east/west coast of US, London, Leeds? Picture from a week-long company retreat this summer in the catskills. Great for a ton of reasons for our company.
do) in your app Email platform for web and mobile apps. Quit our jobs almost two years ago now, the last year I’ve been consumed by scaling our backend.
What we do? we make a promise to our customers that we’ll track, segment, and email their customers in “real-time”. high write load (99%) … most of this talk will be from that perspective.
so would love to learn from anyone with experience while I’m here. I have been thinking/experimenting with this almost exclusively for the last year. It’s generally what I think about in the shower most days.
Cache Cache You can get pretty far without needing to do this if you’re read heavy. Up to this point, it’s been easy to add capacity and fault tolerance. Here, I make the case that you have to make compromises. The difference is state. Once you want distributed consensus, you’re in trouble.
3 ElasticSearch considers itself a CP system, built in clustering, synchronous replication, etc. minimum_master_nodes is number of nodes required to operate.
3 If 2 is master for a shard and 3 is a slave, 2 tells 1 it doesn’t have a slave. 3 tells 1 it has lost it’s master, held an election and promoted itself to master. 1 evidentially says, “go for it guys!”. Split brain… lost writes… bad times.
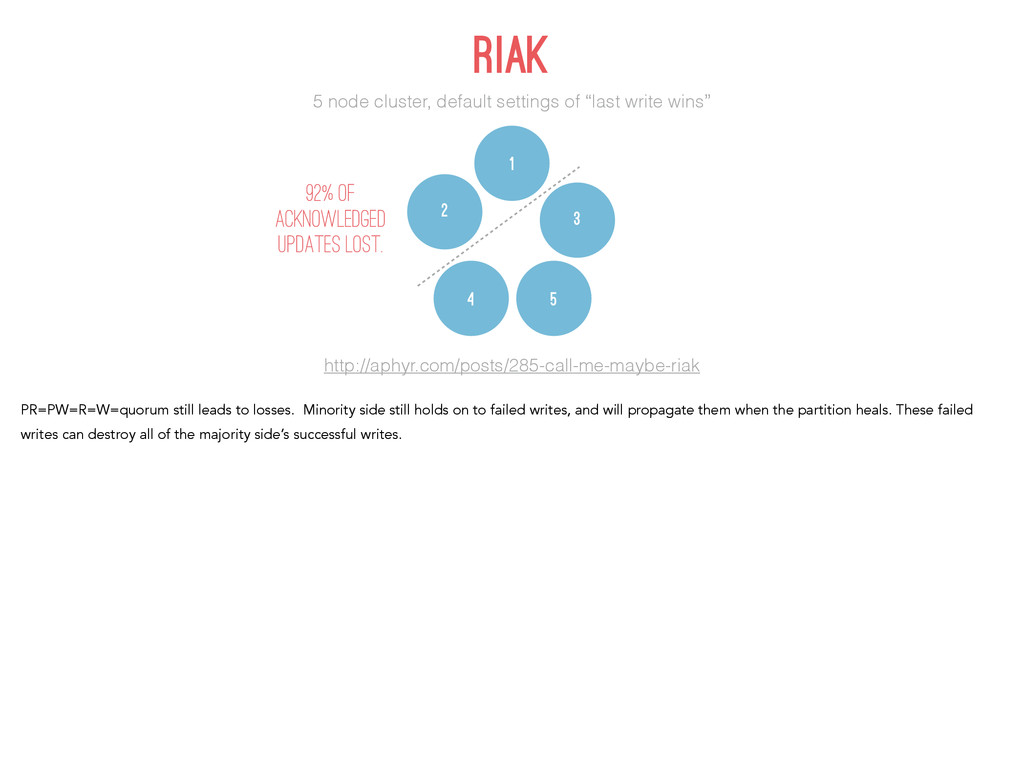
http://aphyr.com/posts/285-call-me-maybe-riak 1 2 3 4 5 Riak considers itself an AP system. Can allow writes if just one node is up, but generally require quorum acknowledgement. In either case, it tries to accept all writes and replicate after a partition heals.
http://aphyr.com/posts/285-call-me-maybe-riak 1 2 3 4 5 71% of acknowledged updates lost. Healthly cluster. By default, it uses “last write wins” based on the vector clock of the update. “Older” updates are discarded. Concurrent writes or writes from a node with an out of sync clock = lost updates.
http://aphyr.com/posts/285-call-me-maybe-riak 1 2 3 4 5 92% of acknowledged updates lost. PR=PW=R=W=quorum still leads to losses. Minority side still holds on to failed writes, and will propagate them when the partition heals. These failed writes can destroy all of the majority side’s successful writes.
lack of an agreed upon terminology for a discussion. What does it mean when a database says it’s distributed, fault tolerant, highly available, etc? Most likely none of them mean the same thing.
created. All data we store in Riak, for example, is immutable. Which gets around the problem of conflicts in an eventually consistent datastore, as it removes the possibility of conflicts. Only “safe” way to have mutable objects is in a consistent store?
there result. Very helpful in the presence of failures. All of our processing operates in this way, if for whatever reason an operation fails, we retry it with exponential backoff.
and partition tolerant - best for small amounts of coordination - limited dataset & throughput - can be hard to operate or use properly Some things did pass Kyles tests. Can be used to do master election for elastic search to remove the split brain problem. handles coordination in many distributed data stores.
+ great for immutable data (no updates). + CRDTs commutative replicated data types. Haven’t experienced must with them yet, but can be great for specific cases where you’d like to update things, like counters, or sets, etc.
DB DB DB DB So, if you’ve made it through that, it may get you here, or you may take it further and break your system into smaller pieces, and multiple data stores for different types of data. Which starts to open up another can of worms…
pieces (or services) in your system who need to navigate the network to communicate in the presence of failures and new instances coming up, it can become a big hairy ball of configuration really quick.
loadbalancers everywhere Each instance responsible for broadcasting availability Options? Have punted on this for awhile. restart: what we do now - chef scripts manually upload new config, rolling restart. DNS is slow to update… heavily cached everywhere. Broadcast: updating something like zookeeper with live nodes of a given service. internal loadbalancers: more complicated configuration.
fairly happy with the result. Based on haproxy, less configuration to add instances, don’t need to rewrite everything to “register” itself in zookeeper, etc. Can use zookeeper for coordination. Recently added some docker support for discovering new docker instances across a number of machines.
DB DB DB DB zookeeper = nerve Each server has an instance of nerve that watches the services on that node. Nerve creates ephemeral nodes in zookeeper when a service is up. If the service goes down, or the node dies, or nerve dies, the ephemeral node is removed.
DB DB DB DB zookeeper = nerve = synapse! & haproxy Haproxy and synapse are run on any nodes that need to communicate. They connect to only their local instance of haproxy, which is configured with the latest live nodes by synapse/nerve. Haproxy is responsible for navigating the faulty network (connection retries, etc).
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![@jrallison [email protected] Thanks! https://speakerdeck.com/jrallison/pivotal-london](https://files.speakerdeck.com/presentations/d39cb300658301315c6732105fd2bdc9/slide_37.jpg){kind=link}