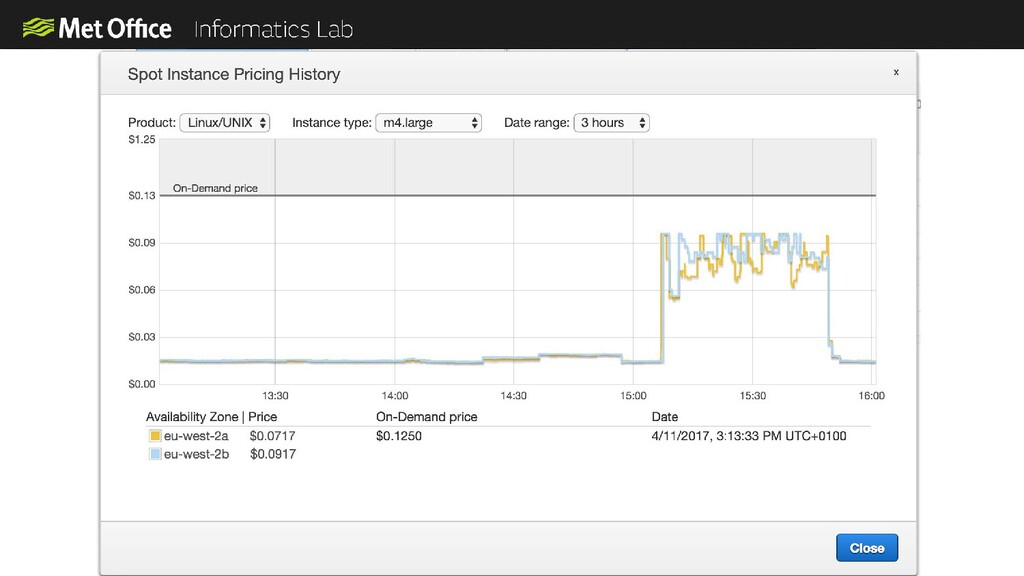
In order to analyse the petabytes of data we have at the Met Office we need very large clusters of servers. However procuring these pieces of infrastructure takes months or even years of planning and large up-front capital expense.
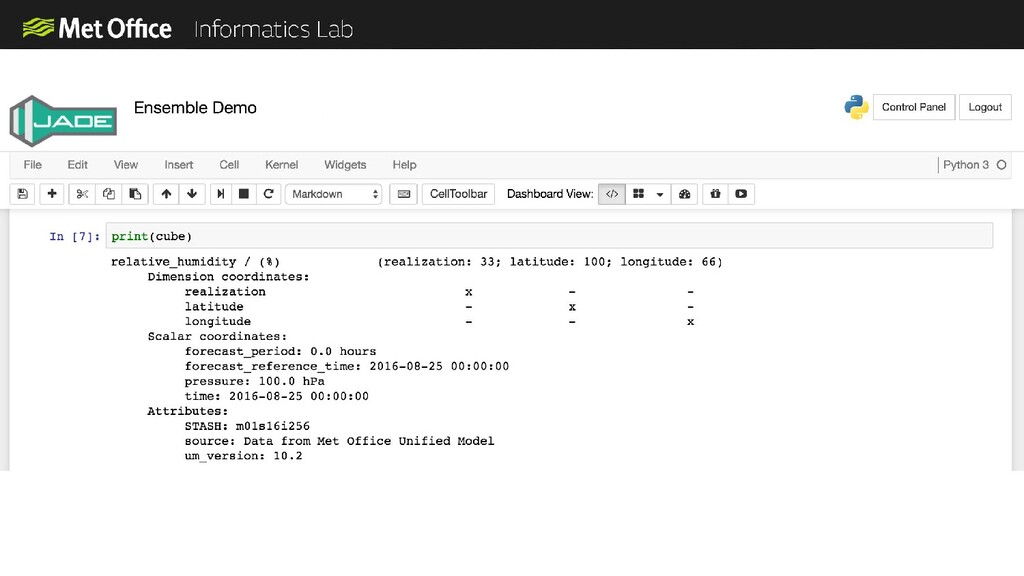
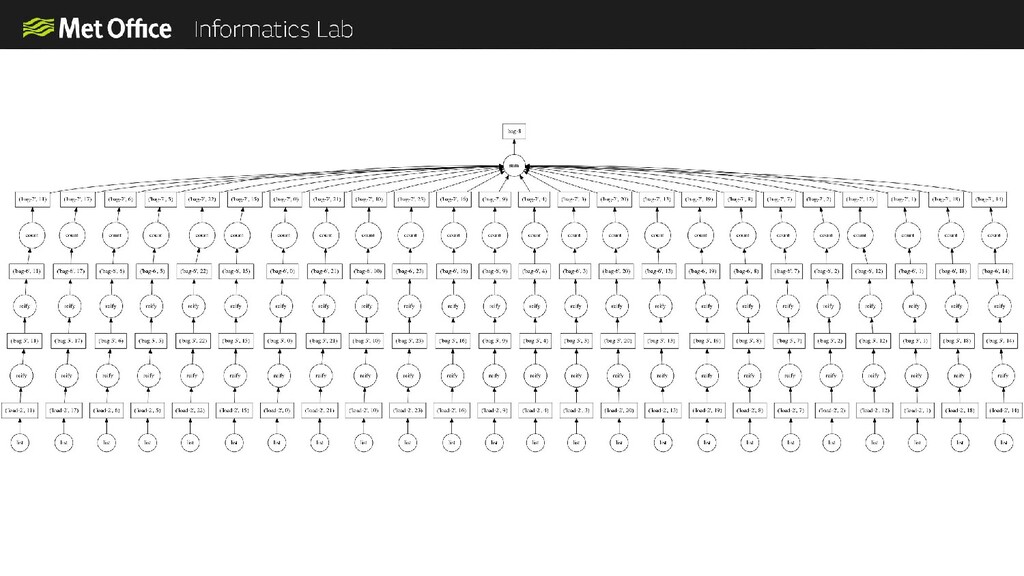
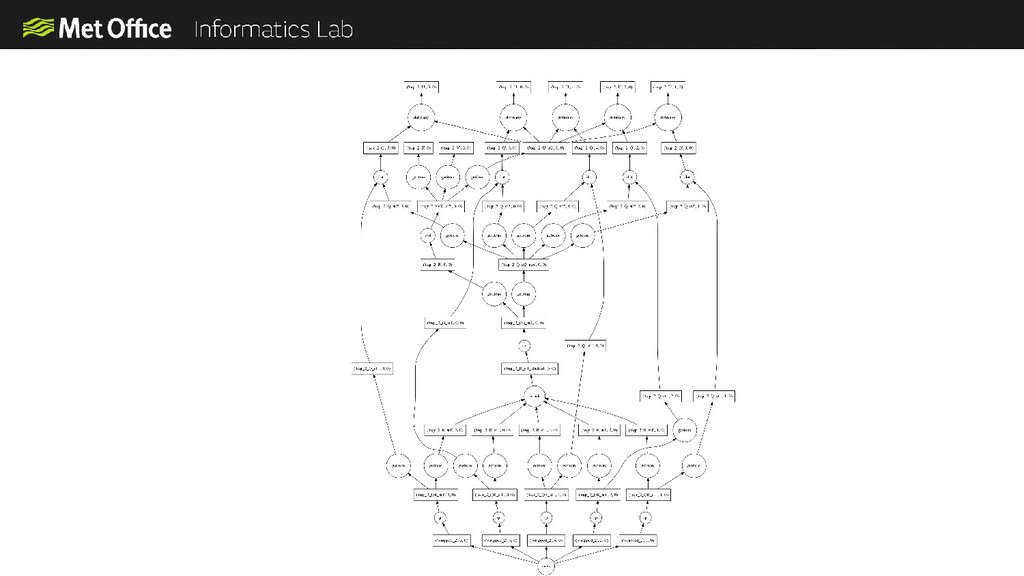
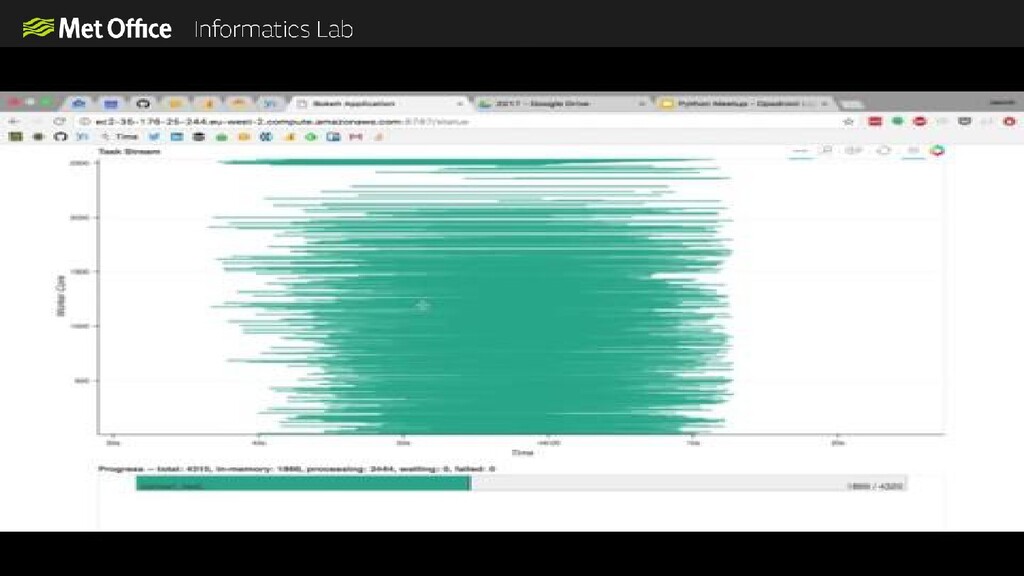
In the Informatics Lab we have been exploring using scalable cloud infrastructure to create next generation data analysis clusters. In our latest prototype we used scalable resources from AWS along with a Python computation scheduler called Dask to create clusters with thousands of CPU cores on-demand. The cluster only exists for the time that we need it and then we can shut it down again, so we only pay for what we use.
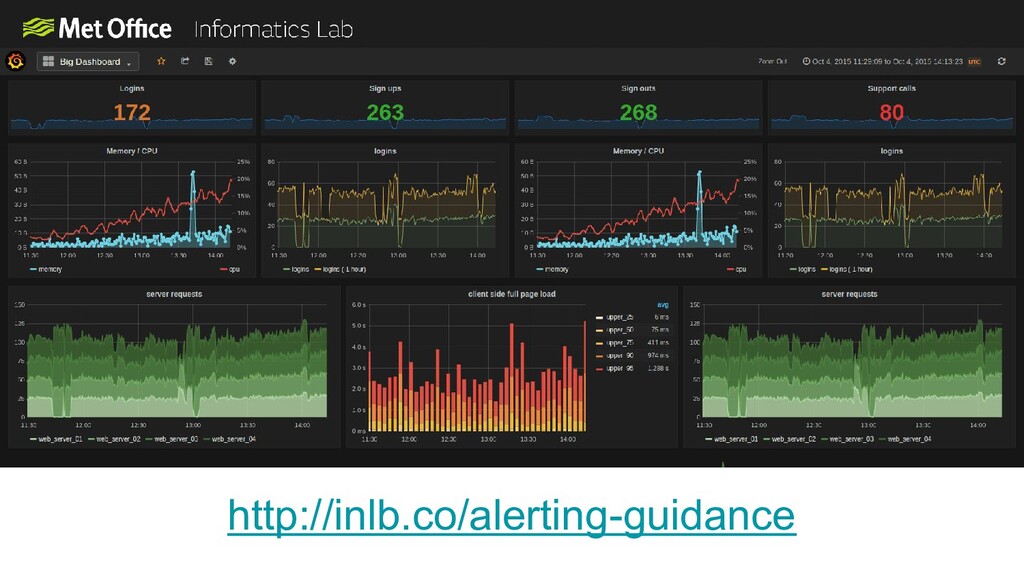
Scaling to these levels takes a lot of thinking about. In order for everything to scale linearly you need to also scale your data access, monitoring, system configuration and everything else to avoid bottlenecks.
This talk will cover the practicalities of building these things, the pitfalls we found when crossing certain thresholds and the new challenges we face when working in this new paradigm.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}