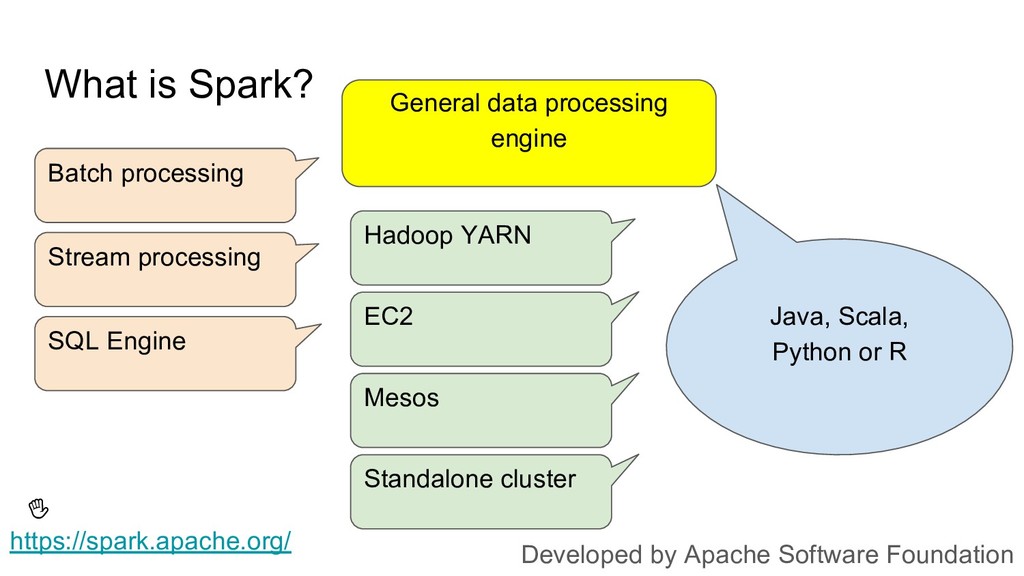
Until very recently, Apache Spark has been a de facto standard choice of a framework for batch data processing. For Python developers, diving into Spark is challenging, because it requires learning the Java infrastructure, memory management, configuration management. The multiple layers of indirection also make it harder to debug things, especially when throwing the Pyspark wrapper into the equation.
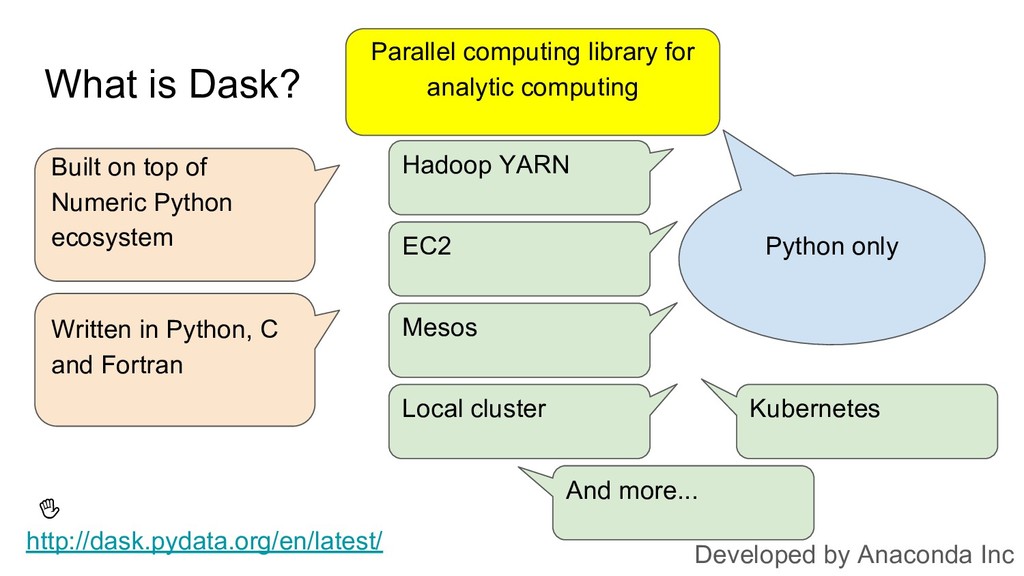
With Dask emerging as a pure Python framework for parallel computing, Python developers might be looking at it with new hope, wondering if it might work for them in place of Spark. In this talk, I’m using a data aggregation example to highlight the important differences between the two frameworks, and make it clear how involved the switch may be.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Write JSON with Dask (tr.to_bag() .map(lambda t: t[0]) .map(json.dumps) .to_textfiles('./aggs_dask/*.json'))](https://files.speakerdeck.com/presentations/44a38fb809b44d8eb7f5e6d5ba8839cc/slide_43.jpg){kind=link}
{kind=link}
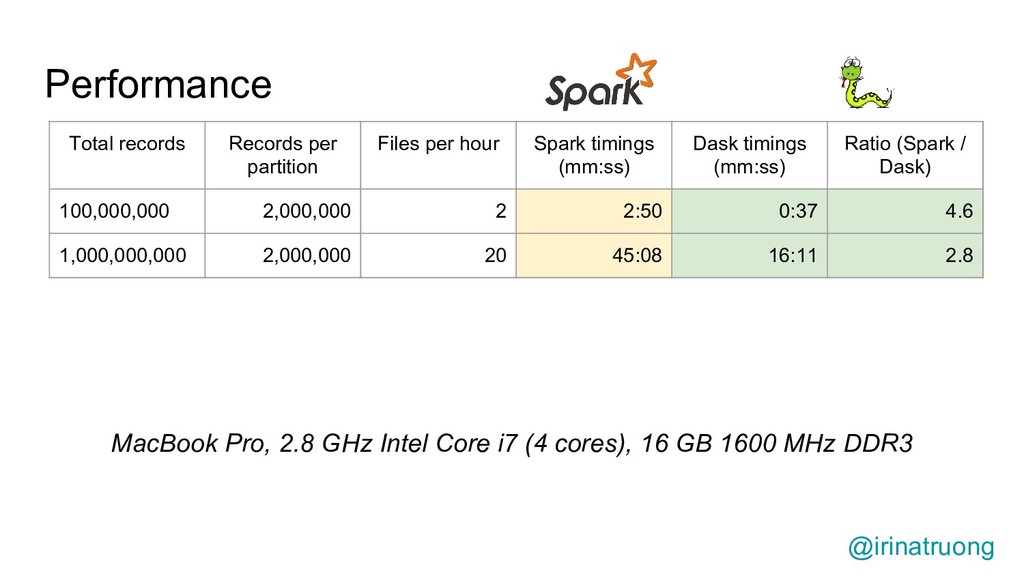{kind=link}
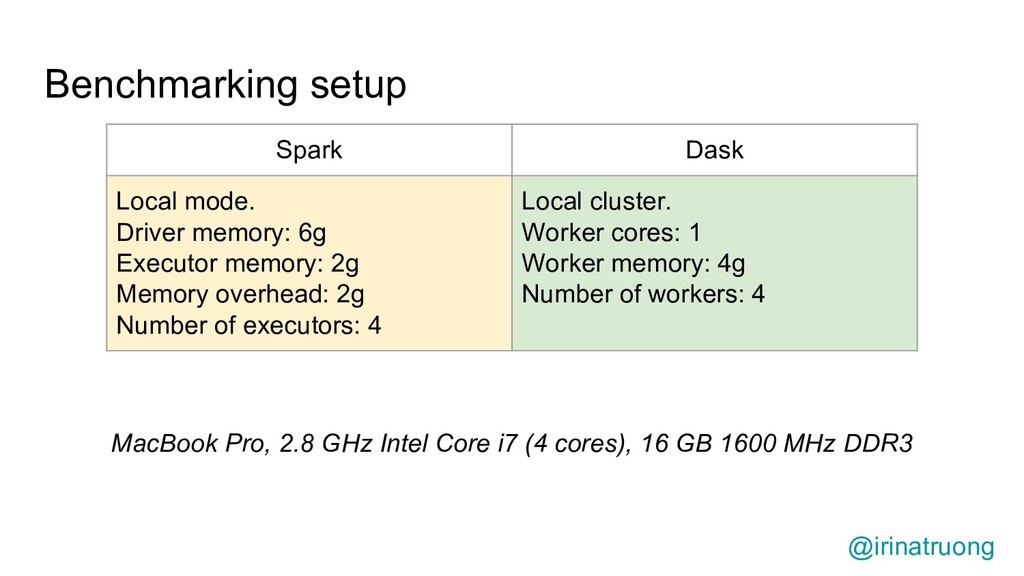{kind=link}
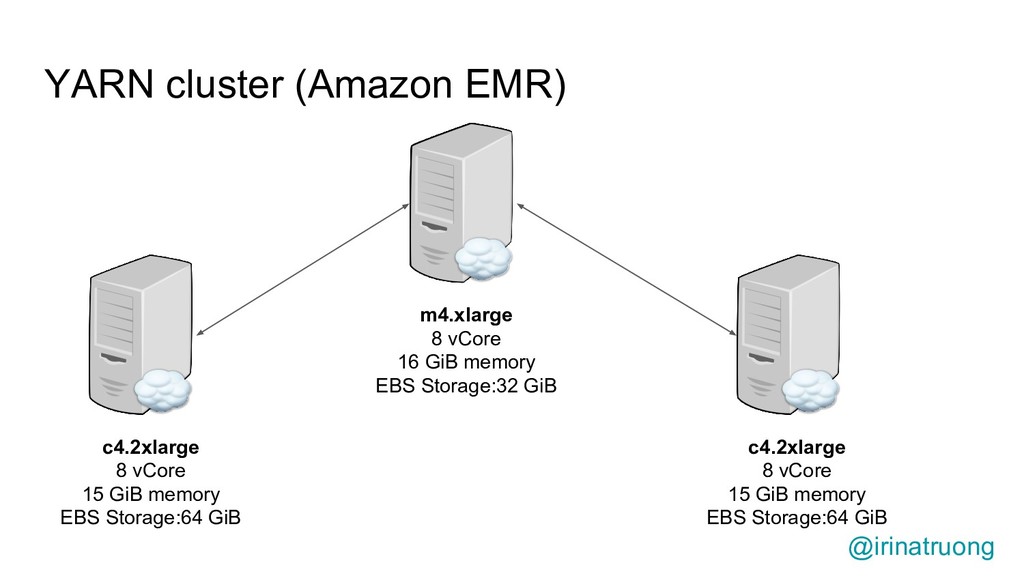{kind=link}
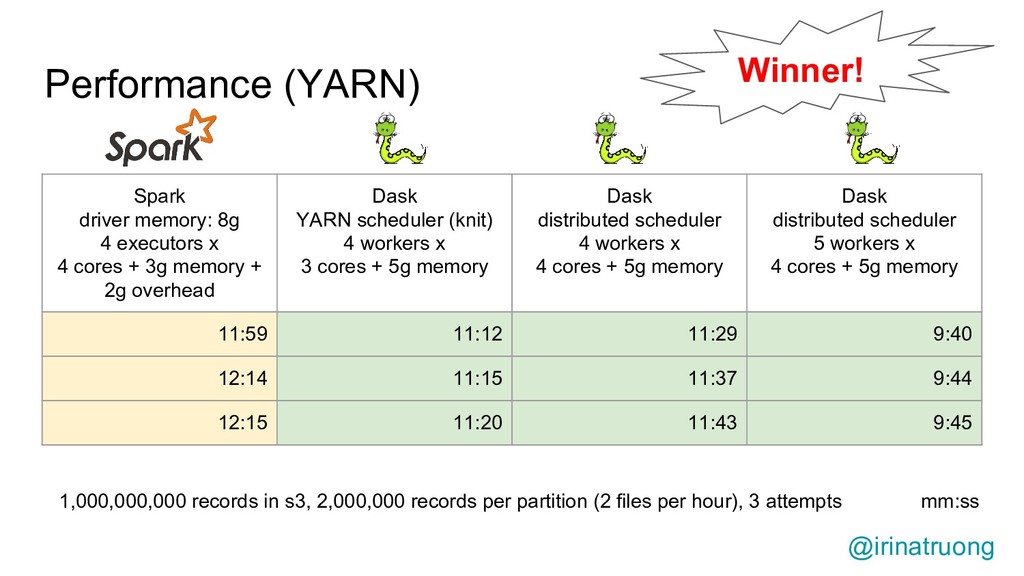{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}