function on Honestbee.com • Mission critical part of production setup • Downtime will cause major service disruption • Stats: ◦ Product index: ~3,300,000 documents ◦ Query latency: ~30ms ◦ Queries per hr: 15-20k • ES v2.3, 5.3 • Kubernetes v1.5, v1.7
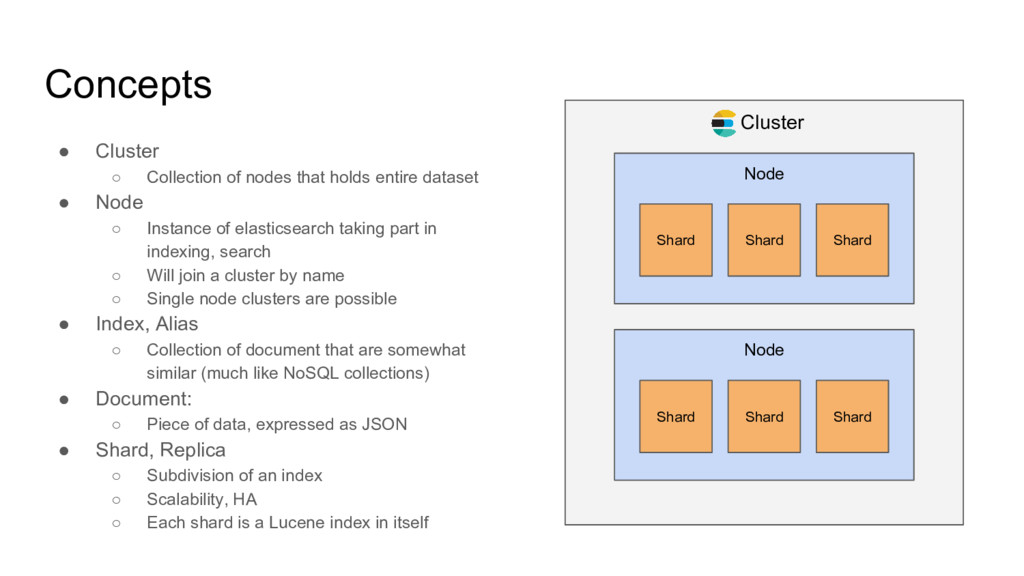
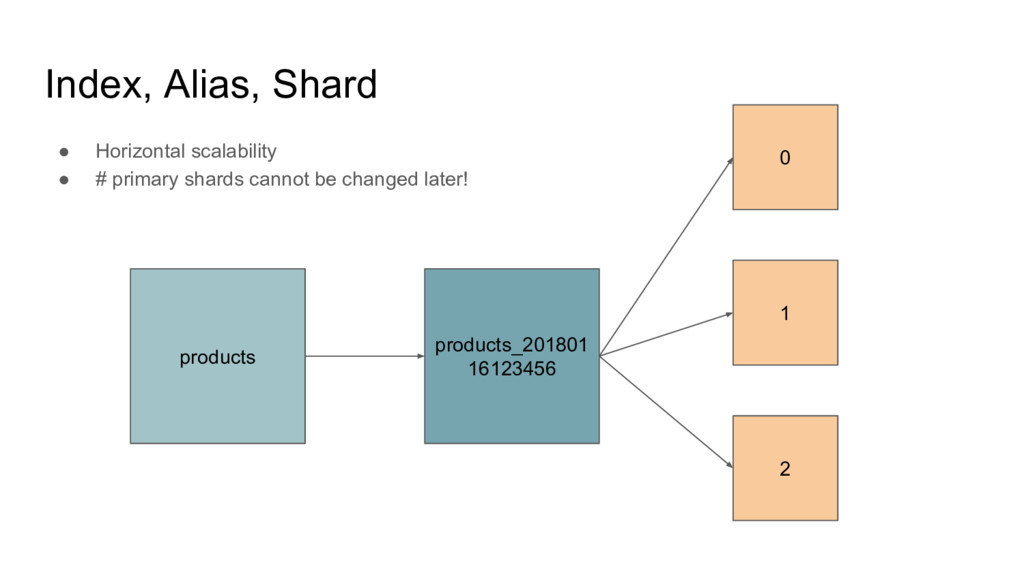
dataset • Node ◦ Instance of elasticsearch taking part in indexing, search ◦ Will join a cluster by name ◦ Single node clusters are possible • Index, Alias ◦ Collection of document that are somewhat similar (much like NoSQL collections) • Document: ◦ Piece of data, expressed as JSON • Shard, Replica ◦ Subdivision of an index ◦ Scalability, HA ◦ Each shard is a Lucene index in itself Cluster Node Shard Shard Shard Node Shard Shard Shard
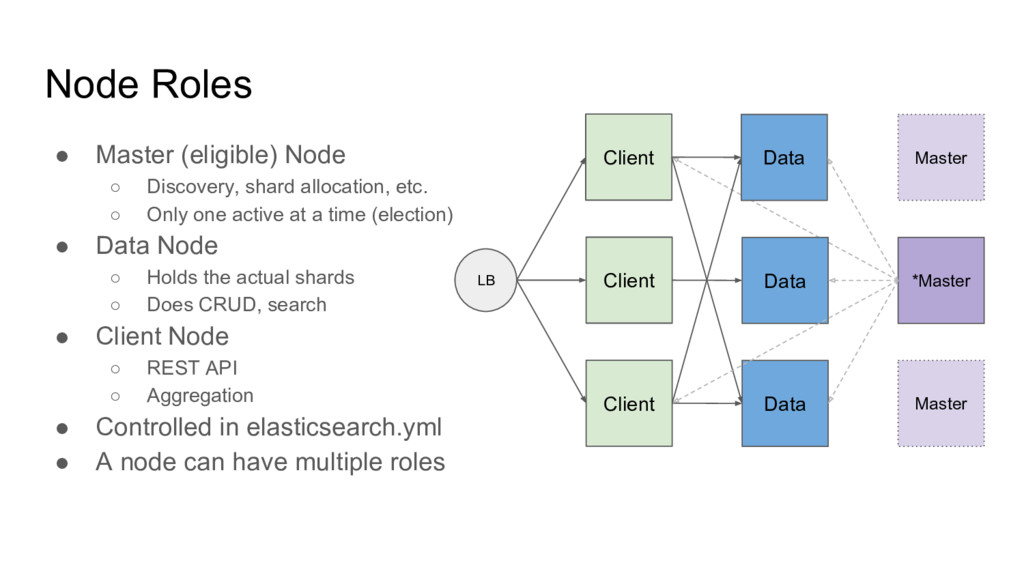
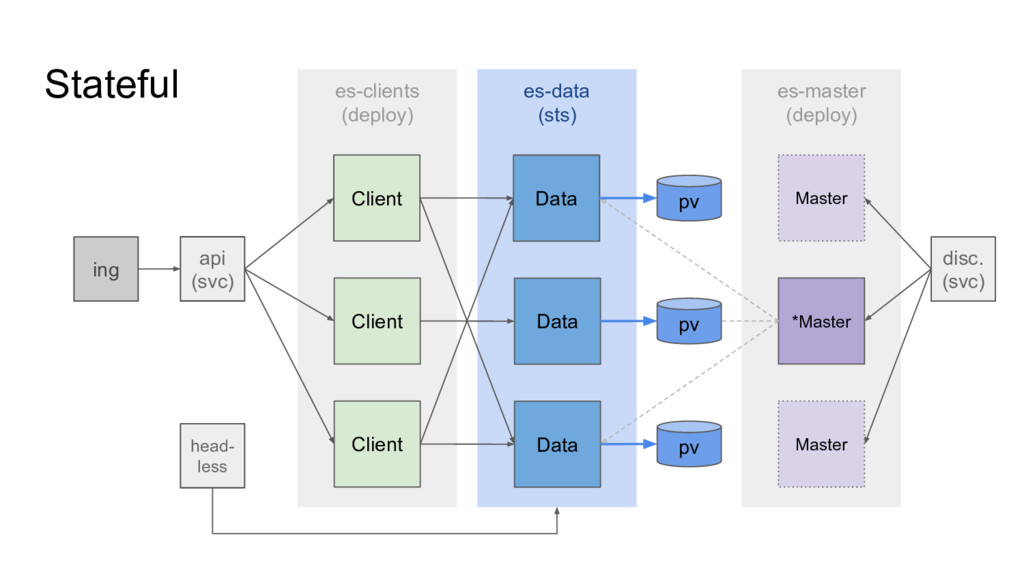
etc. ◦ Only one active at a time (election) • Data Node ◦ Holds the actual shards ◦ Does CRUD, search • Client Node ◦ REST API ◦ Aggregation • Controlled in elasticsearch.yml • A node can have multiple roles Client Client Client Data Data Data LB *Master Master Master
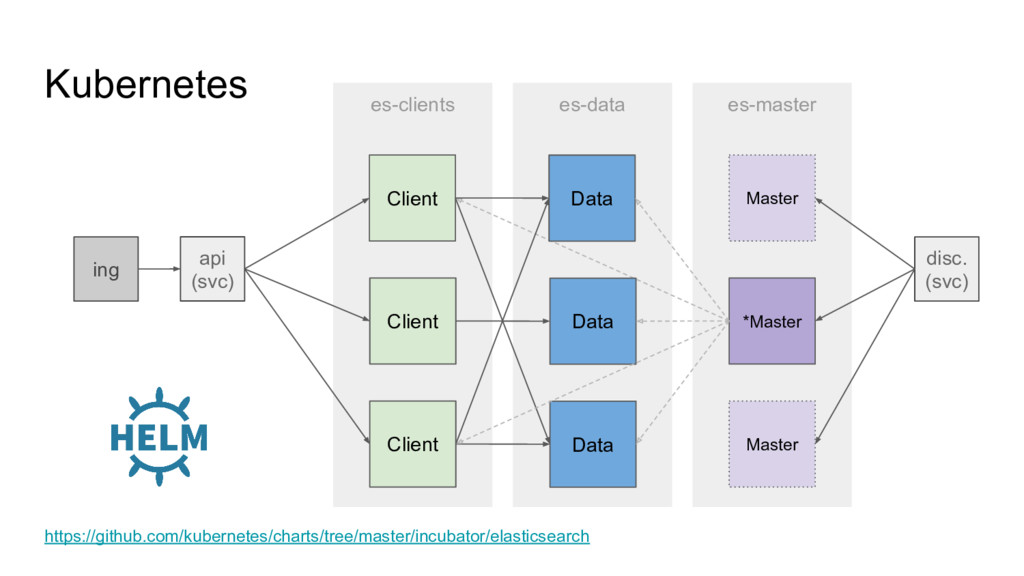
Resources ◦ Config • E.g. 3 masters, >= 3 data nodes, clients as needed • Discovery plugin* (needs access to kube API, RBAC) • Services: ◦ Discovery ◦ API ◦ STS (later) • Optional: Ingress, CM, CronJob, SA, CM *https://github.com/fabric8io/elasticsearch-cloud-kubernetes
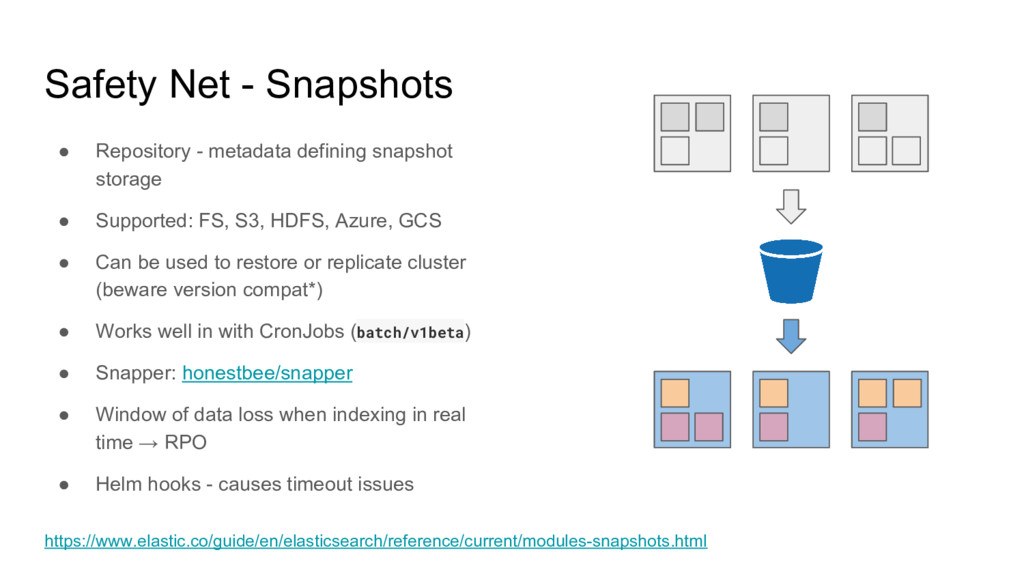
storage • Supported: FS, S3, HDFS, Azure, GCS • Can be used to restore or replicate cluster (beware version compat*) • Works well in with CronJobs (batch/v1beta) • Snapper: honestbee/snapper • Window of data loss when indexing in real time → RPO • Helm hooks - causes timeout issues https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-snapshots.html
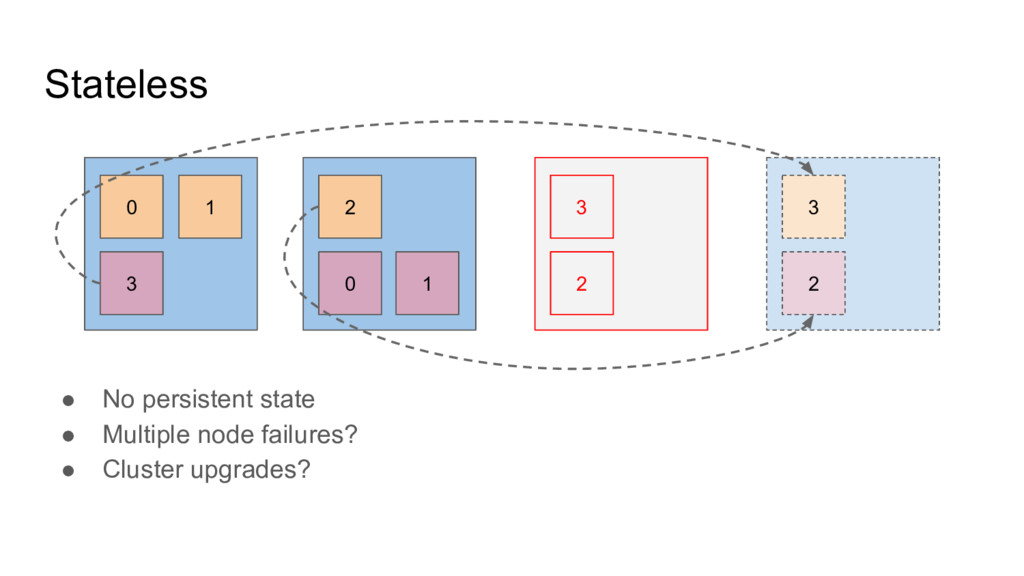
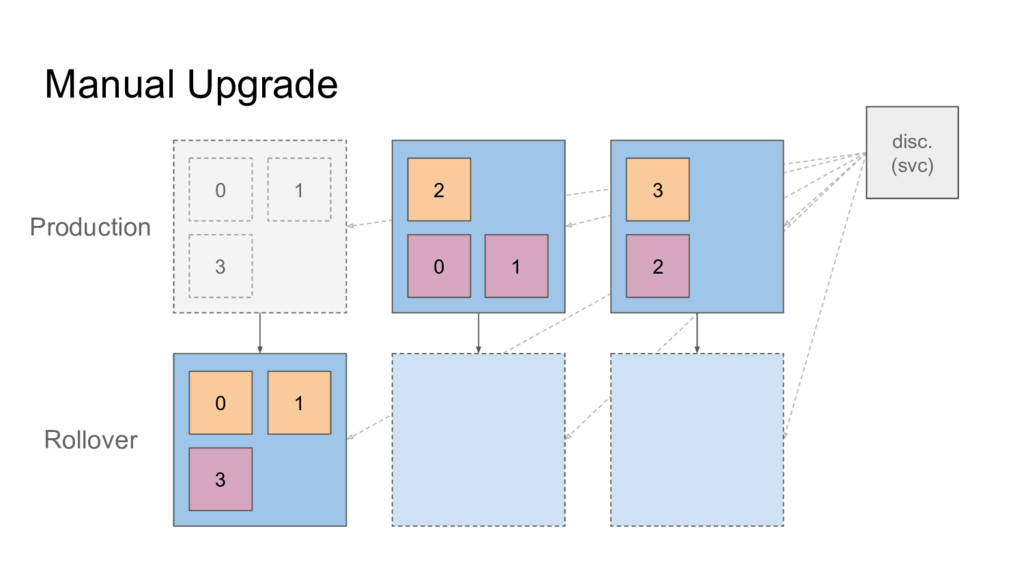
• Very similar to a deployment • But some extra properties: ◦ Pods have a defined order ◦ Different naming pattern ◦ Will be launched and terminated in sequence ◦ Etc. (check reference docs) ◦ Support for PVC template
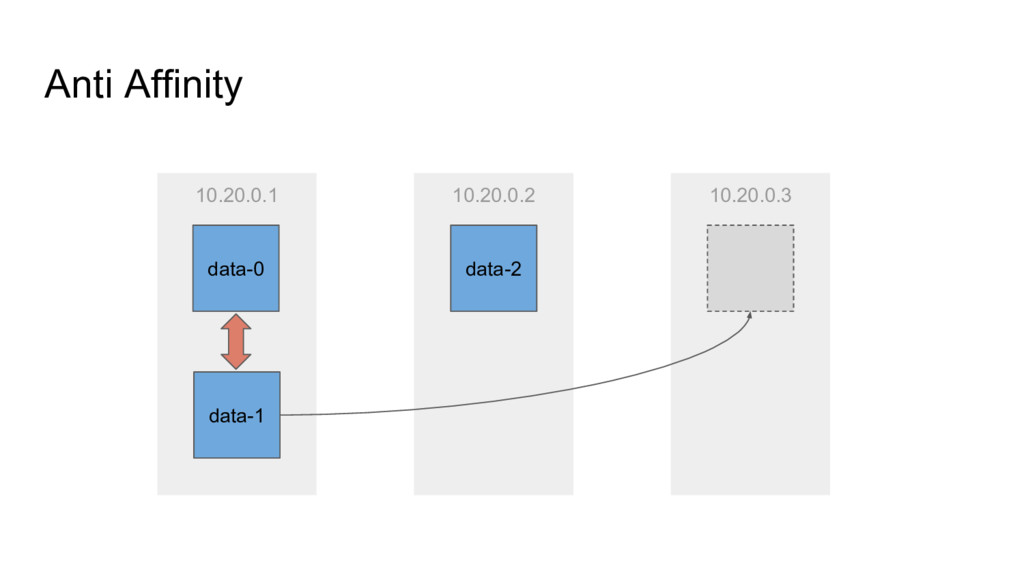
unrelated to each other • Identity not maintained across restarts • Indiv. Pods can have PVC • Multiple pods - how to? • Association PVC to pod when rescheduled? StatefulSet: • Pods are ordered, maintain identity across restart • PVCs are ordered • STS pods ‘remember’ PVs • volumeClaimTemplates • Even survives `helm delete --purge` (by design?)
JVM does not regard cgroups properly!* ◦ Sees ALL memory of the host, ignores container limits ◦ Adjust JVM limits (Xmx, Xms) according to limits for container ◦ Otherwise: OOMKilled • Data nodes: ◦ 50% of available memory as Heap ◦ The rest for OS and Lucene caches • Master/client nodes: ◦ No Lucene caches ◦ ~75% mem as heap, rest for OS • CPU: track actual usage, set limits so scheduler can make decisions *https://banzaicloud.com/blog/java-resource-limits/
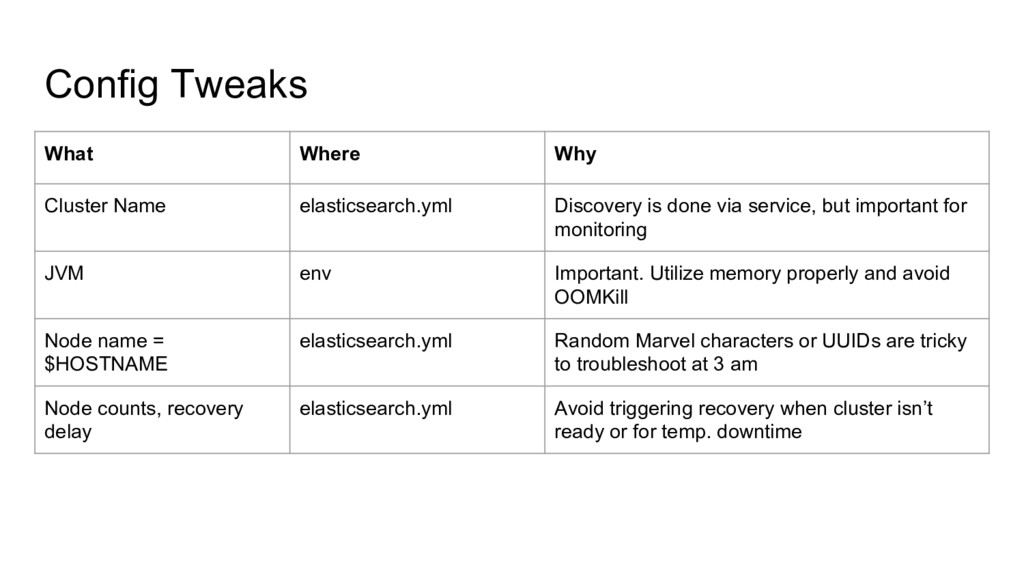
done via service, but important for monitoring JVM env Important. Utilize memory properly and avoid OOMKill Node name = $HOSTNAME elasticsearch.yml Random Marvel characters or UUIDs are tricky to troubleshoot at 3 am Node counts, recovery delay elasticsearch.yml Avoid triggering recovery when cluster isn’t ready or for temp. downtime
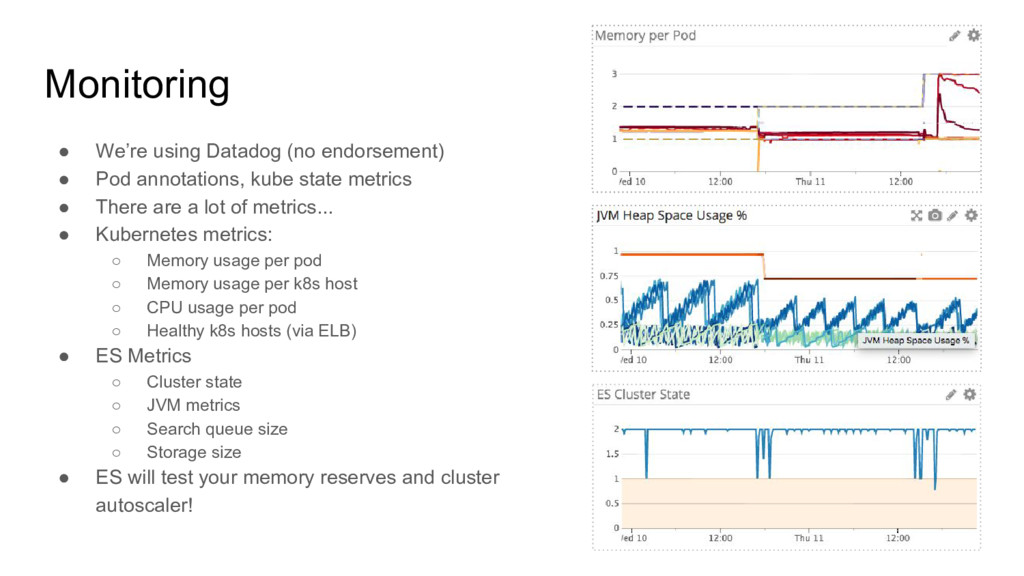
kube state metrics • There are a lot of metrics... • Kubernetes metrics: ◦ Memory usage per pod ◦ Memory usage per k8s host ◦ CPU usage per pod ◦ Healthy k8s hosts (via ELB) • ES Metrics ◦ Cluster state ◦ JVM metrics ◦ Search queue size ◦ Storage size • ES will test your memory reserves and cluster autoscaler!
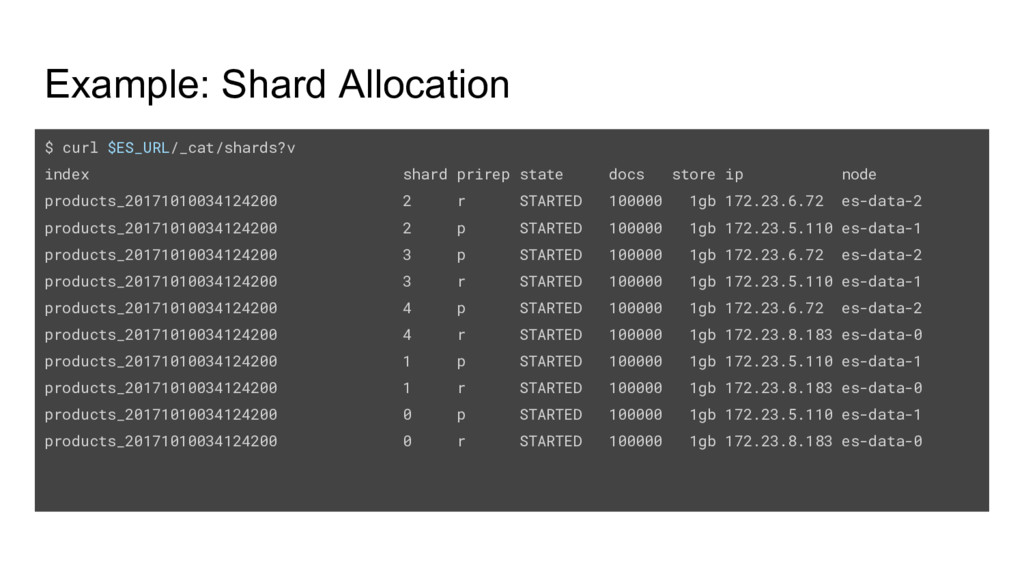
docs store ip node products_20171010034124200 2 r STARTED 100000 1gb 172.23.6.72 es-data-2 products_20171010034124200 2 p STARTED 100000 1gb 172.23.5.110 es-data-1 products_20171010034124200 3 p STARTED 100000 1gb 172.23.6.72 es-data-2 products_20171010034124200 3 r STARTED 100000 1gb 172.23.5.110 es-data-1 products_20171010034124200 4 p STARTED 100000 1gb 172.23.6.72 es-data-2 products_20171010034124200 4 r STARTED 100000 1gb 172.23.8.183 es-data-0 products_20171010034124200 1 p STARTED 100000 1gb 172.23.5.110 es-data-1 products_20171010034124200 1 r STARTED 100000 1gb 172.23.8.183 es-data-0 products_20171010034124200 0 p STARTED 100000 1gb 172.23.5.110 es-data-1 products_20171010034124200 0 r STARTED 100000 1gb 172.23.8.183 es-data-0
run with same permissions as the ES cluster • If you really have to: ◦ Prefer sandboxed (mustache, expressions) ◦ Use parameterised scripts! ◦ Test impact on your cluster carefully, mem, cpu usage ◦ Sanitise input, ensure cluster is not public, don’t run as root
{kind=link}
![Elasticsearch [is] a distributed, multitenant-capable full-text search engine with an](https://files.speakerdeck.com/presentations/8c583c94b47e41629ab82a5ce82ca4d0/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Example: JVM heap usage curl $ES_URL/_nodes/<node_name> | jq '.nodes[].jvm.mem' {](https://files.speakerdeck.com/presentations/8c583c94b47e41629ab82a5ce82ca4d0/slide_28.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}