arguments Doesn’t cause any observable side-effects Allows referential transparency as time does not affect the result of a function invocation (function is transparent to time) Allows memoization, algebraic manipulation and increase testability
symbol in a scope In Clojure, everything is an expression and return a value NO VARIABLE and NO STATEMENT ! But provide Software Transactional Memory for shared « variable »
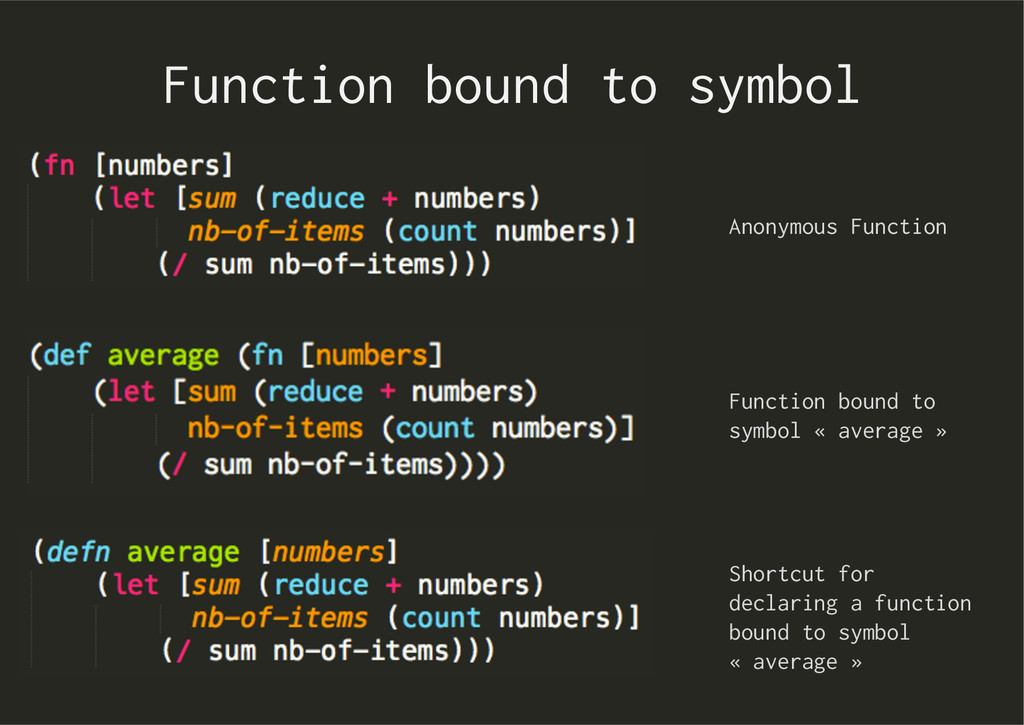
as saying: « Let symbol sum have the value of expression (reduce + numbers) and symbol nb-of-items have the value of expression (count numbers) in body (/ sum nb-of-items) »
defined at the time of their construction and can’t be changed thereafter How to get something done if things can’t change ? Use recursion instead of mutation with persistent data structure that allows structural sharing
really needed != eager (eager = statement or arguments to function are immediately evaluated) Java && (logical and) has lazy evaluation Clojure’s sequence are lazy, allows infinite sequence
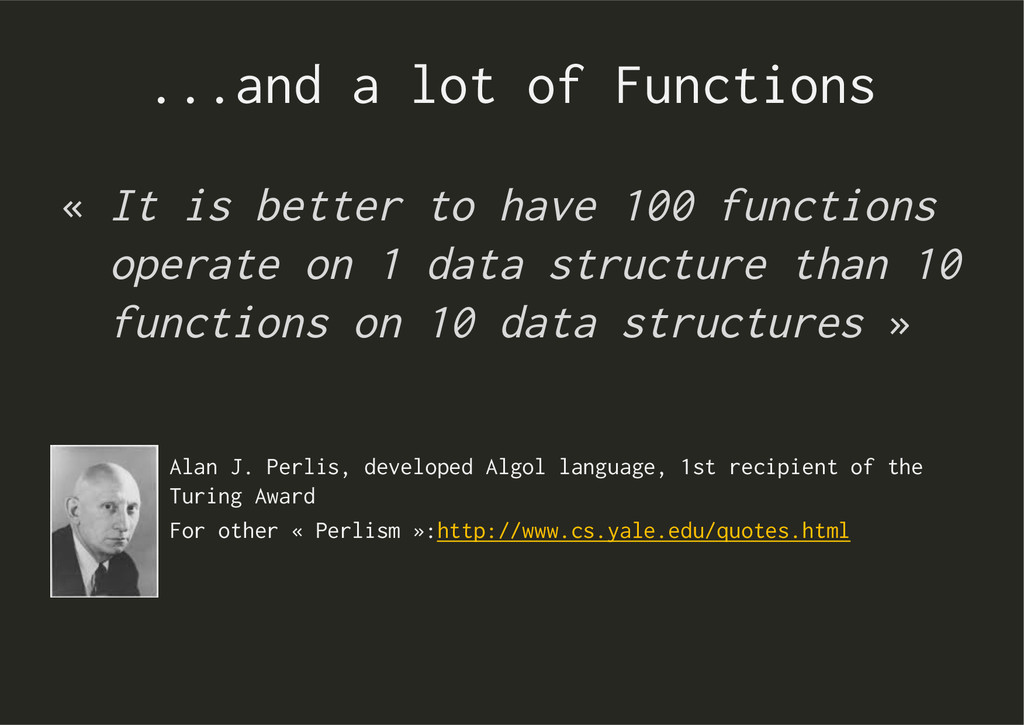
language, 1st recipient of the Turing Award For other « Perlism »:http://www.cs.yale.edu/quotes.html « It is better to have 100 functions operate on 1 data structure than 10 functions on 10 data structures »
the data is not mutated. Rather, a new immutable version of the data structure is returned Structural sharing is the technique used to make Clojure's persistent data structures efficient Structural sharing relies on the data's immutability to make sharing possible between the old and new instances of the data
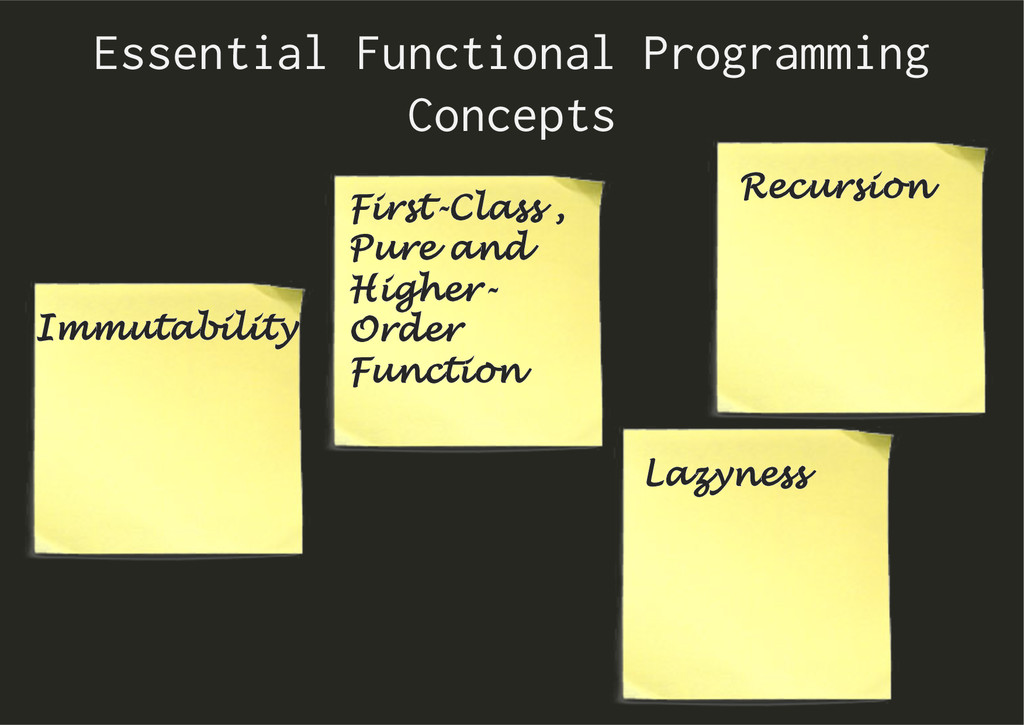
» Simplicity, freedom to focus, empowerment, consistency, and clarity Value Driven Programming or Facts-Oriented Programming instead of Place-Oriented Programming Libraries not Frameworks
and run, but something with which you can interact ⇒ REPL Oriented Programming Anything you enter into the REPL or load using load-file is automatically compiled to JVM bytecode on the fly
small core Almost no syntax Core advantage still code-as-data and syntactic abstraction What about the standard Lisps (Common Lisp and Scheme)? – Slow/no innovation post standardization – Core data structures mutable, not extensible – No concurrency in specs – Good implementations already exist for JVM (ABCL, Kawa, SISC et al) – Standard Lisps are their own platforms Clojure is a Lisp not constrained by backwards compatibility – Extends the code-as-data paradigm to maps and vectors – Defaults to immutability – Core data structures are extensible abstractions – Embraces a platform (JVM) excerpt from clojure.org/rationale
everything is an expression that return a value, there are no statements, hence the term « value-based programming ». Clojure: returns true or false (so can be evaluated) Java: returns nothing but can change state
list in the form It enables very powerful meta-programming (quote exp) and (eval exp) « Code is Data, Data is Code » from homo - the same - and icon - representation -
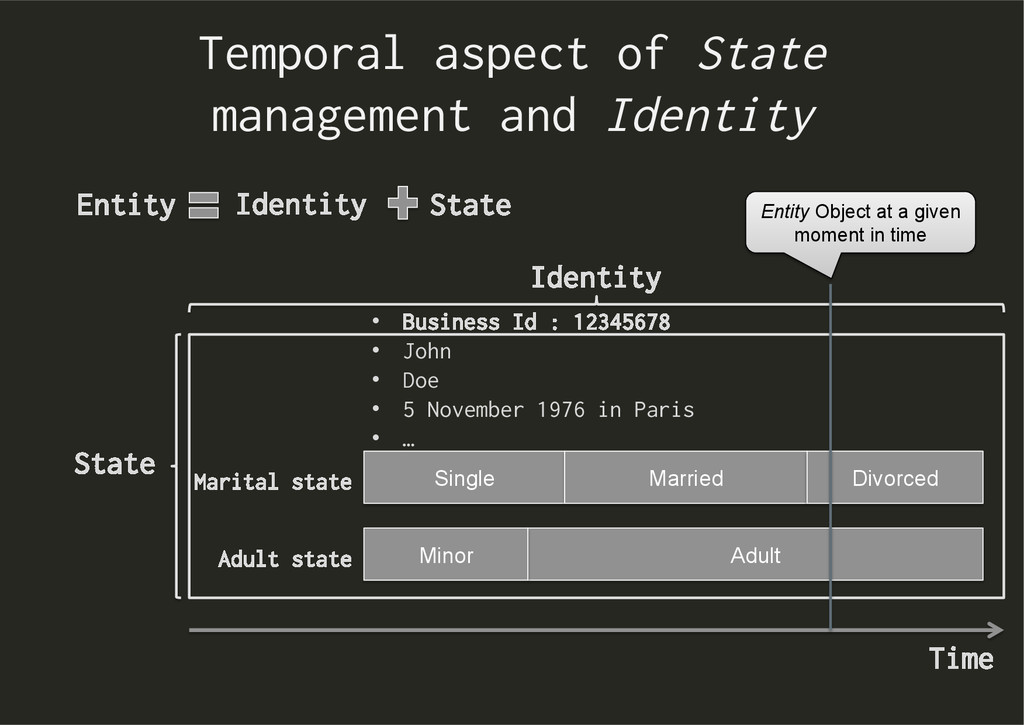
Adult Minor Time Adult state Marital state Divorced • Business Id : 12345678 • John • Doe • 5 November 1976 in Paris • … Entity State Entity Object at a given moment in time Identity State
State 3 Function Function Event triggers Event triggers • value 1a • value 1b • value 1c • value 1a • value 1b • value 1c • value 2a • value 2b • value 1a • value 1b • value 1c • value 2a • value 2b • value 3a Publish Internal Event Publish Internal Event ... Time
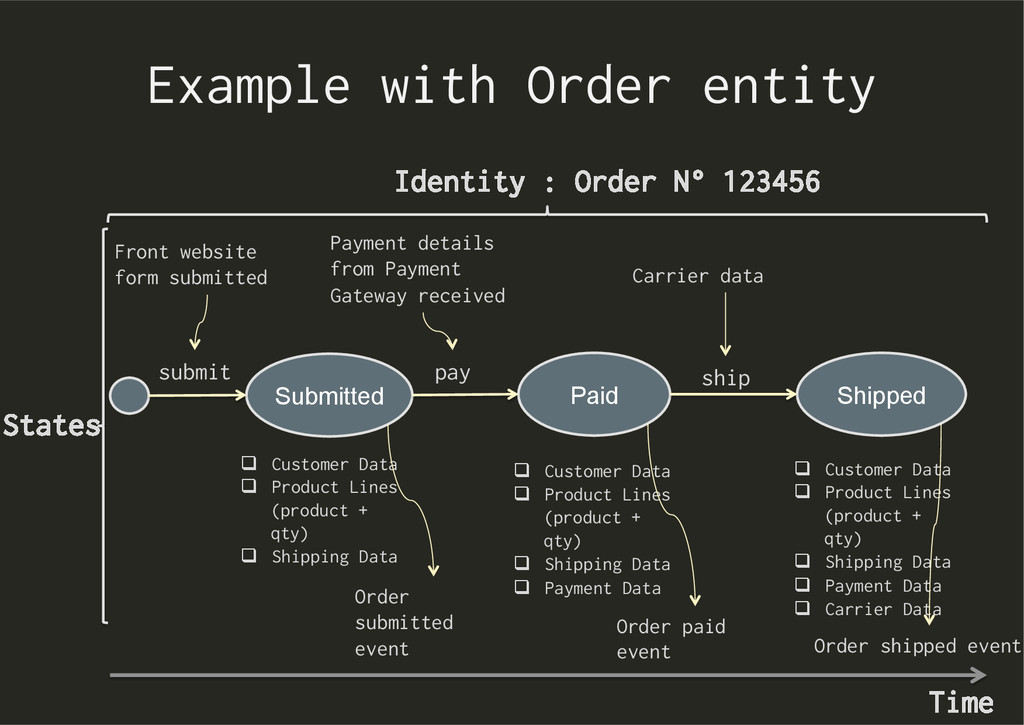
Paid Shipped pay ship Payment details from Payment Gateway received Carrier data q Customer Data q Product Lines (product + qty) q Shipping Data States submit q Customer Data q Product Lines (product + qty) q Shipping Data q Payment Data q Customer Data q Product Lines (product + qty) q Shipping Data q Payment Data q Carrier Data Front website form submitted Order submitted event Order paid event Order shipped event Time
values. How? facts don’t change when you incorporate time in the data. Time in data allows the past to be retained (or not), and supports point-in-time queries. 'latest' view in traditional database vs retaining all changes. Datomic is a database of facts, not places. Atomic Data - the Datom – Facts are recorded as independent atoms of information. Datomic calls such atomic facts 'datoms'. A datom consists of an entity, attribute, value and transaction (time). Minimal Schema – All databases have a schema, whether they are written down or not. The schema required to encode datoms consisting primarily of the attribute definitions, which specify name, type, cardinality etc. The Database – A Datomic database is just a set of datoms, indexed in various ways. These indexes contain all of the data, not pointers to data (i.e. they are covering indexes). The storage service and caches are just a distribution network for the data segments of these indexes, all of which are immutable, and thus effectively and coherently cached.
is a library that gets embedded in the applications – Submits transactions to, and accepts changes from, the transactor – Includes all communication components for talking to transactors and storage services – Provides data access, caching, and query capability to the application, reading from the storage service as needed Transactors – Accept transactions – Process them serially – Commit the results to the storage service – all writes are synchronously made to redundant storage – Transmit changes to the peers – Index in the background, place indexes in storage service Storage services – Provide an interface to highly reliable, redundant storage – Available from third-parties: Amazon DynamoDB, RDBMS, Infinispan
reads are separated from writes, writes are never held up by queries. In the Datomic architecture, the transactor is dedicated to transactions, and need not service reads at all! Integrated data distribution – Each peer and transactor manages its own local cache of data segments, in memory. This cache self-tunes to the working set of that application. Every peer gets its own brain (query engine and cache) – Traditional client-server databases leads to impedance mismatch. The problem, though, isn't that databases are insufficiently object-oriented, rather, that applications are insufficiently declarative. Moving a proper, index-supported, declarative query engine into applications will enable them to work with data at a higher level than ever before, and at application-memory speeds. Elasticity – Application servers are frequently scaled up and down as demand fluctuates, but traditional databases, even with read-replication configured, have difficulty scaling query capability similarly. Putting query engines in peers makes query capability as elastic as the applications themselves. In addition, putting query engines into the applications themselves means they never wait on each other's queries. Ready for the cloud – All components are designed to run on commodity servers, with expectations that they, and their attached storage, are ephemeral. The speed of memory – While the (disk-backed) storage service constitutes the data of record, the rest of the system operates primarily in memory.
language into the source code • Clojure’s idiom is about (very) short name – Ex: def instead of define, inc instead of increment, etc. – That’s not oriented towards understandability but conciseness • Weak typing means a different way of looking after the domain language – Symbols instead of type’s name • The fundamentals of the language are indeed very DDD oriented – Everything returns a Value – Identity, State and Functions does not complects in Entity
{kind=link}
![#whoami Jérémie Grodziski Software Designer and Programmer @jgrodziski [email protected]](https://files.speakerdeck.com/presentations/ee436010883b01318896164c1d05617a/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}