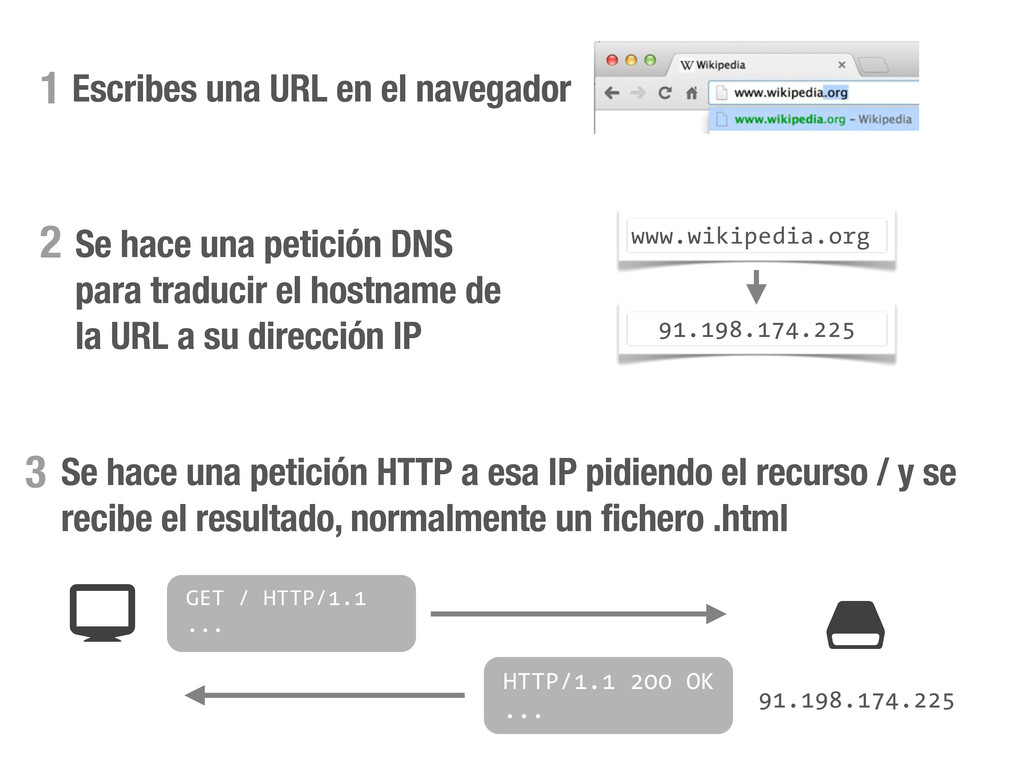
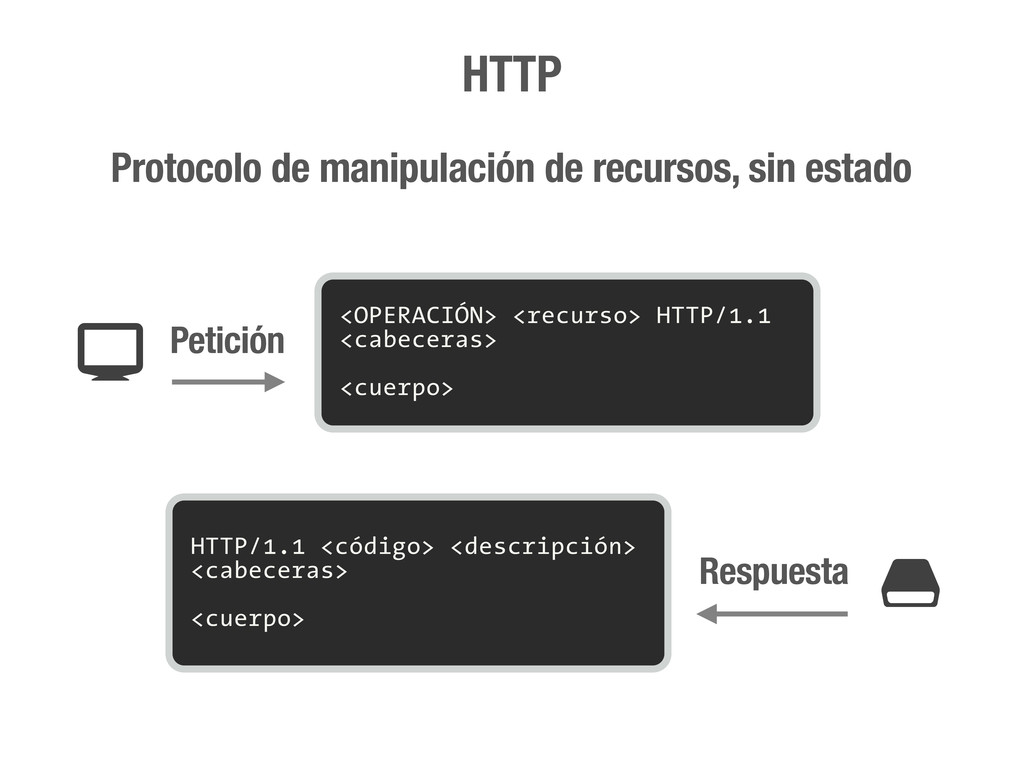
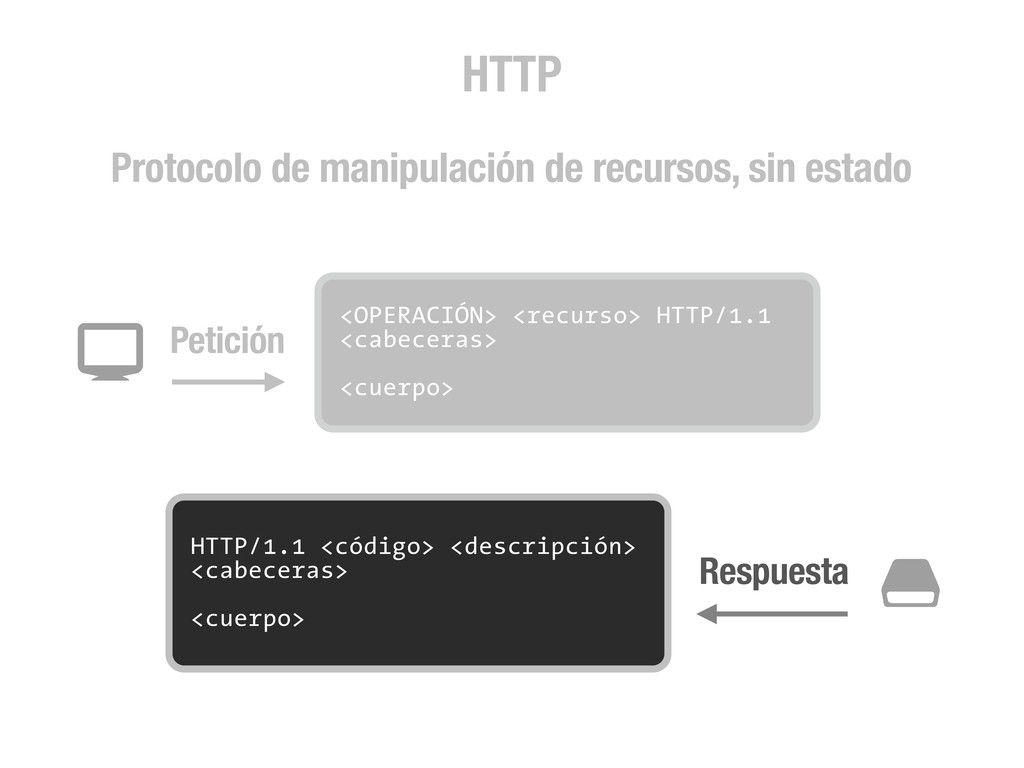
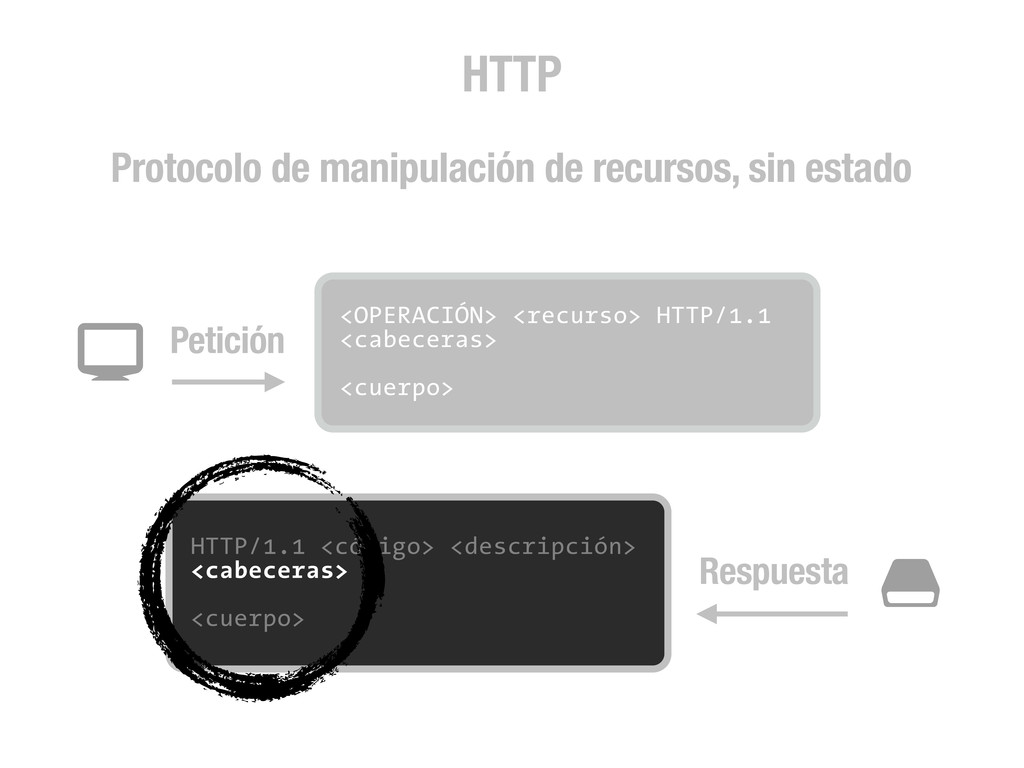
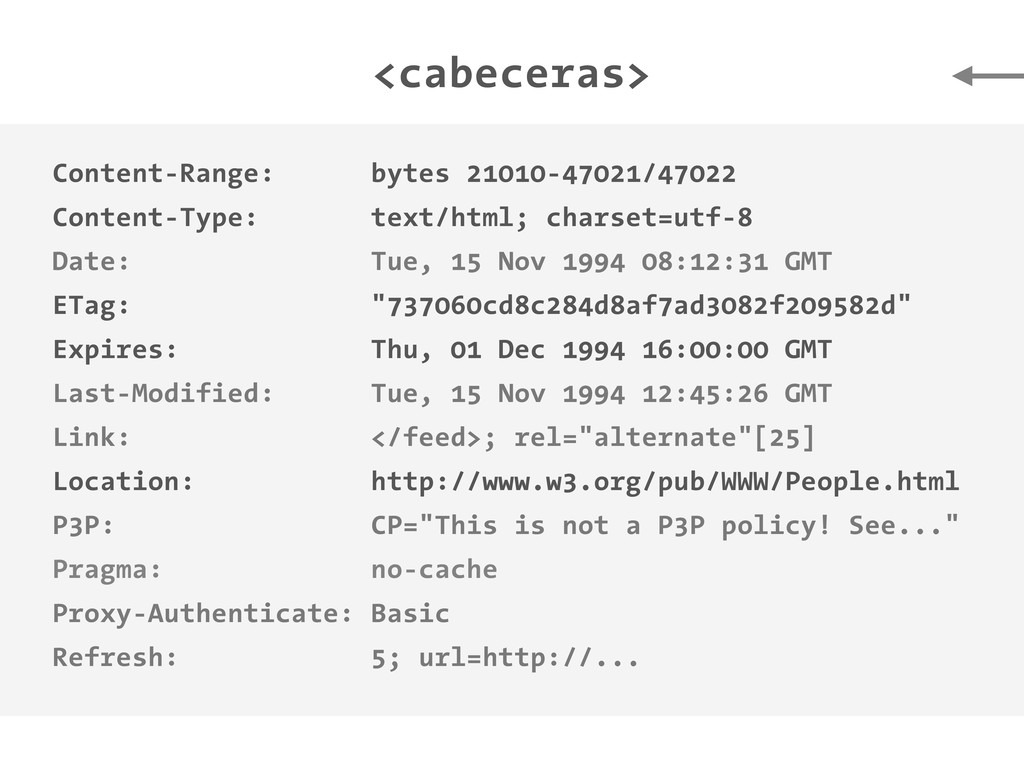
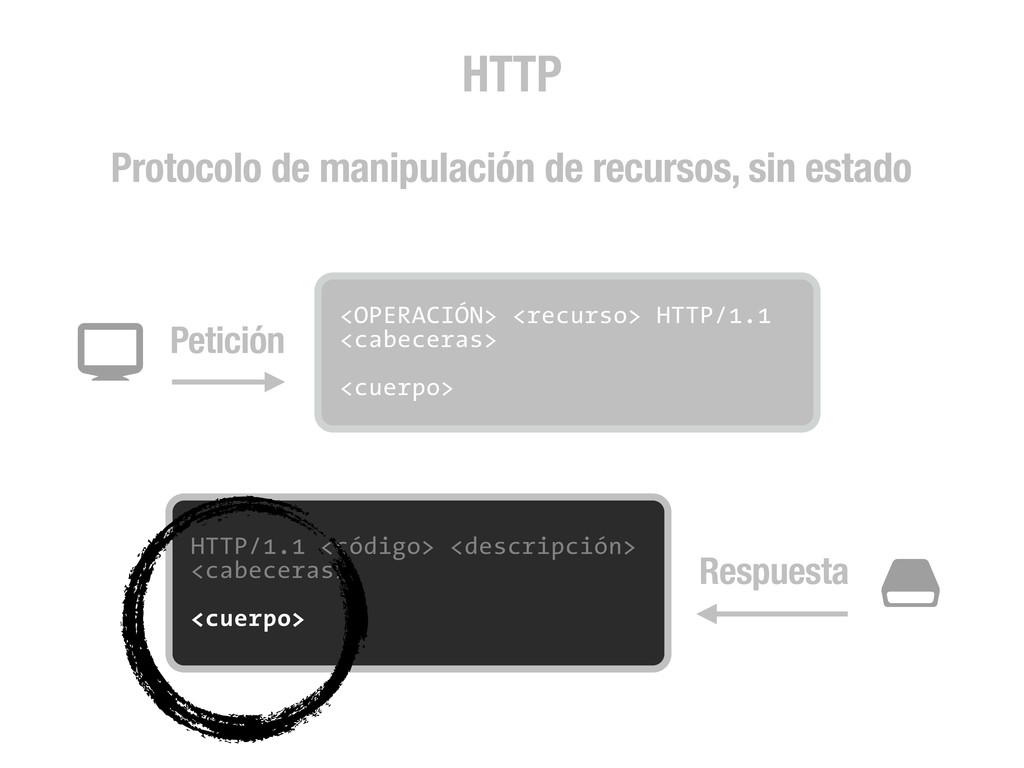
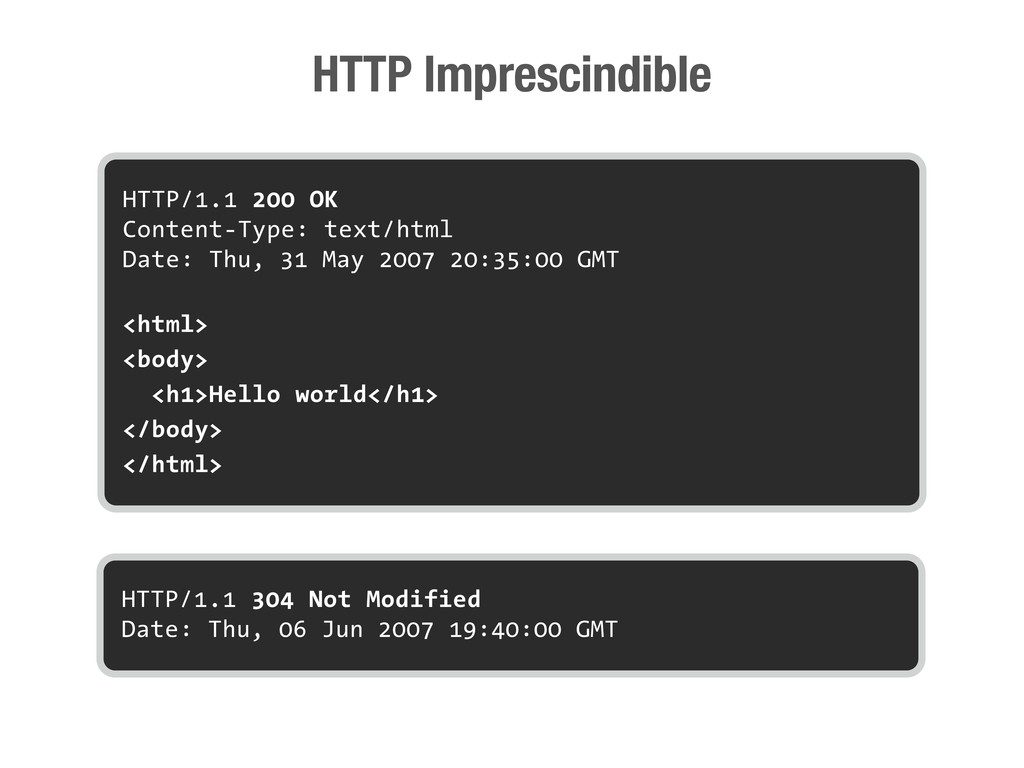
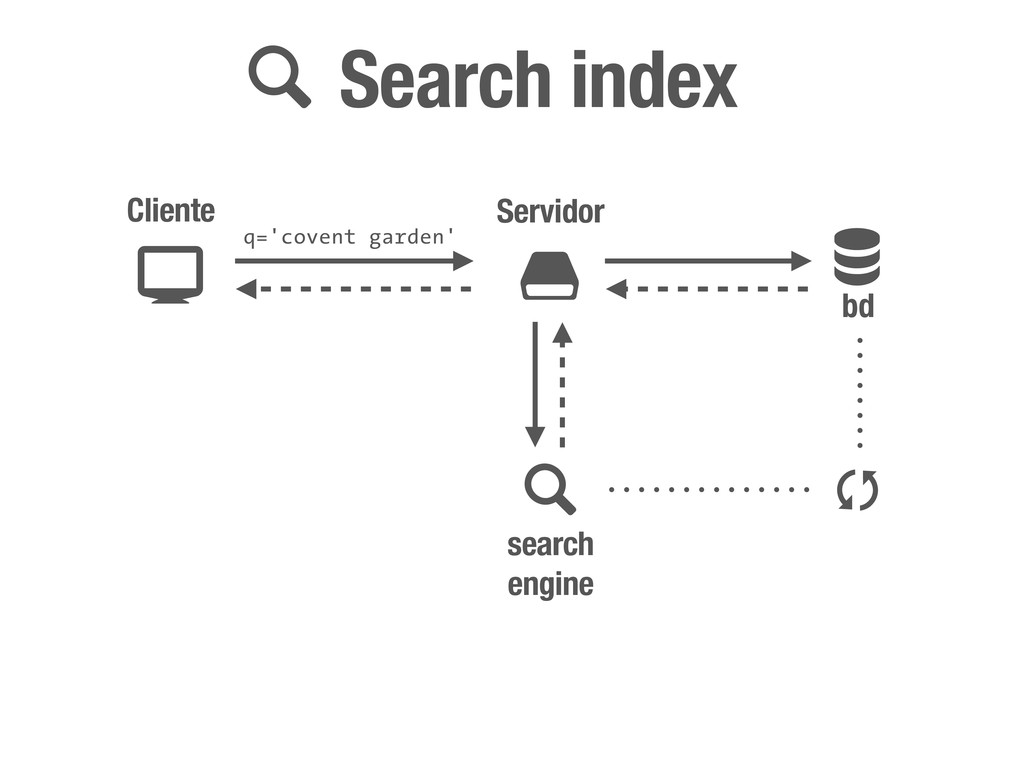
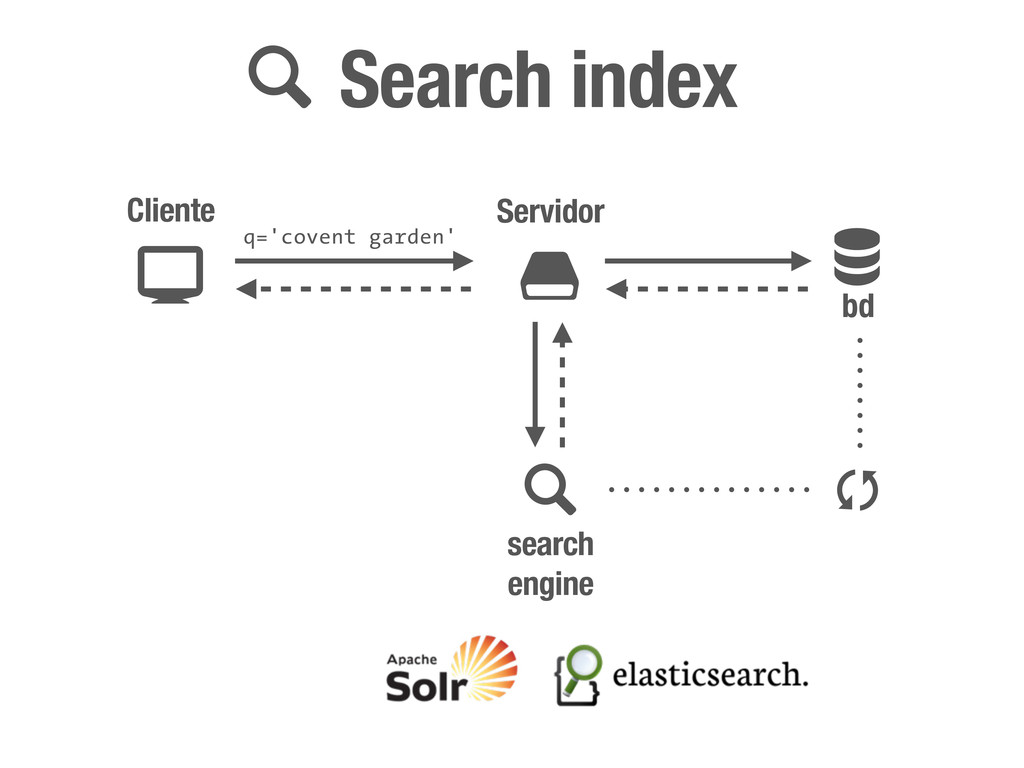
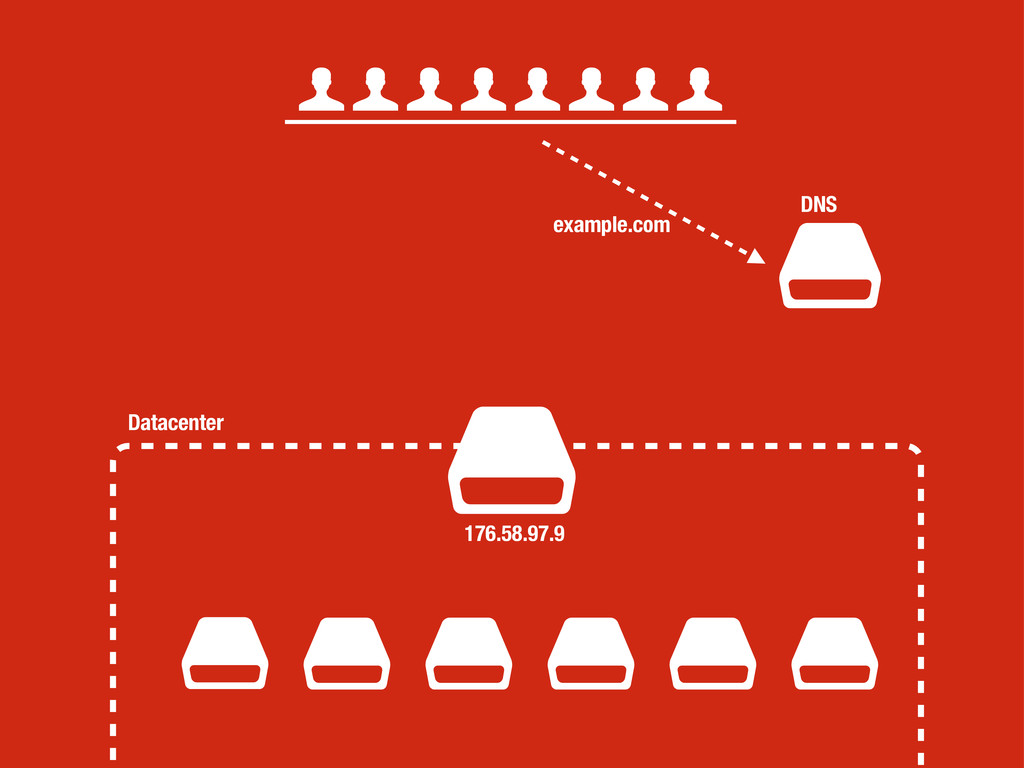
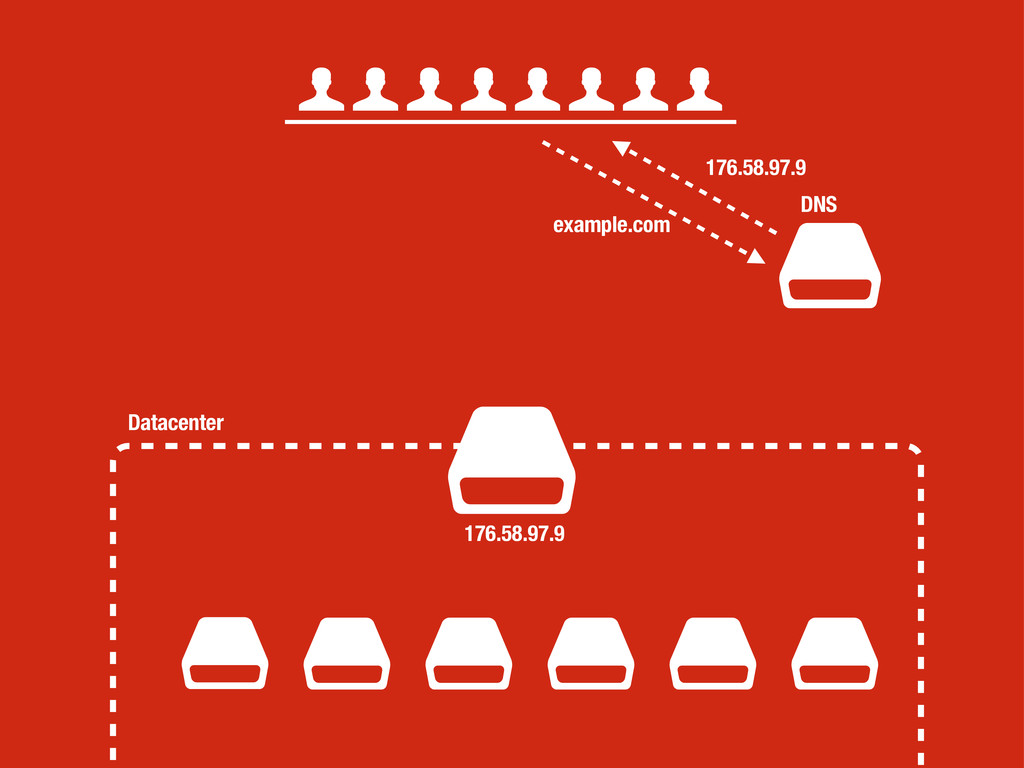
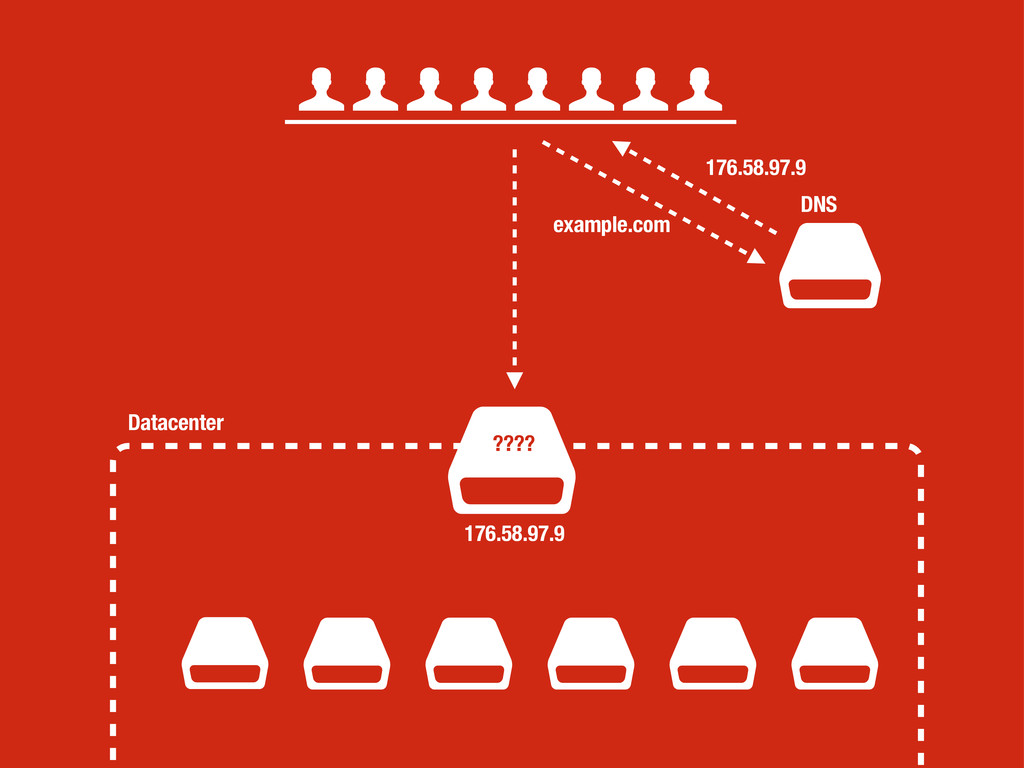
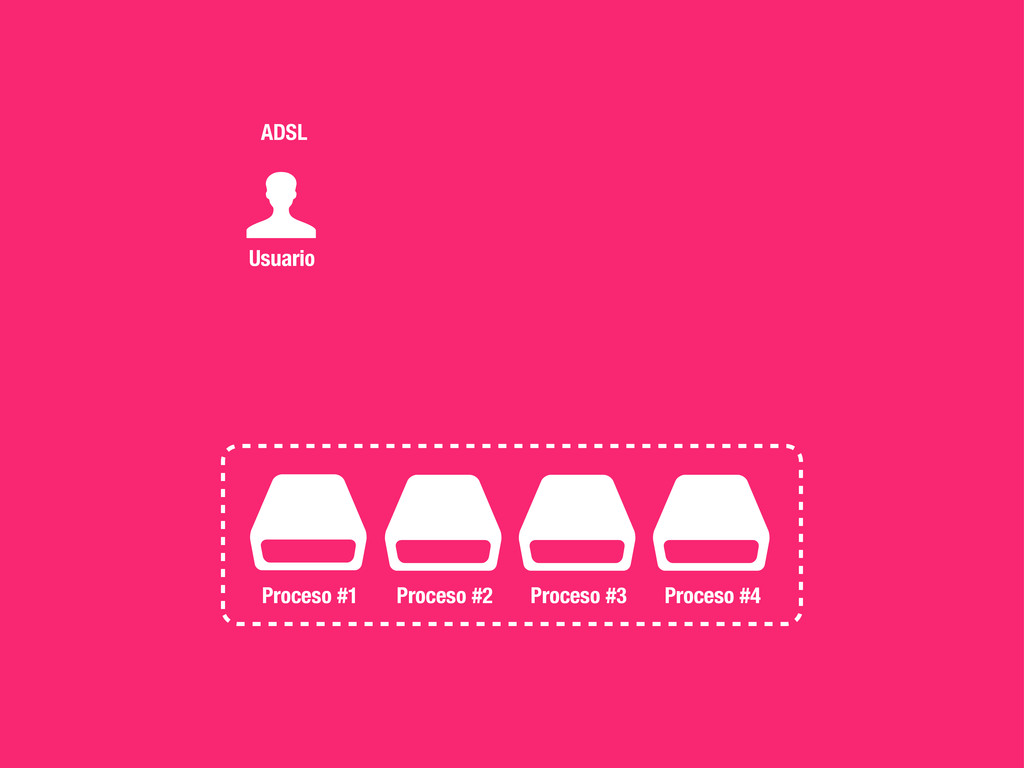
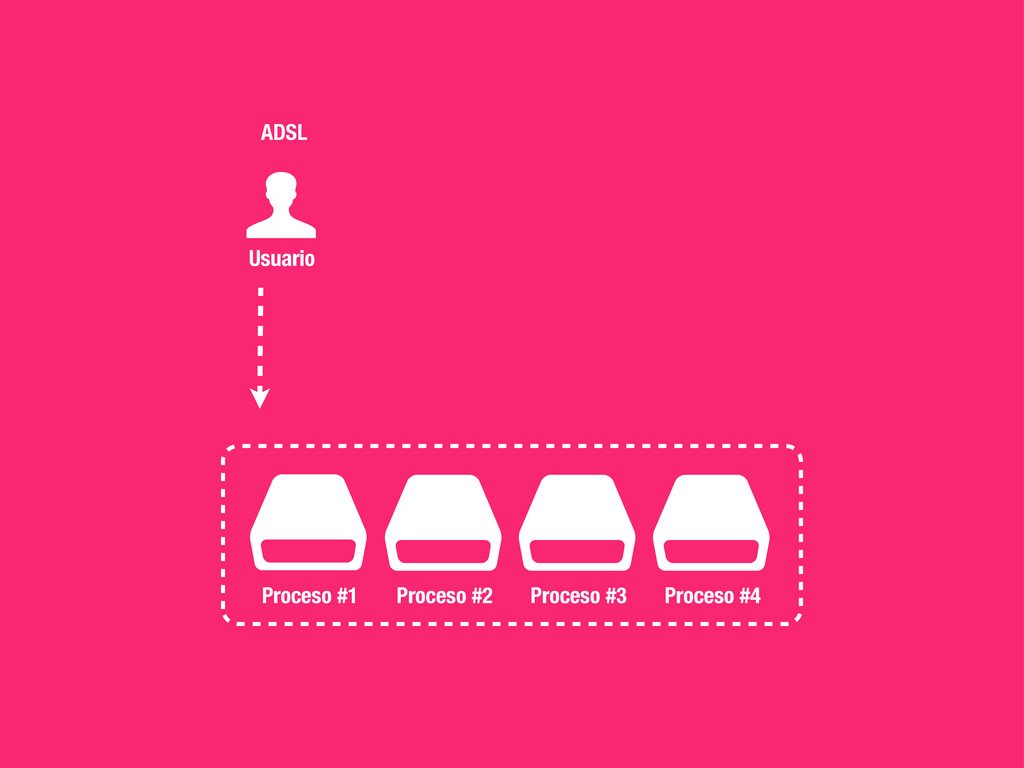
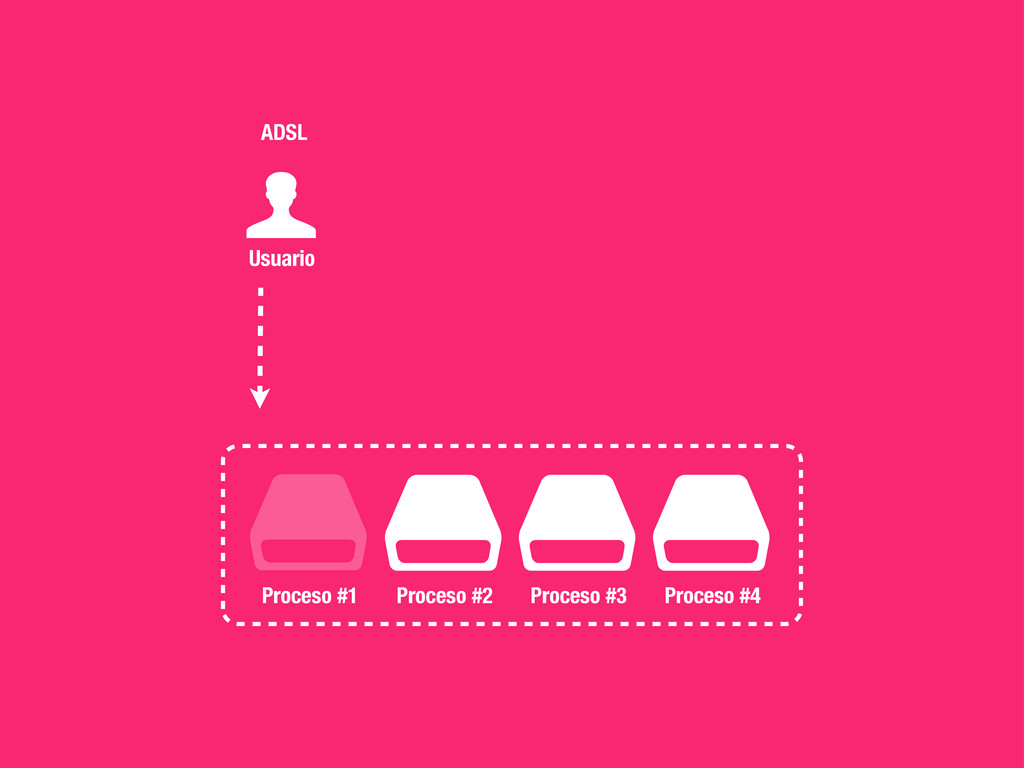
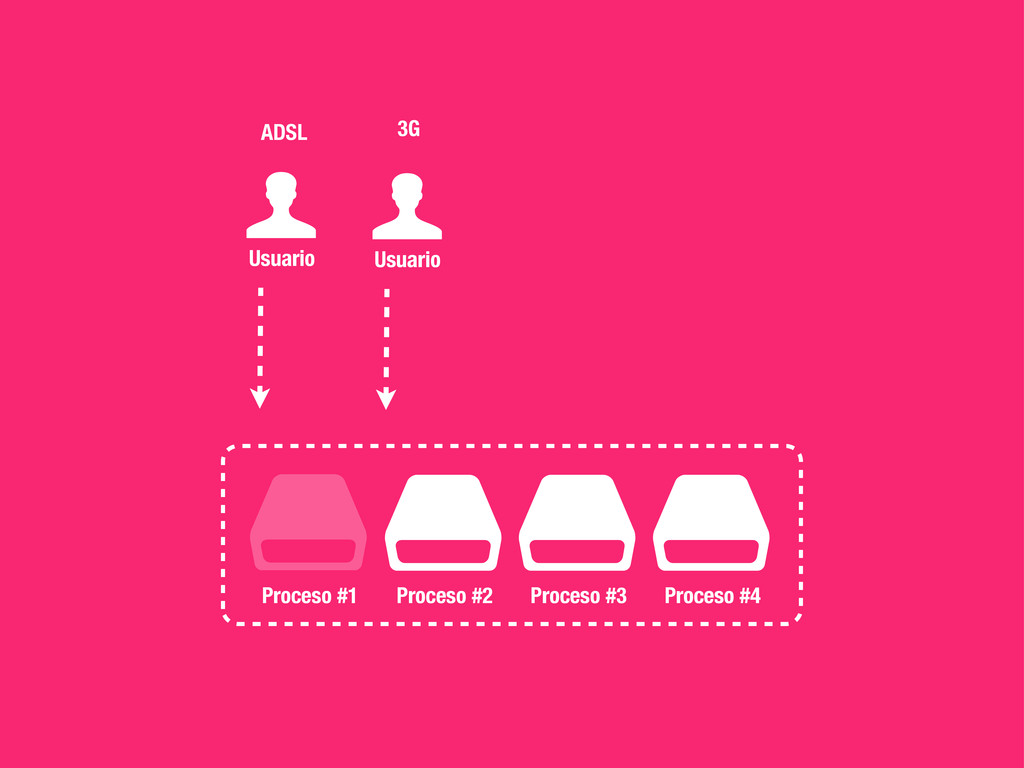
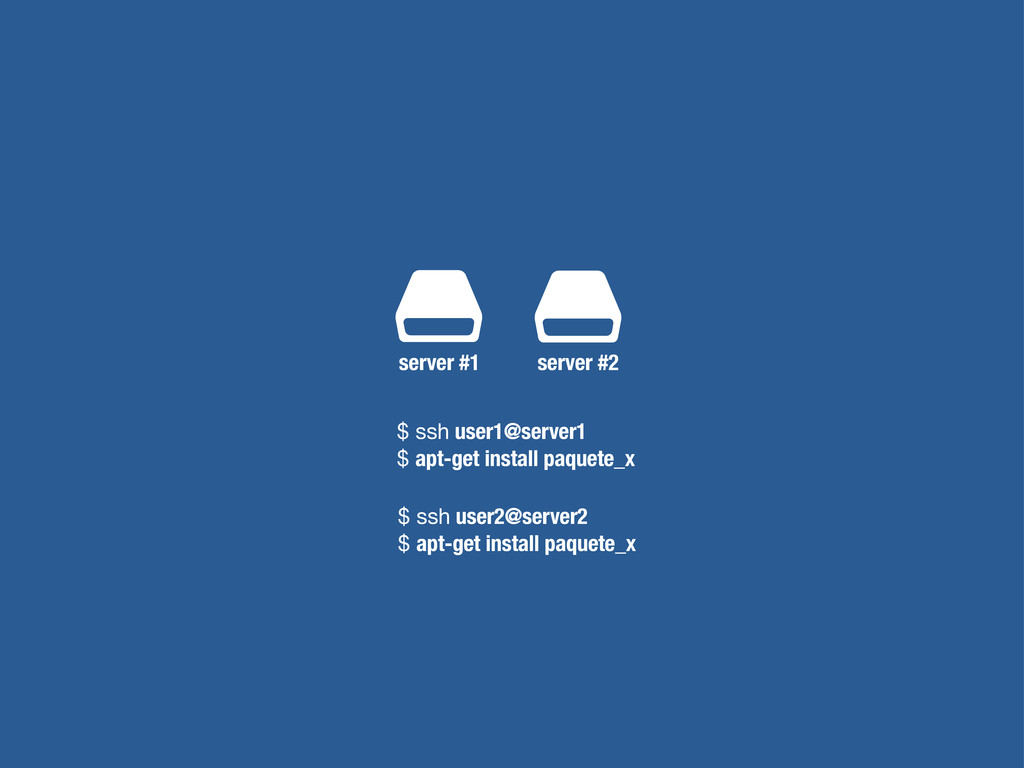
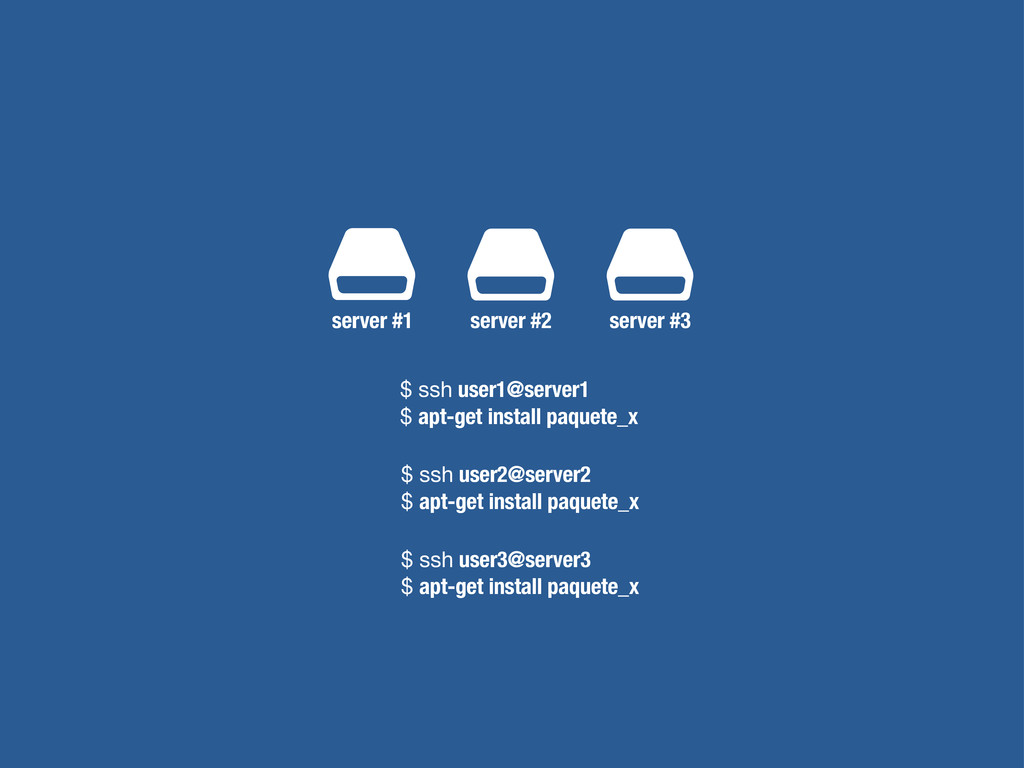
petición DNS para traducir el hostname de la URL a su dirección IP 2 Se hace una petición HTTP a esa IP pidiendo el recurso / y se recibe el resultado, normalmente un fichero .html 3 www.wikipedia.org 91.198.174.225 91.198.174.225 GET / HTTP/1.1 ... HTTP/1.1 200 OK ... $ #
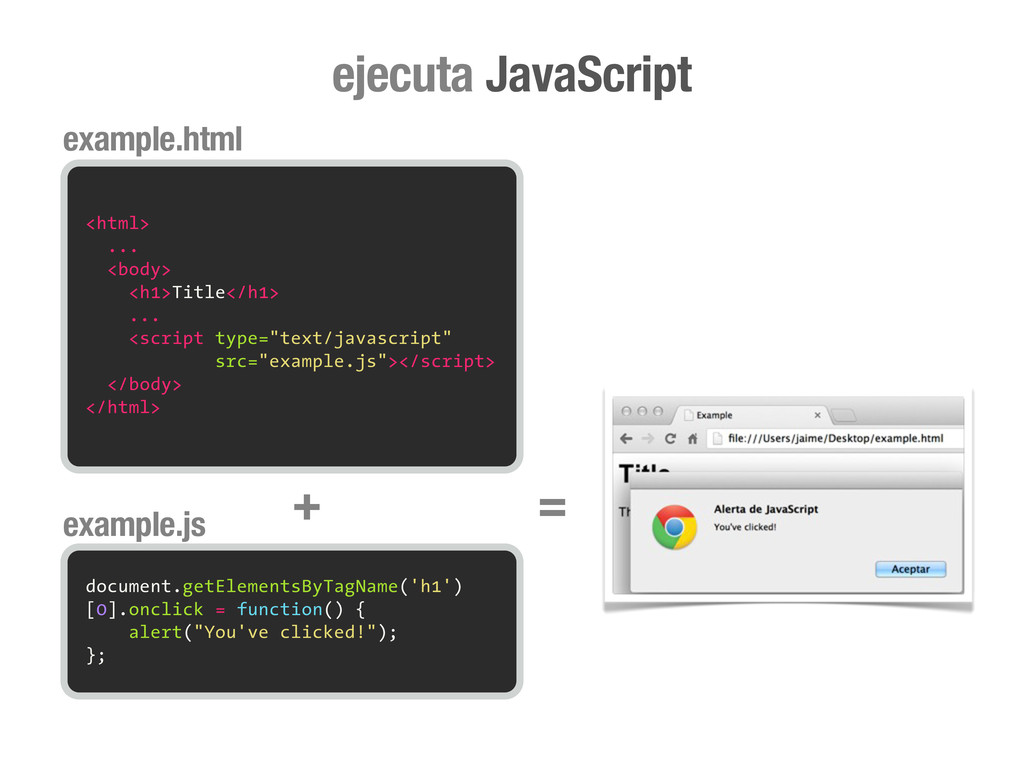
peticiones [DNS+] HTTP para cada recurso (css, img, js, etc) que encuentre referenciado en el código (src=..., href=...) 4 <div class="central-featured-logo-inner"> <img src="//upload.wikimedia.org/wikipedia/commons/Wikipedia-logo.png"> </div> A partir de aquí, y hasta la próxima petición HTTP que fuerce una recarga completa de la página, todo lo que puede ocurrir son efectos CSS y código JavaScript. 5 Desde JavaScript podemos hacer peticiones HTTP asíncronas (AJAX) que fuercen acciones en el servidor y como resultado realicen cambios en el DOM de la página. Y esto es todo.
peticiones [DNS+] HTTP para cada recurso (css, img, js, etc) que encuentre referenciado en el código (src=..., href=...) 4 <div class="central-featured-logo-inner"> <img src="//upload.wikimedia.org/wikipedia/commons/Wikipedia-logo.png"> </div> A partir de aquí, y hasta la próxima petición HTTP que fuerce una recarga completa de la página, todo lo que puede ocurrir son efectos CSS y código JavaScript. 5 Desde JavaScript podemos hacer peticiones HTTP asíncronas (AJAX) que fuercen acciones en el servidor y como resultado realicen cambios en el DOM de la página. Y esto es todo.
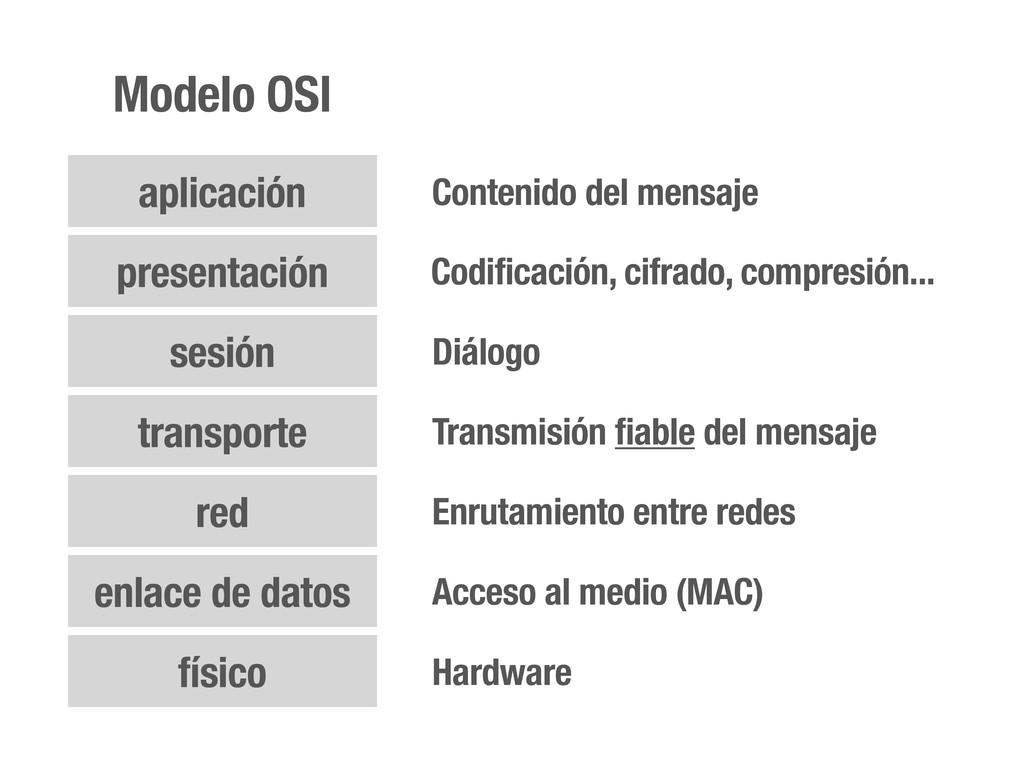
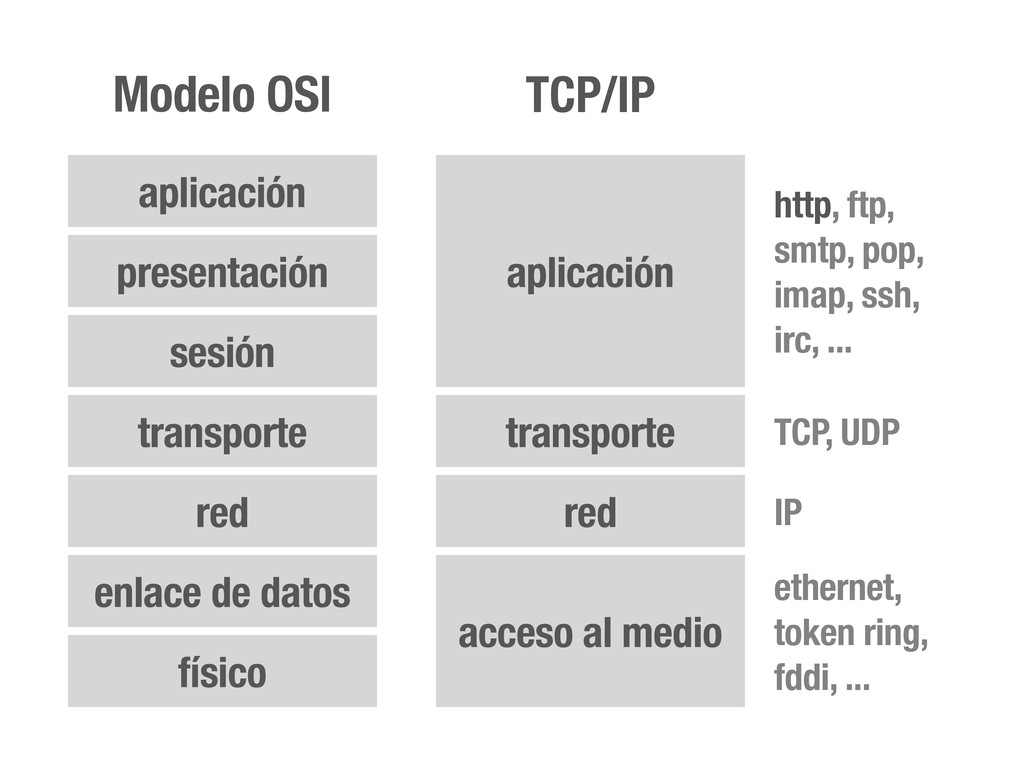
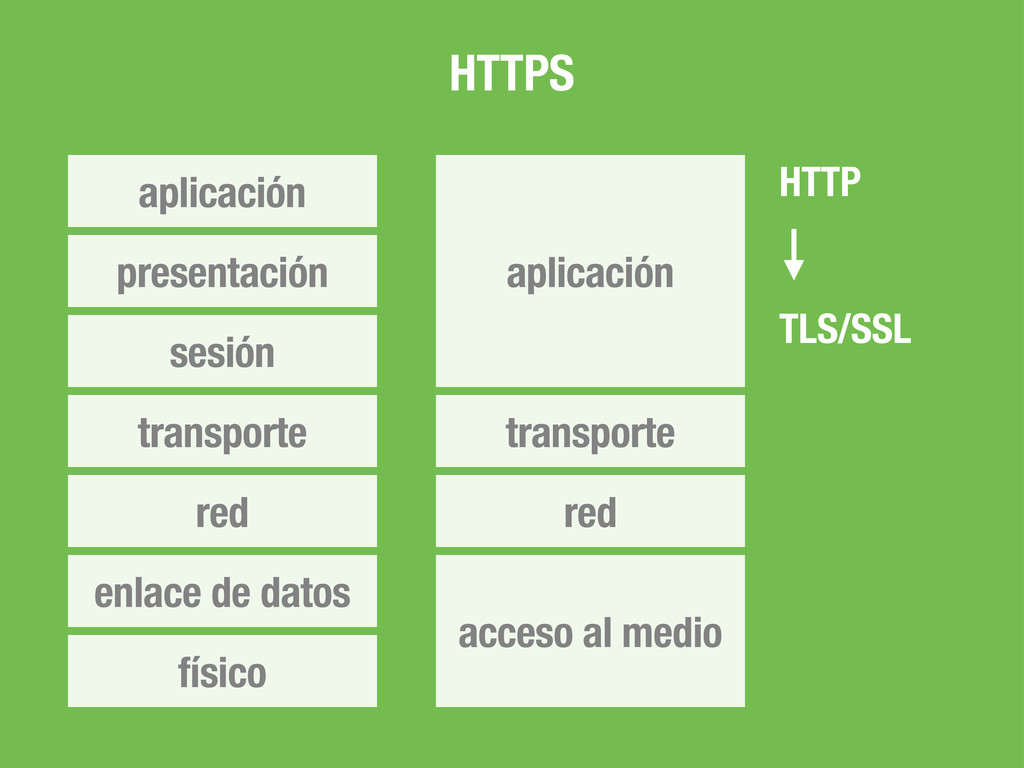
OSI Hardware Acceso al medio (MAC) Enrutamiento entre redes Transmisión fiable del mensaje Diálogo Codificación, cifrado, compresión... Contenido del mensaje
de una aplicación web http://www.wordpress.org/ http://www.wordpress.org/about/ http://www.wordpress.org/support/ http://www.wordpress.org/extend/themes/ http://www.wordpress.org/extend/themes/montezuma ...
Crea un recurso. Reemplaza o crea un recurso. DELETE Elimina un recurso. <OPERACIÓN> <recurso> HTTP/1.1 HEAD Como GET, pero pide sólo las cabeceras. TRACE Diagnóstico. OPTIONS Pregunta por los métodos que soporta el servidor. CONNECT Diagnóstico.
APIs que, entre otras cosas, explota la pureza de estos conceptos http://example.com/recetas/ http://example.com/recetas/453 PUT GET POST DELETE PUT GET POST DELETE Lista las URIs de recetas y quizá otros detalles. Reemplaza la colección de recetas por una nueva. Inserta una nueva receta y devuelve su URI. Borra la colección de recetas. Devuelve el detalle de una receta. Reemplaza o crea (si no existe) una receta. --- Borra una receta.
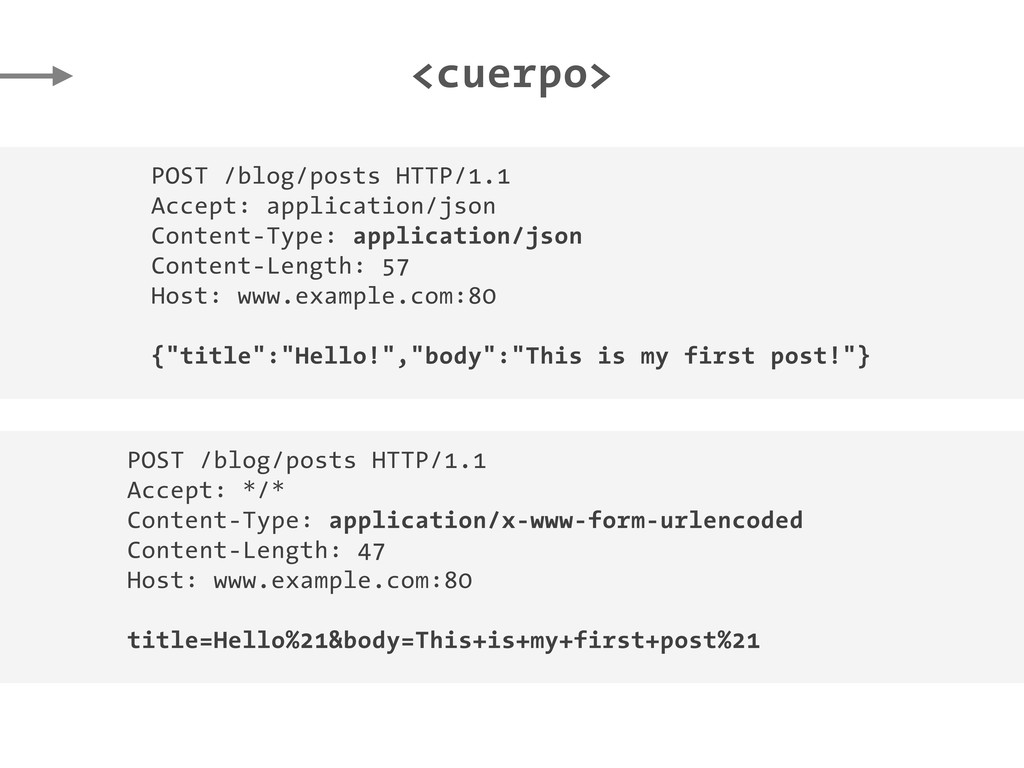
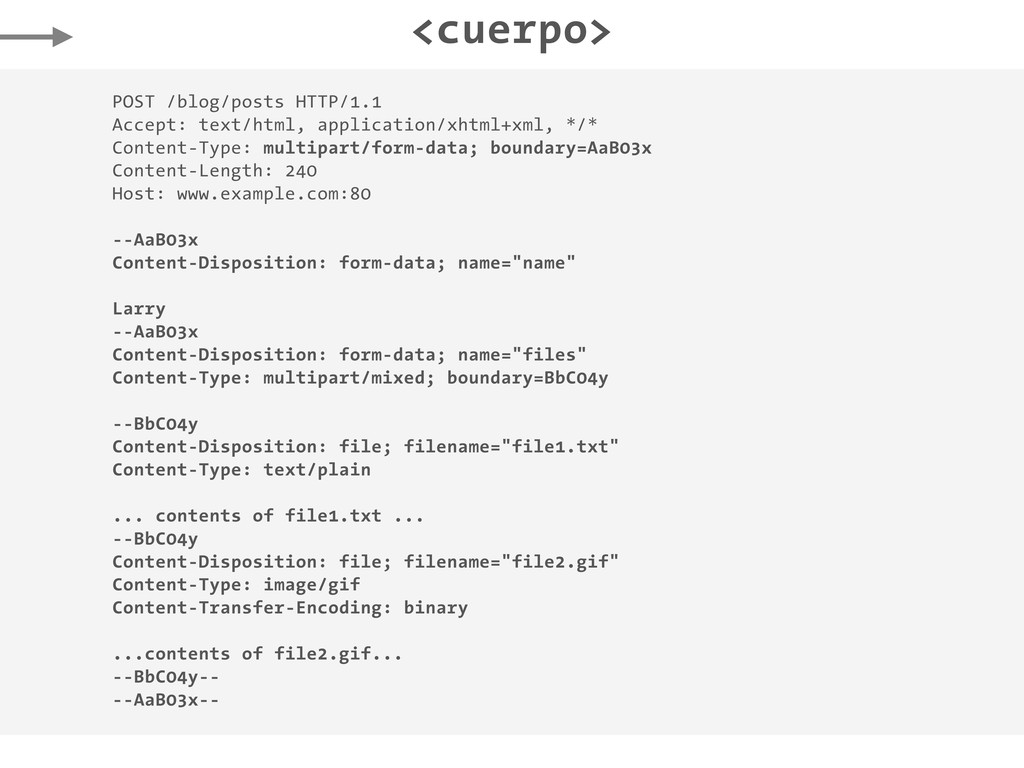
Host: www.example.com:80 {"title":"Hello!","body":"This is my first post!"} POST /blog/posts HTTP/1.1 Accept: */* Content-Type: application/x-www-form-urlencoded Content-Length: 47 Host: www.example.com:80 title=Hello%21&body=This+is+my+first+post%21
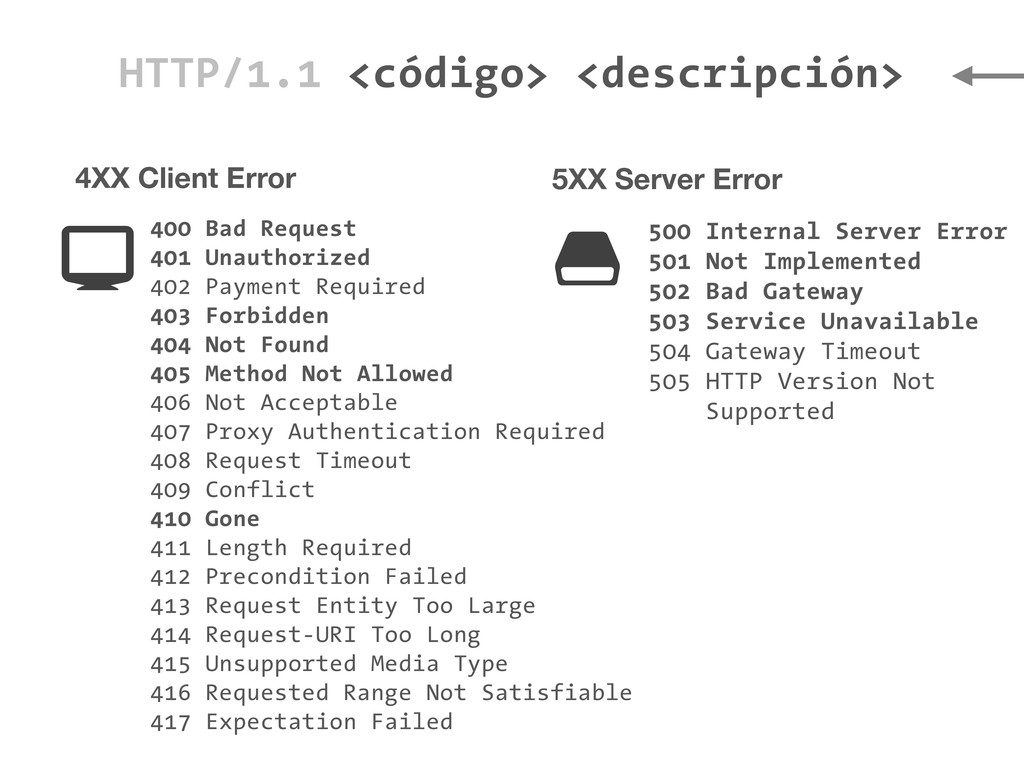
401 Unauthorized 402 Payment Required 403 Forbidden 404 Not Found 405 Method Not Allowed 406 Not Acceptable 407 Proxy Authentication Required 408 Request Timeout 409 Conflict 410 Gone 411 Length Required 412 Precondition Failed 413 Request Entity Too Large 414 Request-URI Too Long 415 Unsupported Media Type 416 Requested Range Not Satisfiable 417 Expectation Failed 500 Internal Server Error 501 Not Implemented 502 Bad Gateway 503 Service Unavailable 504 Gateway Timeout 505 HTTP Version Not Supported 5XX Server Error $
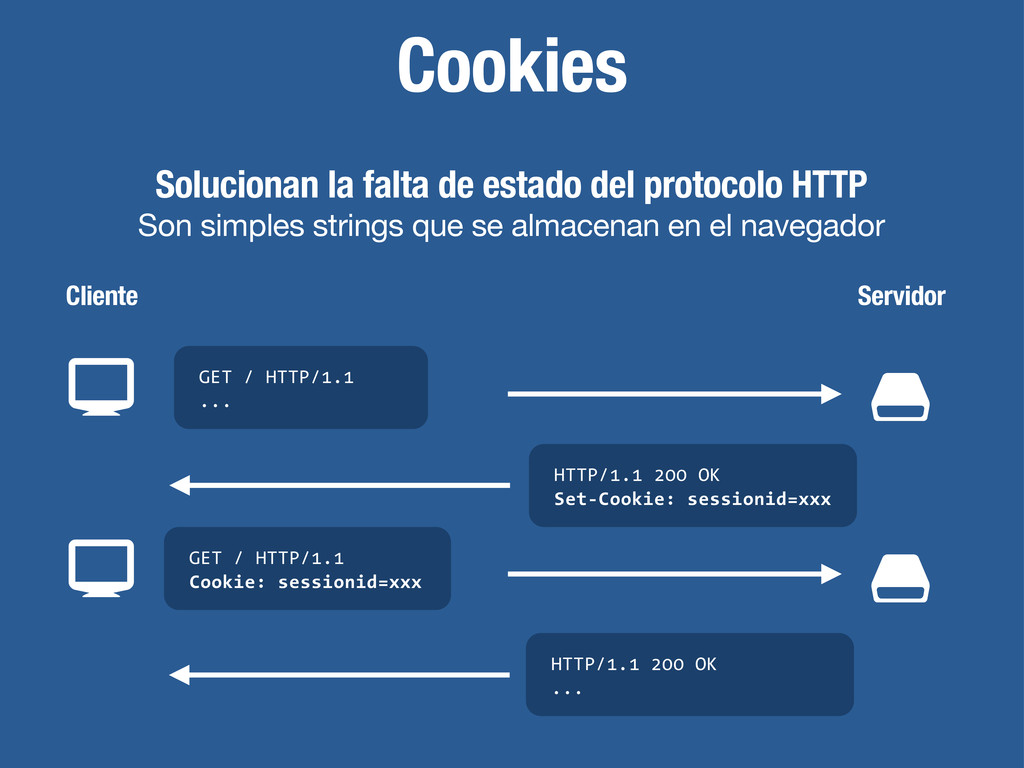
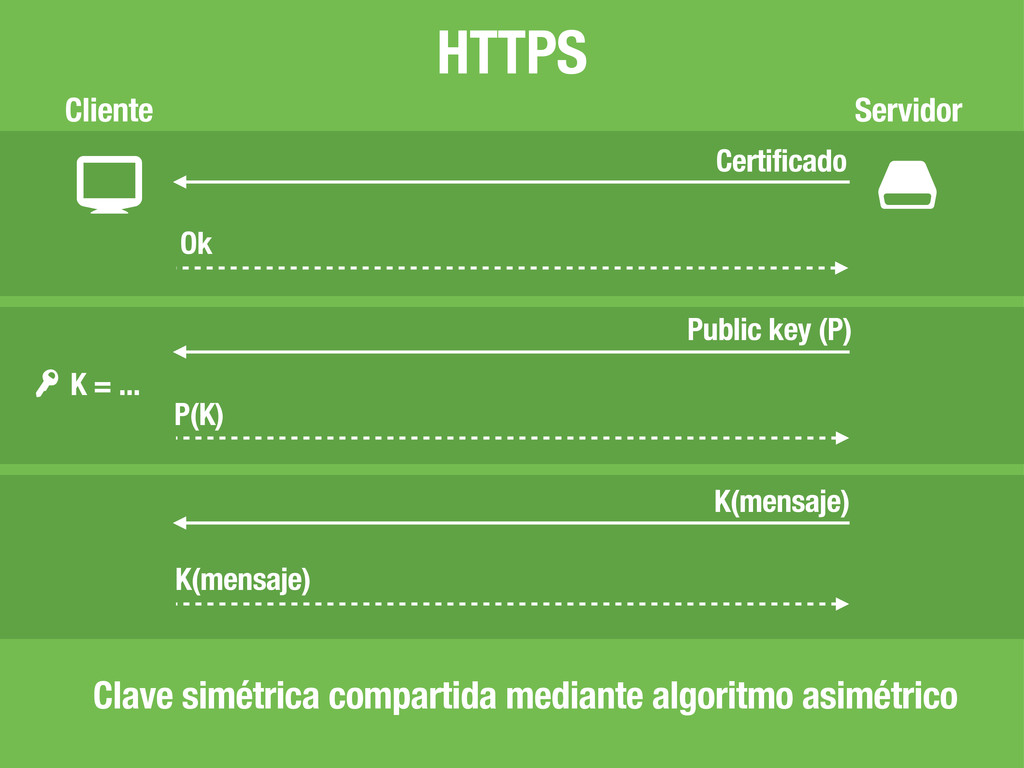
# $ # Son simples strings que se almacenan en el navegador GET / HTTP/1.1 ... GET / HTTP/1.1 Cookie: sessionid=xxx HTTP/1.1 200 OK Set-Cookie: sessionid=xxx HTTP/1.1 200 OK ... Cliente Servidor
GMT; Secure; HttpOnly En qué requests debería enviarse como Cookie: Domain + Path Expires Cuándo el User-Agent debería borrar la cookie Secure Sólo debe enviarse si el tráfico es https HttpOnly Sólo accessible desde HTTP, no desde JavaScript XSS! ⚠ document.cookie = ...
GMT; Secure; HttpOnly En qué requests debería enviarse como Cookie: Domain + Path Expires Cuándo el User-Agent debería borrar la cookie Secure Sólo debe enviarse si el tráfico es https HttpOnly Sólo accessible desde HTTP, no desde JavaScript XSS! ⚠ document.cookie = ...
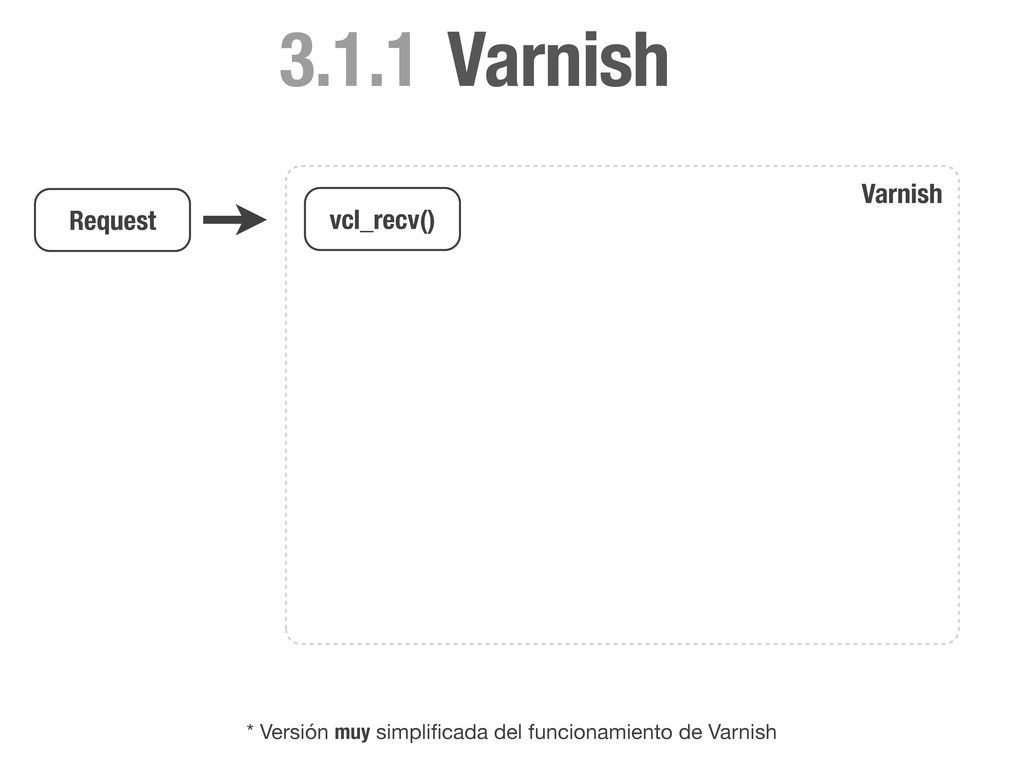
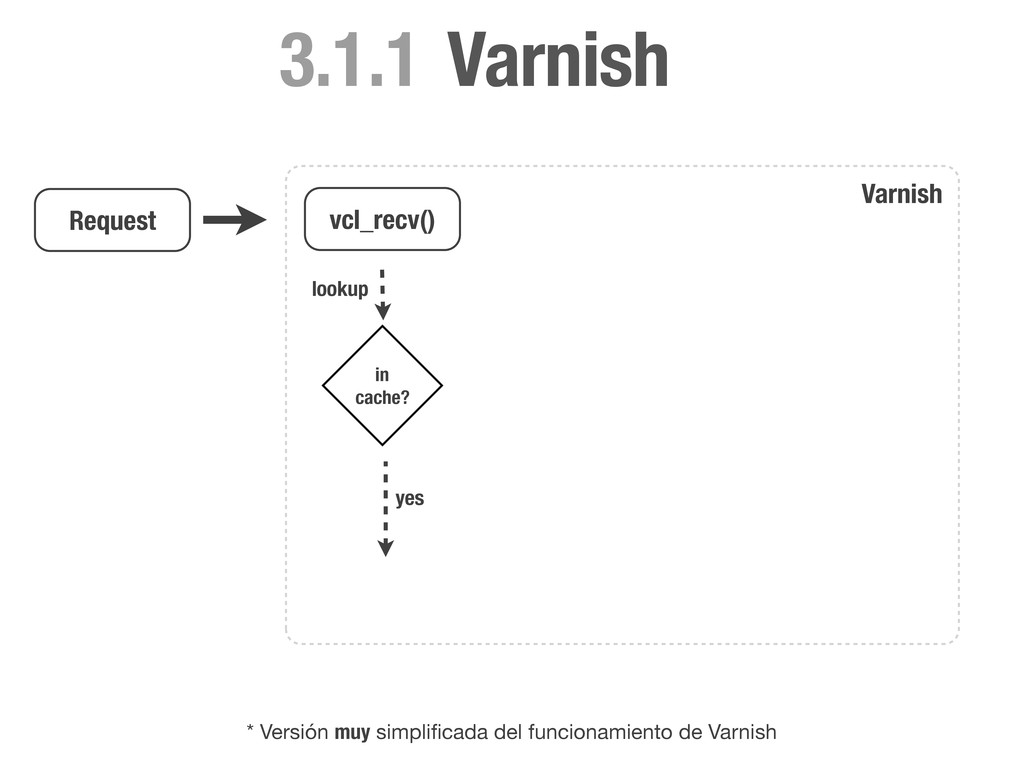
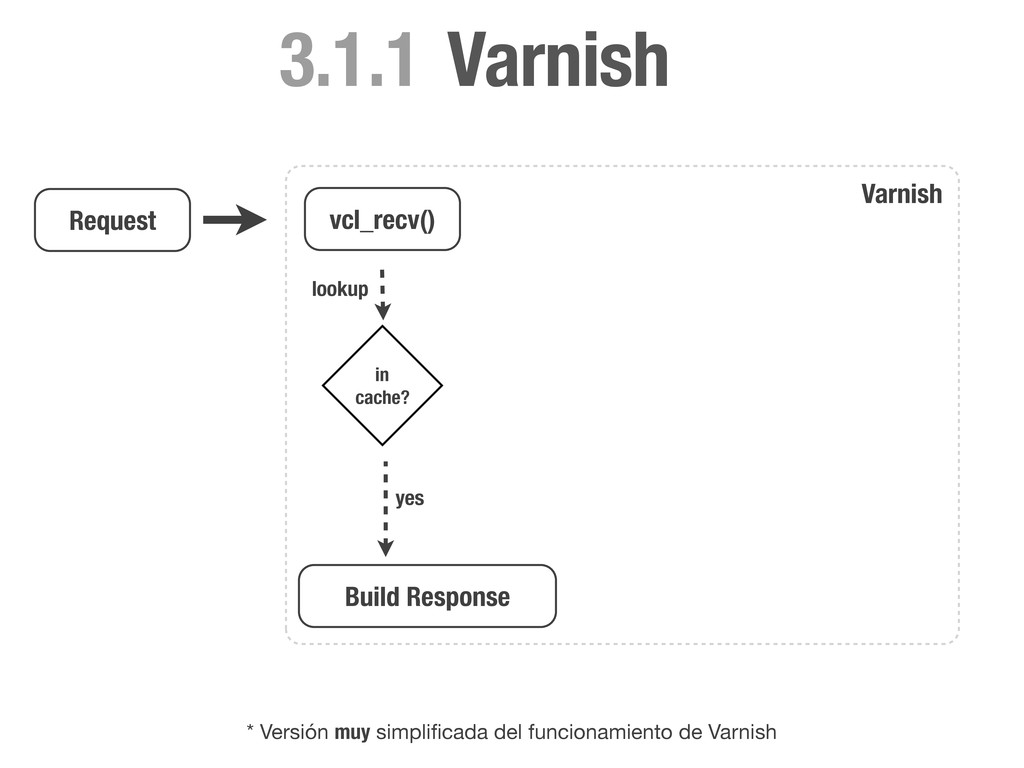
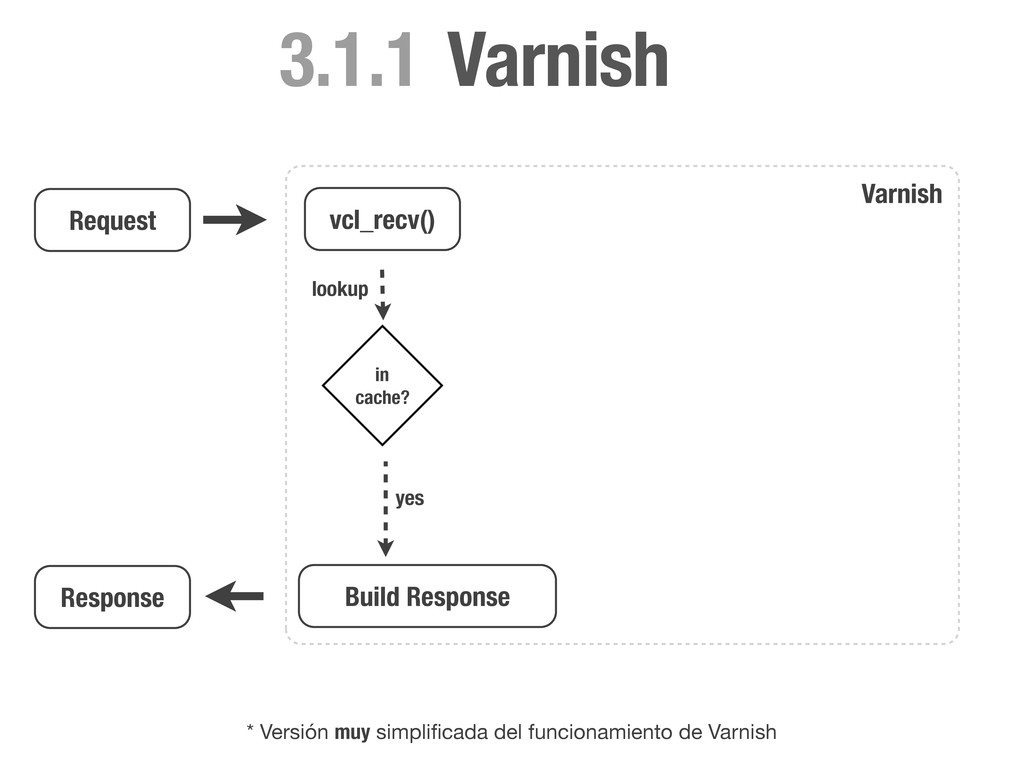
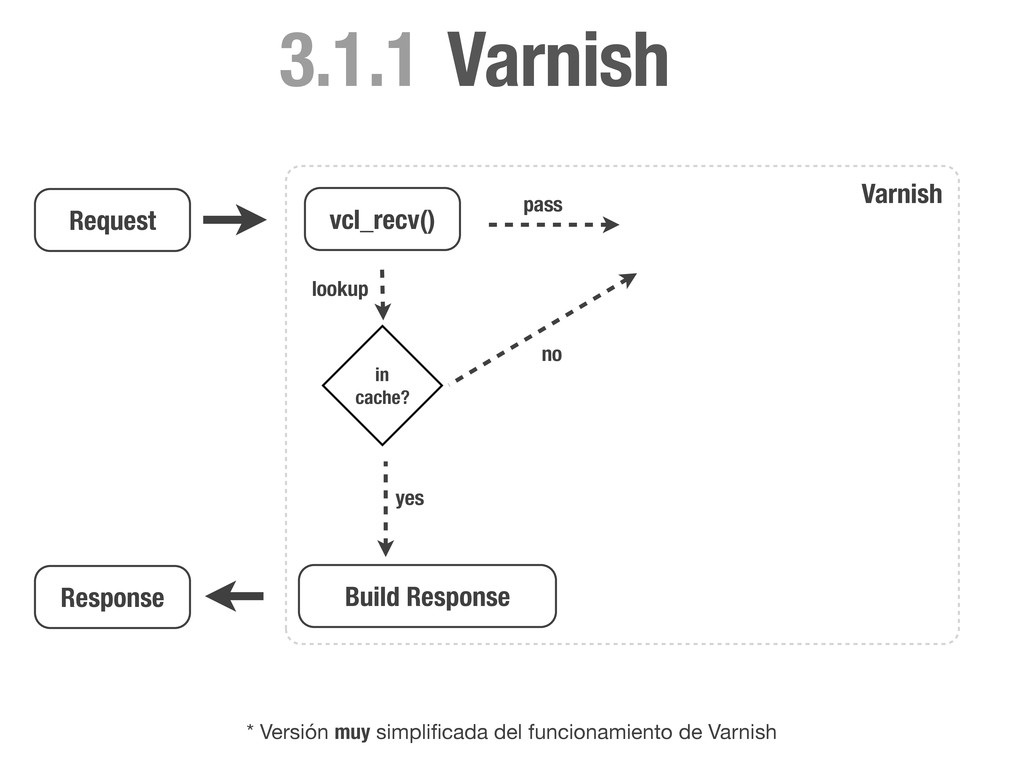
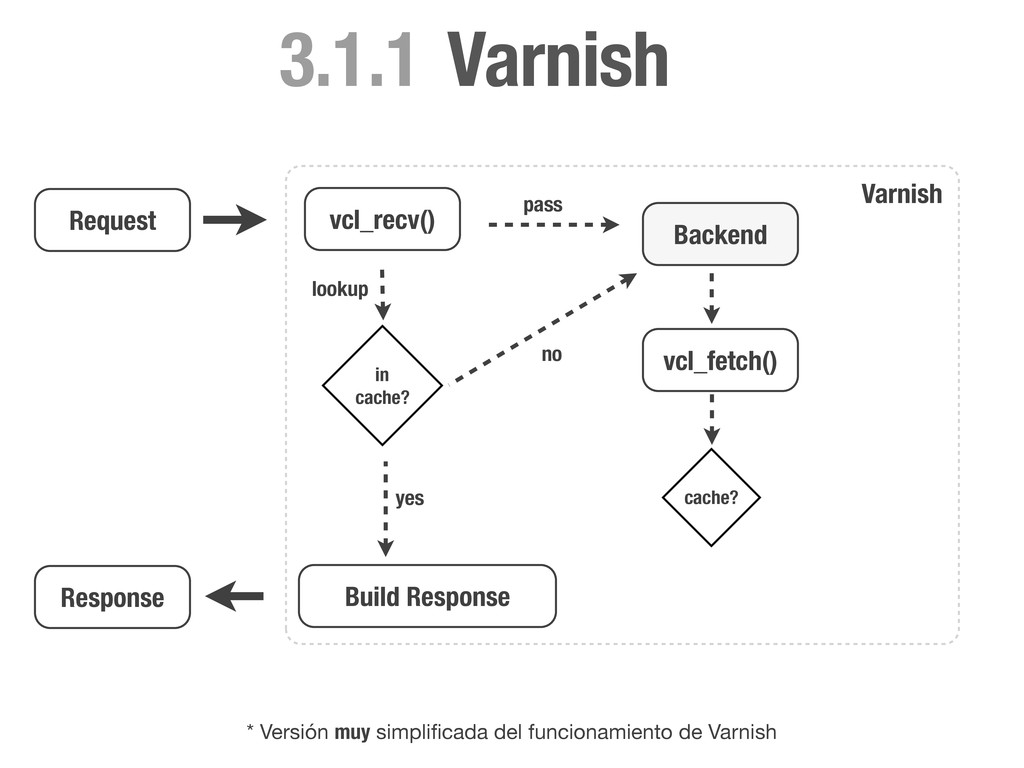
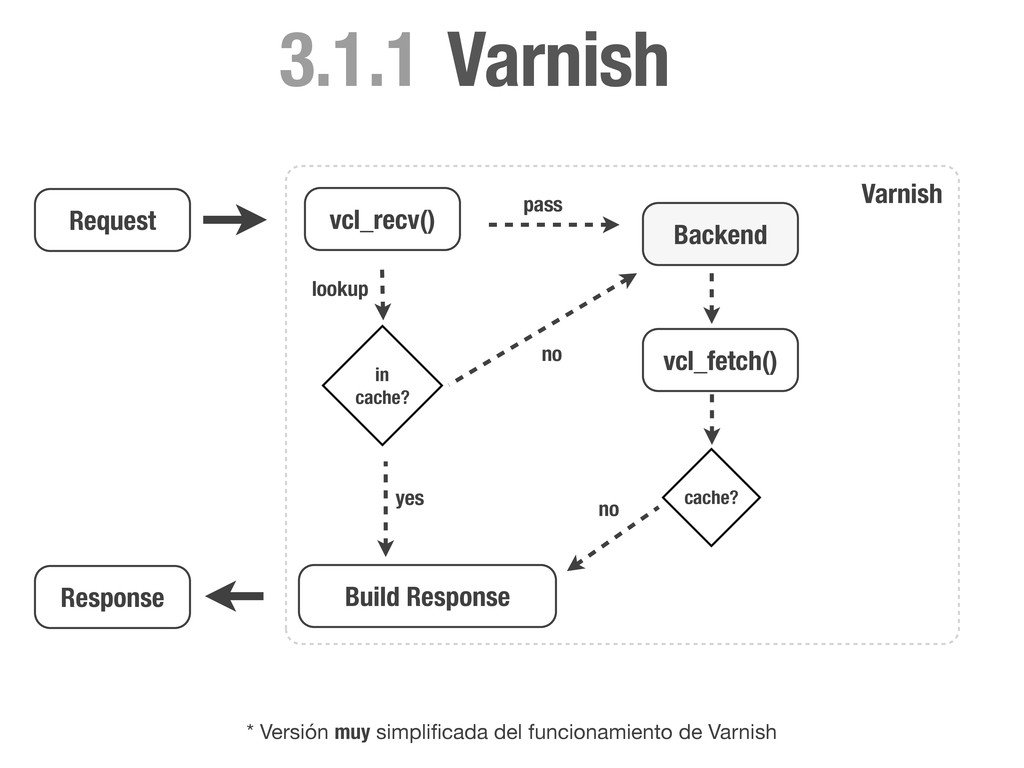
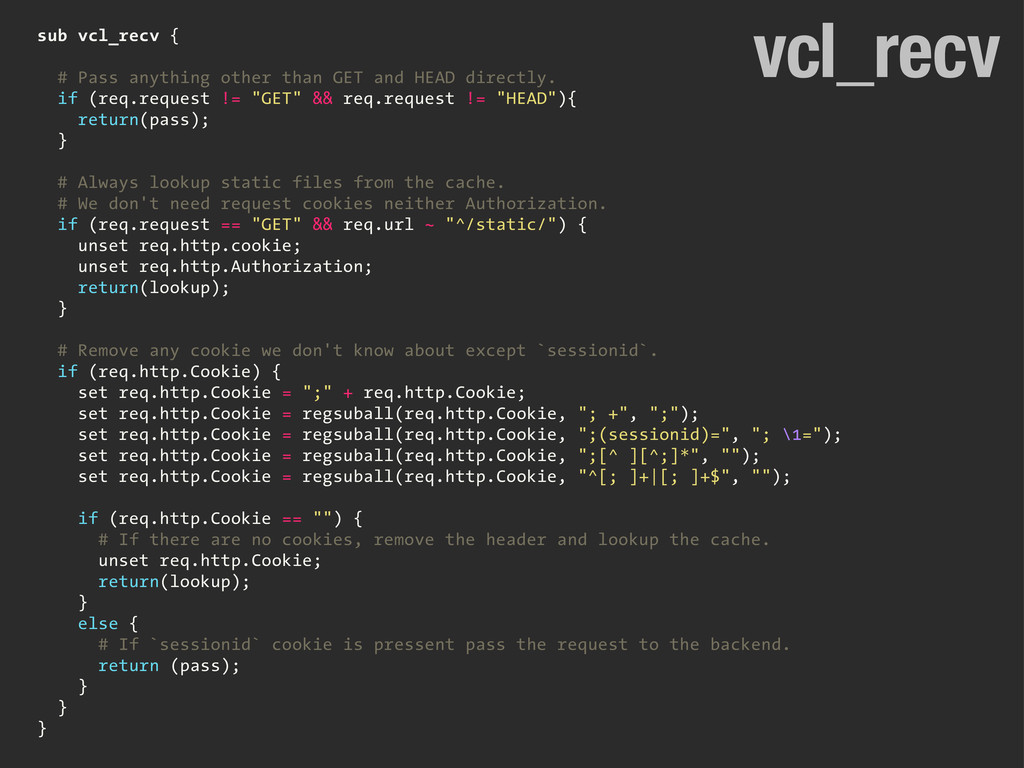
HEAD directly. if (req.request != "GET" && req.request != "HEAD"){ return(pass); } # Always lookup static files from the cache. # We don't need request cookies neither Authorization. if (req.request == "GET" && req.url ~ "^/static/") { unset req.http.cookie; unset req.http.Authorization; return(lookup); } # Remove any cookie we don't know about except `sessionid`. if (req.http.Cookie) { set req.http.Cookie = ";" + req.http.Cookie; set req.http.Cookie = regsuball(req.http.Cookie, "; +", ";"); set req.http.Cookie = regsuball(req.http.Cookie, ";(sessionid)=", "; \1="); set req.http.Cookie = regsuball(req.http.Cookie, ";[^ ][^;]*", ""); set req.http.Cookie = regsuball(req.http.Cookie, "^[; ]+|[; ]+$", ""); if (req.http.Cookie == "") { # If there are no cookies, remove the header and lookup the cache. unset req.http.Cookie; return(lookup); } else { # If `sessionid` cookie is pressent pass the request to the backend. return (pass); } } } vcl_recv
don't cache it. if (beresp.status >= 400) { return (hit_for_pass); } # Remove cookies if this is a static request and set 1 week of ttl. if (req.url ~ "^/static/") { unset beresp.http.set-cookie; set beresp.ttl = 1w; return (deliver); } else{ # If the response is setting any cookie, don't cache it. if (beresp.http.Set-Cookie) { return (hit_for_pass); } # Cache this response for 10 minutes. set beresp.ttl = 10m; return (deliver); } } vcl_fetch
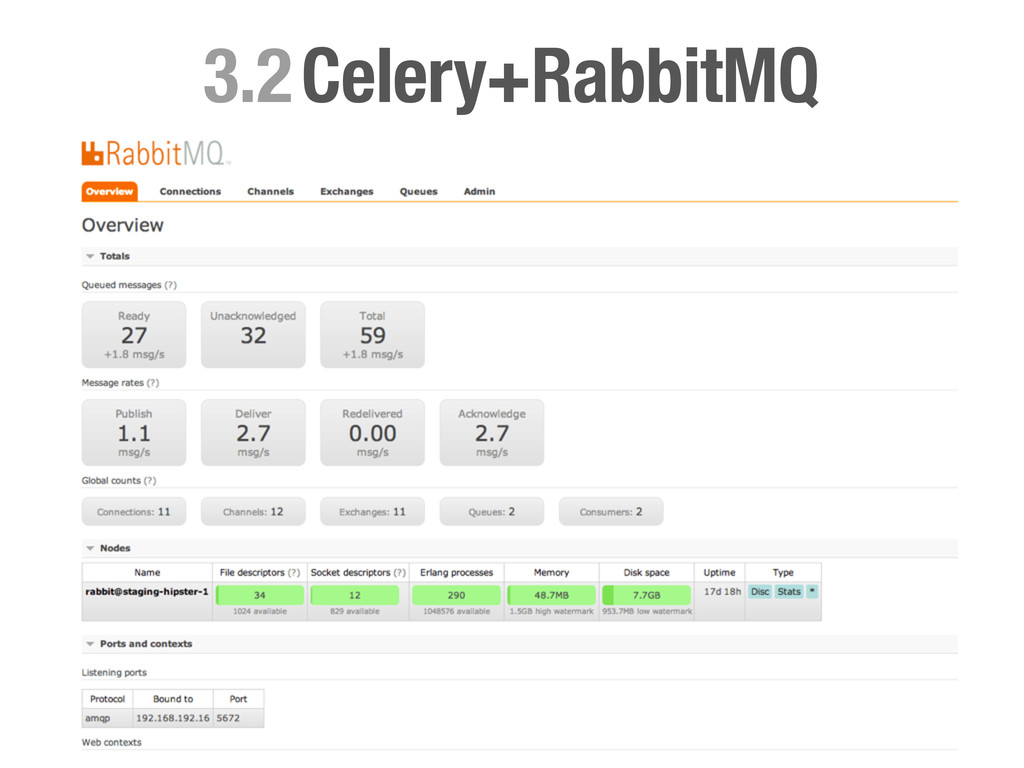
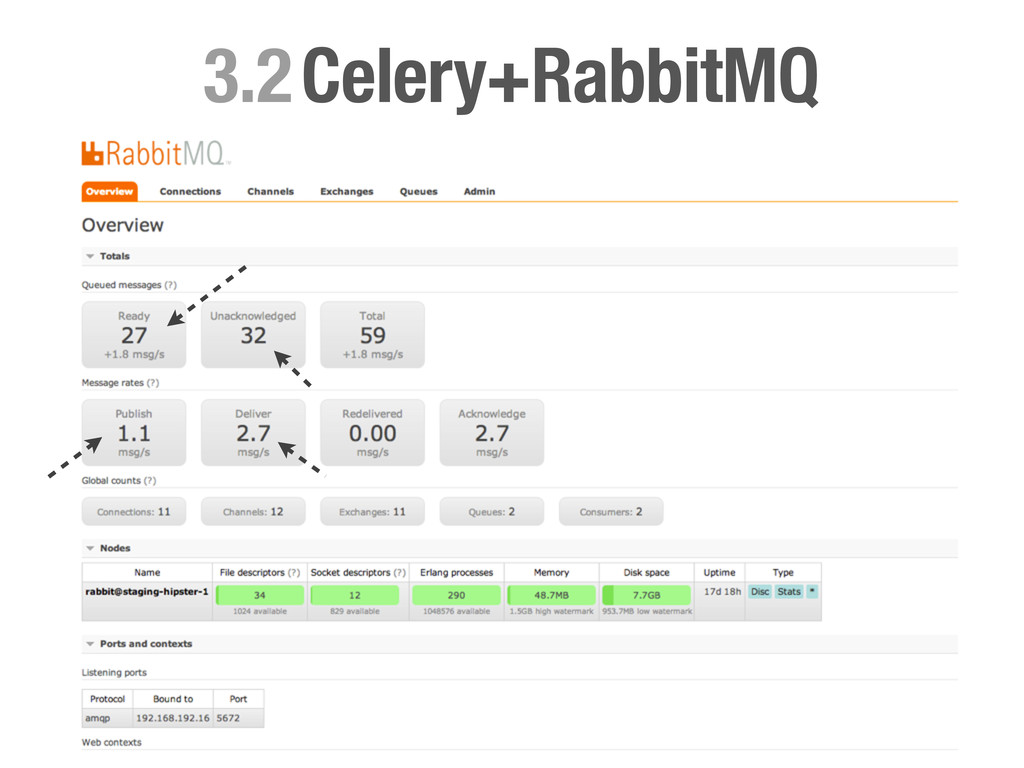
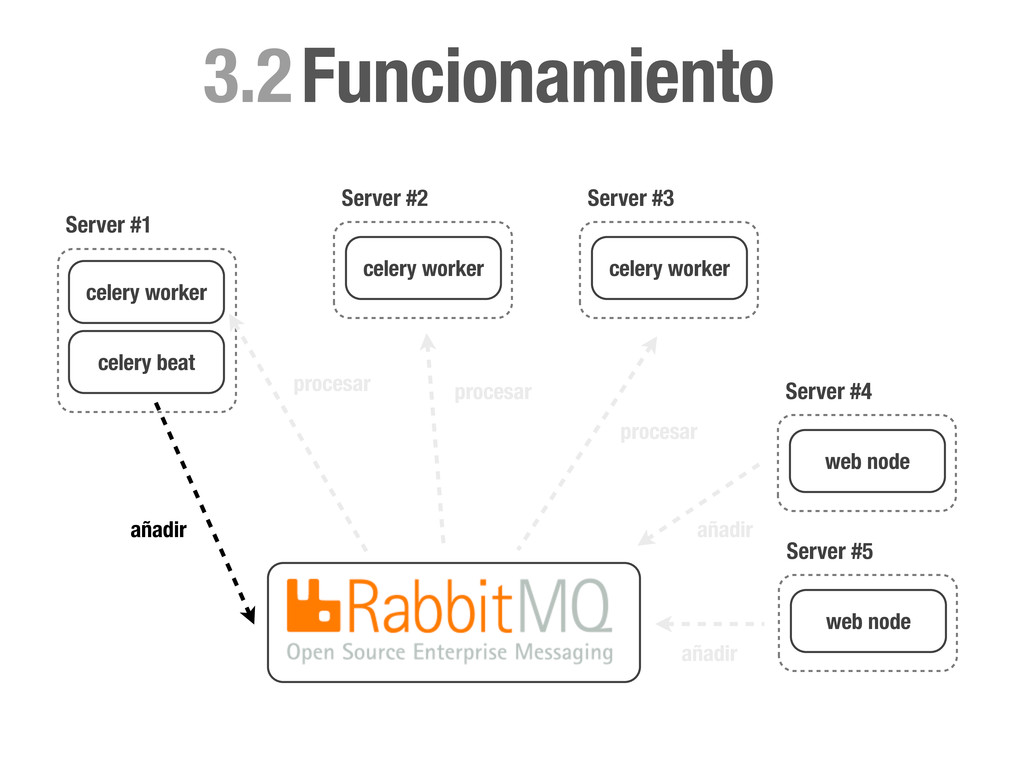
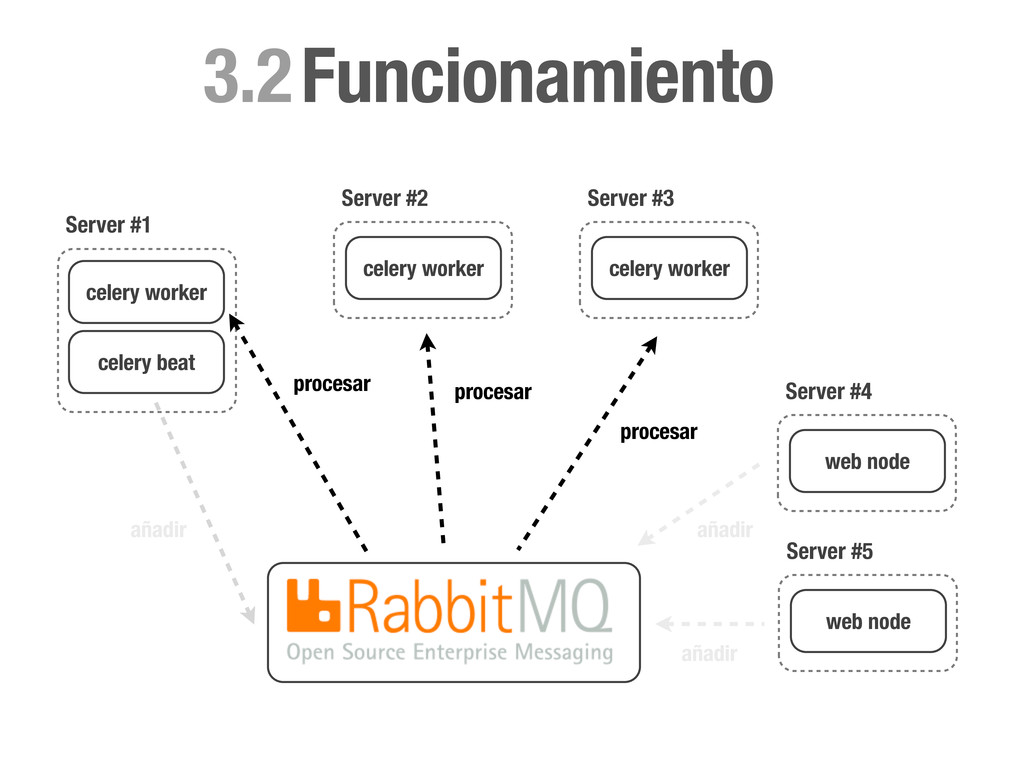
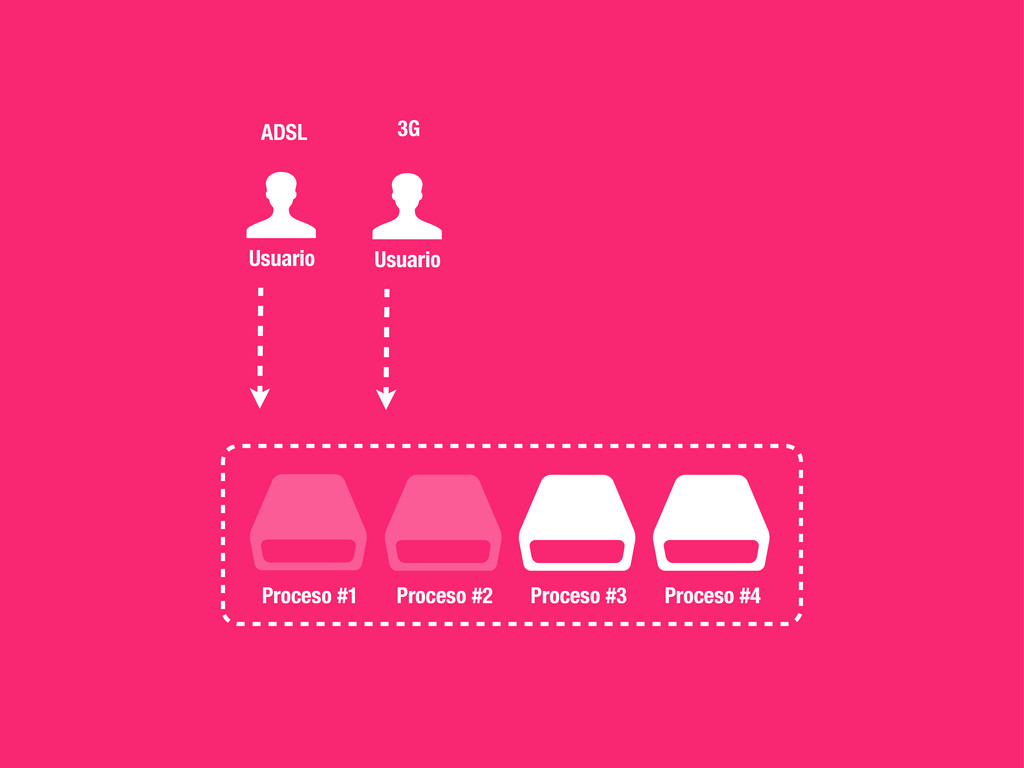
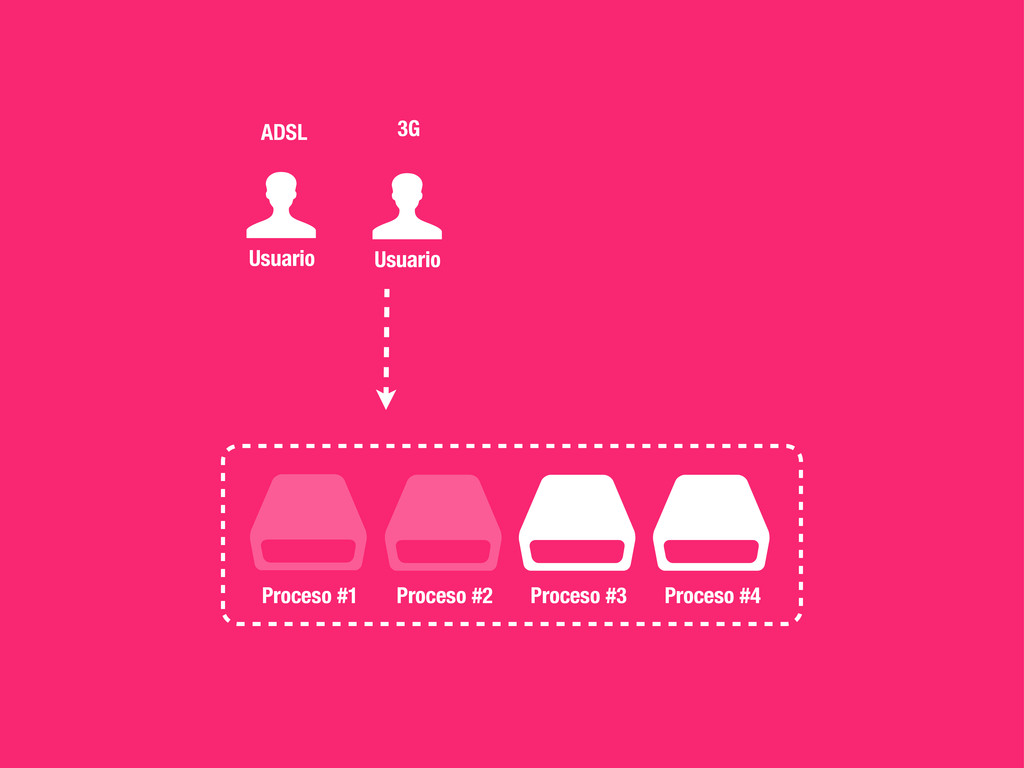
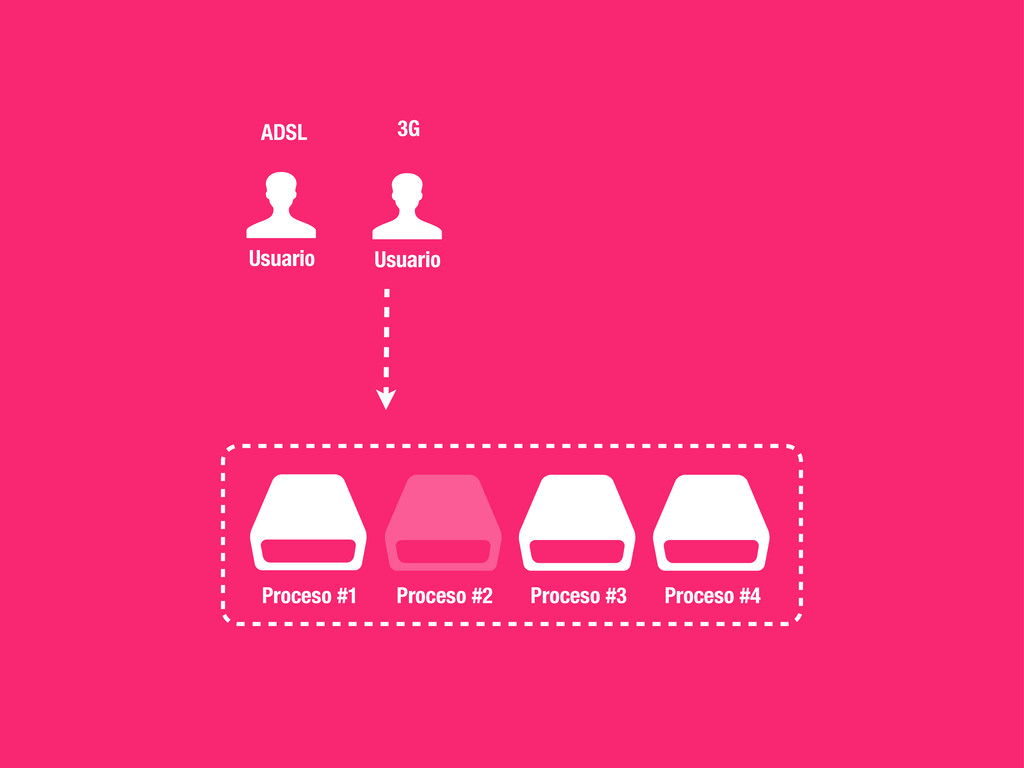
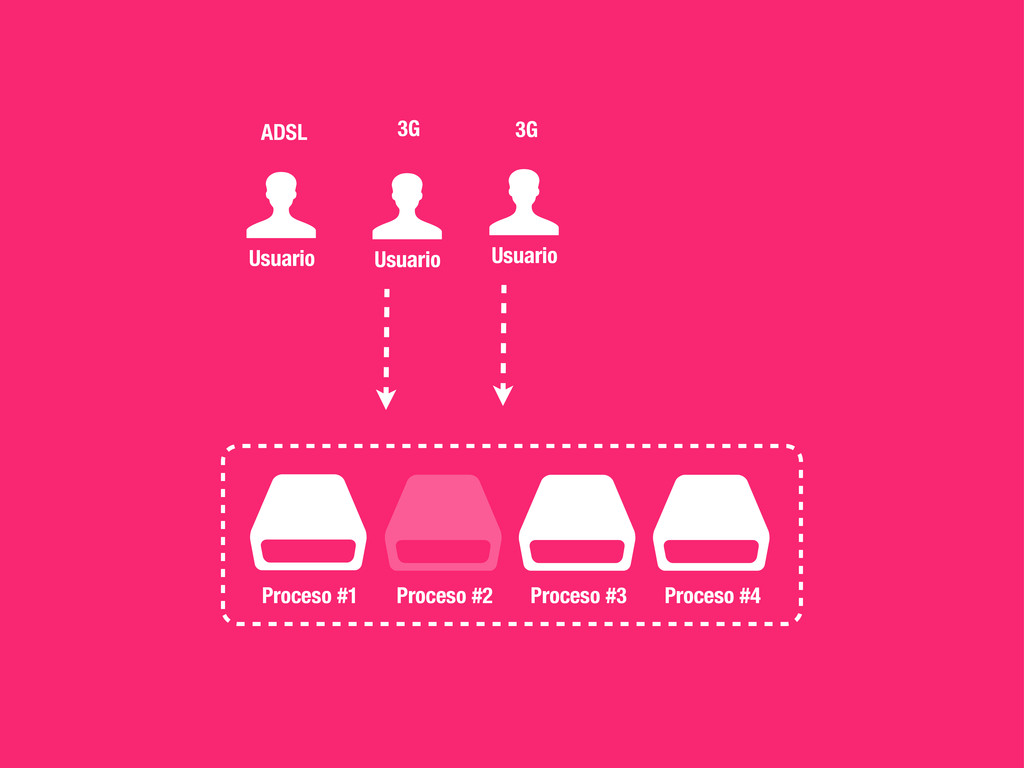
Concurrencia, Distribuido... • Pro: Muy fácil de implementar y escalable. • Casos prácticos: • Enviar un email (Notificationes, ...) • Calcular el karma de de los usuarios del sistema. • Tareas programadas (Limpieza, Post-procesado, etc...) • Regenerar caches etc.. !h#p://celeryproject.org
solo a un worker. • Distribuido: Los nodos son independientes unos de otros y el número puede aumentar y disminuir dinámicamente. • Fiable: Si no se informa a RabbitMQ sobre la finalización de una tarea, esta vuelve a formar parte de la cola. En caso de catástrofe no perdemos tareas. • Rates: Celery nos permite definir rates para nos sobrecargar el sistema o APIs externas. • Tareas Periodicas: Celery beat registrará por nosotros tareas en la cola de la misma manera que lo haría cron.
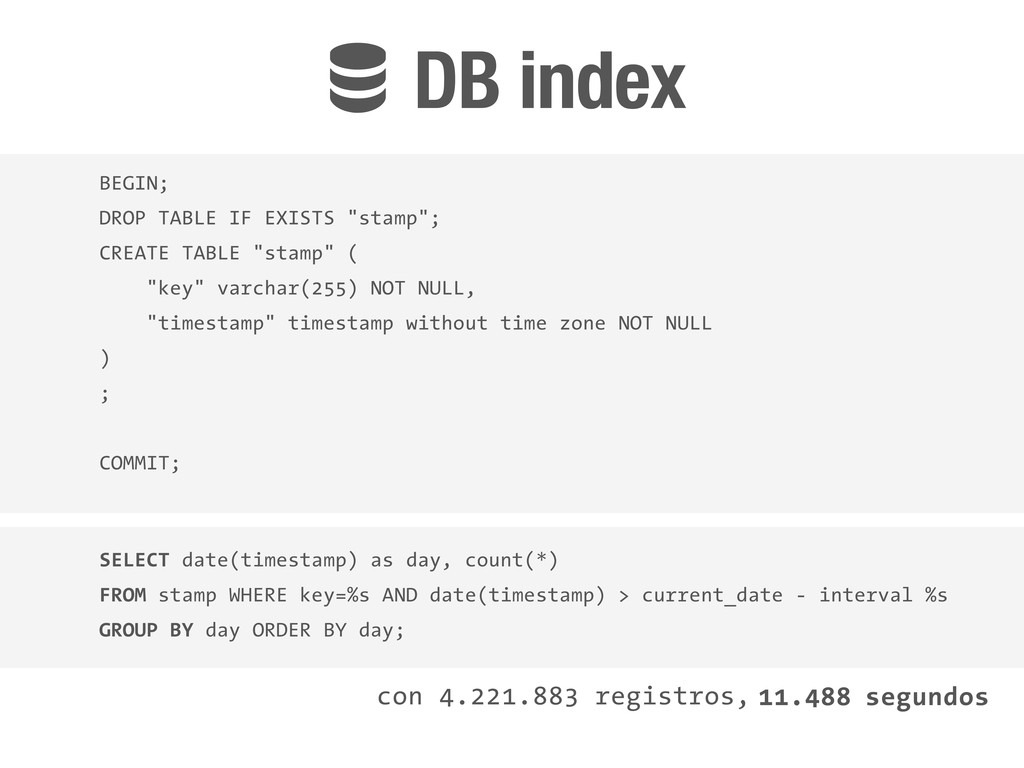
key=%s AND date(timestamp) > current_date - interval %s GROUP BY day ORDER BY day; BEGIN; DROP TABLE IF EXISTS "stamp"; CREATE TABLE "stamp" ( "key" varchar(255) NOT NULL, "timestamp" timestamp without time zone NOT NULL ) ; COMMIT; con 4.221.883 registros, 11.488 segundos
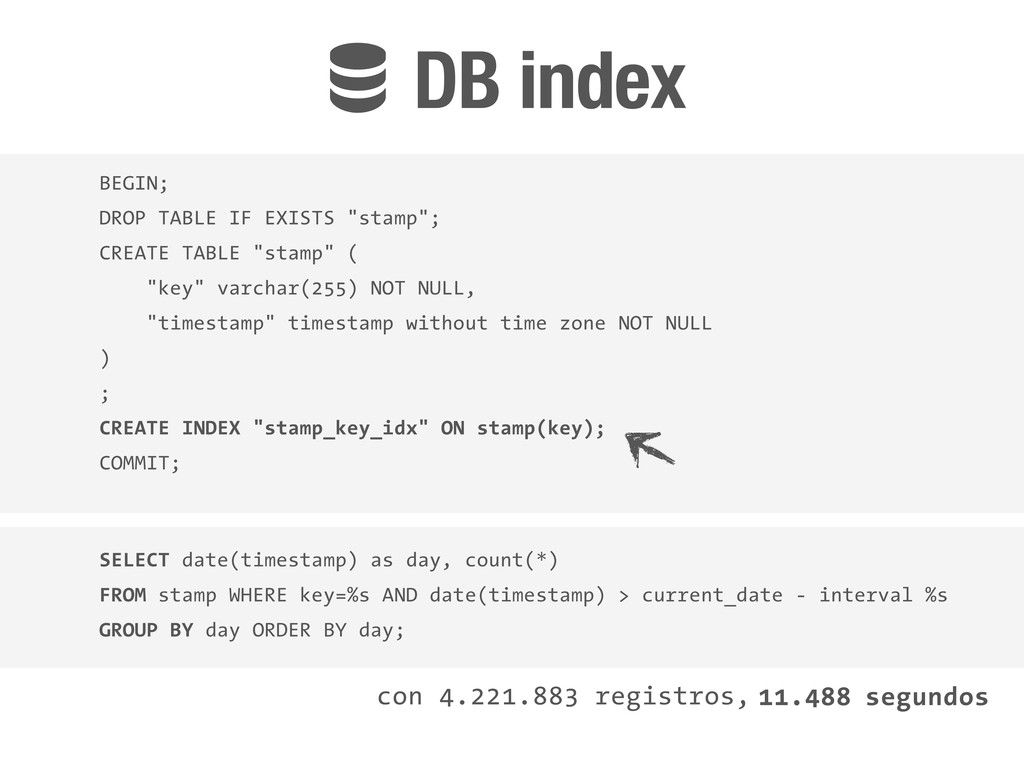
"key" varchar(255) NOT NULL, "timestamp" timestamp without time zone NOT NULL ) ; CREATE INDEX "stamp_key_idx" ON stamp(key); COMMIT; SELECT date(timestamp) as day, count(*) FROM stamp WHERE key=%s AND date(timestamp) > current_date - interval %s GROUP BY day ORDER BY day; con 4.221.883 registros, !DB index 11.488 segundos
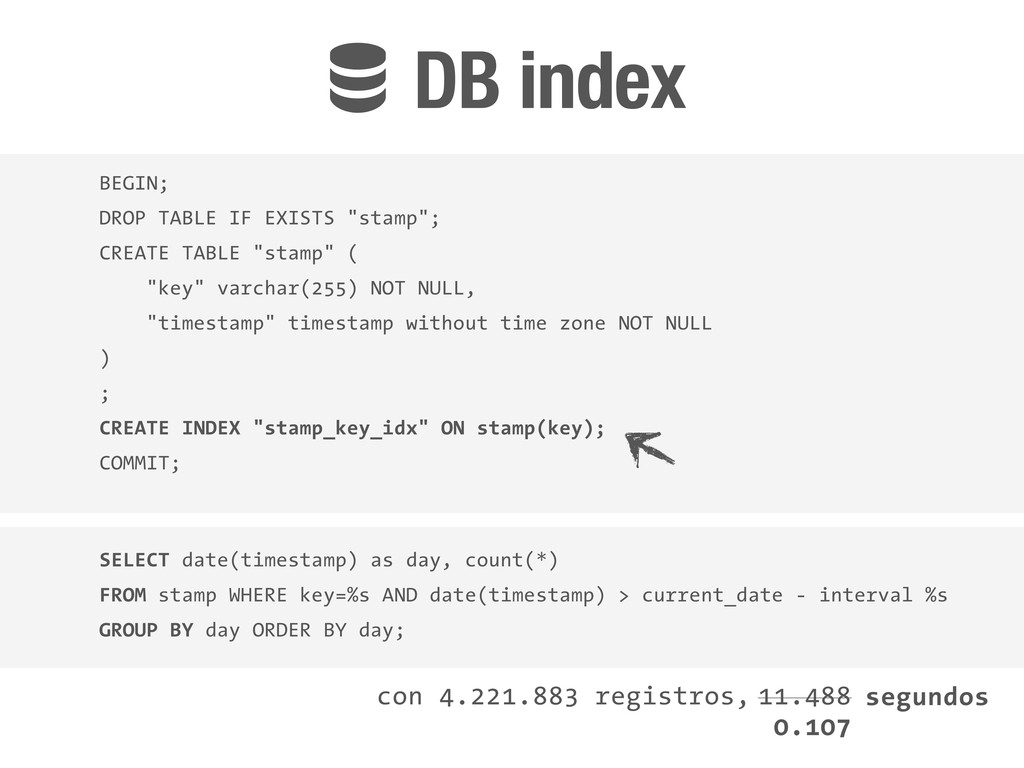
"key" varchar(255) NOT NULL, "timestamp" timestamp without time zone NOT NULL ) ; CREATE INDEX "stamp_key_idx" ON stamp(key); COMMIT; SELECT date(timestamp) as day, count(*) FROM stamp WHERE key=%s AND date(timestamp) > current_date - interval %s GROUP BY day ORDER BY day; con 4.221.883 registros, !DB index 11.488 0.107 segundos
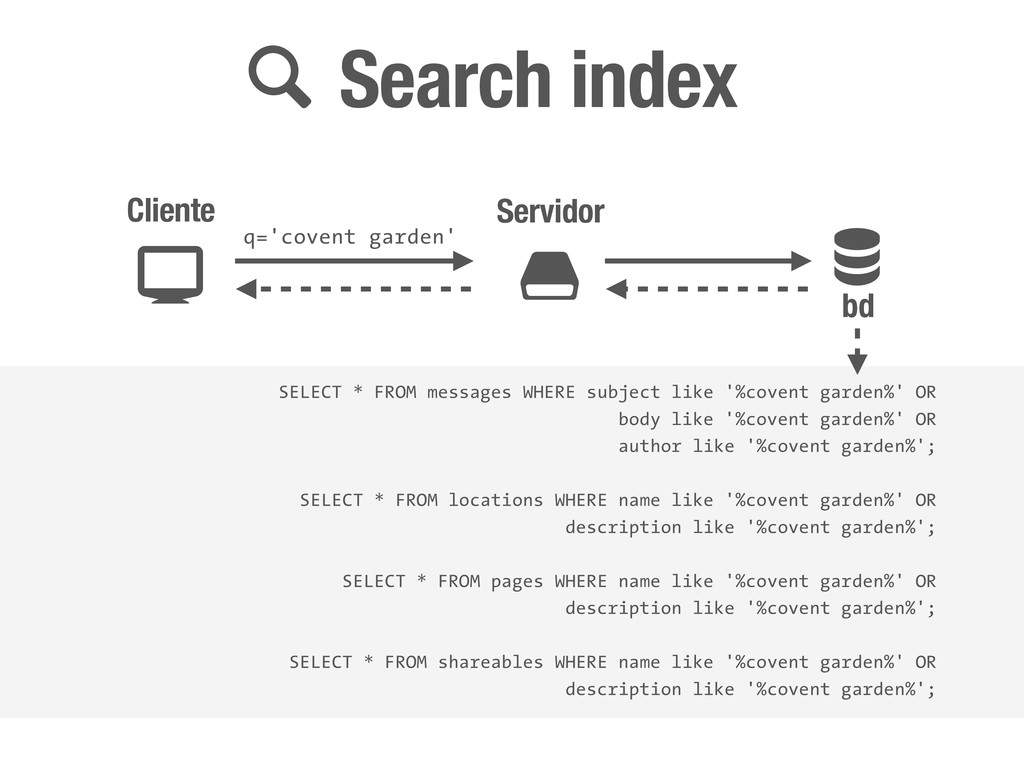
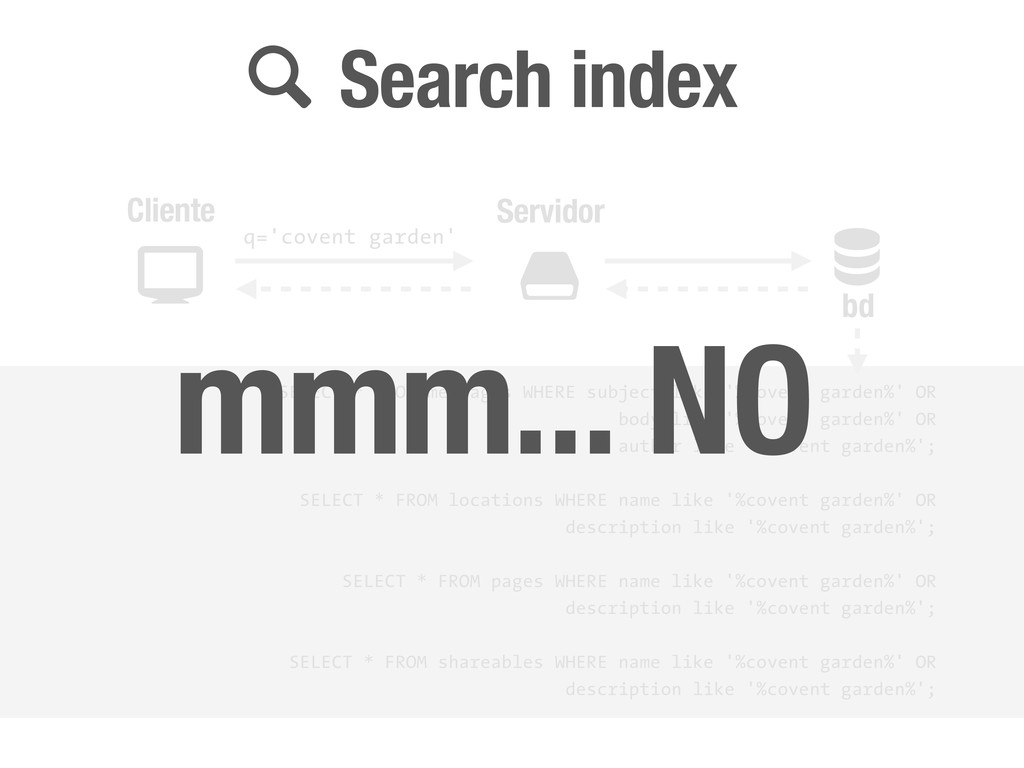
garden' SELECT * FROM messages WHERE subject like '%covent garden%' OR body like '%covent garden%' OR author like '%covent garden%'; SELECT * FROM locations WHERE name like '%covent garden%' OR description like '%covent garden%'; SELECT * FROM pages WHERE name like '%covent garden%' OR description like '%covent garden%'; SELECT * FROM shareables WHERE name like '%covent garden%' OR description like '%covent garden%';
garden' SELECT * FROM messages WHERE subject like '%covent garden%' OR body like '%covent garden%' OR author like '%covent garden%'; SELECT * FROM locations WHERE name like '%covent garden%' OR description like '%covent garden%'; SELECT * FROM pages WHERE name like '%covent garden%' OR description like '%covent garden%'; SELECT * FROM shareables WHERE name like '%covent garden%' OR description like '%covent garden%'; mmm... NO
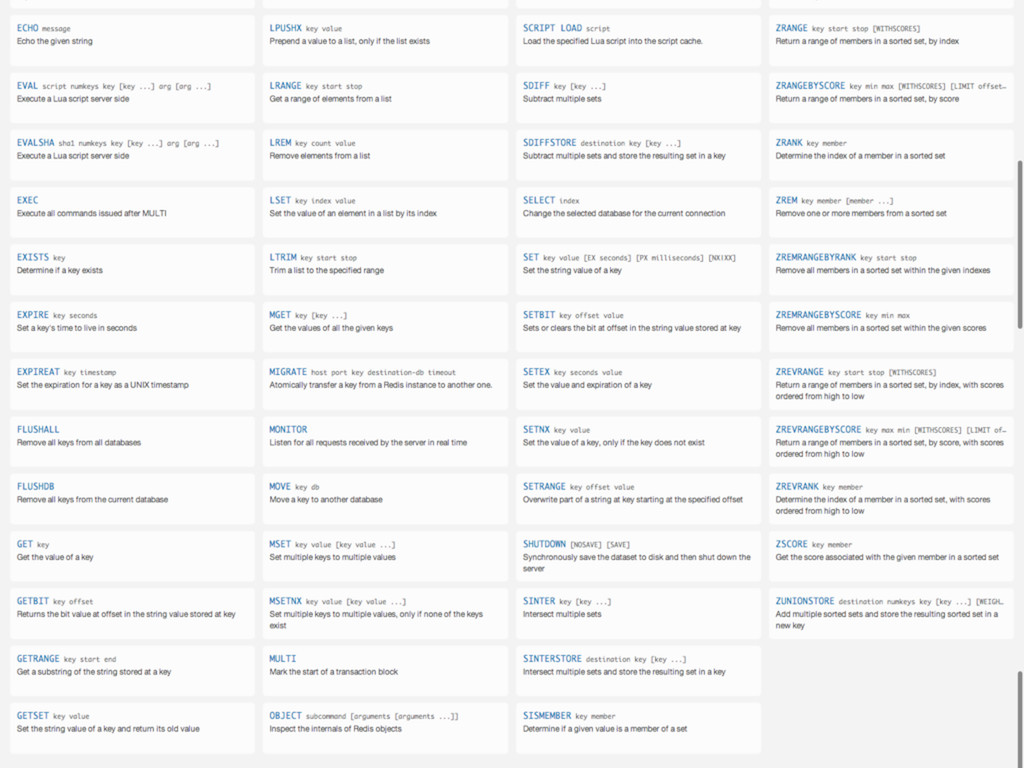
key-value store. It is often referred to as a data structure server since keys can contain strings, hashes, lists, sets and sorted sets. “ ” hashes lists sets sorted sets strings pub/sub scripts
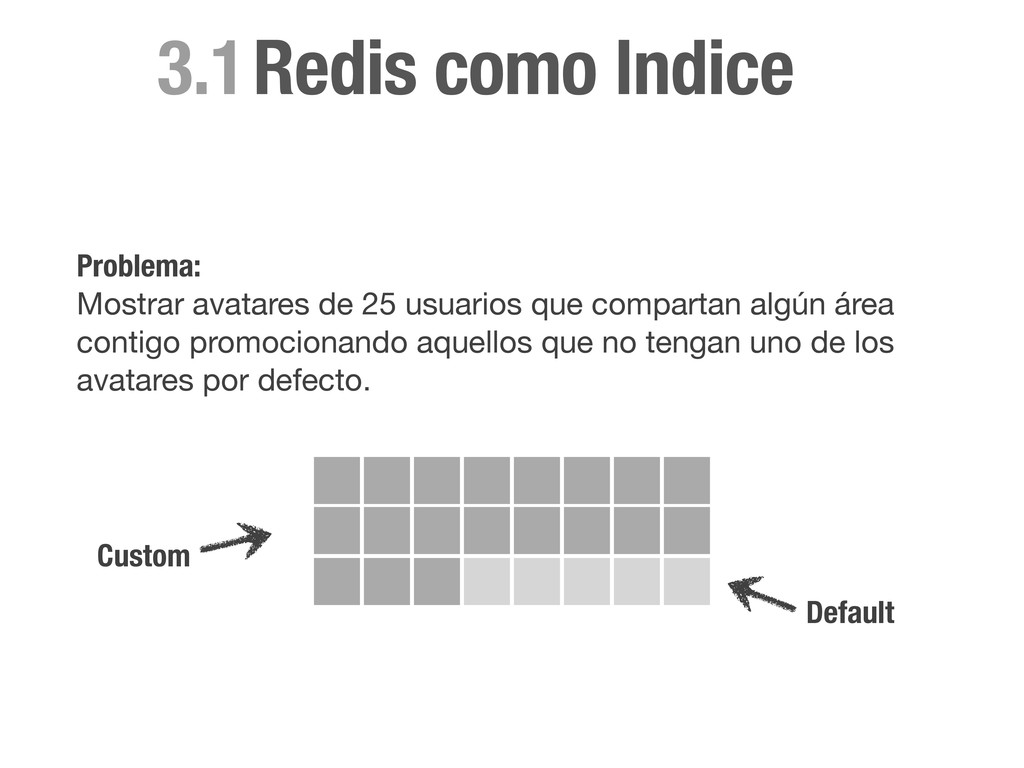
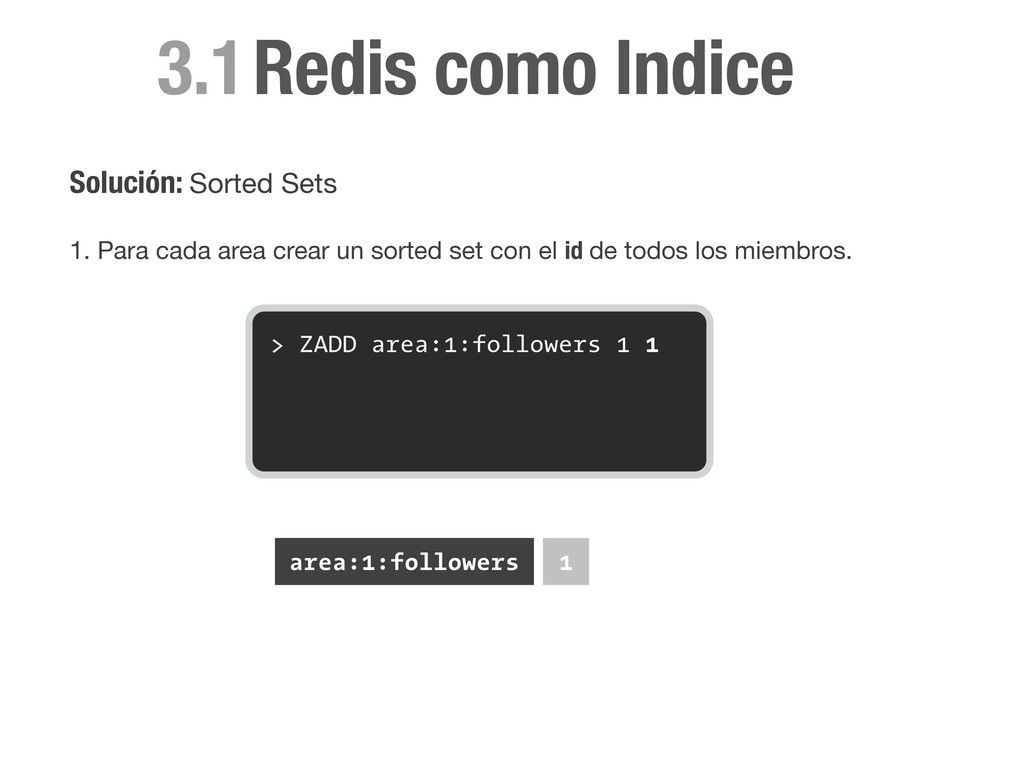
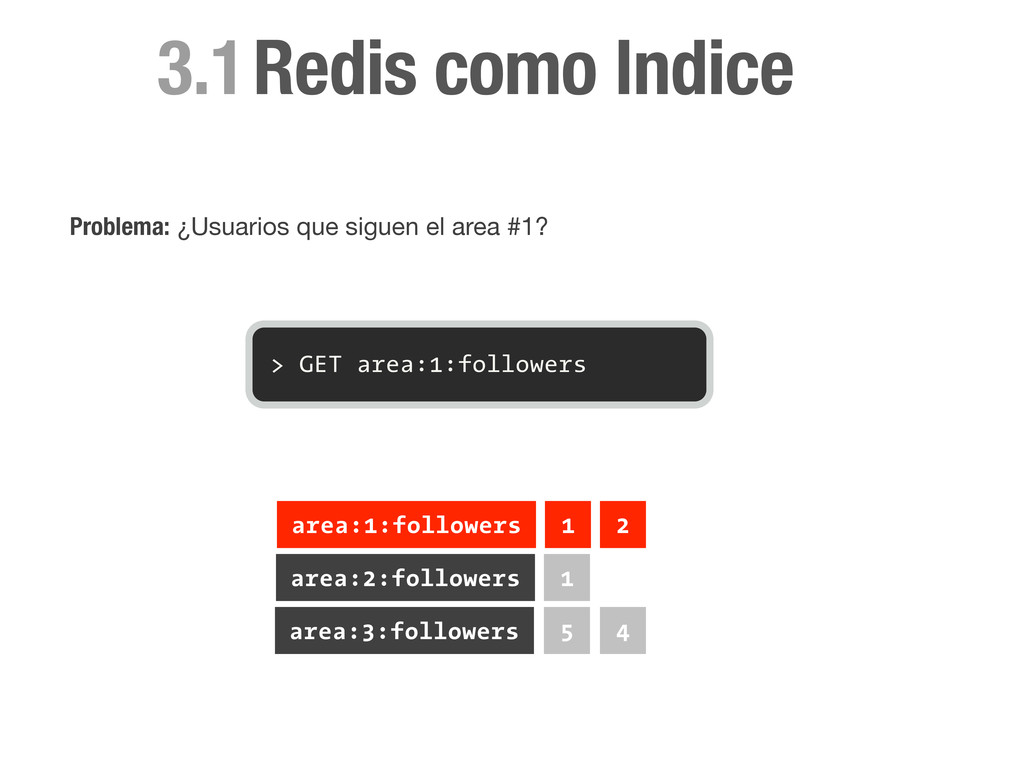
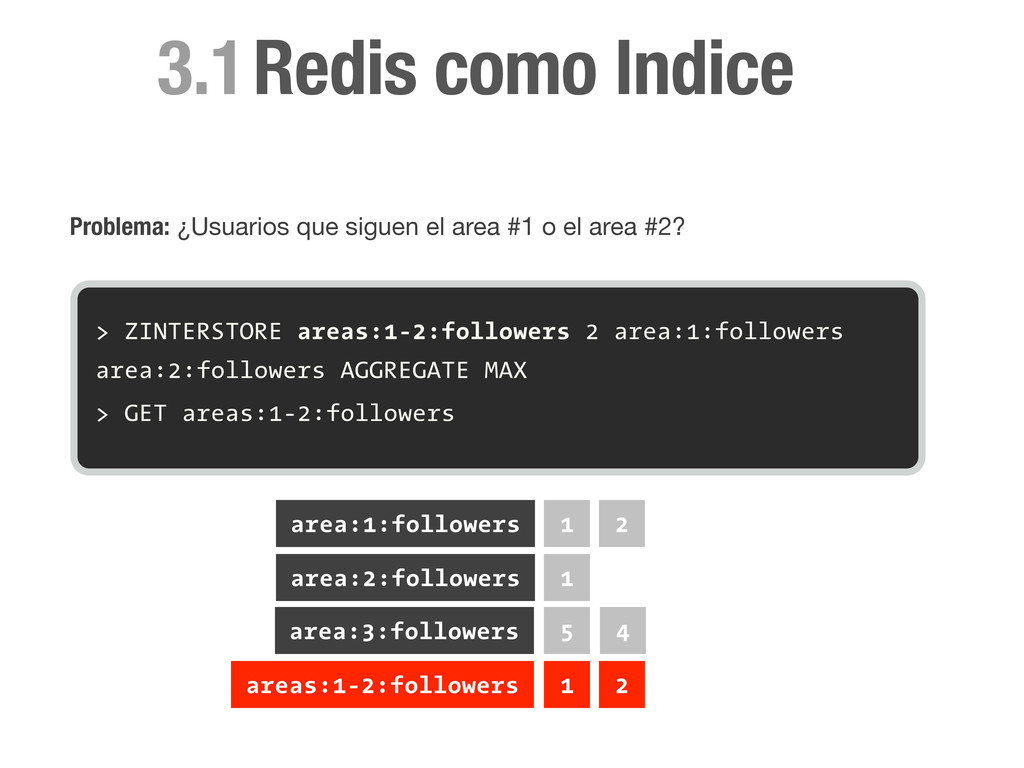
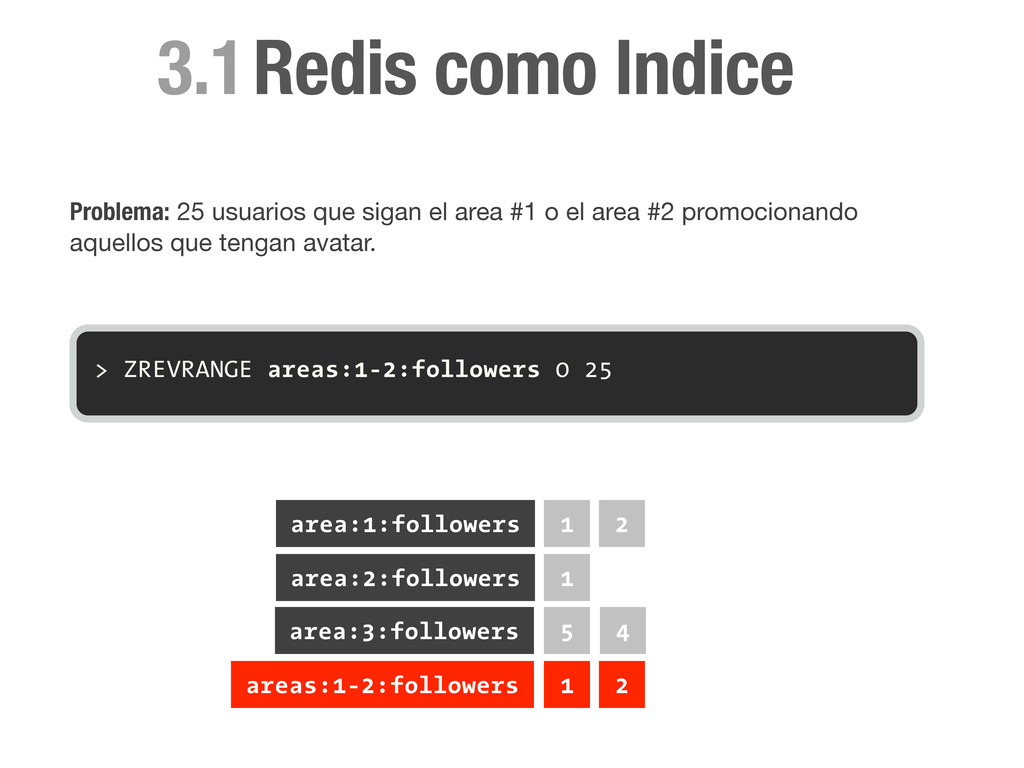
sorted set con el id de todos los miembros. > ZADD area:1:followers 1 1 > ZADD area:1:followers 0 2 > ZADD area:2:followers 1 1 area:1:followers 1 2 area:2:followers 1 Redis como Indice
sorted set con el id de todos los miembros. > ZADD area:1:followers 1 1 > ZADD area:1:followers 0 2 > ZADD area:2:followers 1 1 > ZADD area:3:followers 0 4 area:1:followers 1 2 area:2:followers 1 area:3:followers 4 Redis como Indice
() { // Handle closing of flash messages $('#flashes .close, .flashes .close').live('click', function (e) { $(e.target).closest('li').slideUp(120, function () { // Cleanup after the last one var container = $(this).closest('#flashes, .flashes'), all_messages = container.find('li:visible'); if (all_messages.length < 1) { container.remove(); } }); e.preventDefault(); }); } }; SL.Utils.flash={init:function(){$("#flashes .close, .flashes .close").live("click",function(a){$ (a.target).closest("li").slideUp(120,function(){var a=$(this).closest("#flashes, .flashes"); 1>a.find("li:visible").length&&a.remove()});a.preventDefault()})}}; 585 bytes 255 bytes (~56%) Un paso más del proceso de build + deploy
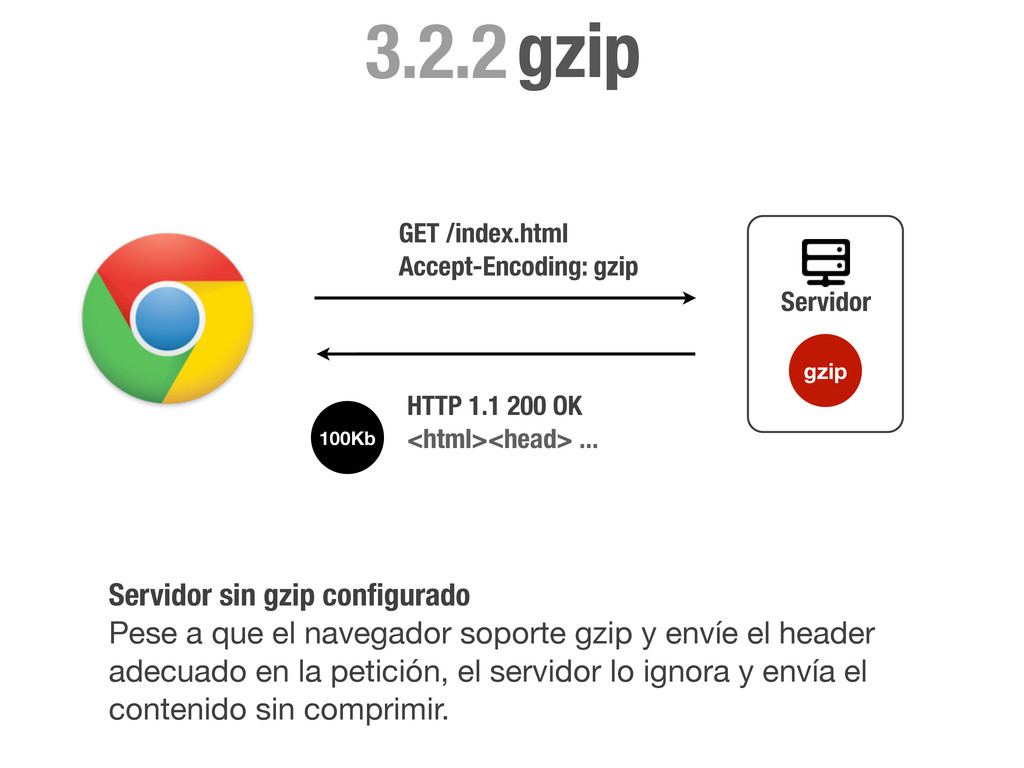
<html><head> ... gzip Servidor Servidor sin gzip configurado Pese a que el navegador soporte gzip y envíe el header adecuado en la petición, el servidor lo ignora y envía el contenido sin comprimir. 100Kb
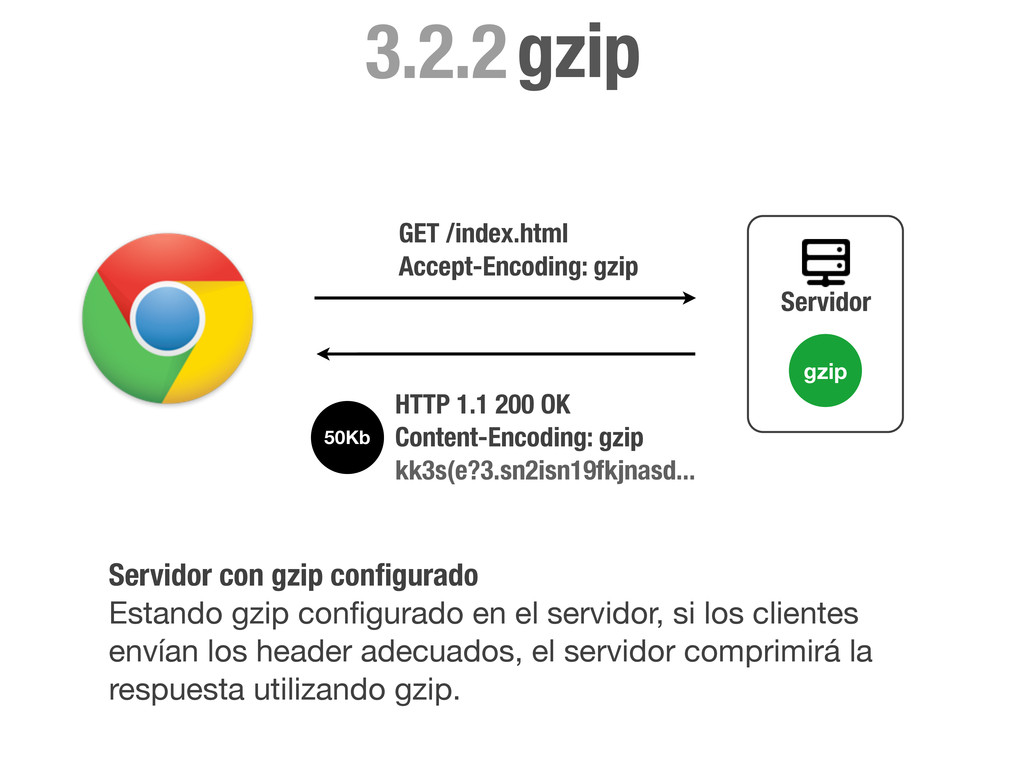
configurado en el servidor, si los clientes envían los header adecuados, el servidor comprimirá la respuesta utilizando gzip. HTTP 1.1 200 OK Content-Encoding: gzip kk3s(e?3.sn2isn19fkjnasd... 50Kb gzip 3.2.2 gzip Servidor
(~12 años) • Netscape <6 • Internet Explorer <5.5 (Julio 2000) • Opera <5 (Enero 2000) • Firefox <0.9.5 (Octubre 2001) •Solo comprimir texto (html, xml, css, js...) • Imágenes, audio y video suelen estar comprimidos utilizando codecs más eficientes y resulta una perdida de tiempo y cpu intentar recomprimirlos. •El 90% del tráfico de internet se genera utilizando navegadores que soportan gzip (Yahoo!) gzip 3.2.2
la manera más eficiente posible a poder ser desde localizaciones geográficamente cercanas al cliente para reducir la latencia. • Reducir tráfico de nuestros servidores web distribuyendo el trafico a otros servidores. • Disminuir el coste. •Amazon S3 • $0.095 por GB Almacenado. • $0.004 por cada 10.000 requests. • $0.120 por GB transferido •Distribuir un video de 50Mb a 100K personas (~5Tb) • $0 (Hosting) + $0.04 (requests) + $585 (transferencia) CDN 3.2.3
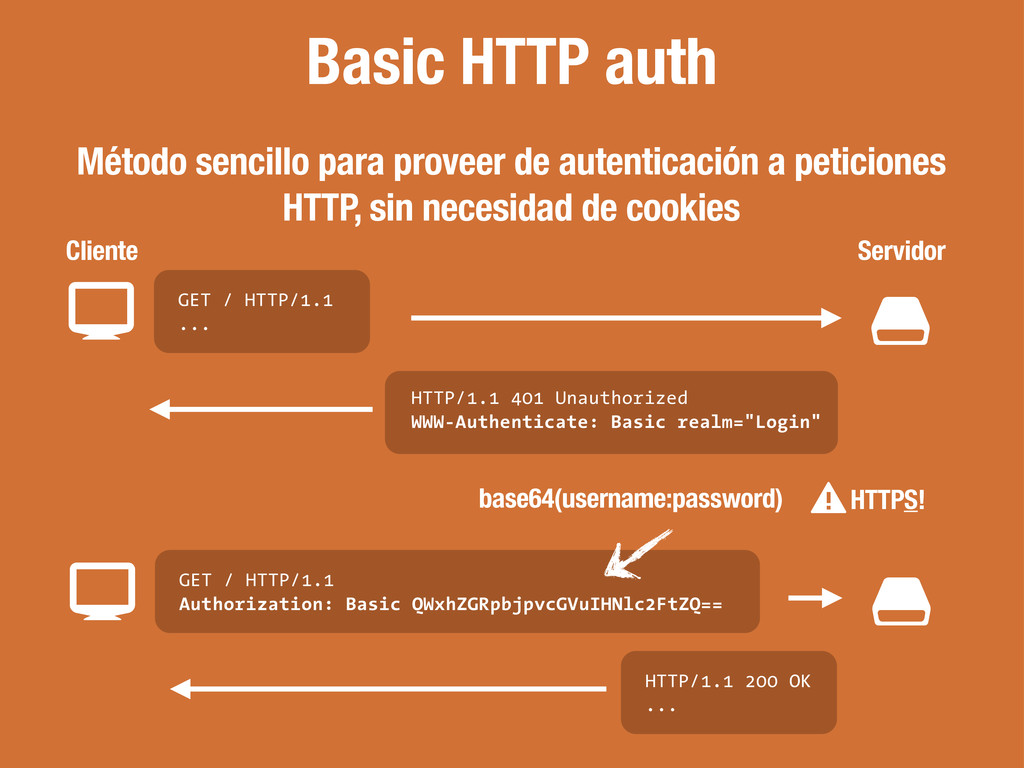
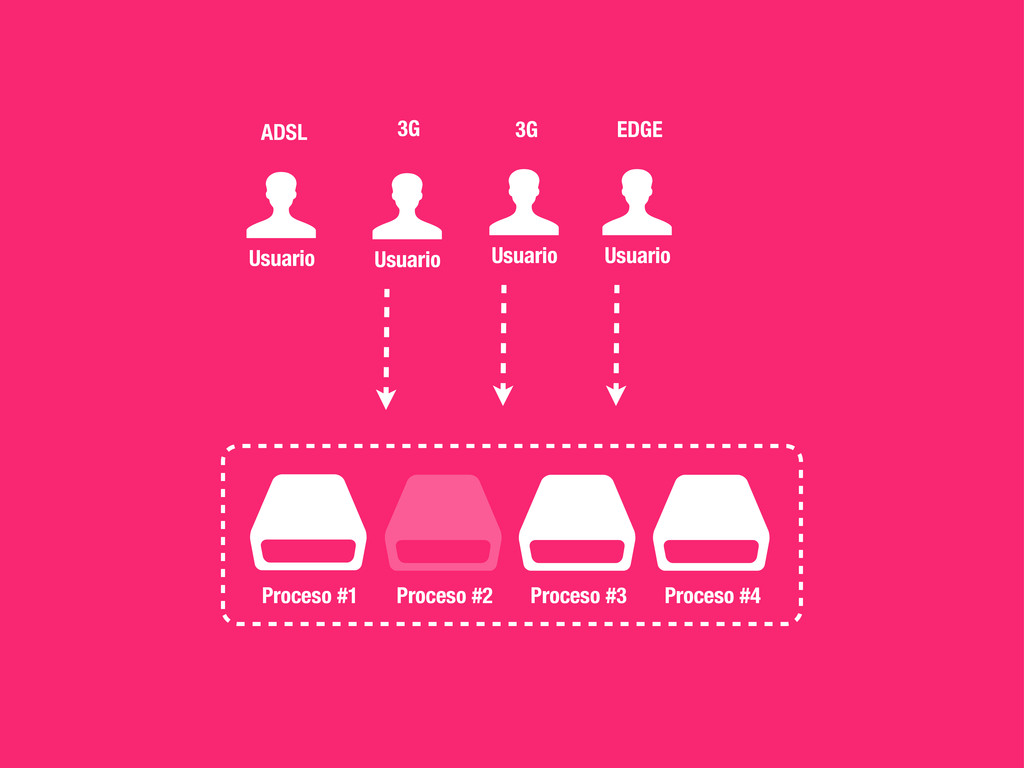
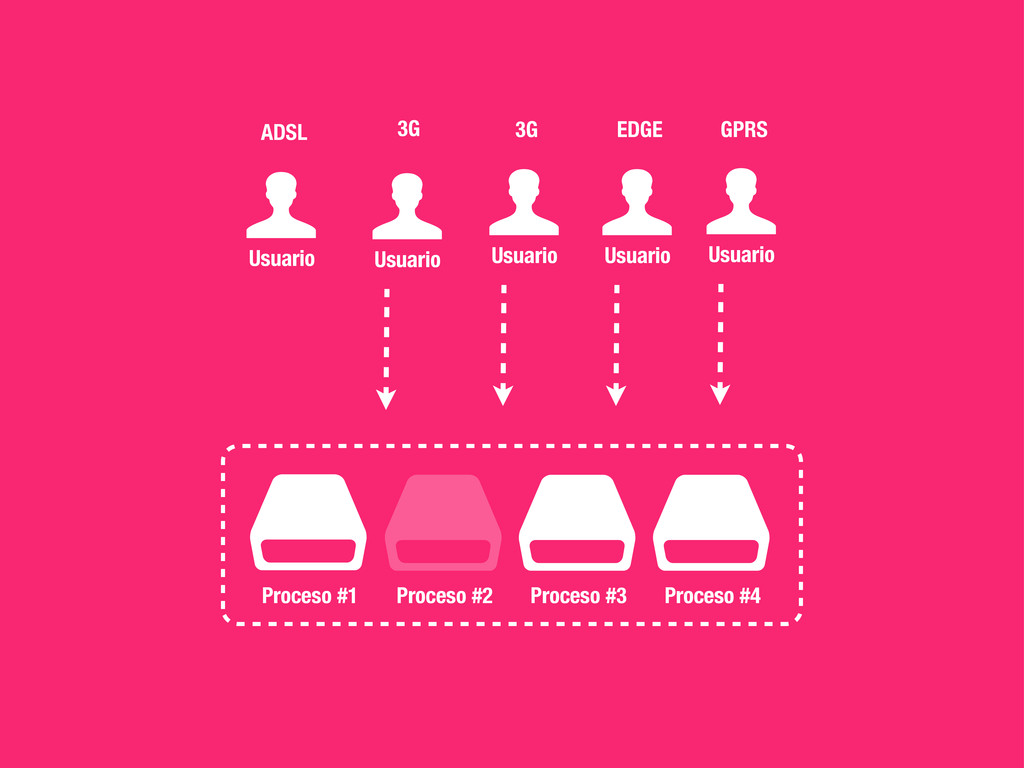
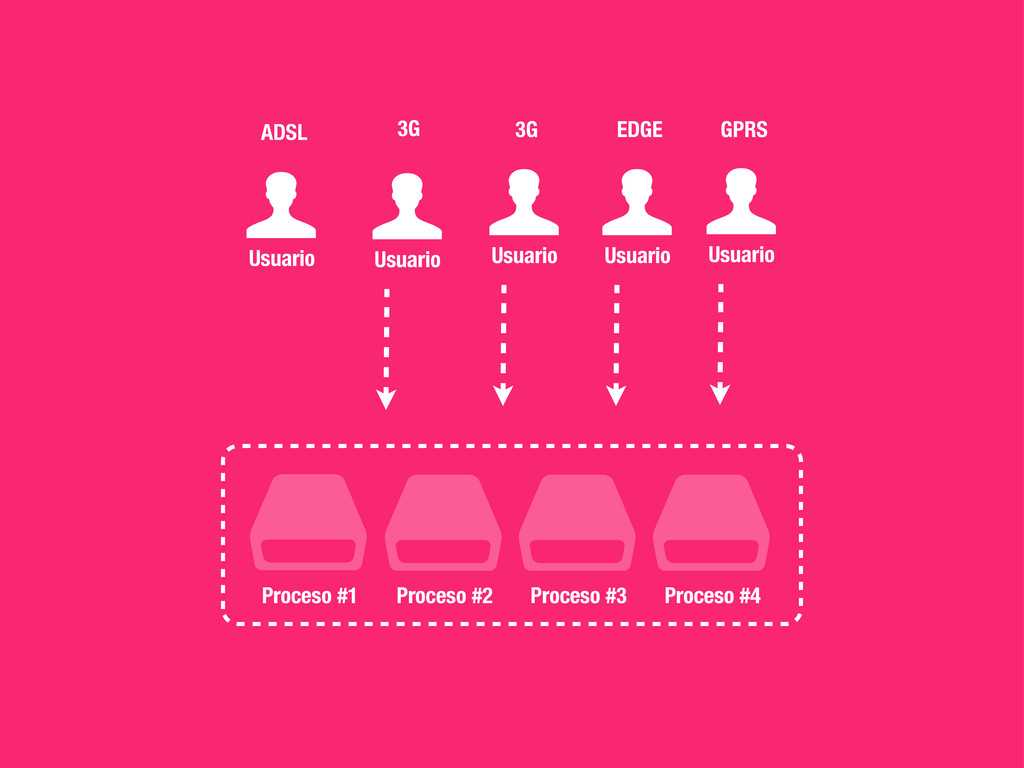
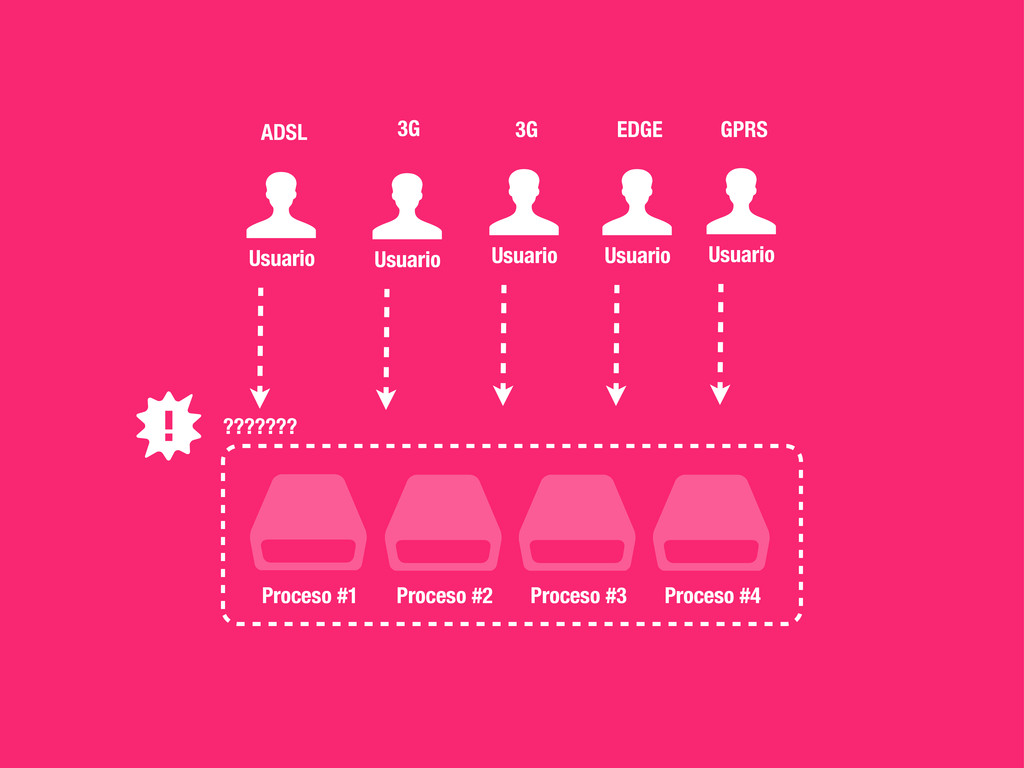
externos 2. CSS al comienzo 3. JS al final 4. Entre 2 y 4 hostnames http://developer.yahoo.com/performance/rules.html 1 A single-user client SHOULD NOT maintain more than 2 connections with any server or proxy. “
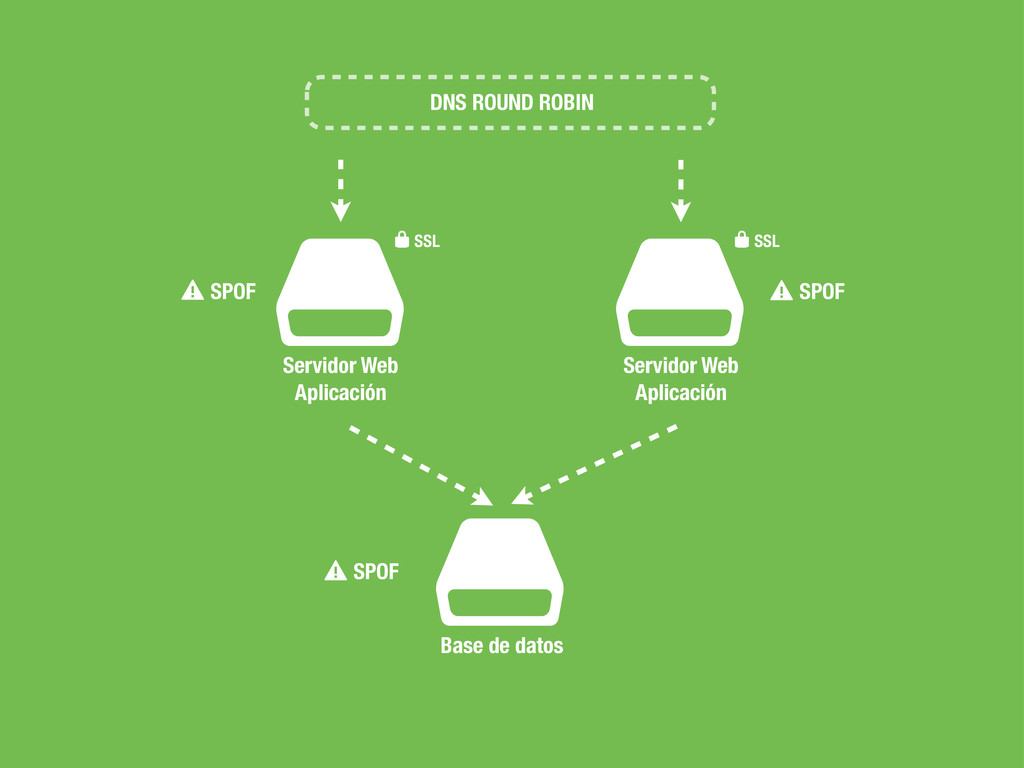
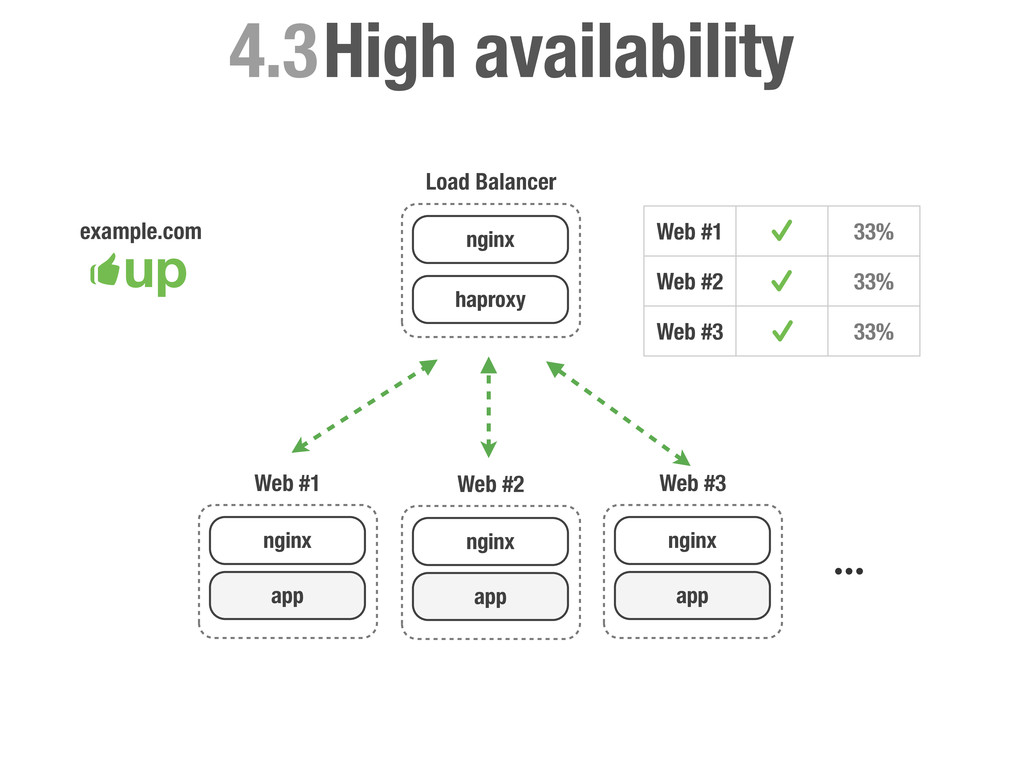
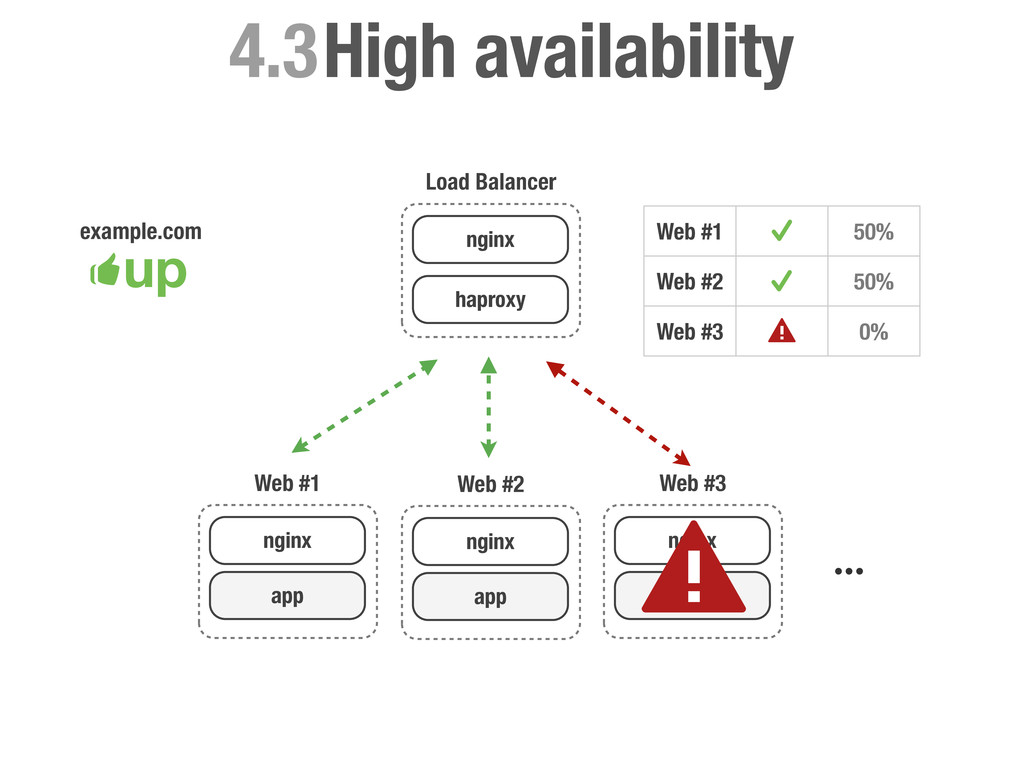
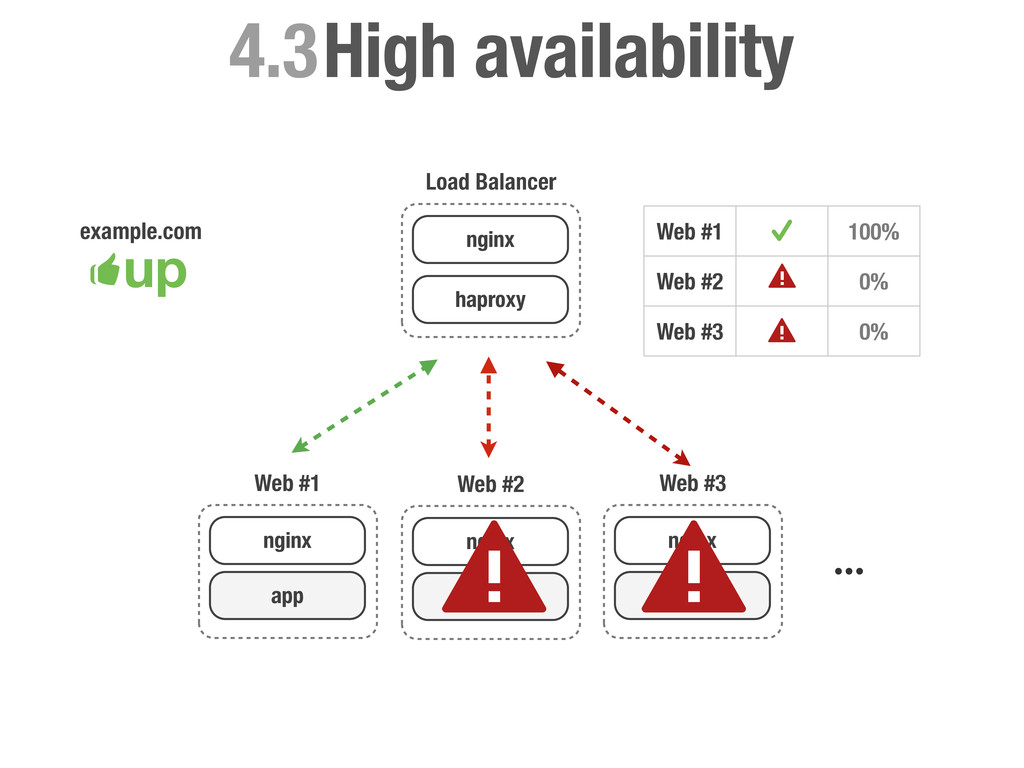
carga más utilizados. Se caracteriza por ser muy eficiente tanto en CPU como en RAM y es famoso por su estabilidad. • Permite balancear tanto tráfico TCP como a un más alto nivel tráfico HTTP. • Nos permite realizar health-check de los servidores backend. • Podemos activar y desactivar servidores manualmente. • Dispone de varios criterios para asignar servidores: Random, Round-robin, Least connection, source, uri, url-parameter etc...
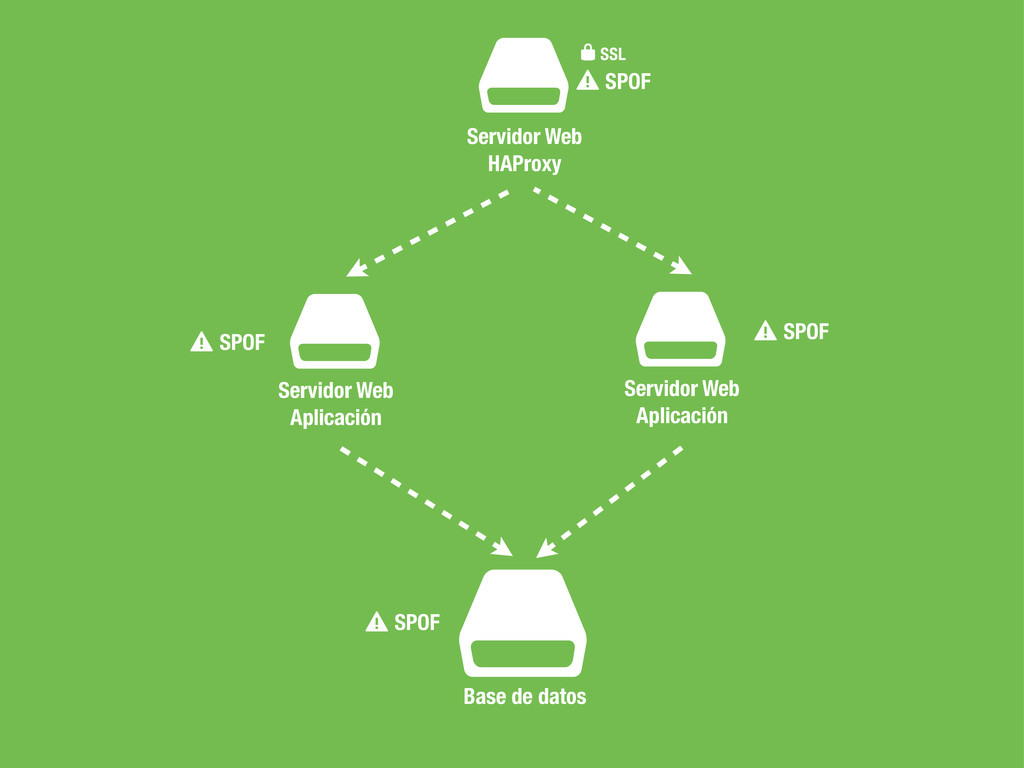
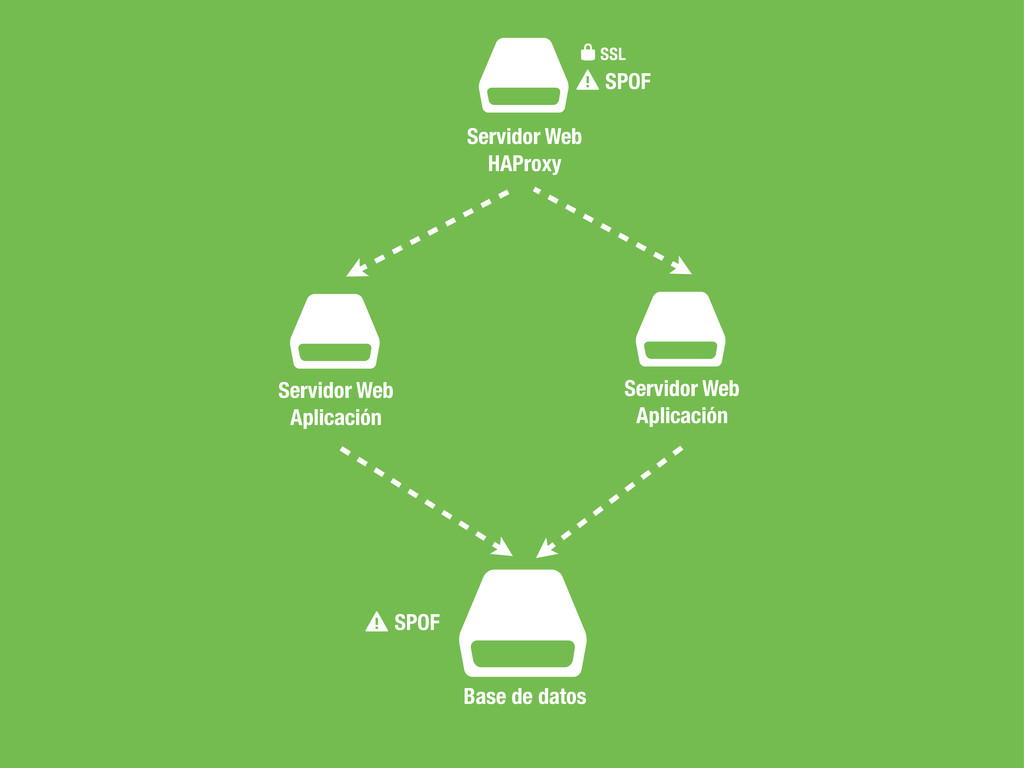
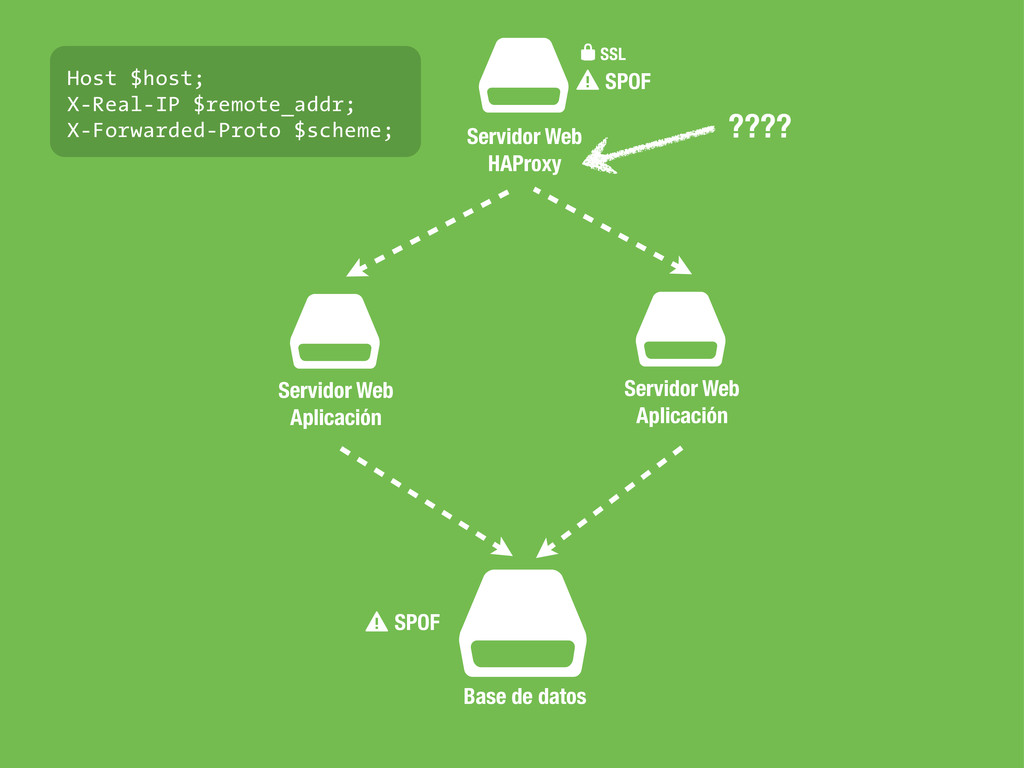
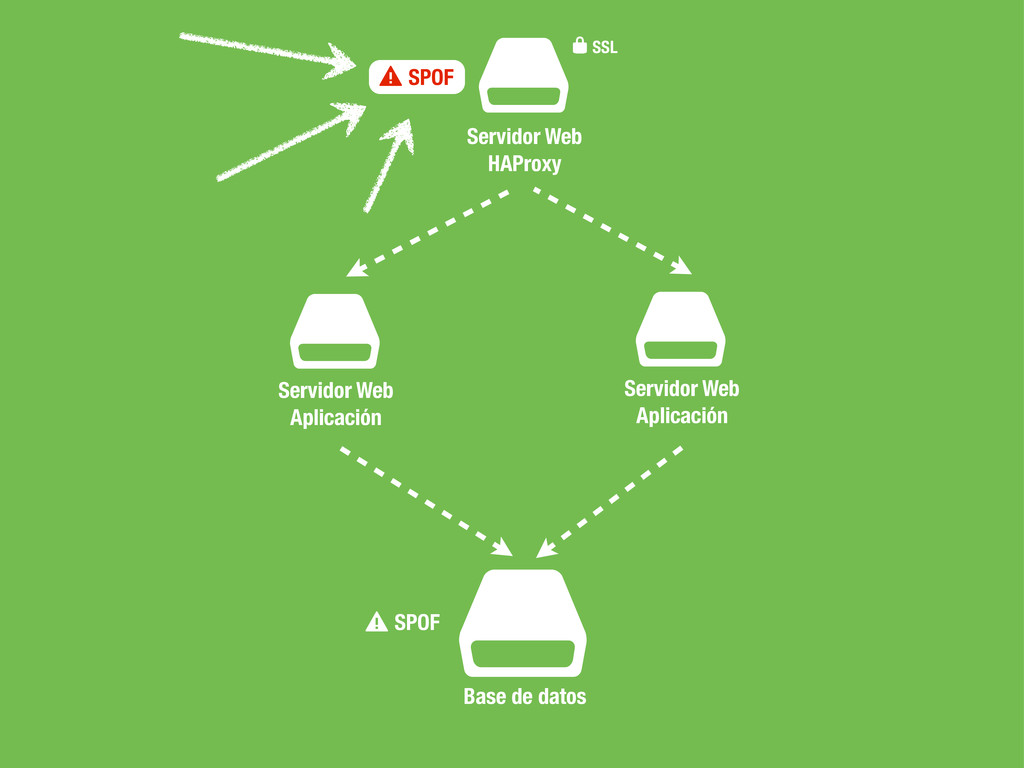
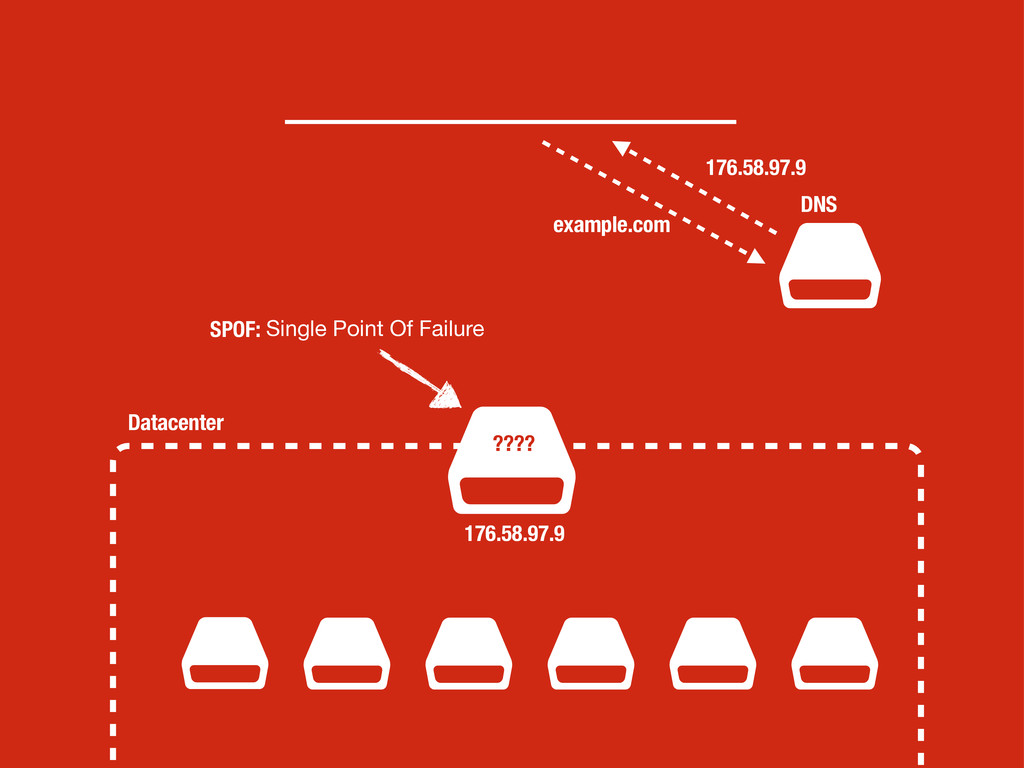
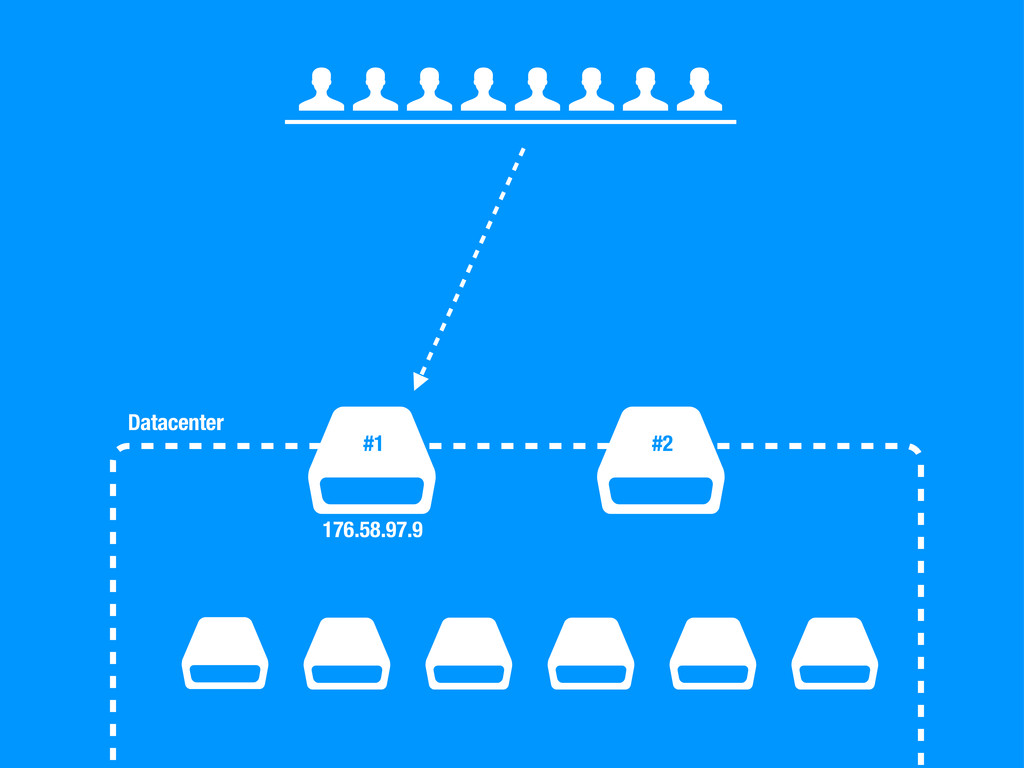
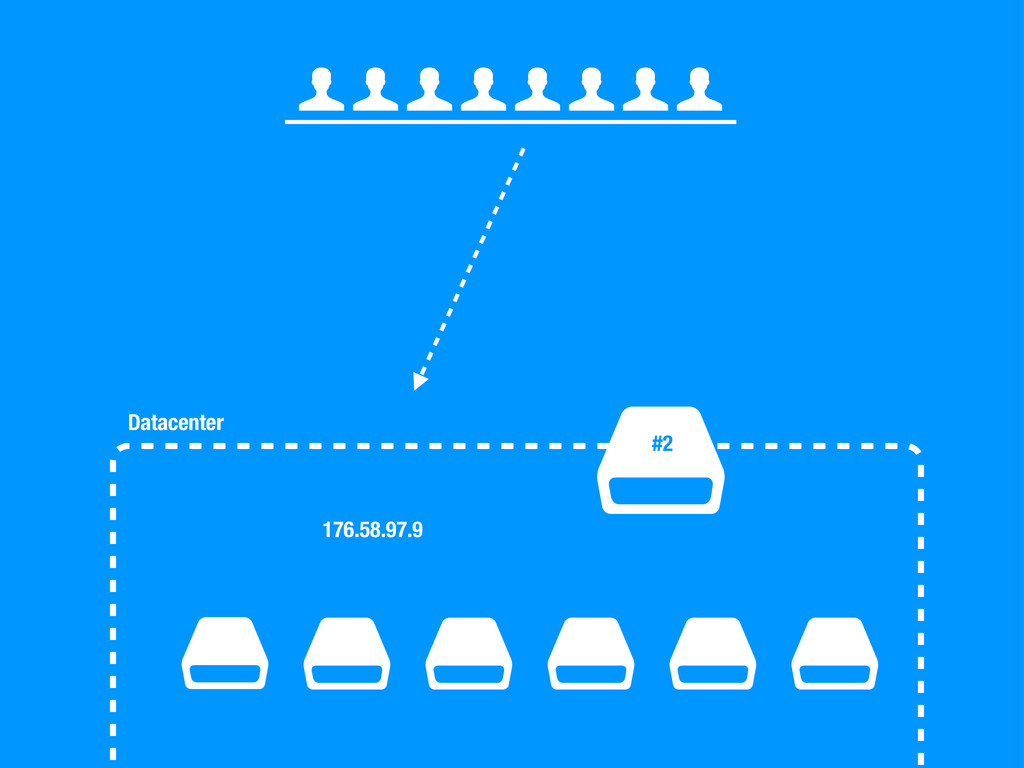
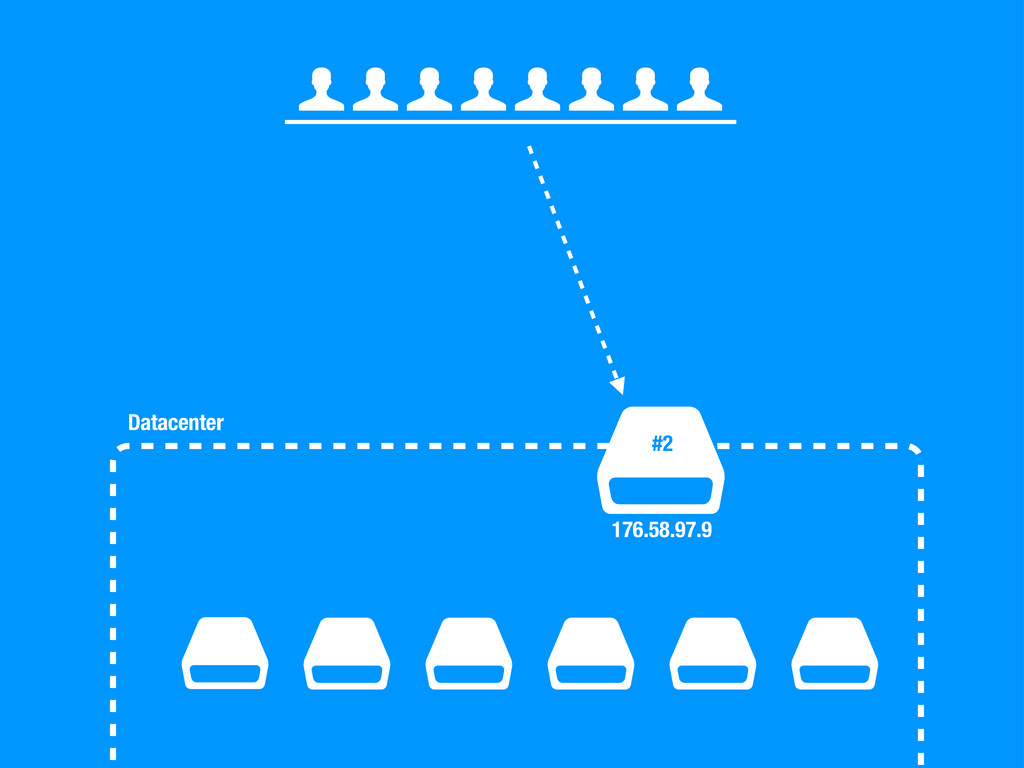
sea un un SPOF, Single point of failure. • En caso de fallo no podemos cambiar la configuración del DNS ya que conllevaría tiempo propagar el cambio. • No podemos poner otra capa de balanceadores por encima del balanceador ya que tendríamos el mismo problema. • Hagamos lo que hagamos ha de ser rápido para evitar downtime en la medida de lo posible.
nos asegura que todos los mensajes enviados se envían a todos los miembros del bus y se asegura de que todo el mundo esté de acuerdo sobre quien está o no está conectado.
initdead 120 udpport 694 ucast eth0 123.123.123.123 auto_failback on node ha-1.example.com node ha-2.example.com use_logd yes crm respawn Heartbeat 4.3 Instalación $ apt-get install heartbeat Comprobar nodos cada dos segundos. Dar un nodo por muerto a los 15s. Alertar pasados 5 segundos. Máximo tiempo de espera en arranque. Puerto. IP. Failback automático al nodo primario. Nodo #1. Nodo #2. Enable log. Arrancar Pacemaker al arranque del cluster. Hemos de configurar hearbeat en ambos nodos 9
chmod 600 /etc/heartbeat/authkeys Heartbeat 4.3 Hemos de configurar hearbeat en ambos nodos 9 Arranque $ service heartbeat start Estado $ service heartbeat status heartbeat OK [pid 2332 et al] is running on ha-1.example.com [ha-1.example.com]...
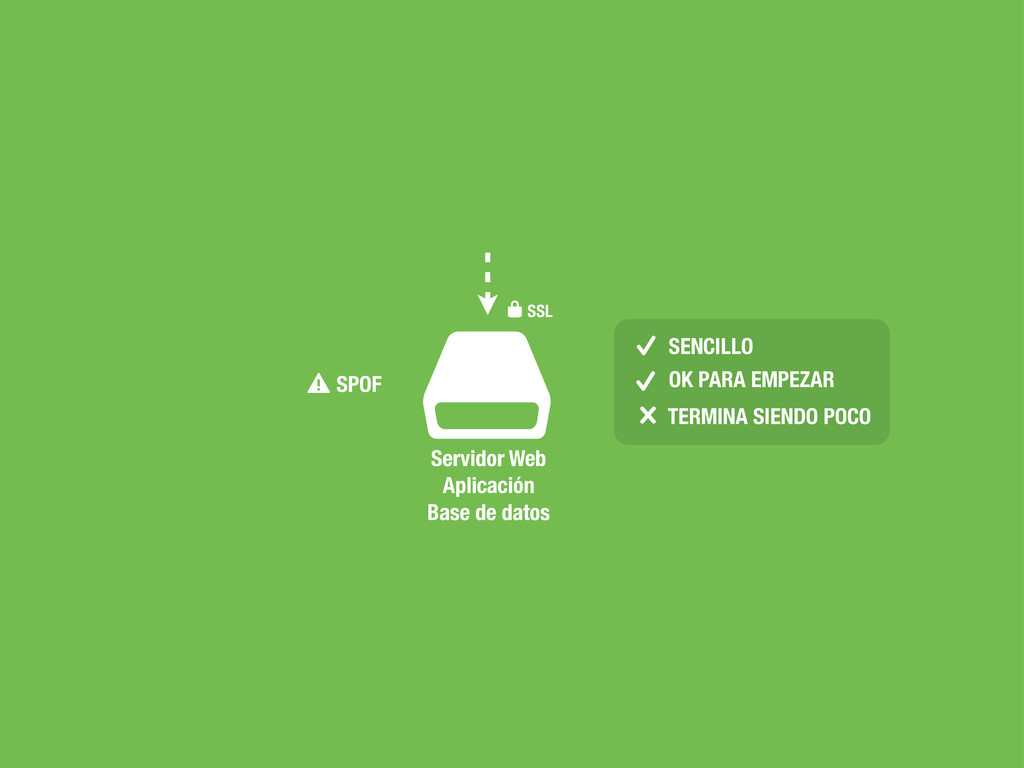
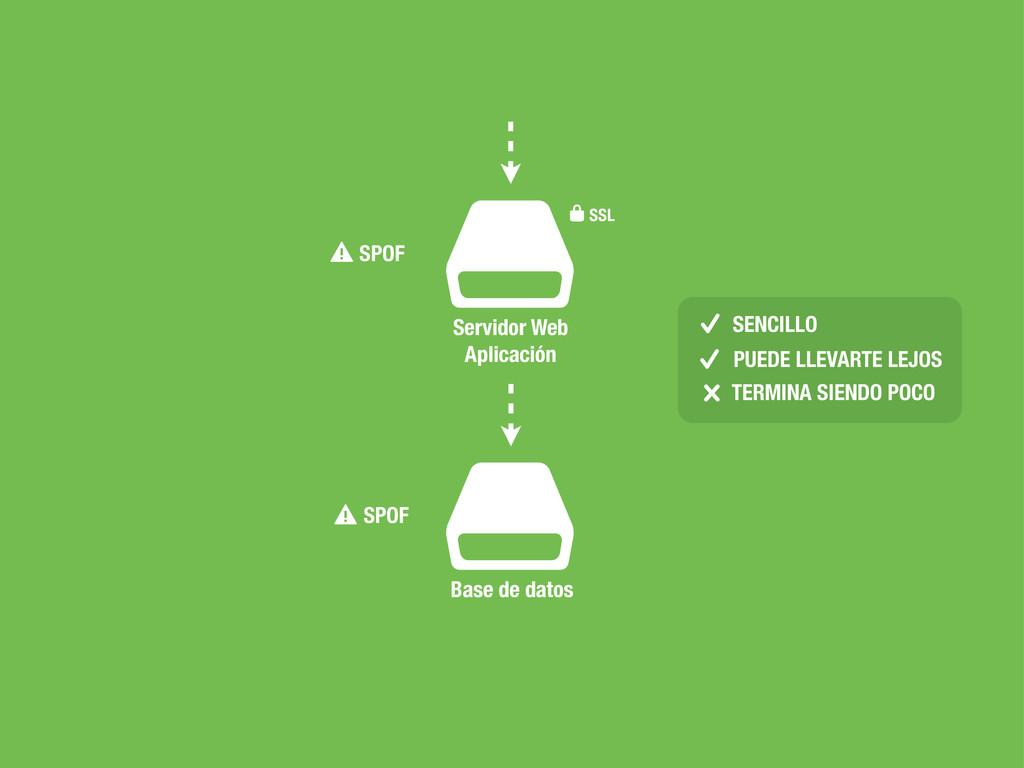
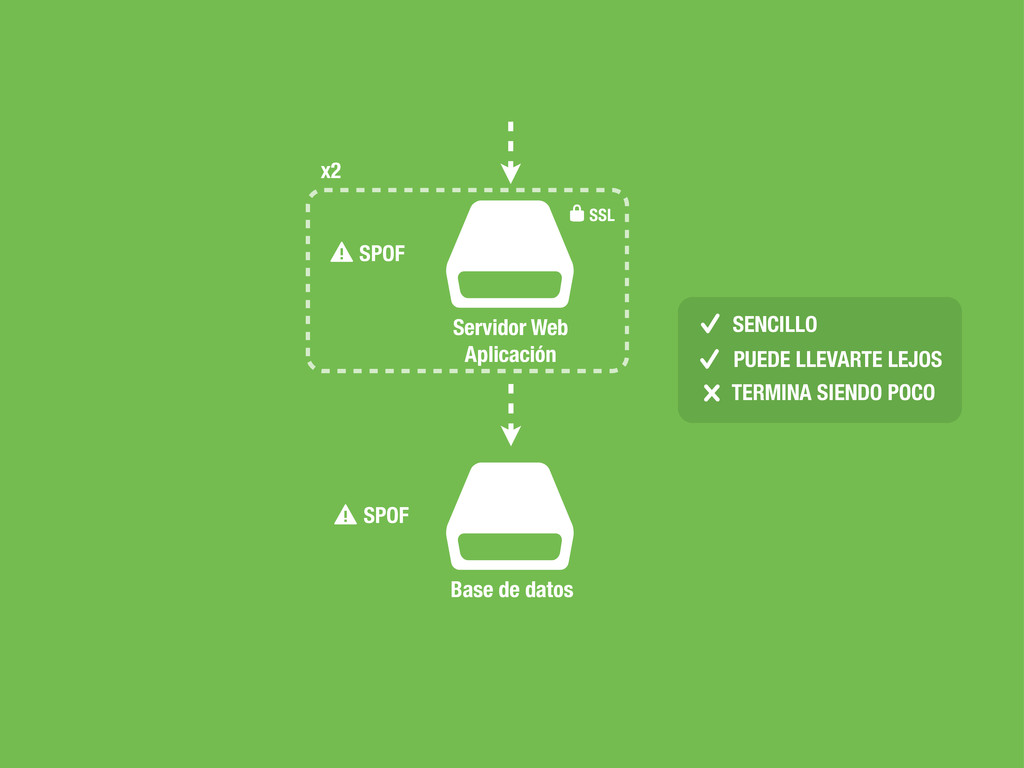
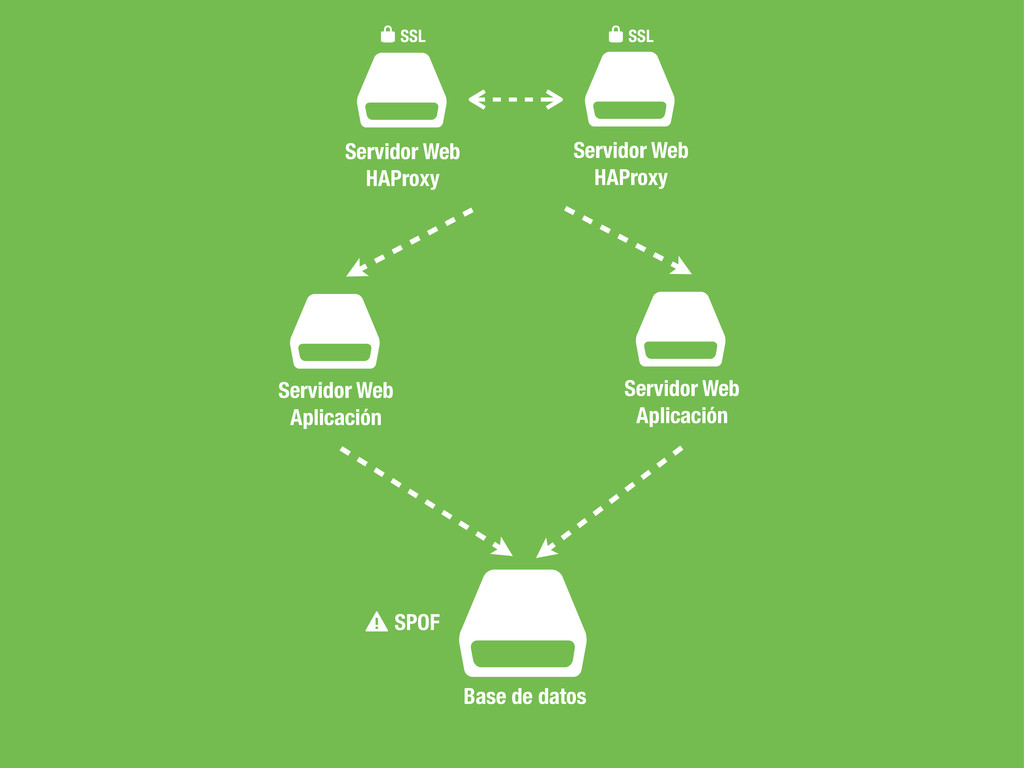
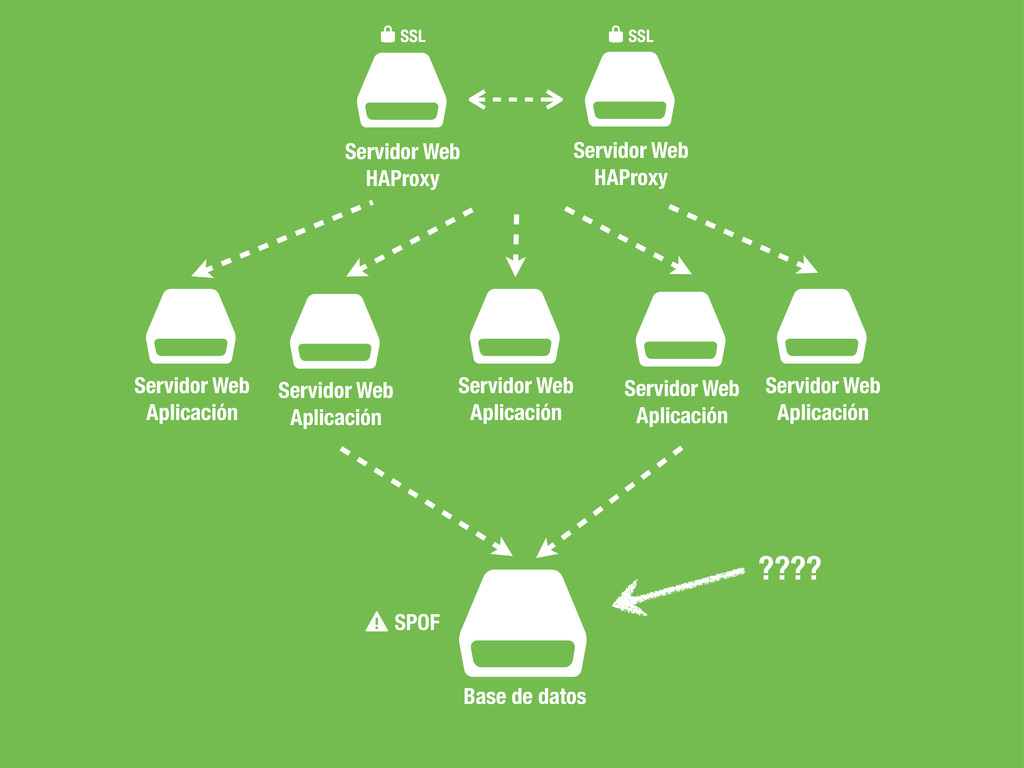
Servidor Web Aplicación $ Servidor Web Aplicación SSL * $ Servidor Web HAProxy SSL * $ Servidor Web Aplicación $ Servidor Web Aplicación $ Servidor Web Aplicación ????
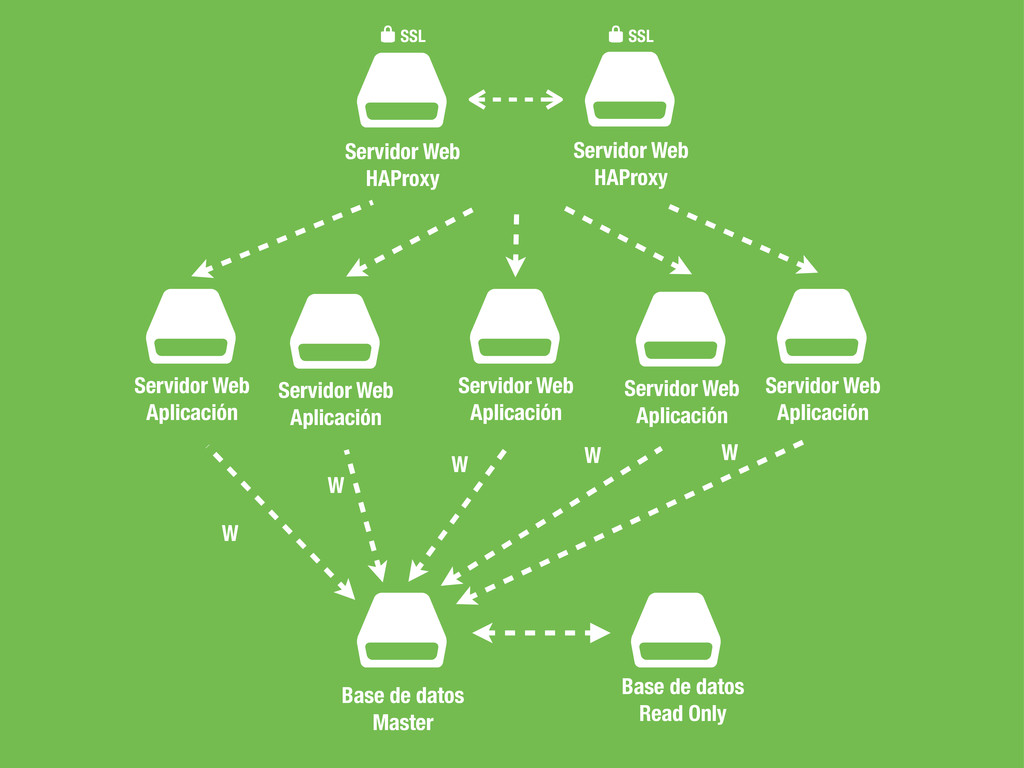
Servidor Web Aplicación $ Servidor Web Aplicación SSL * $ Servidor Web HAProxy SSL * $ Servidor Web Aplicación $ Servidor Web Aplicación $ Servidor Web Aplicación W W W W W $ Base de datos Read Only
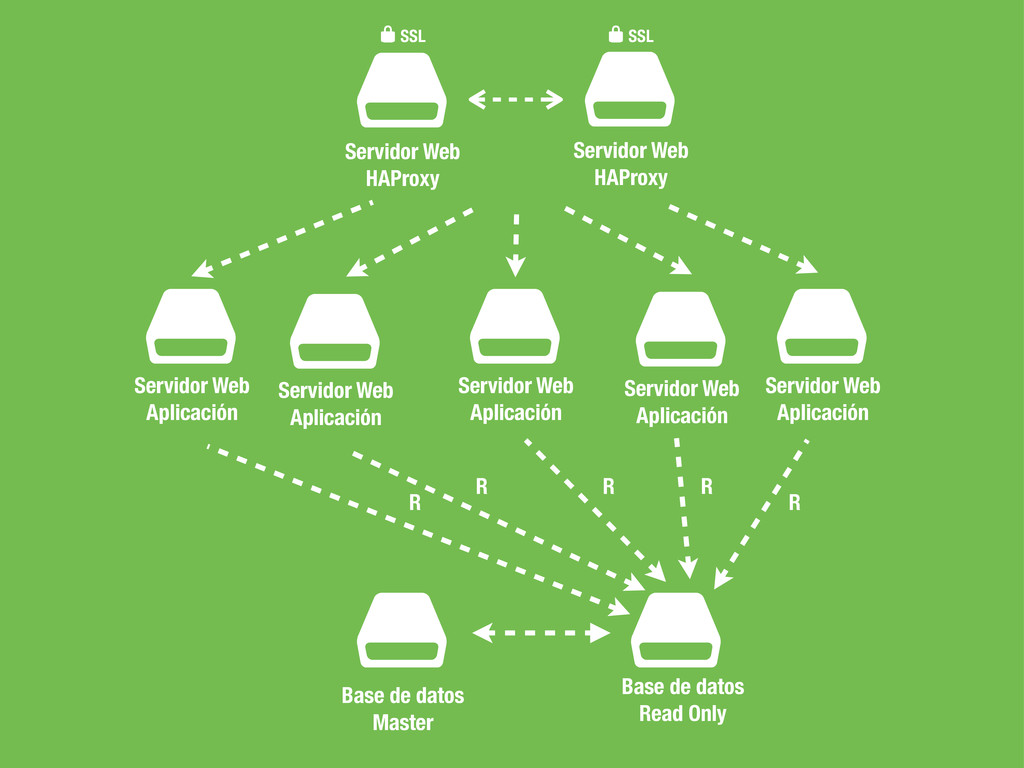
Servidor Web Aplicación $ Servidor Web Aplicación SSL * $ Servidor Web HAProxy SSL * $ Servidor Web Aplicación $ Servidor Web Aplicación $ Servidor Web Aplicación R R R R R $ Base de datos Read Only
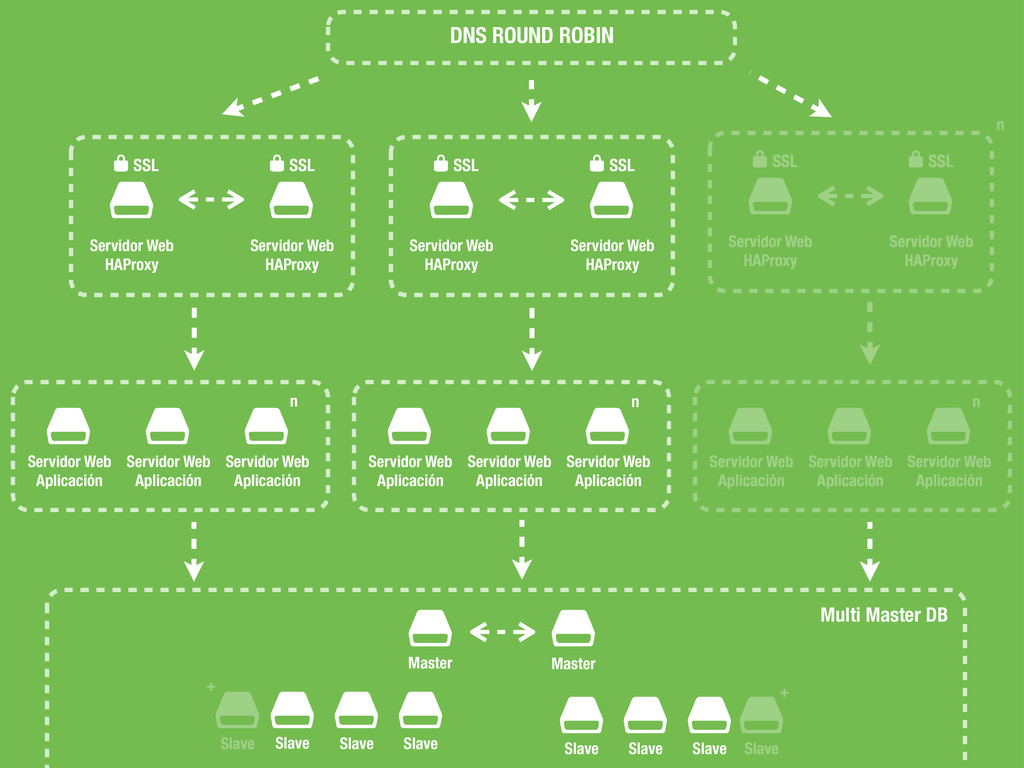
SSL * DNS ROUND ROBIN $ Servidor Web HAProxy SSL * $ Servidor Web HAProxy SSL * $ Servidor Web HAProxy SSL * $ Servidor Web HAProxy SSL * $ Servidor Web Aplicación $ Servidor Web Aplicación $ Servidor Web Aplicación $ Servidor Web Aplicación $ Servidor Web Aplicación $ Servidor Web Aplicación $ Servidor Web Aplicación $ Servidor Web Aplicación $ Servidor Web Aplicación Multi Master DB $ Slave n n n n $ Master $ Master $ Slave $ Slave $ Slave $ Slave $ Slave $ Slave $ Slave + +
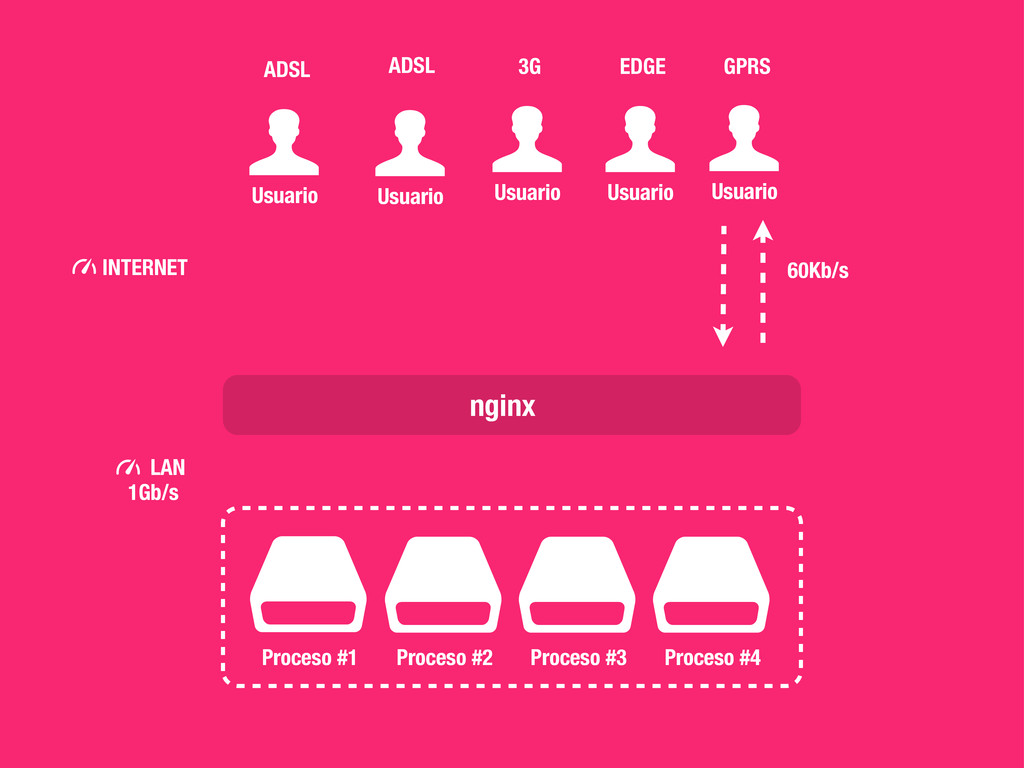
cada empresa suele elegir uno en función de las necesidades y features de cada uno. Nosotros utilizamos nginx dada la sencillez de configuración, la estabilidad, los grandísimos resultados que siempre alcanza en los tests de carga y en particular porque ya hemos trabajado con él y lo conocemos. En realidad nginx lo utilizamos como reverse proxy tanto en los balanceadores de carga como en los servidores web, así como para hacer “spoon-feeding”.
Amazon que nos permite enviar grandes cantidades de emails sin tener que disponer de una infraestructura para tales efectos. ¿Y porqué no un smtp inhouse? El tiempo es oro y el día sólo tiene 24 horas. • Pequeñas empresas que no disponen de personal de sistemas pueden ahorrarse muchos dolores de cabeza (y ganar otros) externalizando servicios como este . • Grandes empresas que necesitan enviar millones de emails en épocas concretas y no desean sobre escalar sus sistemas para estas situaciones puntuales. • El coste es muy competitivo: 0.10 $ por cada 1000 emails. Actualmente enviamos alrededor de 1M de emails al mes, lo cual nos cuesta ~£64.
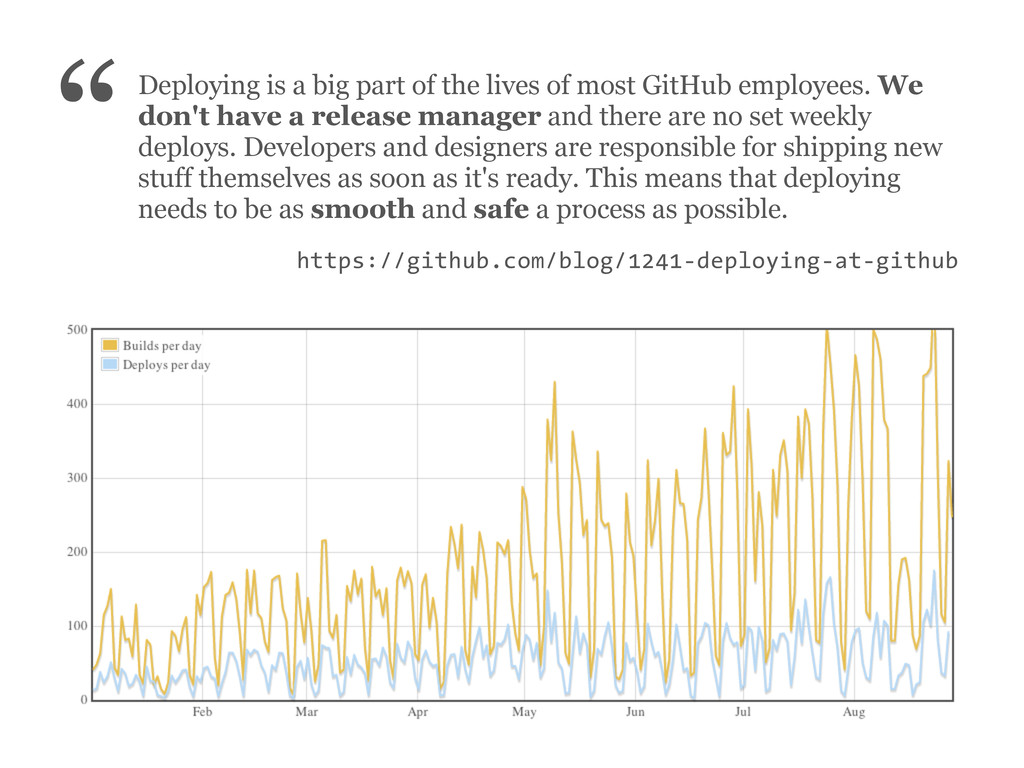
most GitHub employees. We don't have a release manager and there are no set weekly deploys. Developers and designers are responsible for shipping new stuff themselves as soon as it's ready. This means that deploying needs to be as smooth and safe a process as possible. “
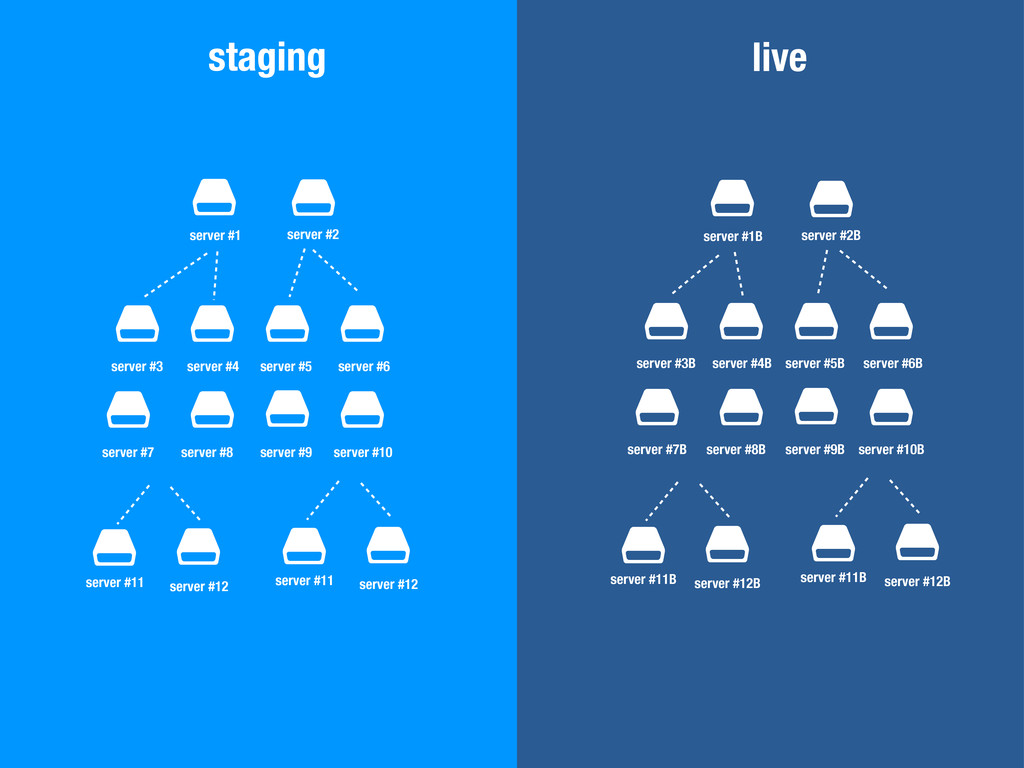
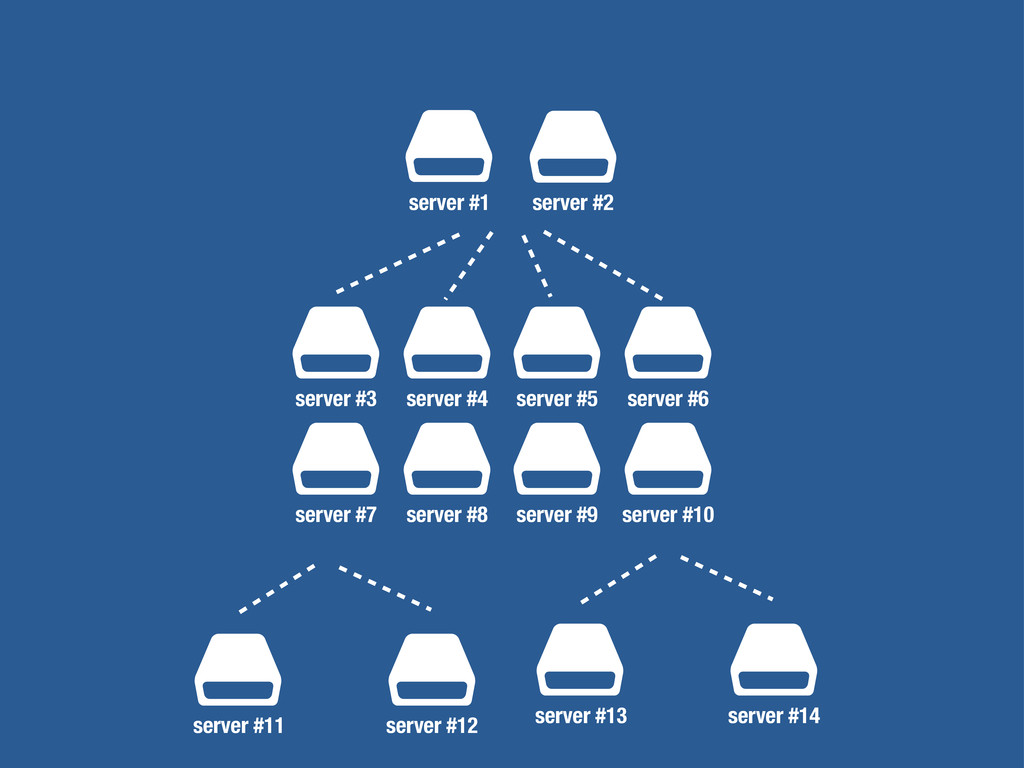
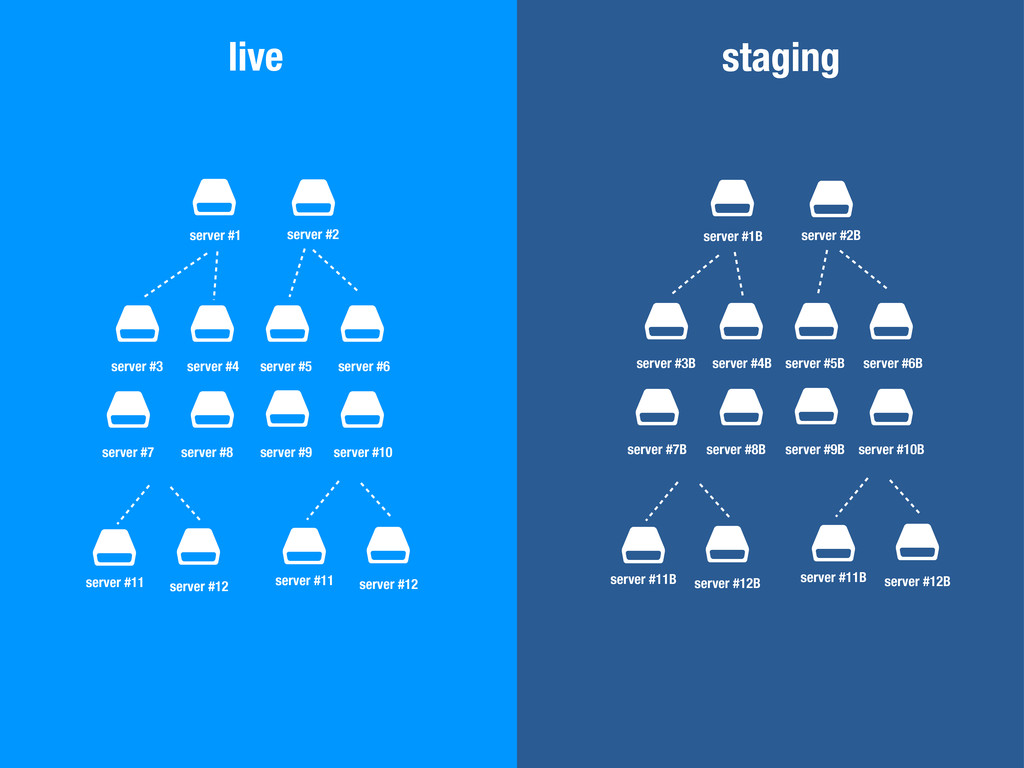
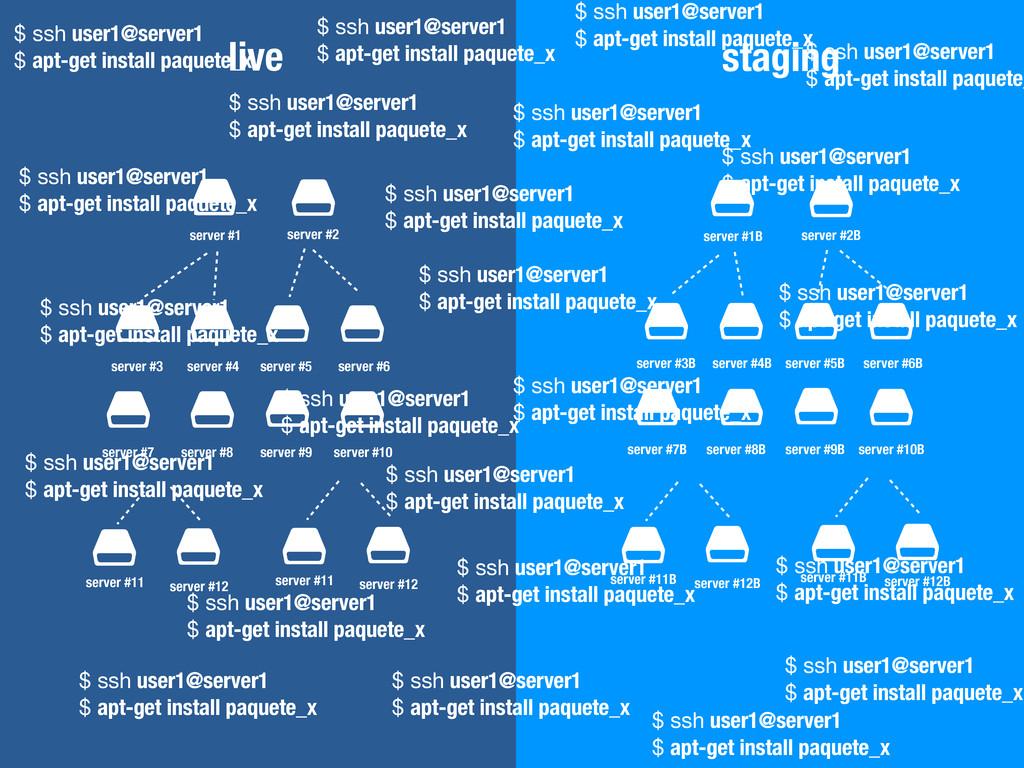
$ $ server #1 server #3 server #11 server #12 server #2 server #4 server #5 server #6 server #7 server #8 server #9 server #10 $ $ server #11 server #12 $ $ $ $ $ $ $ $ $ $ $ $ server #1B server #3B server #11B server #12B server #2B server #4B server #5B server #6B server #7B server #8B server #9B server #10B $ $ server #11B server #12B staging live
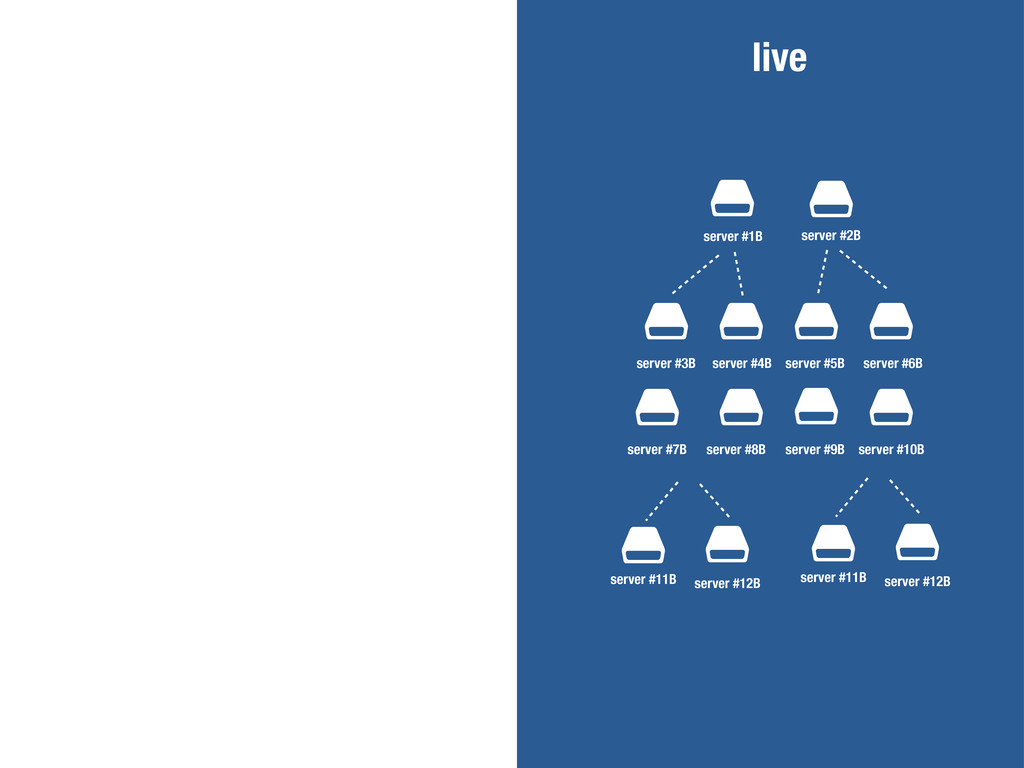
$ $ server #1B server #3B server #11B server #12B server #2B server #4B server #5B server #6B server #7B server #8B server #9B server #10B $ $ server #11B server #12B live
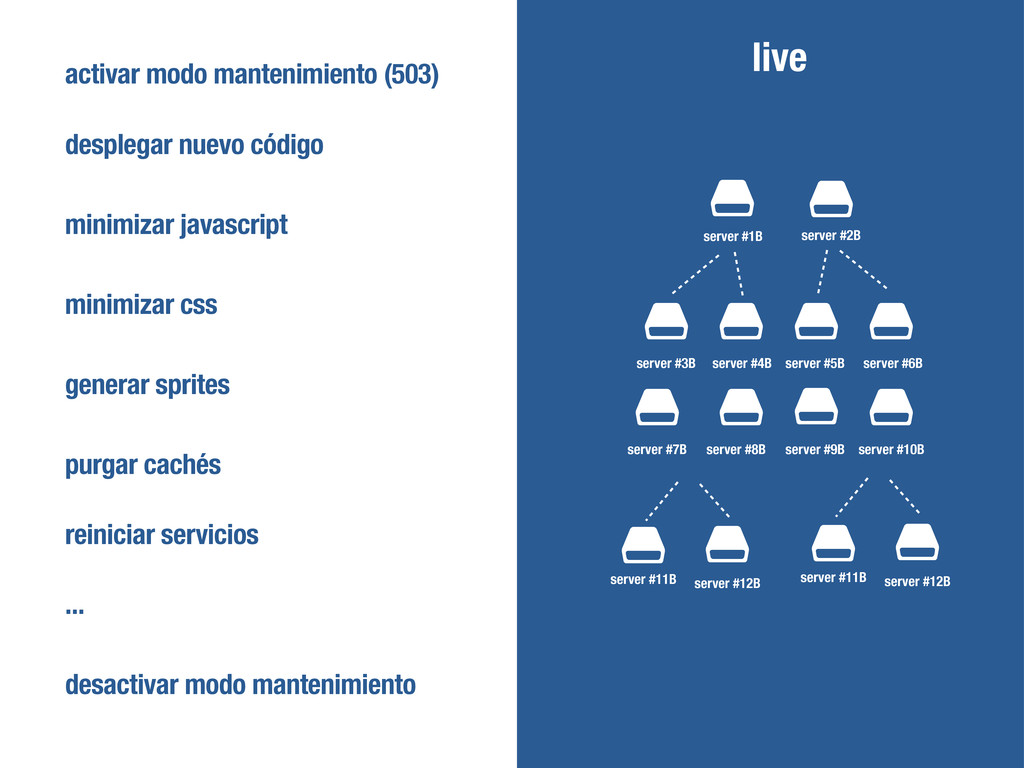
$ $ server #1B server #3B server #11B server #12B server #2B server #4B server #5B server #6B server #7B server #8B server #9B server #10B $ $ server #11B server #12B live activar modo mantenimiento (503) desplegar nuevo código purgar cachés reiniciar servicios minimizar javascript minimizar css generar sprites ... desactivar modo mantenimiento
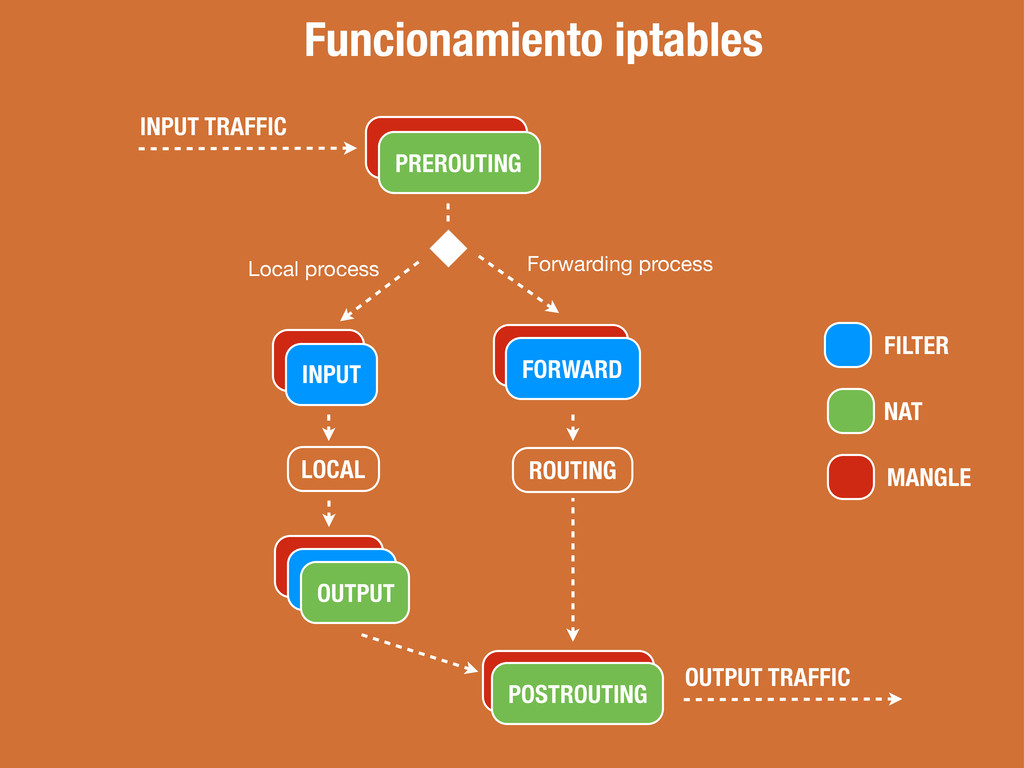
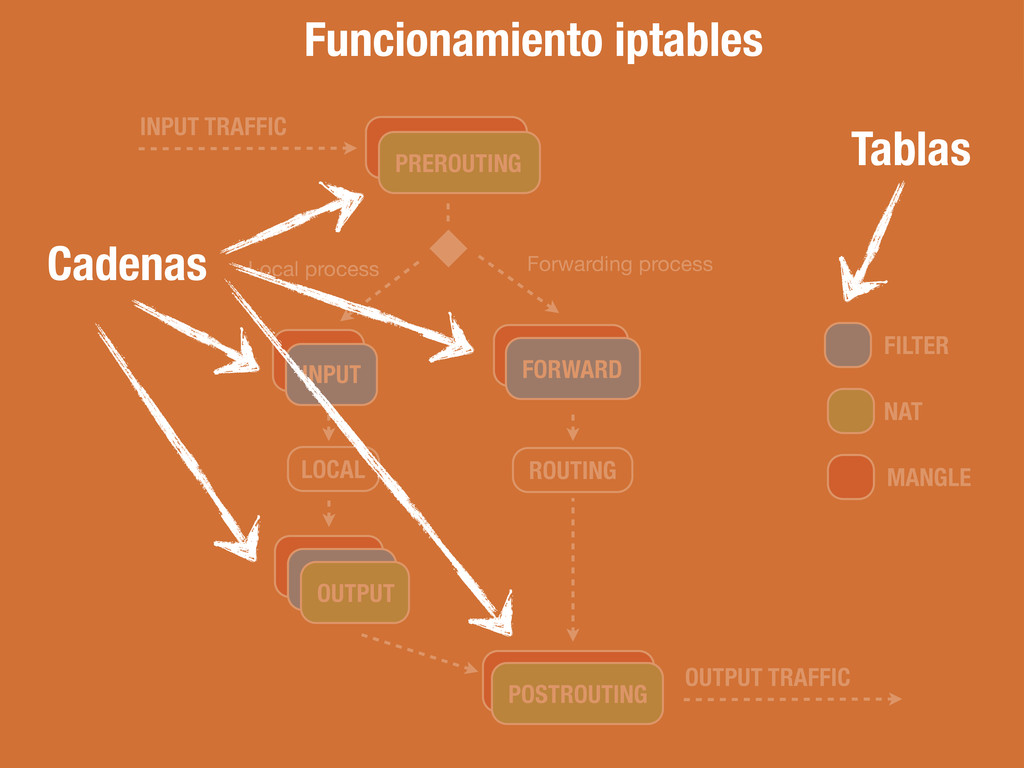
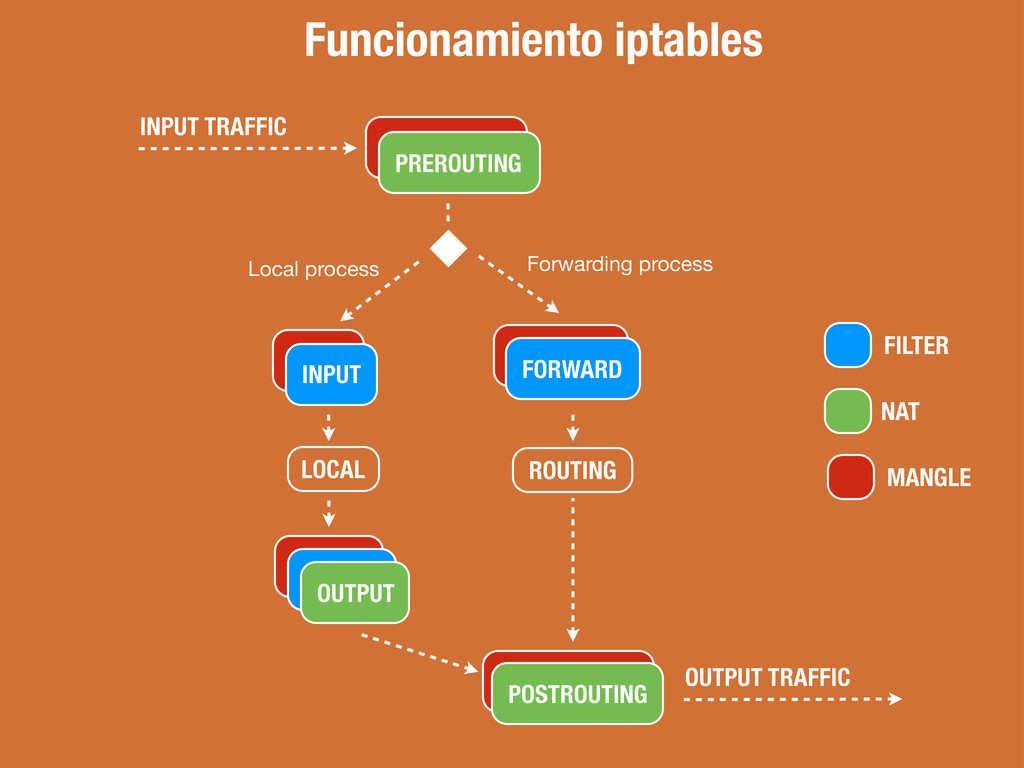
del filtrado de paquetes. Todos los paquetes pasan por esta tabla. Tabla responsable de la reescritura de direcciones y/o puertos. El primer paquete de cada conexión pasa por esta tabla. Tabla responsable de ajustar opciones de paquetes (e.j) QOS. Todos los paquetes pasan por esta tabla.
del filtrado de paquetes. Todos los paquetes pasan por esta tabla. Tabla responsable de la reescritura de direcciones y/o puertos. El primer paquete de cada conexión pasa por esta tabla. Tabla responsable de ajustar opciones de paquetes (e.j) QOS. Todos los paquetes pasan por esta tabla.
Todos los paquetes destinados a este sistema atraviesan esta cadena. Todos los paquetes creados por este sistema atraviesan esta cadena. Todos los paquetes que pasan por este sistema atraviesan esta cadena. El destino de cada una de las reglas dentro de las cadenas puede ser: ACCEPT, DROP, QUEUE, o RETURN (entre otros)
Todos los paquetes destinados a este sistema atraviesan esta cadena. Todos los paquetes creados por este sistema atraviesan esta cadena. Todos los paquetes que pasan por este sistema atraviesan esta cadena. El destino de cada una de las reglas dentro de las cadenas puede ser: ACCEPT, DROP, QUEUE, o RETURN (entre otros)
:INPUT DROP [0:0] :OUTPUT ACCEPT [0:0] :FORWARD DROP [0:0] -A INPUT -m state --state RELATED,ESTABLISHED -j ACCEPT -A INPUT -m state --state INVALID -j DROP -A INPUT -i lo -j ACCEPT -A INPUT -p icmp -j ACCEPT -A INPUT -s $IP/32 -d $IP/32 -p tcp --dport 80 -j ACCEPT
contra servicios como ssh, mail, http etc... • Muy sencillo de instalar y configurar. • Una buena contramedida activa. • Su funcionamiento se basa en leer los logs generados por estos servicios utilizando expresiones regulares. • Además de bloquear el trafico entrante desde estas fuentes se pueden desplegar otras medidas o enviar notificaciones. !h#p://fail2ban.org
de las primeras medidas a tomar al configurar un servidor. • Si disponemos de un servicio como fail2ban estaremos impidiendo en cierta medida que nadie tenga éxito al realizar un ataque de fuerza bruta. • Si por alguna razón el servicio está caído tendríamos nuestra cuenta de root expuesta. • Es muy recomendable no permitir conexiones ssh utilizando root. • Una vez en el sistema podemos identificarnos como root o utilizar sudo. PermitRootLogin no /etc/ssh/sshd_config
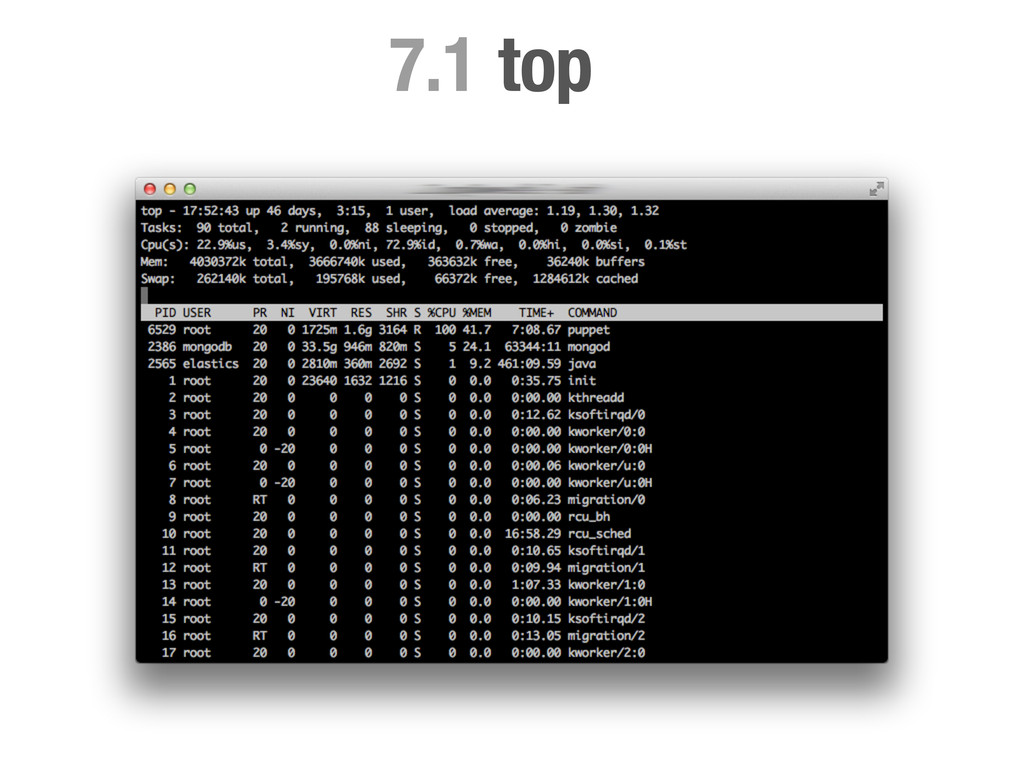
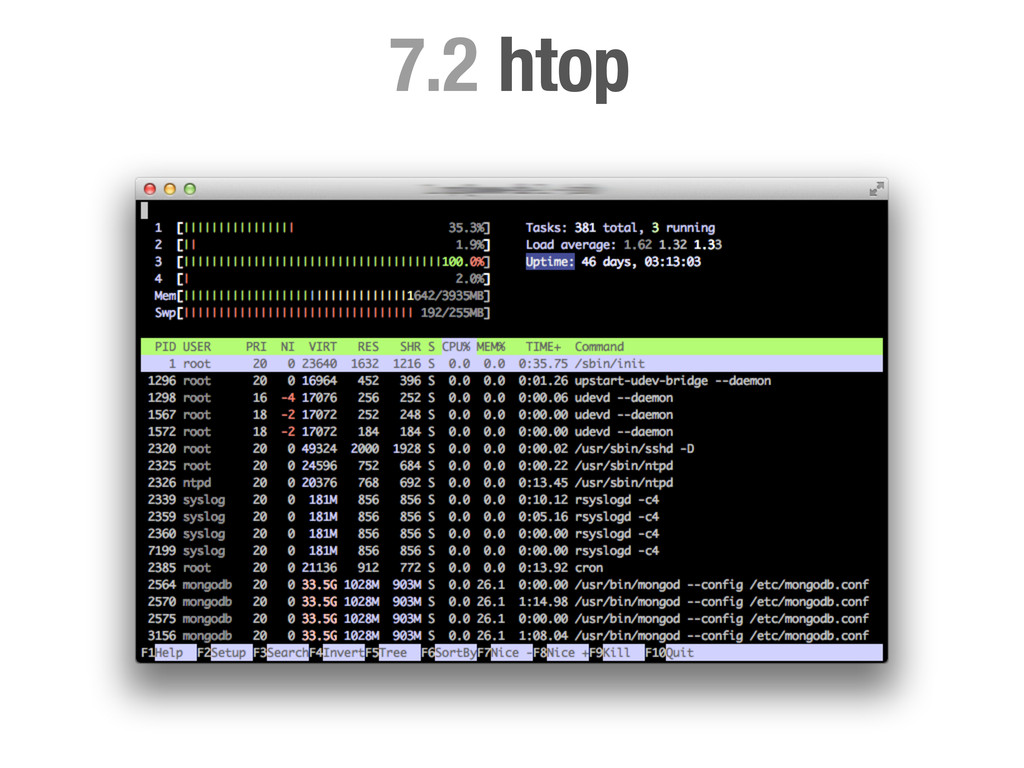
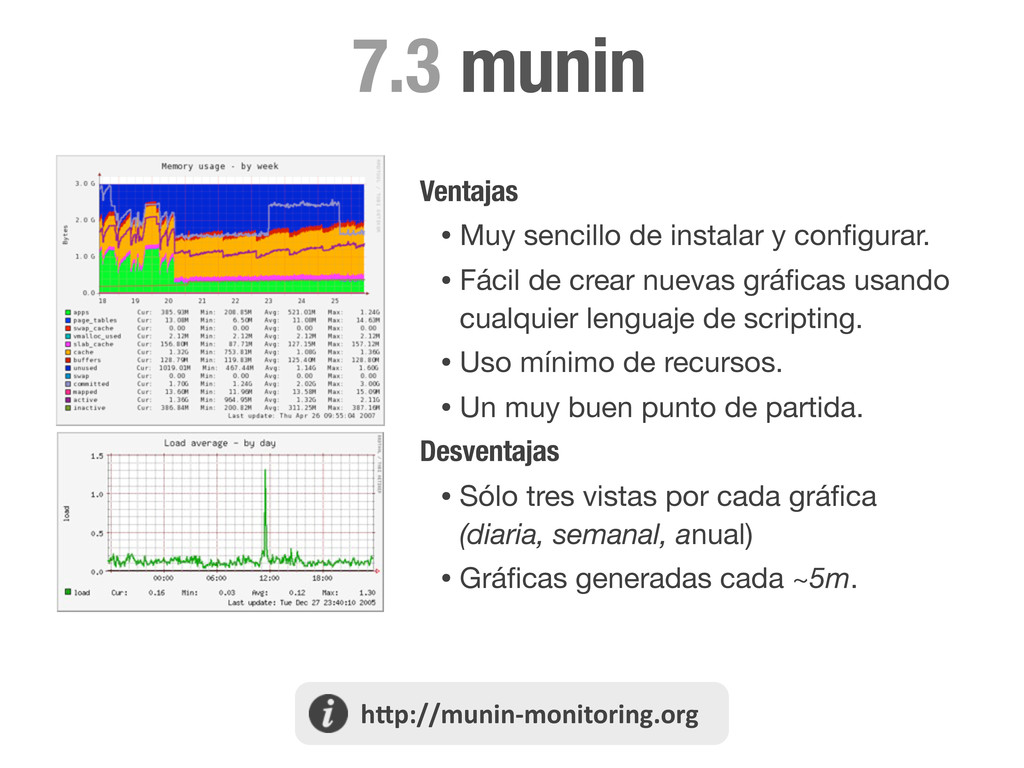
• Fácil de crear nuevas gráficas usando cualquier lenguaje de scripting. • Uso mínimo de recursos. • Un muy buen punto de partida. Desventajas • Sólo tres vistas por cada gráfica (diaria, semanal, anual) • Gráficas generadas cada ~5m. !h#p://munin9monitoring.org
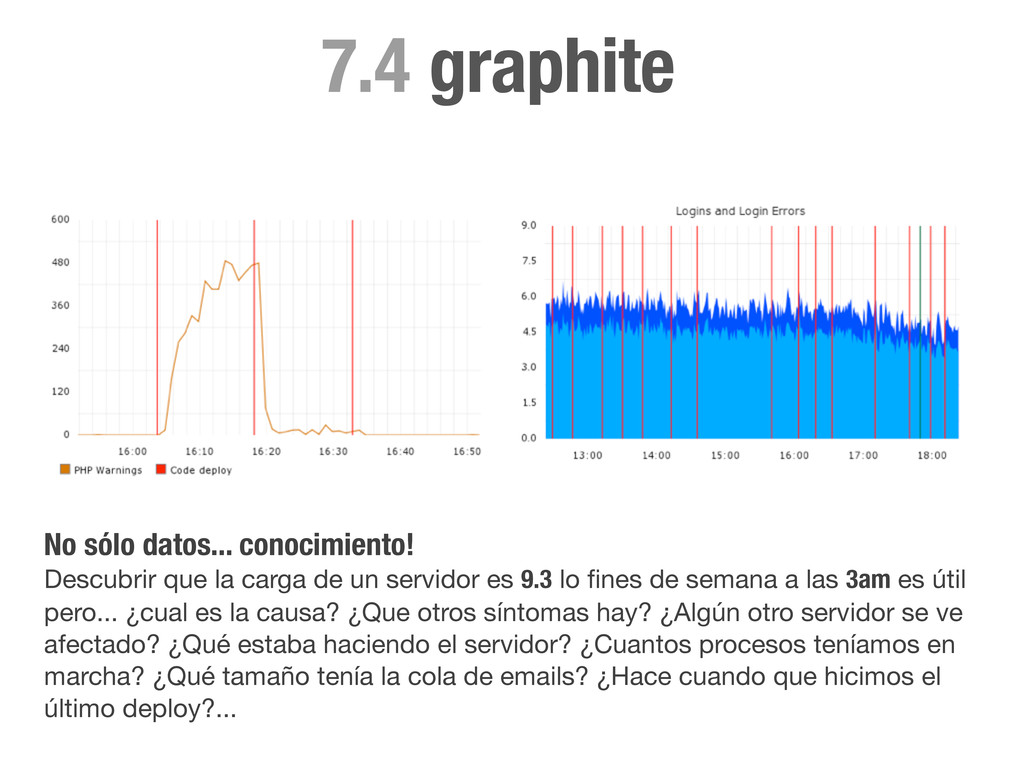
de un servidor es 9.3 lo fines de semana a las 3am es útil pero... ¿cual es la causa? ¿Que otros síntomas hay? ¿Algún otro servidor se ve afectado? ¿Qué estaba haciendo el servidor? ¿Cuantos procesos teníamos en marcha? ¿Qué tamaño tenía la cola de emails? ¿Hace cuando que hicimos el último deploy?...
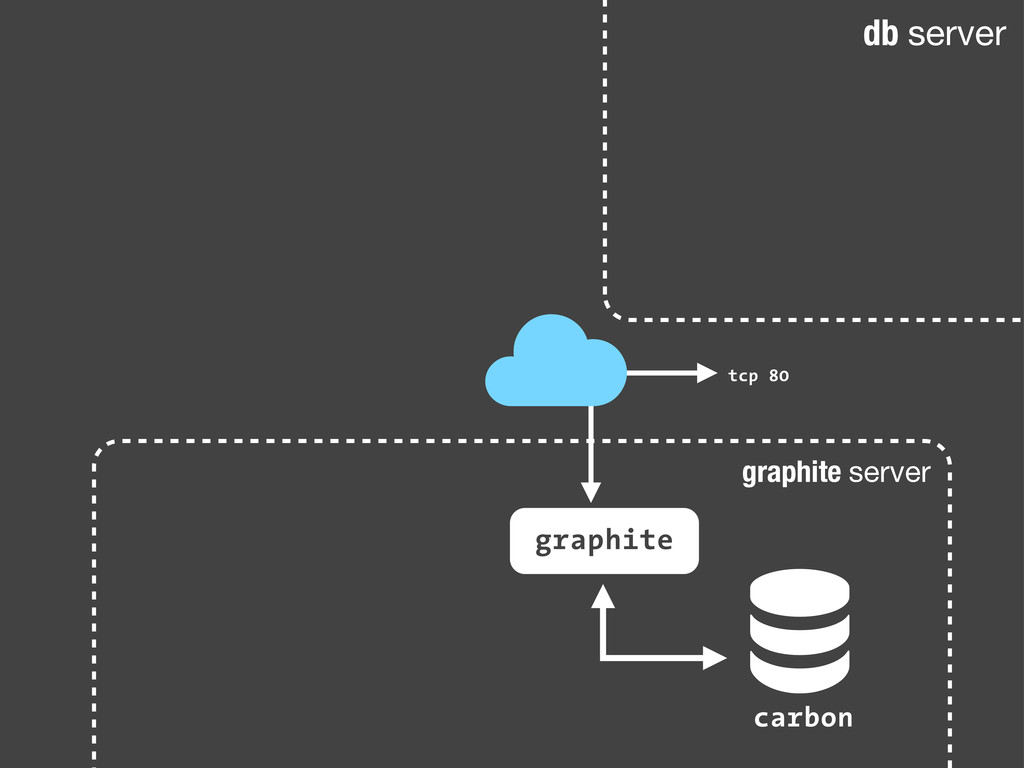
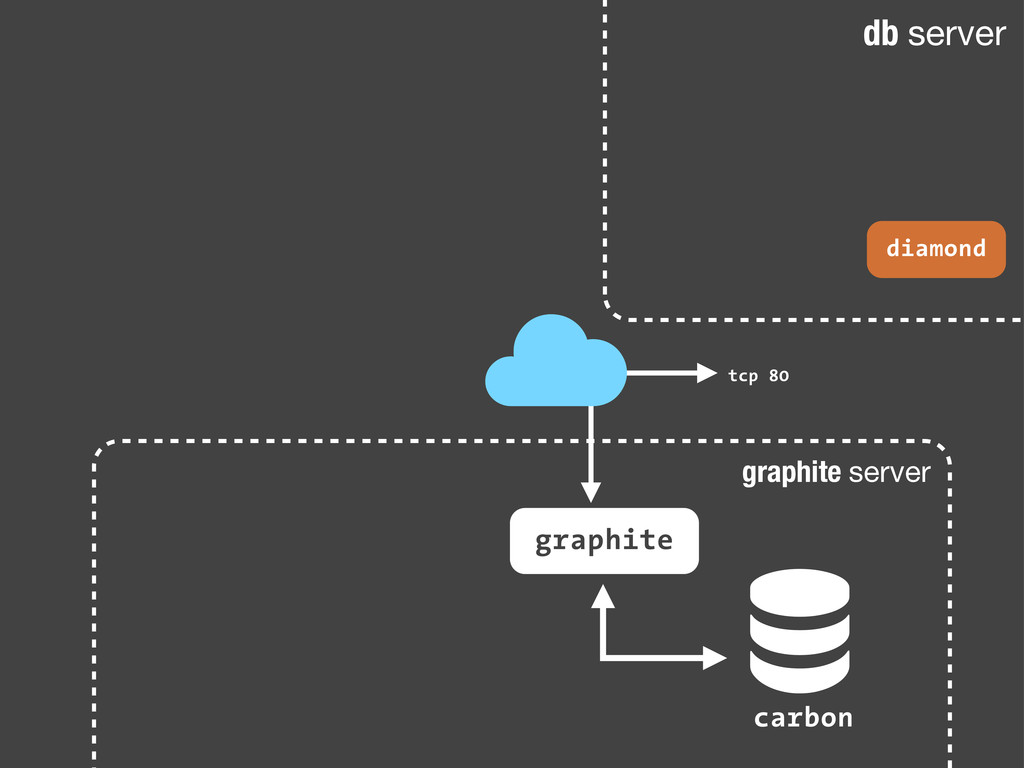
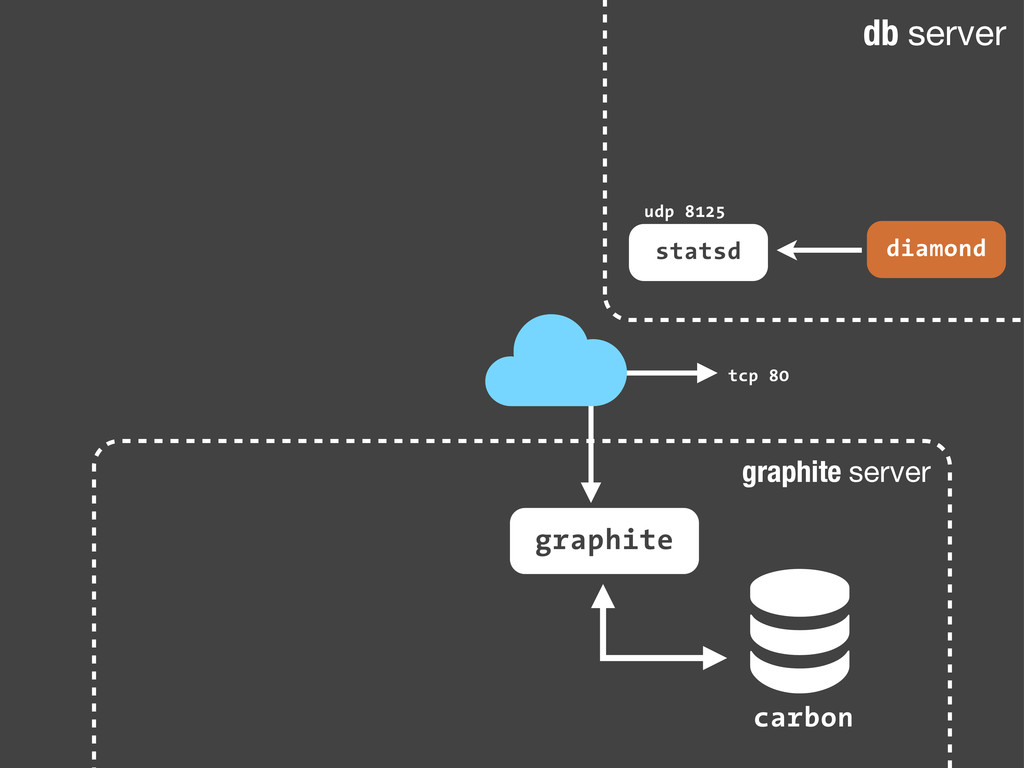
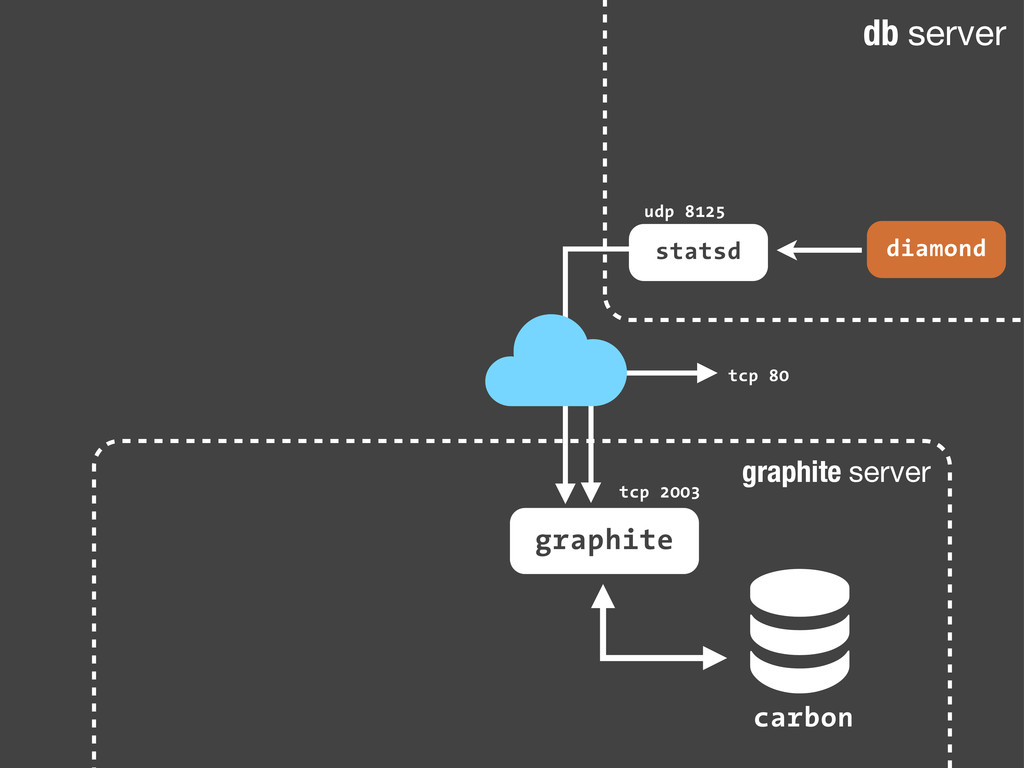
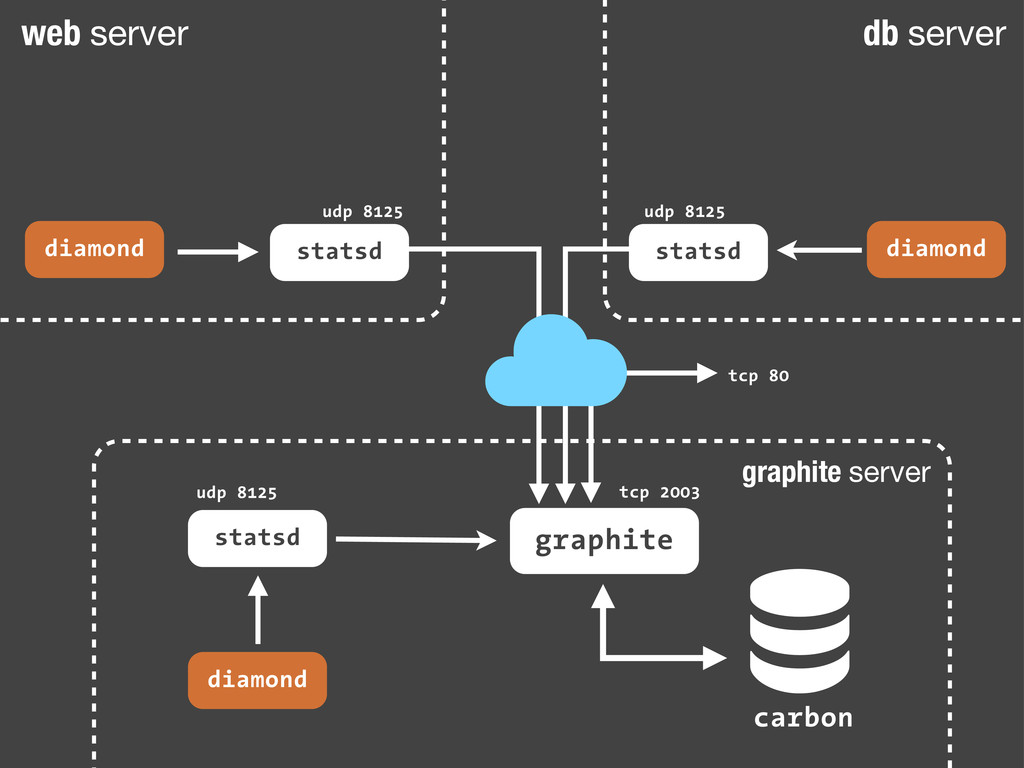
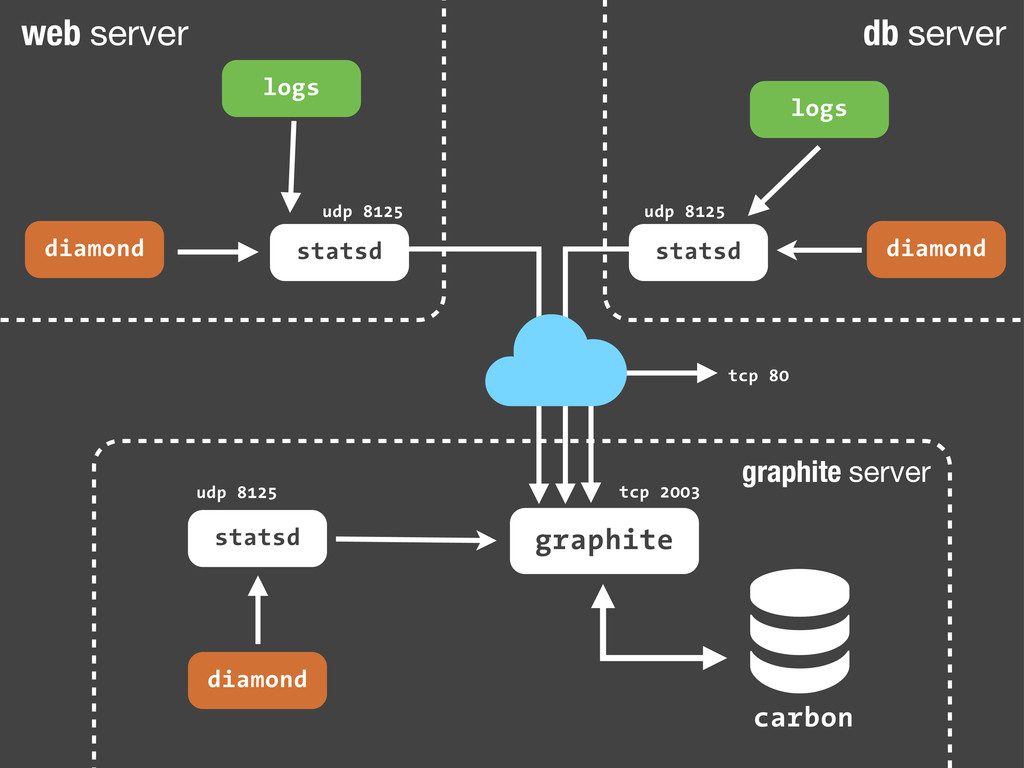
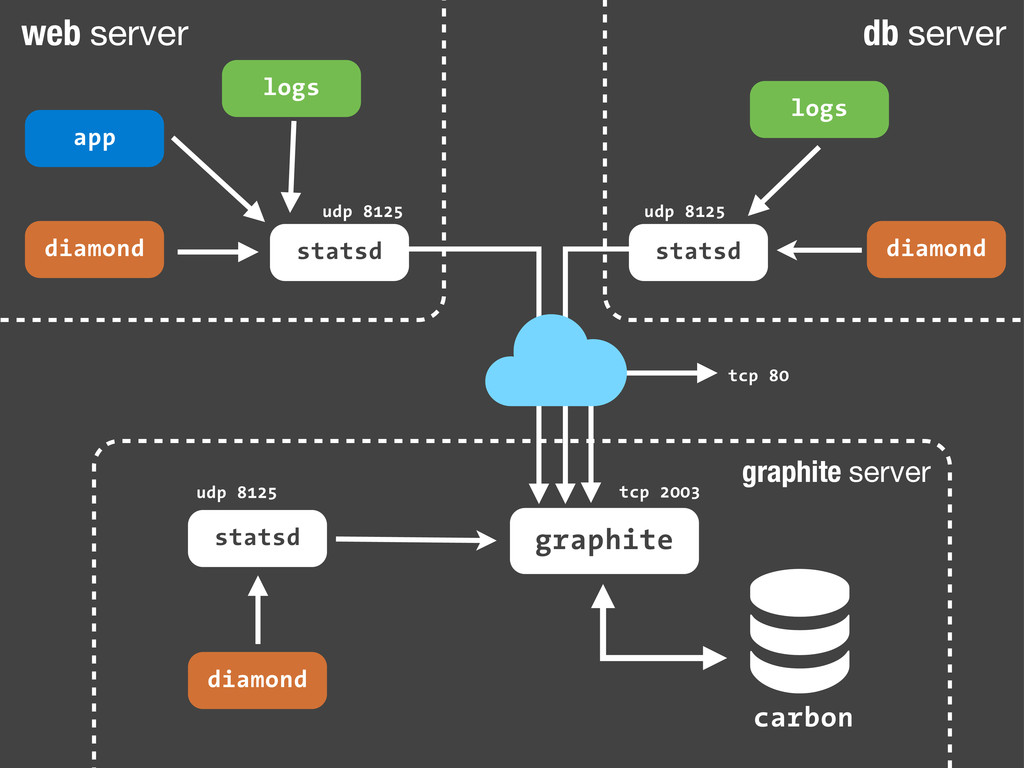
sc.increment('streetlife.emails.immediate.sent') Python echo "streetlife.emails.immediate.sent:1|c" | nc -w 1 -u 127.0.0.1 8125 Bash Son sólo paquetes UDP. Dado que añadir estadísticas consiste en enviar un simple paquete UDP a nuestro servidor de statsd, podemos hacerlo desde cualquier sitio! Nuestra aplicación, un script en bash ... Fire-and-forget!
cuenta que tu web se ha caído porque te lo diga un cliente. Hay docenas de servicios como pingdom que se dedican a testear tu web desde múltiples localizaciones. Features interesantes: • Monitorizar estado y tiempo de respuesta de páginas clave. • Comprobar tiempos de respuesta desde la otra parte del mundo. • Notificaciones SMS. • Uptime reports.
$ $ server #1 server #3 server #11 server #12 server #2 server #4 server #5 server #6 server #7 server #8 server #9 server #10 $ $ server #11 server #12 $ $ $ $ $ $ $ $ $ $ $ $ server #1B server #3B server #11B server #12B server #2B server #4B server #5B server #6B server #7B server #8B server #9B server #10B $ $ server #11B server #12B live staging
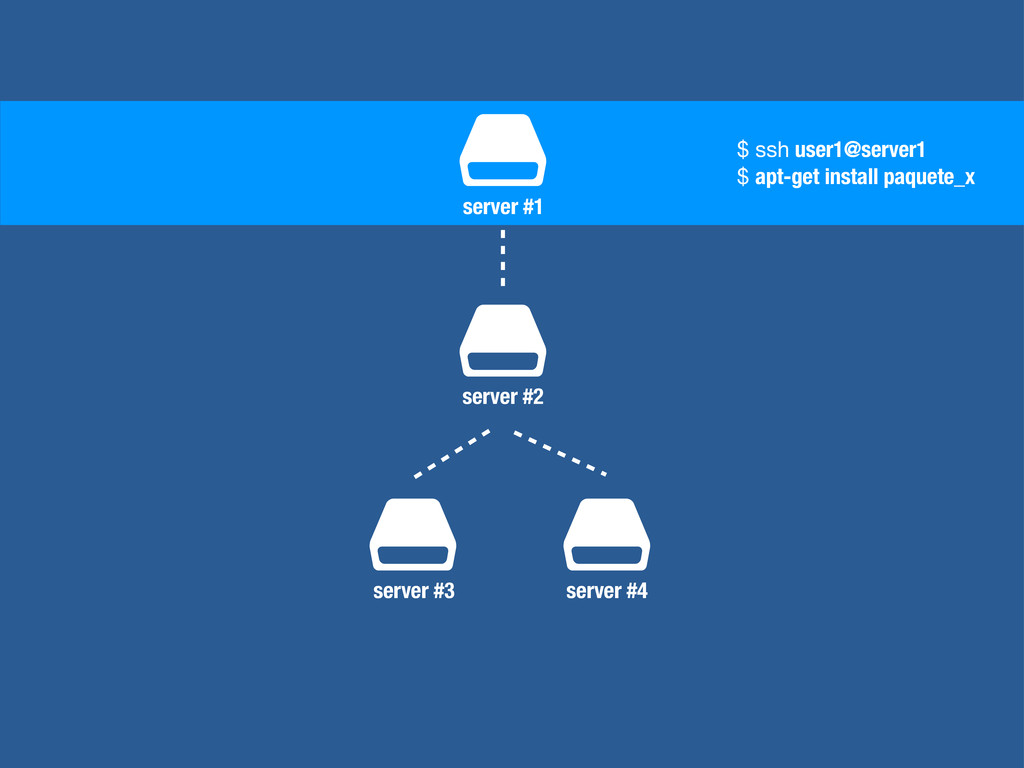
cómo necesitemos. • Generar plantillas que nos permitan generar nuevas máquinas sin mucho esfuerzo y de manera automatizada. • Solucionar casos de catástrofe total ya que podemos regenerar nuestra arquitectura en otro datacenter sin problemas. • Todo del código que automatice este proceso se convierte en último termino en una excelente documentación. • “Code as Infrastructure”
más utilizados. • Nos permite automatizar la configuración de servidores UNIX y Windows. • El lenguaje que se utiliza puede ser tanto Ruby como un lenguaje declarativo propio de Puppet en el que se definen tanto recursos del sistema como el estado de los mismos. • Servicios, usuarios, paquetes, ficheros... • Puppet extrae del sistema información como CPUs, memoria, discos direcciones IP etc... y compila nuestras plantillas junto a esta información. • Puede ejecutarse en modo arquitectura con un servicio central encargado de compilar las plantillas o en modo “solo-mode” en el cual se compilan las plantillas en cada servidor.
a otros sistemas de configuración es que es idempotente. Por ejemplo, podemos ejecutarlo cada 30 minutos y cerciorarnos de que todo está tal y como lo hemos definido. Esta es una gran ventaja dado que además de servirnos como bootstrap para nuevas máquinas, puppet nos permite administrar nuestras máquinas a lo largo de todo su ciclo de vida desde la creación mantenimiento y migración.
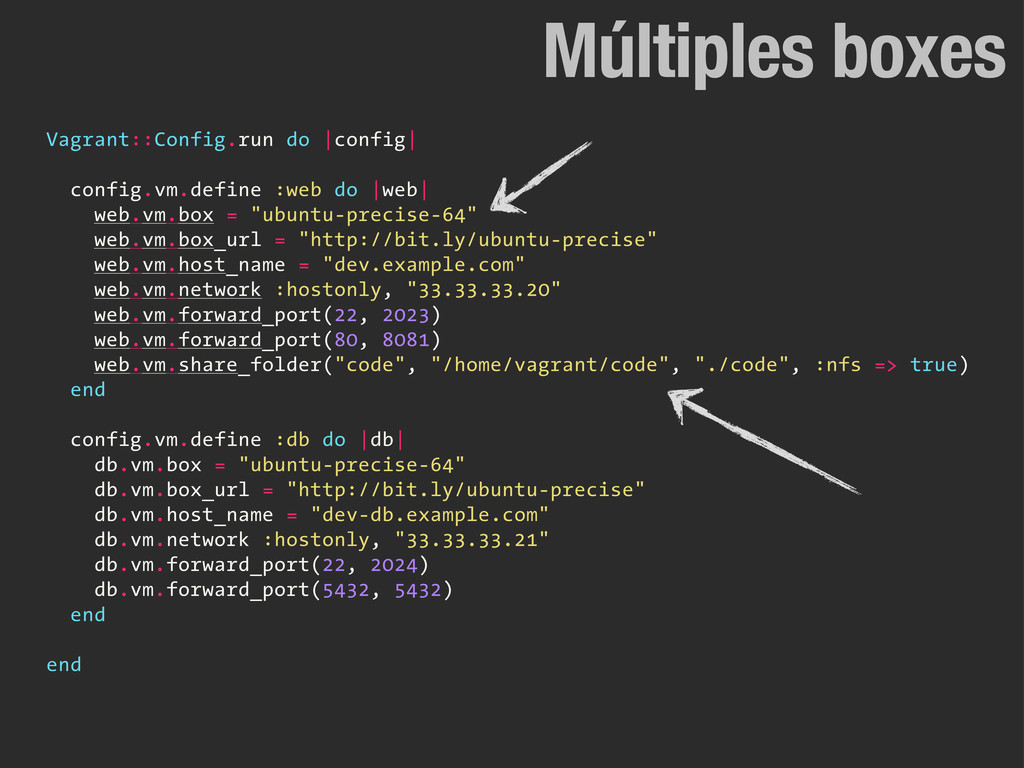
desde la linea de comandos. • Permite crear “instancias” base para crear máquinas desde un estado concreto en cuestión de segundos. • Integración con Puppet y Chef entre otros. • Gracias a vagrant y puppet podemos lograr que todos los miembros del equipo dispongan del mismo setup en local sin mucho quebradero de cabeza. • La puesta en marcha de nuevos empleados se reduce a minutos en vez de días. • Gracias a la sencillez de uso podemos crear distintos setup en cuestión de minutos y comprobar su funcionamiento. • Funciona en todas las plataformas: Linux, OSX y Windows. Vagrant 9.1
it's not already running... [web] Clearing any previously set forwarded ports... [web] Fixed port collision for 22 => 2222. Now on port 2202. [web] Forwarding ports... [web] -- 22 => 2023 (adapter 1) [web] -- 80 => 8081 (adapter 1) [web] Exporting NFS shared folders... [vagrant] Preparing to edit /etc/exports. Administrator privileges will be required... [web] Creating shared folders metadata... [web] Clearing any previously set network interfaces... [web] Preparing network interfaces based on configuration... [web] Booting VM... [web] Waiting for VM to boot. This can take a few minutes. [web] VM booted and ready for use! [web] Configuring and enabling network interfaces... [web] Setting host name... [web] Mounting shared folders... [web] -- v-root: /vagrant [web] -- manifests: /tmp/vagrant-puppet/manifests [web] -- v-pp-m0: /tmp/vagrant-puppet/modules-0 [web] Mounting NFS shared folders... [web] Running provisioner: Vagrant::Provisioners::Puppet... [web] Running Puppet with /tmp/vagrant-puppet/manifests/site.pp... stdin: is not a tty notice: Finished catalog run in 1.70 seconds vagrant up
otras cosas) la ejecución de tests, compilación de documentación, generar reports de test coverage... Ejecuciones • Periódicamente • Por cada commit al repositorio. Configuración • Requiere de un poco de práctica pero una vez configurado no necesita mucho mantenimiento.
(sobre todo cuando no siempre todo el mundo está trabajando desde la misma oficina). Ventajas • Histórico de todas las conversaciones. • Facilidad para compartir rápidamente ficheros, capturas de pantalla etc... • 0 Configuración y entrada amable para no techies. • Salas por departamentos, equipos etc... • Gaticos. • Notificaciones de deploy, mantenimiento etc...
![Jorge&Bas*da me@jorgebas*da.com @jorgebas*da Jaime&Irurzun [email protected] @jaimeirurzun Open Source Modern web](https://files.speakerdeck.com/presentations/7d9e2bb09a1b0130229a7a3bae9869de/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
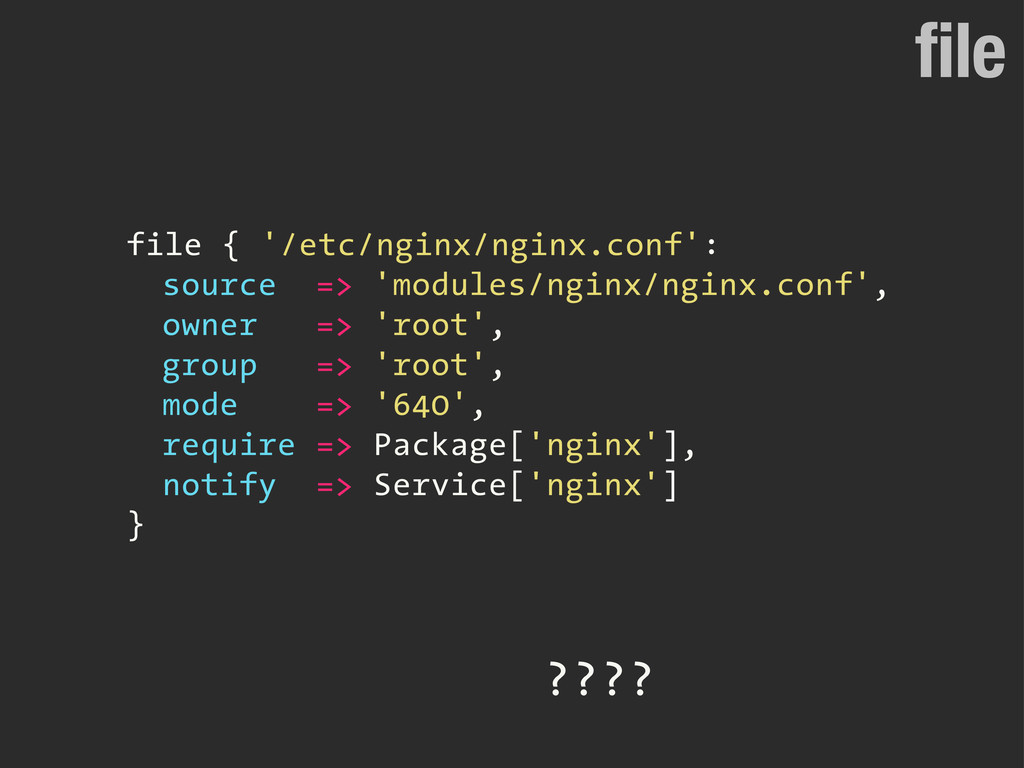
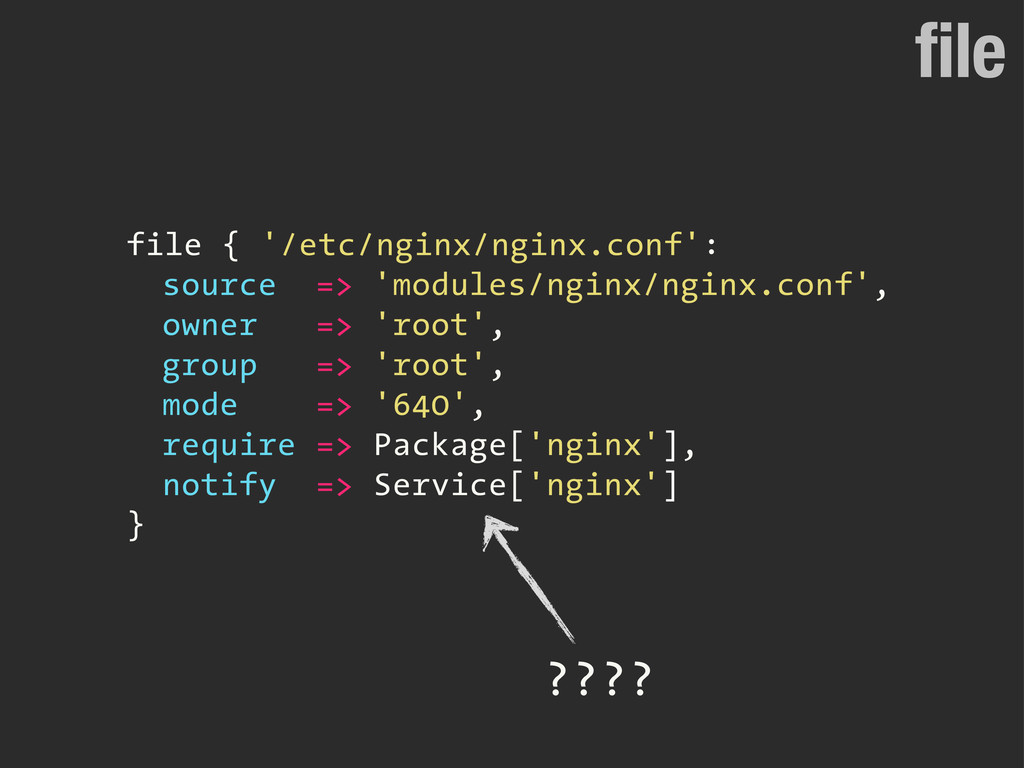
![require, notify Package['nginx'] File['/etc/nginx/nginx.conf'] Service['nginx'] Installed Created Updated](https://files.speakerdeck.com/presentations/7d9e2bb09a1b0130229a7a3bae9869de/slide_301.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![$ vagrant up web [web] VM already created. Booting if](https://files.speakerdeck.com/presentations/7d9e2bb09a1b0130229a7a3bae9869de/slide_311.jpg){kind=link}
{kind=link}
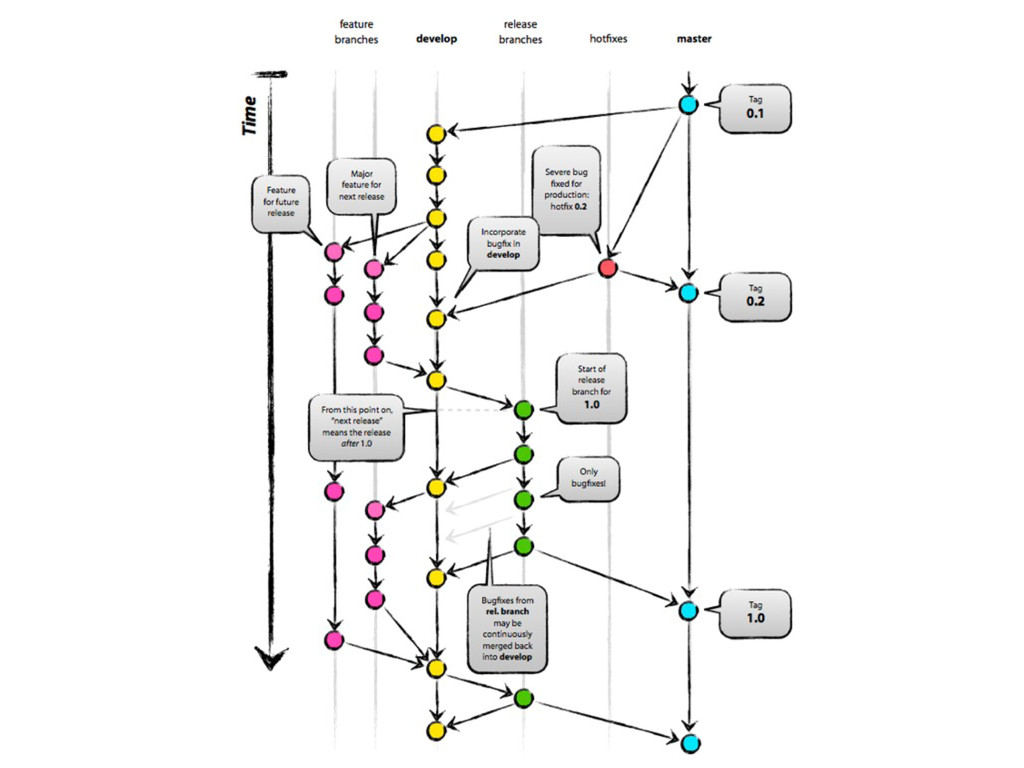{kind=link}
{kind=link}
{kind=link}
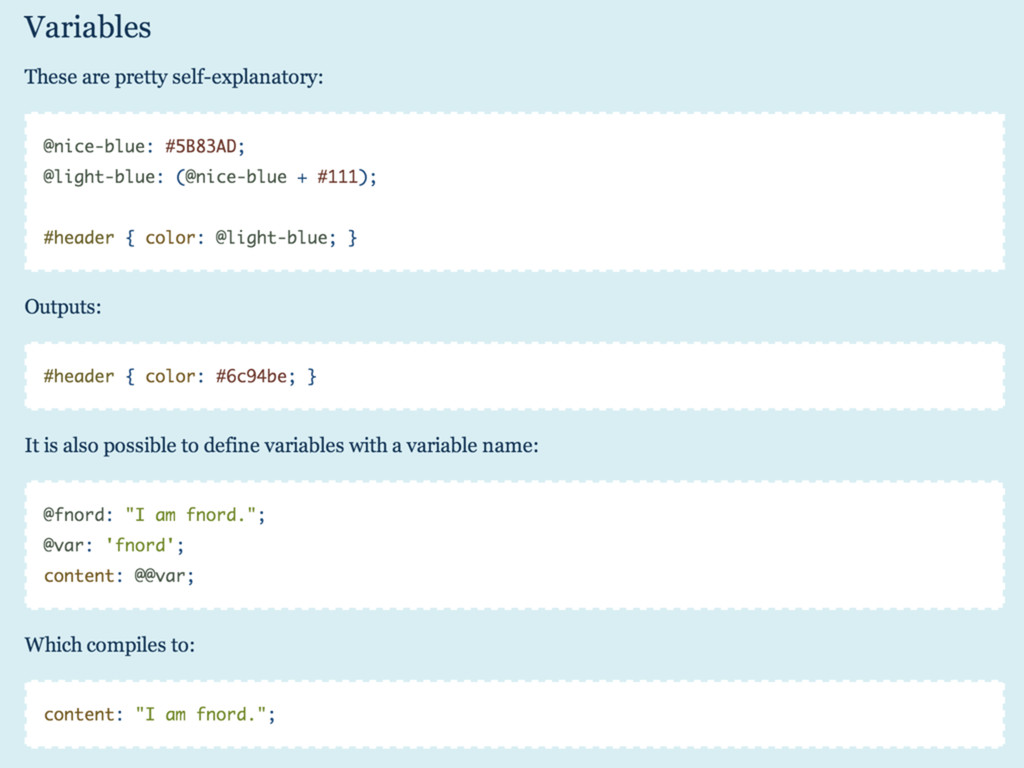{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}