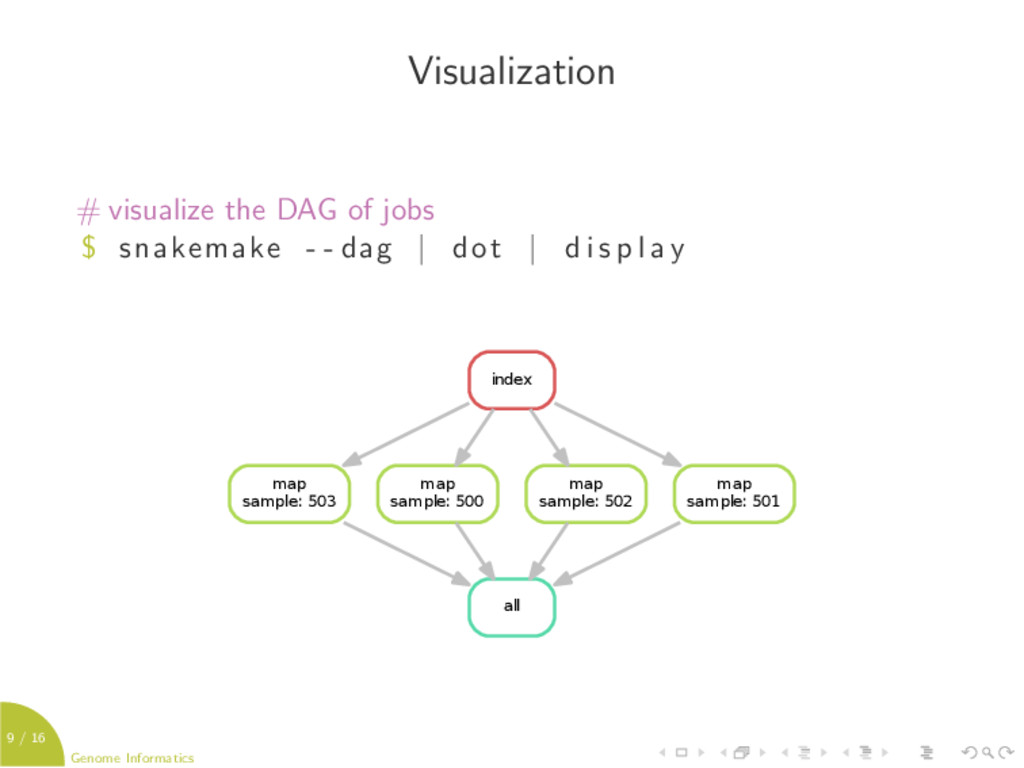
Snakemake aims to reduce the complexity of creating workflows by providing a fast and comfortable execution environment, together with a clean and modern domain specific specification language (DSL) in python style.
This invited talk was given at the Dutch Techcentre for Life Sciences Focus Meeting in Utrecht 2014.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}