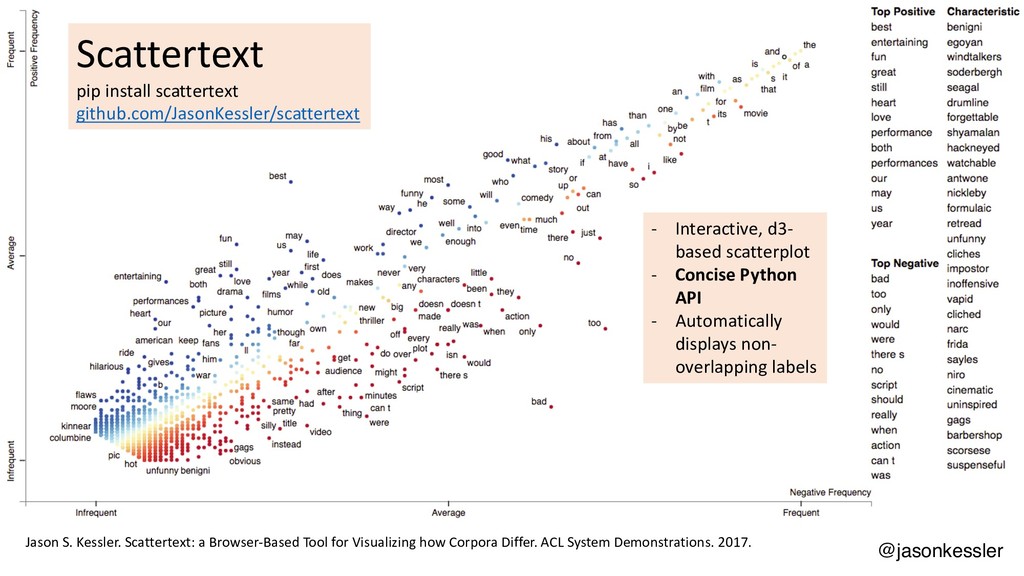
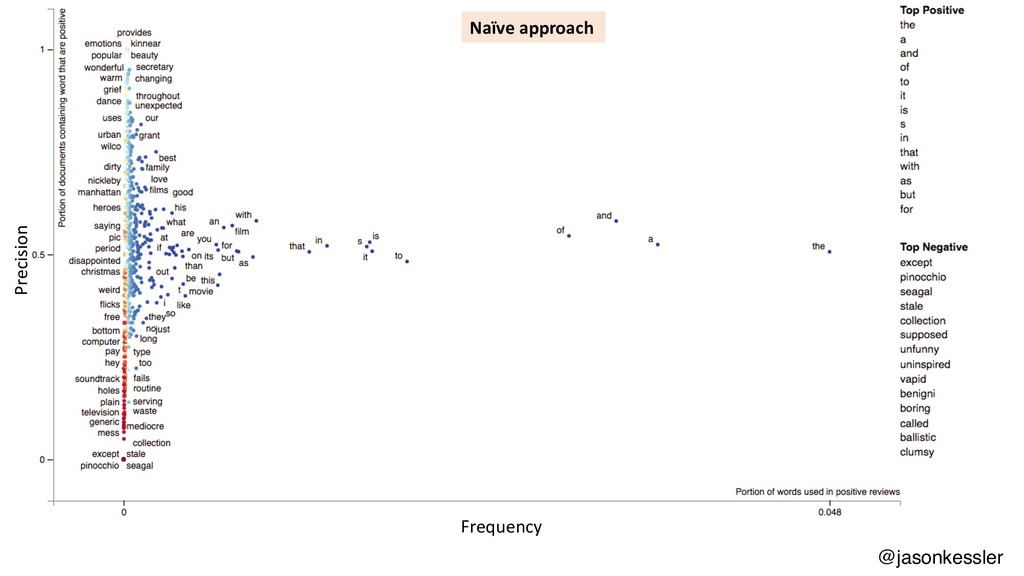
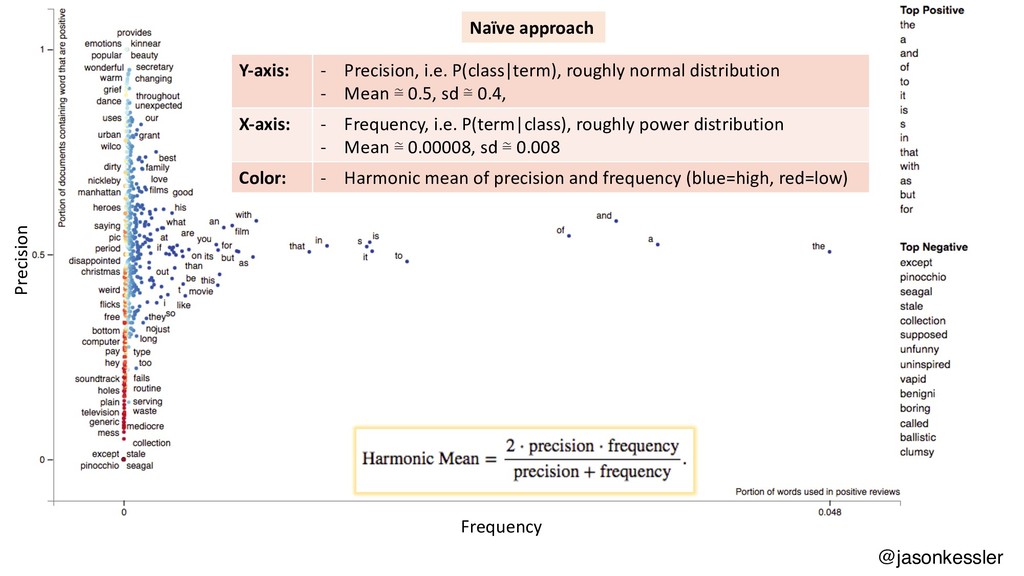
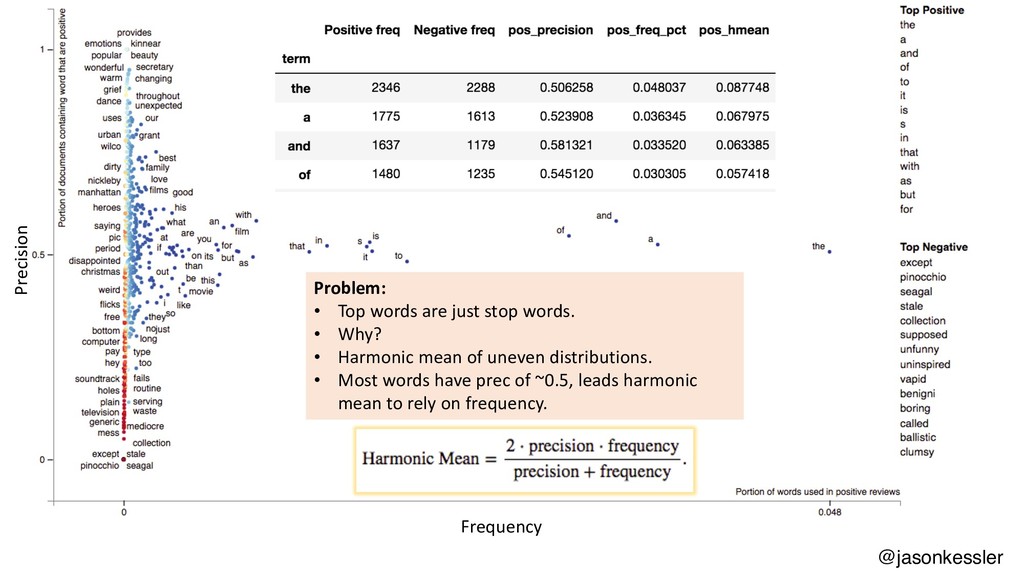
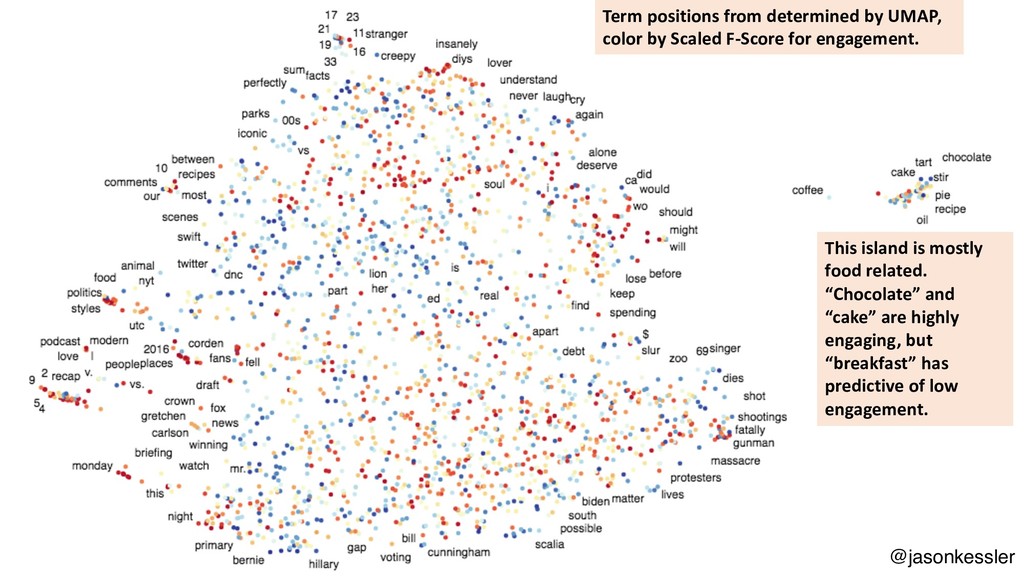
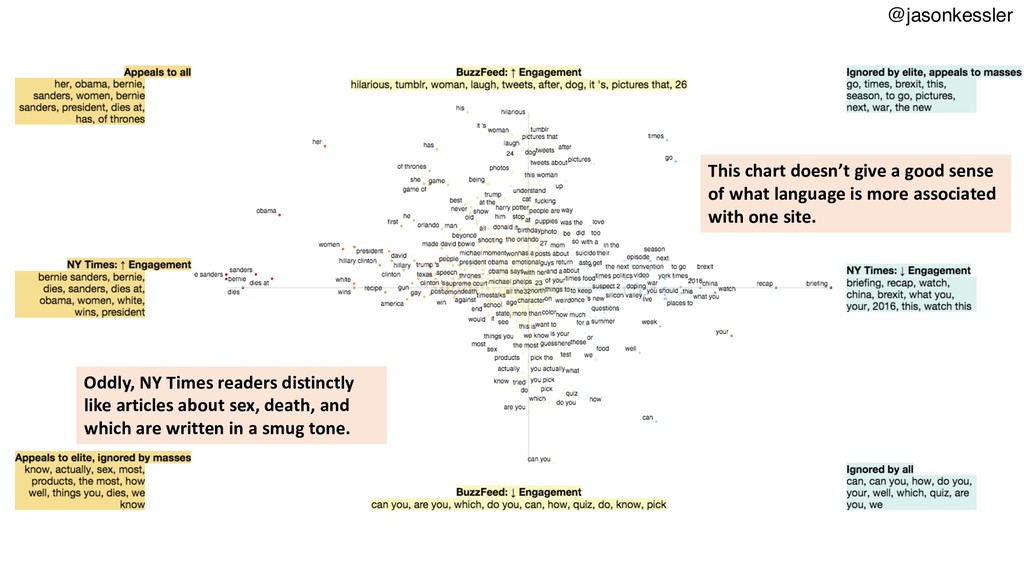
Scattertext is a Python package that lets you compare and contrast how words and phrases are used differently in two types of documents, producing interactive, Javascript-based visualizations. This talk will cover the use of Scattertext, issues in creating dense scatterplots, and discuss statistical term-association and phrase identification algorithms. The code used in the talk will be available as a repository on my Github account, http://www.github.com/JasonKessler/GlobalAI2018
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
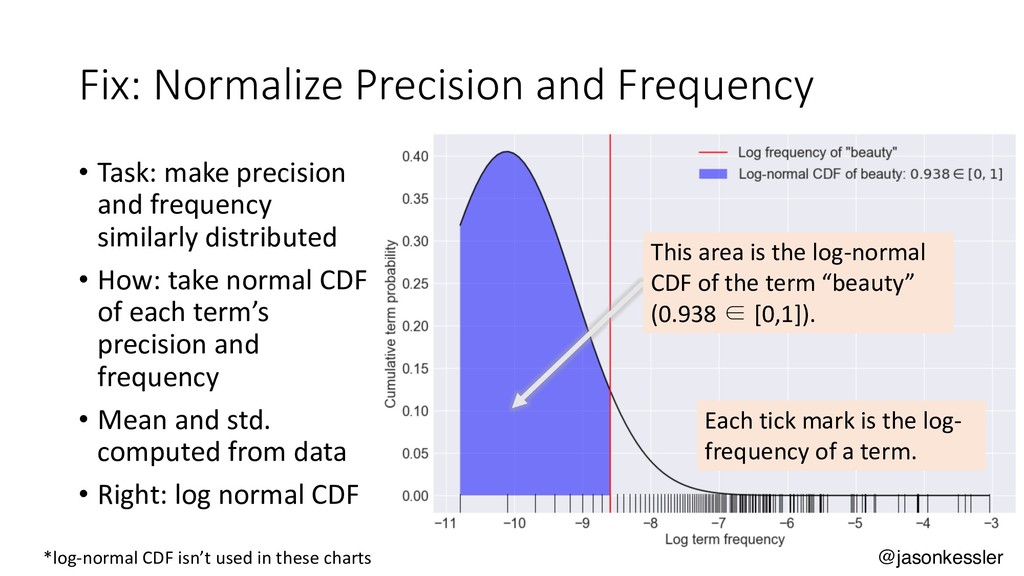{kind=link}
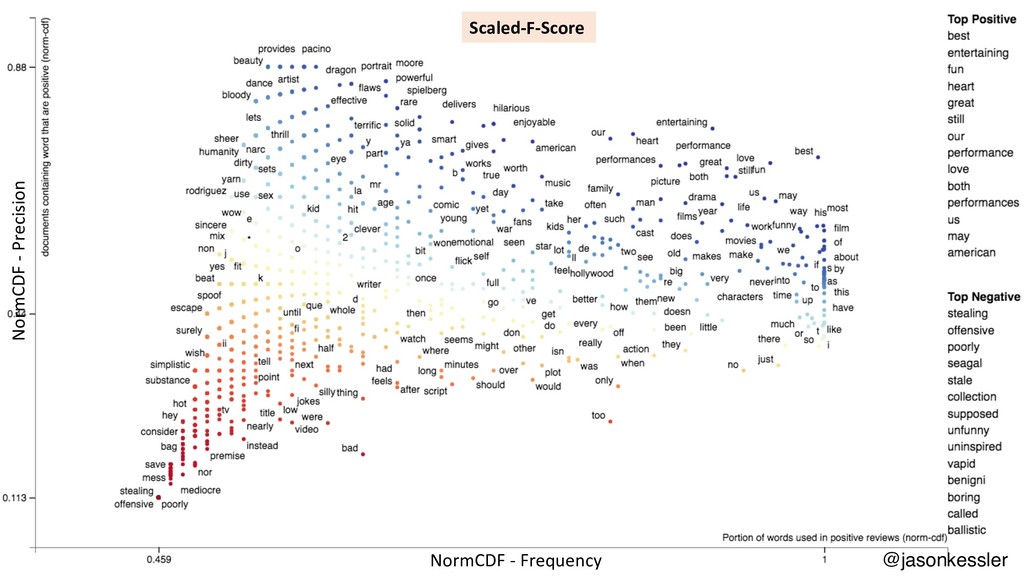{kind=link}
{kind=link}
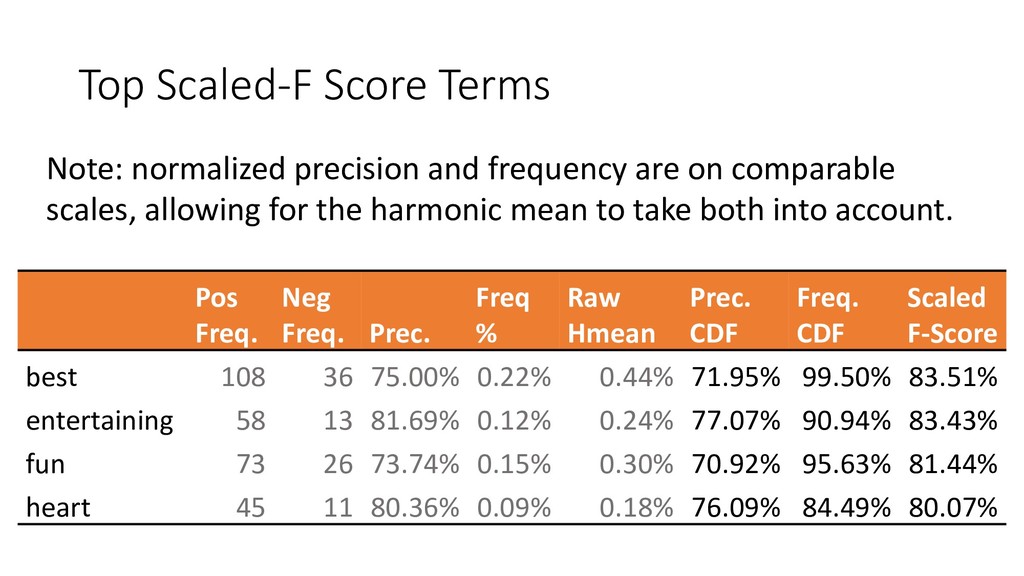{kind=link}
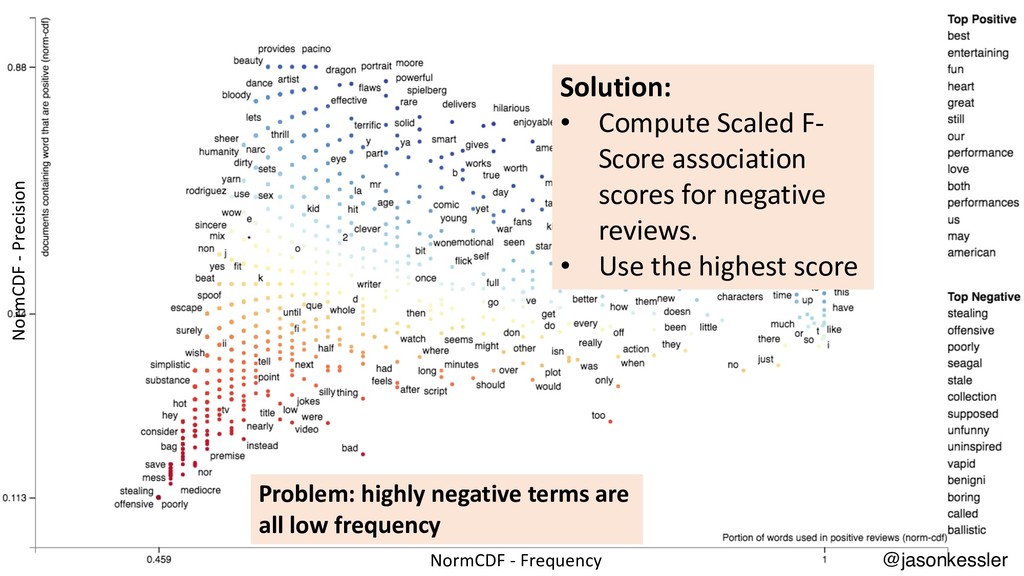{kind=link}
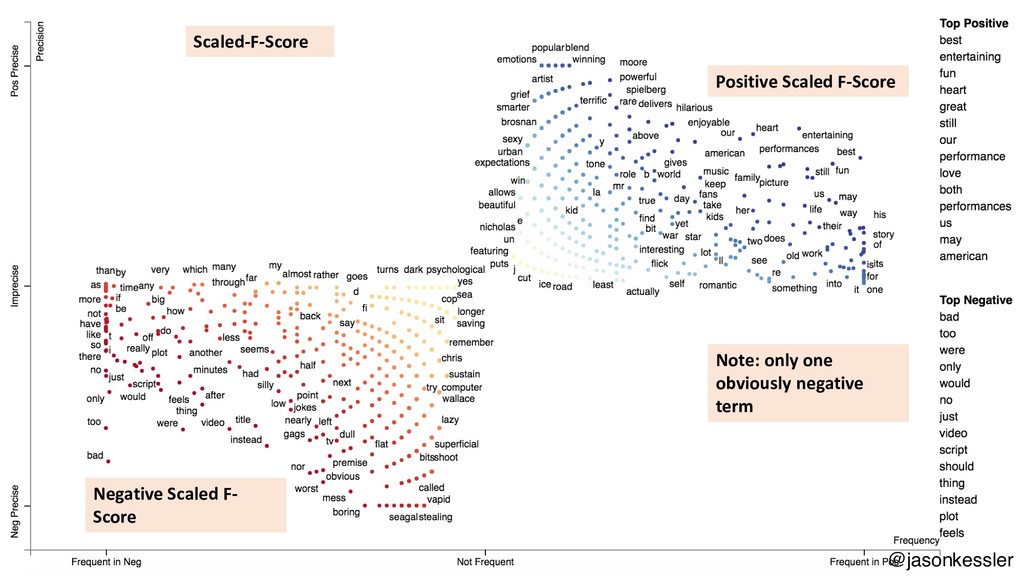{kind=link}
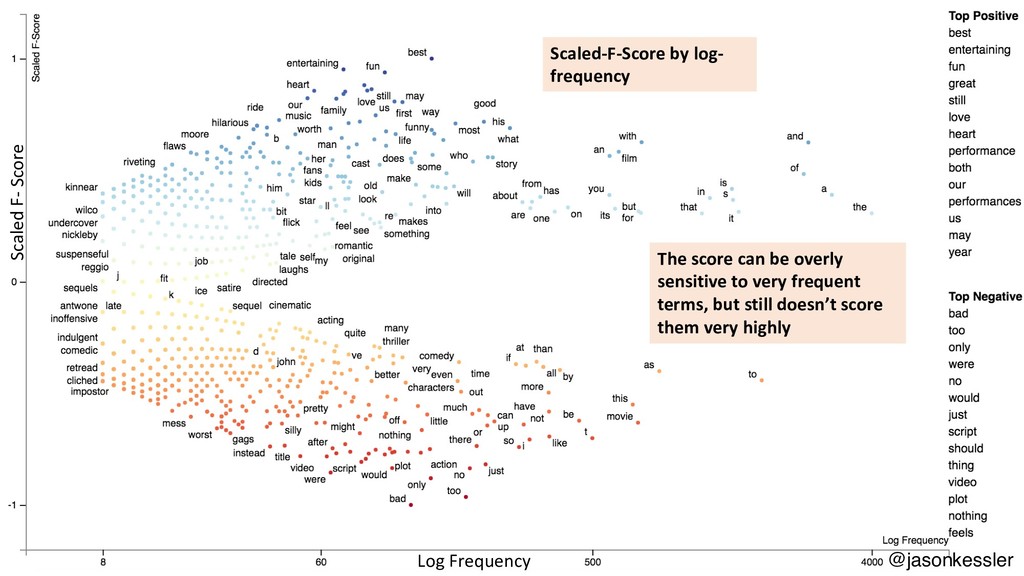{kind=link}
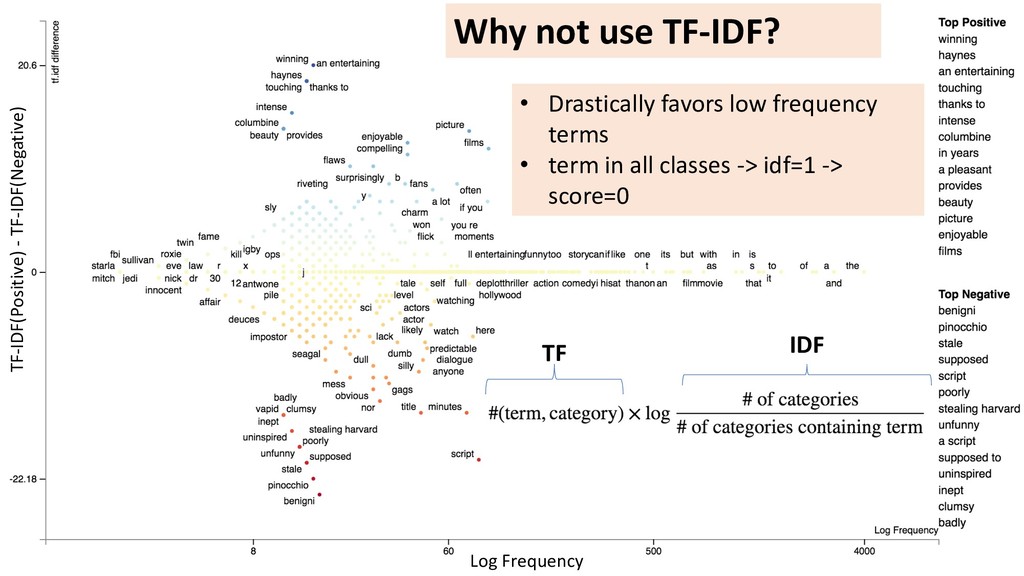{kind=link}
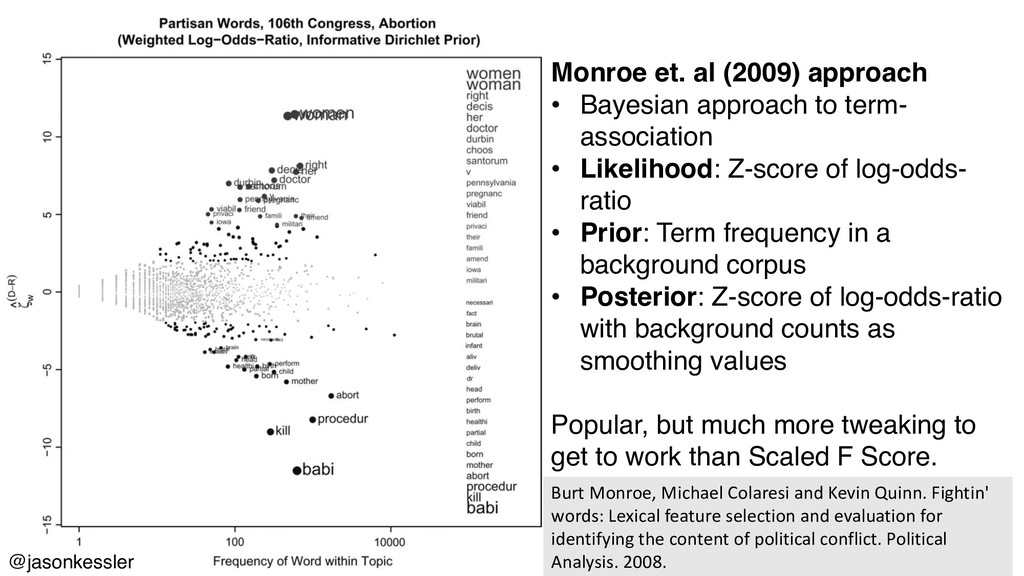{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}