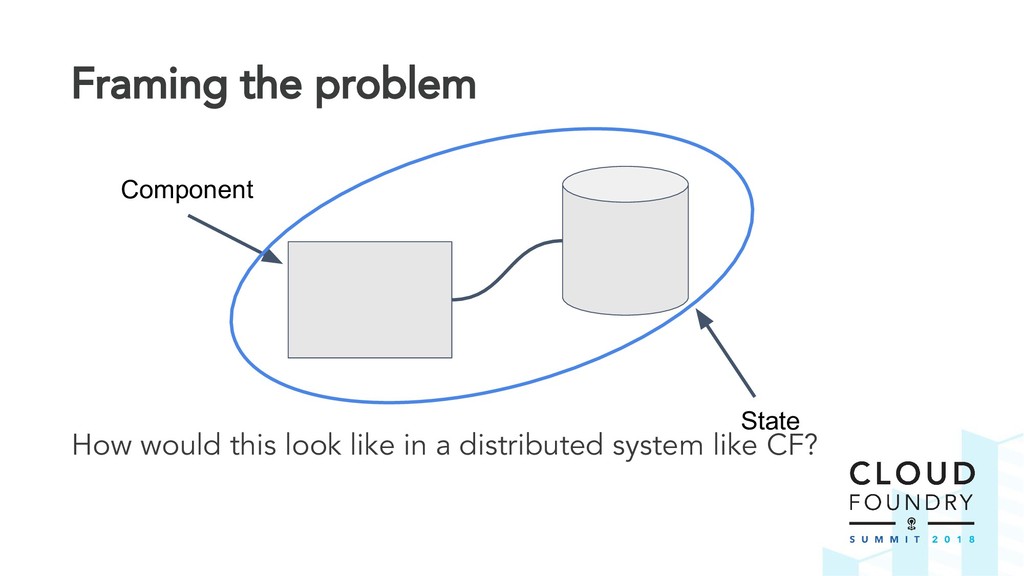
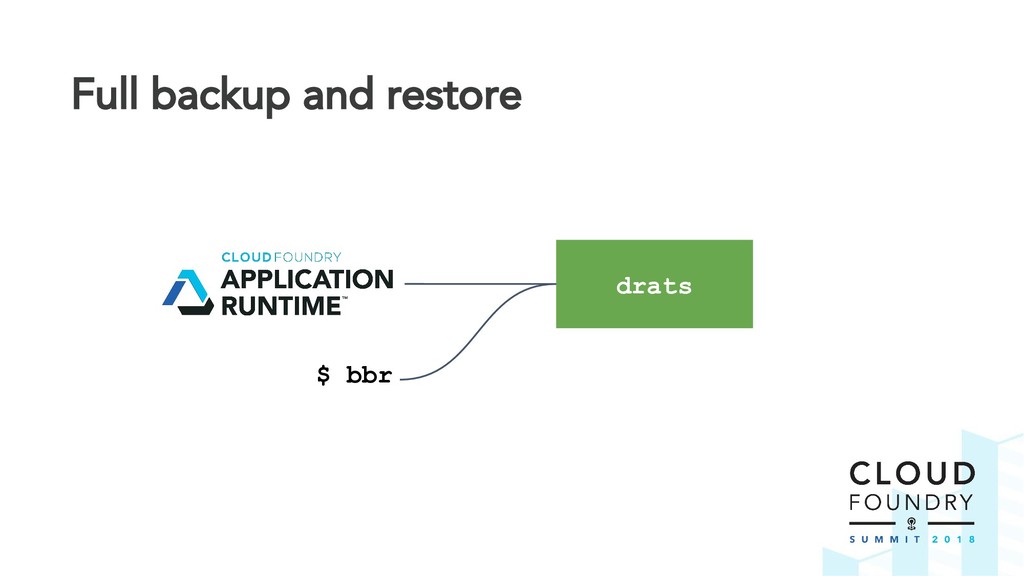
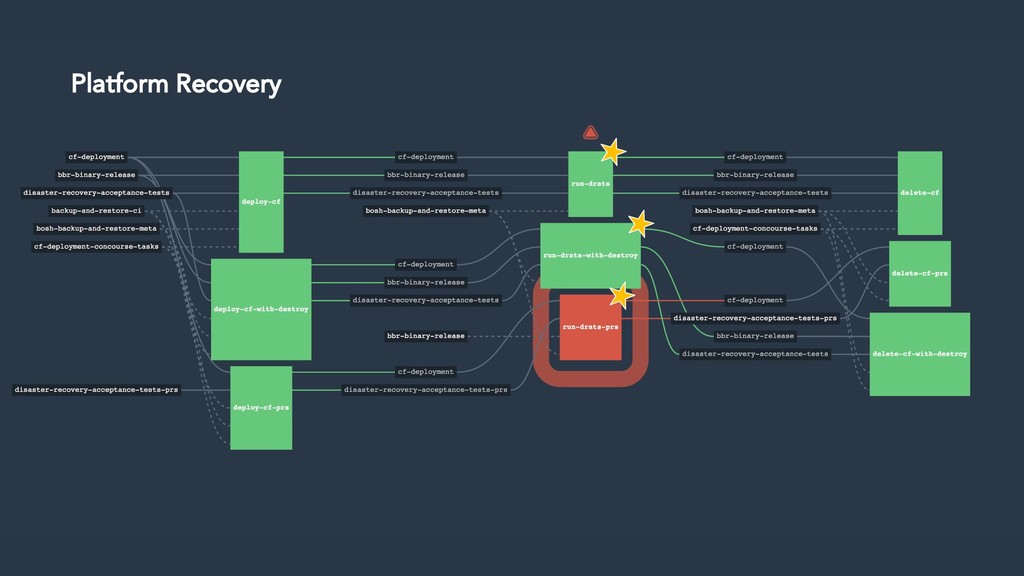
Natural disaster hit your data centre? Don't worry. Cloud Foundry is prepared for disaster from day one thanks to built-in support for BOSH backup and restore (BBR). Nice. But how do we know the platform is ready for catastrophe? What if our worst fears come true?
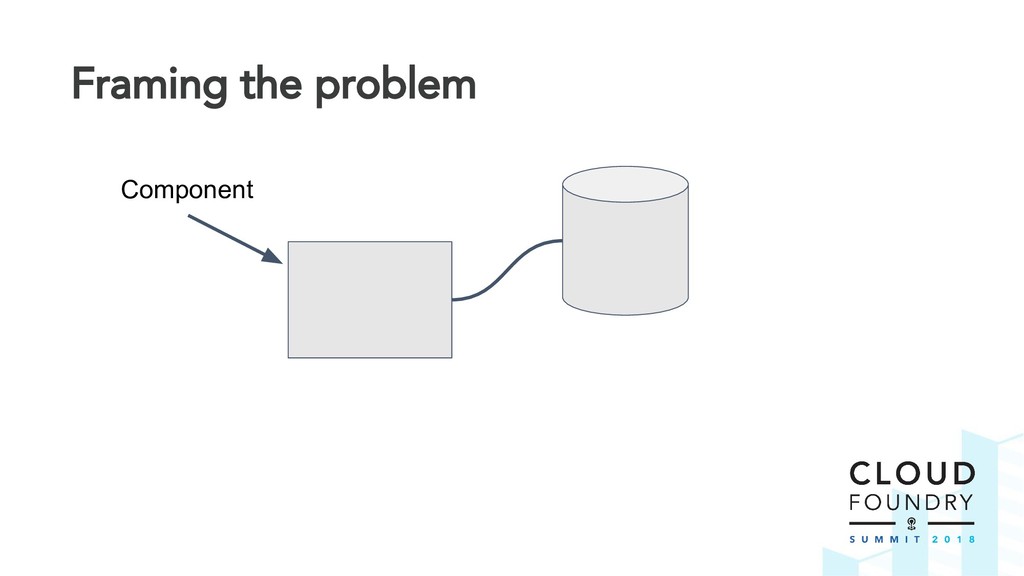
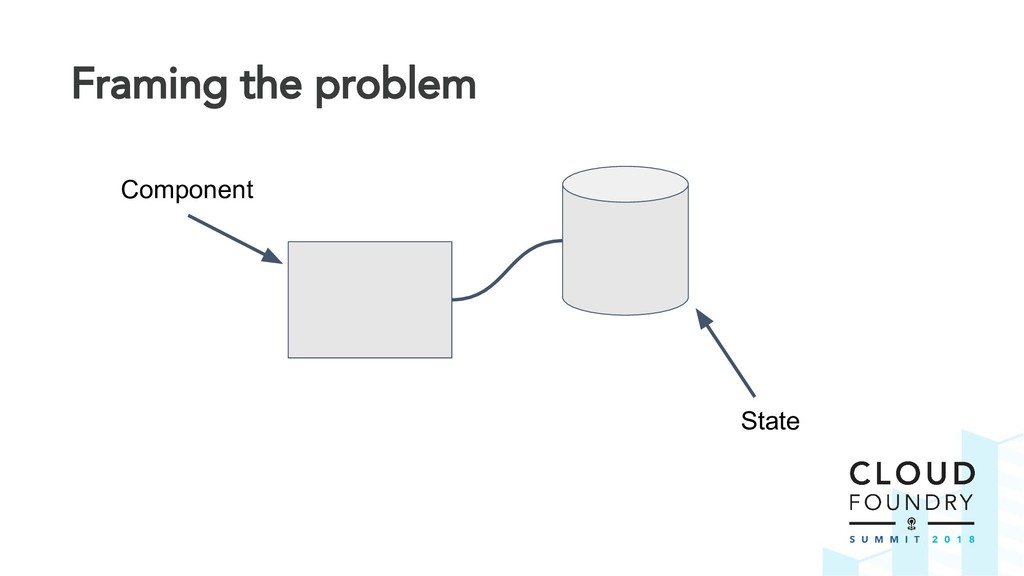
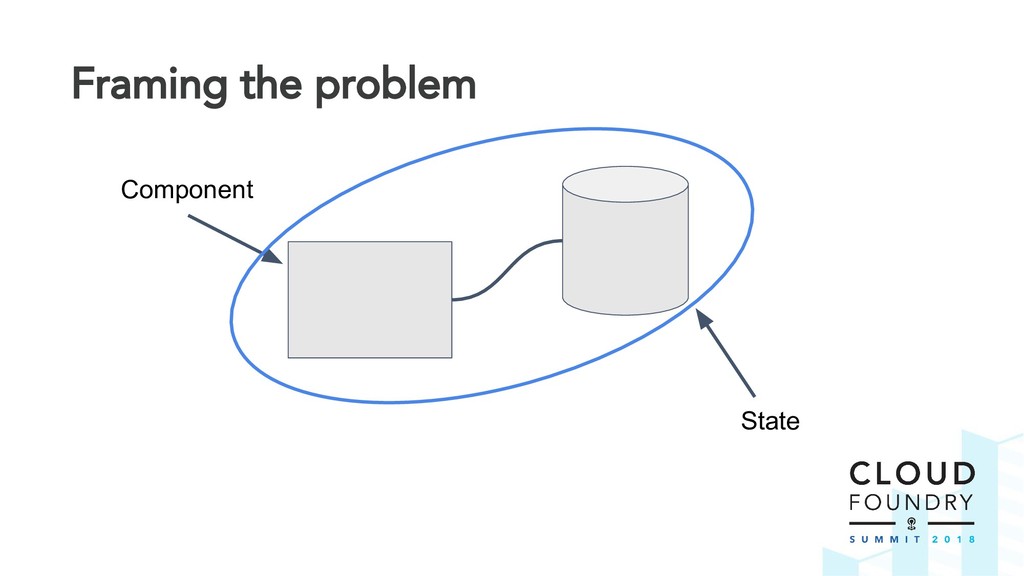
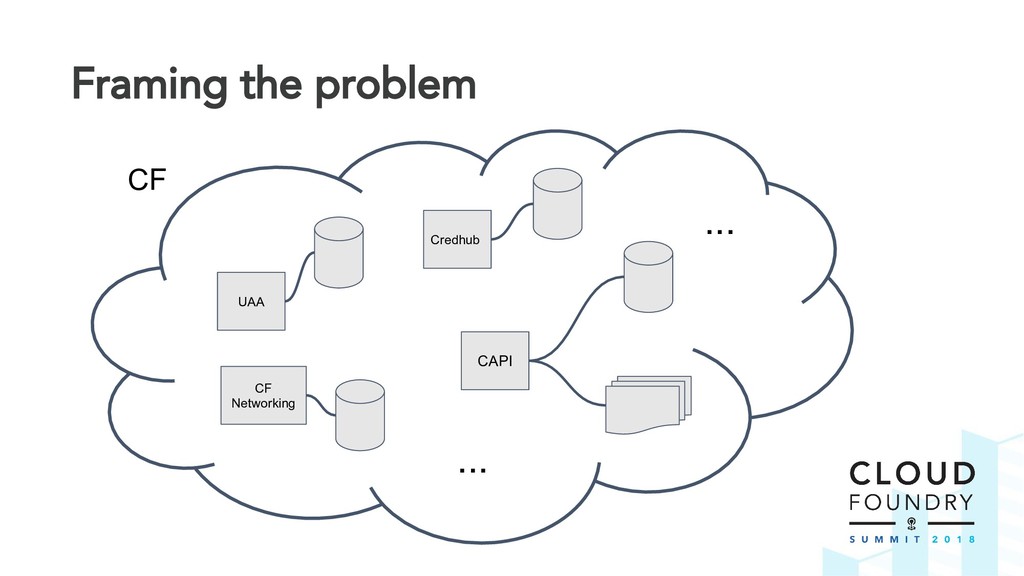
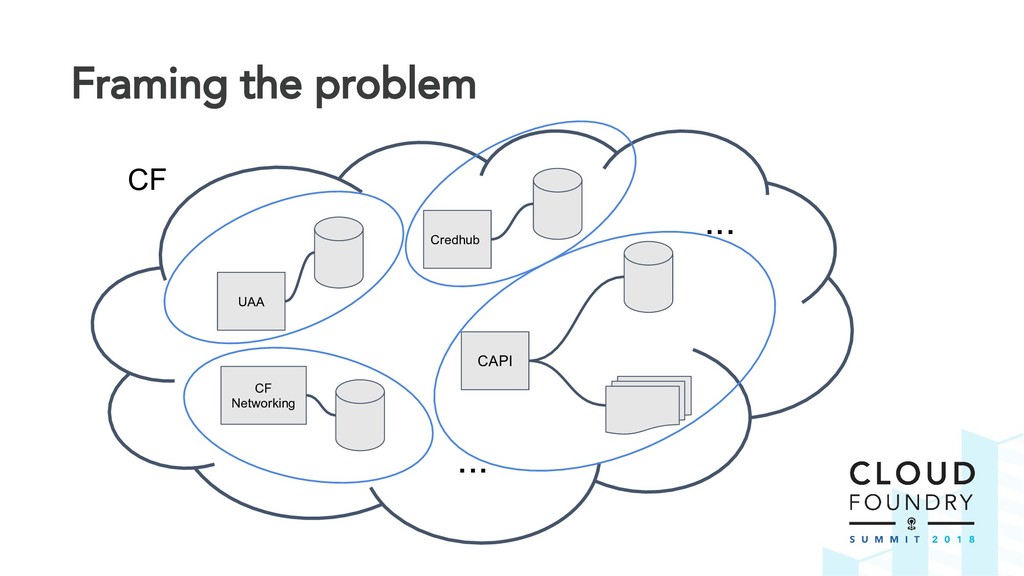
The BBR framework laid the technical foundation for implementing disaster recovery. However, Cloud Foundry is a complex distributed system and contributors are spread across multiple teams and timezones. The challenge was to find a way to drive out this cross-cutting feature across all Cloud Foundry components.
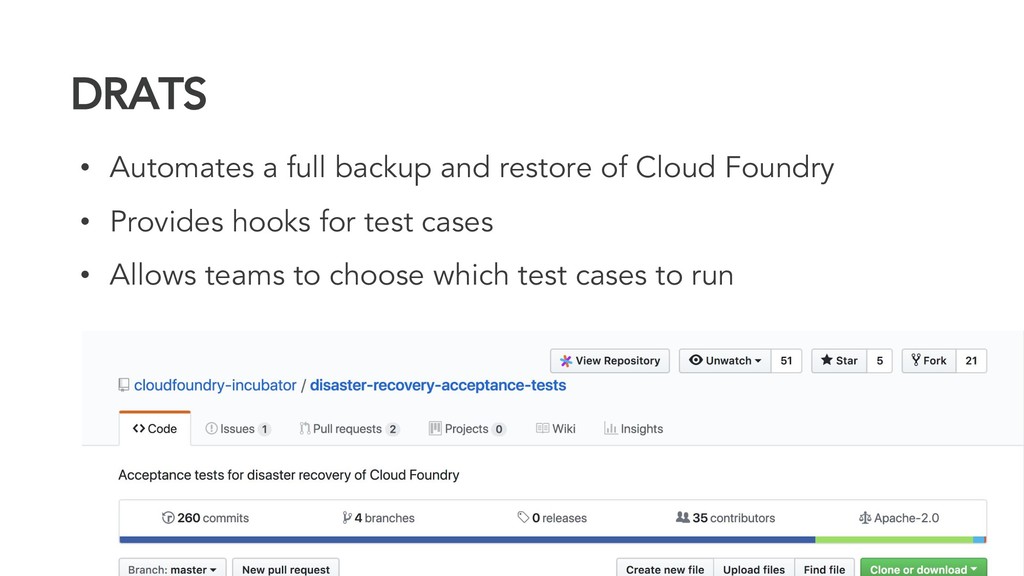
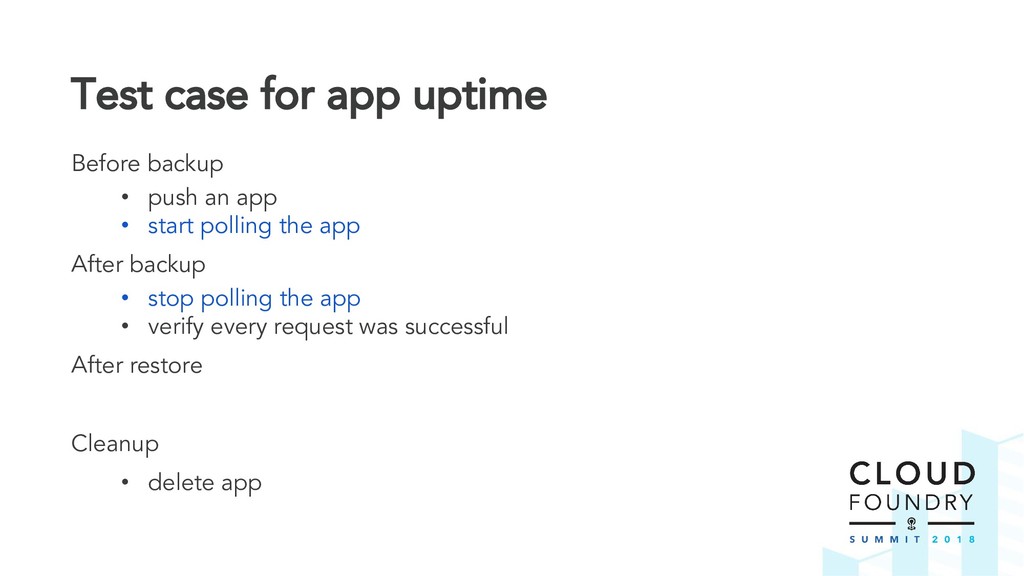
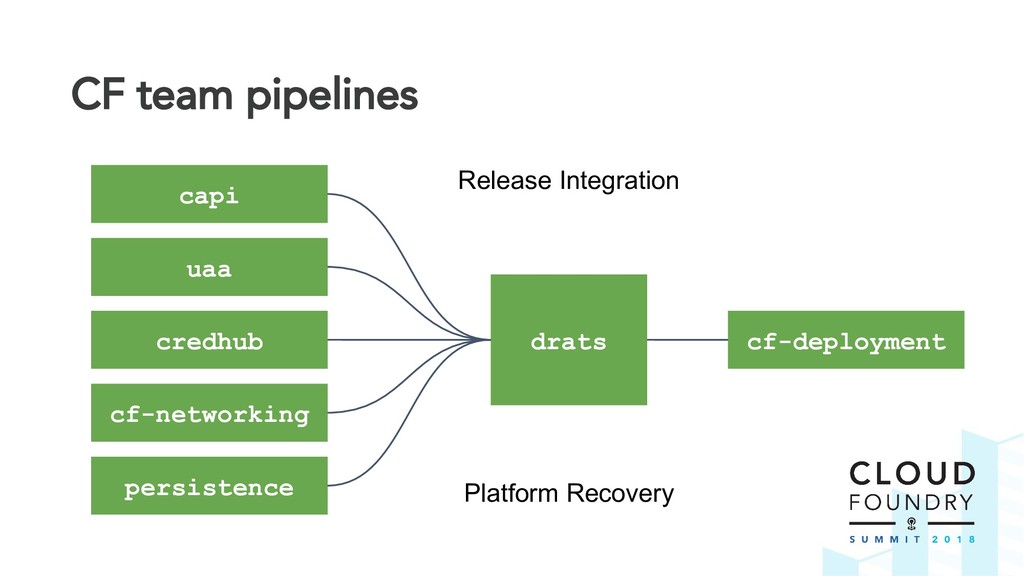
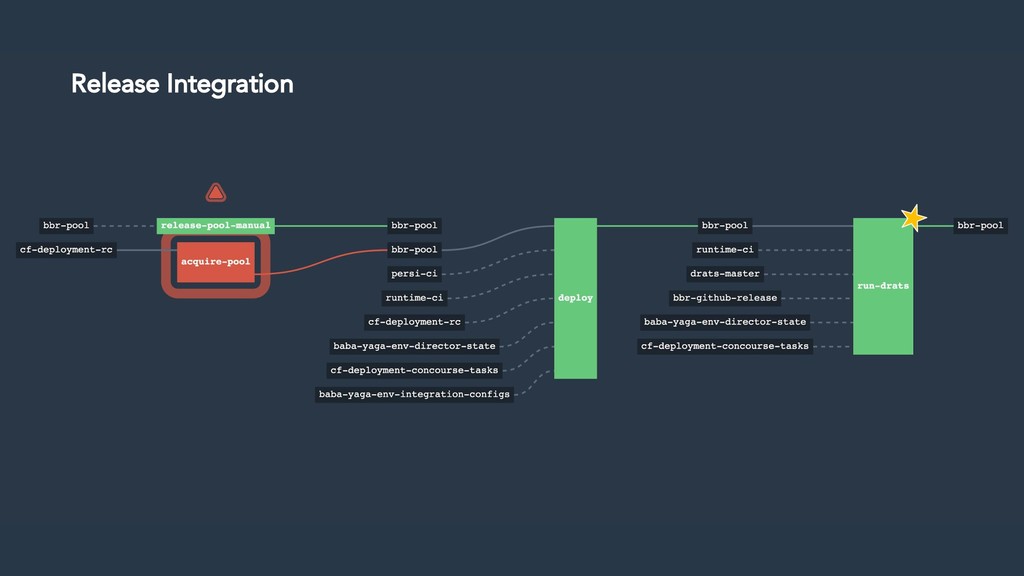
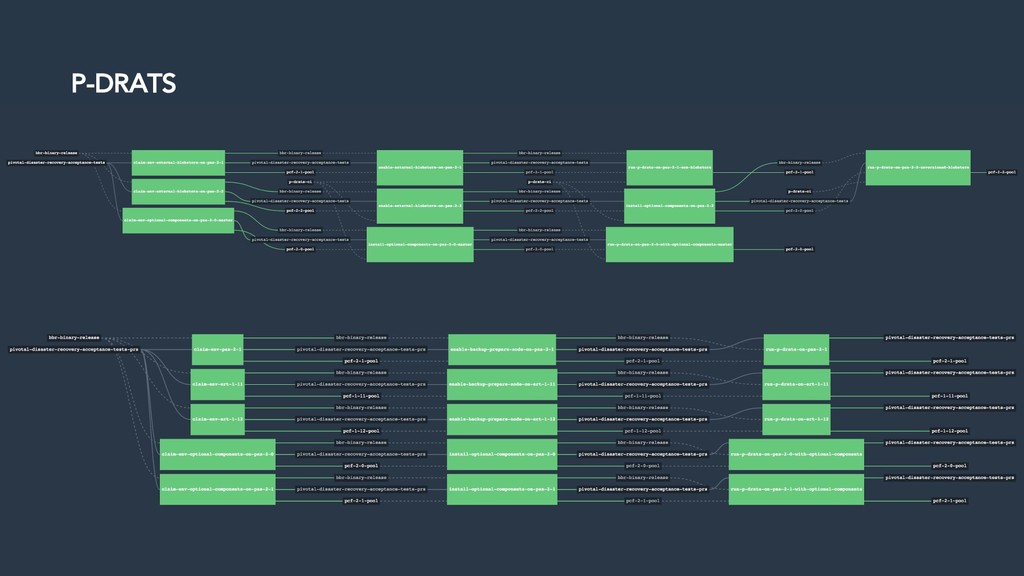
Thus the Disaster Recovery Acceptance Tests (DRATs) were born. Josh and Emmanouil will show you the test framework that continuously tests a critical feature of the platform. DRATs ensures that all the Cloud Foundry components continue to work together, so we can all be confident that the platform can recover when mishaps occur.
After this talk attendees will:
* take away patterns for developing features with cross-cutting concerns.
* understand DRATs and how Cloud Foundry teams test their components.
* understand how to deliver CI tasks that can be shared by many teams in their own CI pipelines.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}