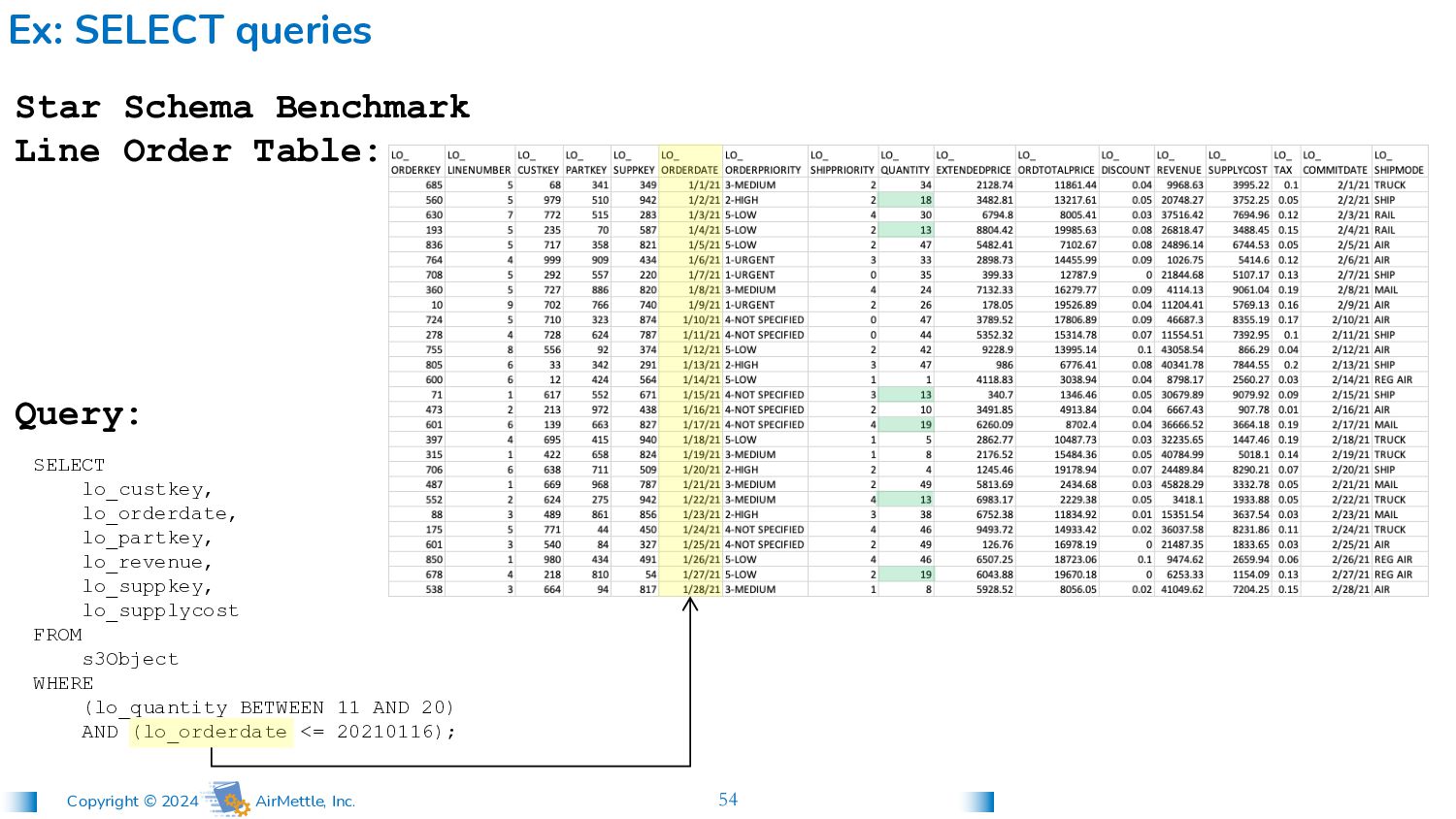
lo_custkey, lo_orderdate, lo_partkey, lo_revenue, lo_suppkey, lo_supplycost FROM s3Object WHERE (lo_quantity BETWEEN 11 AND 20) AND (lo_orderdate <= 20210116); Star Schema Benchmark Line Order Table: Query:
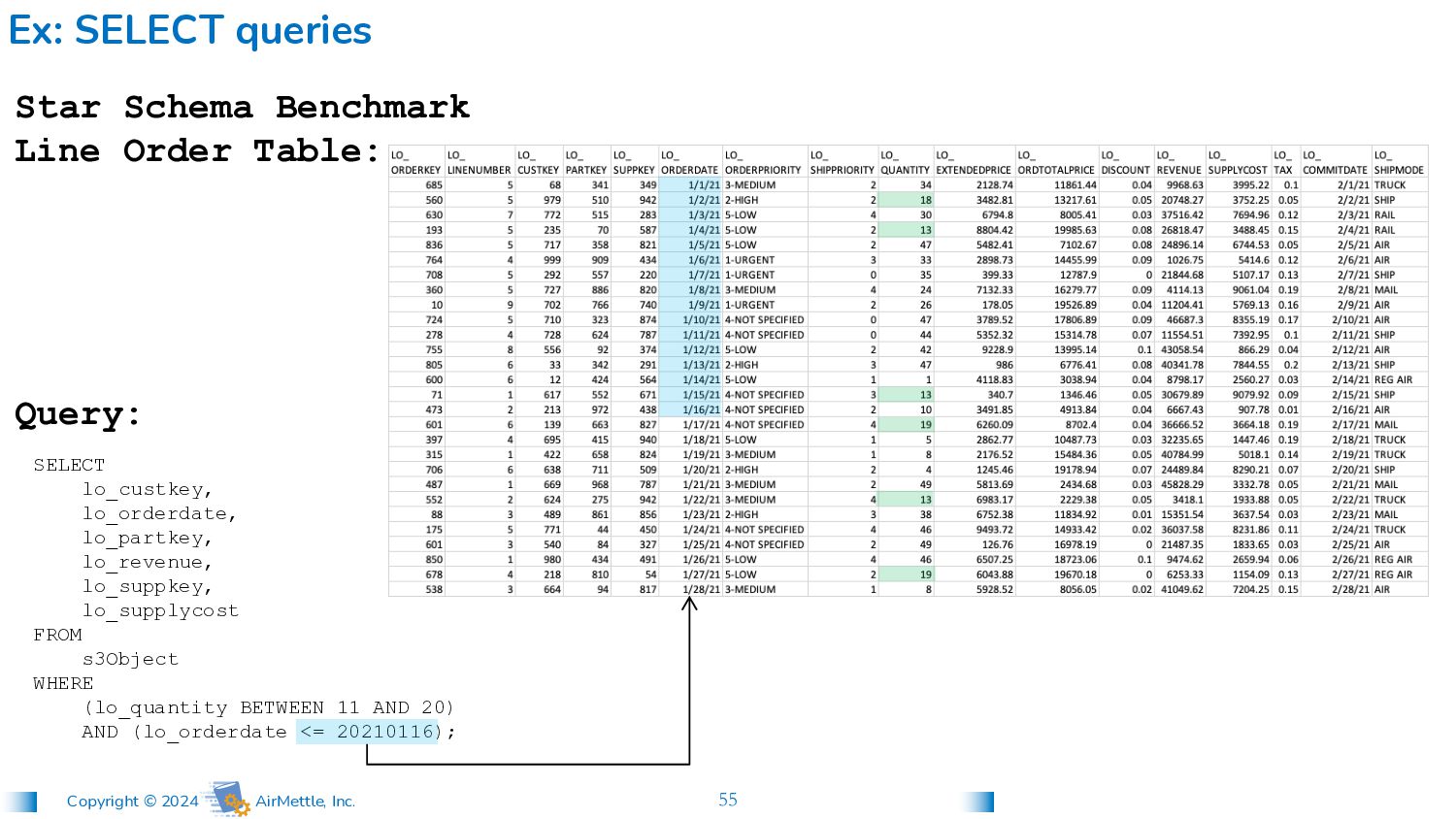
lo_custkey, lo_orderdate, lo_partkey, lo_revenue, lo_suppkey, lo_supplycost FROM s3Object WHERE (lo_quantity BETWEEN 11 AND 20) AND (lo_orderdate <= 20210116); Star Schema Benchmark Line Order Table: Query:
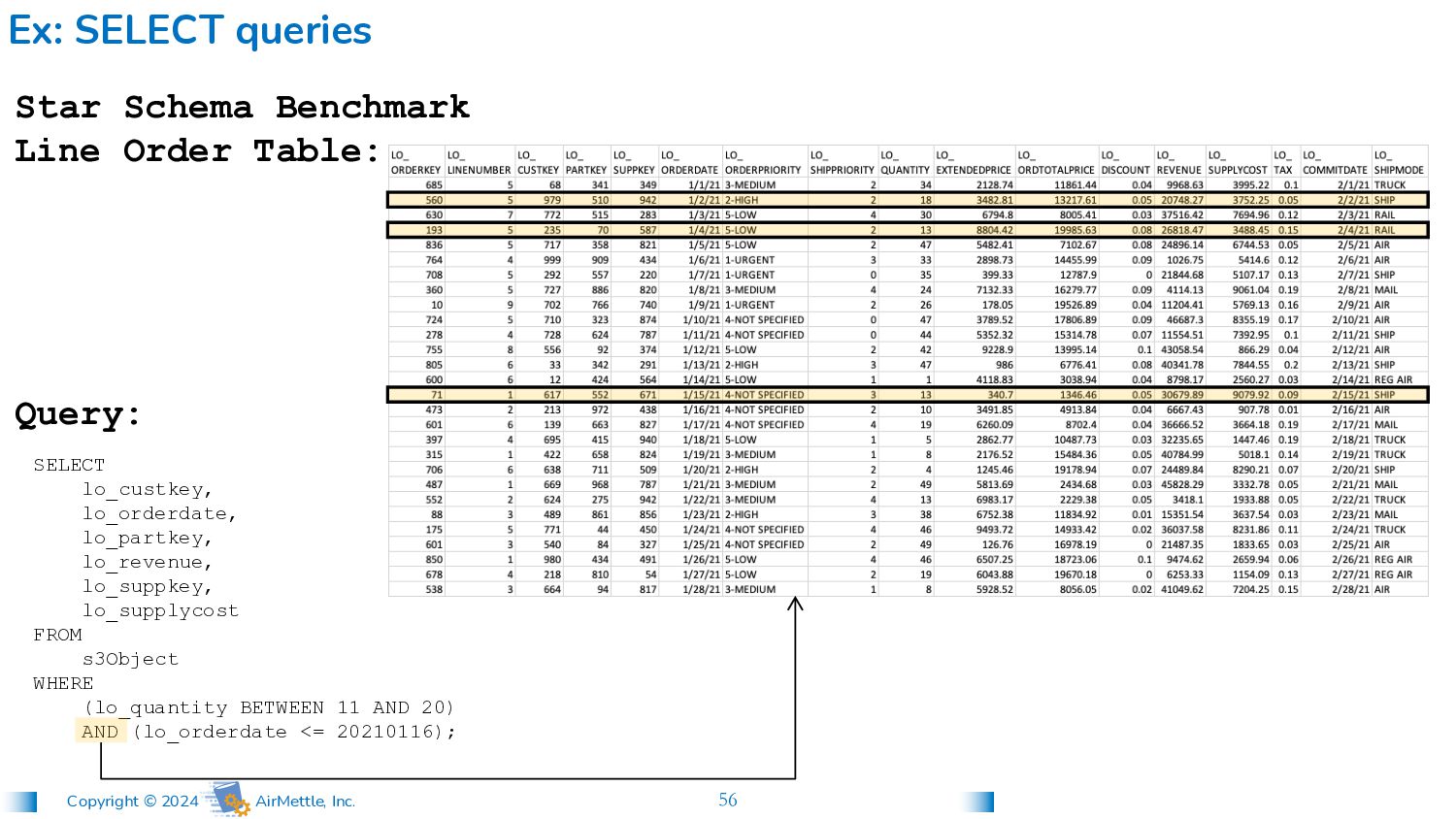
lo_custkey, lo_orderdate, lo_partkey, lo_revenue, lo_suppkey, lo_supplycost FROM s3Object WHERE (lo_quantity BETWEEN 11 AND 20) AND (lo_orderdate <= 20210116); Star Schema Benchmark Line Order Table: Query:
lo_custkey, lo_orderdate, lo_partkey, lo_revenue, lo_suppkey, lo_supplycost FROM s3Object WHERE (lo_quantity BETWEEN 11 AND 20) AND (lo_orderdate <= 20210116); Star Schema Benchmark Line Order Table: Query:
lo_custkey, lo_orderdate, lo_partkey, lo_revenue, lo_suppkey, lo_supplycost FROM s3Object WHERE (lo_quantity BETWEEN 11 AND 20) AND (lo_orderdate <= 20210116); Star Schema Benchmark Line Order Table: Query:
lo_custkey, lo_orderdate, lo_partkey, lo_revenue, lo_suppkey, lo_supplycost FROM s3Object WHERE (lo_quantity BETWEEN 11 AND 20) AND (lo_orderdate <= 20210116); Star Schema Benchmark Line Order Table: Query:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}