forecast accuracy RAPIDS | Dask | XGBoost Processing relationships between 10 million biological entities through more than a billion edges. cuGraph 70% Cost savings 33% Performance improvement RAPIDS Accelerator for Apache Spark RAPIDS Adopted Across Industries
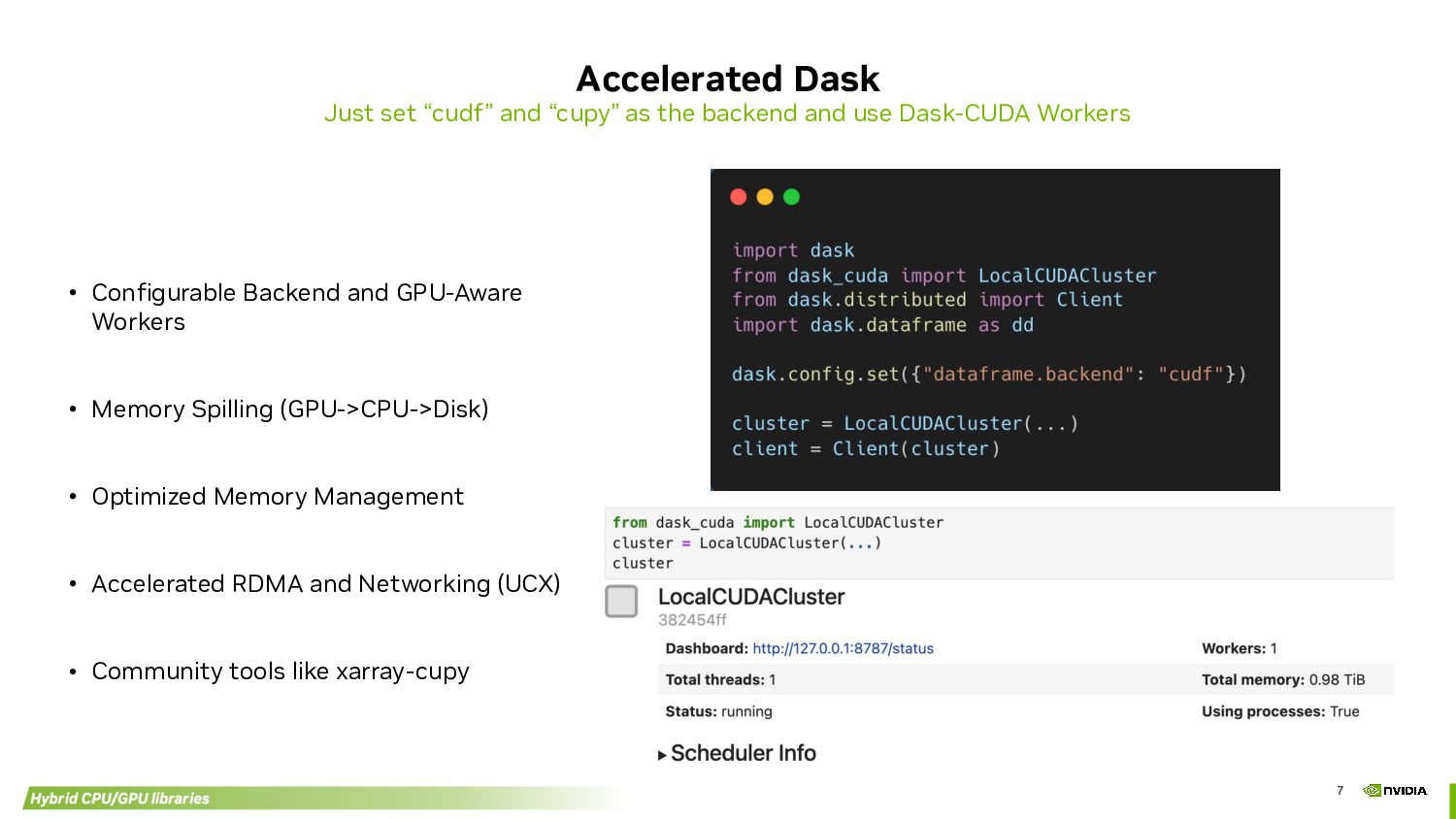
backend and use Dask-CUDA Workers • Configurable Backend and GPU-Aware Workers • Memory Spilling (GPU->CPU->Disk) • Optimized Memory Management • Accelerated RDMA and Networking (UCX) • Community tools like xarray-cupy
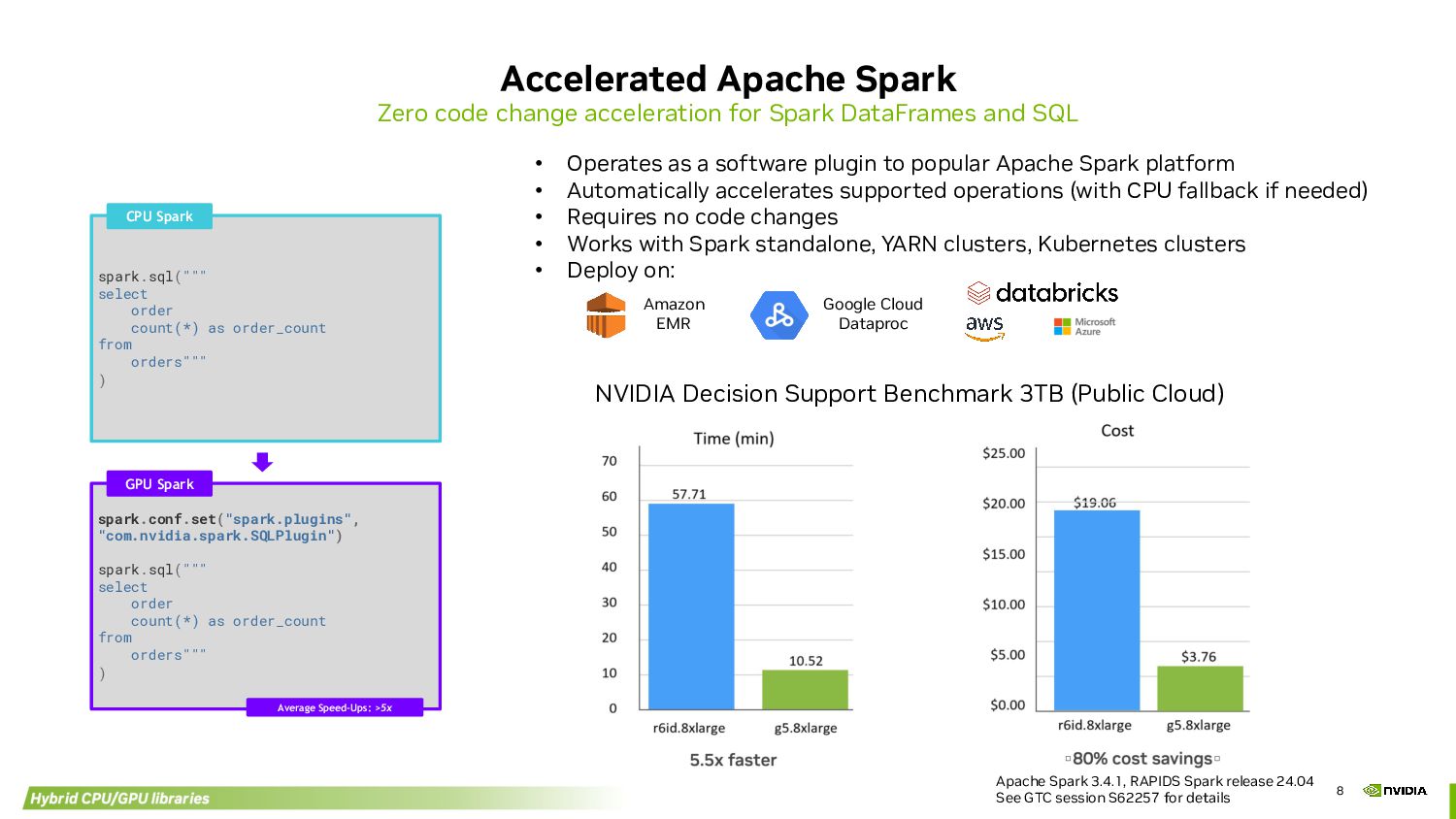
DataFrames and SQL spark.sql(""" select order count(*) as order_count from orders""" ) spark.conf.set("spark.plugins", "com.nvidia.spark.SQLPlugin") spark.sql(""" select order count(*) as order_count from orders""" ) CPU Spark GPU Spark Average Speed-Ups: >5x • Operates as a software plugin to popular Apache Spark platform • Automatically accelerates supported operations (with CPU fallback if needed) • Requires no code changes • Works with Spark standalone, YARN clusters, Kubernetes clusters • Deploy on: Apache Spark 3.4.1, RAPIDS Spark release 24.04 See GTC session S62257 for details NVIDIA Decision Support Benchmark 3TB (Public Cloud) Amazon EMR Google Cloud Dataproc
NetworkX • Zero-code-change GPU-acceleration of for NetworkX code • Accelerates algorithms up to 600x, based on algorithm and graph size • Support for 60 popular graph algorithms and growing • Falls back to using CPU NetworkX for unsupported algorithms NetworkX 3.2, CPU: Intel(R) Xeon(R) Platinum 8480CL 2TB, GPU: NVIDIA H100 80GB pip install nx-cugraph-cu12 --extra-index-url https://pypi.nvidia.com conda install -c rapidsai -c conda-forge -c nvidia nx-cugraph
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}