Adaptive Dataflow: A Database/Networking Convergence
Given at the Stanford database seminar 12/7/2001, this talk makes the case that database and networking research are converging, and gives examples from work in the Telegraph group at Berkeley.
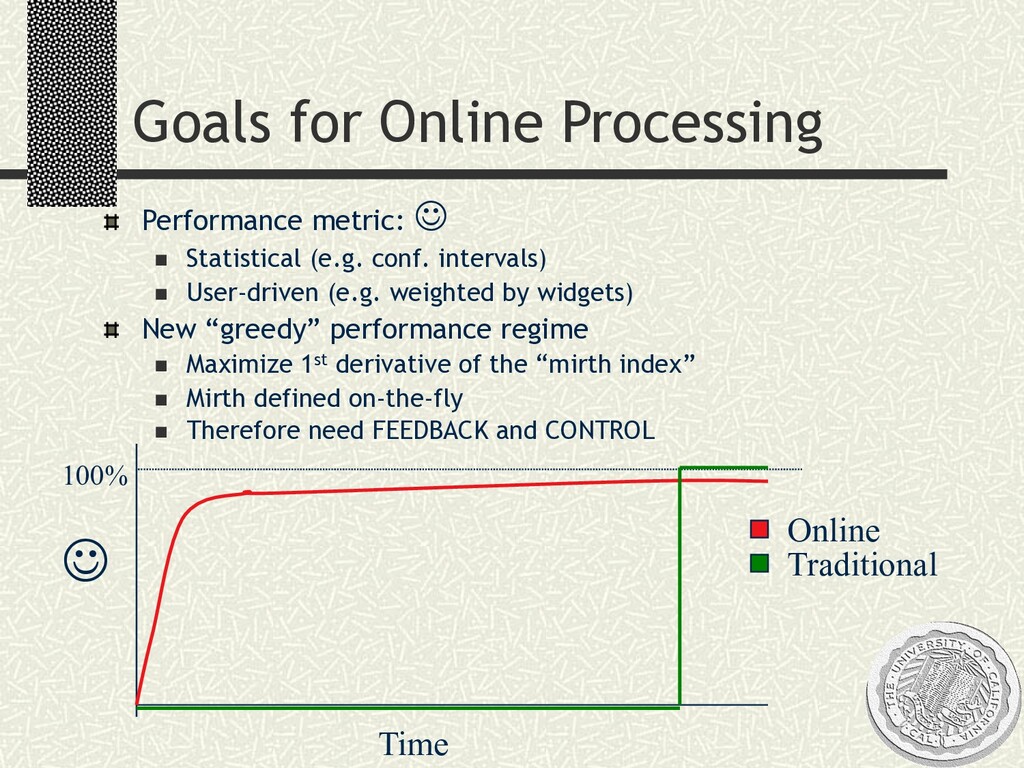
conf. intervals) n User-driven (e.g. weighted by widgets) New “greedy” performance regime n Maximize 1st derivative of the “mirth index” n Mirth defined on-the-fly n Therefore need FEEDBACK and CONTROL Time J 100% Online Traditional
n User feedback, sample variance Goals and data may be different in different “regions” n Group-by, scrollbar position n [An aside: dependencies in selectivity estimation] Q: Query optimization in this world? n Or in any pipelining, volatile environment?? n Where else do we see volatility?
DB model: algebra expressions: (R S) T n Usual DB implementation: pipelining operators! n Subexpressions never materialized n Typical implementation is more flexible than algebra n We can reorder in-flight operators n Other gains possible by breaking the set-oriented boundary… Don’t rewrite graph. Impose a router n Graph edge = absence of routing constraint n Observe operator consumption/production rates n Consumption: cost n Production: cost*selectivity
DBMS grad class, over a year Eric/Joe, point/counterpoint Some tie-ins were obvious: n memory mgmt, storage, scheduling, concurrency Surprising: QP and networks go well side by side n E.g. eddies and TCP Congestion Control n Both use back-pressure and simple Control Theory to “learn” in an unpredictable dataflow environment n Eddies close to the n-armed bandit problem
protocols: data xfer n Data Manipulation (buffer, checksum, encryption, xfer to/fr app space, presentation) n Transfer Control (flow/congestion ctl, detecting xmission probs, acks, muxing, timestamps, framing) -- Clark & Tennenhouse, “Architectural Considerations for a New Generation of Protocols”, SIGCOMM ‘90 Basic Internet assumption: n “a network of unknown topology and with an unknown, unknowable and constantly changing population of competing conversations” (Van Jacobson)
xfer control, not so good at data manipulation Some C&T wacky ideas for better data manipulation n Xfer semantic units, not packets (ALF) n Auto-rewrite layers to flatten them (ILP) n Minimize cross-layer ordering constraints n Control delivery in parallel via packet content C & T’s Wacky Ideas
unbounded data producers and consumers (“streams” … “continuous queries”) n We couldn’t know our producers’ behavior or contents?? (“federation” … “mediators”) n We couldn’t predict user behavior? (“control”) n We couldn’t predict behavior of components in the dataflow? (“networked services”) n We had partial failure as a given? (oops, have we ignored this?) Yes … networking people have been here! n Remember Van Jacobson’s quote?
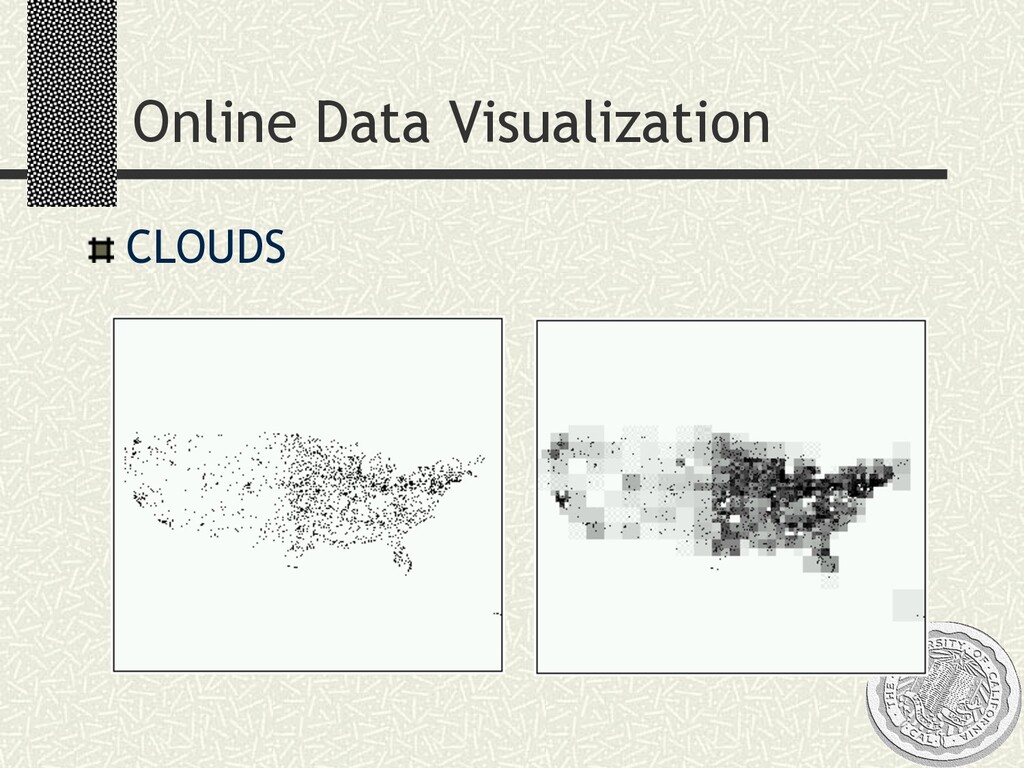
n Volatility n Rich Queries Clearly: n Long-running data analysis a la CONTROL n Continuous queries n Queries over Internet sources and services Two emerging scenarios: n Sensor networks n P2P query processing
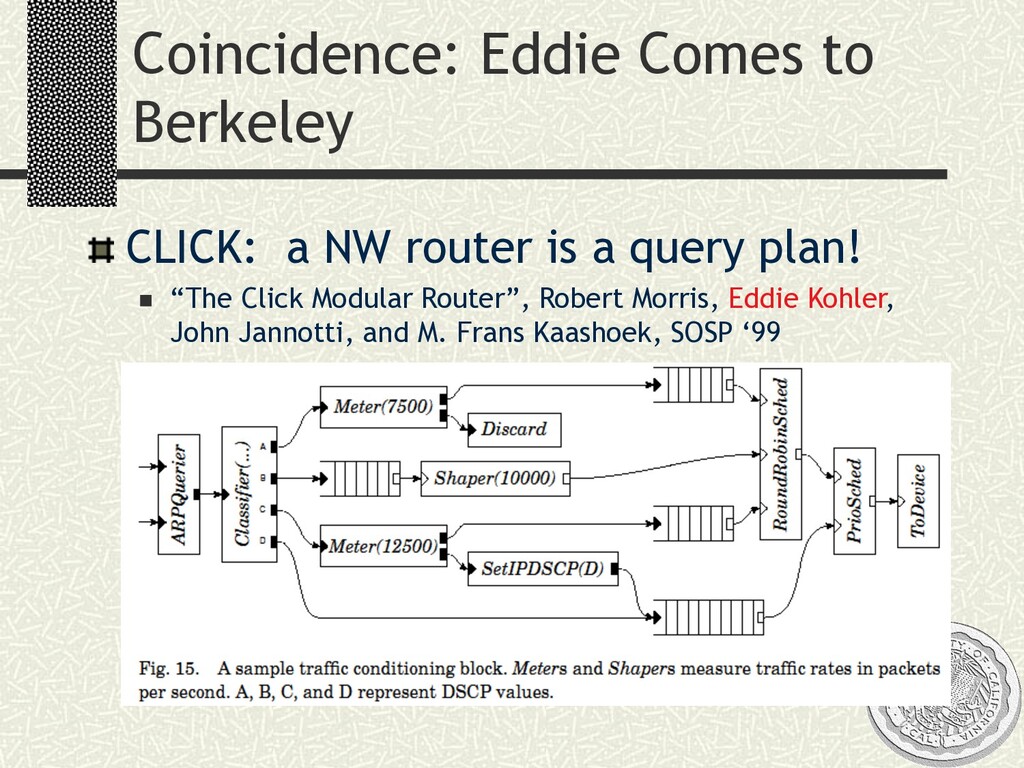
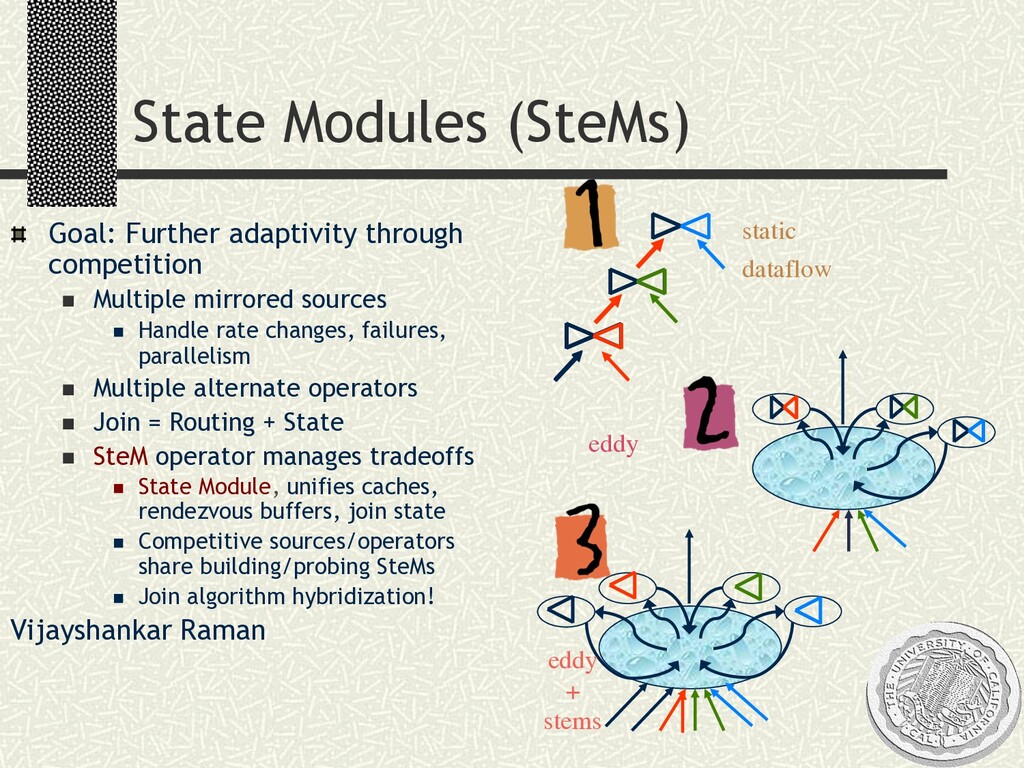
Dataflow programming model n A la Volcano, CLICK: push and pull. “Fjords”, ICDE02 n Extensible set of pipelining operators, including relational ops, grouped filters (e.g. XFilter) n SQL parser for convenience (looking at XQuery) n Adaptivity operators n Eddies n + Extensible rules for routing constraints, Competition n SteMs (state modules) n FLuX (Fault-tolerant Load-balancing eXchange) n Bounded and continuous: n Data sources n Queries
mirrored sources n Handle rate changes, failures, parallelism n Multiple alternate operators n Join = Routing + State n SteM operator manages tradeoffs n State Module, unifies caches, rendezvous buffers, join state n Competitive sources/operators share building/probing SteMs n Join algorithm hybridization! Vijayshankar Raman static dataflow eddy eddy + stems
flows need high availability n Big flows need parallelism n Adaptive Load-Balancing req’d n FLuX operator: Exchange plus… n Adaptive flow partitioning (River) n Transient state replication & migration n RAID for SteMs n Needs to be extensible to different ops: n Content-sensitivity n History-sensitivity n Dataflow semantics n Optimize based on edge semantics n Networking tie-in again: • At-least-once delivery? • Exactly-once delivery? • In/Out of order? n Migration policy: the ski rental analogy Mehul Shah
this stuff! Address adaptivity 1st. 4 Ideas in CACQ: n Use eddies to allow reordering of ops. n But one eddy will serve for all queries n Explicit tuple lineage n Mark each tuple with per-op ready/done bits n Mark each tuple with per-query completed bits n Queries are data: join with Grouped Filter n Much like XFilter, but for relational queries n Joins via SteMs, shared across all queries n Note: mixed-lineage tuples in a SteM. I.e. shared state is not shared algebraic expressions! n Delete a tuple from flow only if it matches no query Next: F.T. CACQ via FLuXen Sam Madden, Mehul Shah, Vijayshankar Raman
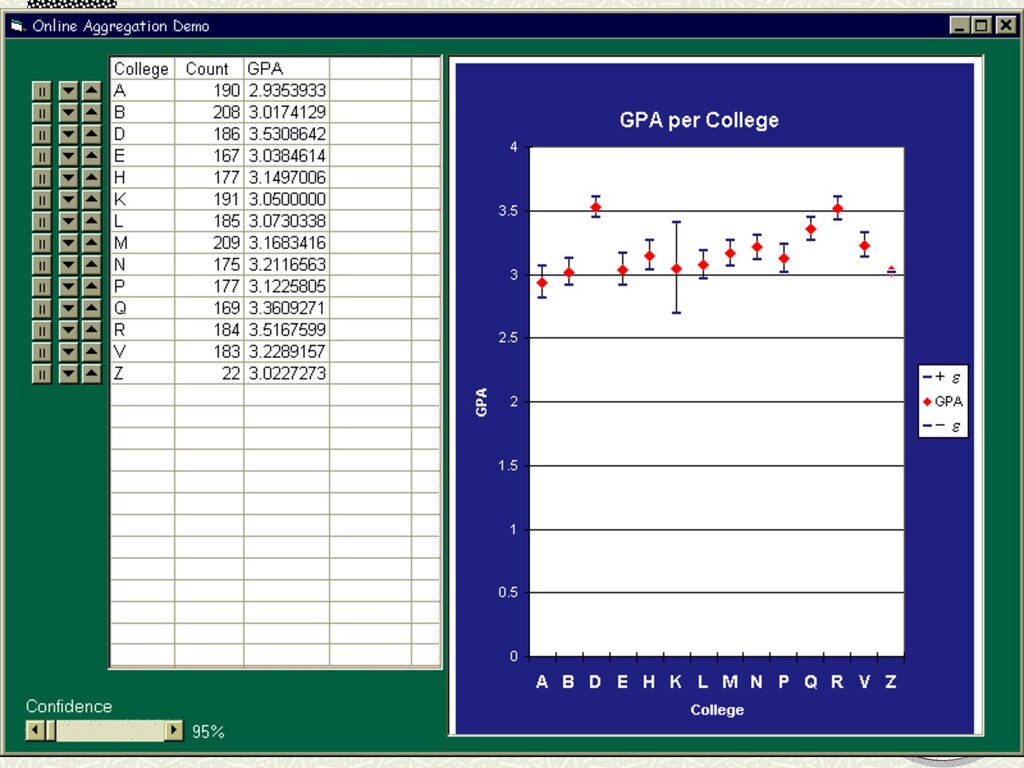
communication n Power constraints Query workload: n Aggregation & approximation n Queries and Continuous Queries Challenges: n Push the processing into the network n Deal with volatility & failure n CONTROL issues: data variance, user desires Joint work with Ramesh Govindan, Sam Madden, Wei Hong and David Culler (Intel Berkeley Lab) Simple example: Aggregation query
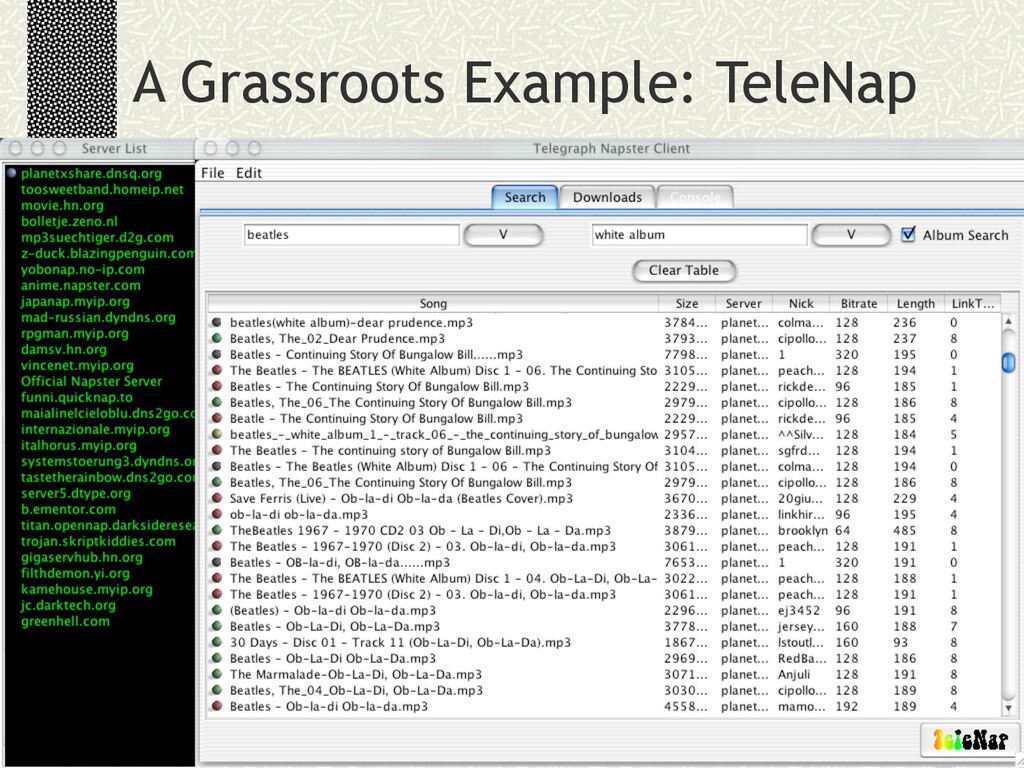
filesharing volume (1.8Gfiles in October 2001) n No business case to date Challenge: scale DDBMS QP ideas to P2P n Motivate why n Pick the right parts of DBMS research to focus on n Storage: no! QP: yes. n Make it work: n Scalability well beyond our usual target n Admin constraints n Unknown data distributions, load n Heterogeneous comm/processing n Partial failure Joint work with Scott Shenker, Ion Stoica, Matt Harren, Ryan Huebsch, Nick Lanham, Boon Thau Loo
Exchange model: encapsulate in ops? n Interesting adaptive policy problems n E.g. eddy routing, flux migration n Control Theory, Machine Learning n Encompasses another CS goal? n “No-knobs”, “Autonomic”, etc. New performance regimes n Decent performance in the common case n Mean/Variance more important than MAX n Interactive Metrics n Time to completion often unimportant/irrelevant
Kabra/DeWitt or Tukwila n E.g. SteMs vs. Materialized Views n E.g. CACQ vs. NiagaraCQ n Some clean theory here would be nice n Current routing correctness proofs are inelegant Extensibility n Model/language of choice is not clear n SEQ? Relational? XQuery? n Extensible operators, edge semantics n [A whine about VLDB’s absurd “Specificity Factor”]
n The CS262 experiment is a success n Our students are getting a bigger picture than before n I’m learning, finding new connections n May morph to OS/Nets, Nets/DB n Eventually rethink the systems software curriculum at the undergraduate level too n Nets folks are coming our way n Doing relevant work, eager to collaborate n DB community needs to branch out n Outbound: Better proselytizing in CS n Inbound: Need new ideas
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}