way that fosters unexpected innovation Distributed programming is hard! • Parallelism, consistency, partial failure, … Autoscaling makes it harder! Today’s compilers don’t address distributed concerns The Big Question Programming the Cloud: A Grand Challenge for Computing
hide how data is laid out and how queries are executed. The cloud was invented to hide how computing resources are laid out and how computations are executed.
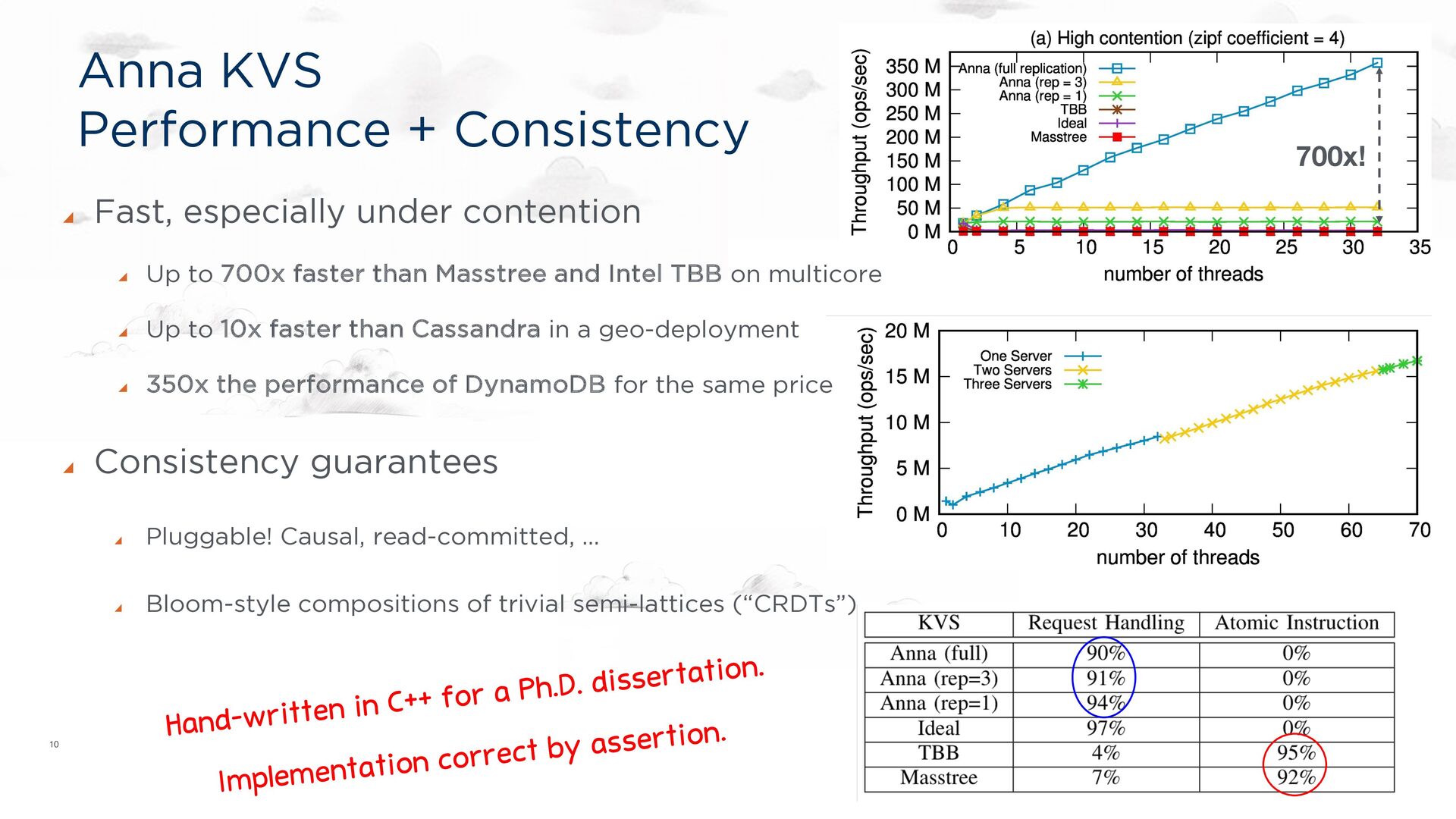
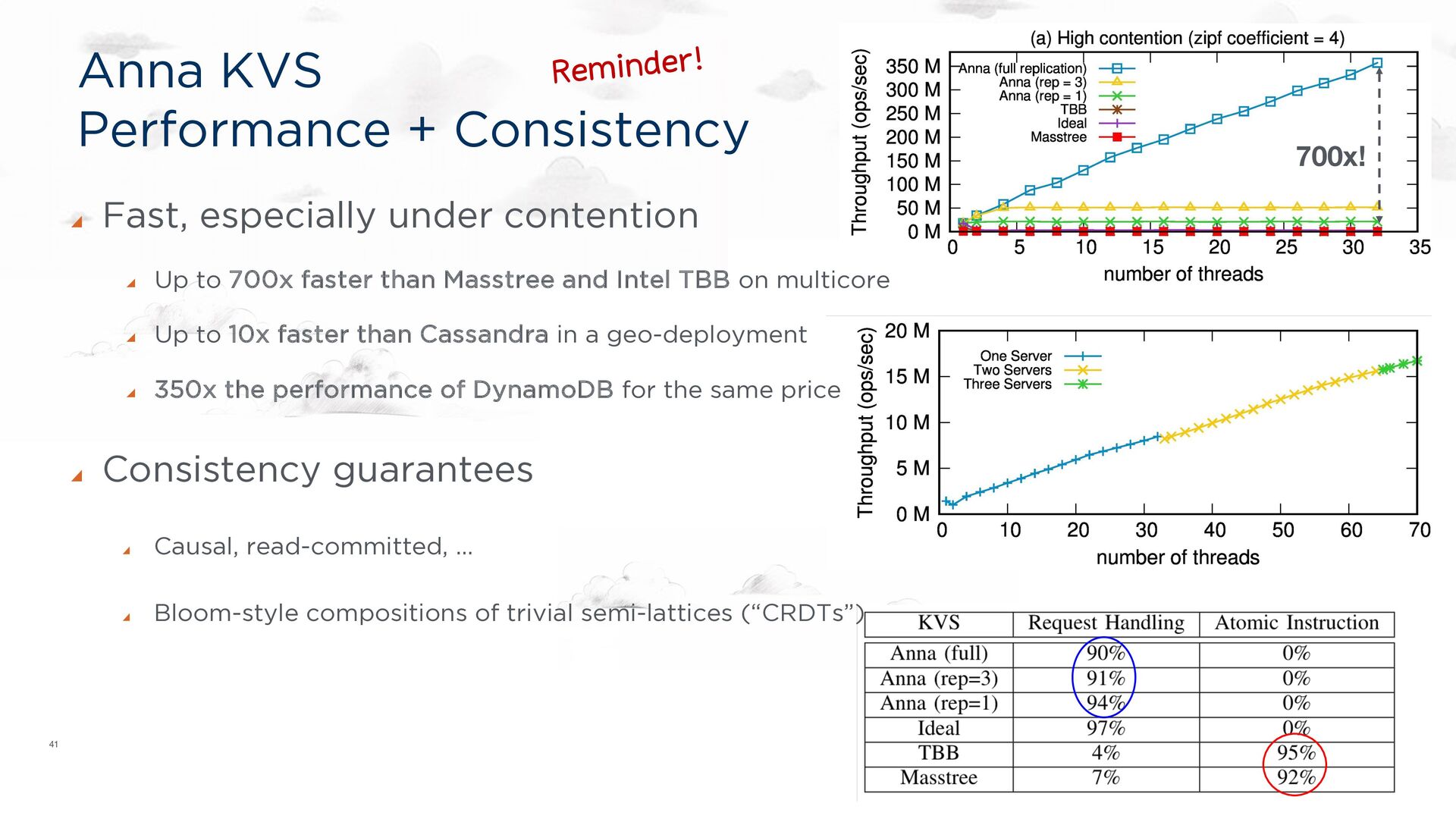
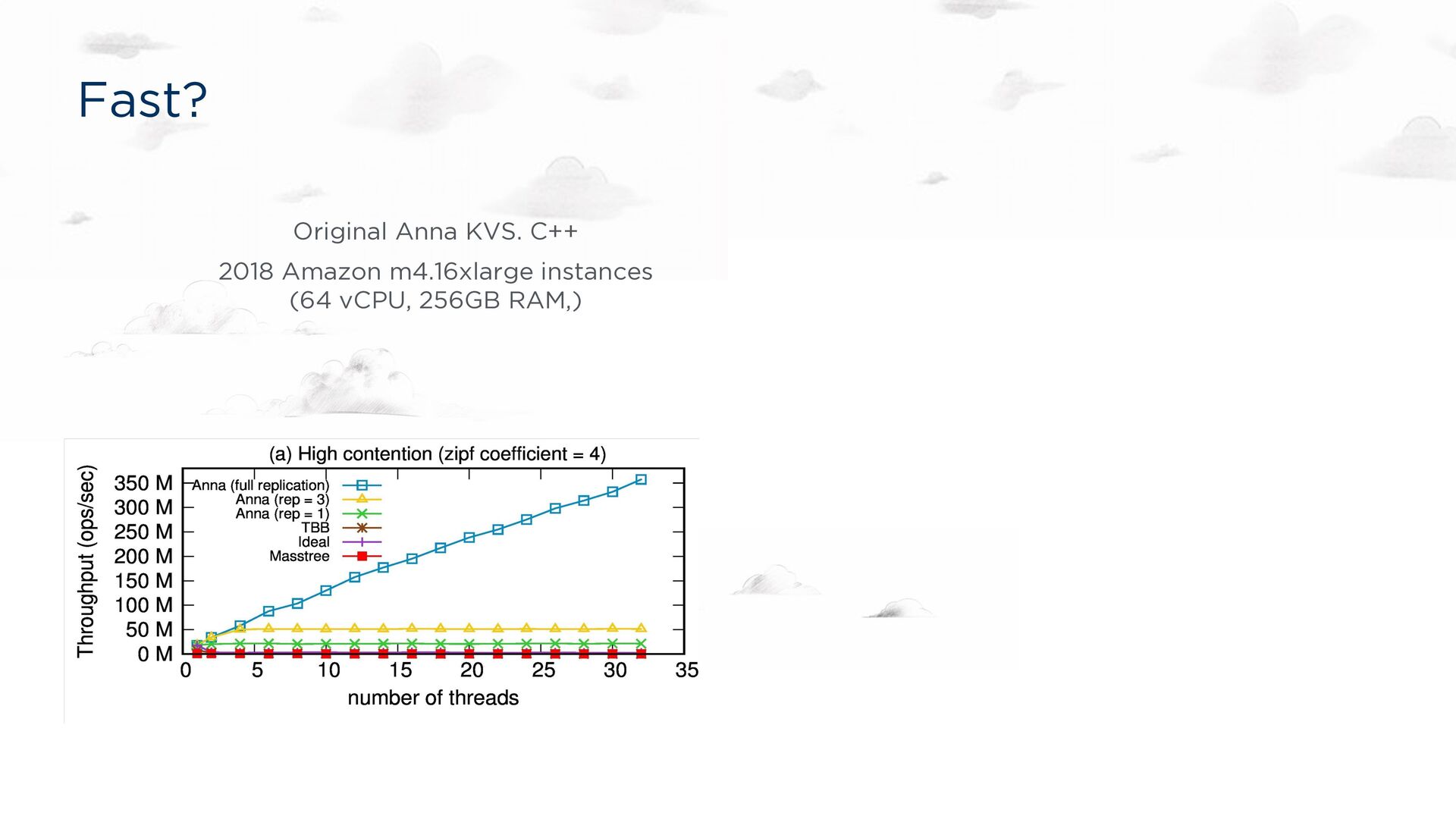
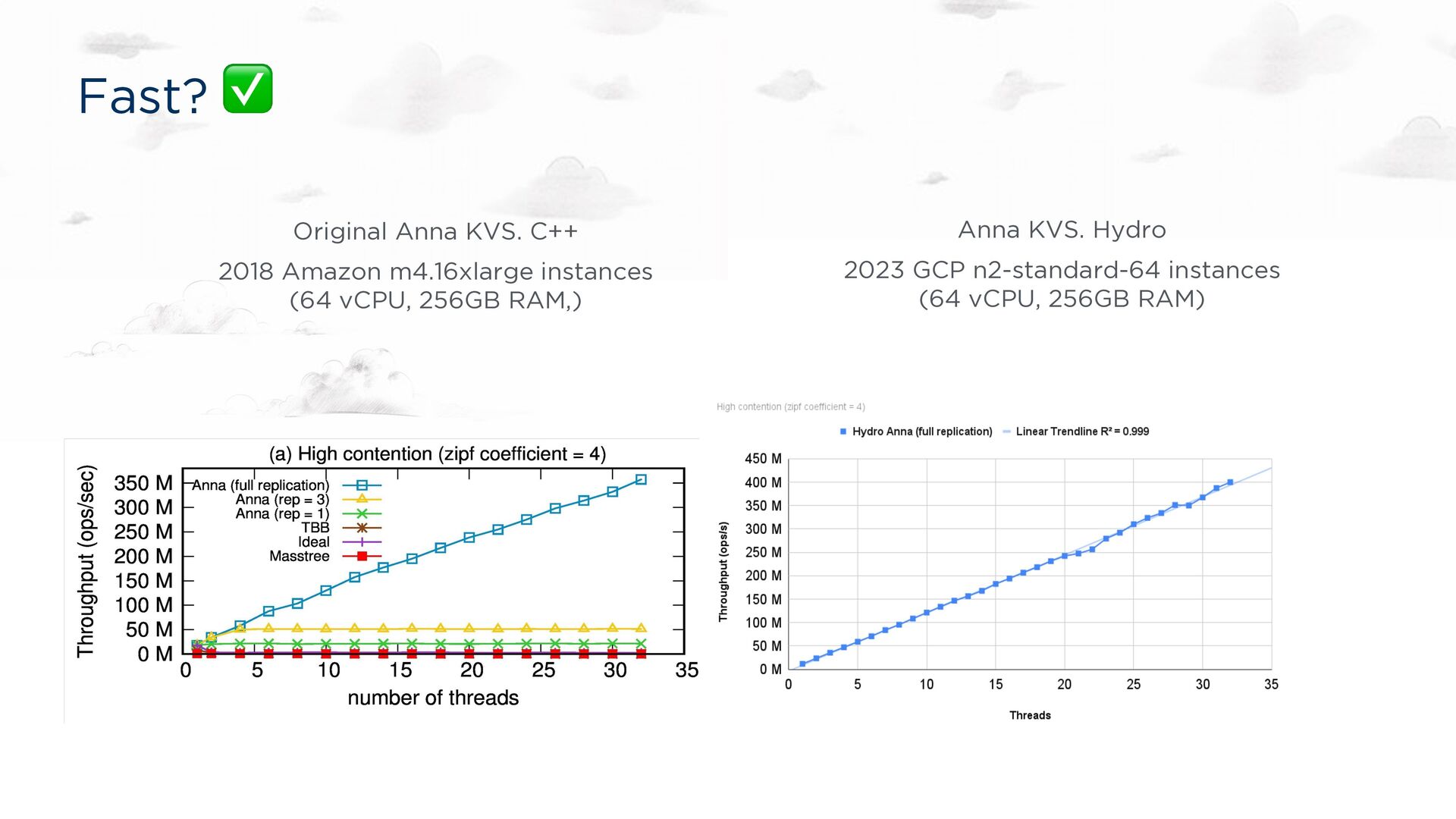
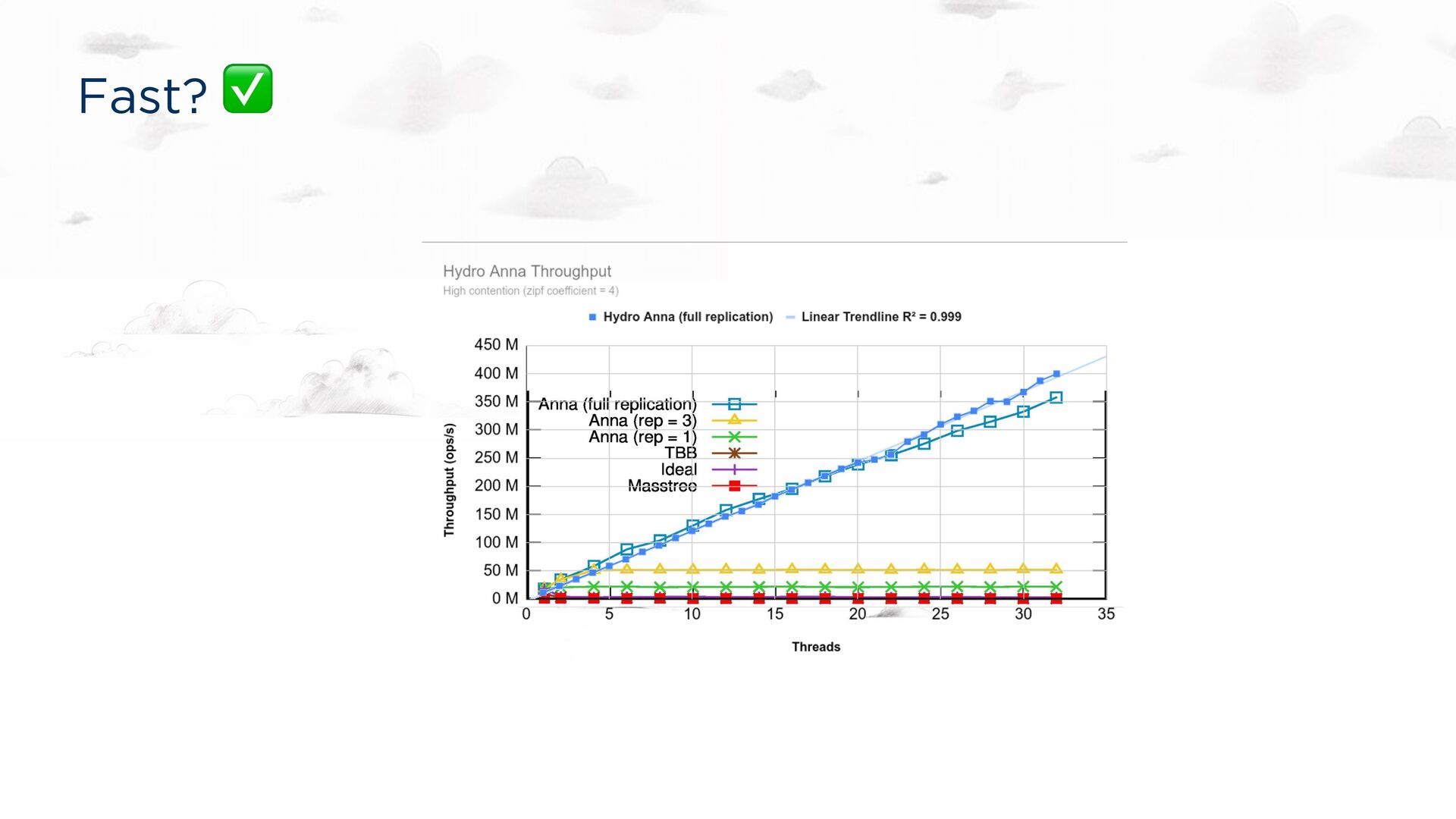
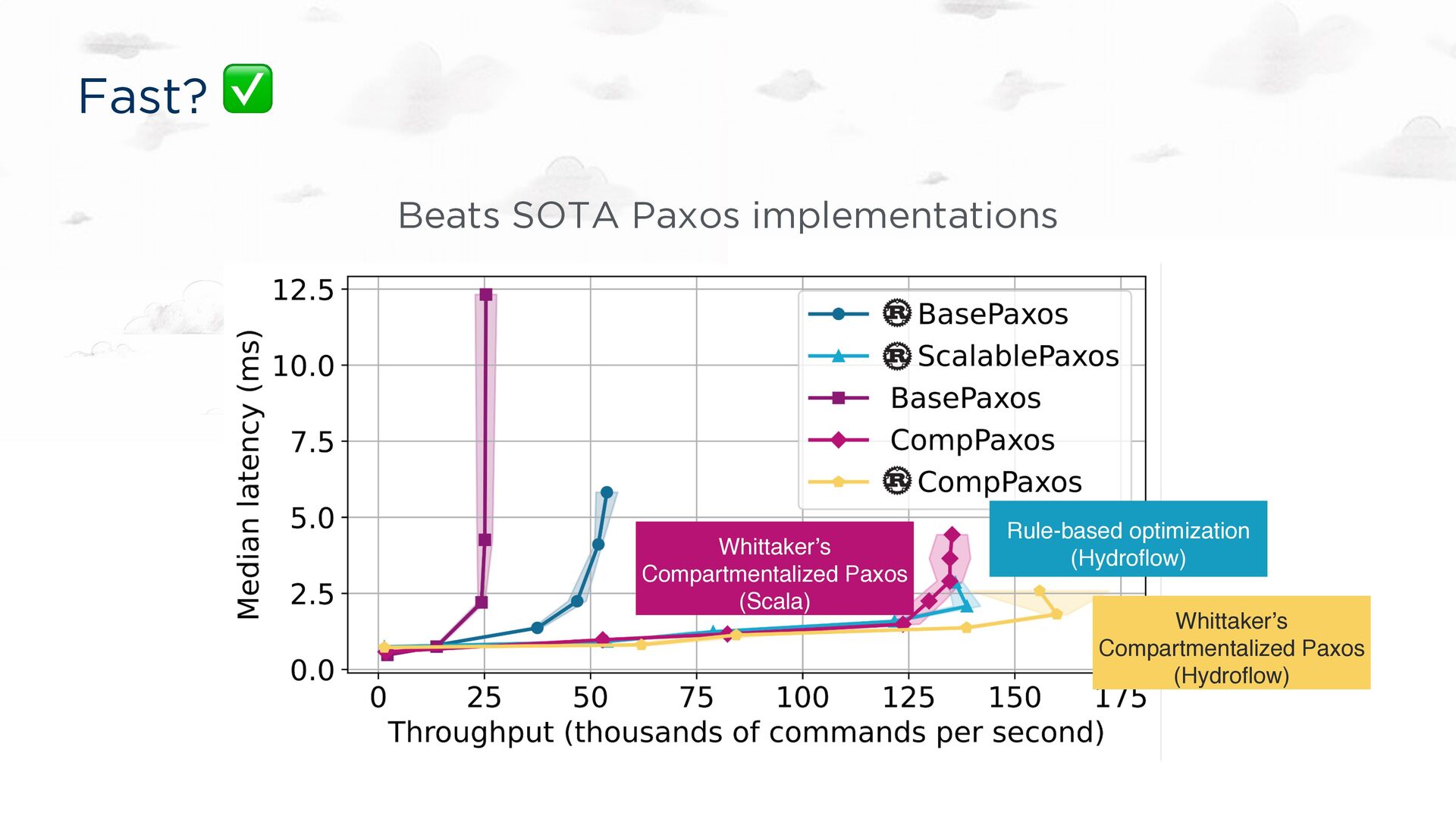
for a Ph.D. dissertation. Implementation correct by assertion. Fast, especially under contention Up to 700x faster than Masstree and Intel TBB on multicore Up to 10x faster than Cassandra in a geo-deployment 350x the performance of DynamoDB for the same price Consistency guarantees Pluggable! Causal, read-committed, … Bloom-style compositions of trivial semi-lattices (“CRDTs”)
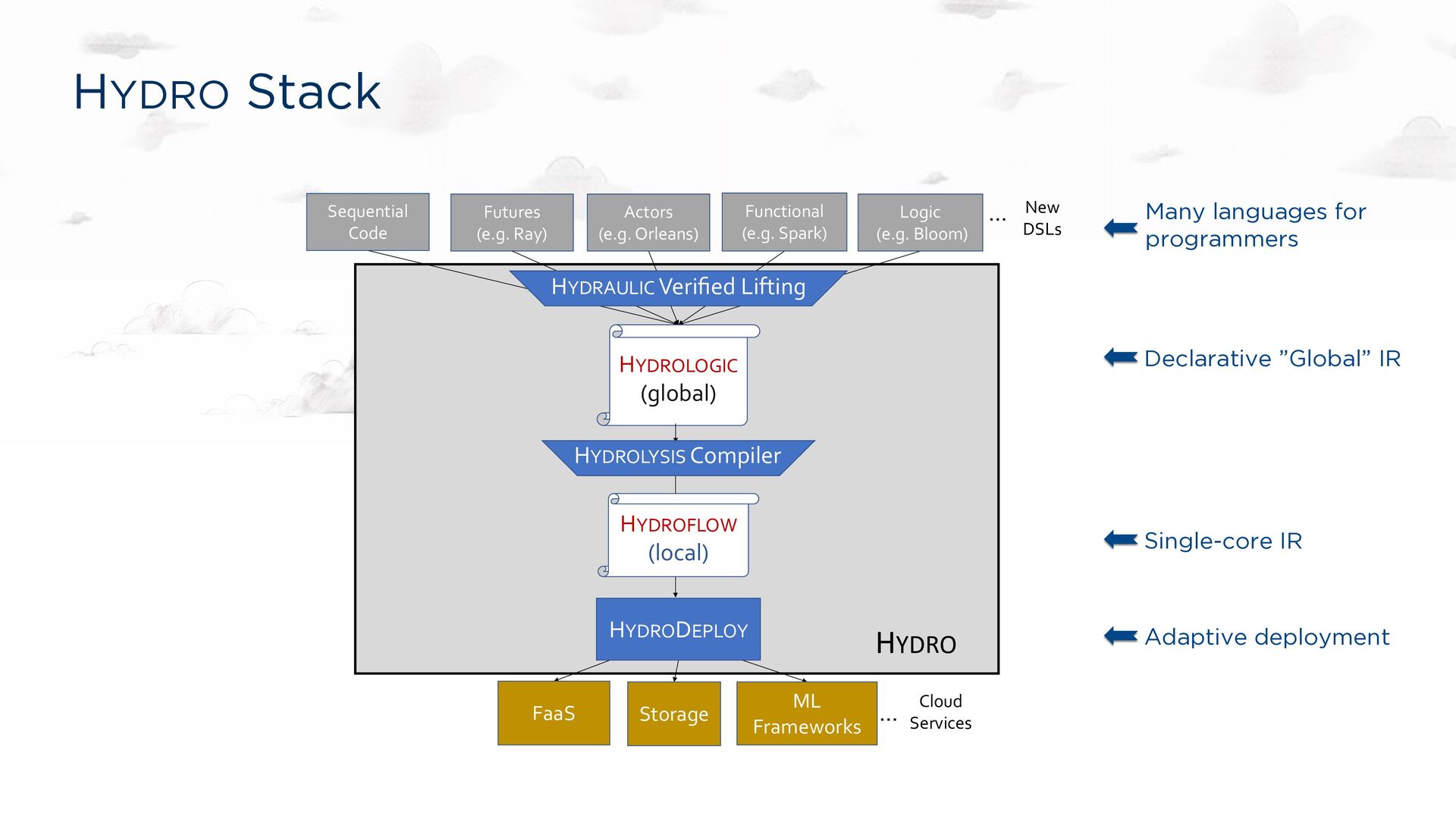
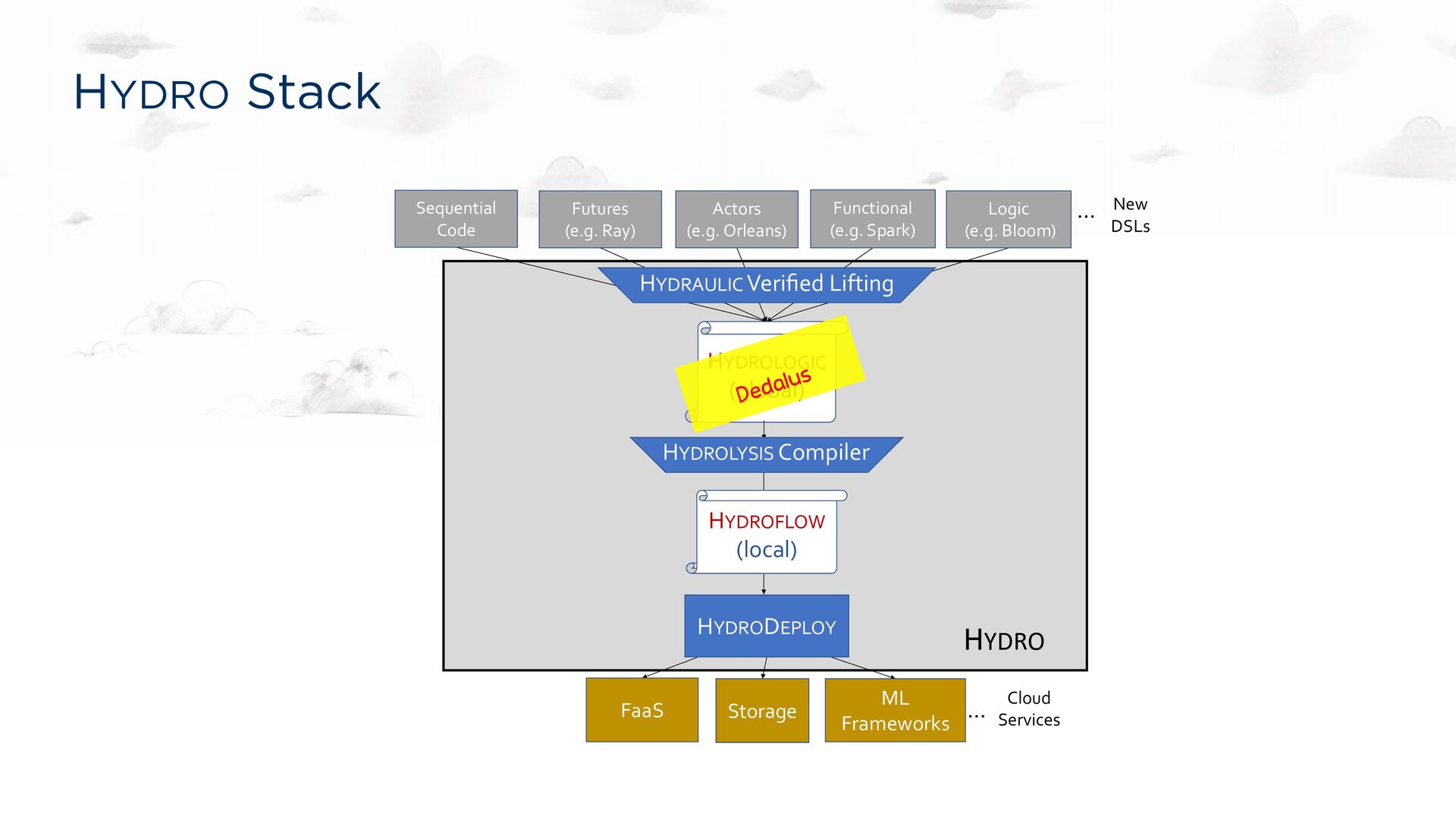
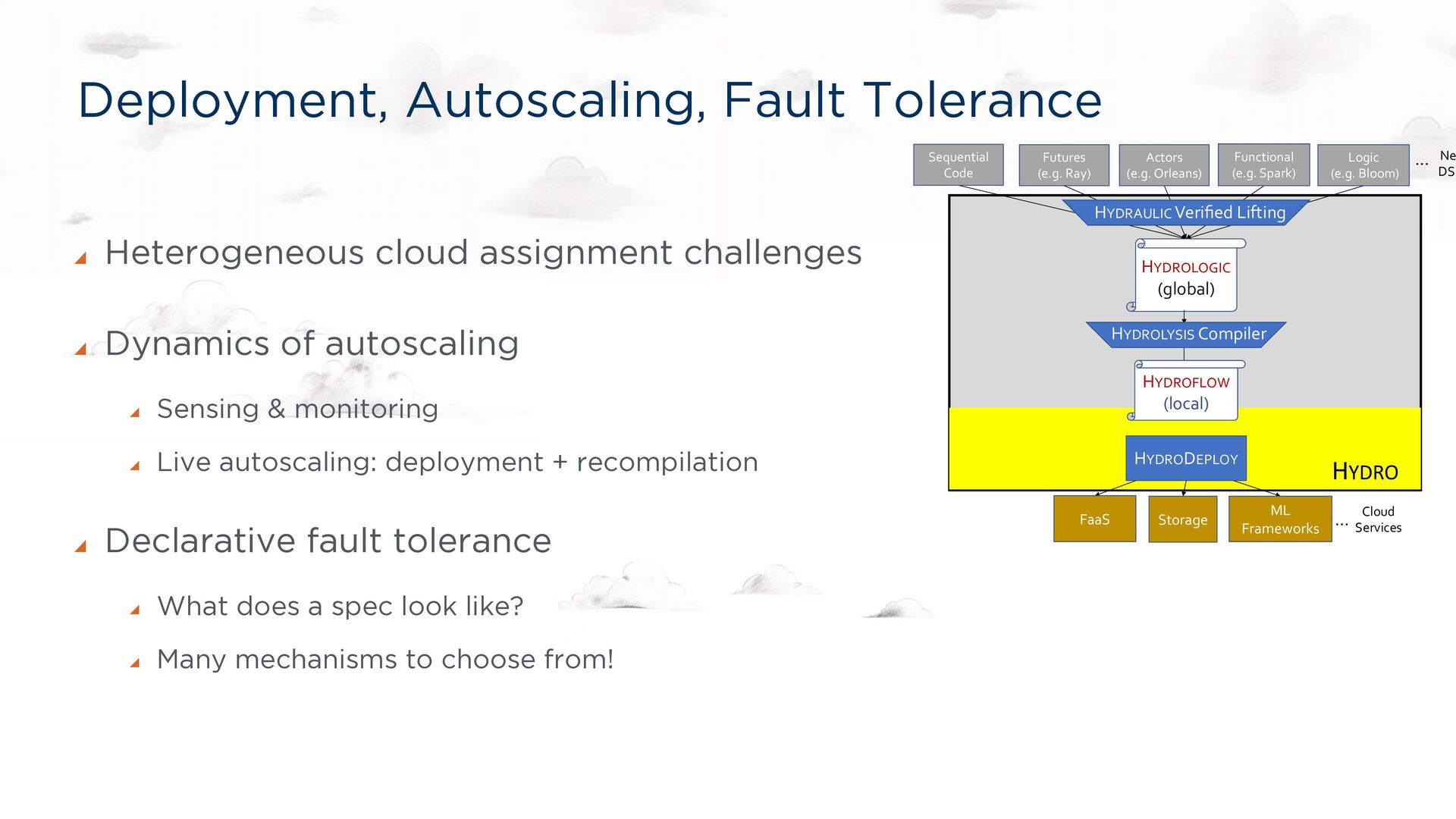
Optimizations for Elastic Distributed Computing Compiler Guarantees for Distributed Correctness Checks Goals Fast: low latency and high throughput Flexible: polyglot, easy to adopt, easy to extend Cost-effective: good use of cloud resources CIDR 19
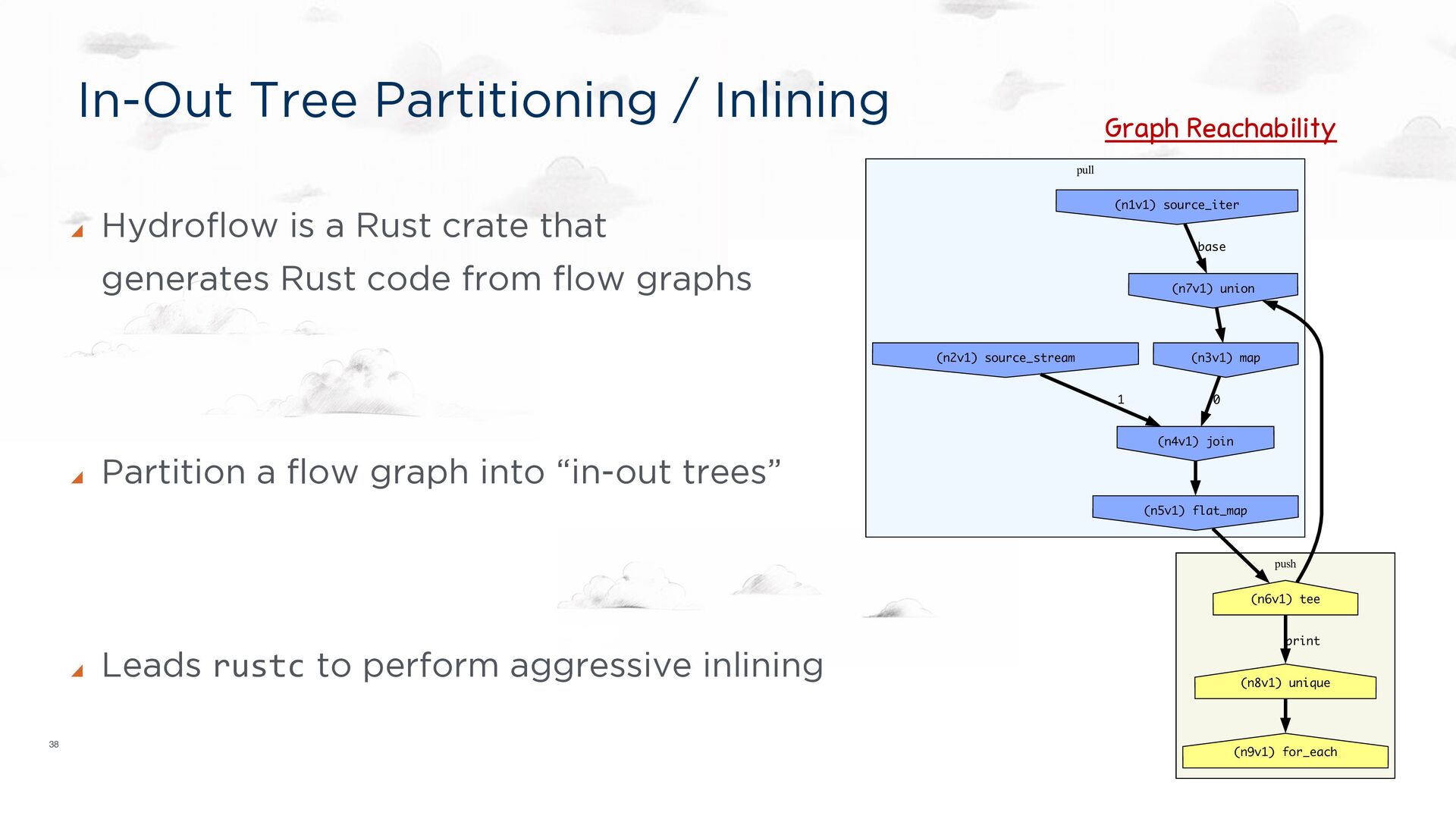
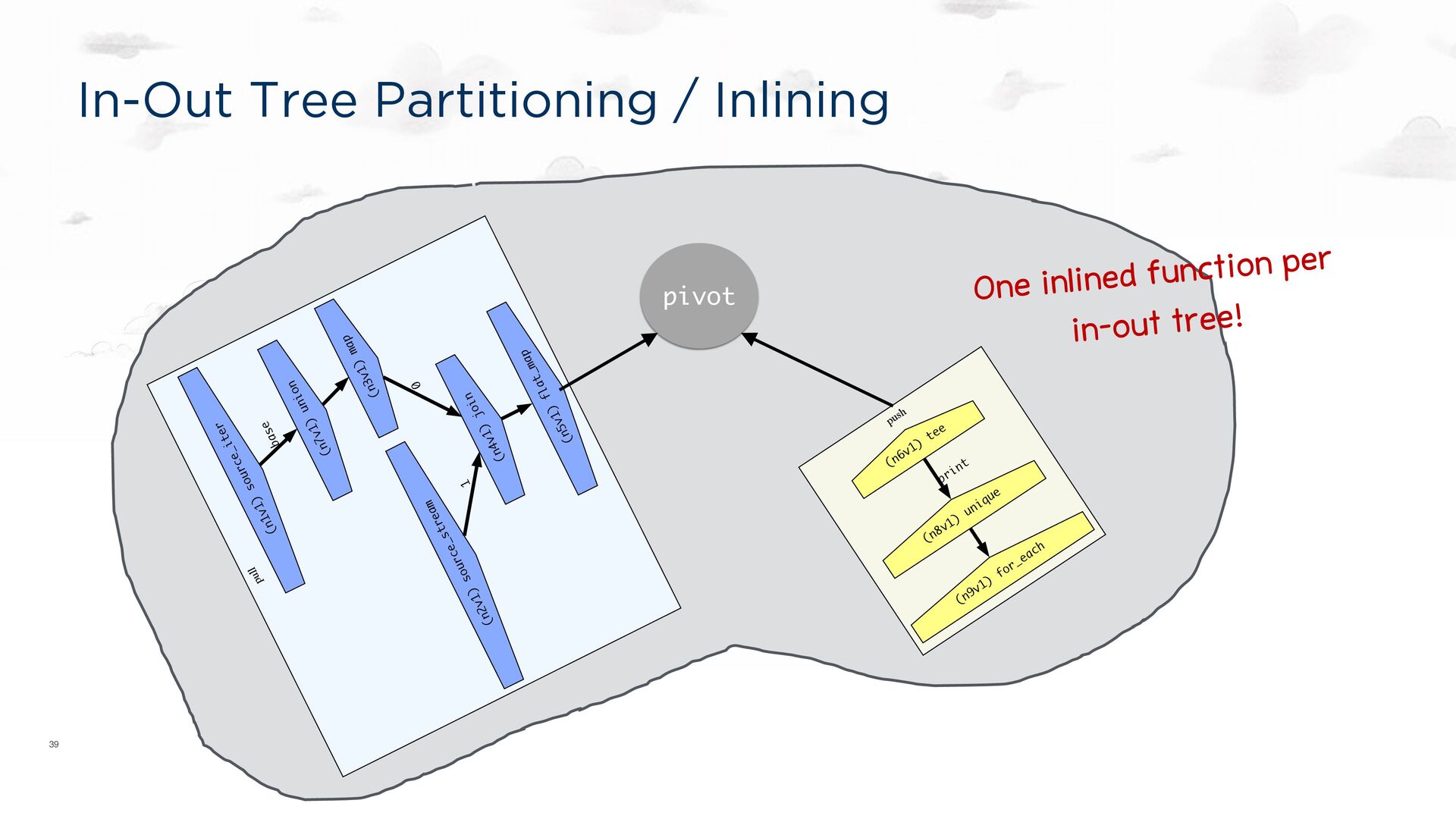
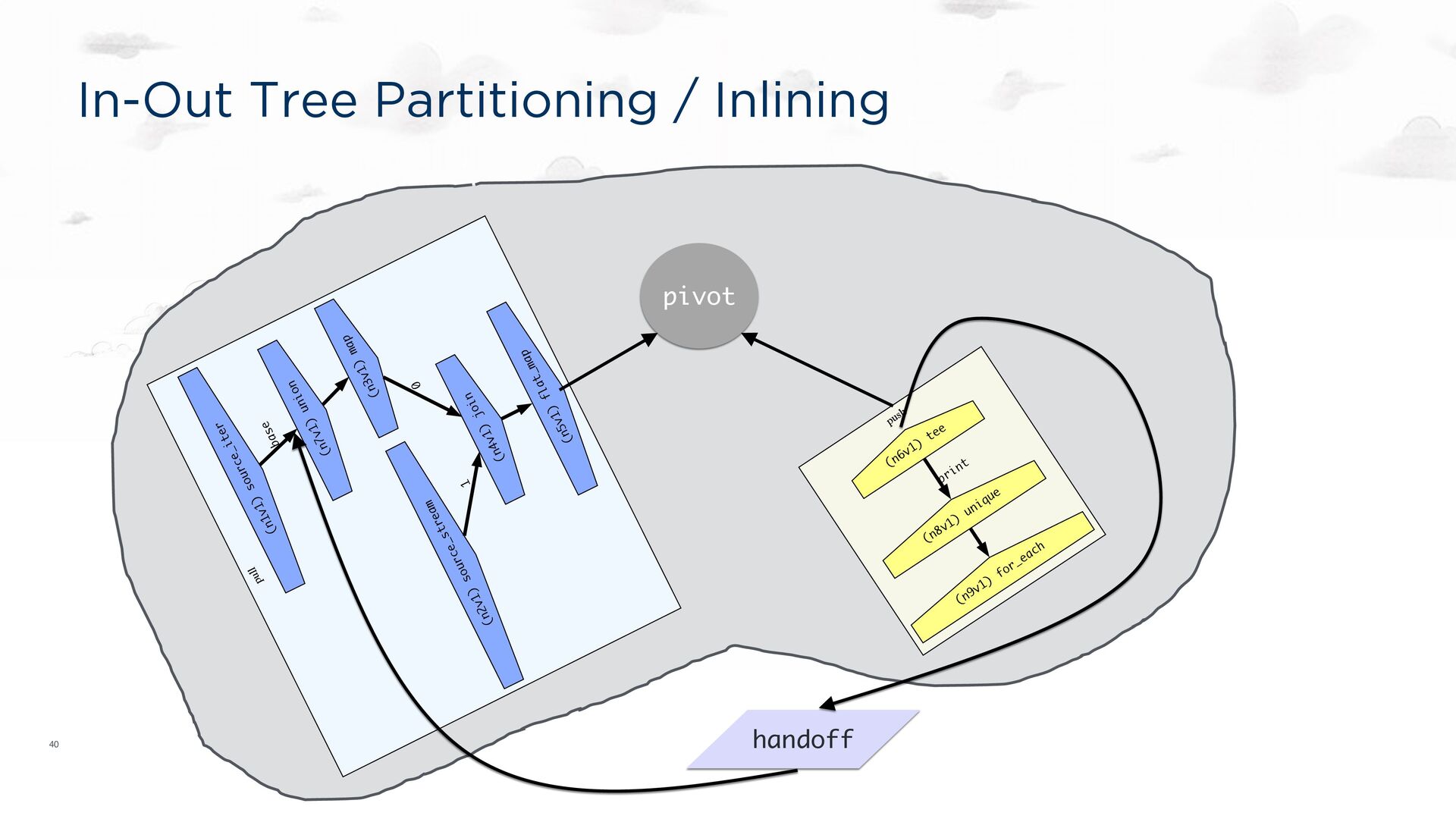
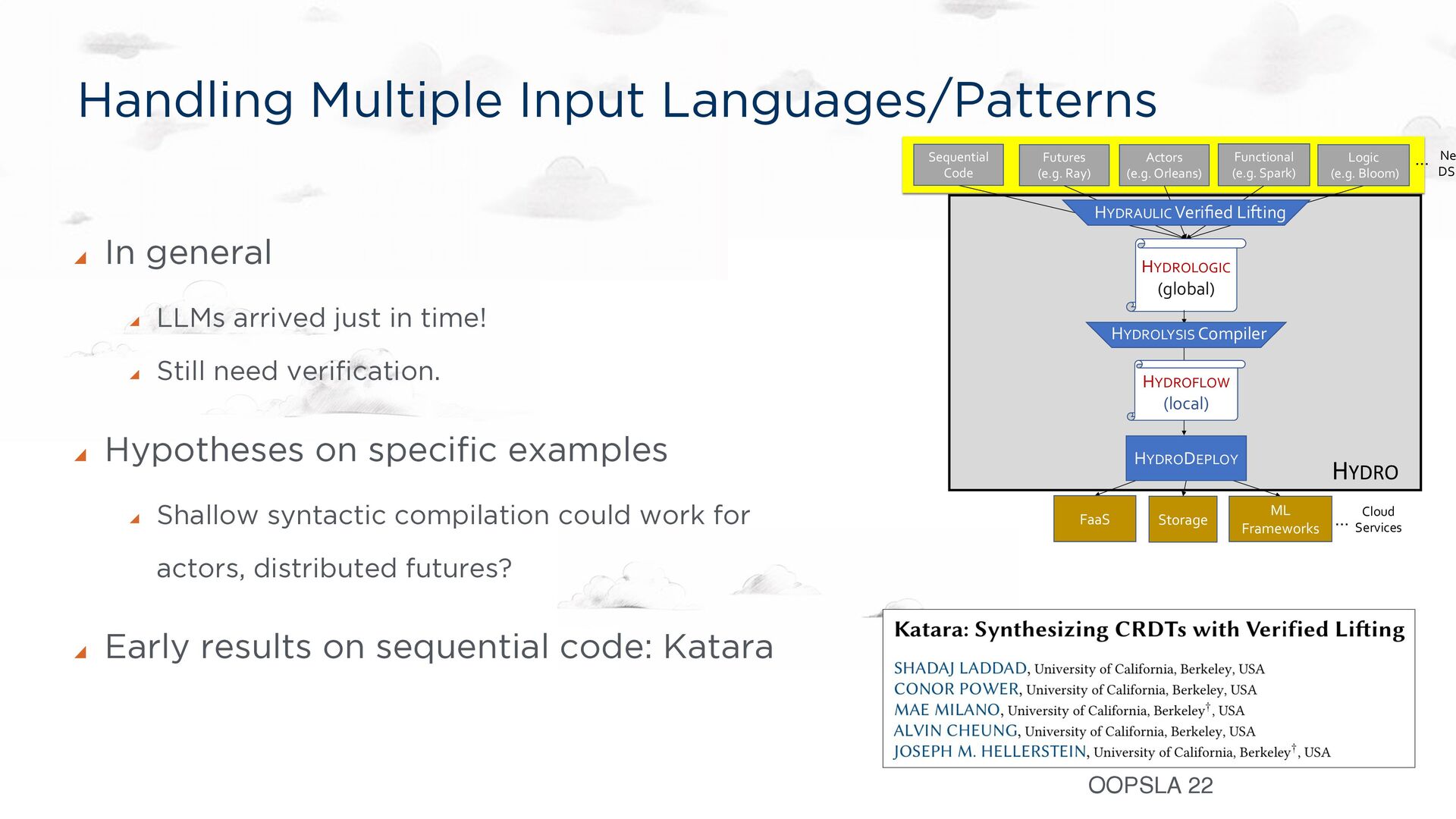
the spirit of LLVM, Halide, etc. Still: a compiler target. Each transducer to be run on a single core A dataflow graph specification language https://hydro.run/docs/hydroflow/ my_flow = op1() -> op2(); my_flow op1 op2
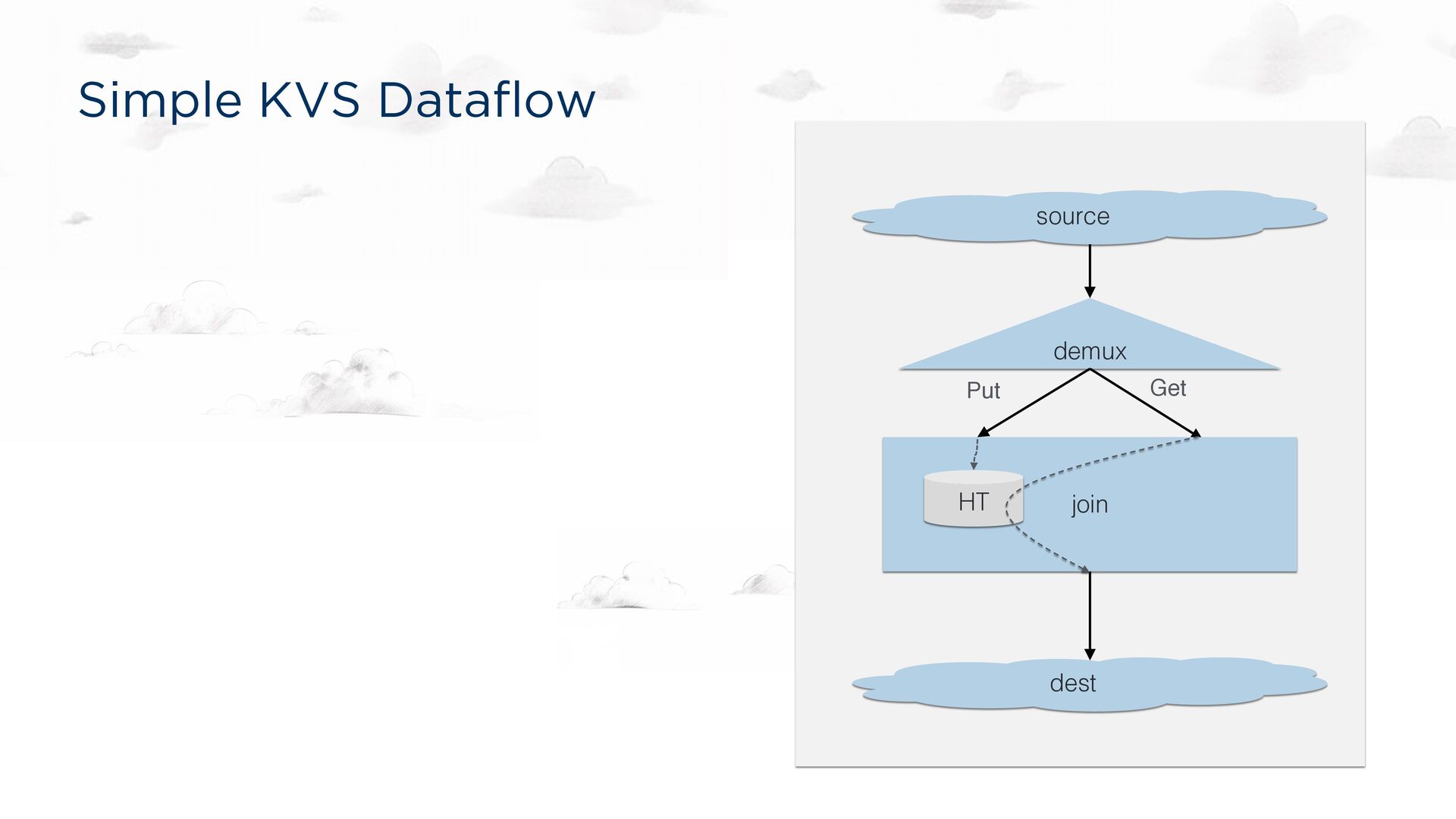
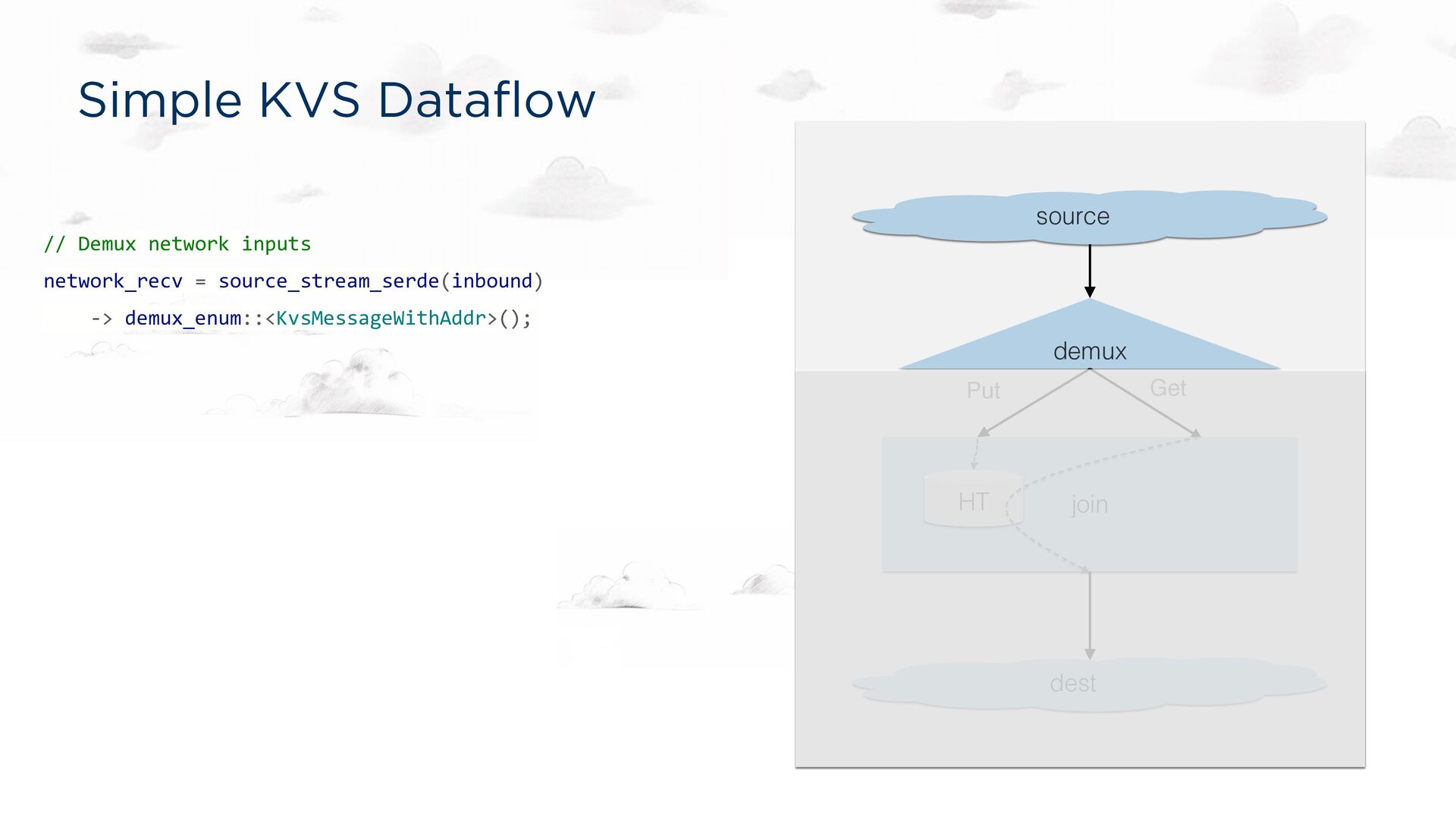
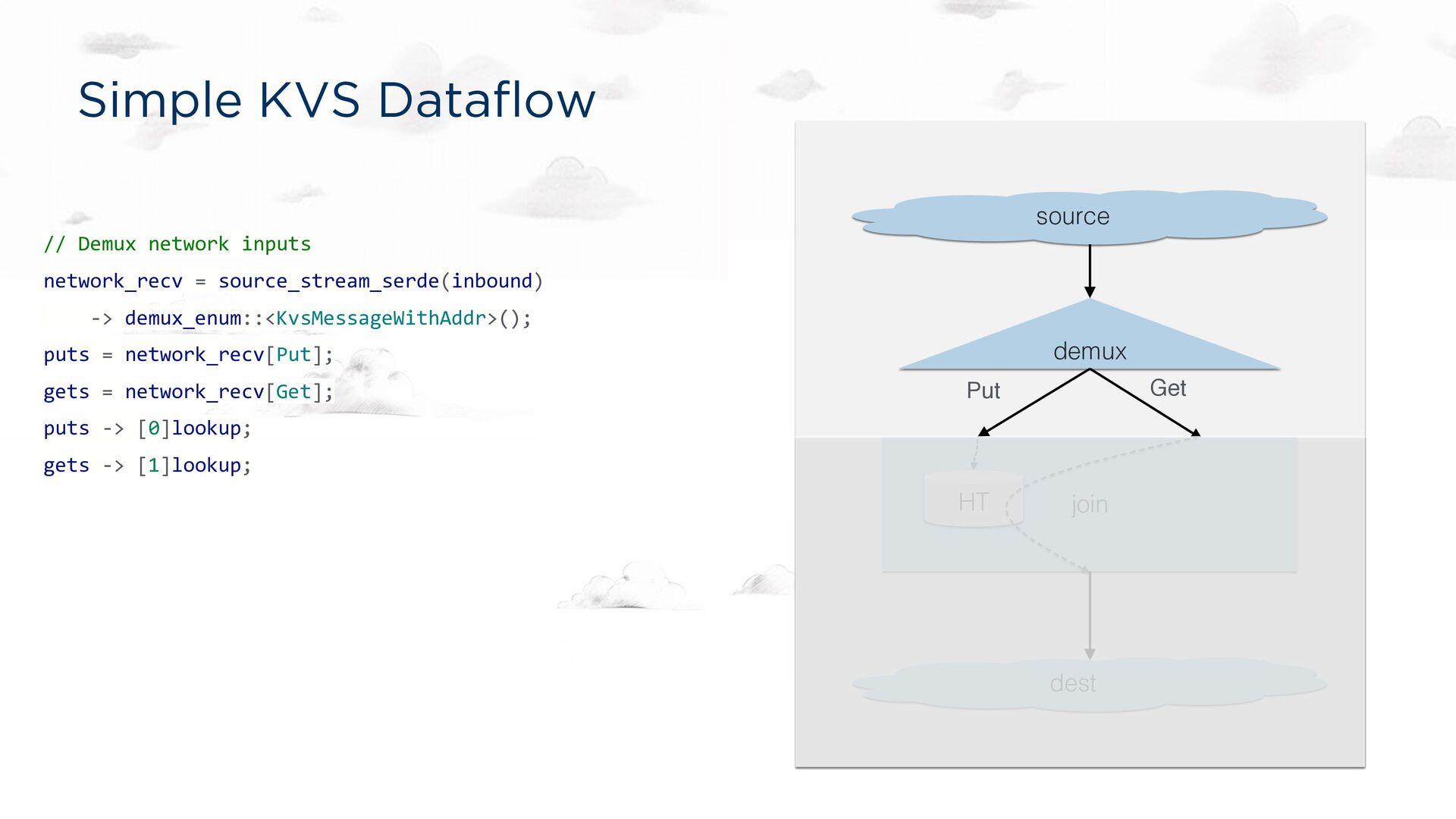
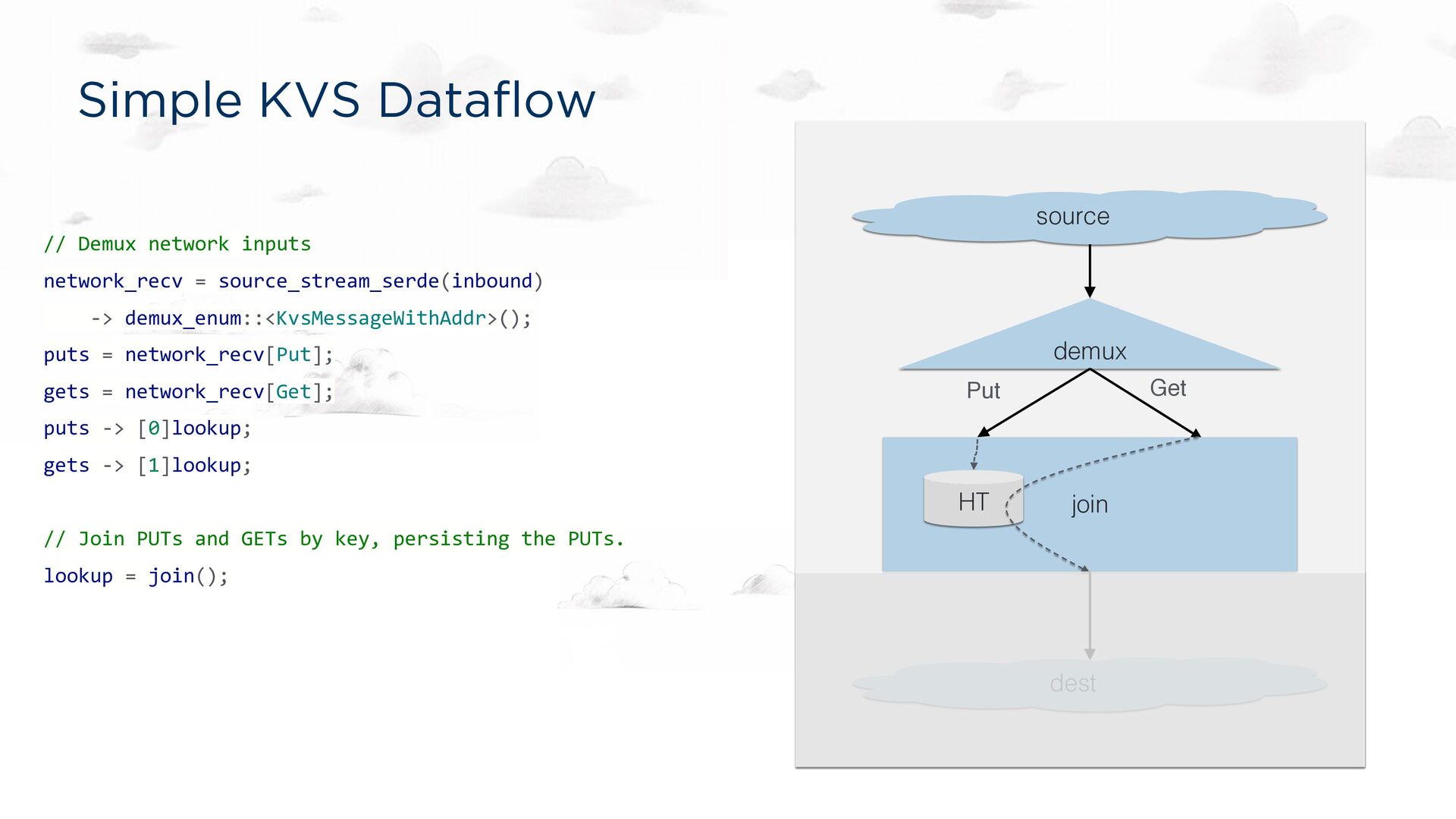
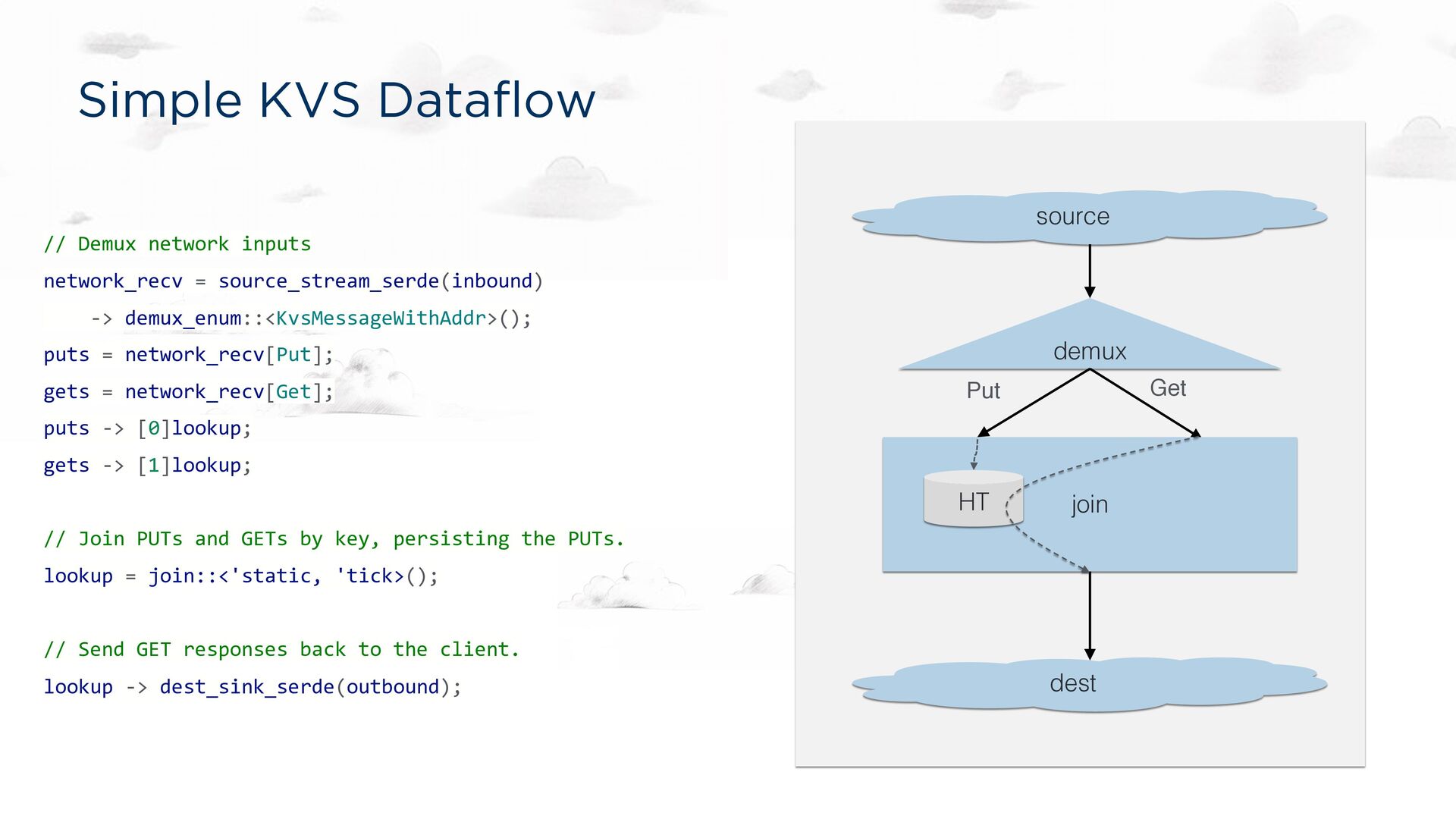
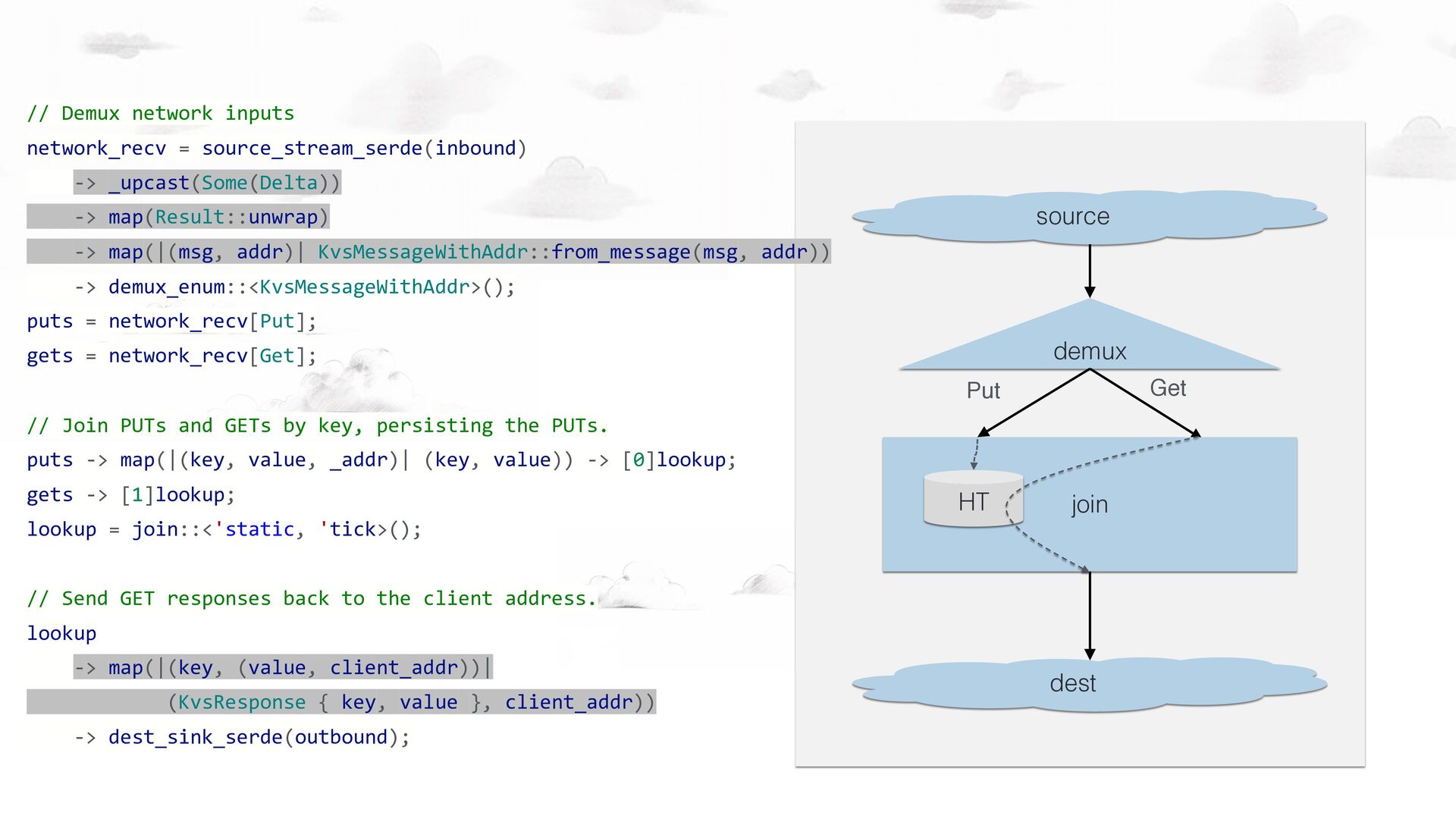
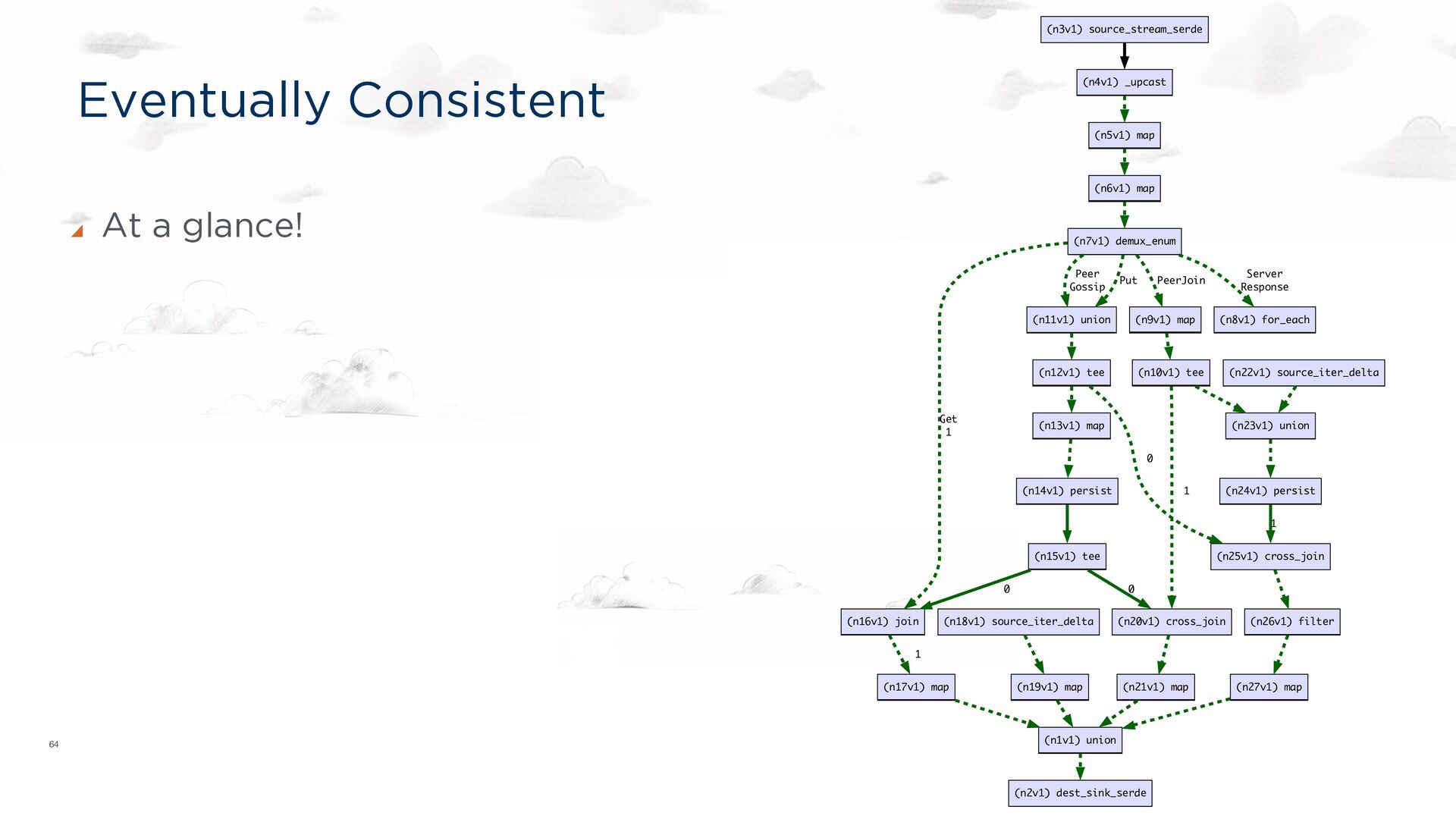
-> demux_enum::<KvsMessageWithAddr>(); puts = network_recv[Put]; gets = network_recv[Get]; puts -> [0]lookup; gets -> [1]lookup; // Join PUTs and GETs by key, persisting the PUTs. lookup = join::<'static, 'tick>(); // Send GET responses back to the client. lookup -> dest_sink_serde(outbound); source demux dest Put Get join HT
programming (Hydroflow+) Cyclic graphs & recursion as in Datalog Stratification of blocking operators (negation/∀, fold, etc.) A single clock per transducer, as in Dedalus See The Hydro Book: https://hydro.run/docs/hydroflow/
under contention Up to 700x faster than Masstree and Intel TBB on multicore Up to 10x faster than Cassandra in a geo-deployment 350x the performance of DynamoDB for the same price Consistency guarantees Causal, read-committed, … Bloom-style compositions of trivial semi-lattices (“CRDTs”)
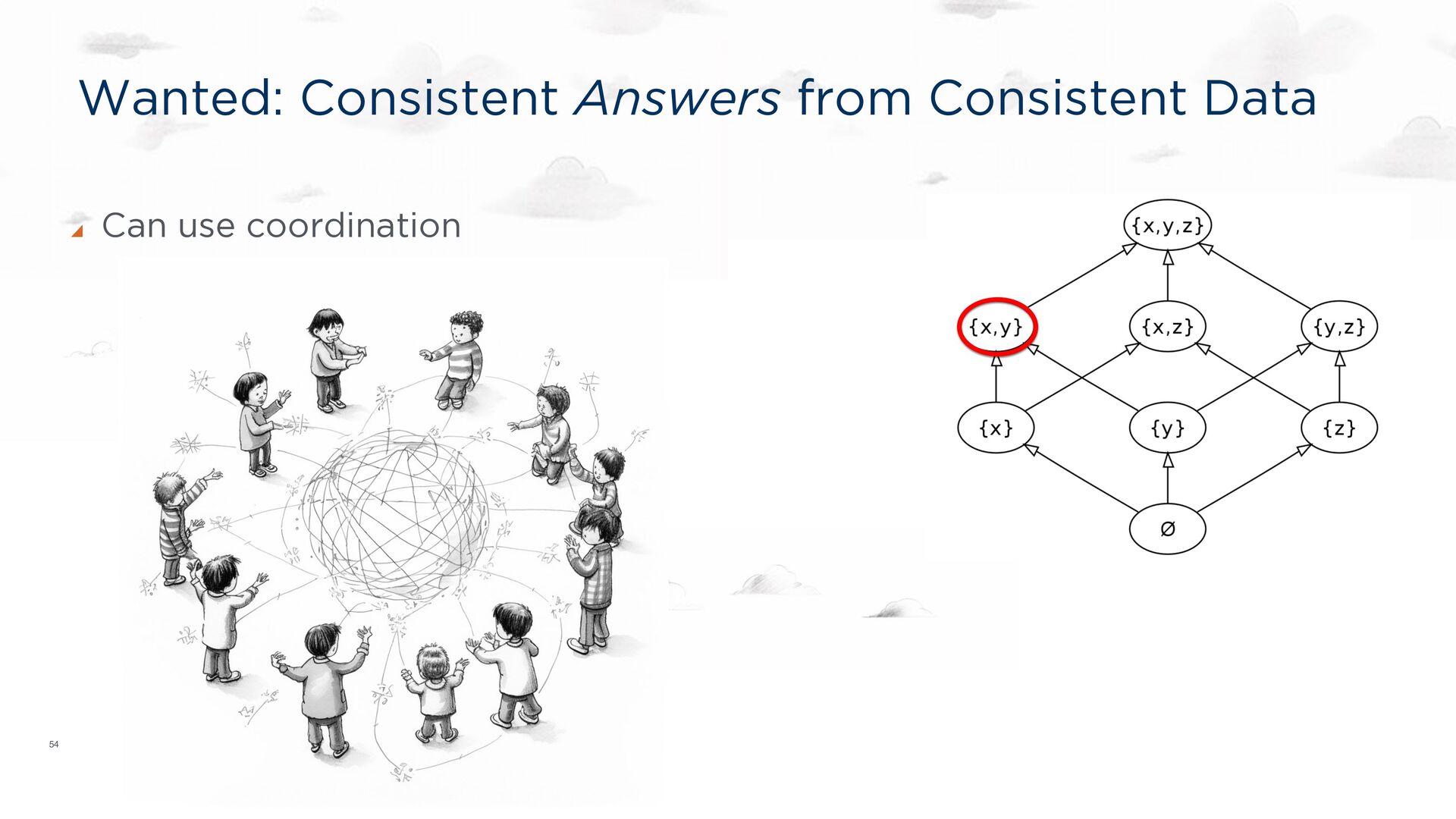
will agree) on common knowledge. Classic example: data replication How do we know if they agree on the value of a mutable variable x? If they disagree now, what could happen later? Split Brain divergence! We want to generalize to program outcomes! x = ❤ x = 💩
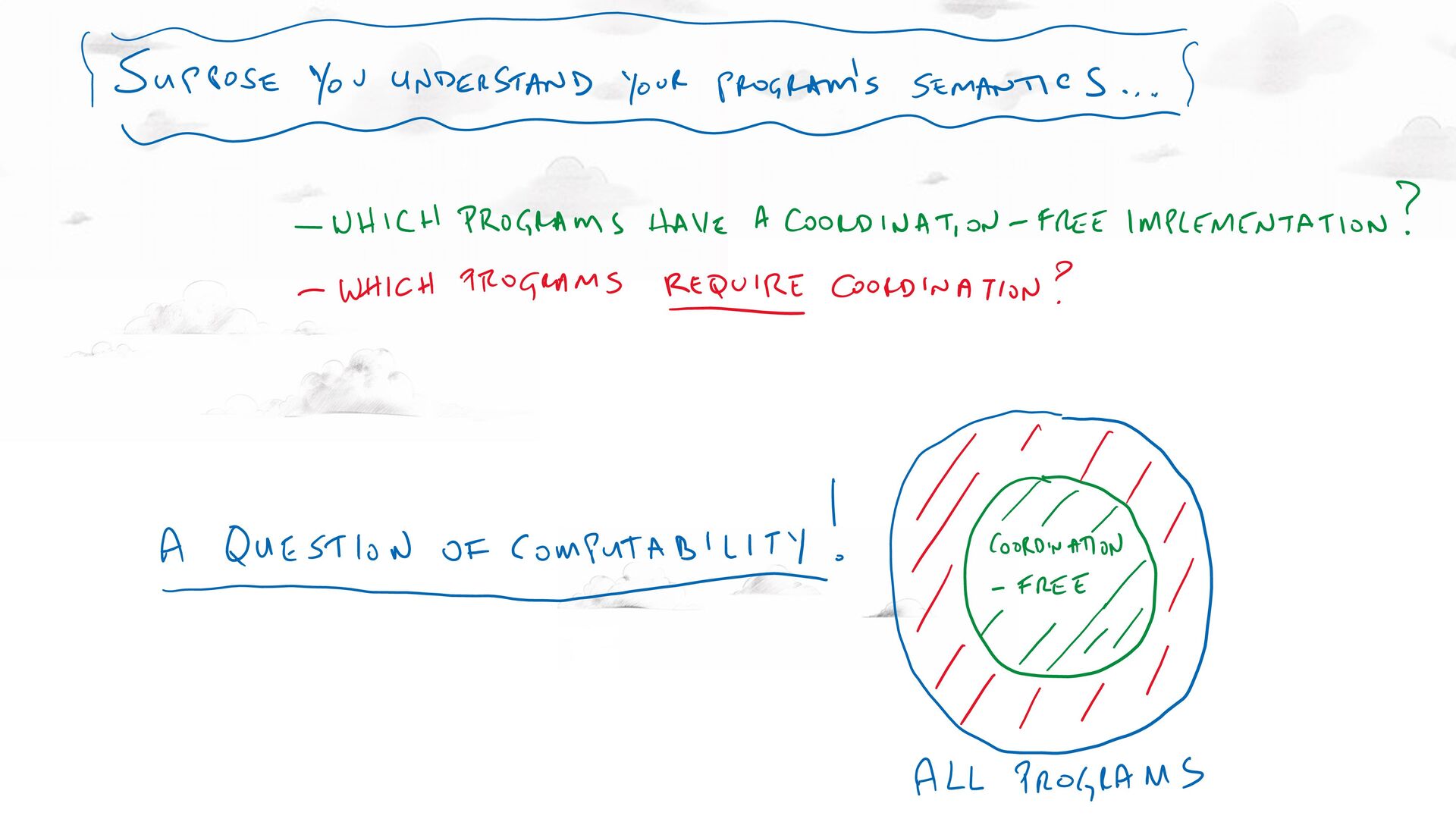
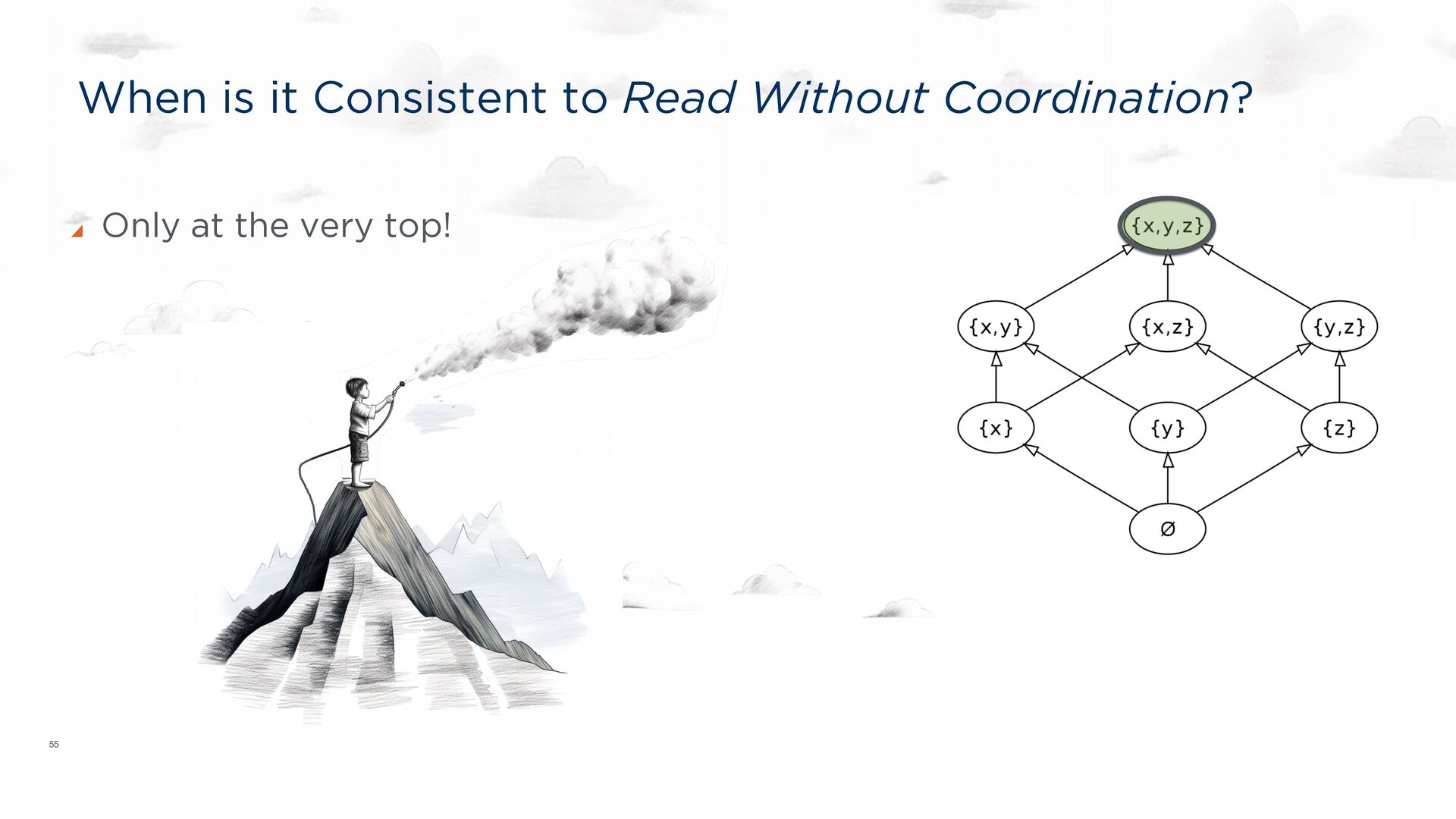
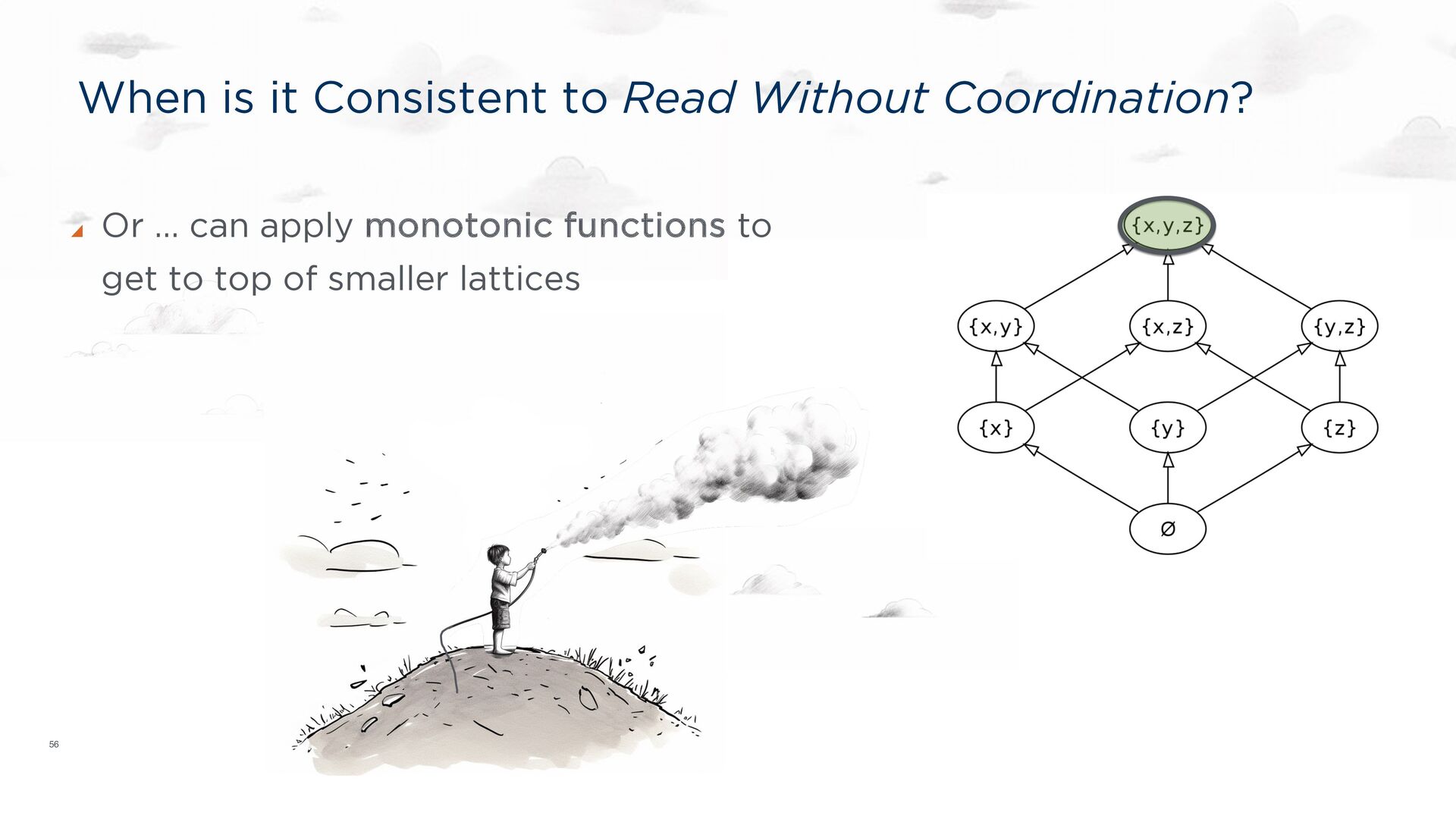
distributed logic. ACM PODS Keynote, June 2010 ACM SIGMOD Record, Sep 2010. Ameloot TJ, Neven F, Van den Bussche J. Relational transducers for declarative networking. JACM, Apr 2013. Ameloot TJ, Ketsman B, Neven F, Zinn D. Weaker forms of monotonicity for declarative networking: a more fine-grained answer to the CALM-conjecture. ACM TODS, Feb 2016. CALM: CONSISTENCY AS LOGICAL MONOTONICITY Theorem (CALM): A distributed program has a consistent, coordination-free distributed implementation if and only if it is monotonic. Hellerstein, JM, Alvaro, P. Keeping CALM: When Distributed Consistency is Easy. CACM, Sept, 2020.
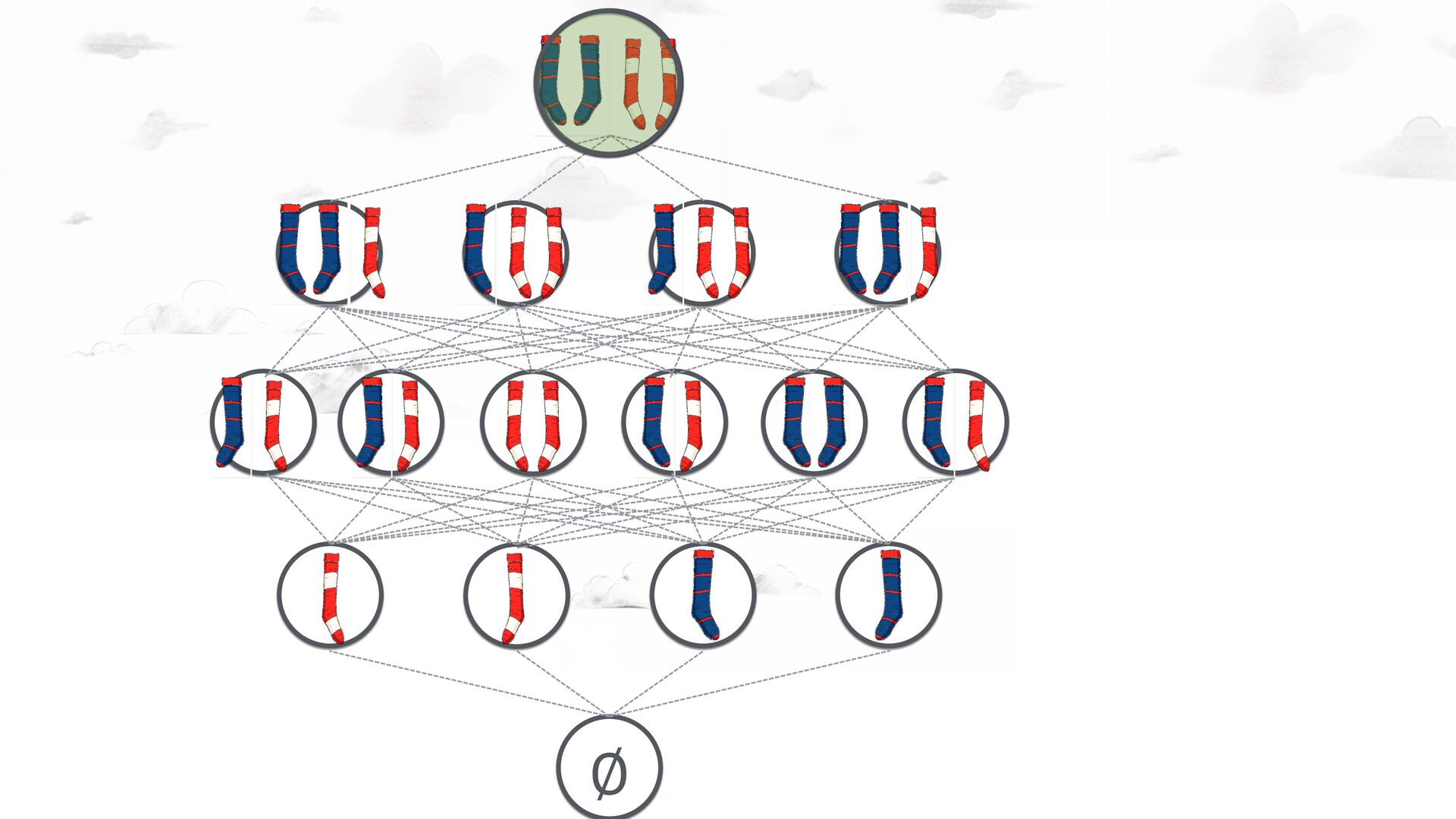
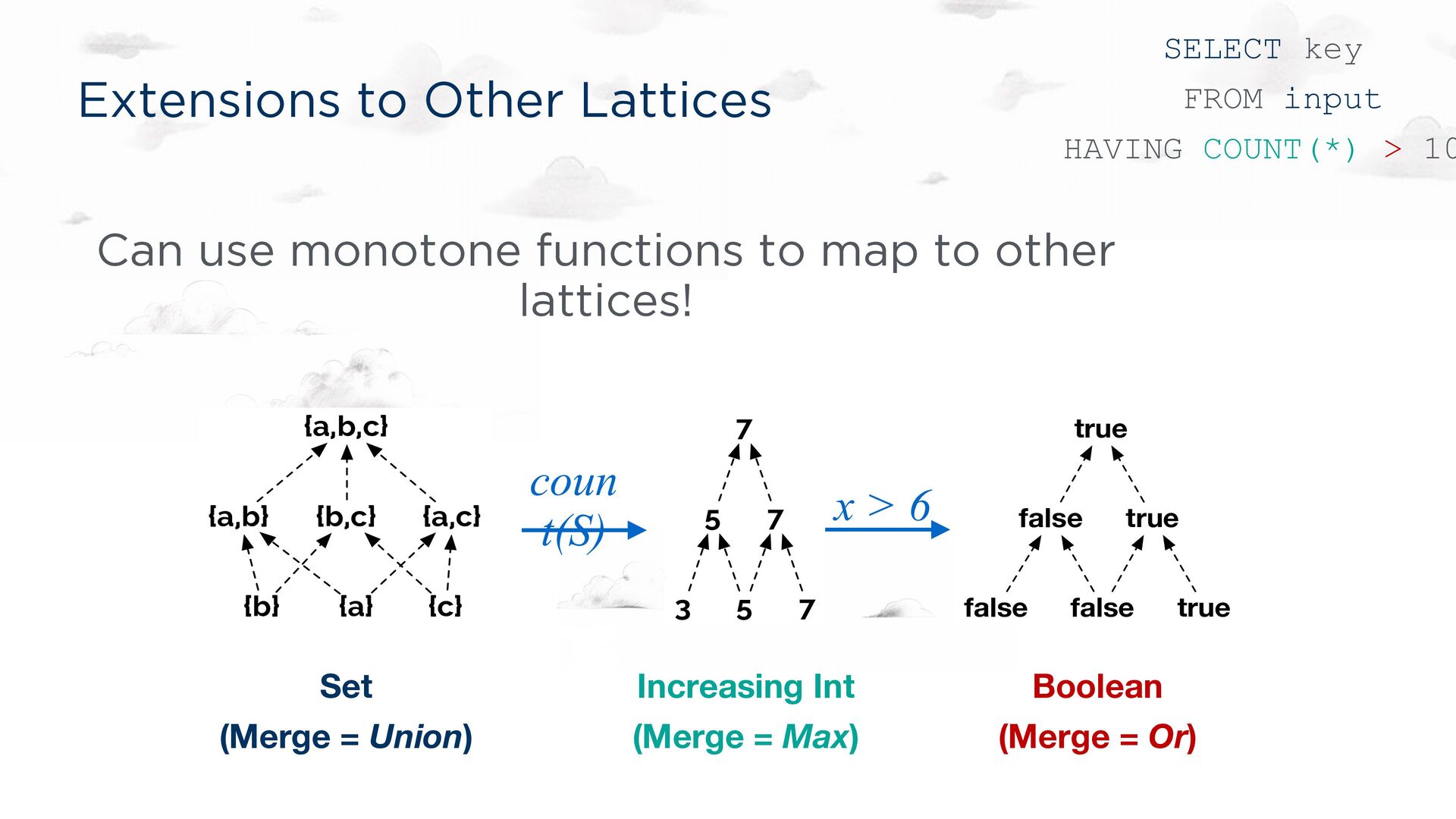
(y + z) = (x + y) + z Commutative: x + y = y + x Idempotent: x + x = x Every semi-lattice corresponds to a partial order: x <= y ⇔ x + y = y Partial orders are compatible with many total orders! CALM connection: monotonicity in the lattice’s partial order
{RandomBatch, Dups} “Happenstance” total order ‘a Type: Seq<Lattice<L>> Props: {RandomBatch, Dups} Latticeflow of points from L to be monotonically accumulated Type: Lattice<L> Props: {NonDeterministic} Type: Seq<Lattice<L>> Props: {RandomBatch, Dups} (n1v1) source_stream_serde (n2v1) _upcast (n3v1) map (n4v1) fold (n5v1) demux_enum Cumulative Lattice point L RandomBatch input to NonMonotonic op produces NonDeterministic output!
None “Happenstance” total order ‘a Type: Seq<Lattice<L>> Props: None Latticeflow of points from L to be monotonically accumulated Type: T’ Props: None Type: Seq<Lattice<L>> Props: None (n1v1) source_iter (n2v1) _upcast (n3v1) map (n4v1) fold (n5v1) demux_enum Cumulative Lattice point L
demux_enum Dataflow Types & Properties (WIP) Type: (Seq<T>, ‘a) Props: {RandomBatch, Dups} “Happenstance” total order ‘a Type: Seq<Lattice<L>> Props: {RandomBatch, Dups} Latticeflow of points from L to be monotonically accumulated Type: Lattice<L> Props: None Type: Seq<Lattice<L>> Props: {RandomBatch, Dups} Cumulative Lattice point L
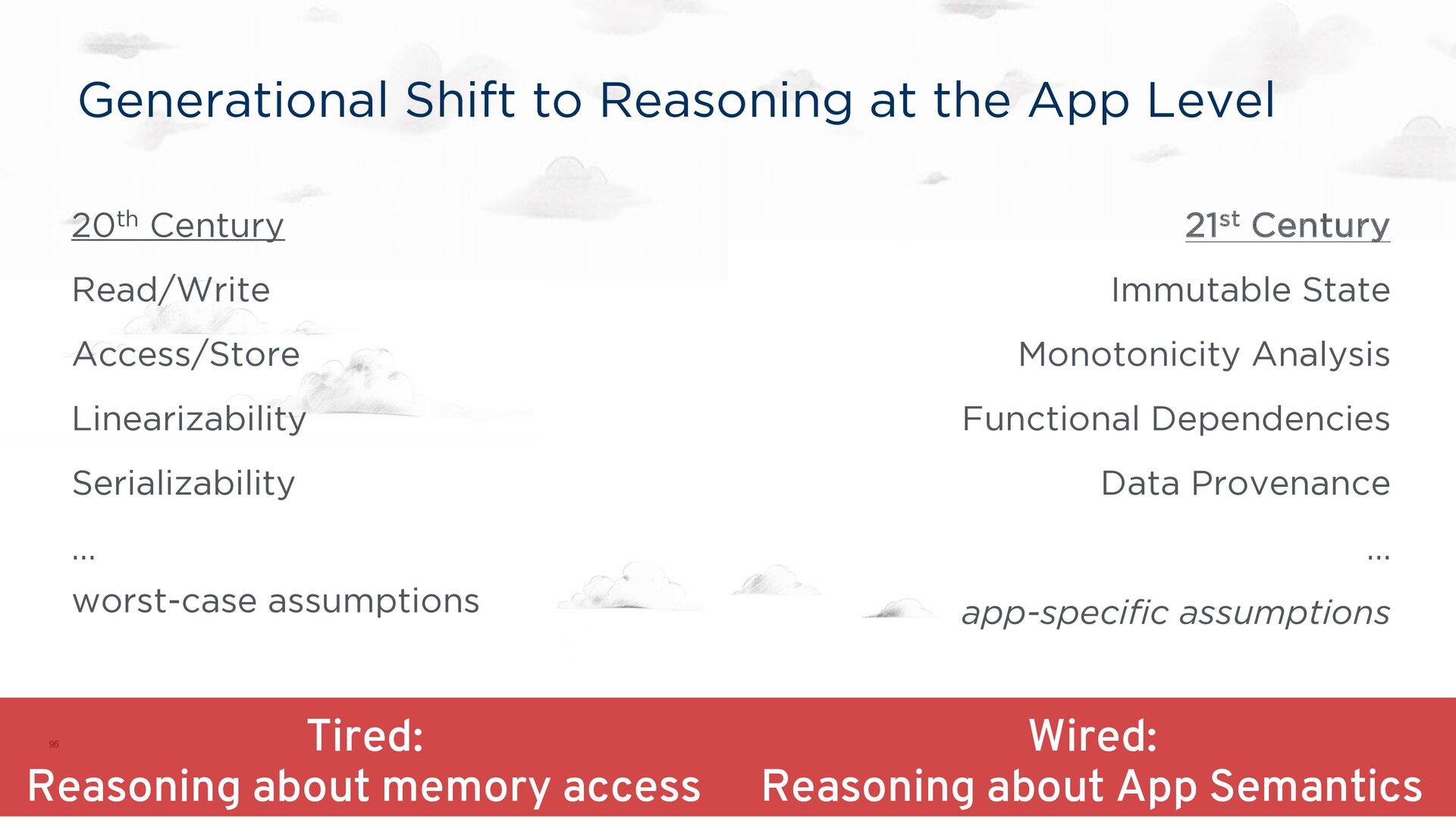
from the type system Functional dependencies from DB theory to co-partition state Data provenance helps us understand how results get generated No surprise that a data-centric approach helps! Theme In Distributed Systems, the hard part is the data (state + messages) Dedalus
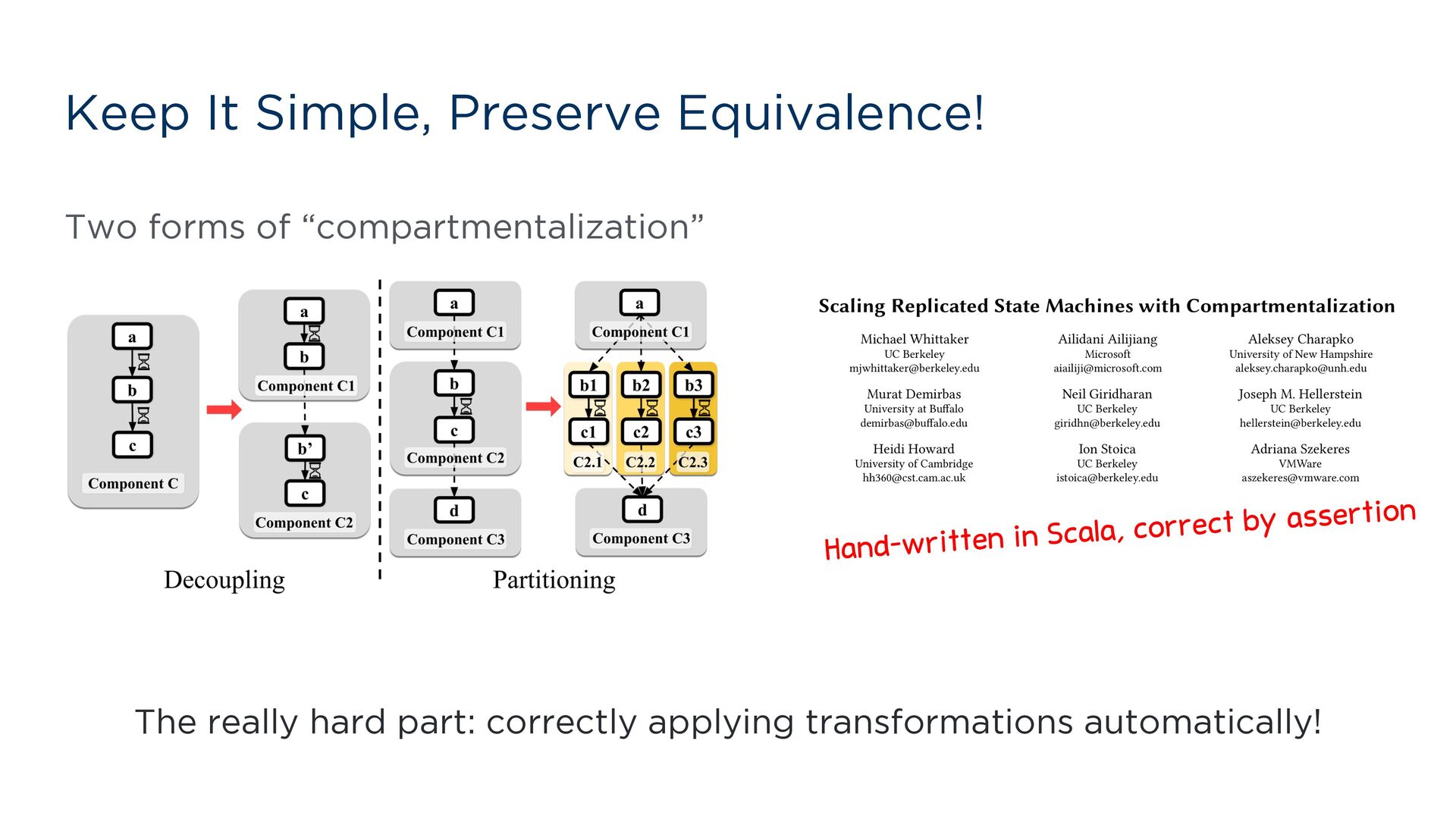
most code is mostly monotonic Even coordination protocols are mostly monotonic! Michael Whittaker’s work on Compartmentalized Paxos Next challenge: automatically move non- monotonic (sequential/coordinated) code off the critical path and autoscale everything else. VLDB 2021
scalability is to batter the consistency mechanisms down to a minimum move them off the critical path hide them in a rarely visited corner of the system, and then make it as hard as possible for application developers to get permission to use them —James Hamilton (IBM, MS, Amazon) in Birman, Chockler: “Toward a Cloud Computing Research Agenda”, LADIS 2009 ” “
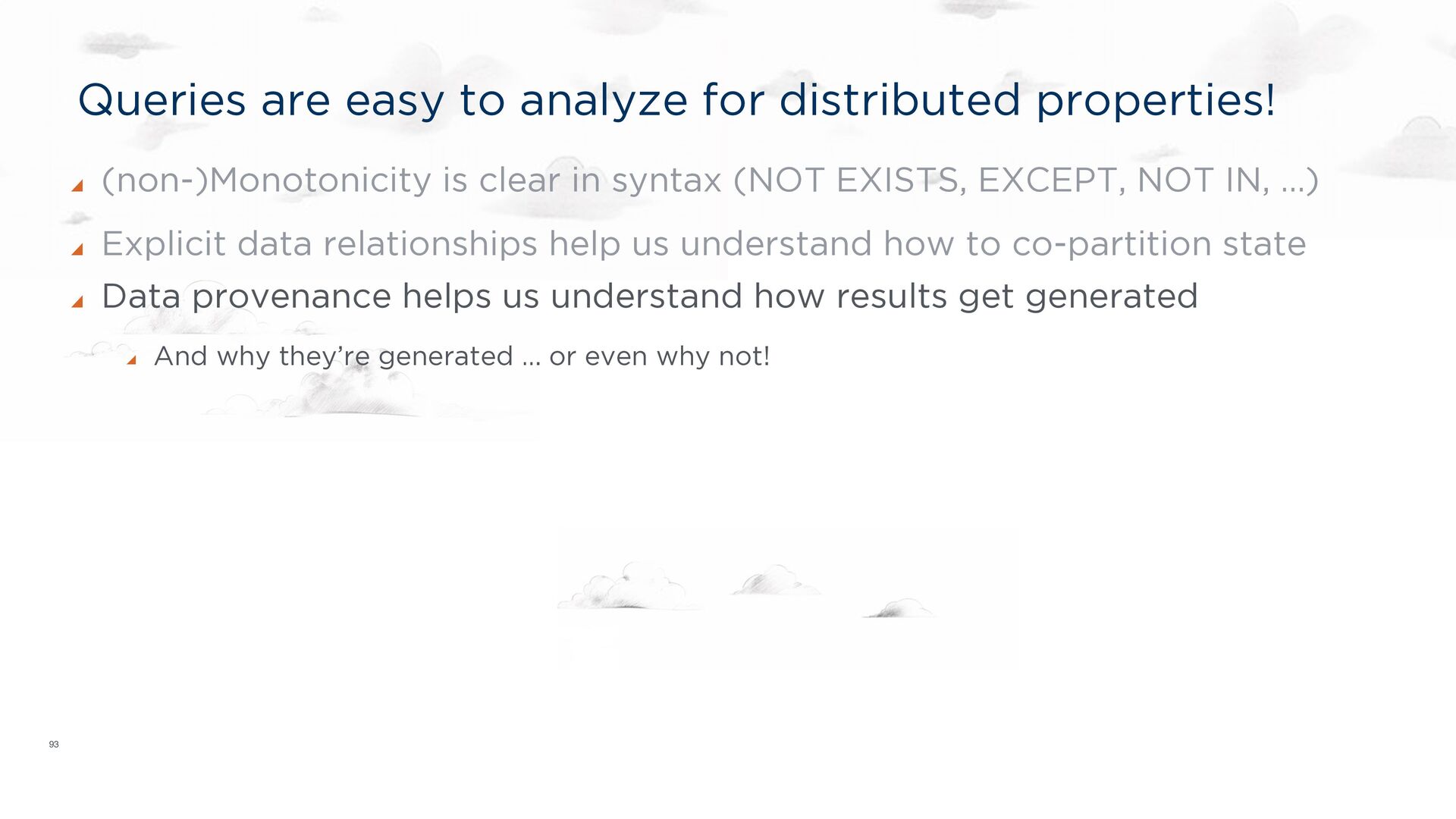
is clear in syntax (NOT EXISTS, EXCEPT, NOT IN, …) Explicit data relationships help us understand how to co-partition state Keys and foreign keys More generally, Dependency Theory UserID MessageID Channel ID 27 “What’s for dinner” 101 11 “Burritos please!” 101 CID Owner ID 101 11 14 “Monotonicity is cool!” 102 102 14 27 “Excelente!” 101 Channel ID → CID
is clear in syntax (NOT EXISTS, EXCEPT, NOT IN, …) Explicit data relationships help us understand how to co-partition state Keys and foreign keys More generally, Dependency Theory UserID MessageID Channel ID 27 “What’s for dinner” 101 11 “Burritos please!” 101 CID Owner ID 101 11 14 “Monotonicity is cool!” 102 102 14 27 “Excelente!” 101 Channel ID → CID
is clear in syntax (NOT EXISTS, EXCEPT, NOT IN, …) Explicit data relationships help us understand how to co-partition state Keys and foreign keys More generally, Dependency Theory UserID MessageID Channel ID 27 “What’s for dinner” 101 11 “Burritos please!” 101 CID Owner ID 101 11 14 “Monotonicity is cool!” 102 102 14 27 “Excelente!” 101 UserID MessageID Channel ID CID Owner ID Channel ID → CID
is clear in syntax (NOT EXISTS, EXCEPT, NOT IN, …) Explicit data relationships help us understand how to co-partition state Data provenance helps us understand how results get generated And why they’re generated … or even why not!
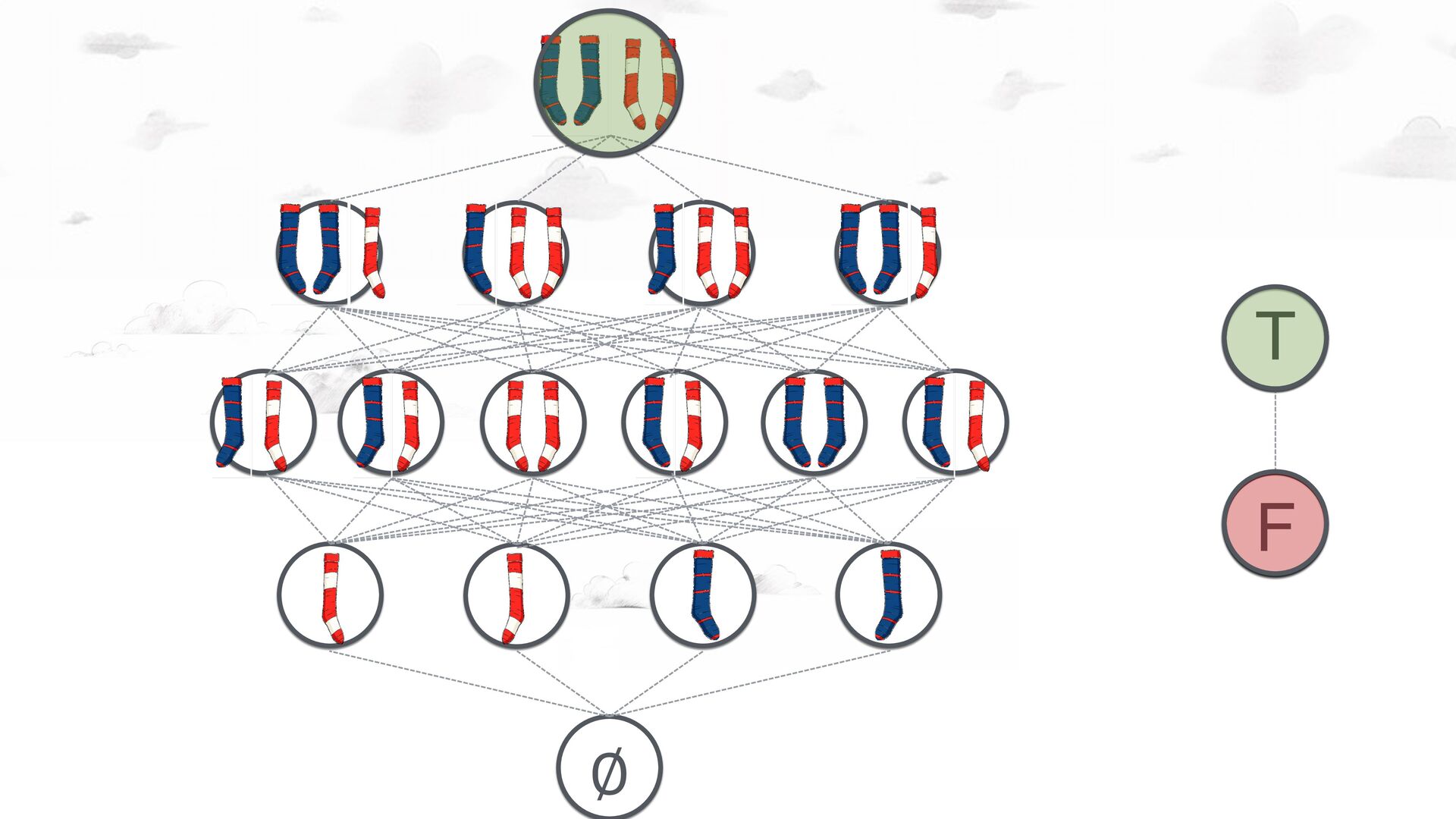
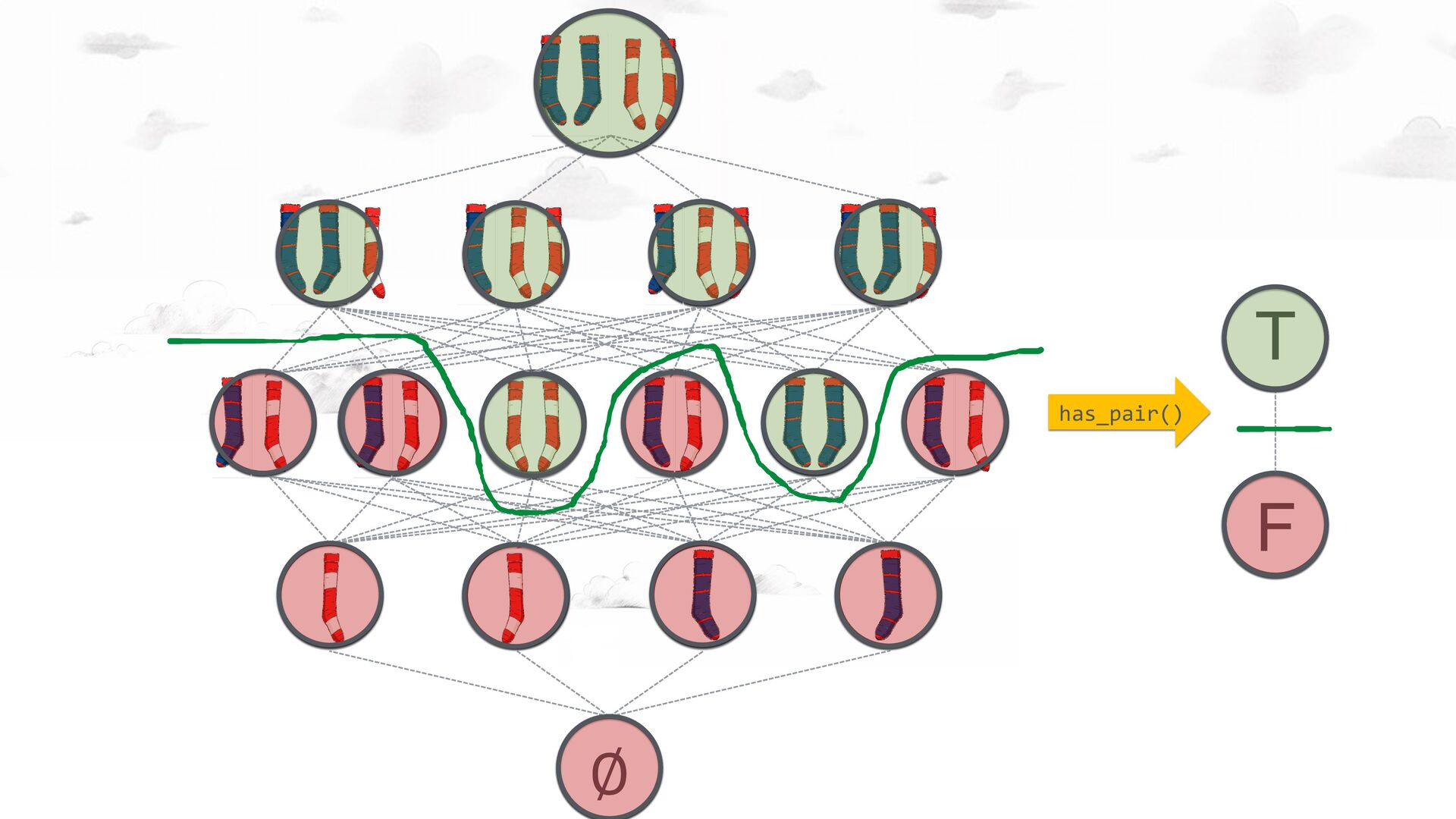
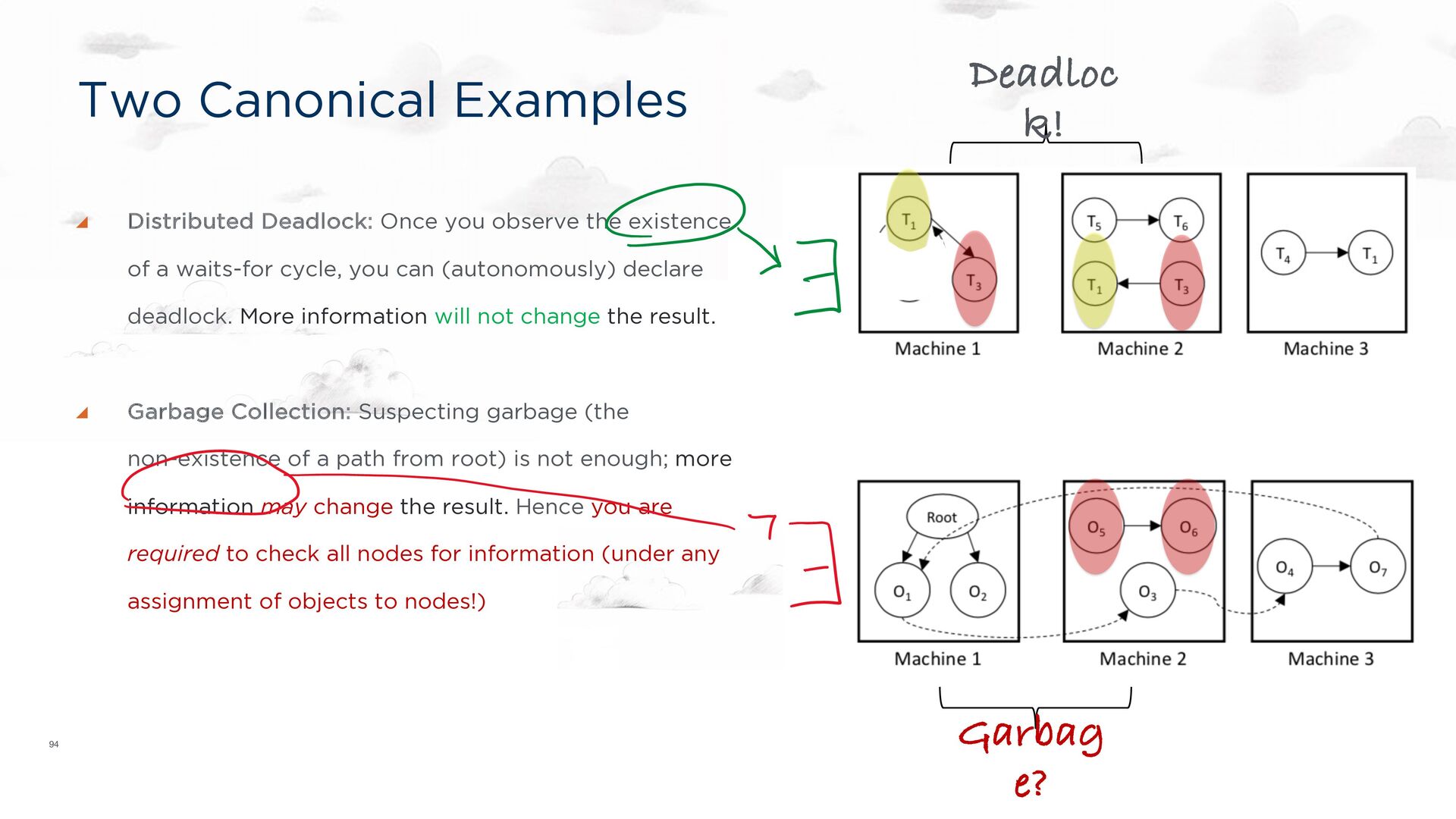
waits-for cycle, you can (autonomously) declare deadlock. More information will not change the result. Garbage Collection: Suspecting garbage (the non-existence of a path from root) is not enough; more information may change the result. Hence you are required to check all nodes for information (under any assignment of objects to nodes!) Two Canonical Examples Deadloc k! Garbag e?
only method “mathematically sound rules to guarantee state convergence” — Shapiro, et al. guarantees eventual consistency of state in the end times But what do folks do with them in the mean time? “multiple active copies present accurate views of the shared datasets at low latencies” — TechBeacon blog 2022 Hmmm…. VLDB 23
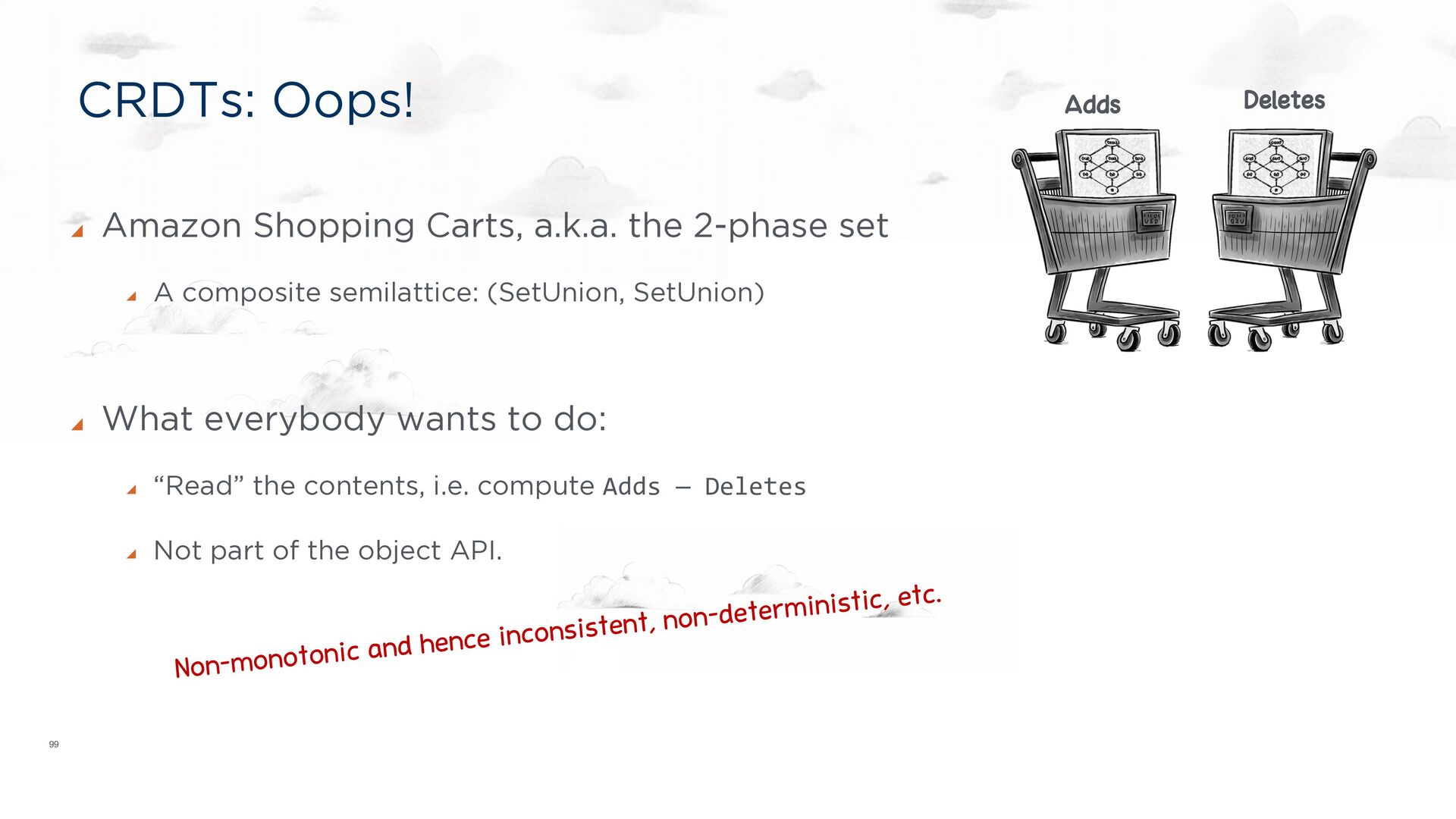
A composite semilattice: (SetUnion, SetUnion) What everybody wants to do: “Read” the contents, i.e. compute Adds — Deletes Not part of the object API. Adds Deletes Non-monotonic and hence inconsistent, non-deterministic, etc.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank You! https://hydro.run [email protected] 7](https://files.speakerdeck.com/presentations/7c9f089cff9547a9ac4c972d7b732f1f/slide_77.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
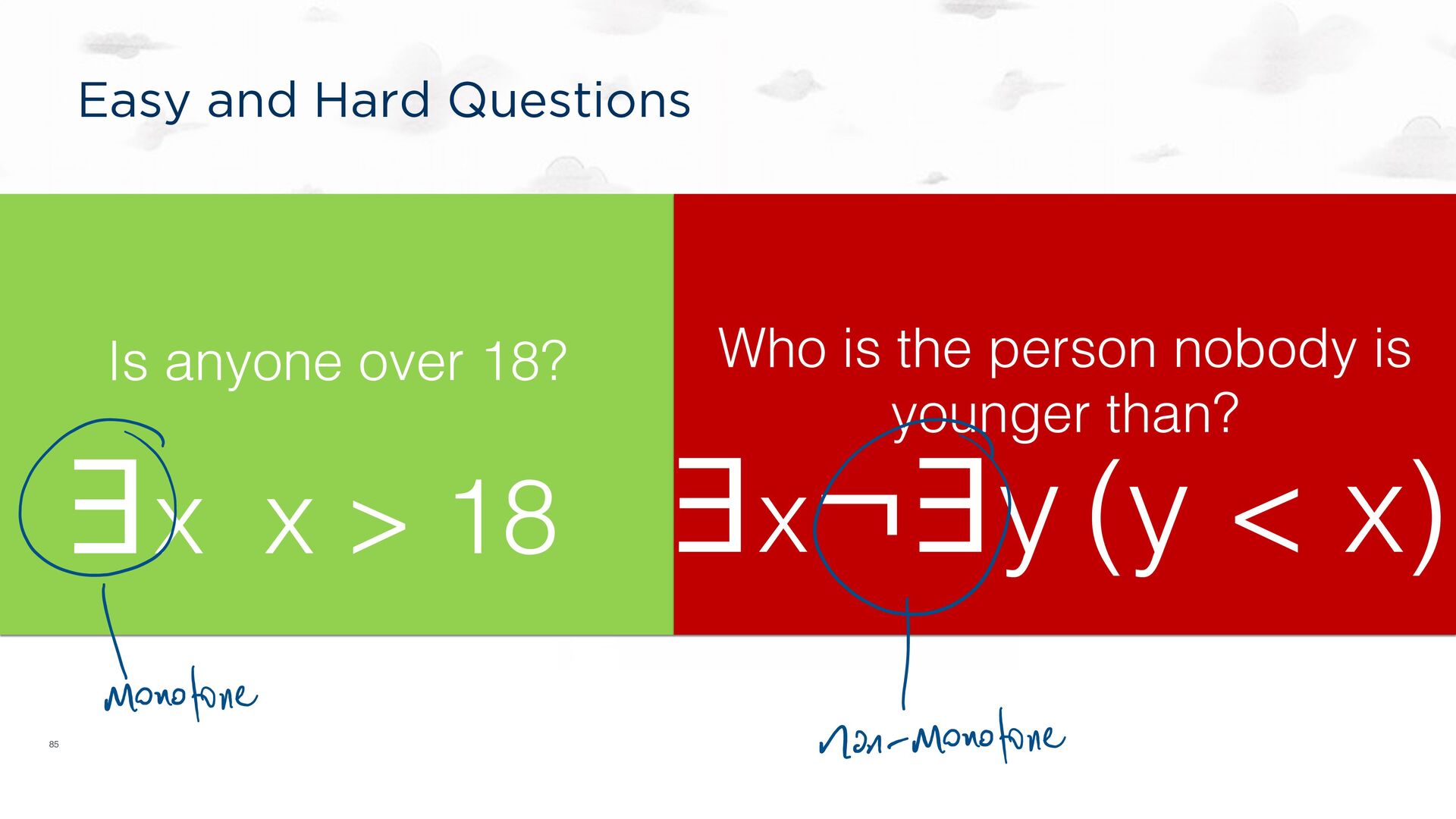{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}