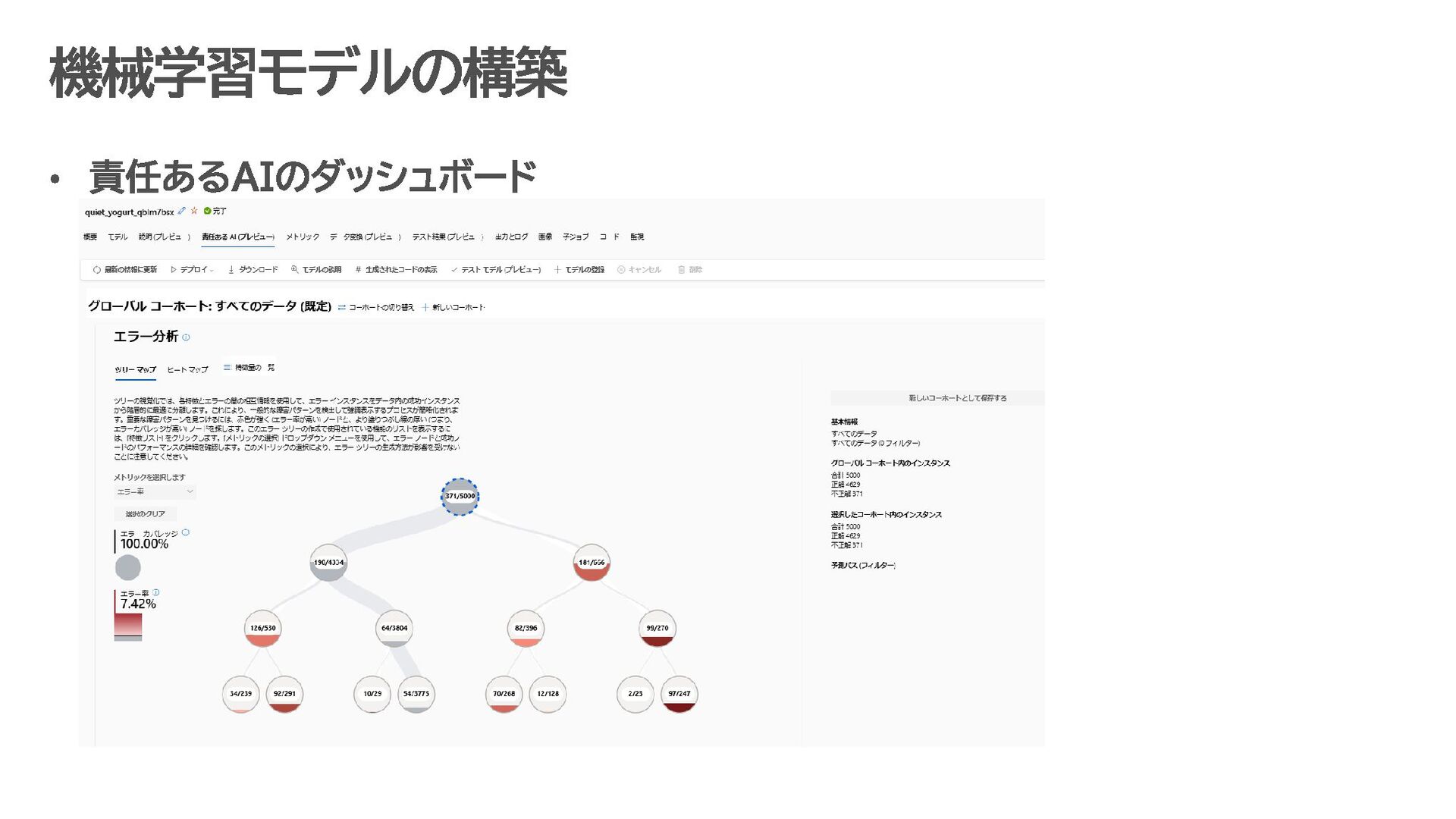
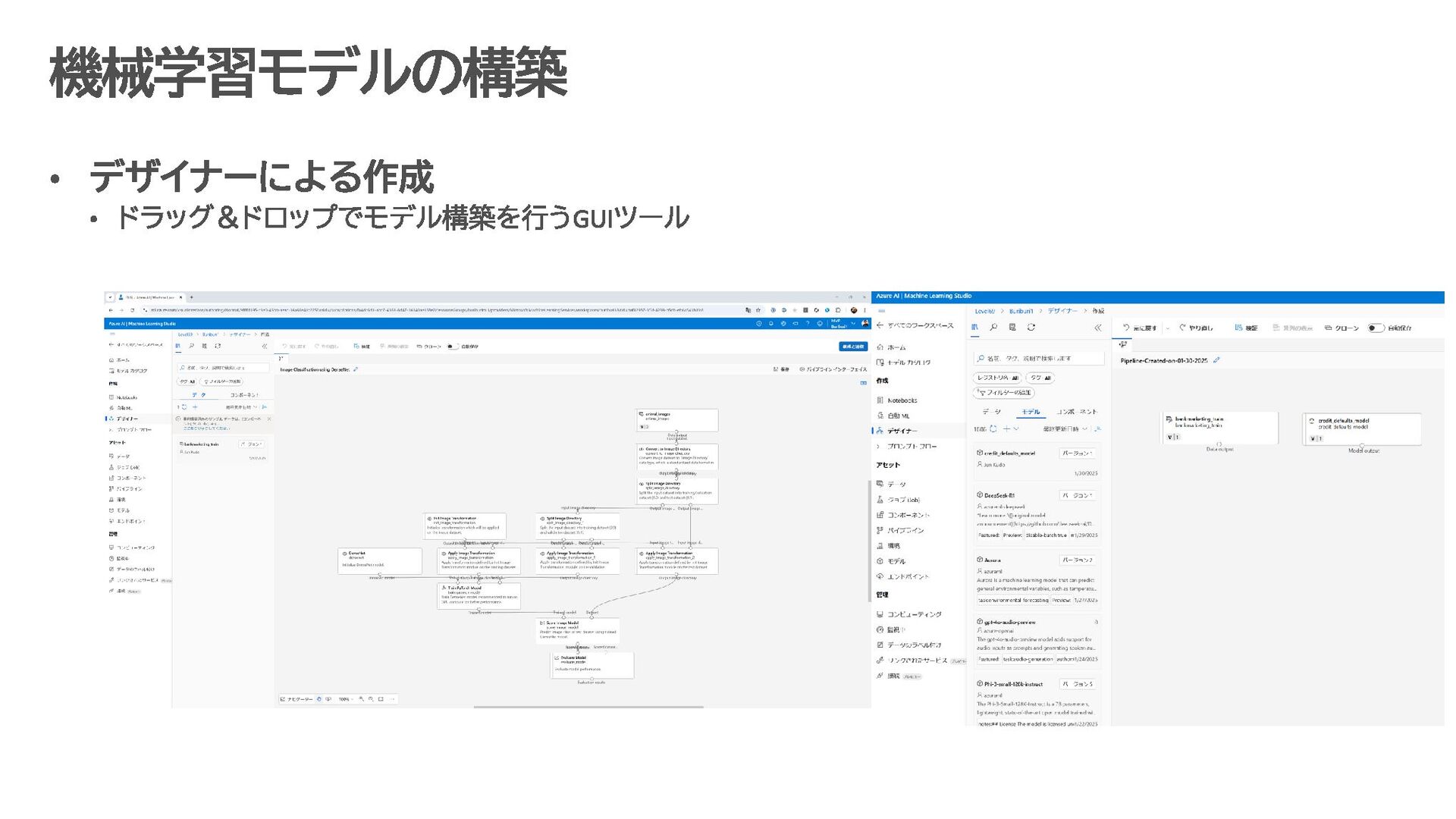
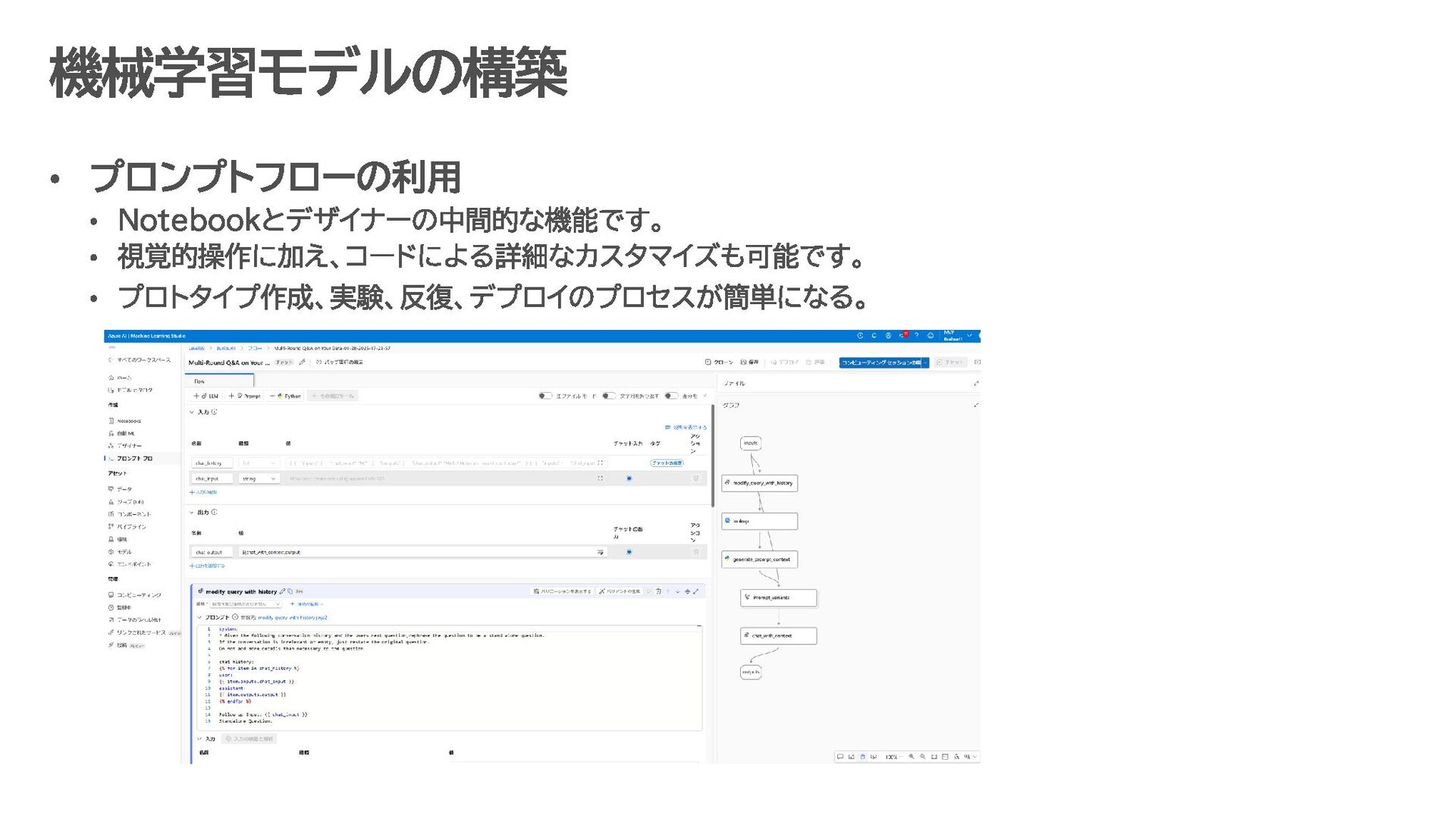
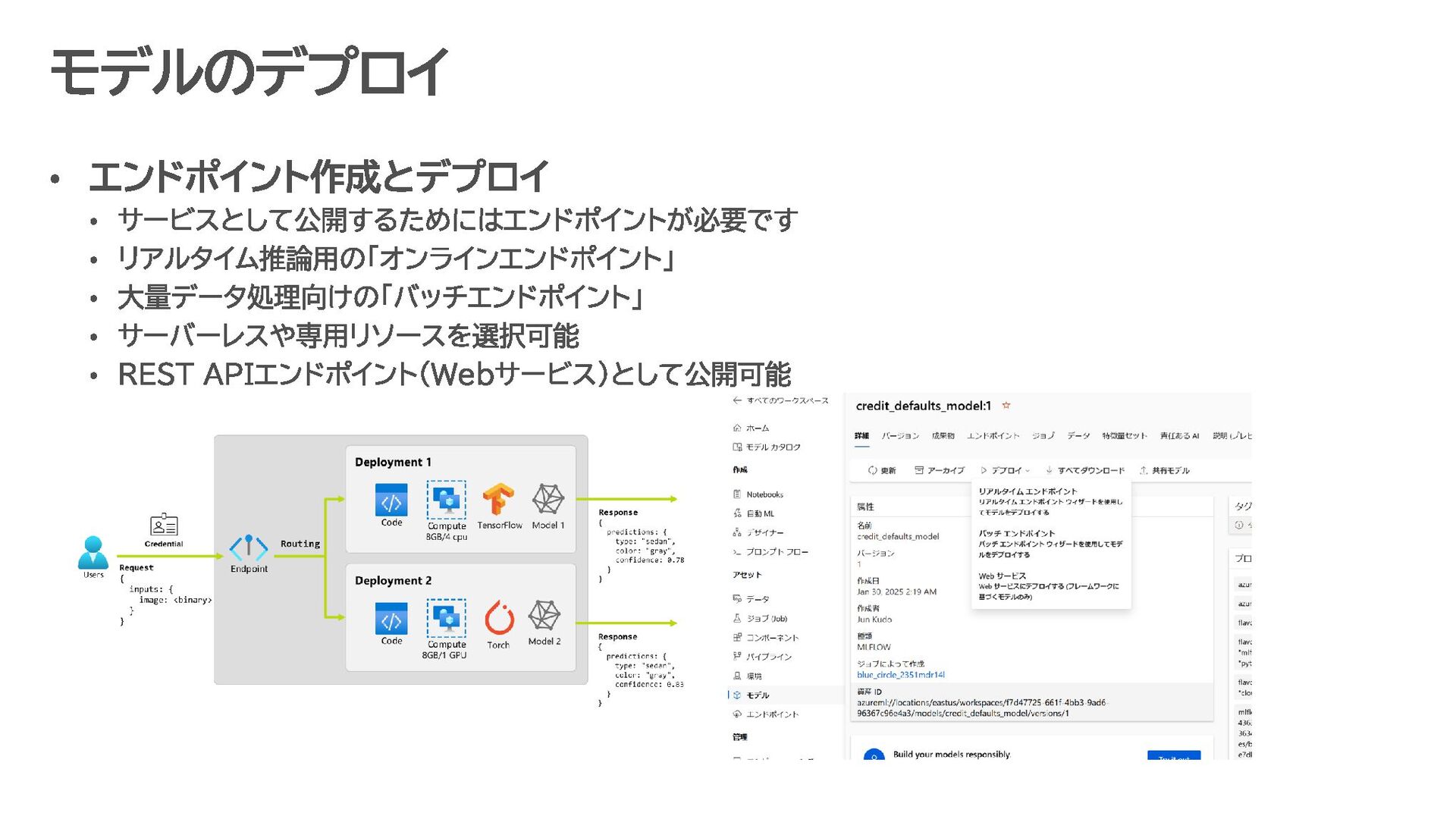
カテゴリの定義 Azure AI Foundry Azure AI Services Azure Machine Learning Studio Trustworthy AI https://mvp.microsoft.com/ja-jp/faq?section=mvp#mvp-technology-structure-0
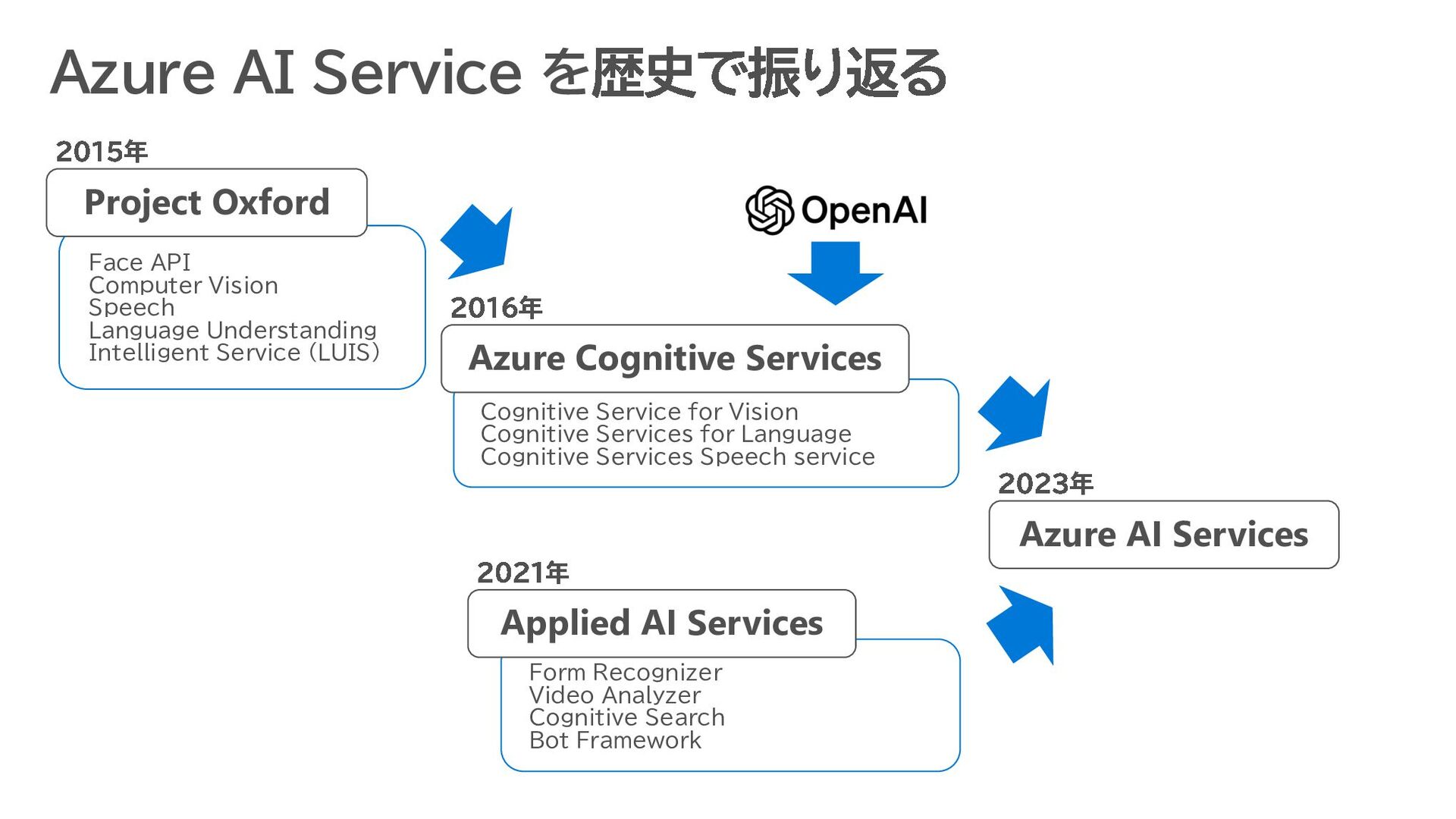
for Vision Cognitive Services for Language Cognitive Services Speech service Face API Computer Vision Speech Language Understanding Intelligent Service (LUIS) Azure AI Service を歴史で振り返る Project Oxford 2015年 Azure Cognitive Services 2016年 Azure AI Services 2023年 Applied AI Services 2021年
Azure Container Apps Azure Functions Azure Service Fabric Azure Batch Azure Red Hat OpenShift Azure Spring Apps Azure AI サービスには、Docker コンテナーがいくつか用意されており、これにより、Azure で使用できるものと同じ API をオンプレミスで使用できます。 Container Services サービス コンテナー Anomaly Detector Anomaly Detector (イメージ) LUIS LUIS (イメージ) 言語サービス キー フレーズ抽出 (イメージ) 言語サービス テキスト言語検出 (イメージ) 言語サービス 感情分析 (イメージ) 言語サービス Text Analytics for Health (画像) 言語サービス 固有表現認識 (画像) 言語サービス カスタム固有表現認識 (イメージ) Language サービス 概要作成 (画像) Translator Translator (画像) Speech Service API 音声テキスト変換 (イメージ) Speech Service API カスタム音声テキスト変換 (イメージ) Speech Service API ニューラル テキスト読み上げ (イメージ) Speech Service API Speech 言語識別 (イメージ) Azure AI Vision Read OCR (イメージ) 空間分析 空間分析 (イメージ)
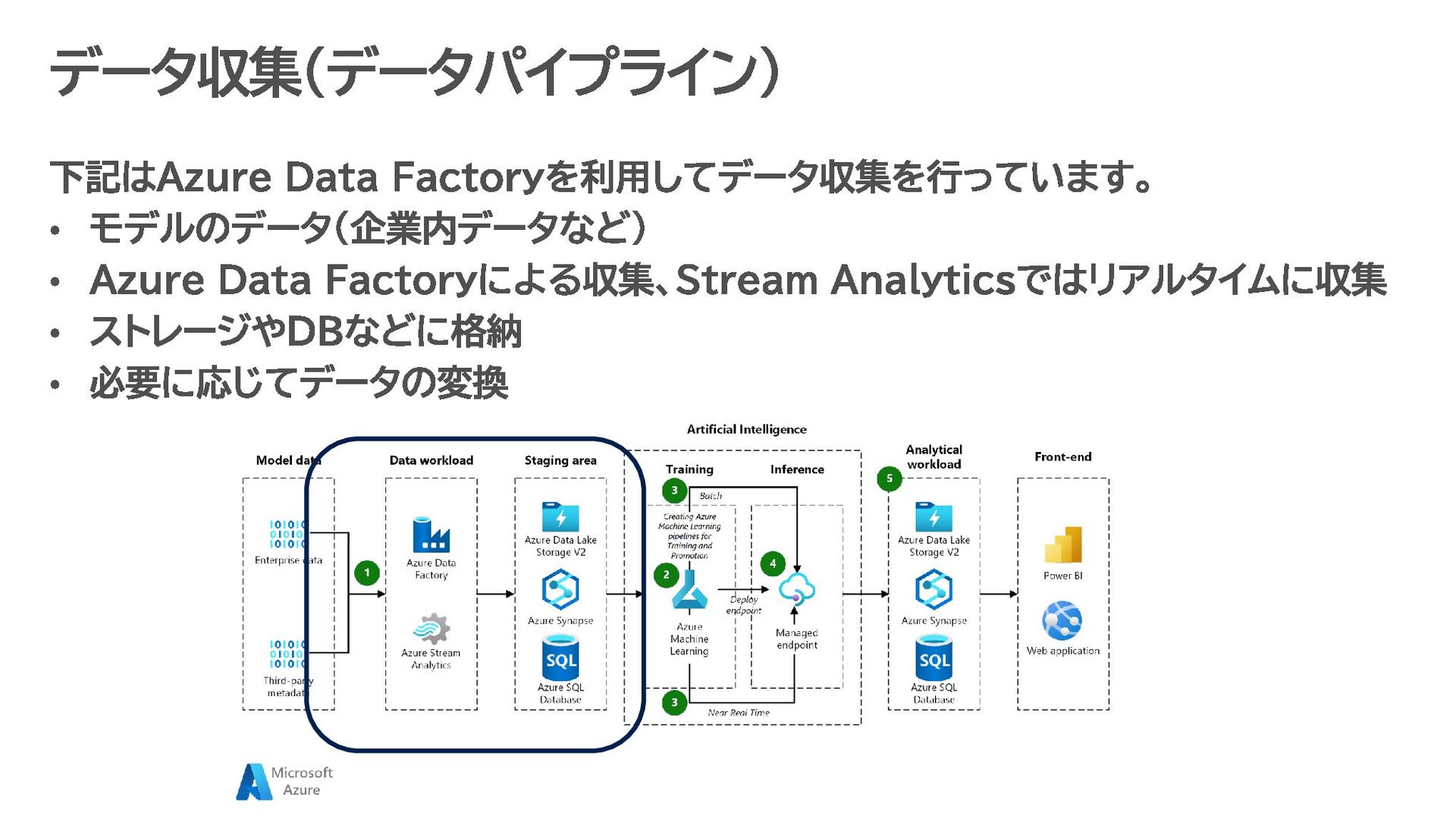
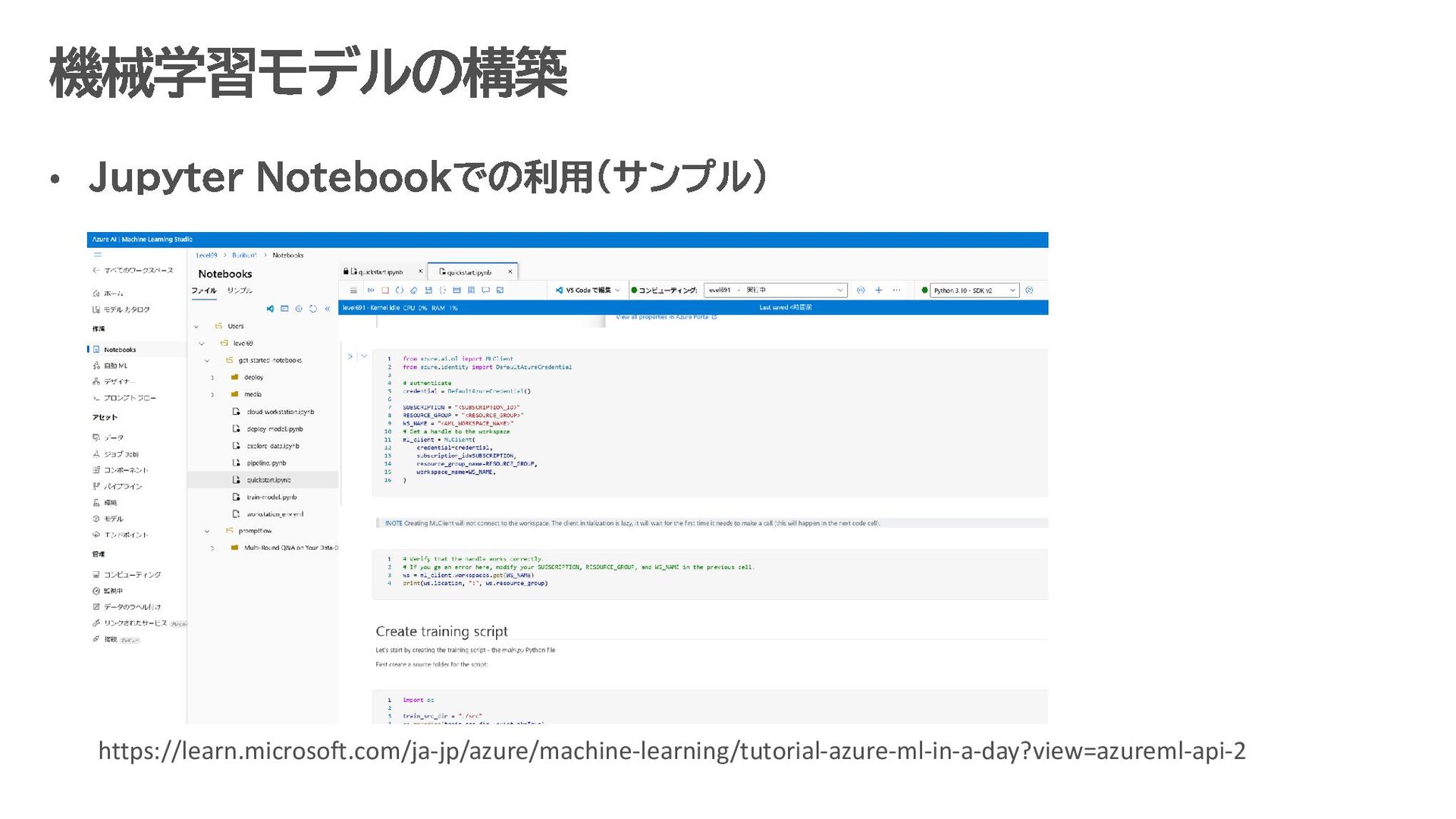
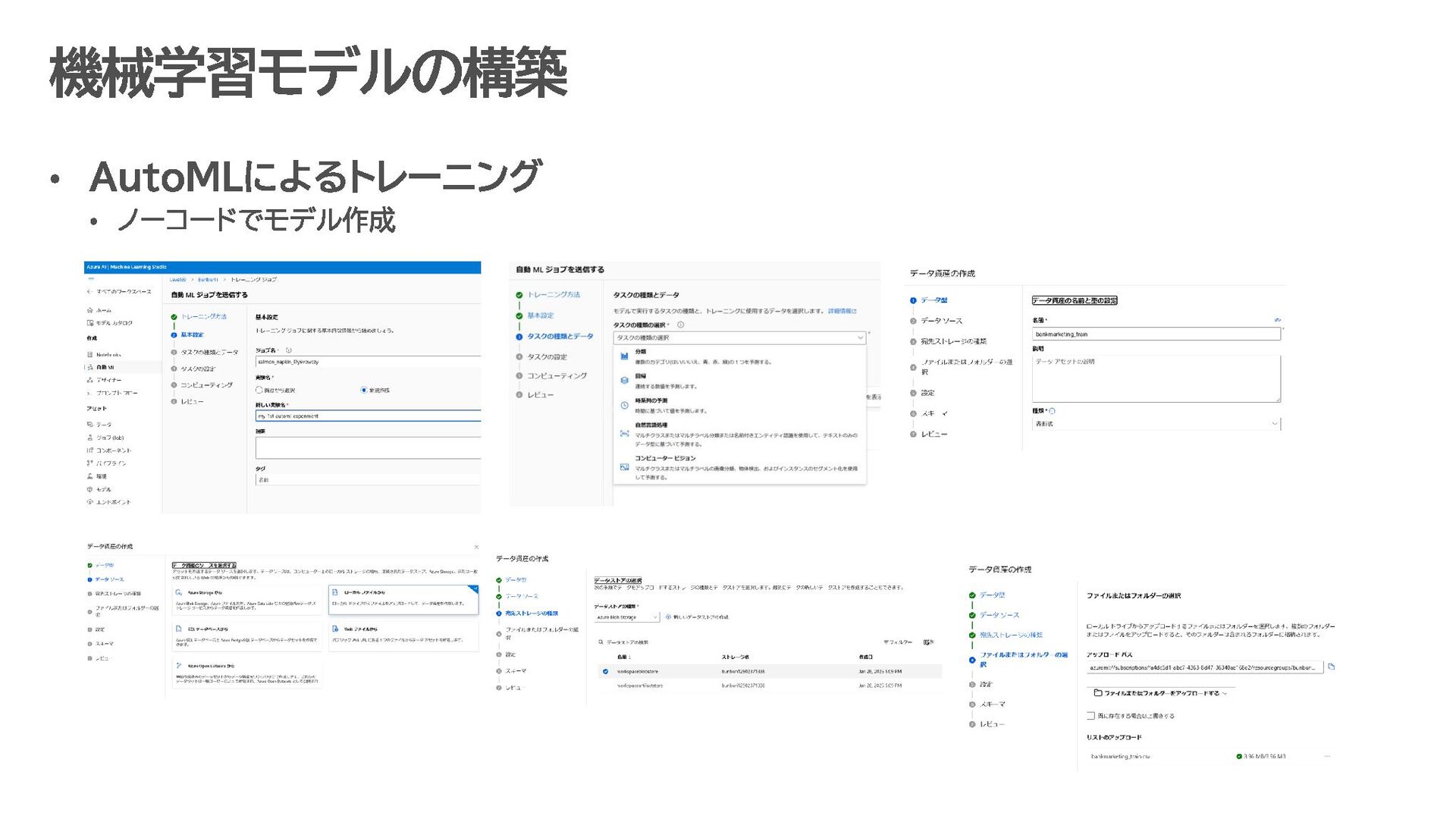
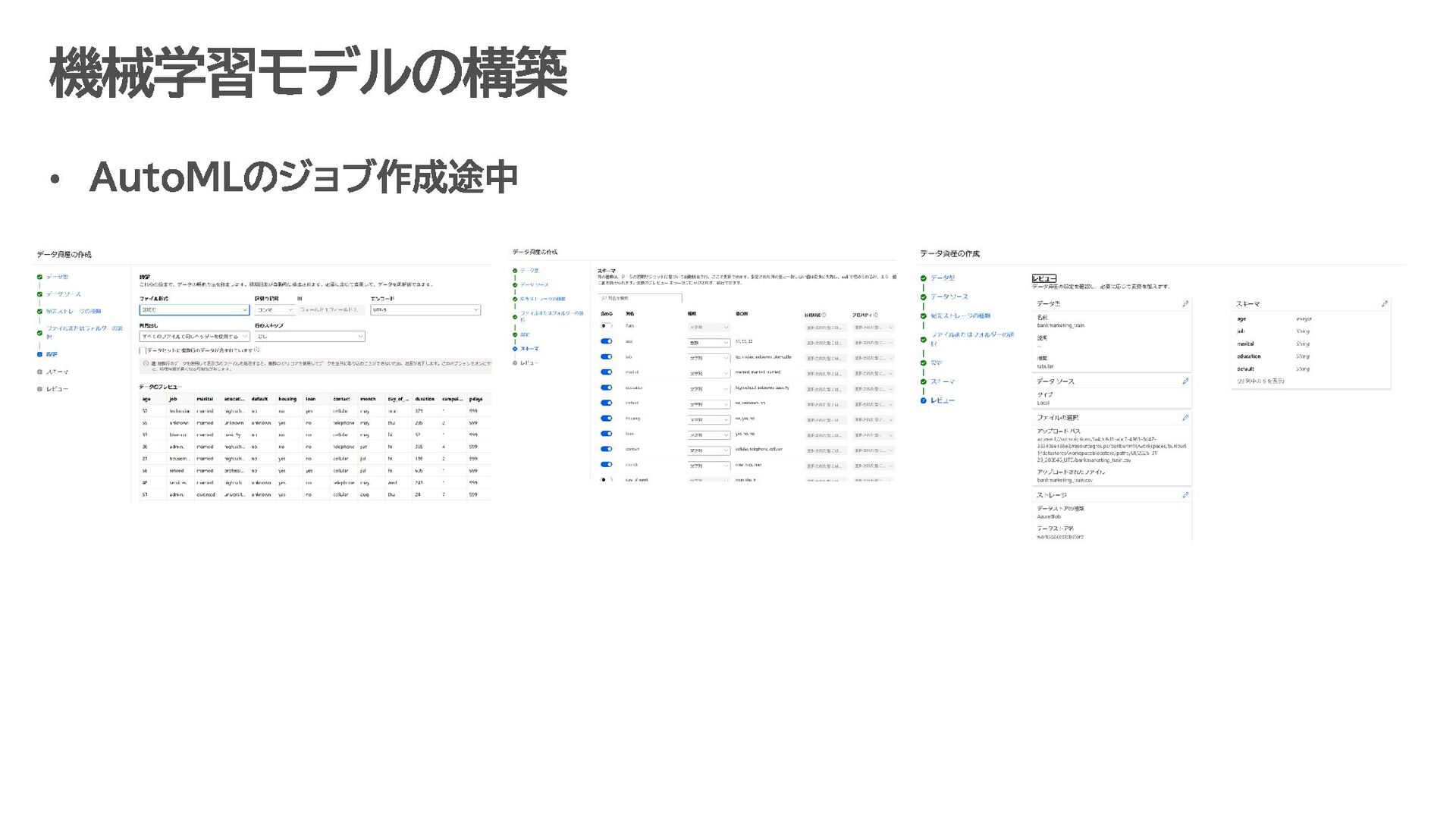
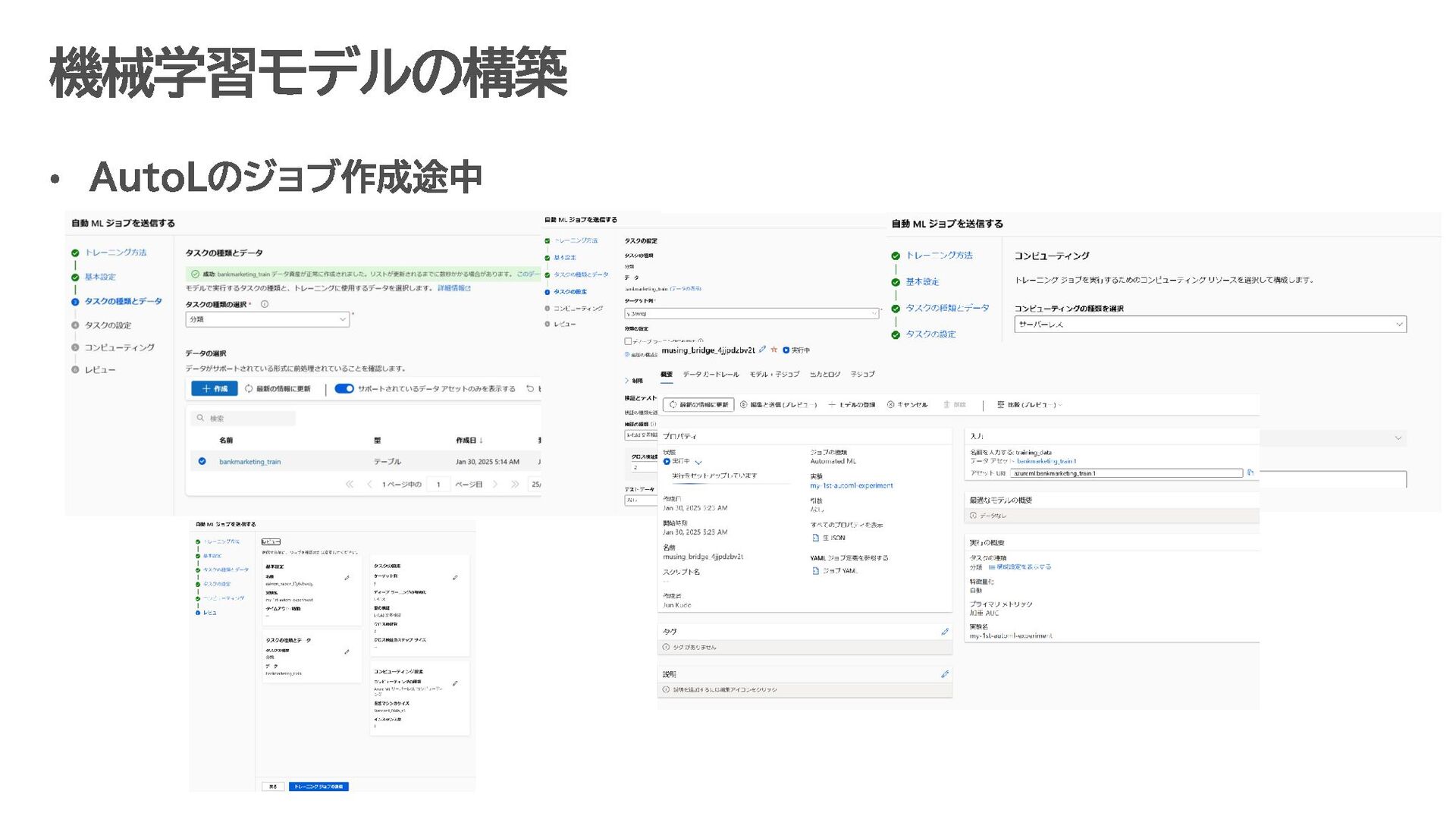
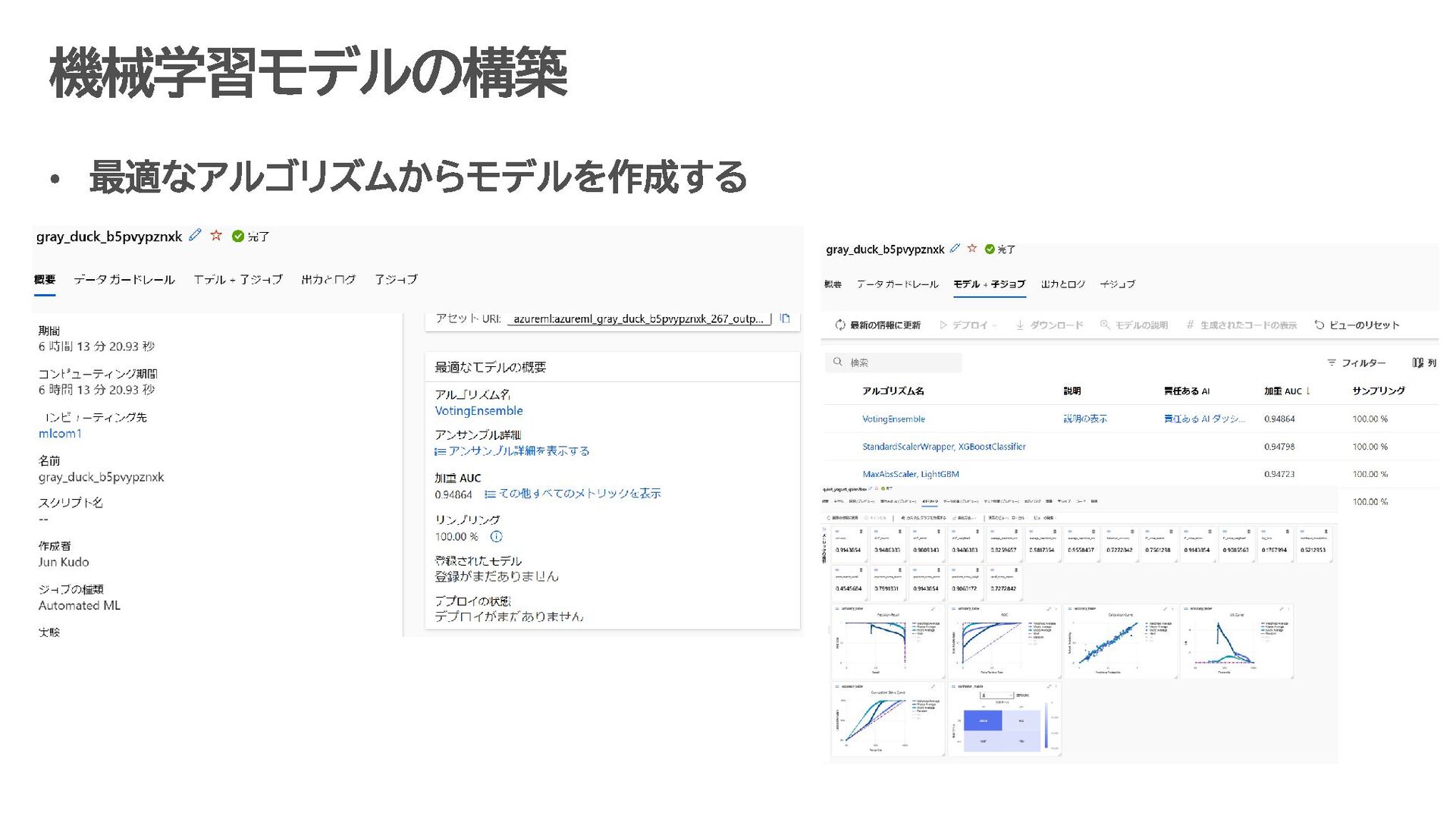
す。 データ収集・蓄積 IoT デバイス、アプリケーション、ログなどから生成されるデータを Azure Data Lake に保存。 データ形式: JSON、CSV、Parquet など。 データ処理・準備 Azure Synapse Analytics や Azure Databricks で、Azure Data Lake 上のデータをクレンジング・整形。 ETL(抽出、変換、ロード)処理で必要なデータを AI モデルに適した形に変換。 機械学習モデルの構築 Azure Machine Learning を使い、Data Lake 上のデータを活用して予測モデルを開発。 Jupyter Notebook などの開発環境で、Python や R を用いたモデル構築が可能。 AI モデルのトレーニングとデプロイ Data Lake 内の膨大なデータを使ってモデルをトレーニング。 トレーニング済みモデルは Kubernetes クラスターや Azure Functions にデプロイし、リアルタイムで推論可能。 分析結果の可視化と自動化 Power BI を使って、モデルが生成した分析結果を可視化。 Azure Data Factory を用いて、データの流れを自動化するパイプラインを構築 Data Lake
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
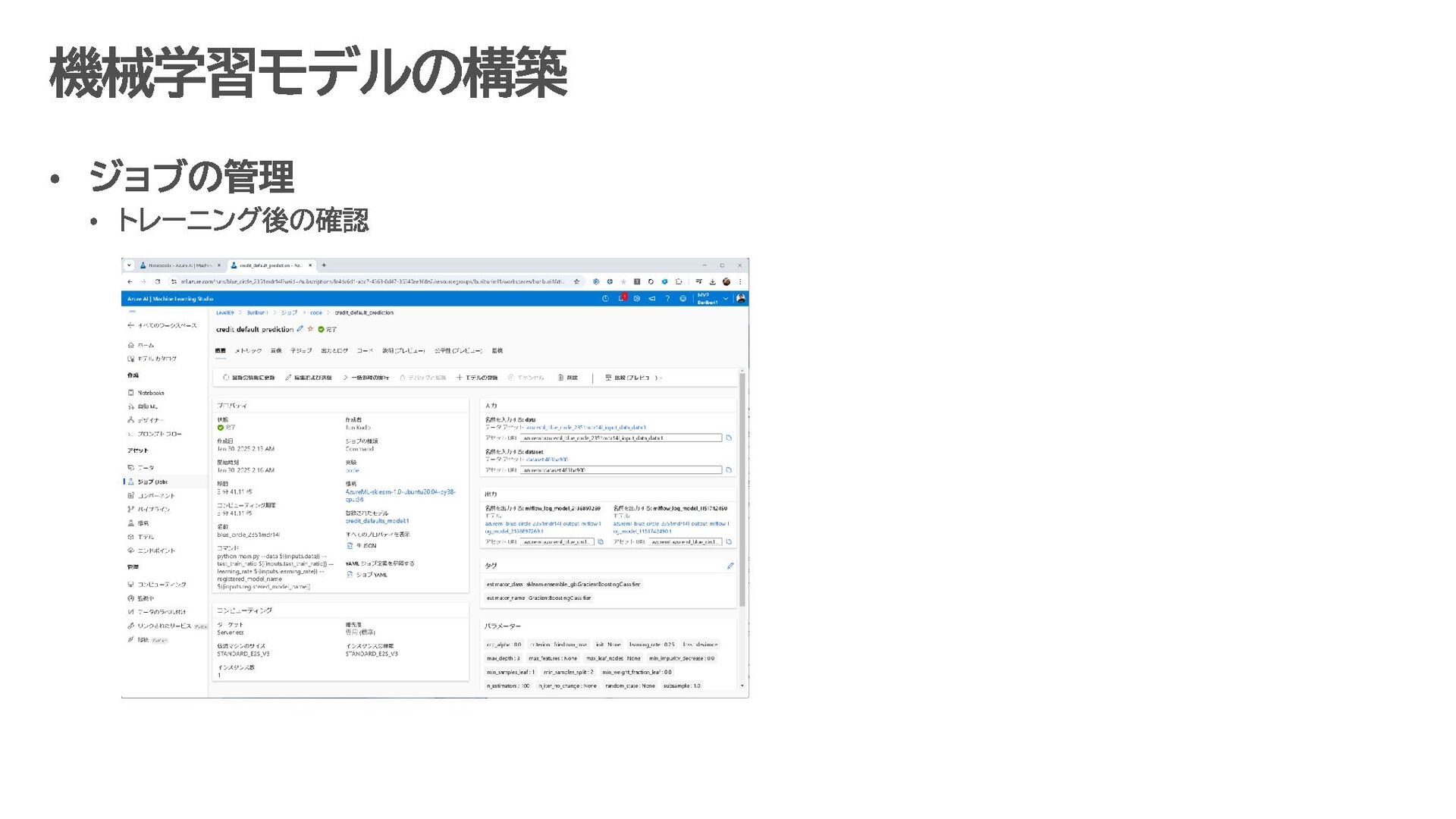{kind=link}
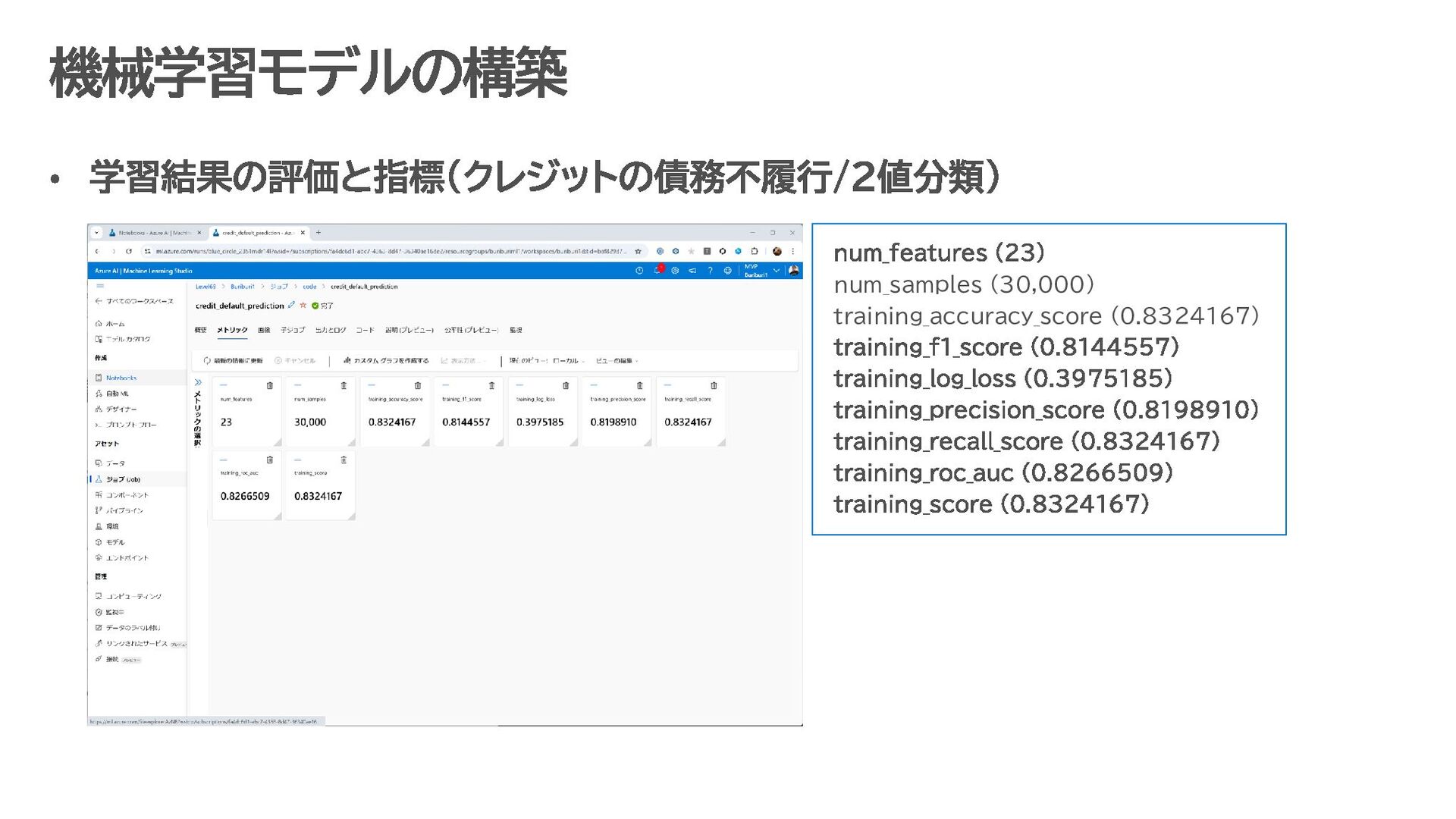{kind=link}
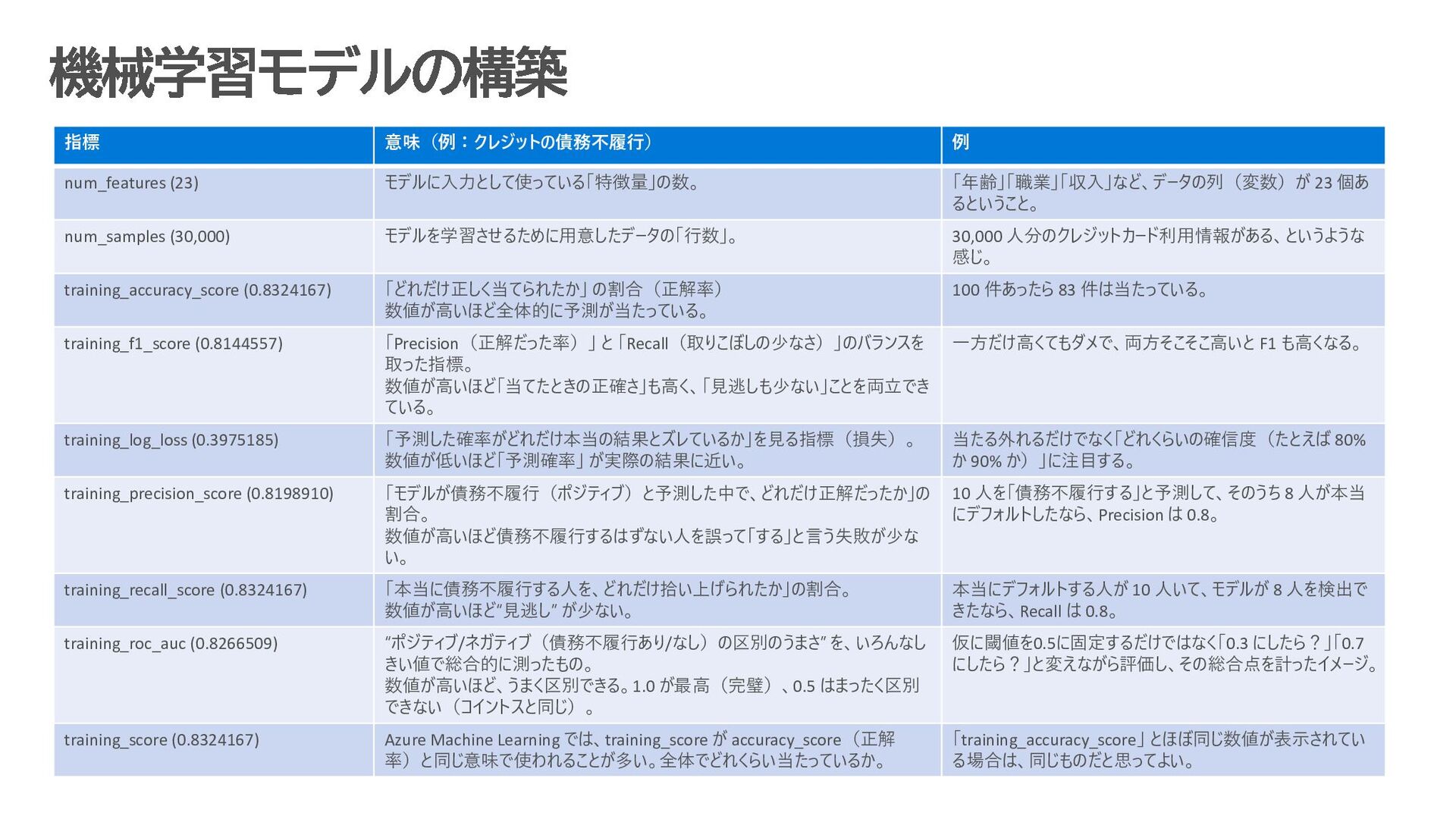{kind=link}
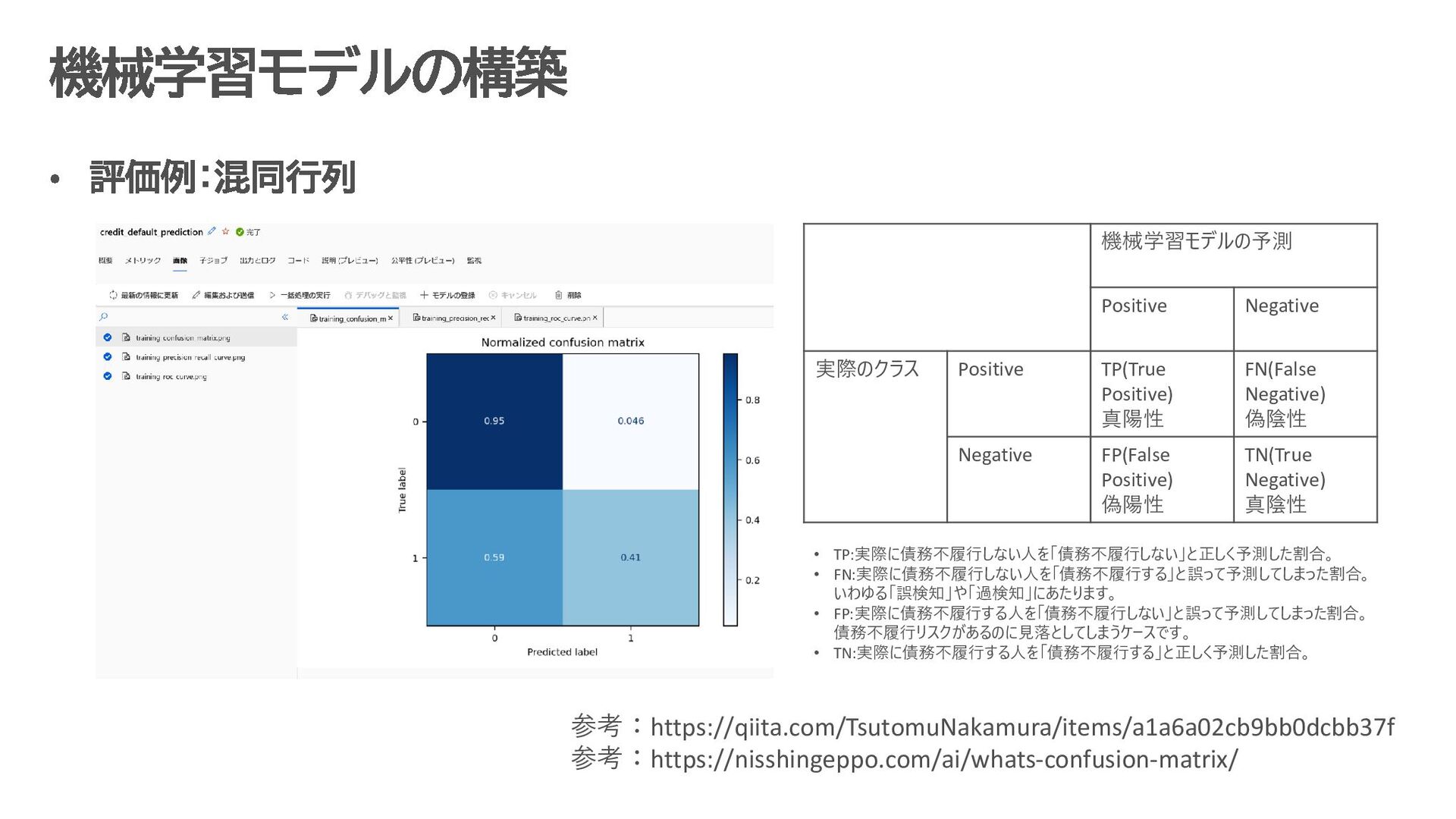{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}