DataEngConf 2017 - Beyond 50,000 Partitions: How Heroku Operates and Pushes the Limits of Kafka at Scale
Talk at DataEngConf 2017. This talk covers some deeper details regarding Kafka internals and various challenges Heroku faced while operating Kafka in production at scale.
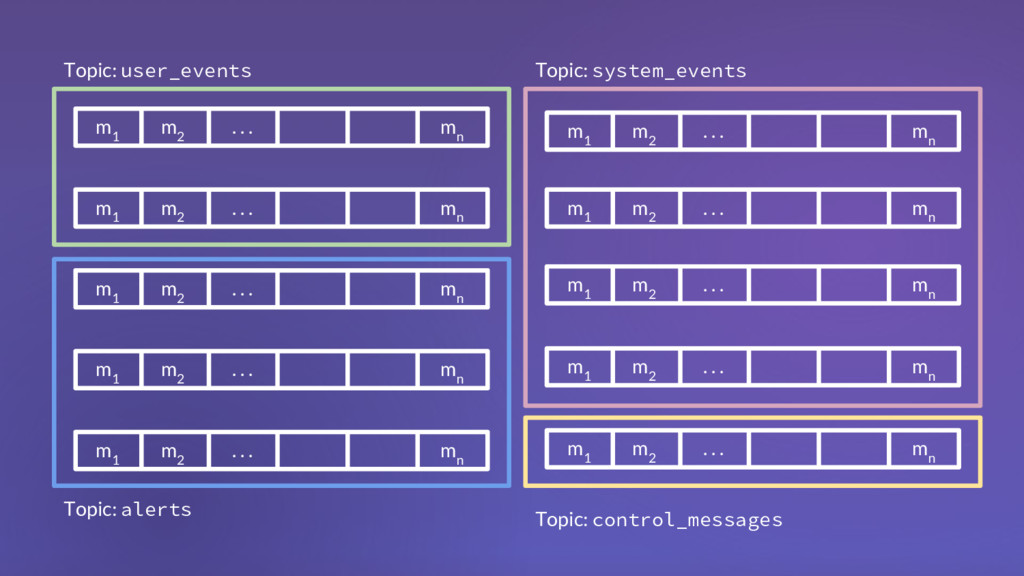
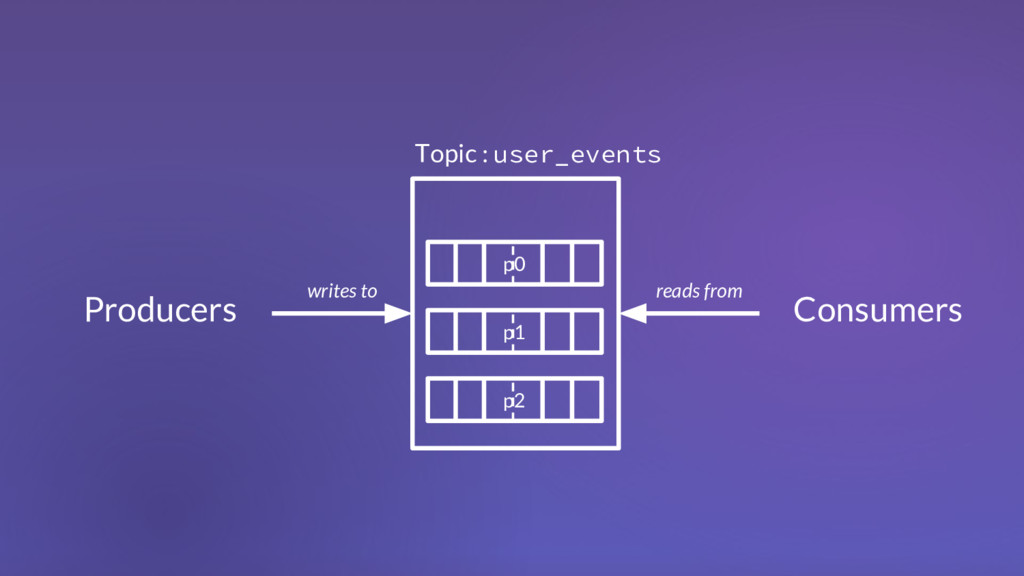
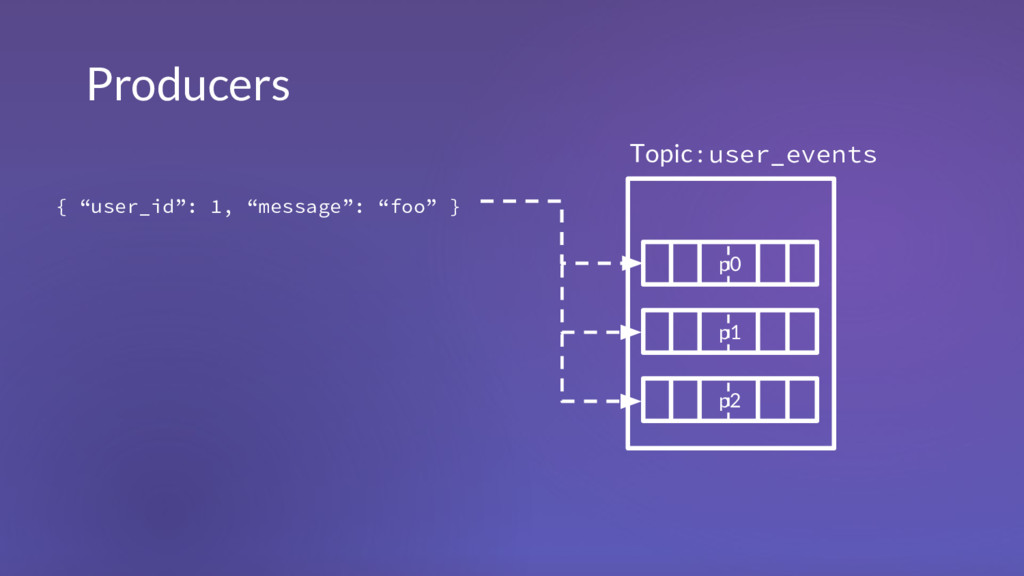
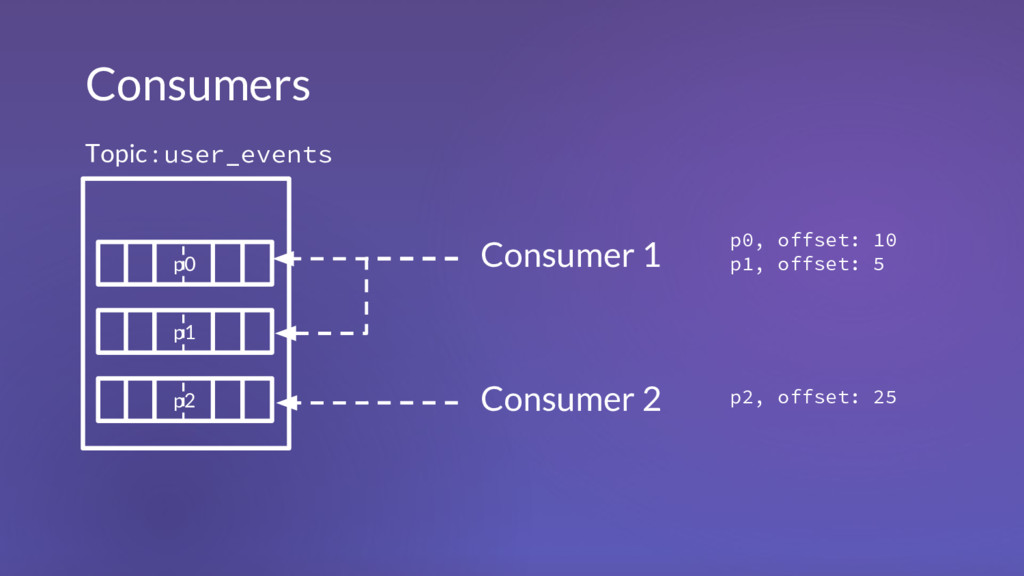
1 m 2 . . . m n m 1 m 2 . . . m n m 1 m 2 . . . m n m 1 m 2 . . . m n m 1 m 2 . . . m n m 1 m 2 . . . m n m 1 m 2 . . . m n m 1 m 2 . . . m n m 1 m 2 . . . m n Topic: user_events Topic: system_events Topic: alerts Topic: control_messages
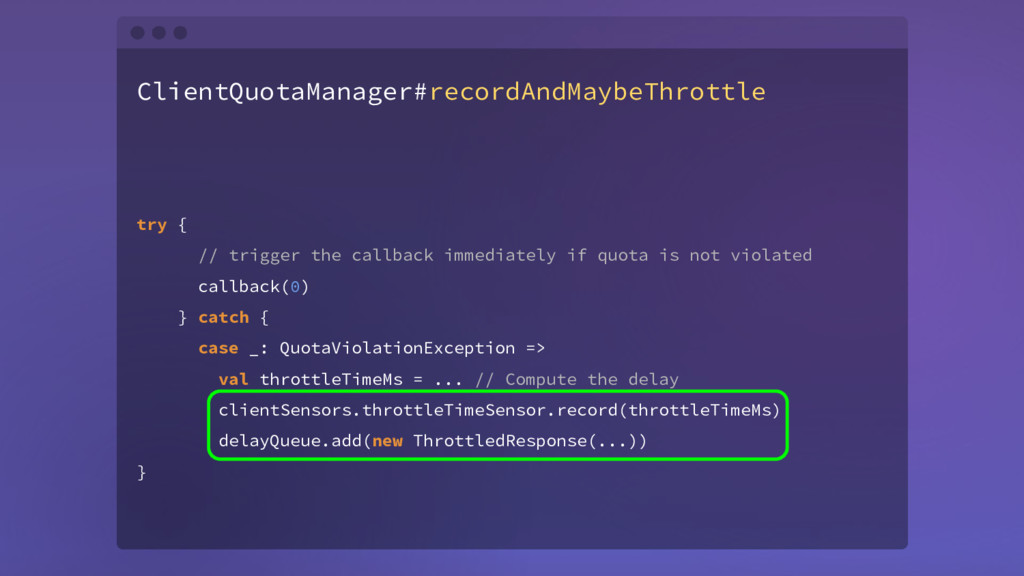
is not violated callback(0) } catch { case _: QuotaViolationException => val throttleTimeMs = ... // Compute the delay clientSensors.throttleTimeSensor.record(throttleTimeMs) delayQueue.add(new ThrottledResponse(...)) }
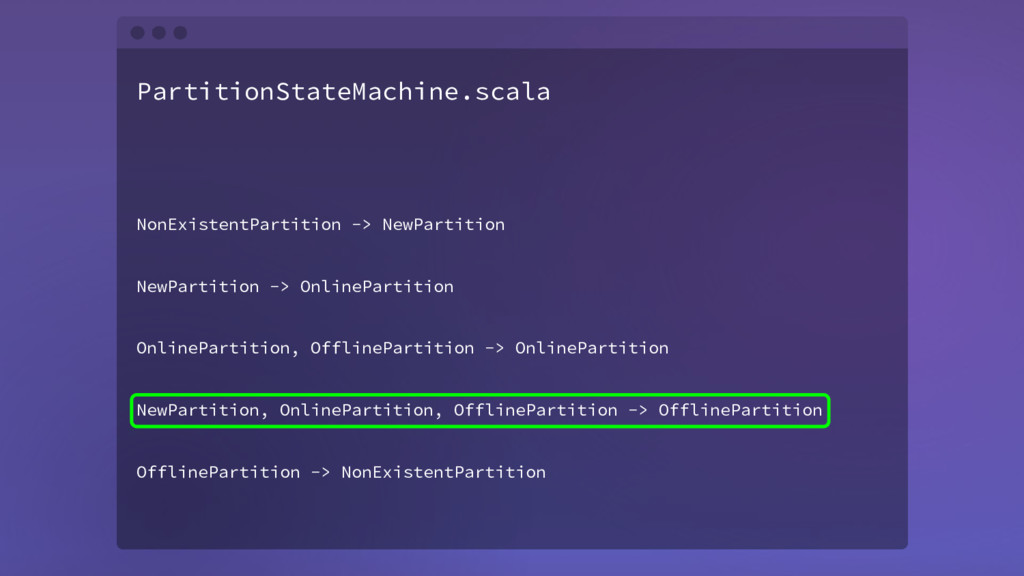
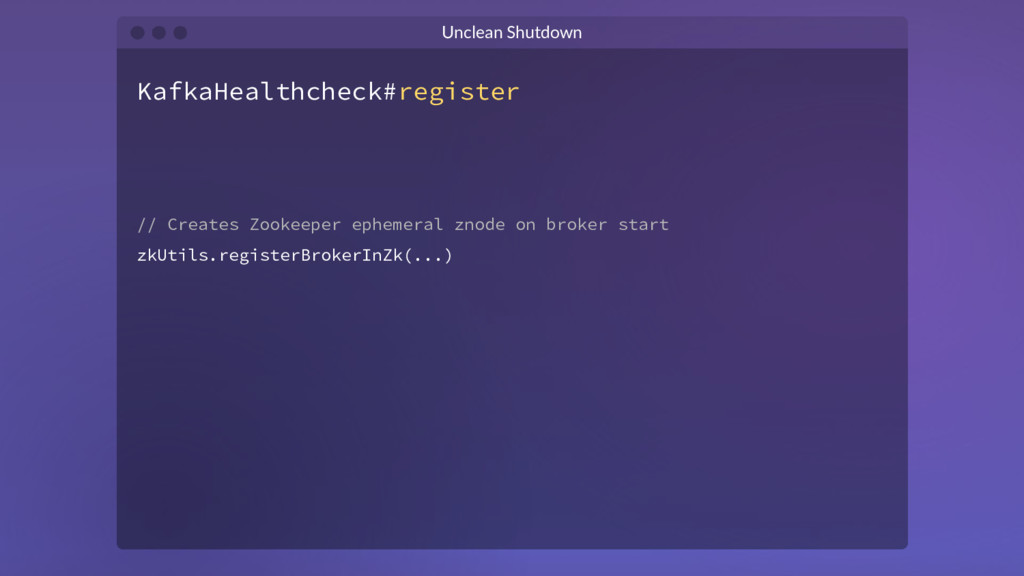
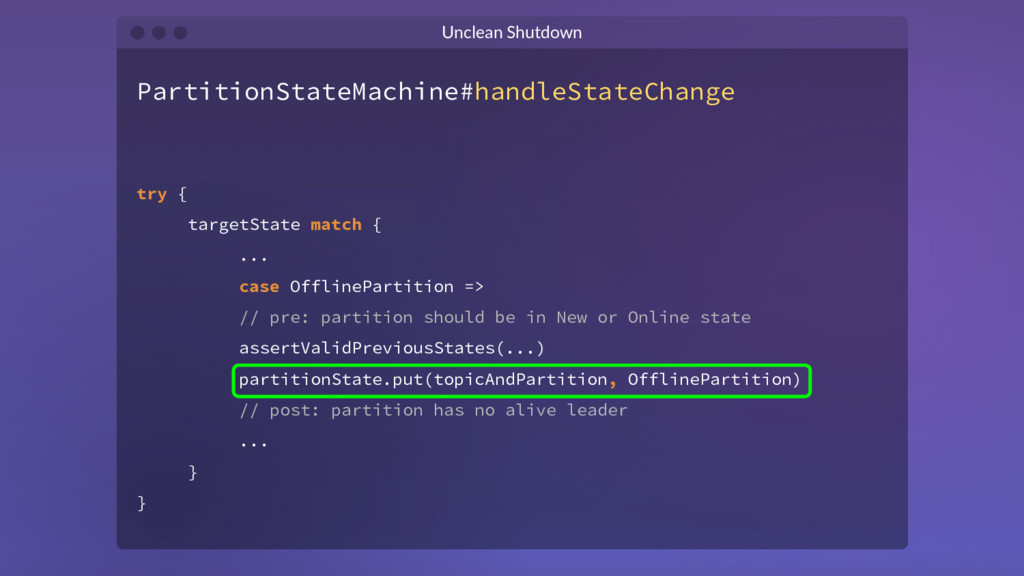
// pre: partition should be in New or Online state assertValidPreviousStates(...) partitionState.put(topicAndPartition, OfflinePartition) // post: partition has no alive leader ... } } Unclean Shutdown
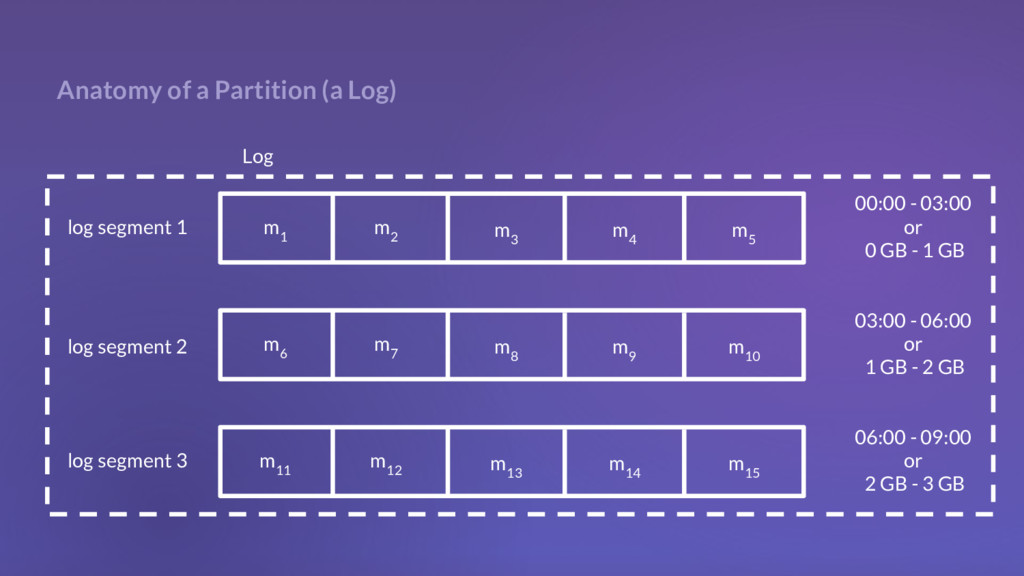
2 m 3 m 4 m 5 log segment 1 m 6 m 7 m 8 m 9 m 10 log segment 2 m 11 m 12 m 13 m 14 m 15 log segment 3 00:00 - 03:00 or 0 GB - 1 GB 03:00 - 06:00 or 1 GB - 2 GB 06:00 - 09:00 or 2 GB - 3 GB
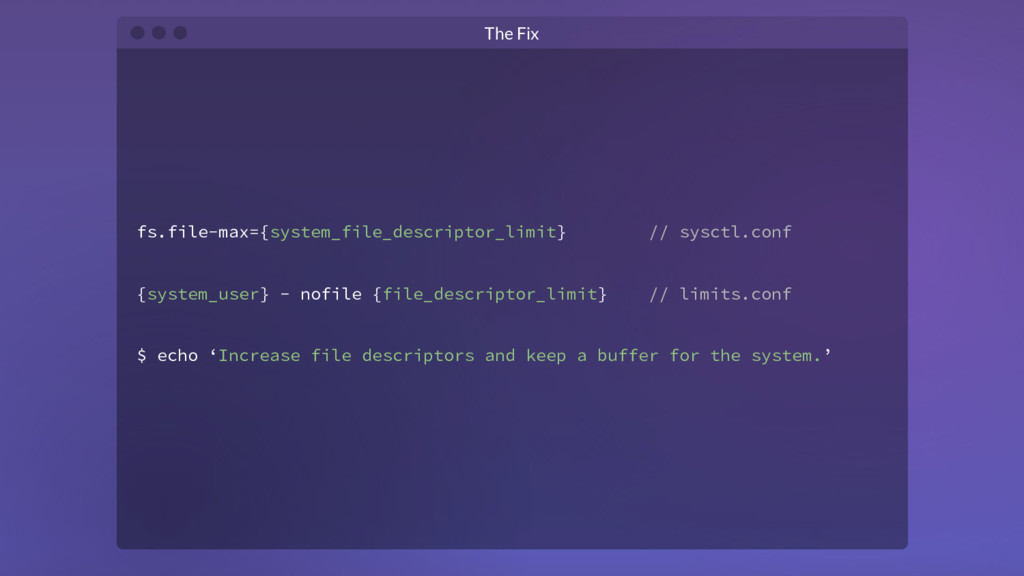
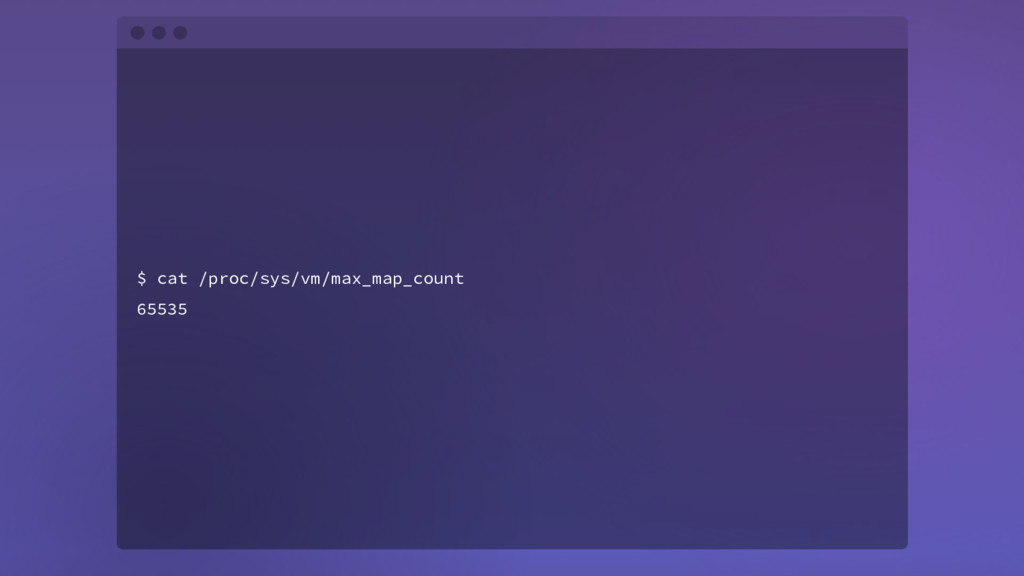
segments consists of 3 actual files on disk: .log, .index, and .timeindex However, in our testing, we found on average, ~1.5 FDs per log segment Kafka tries to hold FDs only for active segments
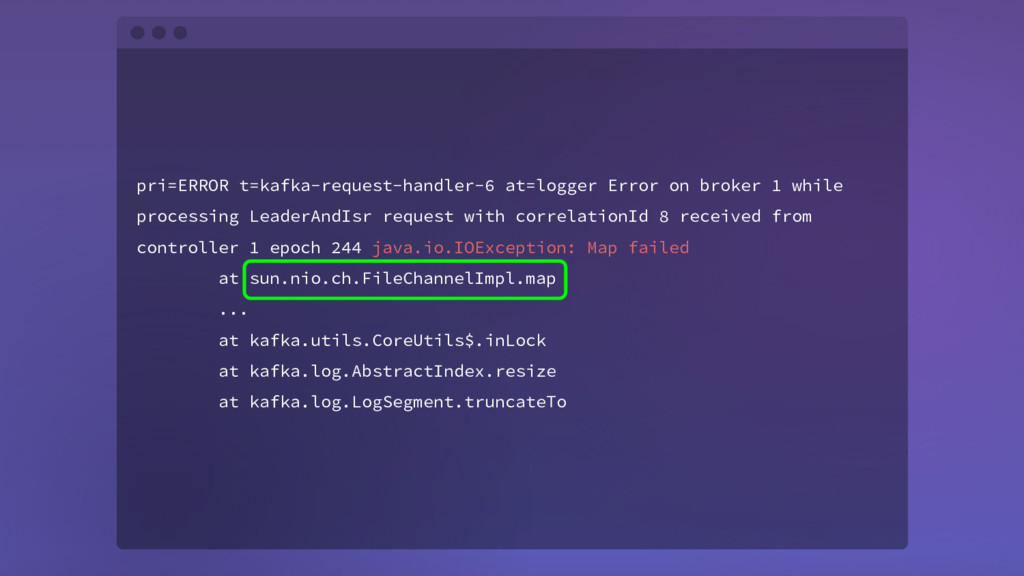
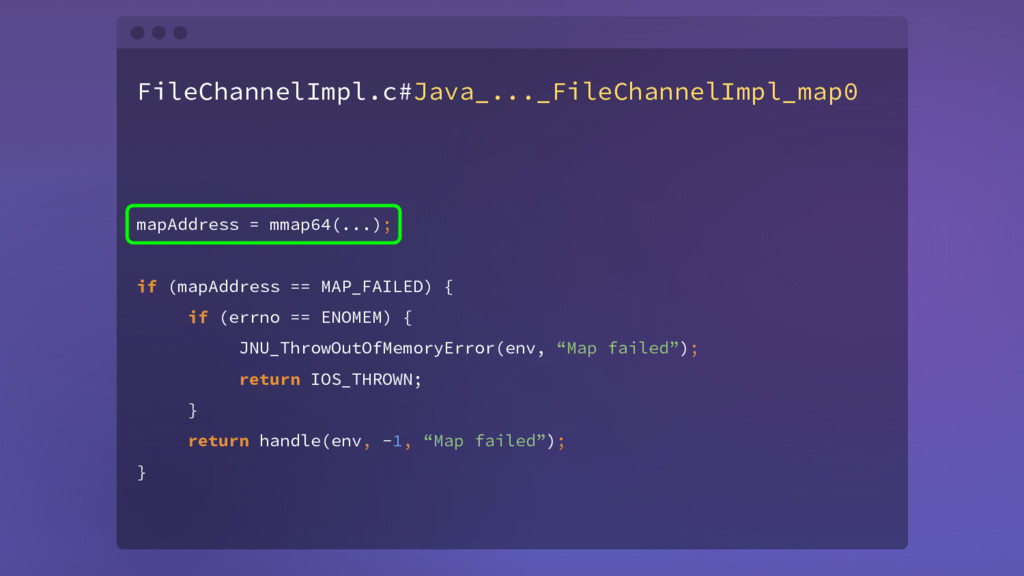
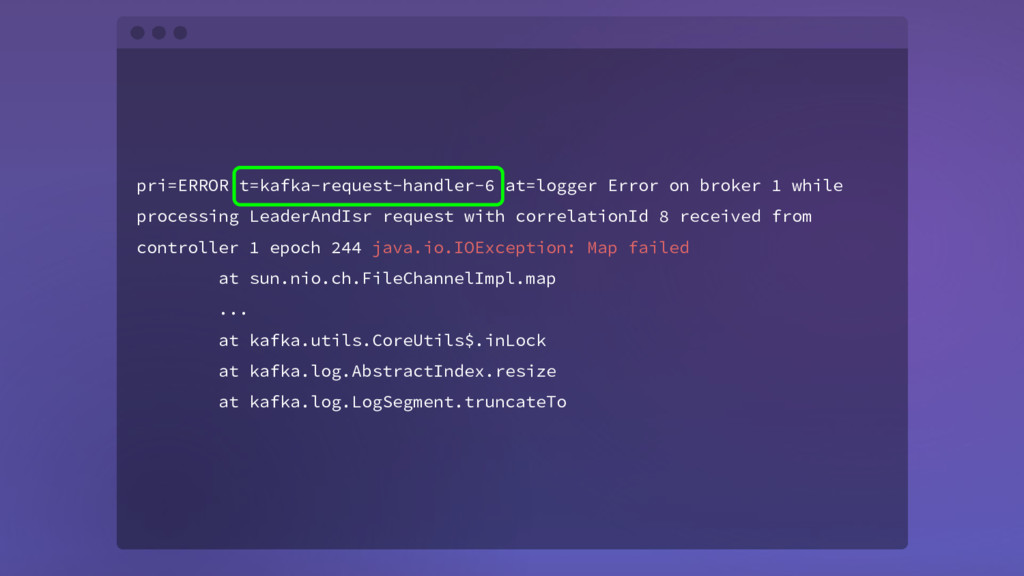
request with correlationId 8 received from controller 1 epoch 244 java.io.IOException: Map failed at sun.nio.ch.FileChannelImpl.map ... at kafka.utils.CoreUtils$.inLock at kafka.log.AbstractIndex.resize at kafka.log.LogSegment.truncateTo
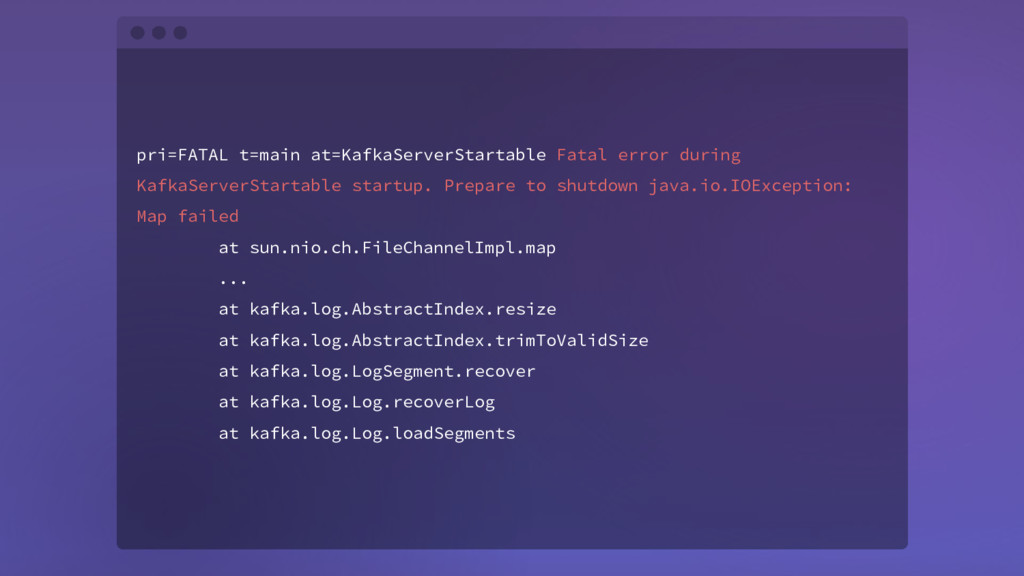
shutdown java.io.IOException: Map failed at sun.nio.ch.FileChannelImpl.map ... at kafka.log.AbstractIndex.resize at kafka.log.AbstractIndex.trimToValidSize at kafka.log.LogSegment.recover at kafka.log.Log.recoverLog at kafka.log.Log.loadSegments
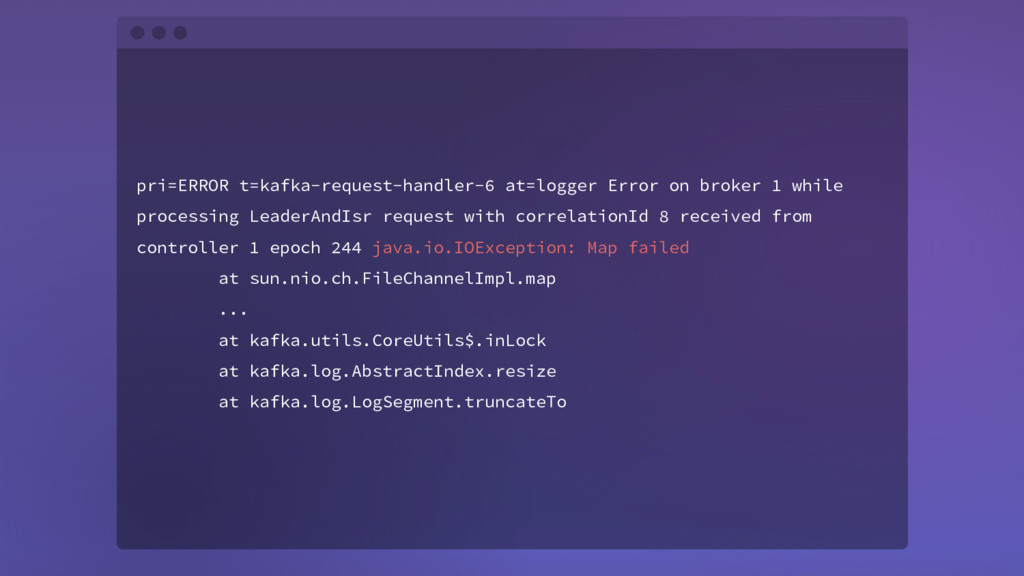
request with correlationId 8 received from controller 1 epoch 244 java.io.IOException: Map failed at sun.nio.ch.FileChannelImpl.map ... at kafka.utils.CoreUtils$.inLock at kafka.log.AbstractIndex.resize at kafka.log.LogSegment.truncateTo
request with correlationId 8 received from controller 1 epoch 244 java.io.IOException: Map failed at sun.nio.ch.FileChannelImpl.map ... at kafka.utils.CoreUtils$.inLock at kafka.log.AbstractIndex.resize at kafka.log.LogSegment.truncateTo
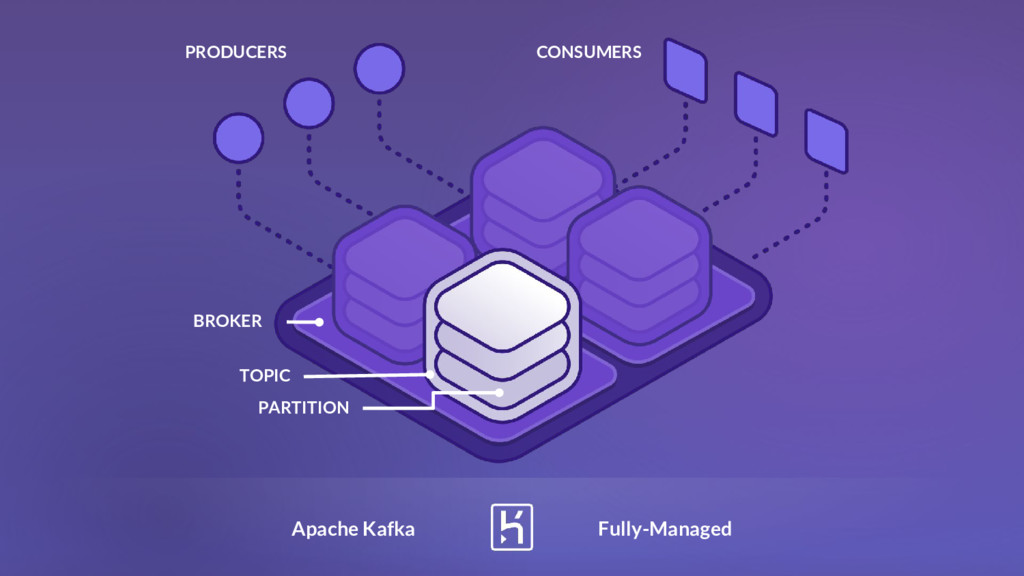
configure, scalable Heroku offers fully-managed Apache Kafka Integrated with the Heroku ecosystem Lots to consider when operating at scale An operational undertaking
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![pri=FATAL t=ReplicaFetcherThread-0-6 at=ReplicaFetcherThread [ReplicaFetcherThread-0-6], Disk error while replicating data for](https://files.speakerdeck.com/presentations/564e46d3e6c349b5a41590cef2dea868/slide_134.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[GC pause (G1 Evacuation Pause) (young), 0.0167712 secs] ... [Eden:](https://files.speakerdeck.com/presentations/564e46d3e6c349b5a41590cef2dea868/slide_139.jpg){kind=link}
![$ htop Mem[|||||||||||||||||||||||||||||||||||||||||||||||||||||||||4911/1604MB]](https://files.speakerdeck.com/presentations/564e46d3e6c349b5a41590cef2dea868/slide_140.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank you. Jeff Chao jchao [at] heroku.com](https://files.speakerdeck.com/presentations/564e46d3e6c349b5a41590cef2dea868/slide_188.jpg){kind=link}
{kind=link}