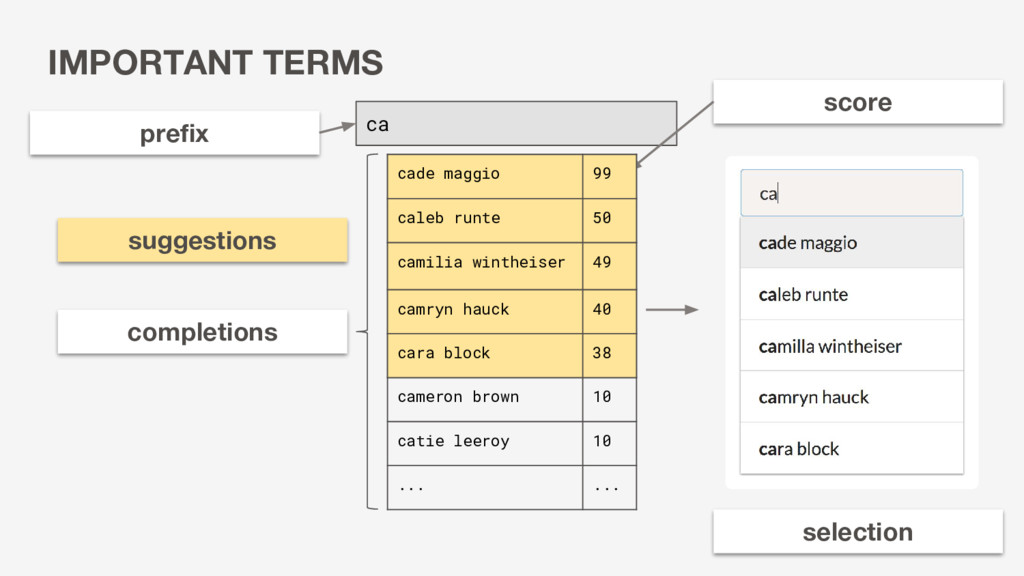
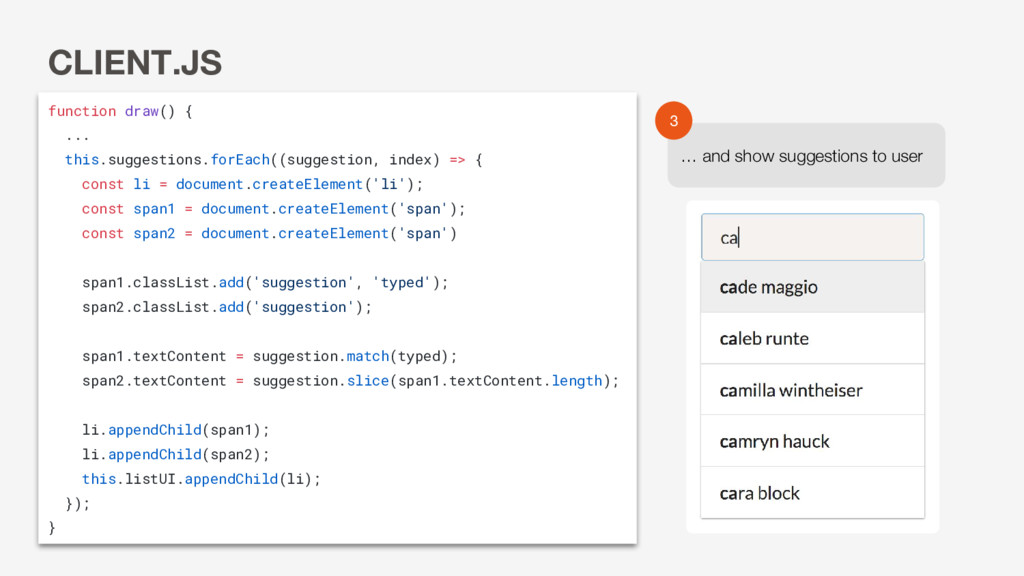
powers autocomplete suggestions • Dynamically updates and ranks autocomplete suggestions based on user input • Easy to use service for app developers to implement on any search field in their app
stages of the project • How we thought about tradeoffs as we designed and built a system from scratch • How we chose the right data structures, algorithms, and data stores for the system • How we built a system with the flexibility to scale as we get more users
Suggestions should be dynamically ranked and relevant to the app user Implications & Approach • We want to prioritize speed of reads • We need a ranking algorithm
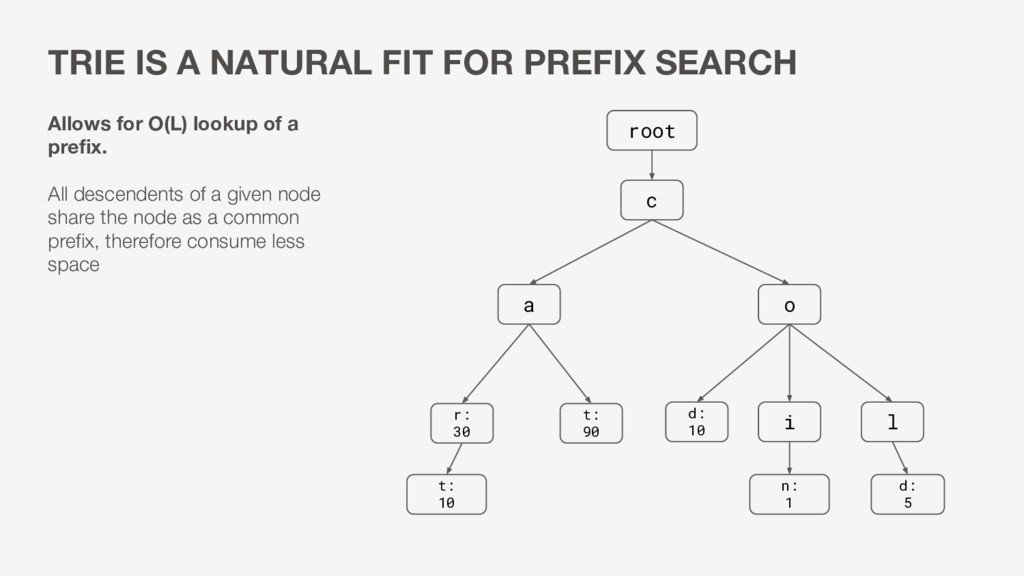
the number of keys/nodes (e.g. prefixes) in our dataset • K - the number of completions for a given prefix • L - the length of the string we are looking up
a given node share the node as a common prefix, therefore consume less space TRIE IS A NATURAL FIT FOR PREFIX SEARCH c a o r: 30 t: 90 i l n: 1 root d: 5 d: 10 t: 10
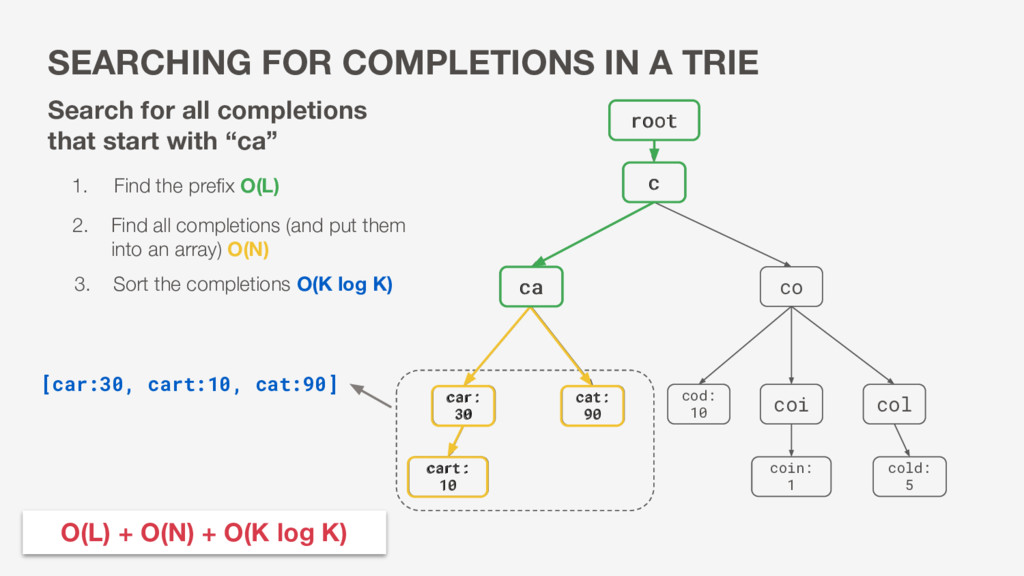
30 cat: 90 coi col coin: 1 root cold: 5 cod: 10 cart: 10 O(L) + O(N) + O(K log K) [car:30, cart:10, cat:90] 1. Find the prefix O(L) 2. Find all completions (and put them into an array) O(N) 3. Sort the completions O(K log K) Search for all completions that start with “ca” car: 30 cat: 90 cart: 10 c ca root
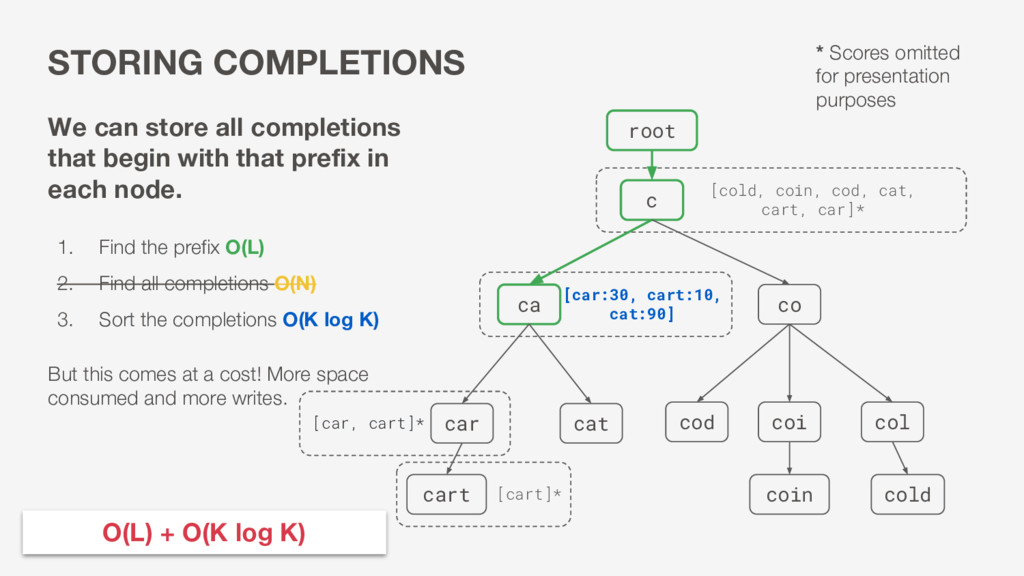
root cold cod cart We can store all completions that begin with that prefix in each node. 1. Find the prefix O(L) 2. Find all completions O(N) 3. Sort the completions O(K log K) But this comes at a cost! More space consumed and more writes. O(L) + O(K log K) [car:30, cart:10, cat:90] * Scores omitted for presentation purposes [cold, coin, cod, cat, cart, car]* [car, cart]* [cart]*
max length of prefixes we store Hold L constant • “Tyrannosaurus Rex lived during the late Cretaceous period” Limit completion bucket size in node Hold K constant • Only need enough to support suggestions and ranking O(L) + O(K log K) O(1) + O(1) O(1)
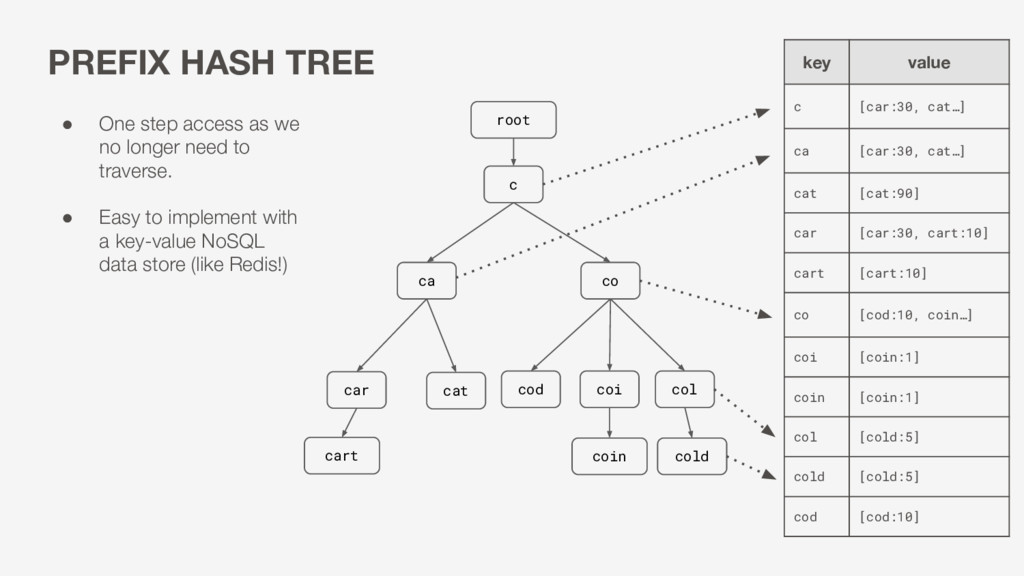
coin root cold cod cart • One step access as we no longer need to traverse. • Easy to implement with a key-value NoSQL data store (like Redis!) key value c [car:30, cat…] ca [car:30, cat…] cat [cat:90] car [car:30, cart:10] cart [cart:10] co [cod:10, coin…] coi [coin:1] coin [coin:1] col [cold:5] cold [cold:5] cod [cod:10]
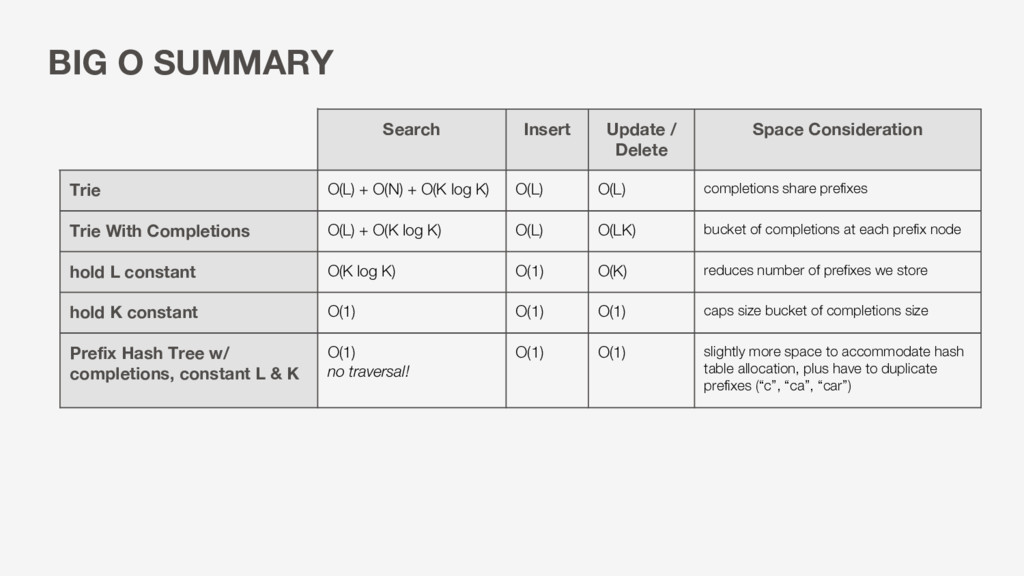
Trie O(L) + O(N) + O(K log K) O(L) O(L) completions share prefixes Trie With Completions O(L) + O(K log K) O(L) O(LK) bucket of completions at each prefix node hold L constant O(K log K) O(1) O(K) reduces number of prefixes we store hold K constant O(1) O(1) O(1) caps size bucket of completions size Prefix Hash Tree w/ completions, constant L & K O(1) no traversal! O(1) O(1) slightly more space to accommodate hash table allocation, plus have to duplicate prefixes (“c”, “ca”, “car”)
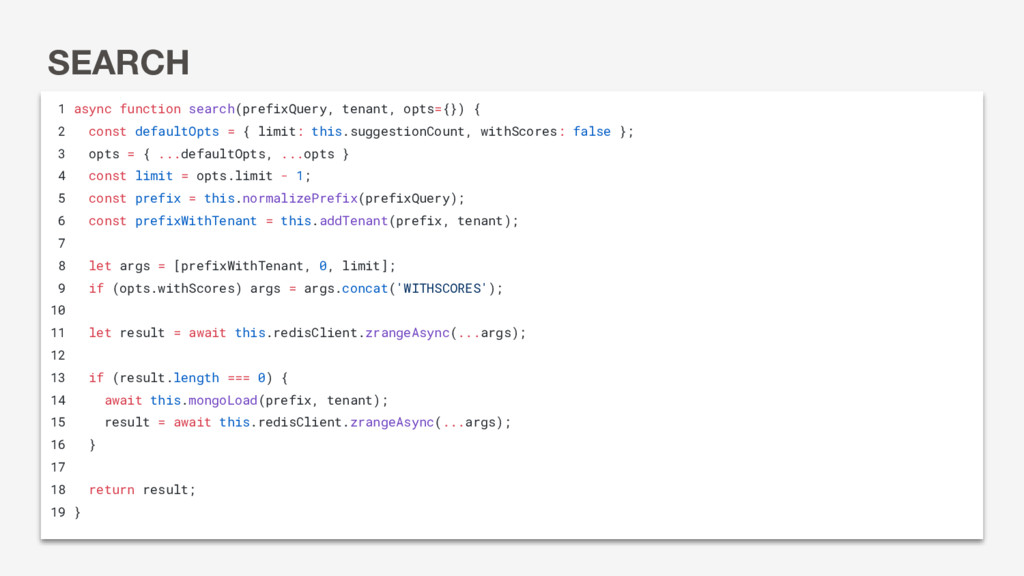
cat [cat:90] car [car:30, cart:10] cart [cart:10] co [cod:10, coin…] coi [coin:1] coin [coin:1] col [cold:5] cold [cold:5] cod [cod:10] Which Redis data structure to use for completions? • Entirely in-memory meets our performance requirement • Native in-memory data structures for managing completions
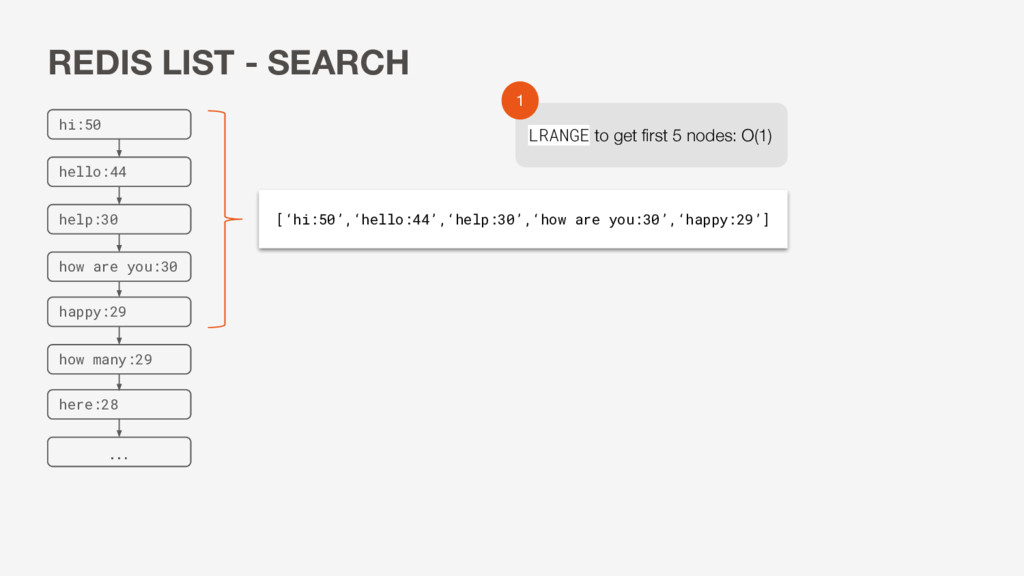
you:30 here:28 happy:29 how many:29 [‘hi:50’,‘hello:44’,‘help:30’,‘how are you:30’,‘happy:29’,‘how many:29’,’here:28’, ...] LRANGE to get entire list: O(K) 1
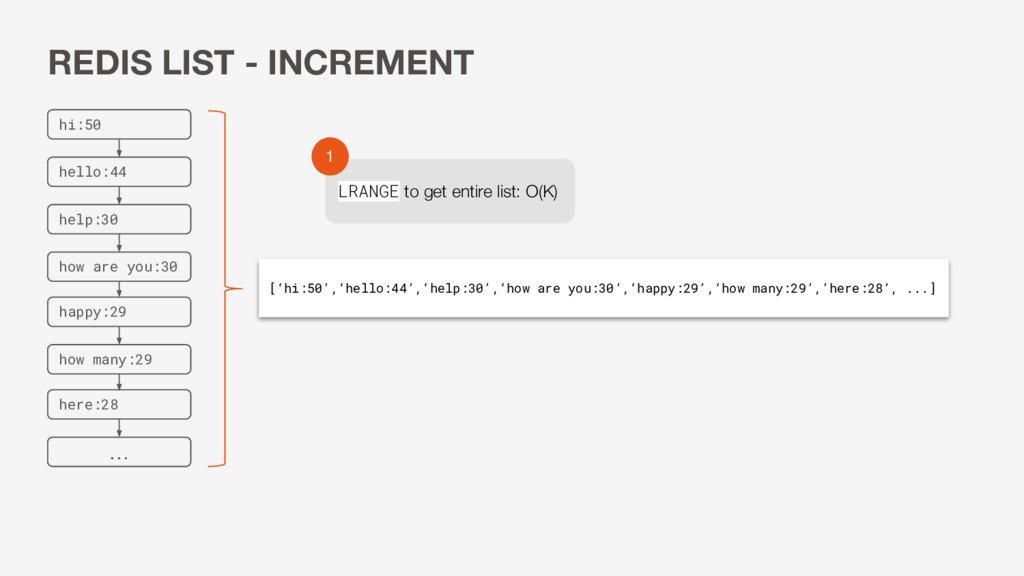
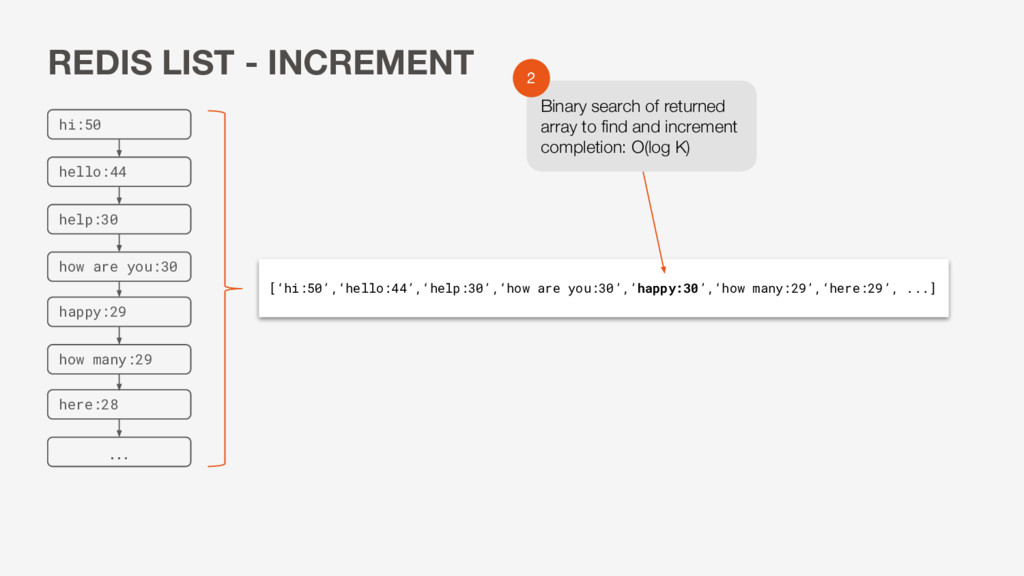
many:29 [‘hi:50’,‘hello:44’,‘help:30’,‘how are you:30’,’happy:30’,‘how many:29’,‘here:29’, ...] Binary search of returned array to find and increment completion: O(log K) 2 REDIS LIST - INCREMENT
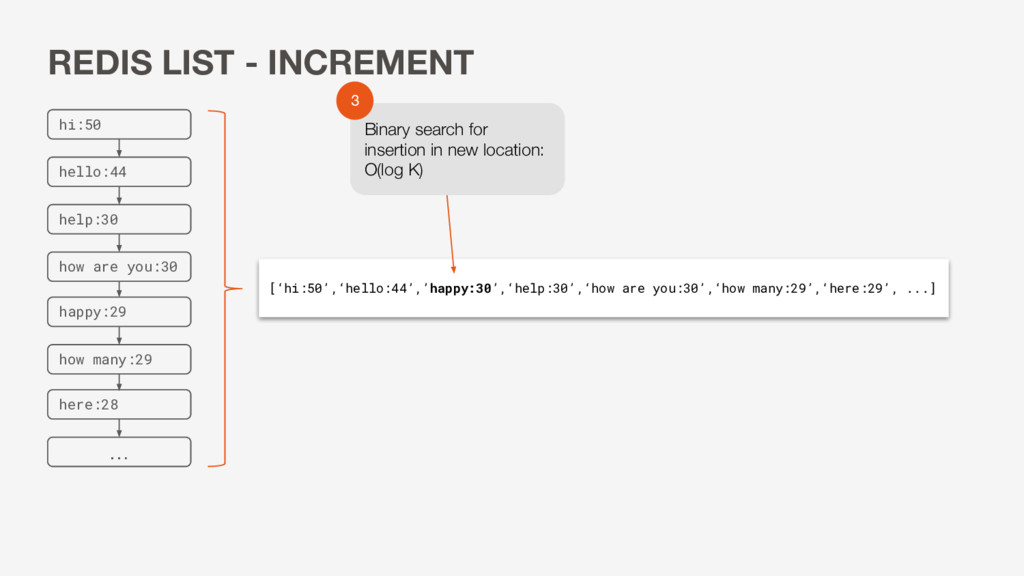
many:29 [‘hi:50’,‘hello:44’,’happy:30’,‘help:30’,‘how are you:30’,‘how many:29’,‘here:29’, ...] Binary search for insertion in new location: O(log K) 3 REDIS LIST - INCREMENT
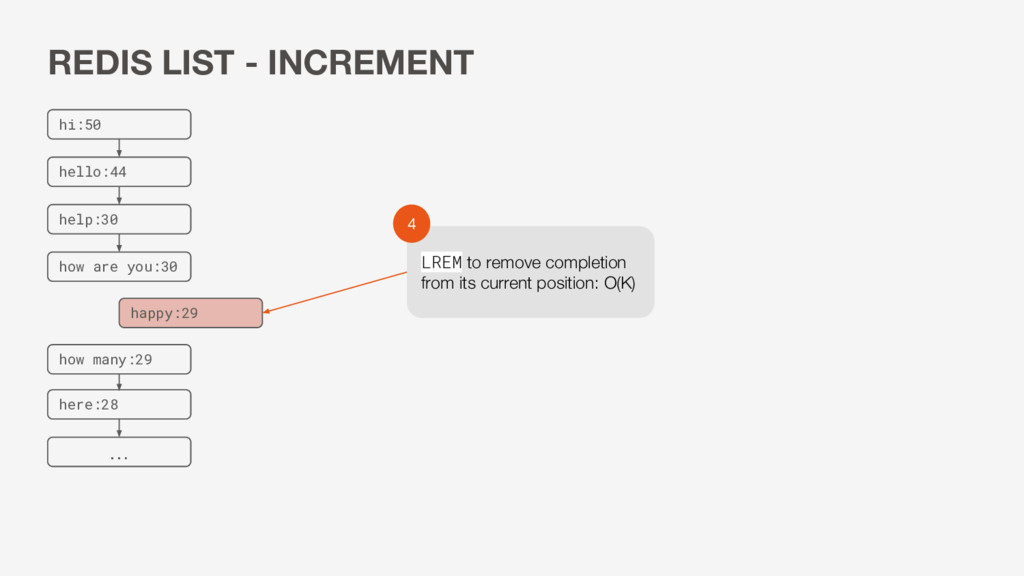
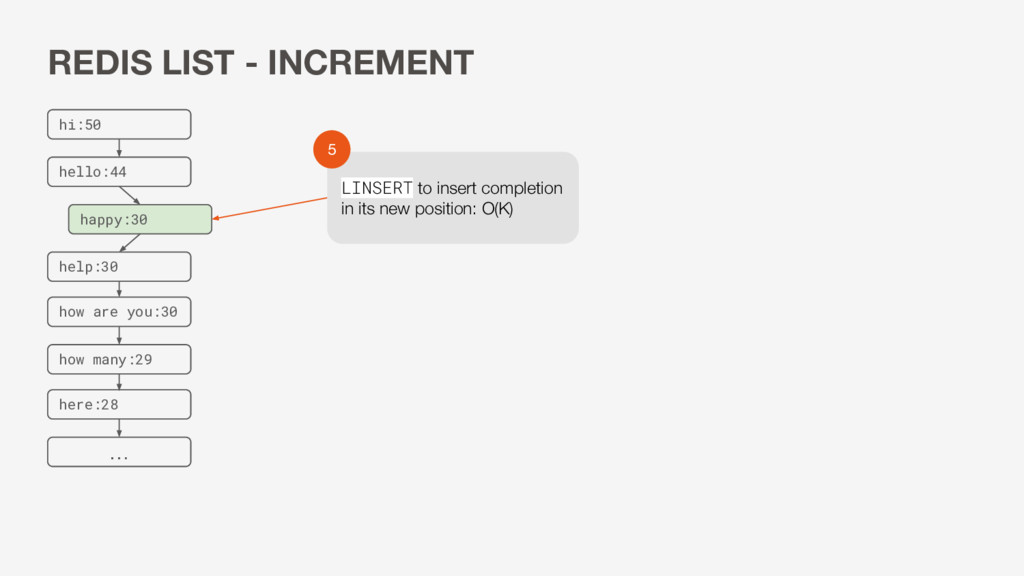
O(K) *Round Trips: 2 • 2 round trips per update • May have concurrency issues • Large payload • No uniqueness guarantee • Have to sort in JavaScript instead of on DB level … hi:50 hello:44 happy:30 help:30 here:28 how are you:30 how many:29
30 how are you 30 happy 29 how many 29 here 28 ... ... h Key Value • Sorted sets in Redis are implemented with skip lists • Handles uniqueness and order • Most operations are O(log K)
you 30 happy 29 how many 29 here 28 ... ... [‘hi’,‘hello’,‘help’,‘how are you’,‘happy’] ZRANGE to get first 5 elements: O(log K) 1 REDIS SORTED SET - SEARCH
44 happy 30 help 30 how are you 30 happy 29 how many 29 here 28 ... ... ZINCRBY to increment score: O(log K) Redis handles order and uniqueness constraint. 1
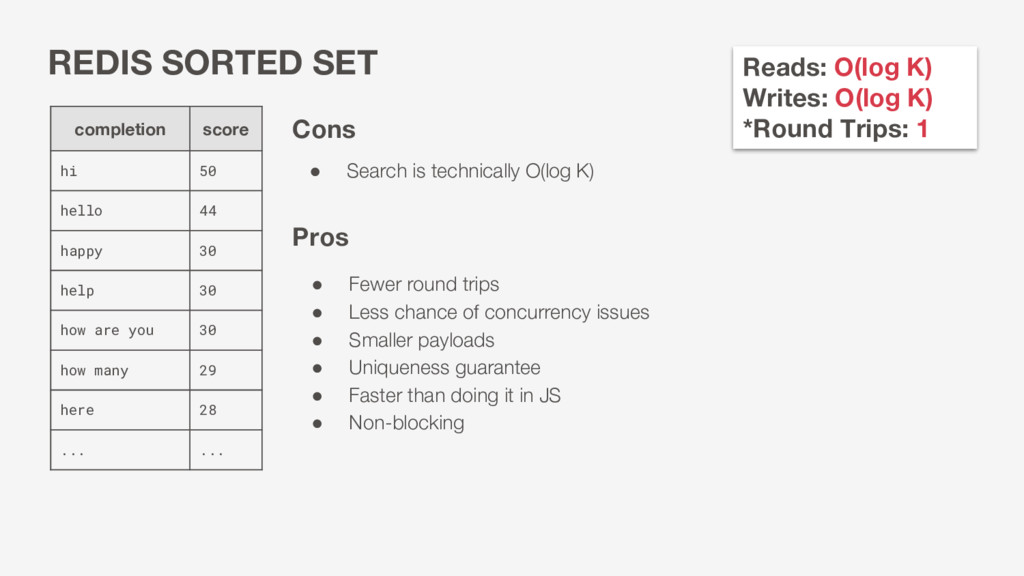
Pros completion score hi 50 hello 44 happy 30 help 30 how are you 30 how many 29 here 28 ... ... Reads: O(log K) Writes: O(log K) *Round Trips: 1 • Fewer round trips • Less chance of concurrency issues • Smaller payloads • Uniqueness guarantee • Faster than doing it in JS • Non-blocking
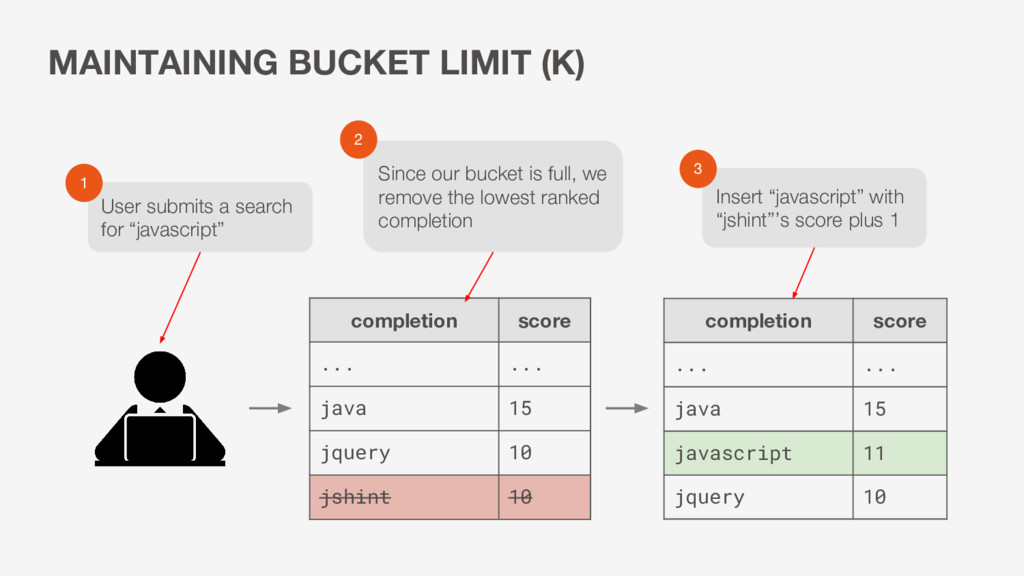
jquery 10 jshint 10 completion score ... ... java 15 javascript 11 jquery 10 User submits a search for “javascript” 1 Since our bucket is full, we remove the lowest ranked completion Insert “javascript” with “jshint”’s score plus 1 3 2
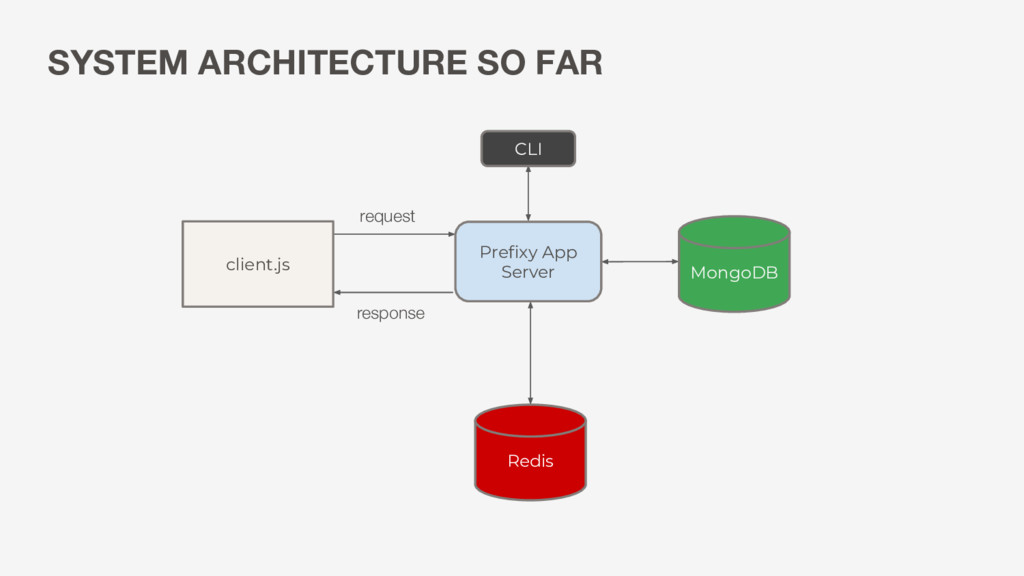
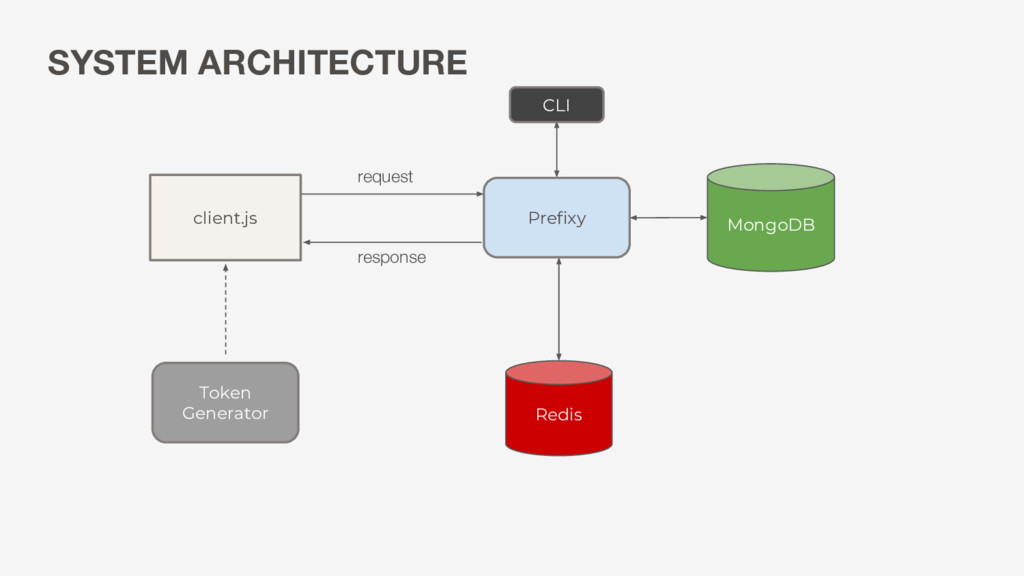
LRU policy in Redis • Persist to MongoDB: able to store more than what we can fit in memory • Reads still fast: generally 1 trip per search, more trips for updates Redis MongoDB Prefixy Always check Redis first 1 If we have a cache miss, check Mongo 2
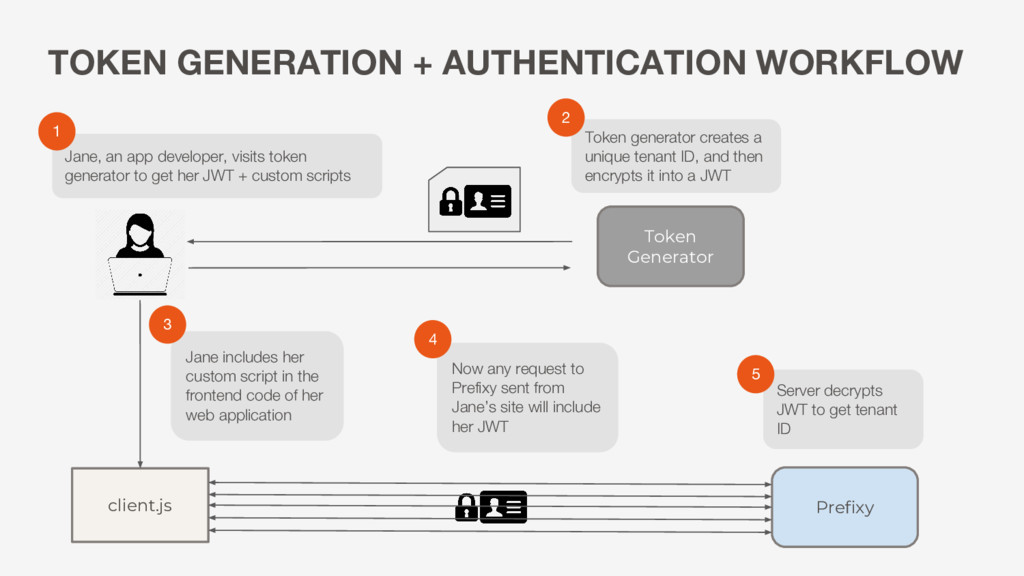
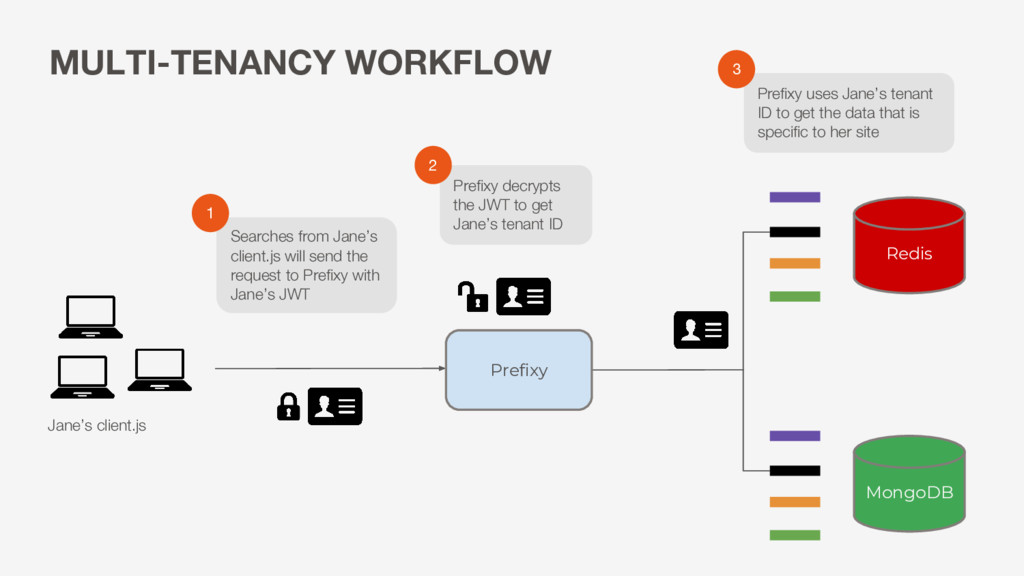
an app developer, visits token generator to get her JWT + custom scripts Now any request to Prefixy sent from Jane’s site will include her JWT Token generator creates a unique tenant ID, and then encrypts it into a JWT Jane includes her custom script in the frontend code of her web application Server decrypts JWT to get tenant ID 1 2 3 4 5
JWT to get Jane’s tenant ID Searches from Jane’s client.js will send the request to Prefixy with Jane’s JWT 1 2 Prefixy uses Jane’s tenant ID to get the data that is specific to her site 3
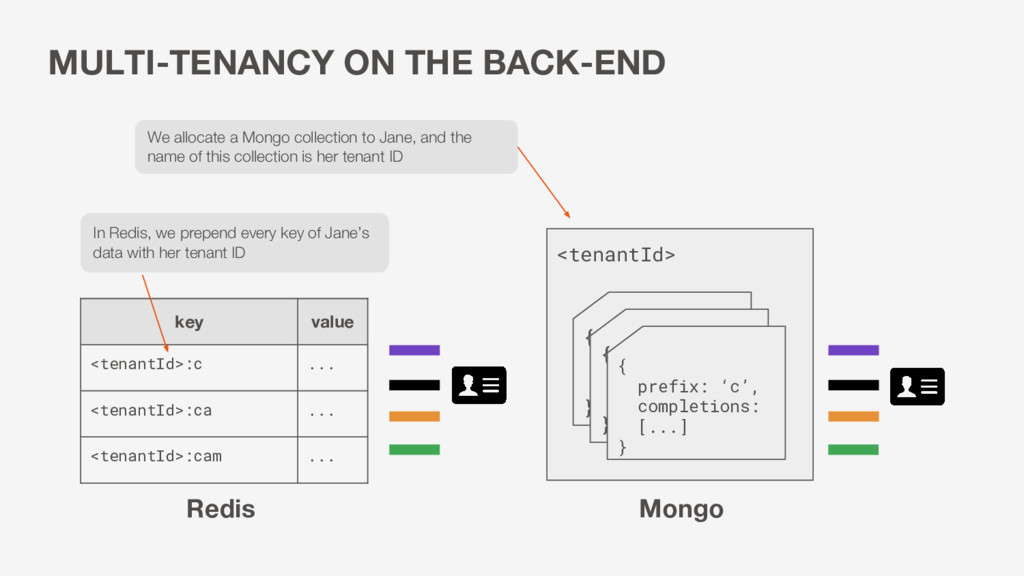
value <tenantId>:c ... <tenantId>:ca ... <tenantId>:cam ... { prefix completions } { prefix: ‘c’, completions: [...] } Redis Mongo We allocate a Mongo collection to Jane, and the name of this collection is her tenant ID In Redis, we prepend every key of Jane’s data with her tenant ID
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![WHY REDIS? key value c [car:30, cat…] ca [car:30, cat…]](https://files.speakerdeck.com/presentations/d93918faeb7741179e46bd0408fb2696/slide_15.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![QUESTIONS? jayshenk.com [email protected] @jay_shenk](https://files.speakerdeck.com/presentations/d93918faeb7741179e46bd0408fb2696/slide_42.jpg){kind=link}