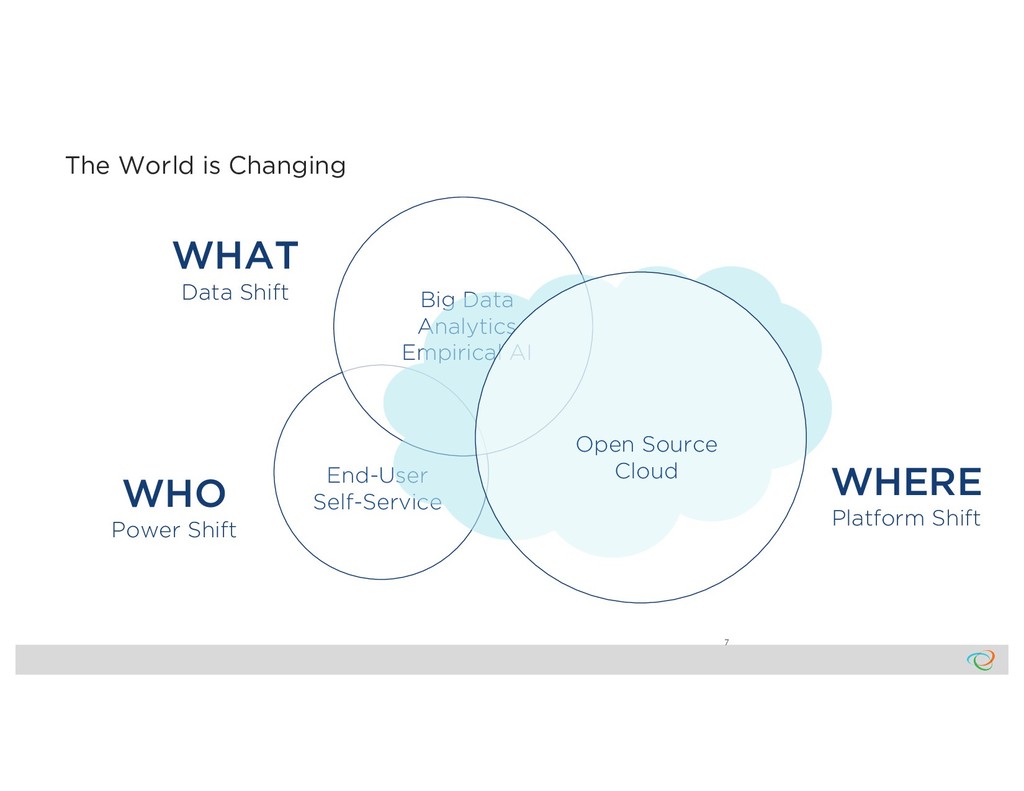
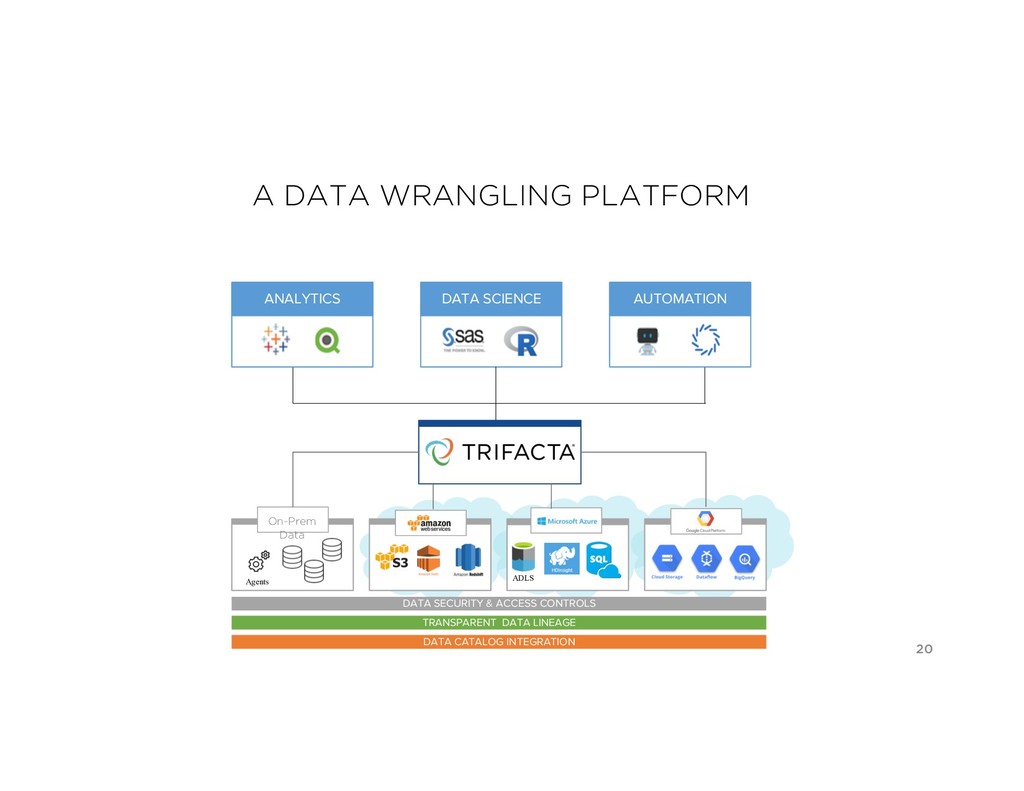
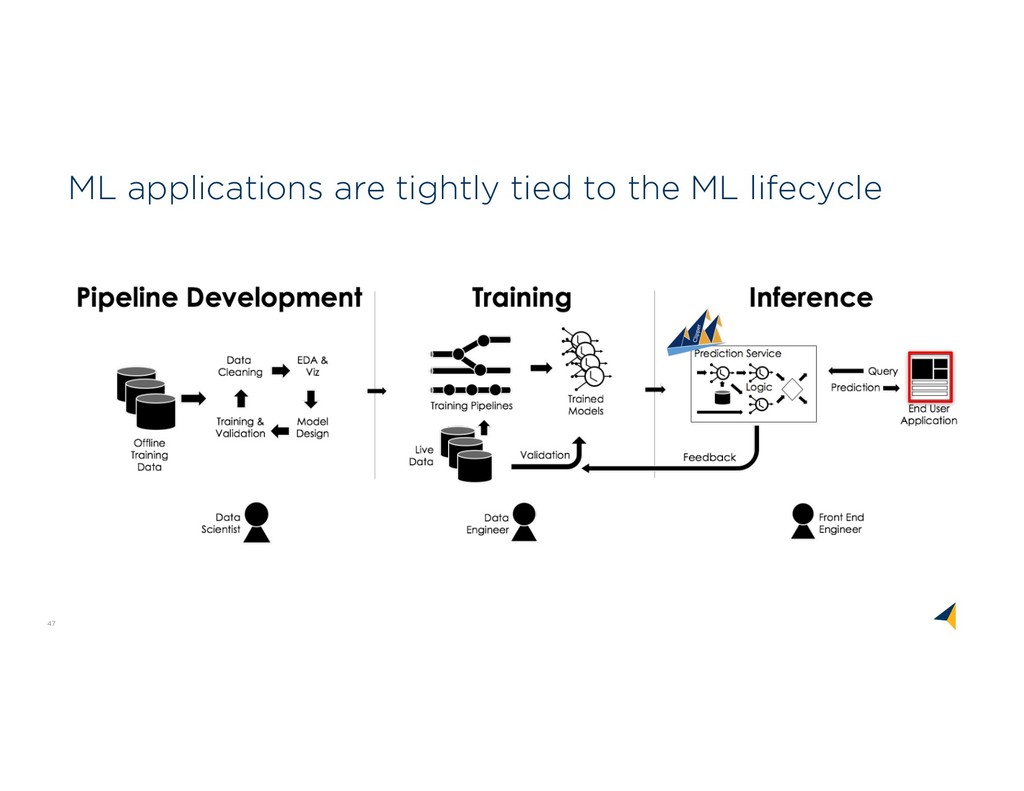
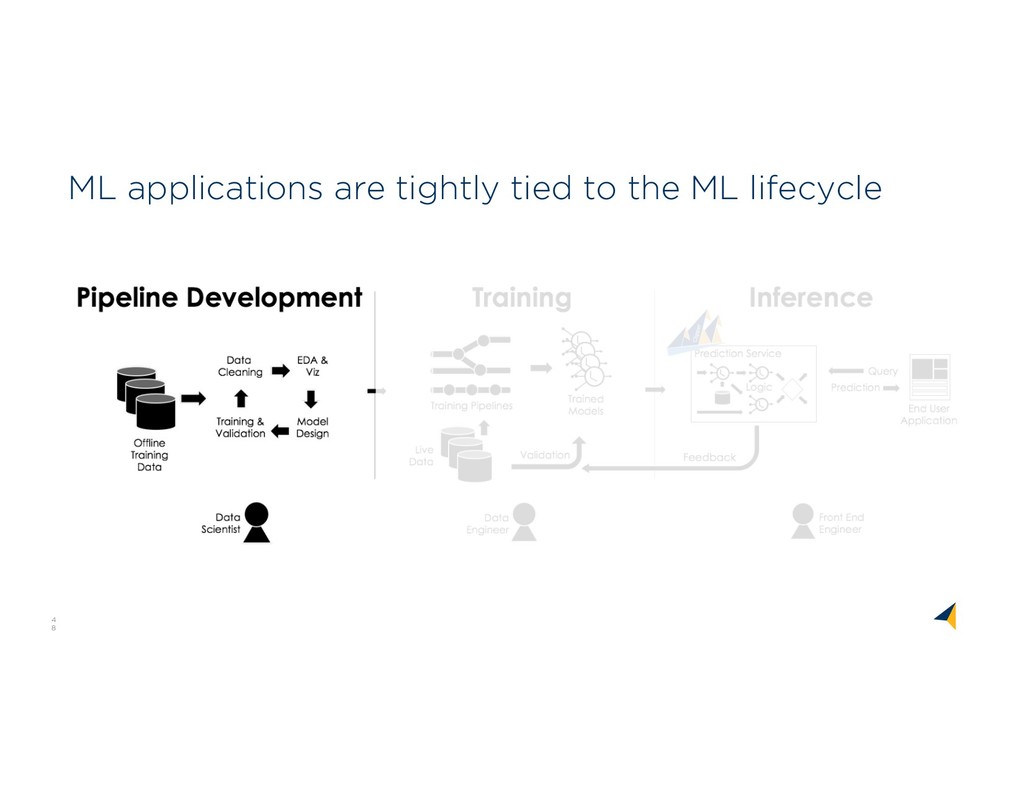
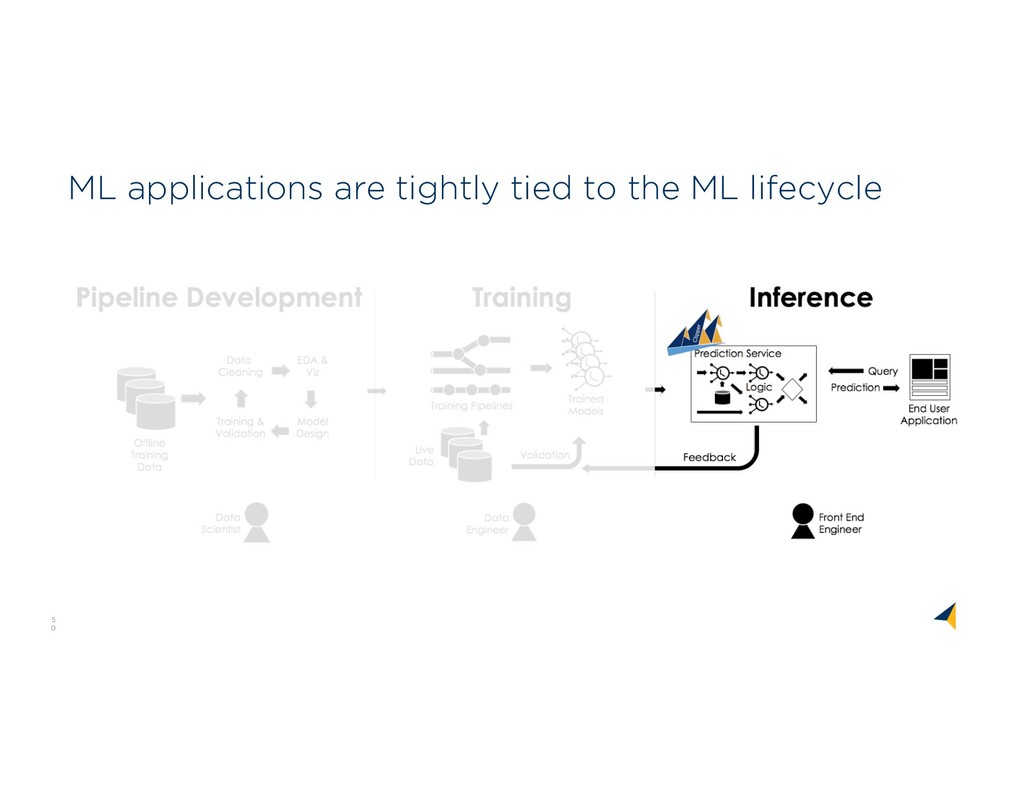
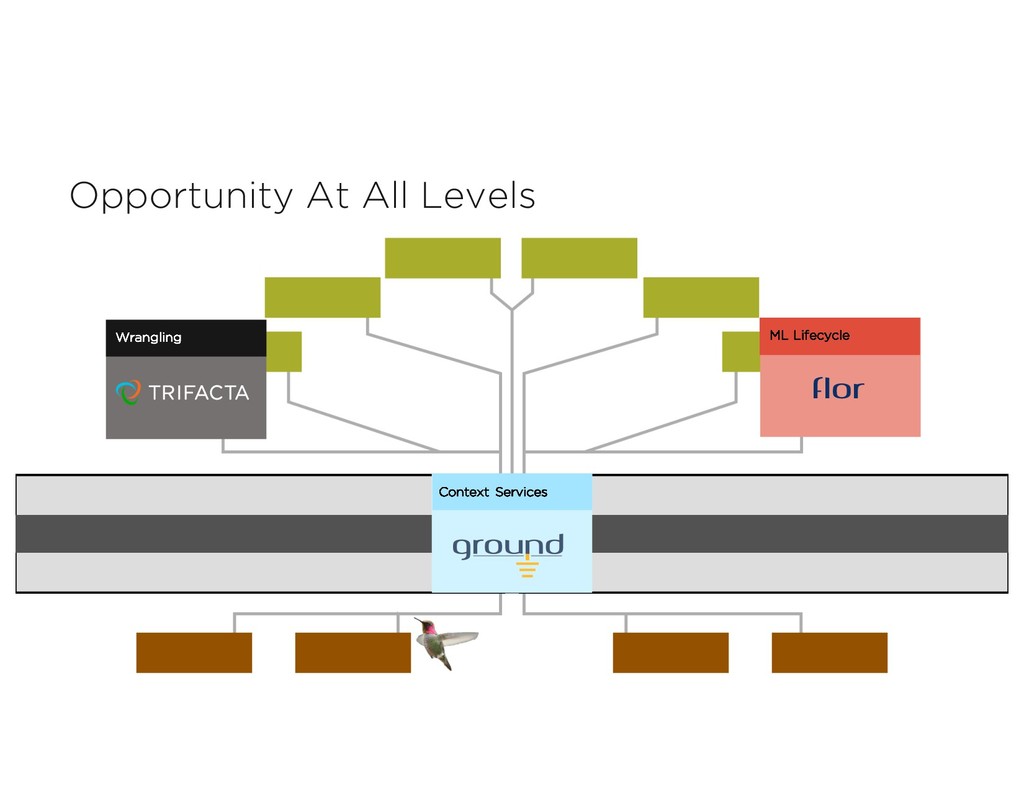
Market WHO WHA T WHER E Problem Relevance 80% Data Prep Market Use Cases Platform Challenges O n-Pre m Da ta A g e n t s A D L S D AT A S E CU RIT Y & ACCE S S CON T ROLS T RAN S P ARE N T D AT A LIN E AG E D AT A CAT ALOG IN T E G RAT ION ANALYTICS DATA SCIENCE AUTOMATION Perspectives on Data Context Wrangling Context Services Six years with Trifacta and Google Cloud Dataprep The Common Ground model, and Ground system Managing the rise of Empirical AI flor ML Lifecycle
WHO WHAT WHERE Problem Relevance 80% Data Prep Market Use Cases Platform Challenges O n-Pre m Da ta A ge nts A D LS D AT A S E CU RIT Y & ACCE S S CON T ROLS T RAN S P ARE N T D AT A LIN E AG E D AT A CAT ALOG IN T E G RAT ION ANALYTICS DATA SCIENCE AUTOMATION
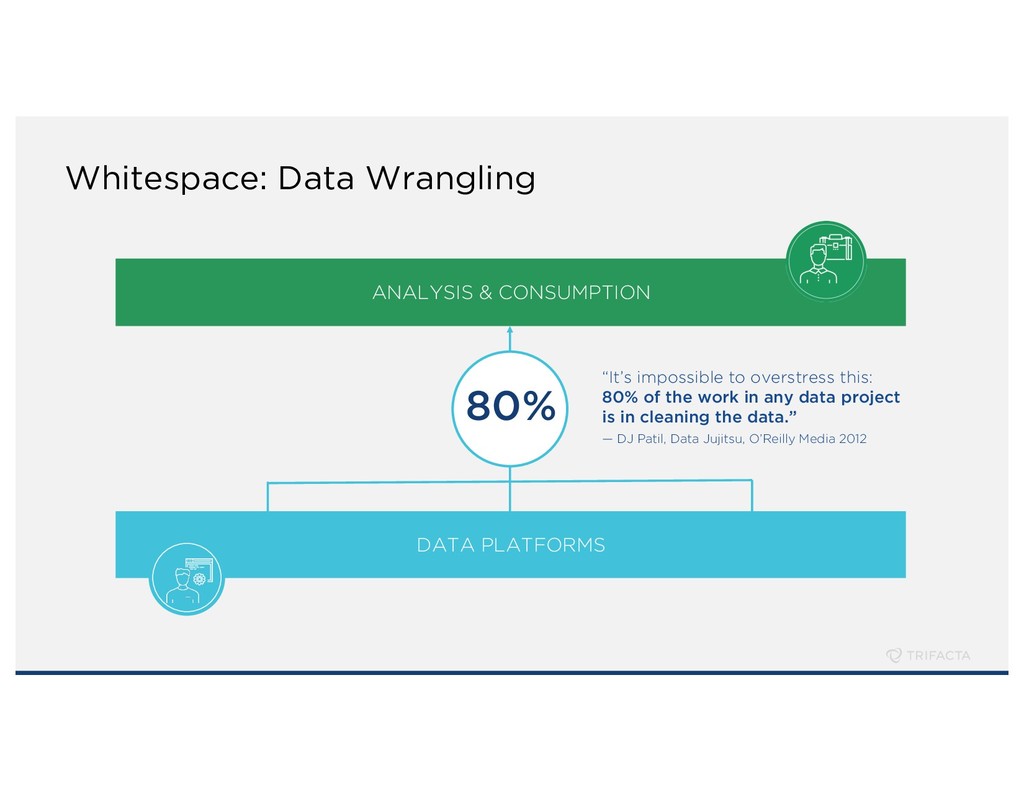
can.” — DJ Patil, Building Data Science Teams, 2011 “There is no point in bringing data … into the data warehouse environment without integrating it.” — Bill Inmon, Building the Data Warehouse, 2005 2018: Business Value From A Quantified World
+ Immediate feedback on multiple choices + Data quality indicators “Wrangler: Interactive Visual Specification of Data Transformation Scripts.” S. Kandel, A.Paepcke, J.M. Hellerstein, J. Heer. CHI 2011. “Proactive Wrangling: Mixed-Initiative End-User Programming of Data Transformation Scripts”, P.J. Guo, S. Kandel, J. M. Hellerstein, J. Heer. UIST 2011. “Enterprise Data Analysis and Visualization: An Interview Study.” S. Kandel, A. Paepcke, J.M. Hellerstein, and J. Heer IEEE VAST 2012 “Profiler: Integrated Statistical Analysis and Visualization for Data Quality Assessment”, S. Kandel, et al. AVI 2012. “Predictive Interaction for Data Transformation” J. Heer, J.M. Hellerstein and S. Kandel CIDR 2015
well established Forrester did its first “Wave” ranking in 2017 Gartner now estimates > $1 Billion market for Data Prep by 2021 12 “Trifacta delivers a strong balance for self-service by analysts and business users. Customer references gave high marks to Trifacta’s ease of use. Trifacta leverages machine learning algorithms to automate and simplify the interaction with data.”
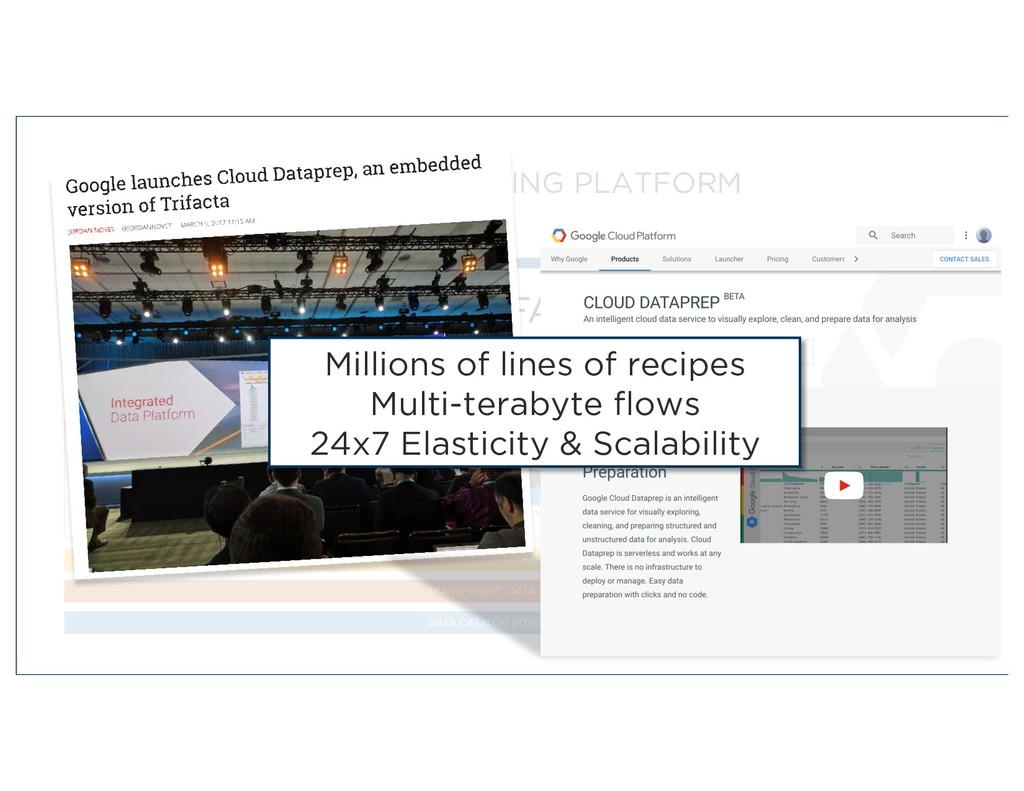
SECURITY & ACCESS CONTROLS TRANSPARENT DATA LINEAGE DATA CATALOG INTEGRATION Millions of lines of recipes Multi-terabyte flows 24x7 Elasticity & Scalability
days with Trifacta • Refuted an assumption in analysis that would not have been possible without enriching datasets • Expects to scale this model to other, similar outbreaks, such as Zika or Ebola Benefits In future, we need to combine “a variety of sources to identify jurisdictions that, like this county in Indiana, may be at risk of an IDU- related HIV outbreak. These data include drug arrest records, overdose deaths, opioid sales and prescriptions, availability of insurance, emergency medical services, and social and demographic data.” - CDC “The Anatomy of an HIV Outbreak Response in a Rural Community” E. M. Campbell, H. Jia, A. Shankar, et al. “Detailed Transmission Network Analysis of a Large Opiate-Driven Outbreak of HIV Infection in the United States”. Journal of Infectious Diseases, 216(9), 27 November 2017, 1053–1062. https://academic.oup.com/jid/article/216/9/1053/4347235 https://blogs.cdc.gov/publichealthmatters/2015/06/the-anatomy-of-an-hiv outbreak-response-in-a-rural-community/
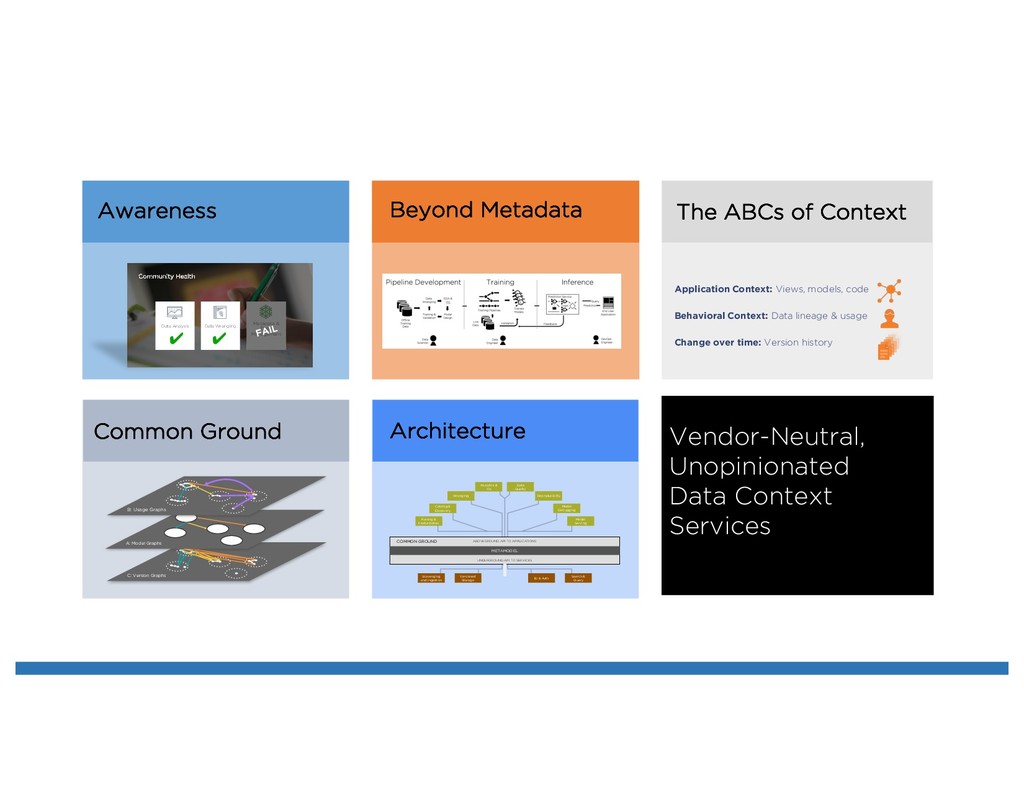
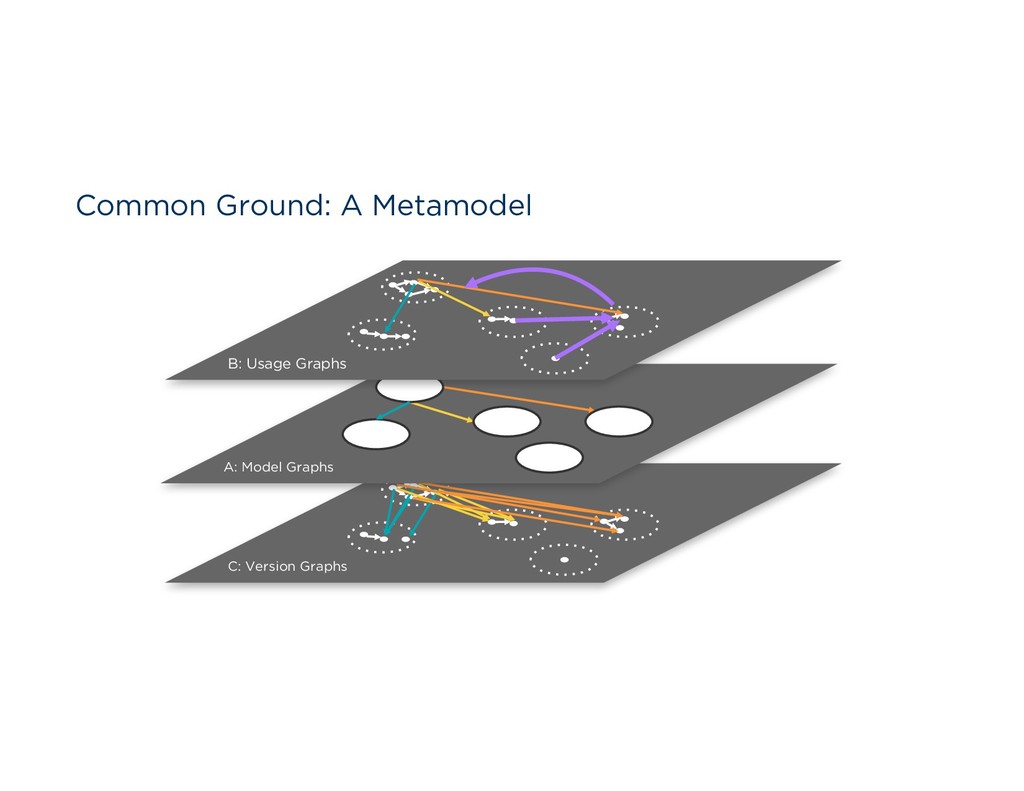
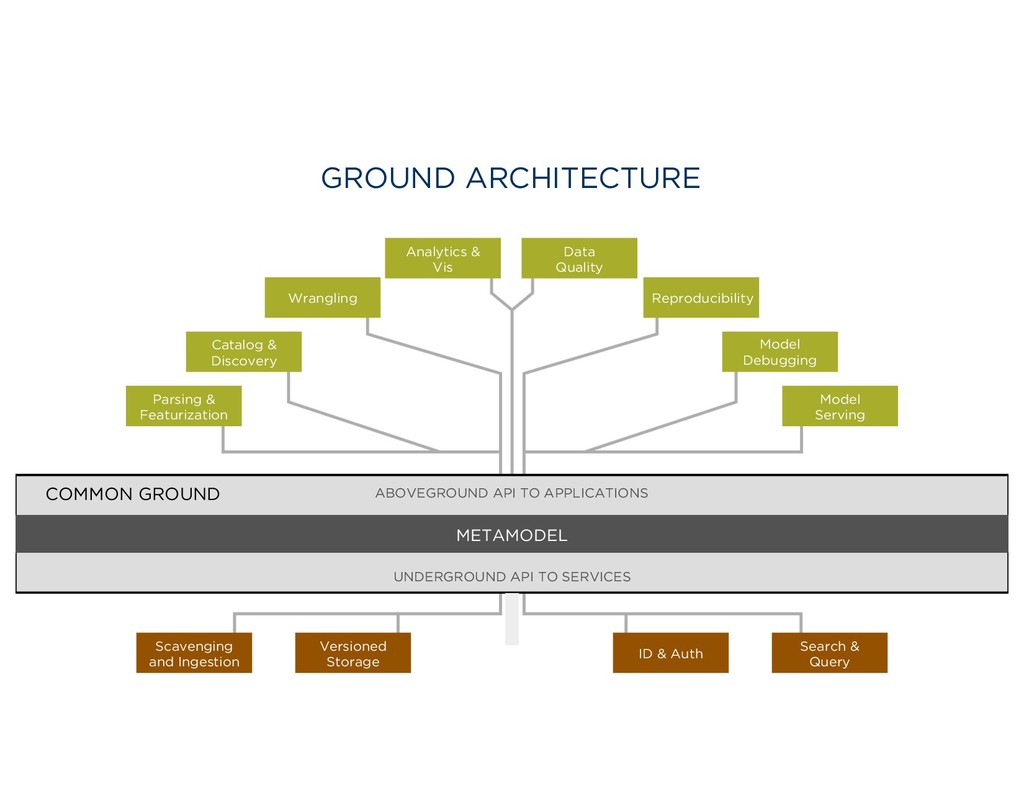
Featurization Catalog & Discovery Wrangling Analytics & Vis Data Quality Reproducibility Scavenging and Ingestion Search & Query Versioned Storage ID & Auth ABOVEGROUND API TO APPLICATIONS UNDERGROUND API TO SERVICES METAMODEL COMMON GROUND Common Ground C: Version Graphs A: Model Graphs B: Usage Graphs The ABCs of Context Application Context: Views, models, code Behavioral Context: Data lineage & usage Change over time: Version history Awareness Community Health Metadata & Data Management Data Analysis Data Wrangling Perspectives on Data Context Wrangling Context Services Six years with Trifacta and Google Cloud Dataprep The Common Ground model, and Ground system Managing the rise of Empirical AI flor ML Lifecycle
Model Debugging Parsing & Featurization Catalog & Discovery Wrangling Analytics & Vis Data Quality Reproducibility Scavenging and Ingestion Search & Query Versioned Storage ID & Auth ABOVEGROUND API TO APPLICATIONS UNDERGROUND API TO SERVICES METAMODEL COMMON GROUND Common Ground C: Version Graphs A: Model Graphs B: Usage Graphs The ABCs of Context Application Context: Views, models, code Behavioral Context: Data lineage & usage Change over time: Version history Awareness Community Health Metadata & Data Management Data Analysis Data Wrangling
The last thing anybody wants to work on Isn’t this just metadata? Community Health Metadata & Data Management Data Analysis Data Wrangling Time to Go Meta (on Use) Strata New York 2015 Grounding Big Data Strata San Jose 2016 Data Relativism Strata London Keynote 2016 https://speakerdeck.com/jhellerstein
& Discovery Wrangling Analytics & Vis Data Quality Reproducibility Scavenging and Ingestion Search & Query Versioned Storage ID & Auth ABOVEGROUND API TO APPLICATIONS UNDERGROUND API TO SERVICES METAMODEL COMMON GROUND
& Discovery Wrangling Analytics & Vis Data Quality Reproducibility Scavenging and Ingestion Search & Query Versioned Storage ID & Auth ABOVEGROUND API TO APPLICATIONS UNDERGROUND API TO SERVICES METAMODEL COMMON GROUND
Lifecycle Flor: Lifecycle Mgmt flor Demo ML Lifecycle Management: A Context-Rich Application Big Data Context Beyond Metadata The ABCs of Context flor Common Ground Architecture Model Serving Model Debugging Parsing & Featurization Catalog & Discovery Wrangling Analytics & Vis Data Quality Reproducibility Scavenging and Ingestion Search & Query Versioned Storage ID & Auth ABOVEGROUND API TO APPLICATIONS UNDERGROUND API TO SERVICES METAMODEL COMMON GROUND Perspectives on Data Context Wrangling Context Services Six years with Trifacta and Google Cloud Dataprep The Common Ground model, and Ground system Managing the rise of Empirical AI flor ML Lifecycle
old” science! ML & AI generate combinatorially more experiments and data A Transformed Scientific Method E HAVE TO DO BETTER AT PRODUCING TOOLS to support the whole re- search cycle—from data capture and data curation to data analysis and data visualization. Today, the tools for capturing data both at the mega-scale and at the milli-scale are just dreadful. After you have captured the data, you need to curate it before you can start doing any kind of data analysis, and we lack good tools for both data curation and data analysis. Then comes the publication of the results of your research, and the published literature is just the tip of the data iceberg. By this I mean that people collect a lot of data and then reduce this down to some number of column inches in Science or Nature—or 10 pages if it is a computer science person writing. So what I mean by data iceberg is that there is a lot of data that is collected but not curated or published in any systematic way. There are some exceptions, and I think that these cases are a good place for us to look for best practices. I will talk about how the whole process of peer review has got to change and the way in which I think it is changing and what CSTB can do to help all of us get access to our research. W 1 National Research Council, http://sites.nationalacademies.org/NRC/index.htm; Computer Science and Telecom- munications Board, http://sites.nationalacademies.org/cstb/index.htm. 2 This presentation is, poignantly, the last one posted to Jim’s Web page at Microsoft Research before he went missing at sea on January 28, 2007—http://research.microsoft.com/en-us/um/people/gray/talks/NRC-CSTB_eScience.ppt. EDITED BY TONY HEY, STEWART TANSLEY, AND KRISTIN TOLLE | Microsoft Research Based on the transcript of a talk given by Jim Gray to the NRC-CSTB1 in Mountain View, CA, on January 11, 20072 Jim Gray, 2007
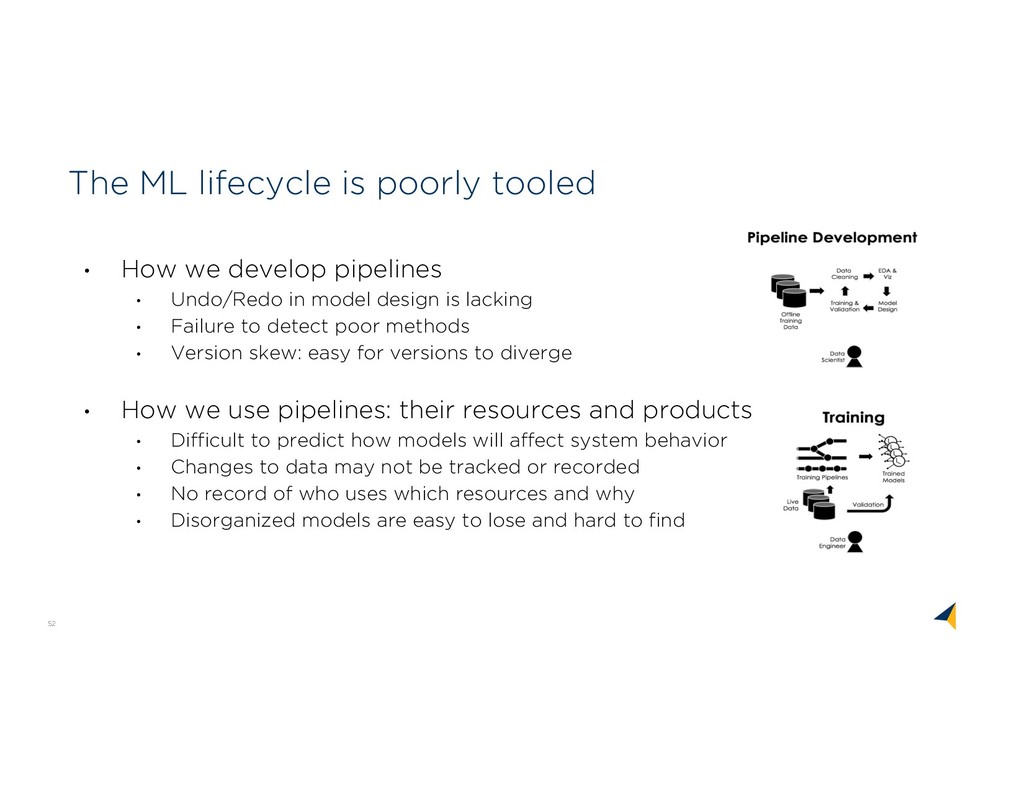
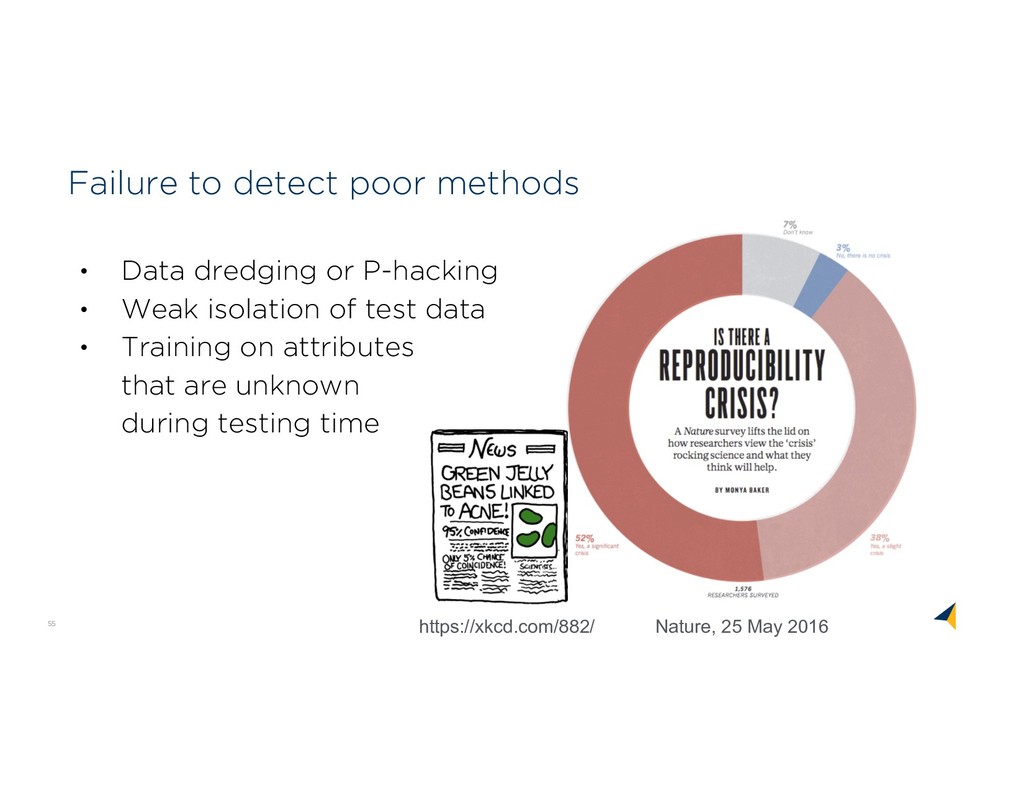
design is lacking • Failure to detect poor methods • Version skew: easy for versions to diverge • How we use pipelines: their resources and products • Difficult to predict how models will affect system behavior • Changes to data may not be tracked or recorded • No record of who uses which resources and why • Disorganized models are easy to lose and hard to find The ML lifecycle is poorly tooled
to find Models will likely be organized by an individual’s standard, but not by an organization’s standards. https://xkcd.com/1459/ http://dilbert.com/strip/2011-04-23
of alternative model designs 2. Passively track and sync the history and versions of a pipeline and its executions across multiple machines 3. Answer questions about the history and provenance, and procure artifacts from the versions • Approach: • Build a system to leverage widely used tools in a principled manner.
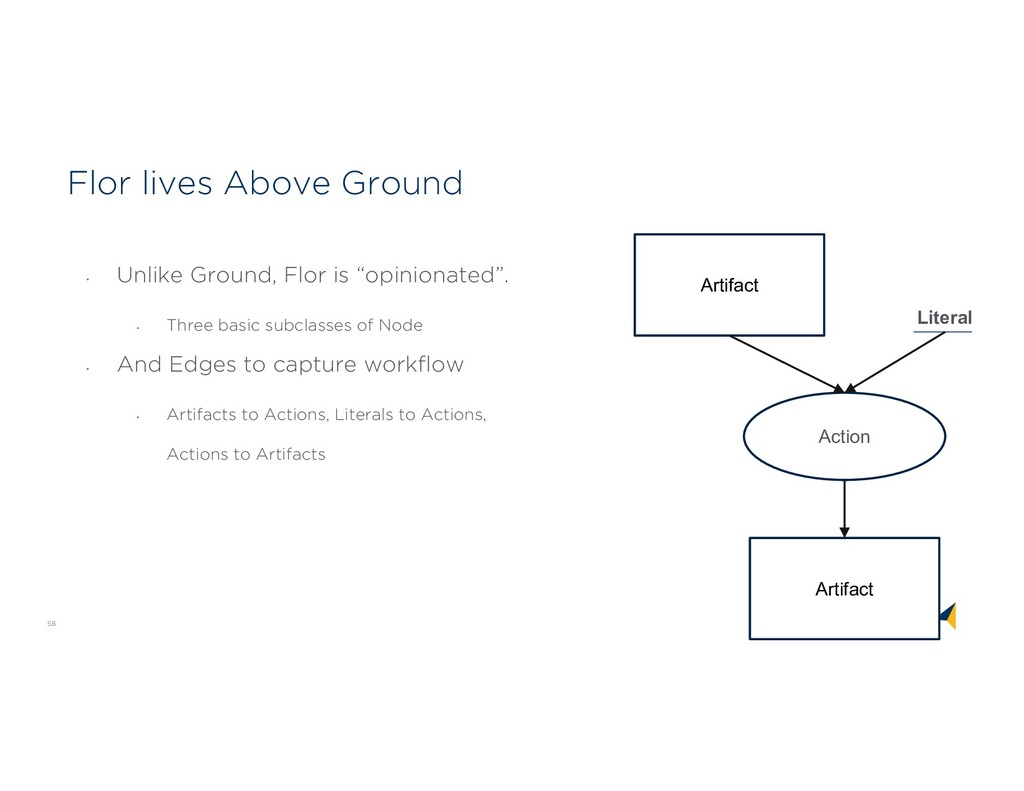
“opinionated”. • Three basic subclasses of Node • And Edges to capture workflow • Artifacts to Actions, Literals to Actions, Actions to Artifacts Artifact Literal Action Artifact
artifacts are versioned in Git, and associated with their respective experiments • New run = New commit • Metadata versioning: git history reflected in ground. ArtifactVersions autogenerated to track git commits. • Provenance: The provenance relationships between objects (artifacts or otherwise) are recorded in Ground
any artifact, in context • Know which artifact to materialize • Replay all previous experiments, with new data • [Opportunity] Sync local and remote versions of the pipeline, run the pipeline anywhere
artifacts are versioned in Git, and associated with their respective experiments • Metadata versioning: git history reflected in ground. ArtifactVersions autogenerated to track git commits. • Provenance: The provenance relationships between objects (artifacts or otherwise) are recorded in Ground • Parallel multi-trial experiments • Our example (3x): num_est=15, num_est=20, num_est=30.
Materialize any artifact, in richer context • Know which artifact to materialize • Replay all previous experiments, with new data • [Opportunity] Sync local and remote versions of the pipeline, run the pipeline anywhere • [Opportunity] Scripting, set literal from the command line or externally
versioned in Git, and associated with their respective experiments • New run = New commit • Provenance: The relationships between objects, artifacts or otherwise, are recorded in Ground • Parallel multi-trial experiments • Trial invariant artifacts don’t have to be recomputed
any artifact, in richer context • Know which artifact to materialize • Replay all previous experiments, with new data • Share resources, with the corresponding changes • Swap components • Maintain the pipeline • [Opportunity] Inter-version Parallelism • [Opportunity] Undo/Redo
• Timestamps • Which resources your experiment used • How many trials your experiment ran • What the configuration was per trial • The evolution of your experiment over time (versions) • The lineage that derived any artifact in the workflow • The metadata you need to retrieve a physical copy of any artifact in the workflow, ever • The current state of your experiment in the file system, in context • Whether you’ve forked any experiment resources, and which ones • When you executed an experiment, whether you executed it to completion, or only partially • Whether you’ve peeked at intermediary results during interactive pipeline development, and what you did in Flor after you learned this information • Whether you peek at the same result multiple times, or each time peek at a different trial and see a different result • The location of the peeked artifacts so they may be re-used in future computations without repeating work • Whether two specifications belonging to the same experiment used the same or different resources, and whether they derived the same artifacts. • Whether any resource or artifact was renamed • ….
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![http://ground-context.org flor http://github.com/ucbrise/jarvis Joe Hellerstein UC Berkeley / Trifacta [email protected]](https://files.speakerdeck.com/presentations/05574c2dcf394843850c210b12fa2781/slide_82.jpg){kind=link}